
VPDを活用して、AIチャットシステムの返答をユーザーに応じて制御する
このチュートリアルでは、RAGを利用したAIチャットシステムで、ユーザーに応じてAIの出力を出し分ける方法を解説します。
RAGとは、AIがファイルやDB内のデータを検索した内容をもとに返答を生成する仕組みですが、参照先のあらゆるデータを一つのデータベースに集約している場合、どのデータを参照して開示して良いかはユーザーの所属組織や職位によって変わってきます。
例えば、人事部のユーザーではないのに社員の給与や評価などのデータをAIの返答によって知れてしまったり、
人事部のユーザーであっても、本来アクセス権を持たない経営データなどの機密情報にアクセスできてしまうといった問題が発生します。
Autonomous AI Databaseに搭載されたSQL拡張型の生成AI機能であるSelect AI with RAGと、 参照先のデータベース側でロールに応じてアクセスを制御する機能であるVPD(Virtual Private Database)を組み合わせて、安全なチャットボットシステムを構築します。
【前提条件】
- OCI生成AIサービスを使用可能な大阪リージョンやシカゴリージョンをサブスクライブしていること Generative AI Models by Region
【所要時間】 1時間
1.オブジェクト・ストアとしてオブジェクト・ストレージを作成します。詳しい手順はこちらをご参照ください。
- 名前: RAG-bucket
- デフォルトストレージ層: 標準層
2.以下のリンクをクリックし、以下のテキストファイルをダウンロードします。
Tokyo-insurance_rag.txtの内容
============================== 契約者情報ドキュメント==============================契約者名:東京支社_契約者001 所属支社:東京支社 年齢:73歳 加入保険:医療保険 保険金額:83,057,936円 健康リスクレベル:高
医療情報: 既往症としてぜんそくがあります(慢性疾患)。 現在は継続的な治療または経過観察中です。 定期的な通院歴があり、医師より生活習慣改善および健康管理の指導を受けています。 将来的な医療費増加リスクについて十分な説明を実施済みです。 保険金請求リスク評価およびアンダーライティング審査において医療履歴を考慮しています。
契約更新日:2027年12月31日
============================== 契約者情報ドキュメント==============================
