
OpenMPIのMPI集合通信チューニング方法(BM.Optimized3.36編)
オープンソースのMPI実装である OpenMPI は、 Modular Component Architecture (以降 MCA と呼称します。)を採用することで、ビルド時に組み込むコンポーネントを介して集合通信を含む多彩な機能を提供し、この MCA パラメータにはMPI集合通信性能に影響するものがあります。
特にMPI集合通信の高速化を意識して開発されている HCOLL や Unified Collective Communication (以降 UCC と呼称します。)は、その特性を理解して適切に利用することで、MPI集合通信性能を大幅に向上させることが可能です。
また OpenMPI は、高帯域・低遅延のMPIプロセス間通信を実現するためにその通信フレームワークに UCX を採用し、この UCX のパラメータにもMPI集合通信性能に影響するパラメータが存在します。
またMPI集合通信は、ノード内並列では実質的にメモリコピーとなるため、メモリ性能に影響するMPIプロセスのコア割当てや NUMA nodes per socket (以降 NPS と呼称します。)もその性能に影響します。
以上を踏まえて本パフォーマンス関連Tipsは、第3世代 Intel Xeon プロセッサを搭載するベア・メタル・シェイプ BM.Optimized3.36 に於ける OpenMPI のMPI集合通信性能にフォーカスし、以下の 計測条件 を組合せたテストケース毎に以下の 実行時パラメータ を変えてその性能を Intel MPI Benchmarks で計測し、最適な 実行時パラメータ の組み合わせを導きます。
[計測条件]
- ノード数 : 1 ・ 2 ・ 4 ・ 8
- ノード当たりMPIプロセス数 : 8 ・ 16 ・ 32 ・ 36
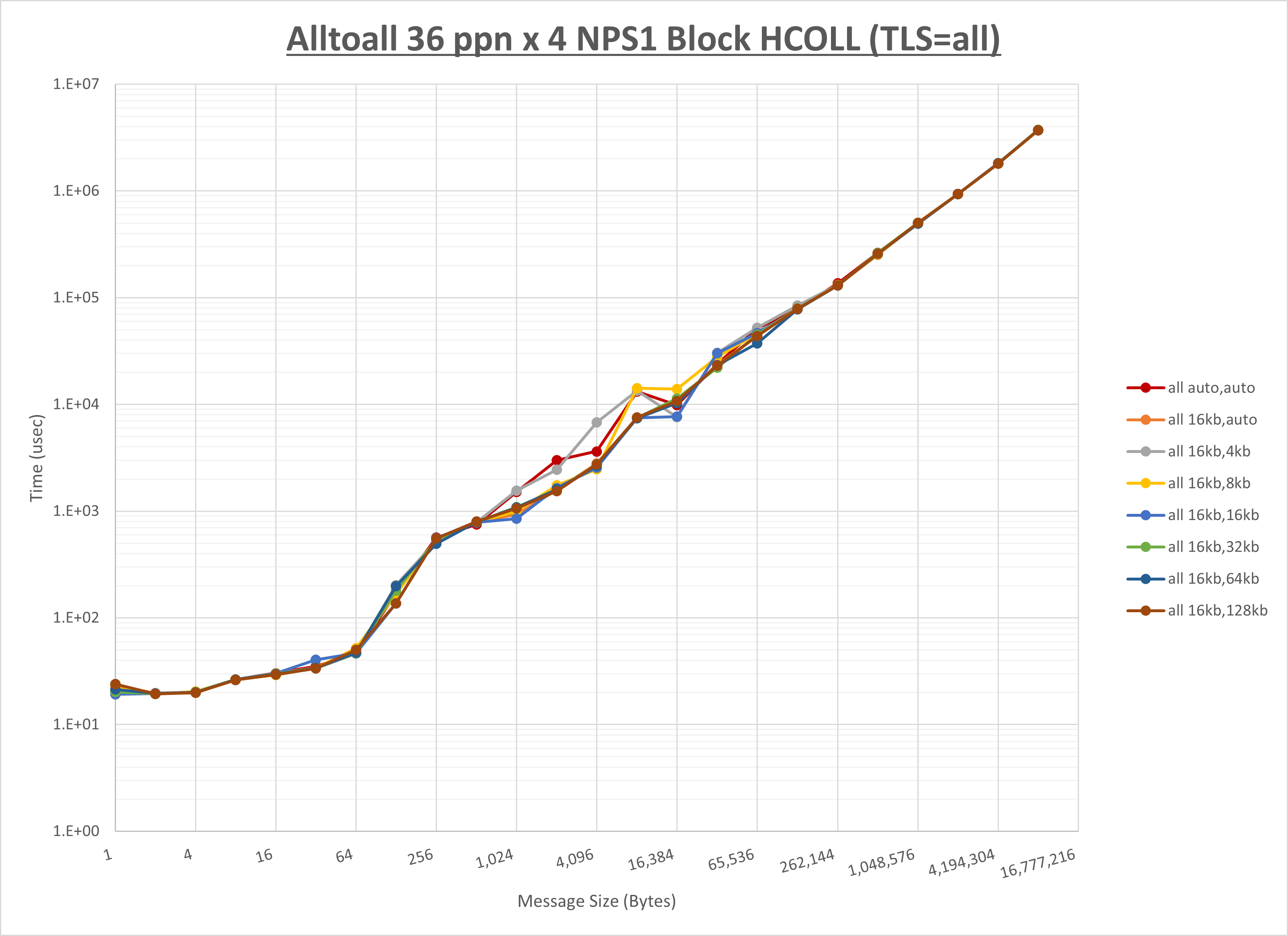
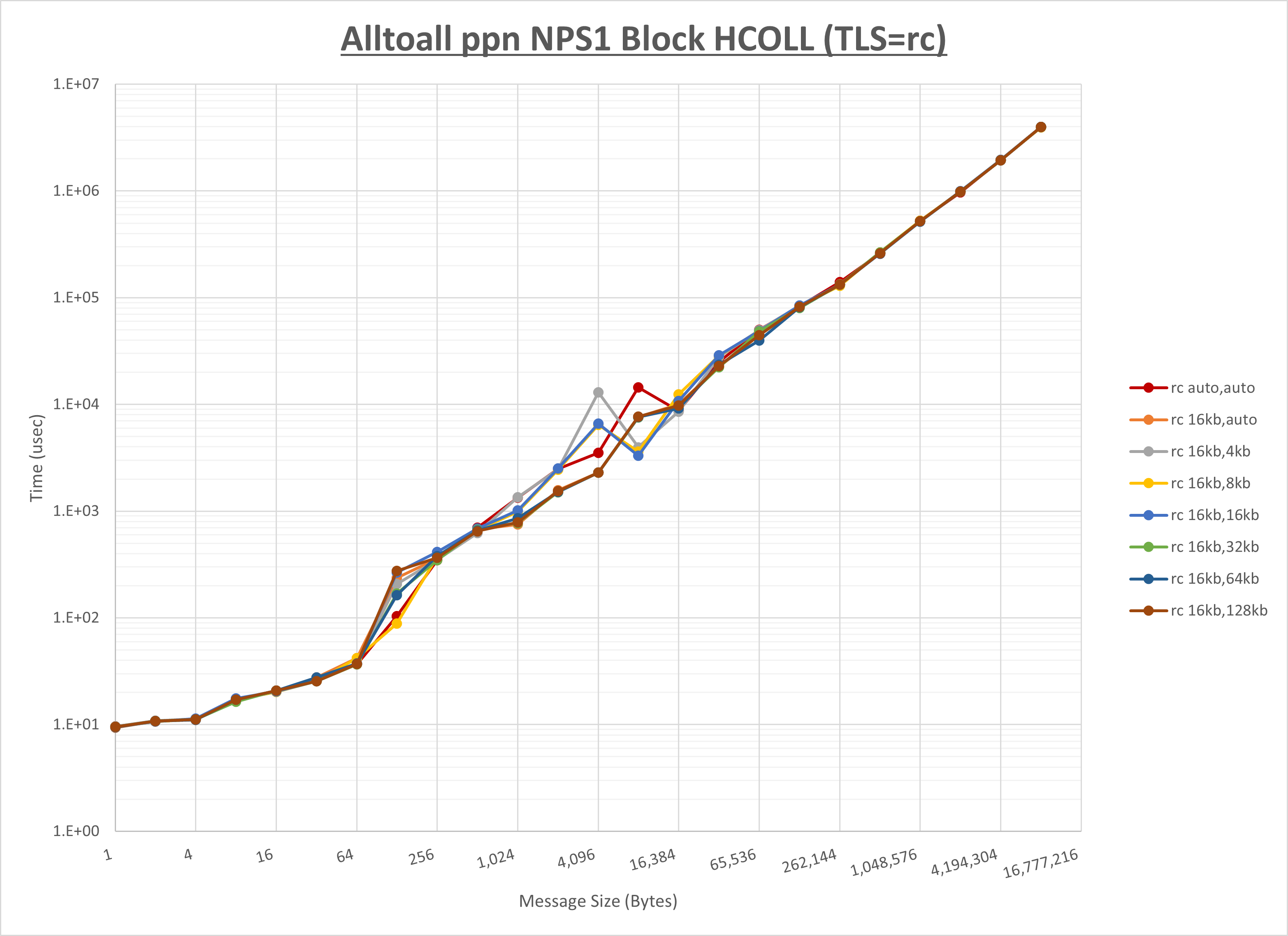
- MPI集合通信関数 : Alltoall ・ Allgather ・ Allreduce ・ Exchange (※1)
※1) Exchange はMPI集合通信関数ではありませんが、 Intel MPI Benchmarks で Parallel Transfer に分類される MPI_Isend ・ MPI_recv ・ MPI_Waitall を組み合わせたベンチマークで、実アプリケーションで頻繁に出現する解析モデル領域分割境界のデータ交換に使用される通信パターンです。
[実行時パラメータ]
- UCX_TLS : all ・ self,sm,rc ・ self,sm,ud ・ self,sm,dc (※2)
- UCX_RNDV_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb (※3)
- UCX_ZCOPY_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb (※4)
- coll_hcoll_enable : 0 ・ 1 (※5)
- coll_ucc_enable : 0 ・ 1 (※6)
- MPIプロセス分割方法 : ブロック分割・サイクリック分割(※7)
- NPS : 1 (以降 NPS1 と呼称します。)・ 2 (以降 NPS2 と呼称します。)
※2) UCX のパラメータで、2ノード以上の 計測条件 で使用します。詳細は OCI HPCパフォーマンス関連情報 の OpenMPIのMPI通信性能に影響するパラメータとその関連Tips の 3-4. UCX_TLS を参照してください。
※3) UCX のパラメータで、詳細は OCI HPCパフォーマンス関連情報 の OpenMPIのMPI通信性能に影響するパラメータとその関連Tips の 3-6. UCX_RNDV_THRESH を参照してください。
※4) UCX のパラメータで、2ノード以上の 計測条件 で使用します。詳細は OCI HPCパフォーマンス関連情報 の OpenMPIのMPI通信性能に影響するパラメータとその関連Tips の 3-7. UCX_ZCOPY_THRESH を参照してください。
※5) MCA のパラメータで、詳細は OCI HPCパフォーマンス関連情報 の OpenMPIのMPI通信性能に影響するパラメータとその関連Tips の 3-1. coll_hcoll_enable を参照してください。なお Exchange は HCOLL の影響を受けないため、 coll_hcoll_enable の評価を行いません。
※6) MCA のパラメータで、詳細は OCI HPCパフォーマンス関連情報 の OpenMPIのMPI通信性能に影響するパラメータとその関連Tips の 3-9. coll_ucc_enable を参照してください。なお Exchange は UCC の影響を受けないため、 coll_ucc_enable の評価を行いません。
※7)NUMAノードに対するMPIプロセスの分割方法で、詳細は OCI HPCパフォーマンス関連情報 の パフォーマンスを考慮したプロセス・スレッドのコア割当て指定方法(BM.Optimized3.36編) を参照してください。
本パフォーマンス関連Tipsで使用する環境を以下に示します。
- 計算ノード
- シェイプ: BM.Optimized3.36
- ノード数: 最大8ノード
- イメージ: Oracle Linux 9.05ベースのHPC クラスタネットワーキングイメージ (※8)
- BIOS設定
- SMT : 無効(※9)
- NPS : NPS1 / NPS2(※9)
- ノード間接続インターコネクト
- クラスタ・ネットワーク (※10)
- リンク速度: 100 Gbps
- OpenMPI : 5.0.8(※11)
- OpenUCX : 1.19.0(※11)
- Intel MPI Benchmarks : 2025.10(※12)
※8)OCI HPCテクニカルTips集 の クラスタネットワーキングイメージの選び方 の 1. クラスタネットワーキングイメージ一覧 の No.13 です。
※9)SMT と NPS の設定方法は、 OCI HPCパフォーマンス関連情報 の パフォーマンスに関連するベアメタルインスタンスのBIOS設定方法 を参照してください。
※10)本テクニカルTipsの2ノード以上の計測は、 クラスタ・ネットワーク の同一リーフスイッチに接続するインスタンスを使用して行っています。同一リーフスイッチに接続するインスタンス間のノード間接続に於ける効果は、 OCI HPCパフォーマンス関連情報 の クラスタ・ネットワークのトポロジーを考慮したノード間通信最適化方法 を参照してください。
※11) OCI HPCテクニカルTips集 の Slurm環境での利用を前提とするUCX通信フレームワークベースのOpenMPI構築方法 に従って構築された OpenMPI と OpenUCX です。