契約者名:東京支社_契約者002 所属支社:東京支社 年齢:30歳 加入保険:医療保険 保険金額:51,805,025円 健康リスクレベル:中
医療情報: 既往症として高血圧があります(慢性疾患)。 現在は継続的な治療または経過観察中です。 定期的な通院歴があり、医師より生活習慣改善および健康管理の指導を受けています。 将来的な医療費増加リスクについて十分な説明を実施済みです。 保険金請求リスク評価およびアンダーライティング審査において医療履歴を考慮しています。
契約更新日:2027年12月31日
Osaka-insurance_rag.txtの内容
============================== 契約者情報ドキュメント==============================契約者名:大阪支社_契約者001 所属支社:大阪支社 年齢:33歳 加入保険:医療保険 保険金額:42,574,469円 健康リスクレベル:低
医療情報: 既往症として脂質異常症があります(慢性疾患)。 現在は継続的な治療または経過観察中です。 定期的な通院歴があり、医師より生活習慣改善および健康管理の指導を受けています。 将来的な医療費増加リスクについて十分な説明を実施済みです。 保険金請求リスク評価およびアンダーライティング審査において医療履歴を考慮しています。
契約更新日:2027年12月31日
============================== 契約者情報ドキュメント==============================
契約者名:大阪支社_契約者002 所属支社:大阪支社 年齢:66歳 加入保険:医療保険 保険金額:616,05,635円 健康リスクレベル:低
医療情報: 既往症として高血圧があります(慢性疾患)。 現在は継続的な治療または経過観察中です。 定期的な通院歴があり、医師より生活習慣改善および健康管理の指導を受けています。 将来的な医療費増加リスクについて十分な説明を実施済みです。 保険金請求リスク評価およびアンダーライティング審査において医療履歴を考慮しています。
契約更新日:2027年12月31日
3.ダウンロードしたをオブジェクト・ストアにアップロードし、オブジェクト・ストアのURIを取得します。このURIは後程使用するので、メモをしておきます(例:https://objectstorage.ap-tokyo-1.oraclecloud.com/n/xxxxxxxxx/b/xxxxxxxxxx/o/)
AIプロバイダーとしてOCI生成AIサービスを使用する場合はこちらの手順に沿ってOCIのリソースにアクセスするためのAPIキーを取得します。
1.以下の設定を入力し、ADBインスタンスを作成します。
:::note warn ADBインスタンス作成時に、以下の点に注意してください。
- 名前:任意(同一コンパートメント内に、同じ名前のADBインスタンスは作成不可のため注意)
- データベース・バージョンの選択:26ai(ベクトル検索を行うため)
- ワークロード・タイプ:レイクハウス
- Always Free:オン(無償でお試しいただく場合) :::
- Database ActionsのSQLワークシートへはADMINとしてログインします(デフォルト)。ユーザーを作成し、必要なロールを付与します。
以下のSQLを実行し、
- アプリを管理するためのユーザーAPP_USERを作成、必要なロールを付与
CREATE USER app_user IDENTIFIED BY W3lcome123##;
- SELECT AIの利用に必要なDBMS_CLOUD_AIパッケージの実行権限を付与
GRANT DWROLE, UNLIMITED TABLESPACE TO app_user;
GRANT EXECUTE ON DBMS_CLOUD_AI TO app_user;
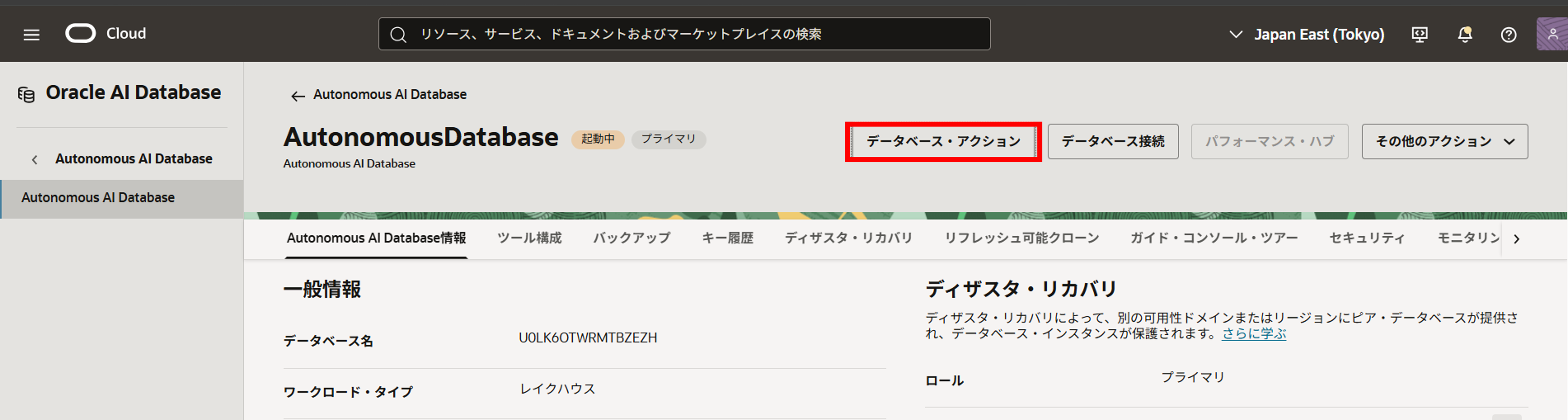
3. ツール構成タブ配下のAPEXのURLをコピーし、APEXにアクセスします。
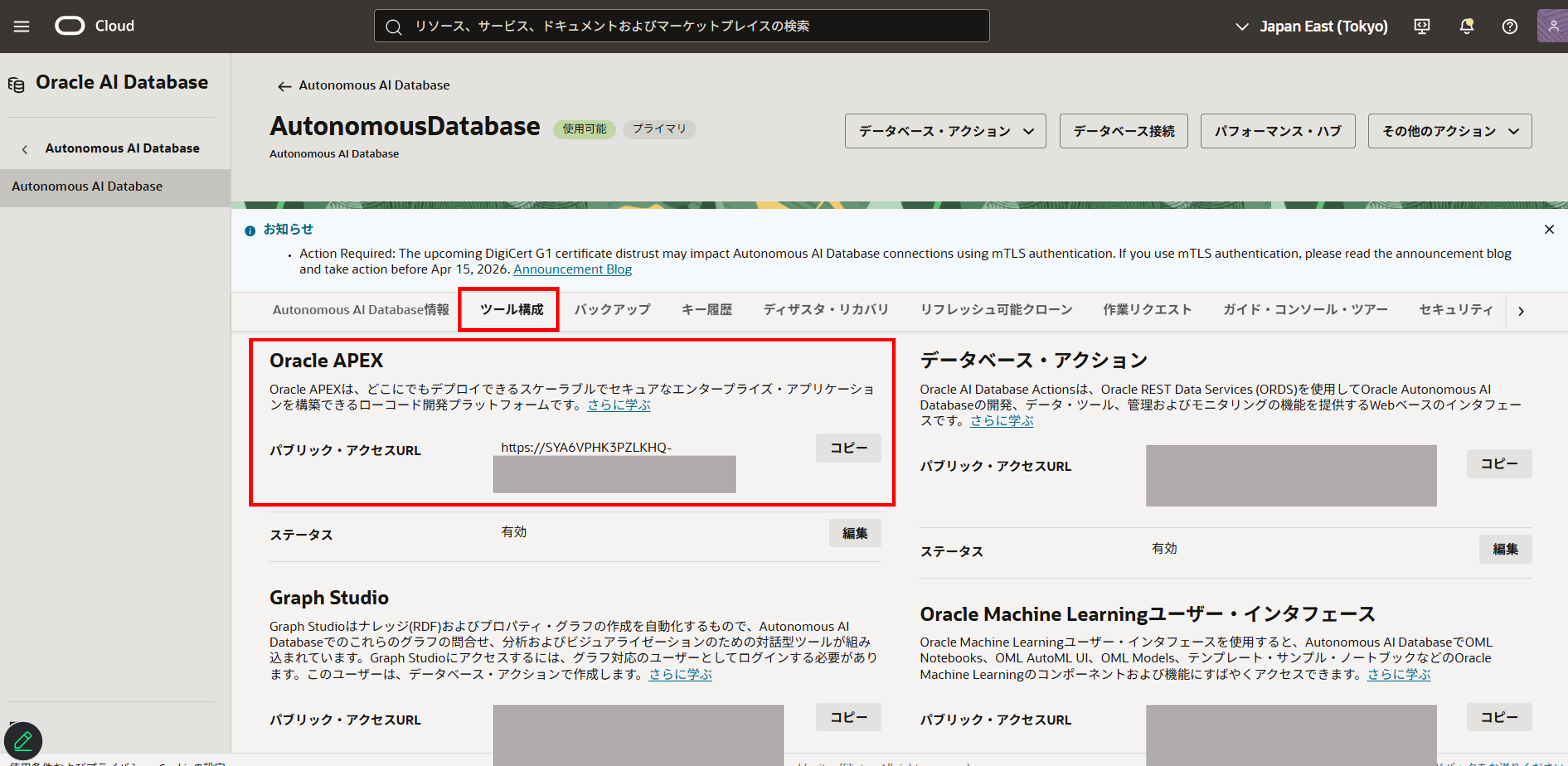
4. コピーしたURLにアクセスし、APEXの管理サービスにADMINユーザーでログインします。パスワードはADBのADMINパスワードと同じです。
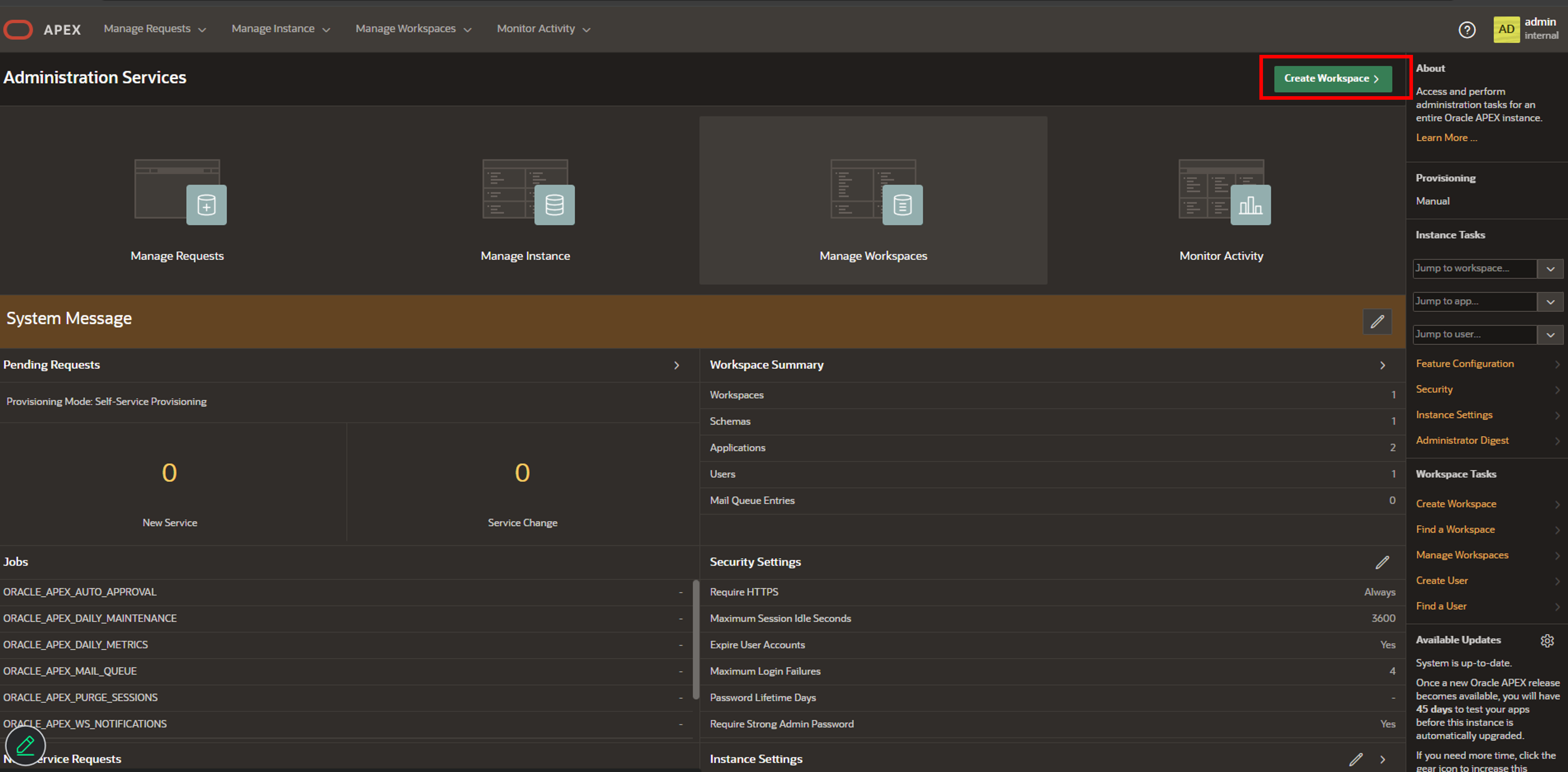
5. ワークスペースの作成をクリックします。
6. 先程APP_USERスキーマを作成したので、既存のスキーマを選択します。
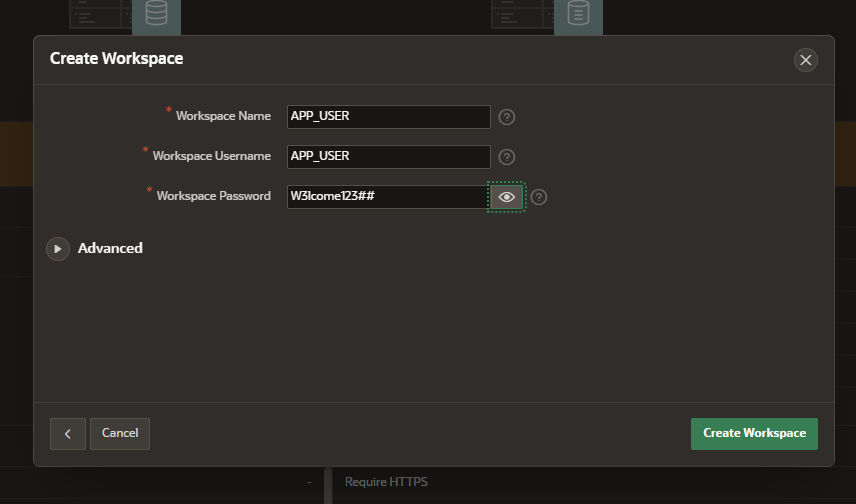
8. 右上でADMINからサインアウトして、APP_USERで再度ログインができるか確認します。
それではSelect AIを利用するために必要なAPIキーの登録と、AIプロファイルの作成します。
1. SQLワークショップ>SQLコマンドをクリックします。
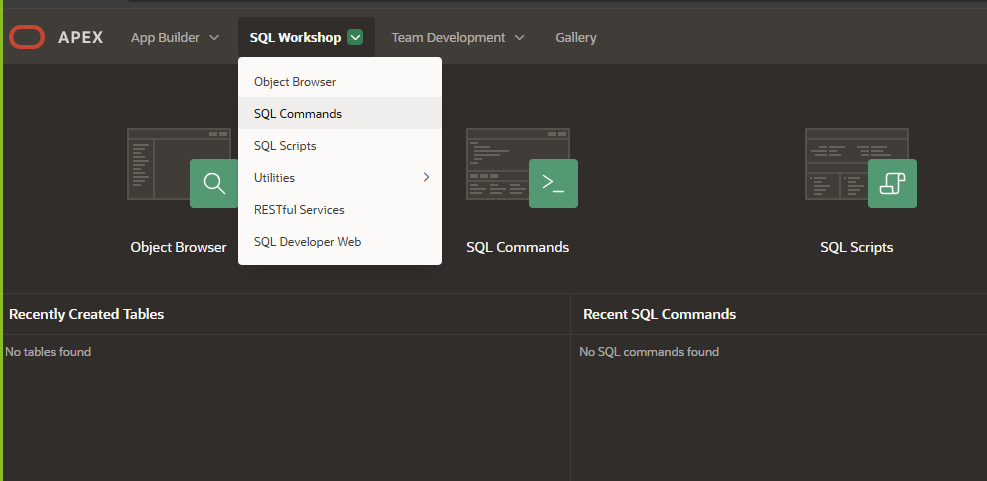
2. DBMS_CLOUD.CREATE_CREDENTIALプロシージャを使用して、OCI生成AIサービスに接続するためのクレデンシャルを作成(APIキーを登録)します。
以下の通りにOCID等を置き換え、プロシージャを実行します。
-