※12) OCI HPCパフォーマンス関連情報 の Intel MPI Benchmarks実行方法 の 1. OpenMPIでIntel MPI Benchmarksを実行する場合 に従って構築された Intel MPI Benchmarks です。
また Intel MPI Benchmarks の計測は、 numactl コマンドを介して以下の実行時オプションを指定して起動します。
$ numactl -l IMB-MPI1 -msglog 0:xx -mem 2.3G -off_cache 39,64 -npmin num_of_procs alltoall/allgather/allreduce/exchange
ここで計測するメッセージサイズの上限( xx )は、MPI集合通信関数とノード数に応じて以下の値を使用します。
この設定値は、計測可能な最大値から決定しています。
| 1ノード | 2ノード | 4ノード | 8ノード | |
|---|---|---|---|---|
| Alltoall | 25 | 24 | 23 | 22 |
| Allgather | 25 | 24 | 23 | 22 |
| Allreduce | 30 | 30 | 30 | 30 |
| Exchange | 29 | 29 | 29 | 29 |
また Intel MPI Benchmarks の計測は、出力中の t_max (集合通信に参加する全てのMPIプロセスの所要時間のうち、最大のものです。)を採用し、各テストケースを5回実施してメッセージサイズ毎に最大値と最小値を除く3回の相加平均を算出、これをそのテストケースのそのメッセージサイズでの結果として使用します。
なお、本パフォーマンス関連Tipsで取得したMPI集合通信特性を使用して実アプリケーションにプロファイリング・チューニングを適用する実例は、 OCI HPCパフォーマンス関連情報 の プロファイリング情報に基づく並列アプリケーションチューニング方法 / プロファイリング情報に基づくOpenFOAMチューニング方法 を参照してください。
以降は、以下 計測条件 の順に解説します。
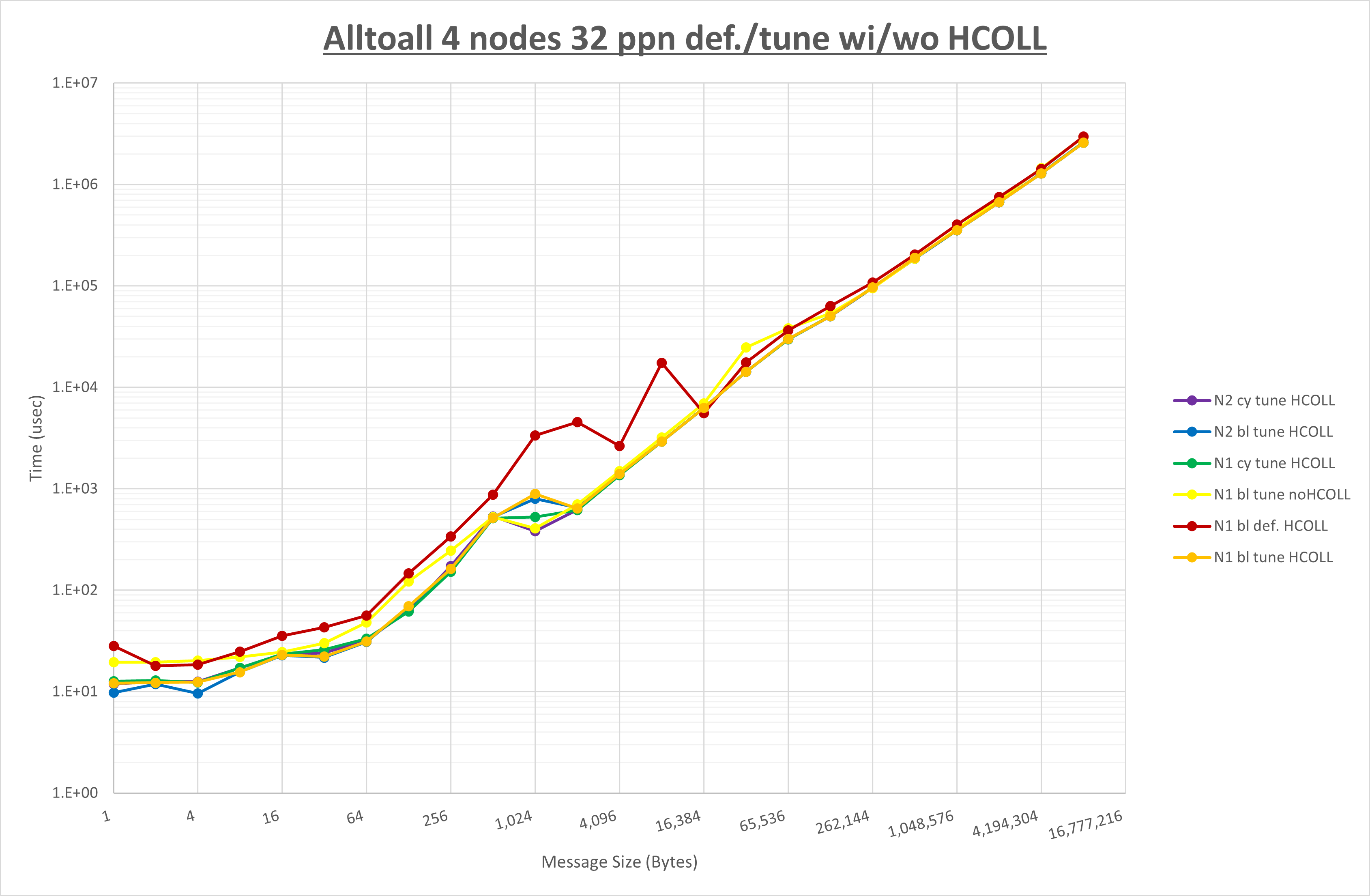
本章は、1ノードに8・16・32・36のMPIプロセスを割当てる場合の Alltoall ・ Allgather ・ Allreduce ・ Exchange の通信性能について、以下の 実行時パラメータ の最適な組み合わせを検証します。
- UCX_RNDV_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb
- coll_hcoll_enable : 0 ・ 1 ( Exchange を除きます。)
- coll_ucc_enable : 0 ・ 1 ( Exchange を除きます。)
- MPIプロセス分割方法 : ブロック分割・サイクリック分割
- NPS : NPS1 ・ NPS2
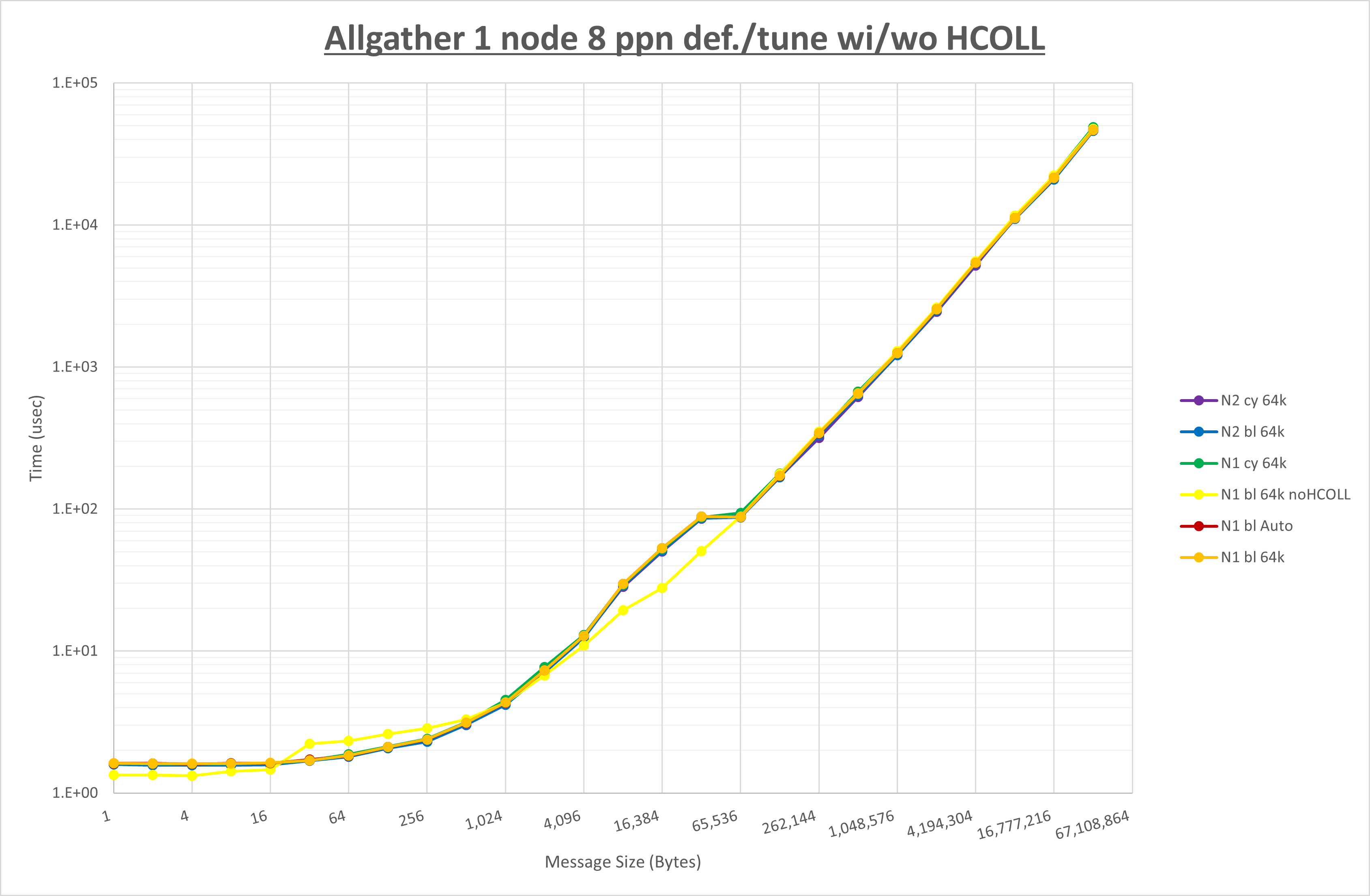
本章は、1ノードに8 MPIプロセスを割当てる場合の最適な 実行時パラメータ の組み合わせをMPI集合通信関数毎に検証し、その結果を考察します。
下表は、各MPI集合通信関数の最適な UCX_RNDV_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_RNDV_THRESH |
|---|---|
| Alltoall | 32KB |
| Allgather | 64KB |
| Allreduce | 128KB |
| Exchange | 32KB |
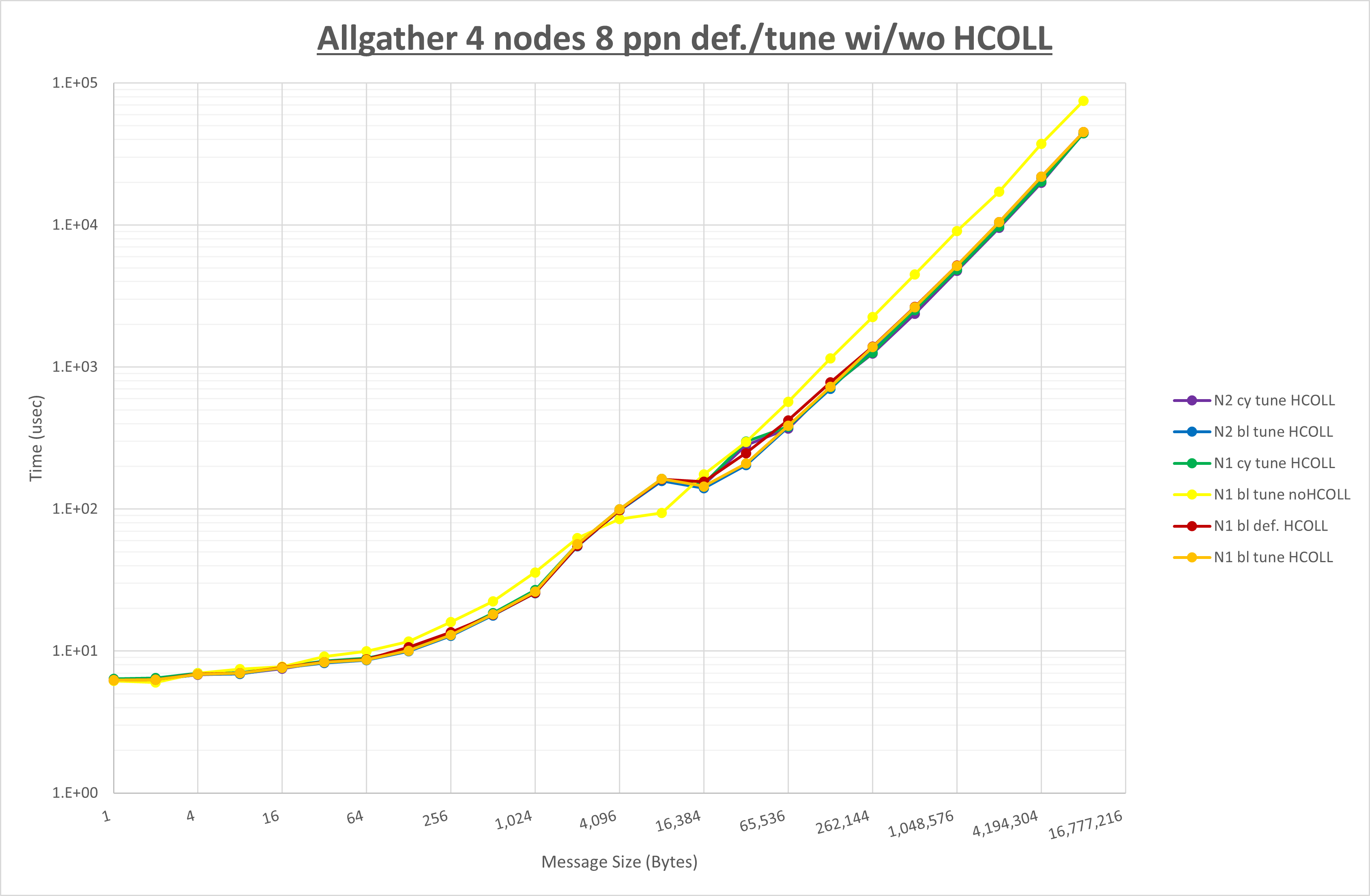
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
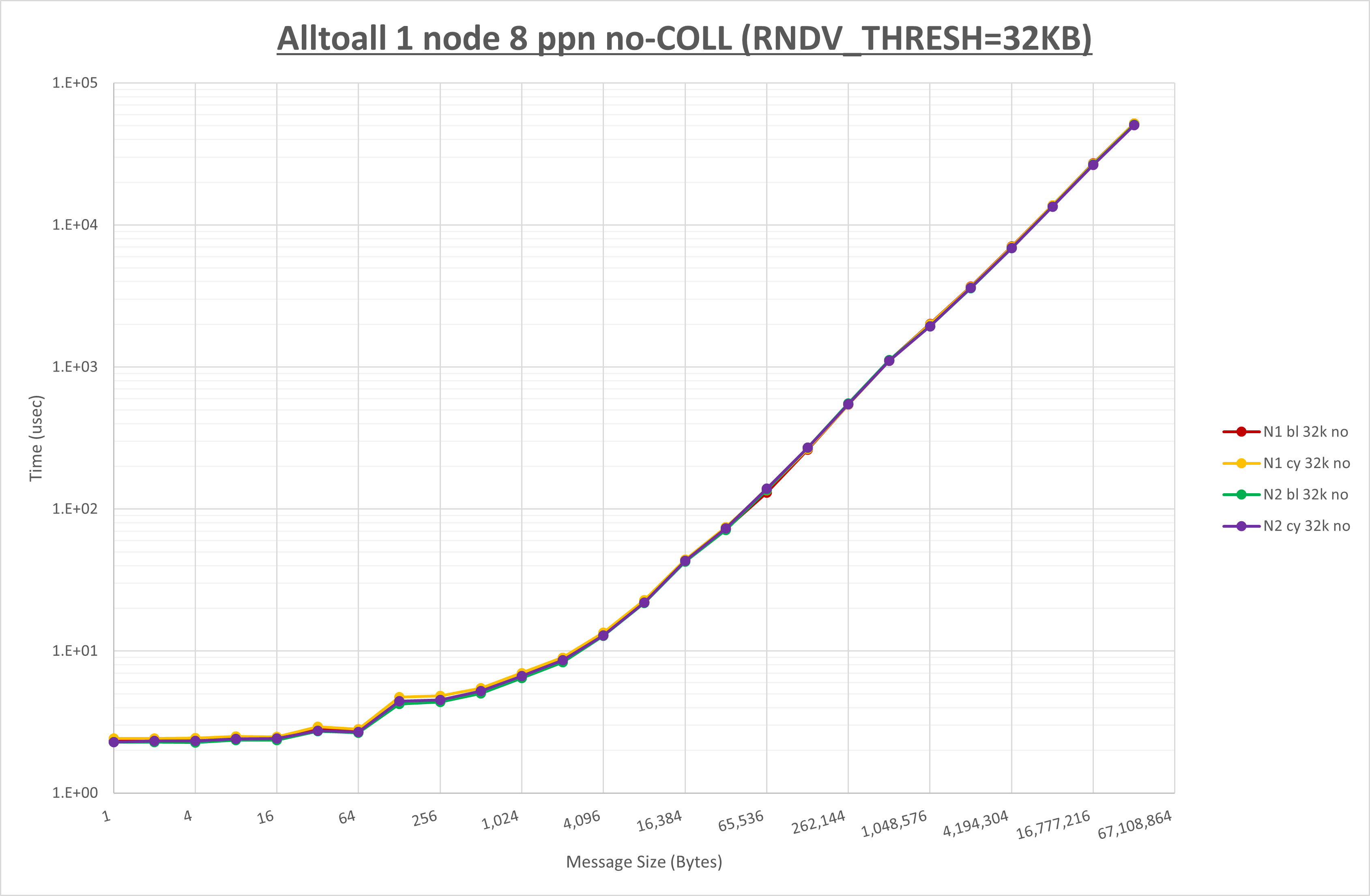
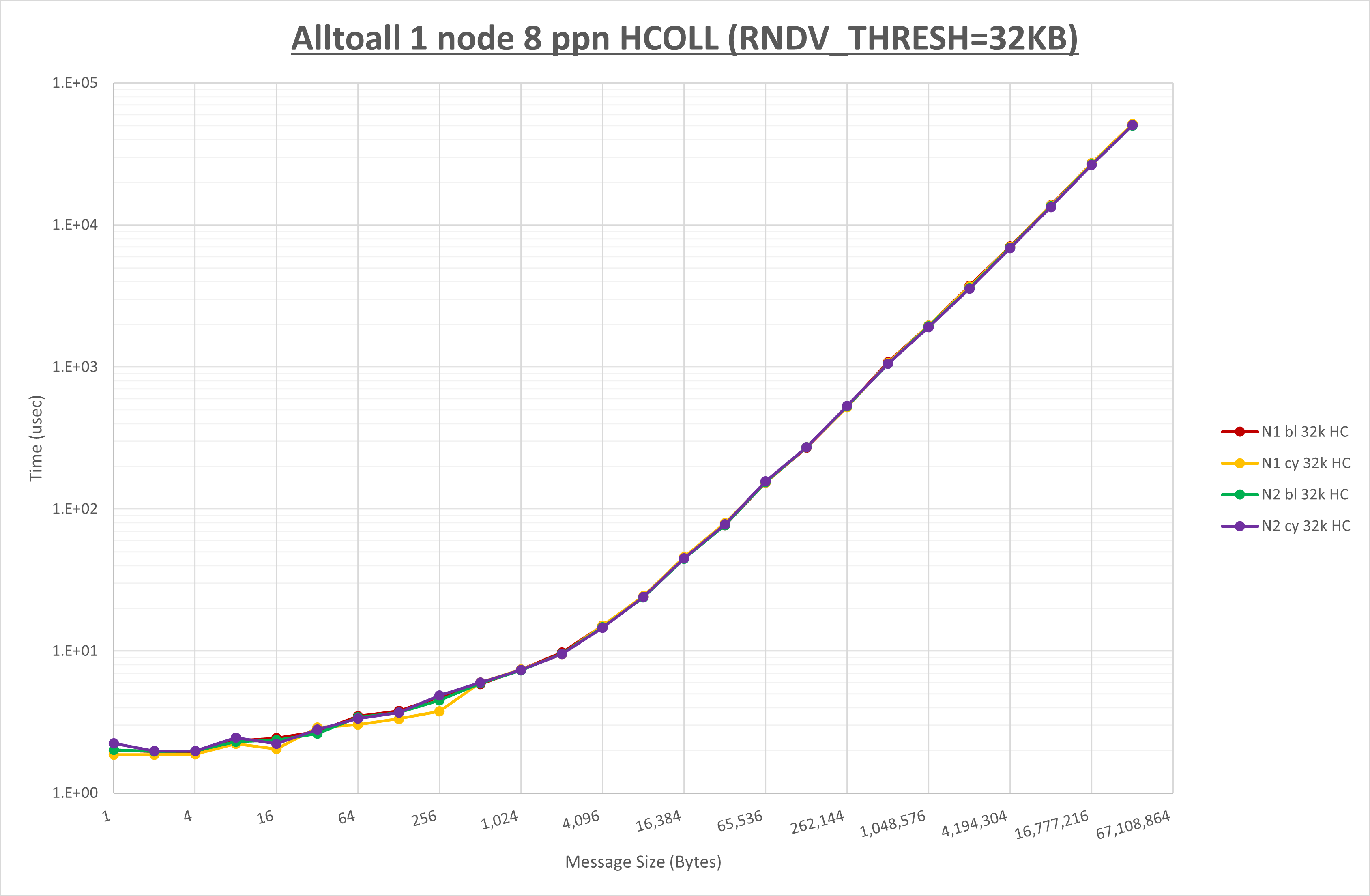
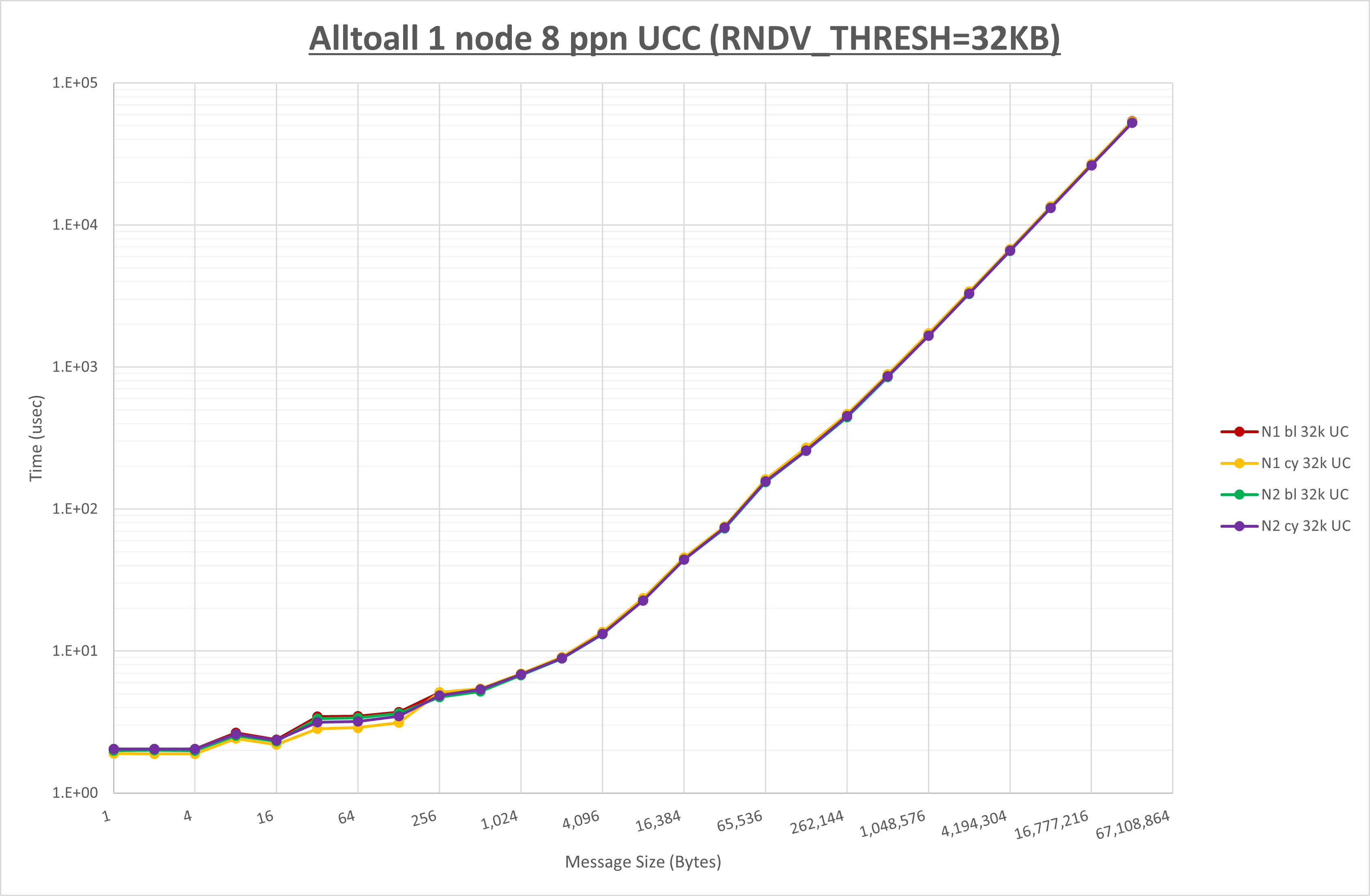
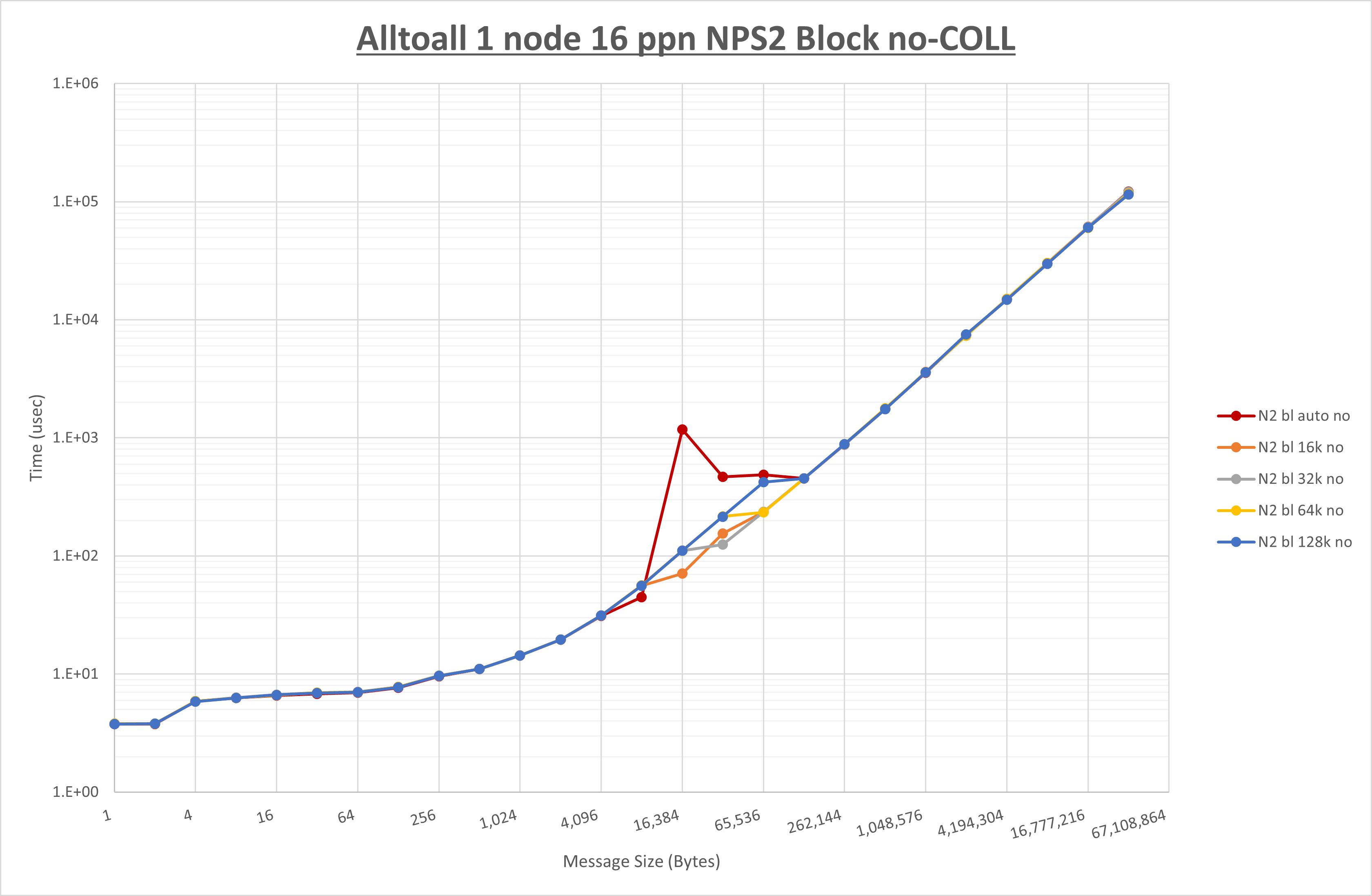
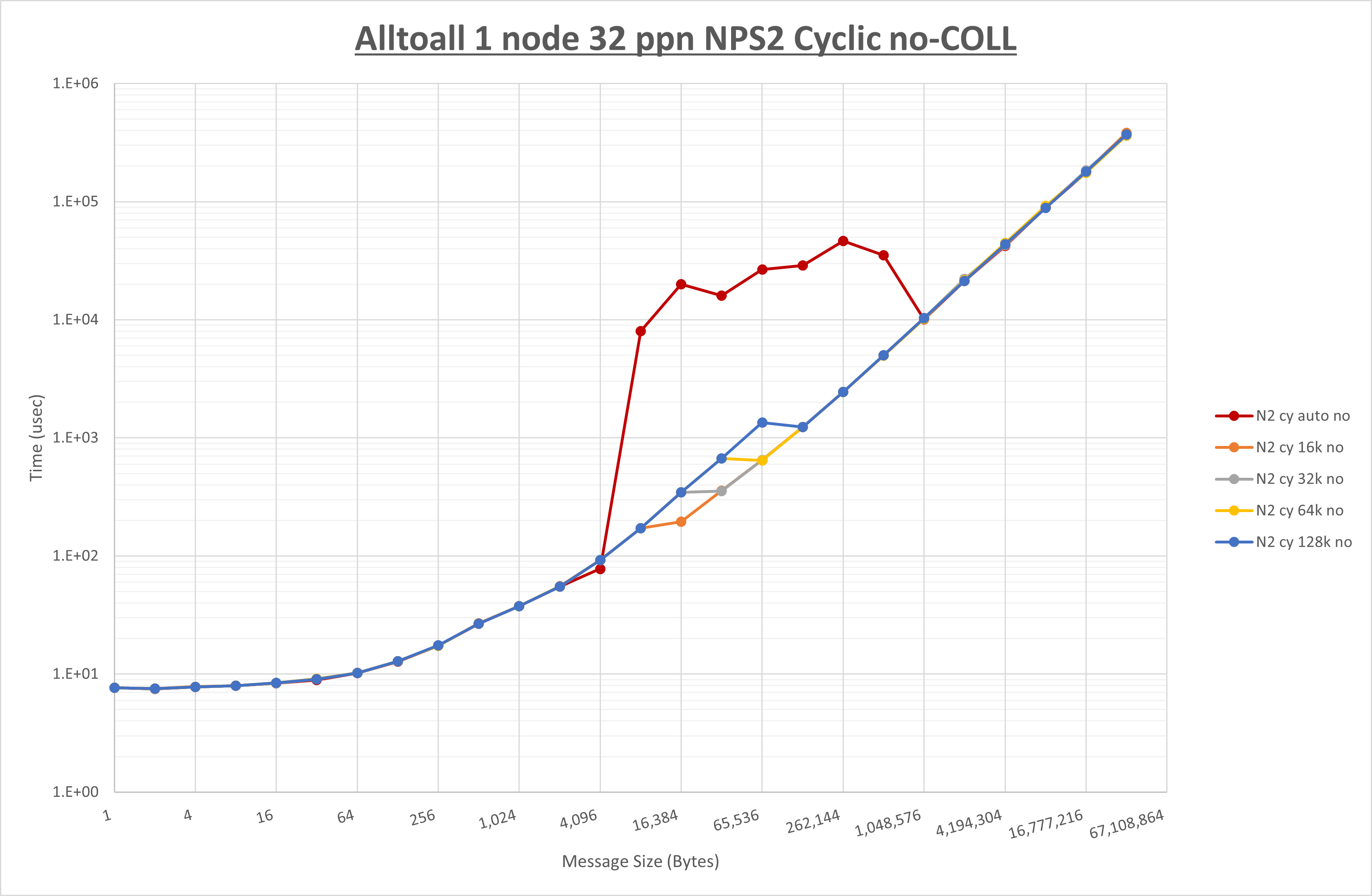
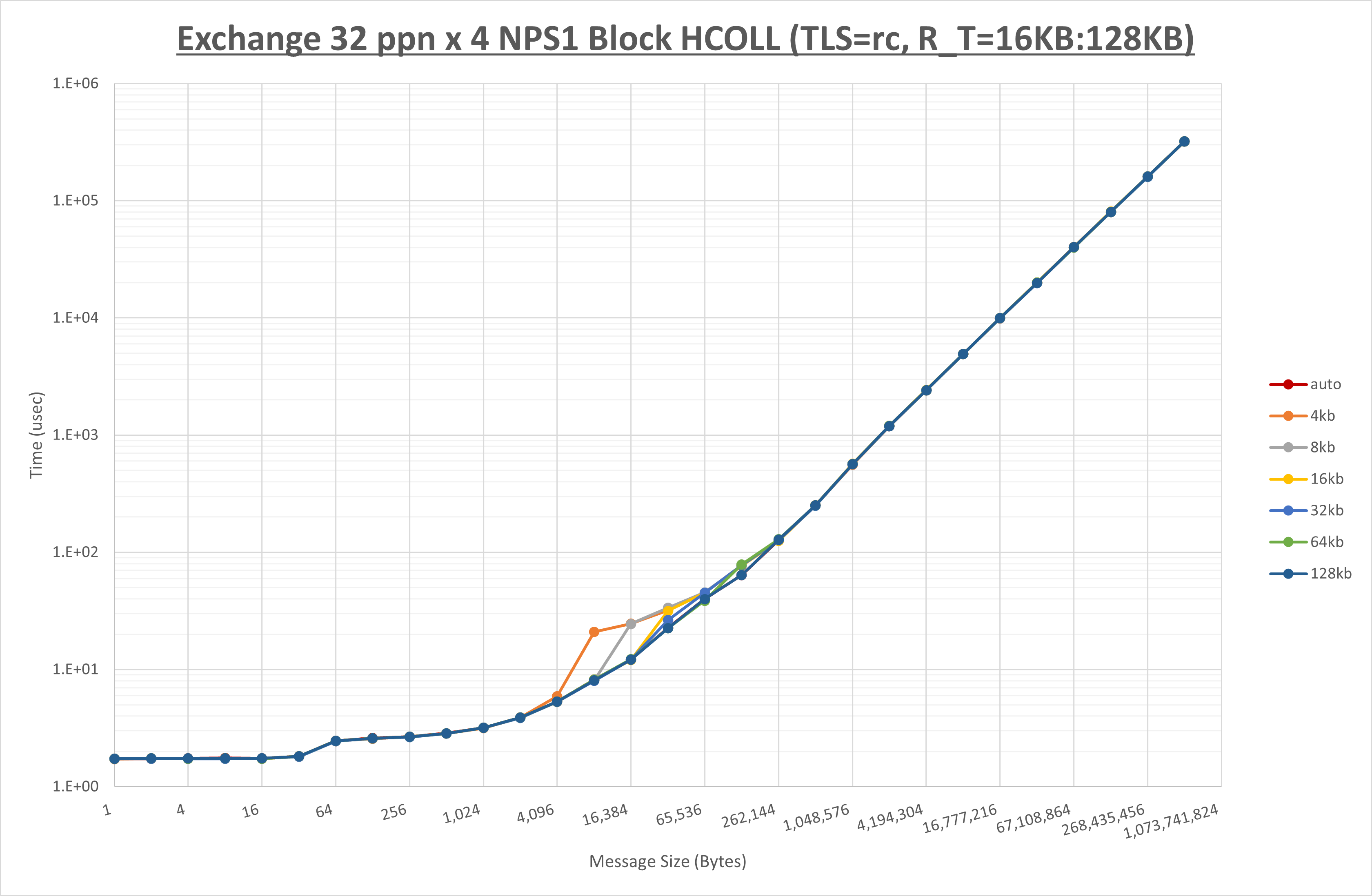
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
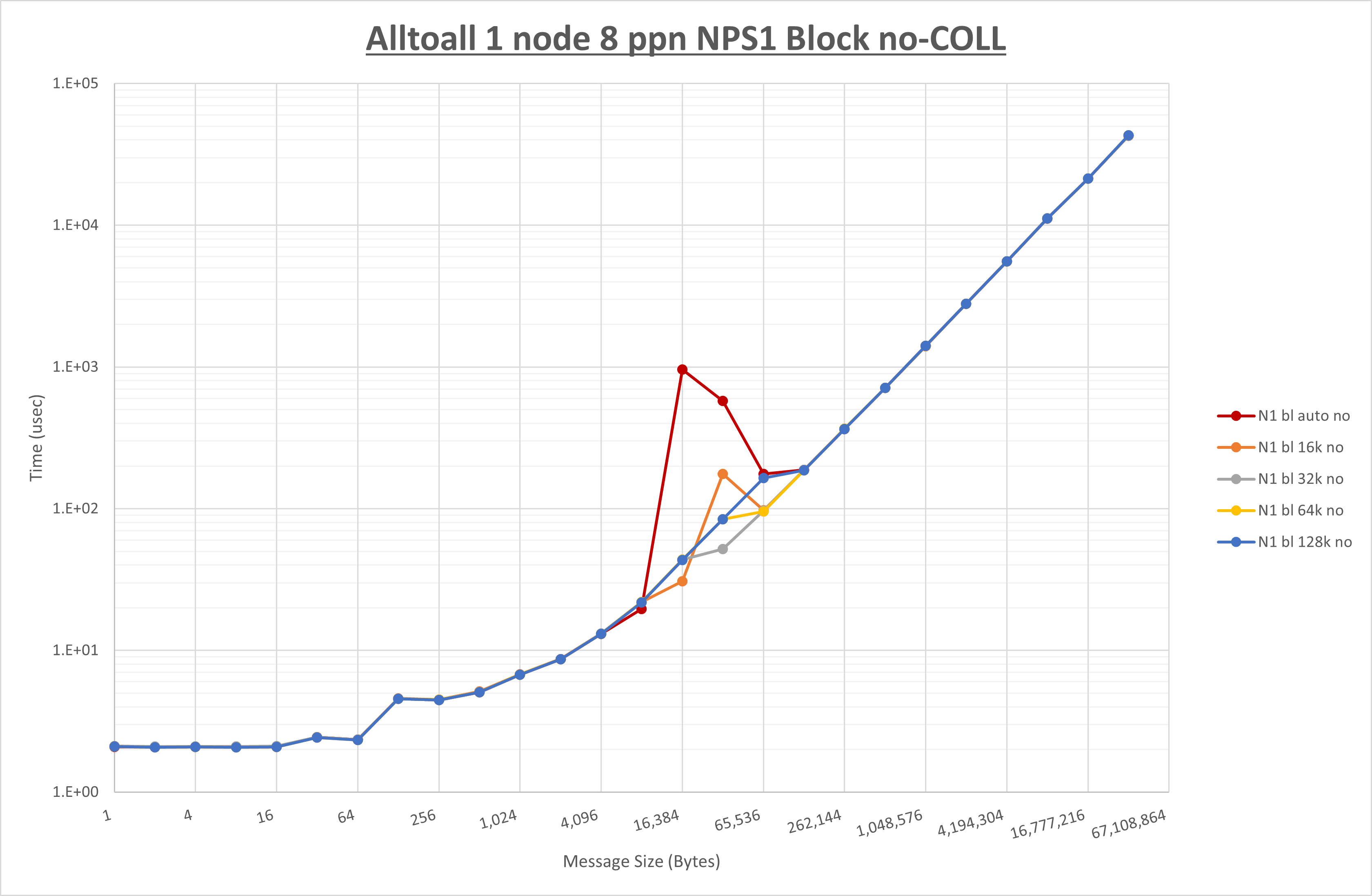
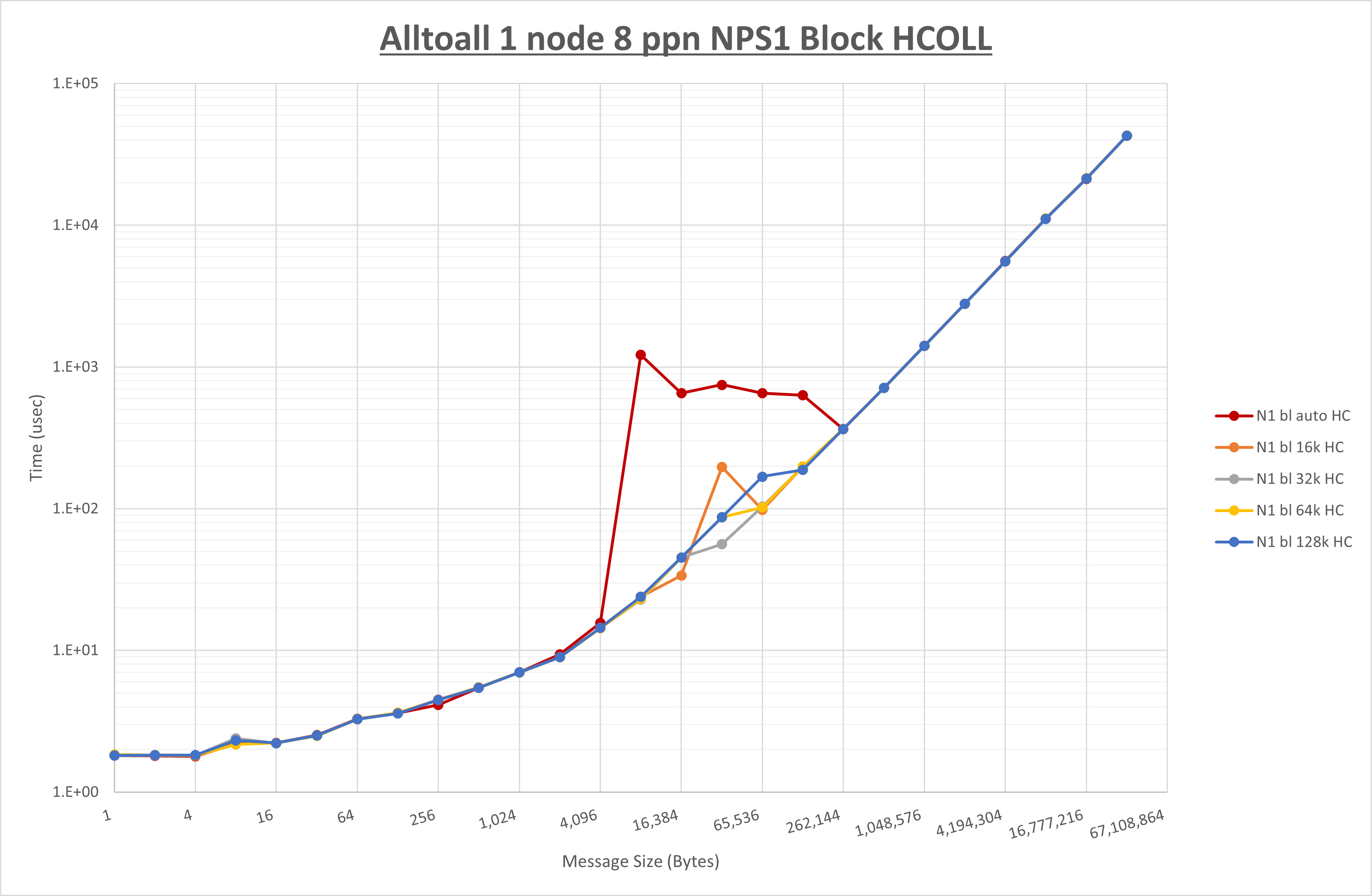
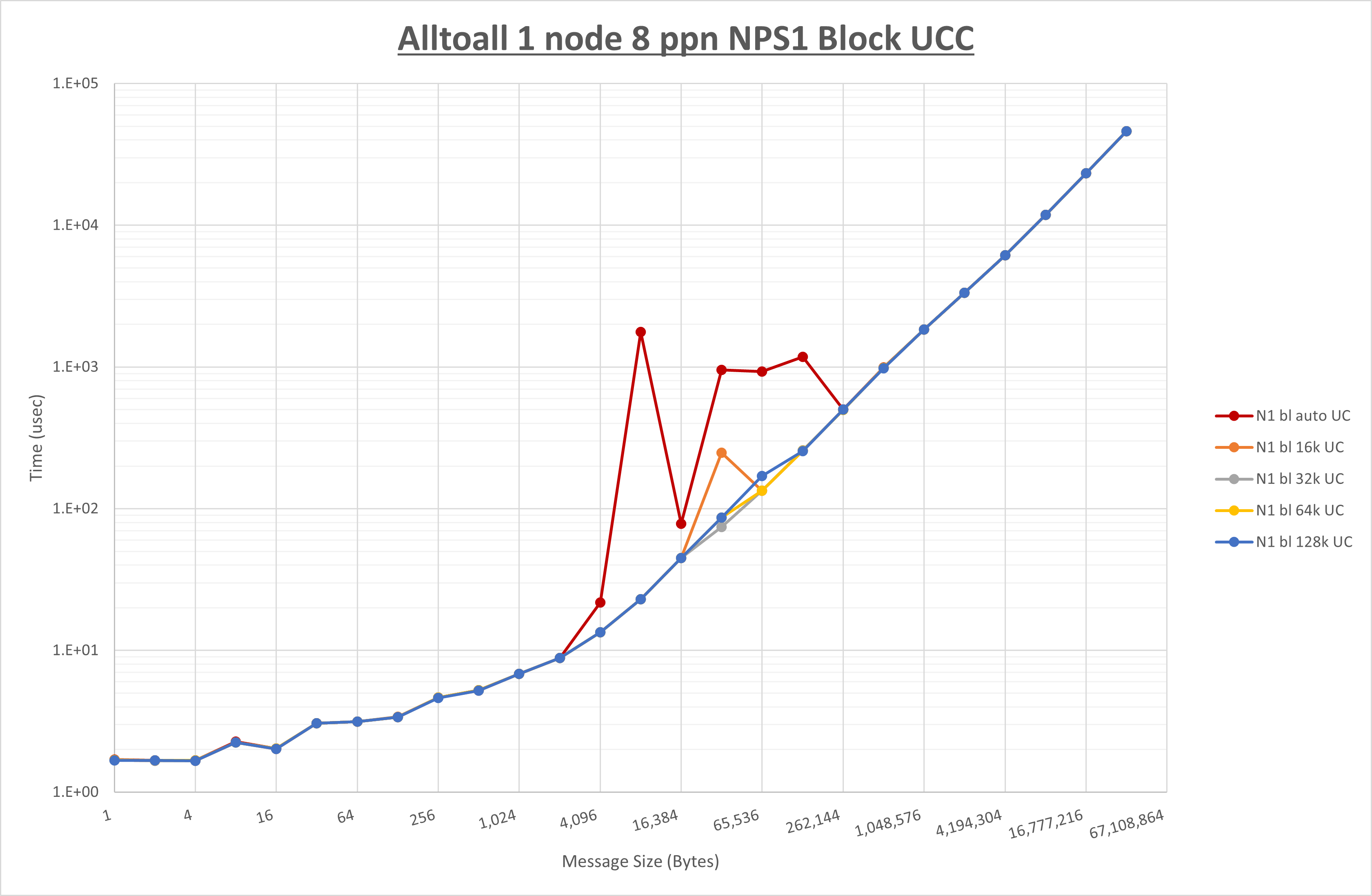
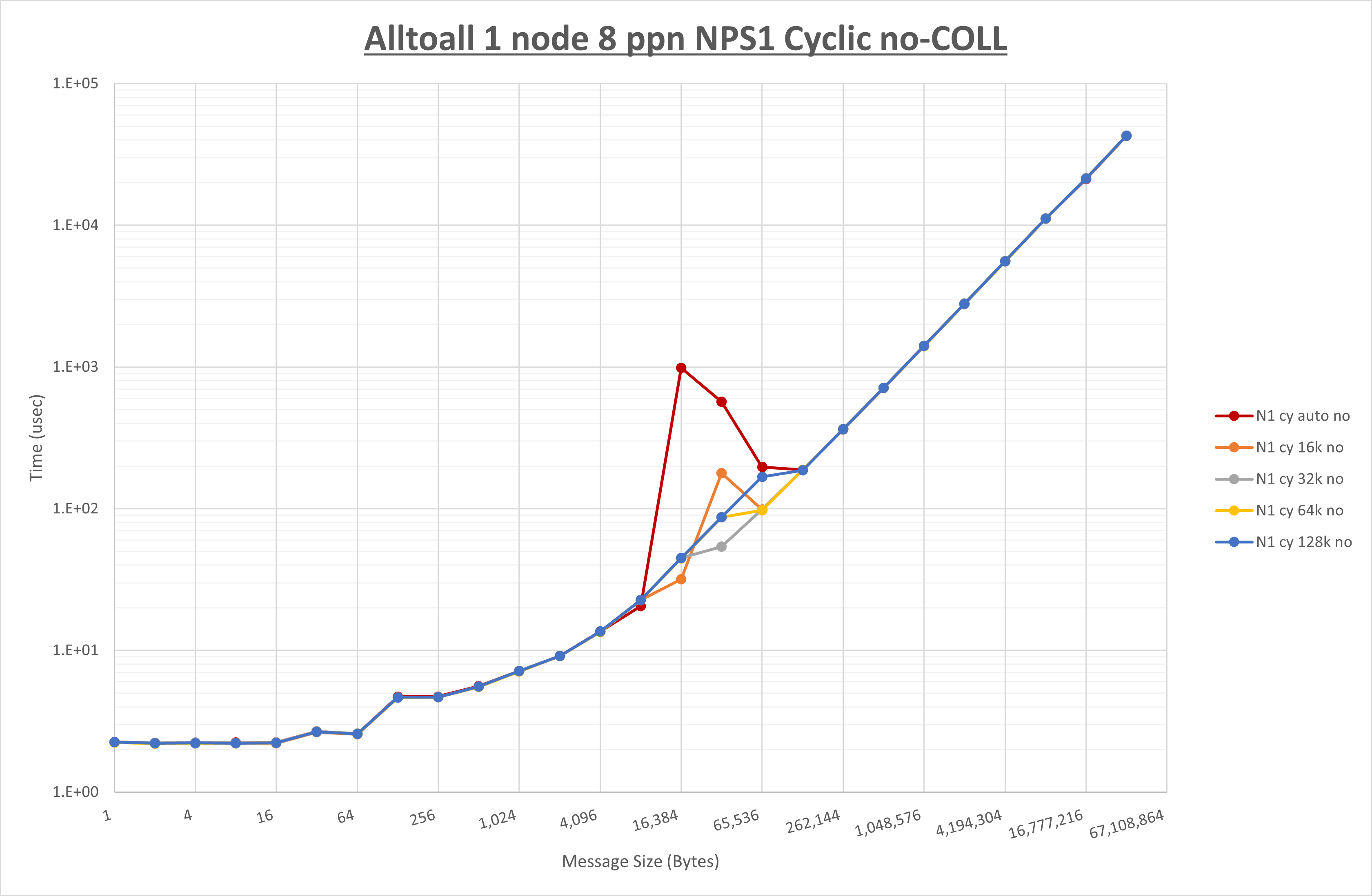
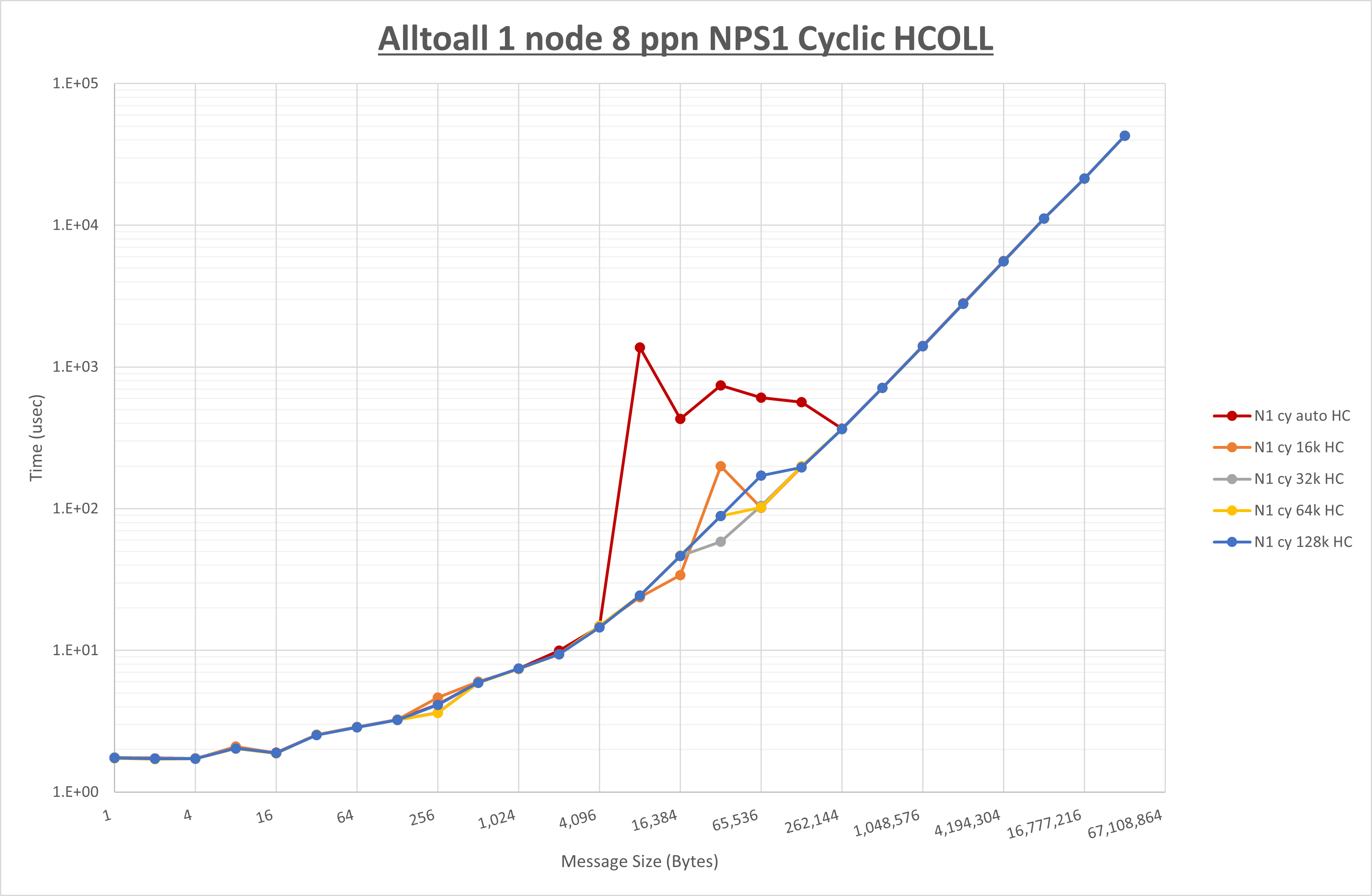
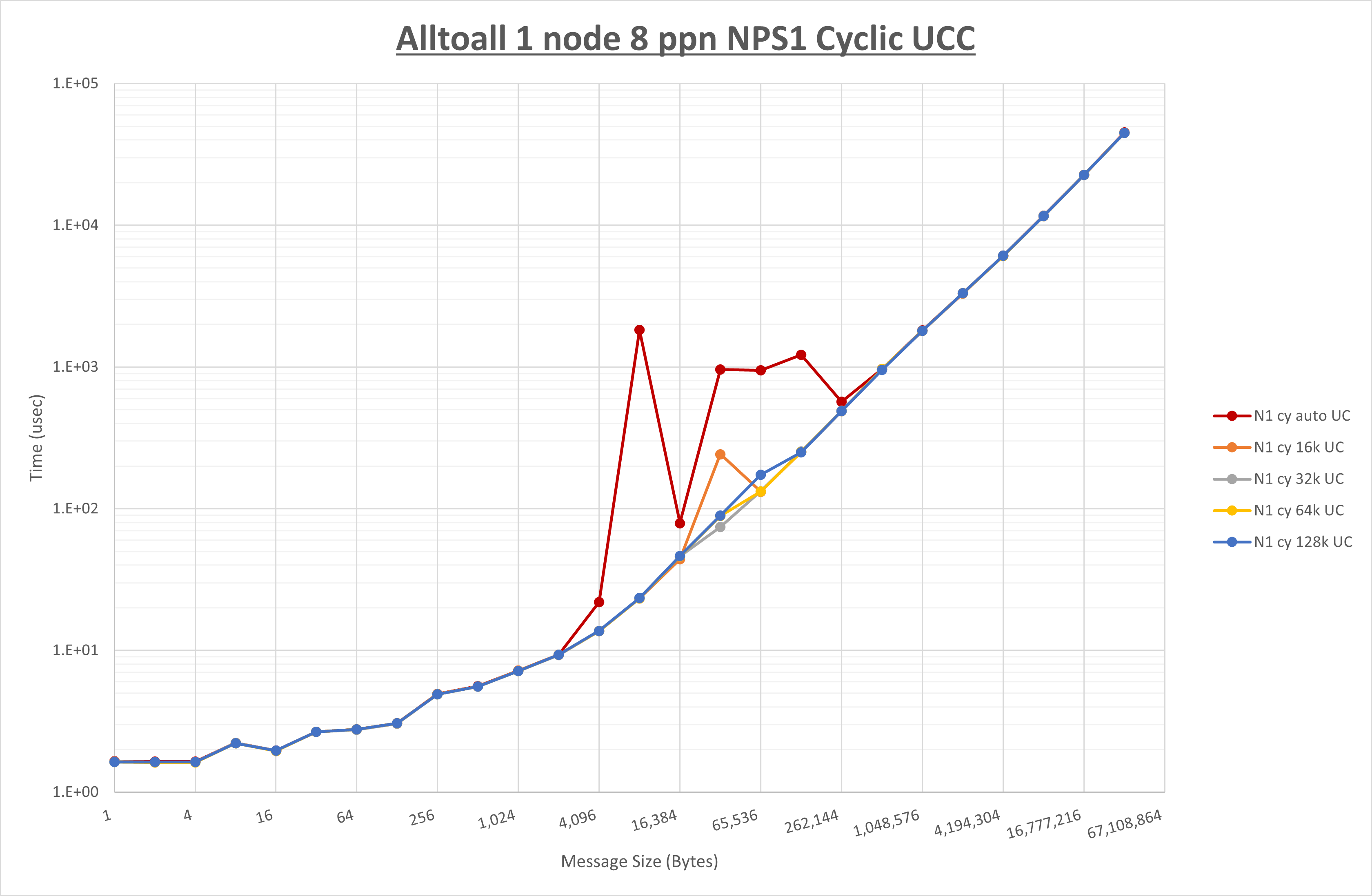
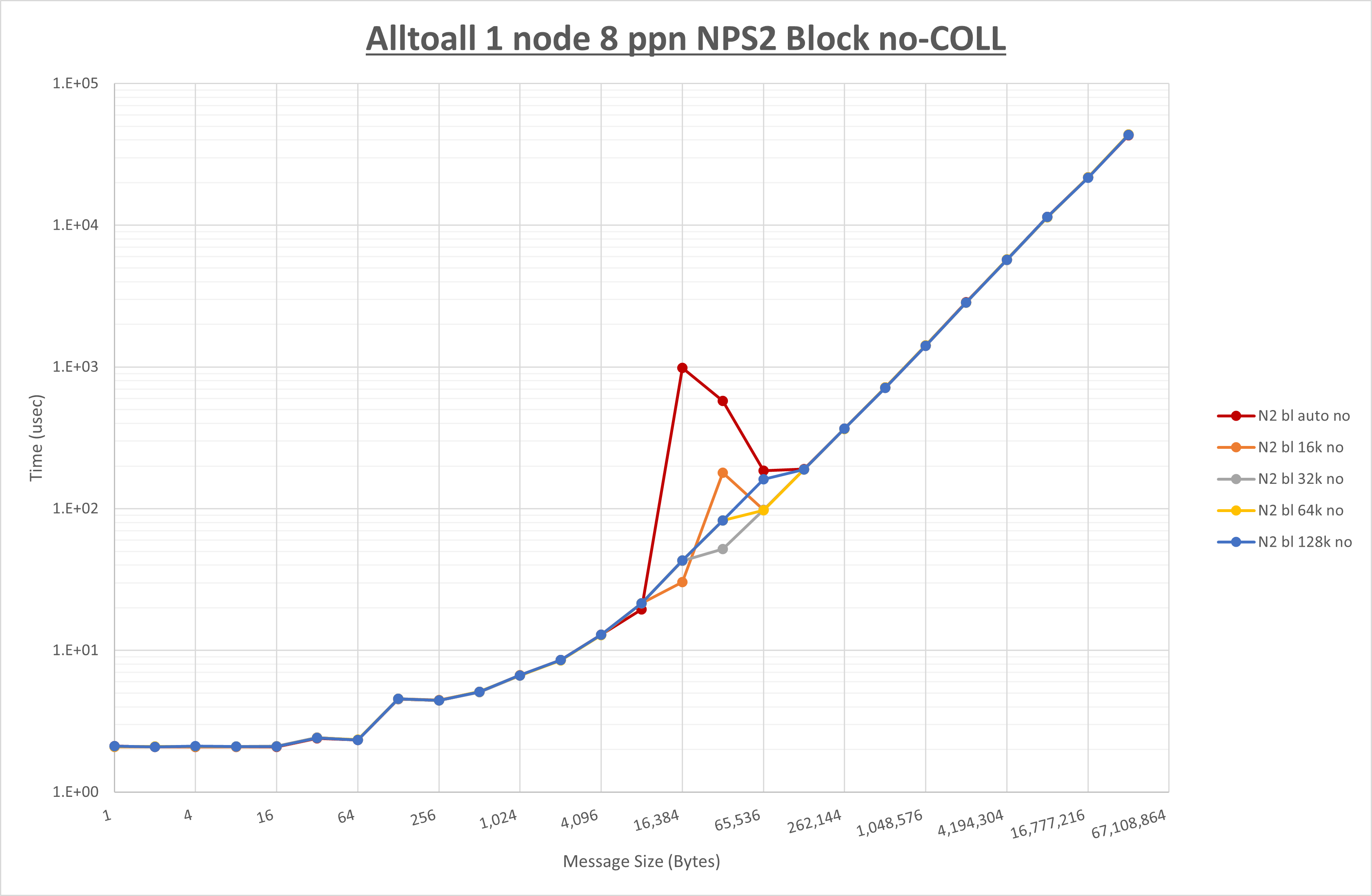
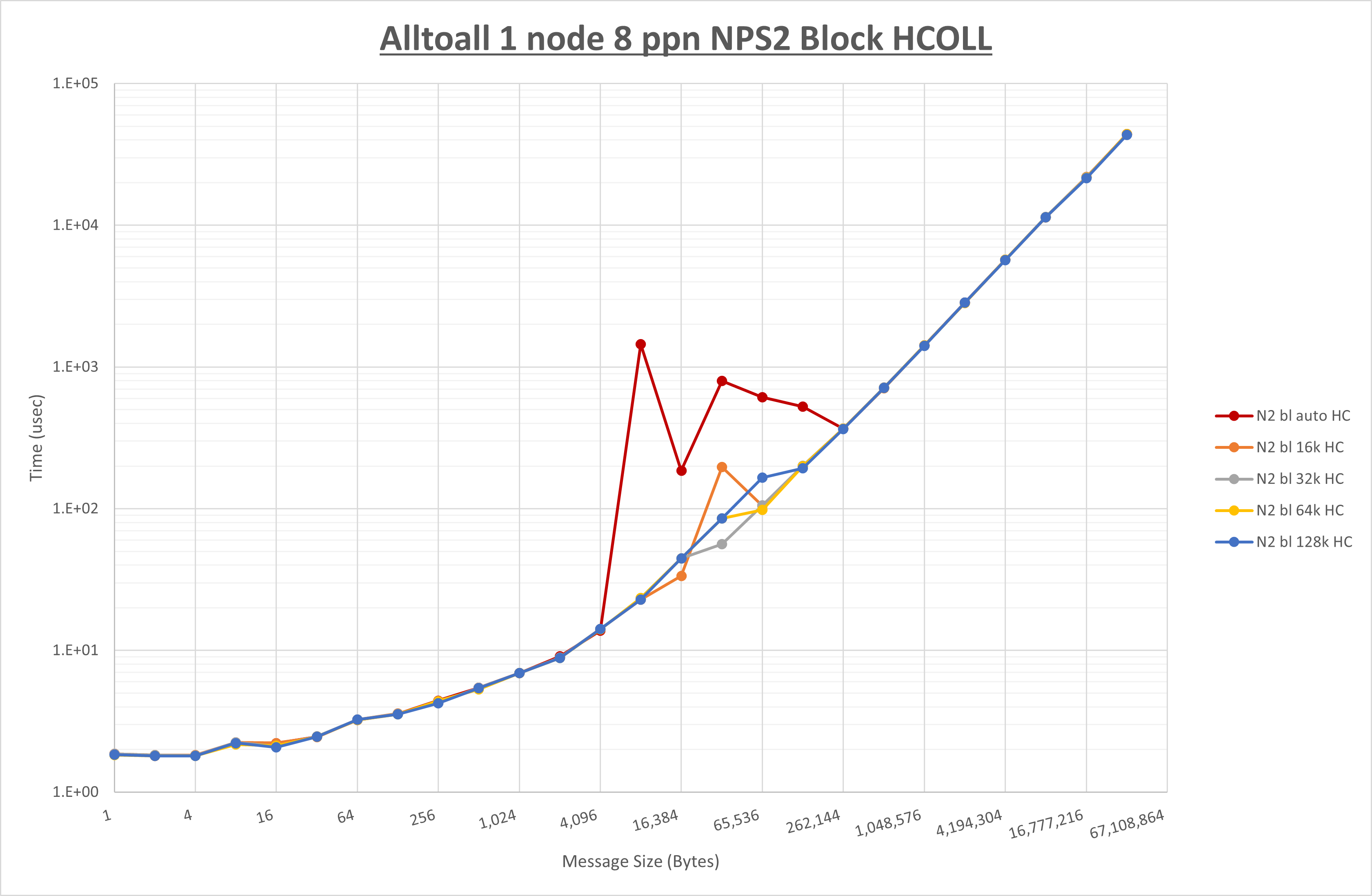
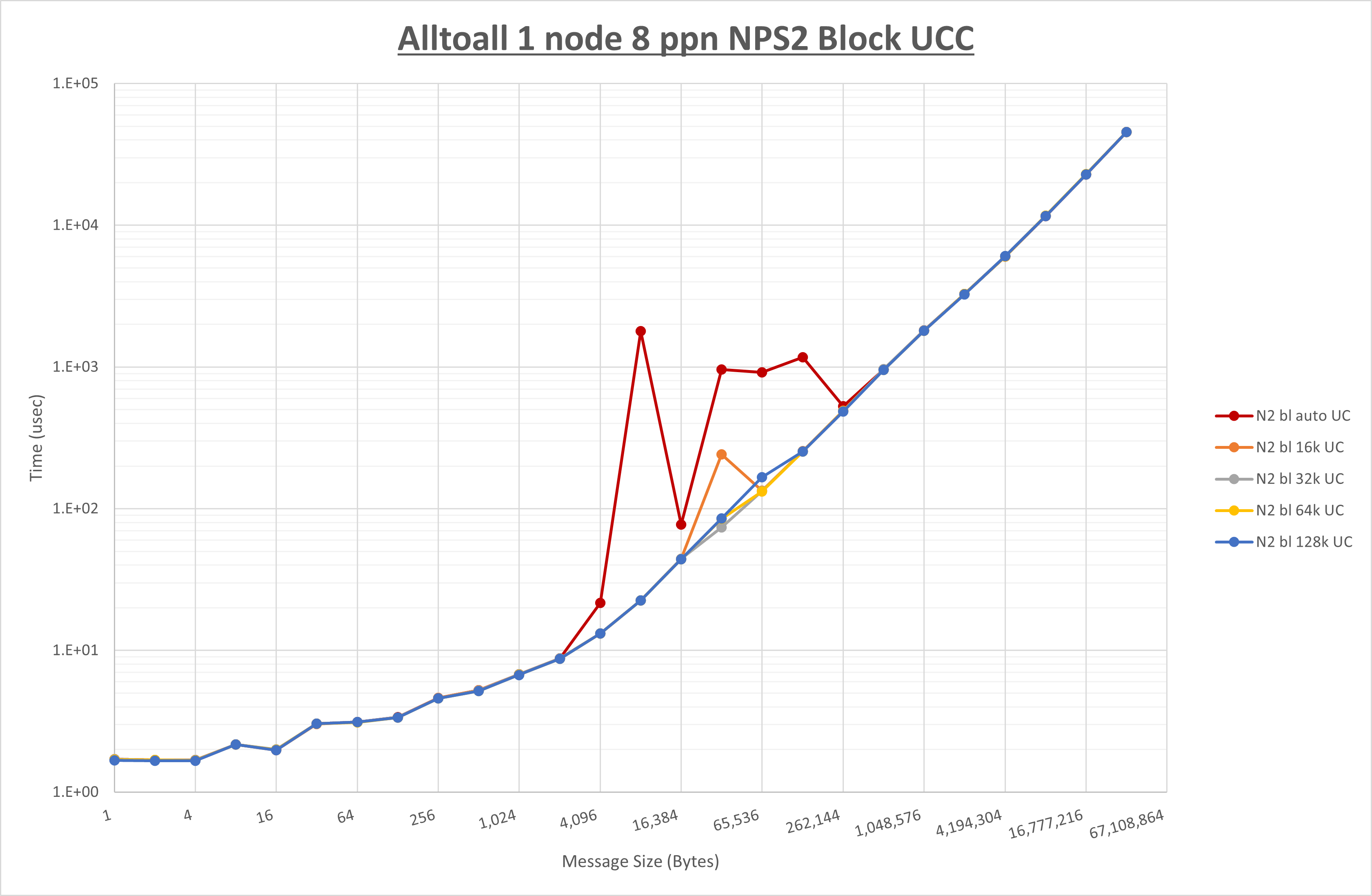
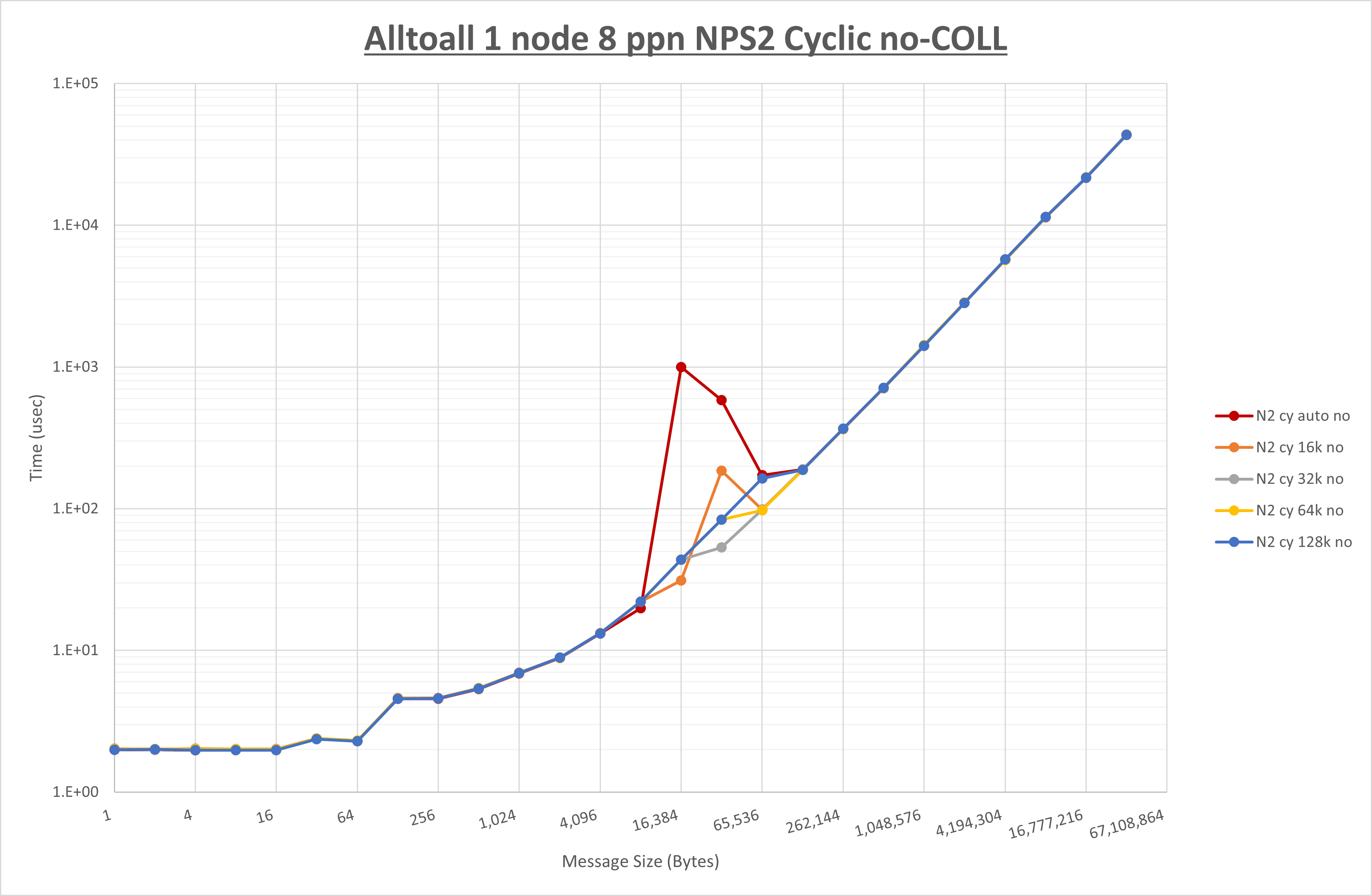
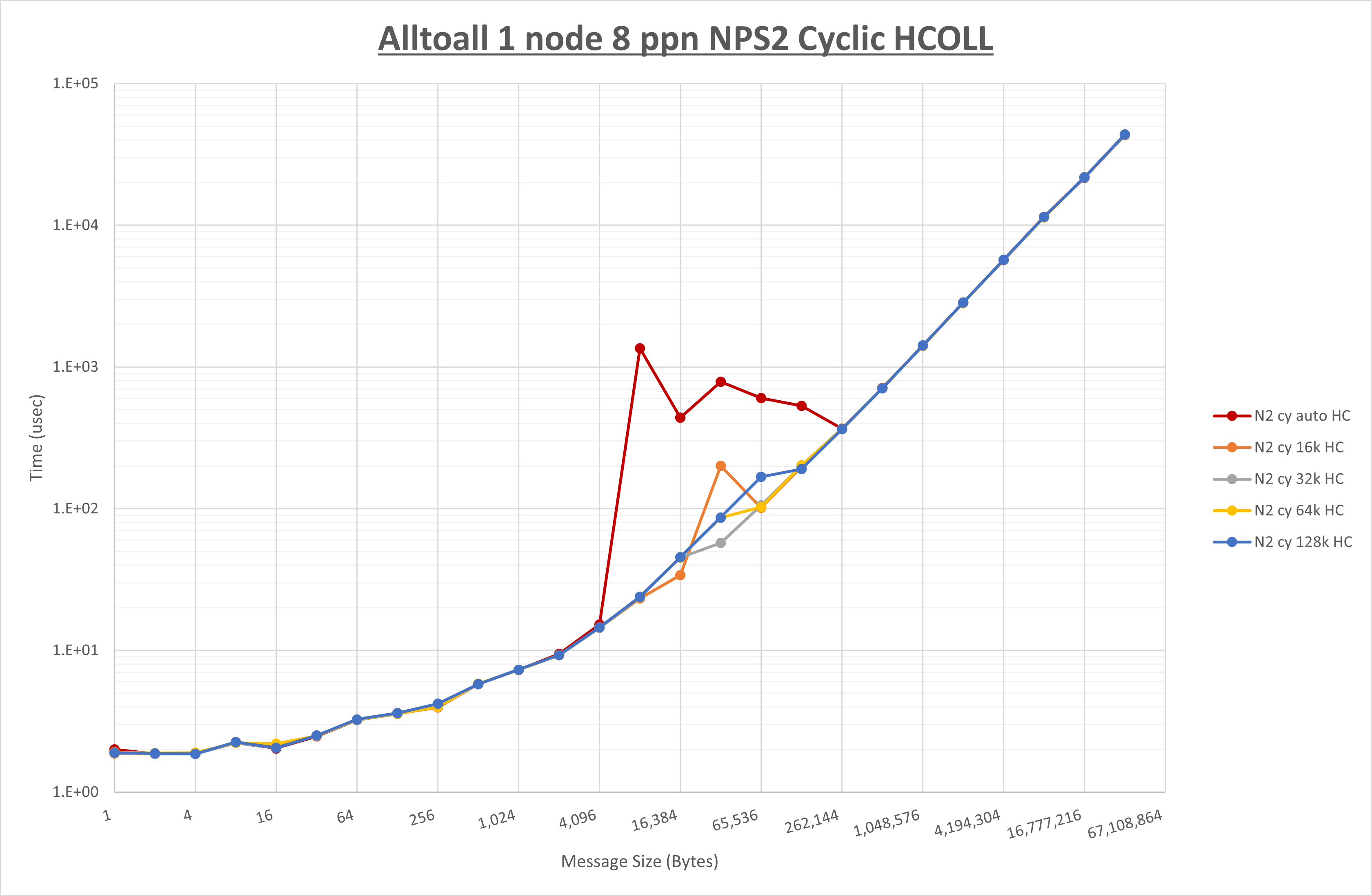
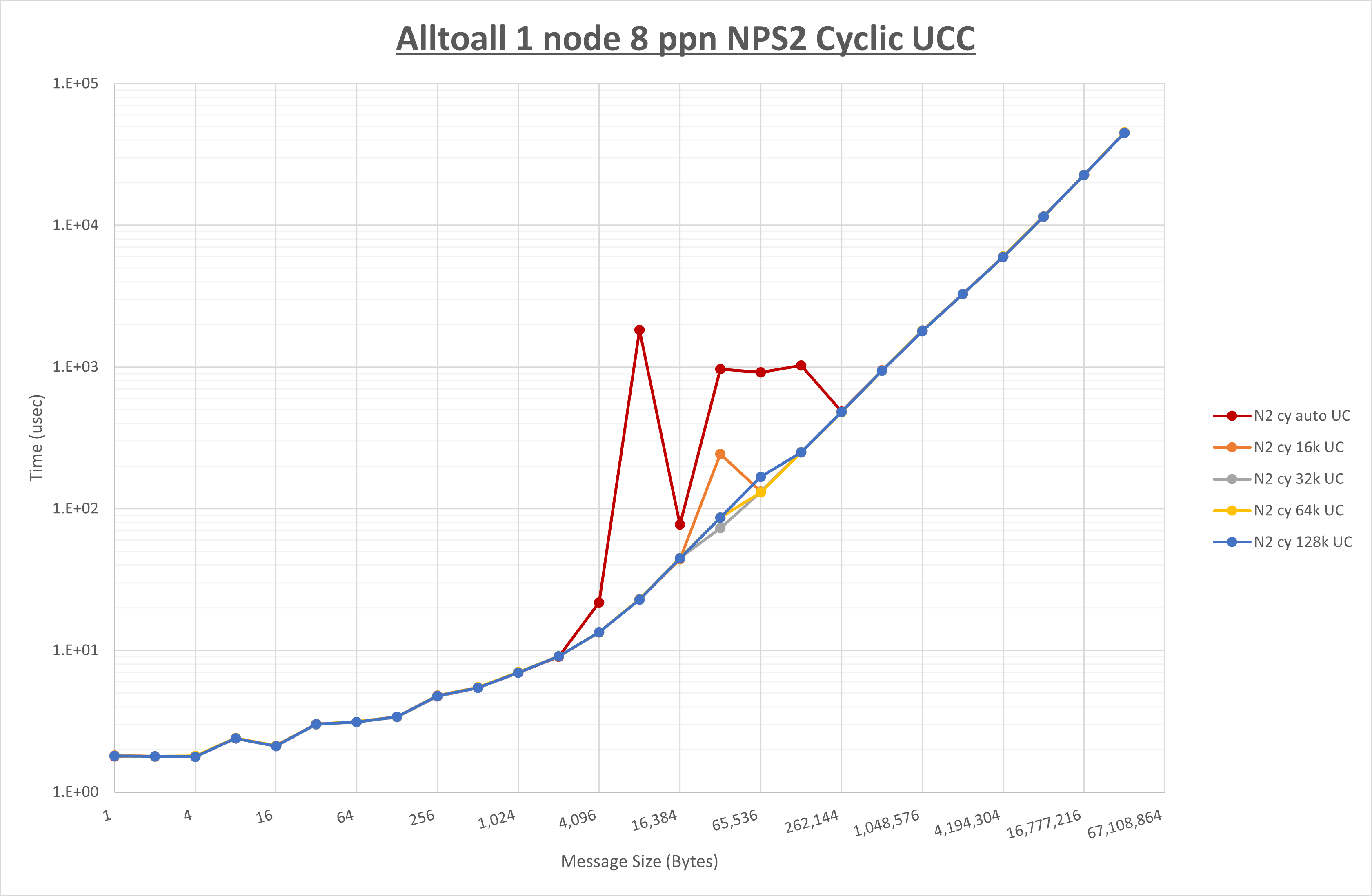
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 32KB | 32KB | 32KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS1 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
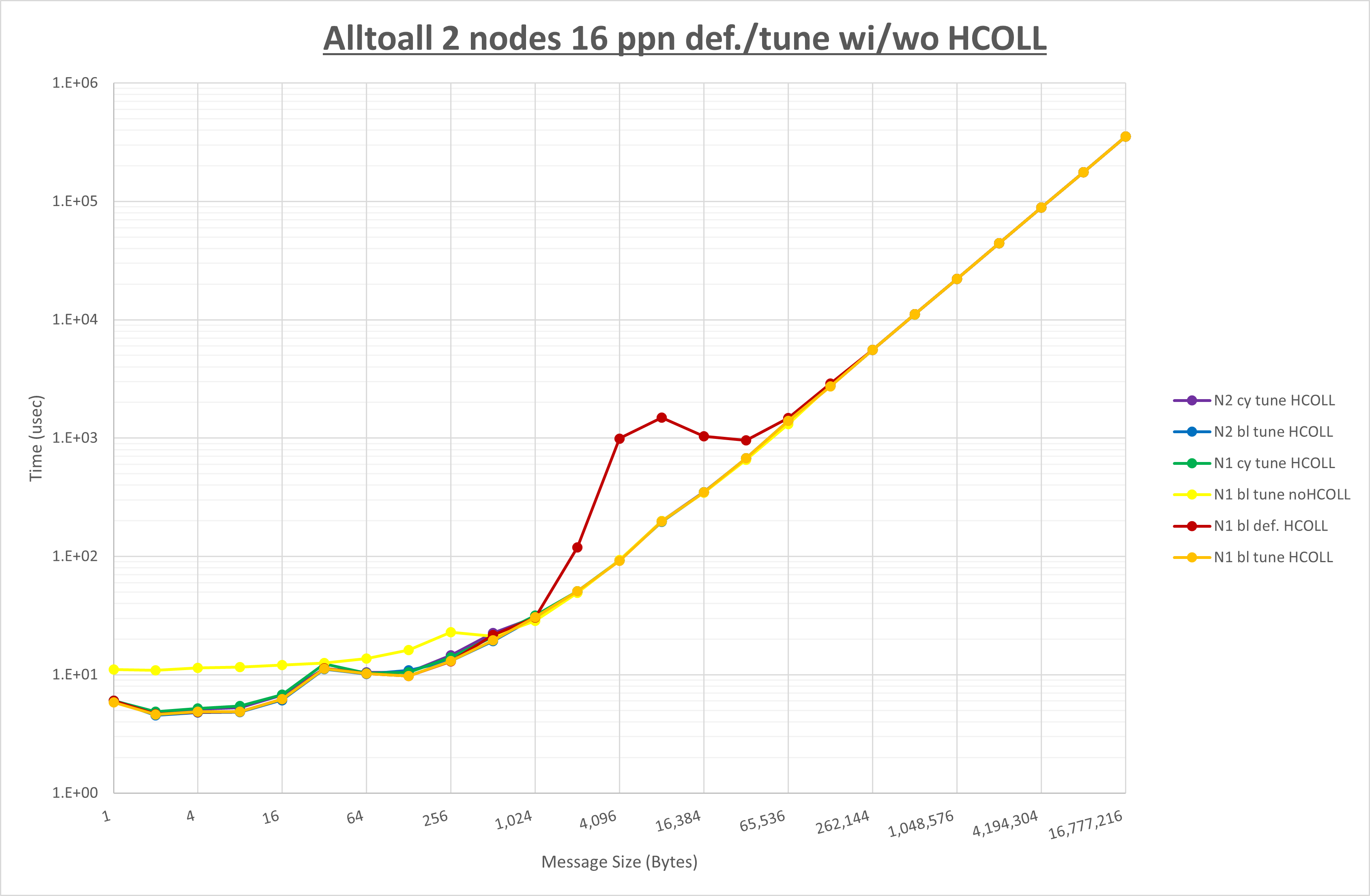
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
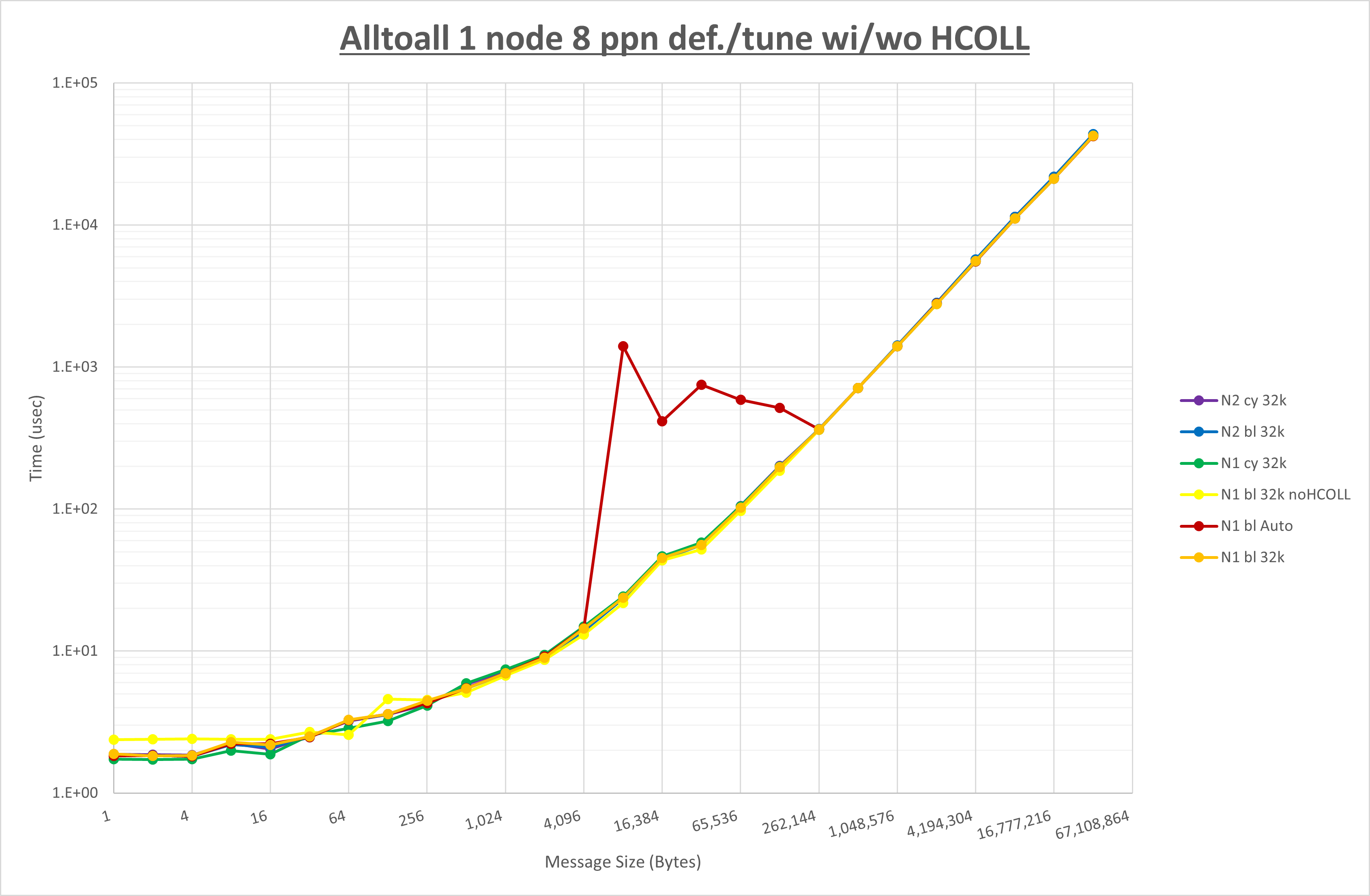
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し16B以下で性能が向上し512Bから64KBで性能が低下
- UCC は no-COLL と比較し4B以下と256KBから2MBで性能が向上し256Bから64KBで性能が低下
- チューニング適用で8KBから32KBの間で大幅に性能が向上
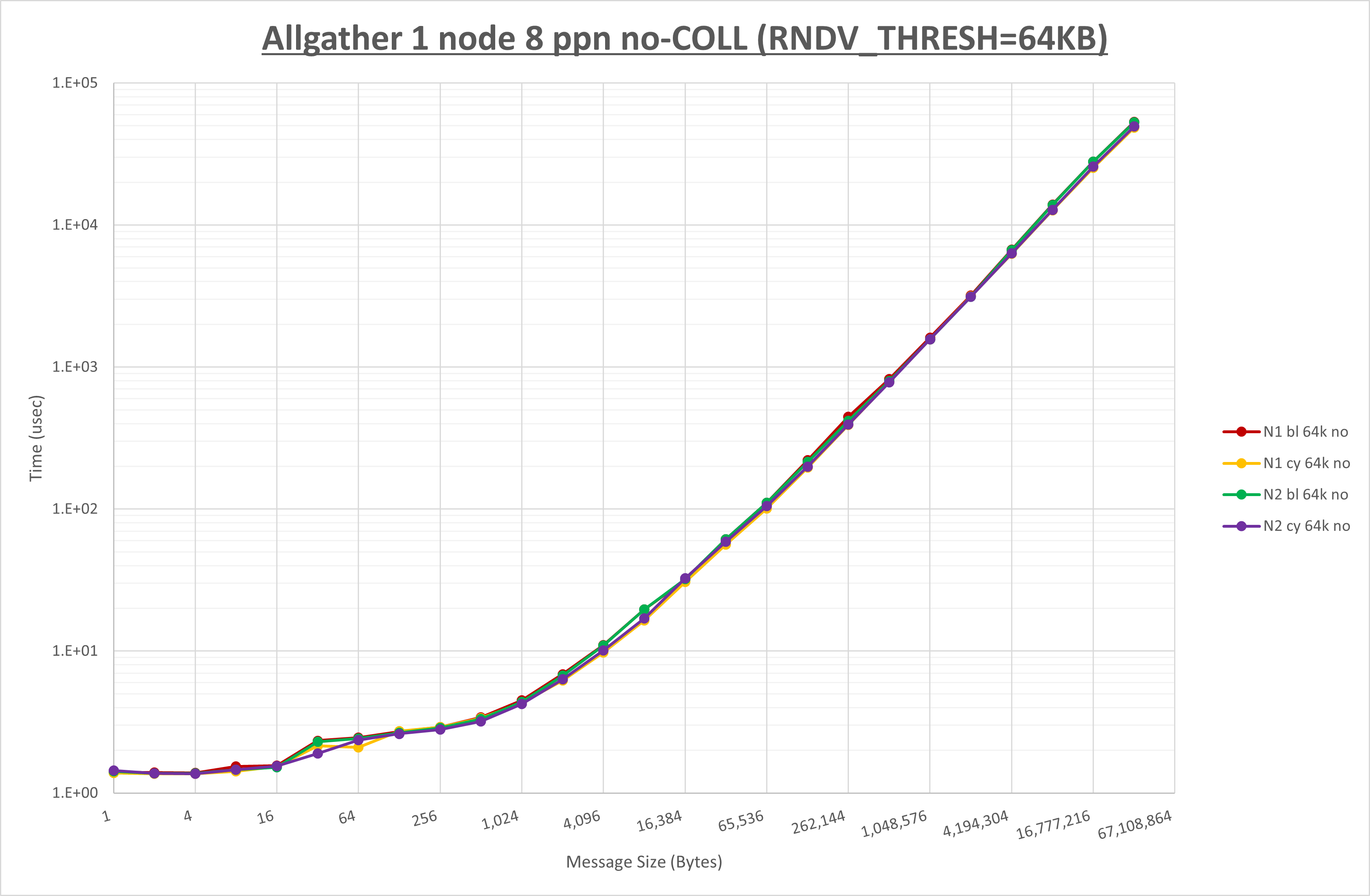
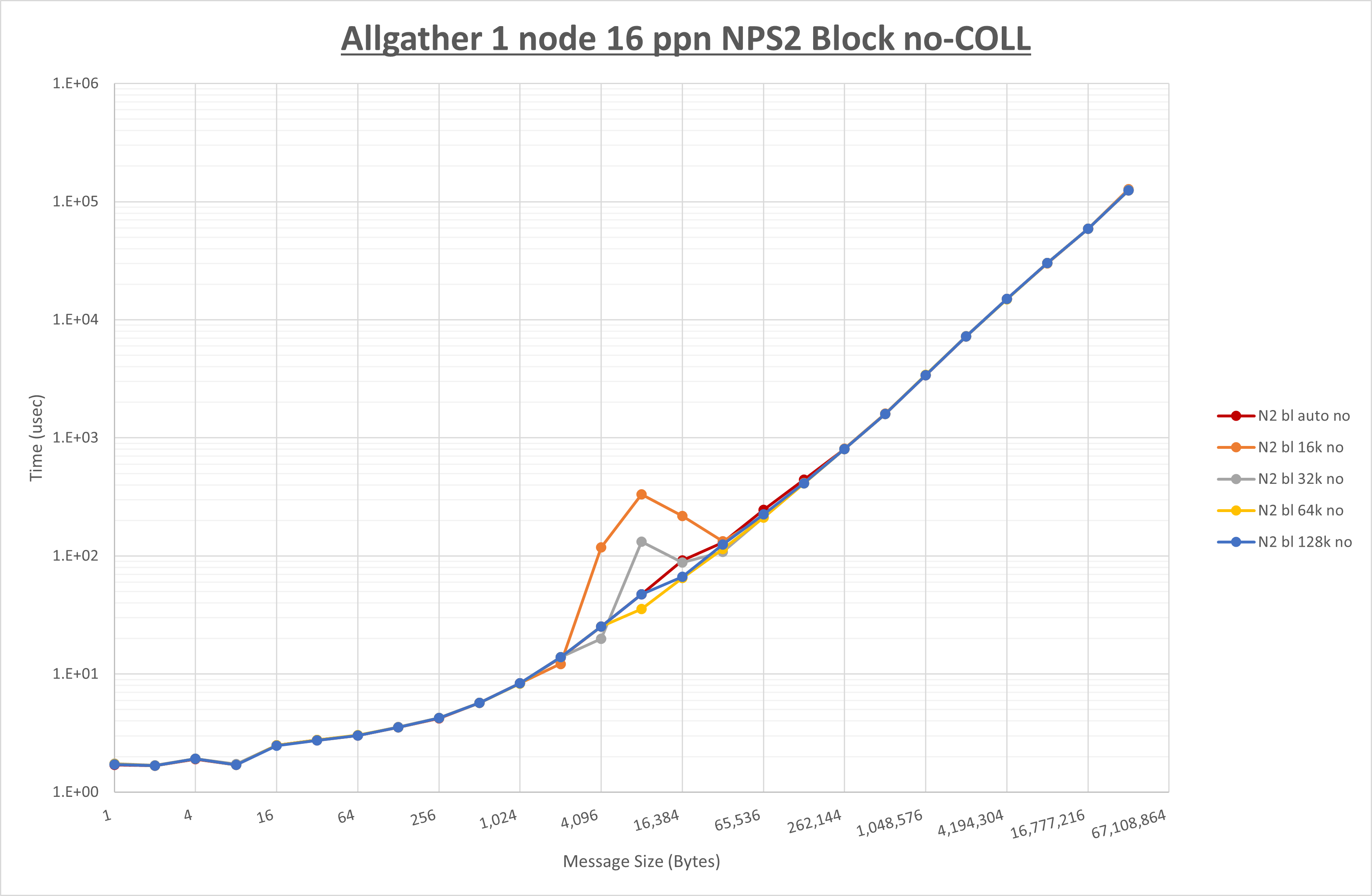
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