credential_name:任意(本チュートリアルではOCI_CREDとしています)
-
user_ocid:先ほどメモを取った構成ファイルを参照し、ユーザーのOCIDを入力
-
tenancy_ocid:先ほどメモを取った構成ファイルを参照し、使用しているテナンシーのOCIDを入力
-
private_key:先程取得した秘密キーの内容をコピー&ペースト
-
fingerprint:先ほどメモを取った構成ファイルを参照し、フィンガープリントを入力
```sql BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( credential_name => 'OCI_CRED', user_ocid => 'ocid1.user.oc1..axxxxxxxxxxxxxxxxq', tenancy_ocid => 'ocid1.tenancy.oc1..aaxxxxxxxxxxxxa', private_key => '-----BEGIN PRIVATE KEY----- MIIEvAIBADANBgkqhkiGQEFA<中略>1D3iheu1ct50SB0aIQz9Ow== -----END PRIVATE KEY-----', fingerprint => 'xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx' ); END; / ```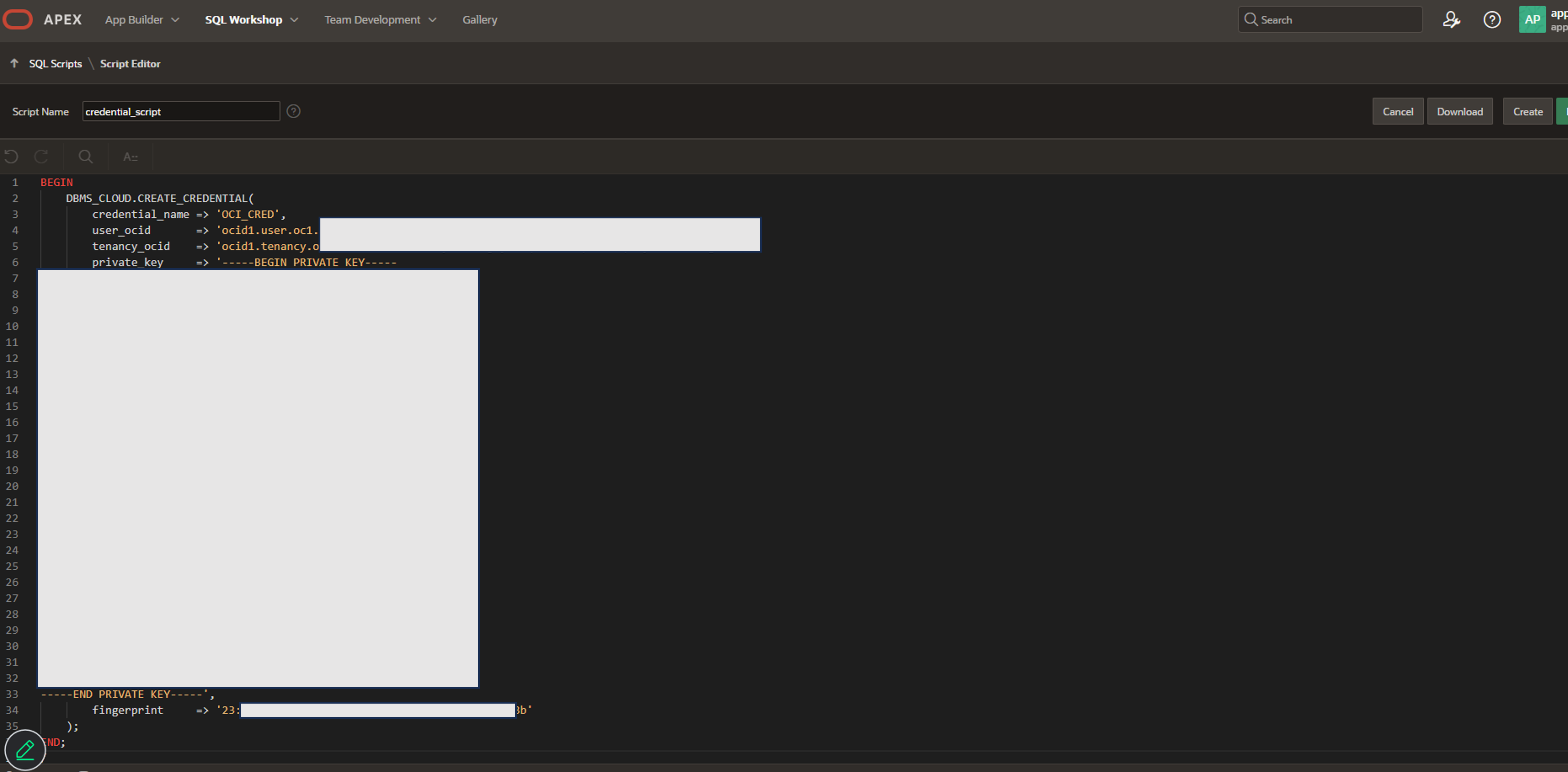
3. DBMS_CLOUD_AI.CREATE_PROFILEプロシージャを使用して、AIプロファイルを作成します。どのLLMを使用するか、どのエンベッディングモデルを使用するかこちらで指定します。
-
プロファイル名:RAG_PROFILE(任意)
-
provider:oci(本記事ではOCI生成AIサービスをAIプロバイダーとして使用)
-
credential_name:OCI_CRED(先ほど作成したクレデンシャル名を指定)
-
vector_index_name: MY_INDEX(任意)
-
embedding_model: cohere.embed-v4.0(任意)
-
model: xai.grok-code-fast-1
リージョンに関する注意点
BEGIN
DBMS_CLOUD_AI.CREATE_PROFILE(
profile_name =>'RAG_PROFILE',
attributes =>'{"provider": "oci",
"credential_name": "OCI_CRED",
"vector_index_name": "MY_INDEX",
"embedding_model": "cohere.embed-v4.0",
"model": "xai.grok-code-fast-1"
}');
end;
/
4. DBMS_CLOUD_AI.CREATE_VECTOR_INDEXプロシージャを使用して、ベクトル索引を作成します。
-
索引名:MY_INDEX(プロファイル作成時に指定した索引名)
-
vector_db_provider:oracle
-
location:先程作成したオブジェクトストレージのURI
-
object_storage_credential_name:OCI_CRED(先ほど作成したオブジェクトストレージのクレデンシャル)
-
profile_name:RAG_PROFILE(先程作成したプロファイル名)
-
vector_dimension:1536
-
vector_distance_metric:cosine
-
chunk_overlap:128
-
chunk_size:400
-
refresh_rate:1(ベクトル索引を更新する間隔。本チュートリアルでは1分毎に索引を更新するように設定します)
BEGIN DBMS_CLOUD_AI.CREATE_VECTOR_INDEX( index_name => 'MY_INDEX', attributes => '{"vector_db_provider": "oracle", "location": "https://objectstorage.ap-tokyo-1.oraclecloud.com/n/xxxxxxxxx/b/xxxxxxxxxx/o/", "object_storage_credential_name": "OCI_CRED", "profile_name": "RAG_PROFILE", "vector_dimension": 1536, "vector_distance_metric": "cosine", "chunk_overlap":128, "chunk_size":400, "refresh_rate":1 }'); END; /
DBMS_CLOUD_AI.CREATE_VECTOR_INDEXプロシージャDBMS_CLOUD_AI.CREATE_VECTOR_INDEXプロシージャを使用するだけで、RAG構成にするために必要な以下の作業が自動で行われます。
DBMS_CLOUD_AI.CREATE_VECTOR_INDEXプロシージャ実行時:
- オブジェクト・ストア内データのチャンキング
- エンベッディングモデルを使用し、チャンク化されたデータをエンベッディング