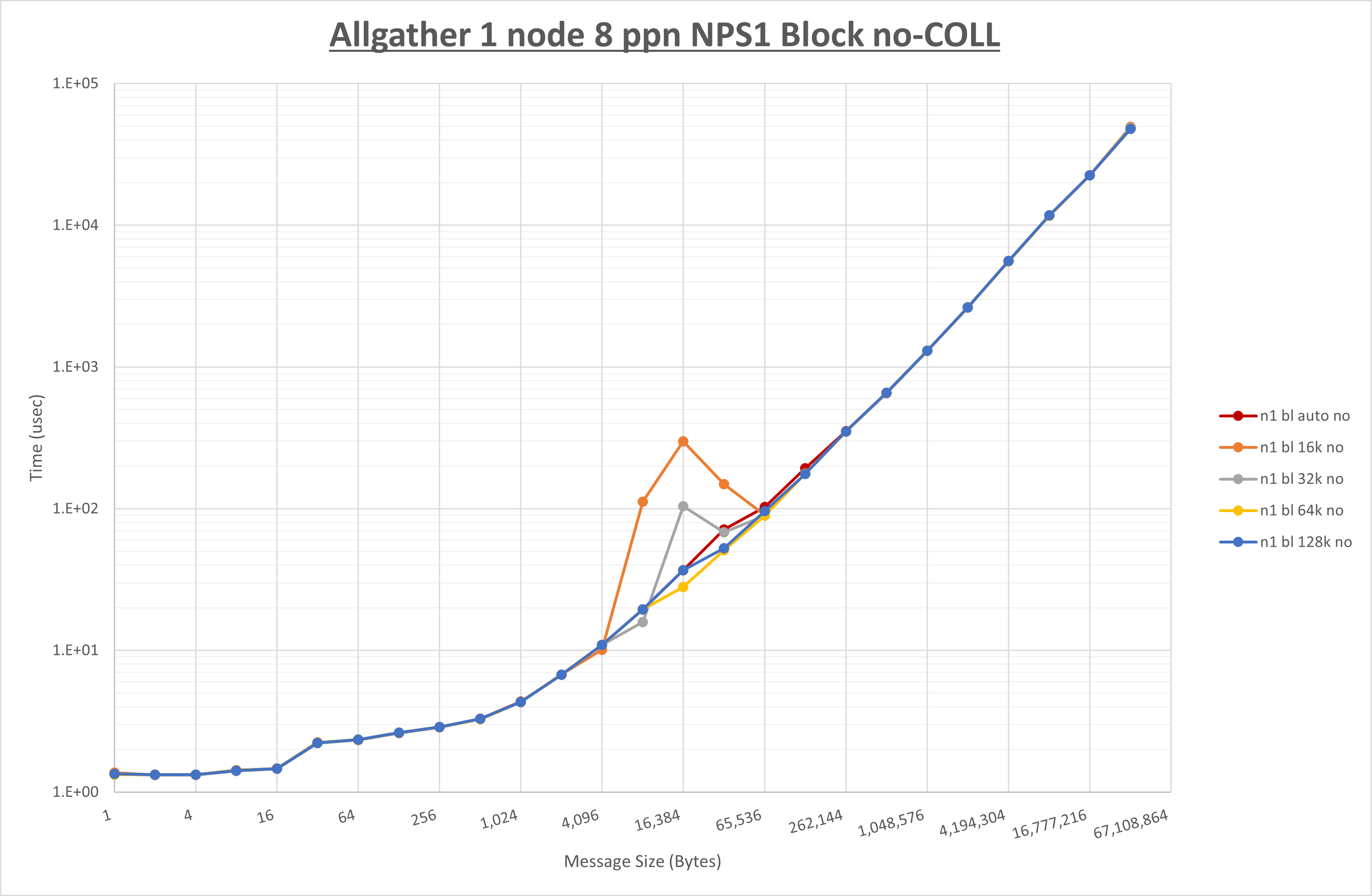
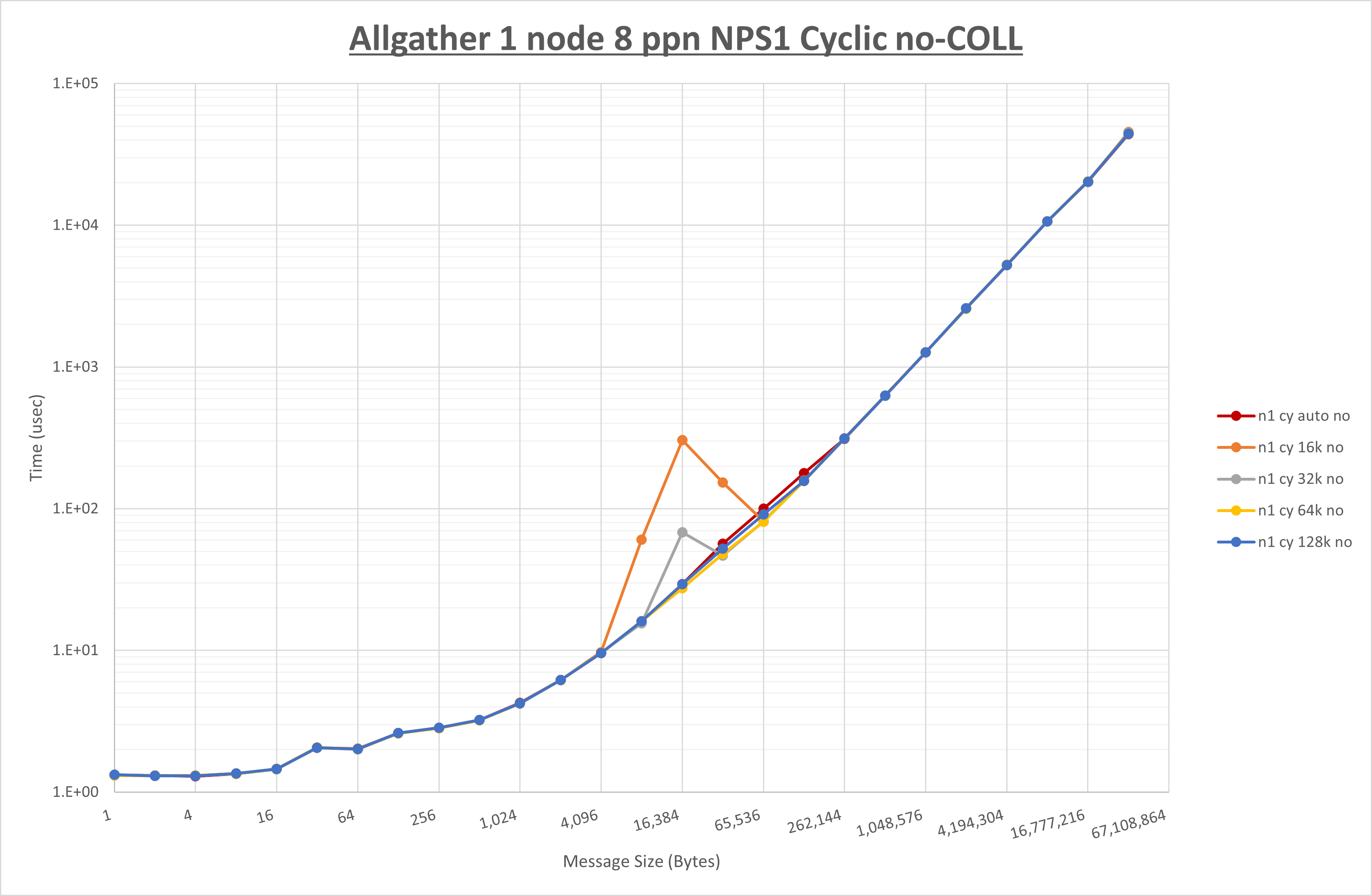
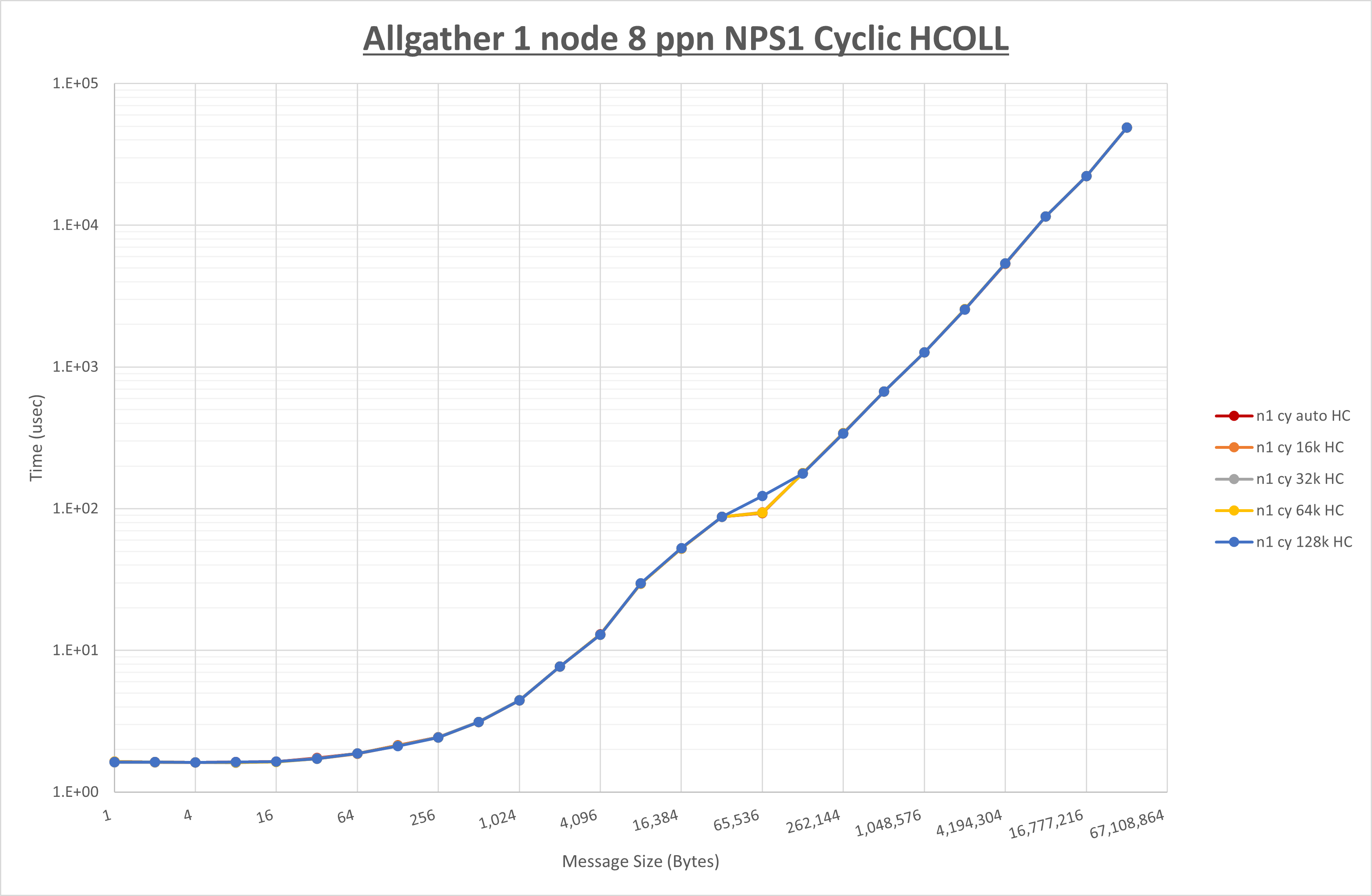
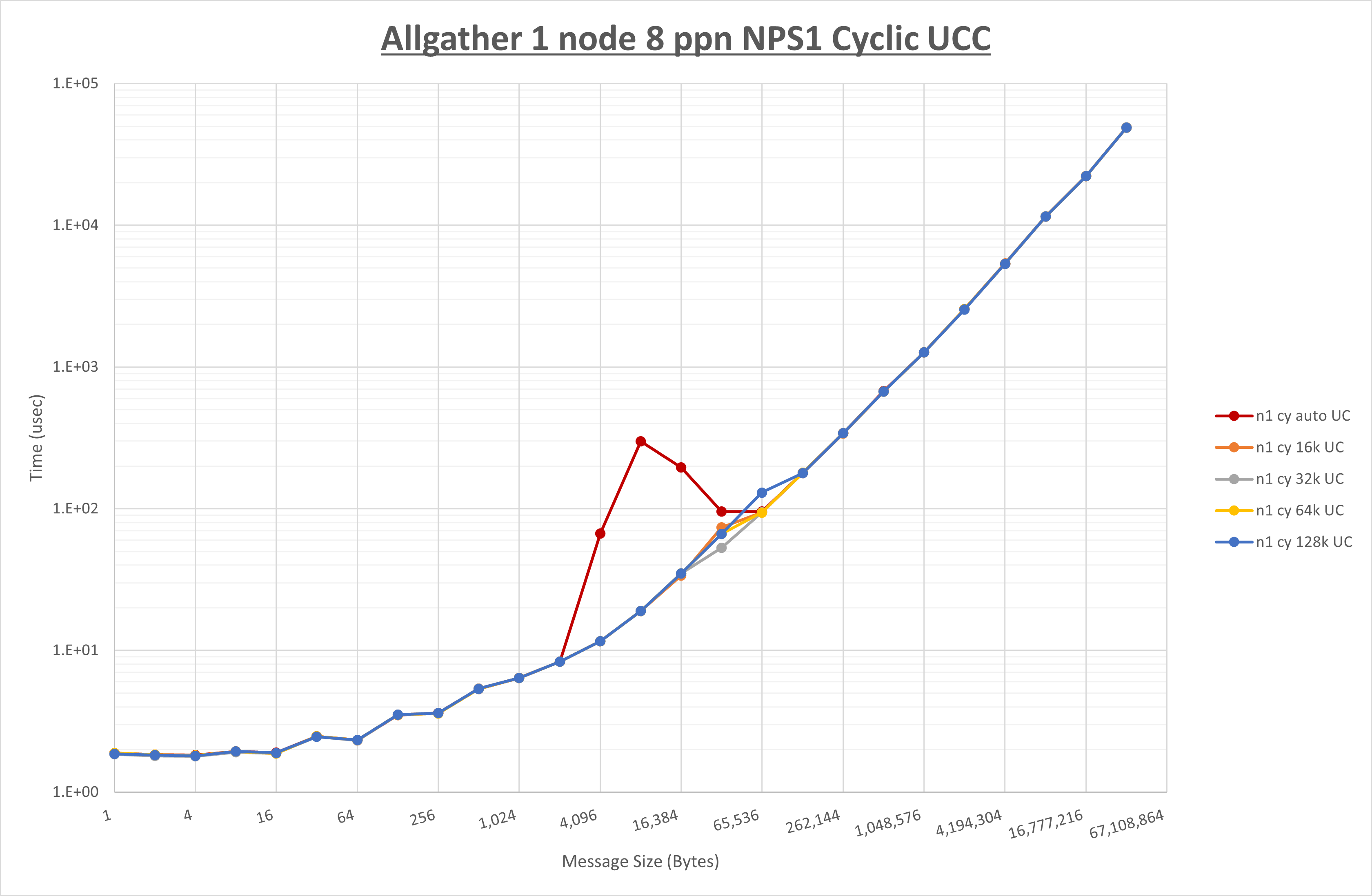
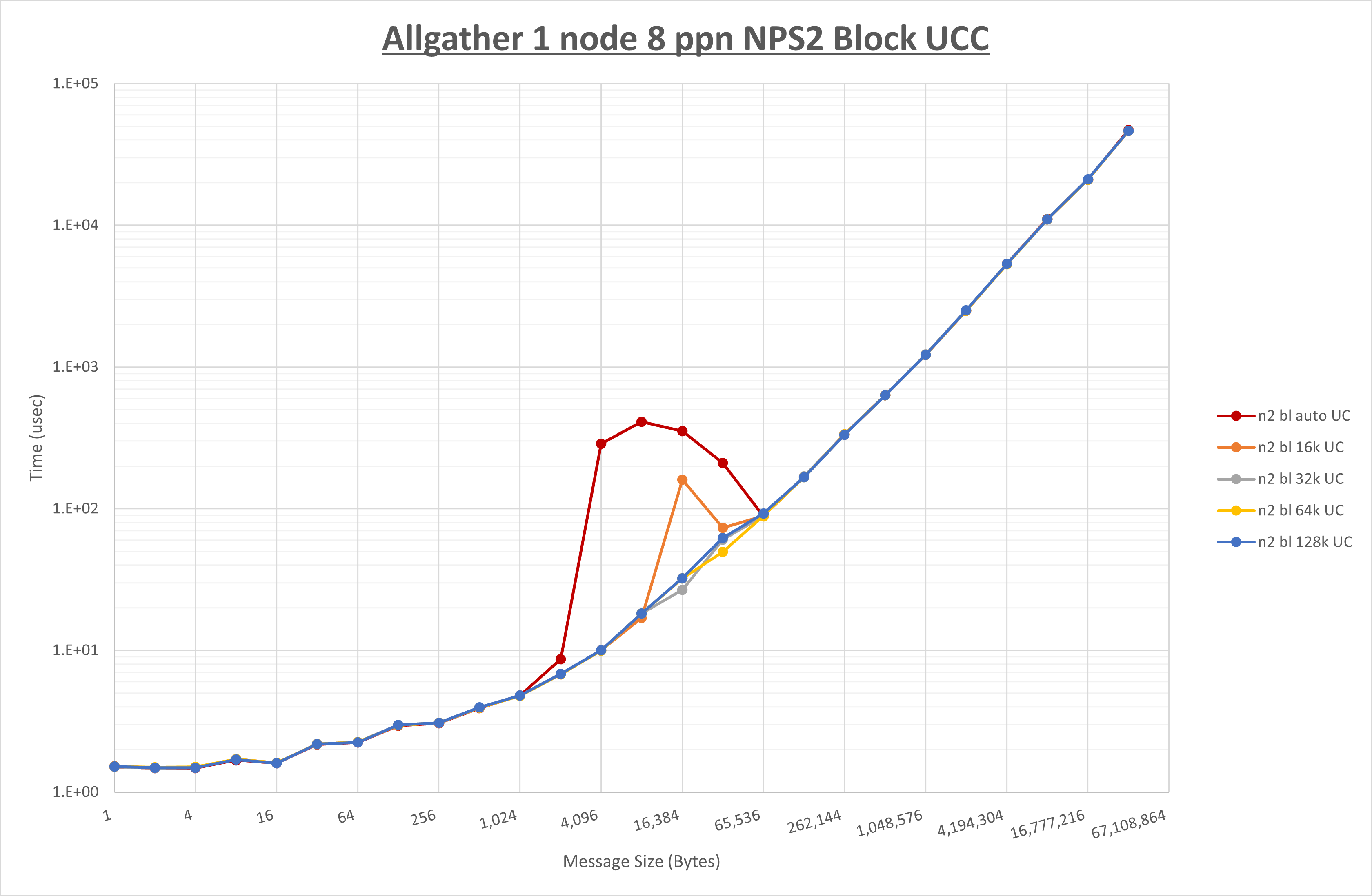
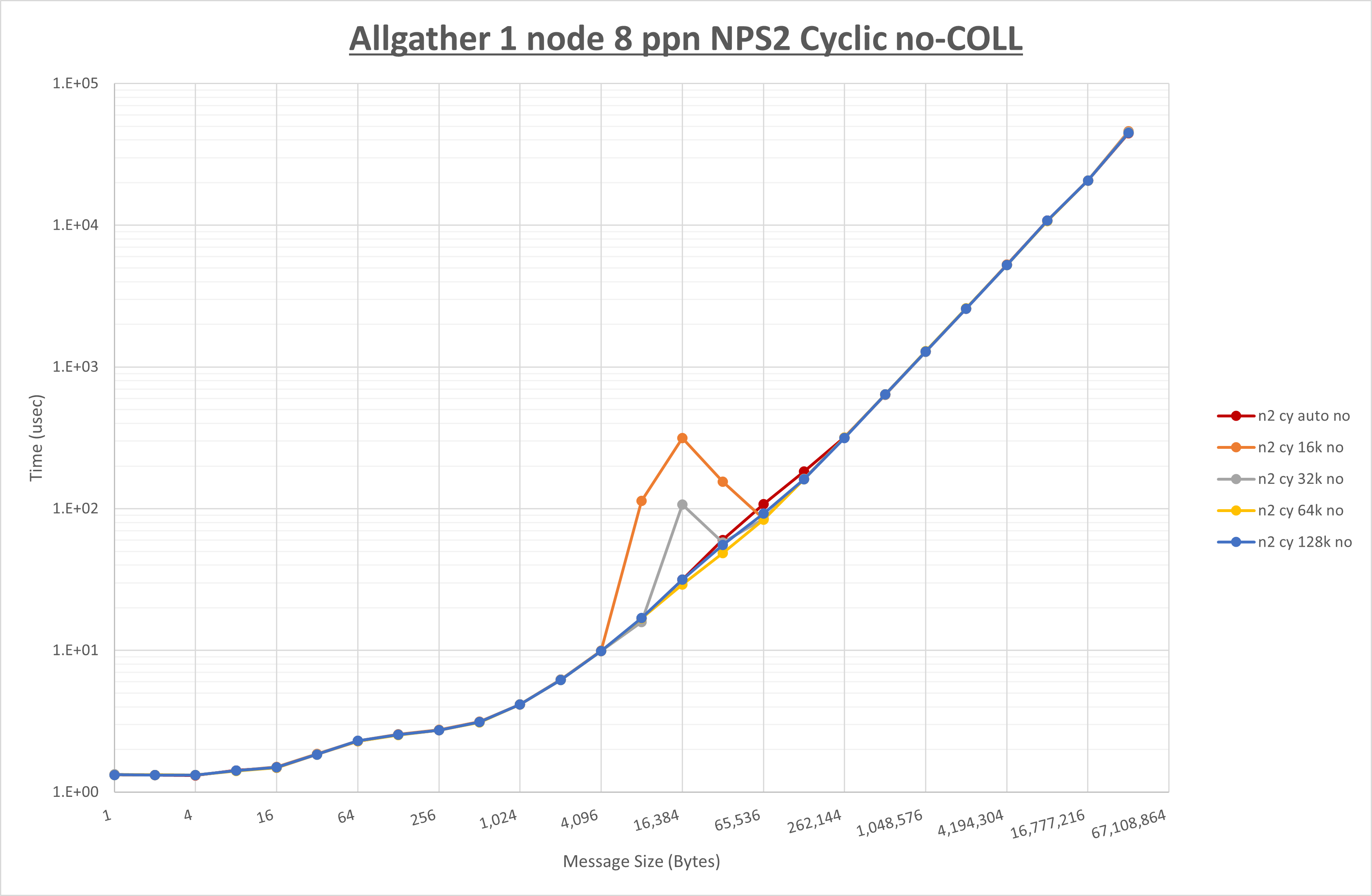
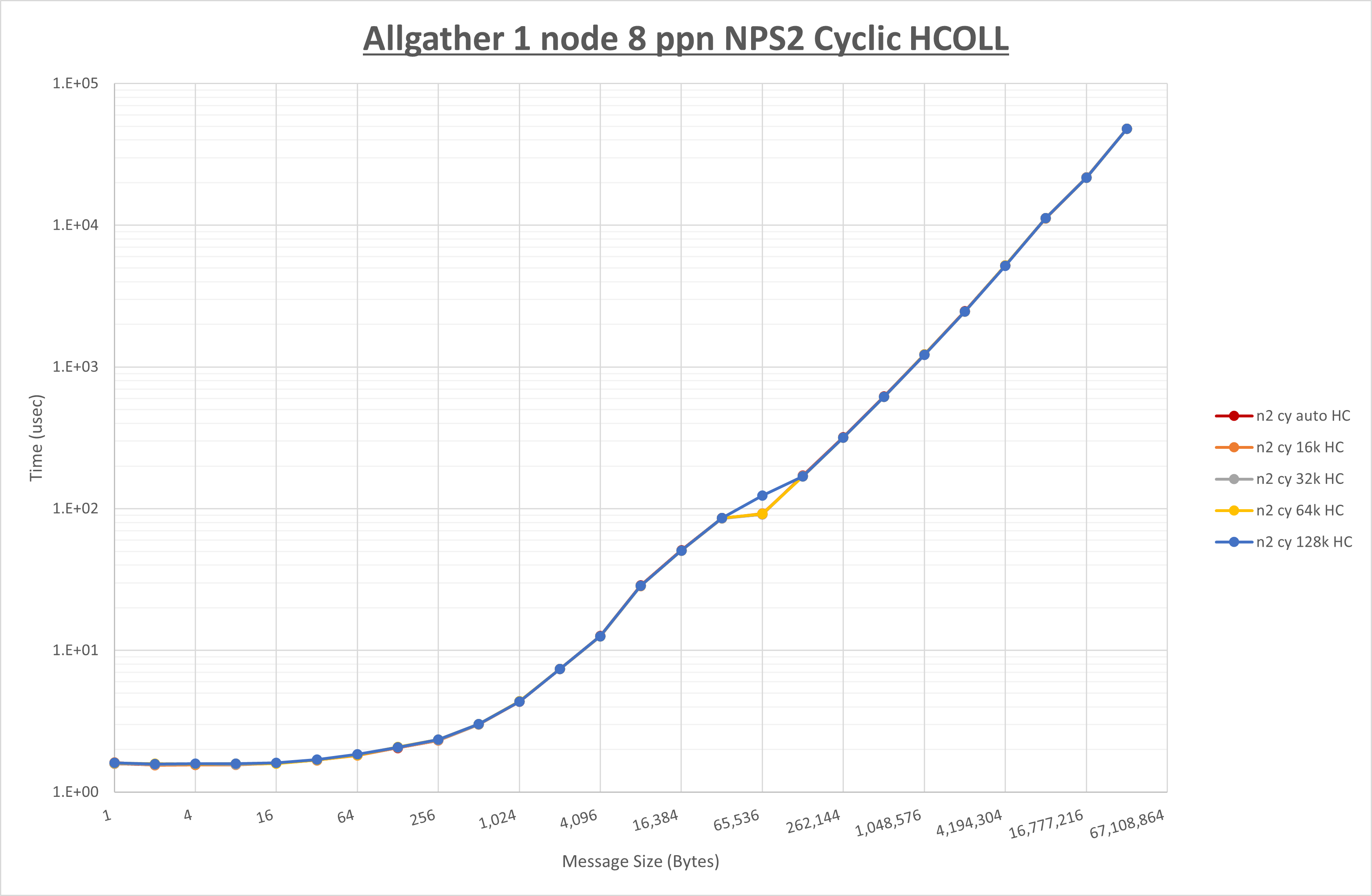
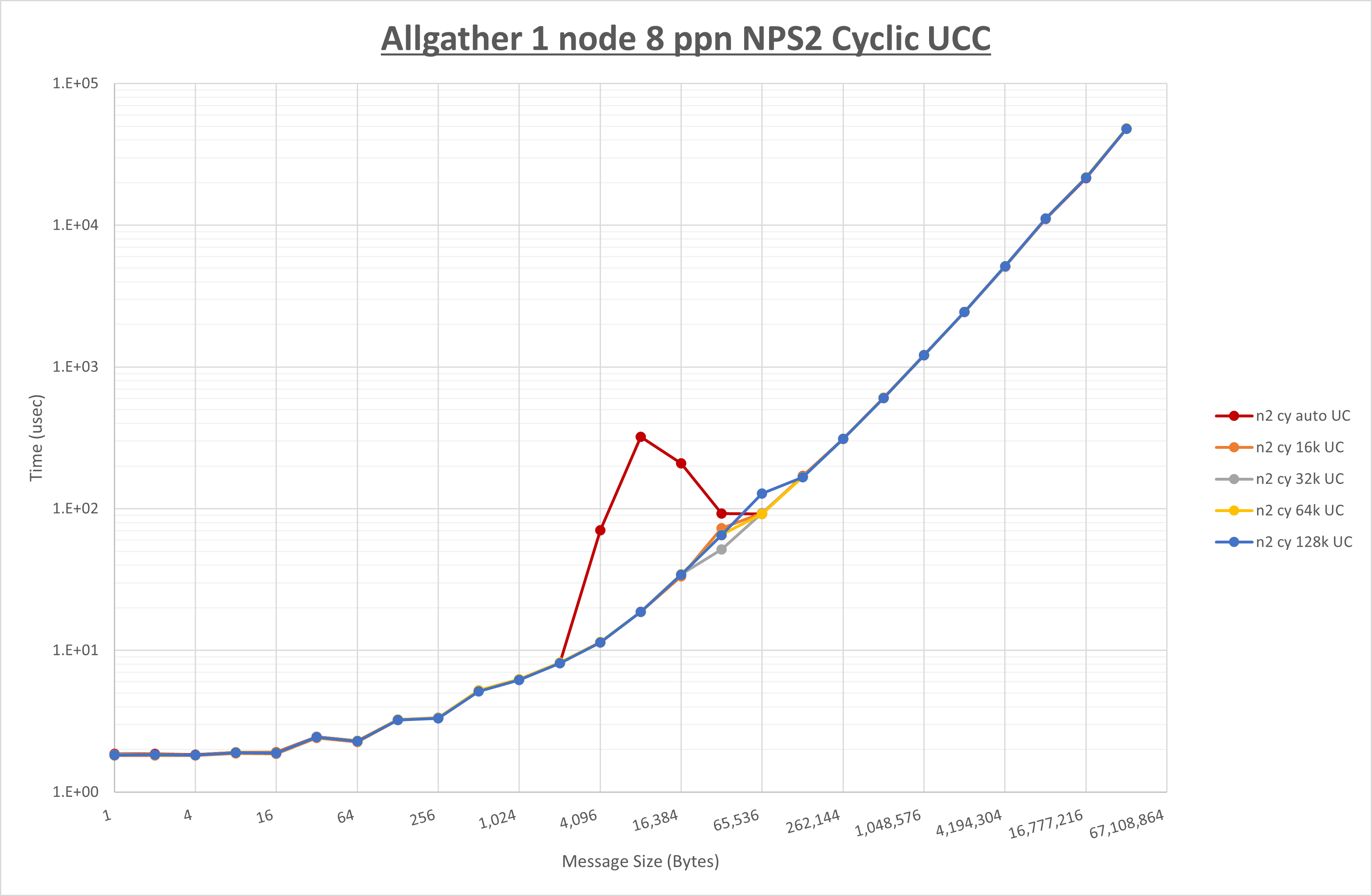
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 64KB | 64KB | 64KB |
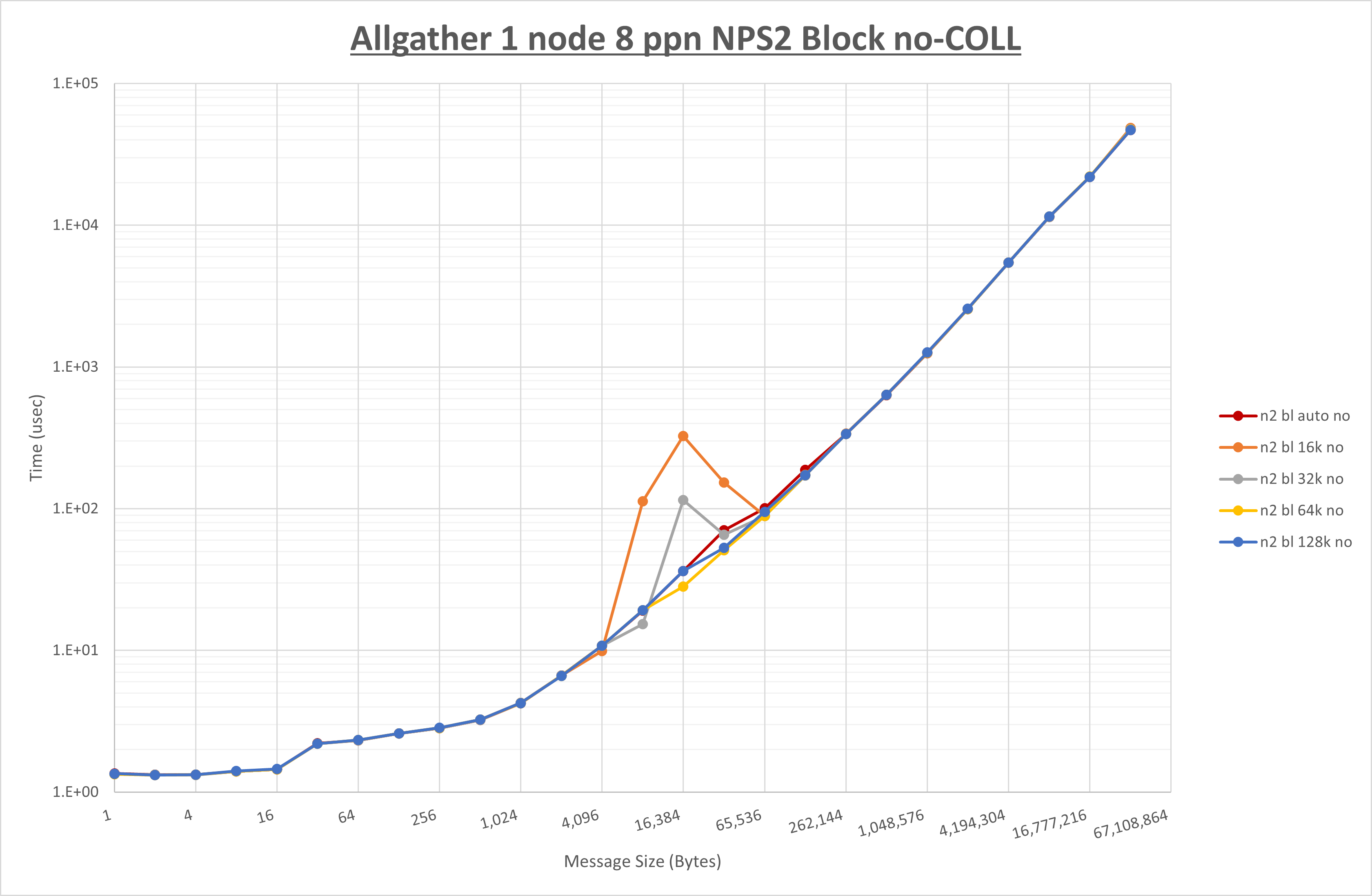
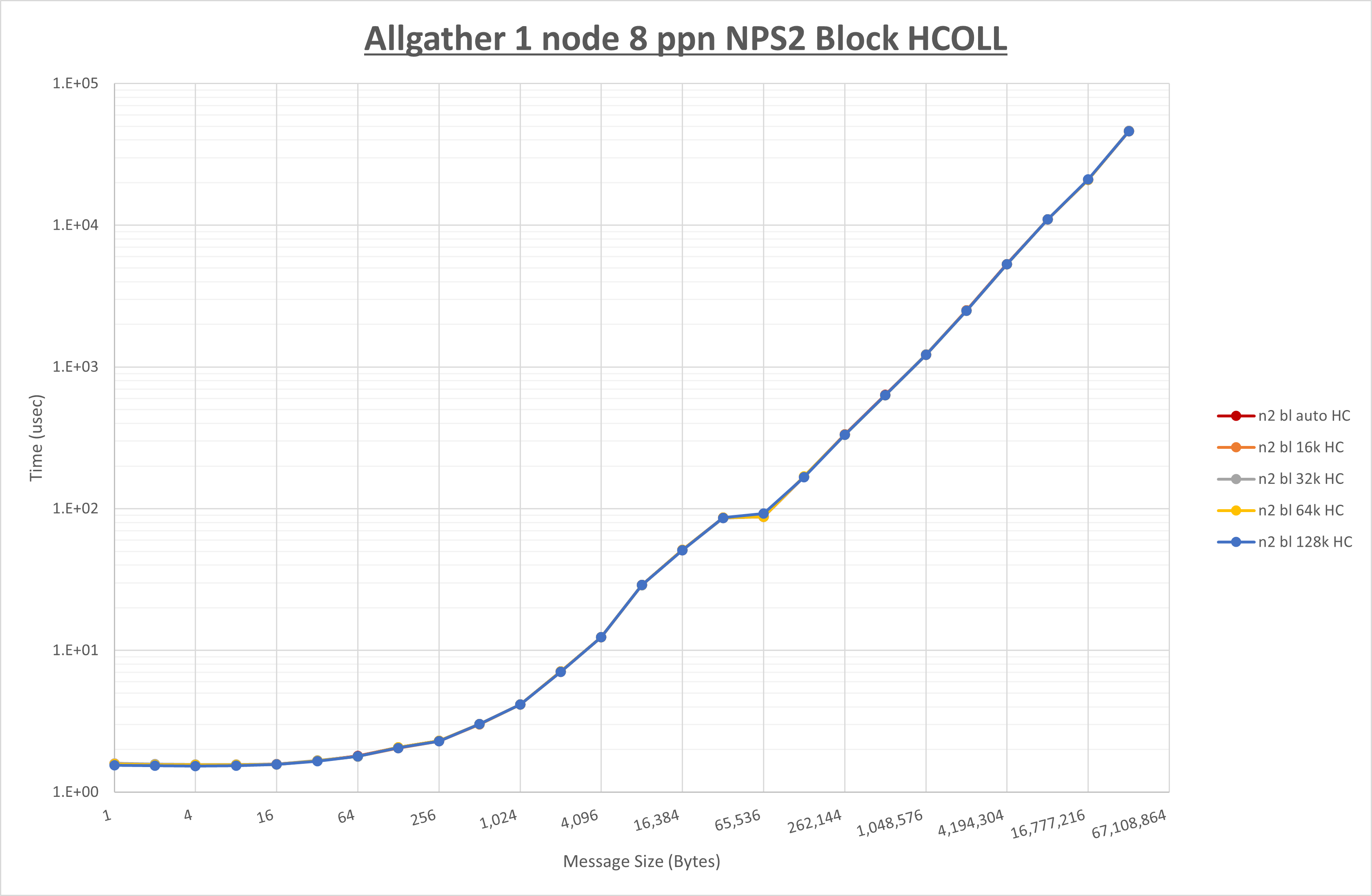
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
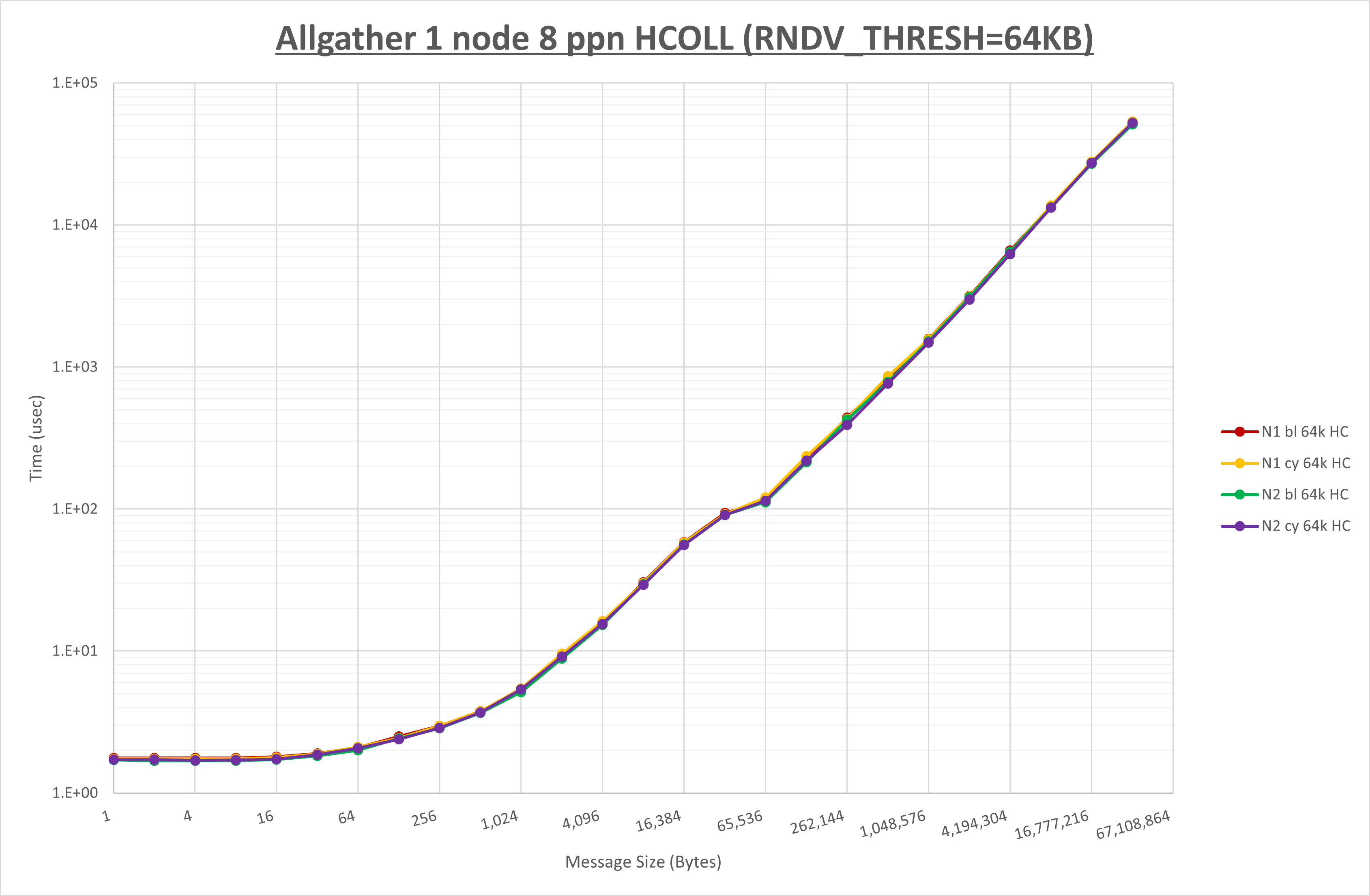
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | ブロック分割 |
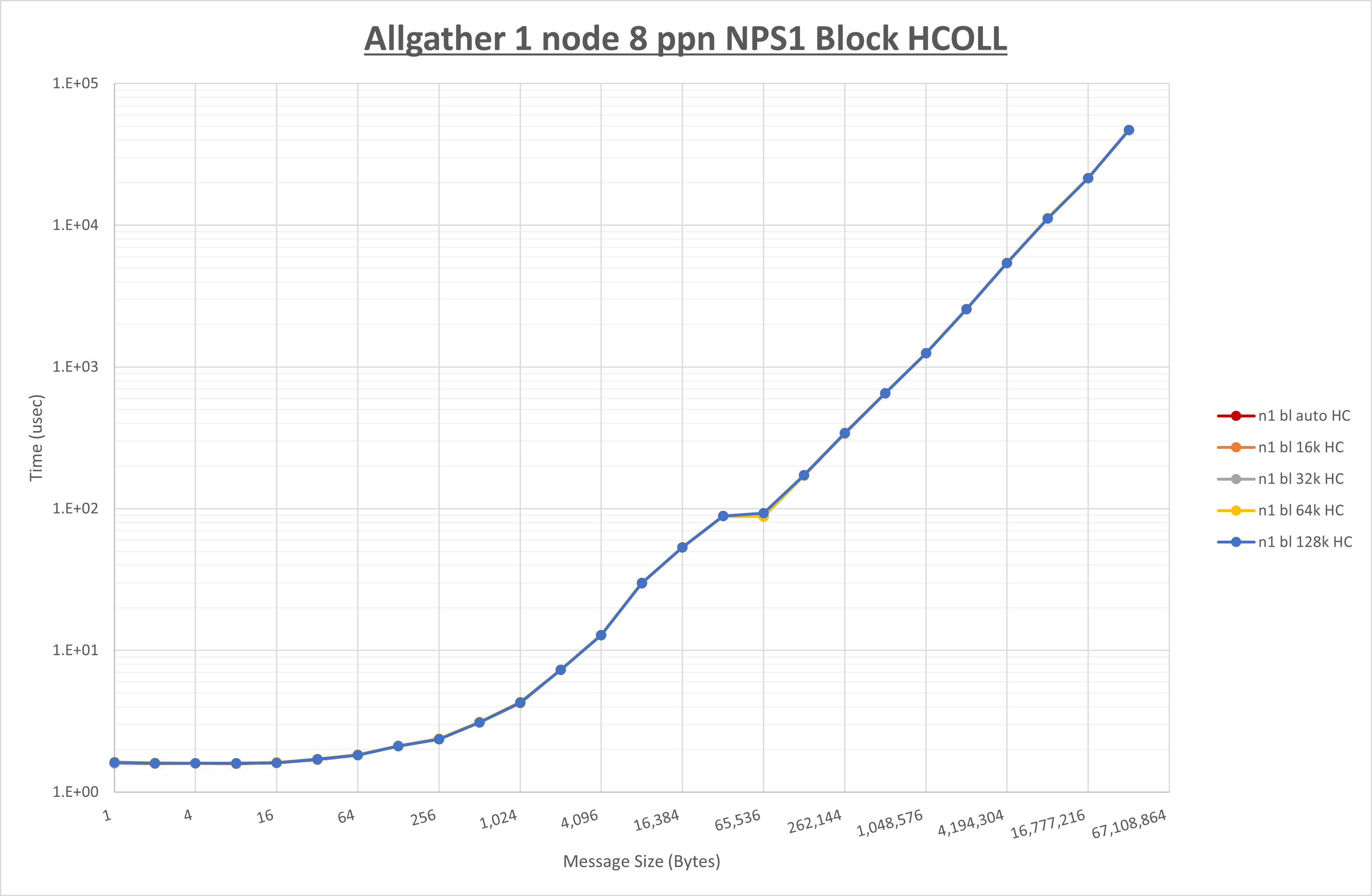
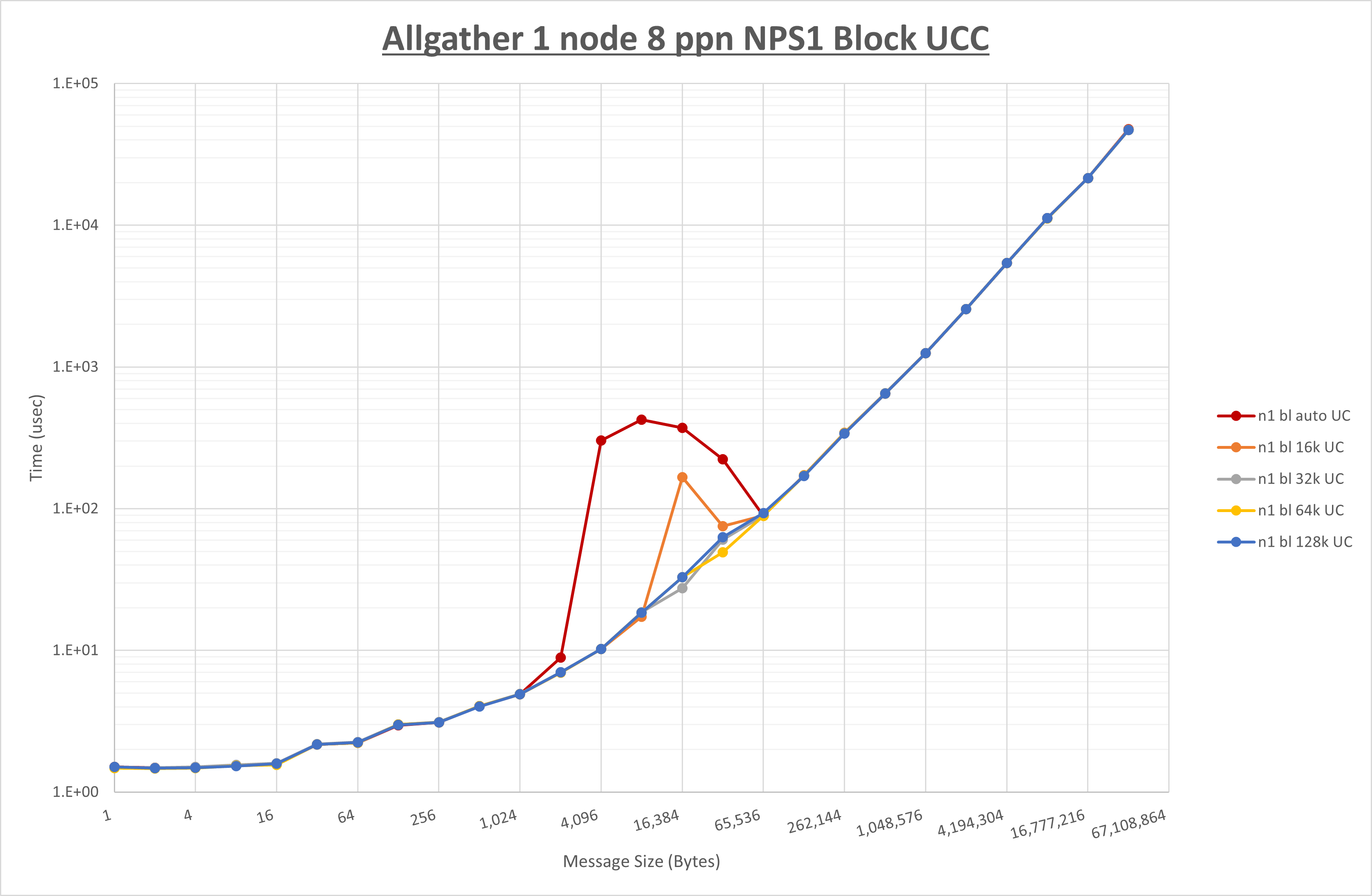
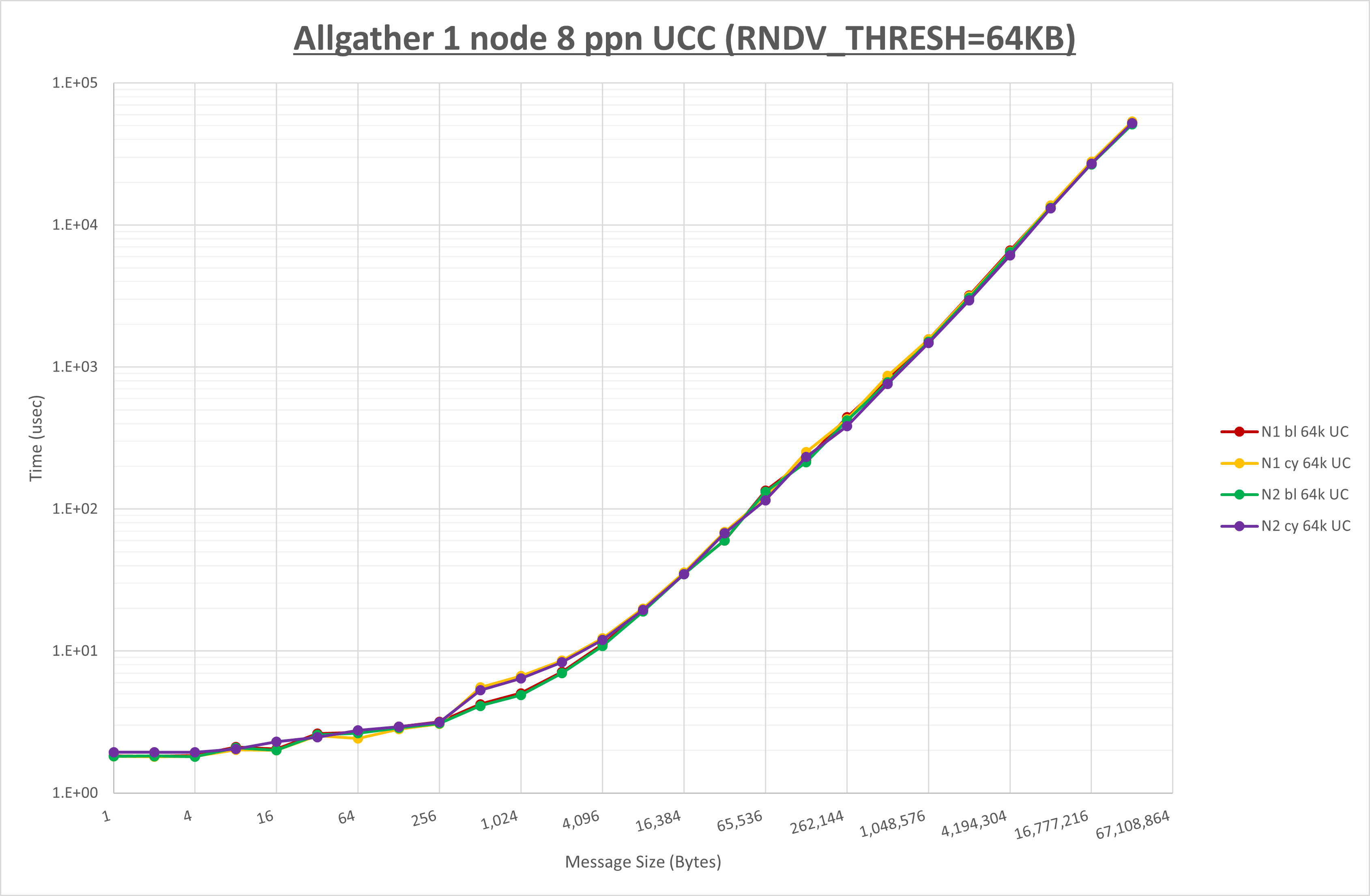
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し64Bから128Bで性能が向上し16B以下と256Bから128KBで性能が低下
- UCC は no-COLL と比較し128KB以下で性能が低下
- チューニング適用による性能差無し
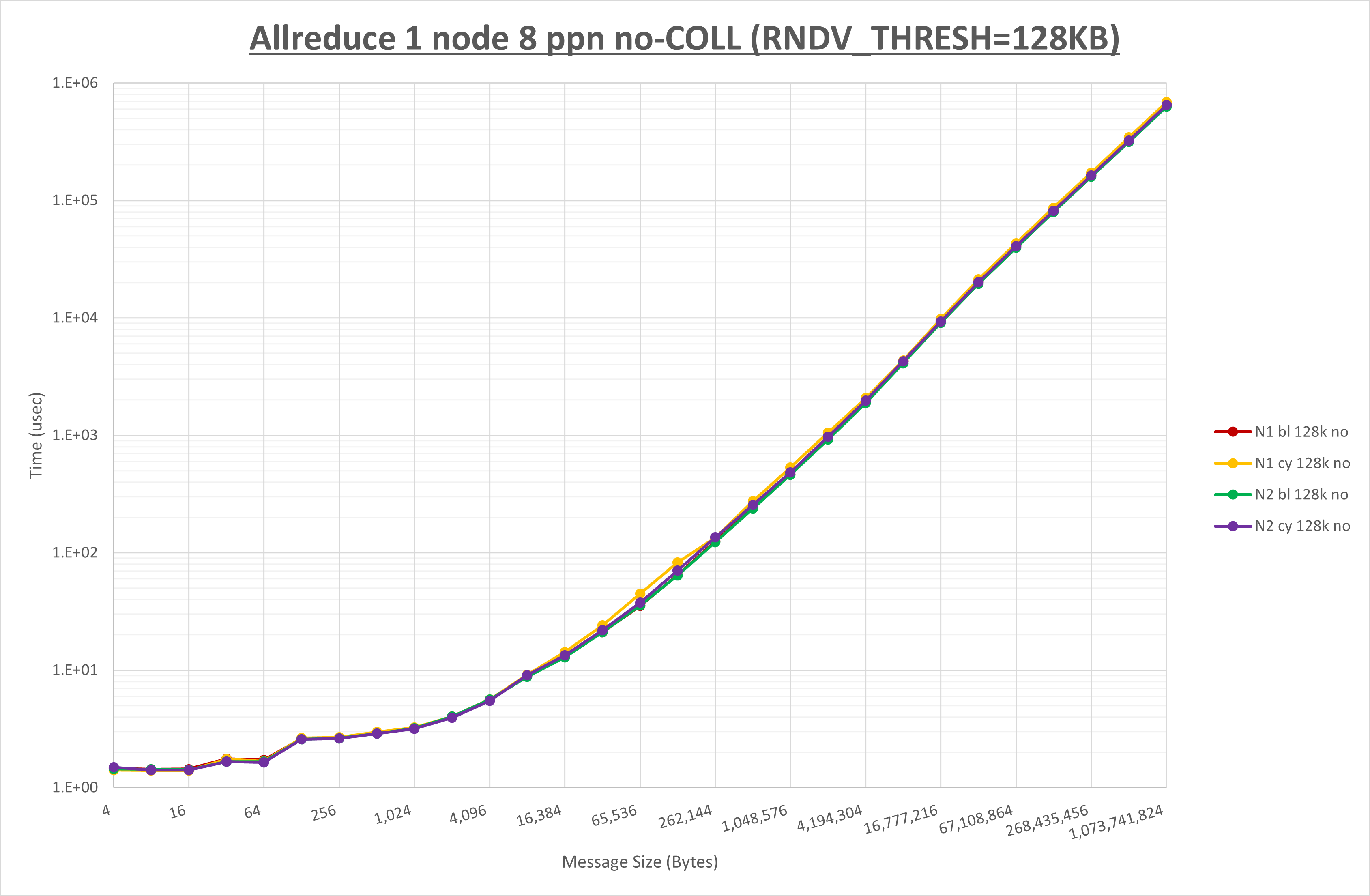
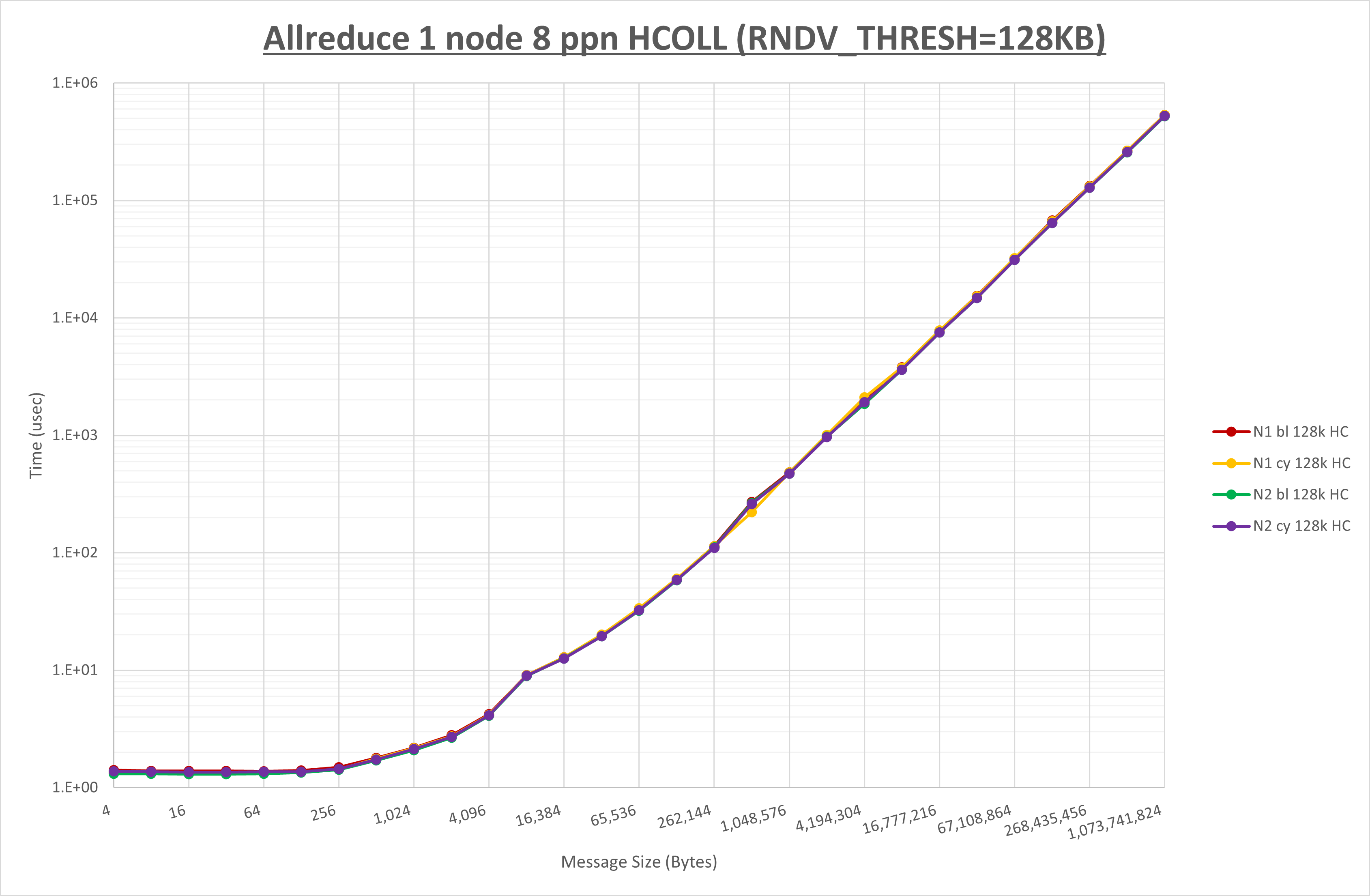
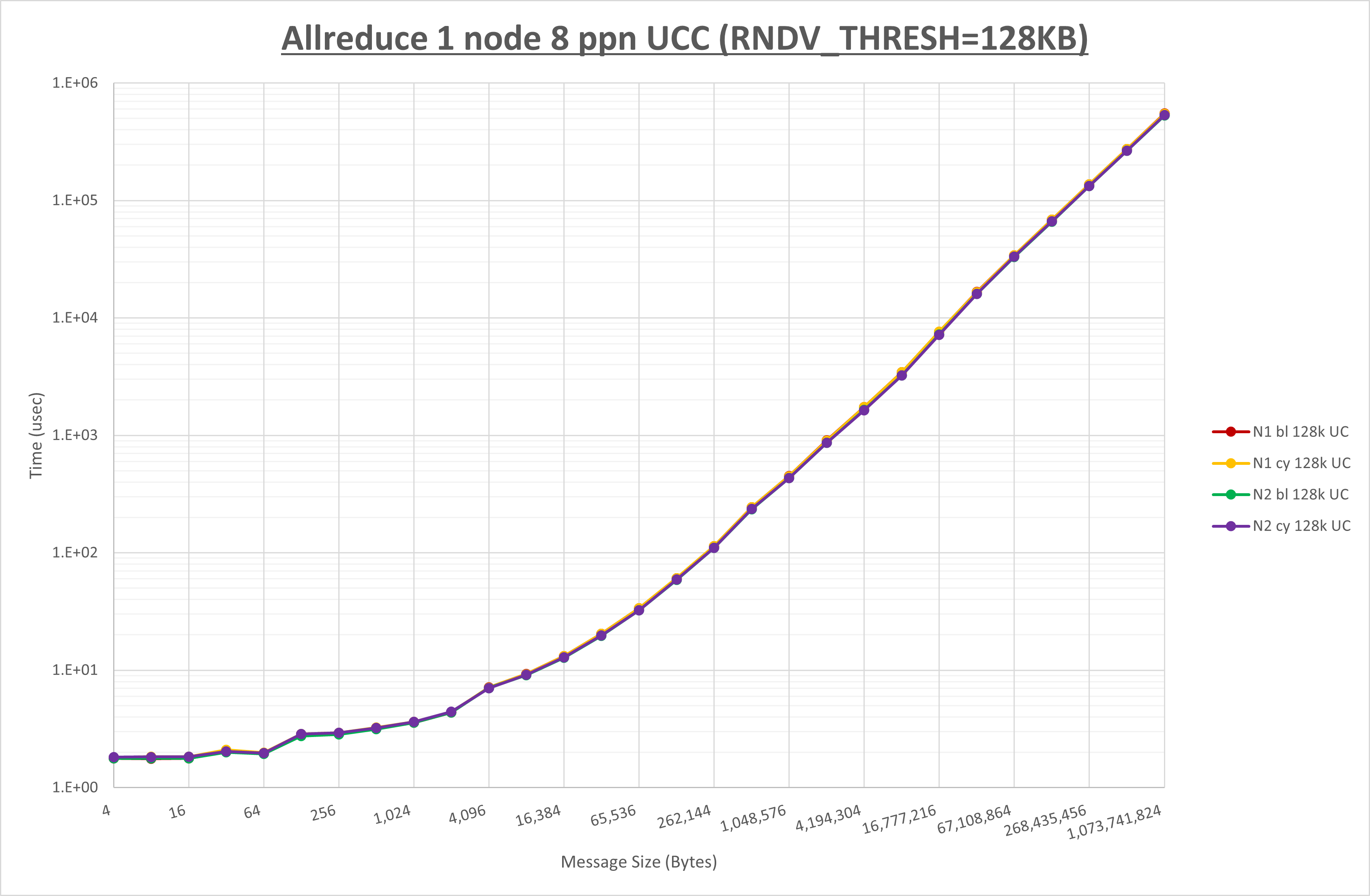
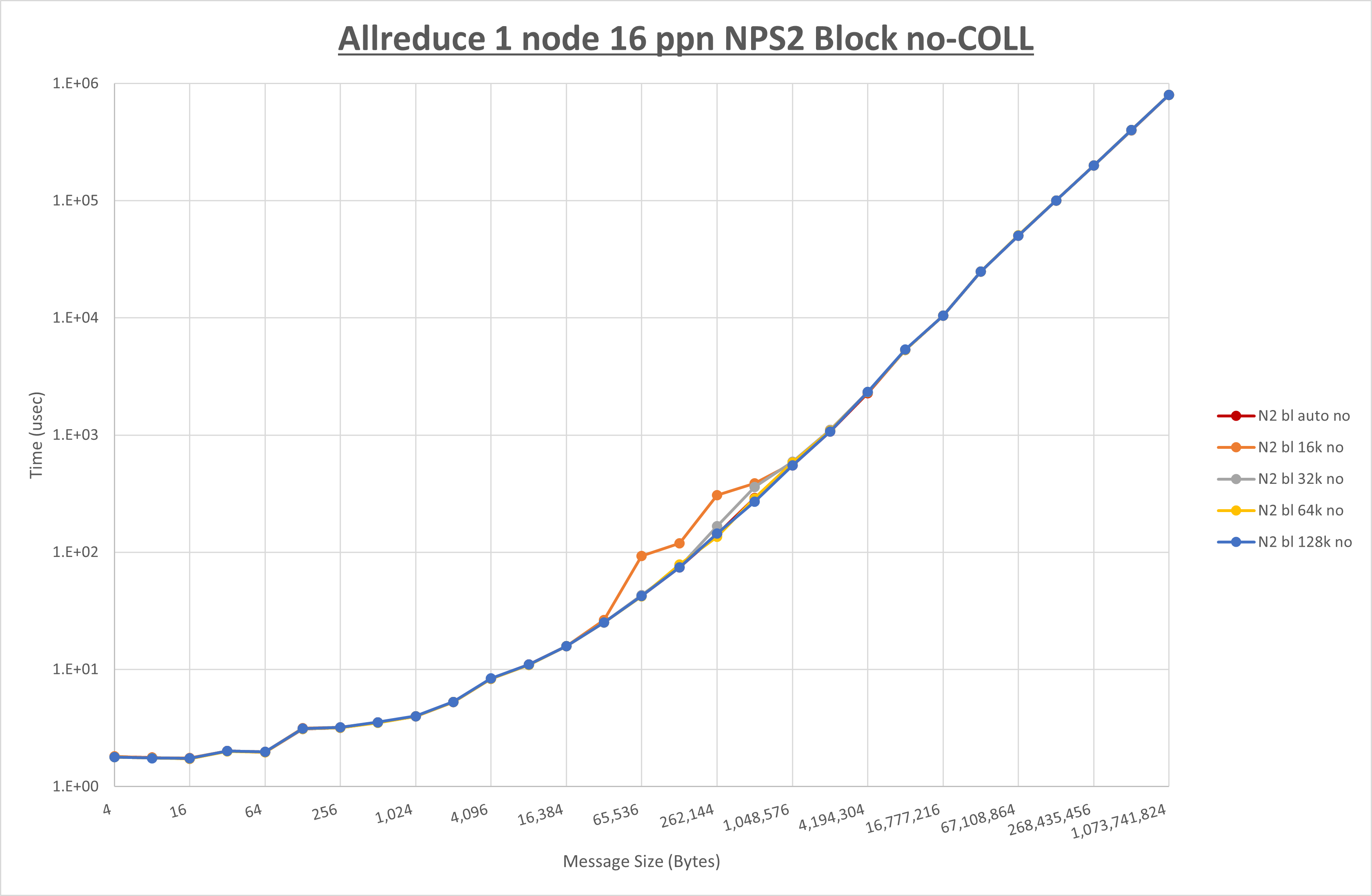
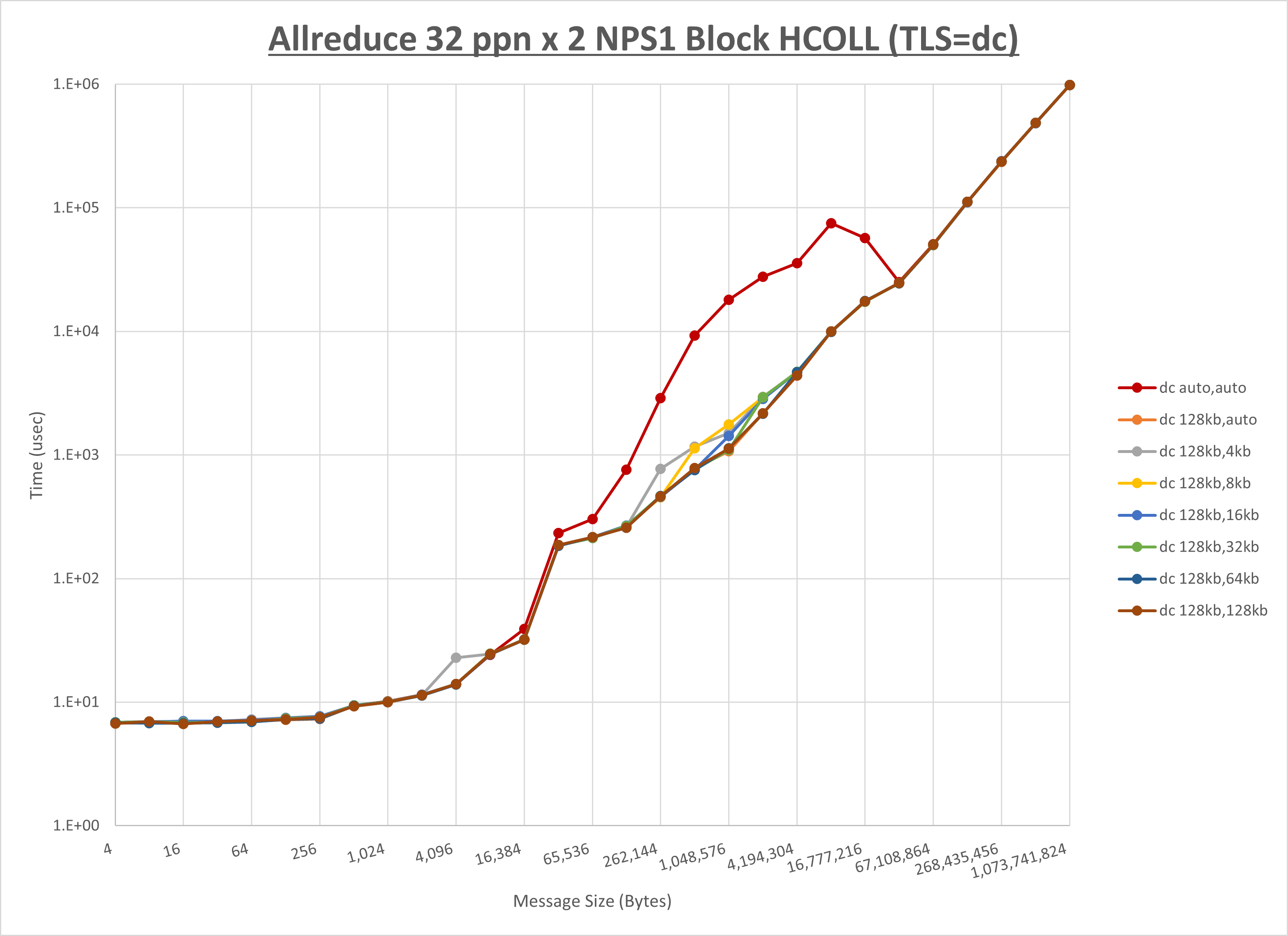
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
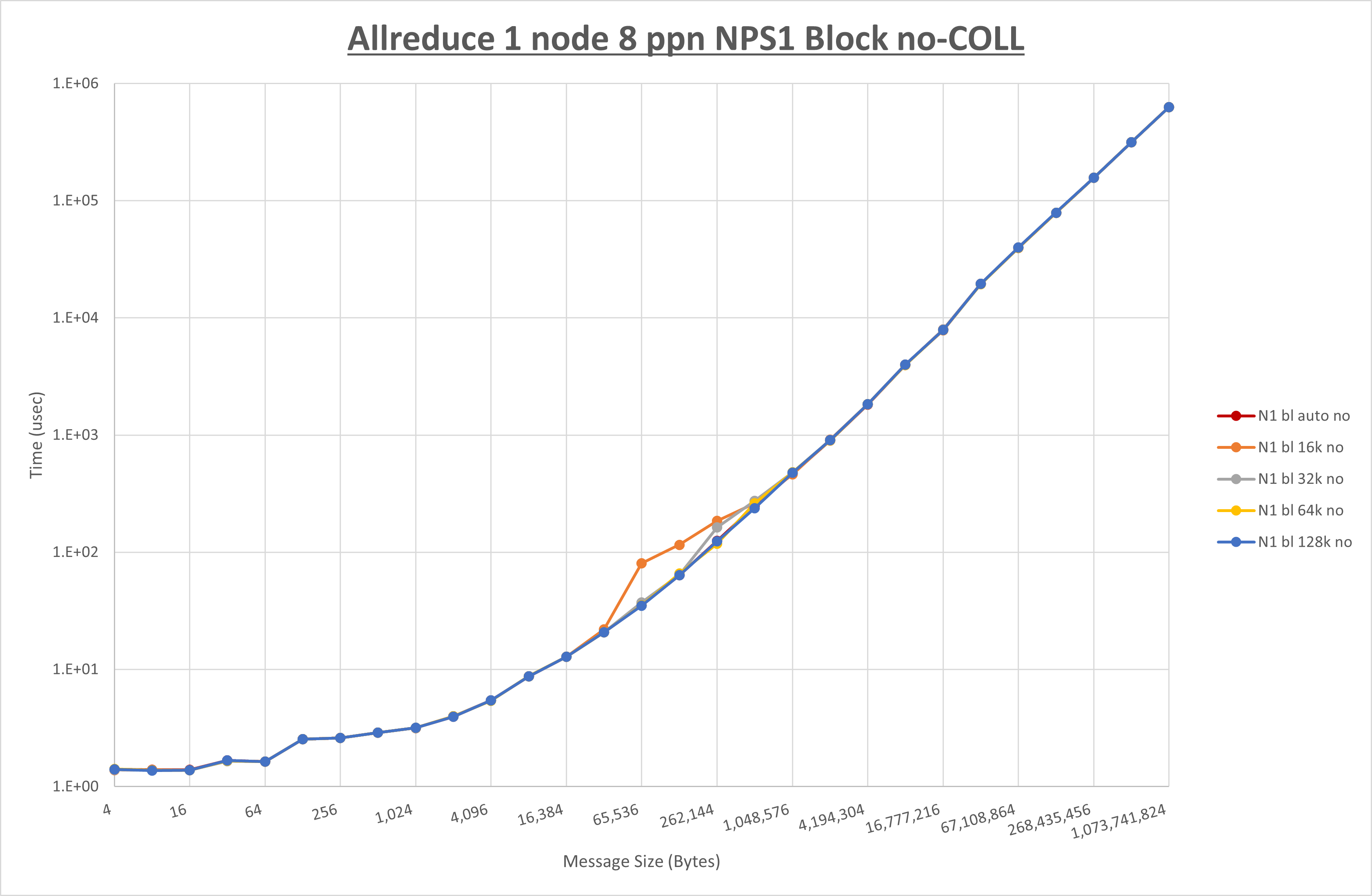
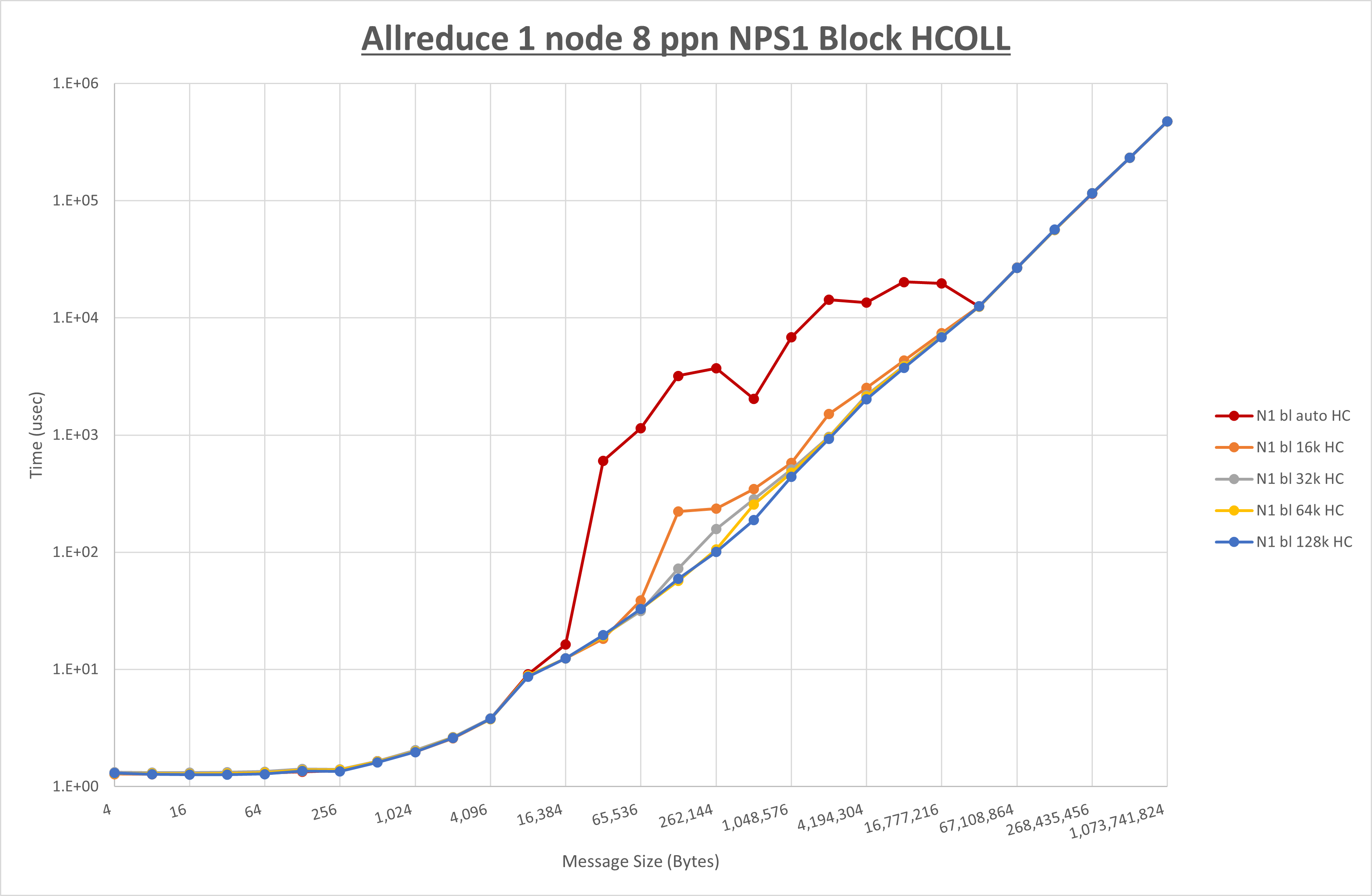
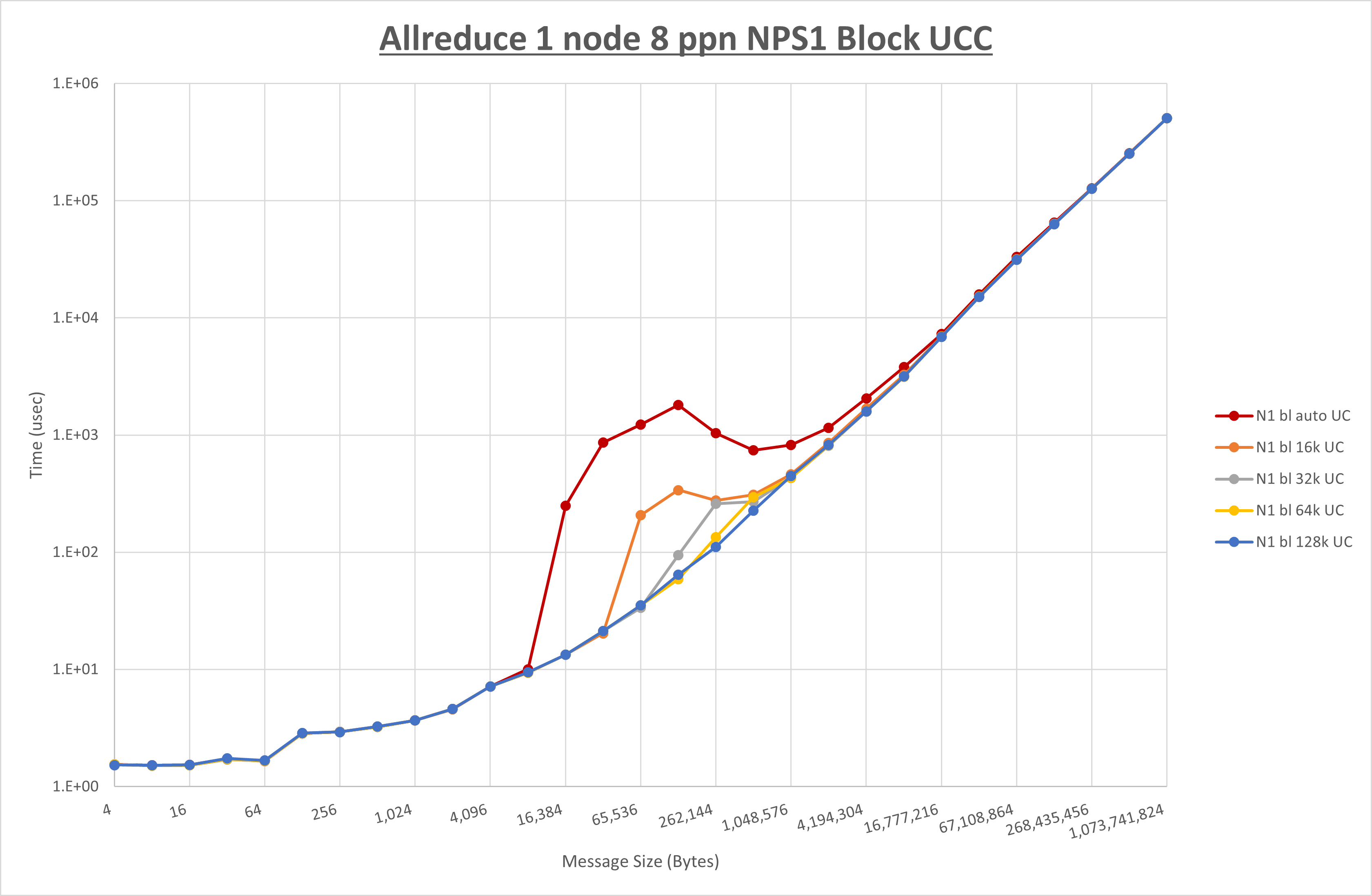
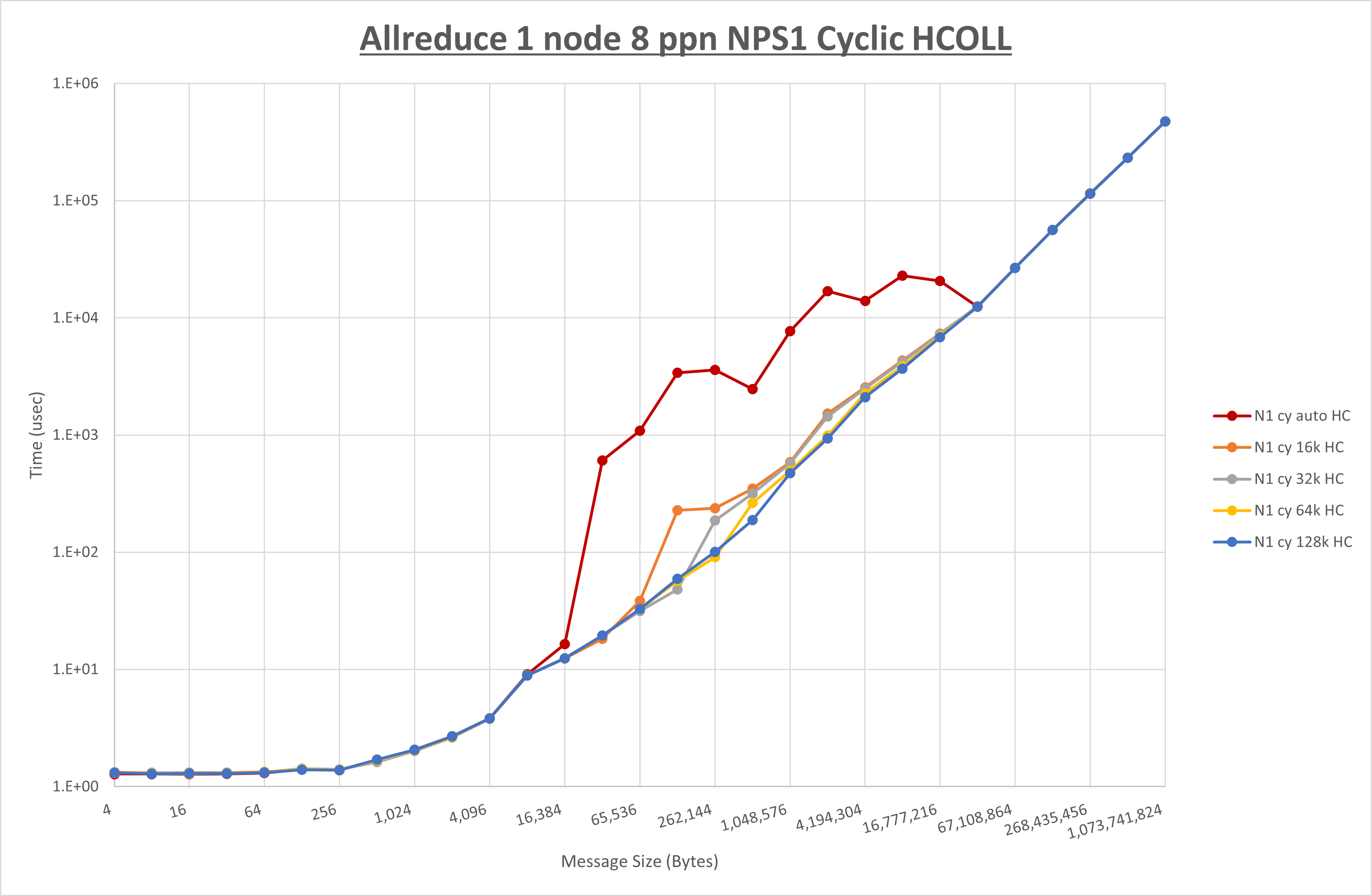
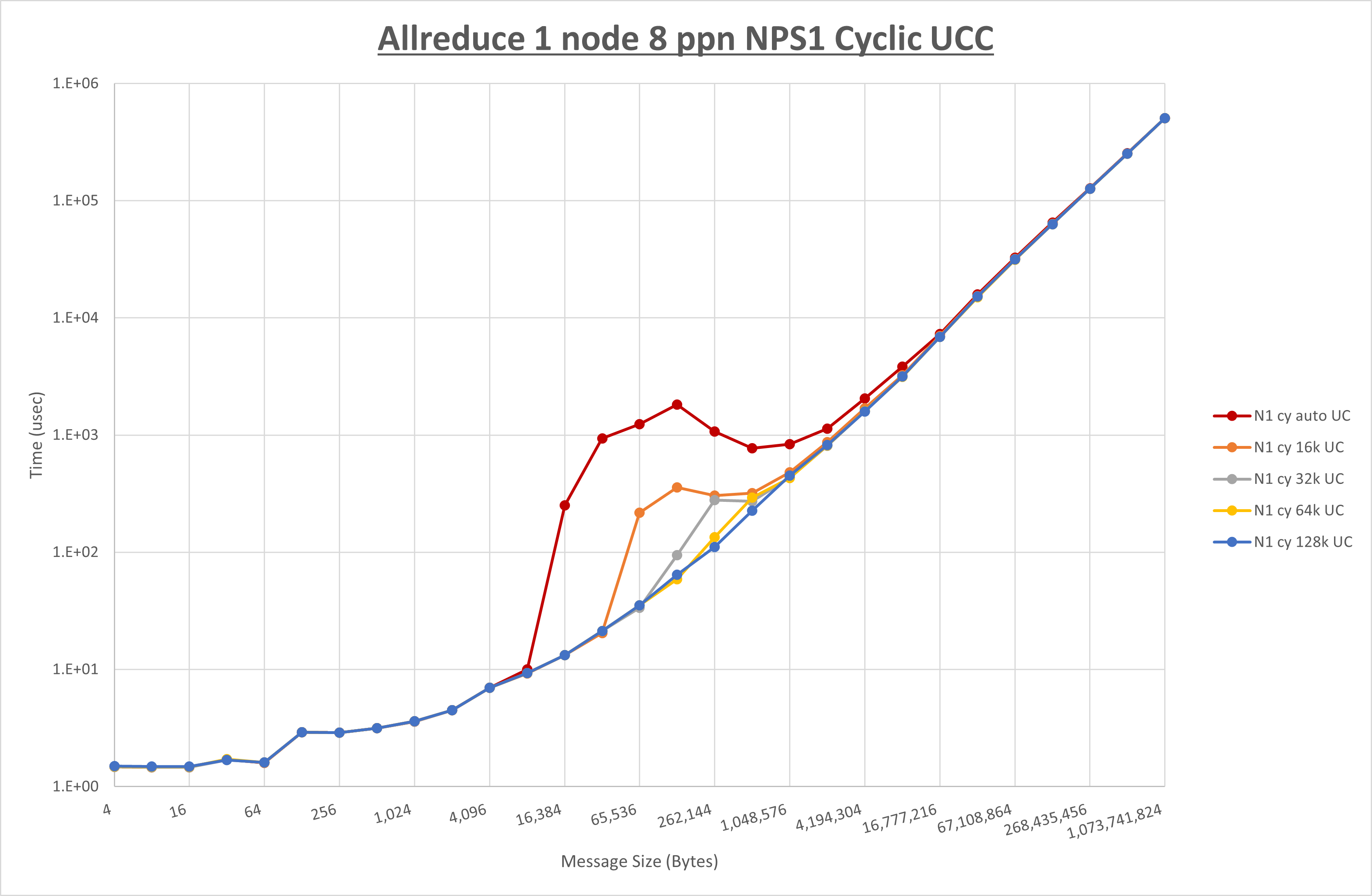
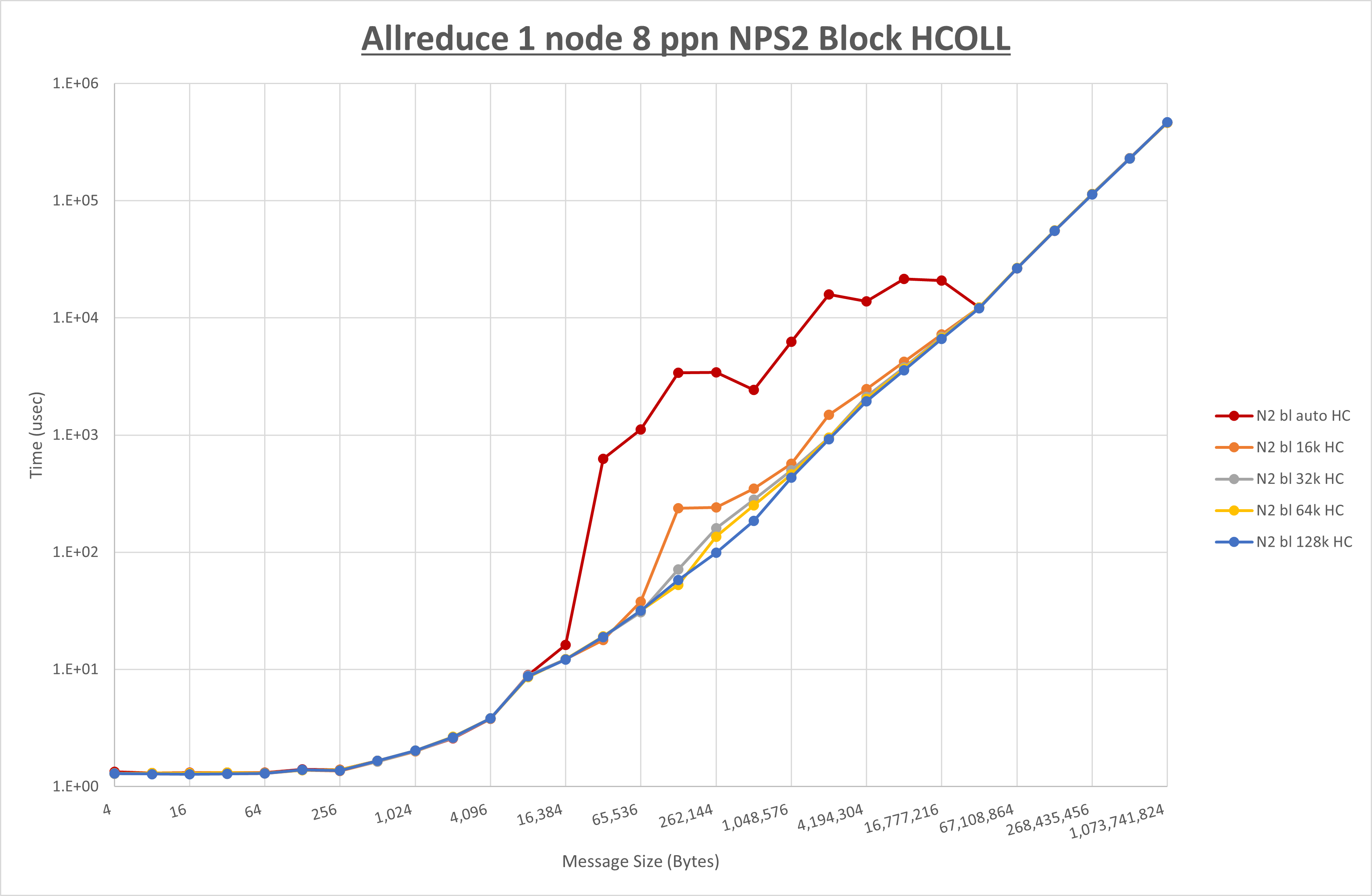
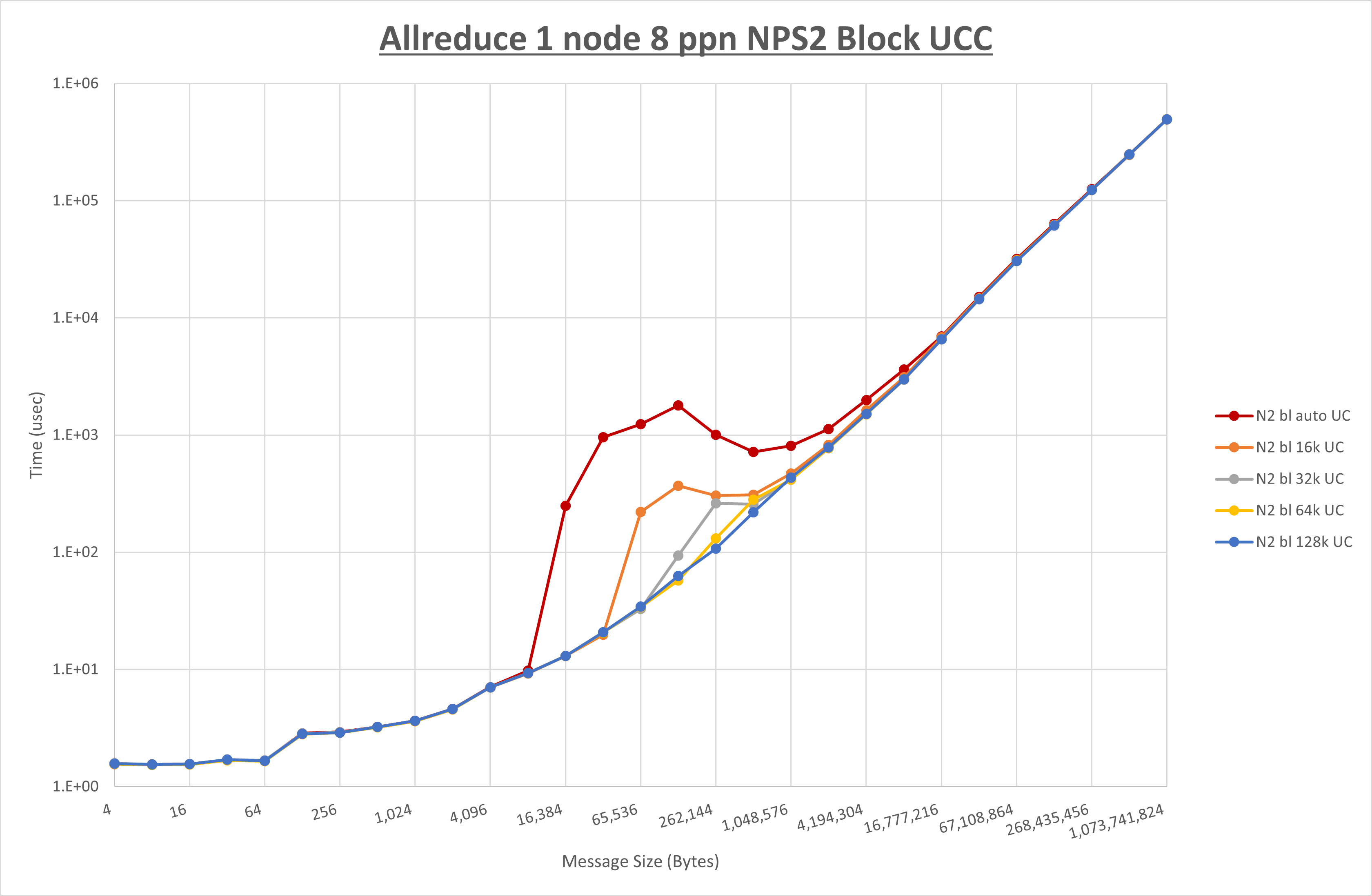
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 128KB | 128KB | 128KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
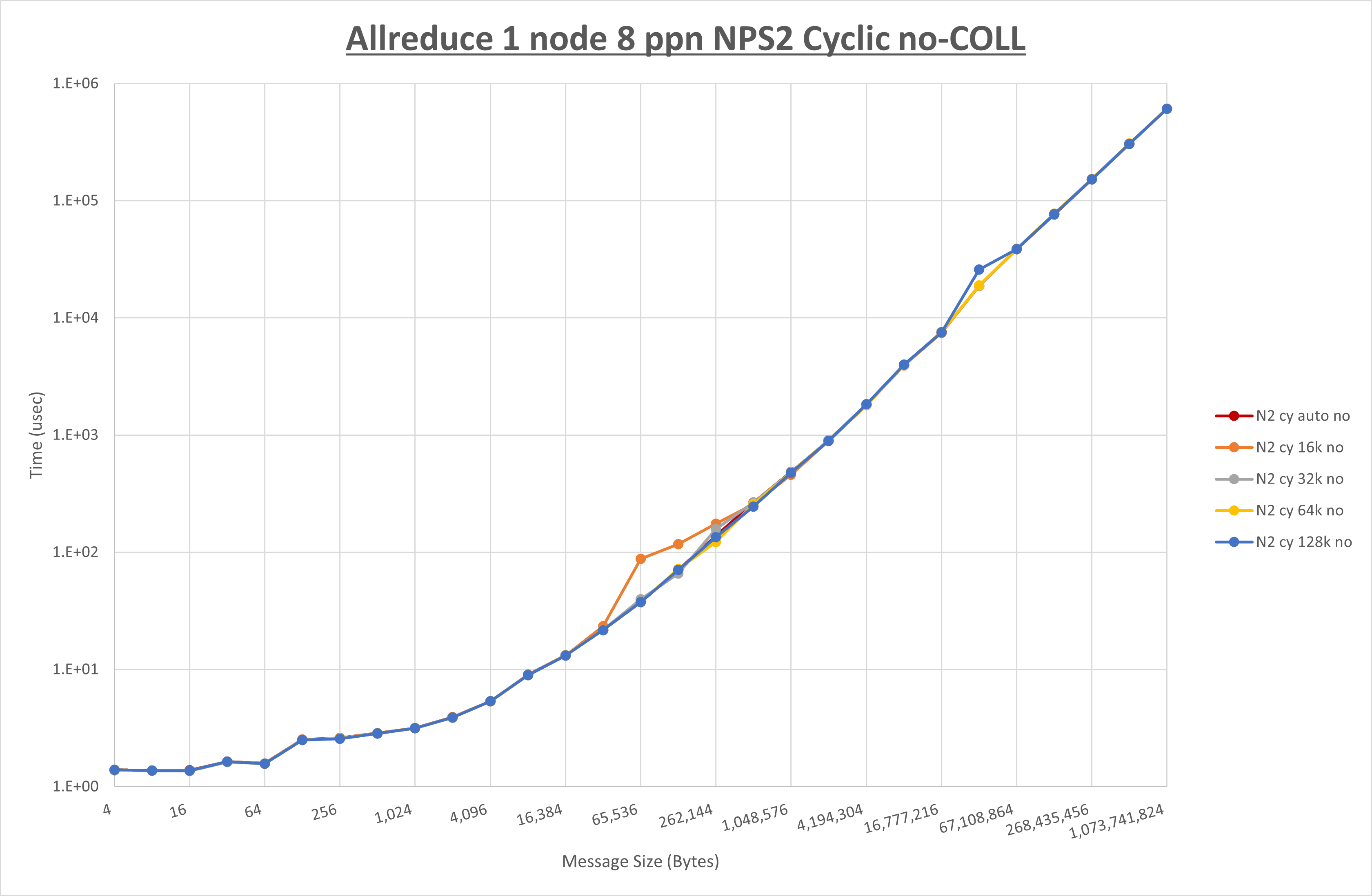
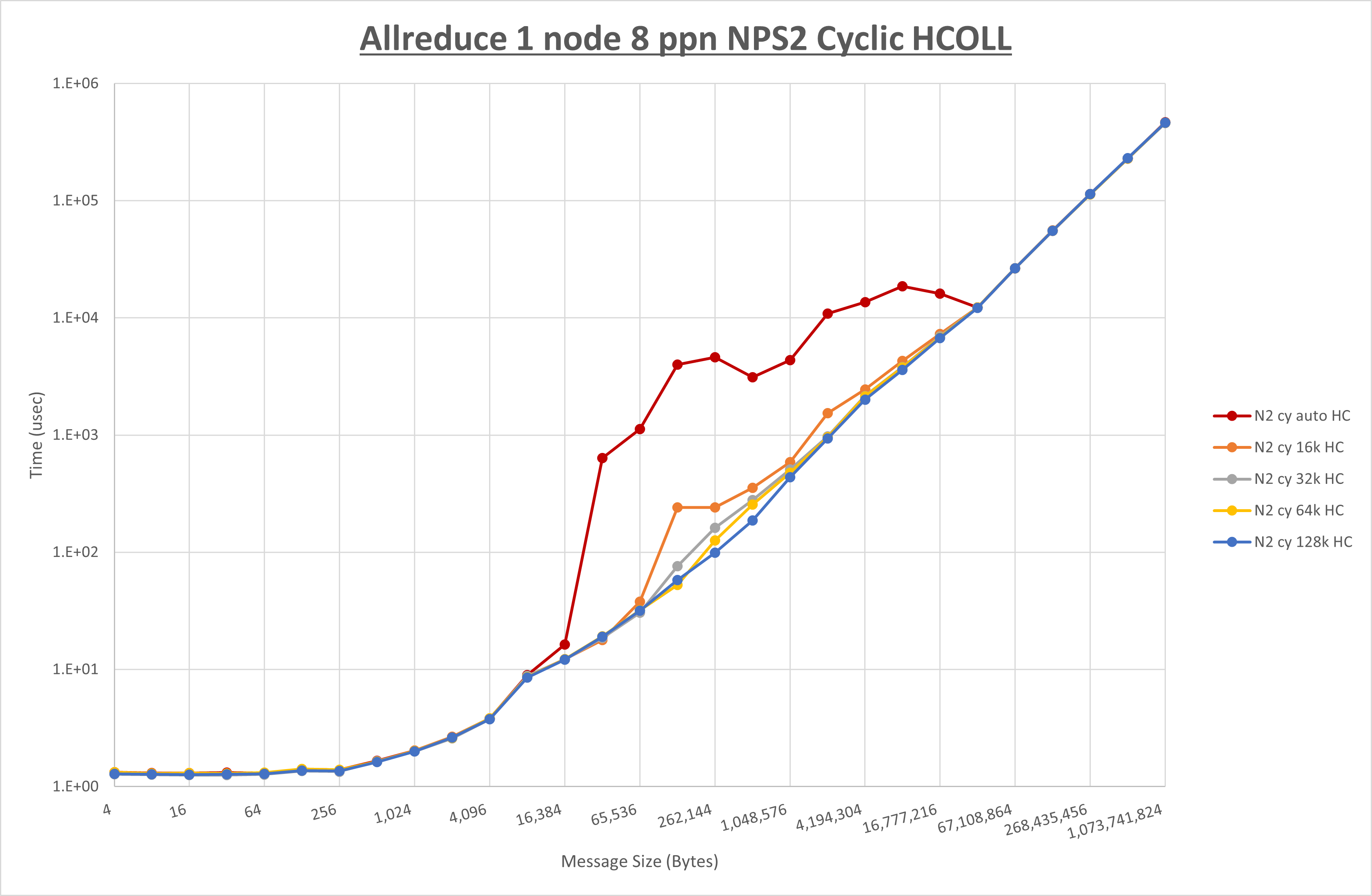
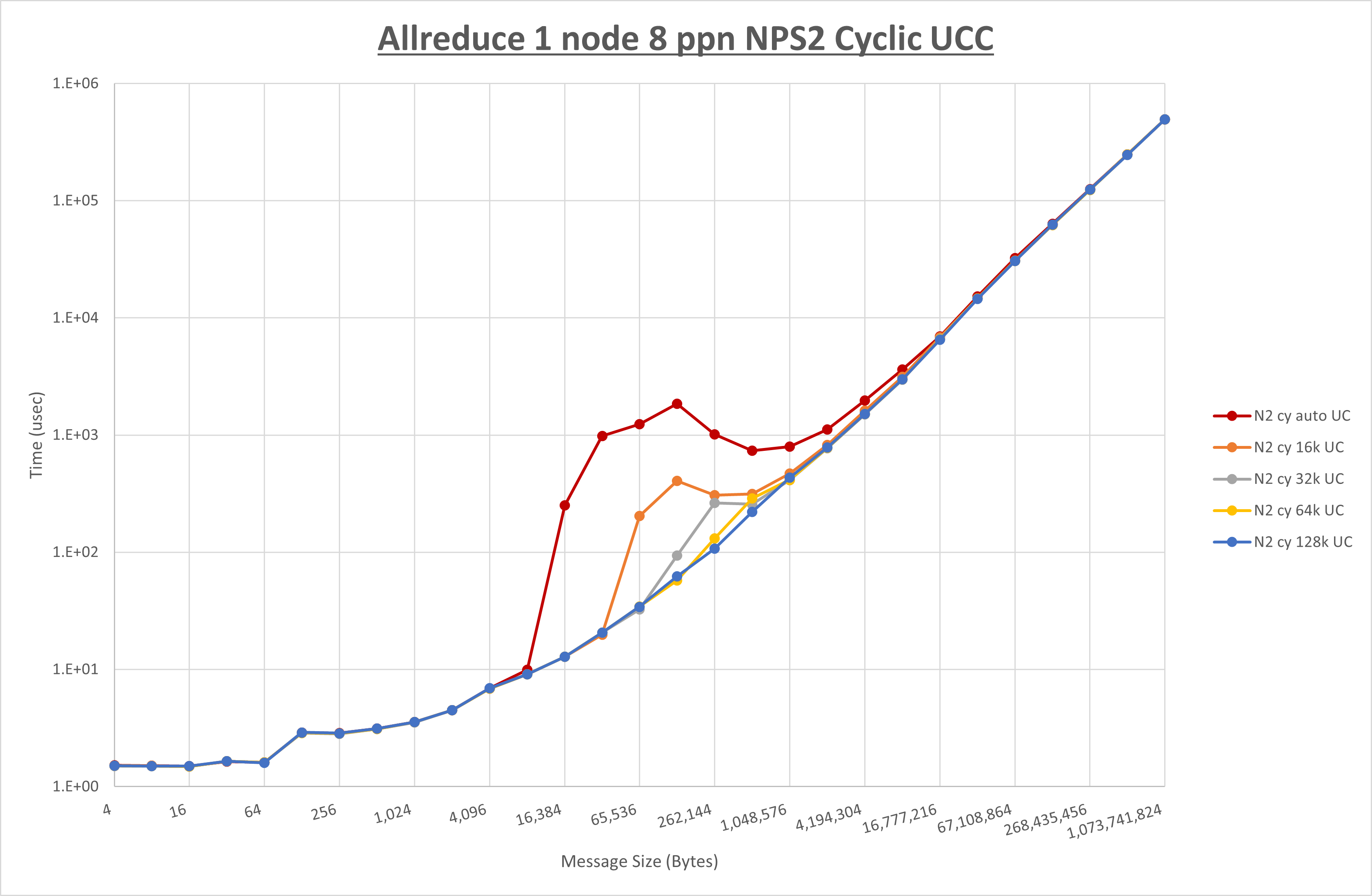
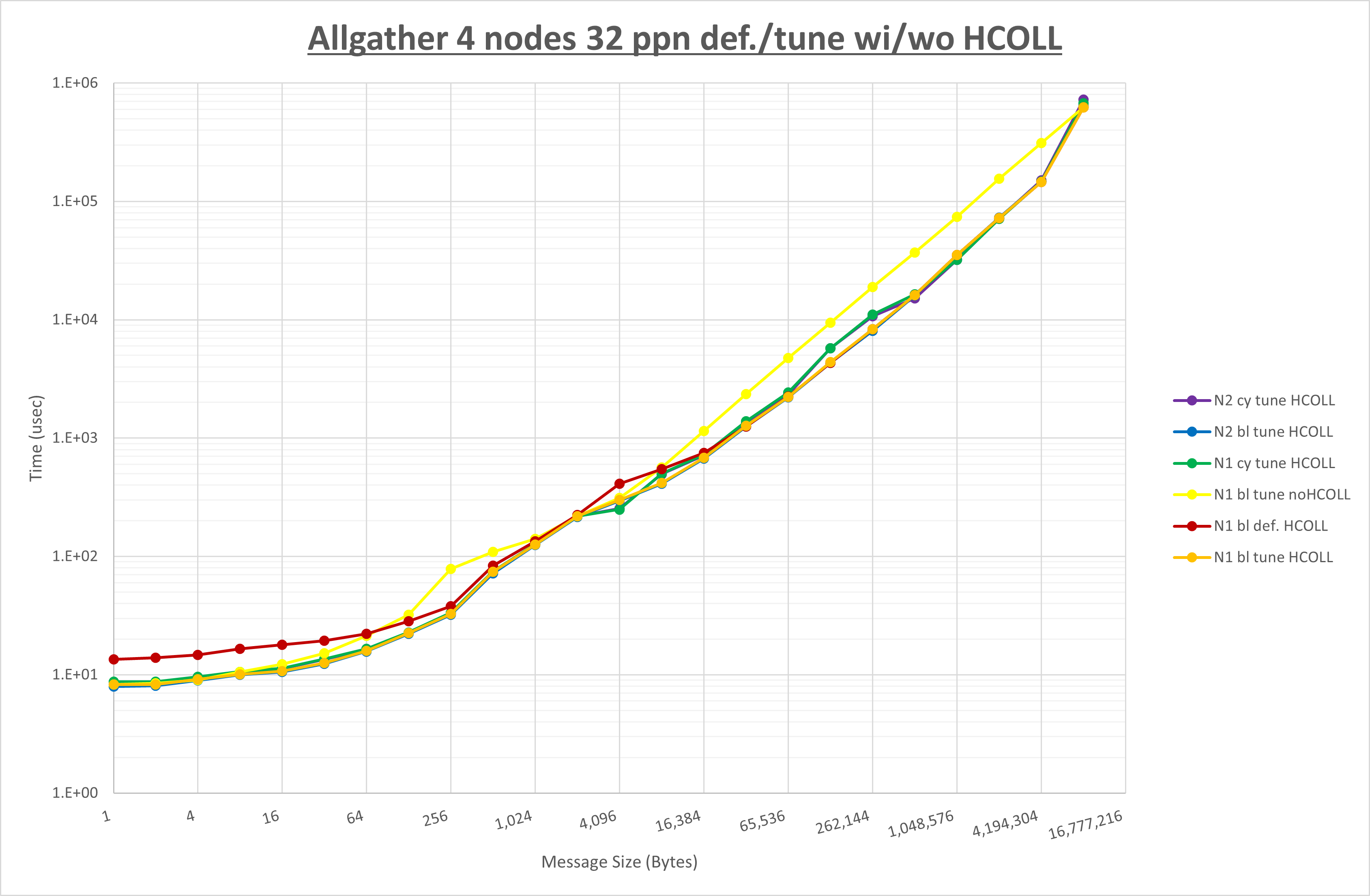
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
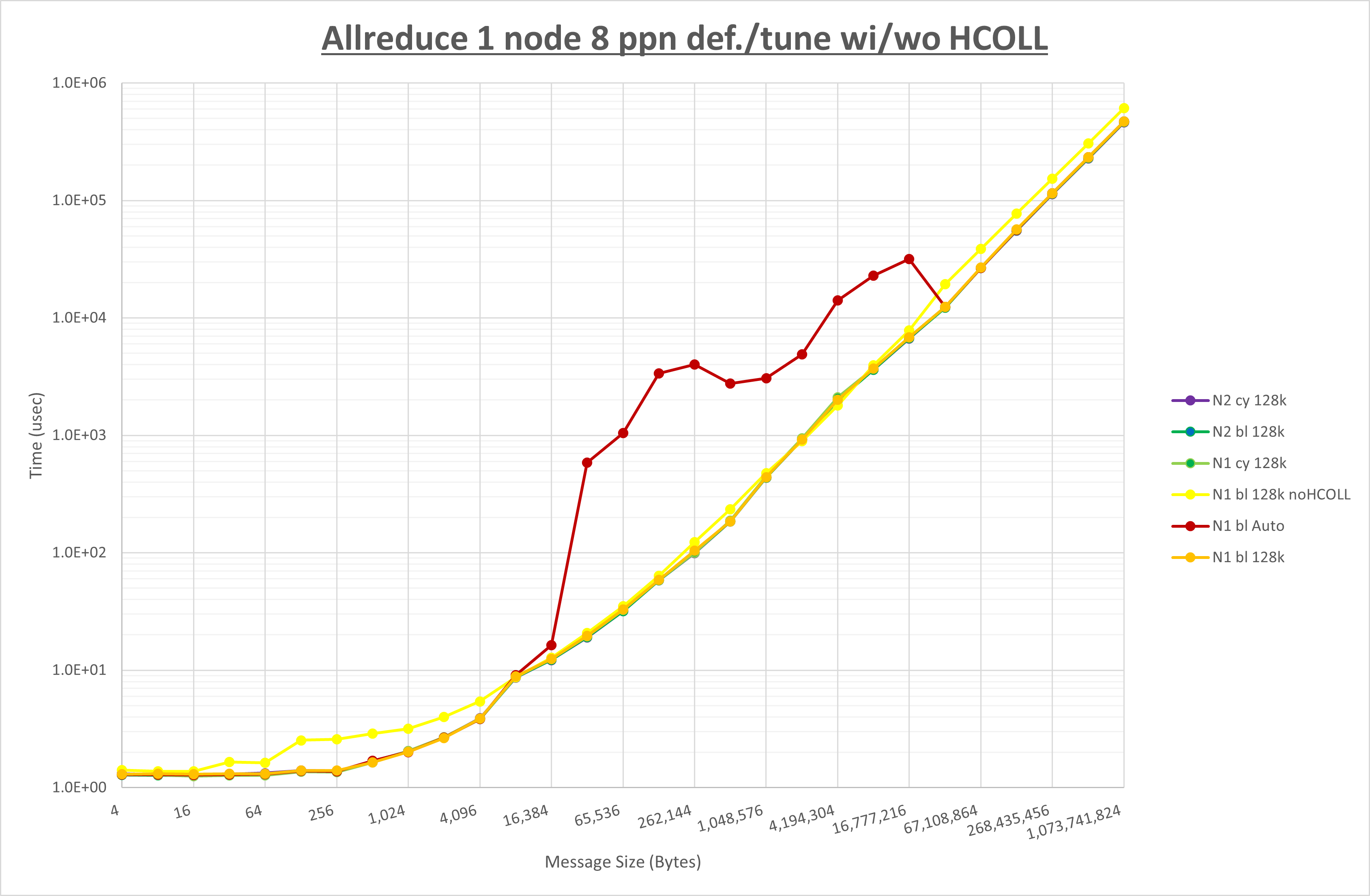
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し256KB以下と8MB以上で性能が向上
- UCC は no-COLL と比較し4MB以上で性能が向上し4KB以下で性能が低下
- チューニング適用で32KBから256KBの間で性能が向上
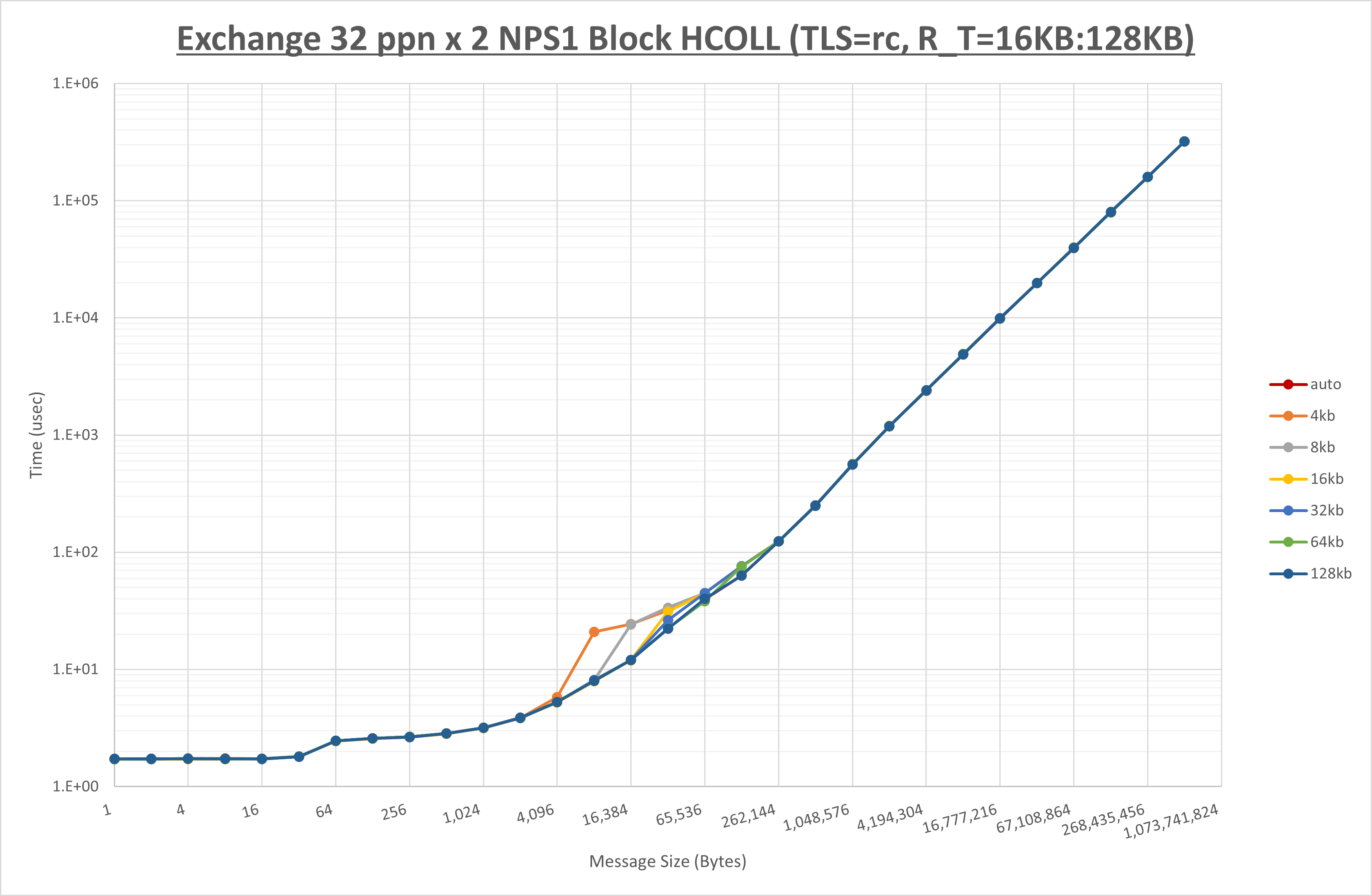
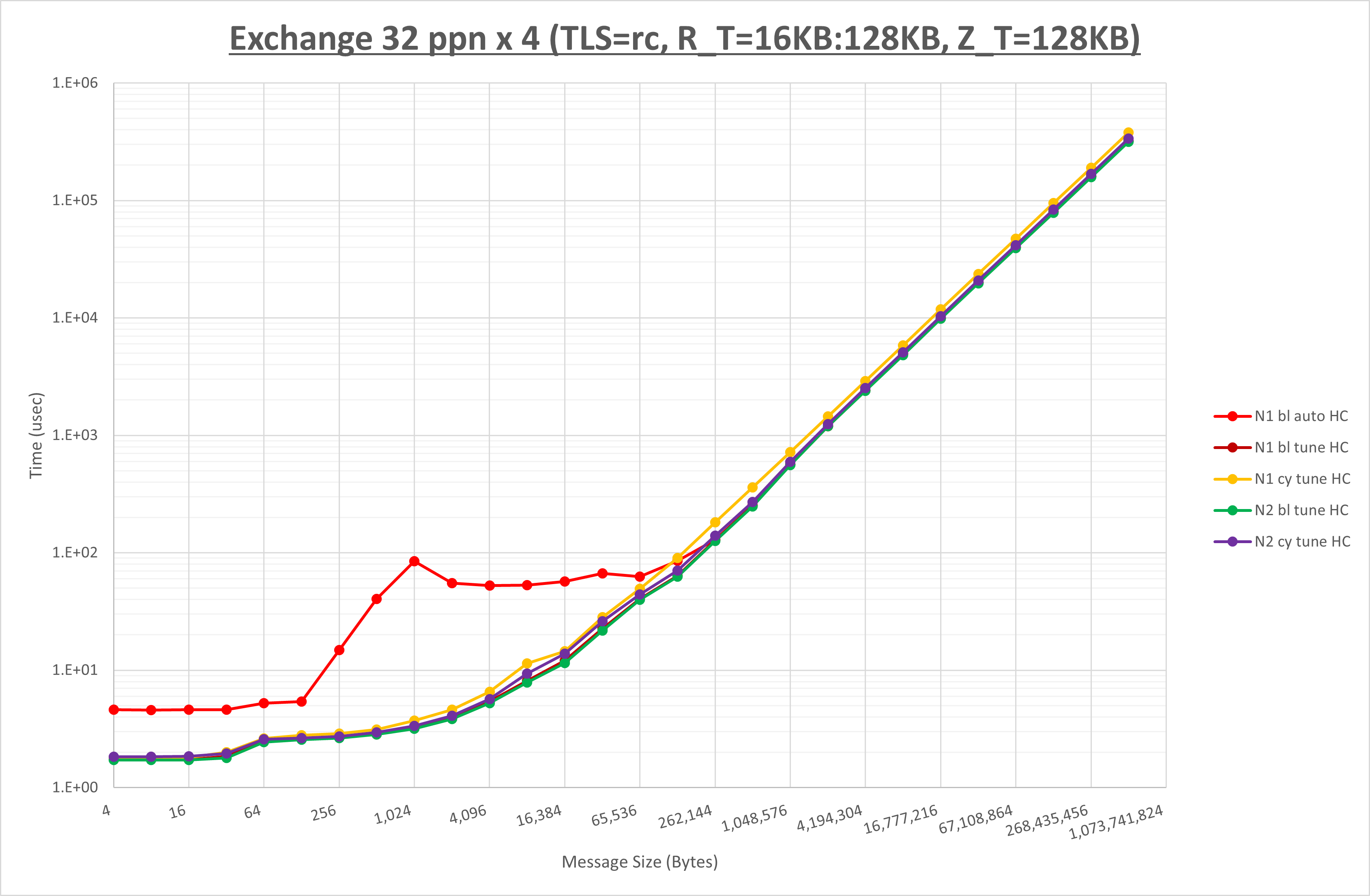
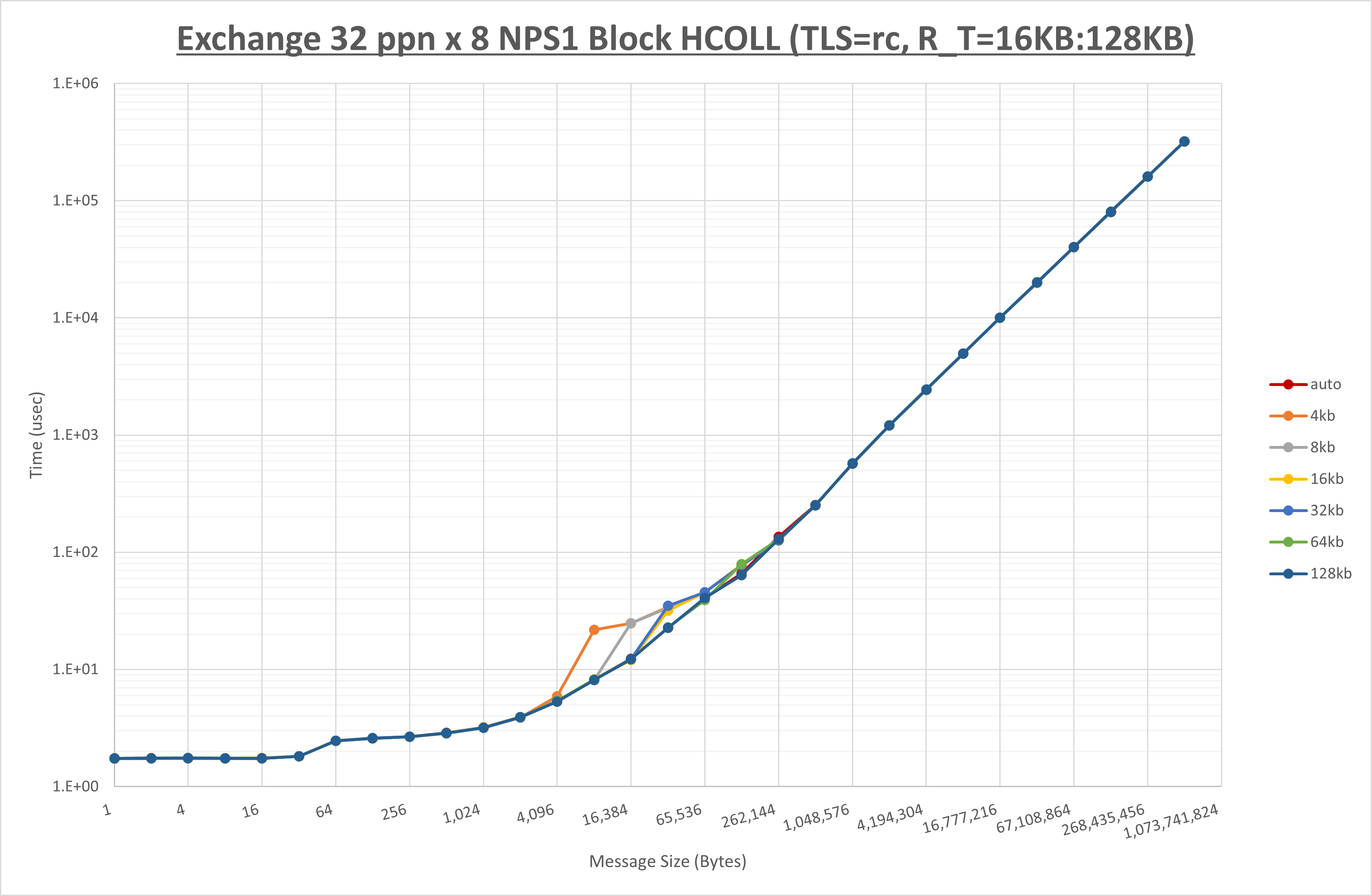
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 NPS とMPIプロセス分割方法の組合せ毎に示しています。
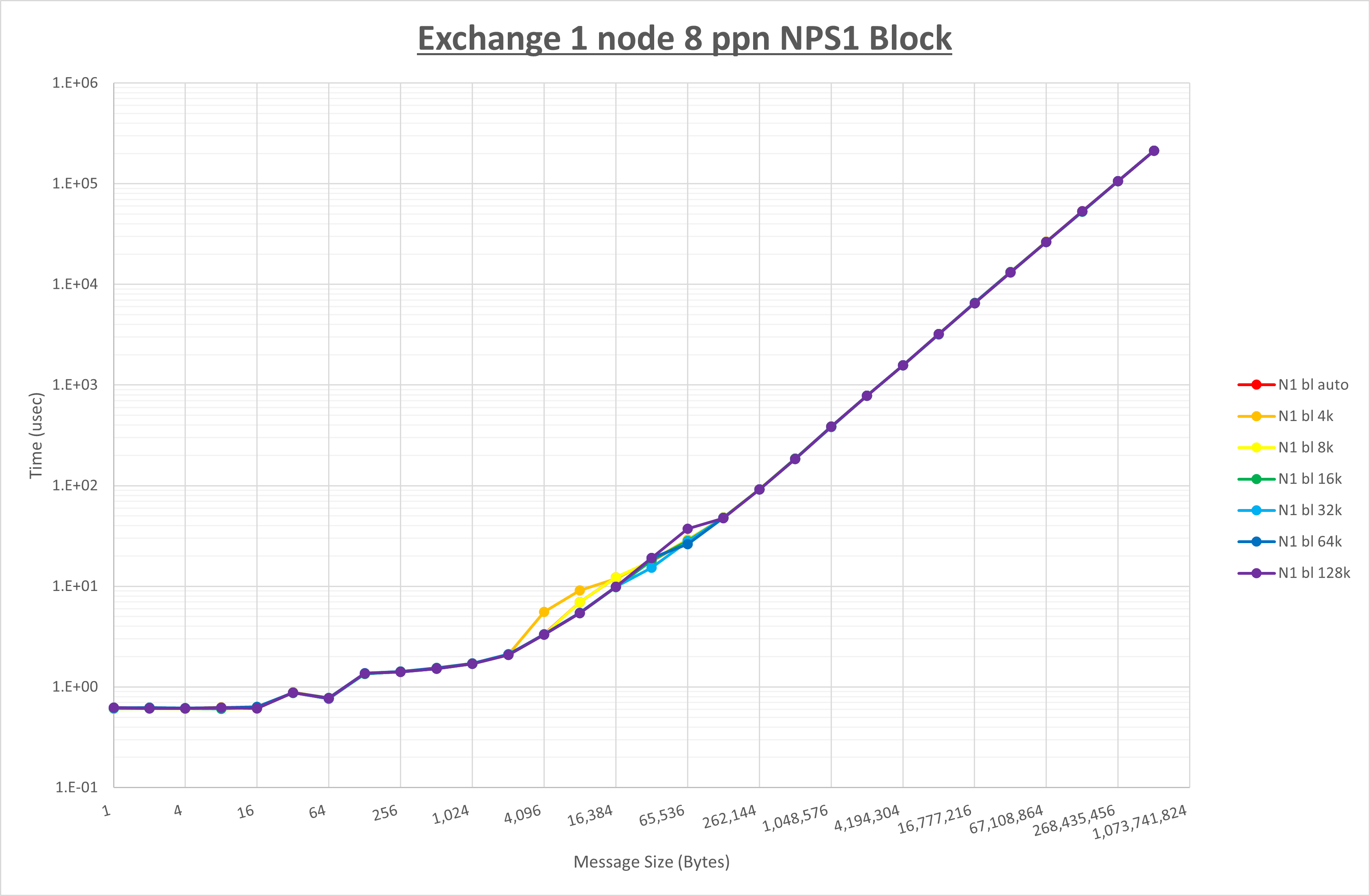
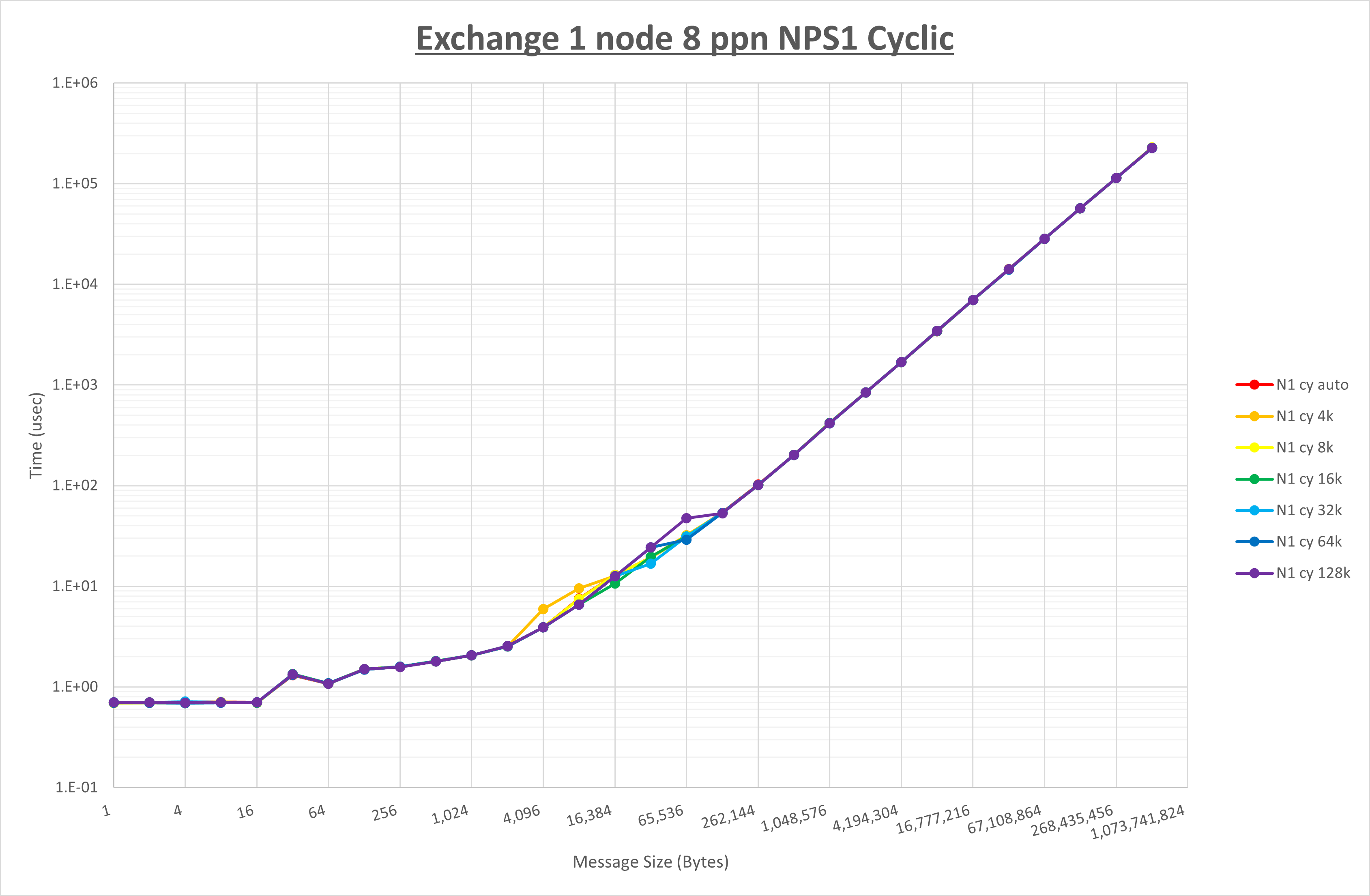
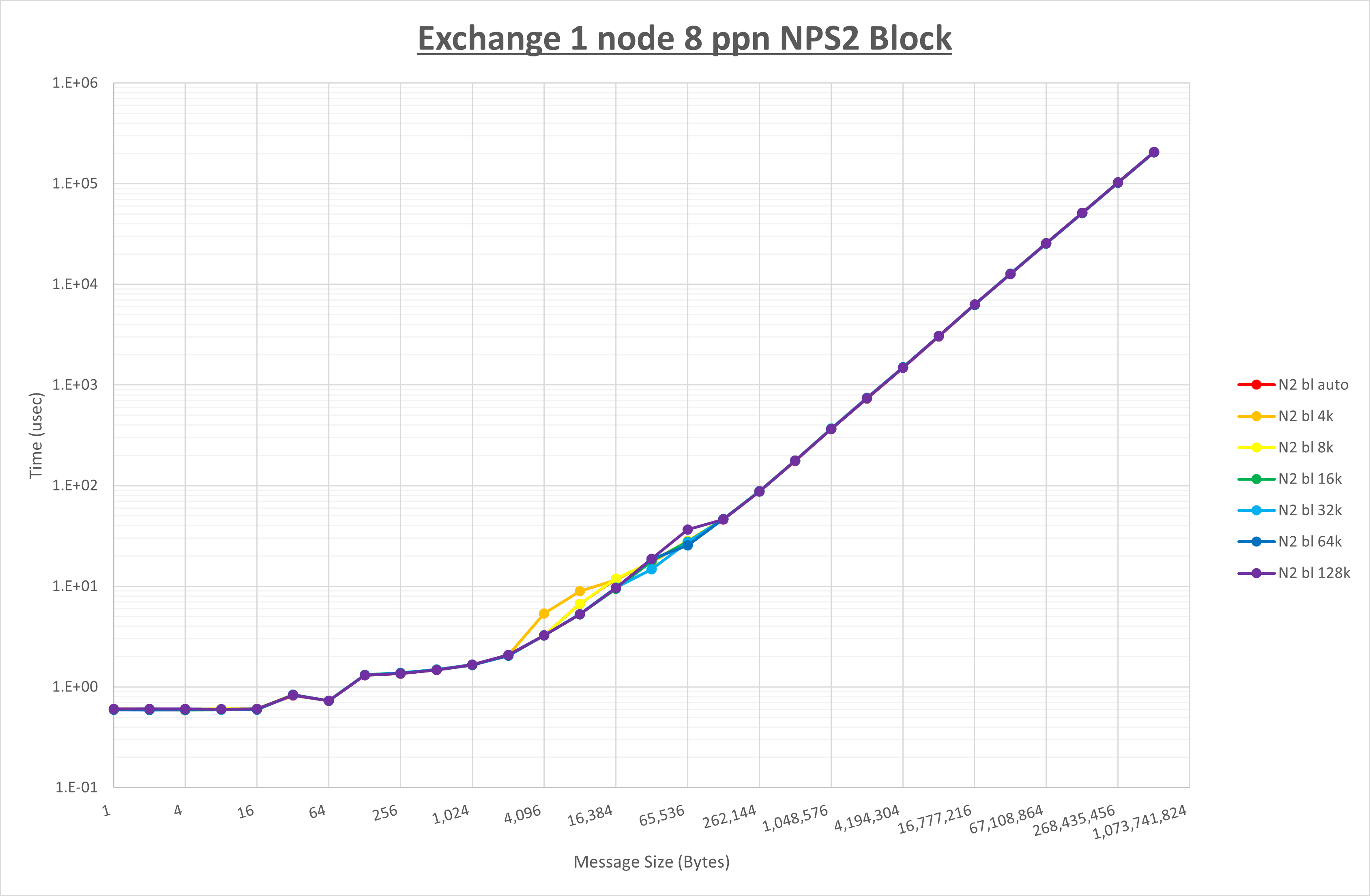
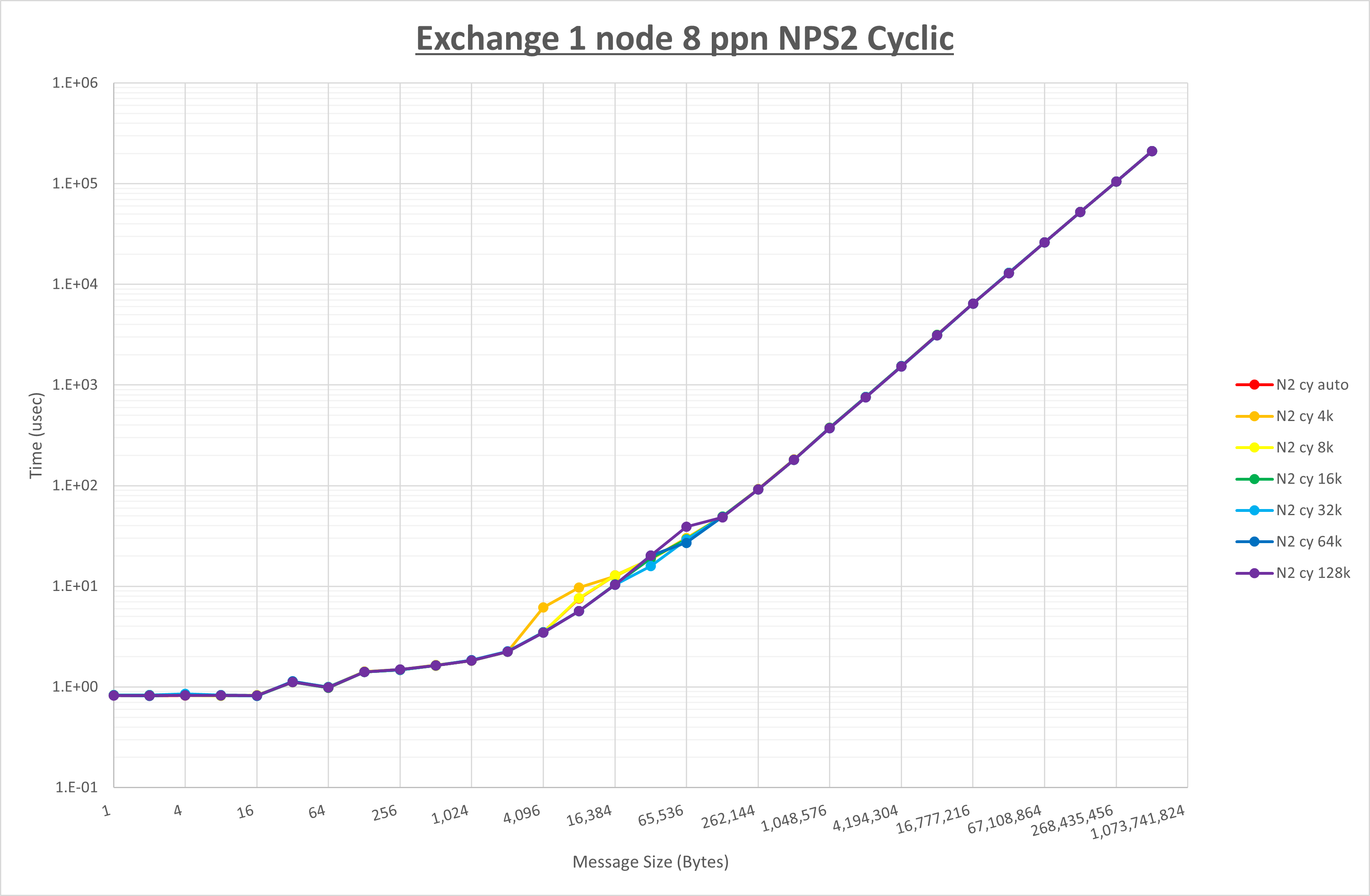
以上より、 NPS とMPIプロセス分割方法の組合せにより UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| NPS1 ブロック分割 |
NPS1 サイクリック分割 |
NPS2 ブロック分割 |
NPS2 サイクリック分割 |
|
|---|---|---|---|---|
| UCX_RNDV_THRESH | 32KB | 32KB | 32KB | 32KB |
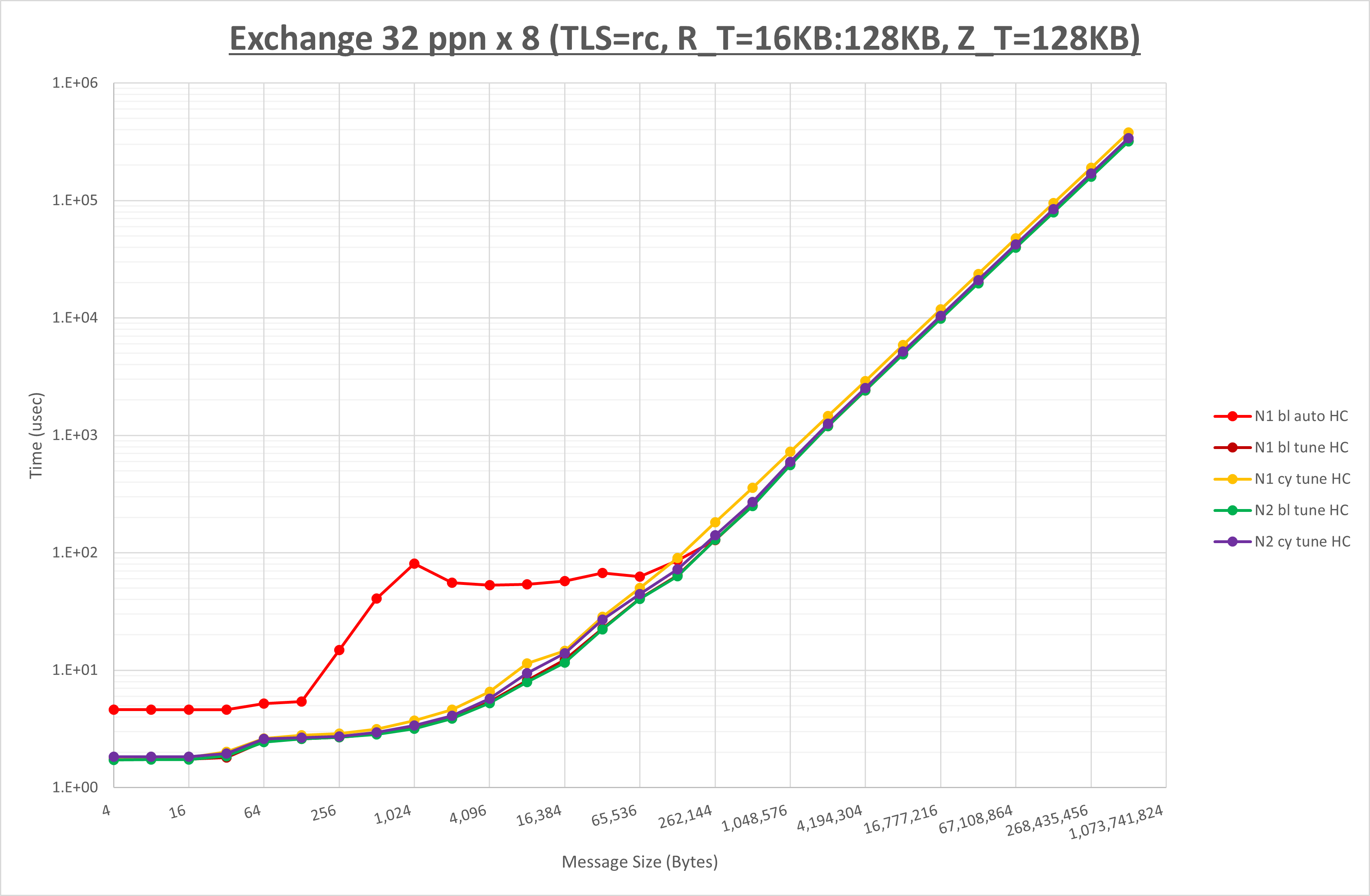
NPS とMPIプロセス分割方法の各組合せを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto )を含めています。
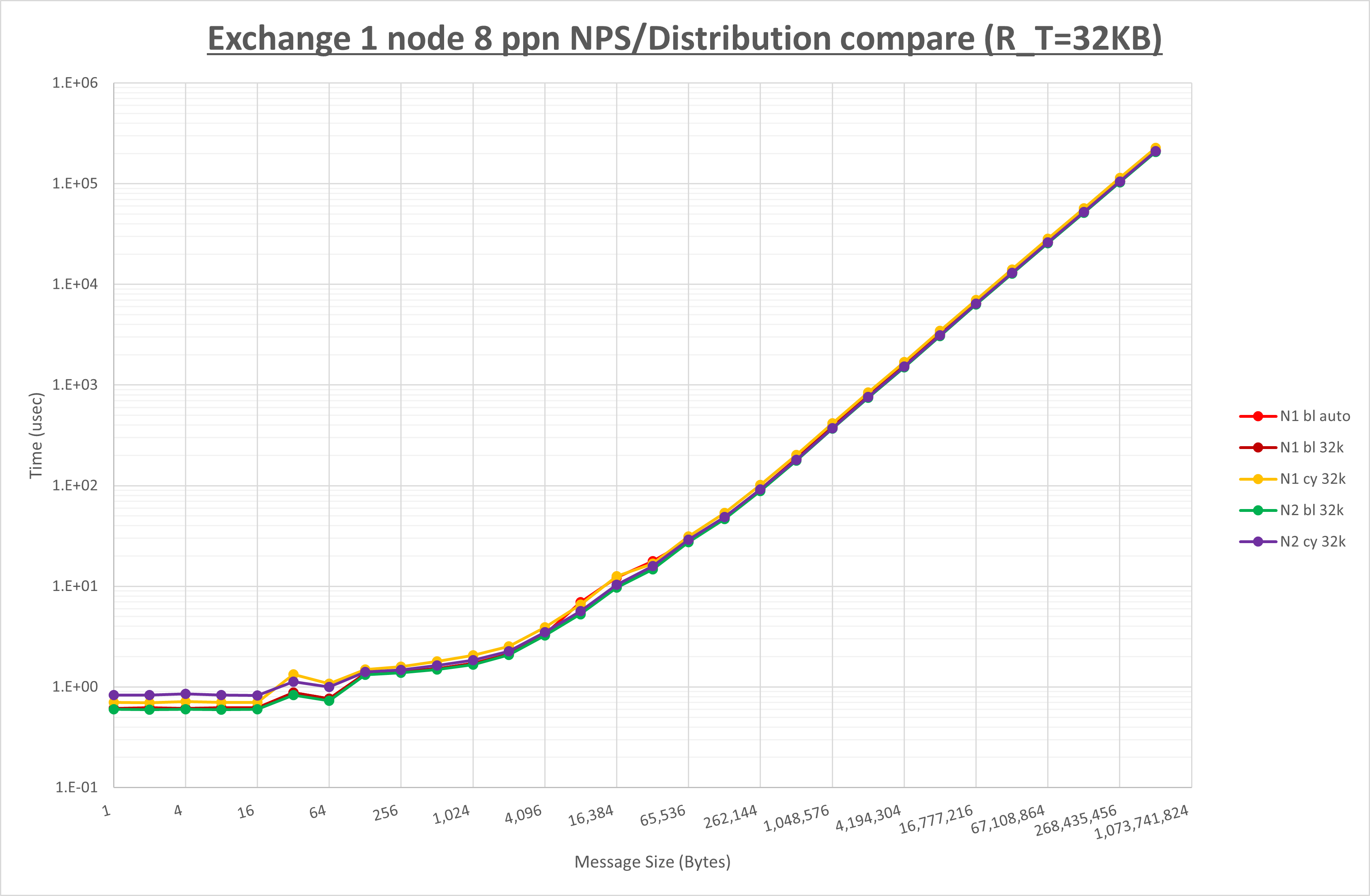
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で8KBから32KBの間で性能が向上
本章は、1ノードに16 MPIプロセスを割当てる場合の最適な 実行時パラメータ の組み合わせをMPI集合通信関数毎に検証し、その結果を考察します。
下表は、各MPI集合通信関数の最適な UCX_RNDV_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_RNDV_THRESH |
|---|---|
| Alltoall | 16KB / 32KB |
| Allgather | 64KB |
| Allreduce | 128KB |