- ベクトル化されたデータを、ベクトル・ストアに格納
- ベクトル索引の作成
- ベクトル索引の自動更新(→ファイル追加時に手動での索引更新不要)
ユーザーから問い合わせがあった時:
- ユーザーからの問い合わせ(プロンプト)のベクトル化
- ベクトル化されたプロンプトを使ってベクトル検索
- ベクトル検索の結果を使ってLLMへ送信するプロンプトの補強
- LLMへのプロンプトの自動送信
- 生成された回答の表示(+回答生成に使用したファイルとその格納先も表示)
1. APEXのワークスペースにログインすると、この様な画面が表示されます。新たなアプリを作成するので、アプリケーション・ビルダーをクリックします。
2. 今回は既に作成済みのアプリケーションをインポートするので、インポートをクリックします。
3. インポートするアプリケーションをダウンロードします。こちらをクリックし、f101.zipというファイルをダウンロードします。
4. ダウンロードしたzipファイルをドラッグアンドドロップし、次へをクリックします。
5. アプリケーションのインストールをクリックします。
6. 次をクリックします。
7. サポートするオブジェクトのインストールもクリックし、表をインポートします。
これでAPEXのアプリケーションをインポートする事が出来ました。
データを出し分けをテストするためのユーザーを2アカウント作成します。
1.右上のCreate Workspaceをクリックし、表示されるモーダル画面で以下のように設定を行います。
東京ユーザーの作成
- New Schema
- Workspace Name: TOKYO_USER_WKSP
- Workspace Username: TOKYO_USER
- Workspace Password: 任意
大阪ユーザーの作成
- New Schema
- Workspace Name: OSAKA_USER_WKSP
- Workspace Username: OSAKA_USER
- Workspace Password: 任意
2.再び、アプリケーション・ビルダーをクリックします。
3.アプリケーション一覧が表示されるので、インポートしたADB Chatアプリの実行ボタンをクリックします。
4.OSAKA_USERでログインします。
5.使用するAIプロファイルを選択します。先程作成したRAG_PROFILEを選択します。
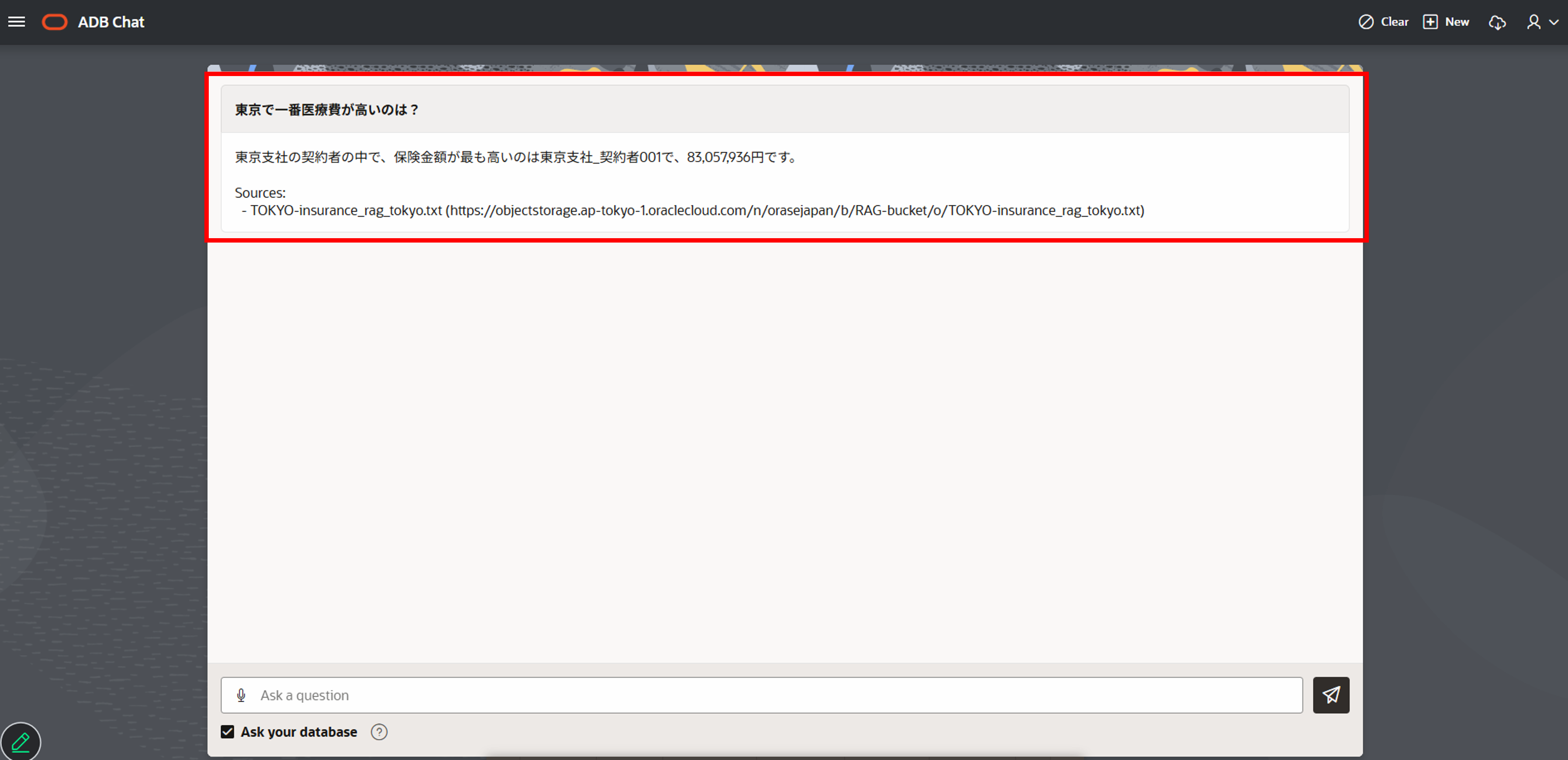
Ask your databaseにチェックを付けて質問するとRAGを利用して生成された返答が返ってきます。
現段階では大阪ユーザーへ東京のデータも元にした回答が返ってきますし、東京ユーザーへ大阪のデータも元にした回答返ってきてしまいます(図はOSAKA_USERで問い合わせた結果)。
ここではユーザー名に応じた回答の出し分けを行うため、データベース側に設定を施していきます。
VPDはルールに応じて表のデータへのアクセスを行および列レベルで制限することができる仕組みです。 ここまでの設定で、MY_INDEX表が自動で作成され、ベクトル化されたデータが入っています。 RAGが動作する際にはこのMY_Index表が利用されるので、問い合わせるユーザーごとにVPDで検索範囲を限定します。
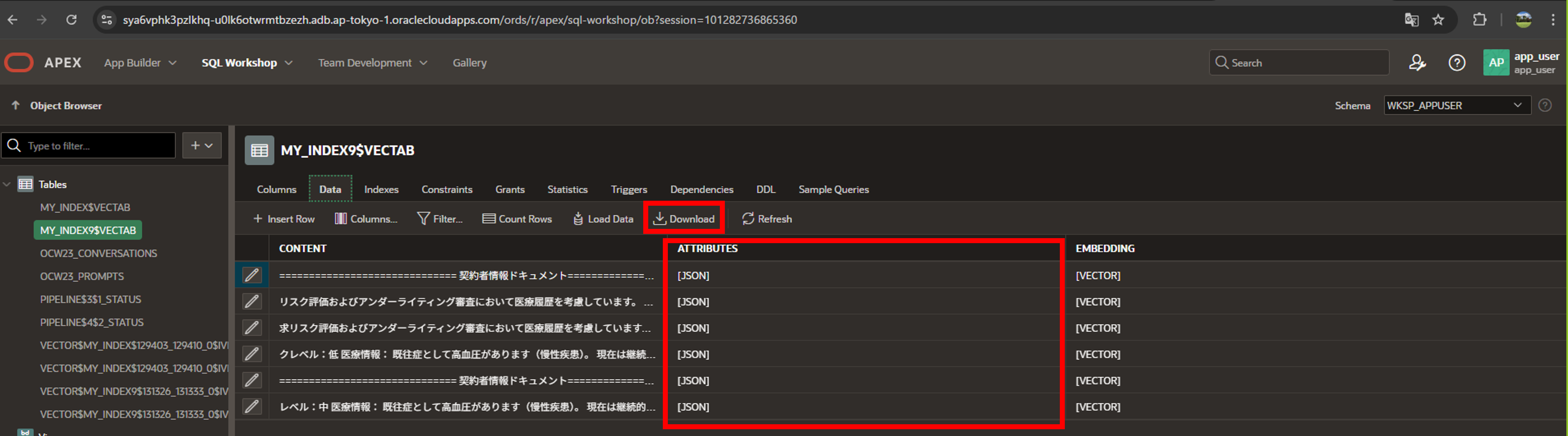
ATTRIBUTES列にはテキストファイル名やロケーションURLなどの情報がjson形式で記録されていますので、ここではファイルの接頭辞(TOKYO/OSAKA)をVPDのルールとして設定します。 データの詳細はCSVファイルをダウンロードして確認できます。
{"object_name":"TOKYO_insurance_rag.txt","object_size":1714,"last_modified":"2026-03-23T07:06:21+00:00","location_uri":"https://objectstorage.ap-xxx-1.oraclecloud.com/n/xxx/b/RAG-bucket/o/","start_offset":545,"end_offset":806}
- 続いて以下のPL/SQLコマンドを実行し、vpdfuncという関数を作成します。 この関数によって、アプリで問い合わせするユーザー名をもとにRAGの検索処理時に参照するデータを制御することができます。 TOKYO_USERではTOKYOから始まるファイルしか参照できず、OSAKA_USERではOSAKAから始まるファイルしか参照できないようになります。
CREATE OR REPLACE FUNCTION vpdfunc
(v_schema VARCHAR2, v_objname VARCHAR2)
RETURN VARCHAR2
AS
v_user VARCHAR2(100);
v_region VARCHAR2(20);
BEGIN
v_user := UPPER(SYS_CONTEXT('USERENV','CLIENT_IDENTIFIER'));
IF v_user Like 'OSAKA_%' THEN
v_region := 'OSAKA';
ELSIF v_user LIKE 'TOKYO_%' THEN