| Exchange | 16KB |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
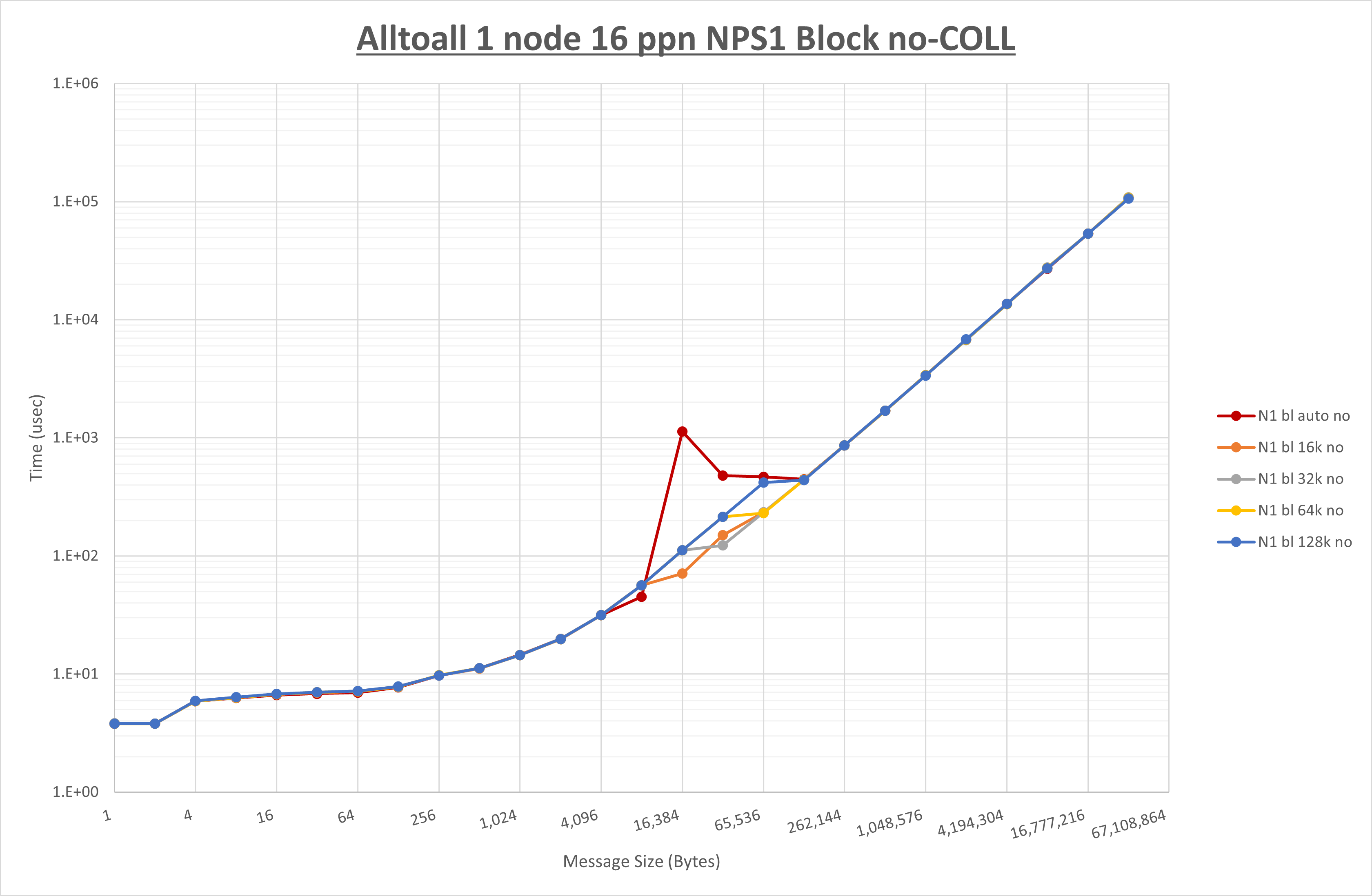
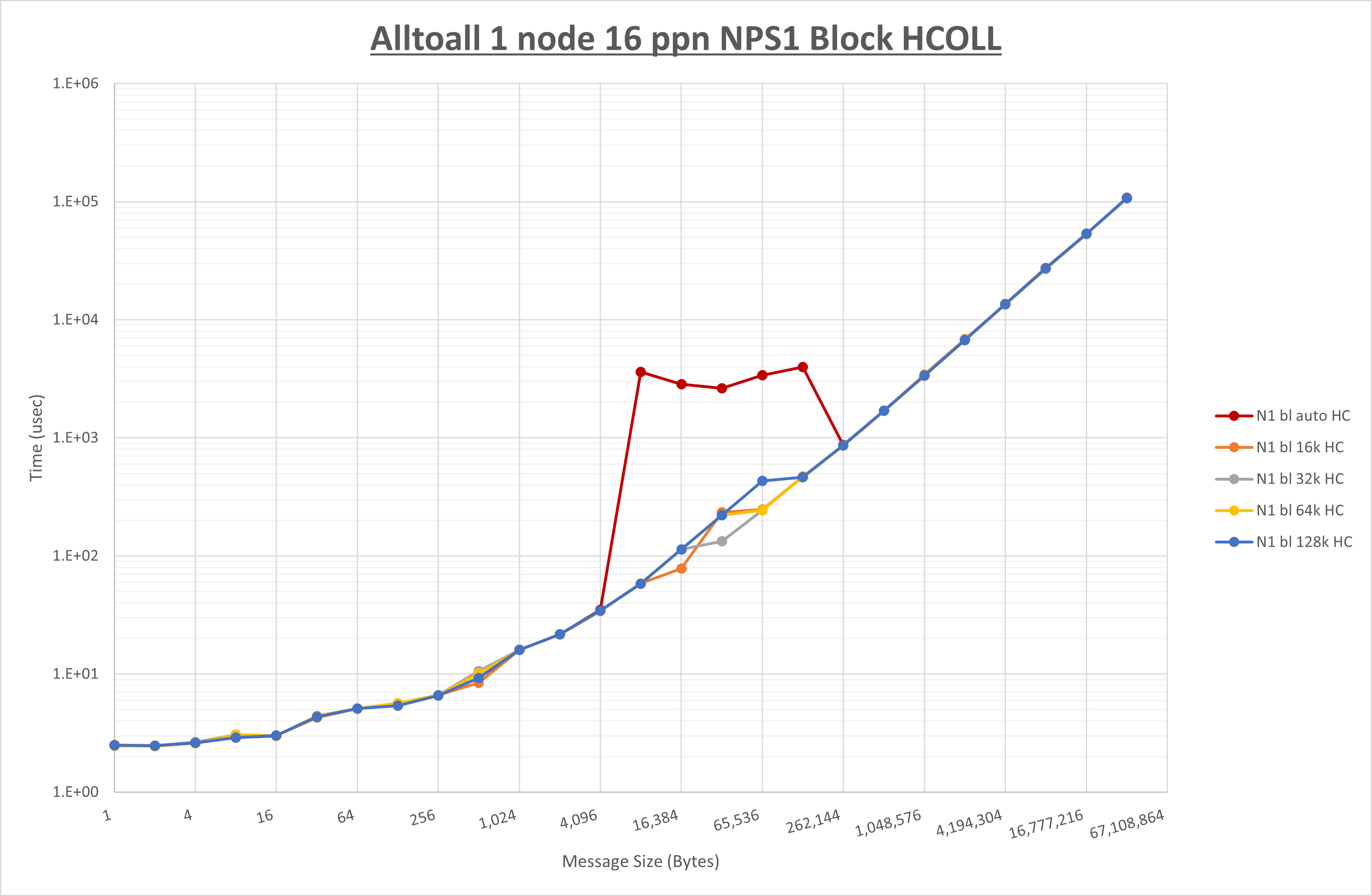
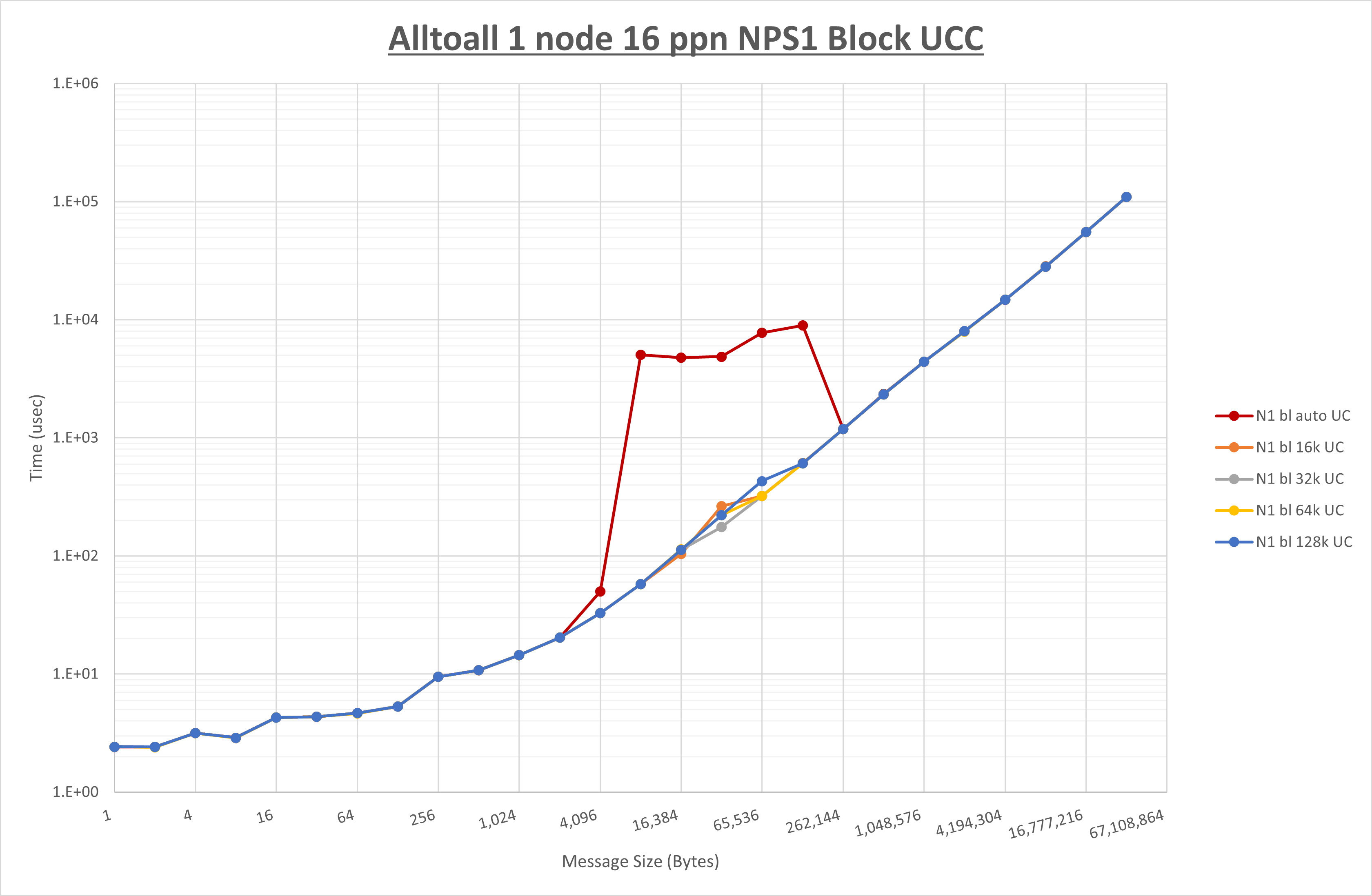
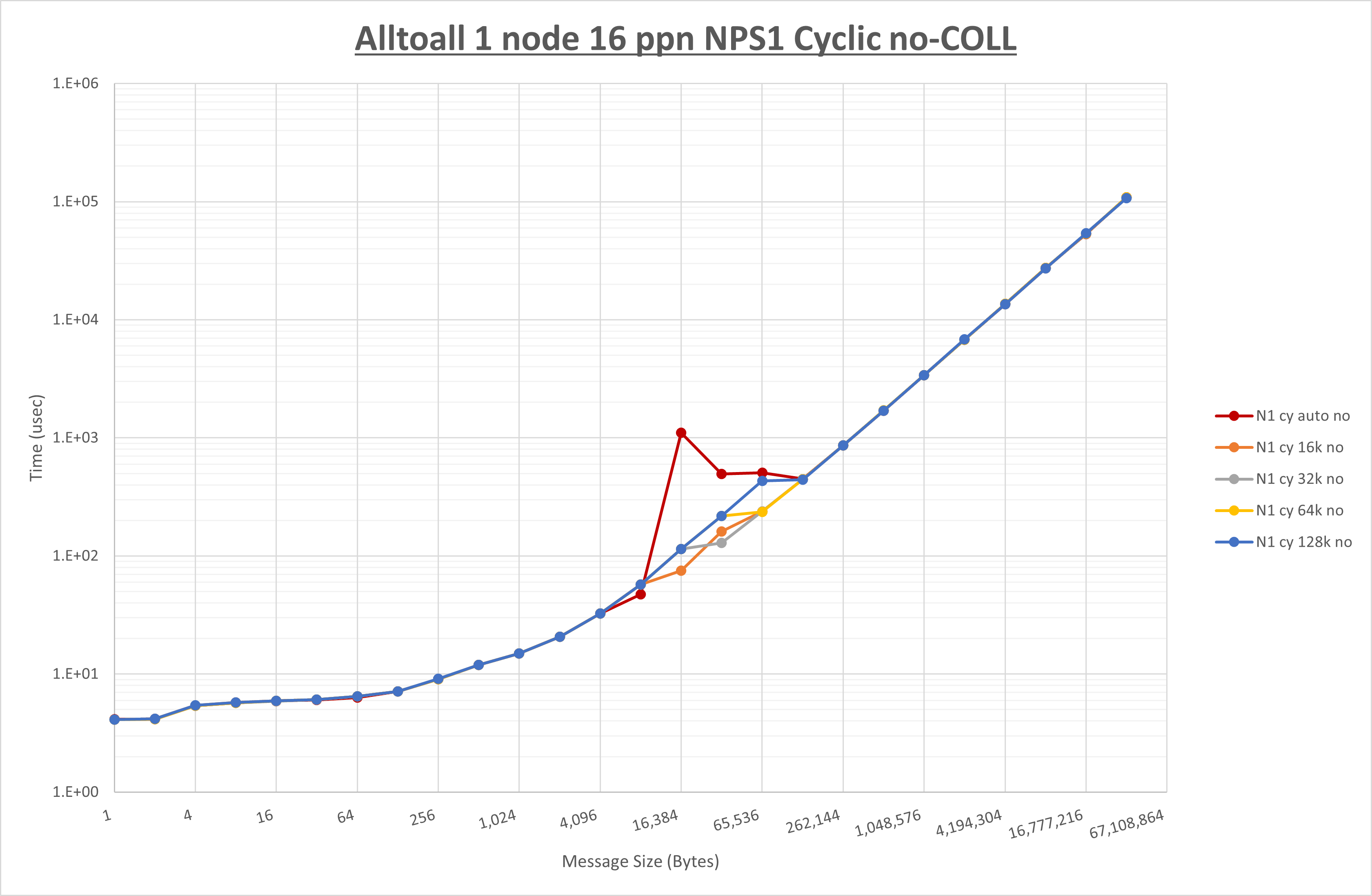
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
 a
a
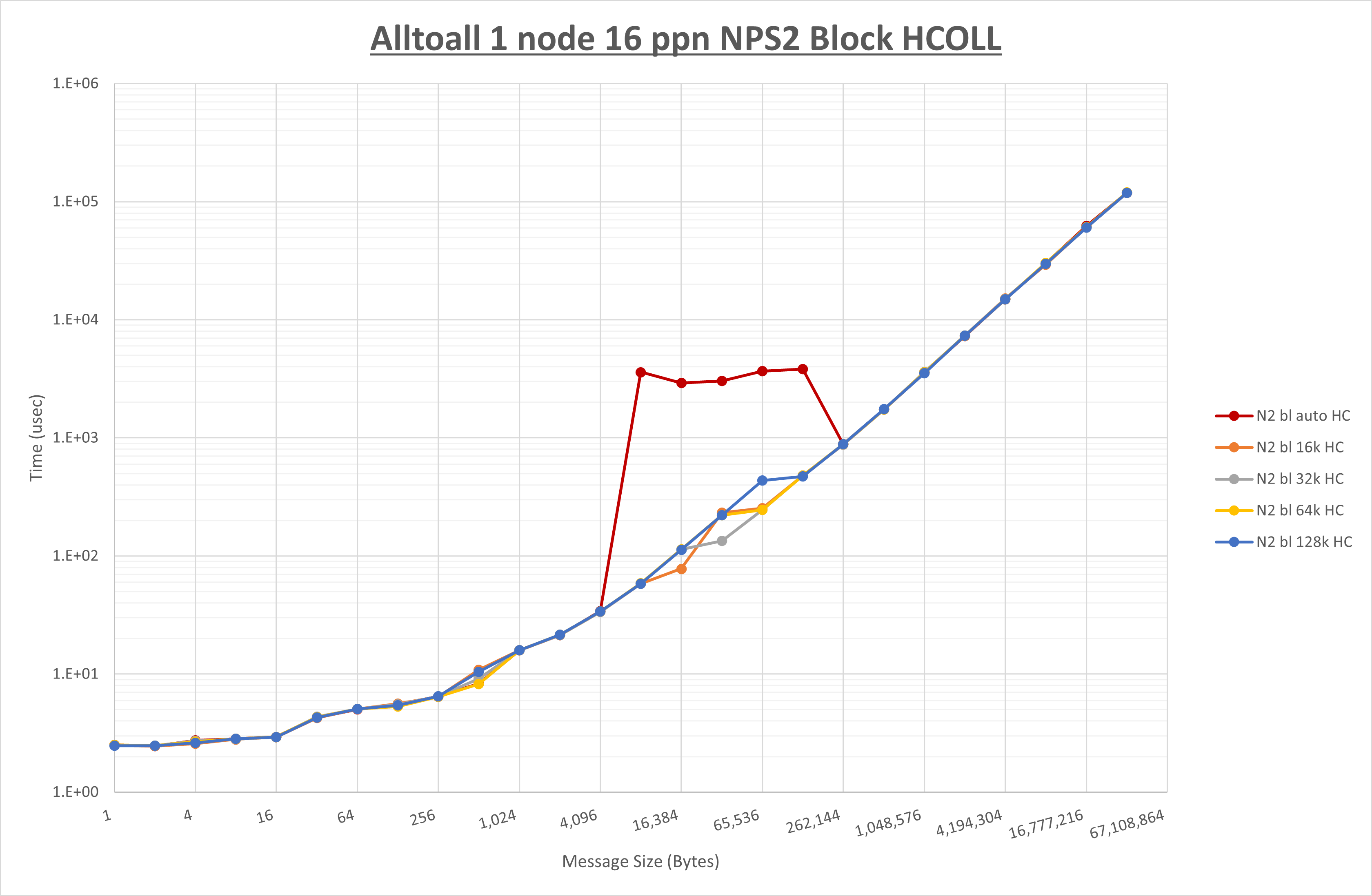
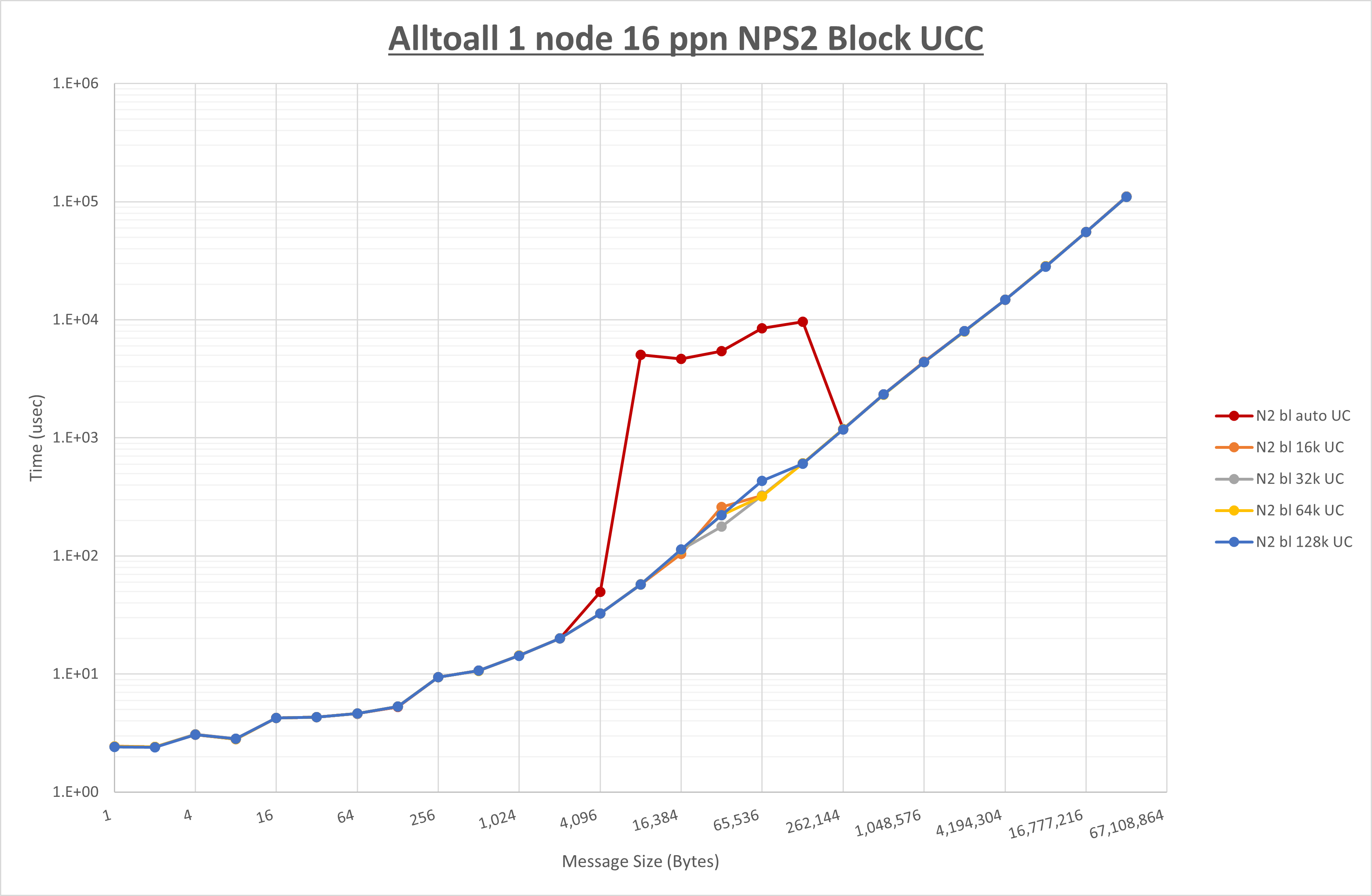
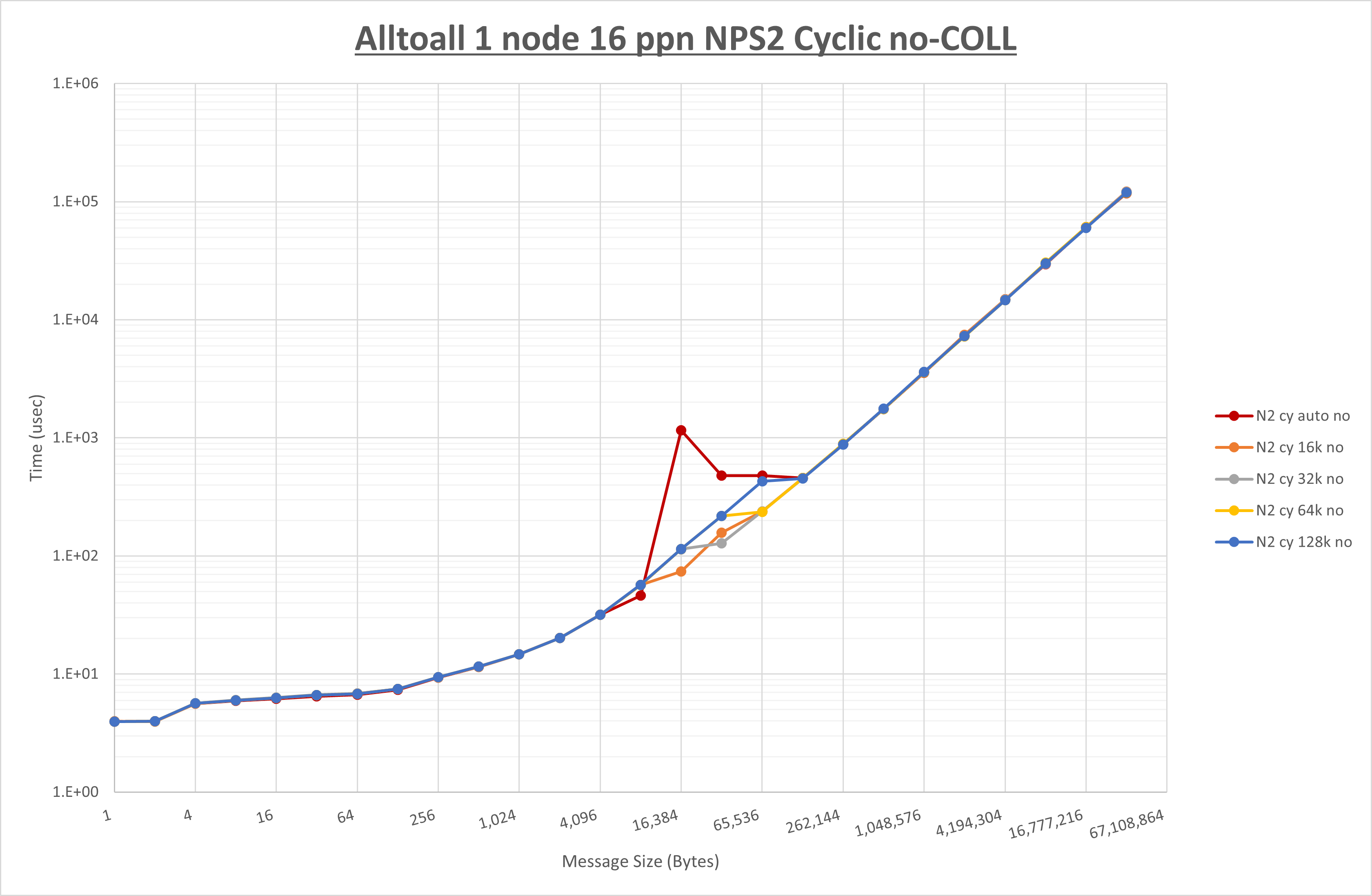
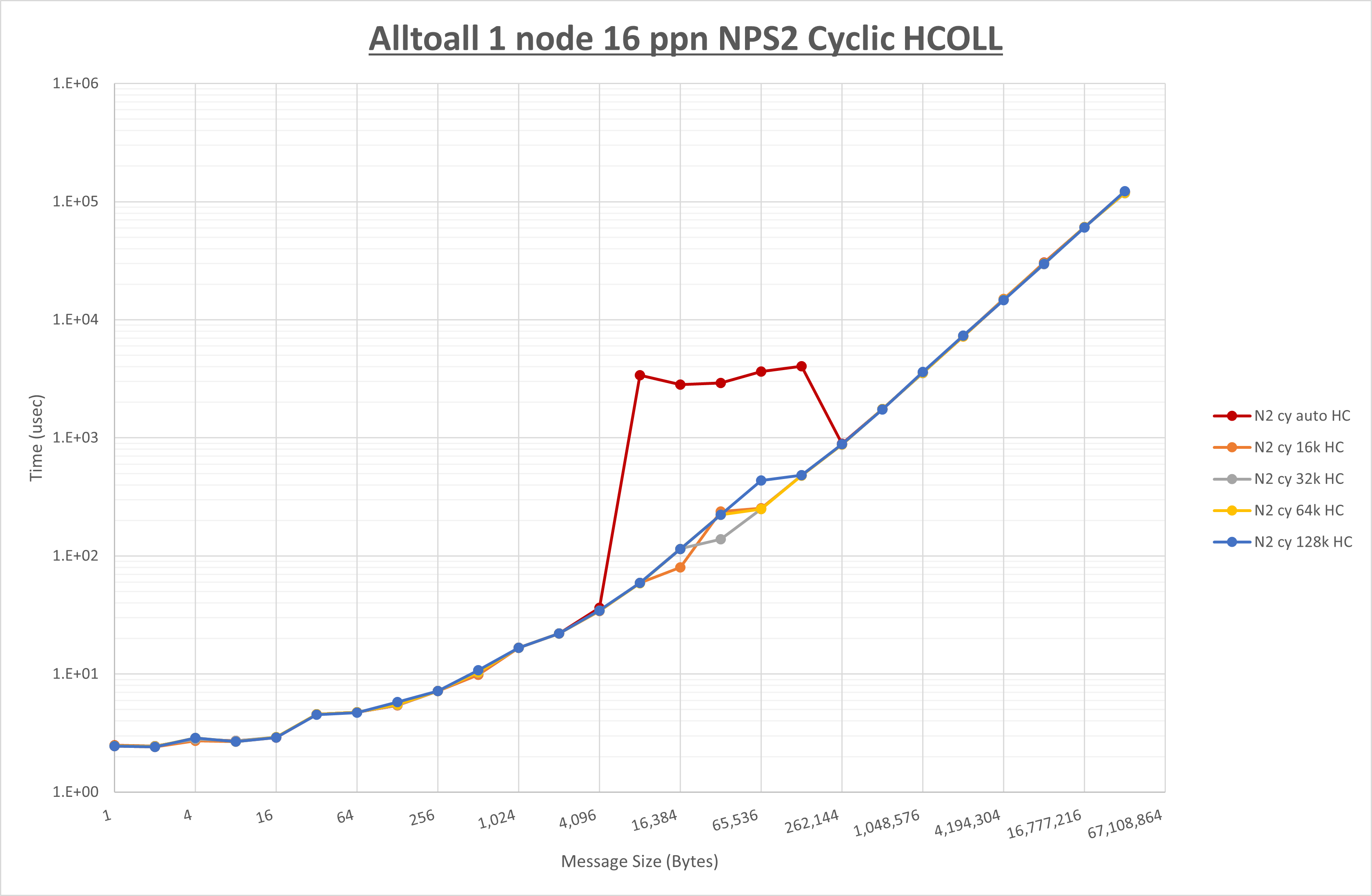
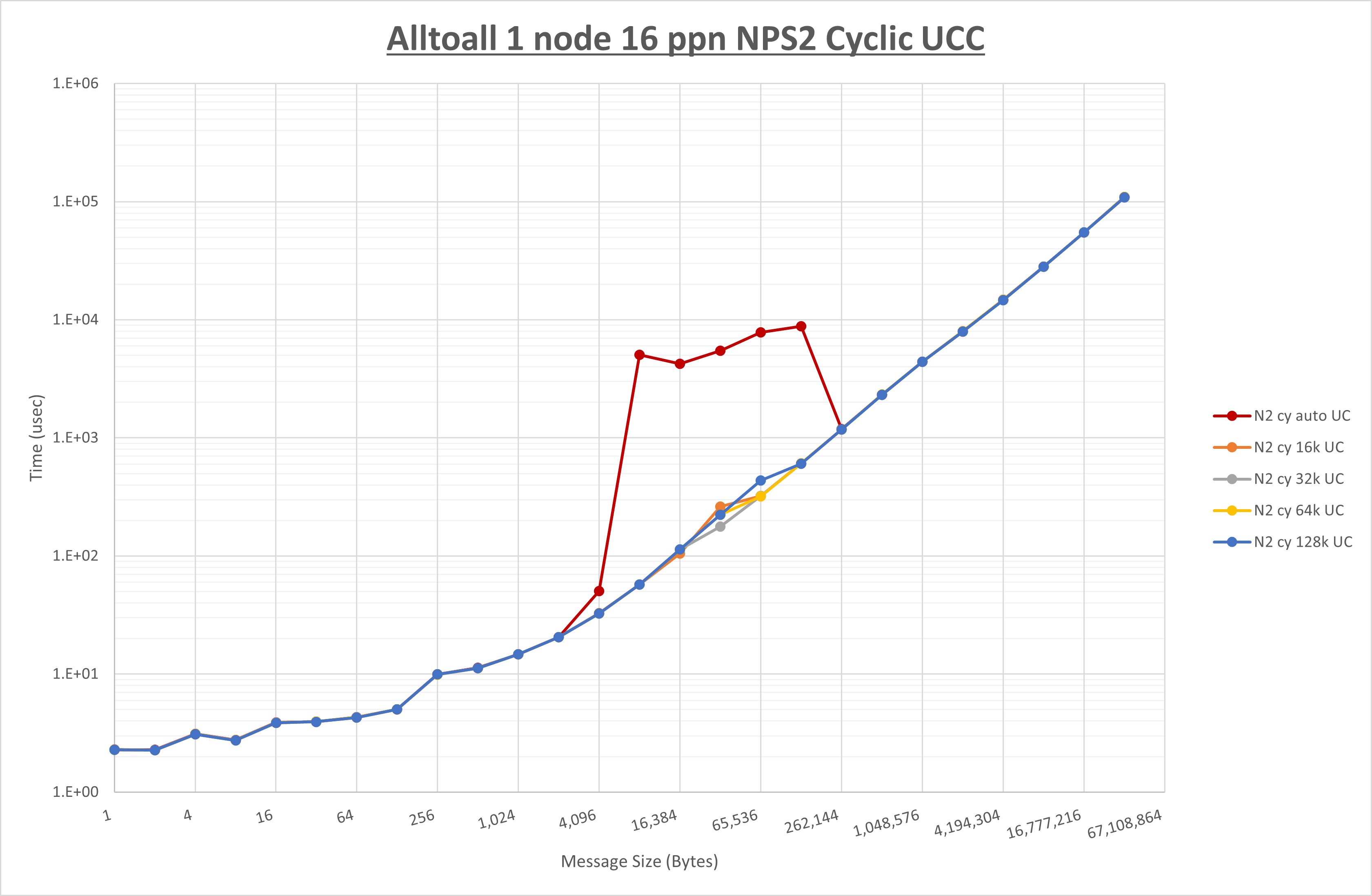
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 32KB | 32KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
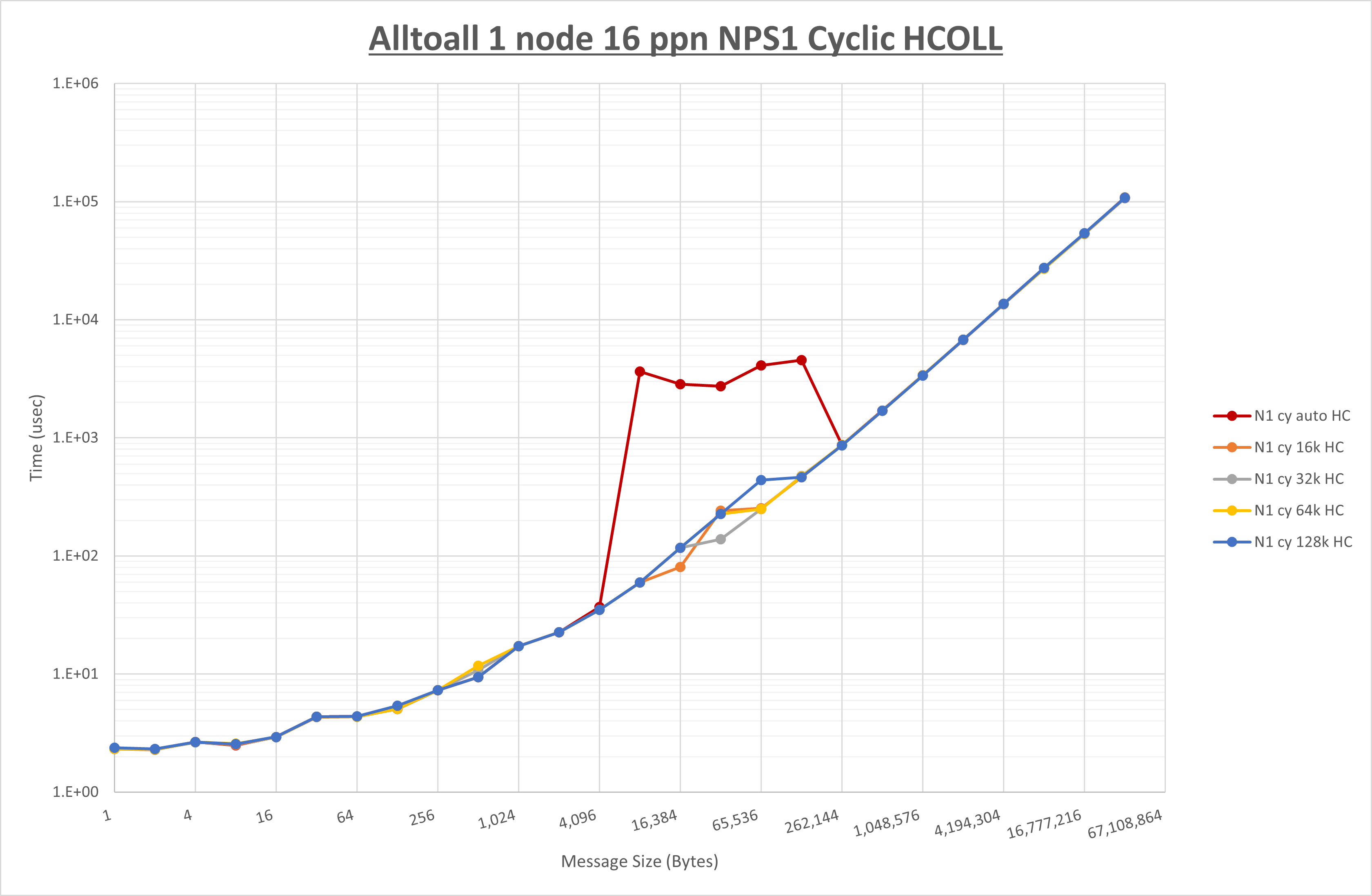
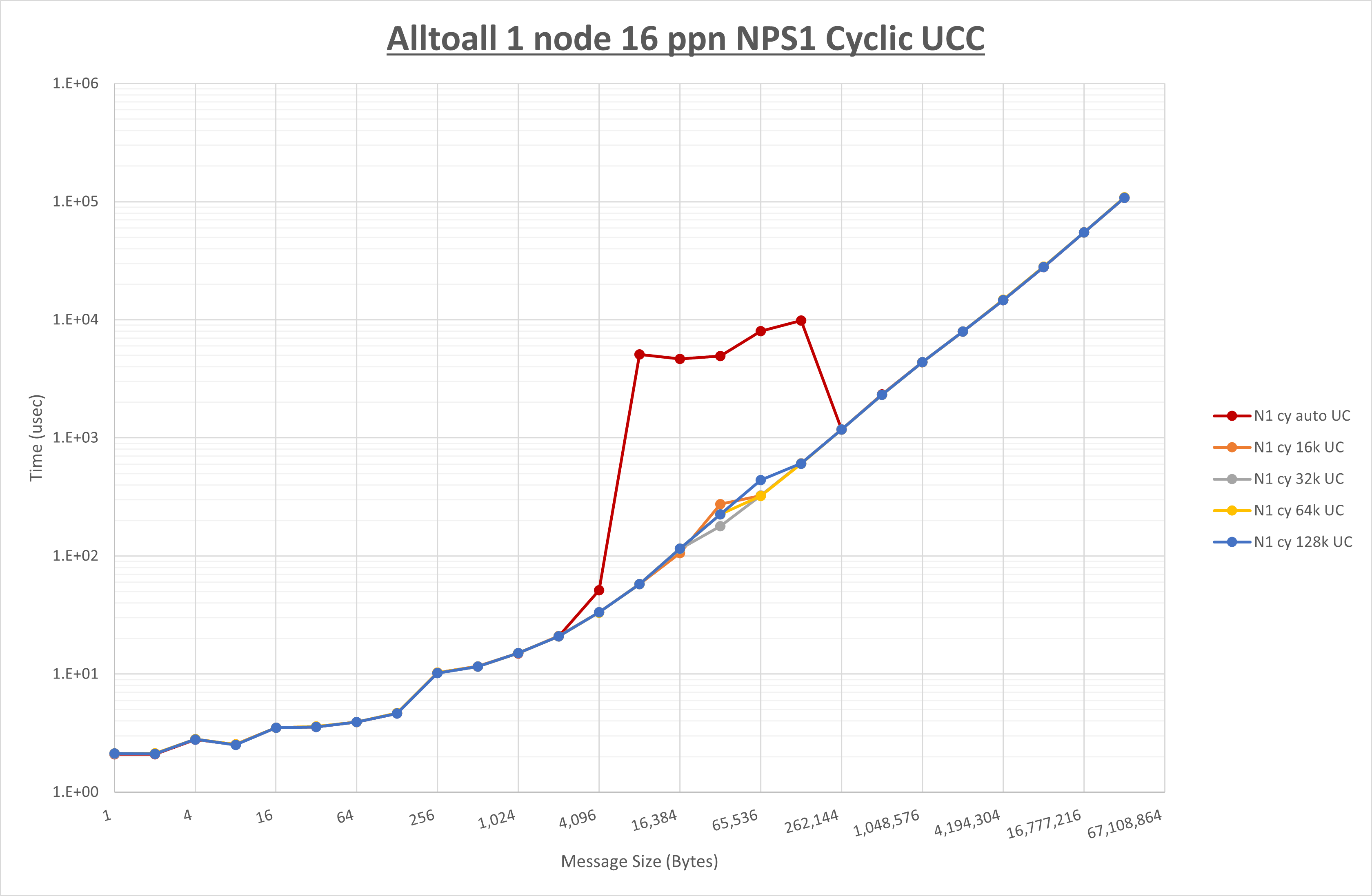
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
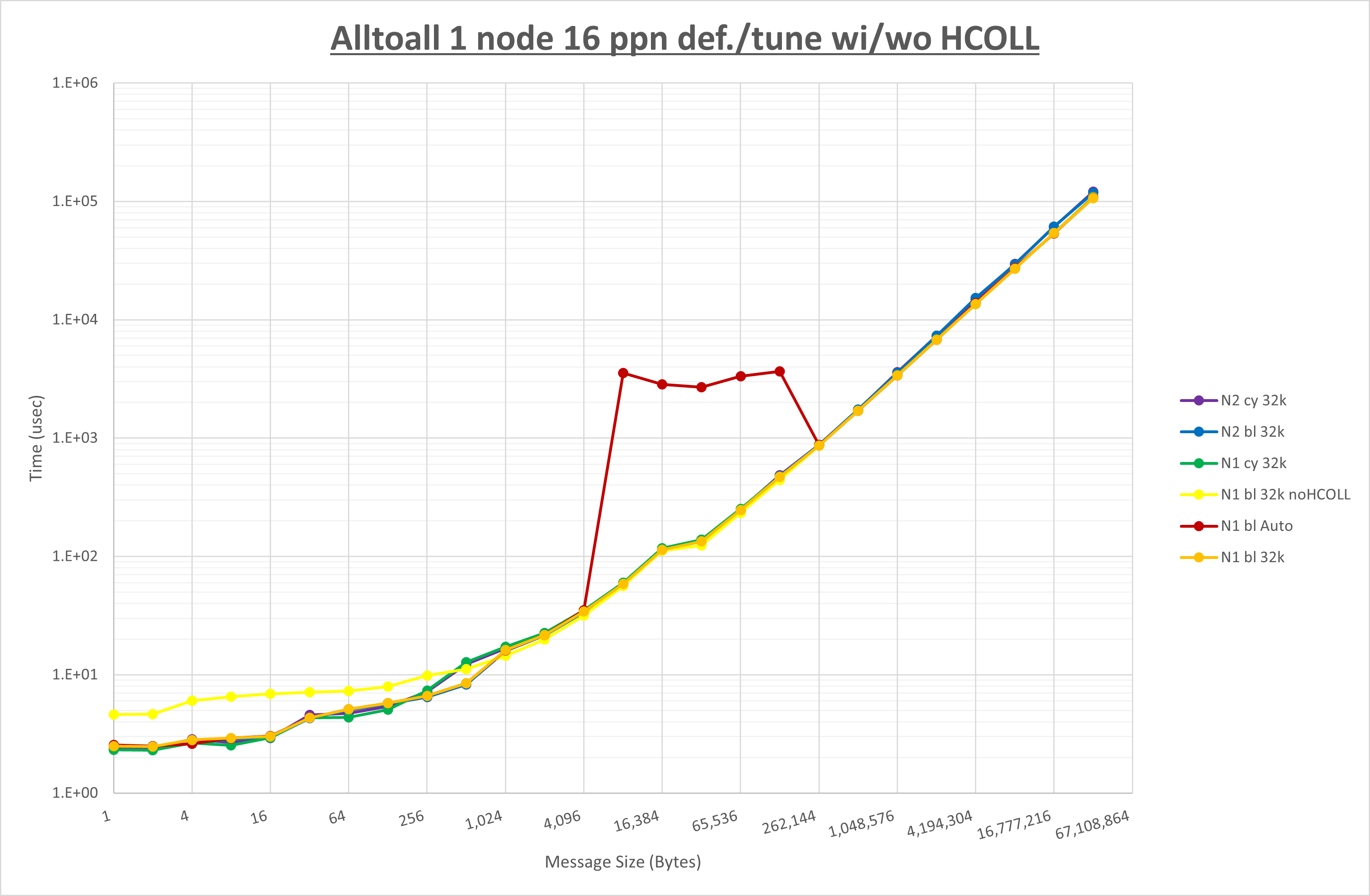
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し256B以下で性能が向上し512Bから128KBで性能が低下
- UCC は no-COLL と比較し128B以下で性能が向上し256KBから4MBで性能が低下
- チューニング適用で8KBから64KBの間で性能が向上
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
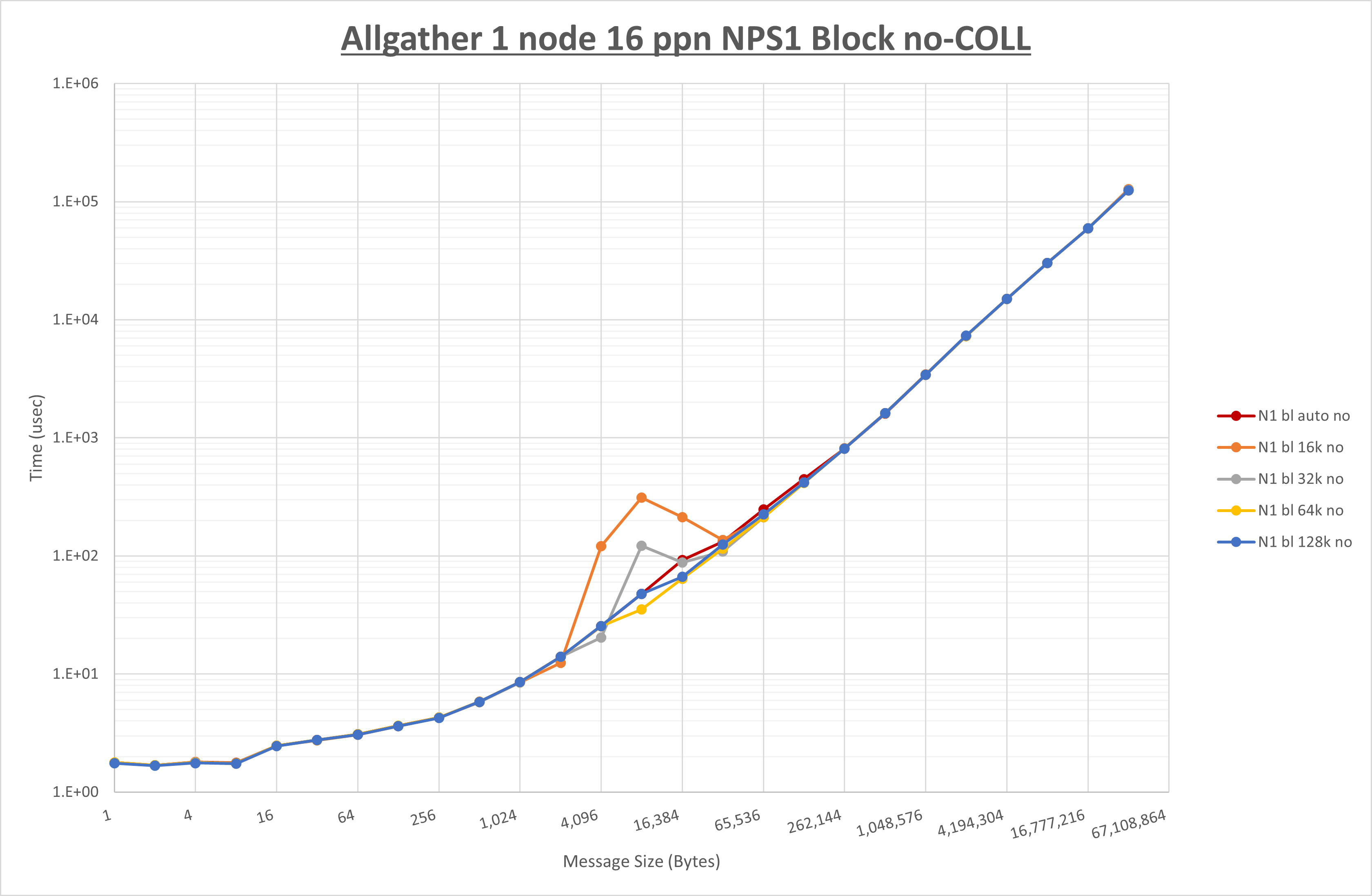
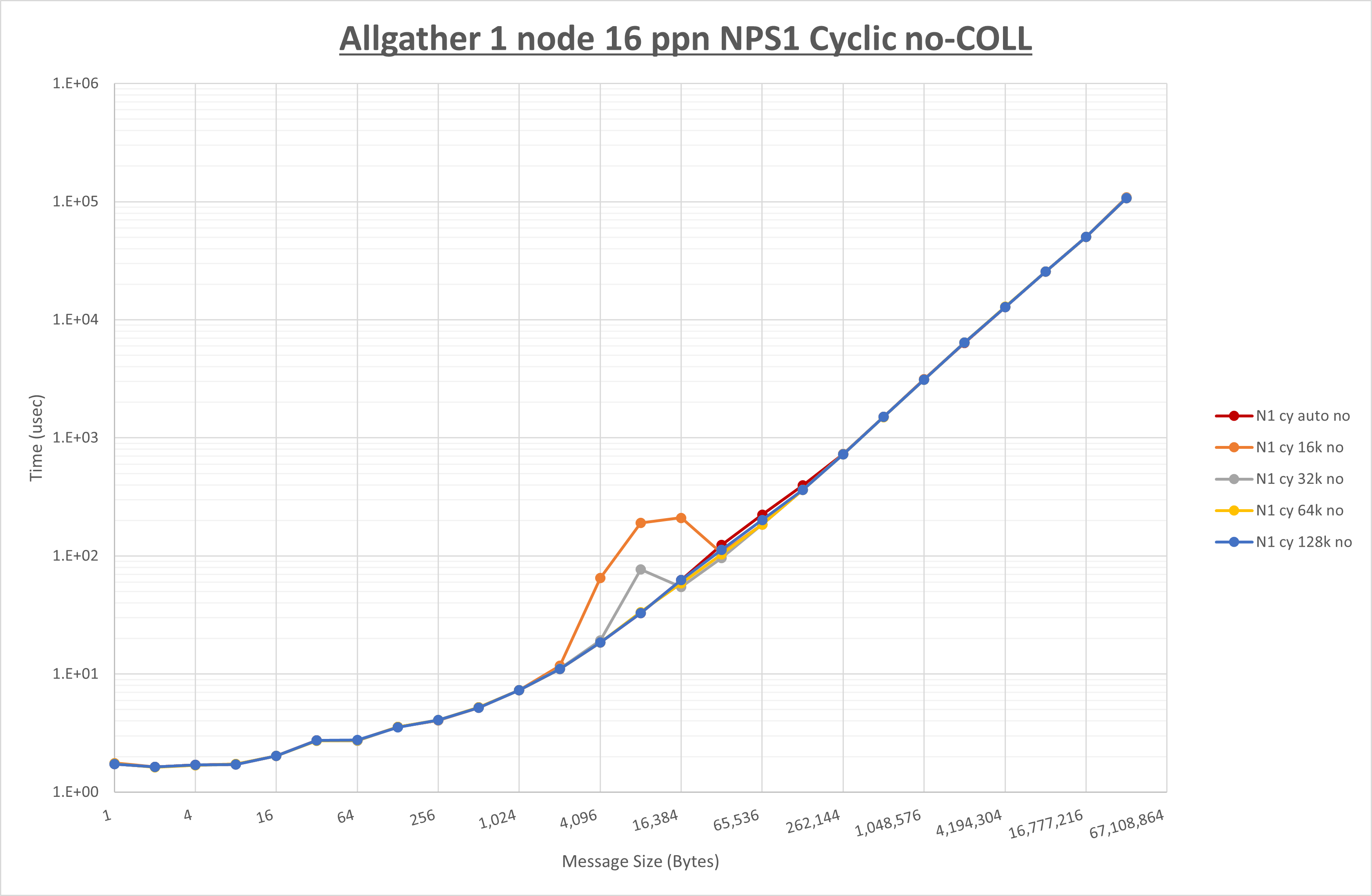
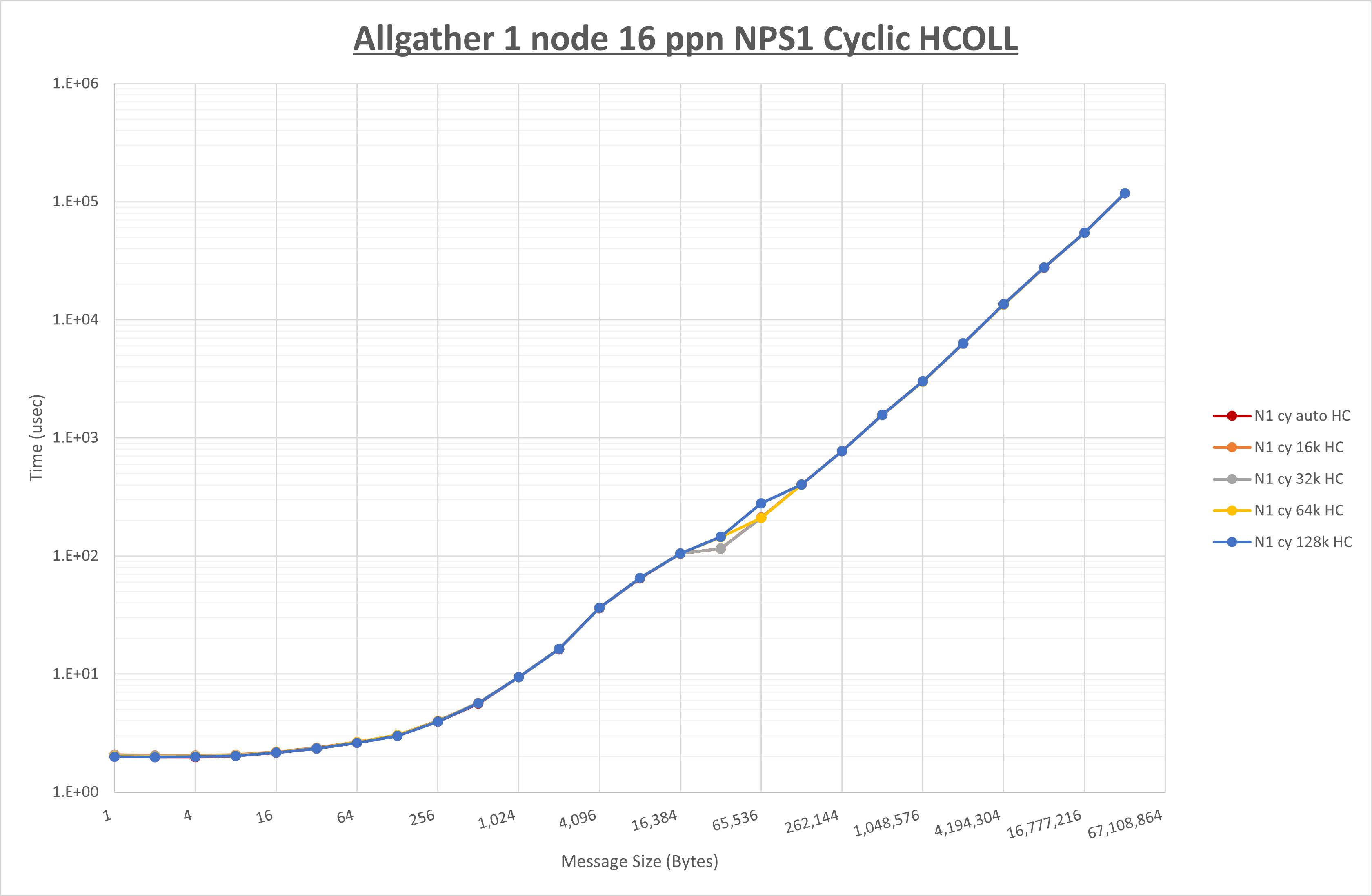
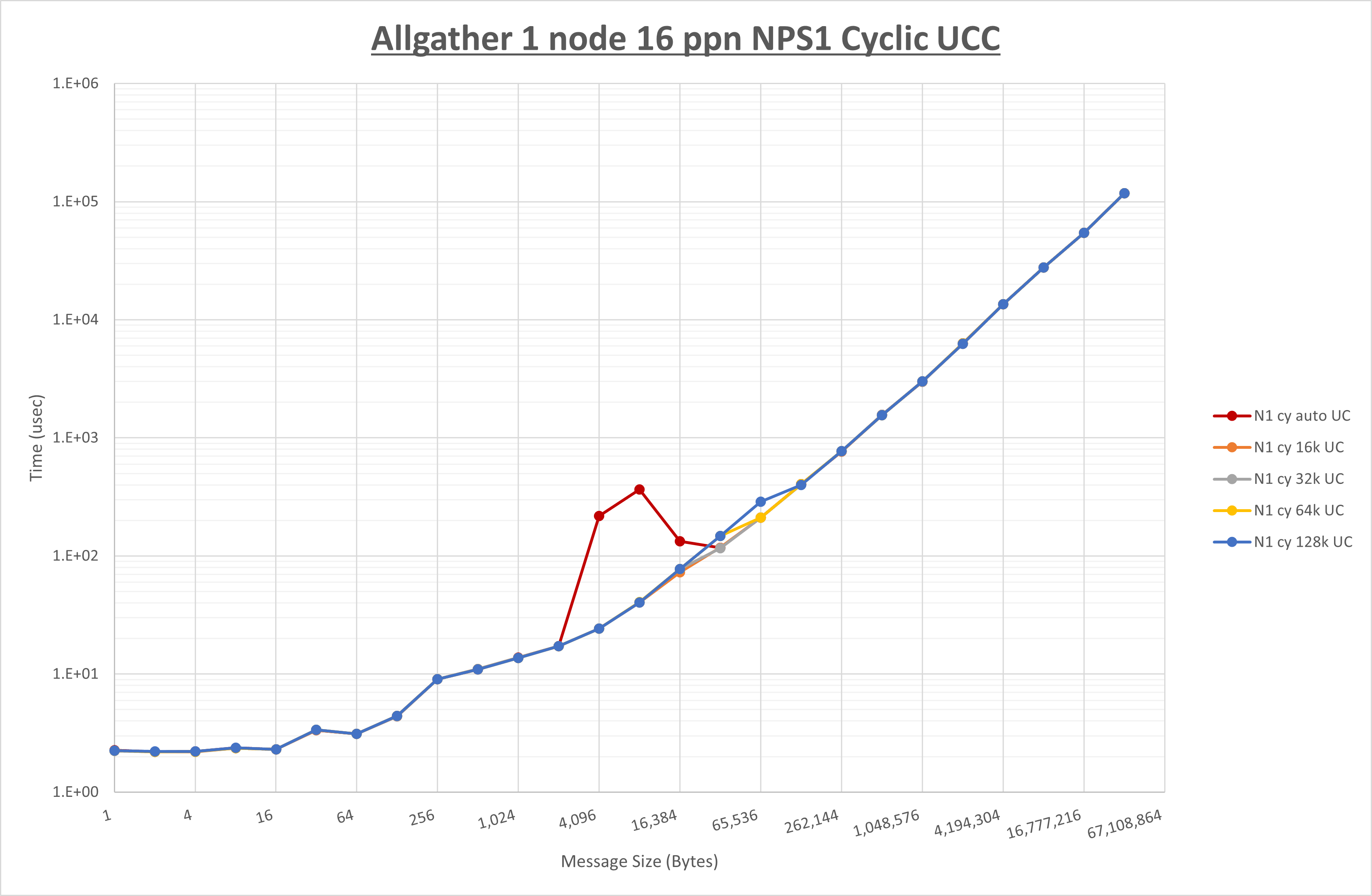
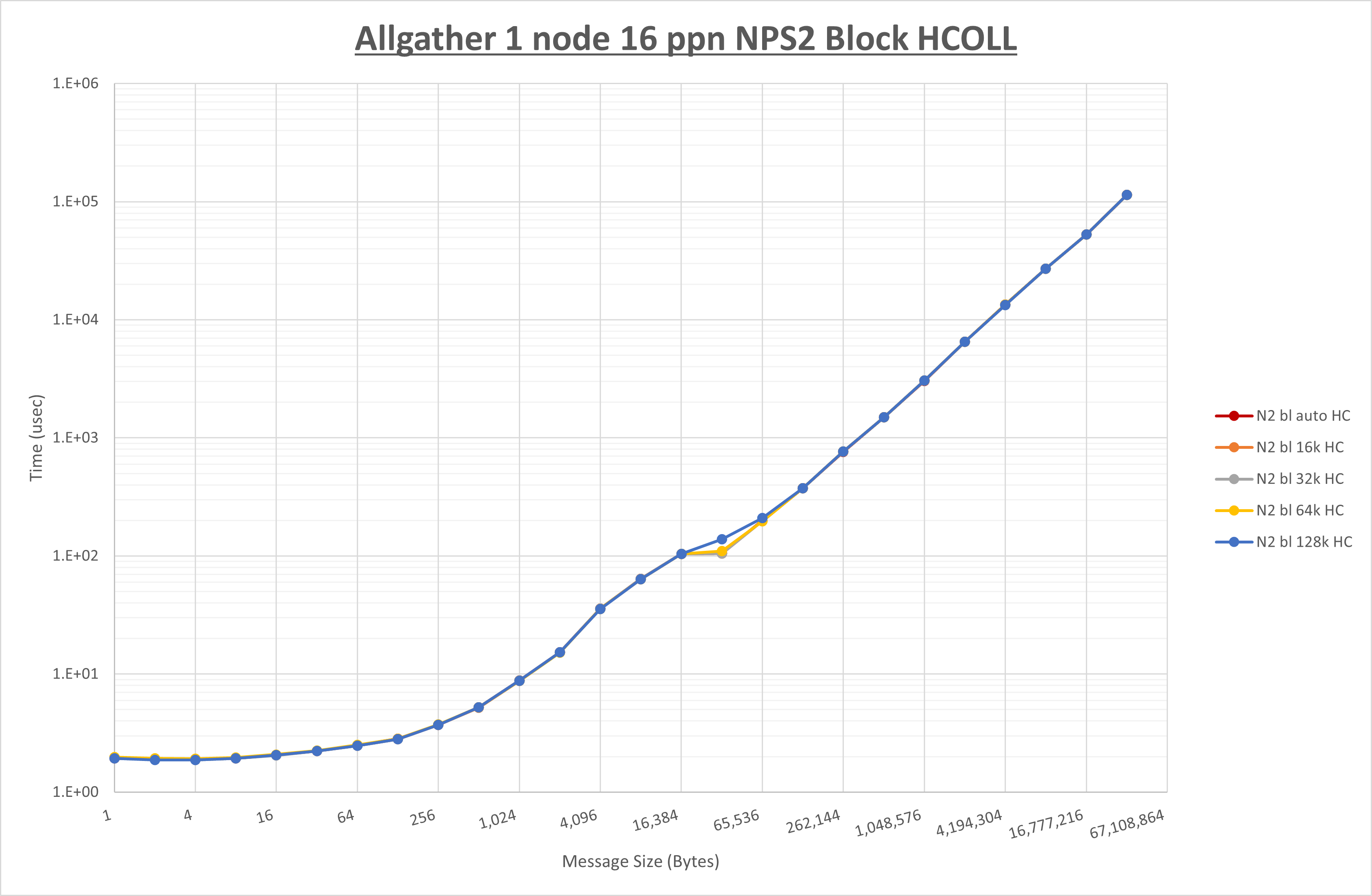
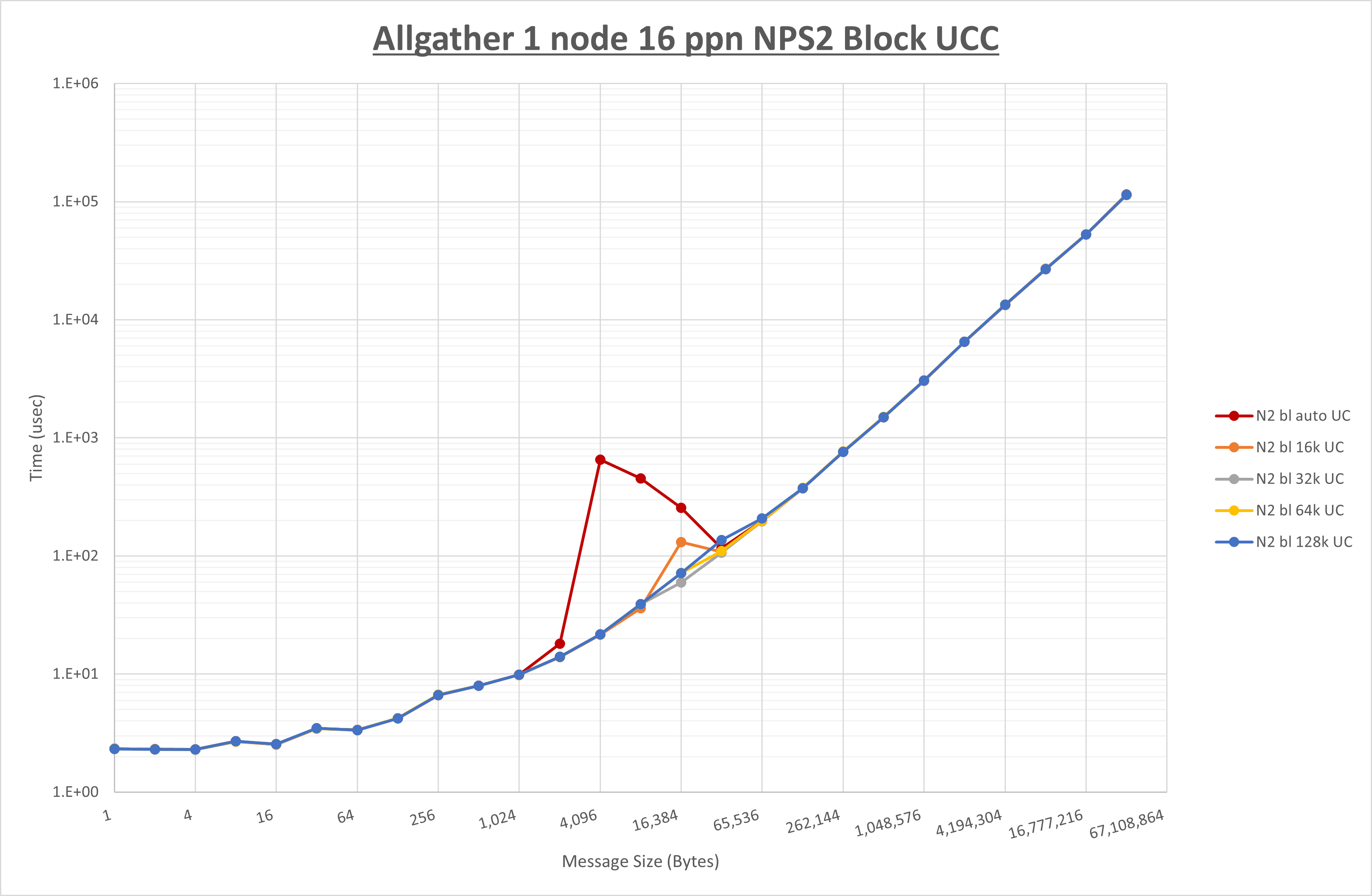
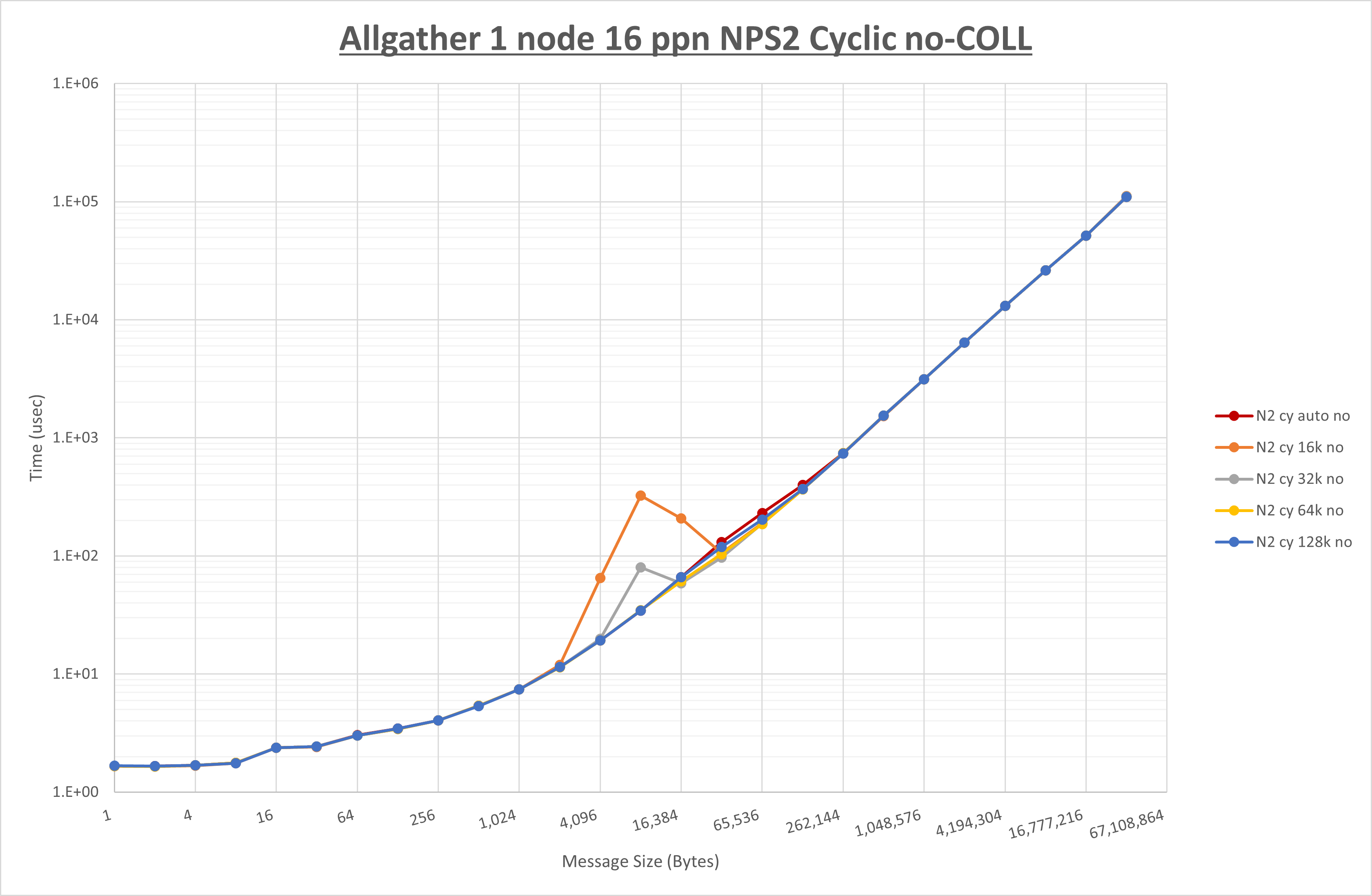
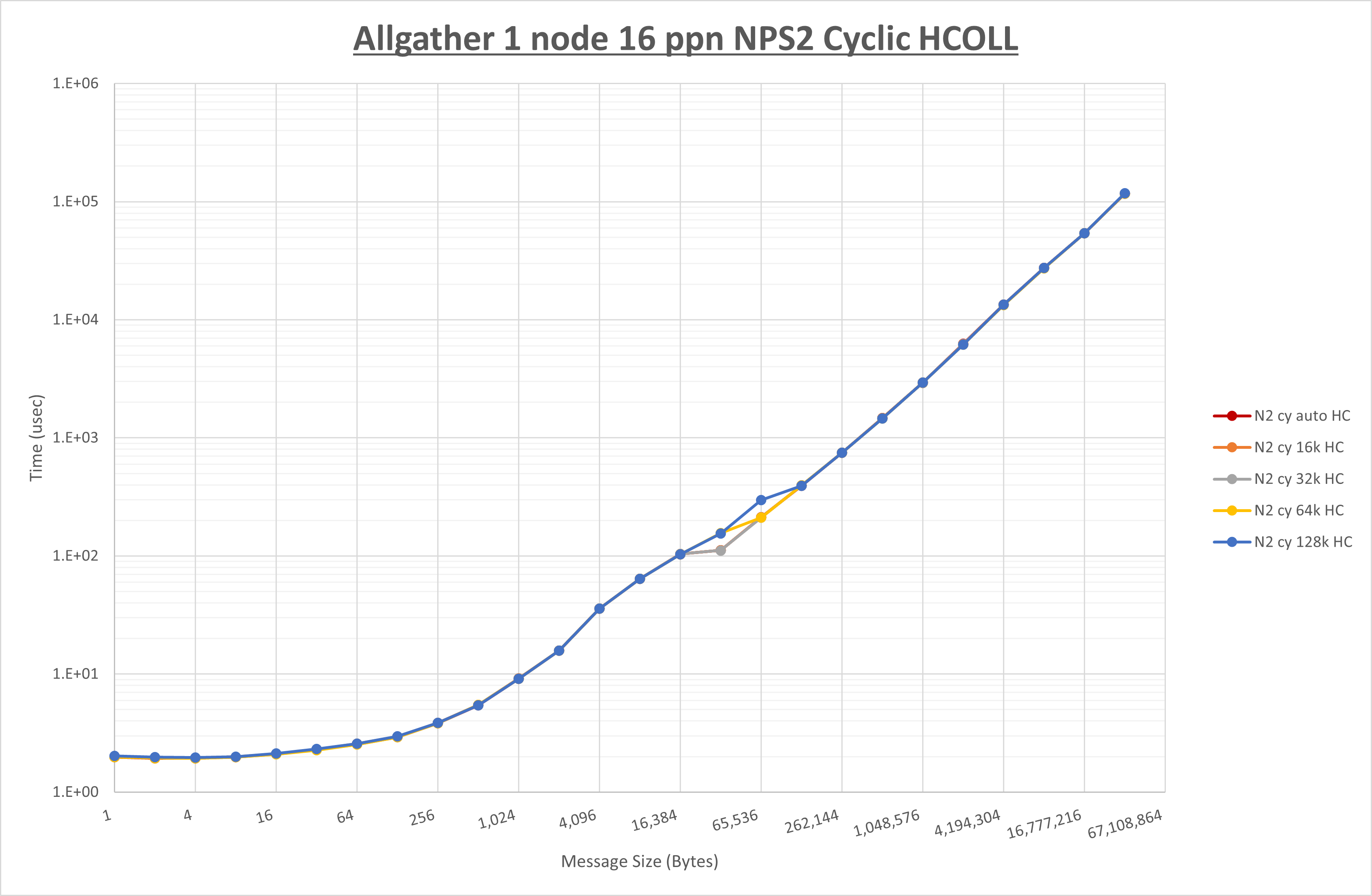
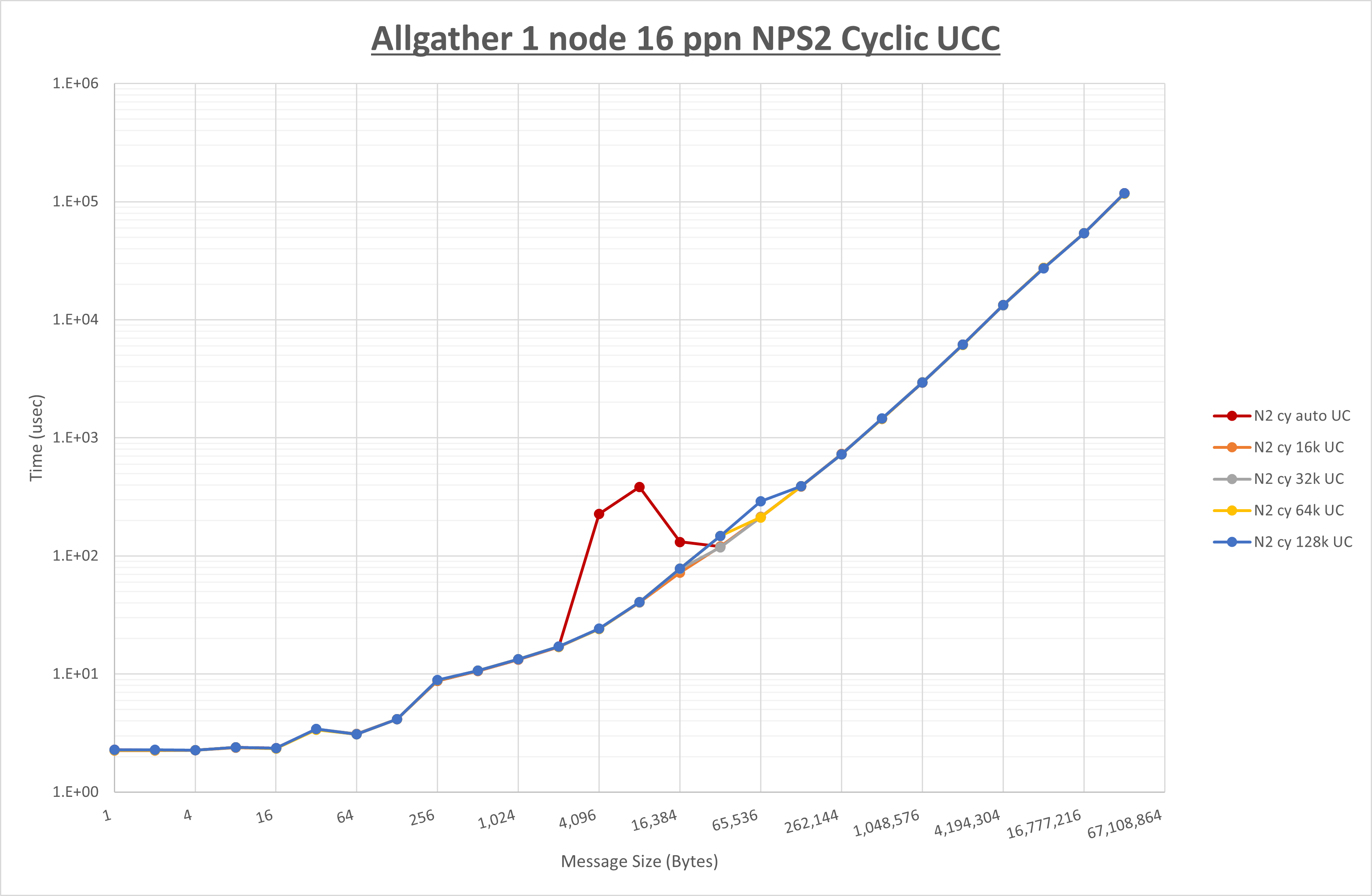
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 64KB | 64KB | 64KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
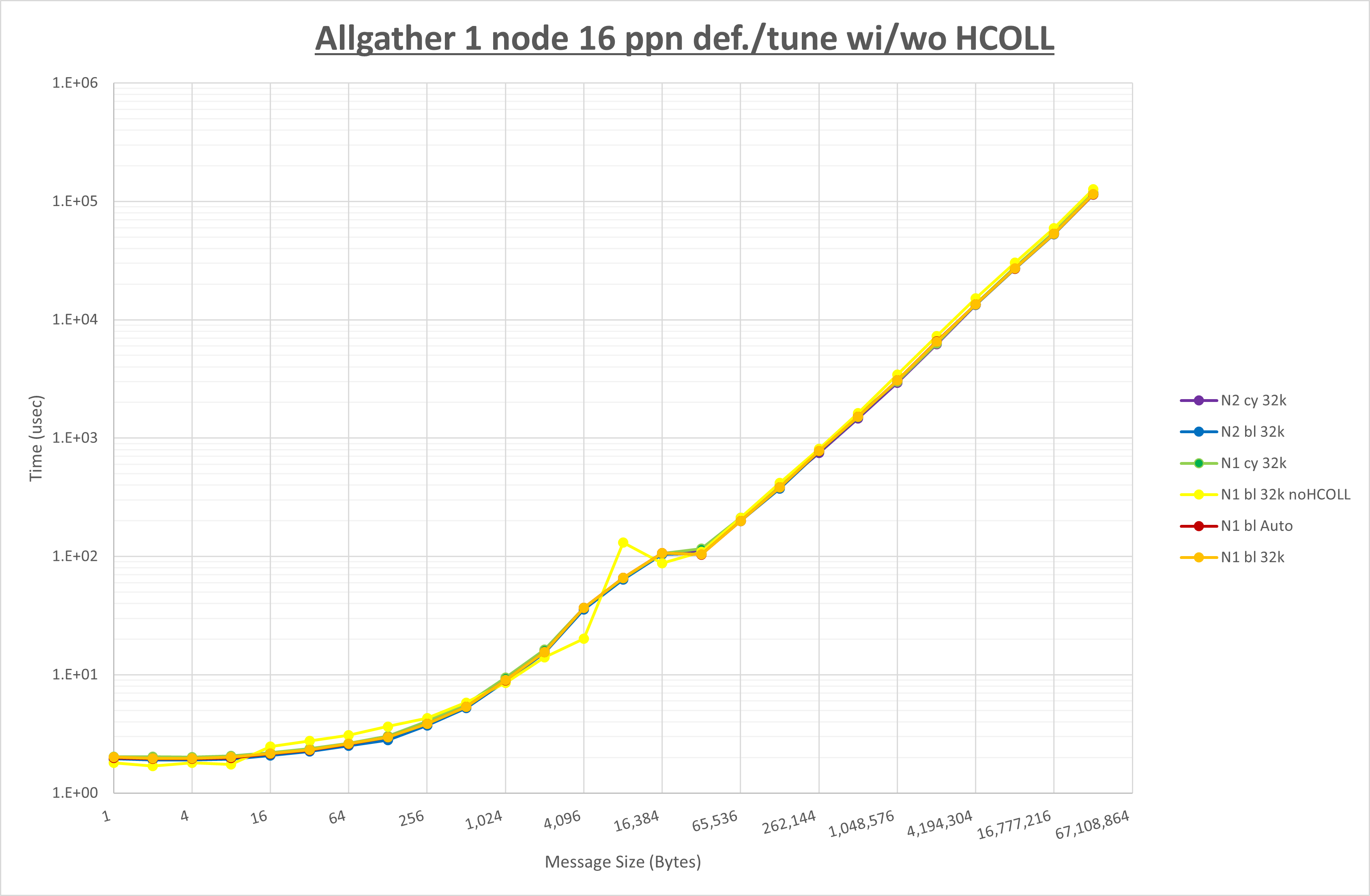
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し64KB以下で性能が低下
- UCC は no-COLL と比較し64KB以下で性能が低下
- チューニング適用による性能差無し
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
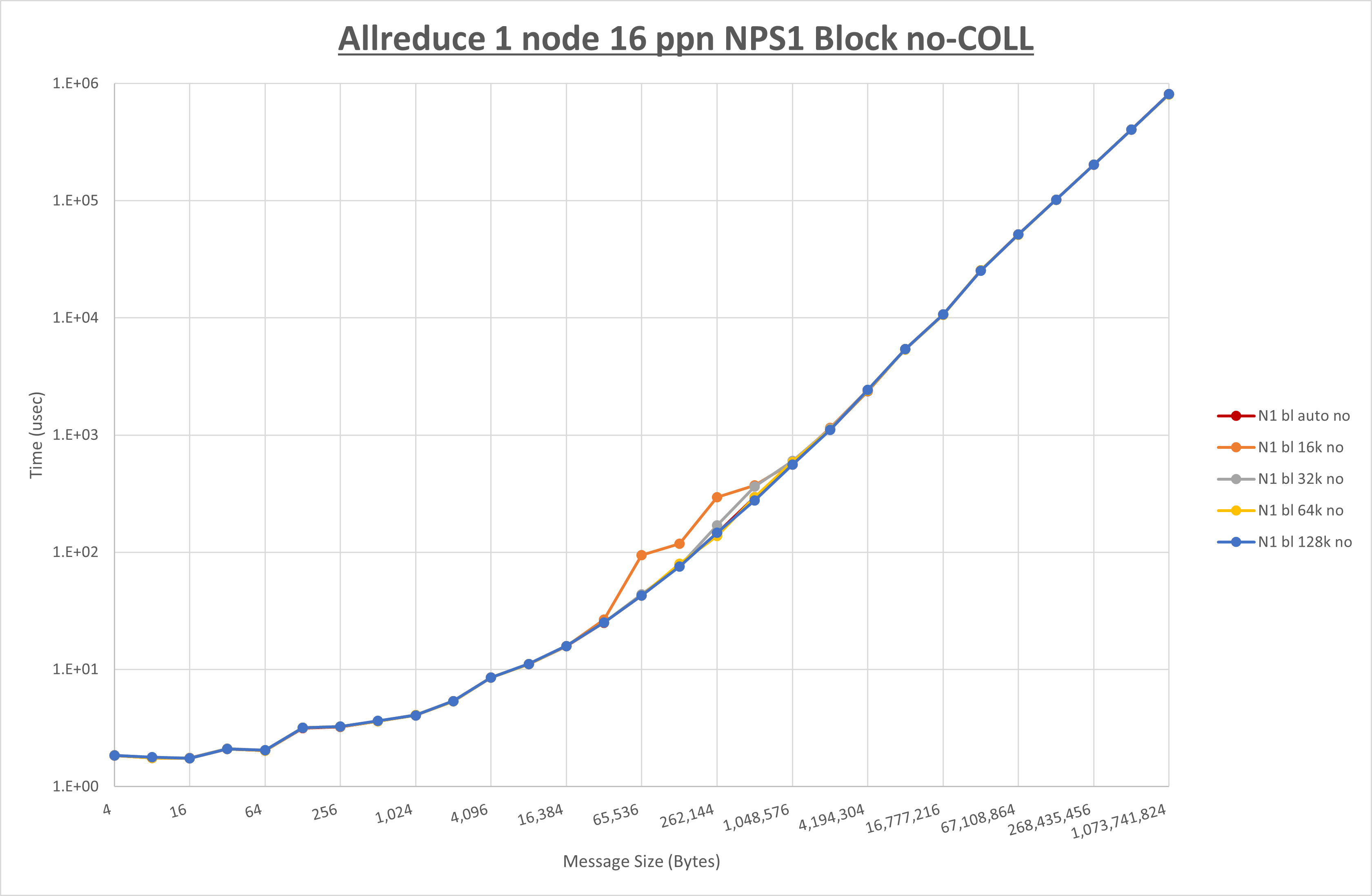
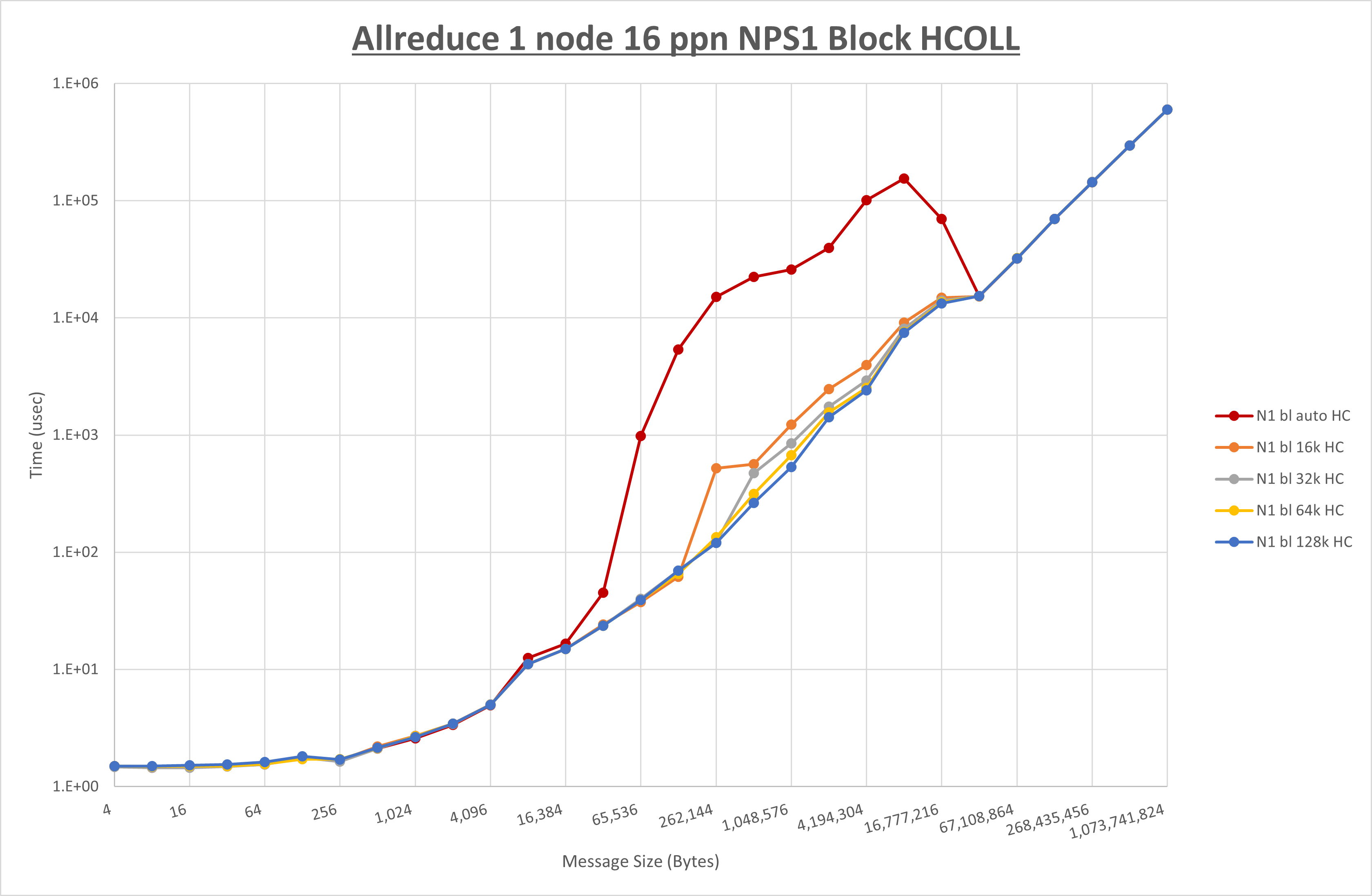
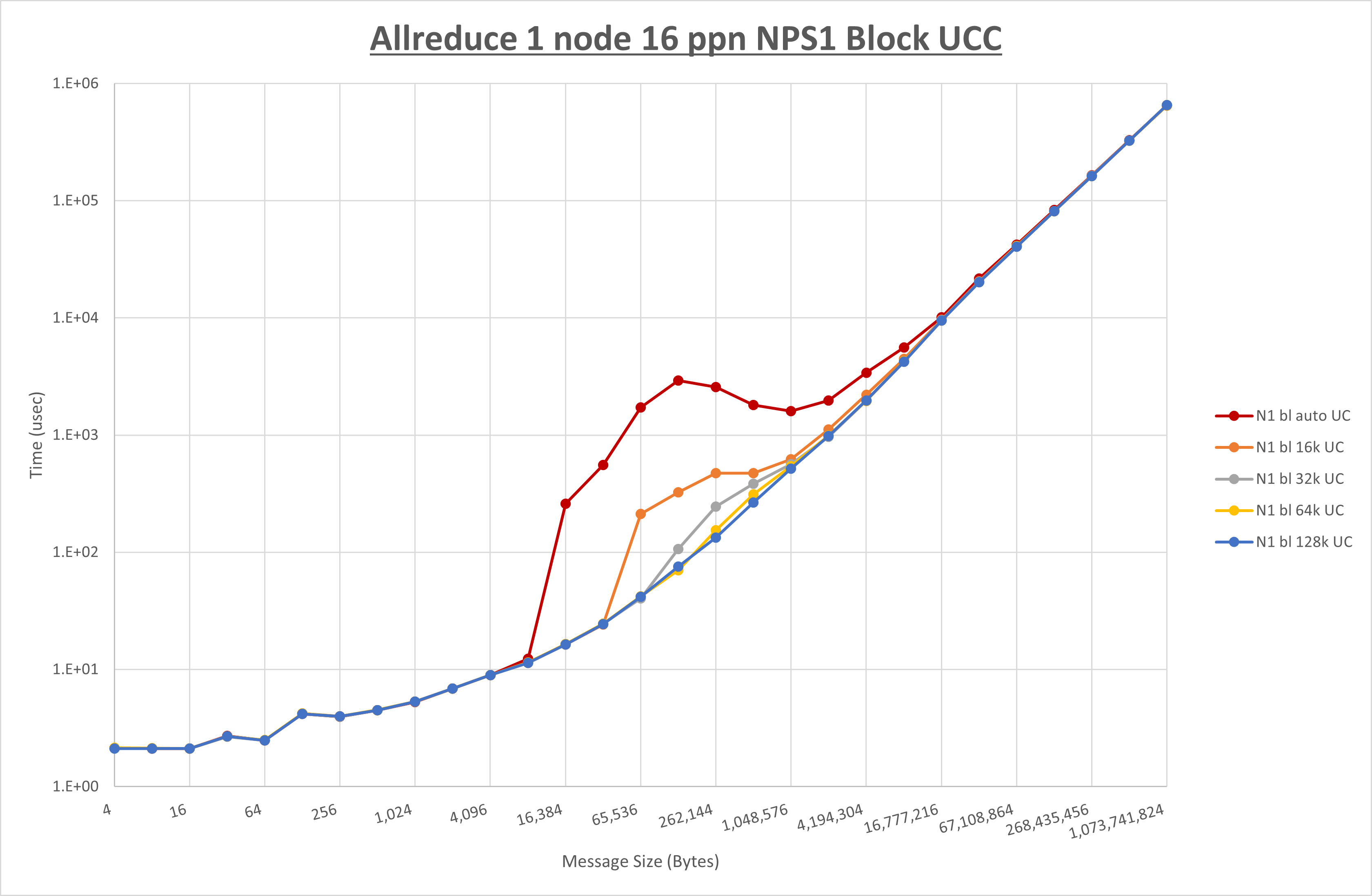
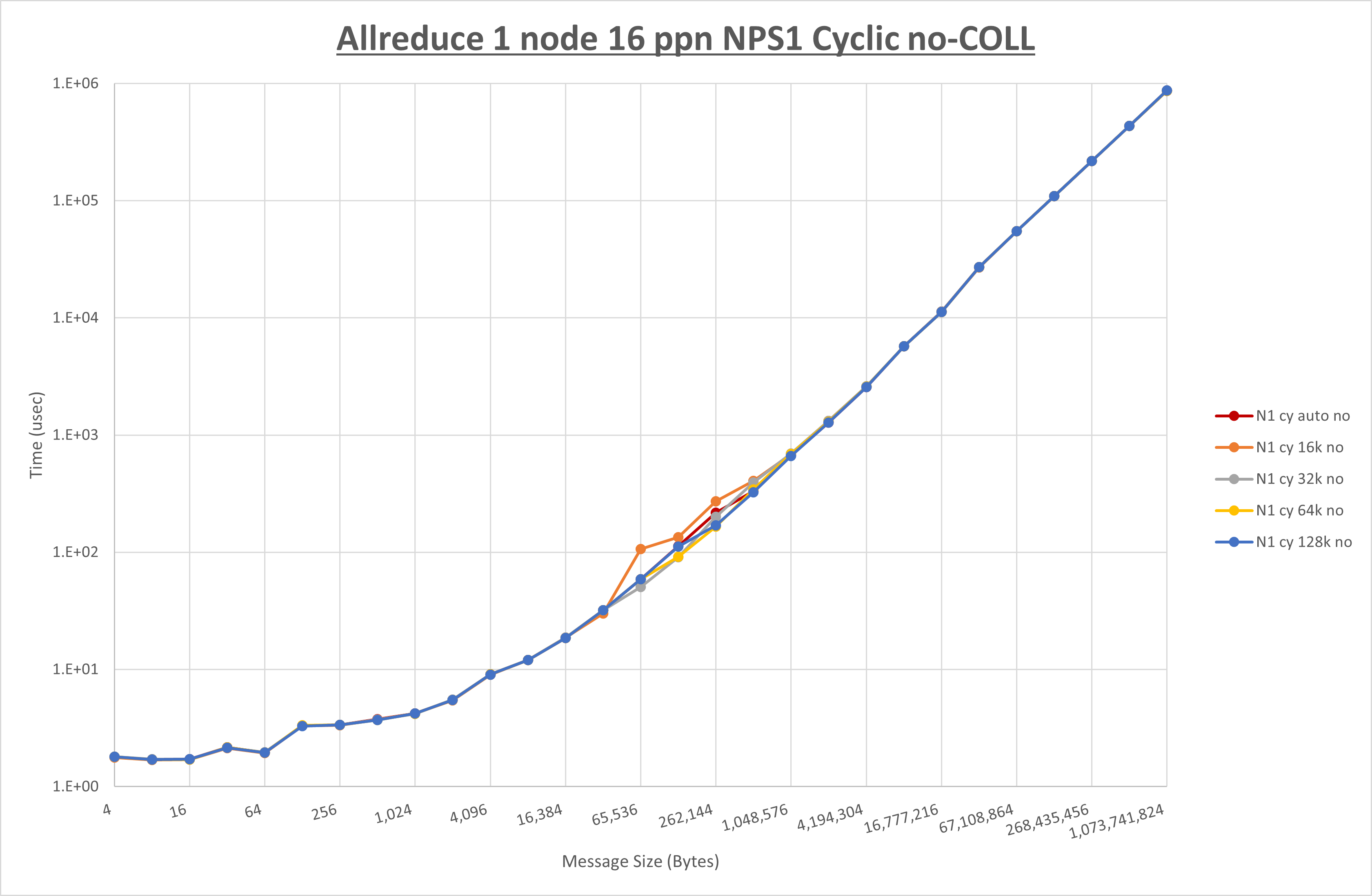
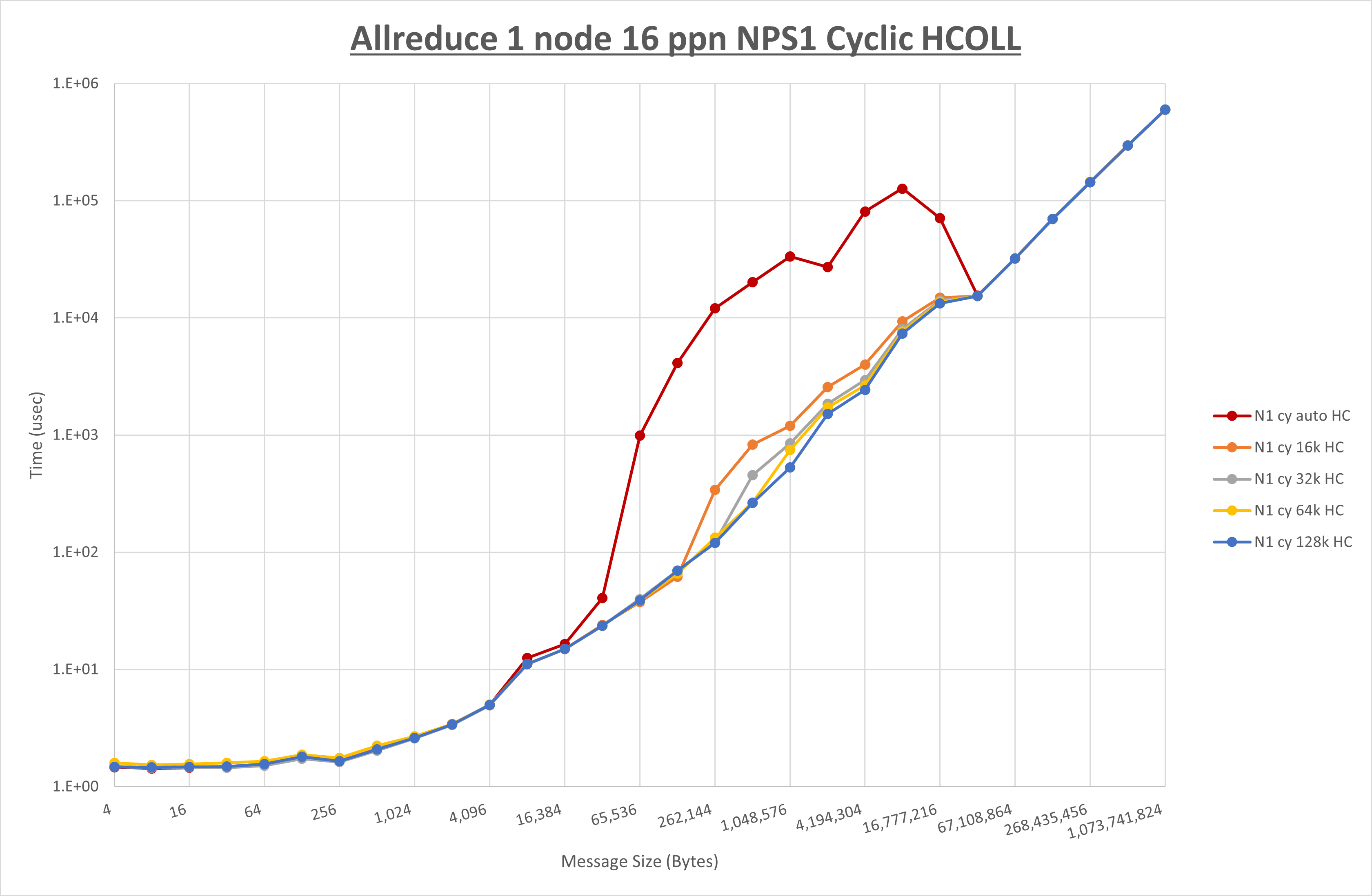
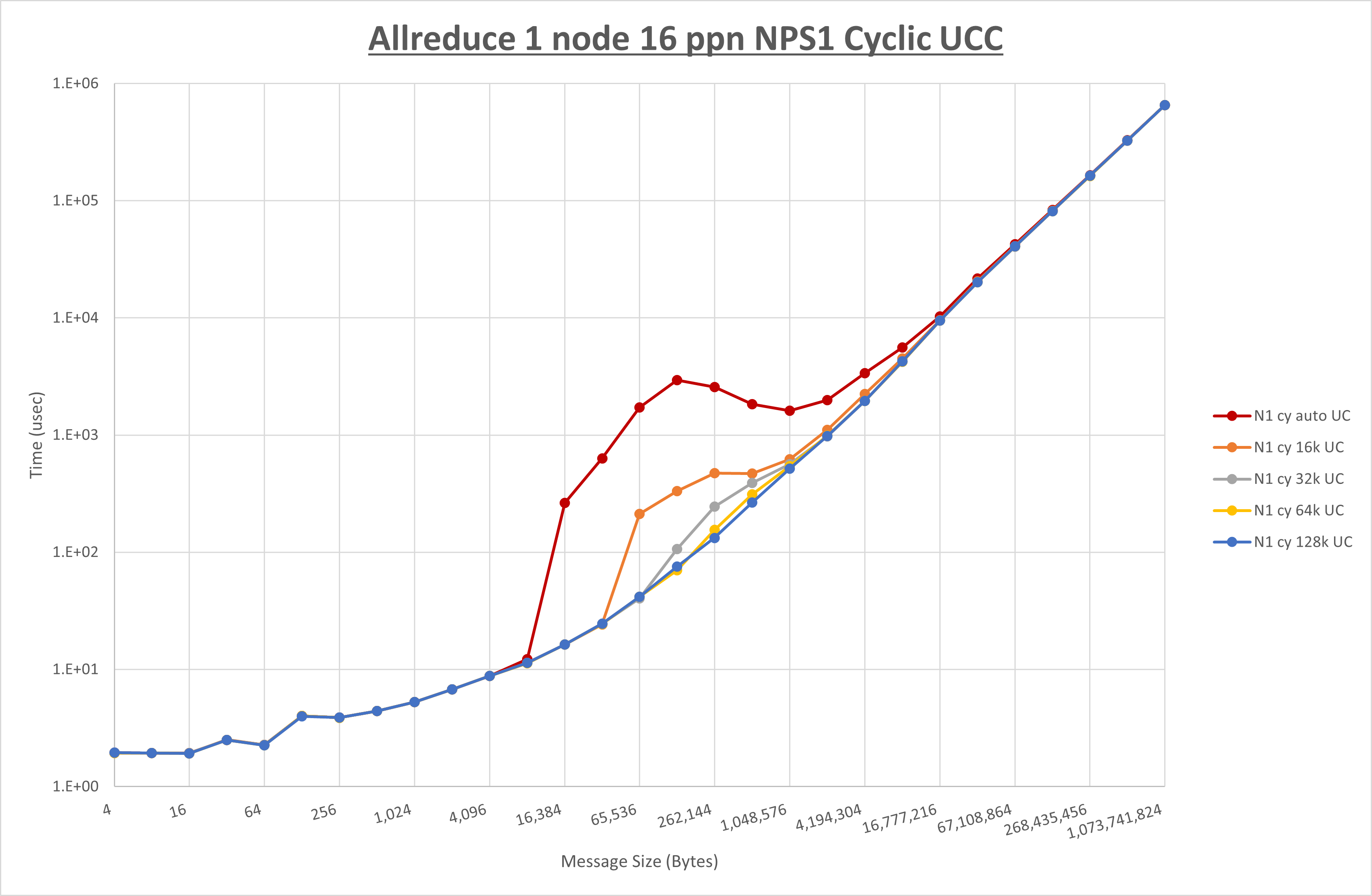
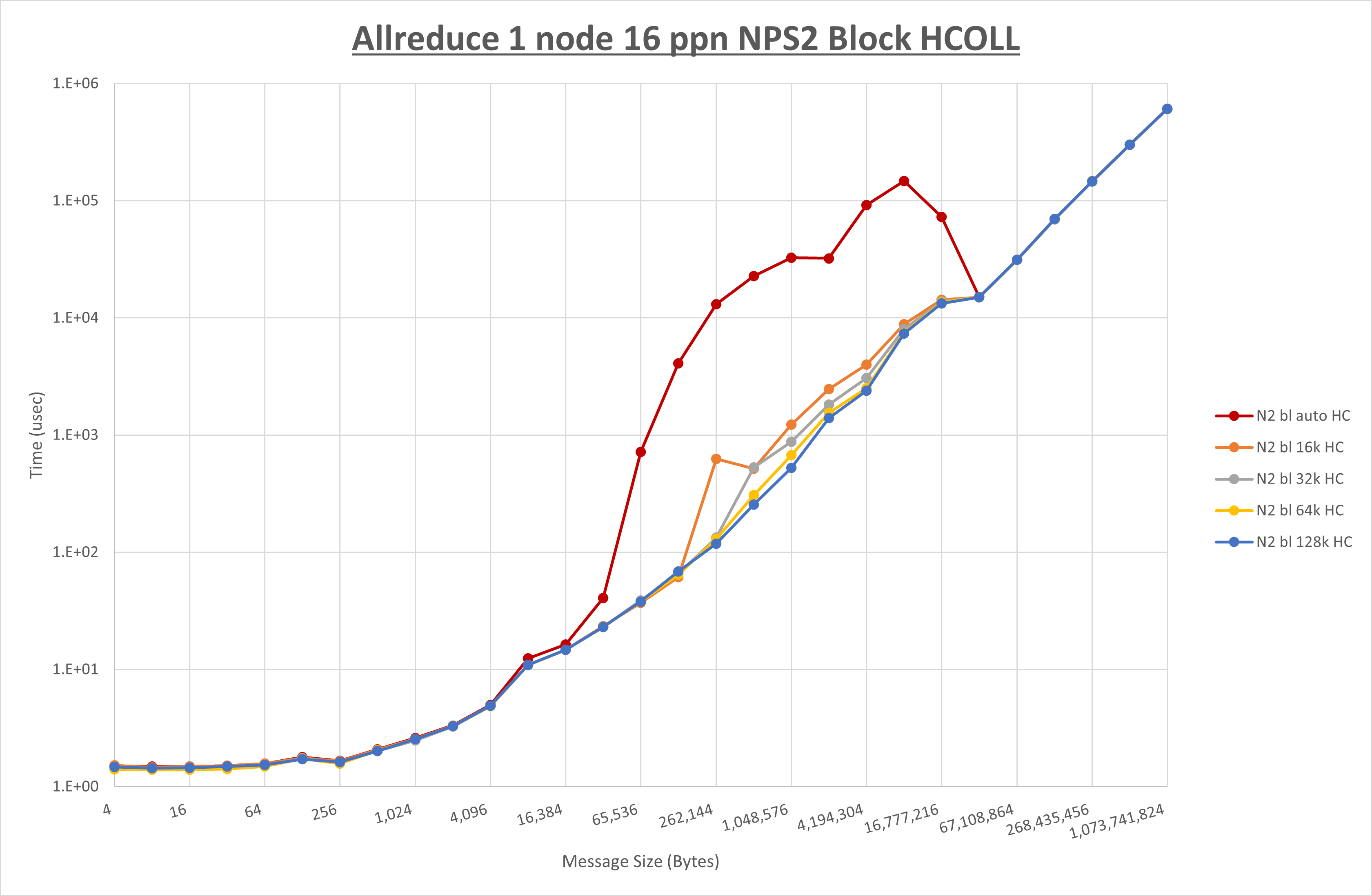
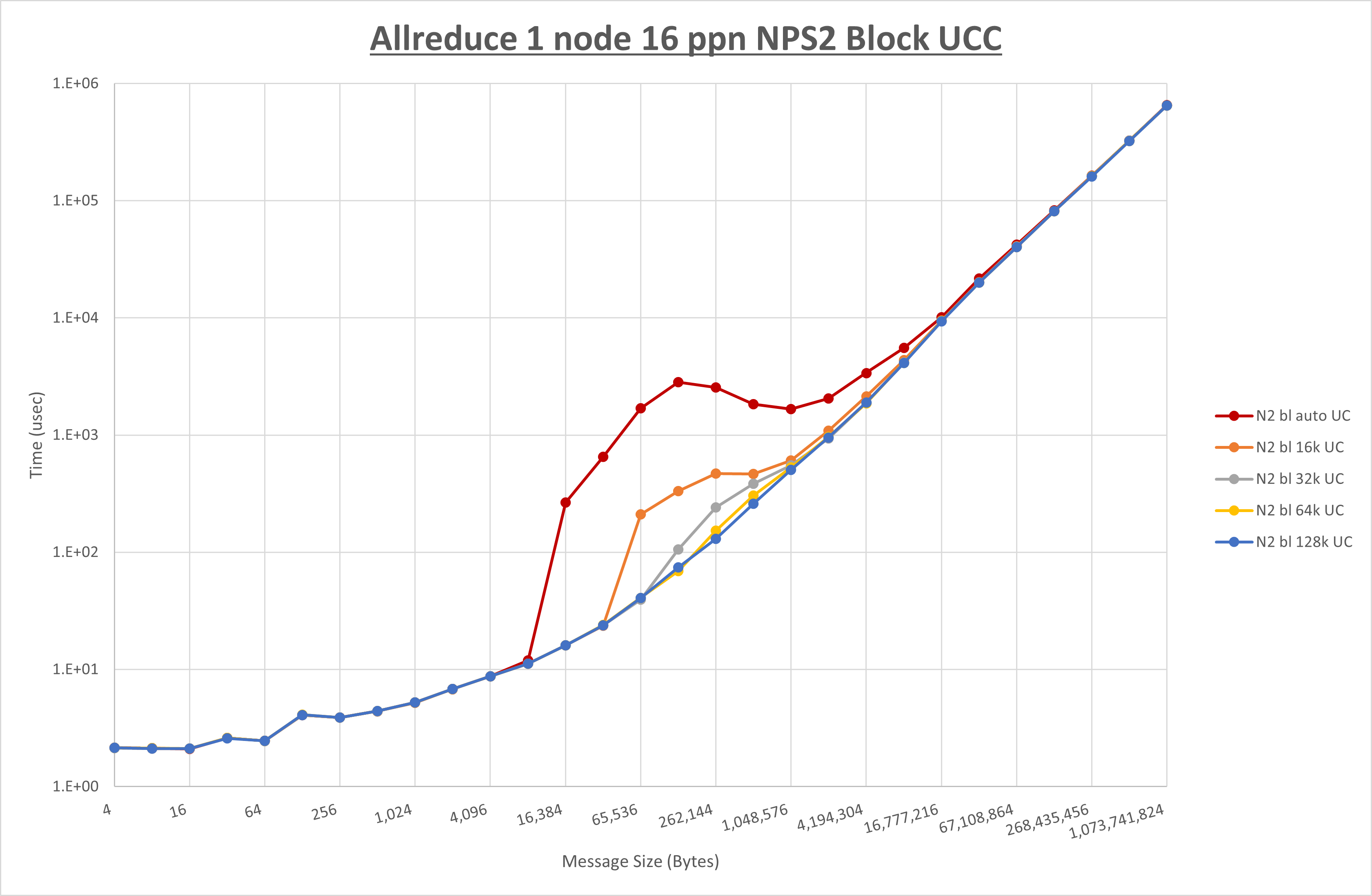
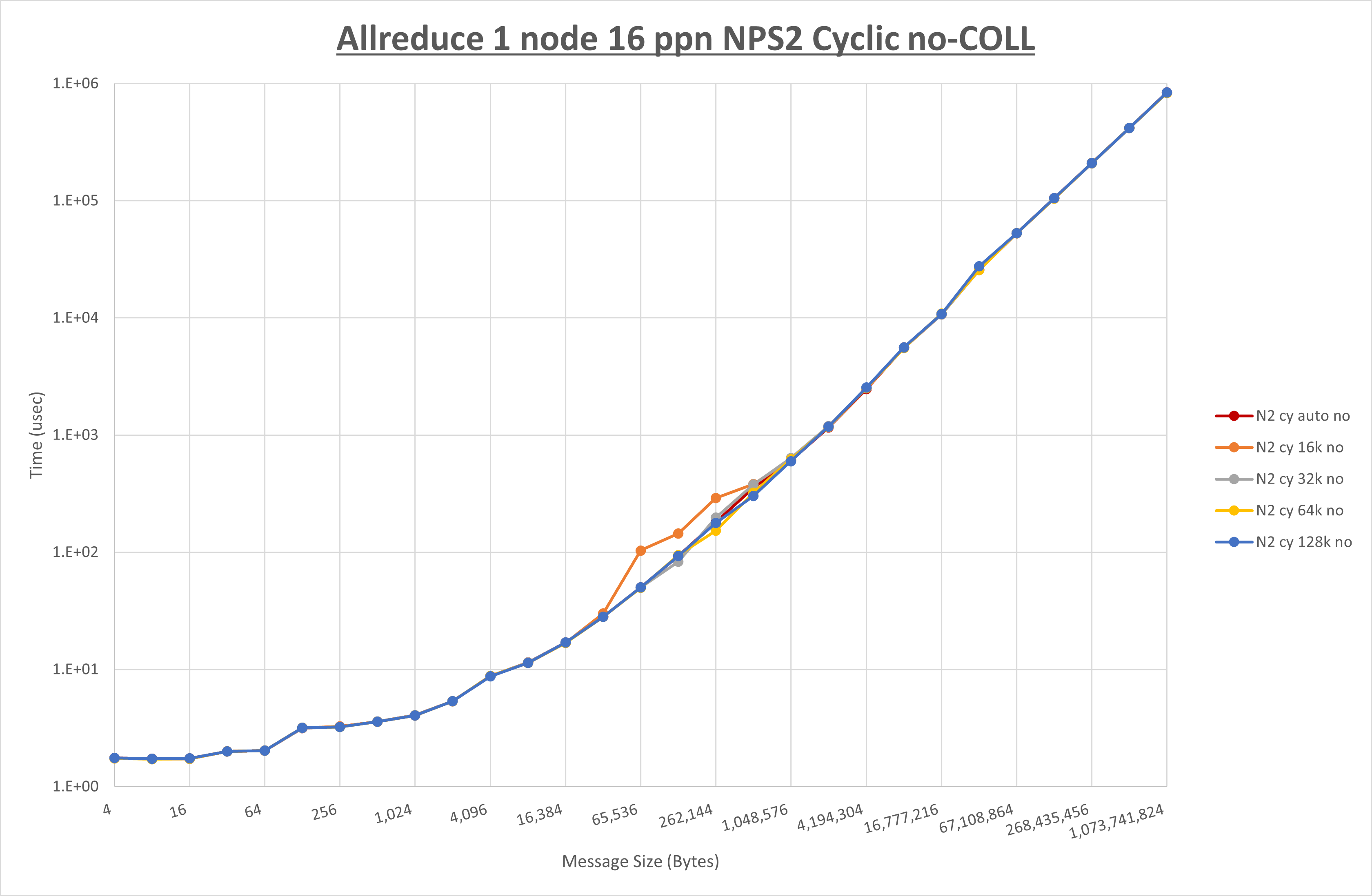
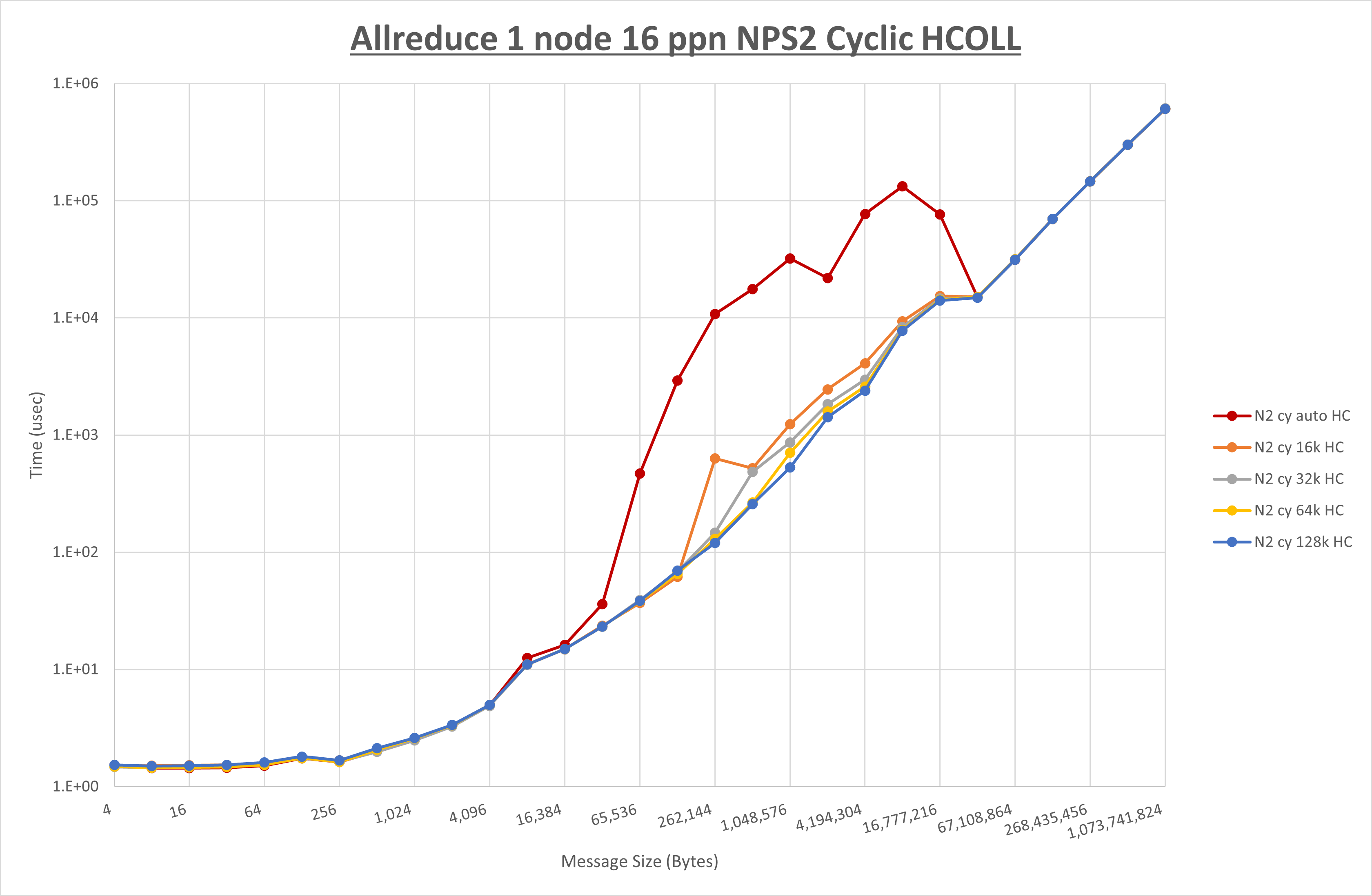
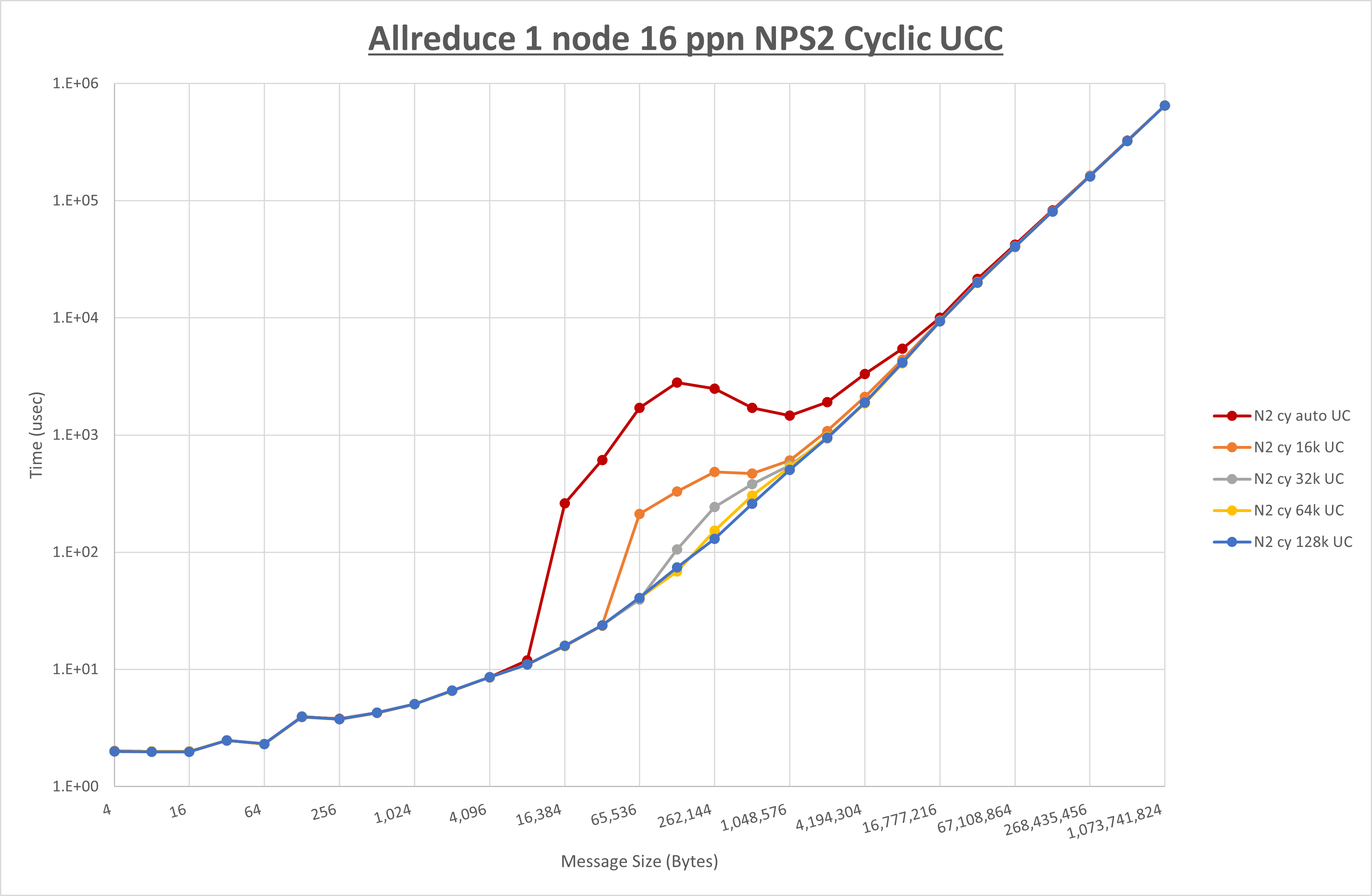
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 128KB | 128KB | 128KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
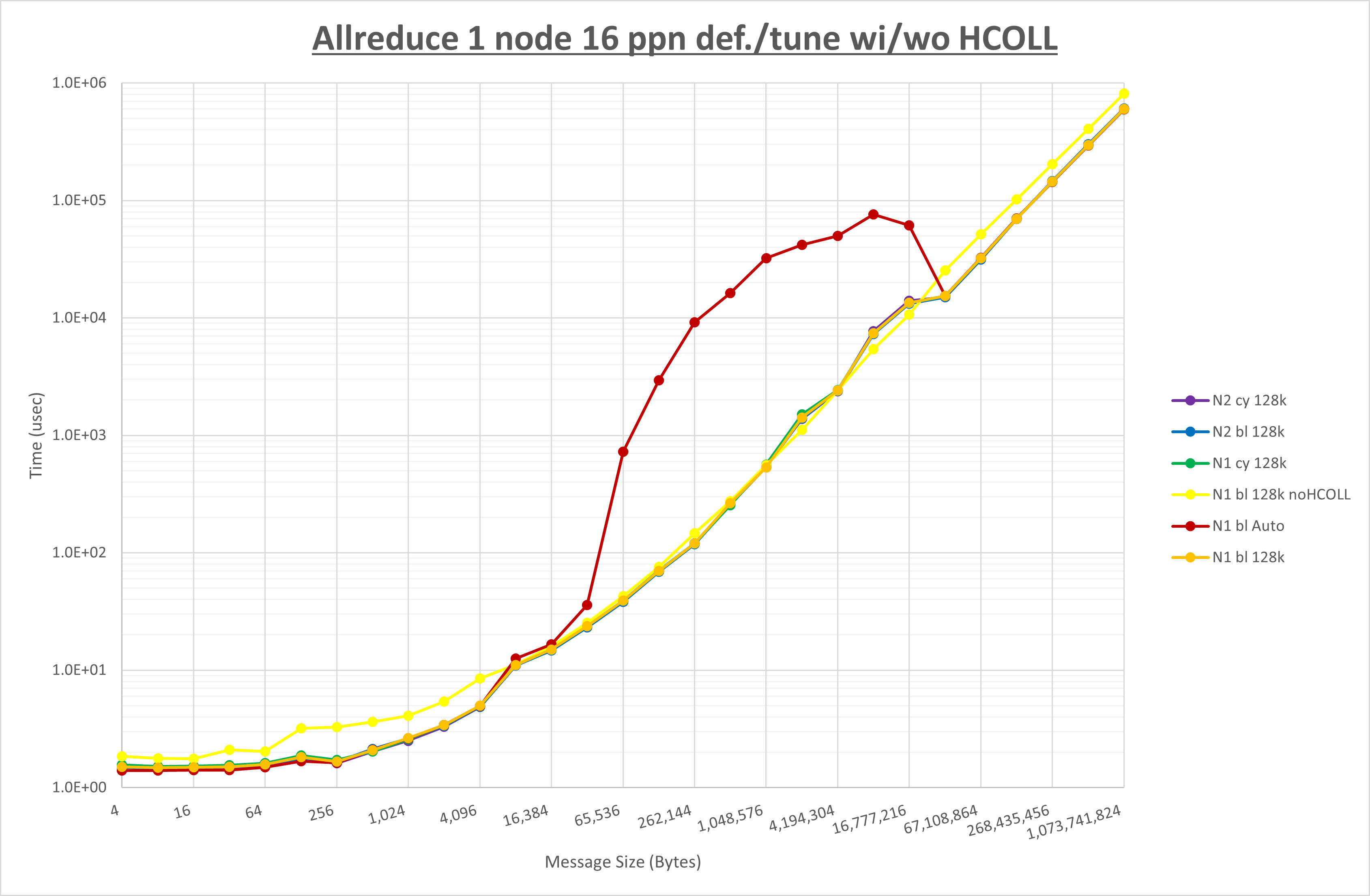
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し4KB以下と32MB以上で性能が向上し1MBから16MBで性能が低下
- UCC は no-COLL と比較し32KB以上で性能が向上し2KB以下で性能が低下
- チューニング適用で64KBから512KBの間で性能が向上
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 NPS とMPIプロセス分割方法の組合せ毎に示しています。
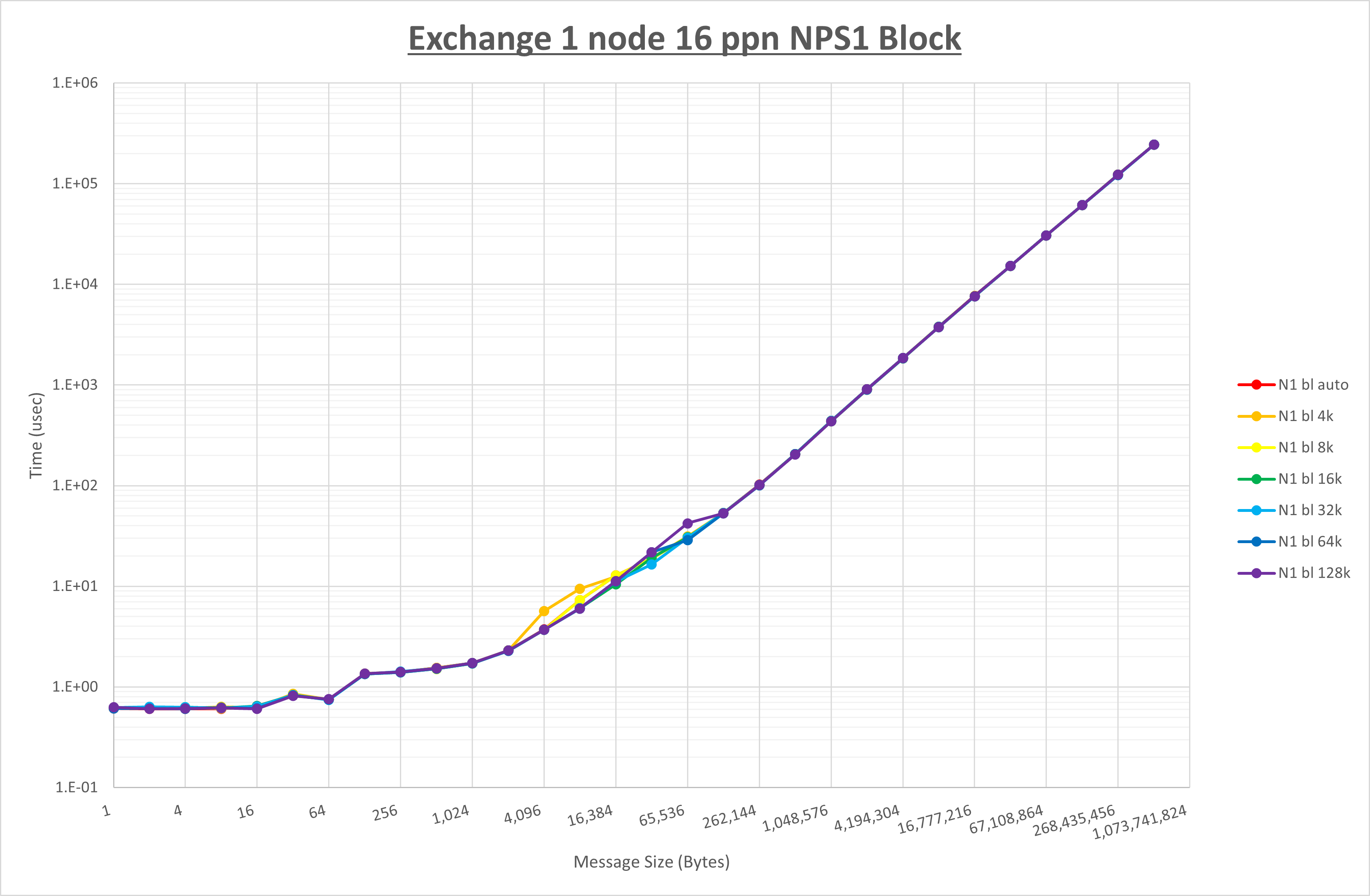
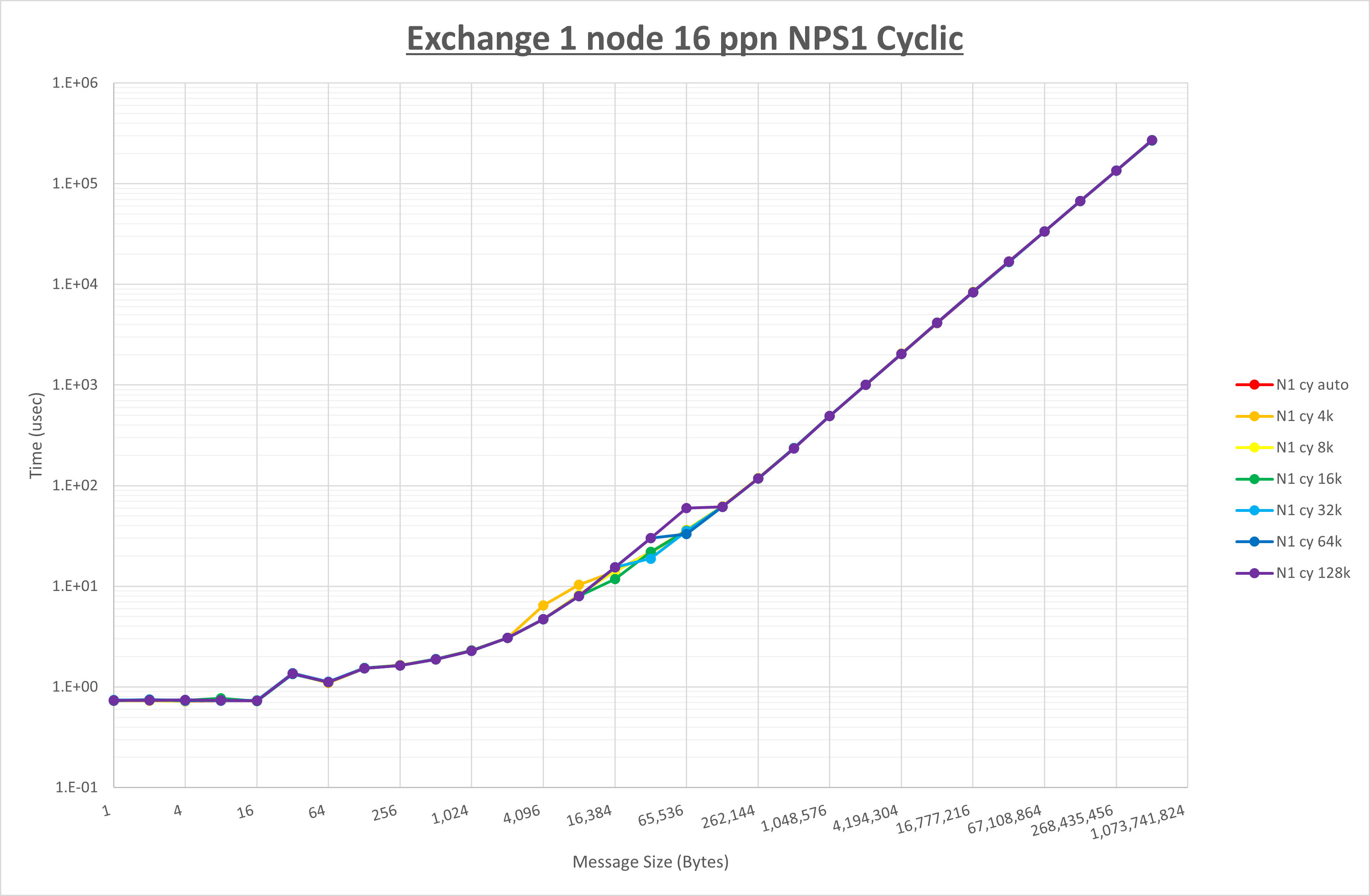
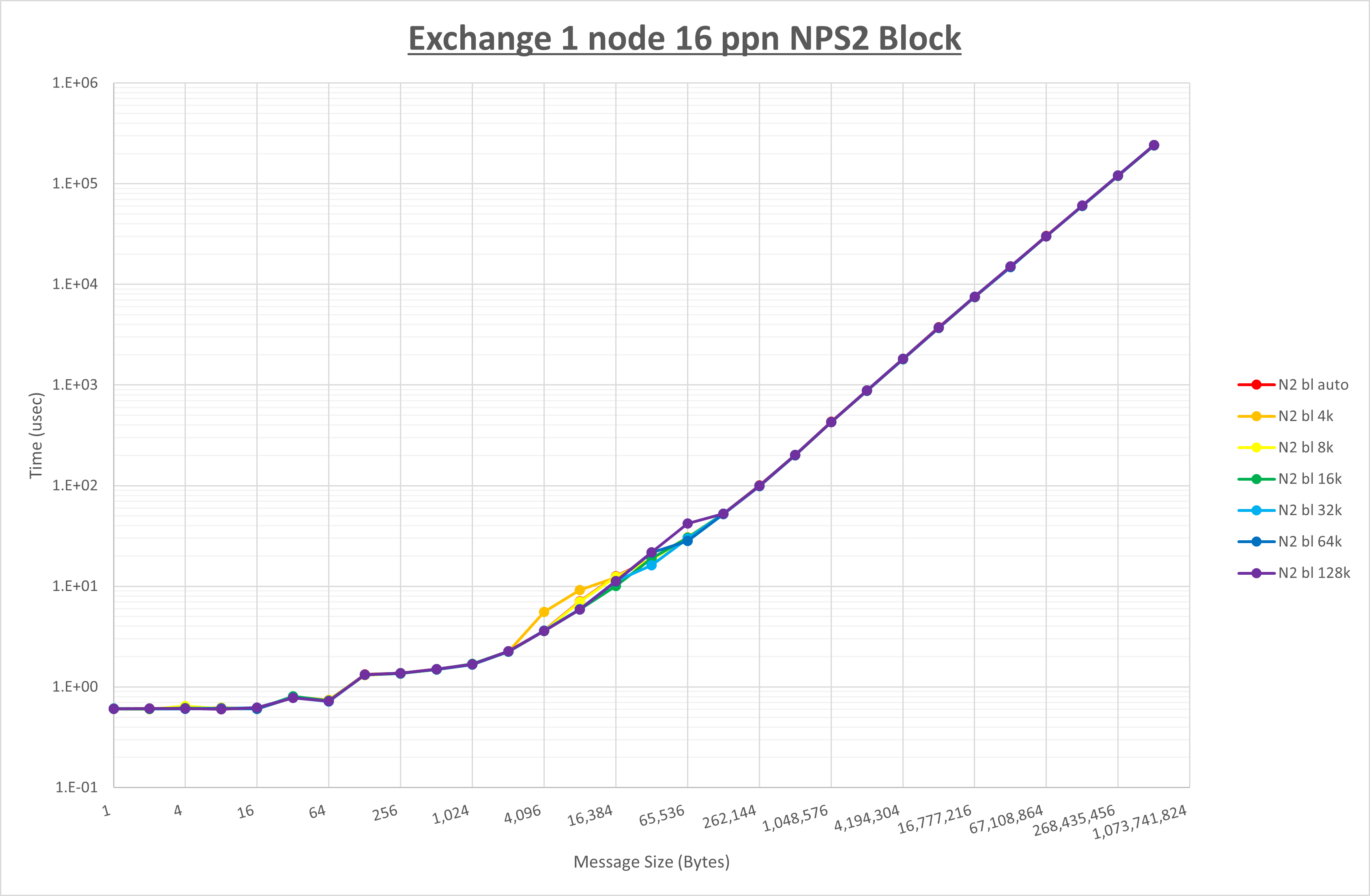
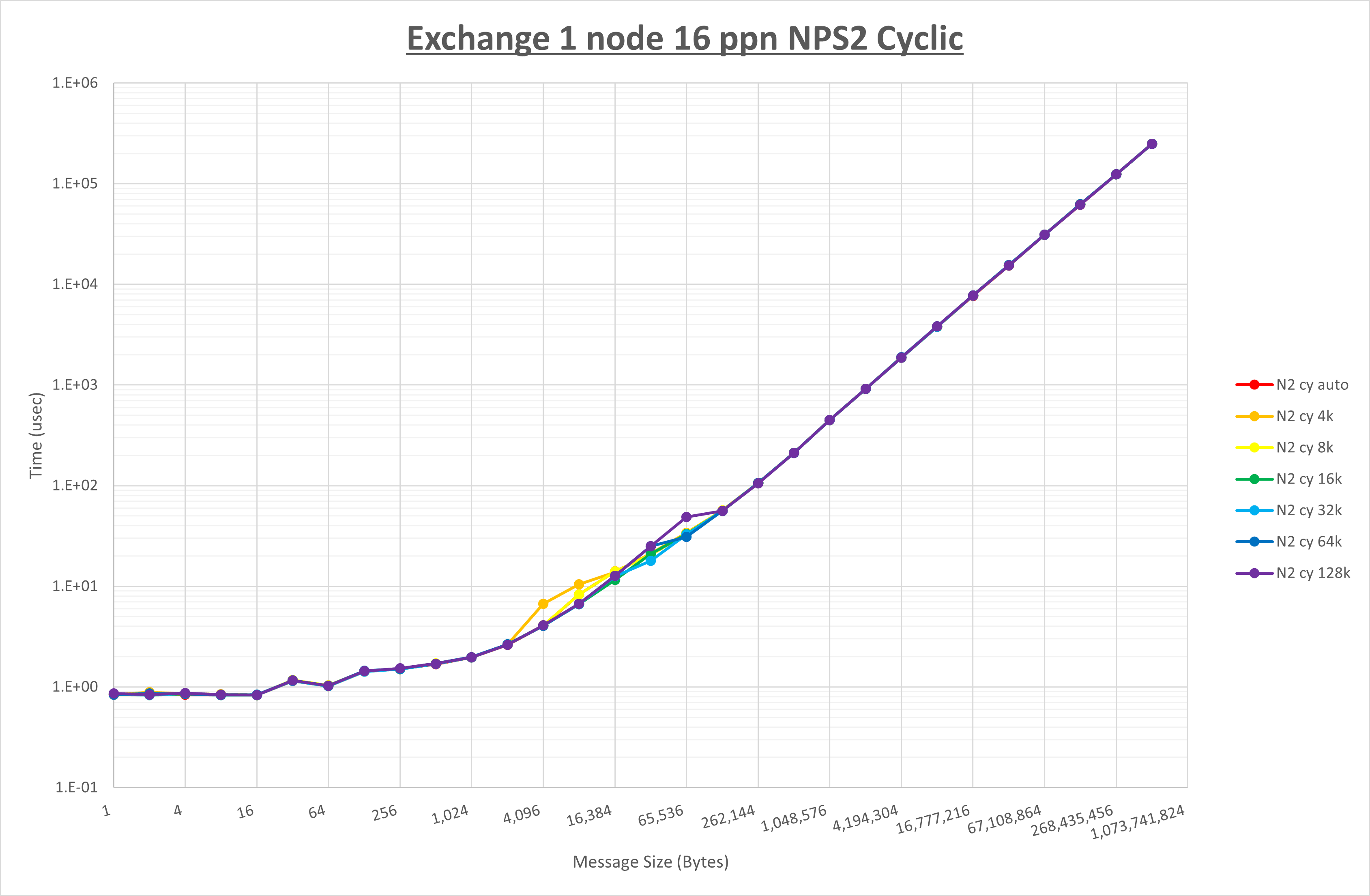
以上より、 NPS とMPIプロセス分割方法の組合せにより UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| NPS1 ブロック分割 |
NPS1 サイクリック分割 |
NPS2 ブロック分割 |
NPS2 サイクリック分割 |
|
|---|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 16KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto )を含めています。
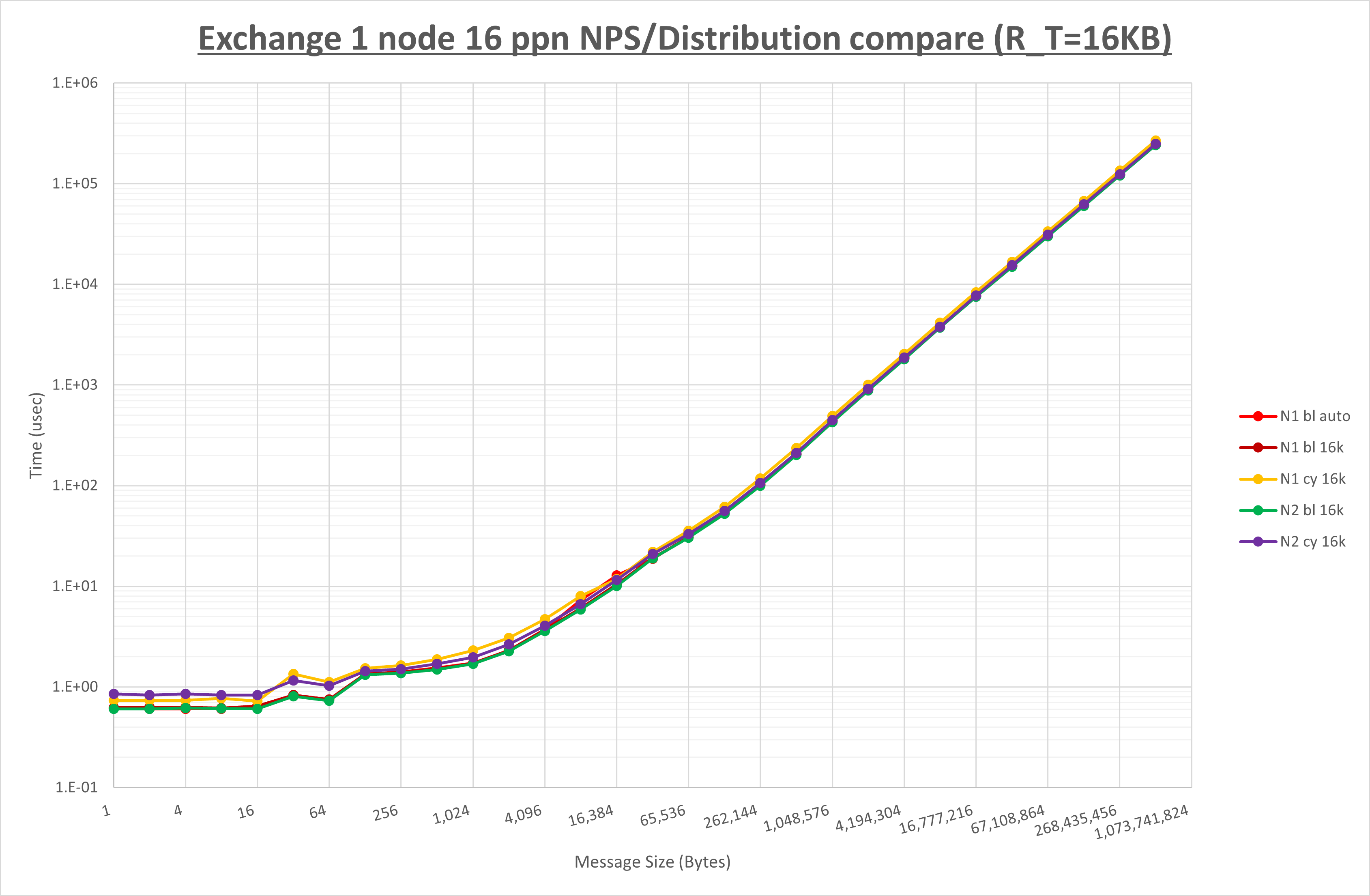
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で8KBから16KBの間で性能が向上