v_region := 'TOKYO';
END IF;
RETURN 'JSON_VALUE(attributes, ''$.object_name'') LIKE ''' || v_region || '%''';
END;
- 最後に、先ほど作成したvpdfunc関数を実行するポリシーを設定します。
BEGIN
DBMS_RLS.ADD_POLICY(
object_schema => 'WKSP_APPUSER',
object_name => 'MY_INDEX$VECTAB',
policy_name => 'VPDPOL',
function_schema => 'ADMIN',
policy_function => 'VPDFUNC');
END;
-
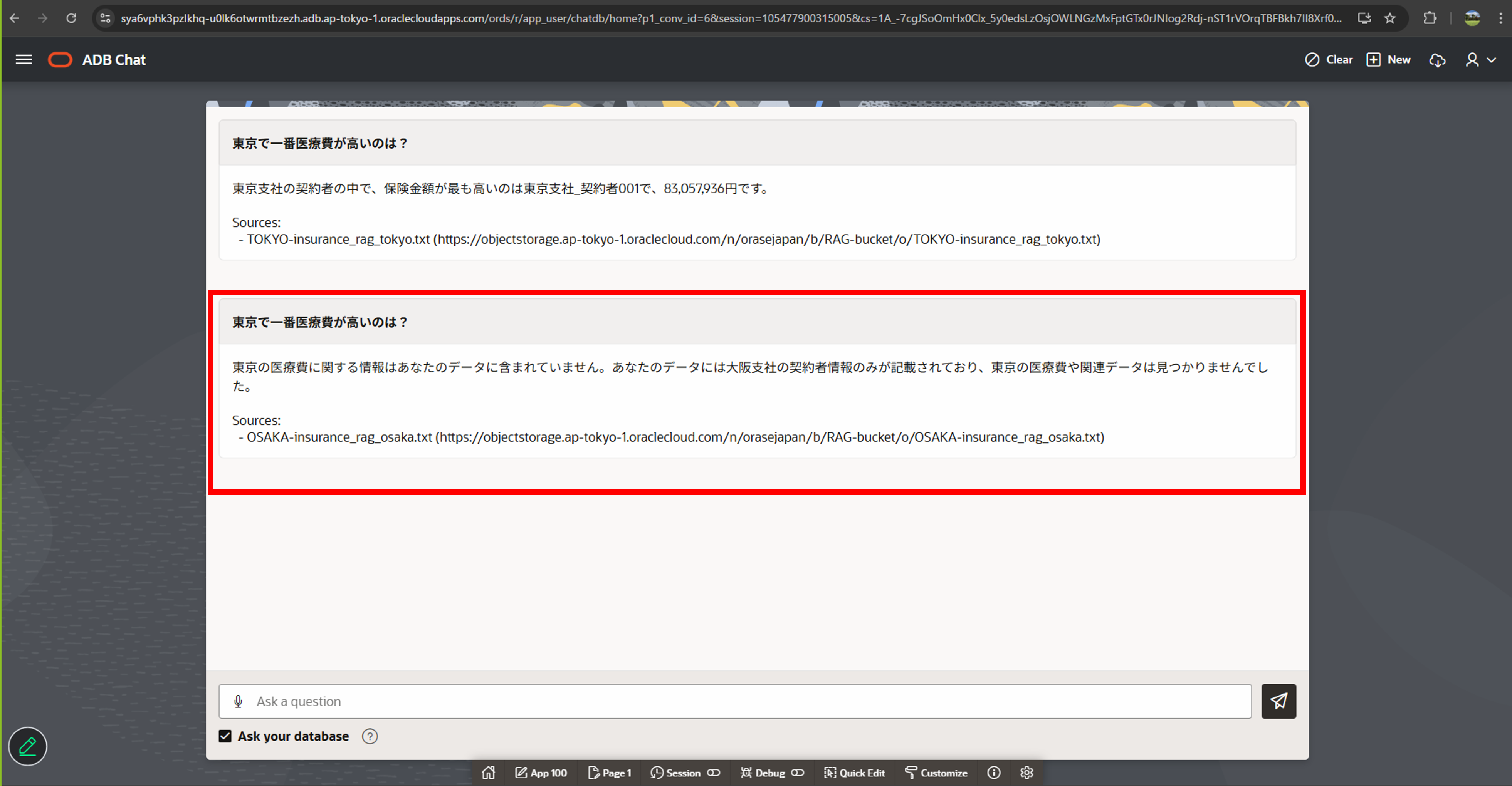
再びアプリにOSAKAユーザーとしてログインして問い合わせを行います。 大阪に関する質問以外は、データが含まれない旨が返ってきます。
-
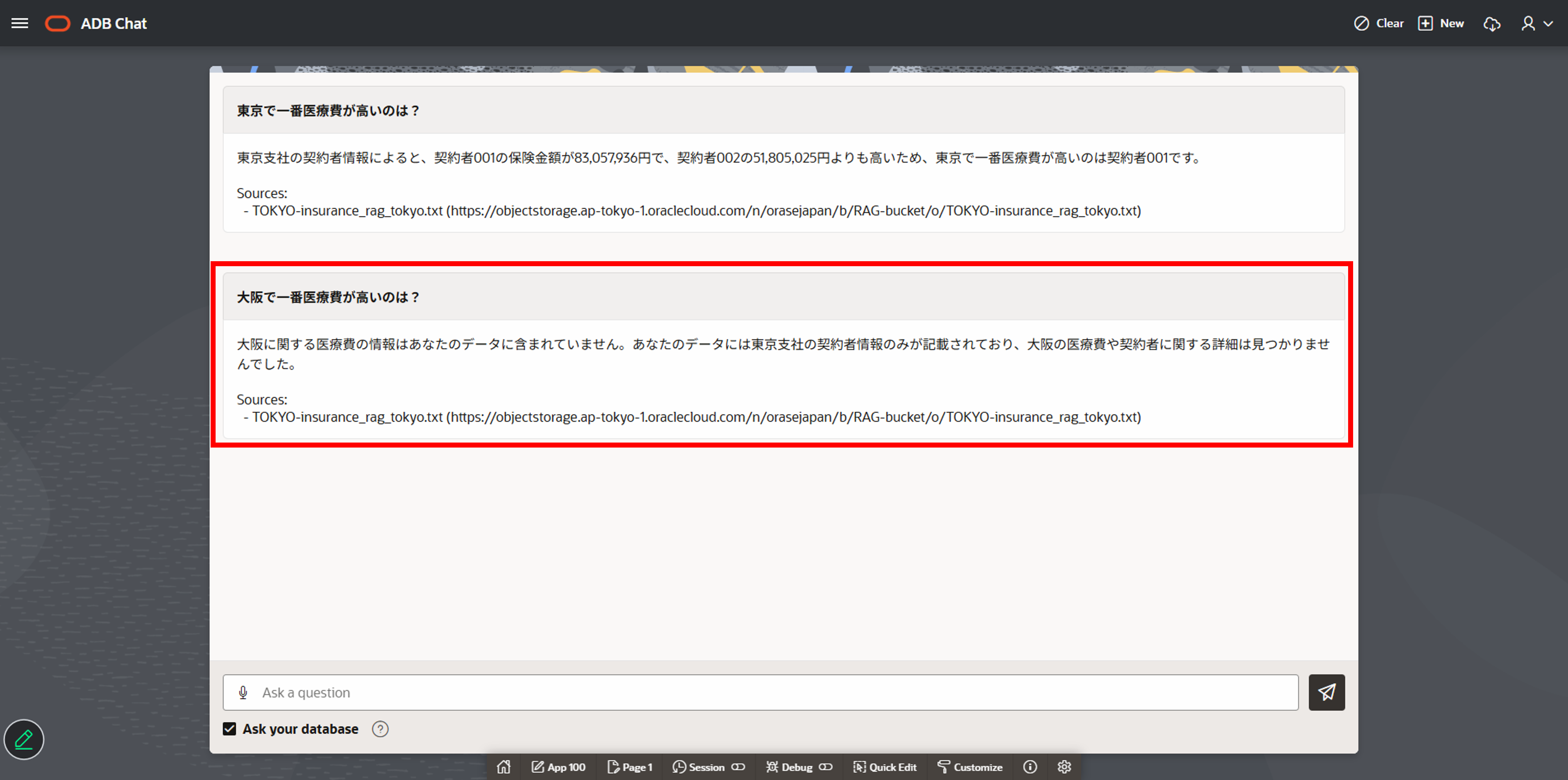
最後にTOKYOユーザーとしてログインして問い合わせを実行します。 東京に関する質問以外は、データが含まれない旨が返ってきます。
本記事では、RAGを用いたチャットシステムにおいて、ユーザーごとに回答内容を適切に出し分ける方法を解説しました。 RAGは非常に強力な仕組みである一方、検索対象のデータに対するアクセス制御を考慮しない場合、意図しない情報開示につながるリスクがあります。
そこで本構成では、Select AI with RAGによる検索・生成の仕組みに対し、データベース側のVPDを組み合わせることで、ユーザーの属性に応じた検索範囲の制御を実現しました。 これにより、**「見せてよいデータだけを検索させる」**という形で、RAGの安全性を担保しています。
このアプローチの重要なポイントは、アプリケーション側ではなくデータベース側で制御を行っている点です。 そのため、アプリケーションの実装に依存せず、一貫したポリシーでデータアクセスを管理できるというメリットがあります。
また、この仕組みは今回のような「拠点ごとのデータ分離」だけでなく、さまざまな応用が可能です。 例えば、以下のようなユースケースにも展開できます。
- 部門ごとのアクセス制御(人事・営業・経営層など)
- 役職に応じた情報開示レベルの制御
- 顧客ごとにデータを分離したマルチテナント型RAG
- 個人情報や機密情報を含むドキュメントの安全な活用
このように、RAGとデータベースのアクセス制御を組み合わせることで、セキュアな生成AIシステムを構築することができます。