本章は、1ノードに32 MPIプロセスを割当てる場合の最適な 実行時パラメータ の組み合わせをMPI集合通信関数毎に検証し、その結果を考察します。
下表は、各MPI集合通信関数の最適な UCX_RNDV_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_RNDV_THRESH |
|---|---|
| Alltoall | 8KB / 16KB |
| Allgather | 16KB |
| Allreduce | 128KB |
| Exchange | 16KB |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
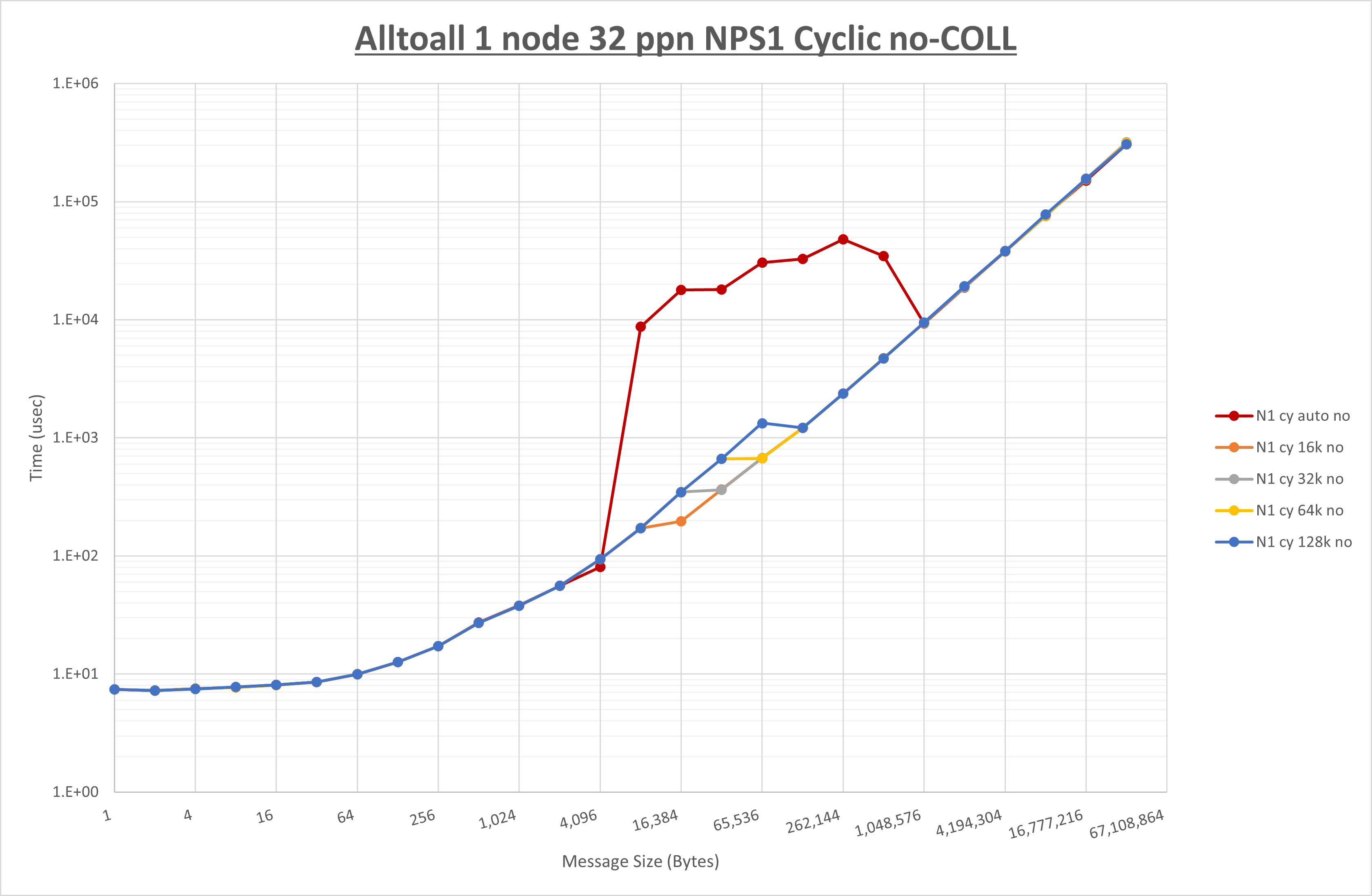
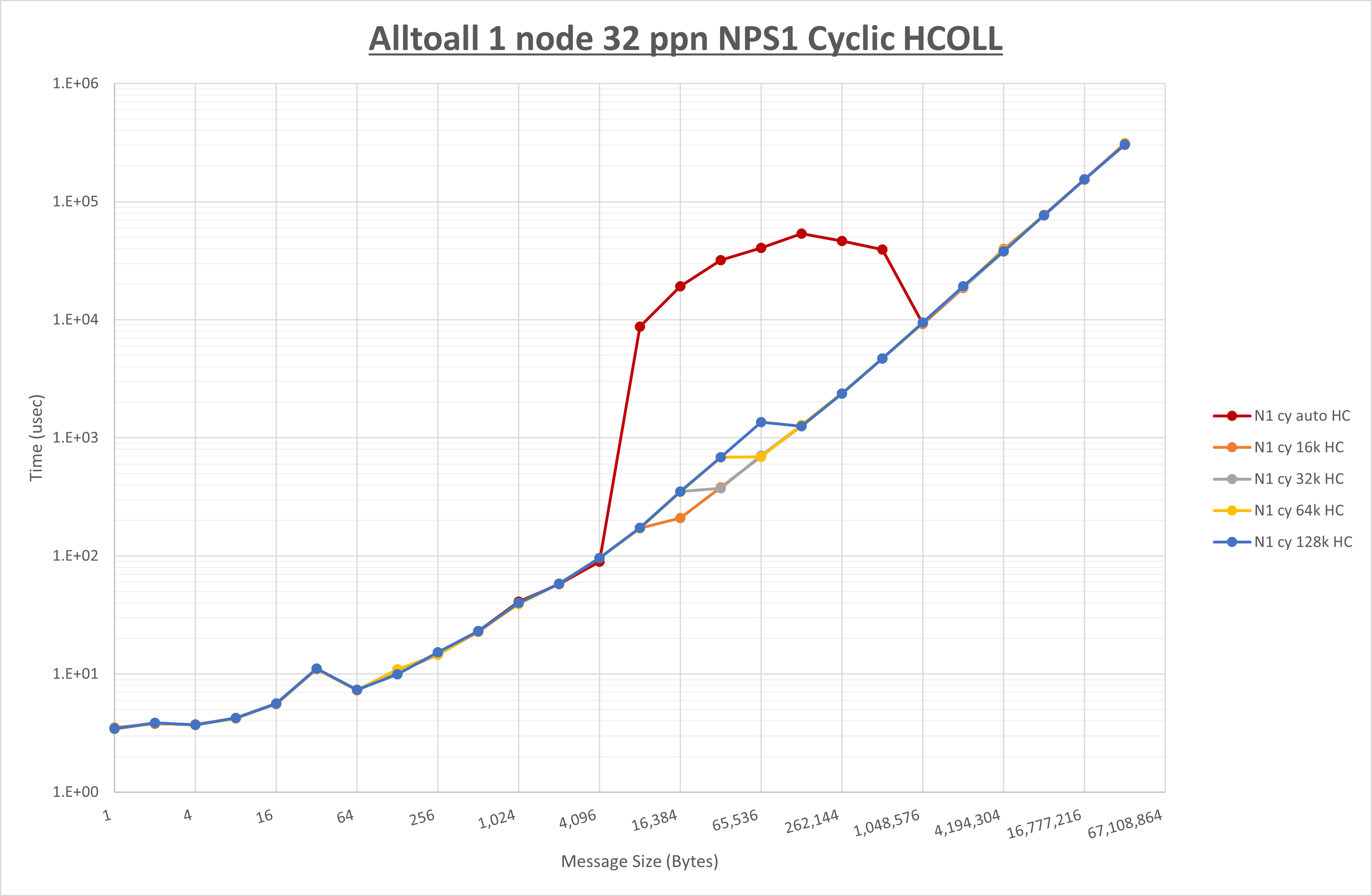
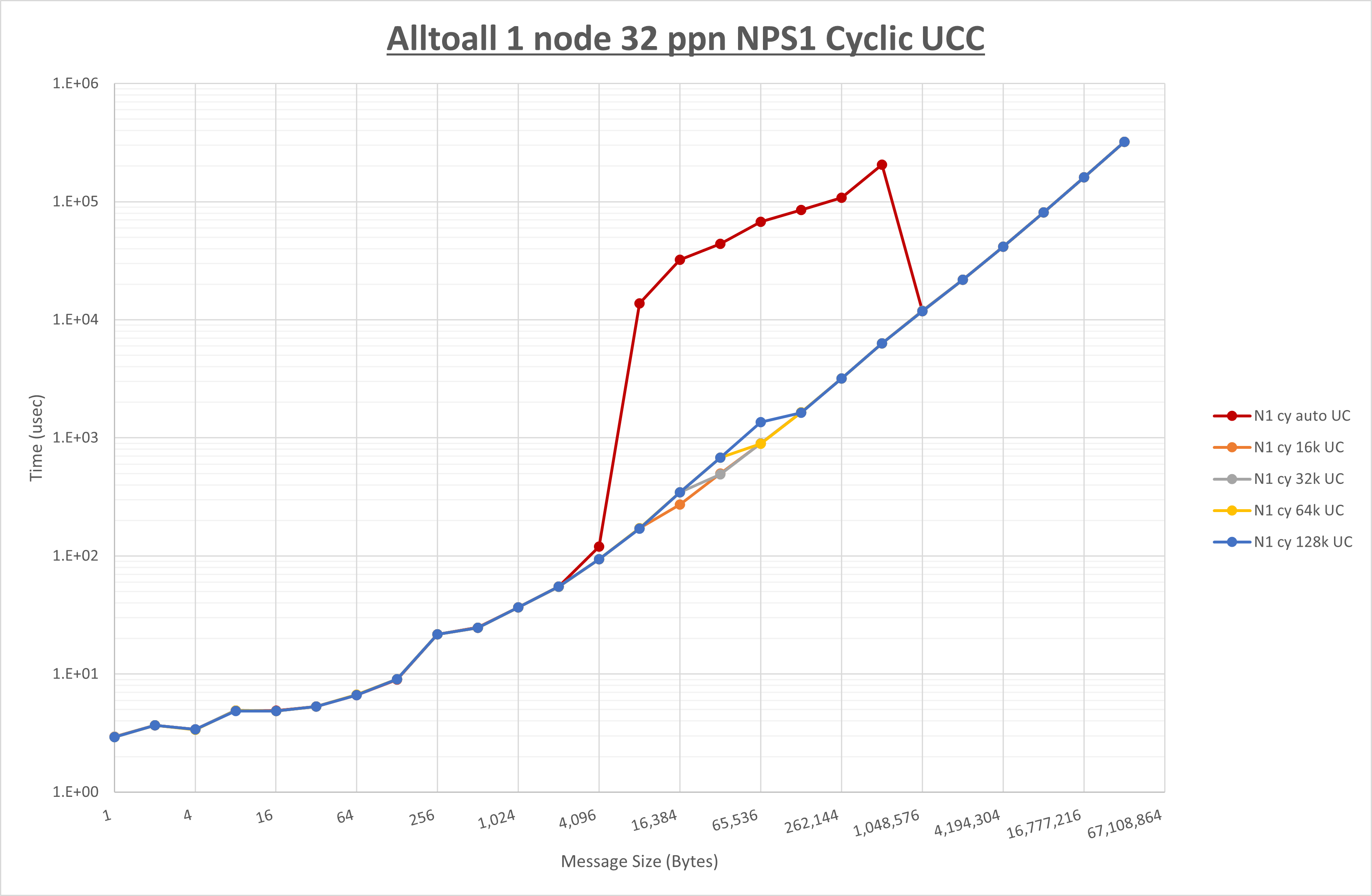
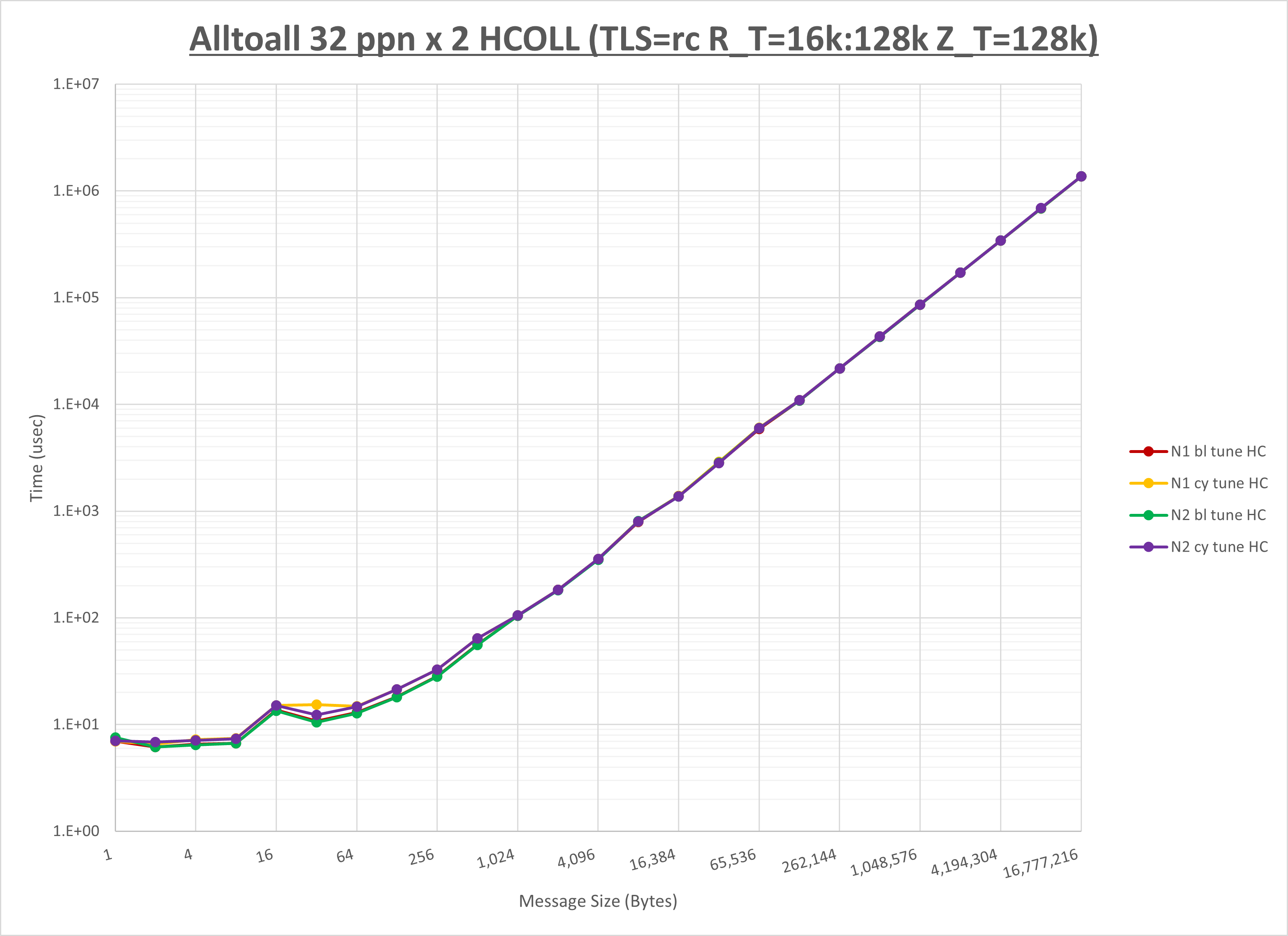
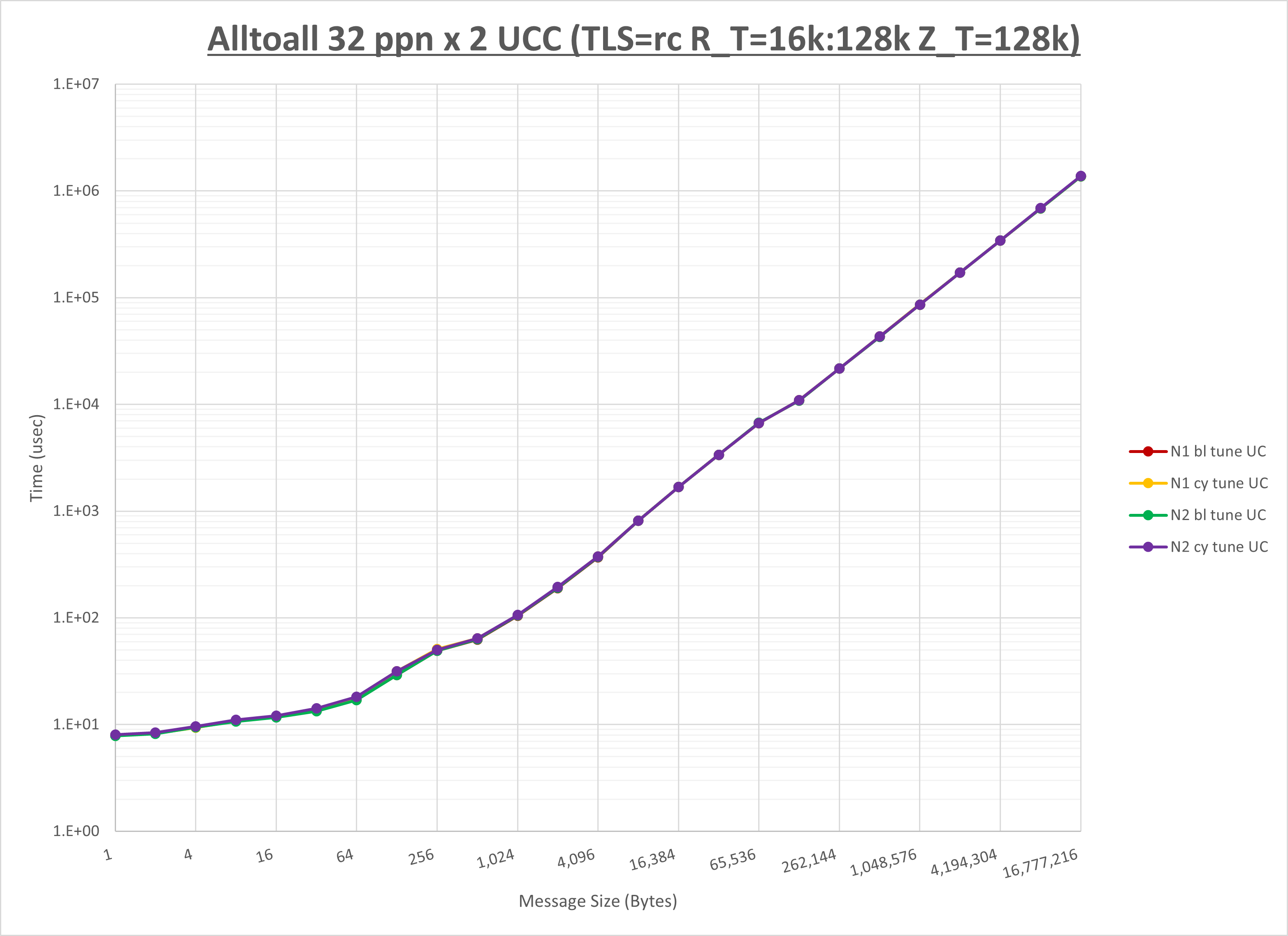
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
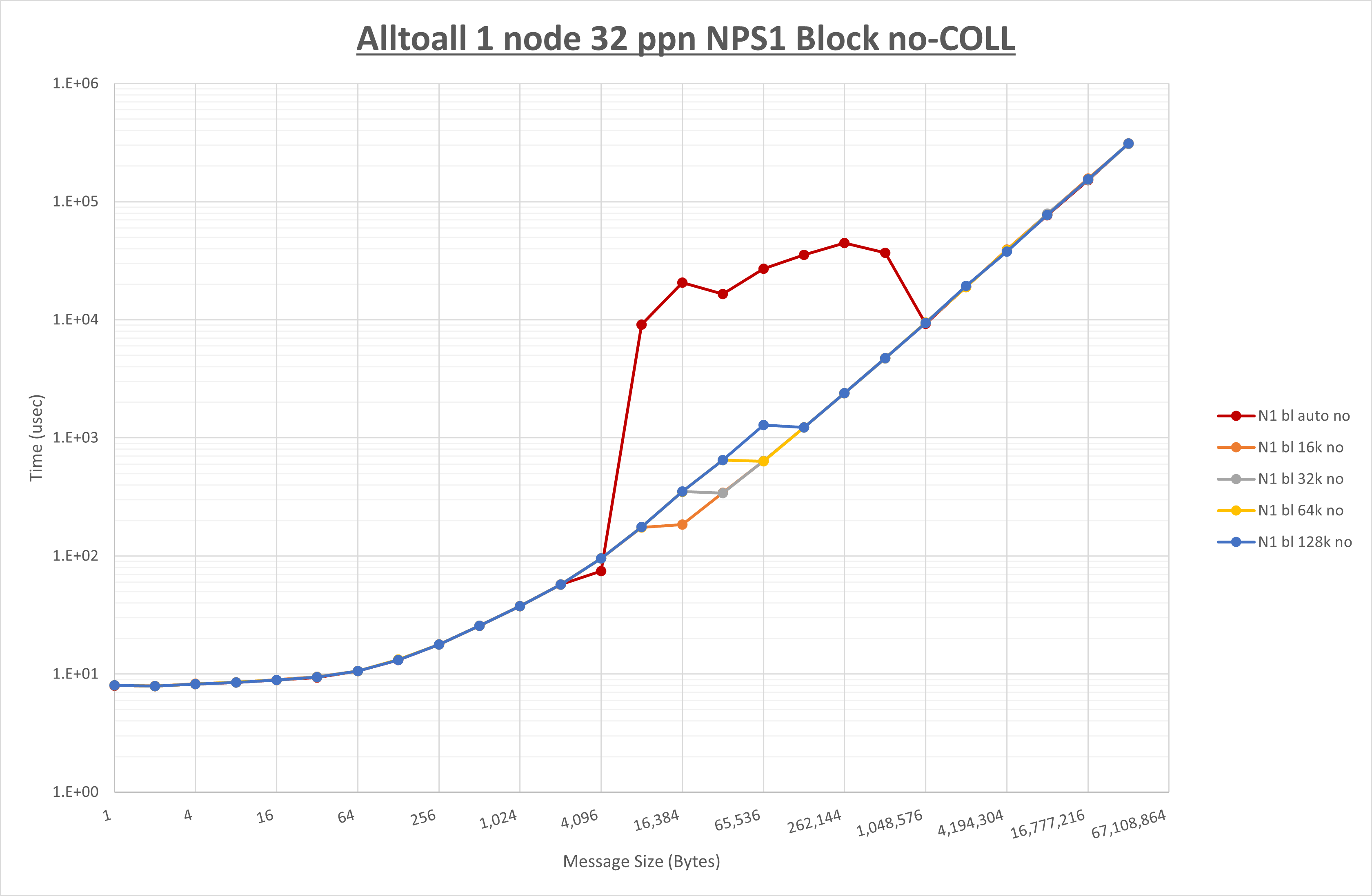
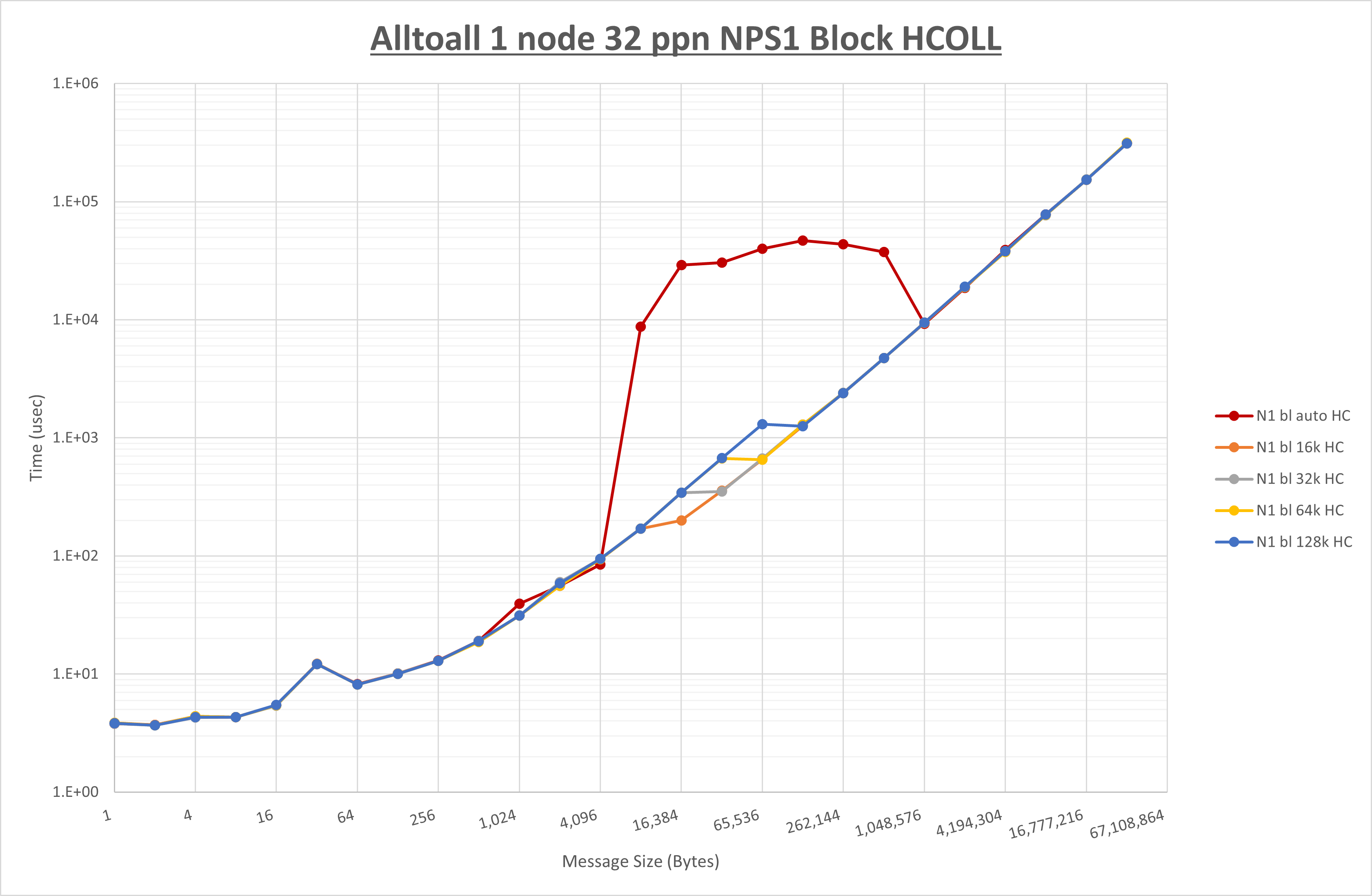
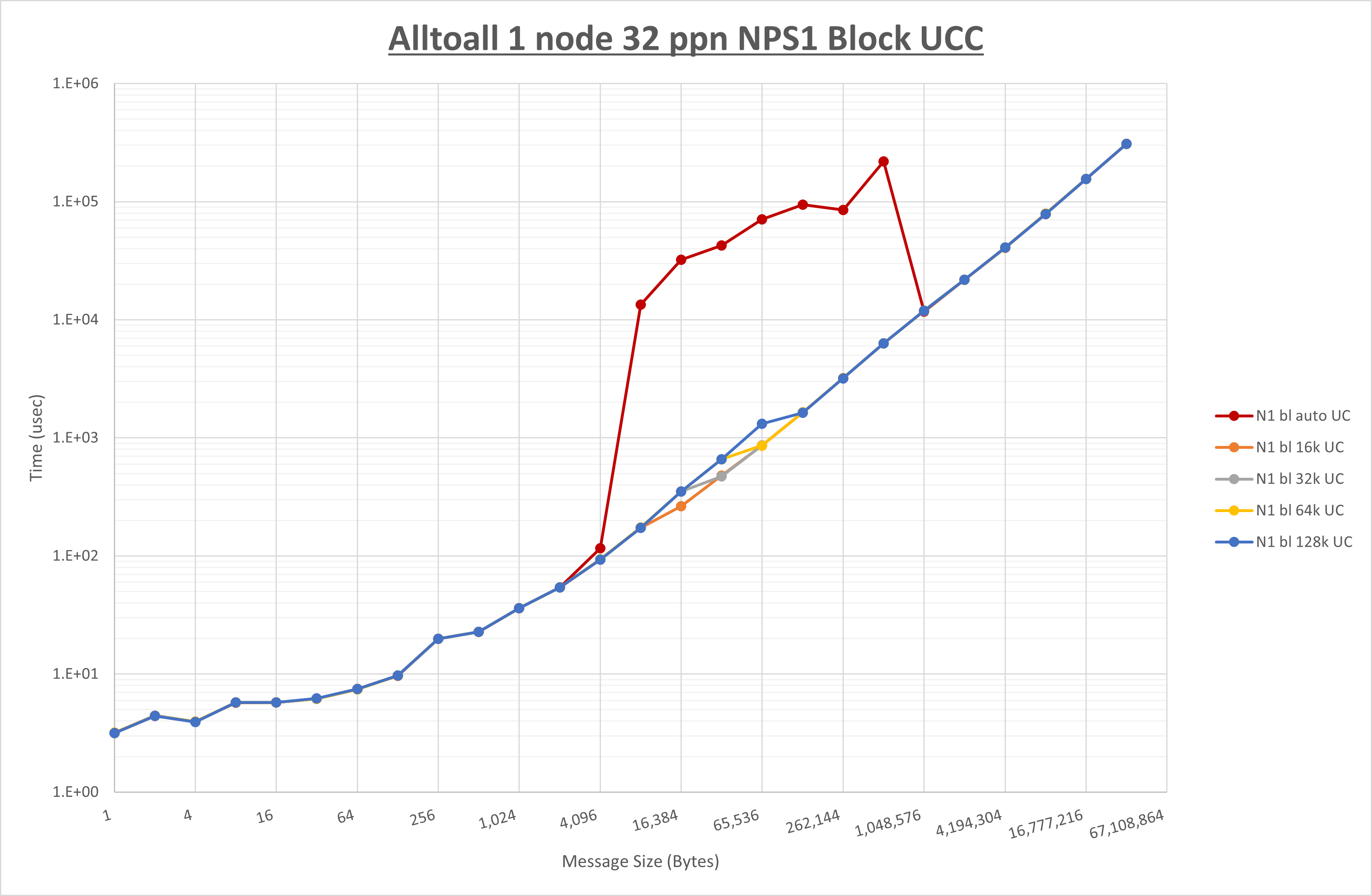
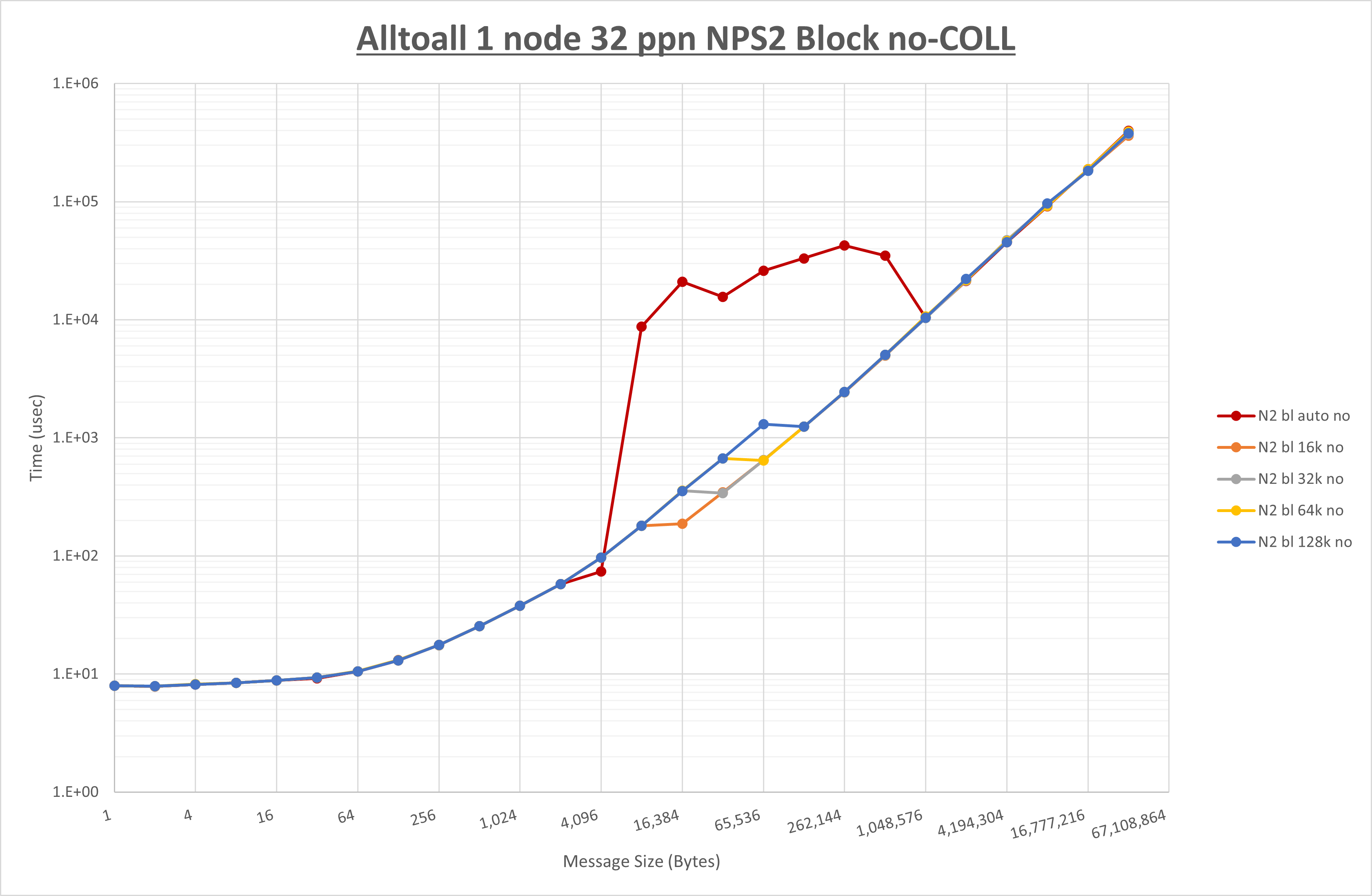
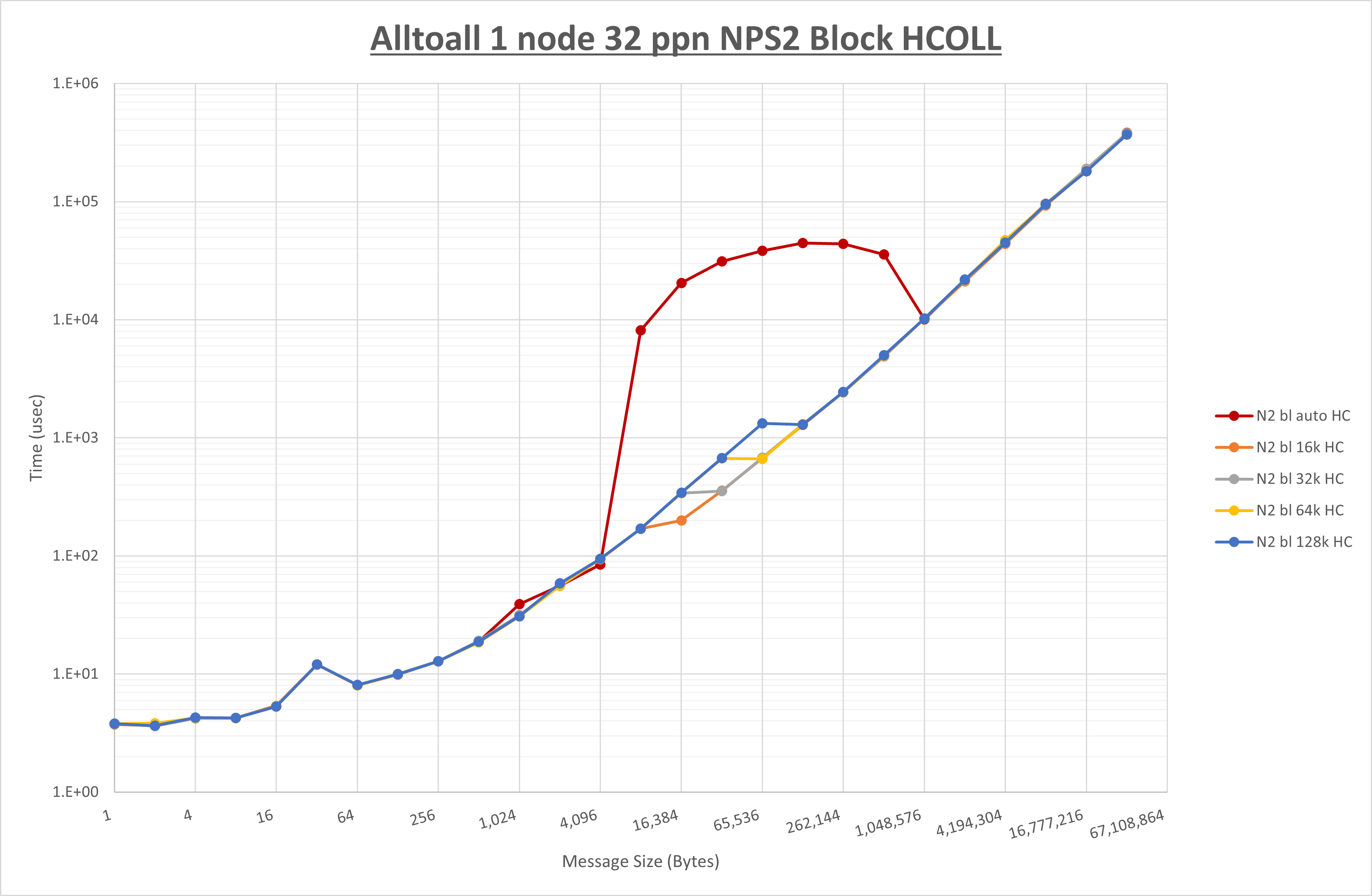
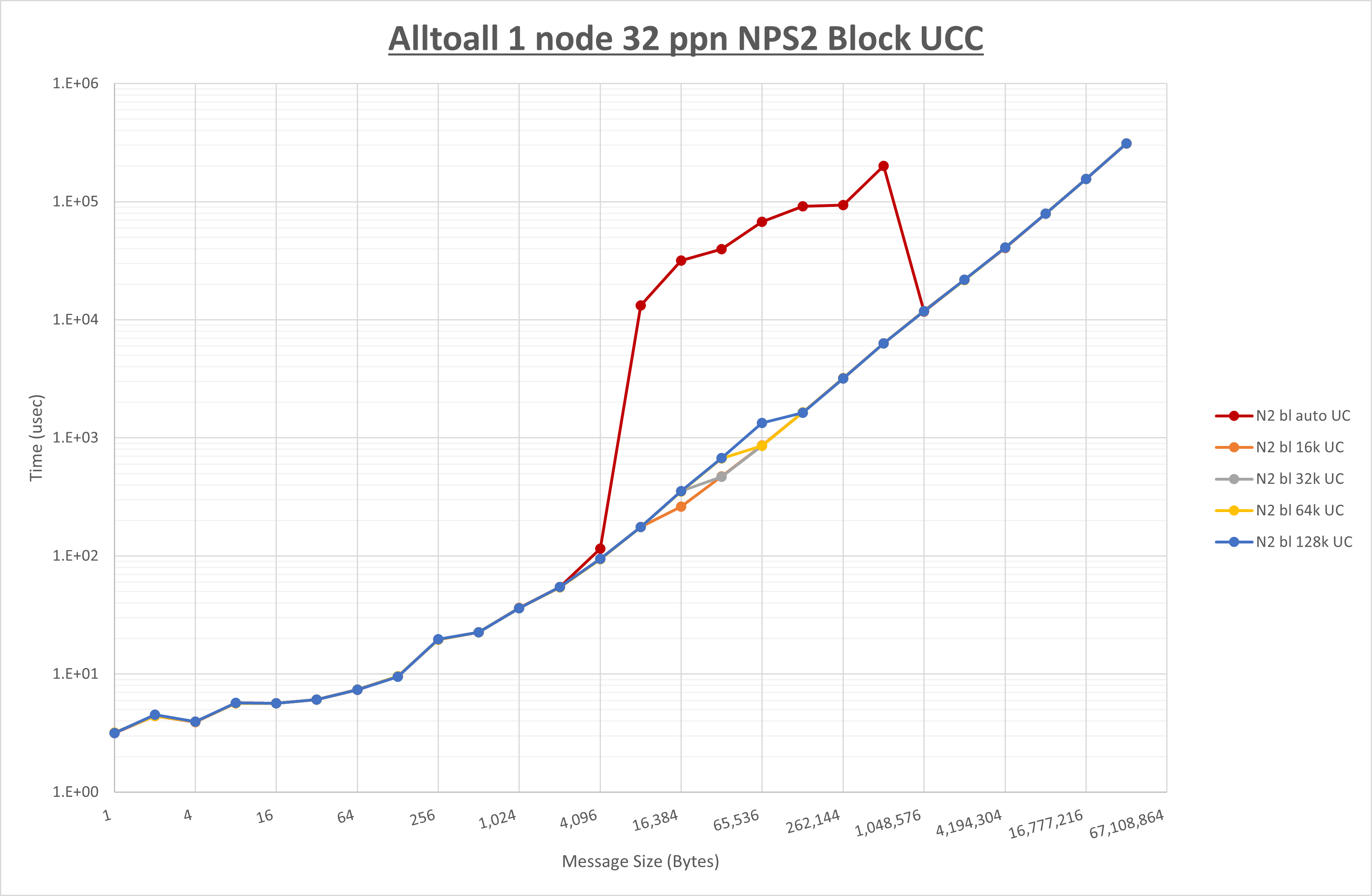
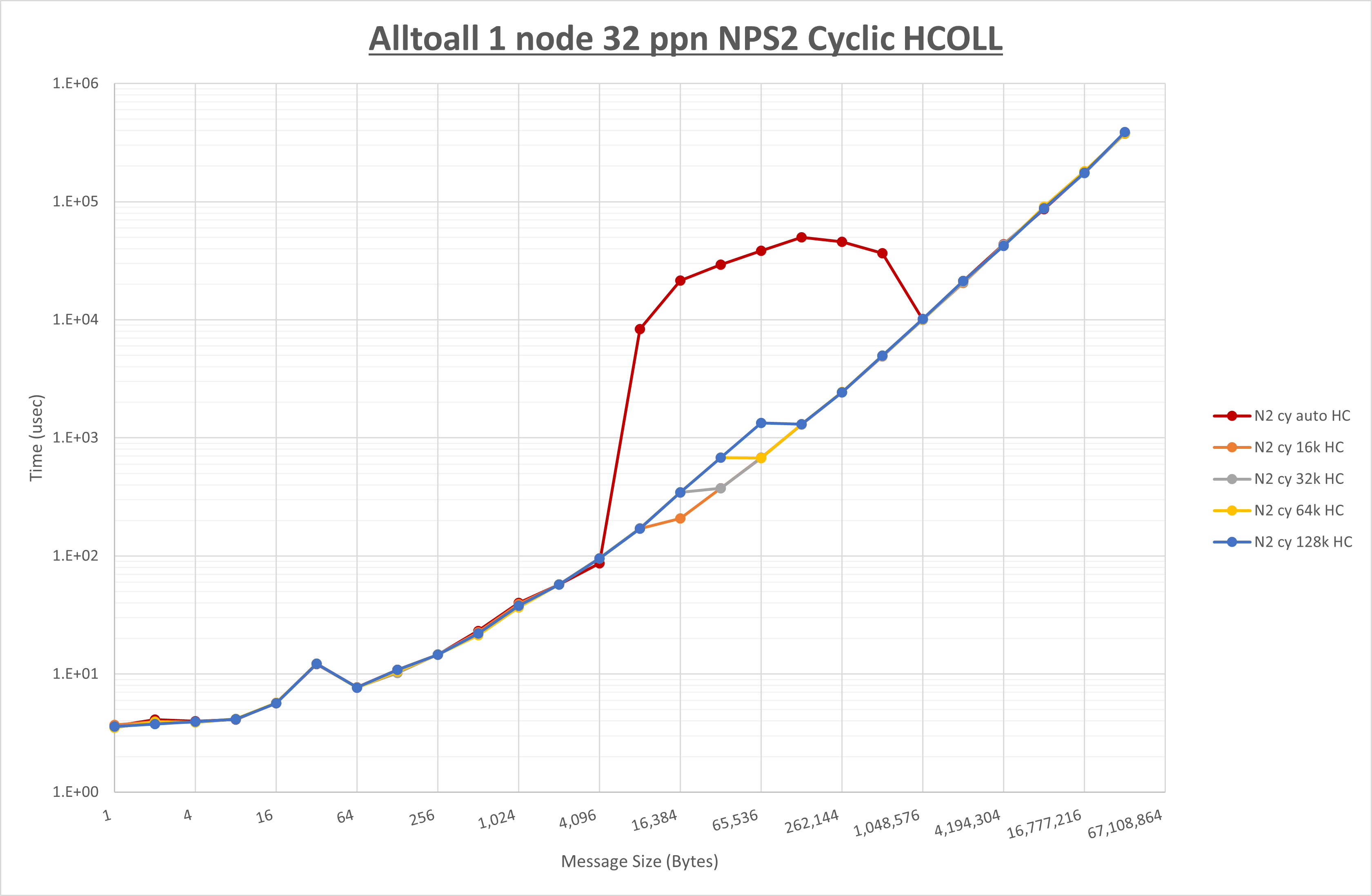
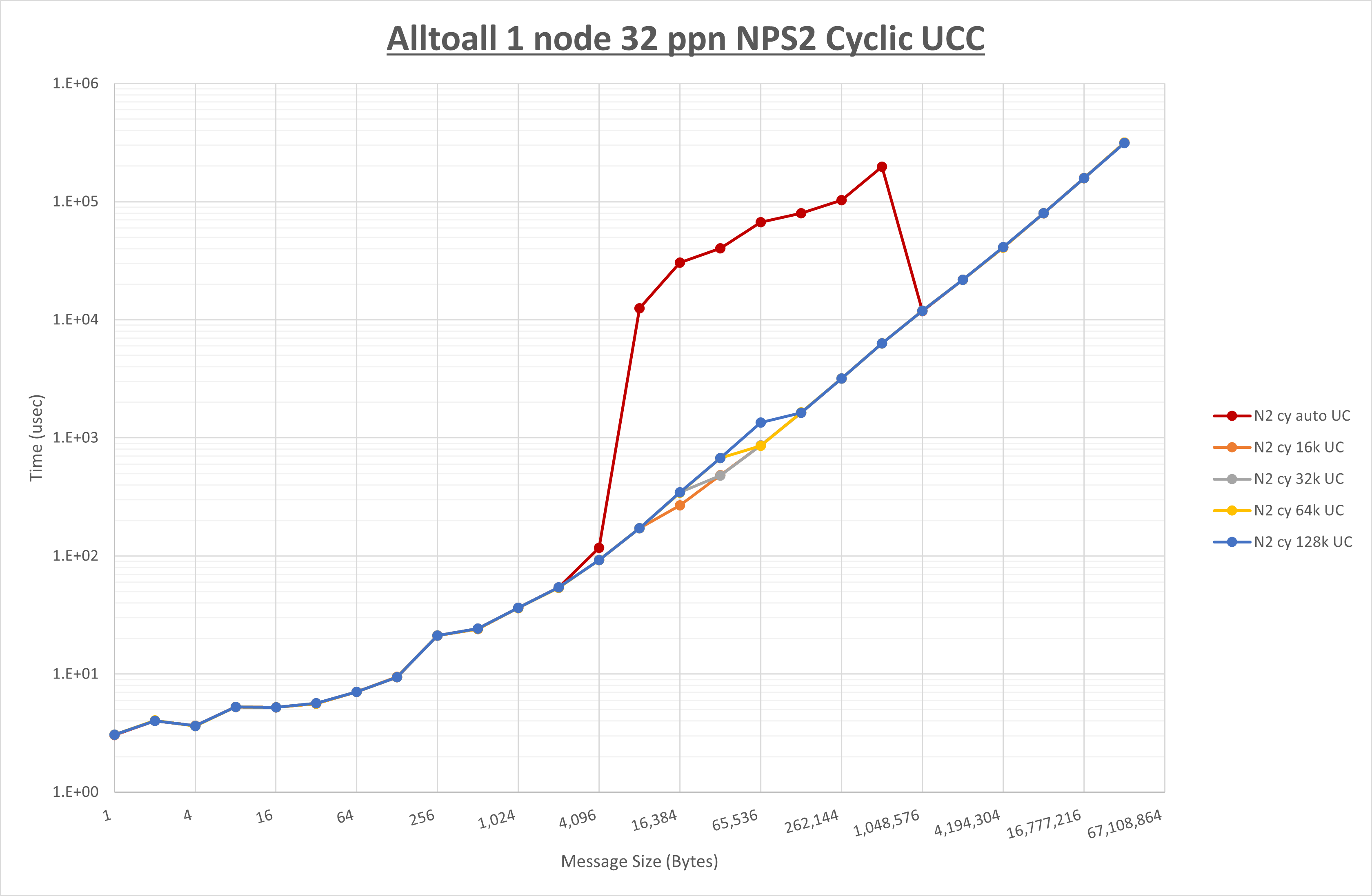
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 8KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
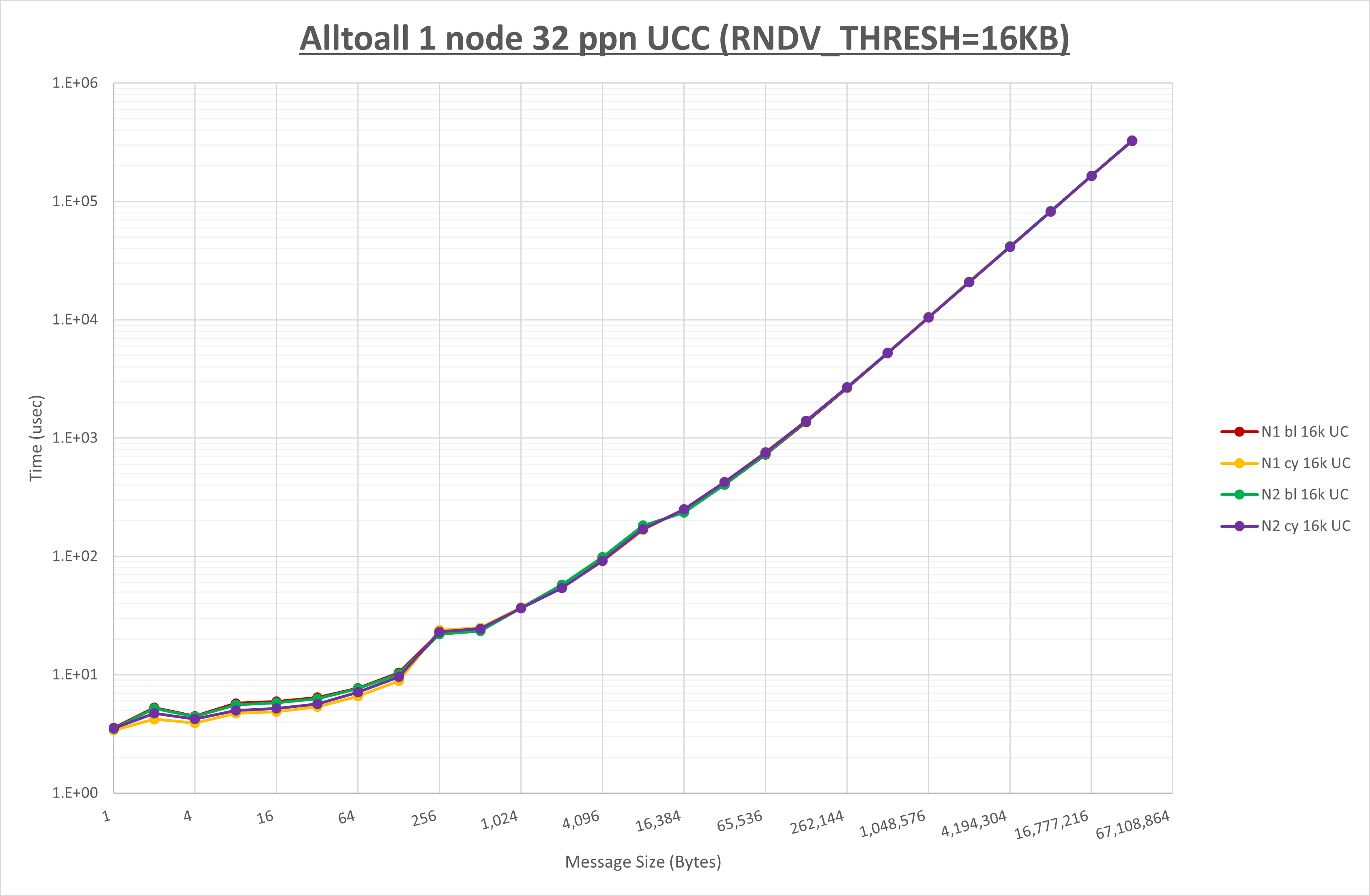
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
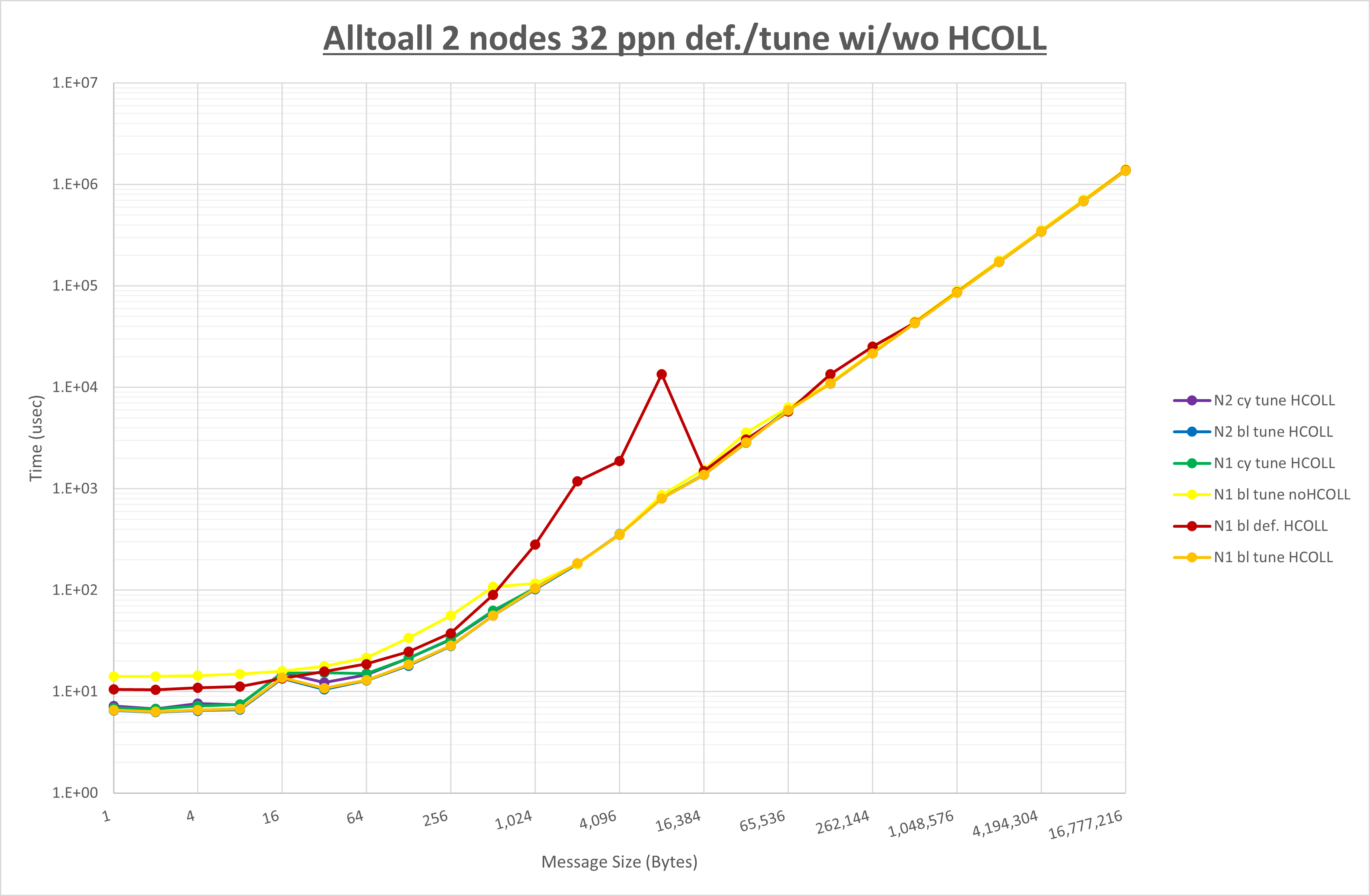
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
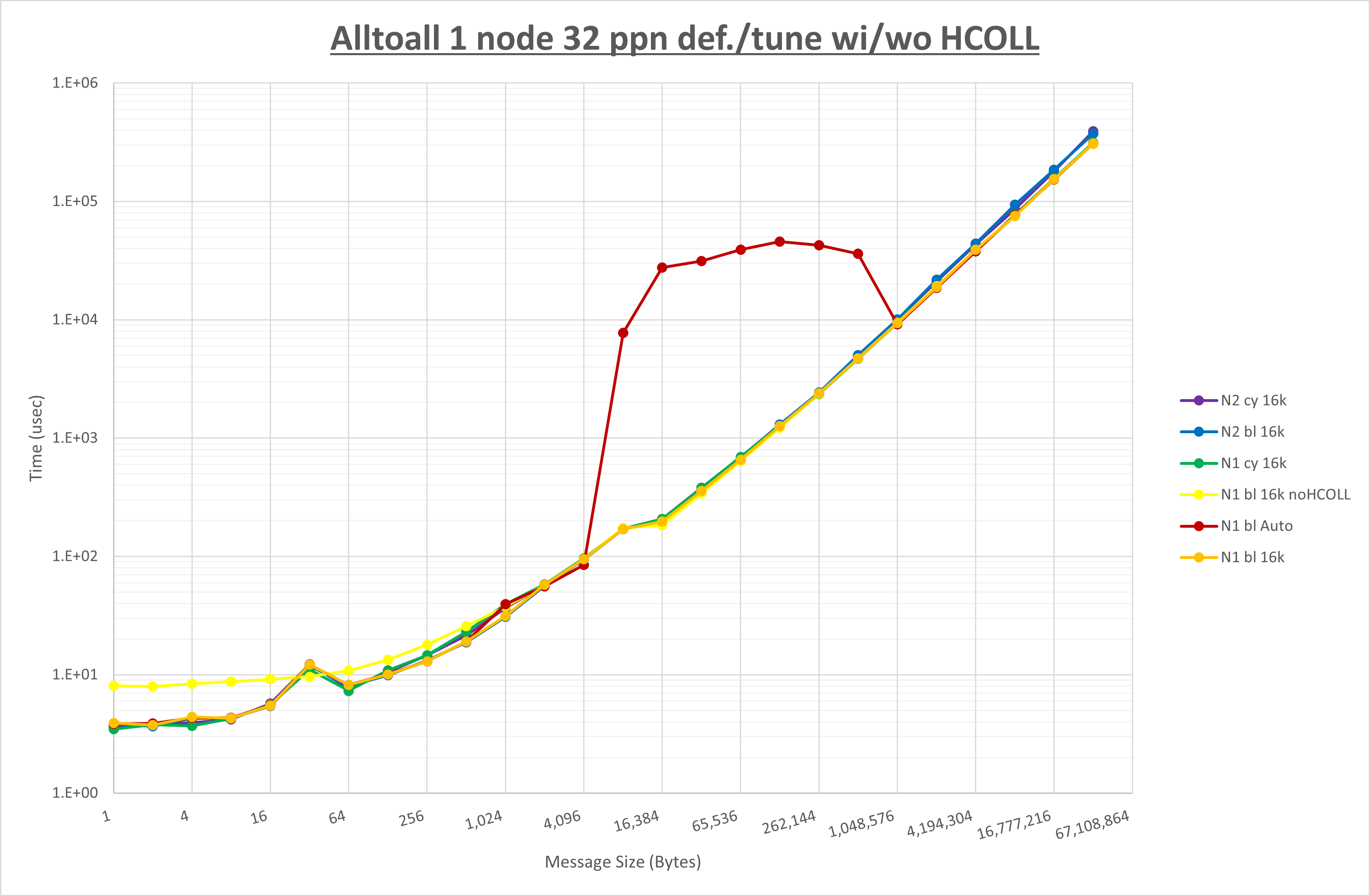
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し16B以下で性能が向上し1KBと64KBで性能が低下
- UCC は no-COLL と比較し128B以下で性能が向上し256Bで性能が低下
- チューニング適用で8KBから16KBの間で性能が向上
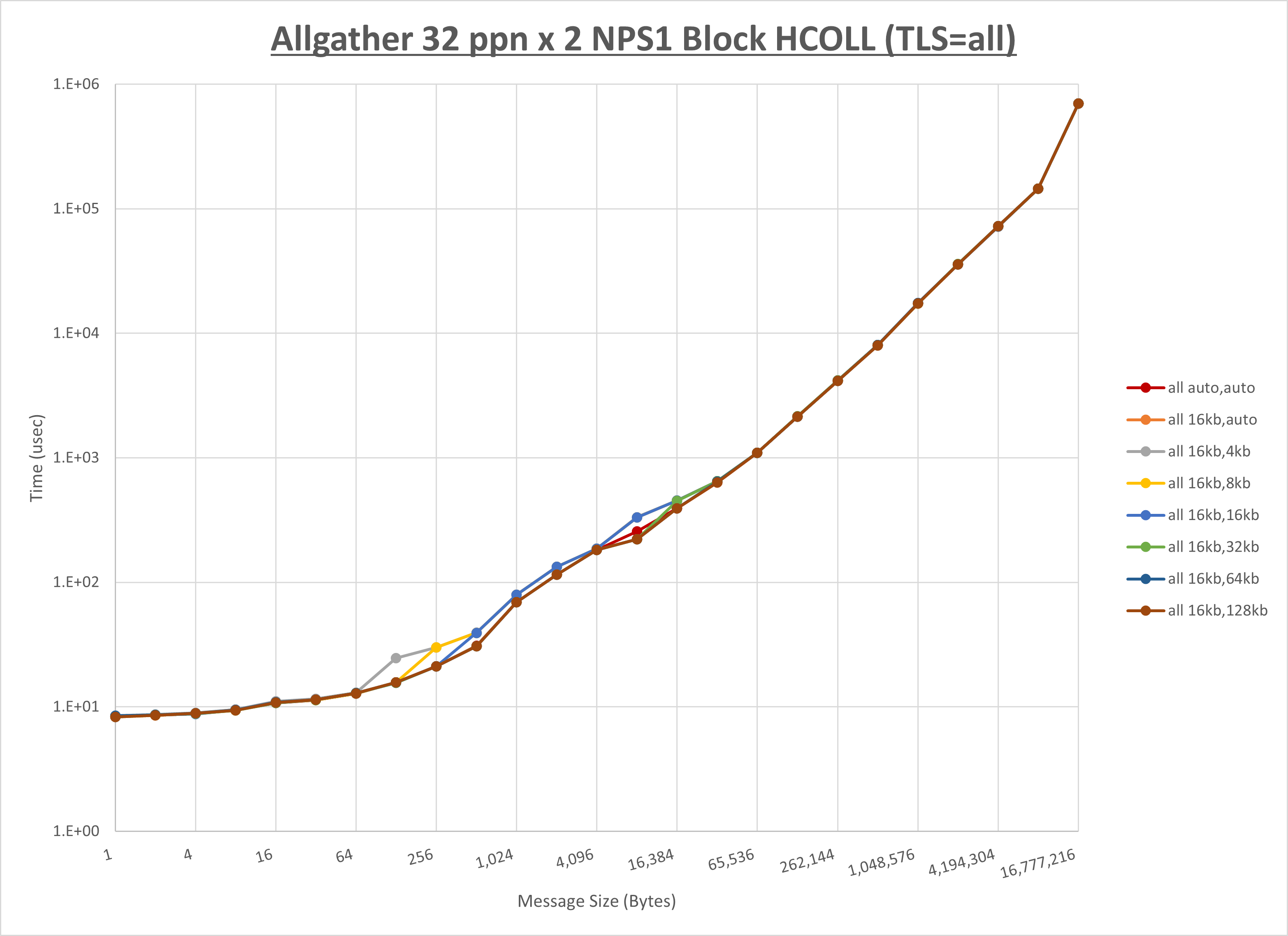
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
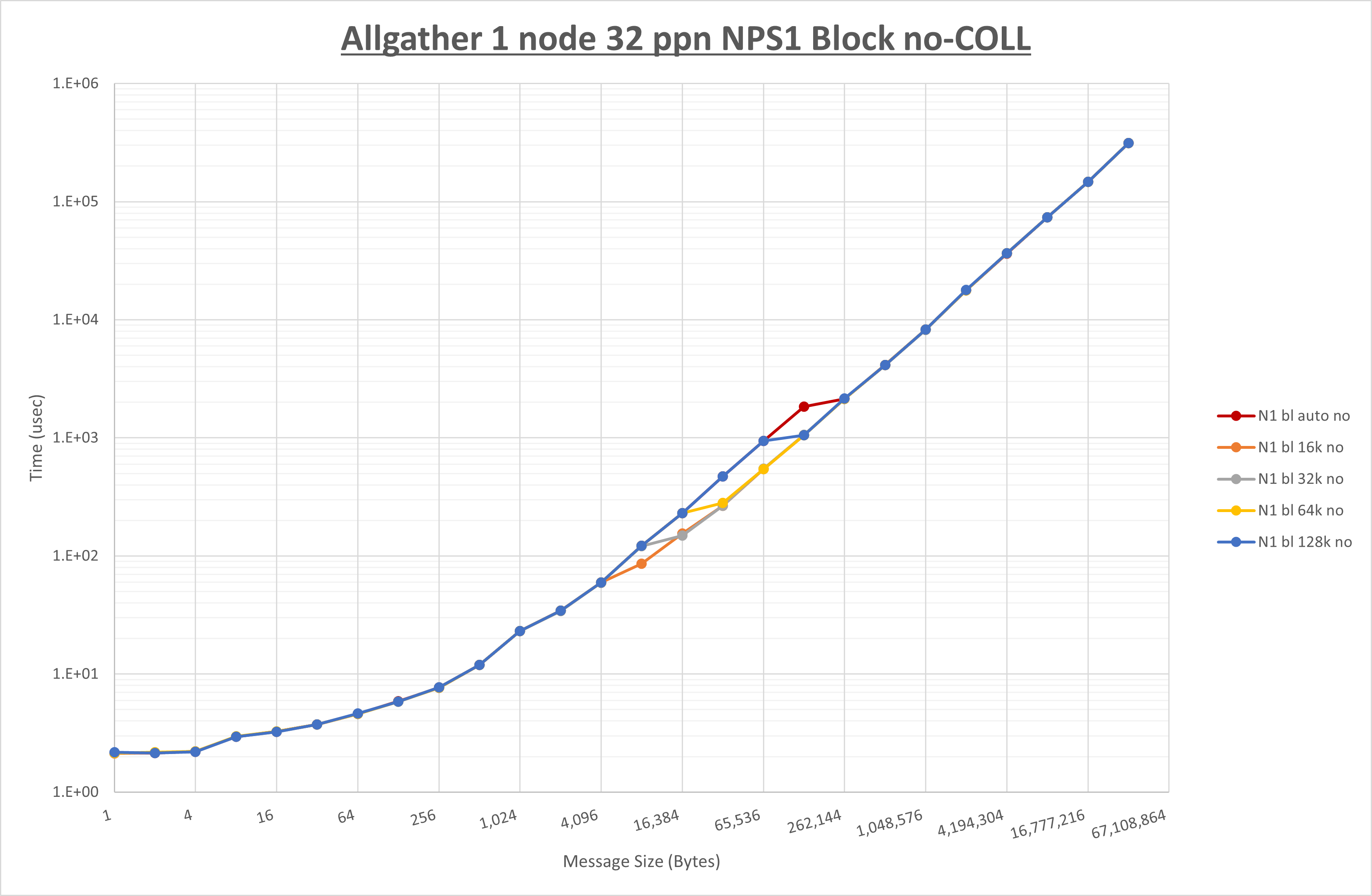
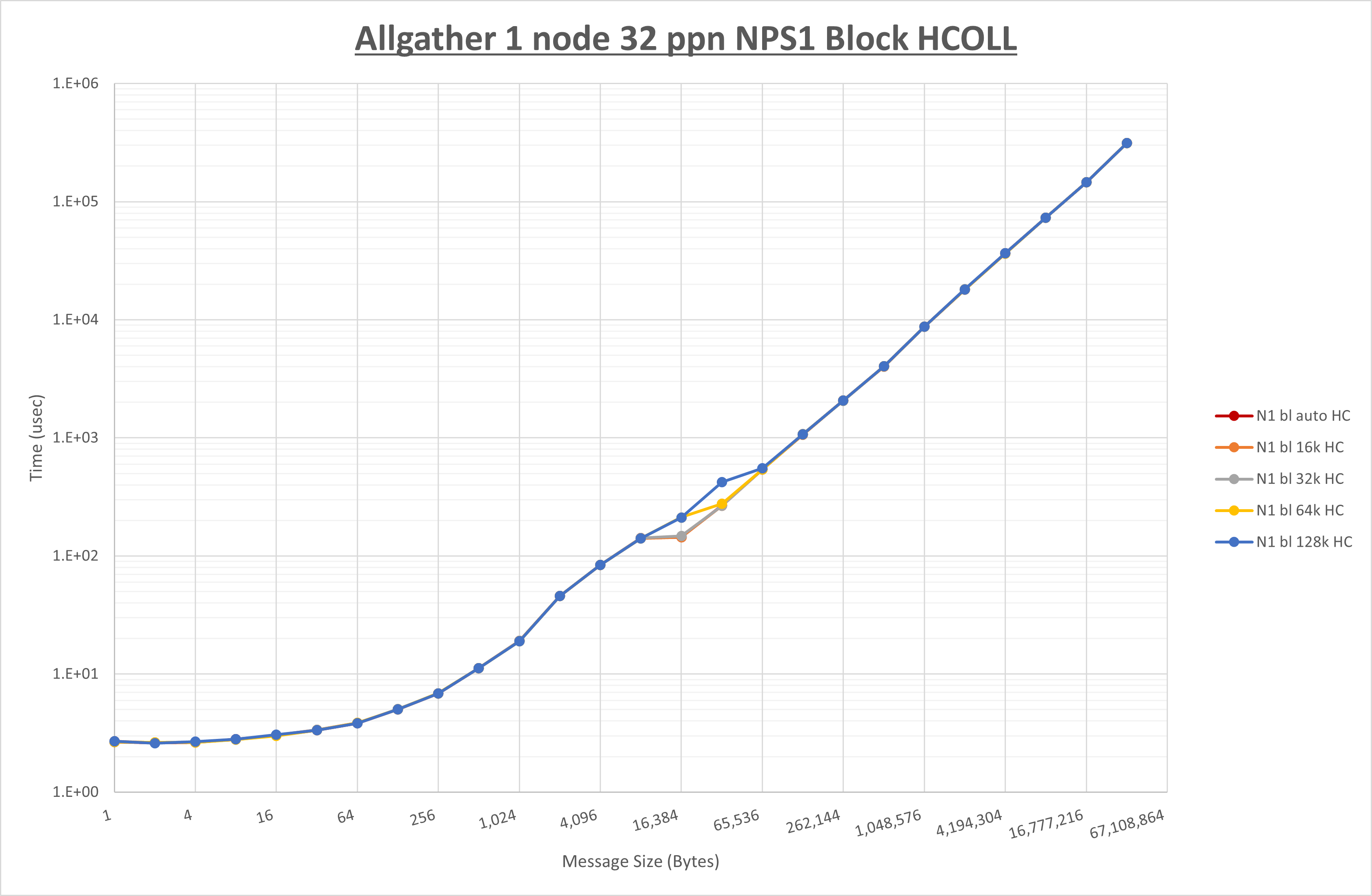
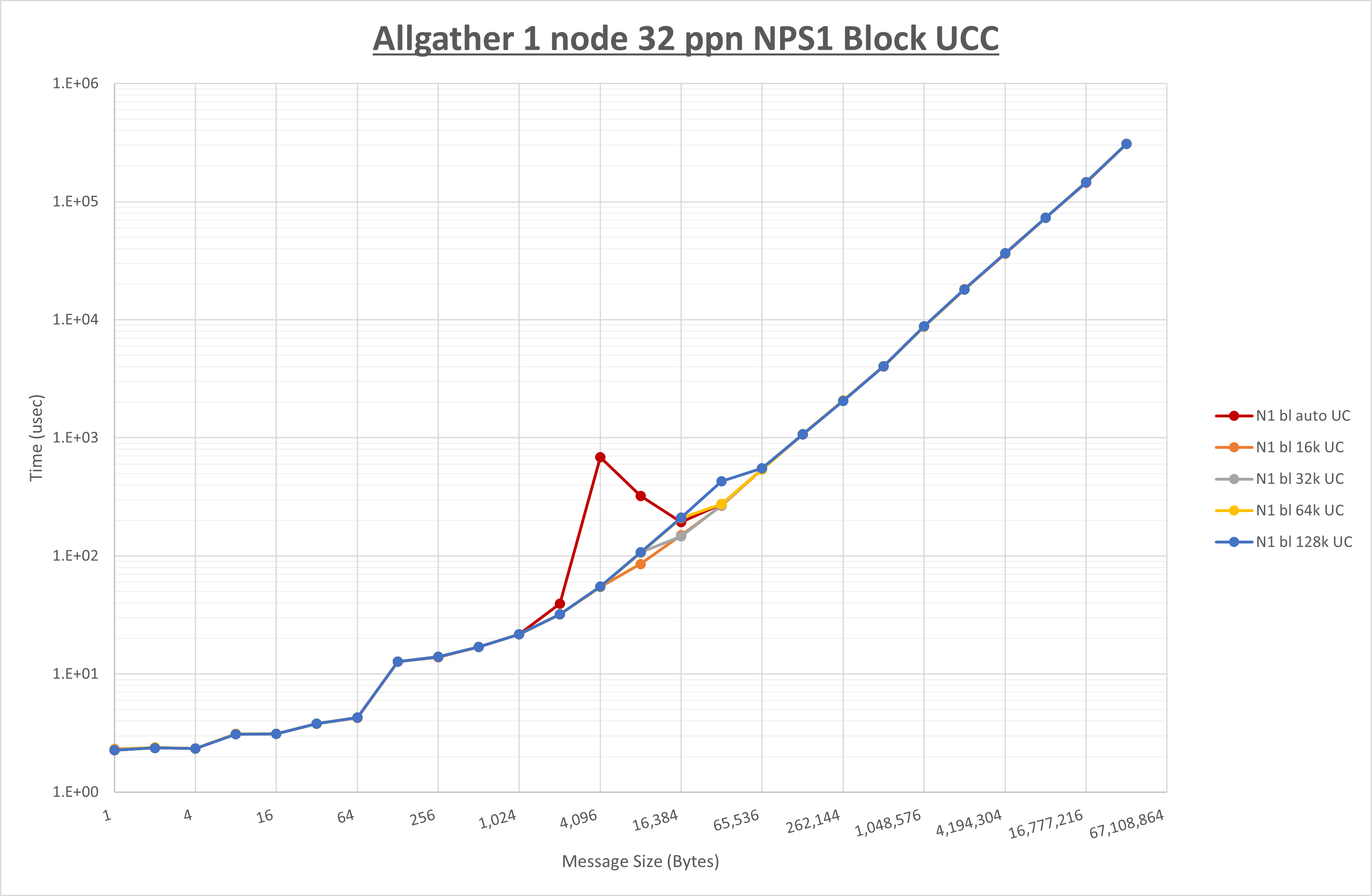
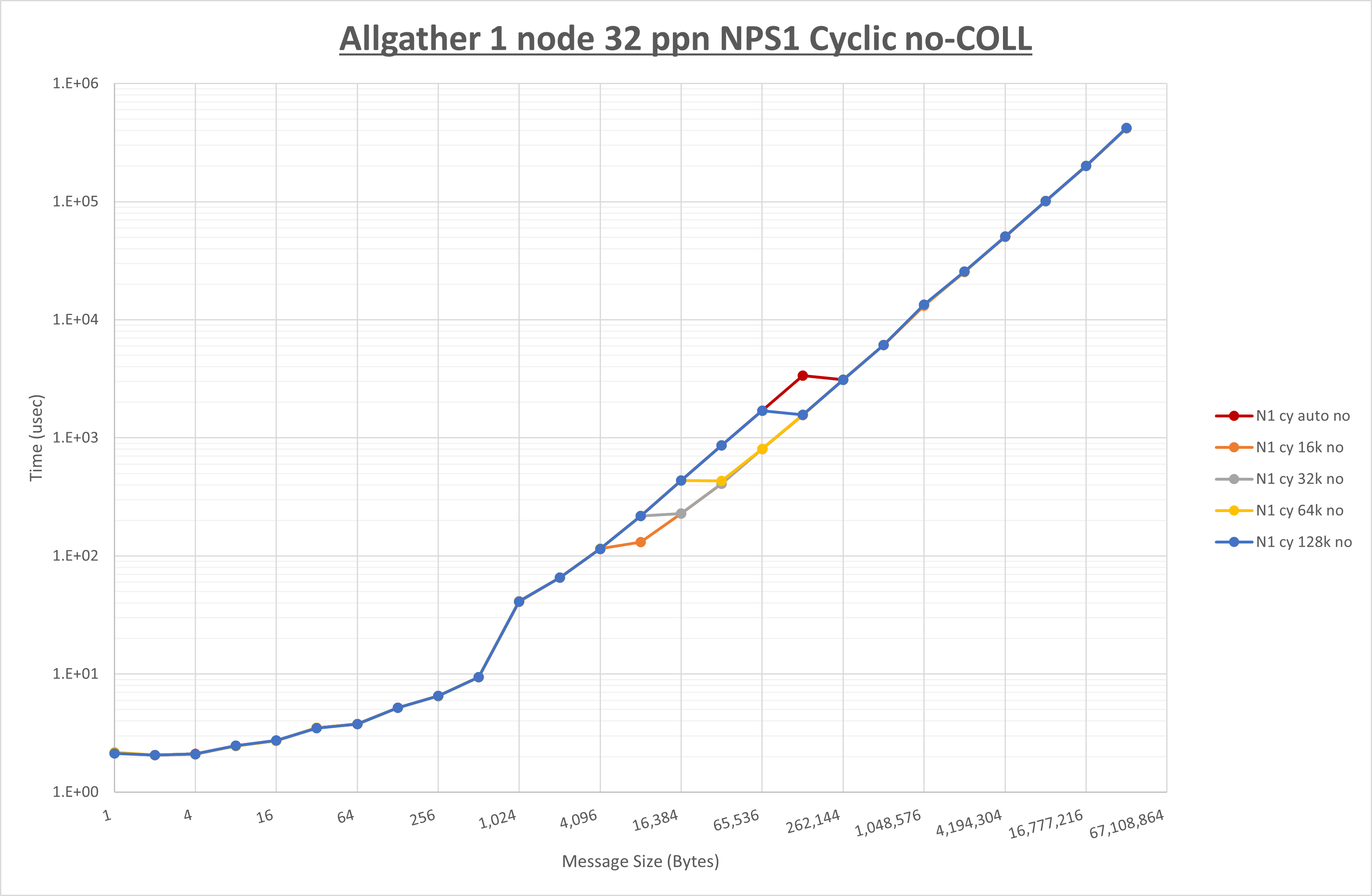
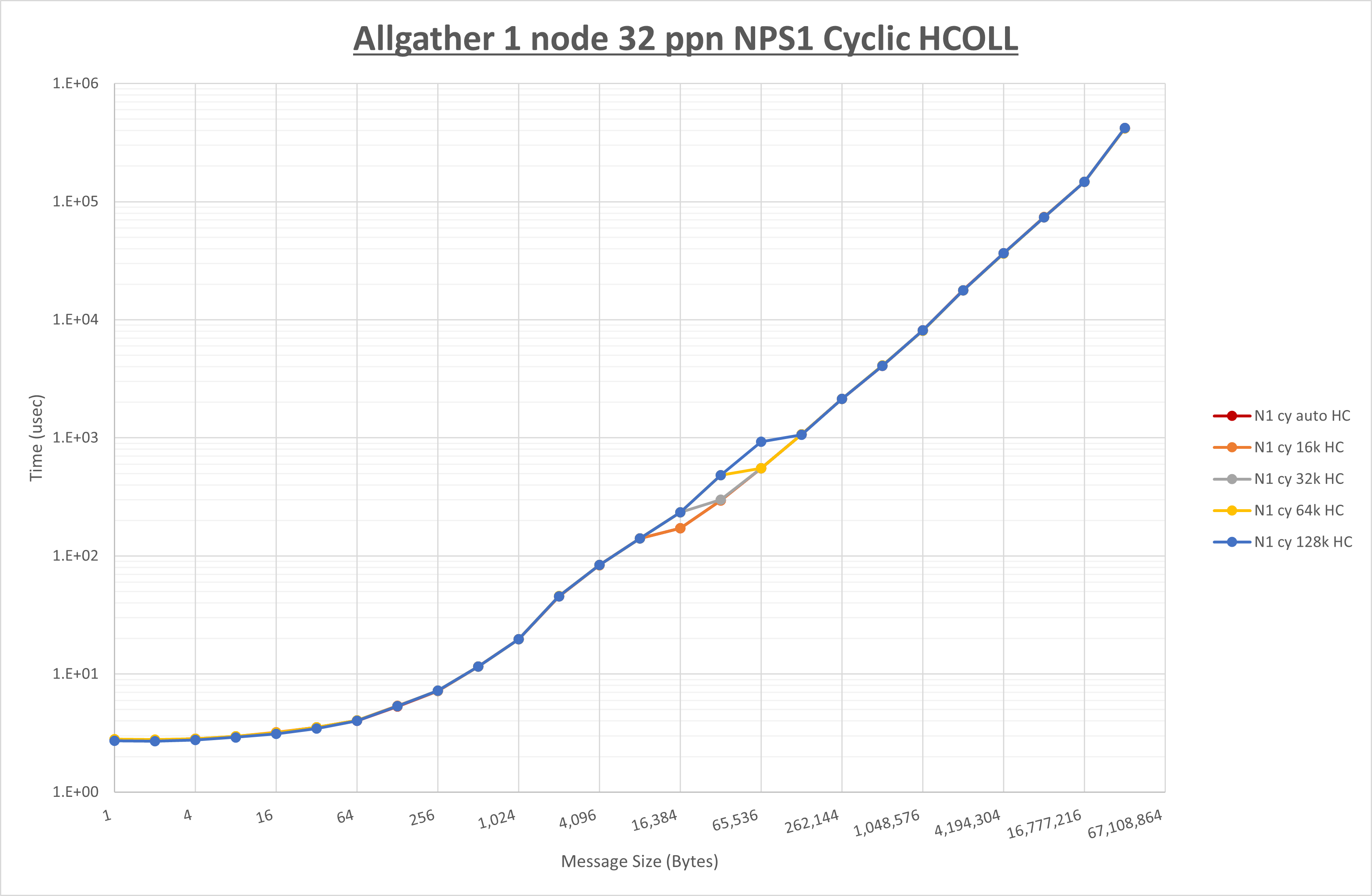
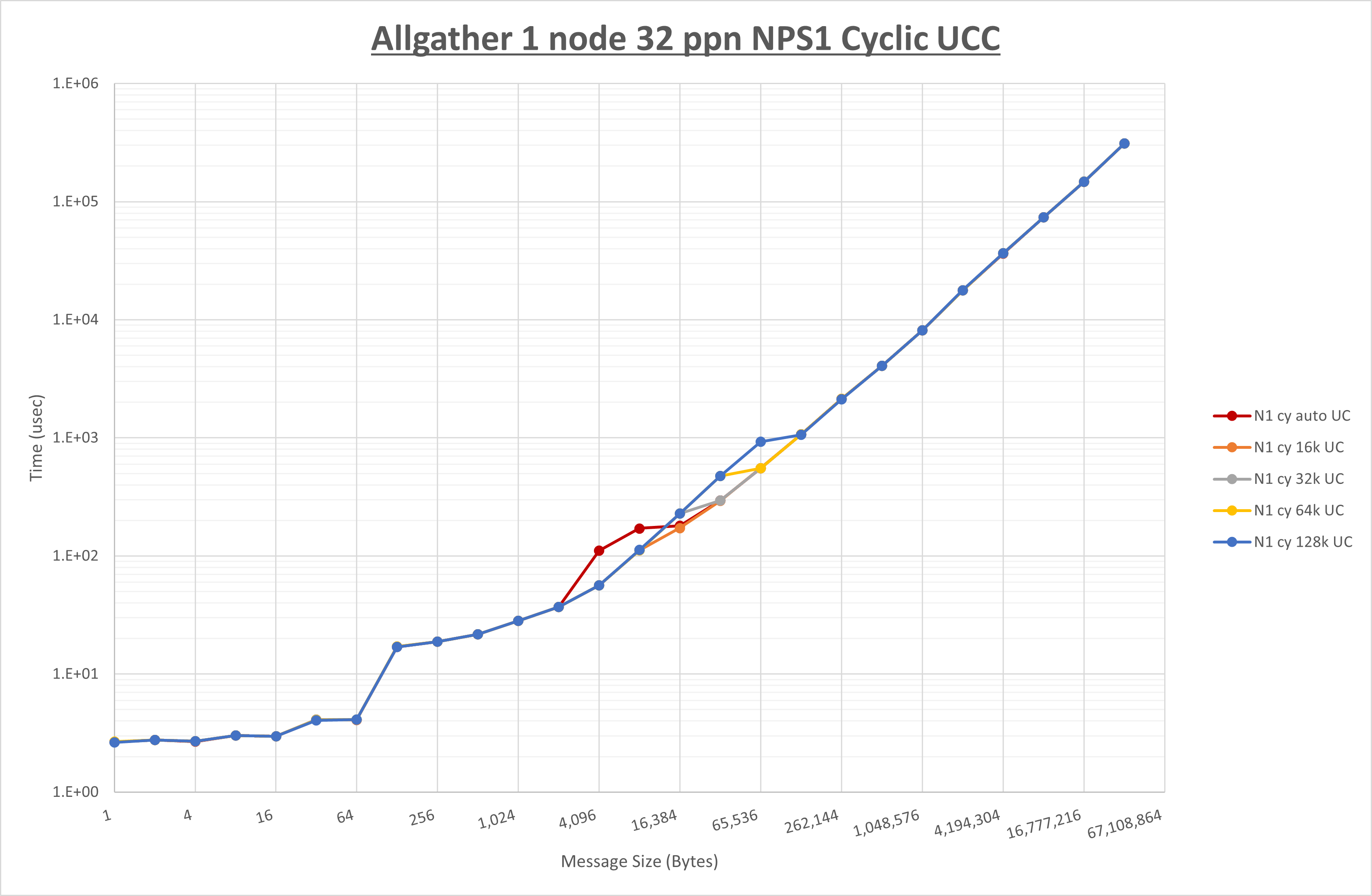
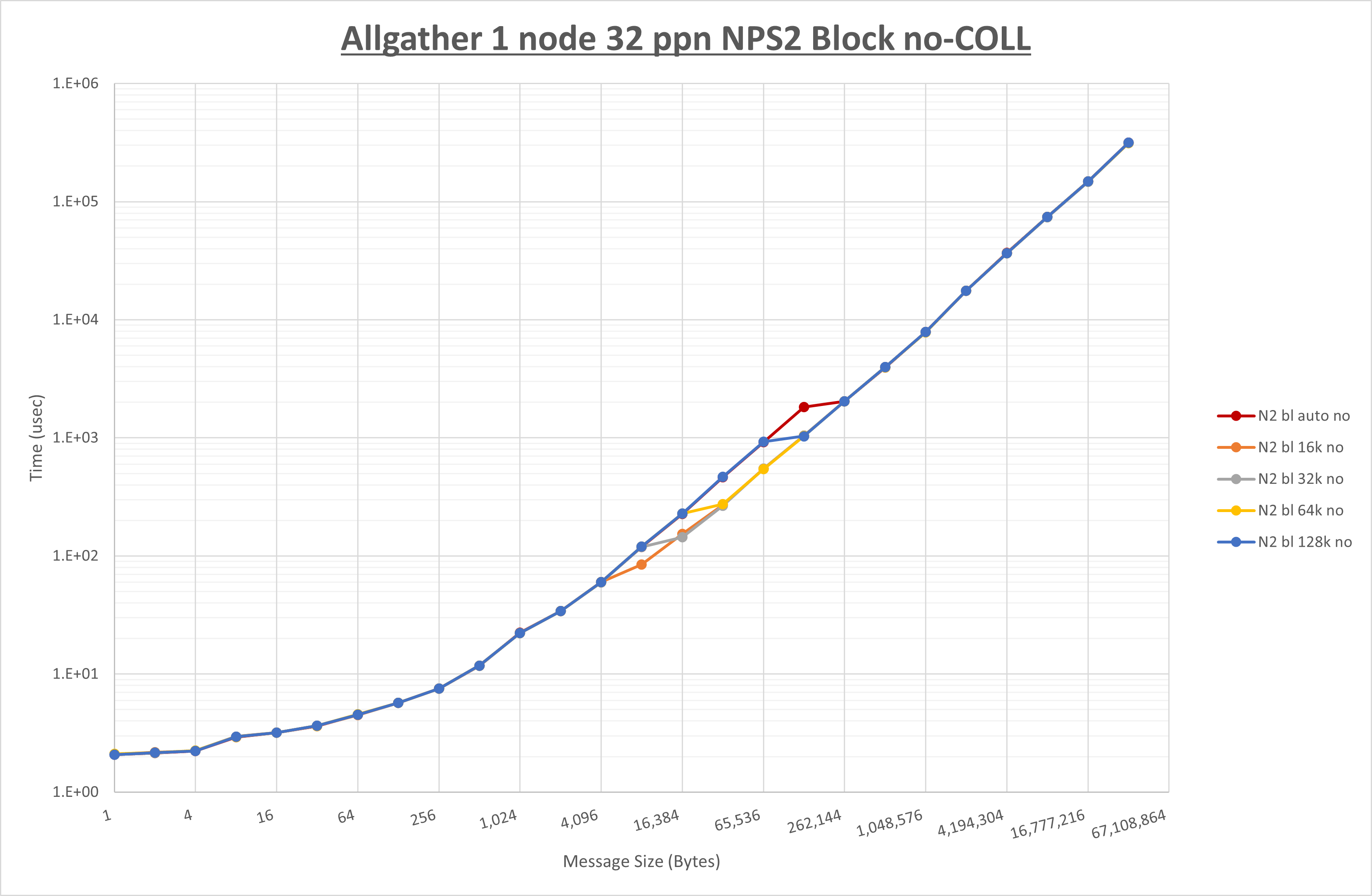
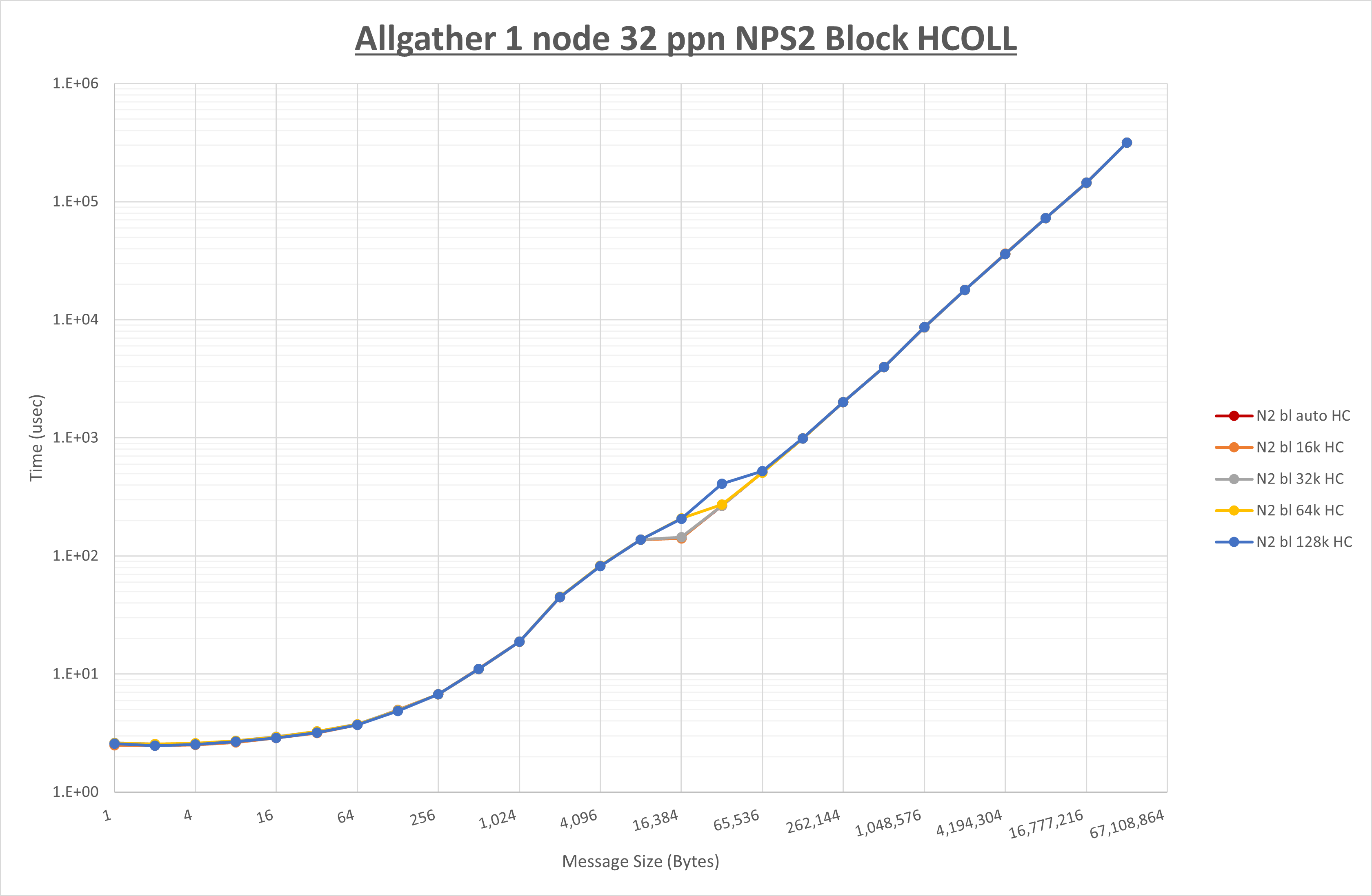
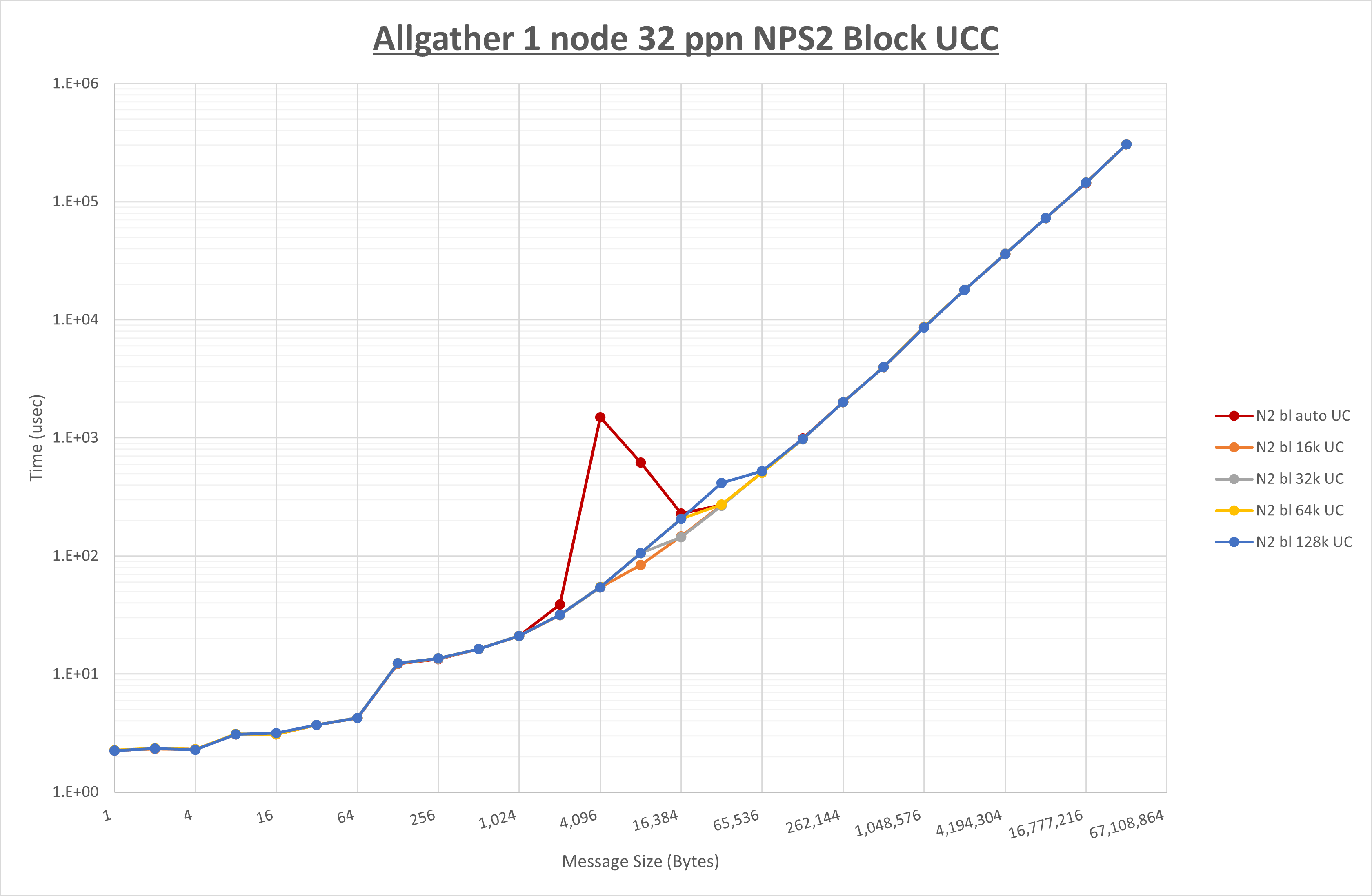
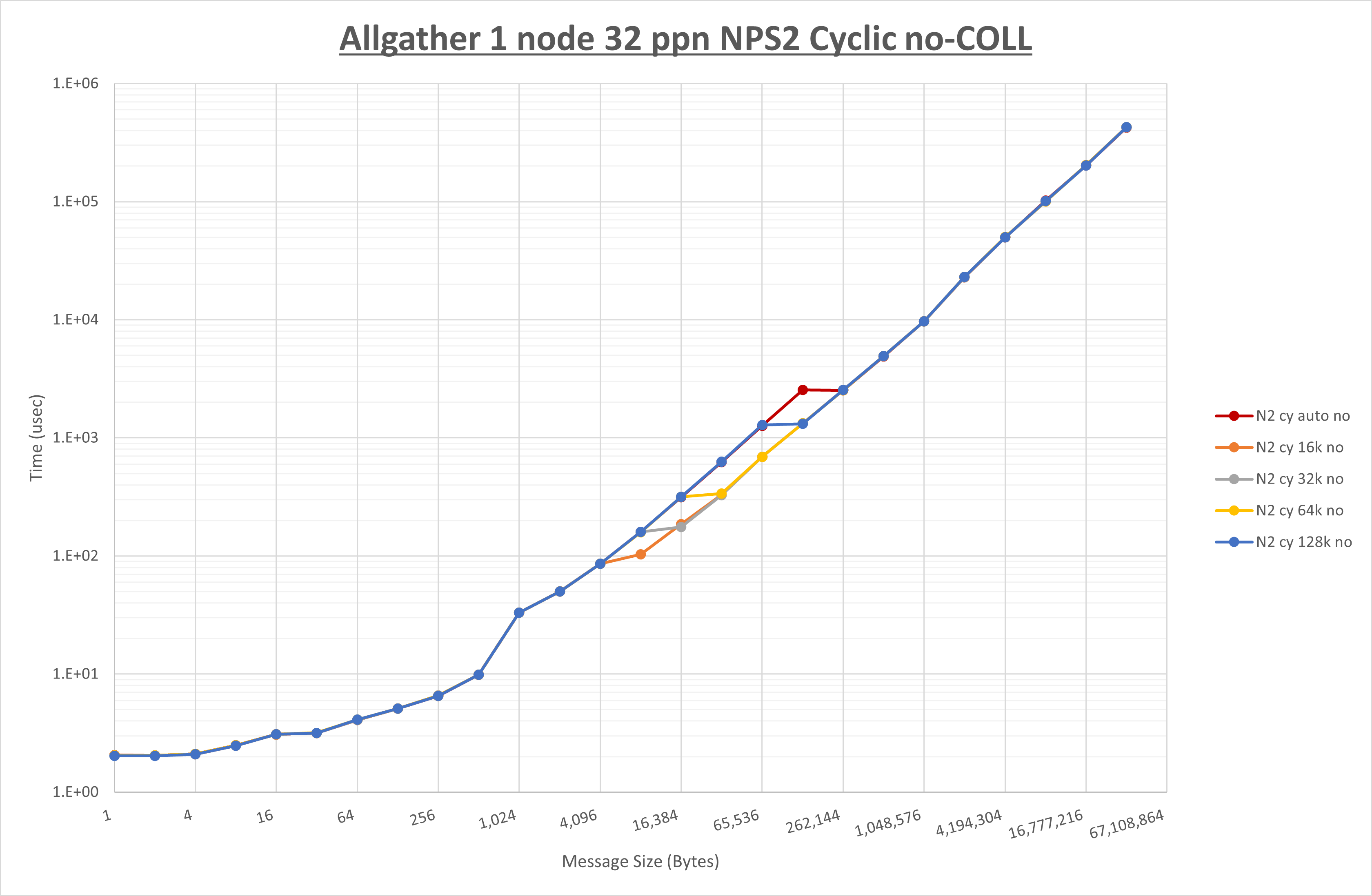
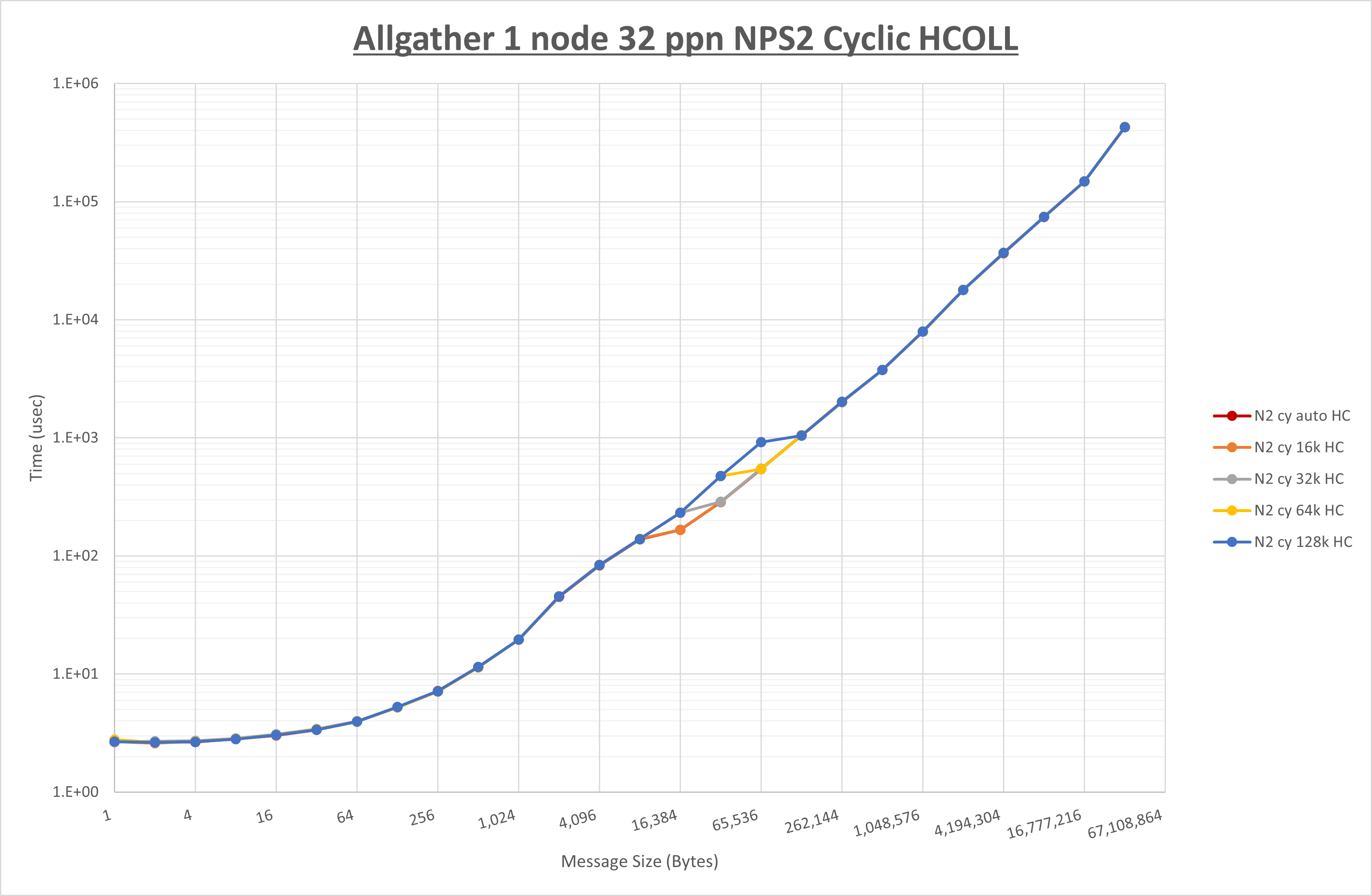
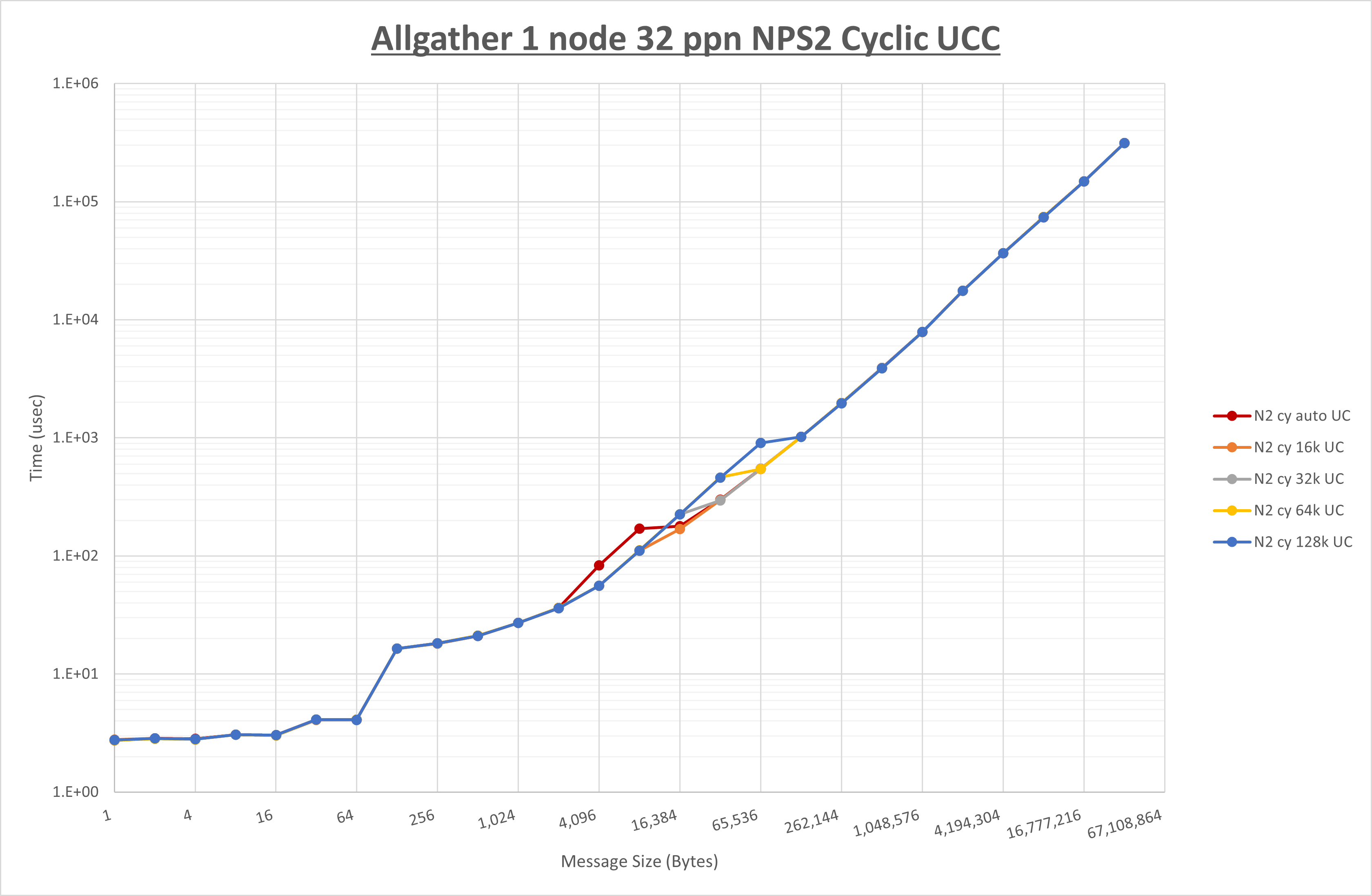
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
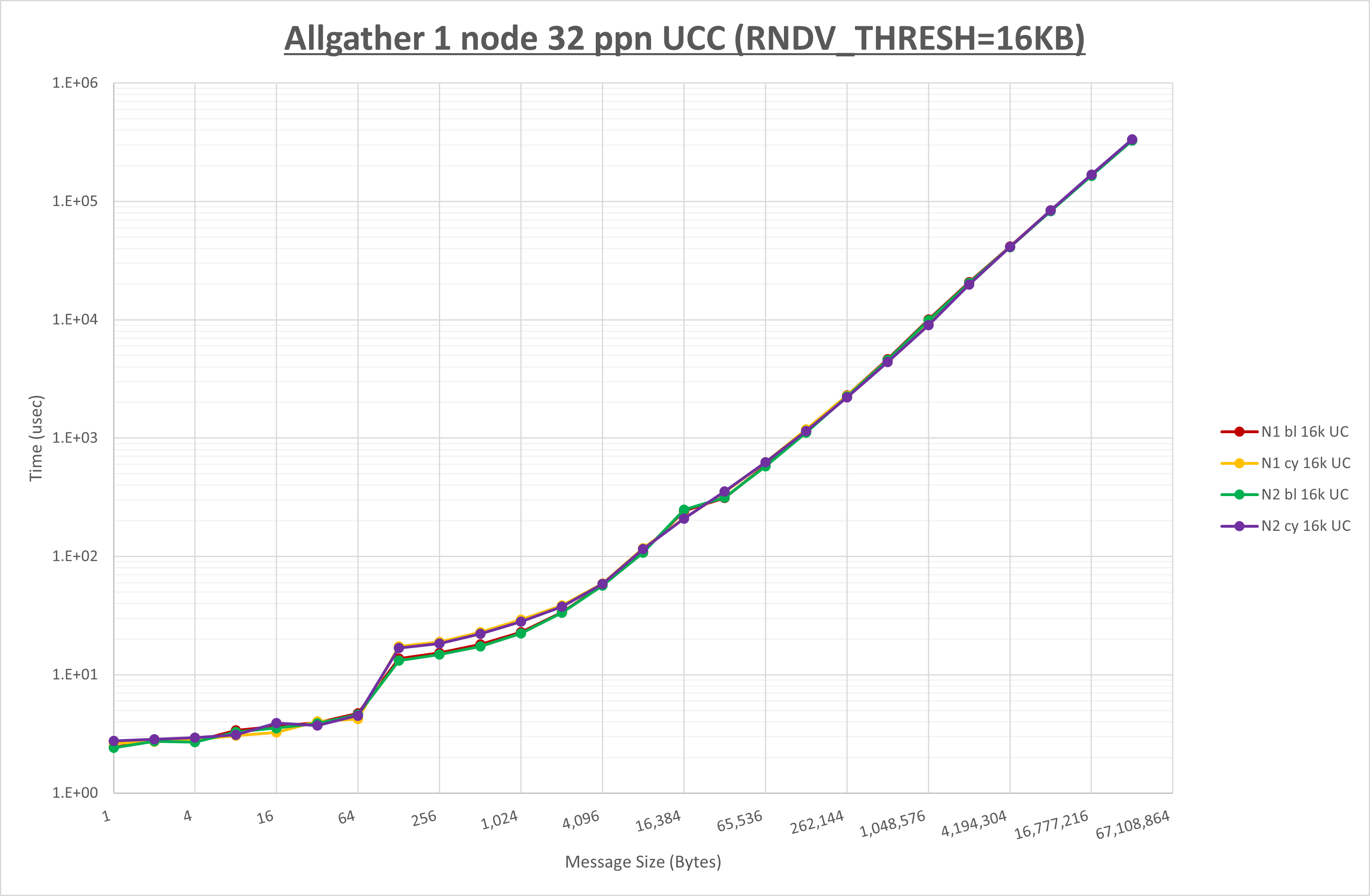
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
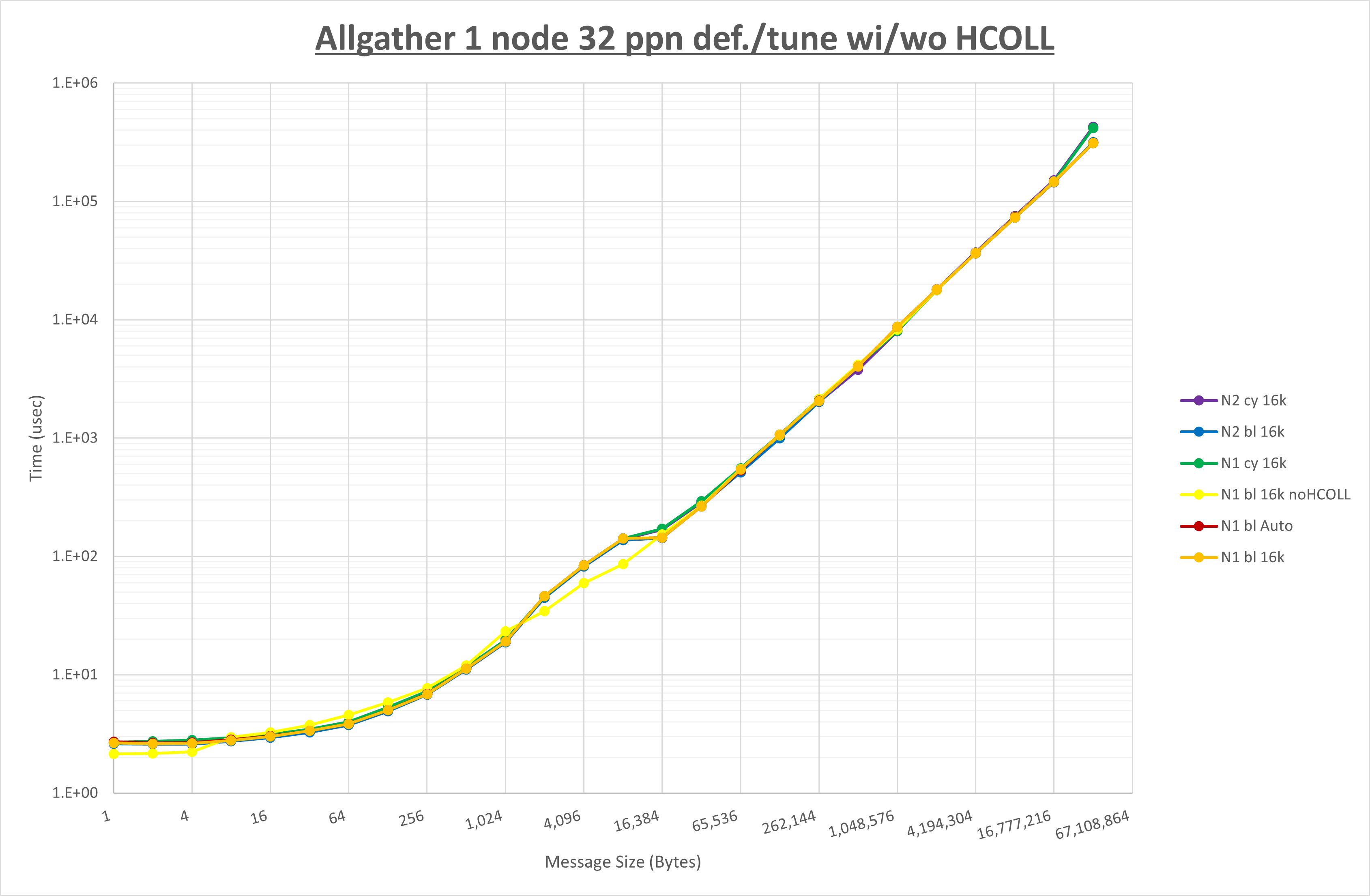
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し8KB以下で性能が低下
- UCC は no-COLL と比較し16KB以下で性能が低下
- チューニング適用による性能差無し
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
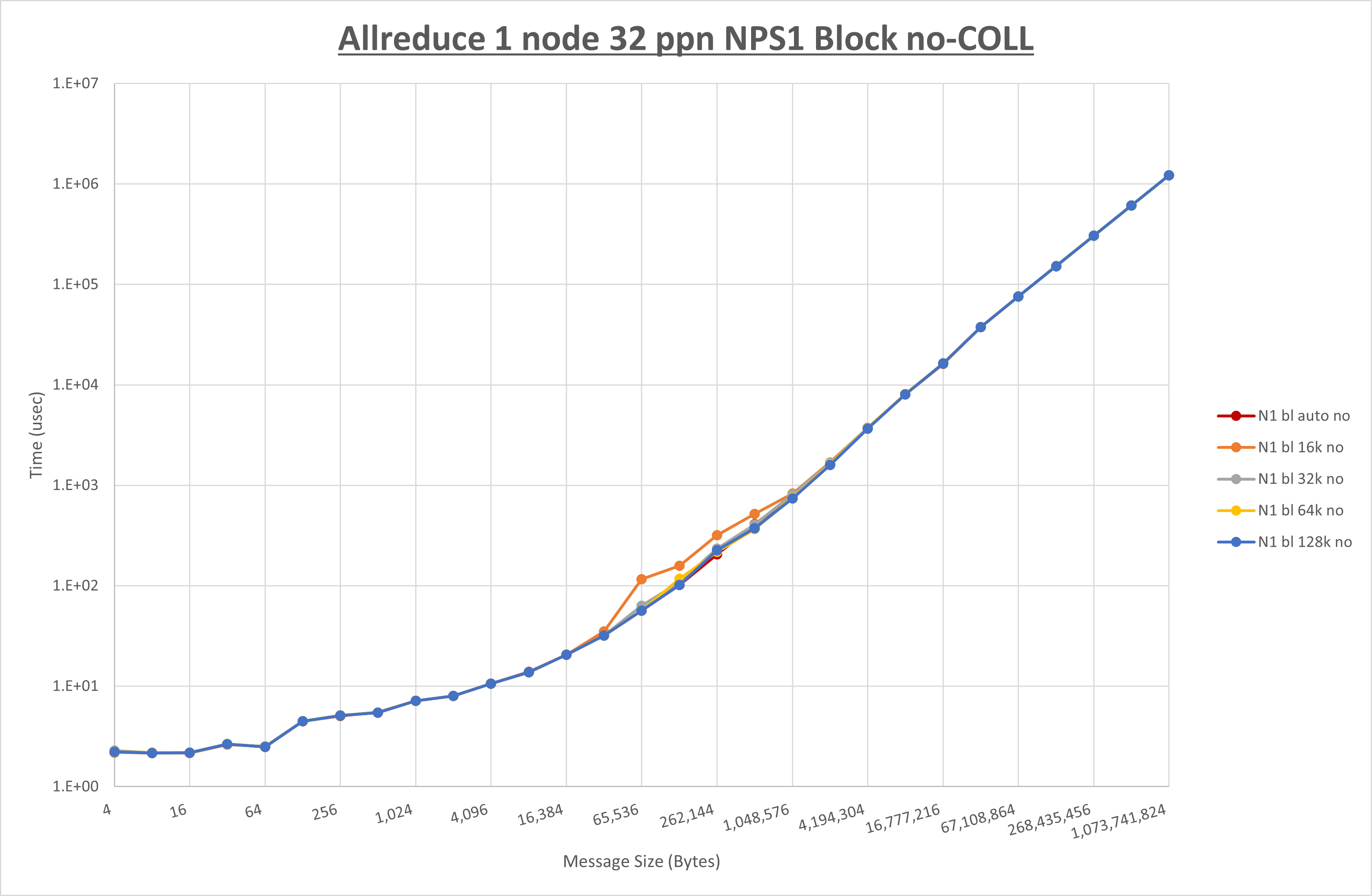
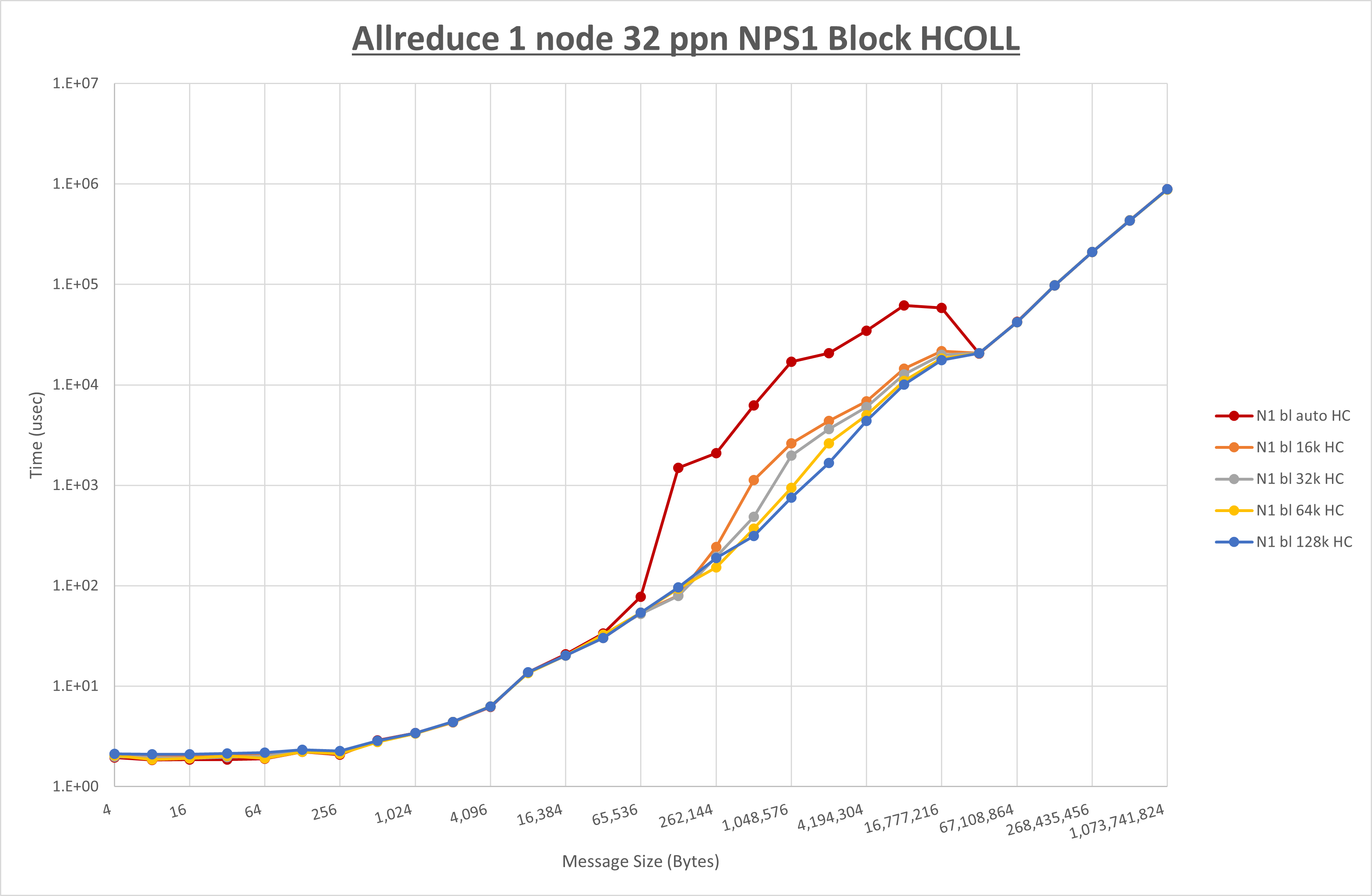
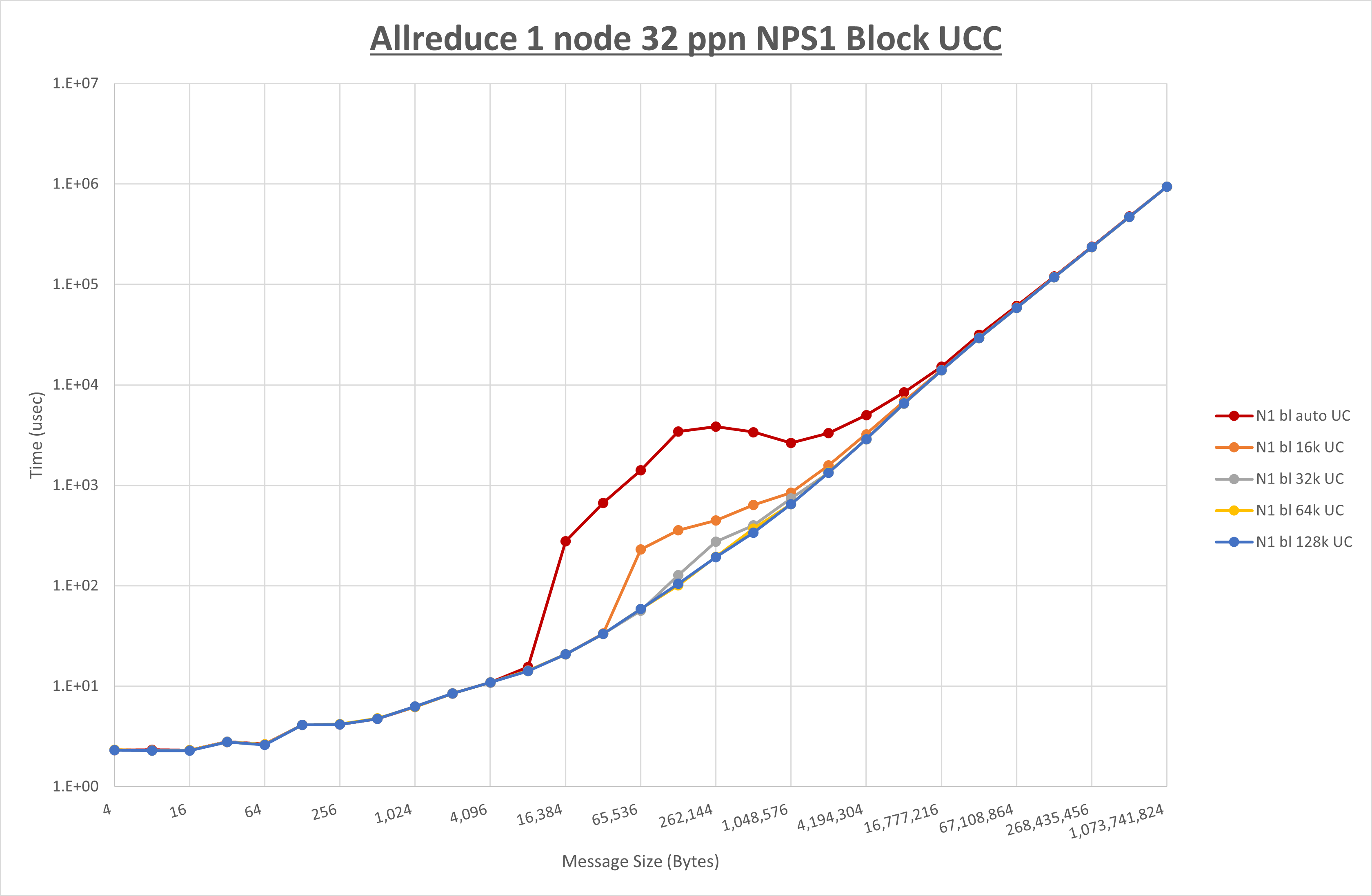
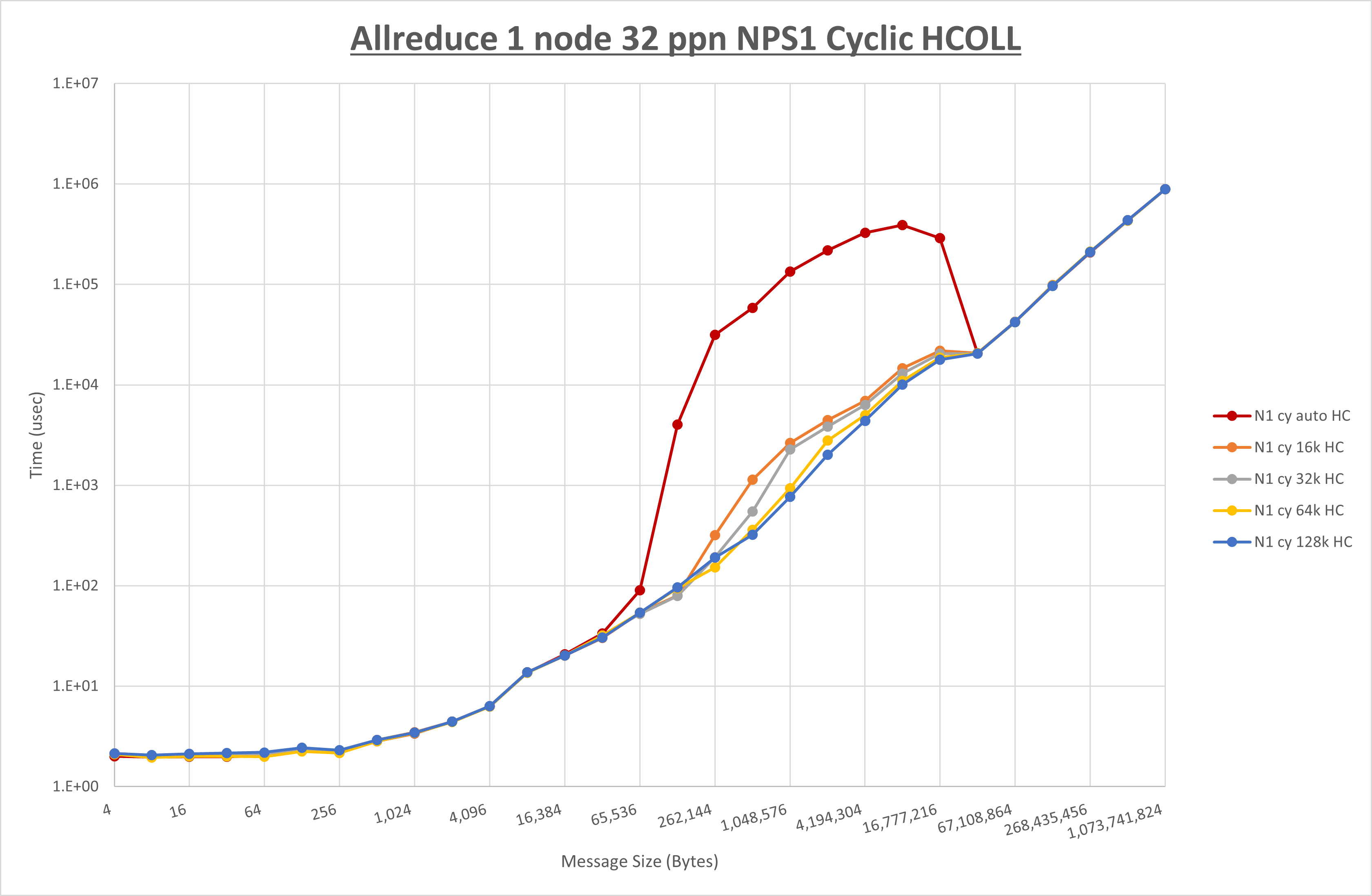
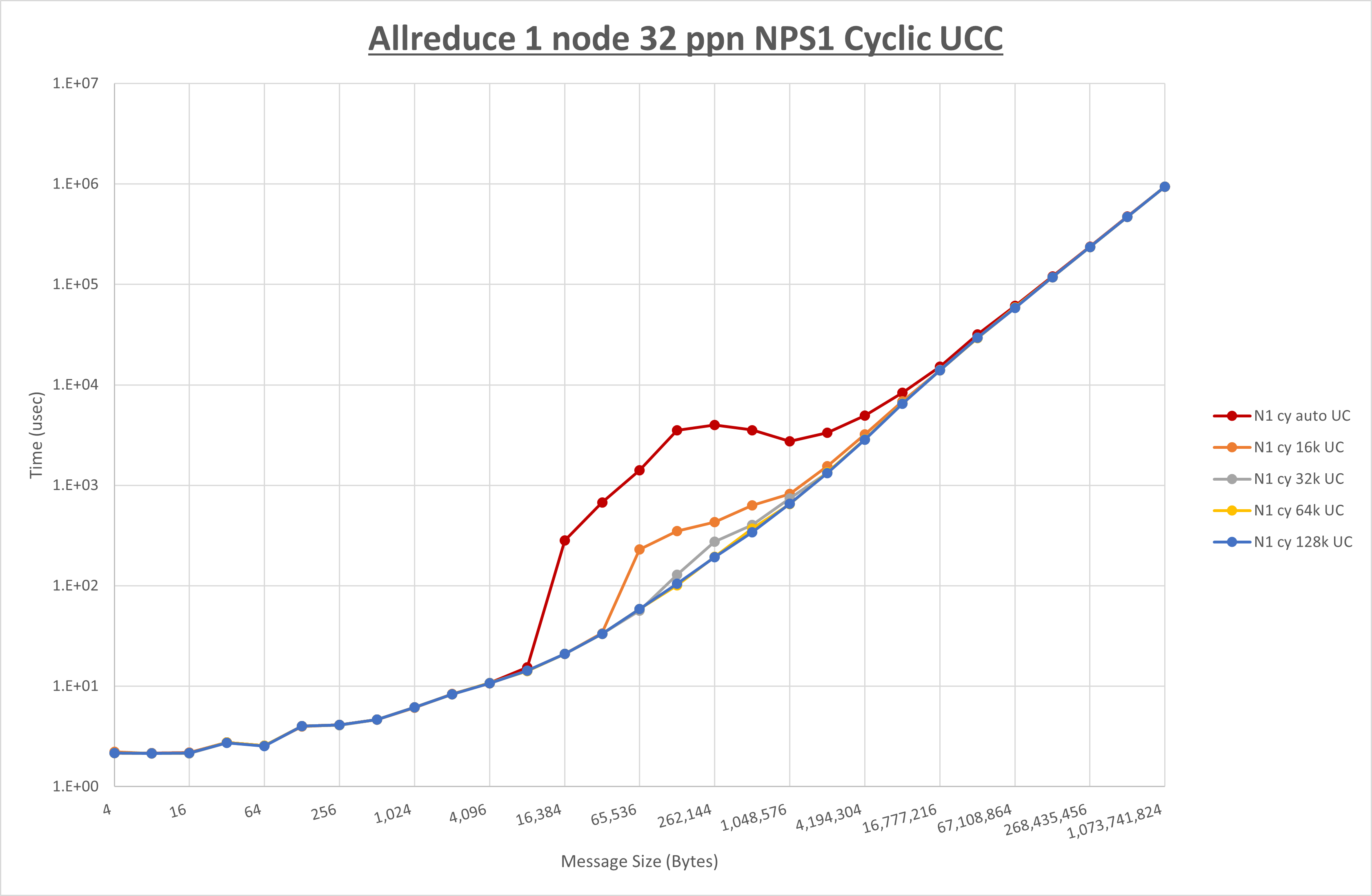
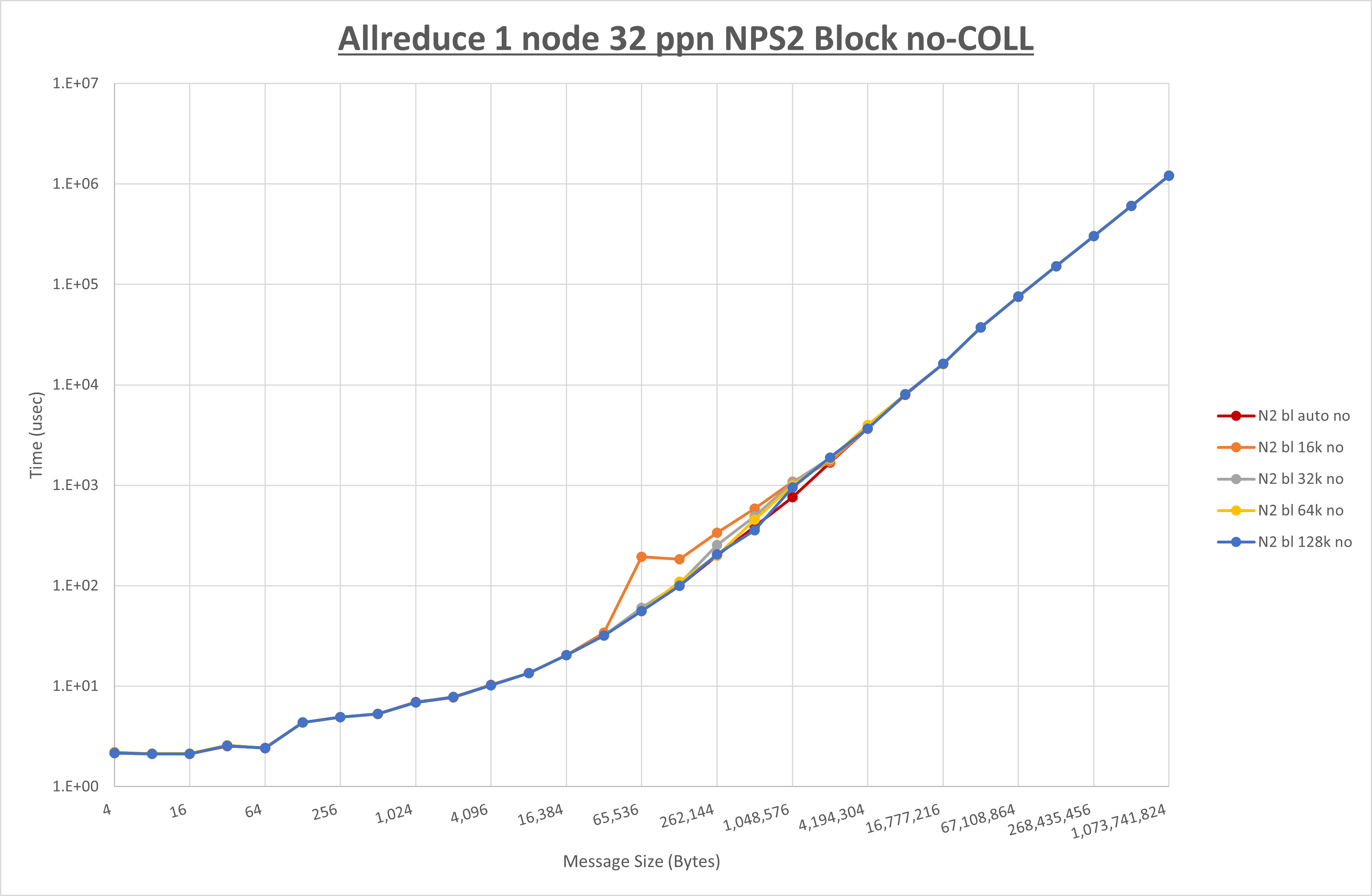
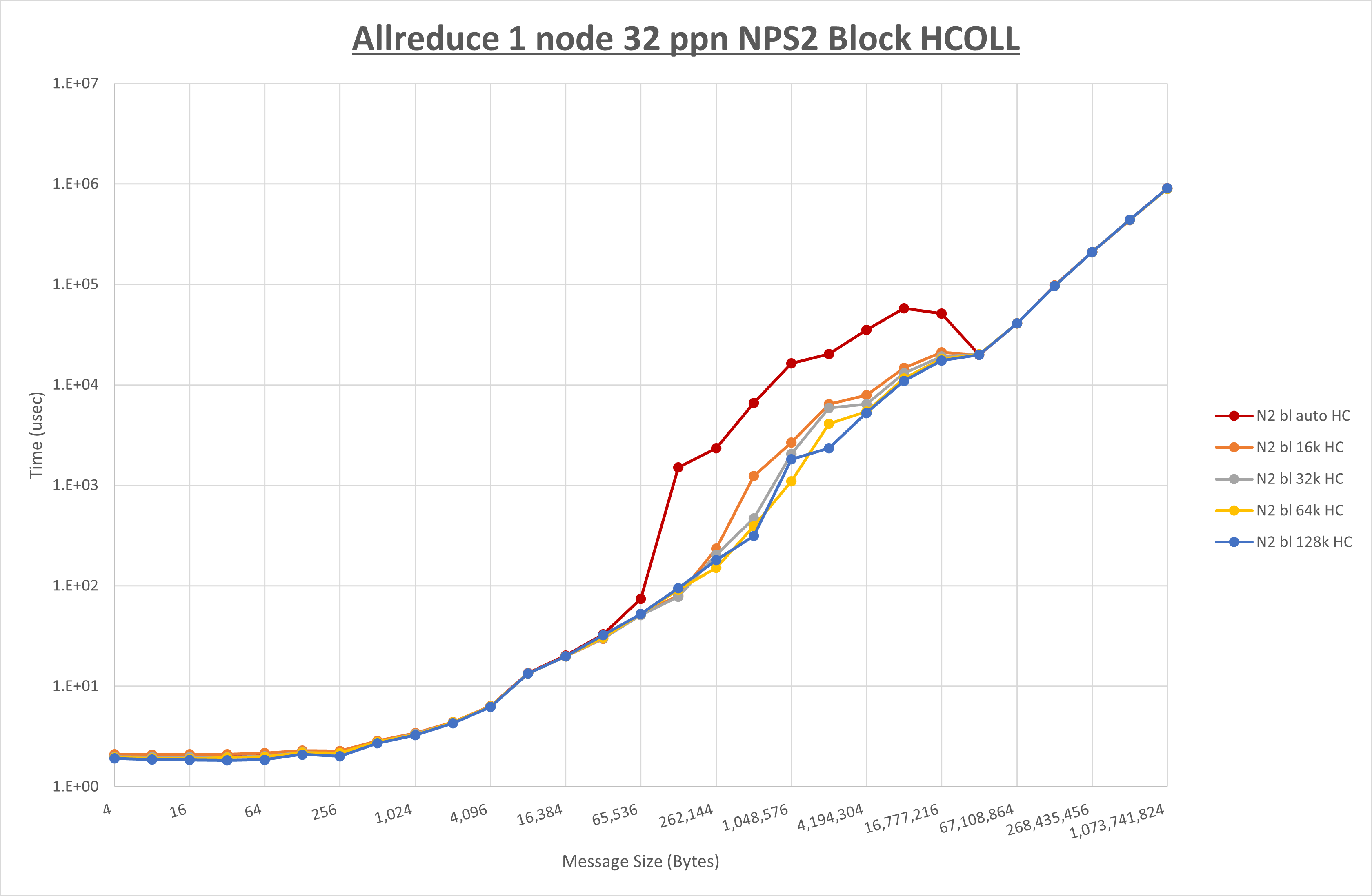
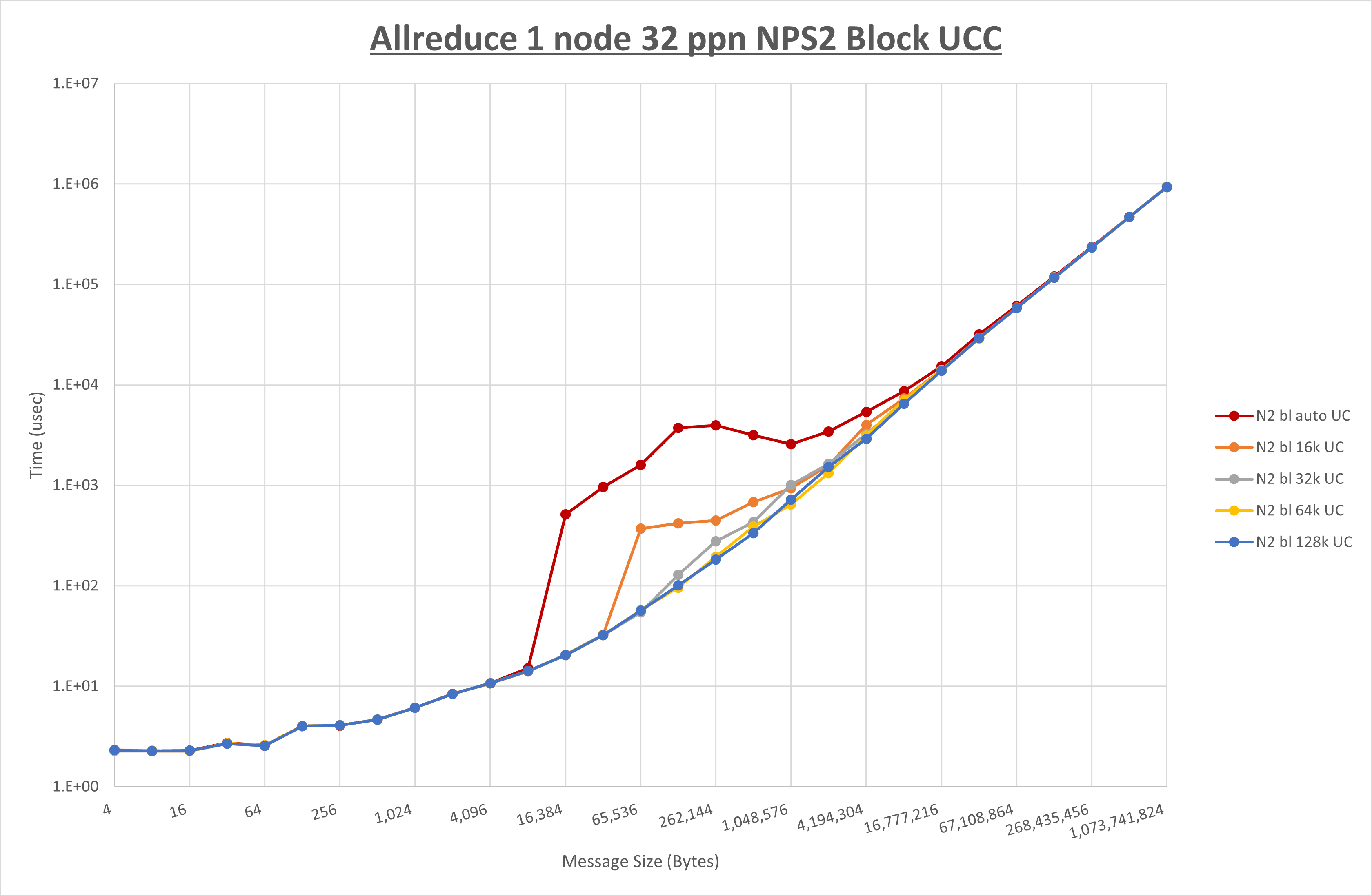
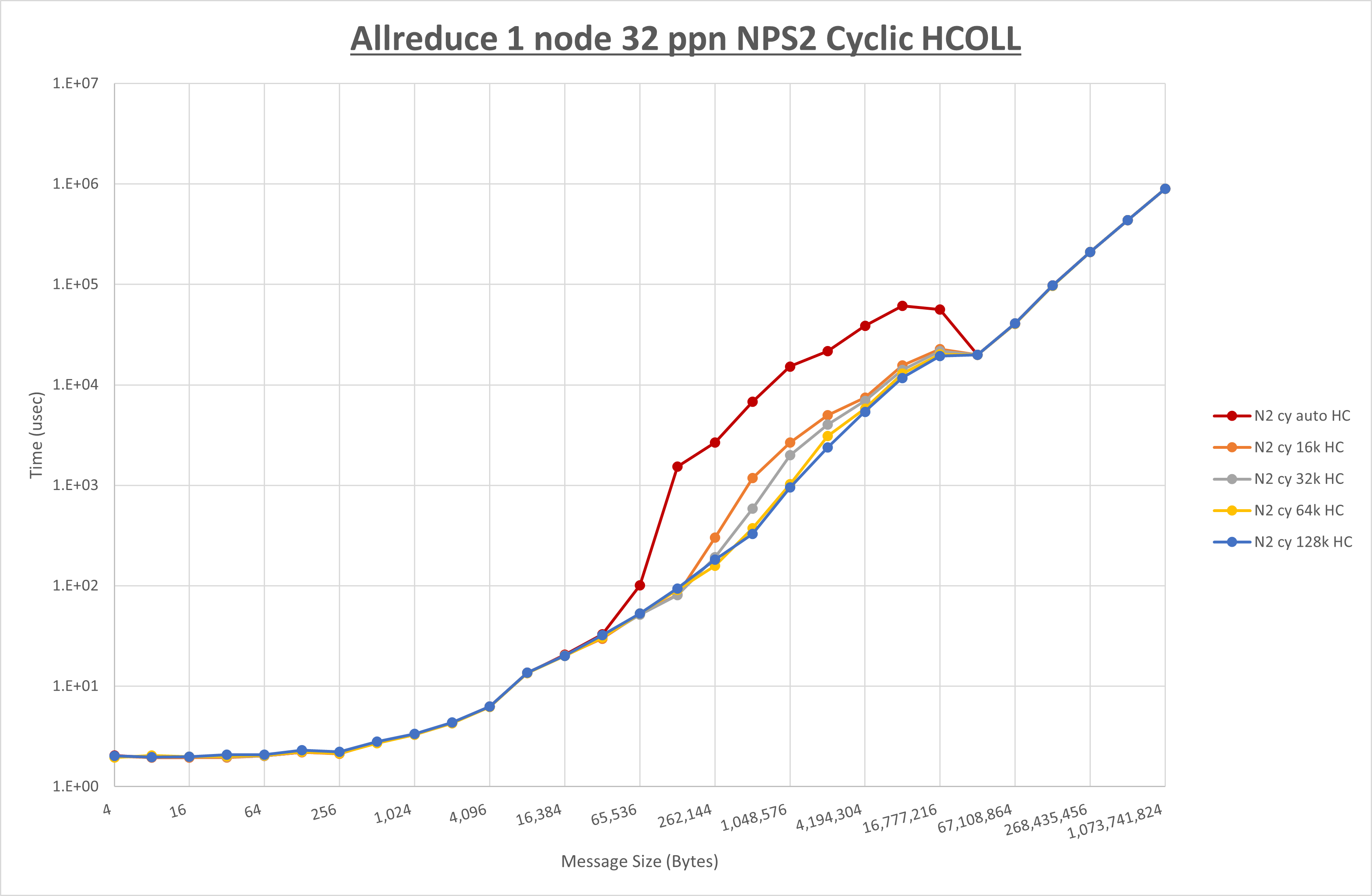
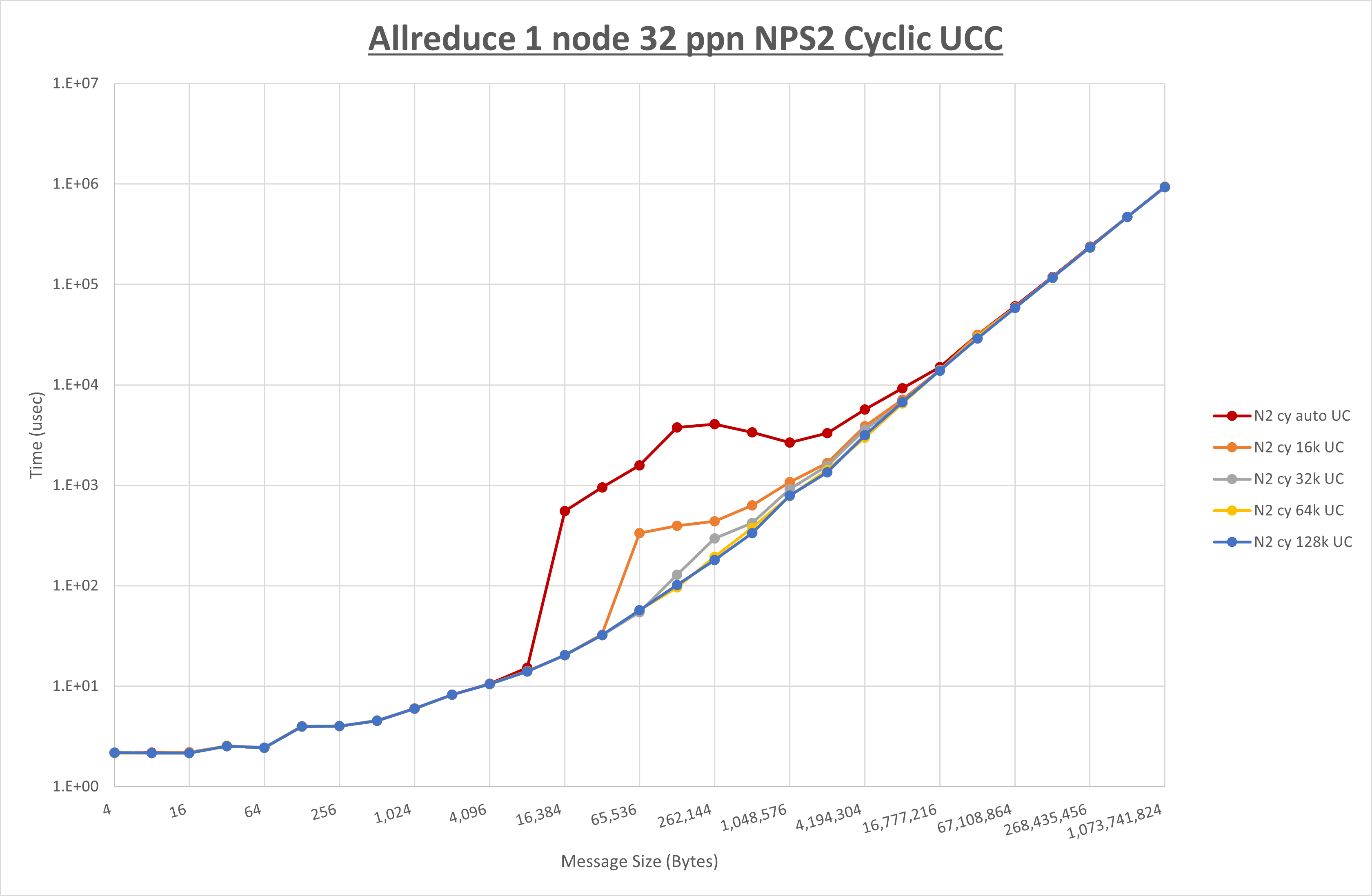
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 128KB | 128KB | 128KB |
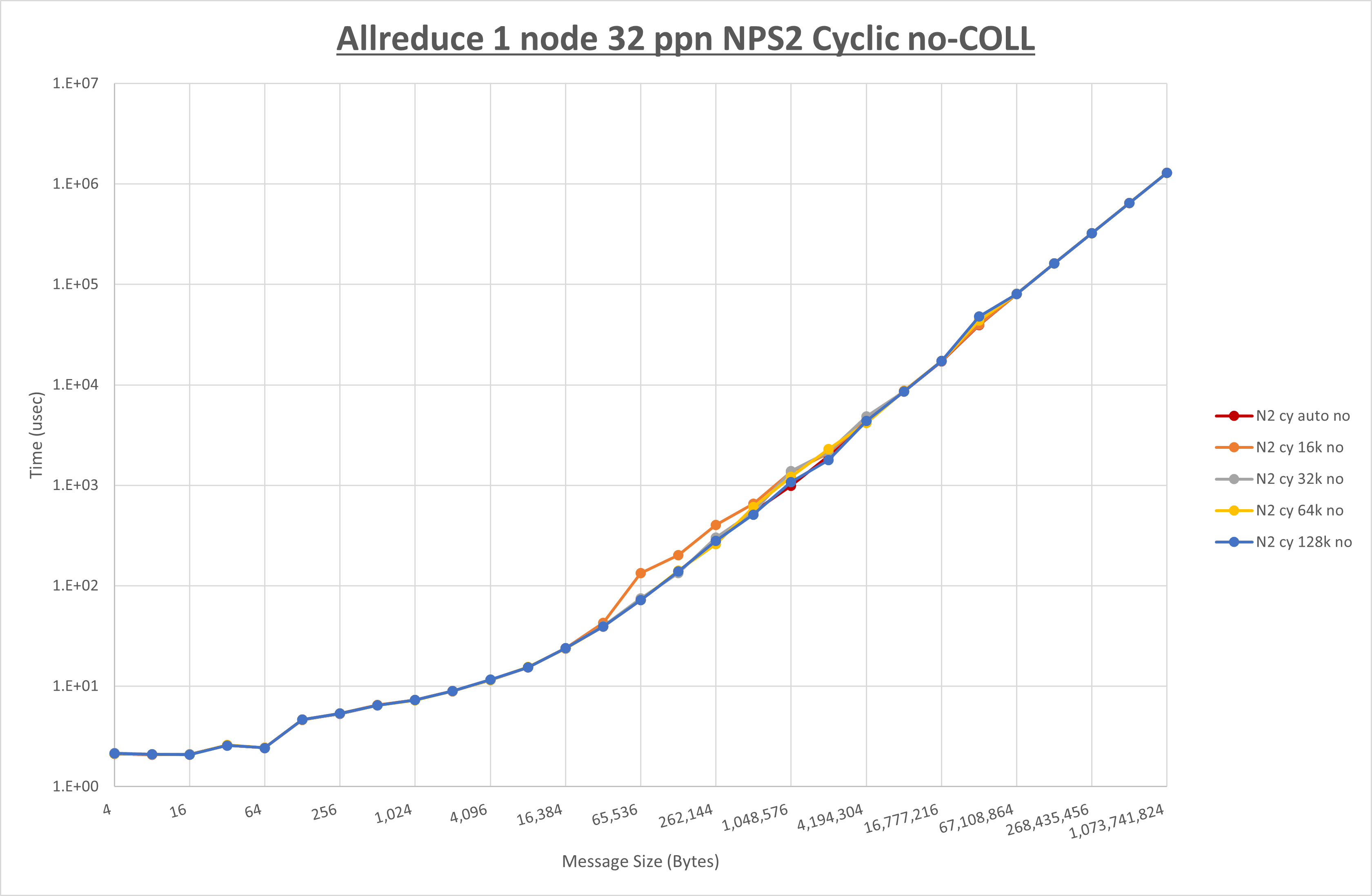
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
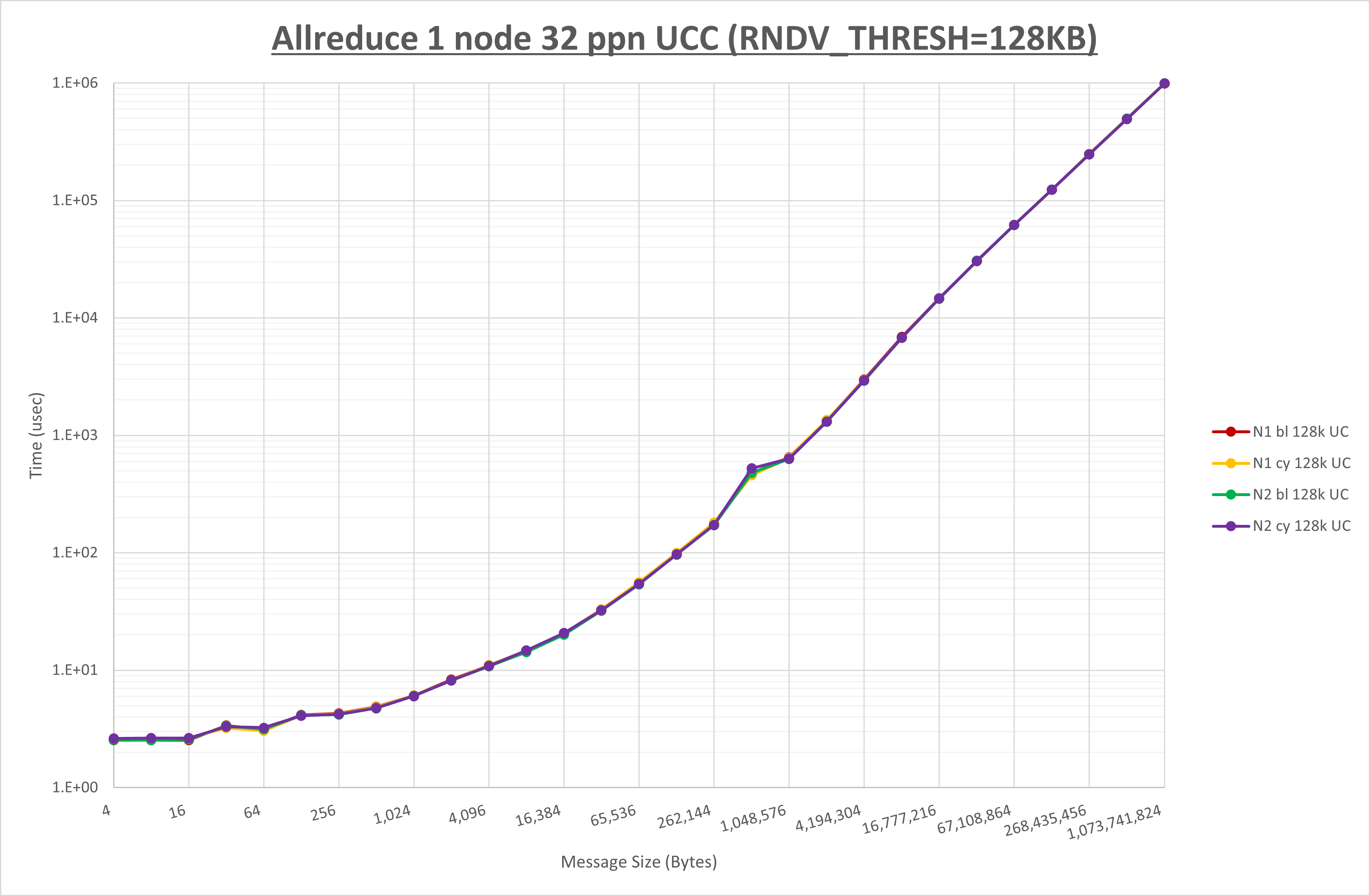
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
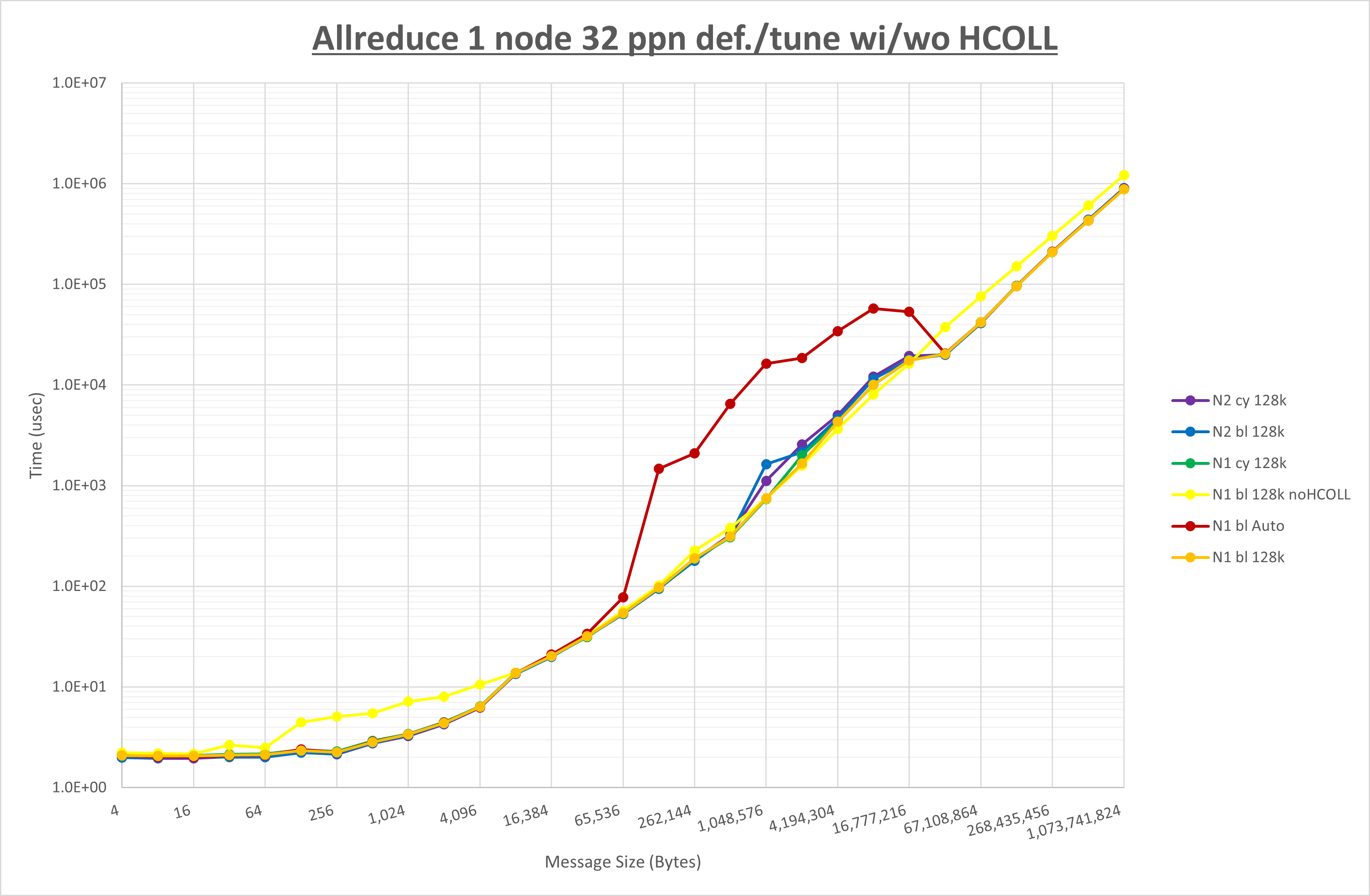
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し4KB以下と32MB以上で性能が向上し1MBから16MBで性能が低下
- UCC は no-COLL と比較し1MB以上で性能が向上し64B以下で性能が低下
- チューニング適用で128KBから2MBの間で性能が向上
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 NPS とMPIプロセス分割方法の組合せ毎に示しています。
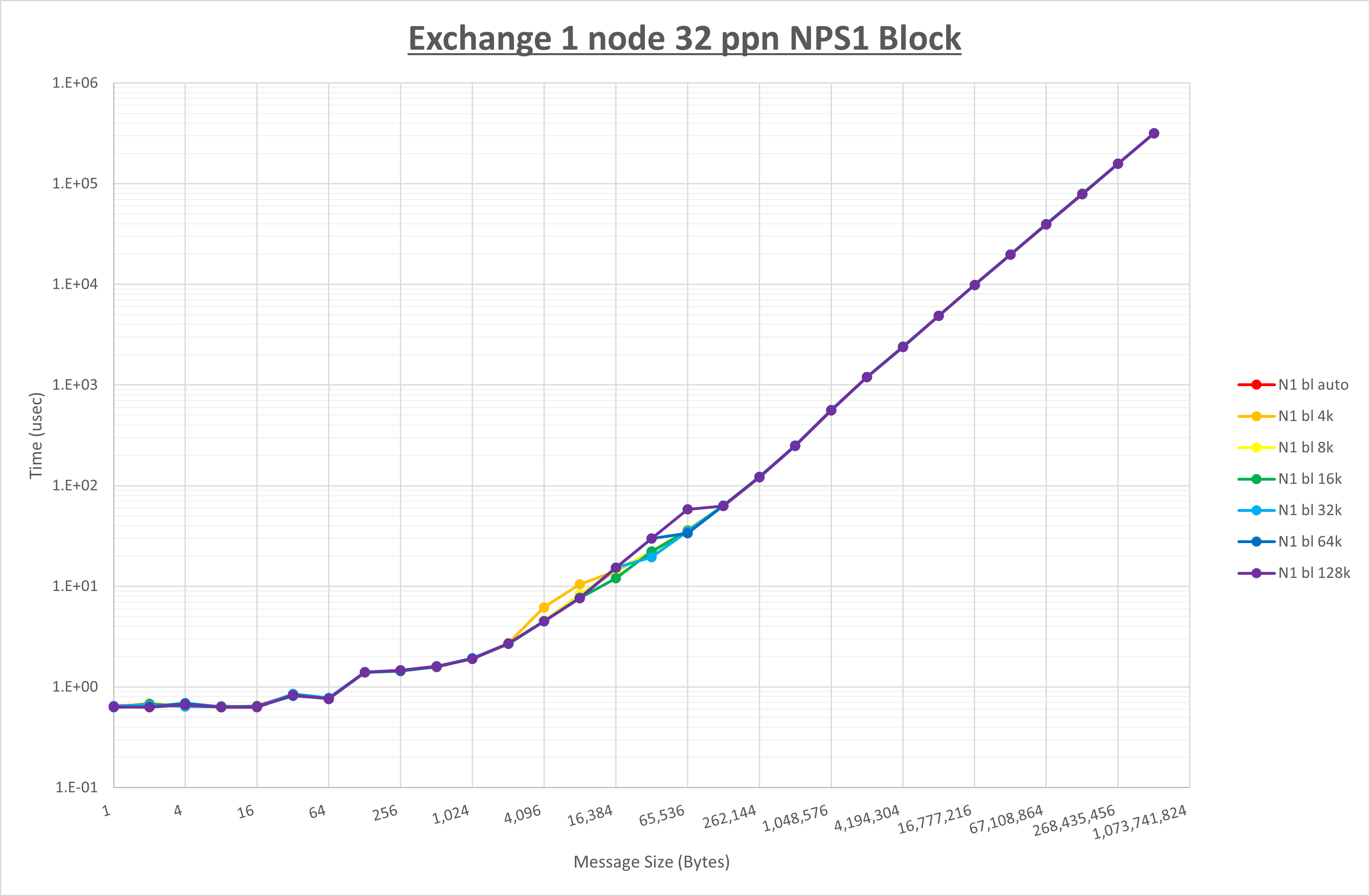
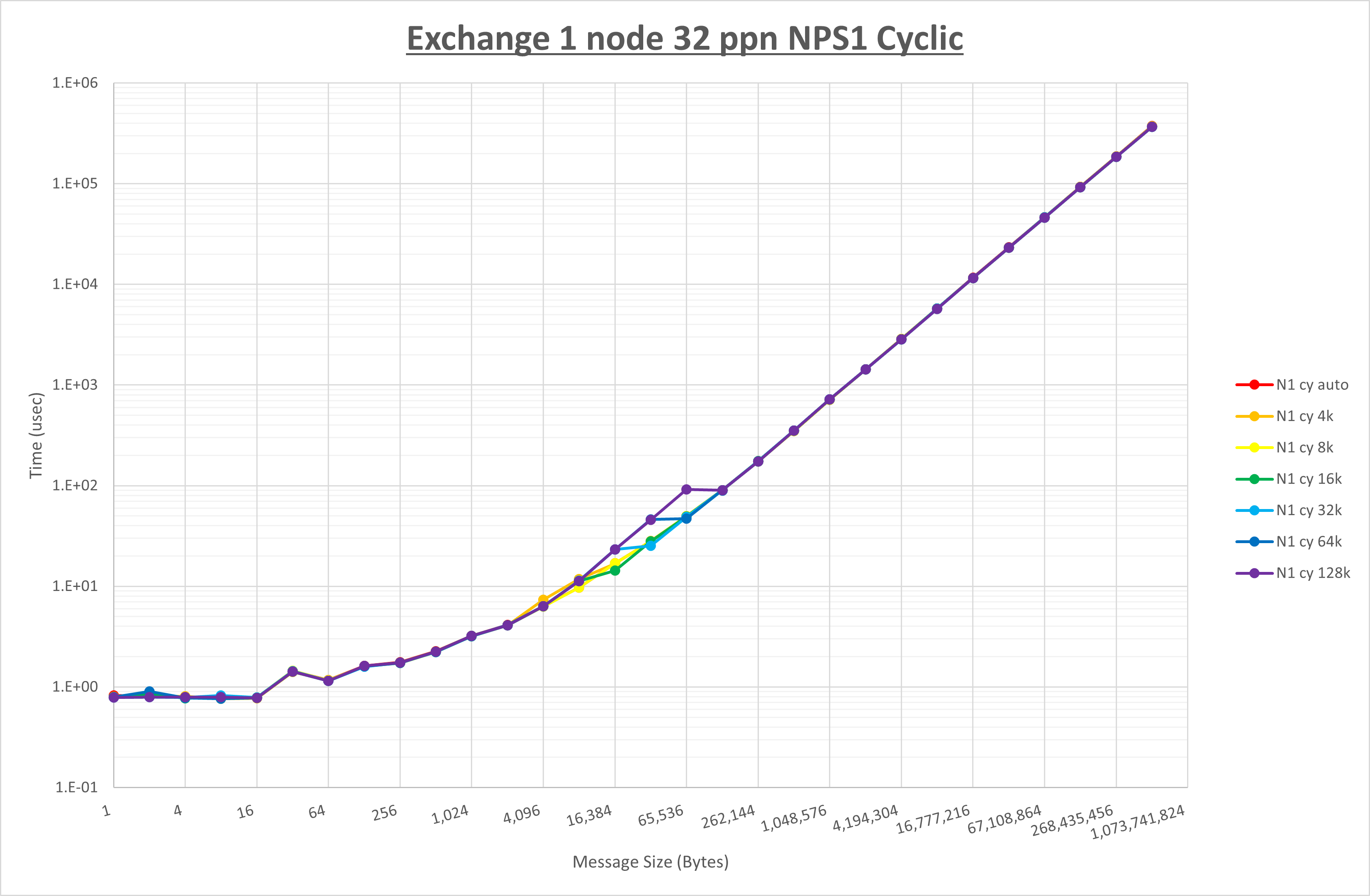
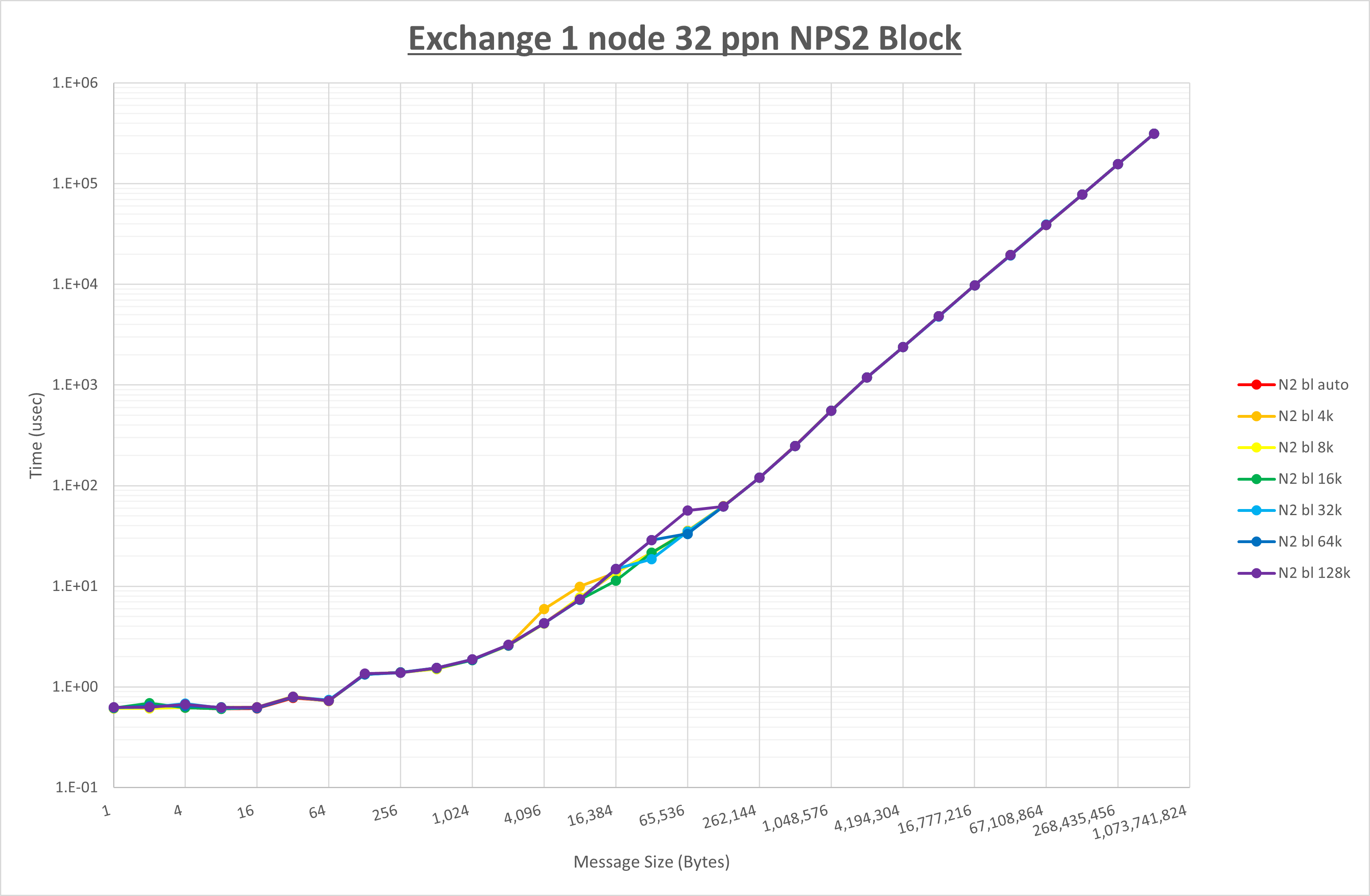
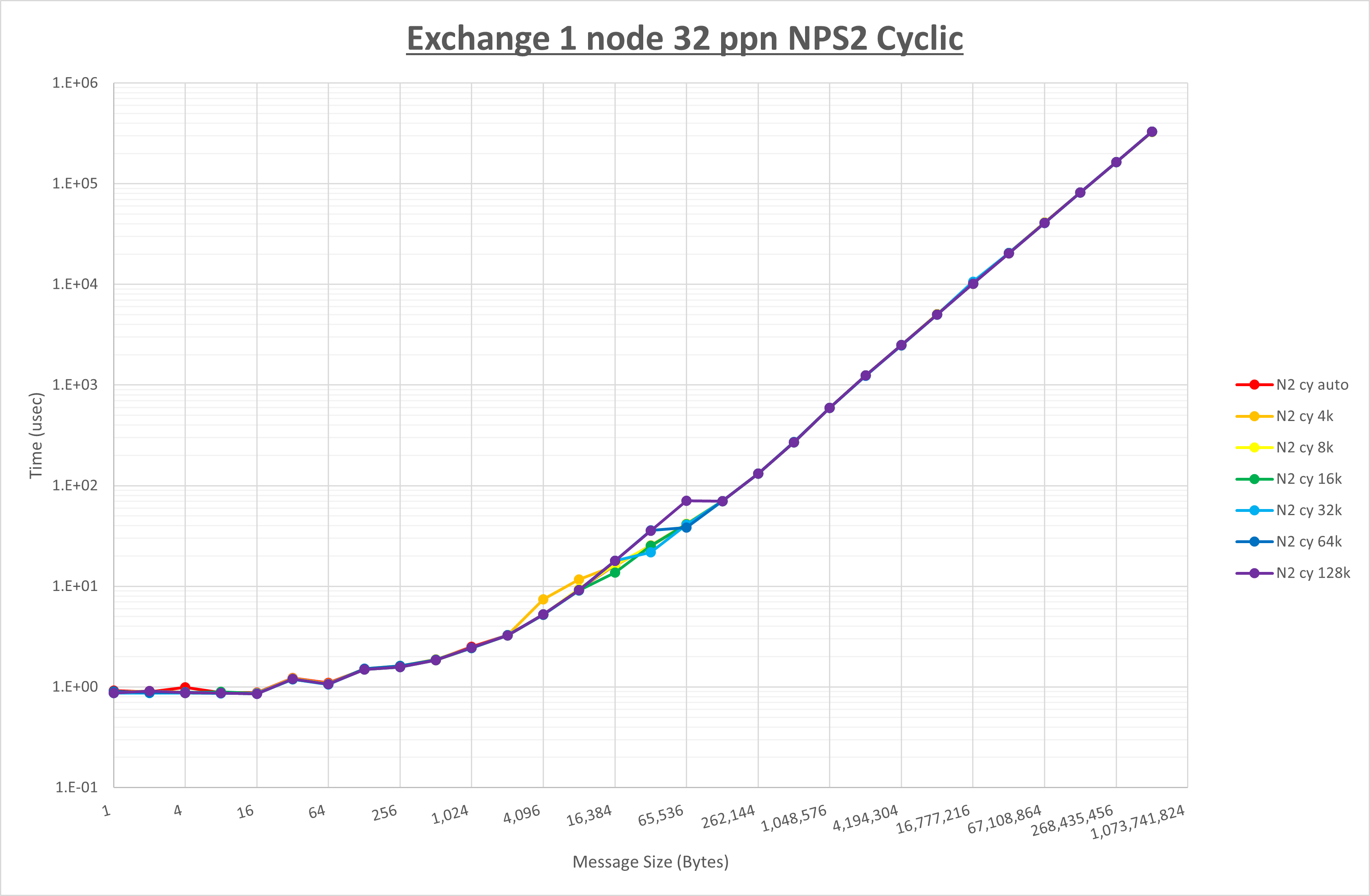
以上より、 NPS とMPIプロセス分割方法の組合せにより UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| NPS1 ブロック分割 |
NPS1 サイクリック分割 |
NPS2 ブロック分割 |
NPS2 サイクリック分割 |
|
|---|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 16KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto )を含めています。
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で8KBから16KBの間で性能が向上
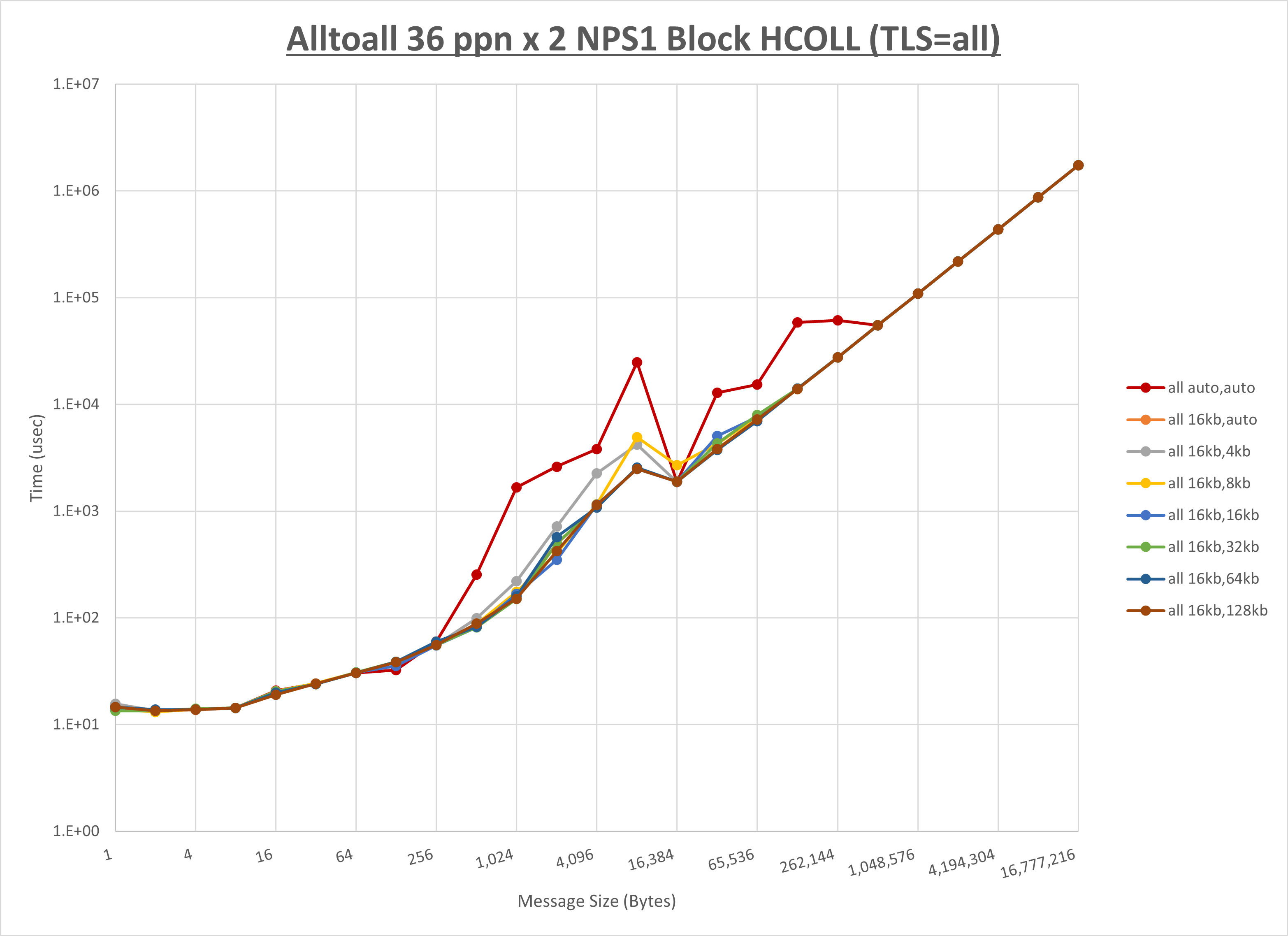
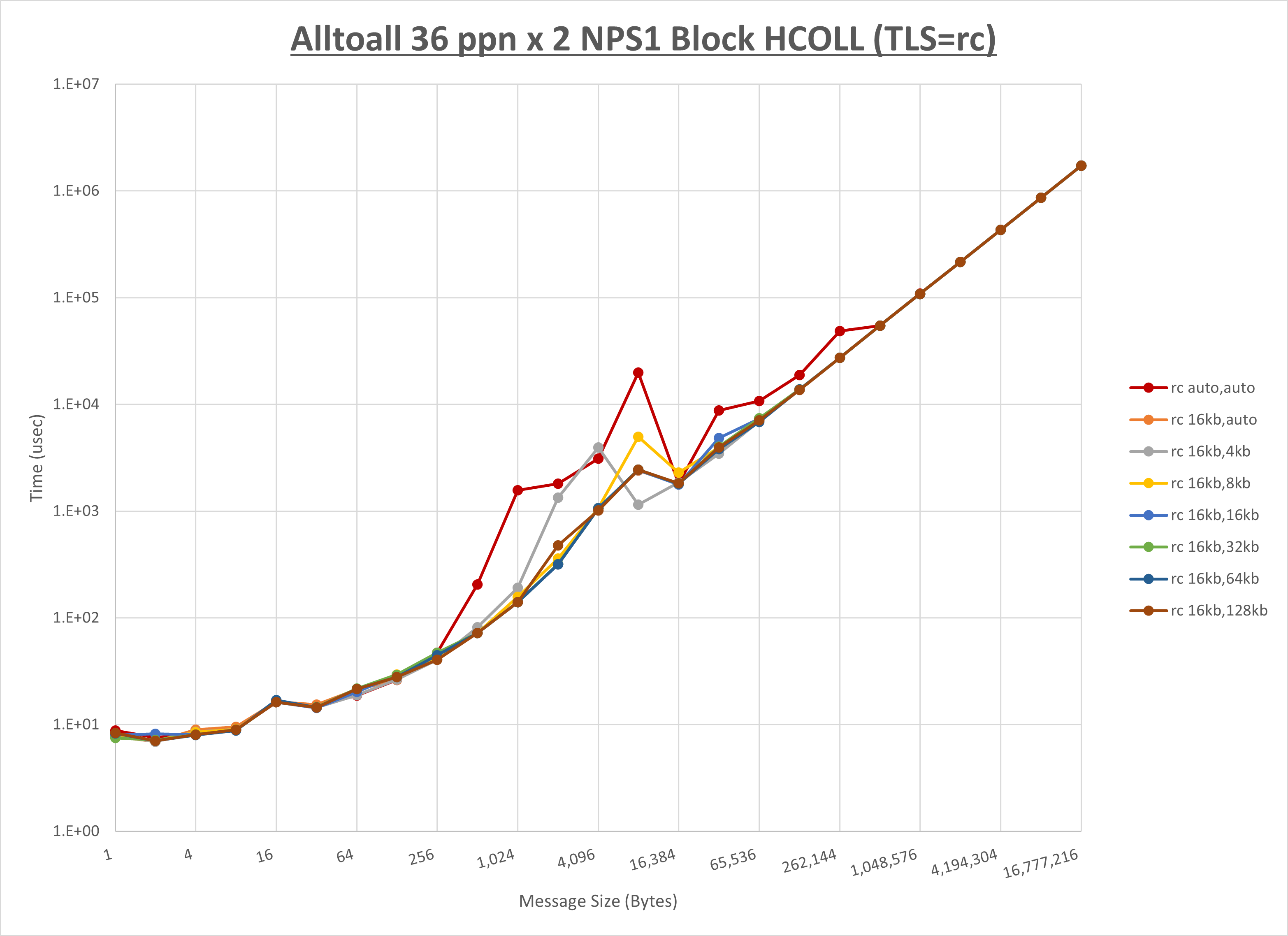
本章は、1ノードに36 MPIプロセスを割当てる場合の最適な 実行時パラメータ の組み合わせをMPI集合通信関数毎に検証し、その結果を考察します。
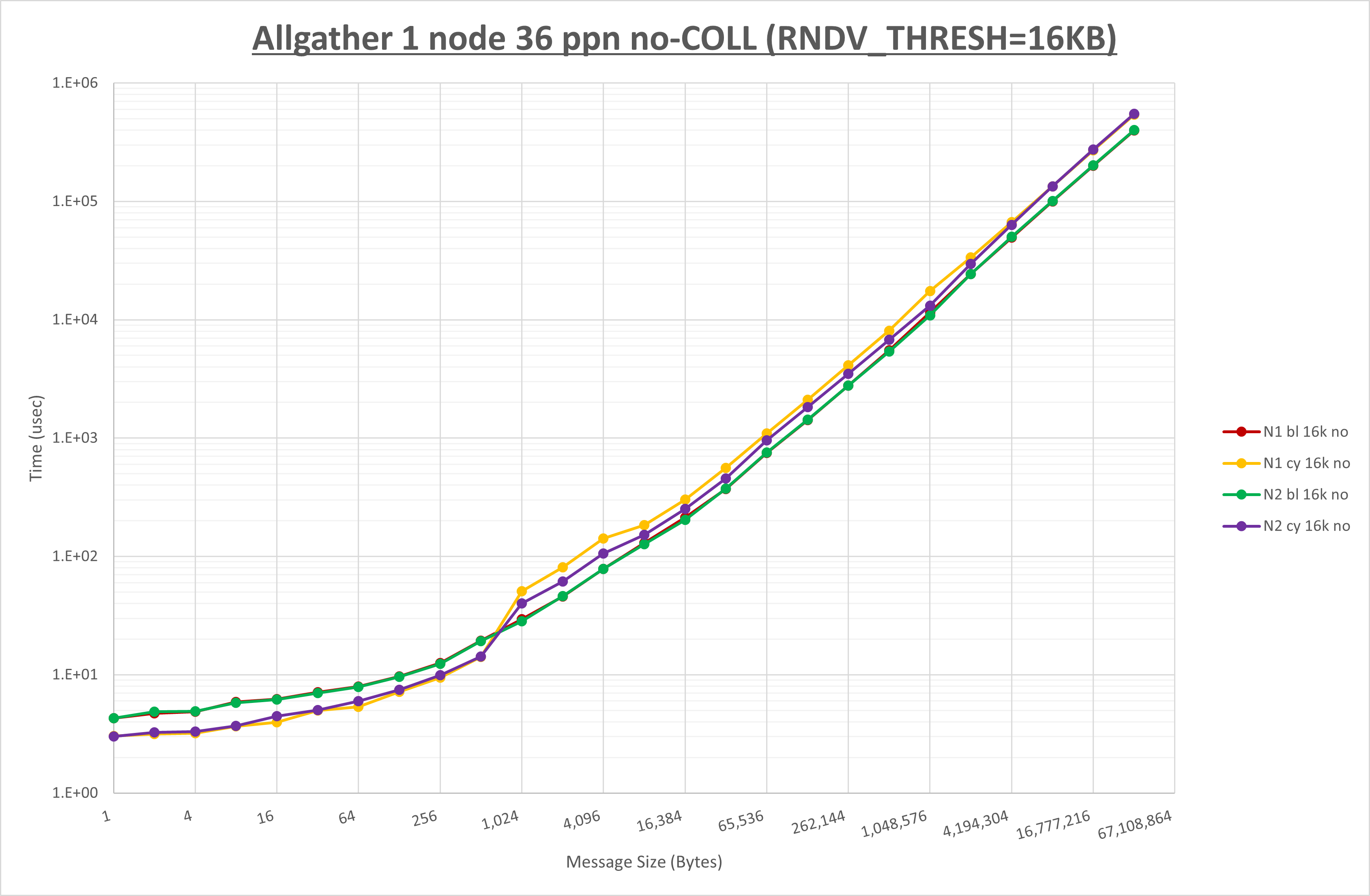
下表は、各MPI集合通信関数の最適な UCX_RNDV_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_RNDV_THRESH |
|---|---|
| Alltoall | 8KB / 16KB |
| Allgather | 16KB |
| Allreduce | 64KB / 128KB |
| Exchange | 16KB |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下
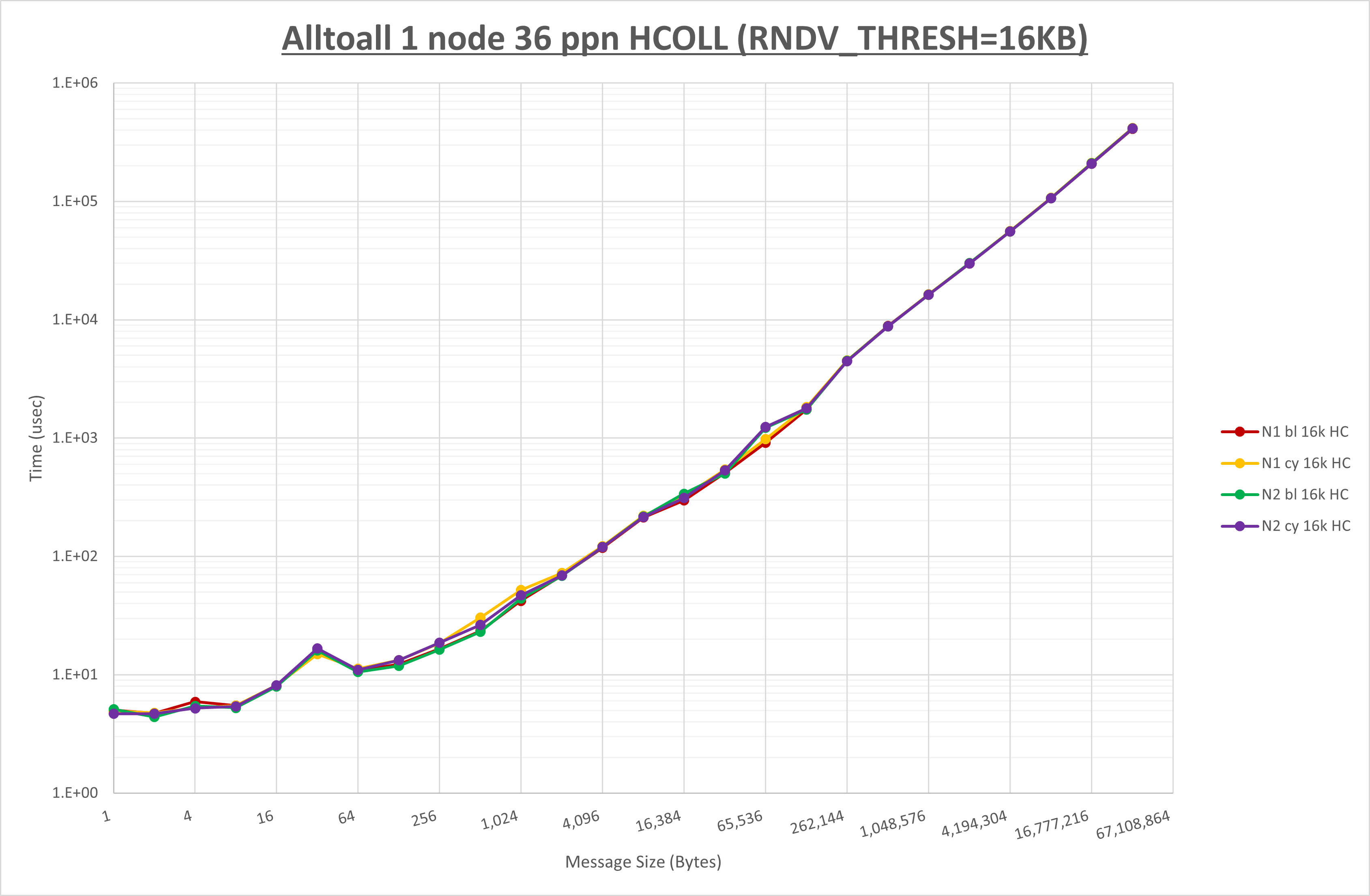
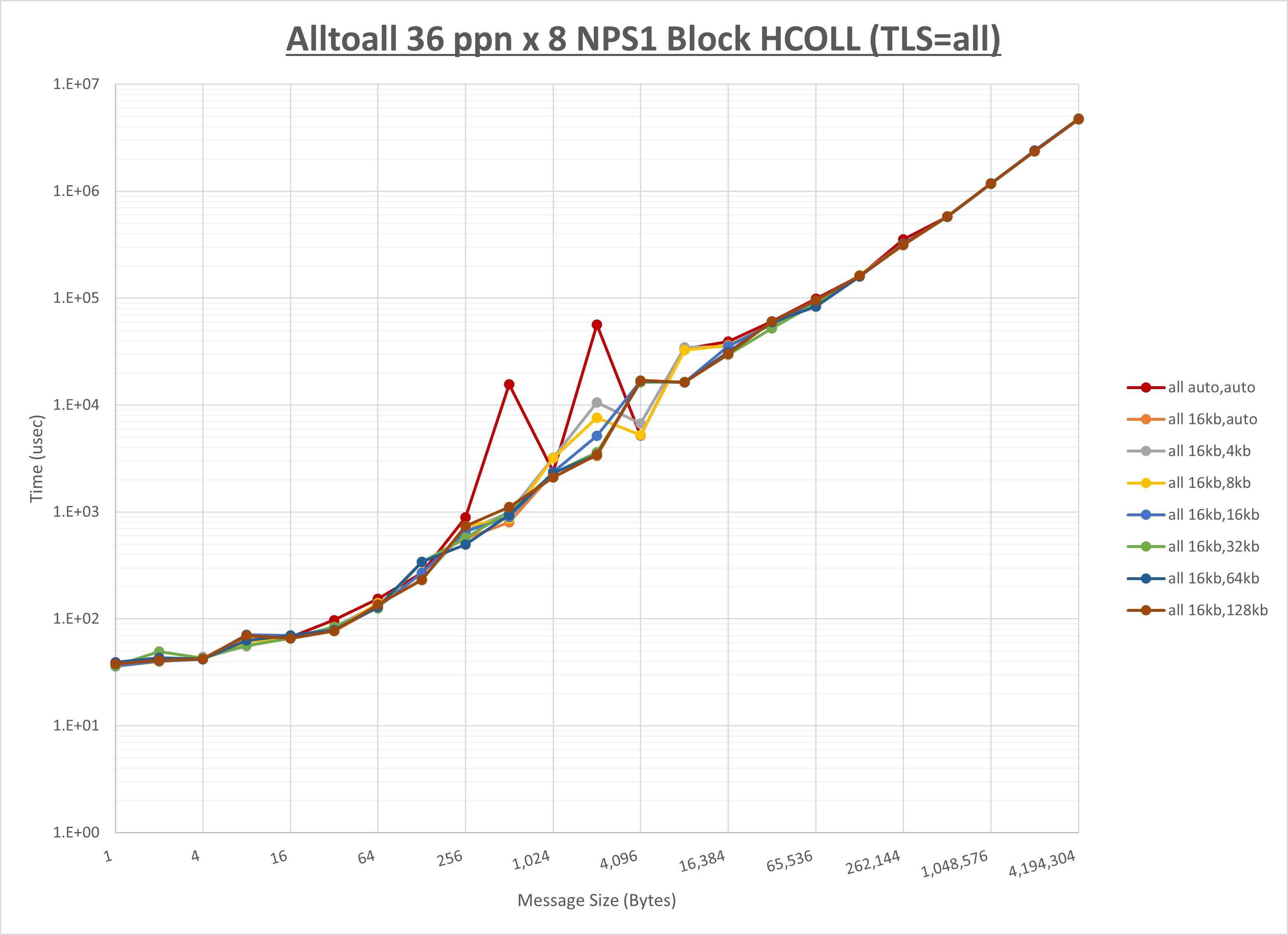
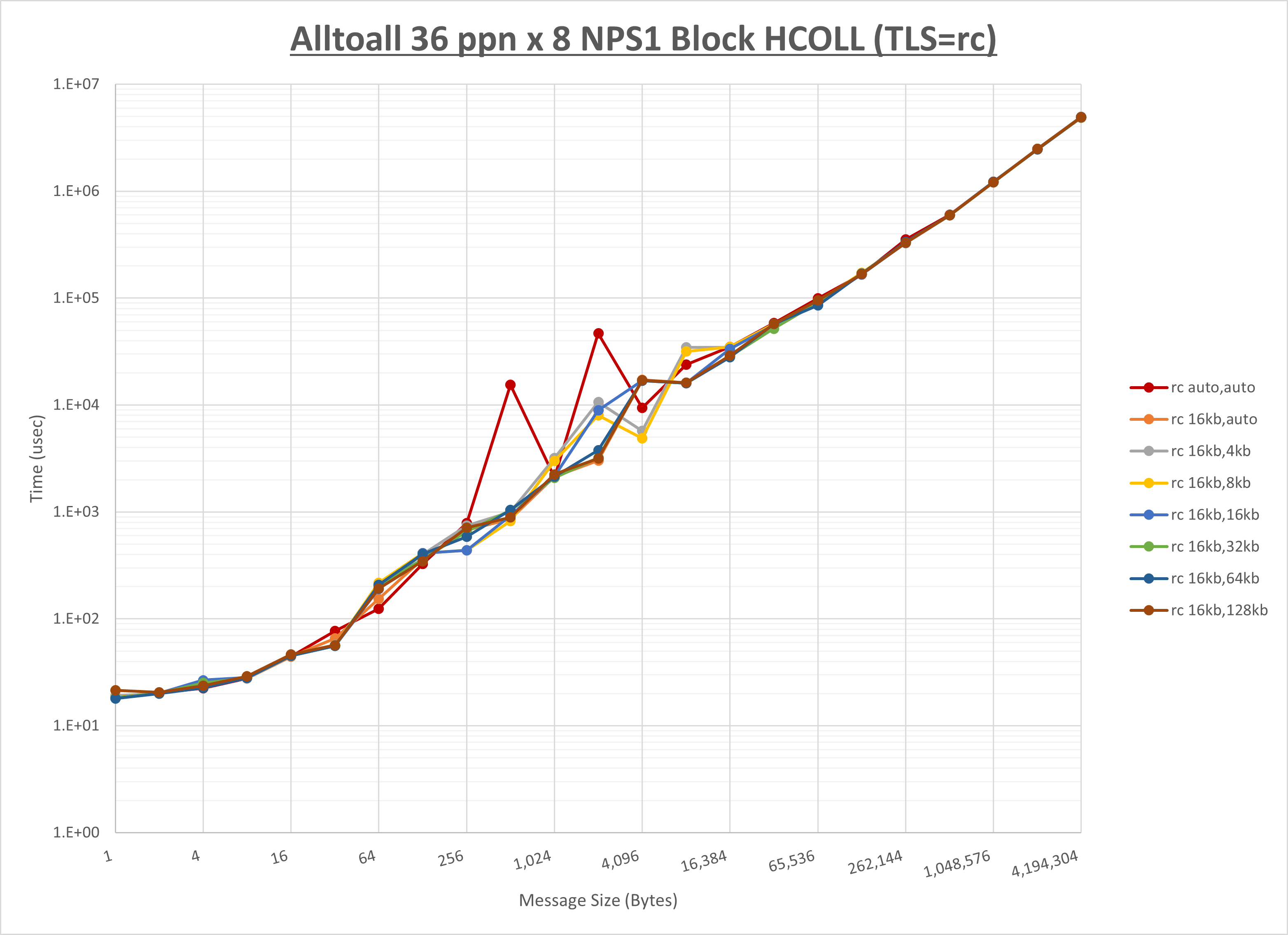
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
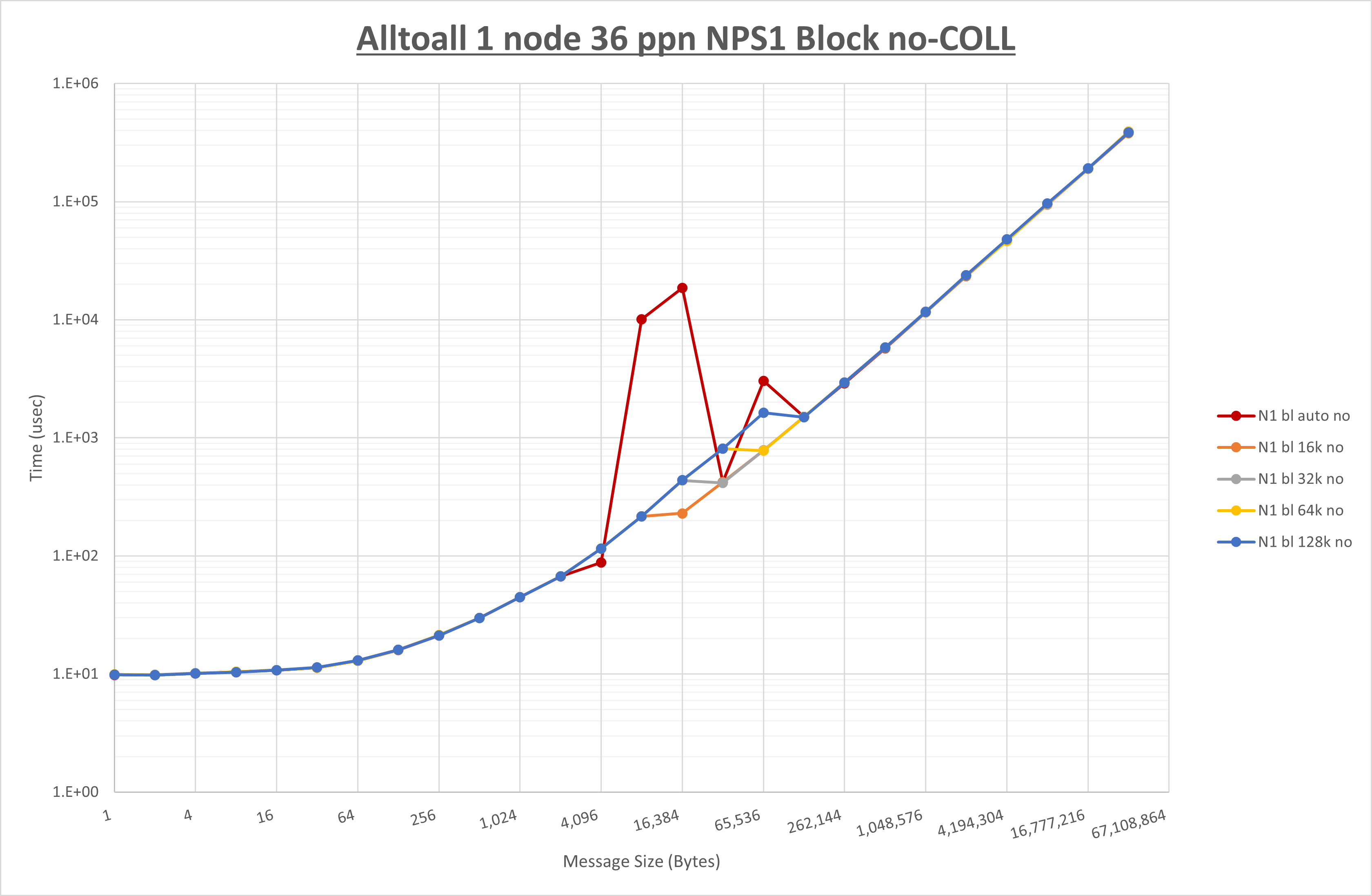
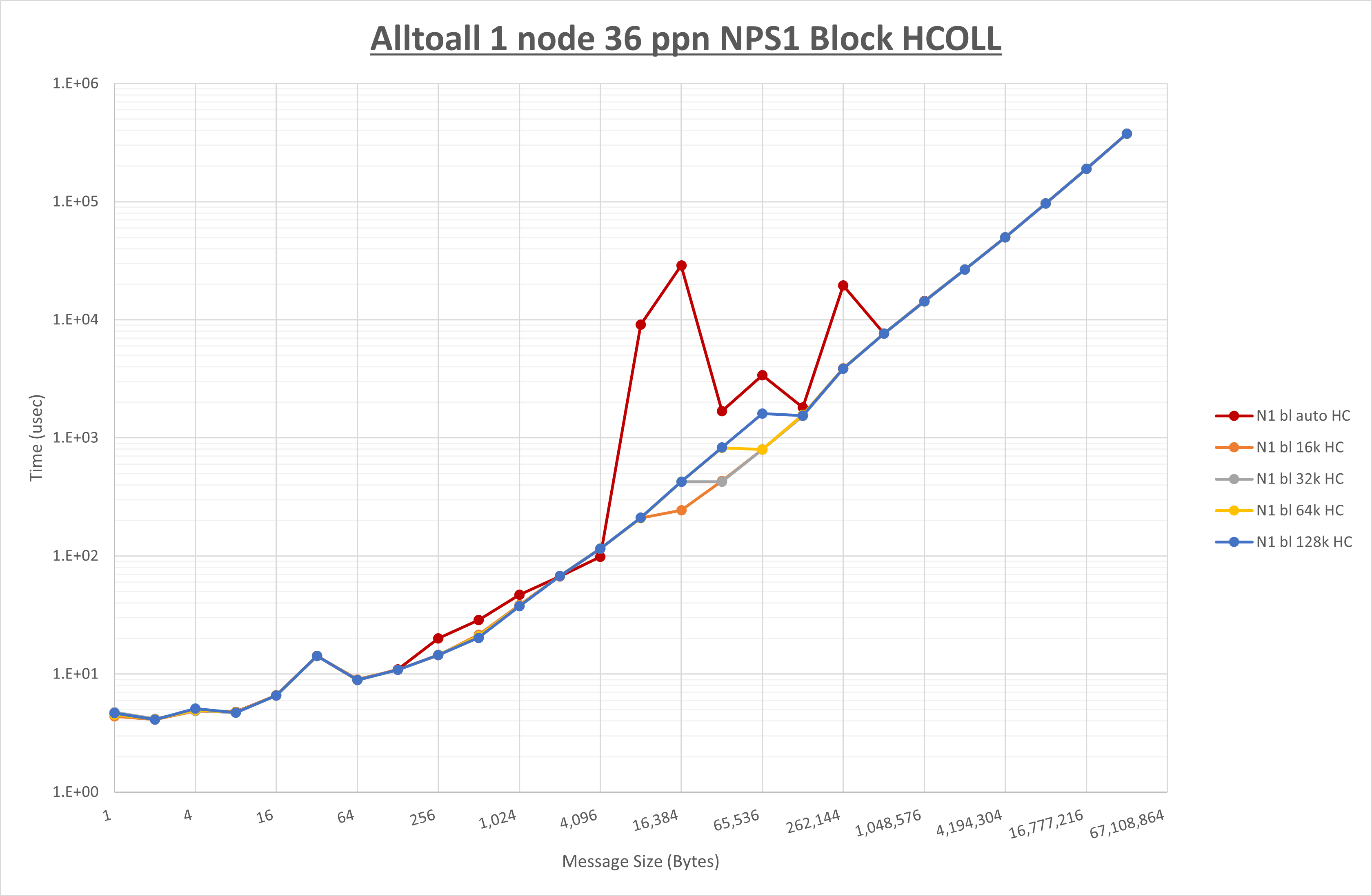
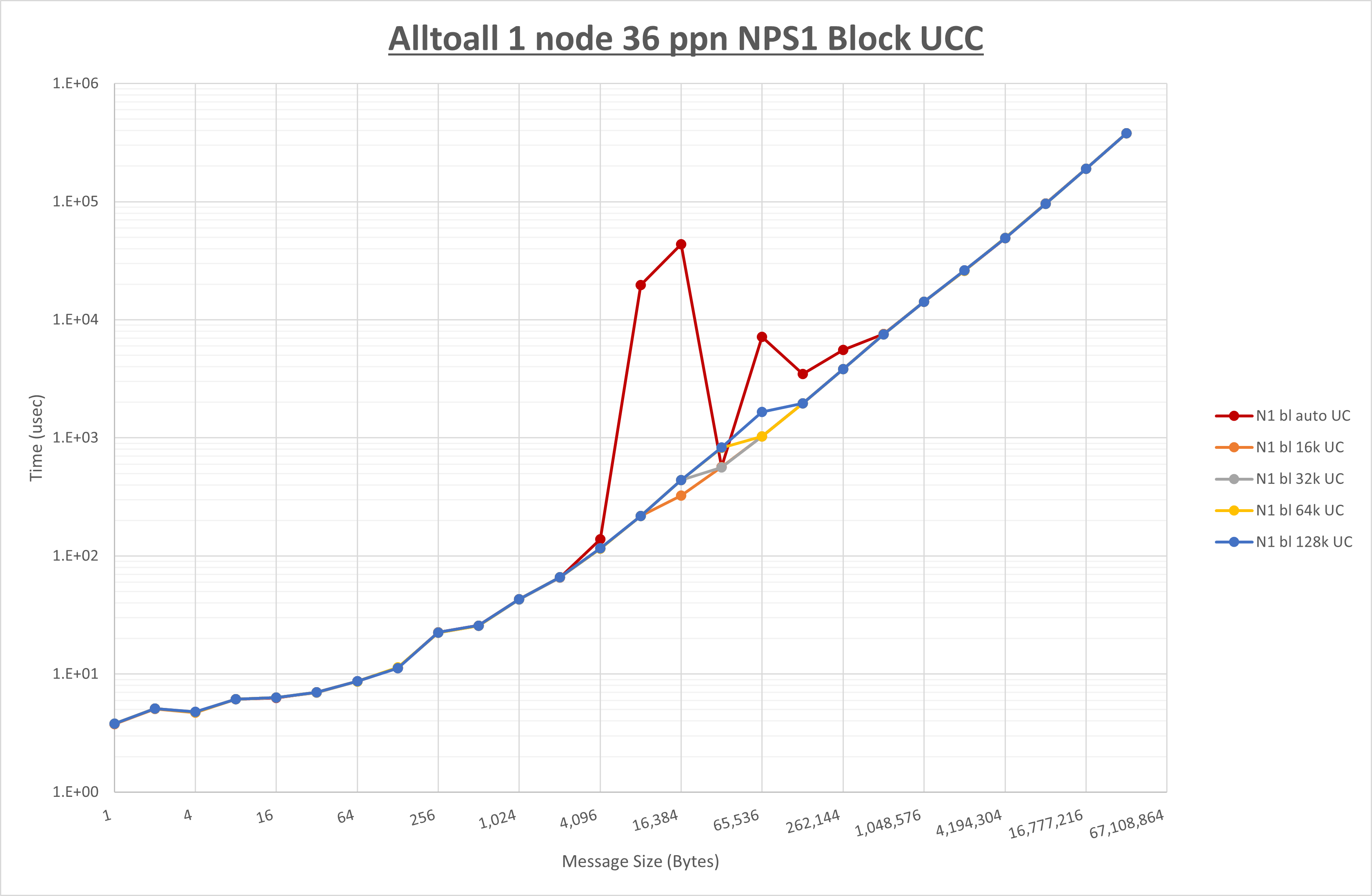
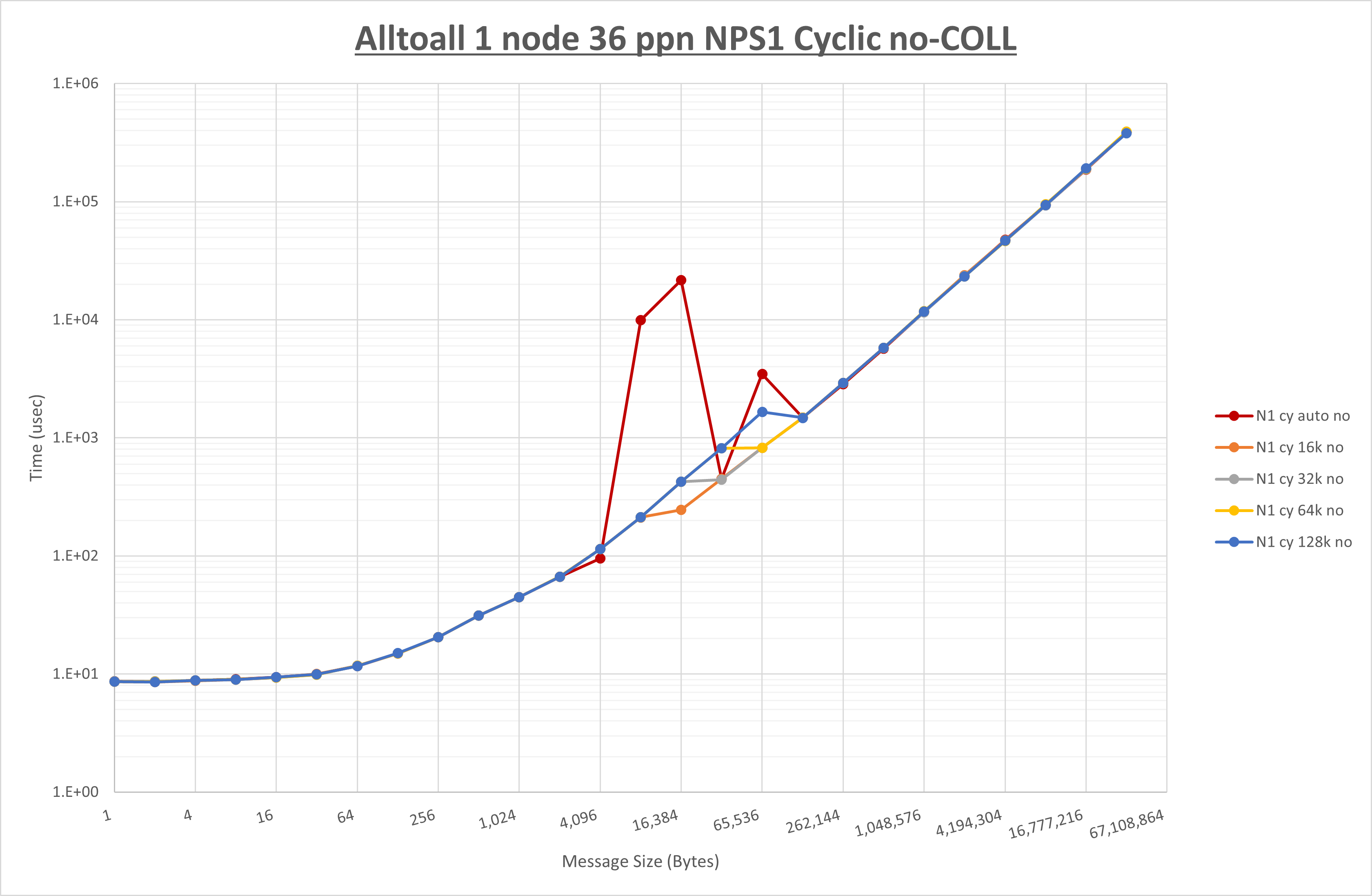
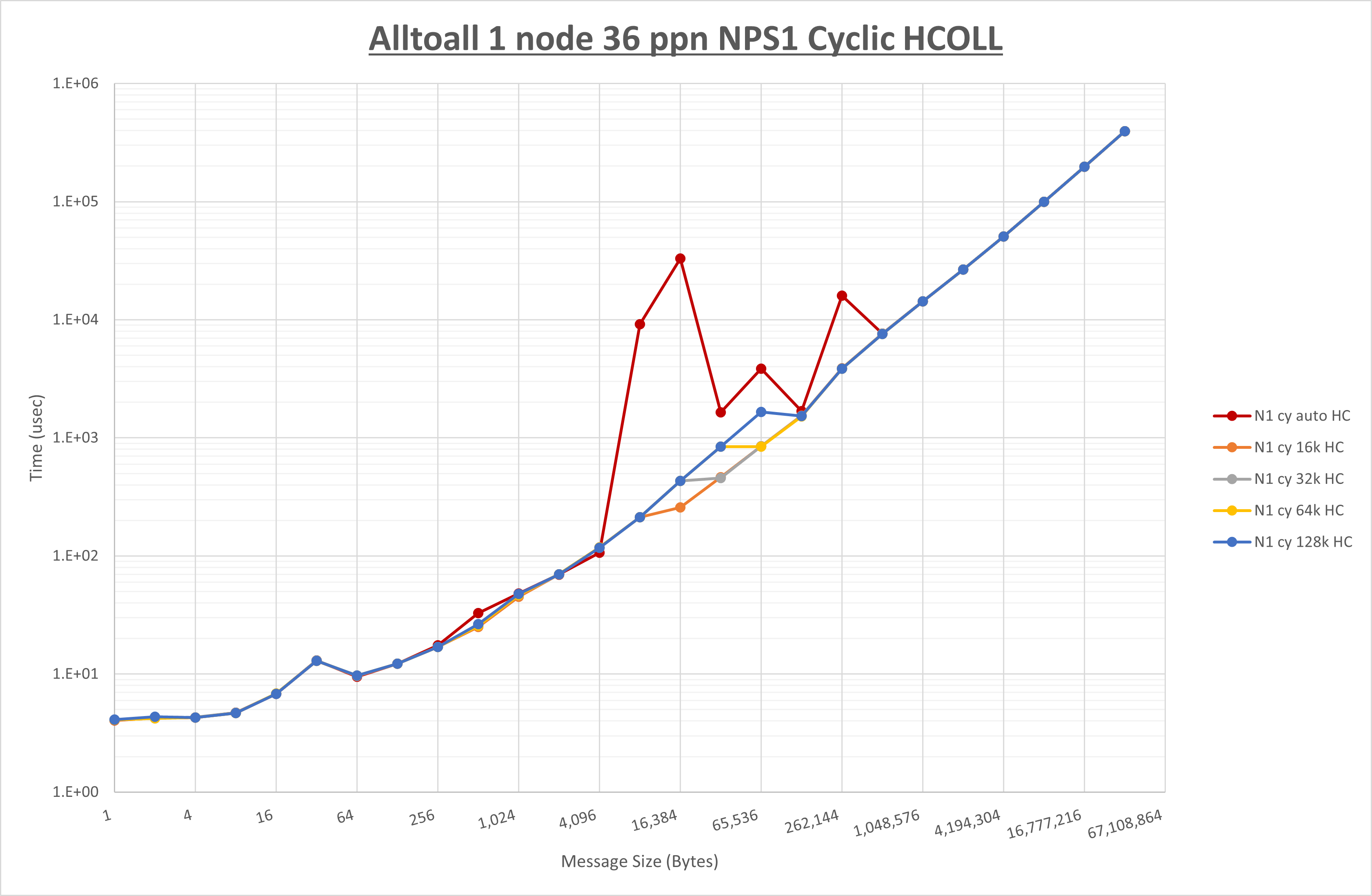
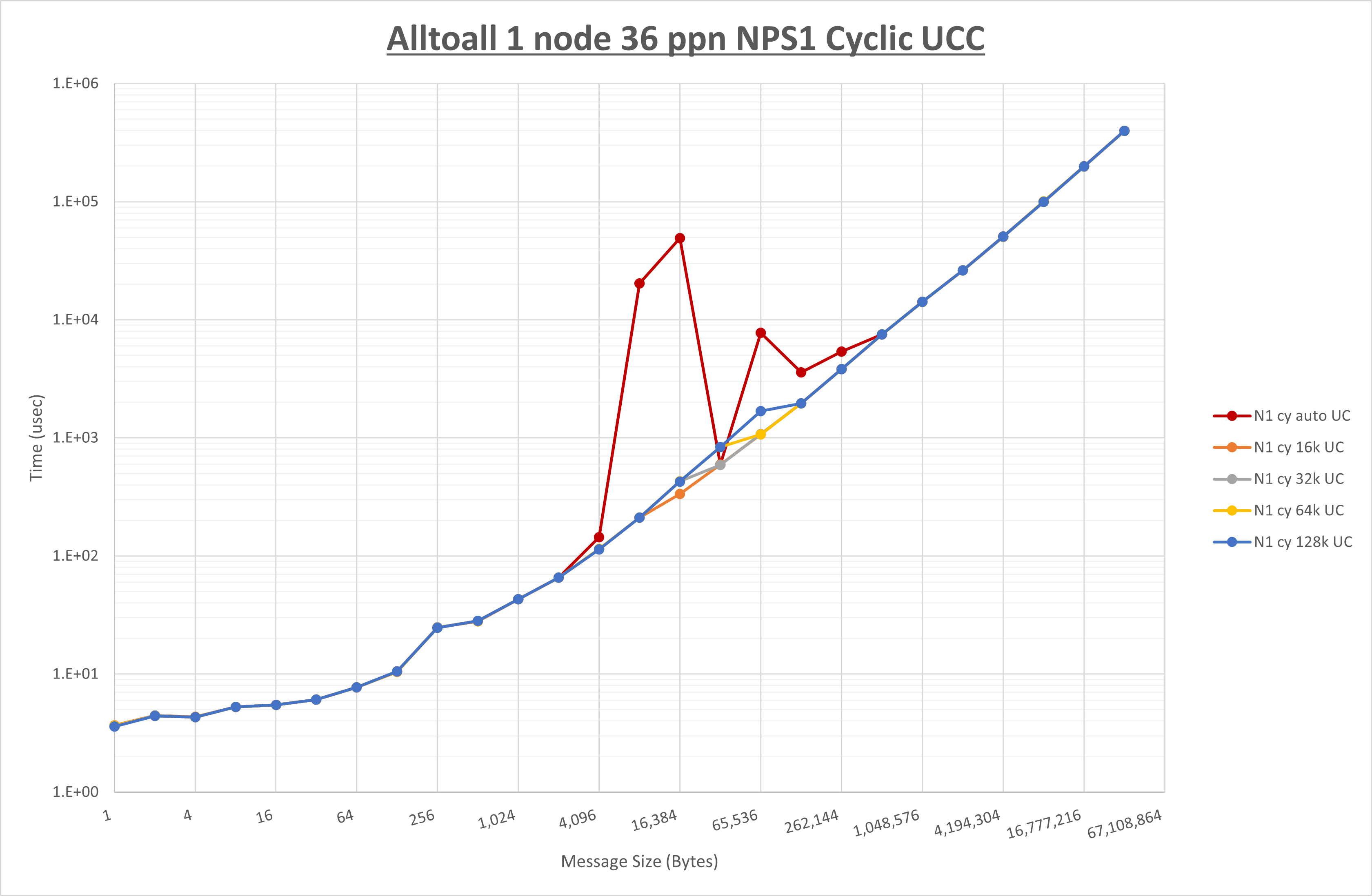
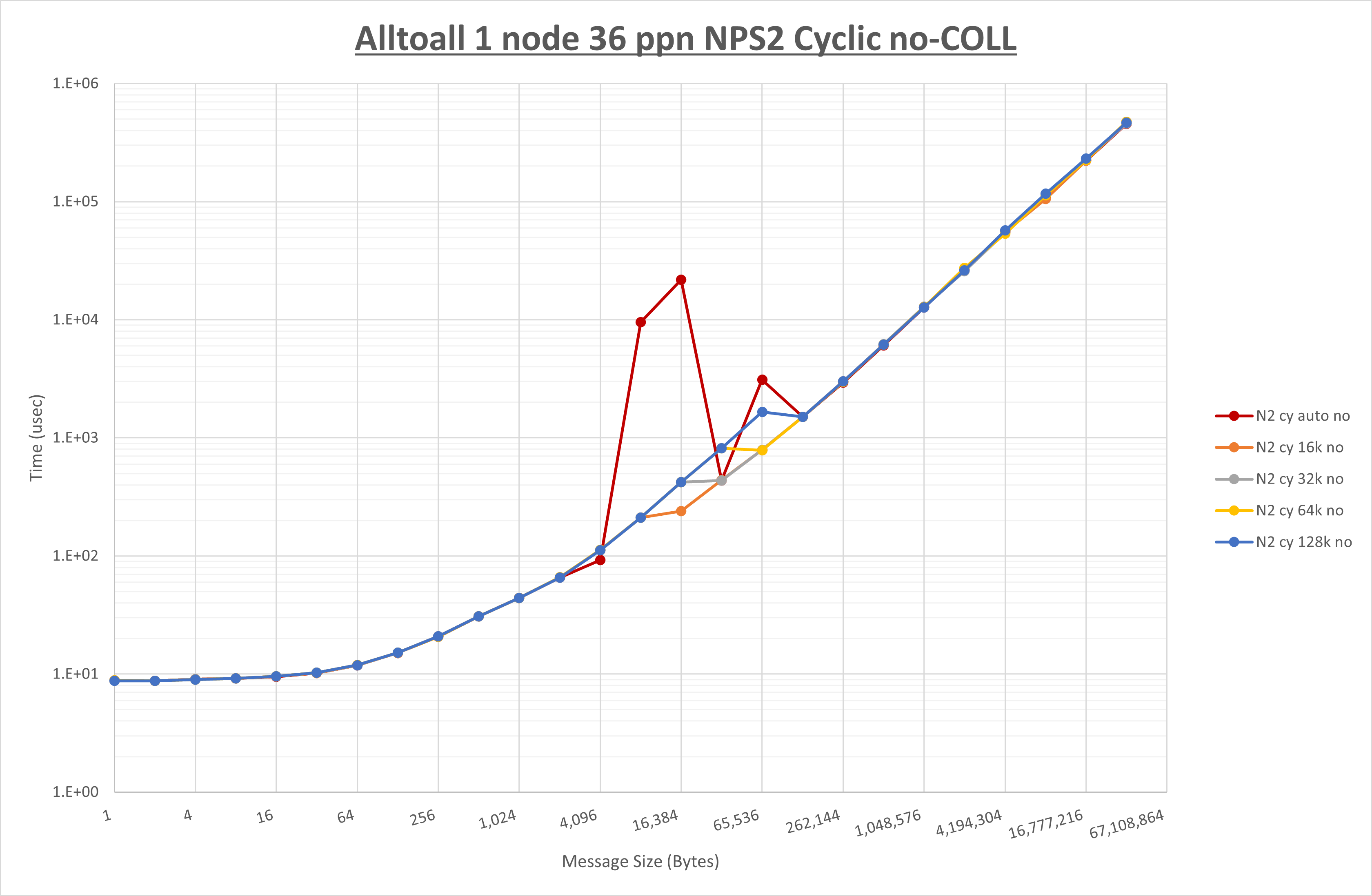
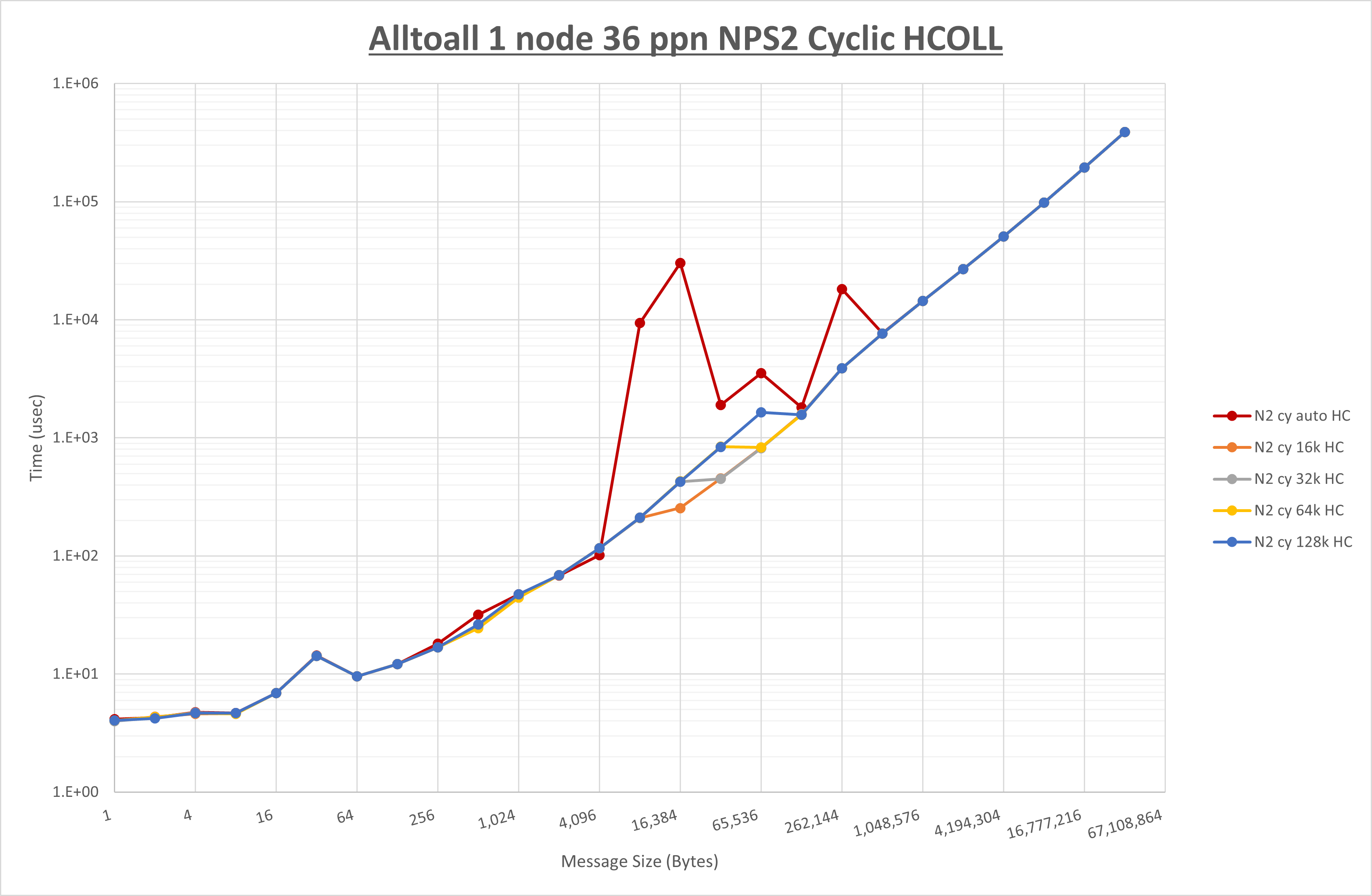
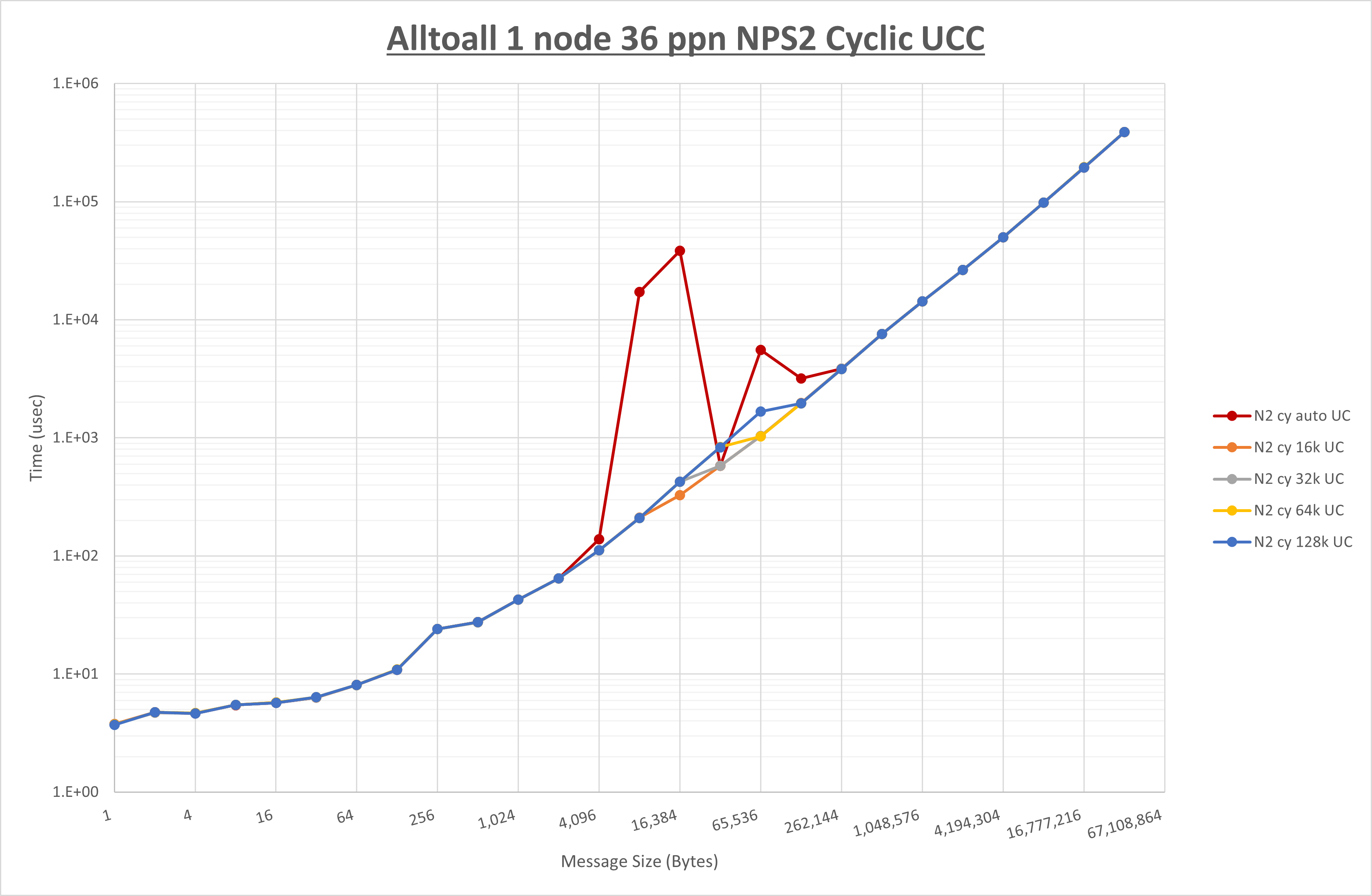
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 8KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
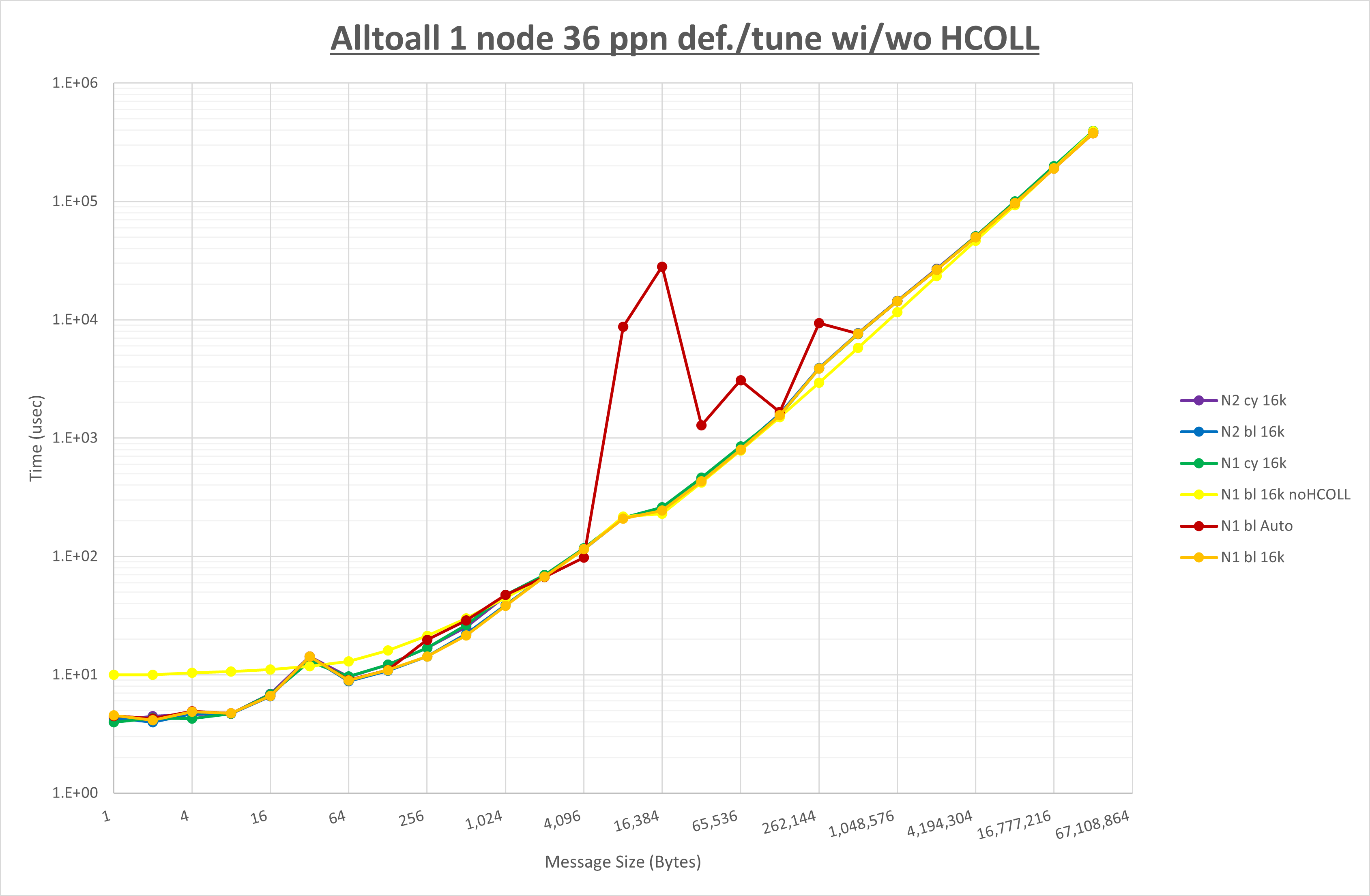
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し512B以下で性能が向上し256KB以上で性能が低下
- UCC は no-COLL と比較し128B以下で性能が向上し8KB以上で性能が低下
- チューニング適用で8KBから16KBの間で性能が向上
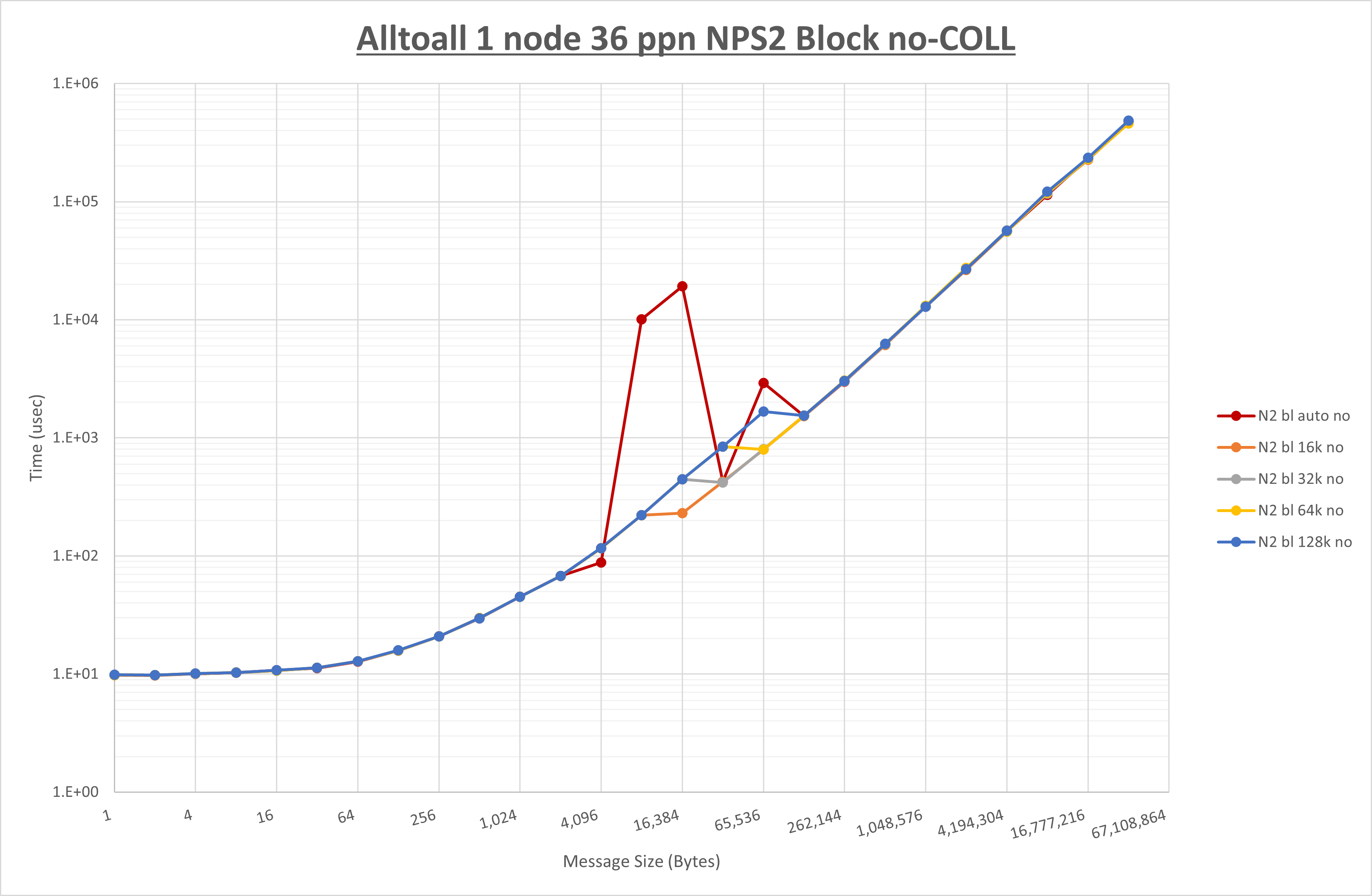
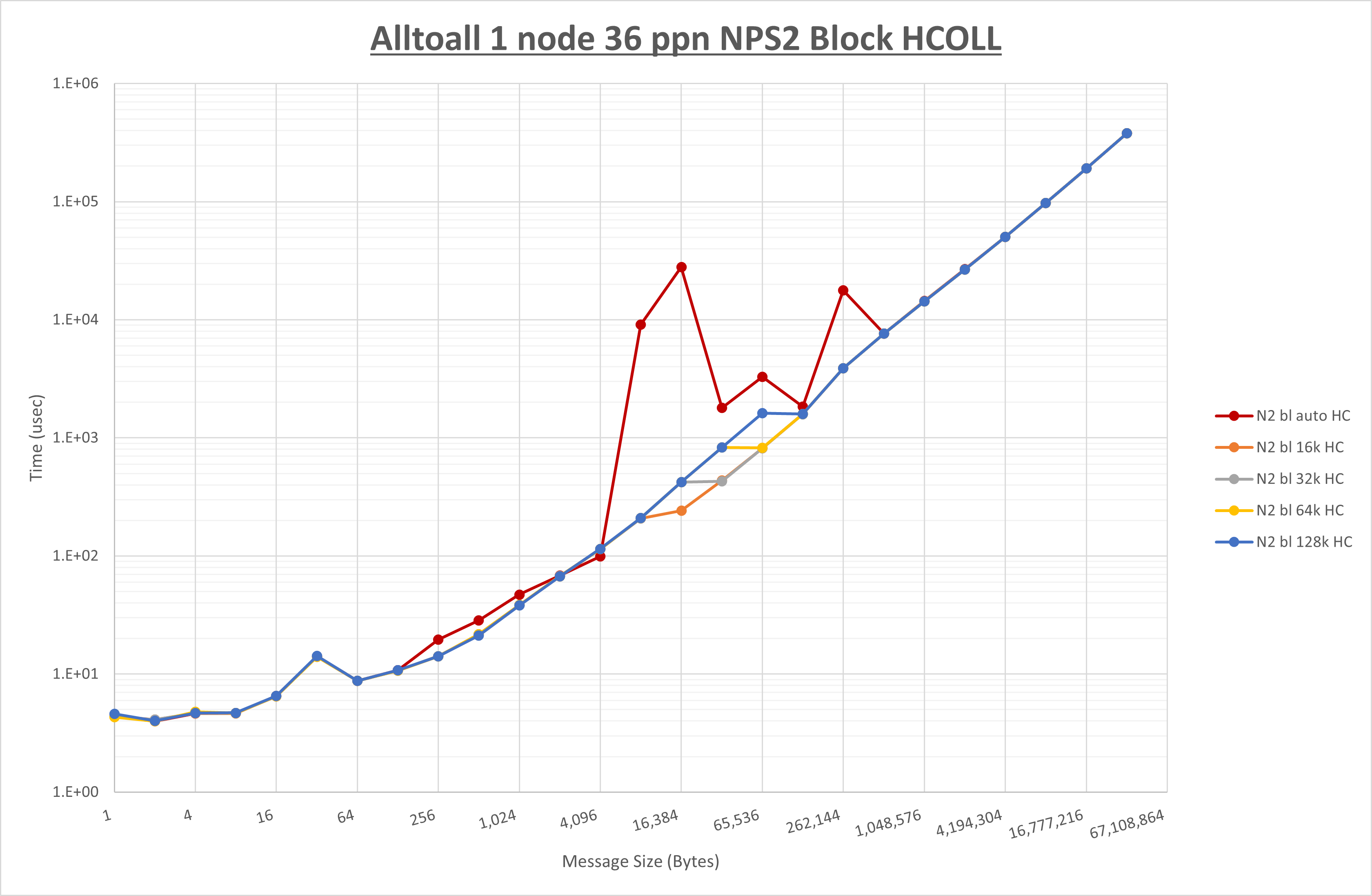
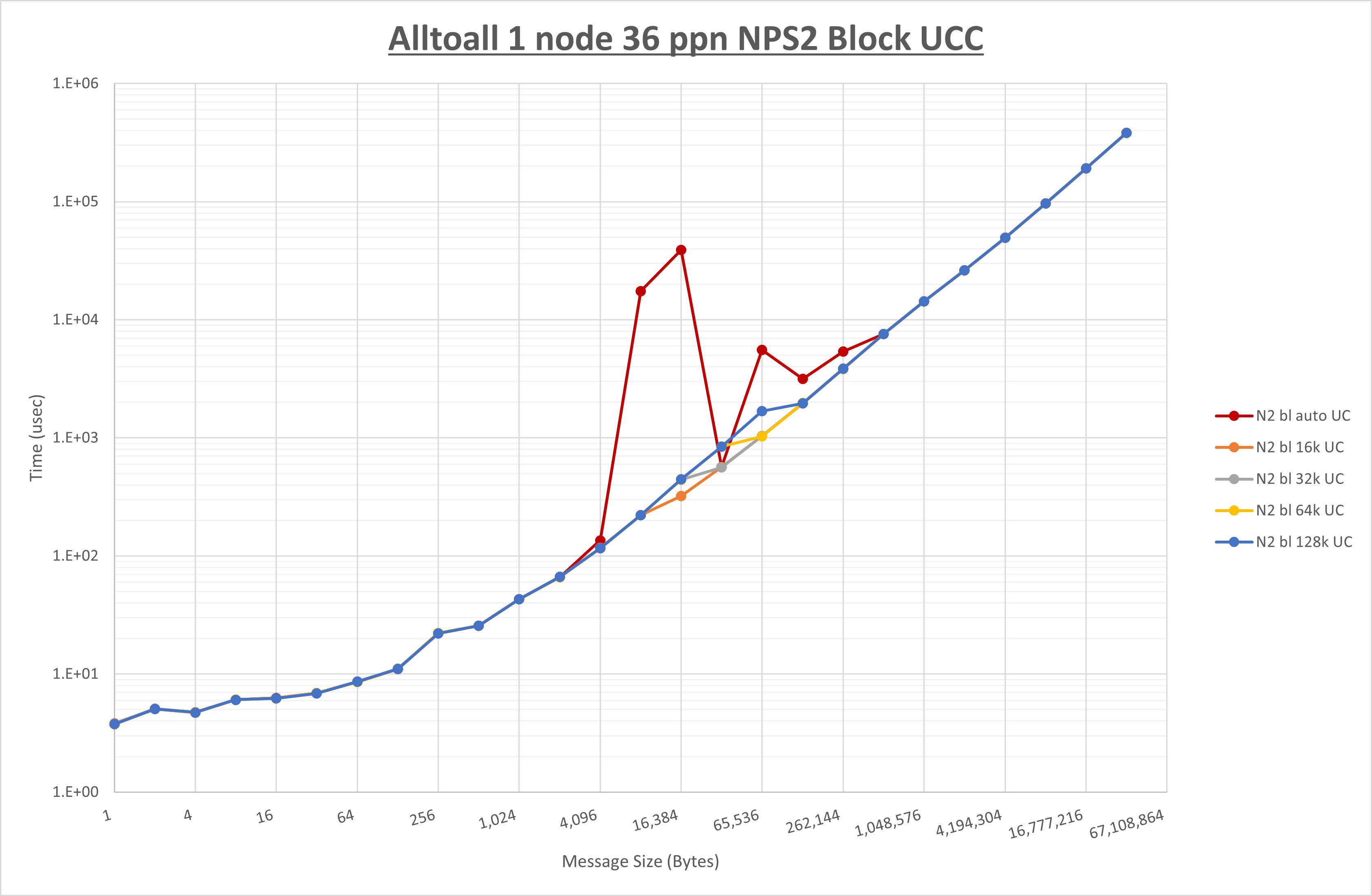
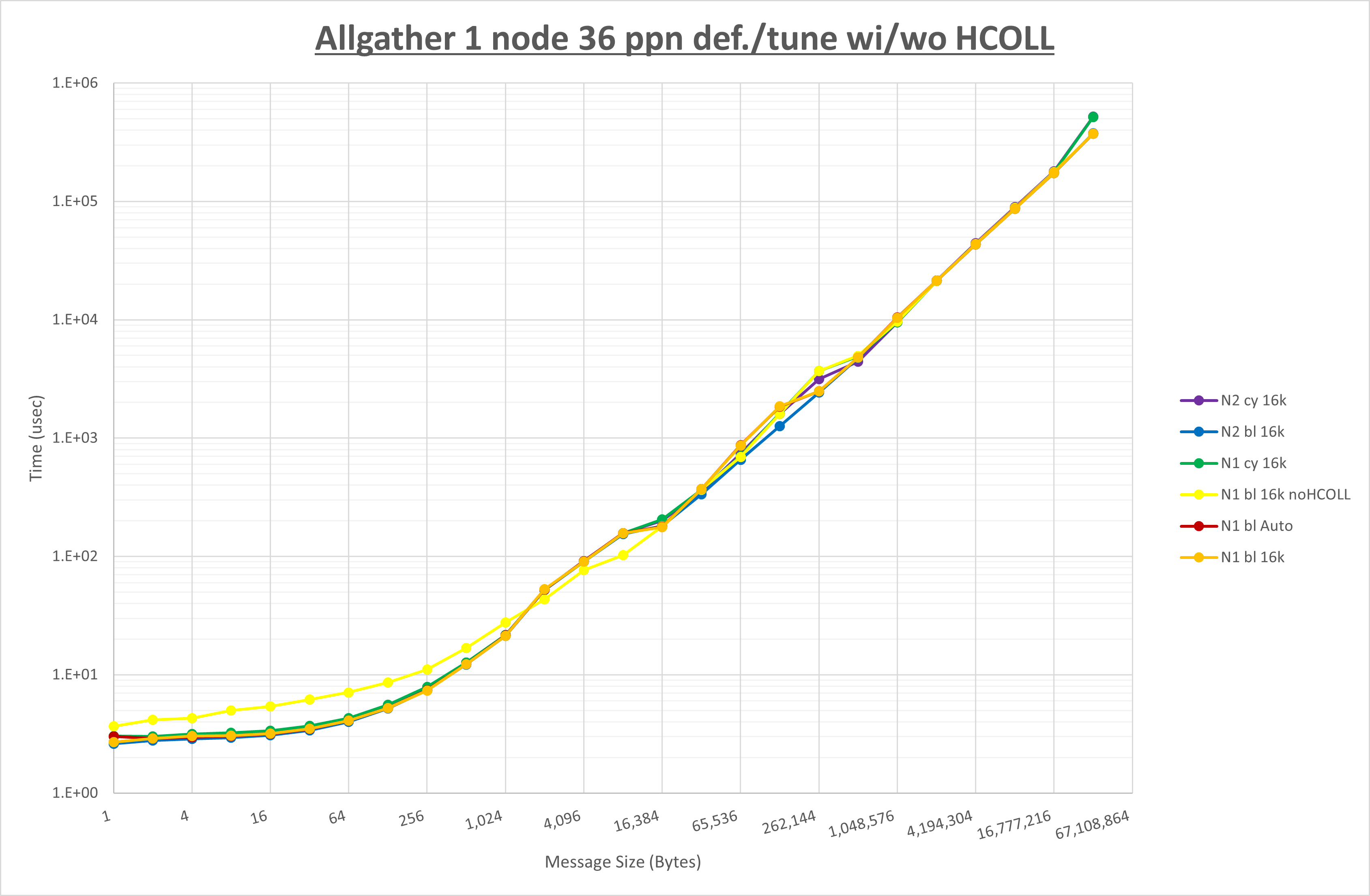
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
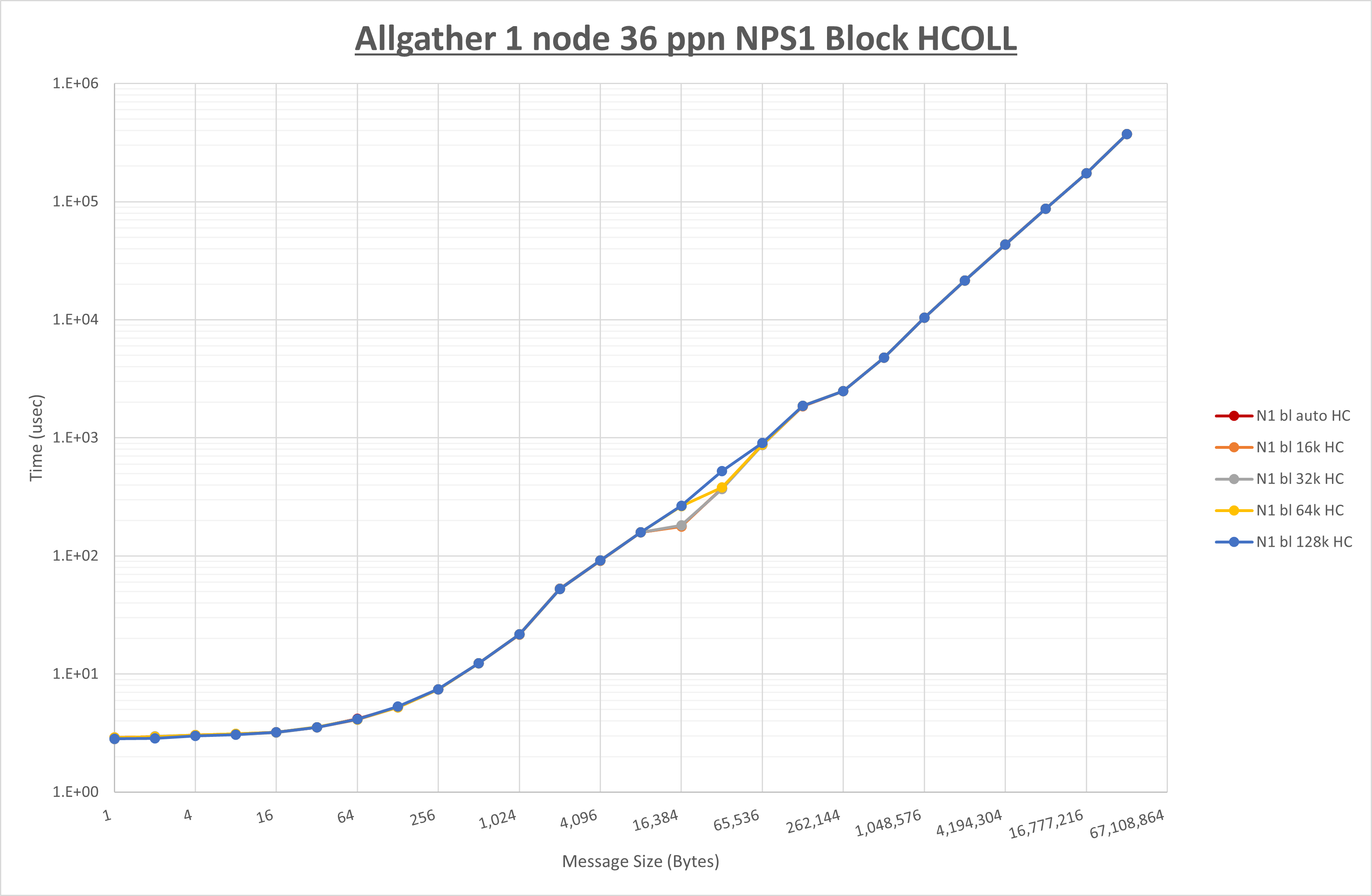
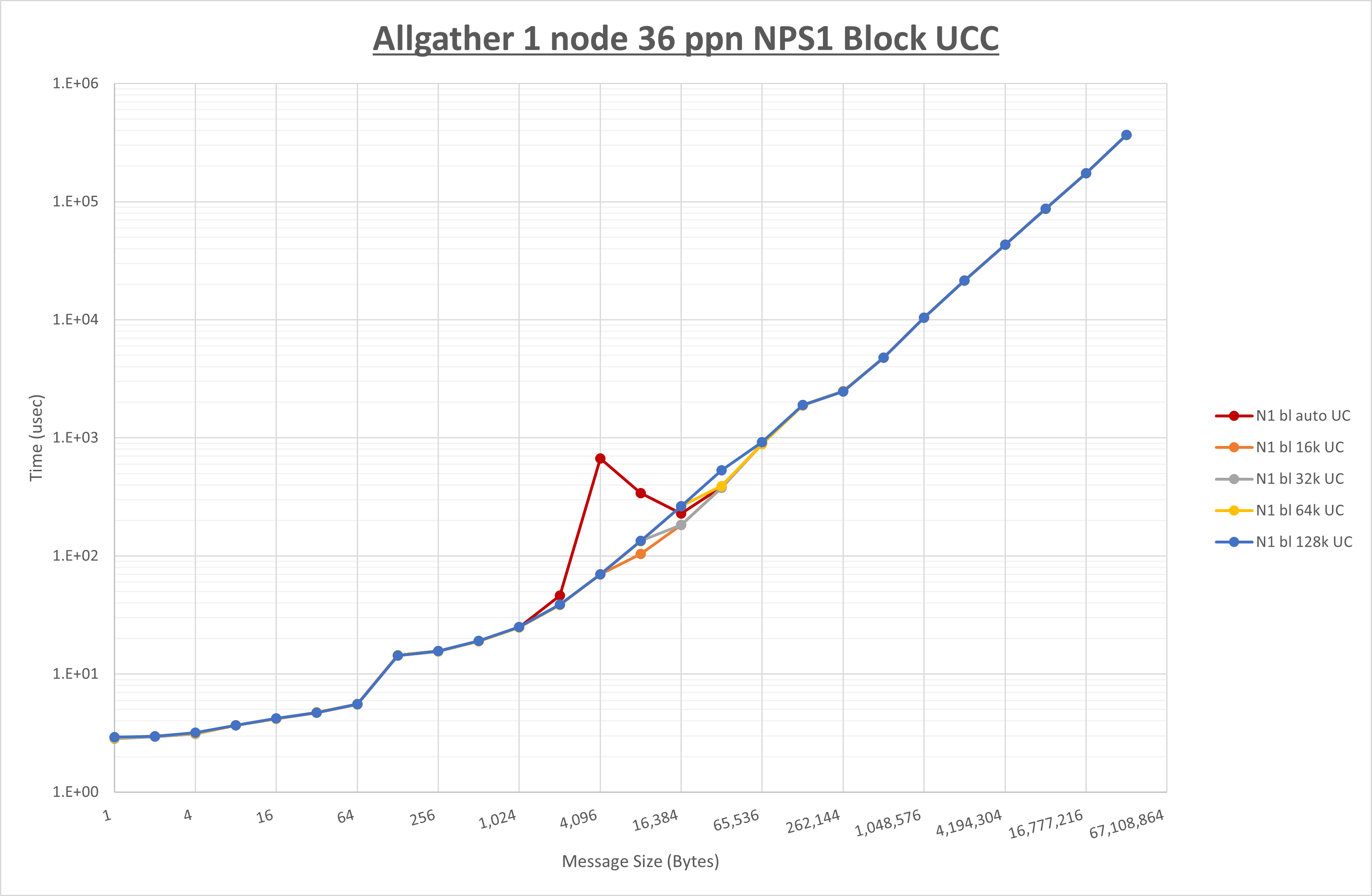
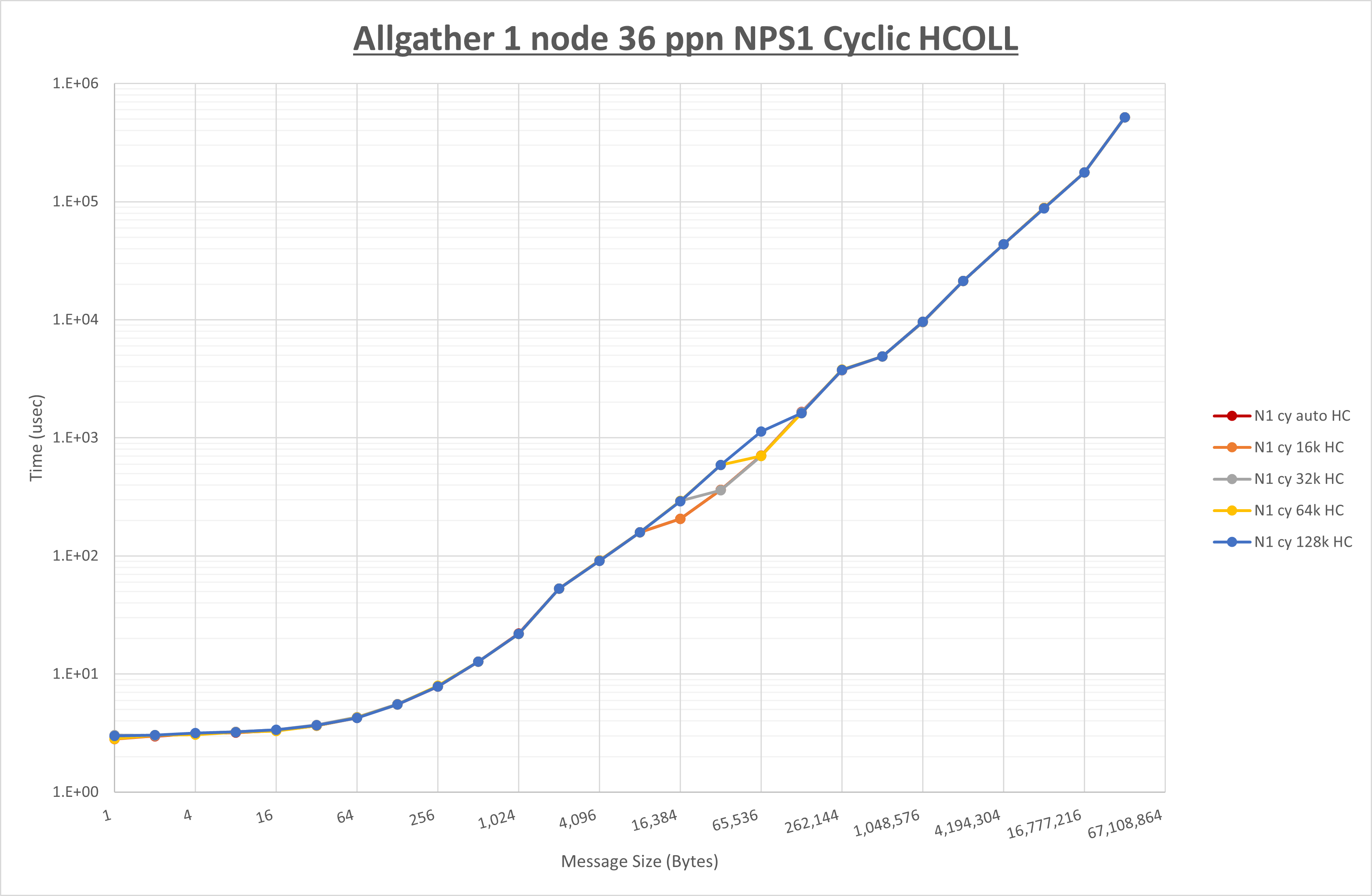
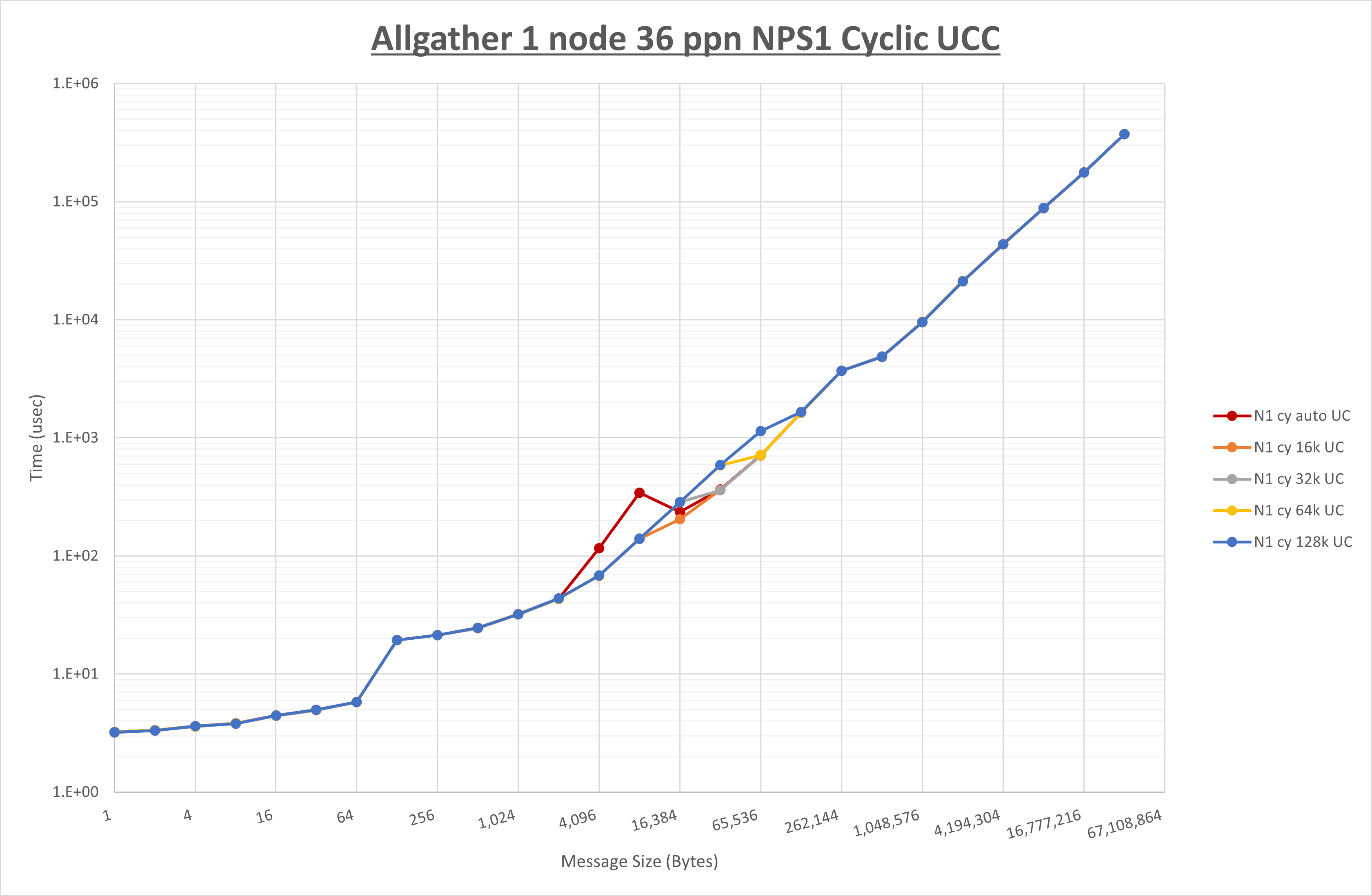
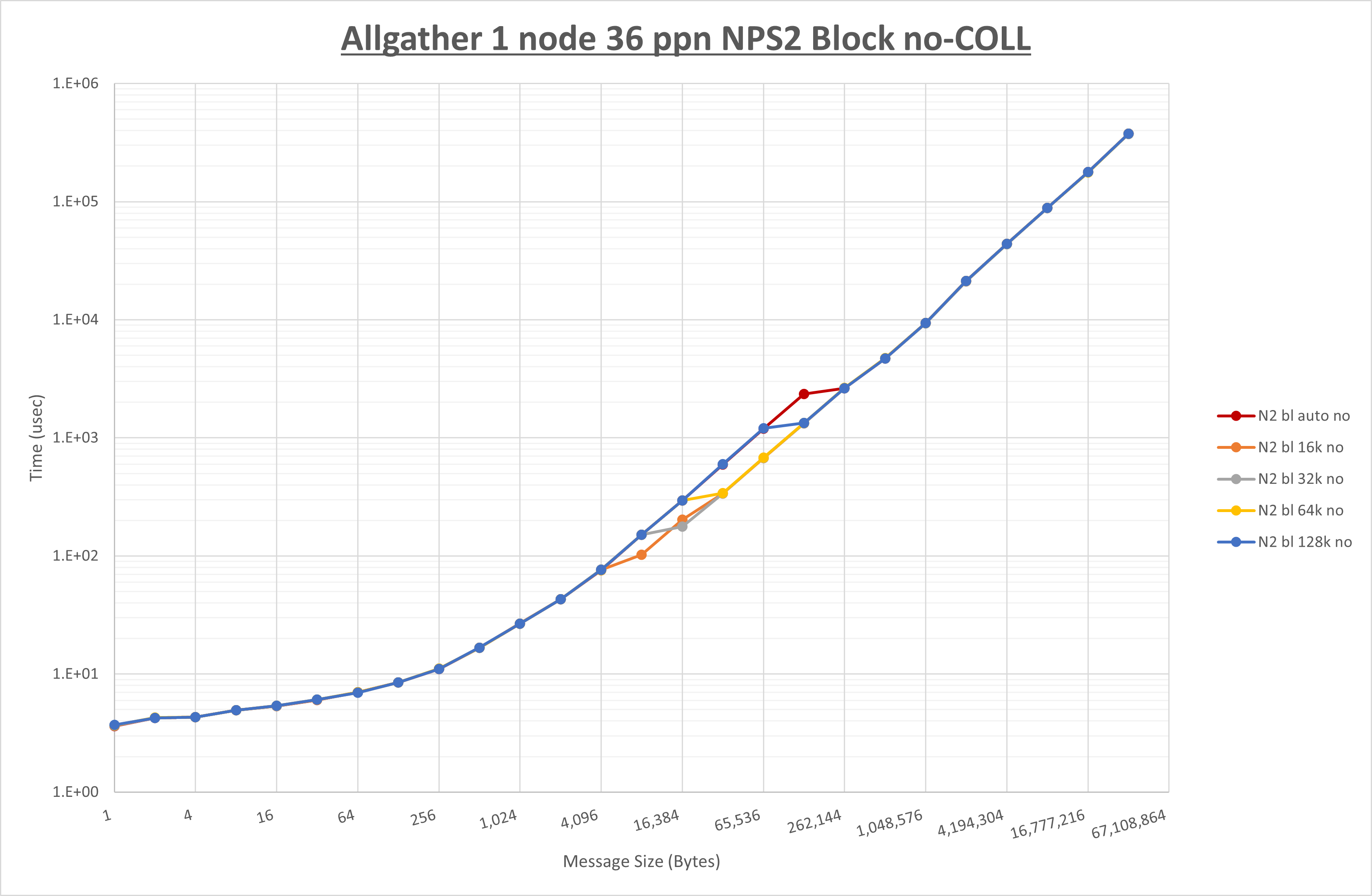
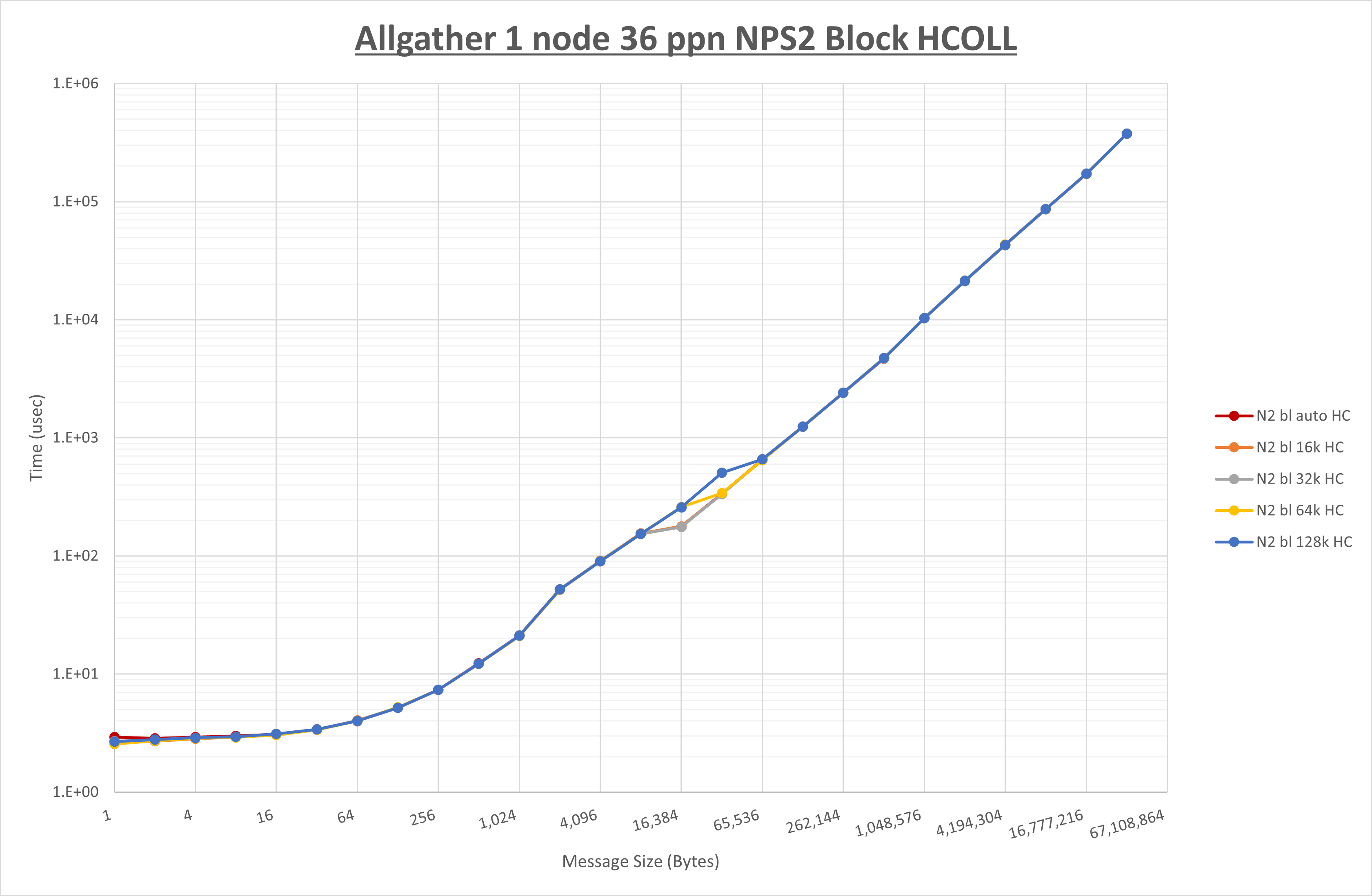
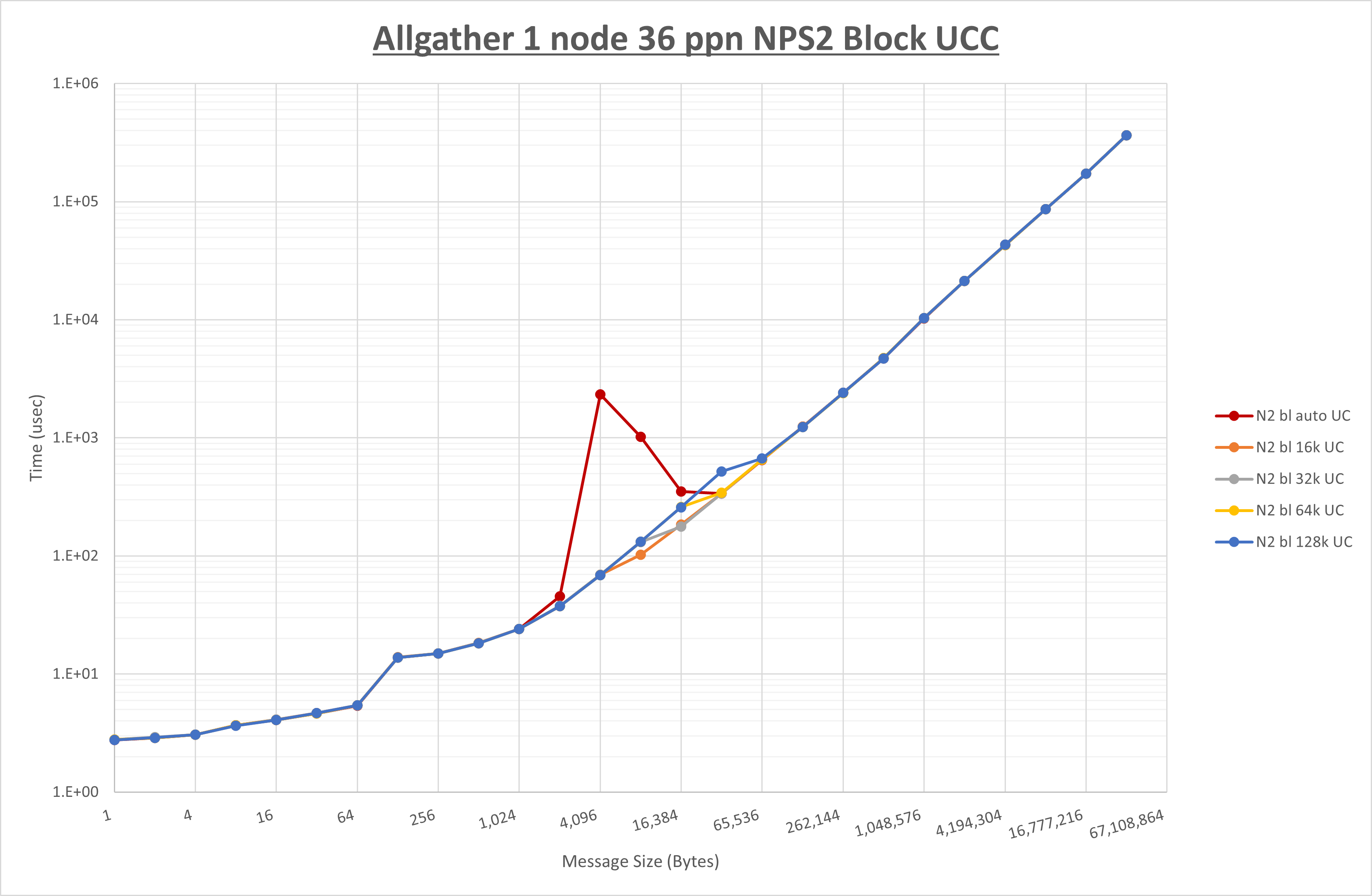
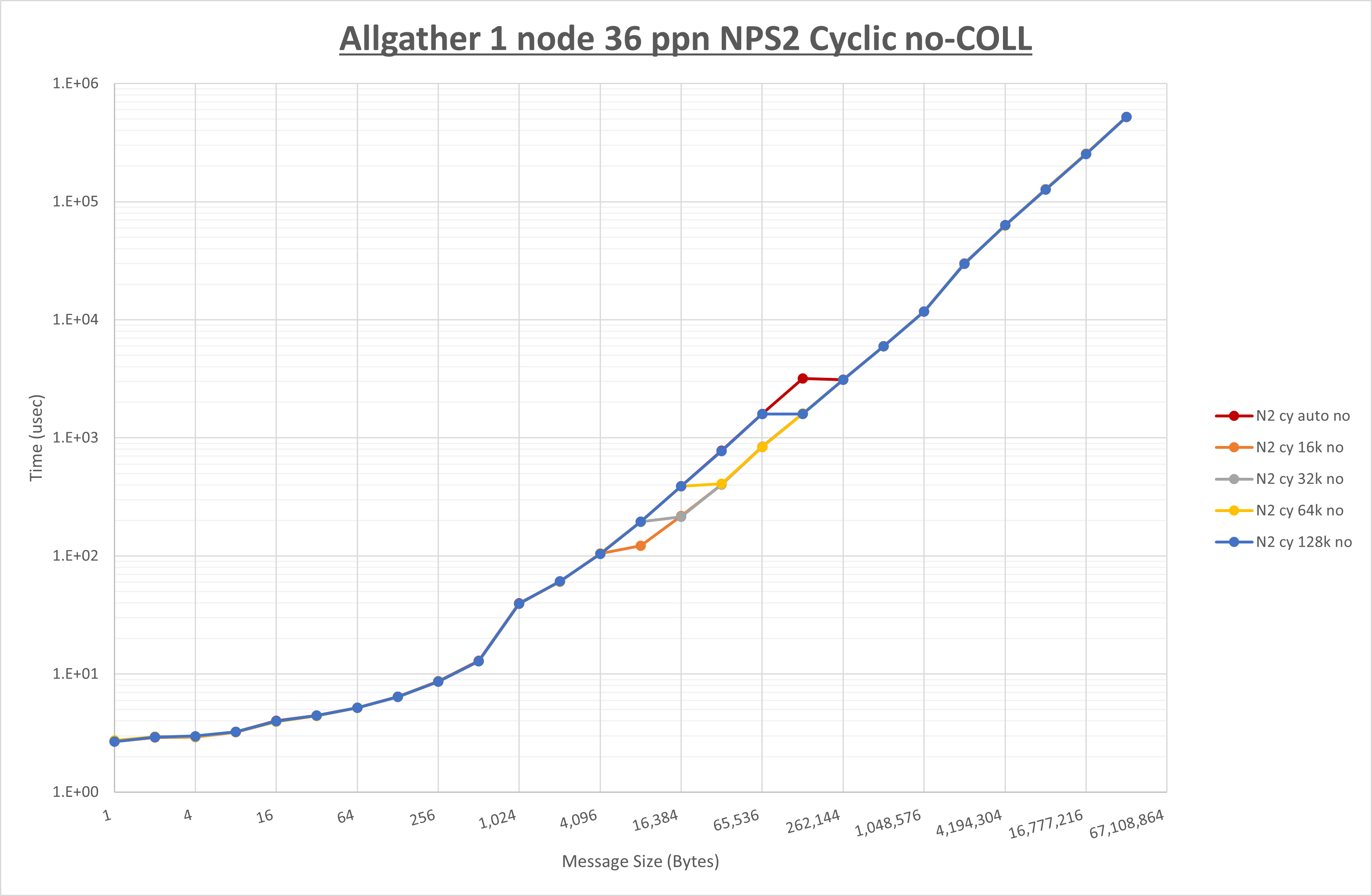
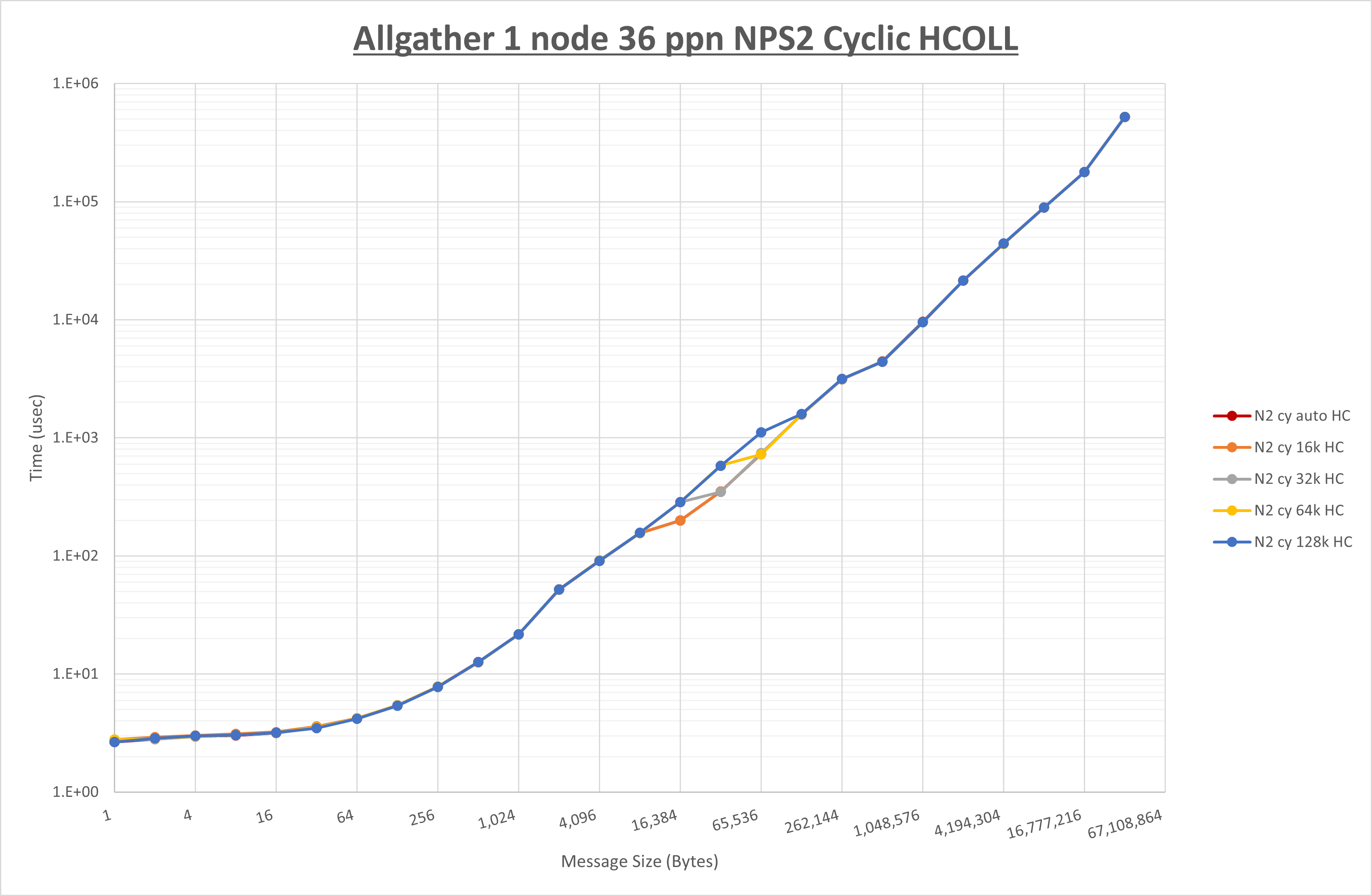
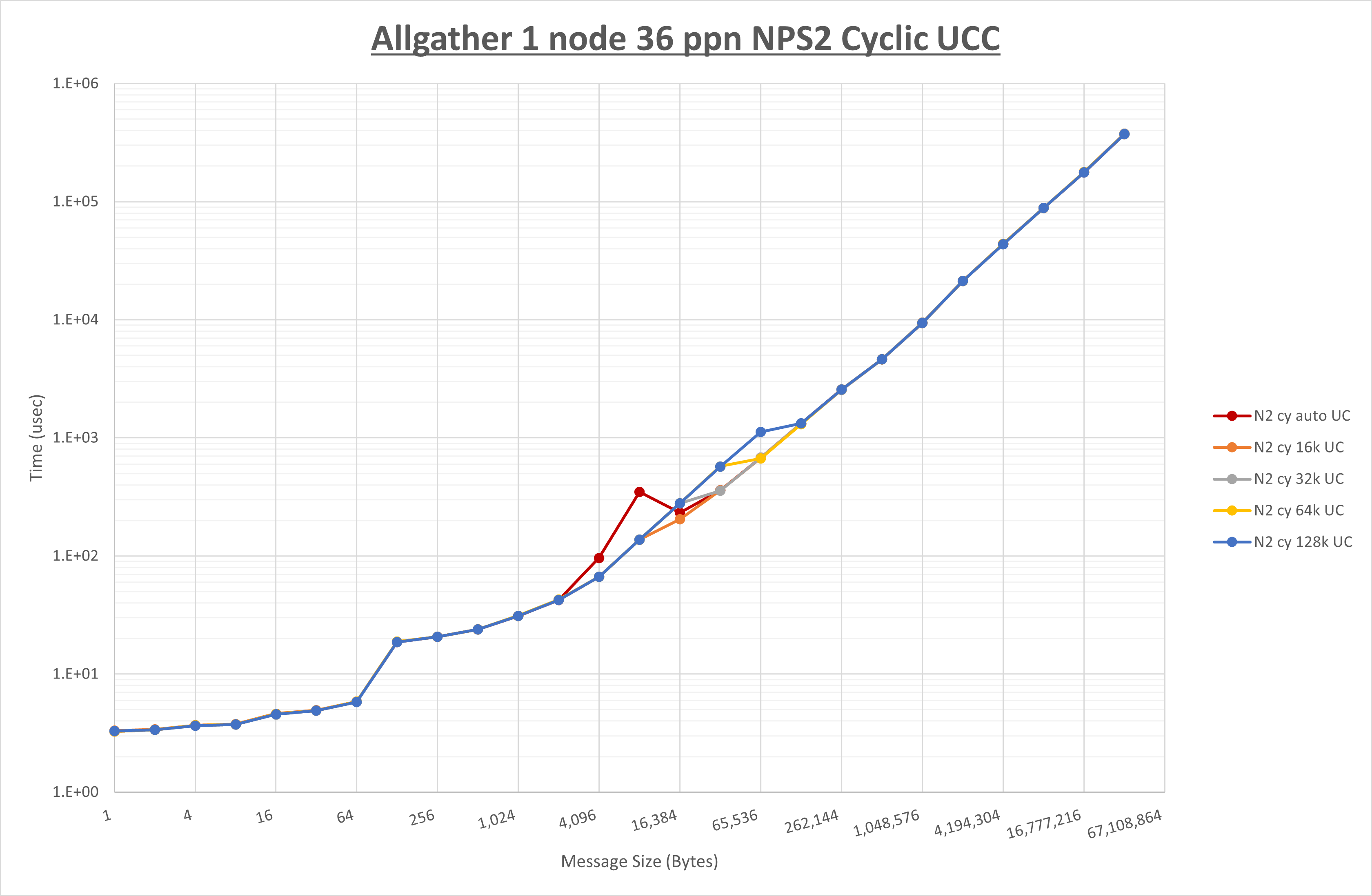
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
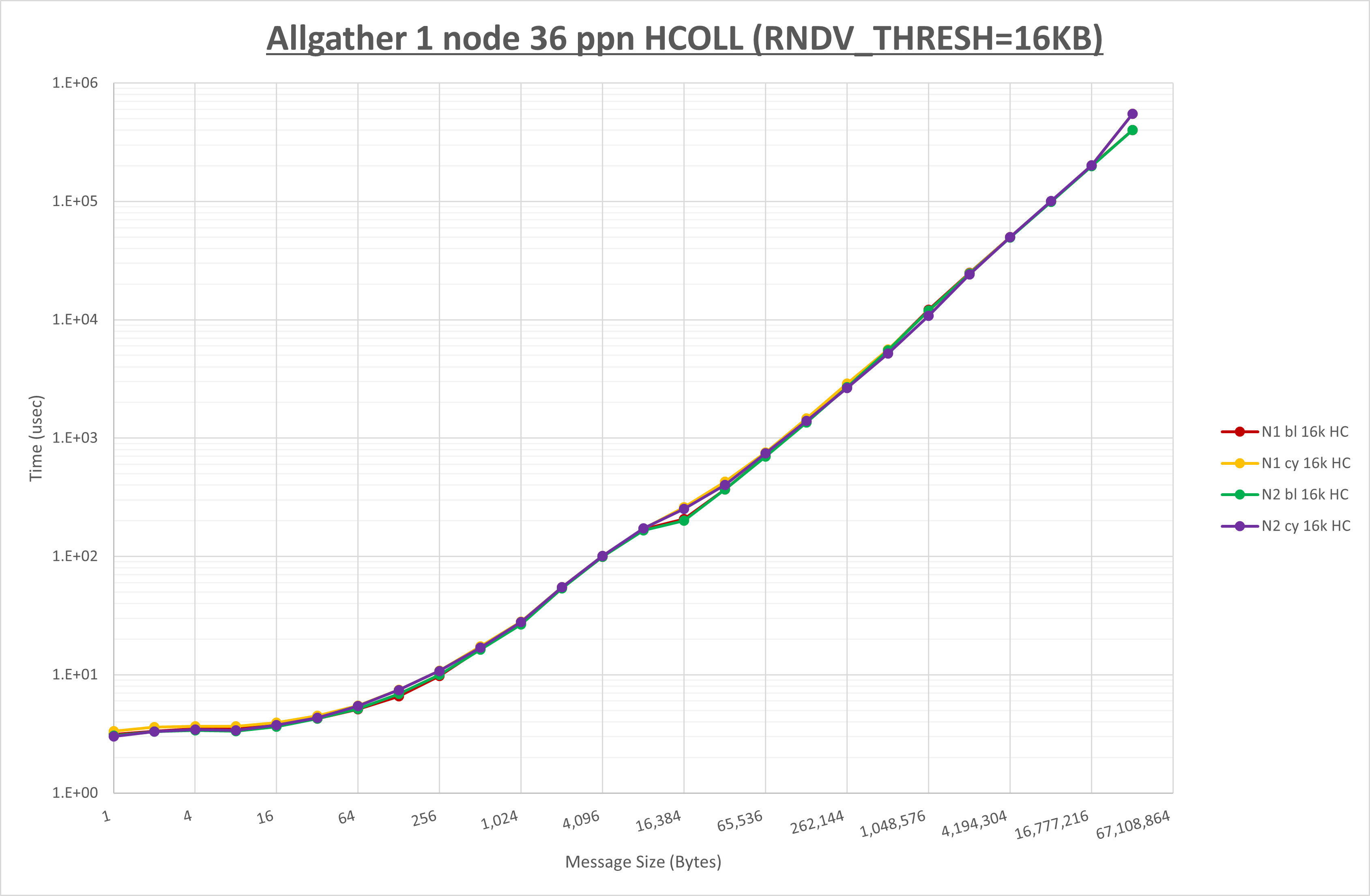
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
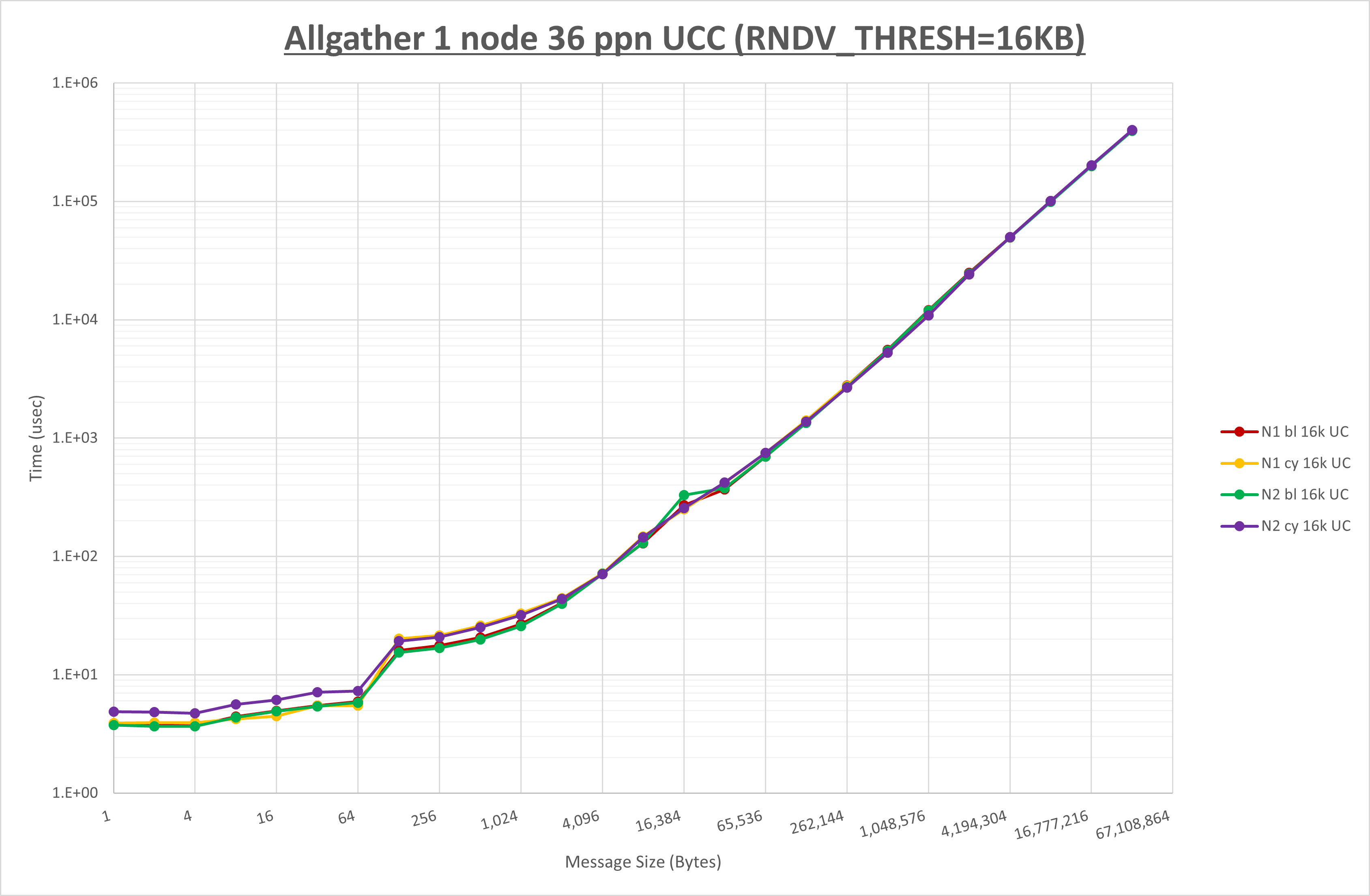
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し1KB以下で性能が向上し2KBから8KBで性能が低下
- UCC は no-COLL と比較し64B以下で性能が向上し128Bから256Bで性能が低下
- チューニング適用による性能差無し
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 NPS 、MPIプロセス分割方法、及び集合通信コンポーネントの組合せ毎に示しています。
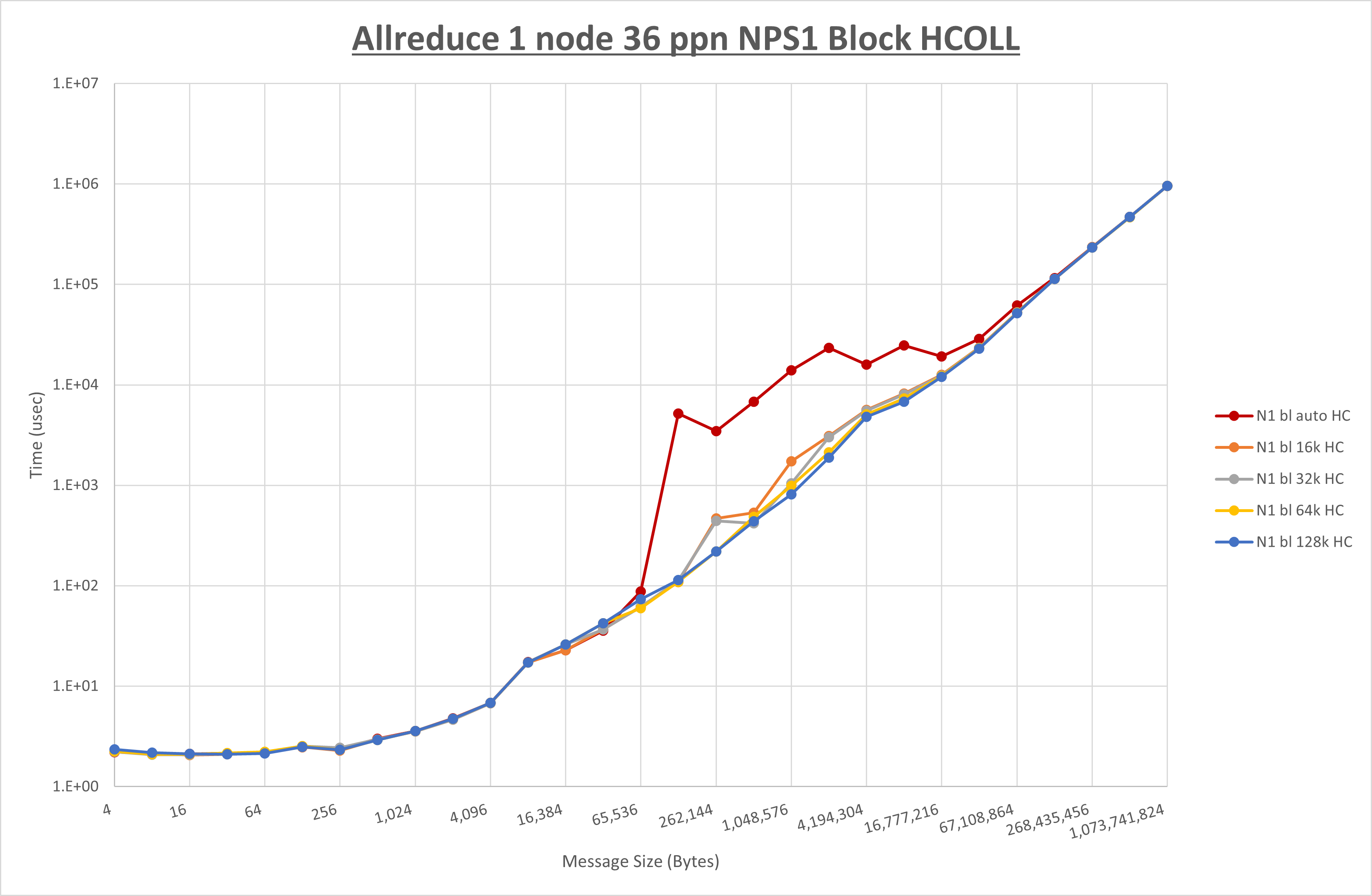
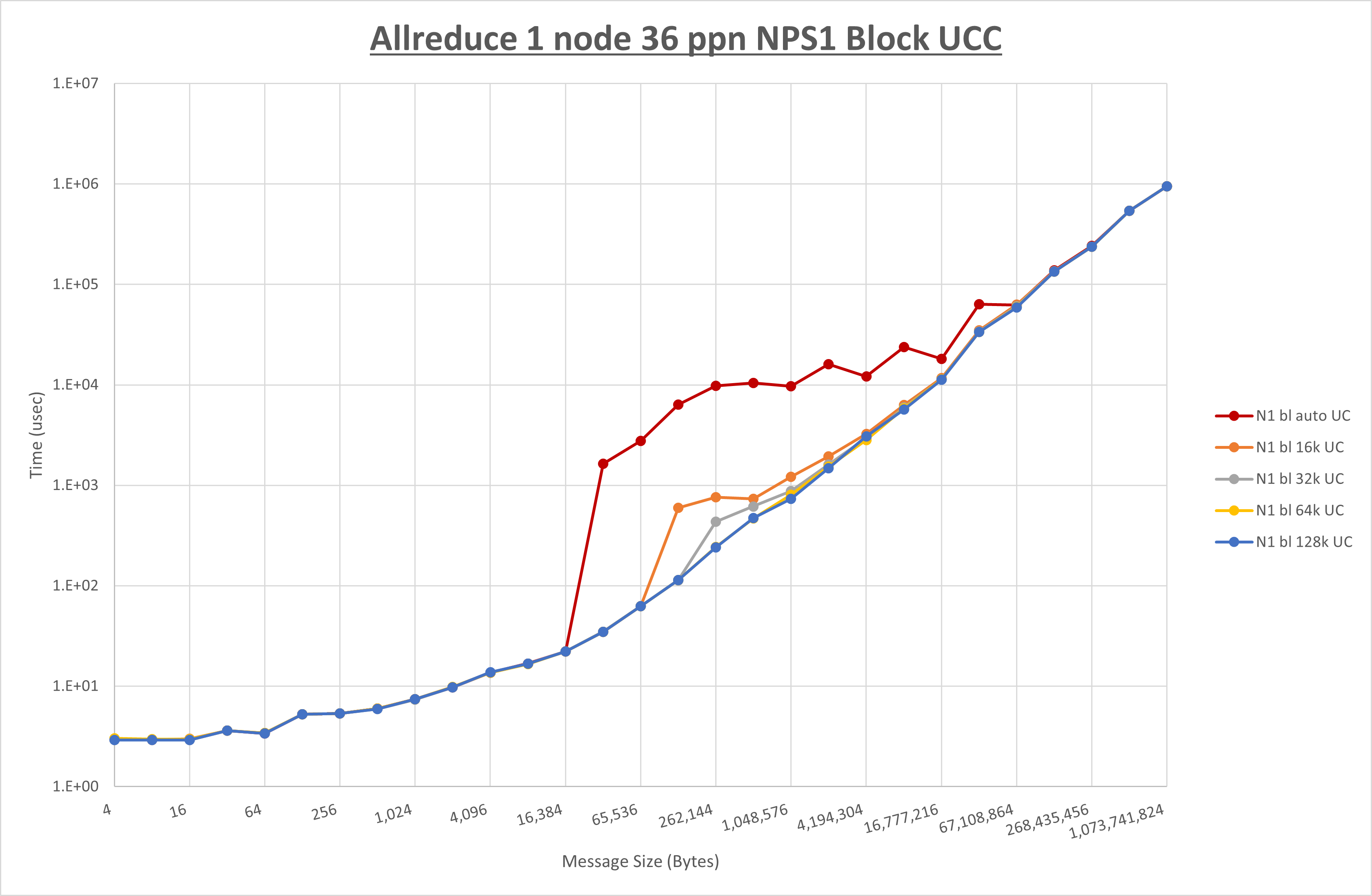
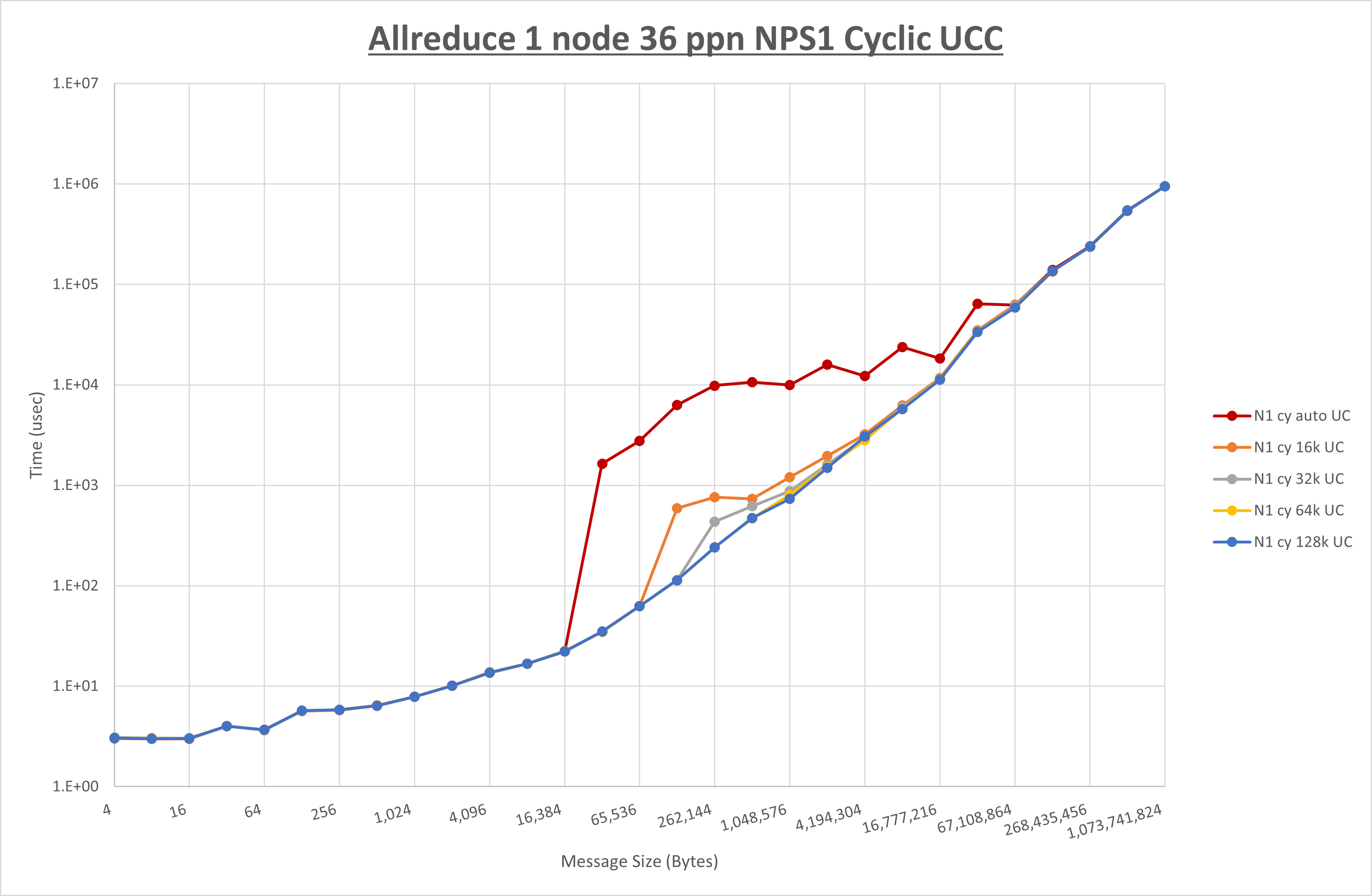
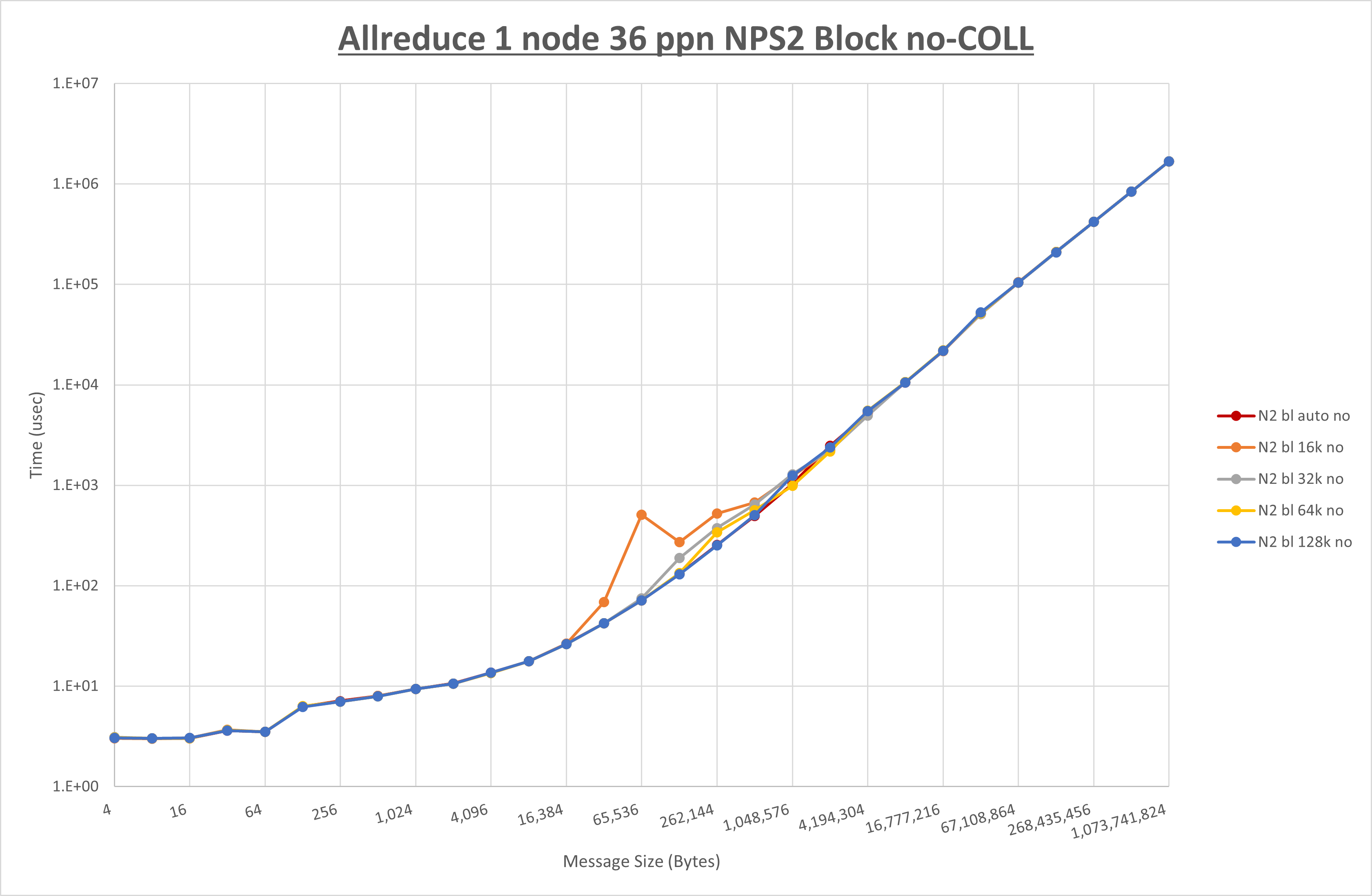
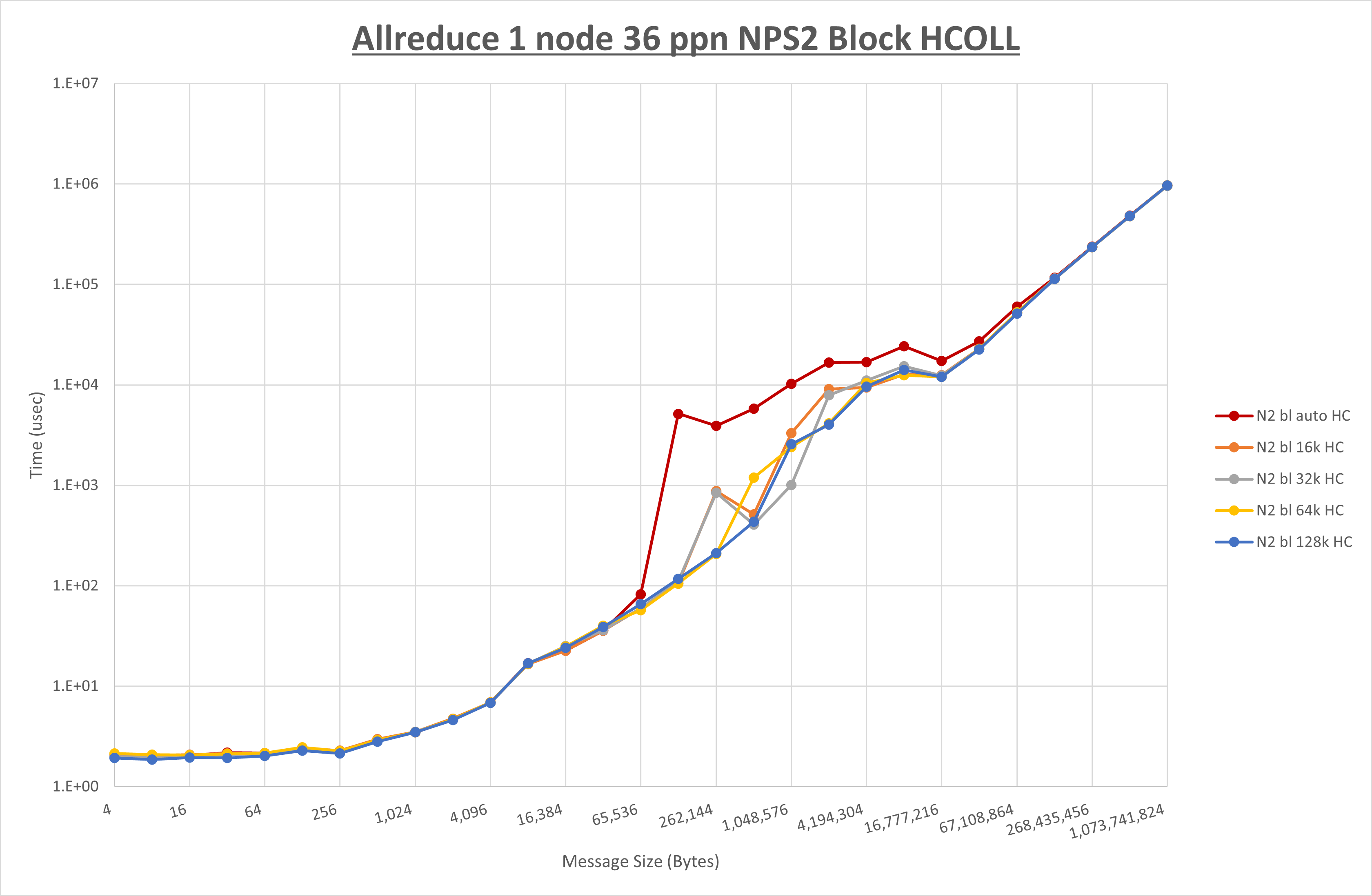
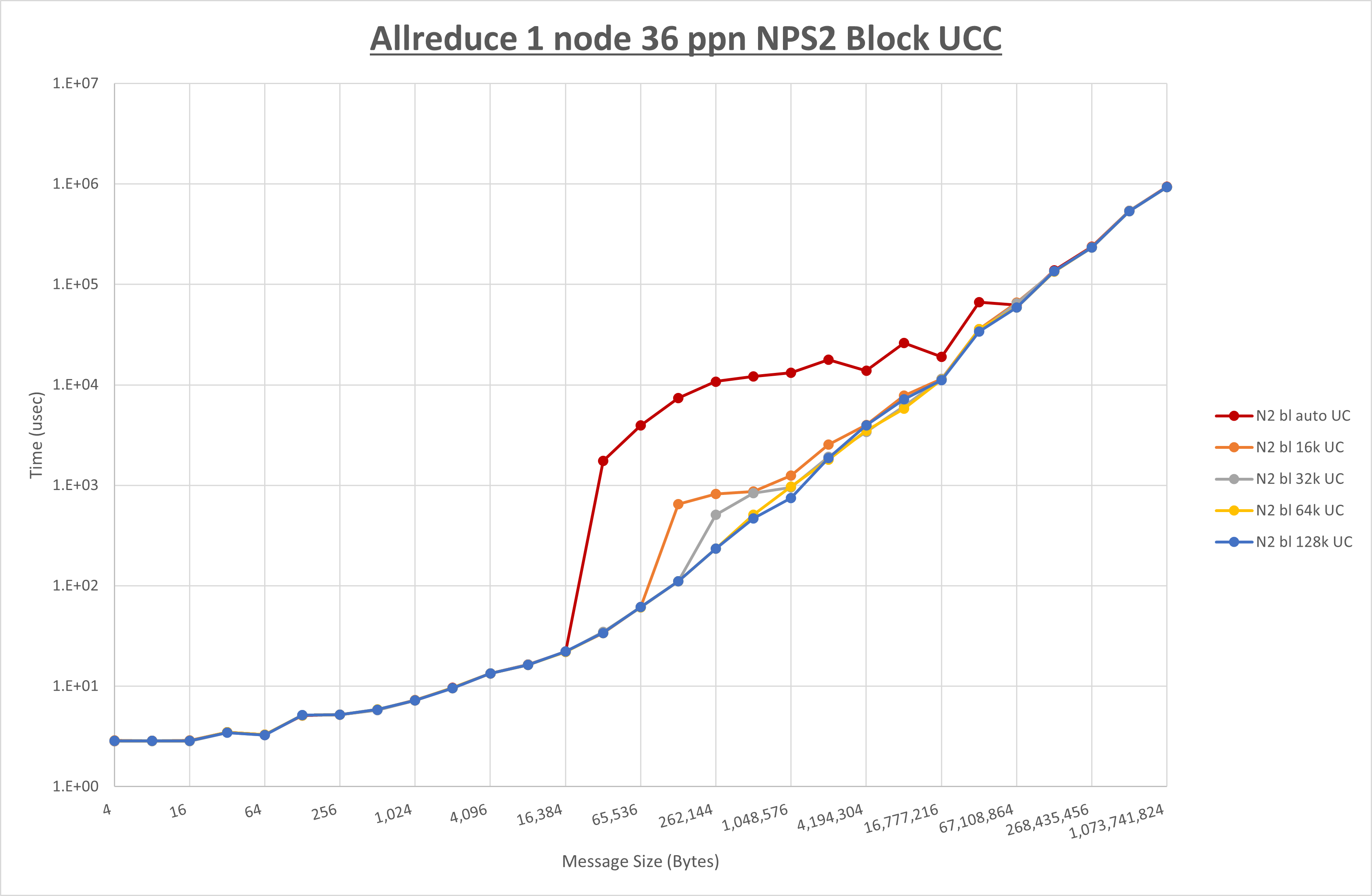
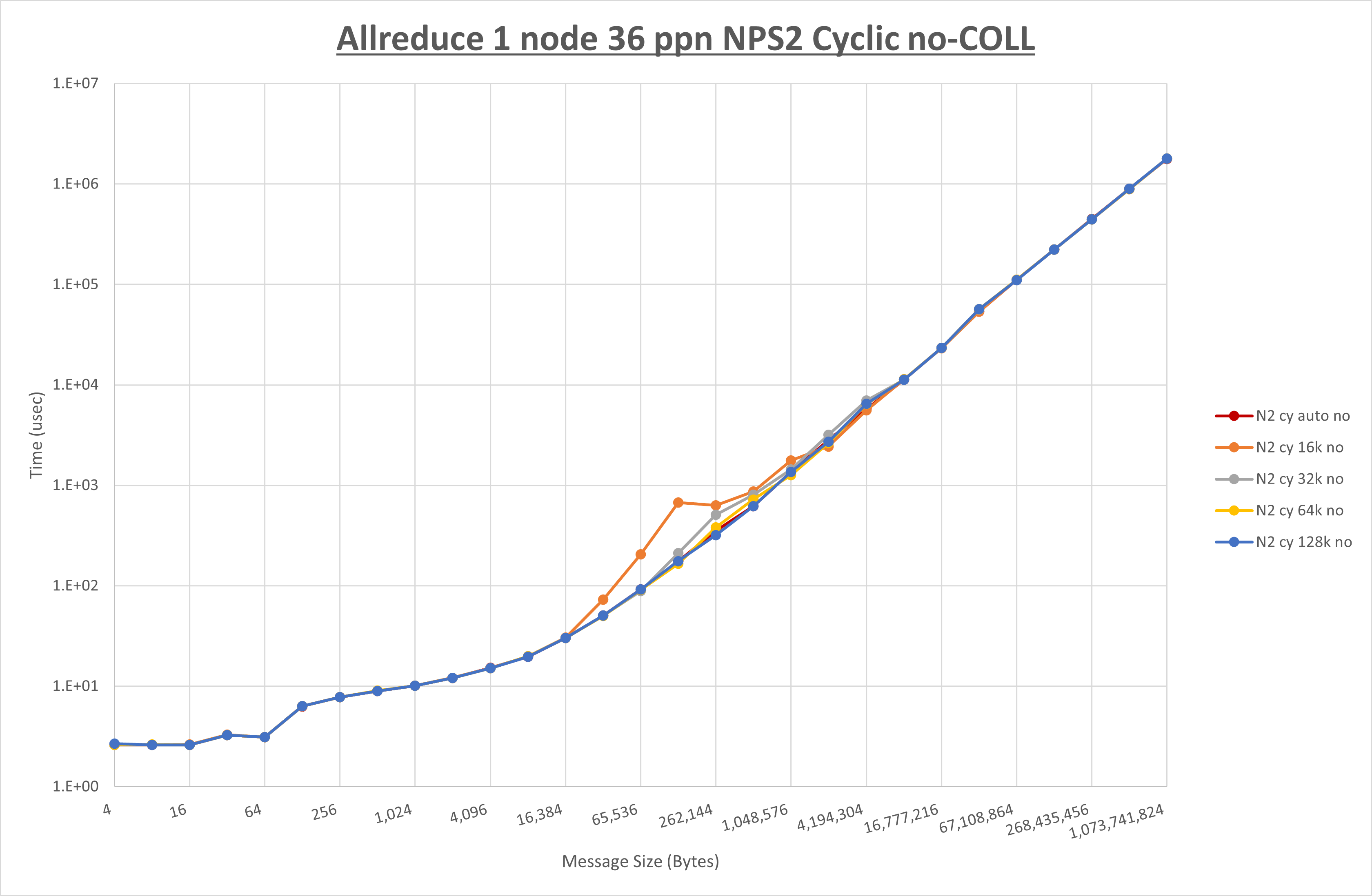
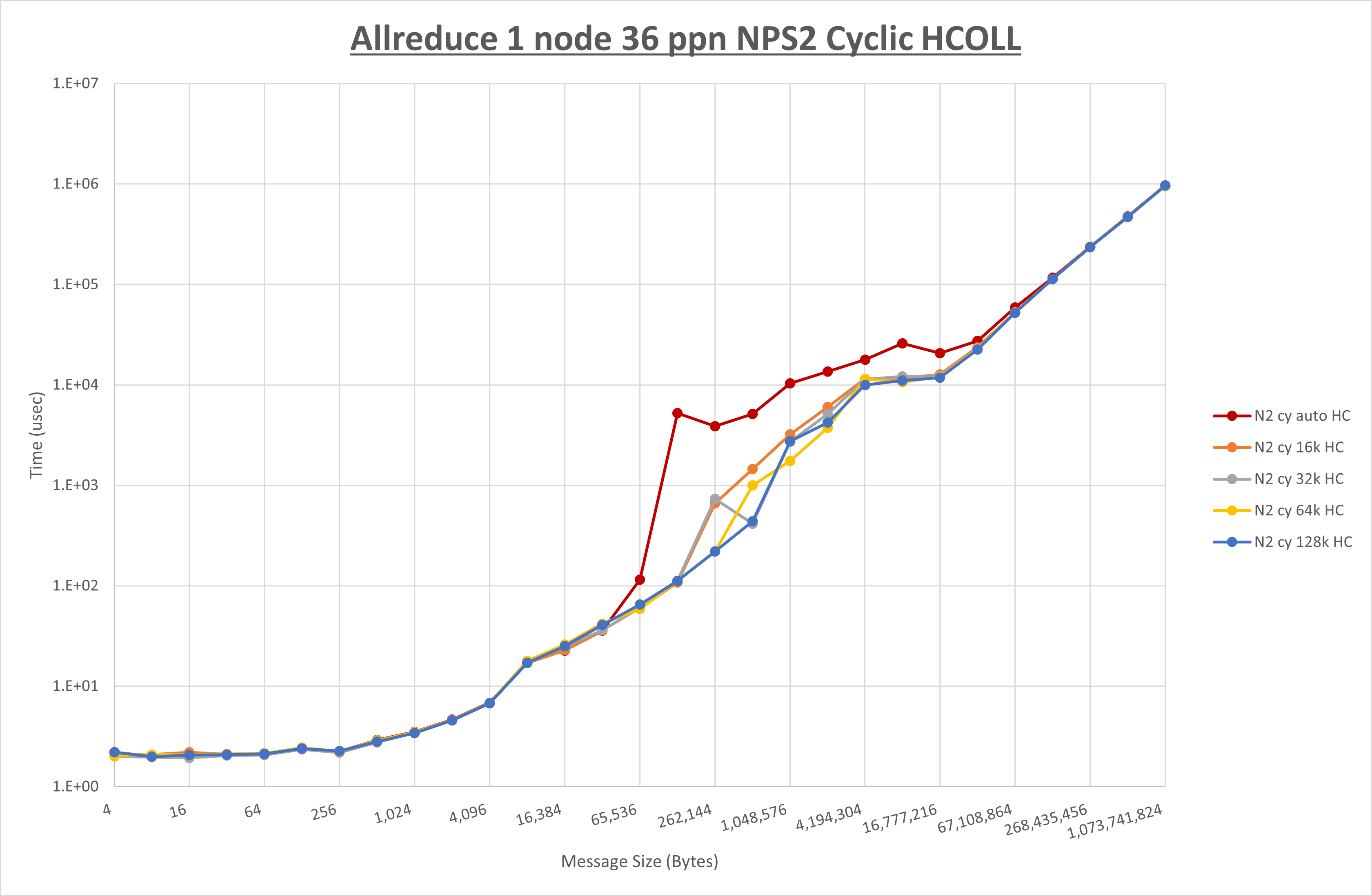
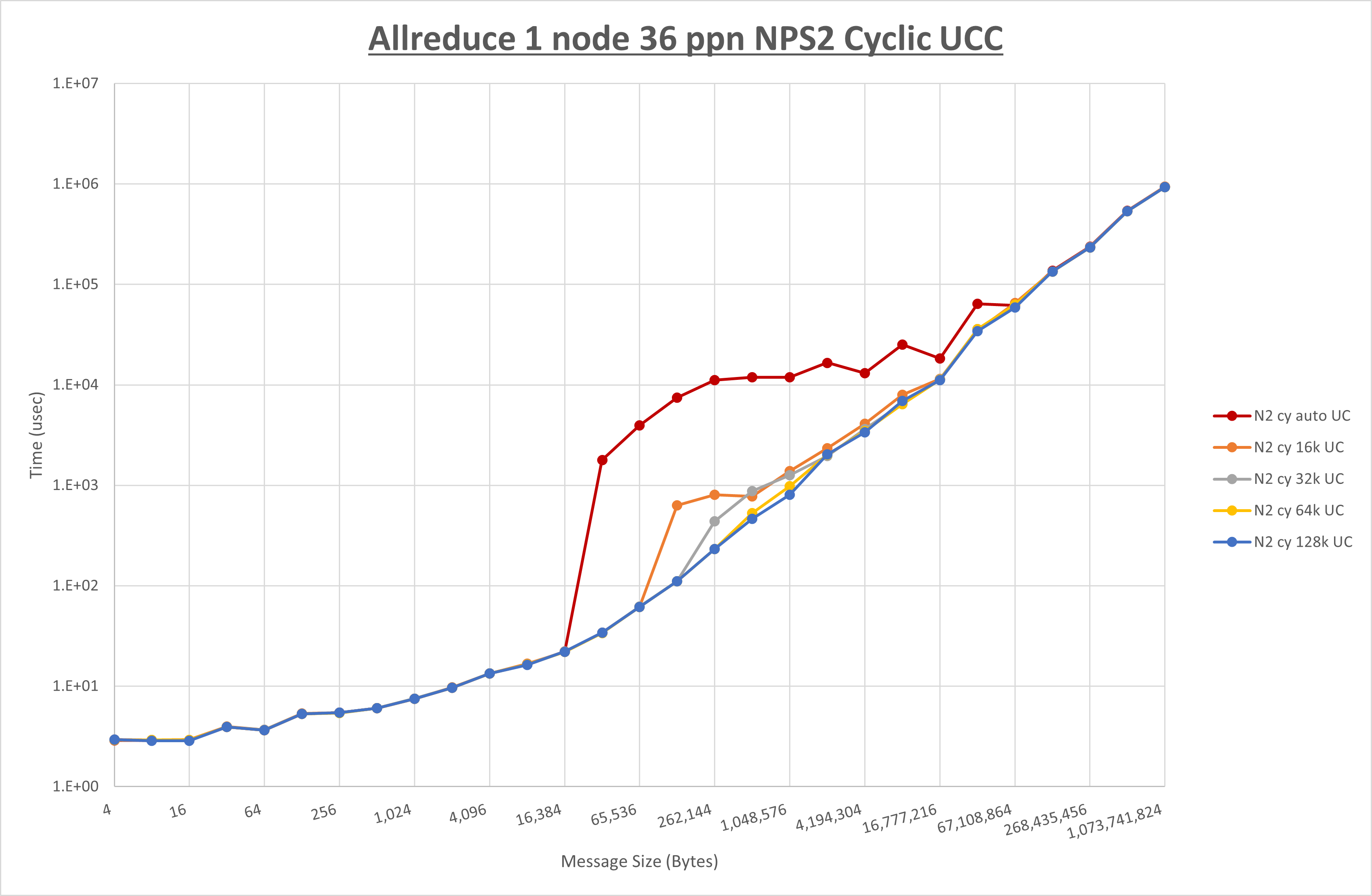
以上より、各集合通信コンポーネントの UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| UCX_RNDV_THRESH | 128KB | 64KB | 64KB |
NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものが以下のグラフです。
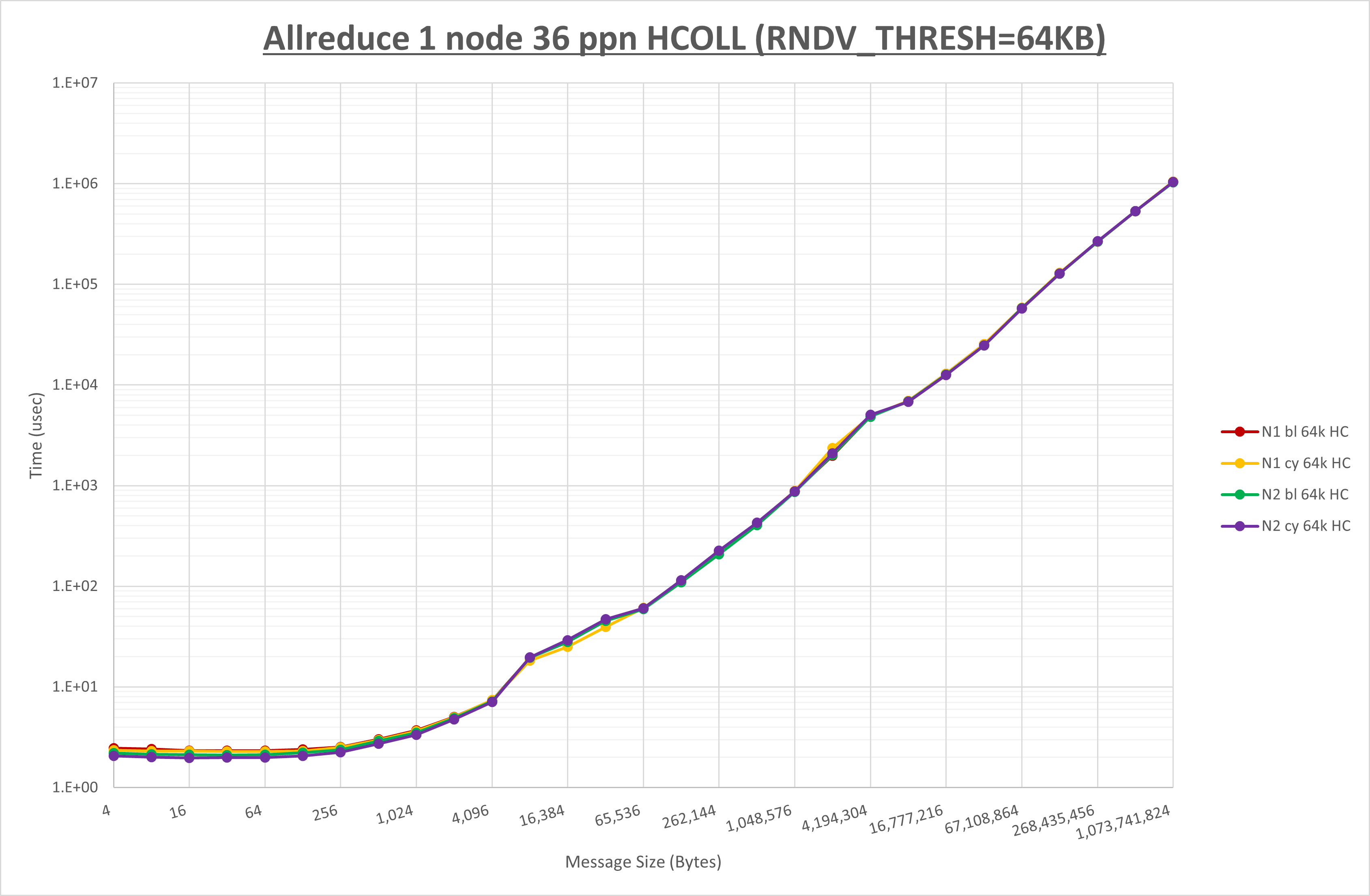
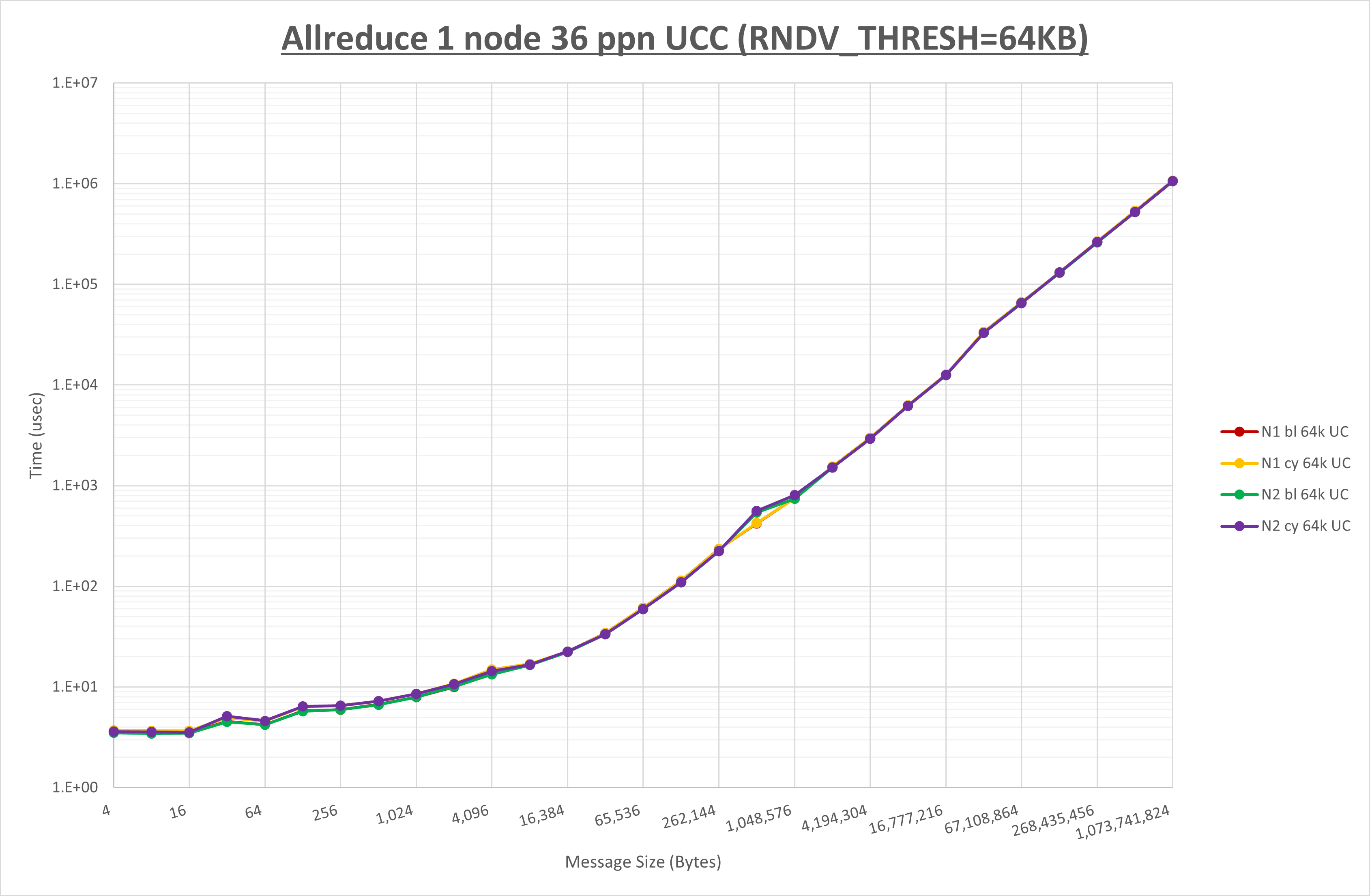
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
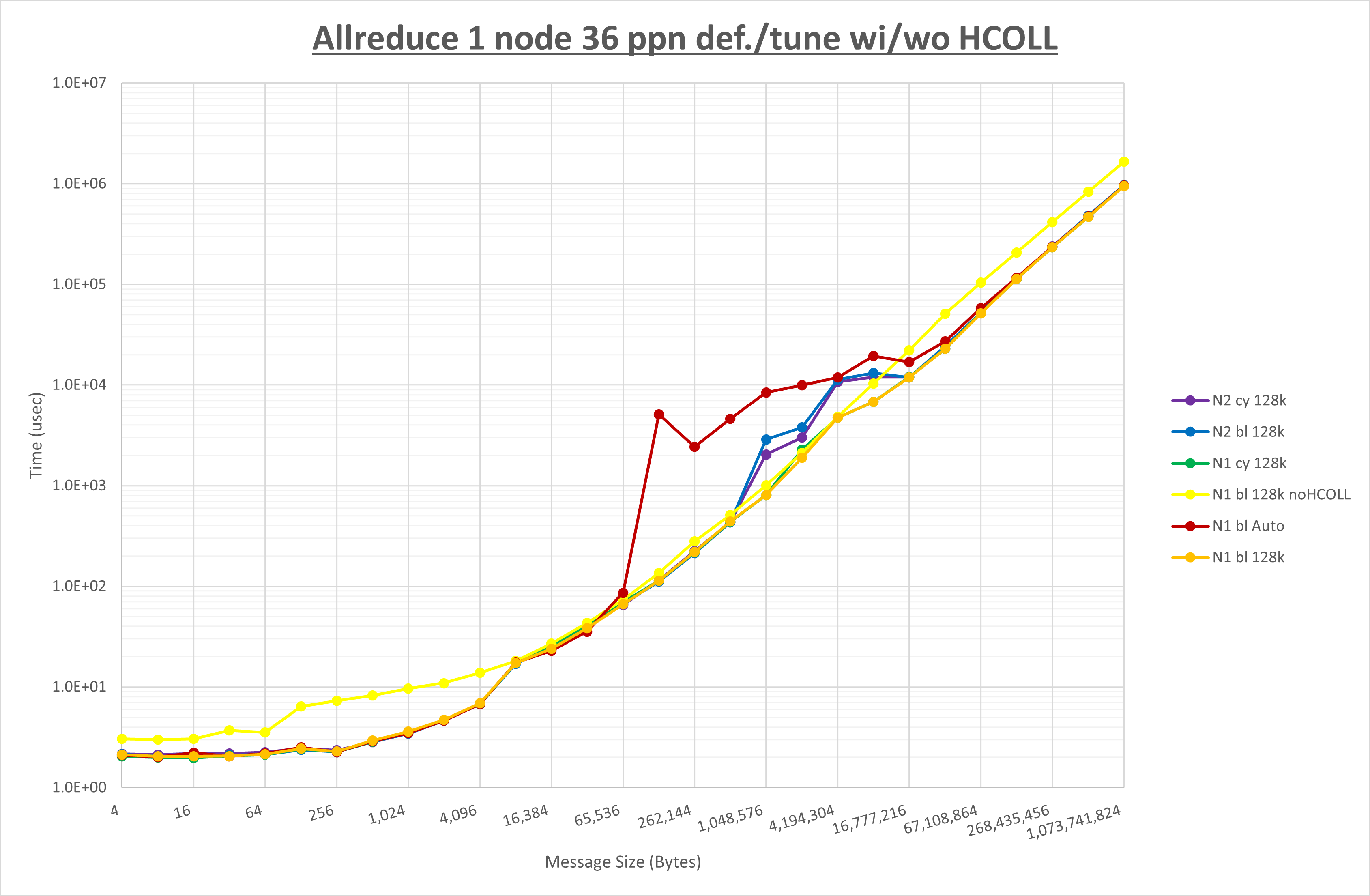
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し4KB以下と64KB以上で性能が向上
- UCC は no-COLL と比較し256KB以下と1MB以上で性能が向上
- チューニング適用で64KBから2MBの間で性能が向上し8KBから32KBで性能が低下
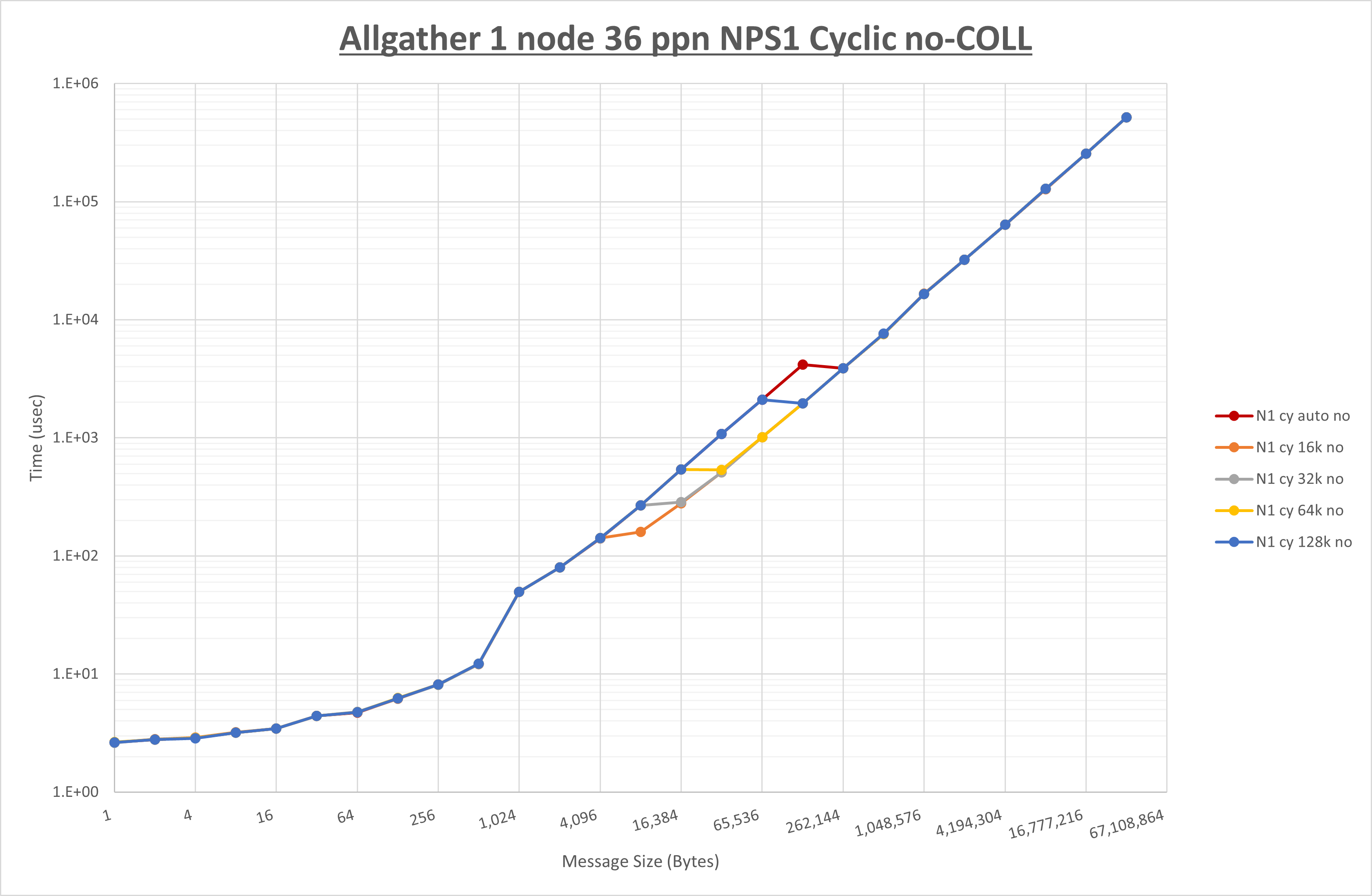
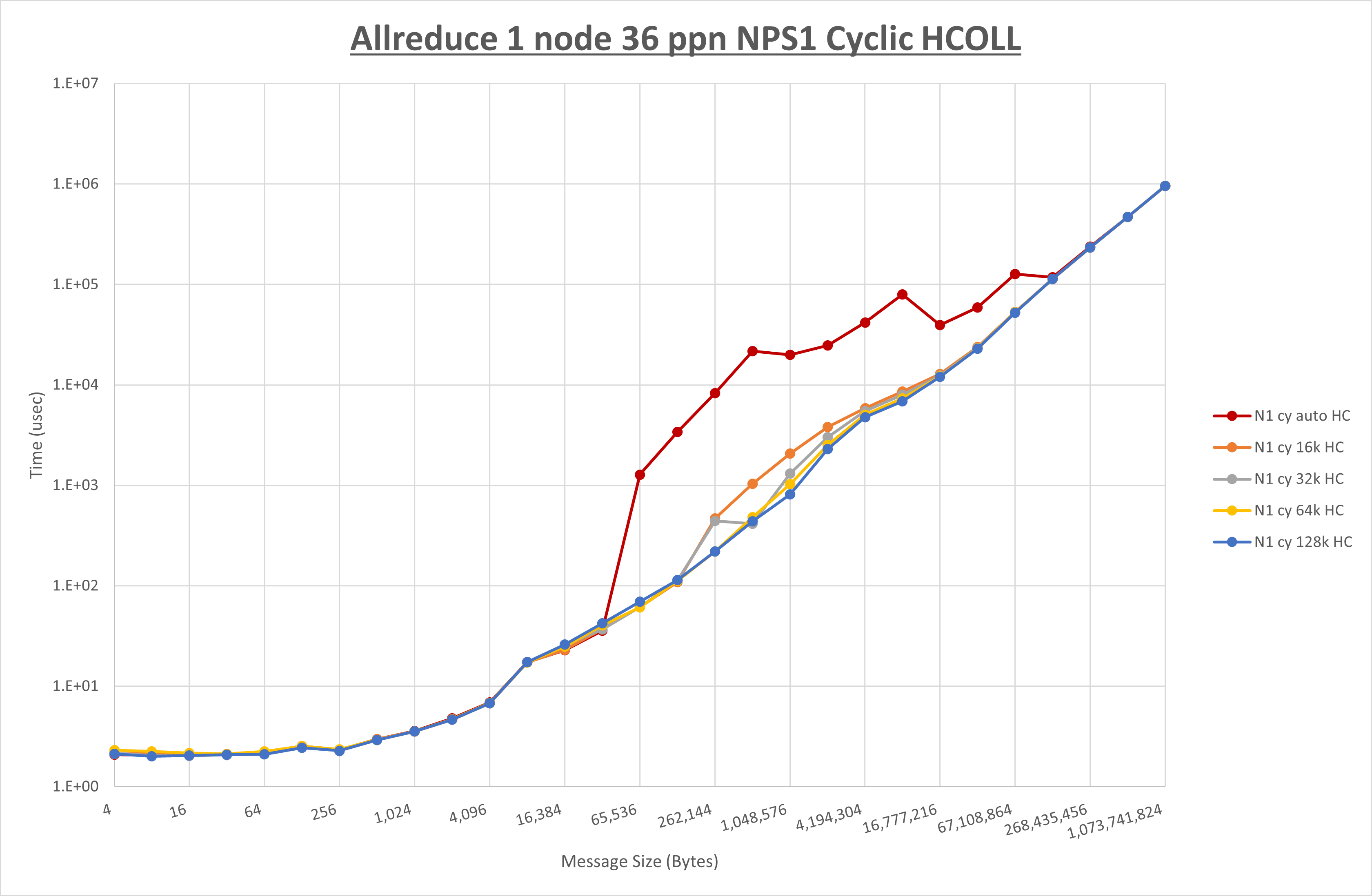
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 NPS とMPIプロセス分割方法の組合せ毎に示しています。
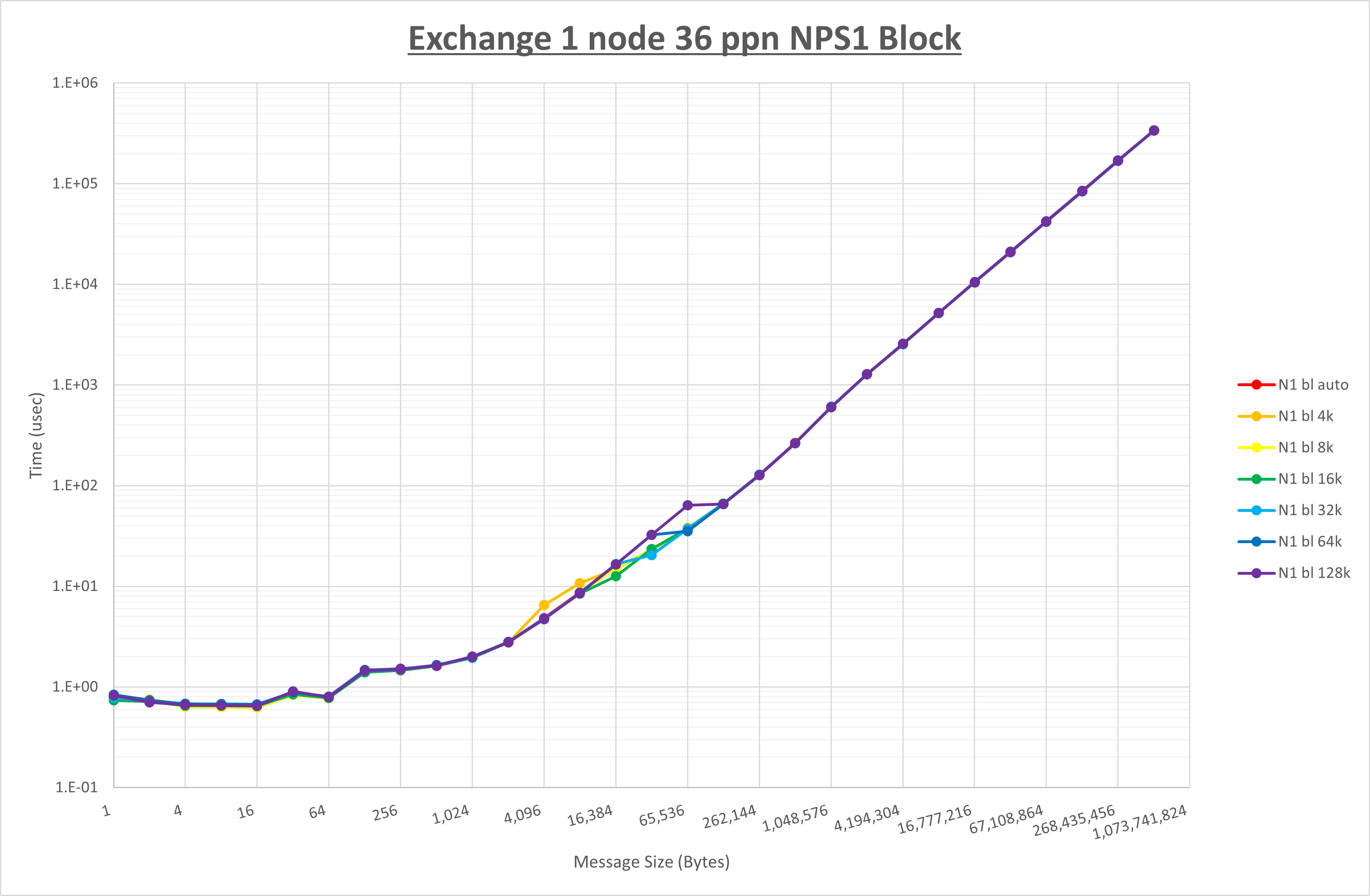
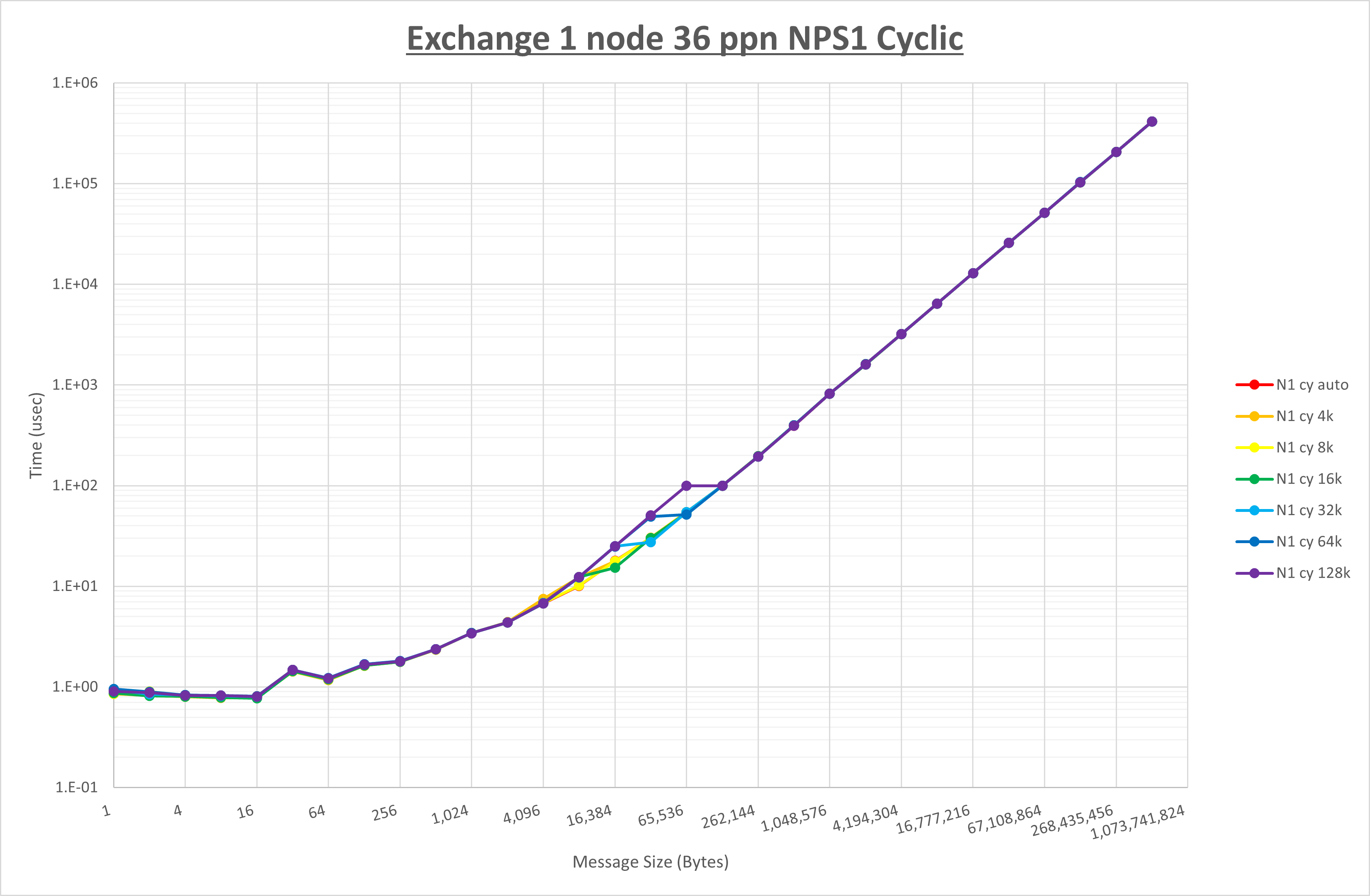
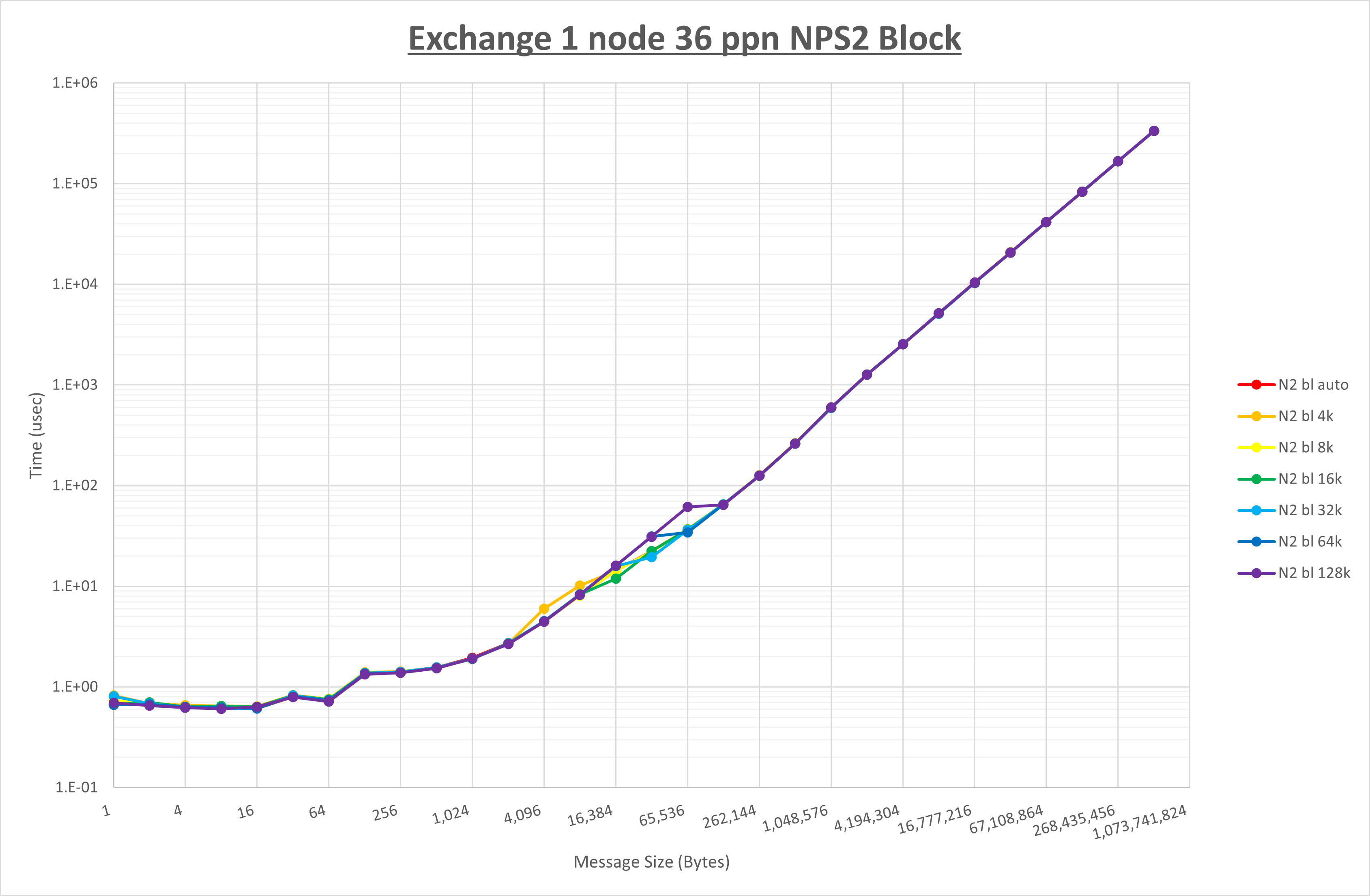
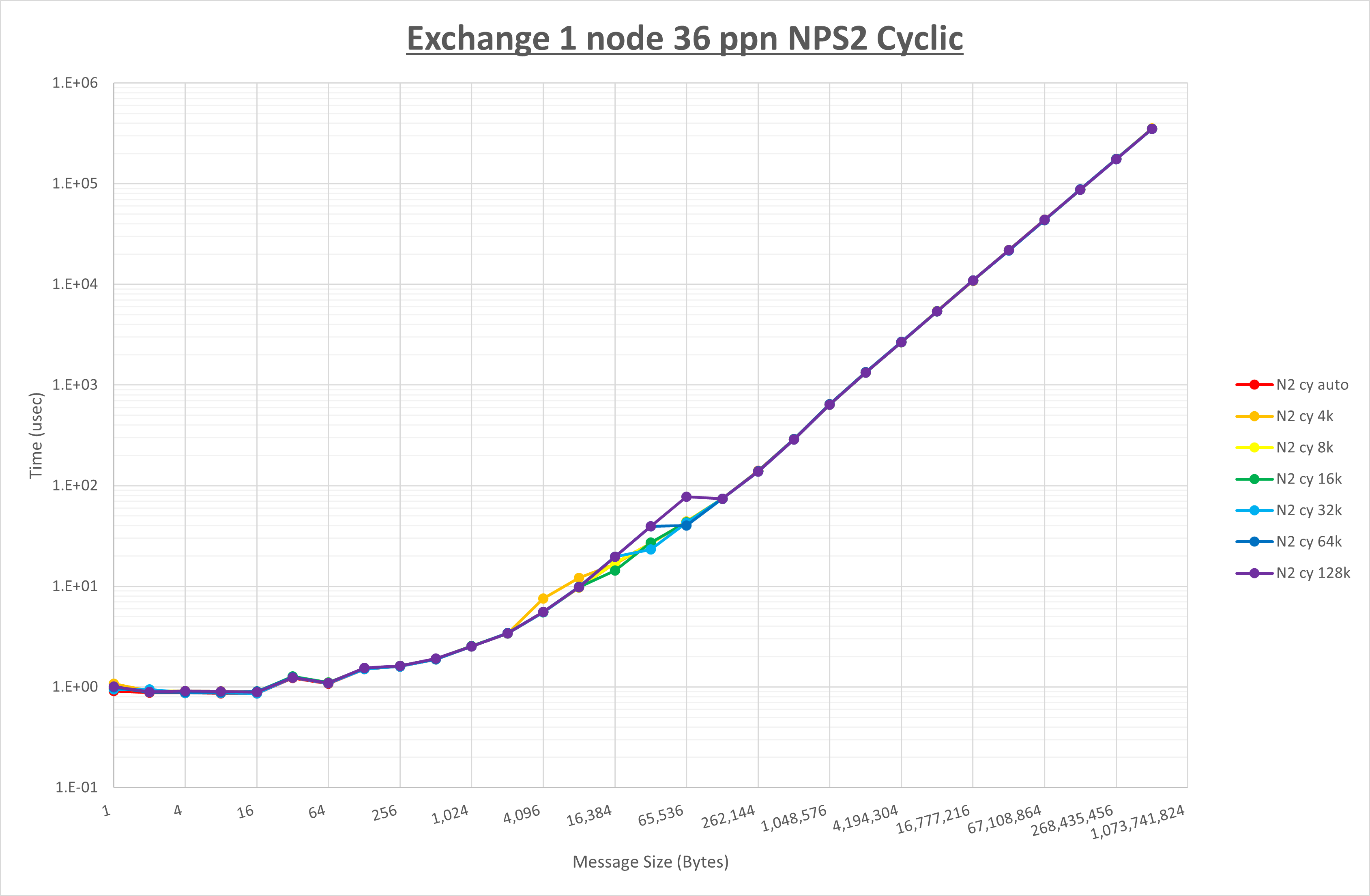
以上より、 NPS とMPIプロセス分割方法の組合せにより UCX_RNDV_THRESH を下表の値とした場合が最も性能が良いと判断してこれを固定、
| NPS1 ブロック分割 |
NPS1 サイクリック分割 |
NPS2 ブロック分割 |
NPS2 サイクリック分割 |
|
|---|---|---|---|---|
| UCX_RNDV_THRESH | 16KB | 16KB | 16KB | 16KB |
NPS とMPIプロセス分割方法の各組合せを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_RNDV_THRESH=auto )を含めています。
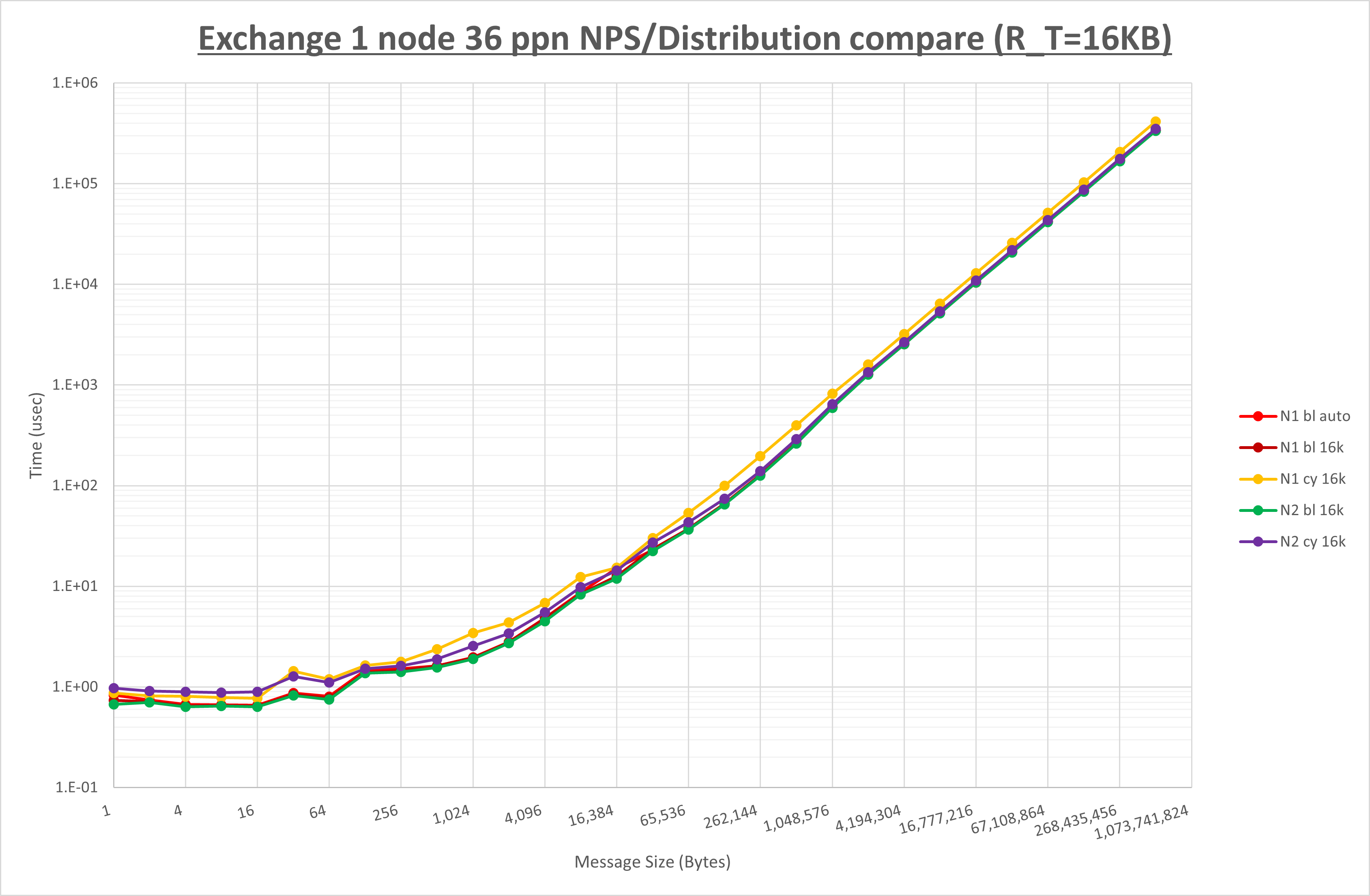
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で16KBの性能が向上
本章は、2ノードにノード当たり8・16・32・36、トータル16・32・64・72のMPIプロセスを割当てる場合の Alltoall ・ Allgather ・ Allreduce ・ Exchange の通信性能について、以下の 実行時パラメータ の最適な組み合わせを検証します。
- UCX_TLS : all ・ self,sm,rc ・ self,sm,ud ・ self,sm,dc
- UCX_RNDV_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb (※13)
- UCX_ZCOPY_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb
- coll_hcoll_enable : 0 ・ 1 ( Exchange を除きます。)
- coll_ucc_enable : 0 ・ 1 ( Exchange を除きます。)
- MPIプロセス分割方法 : ブロック分割・サイクリック分割
- NPS : NPS1 ・ NPS2
※13) UCX_RNDV_THRESH は、ノード内は auto と 1. 1ノード で判明した最適値、ノード間はこの7種類を使用し、以下8個の組合せを検証します。
- intra:auto,inter:auto
- intra:optimal_value,inter:auto
- intra:optimal_value,inter:4kb
- intra:optimal_value,inter:8kb
- intra:optimal_value,inter:16kb
- intra:optimal_value,inter:32kb
- intra:optimal_value,inter:64kb
- intra:optimal_value,inter:128kb
ここで、全ての 実行時パラメータ の組み合わせを検証することは非現実的なため、組み合わせを減らす目的で以下3ステップに分けて検証を行います。
- ステップ1
- UCX_TLS と UCX_RNDV_THRESH を組合せた32個のパターンを検証してこれらの最適値を決定
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ2
- UCX_ZCOPY_THRESH の7パターンを検証してこの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ3
- coll_hcoll_enable / coll_ucc_enable / MPIプロセス分割方法 / NPS を組合せた12パターンを検証してこれらの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- UCX_ZCOPY_THRESH はステップ2で決定した最適値を使用
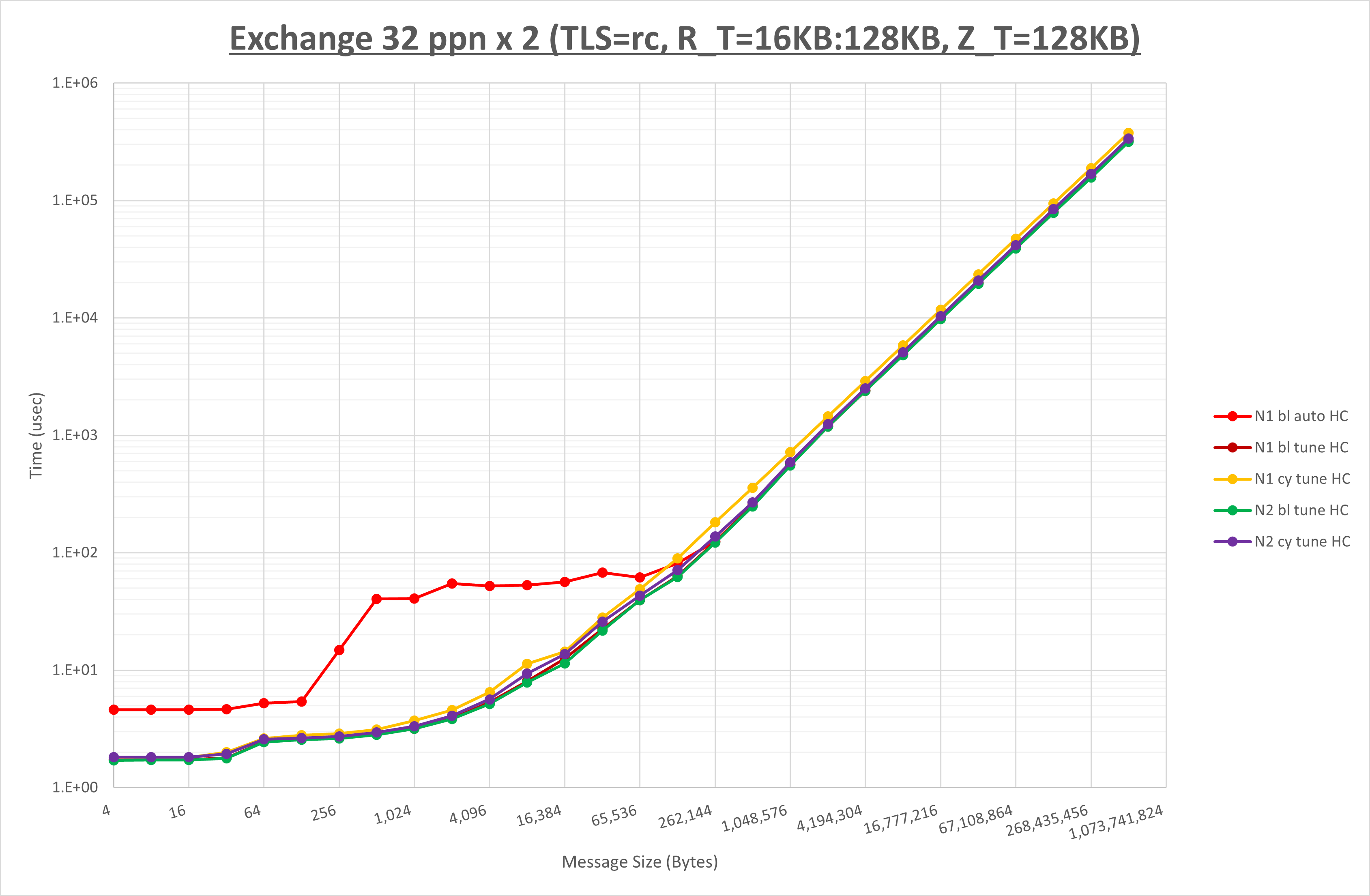
本章は、2ノードにノード当たり8、トータル16のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,rc | intra:32kb,inter:128kb | 128kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,ud | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:32kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-1 Alltoall の HCOLL の結果から32KBとしています。
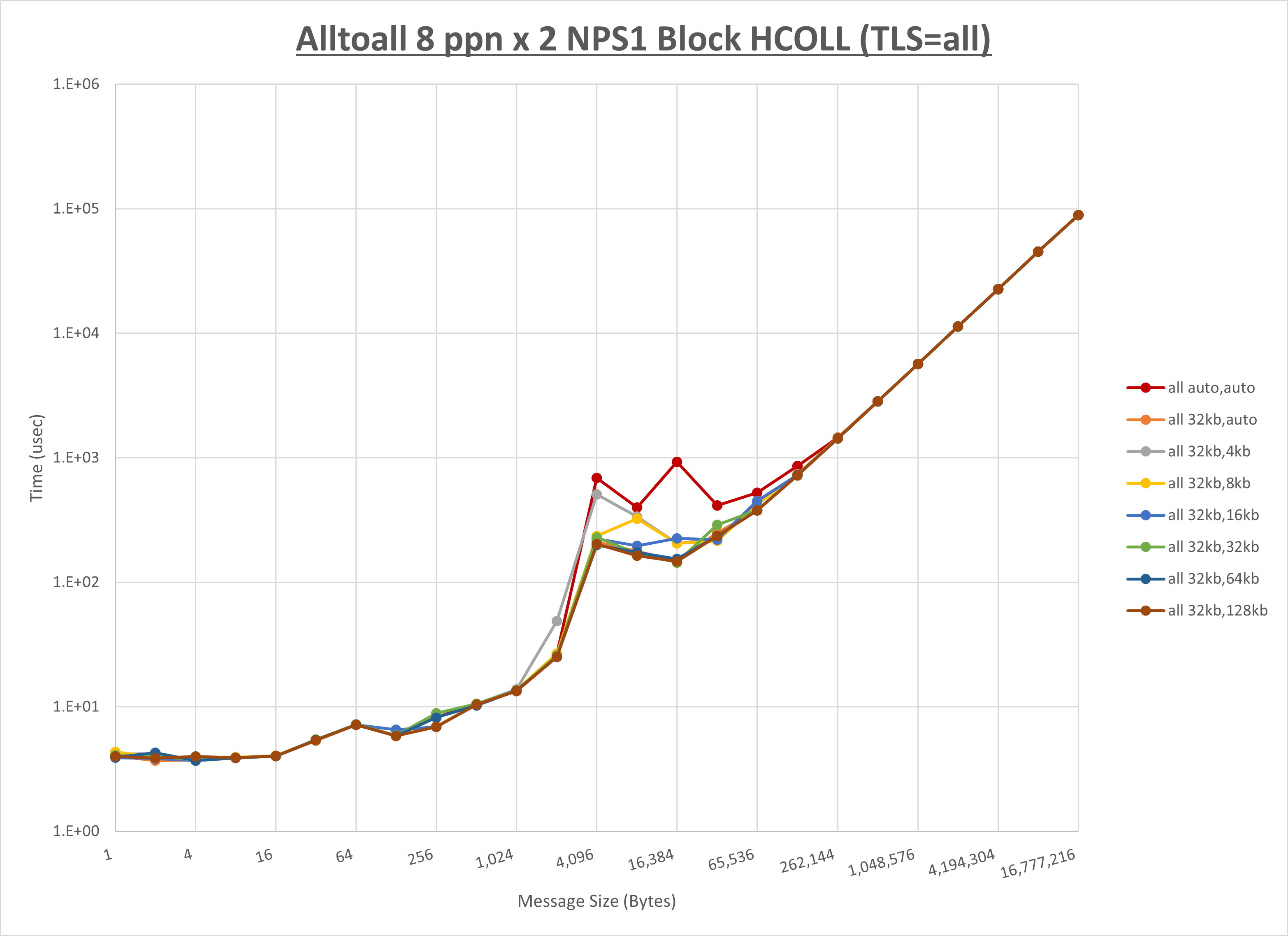
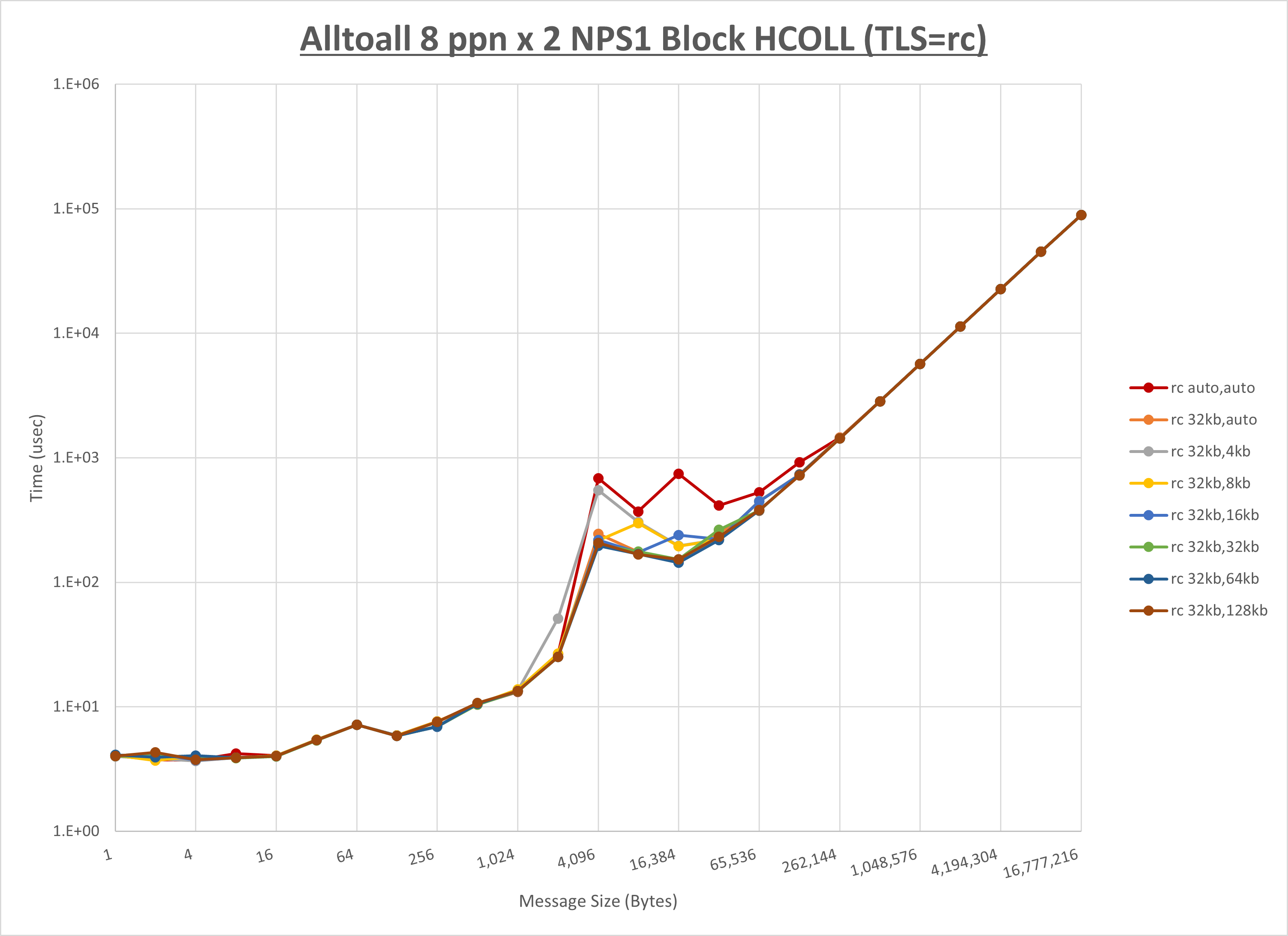
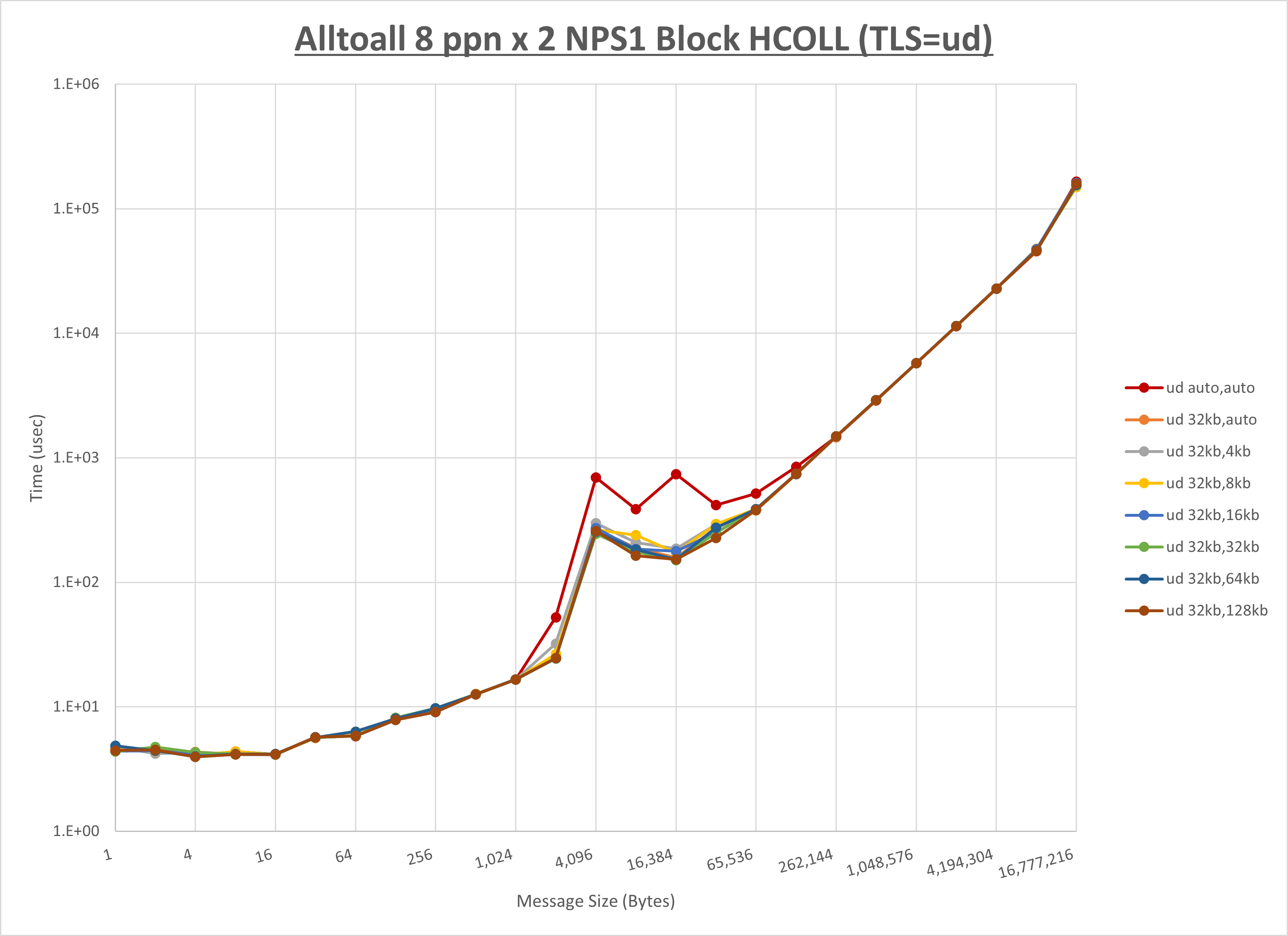
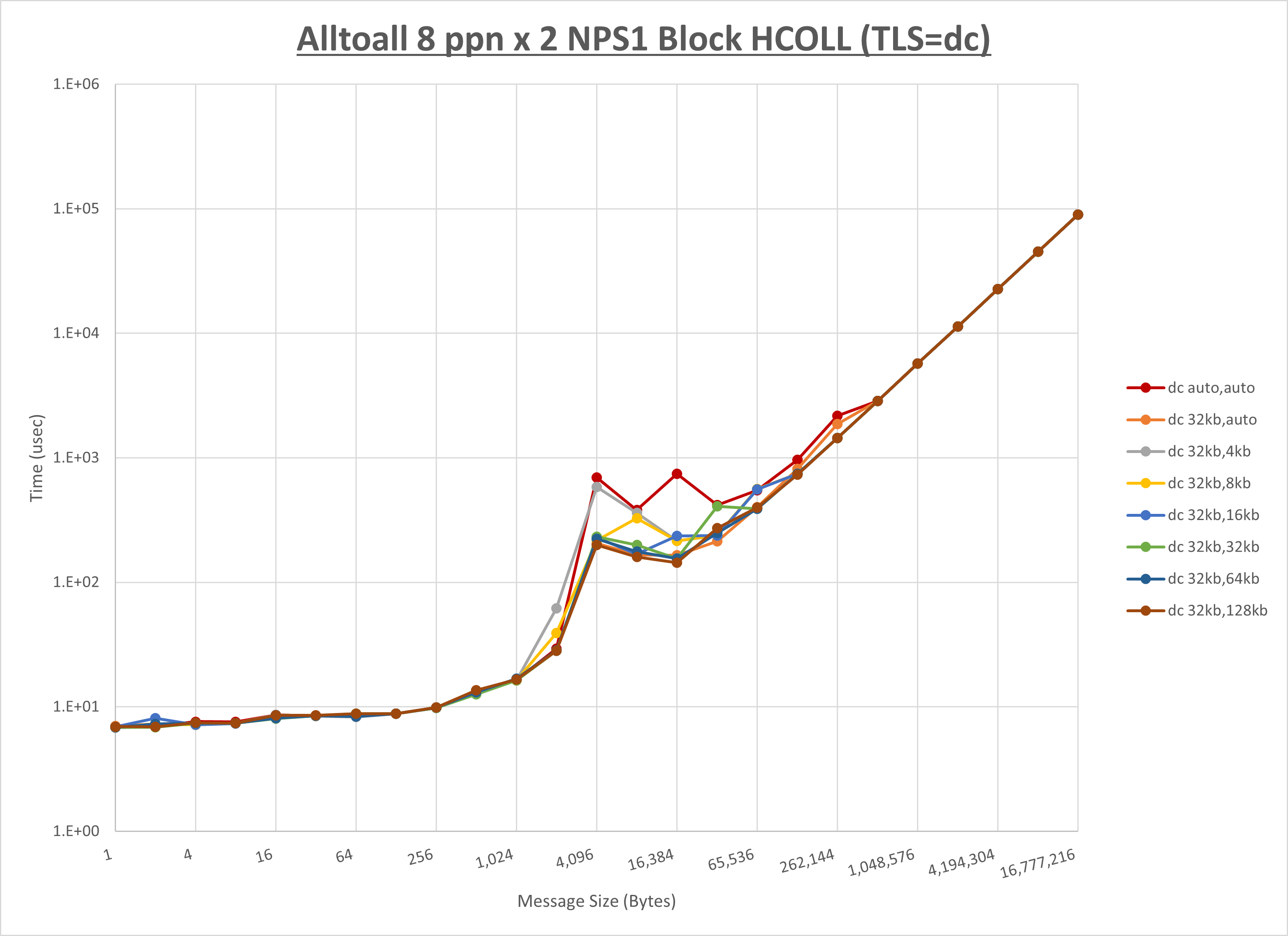
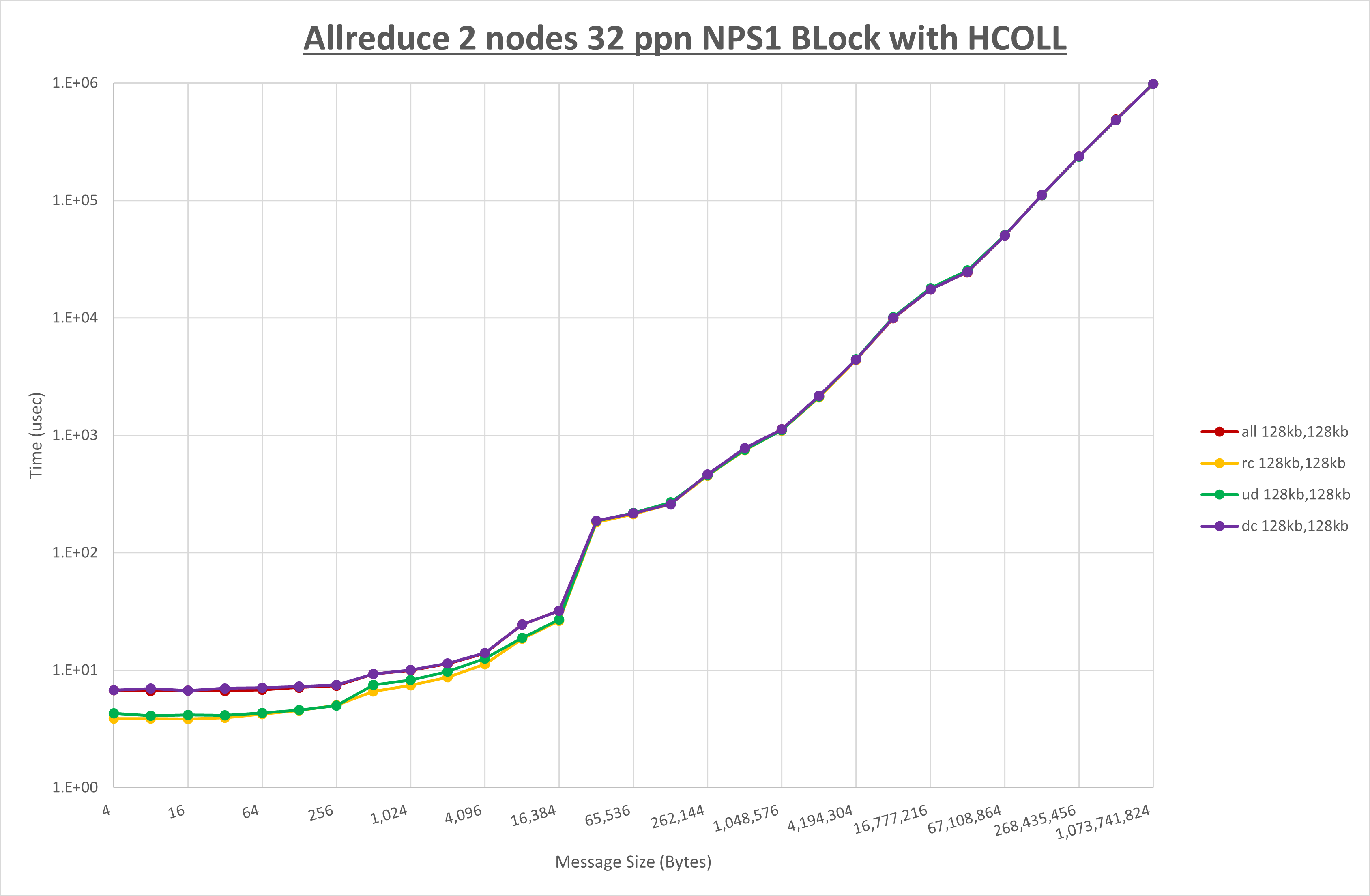
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
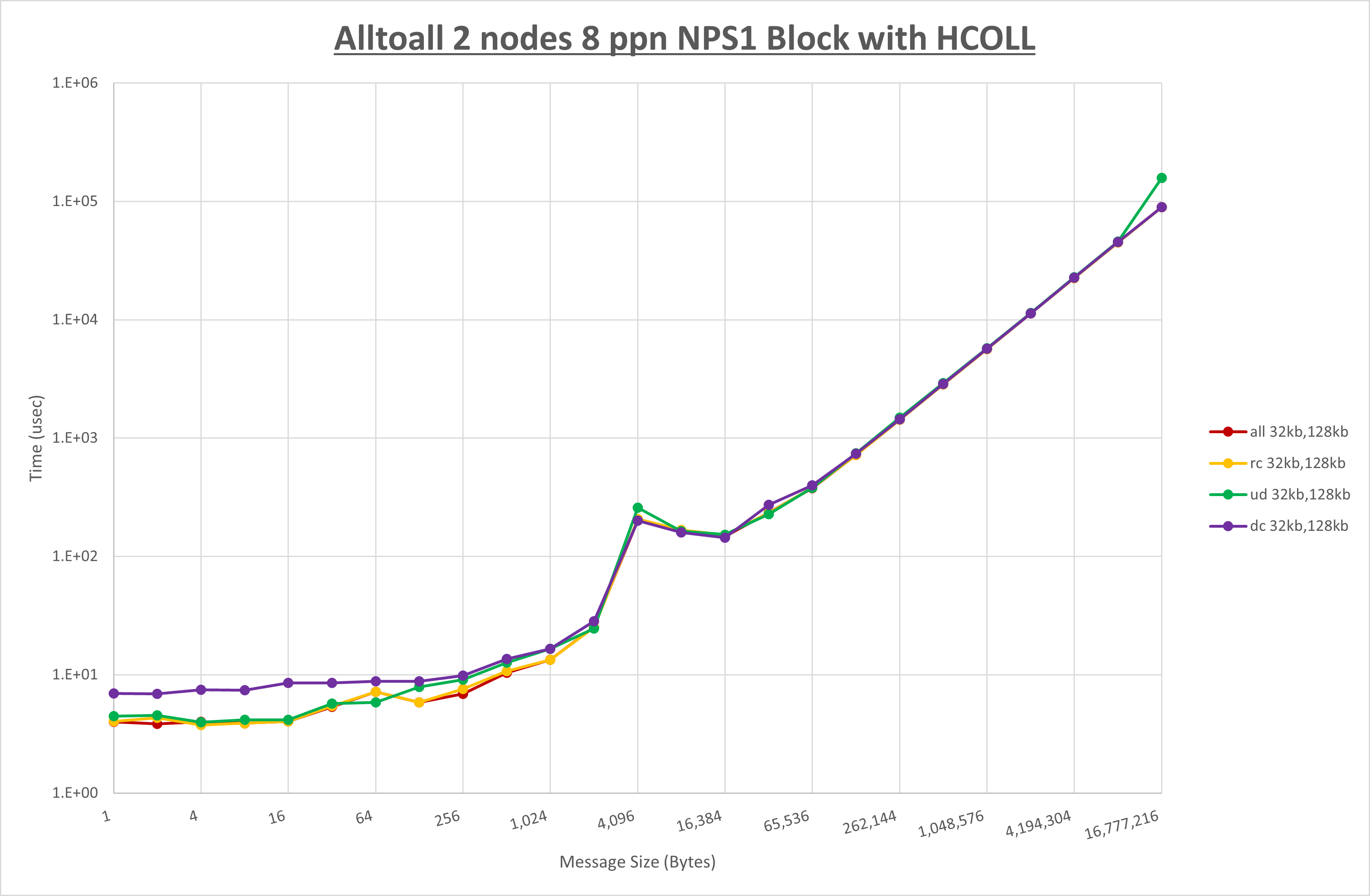
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
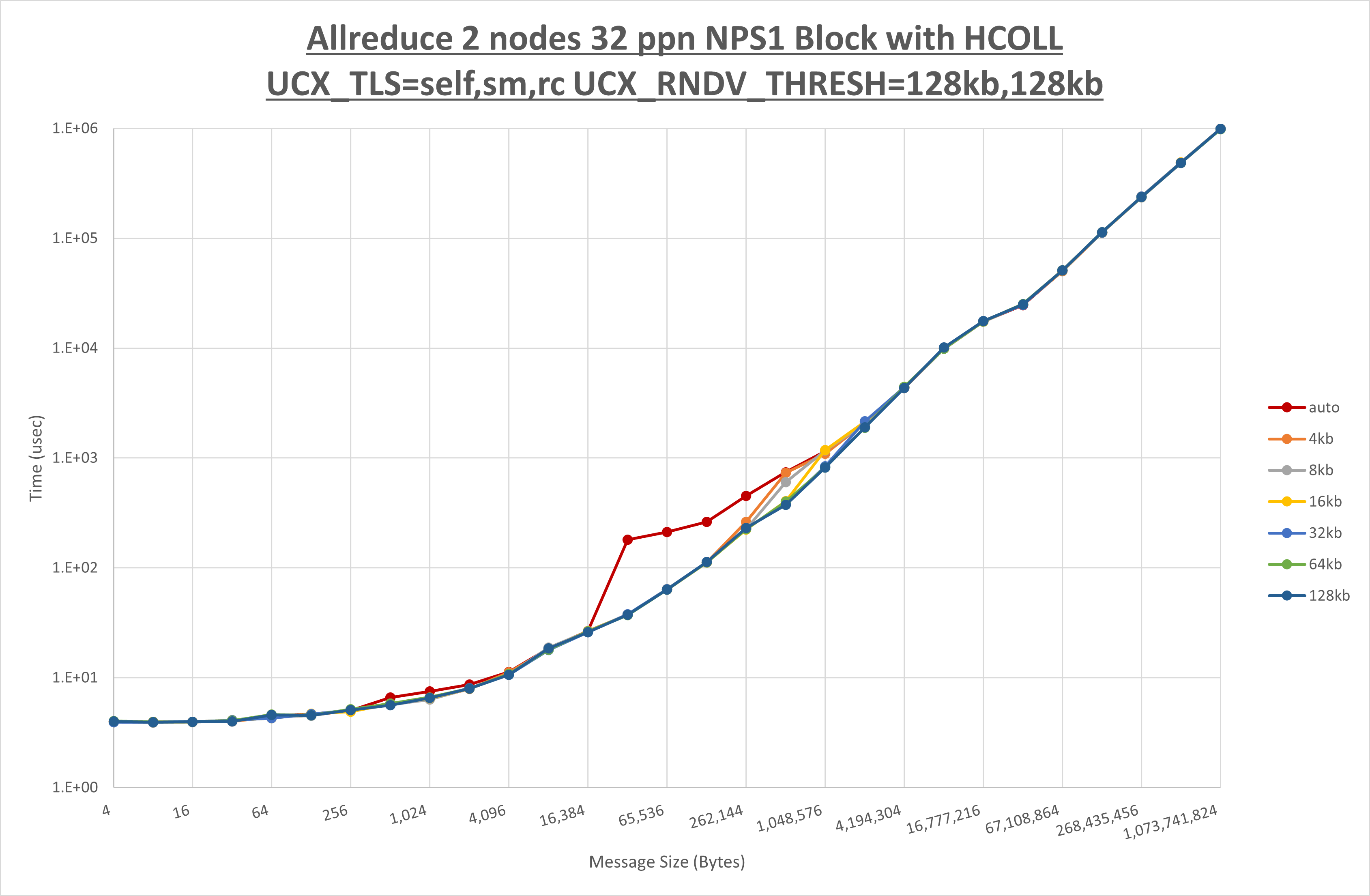
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
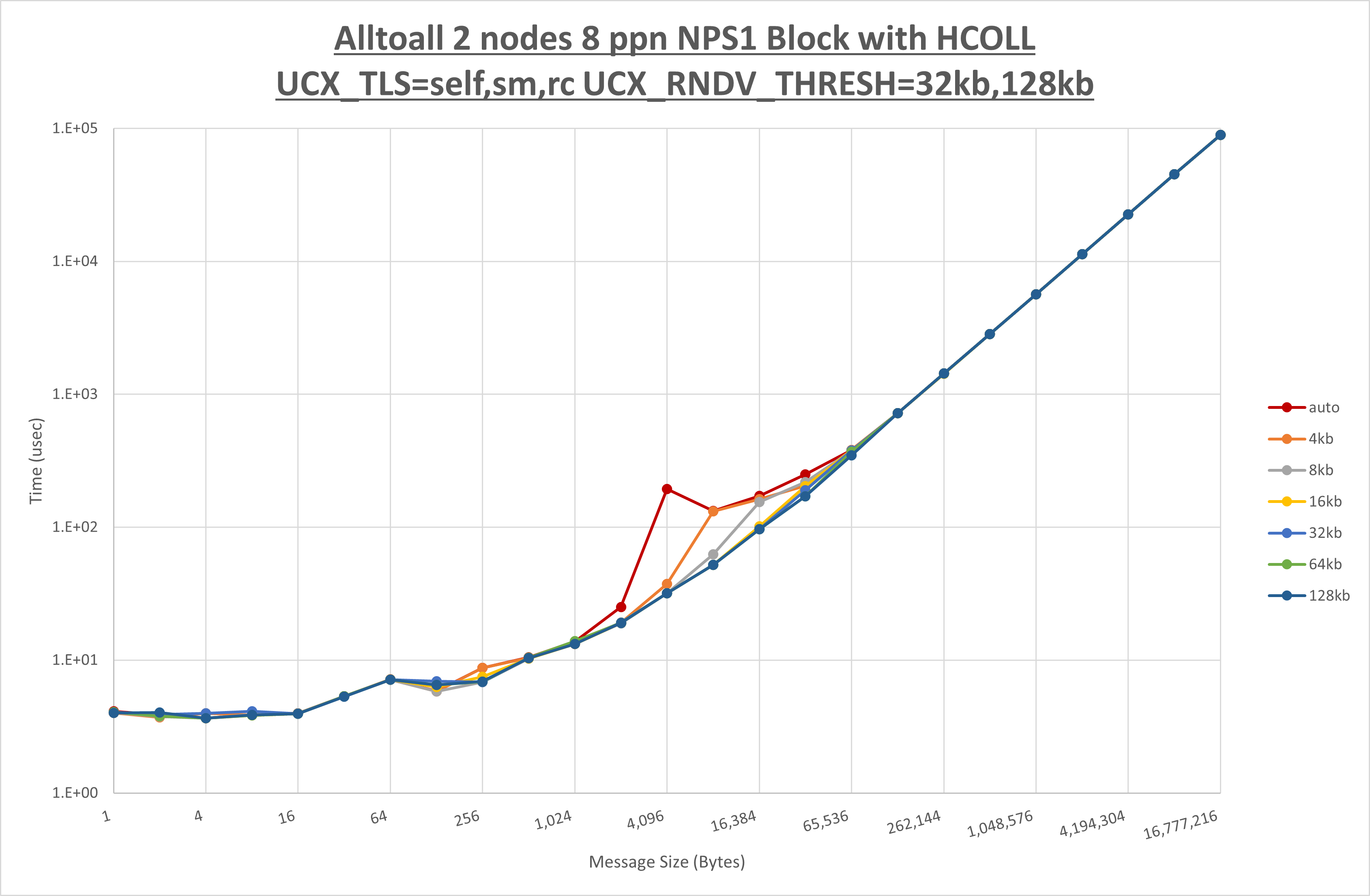
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
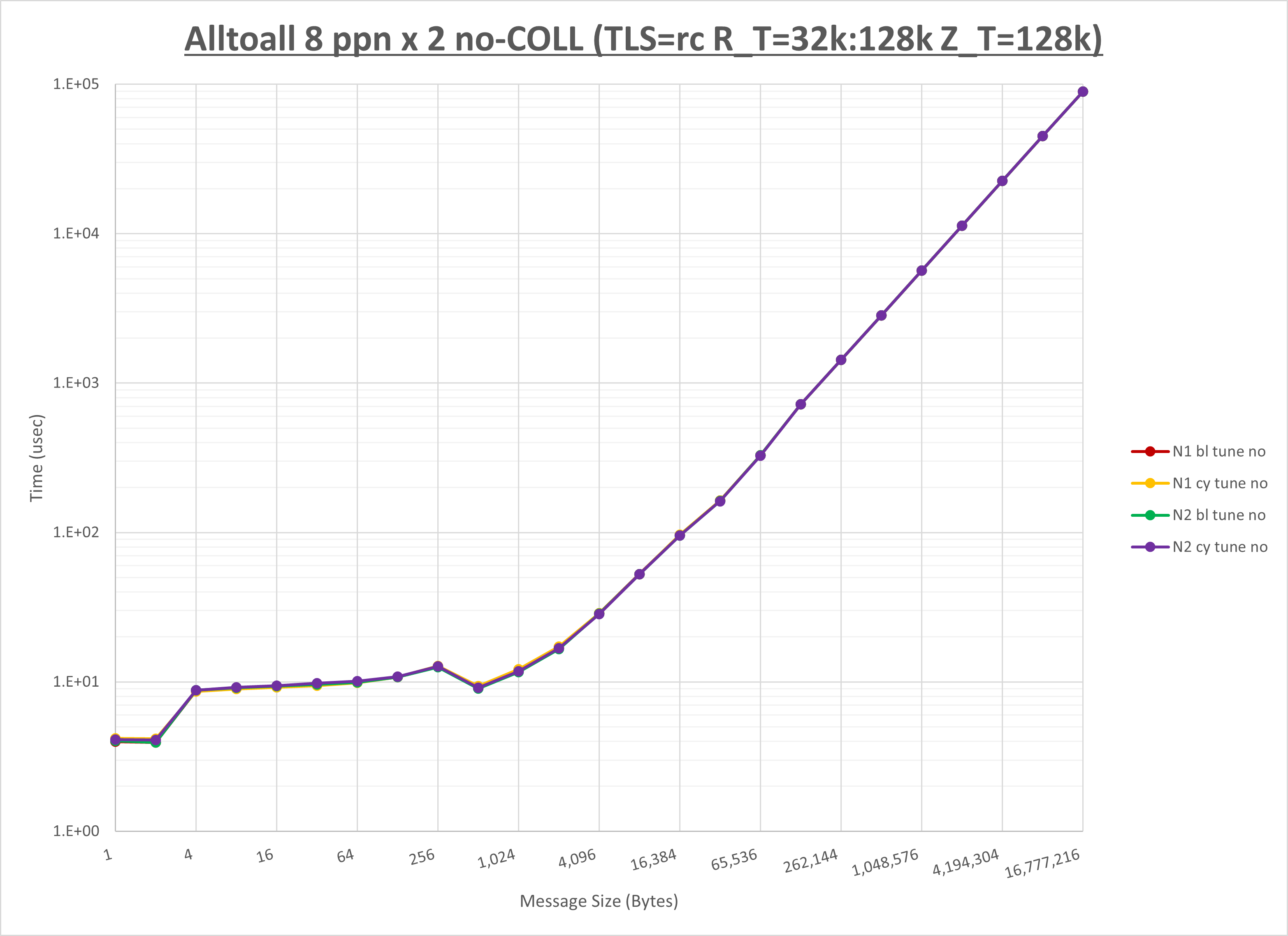
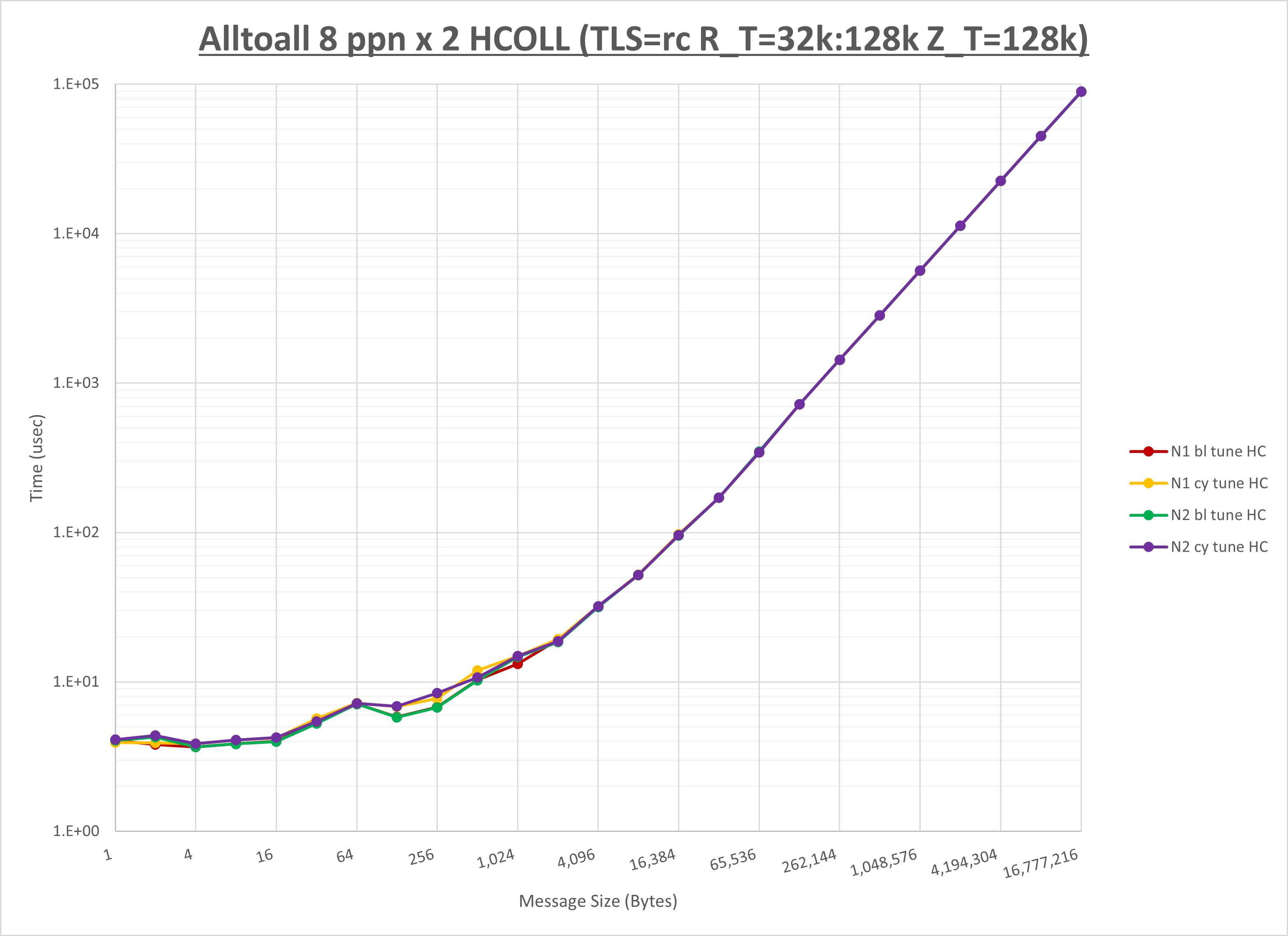
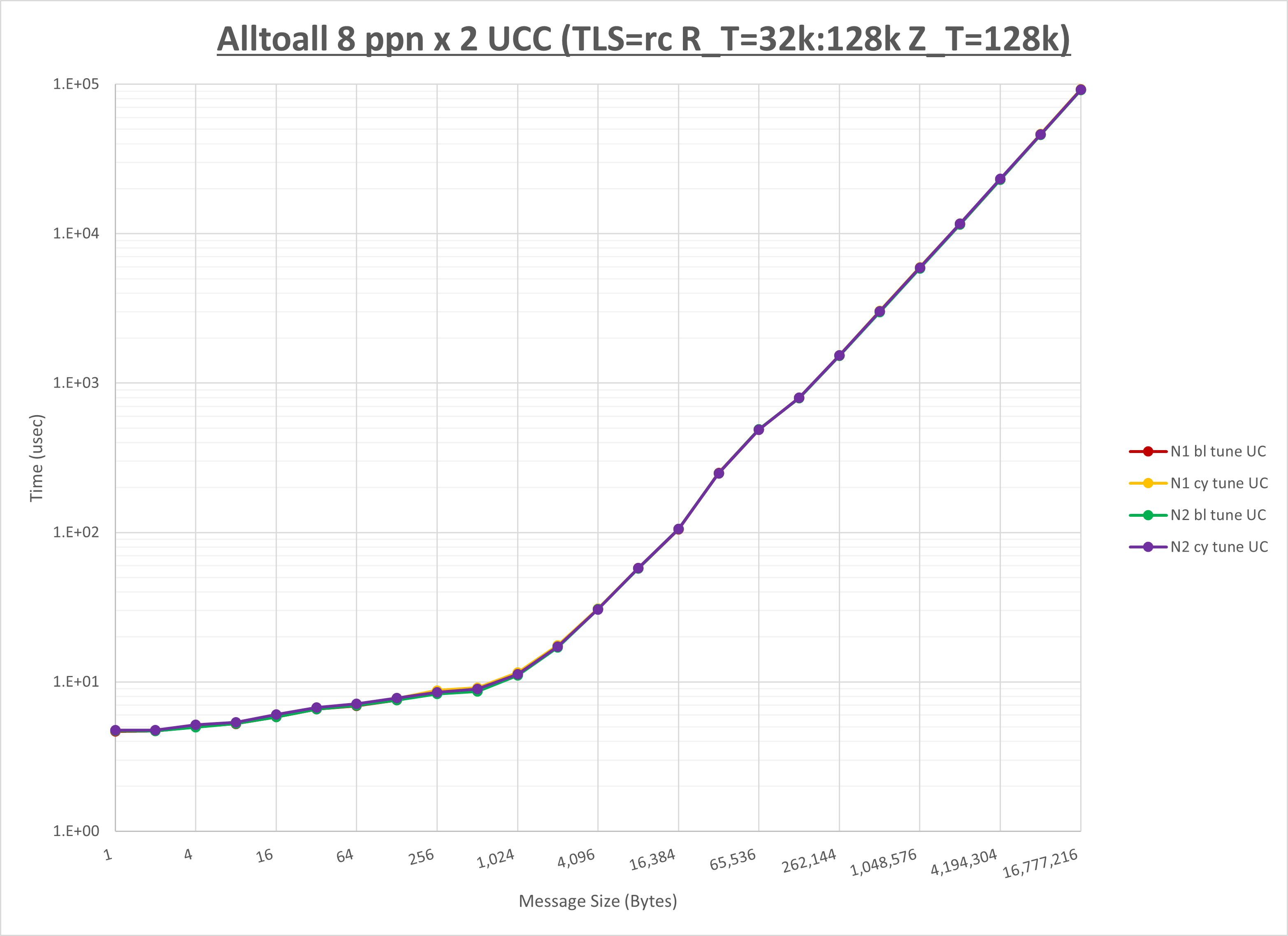
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
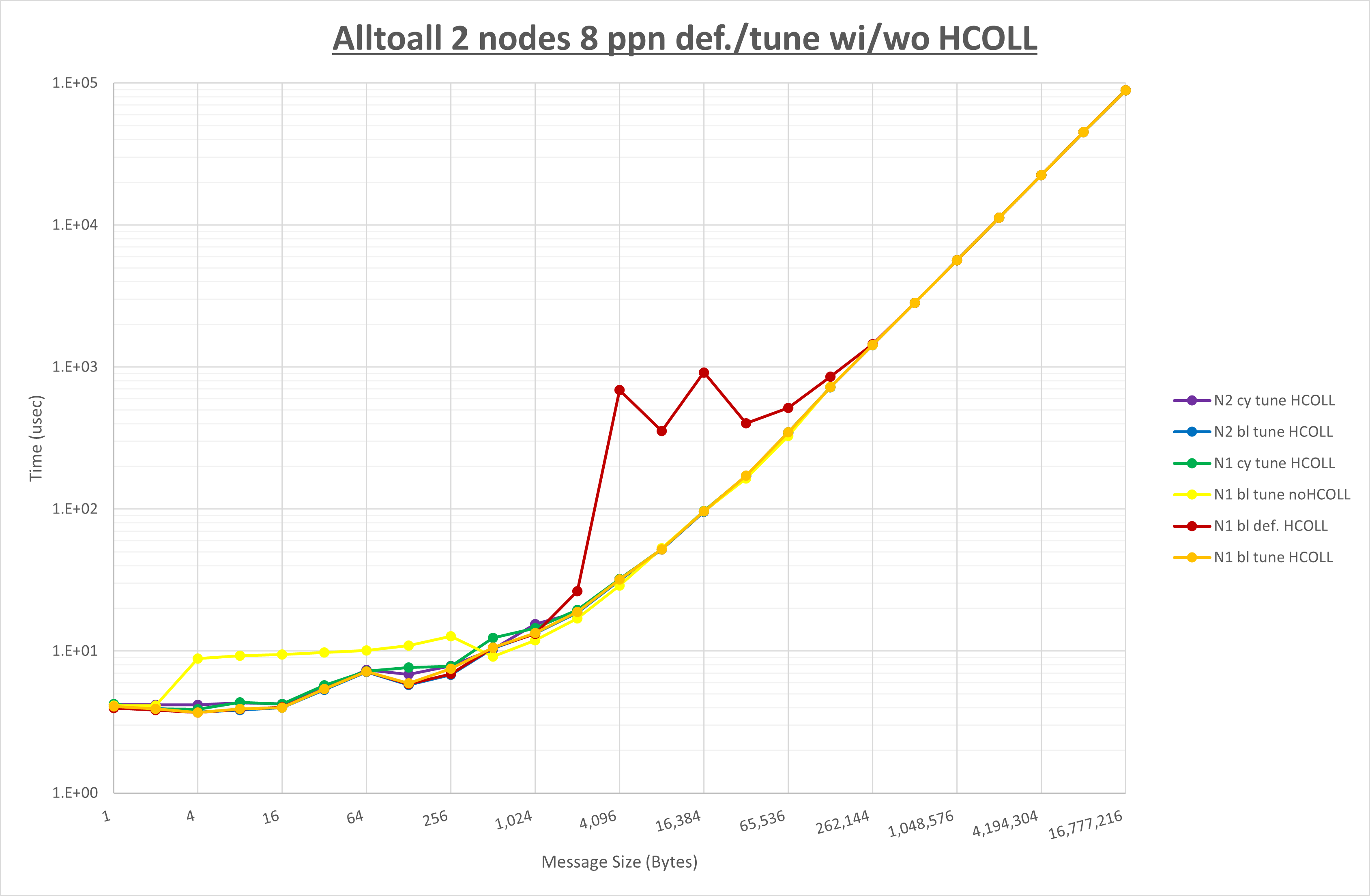
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し4Bから256Bで性能が向上し512Bから4KBで性能が低下
- UCC は no-COLL と比較し4Bから256Bで性能が向上
- チューニング適用で128Bから256Bと16KBと256KBで性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-2 Allgather の HCOLL の結果から64KBとしています。
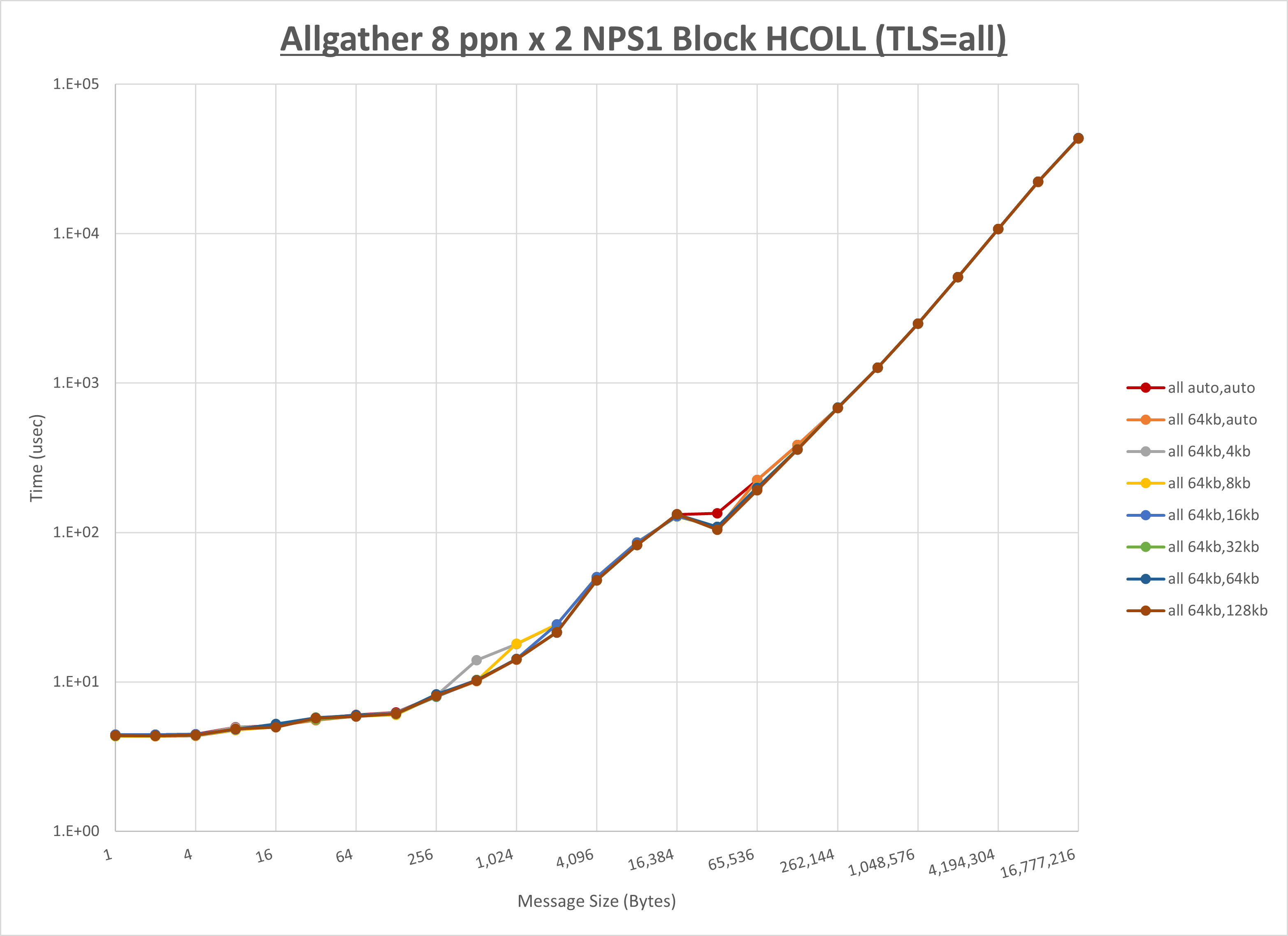
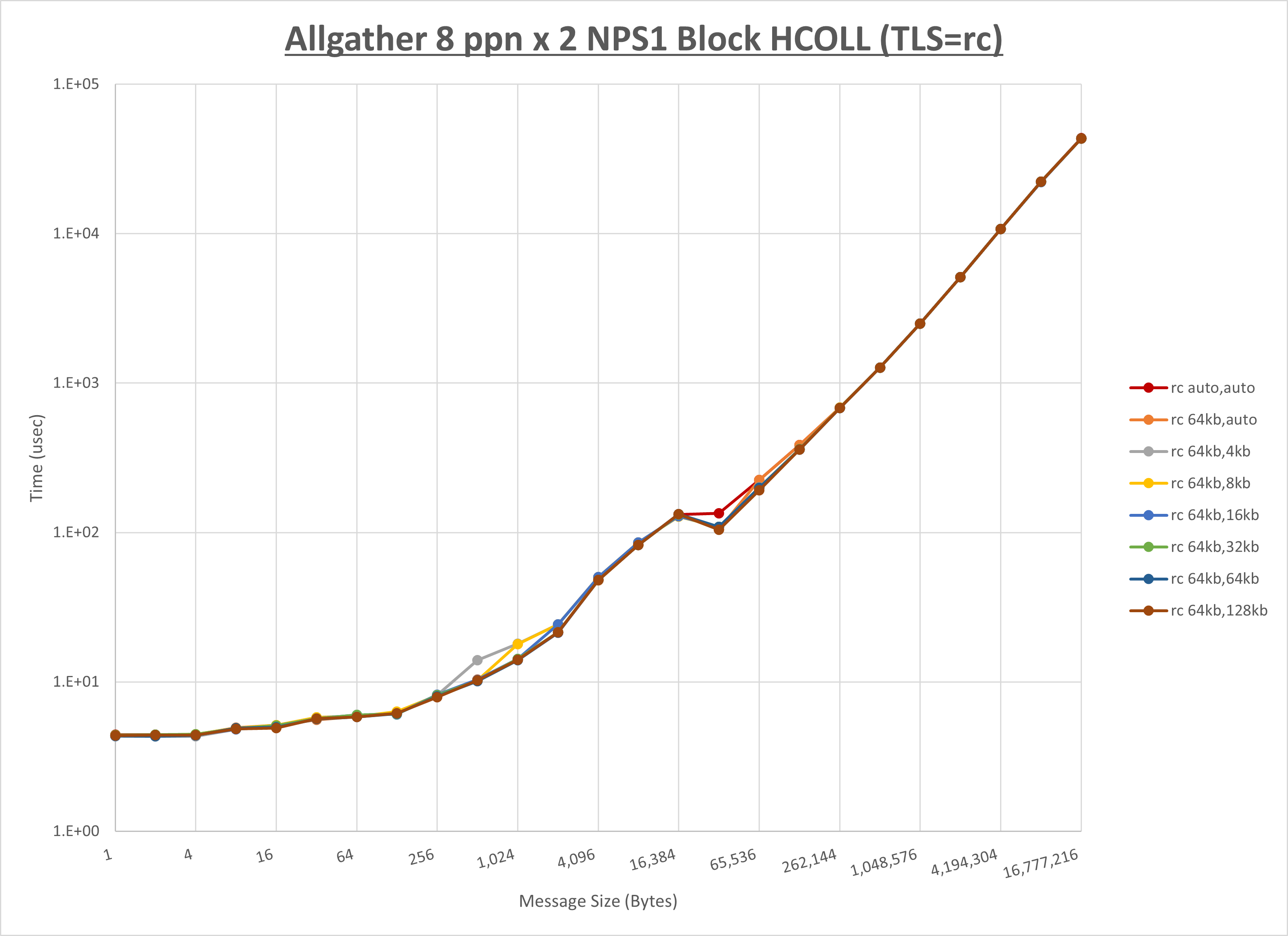
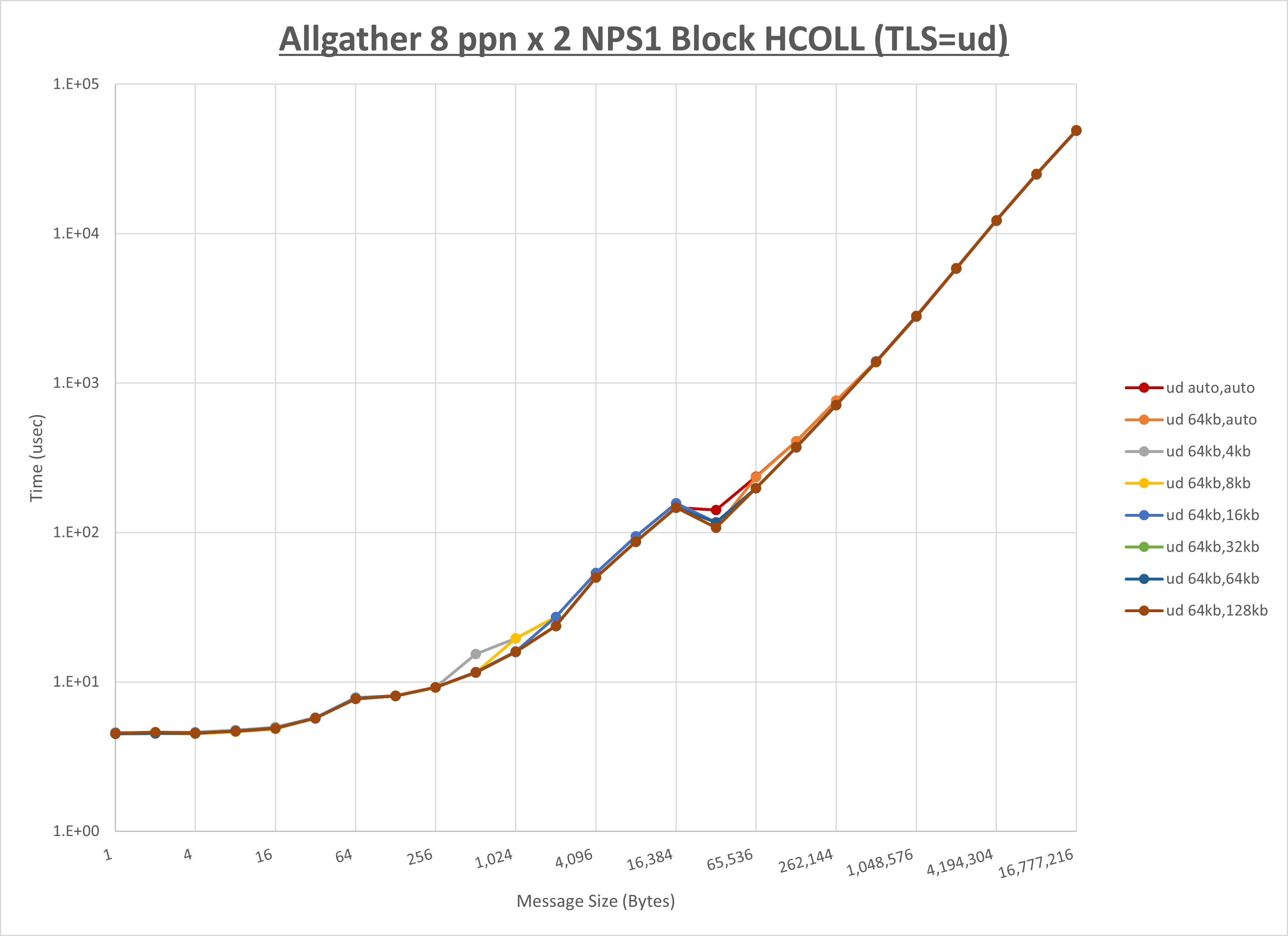
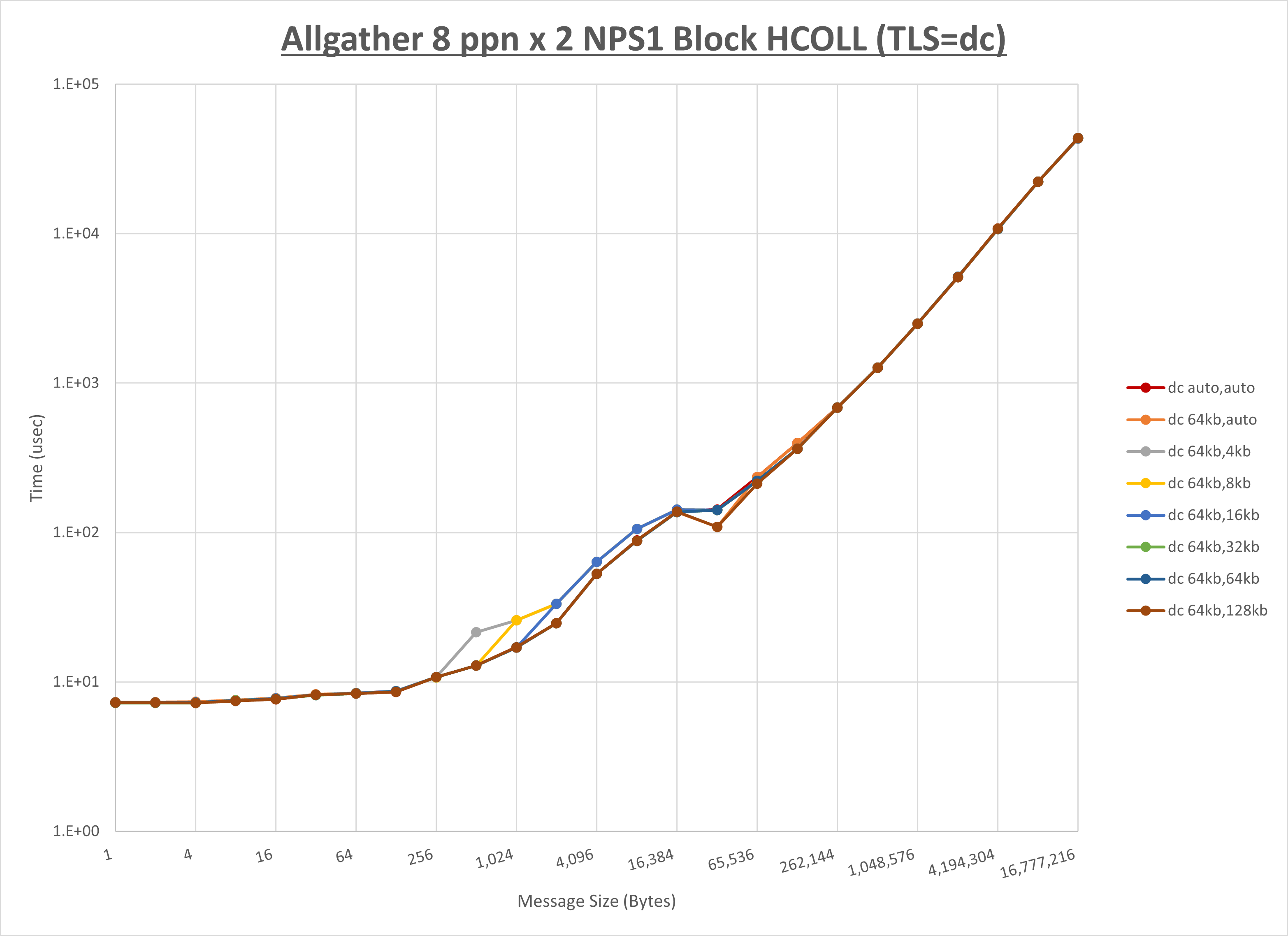
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
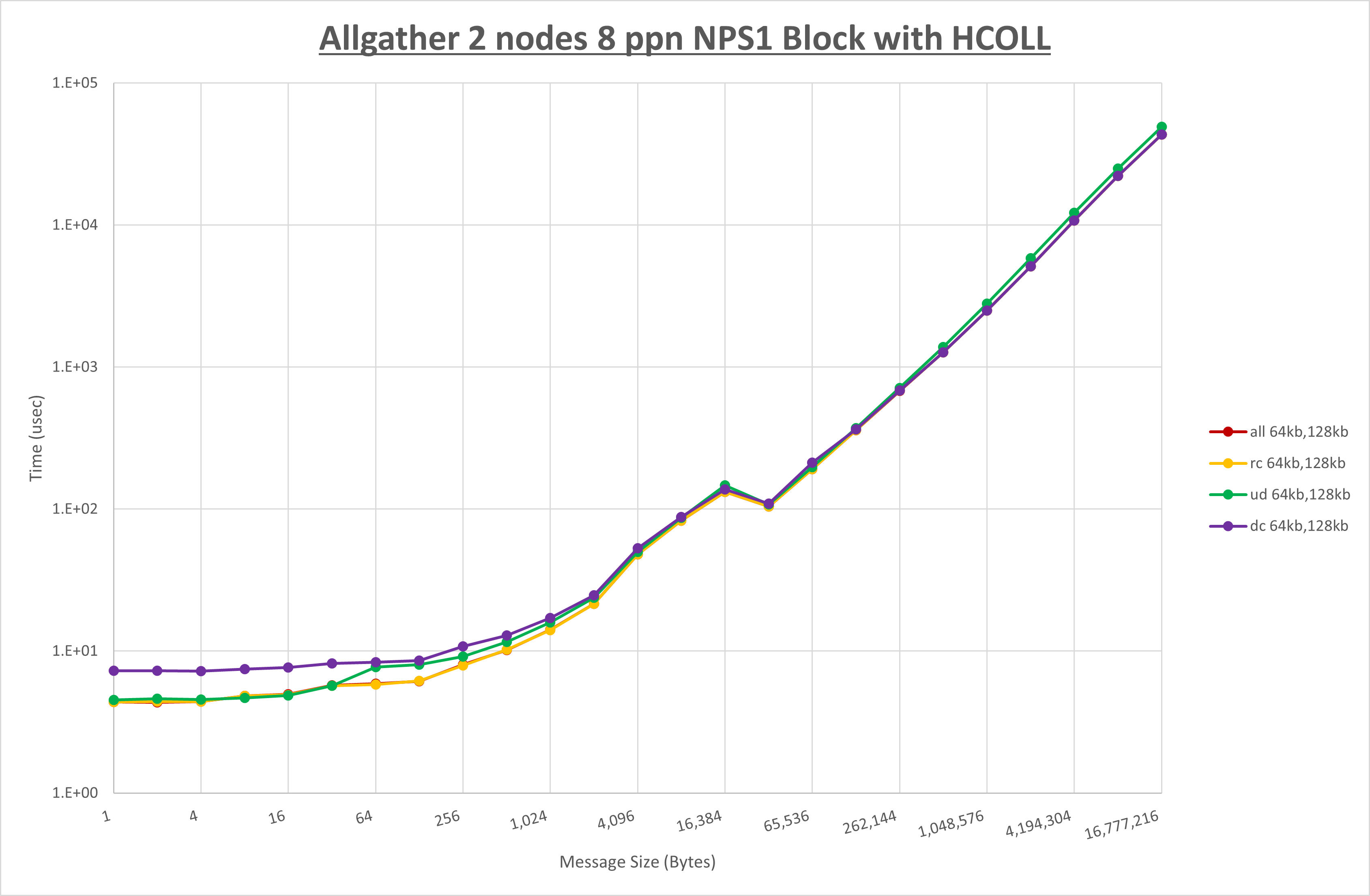
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
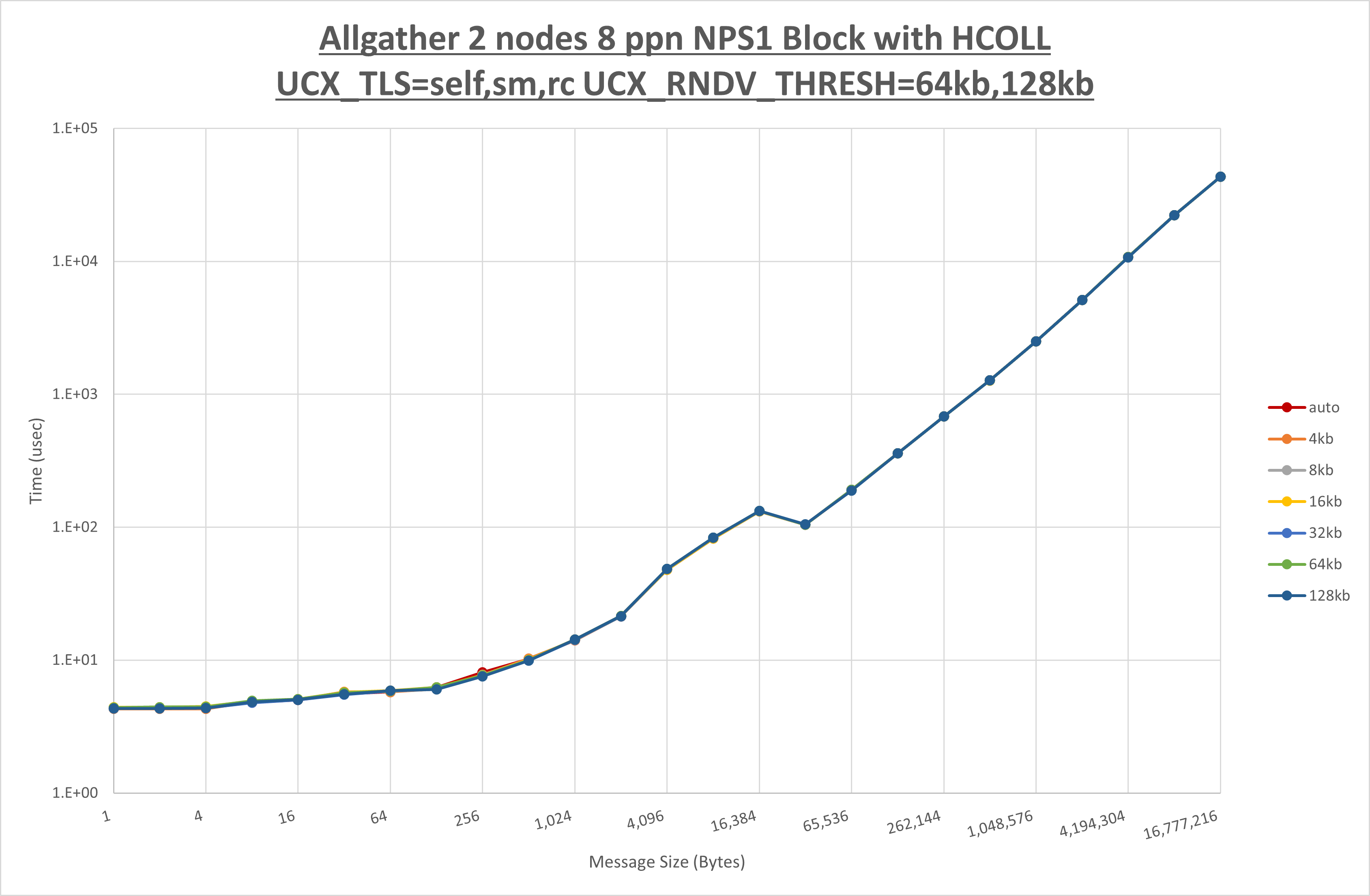
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
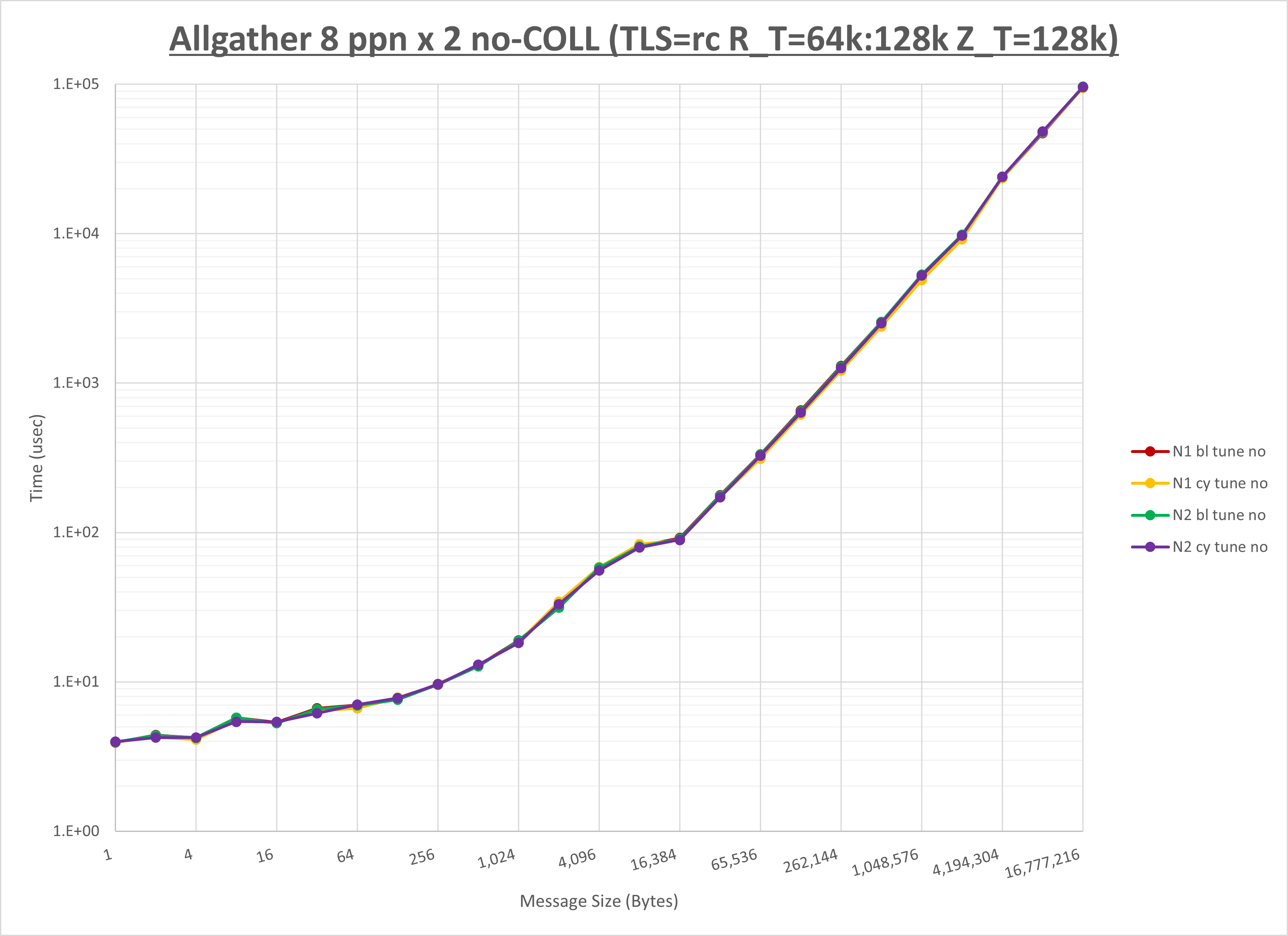
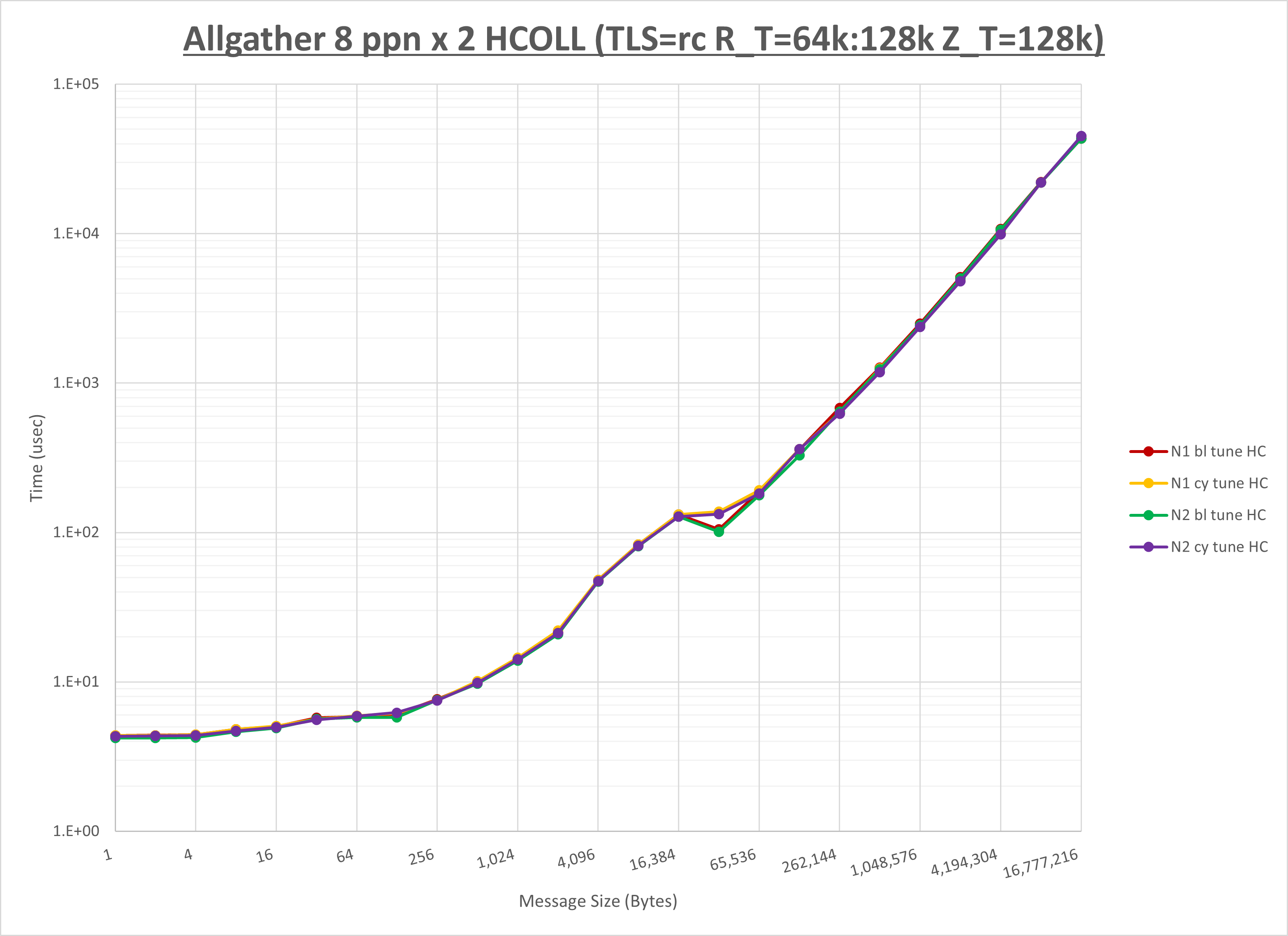
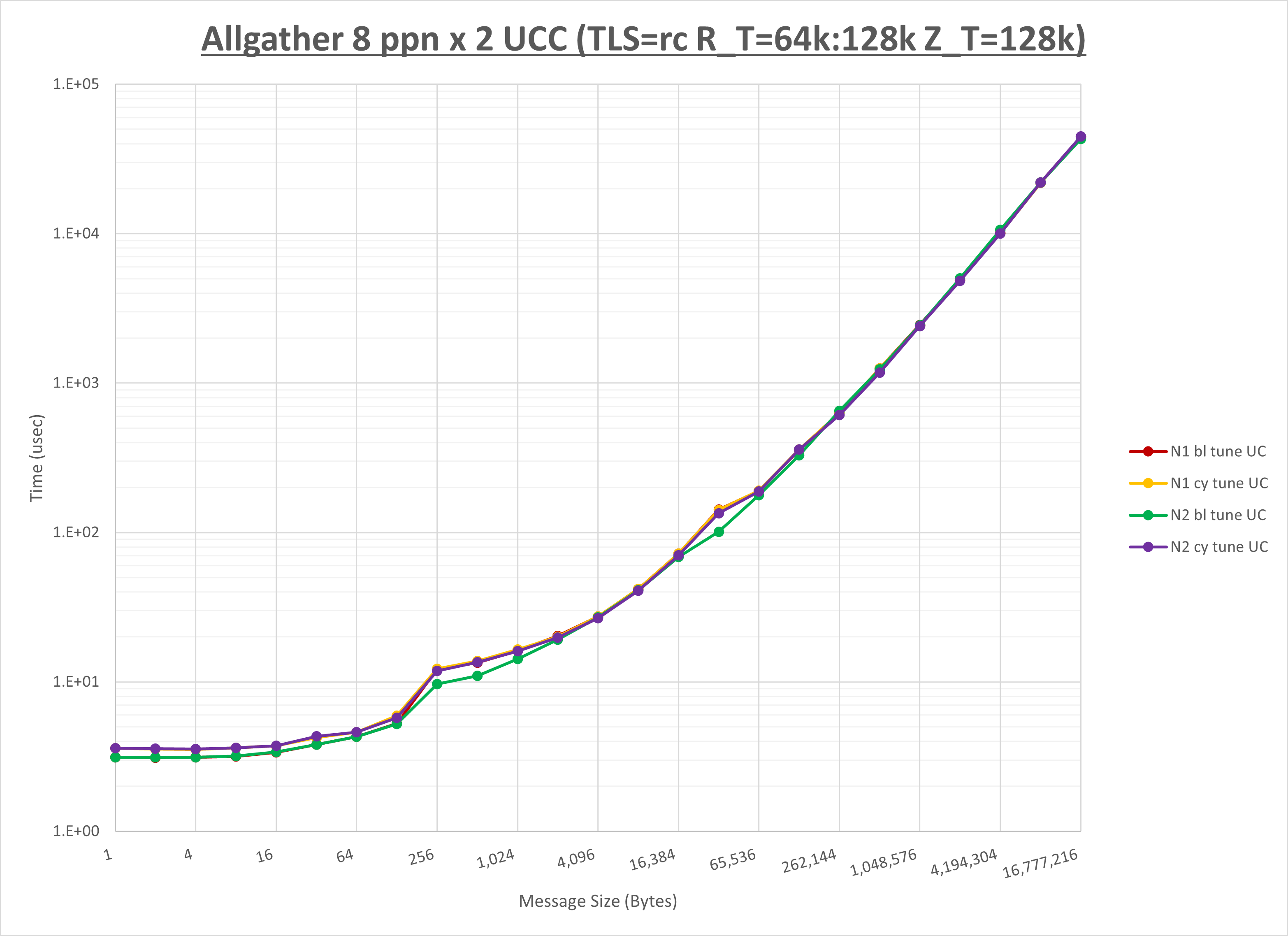
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
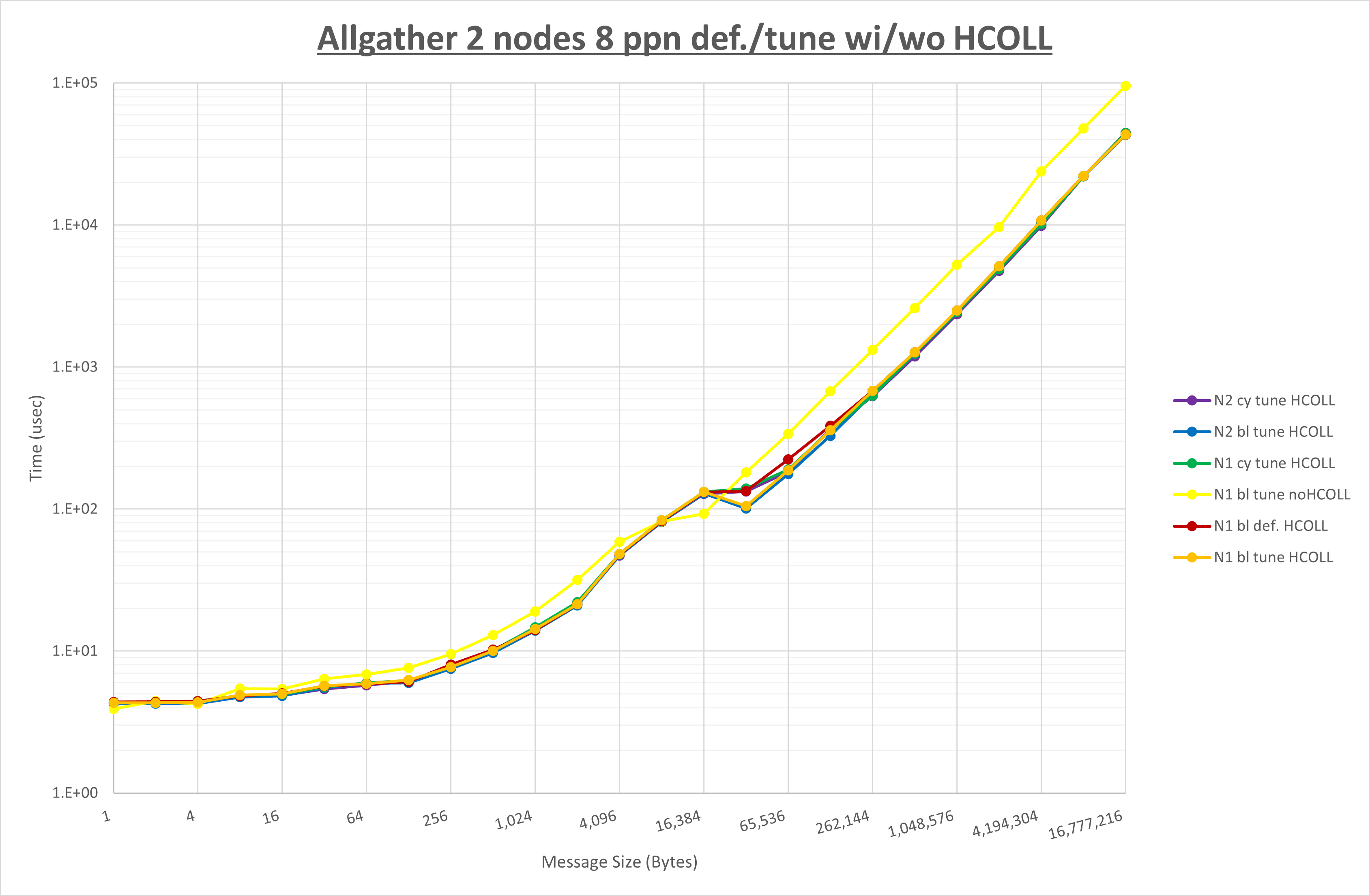
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し8B以上で性能が向上
- UCC は no-COLL と比較し全域でで性能が向上
- チューニング適用で有意な性能の変化無し
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-3 Allreduce の HCOLL の結果から128KBとしています。
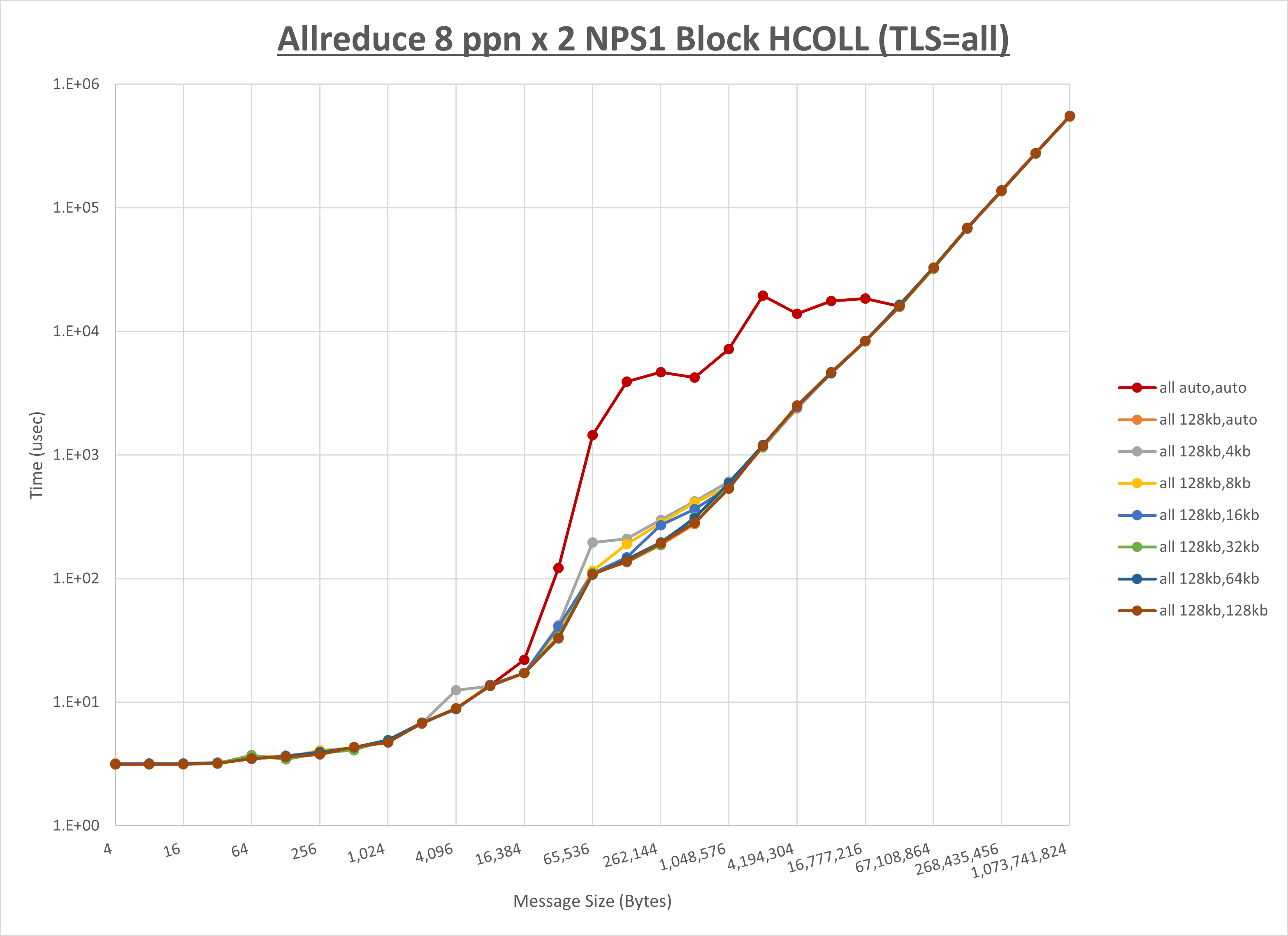
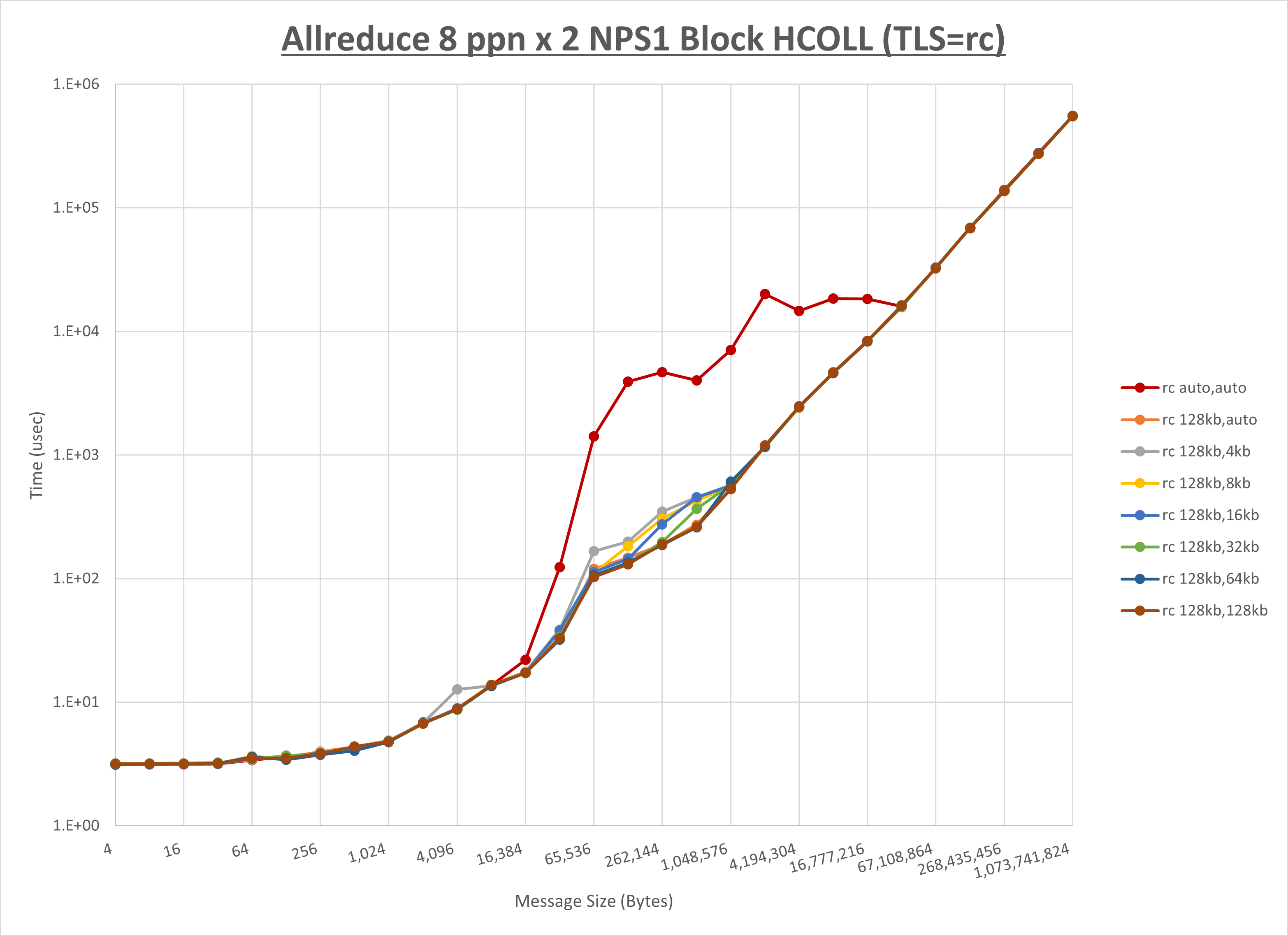
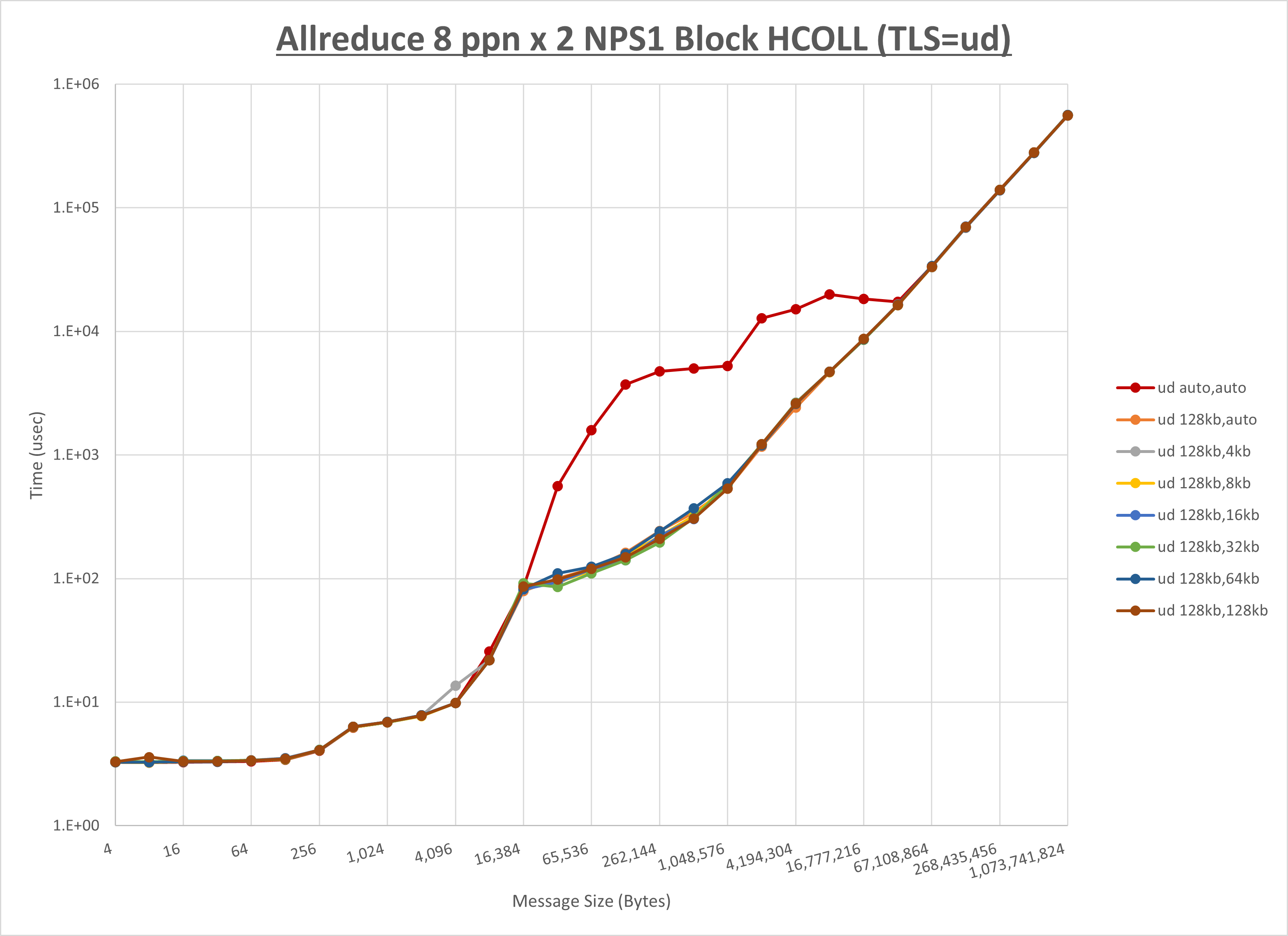
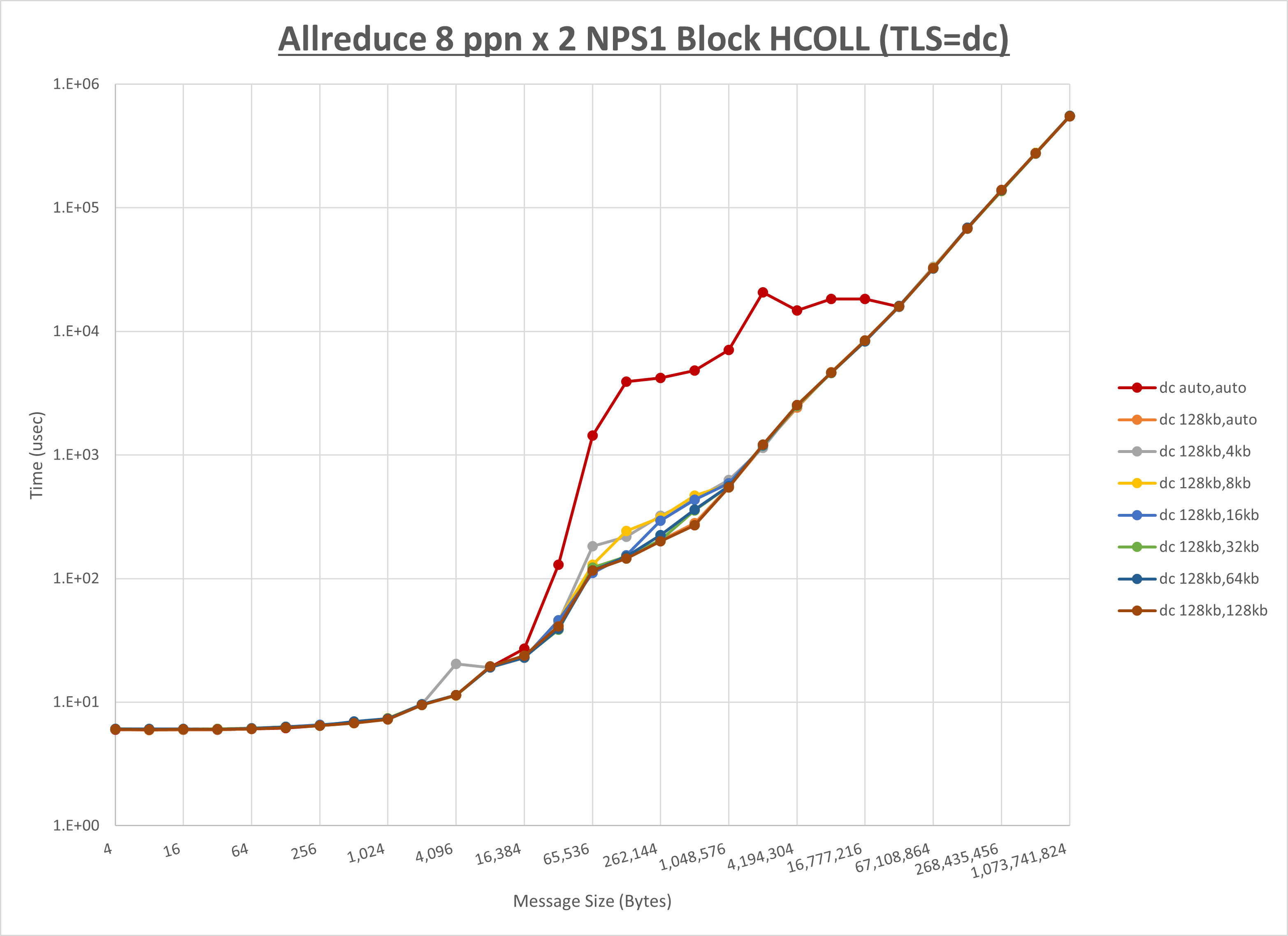
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
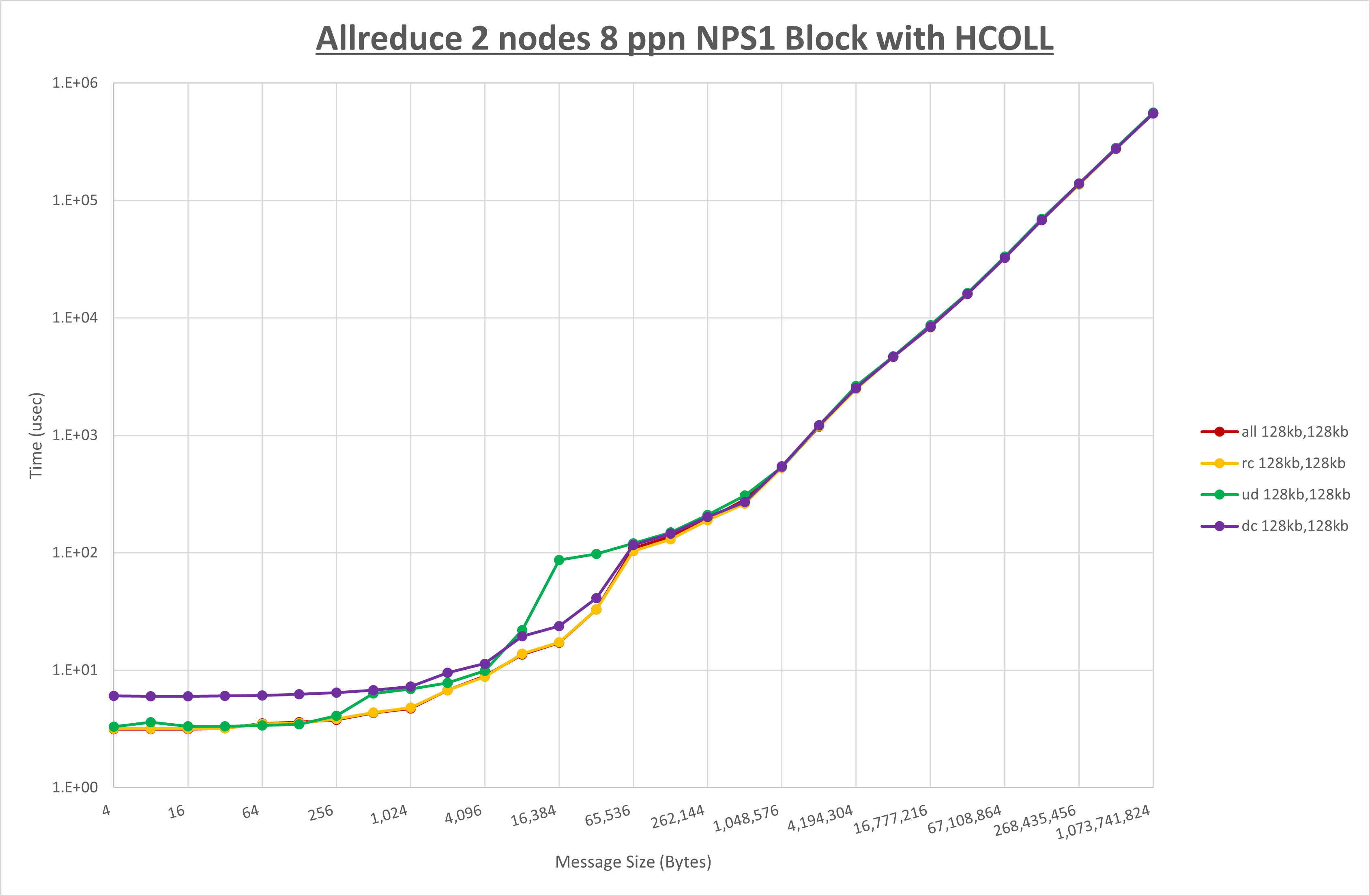
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
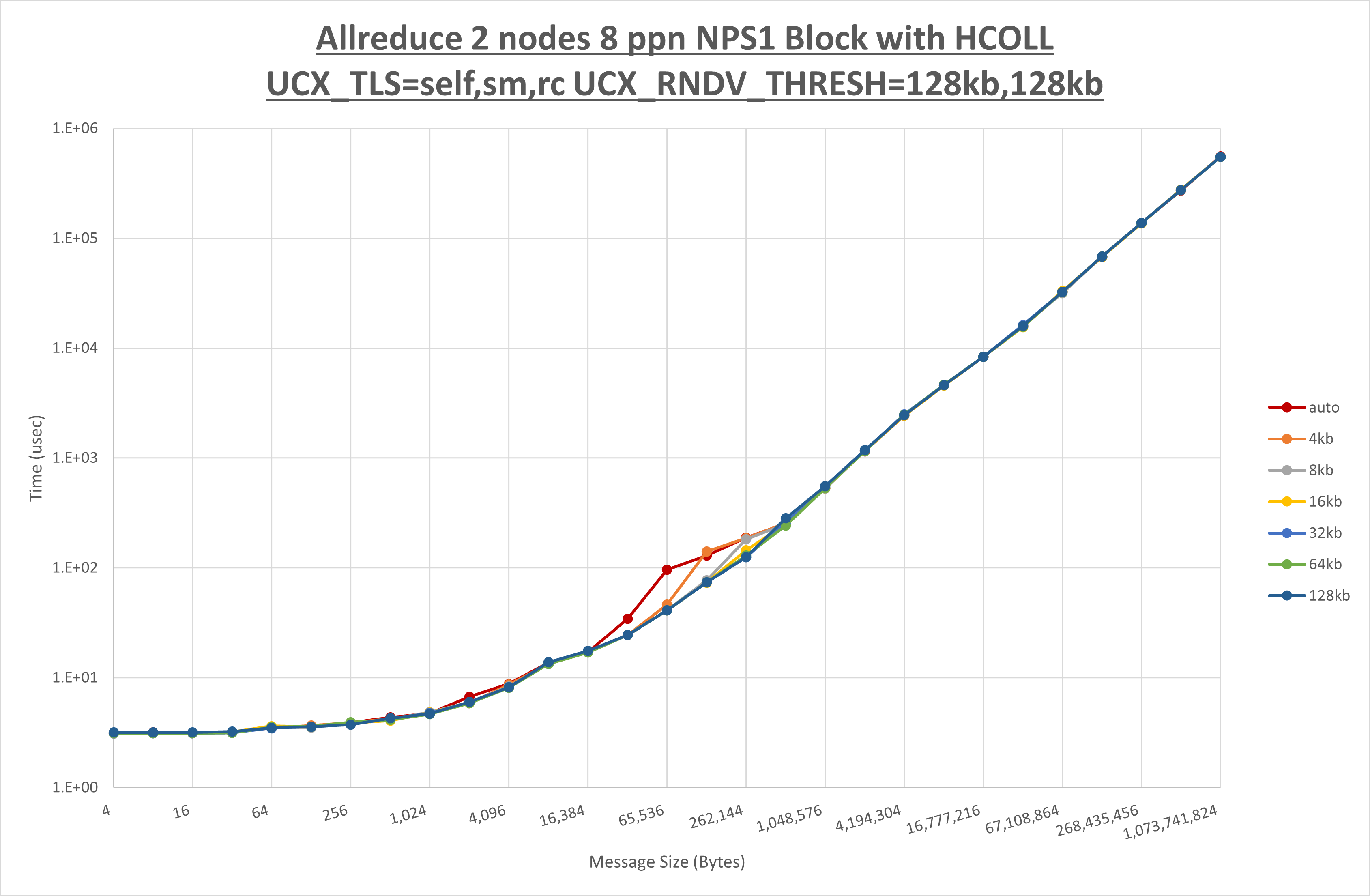
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
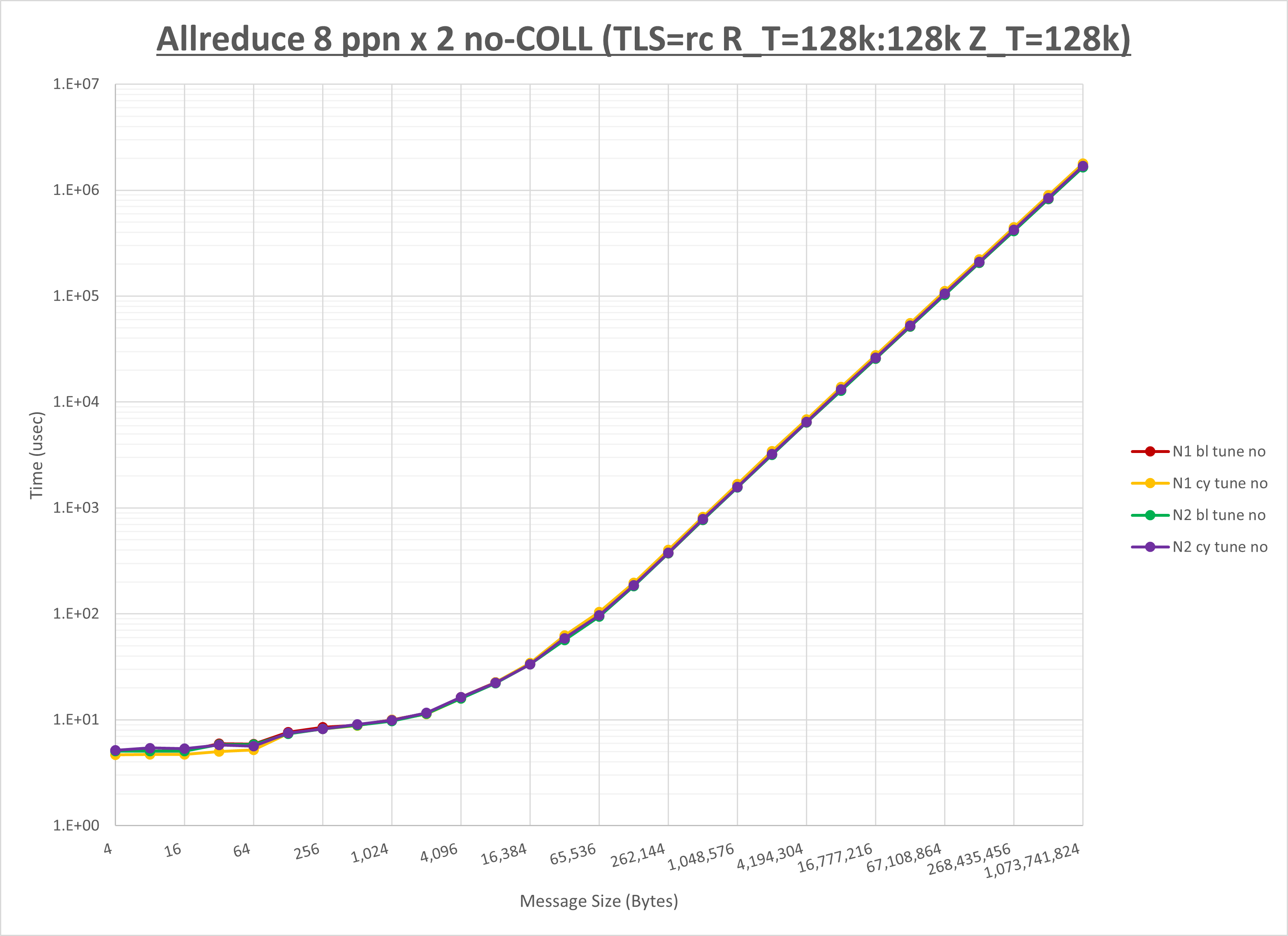
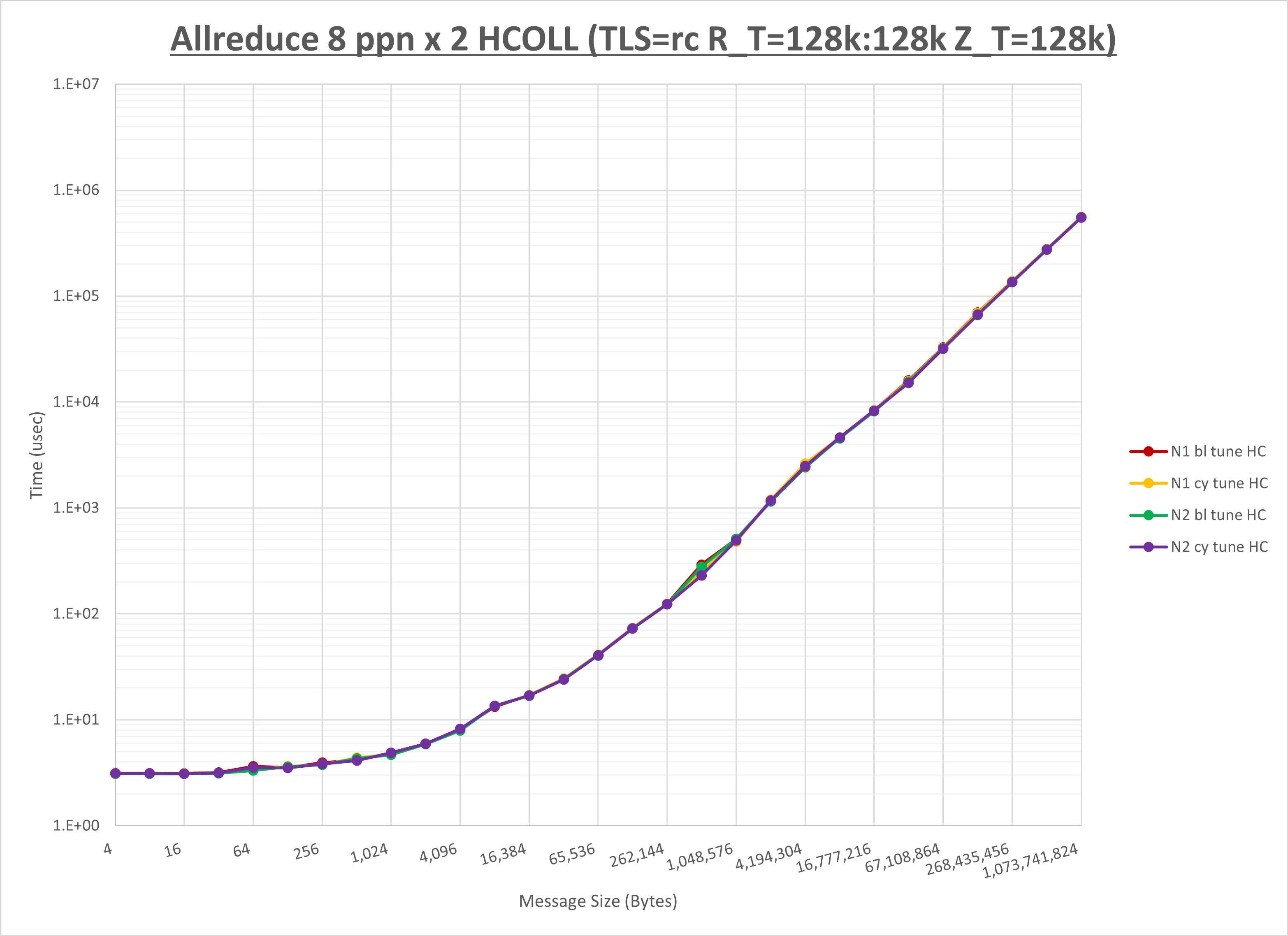
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | サイクリック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
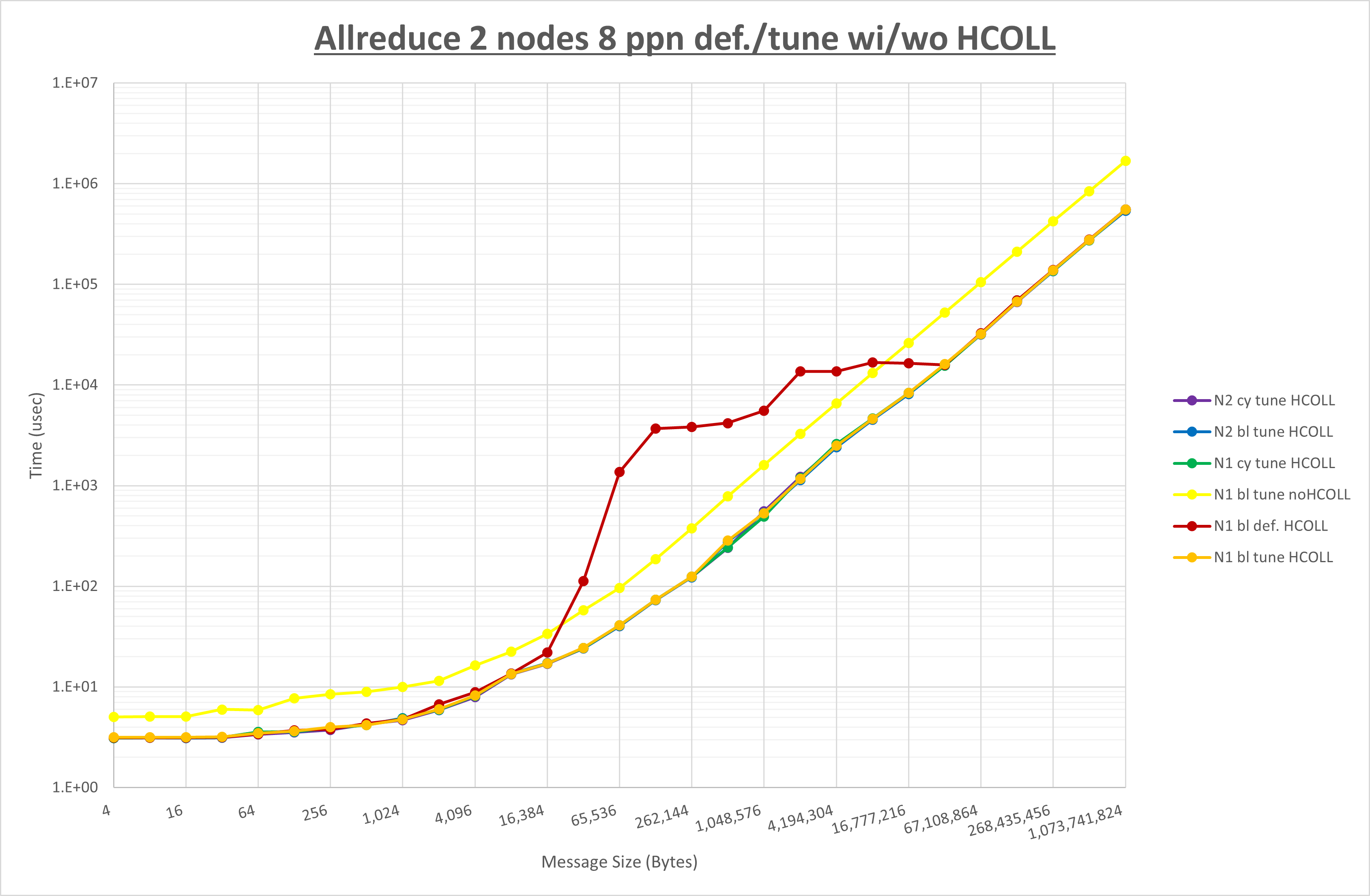
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で64Bから2MBの間で概ね性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-4 Exchange の結果から32KBとしています。
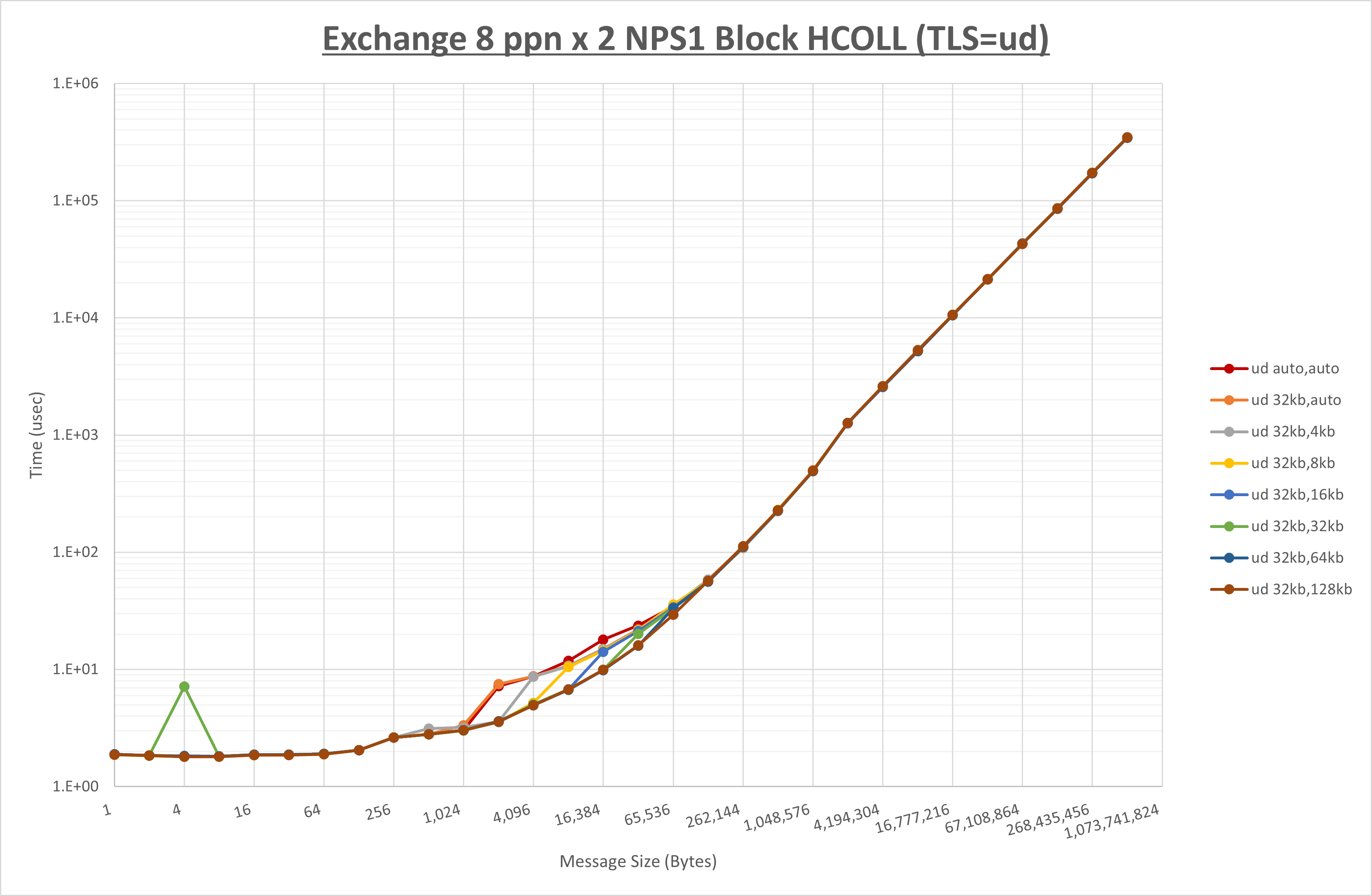
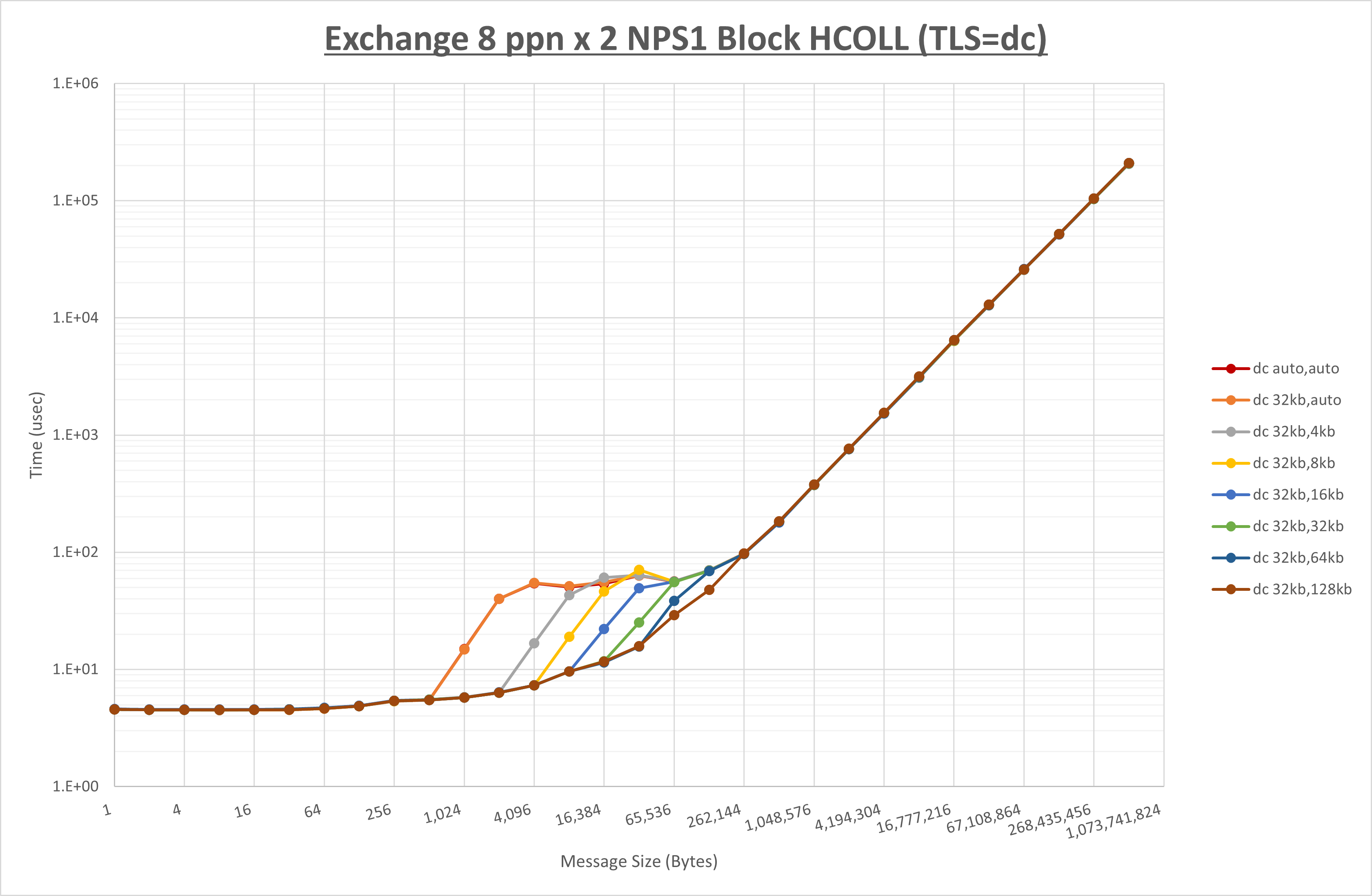
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
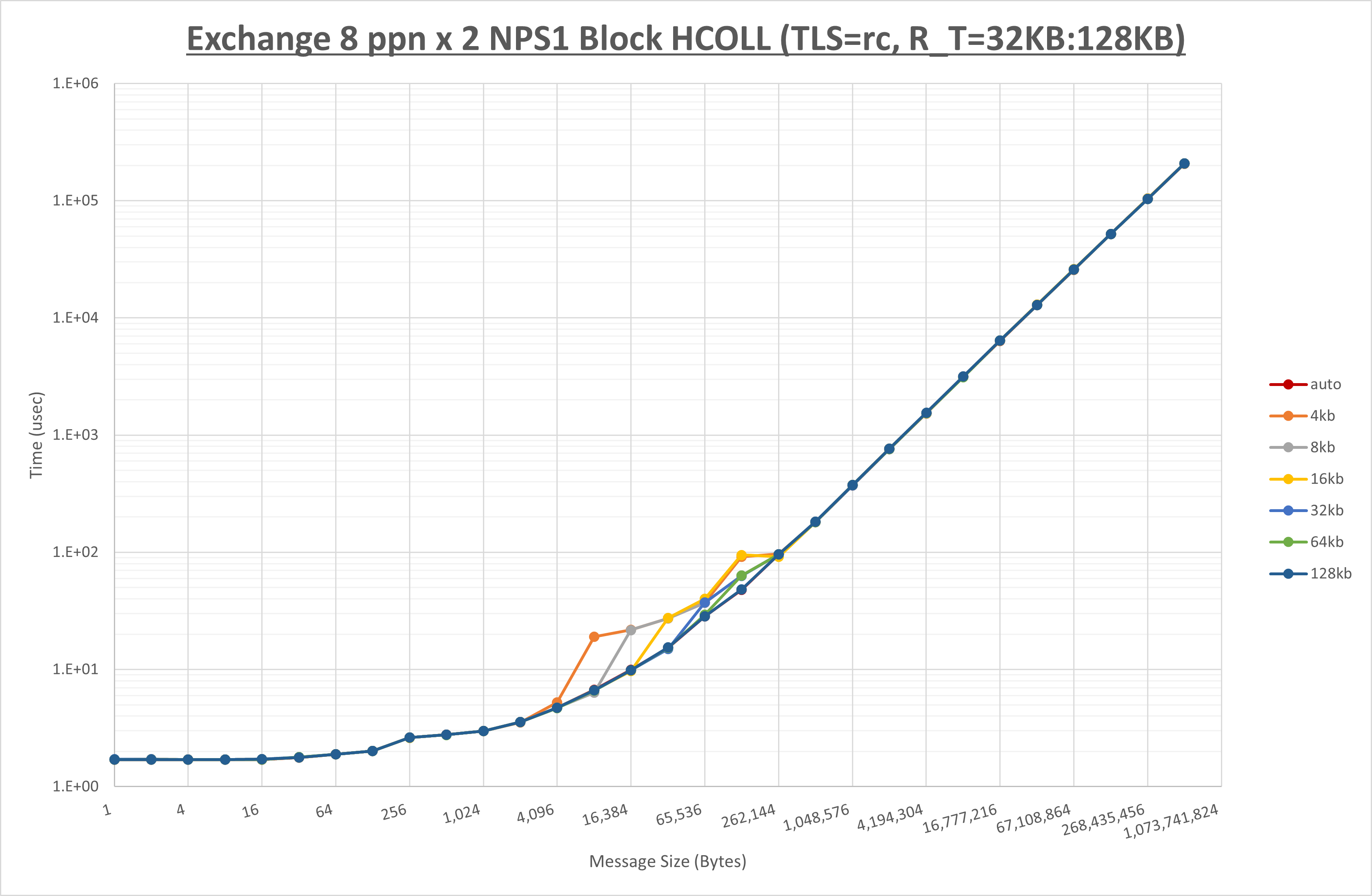
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
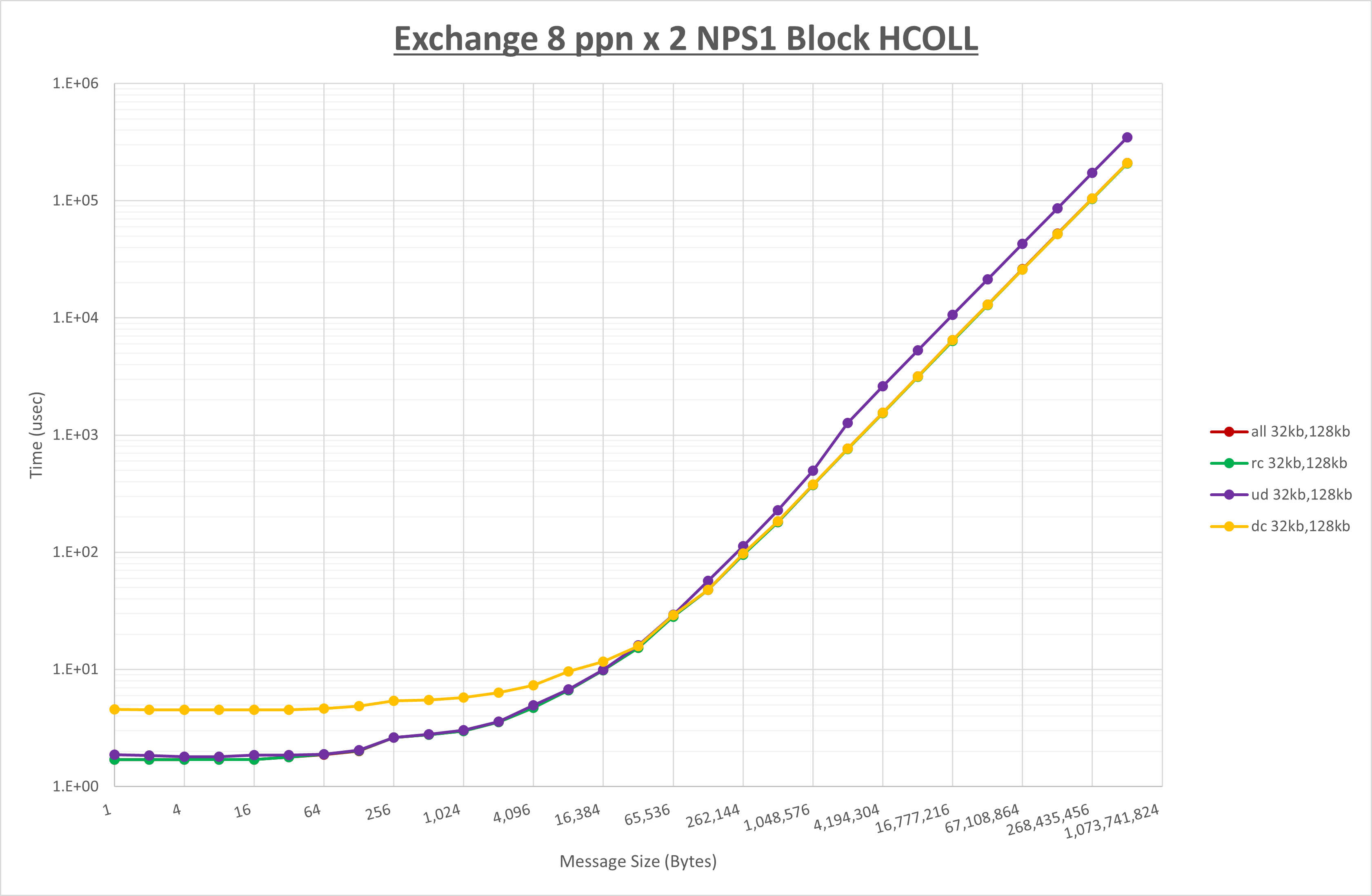
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
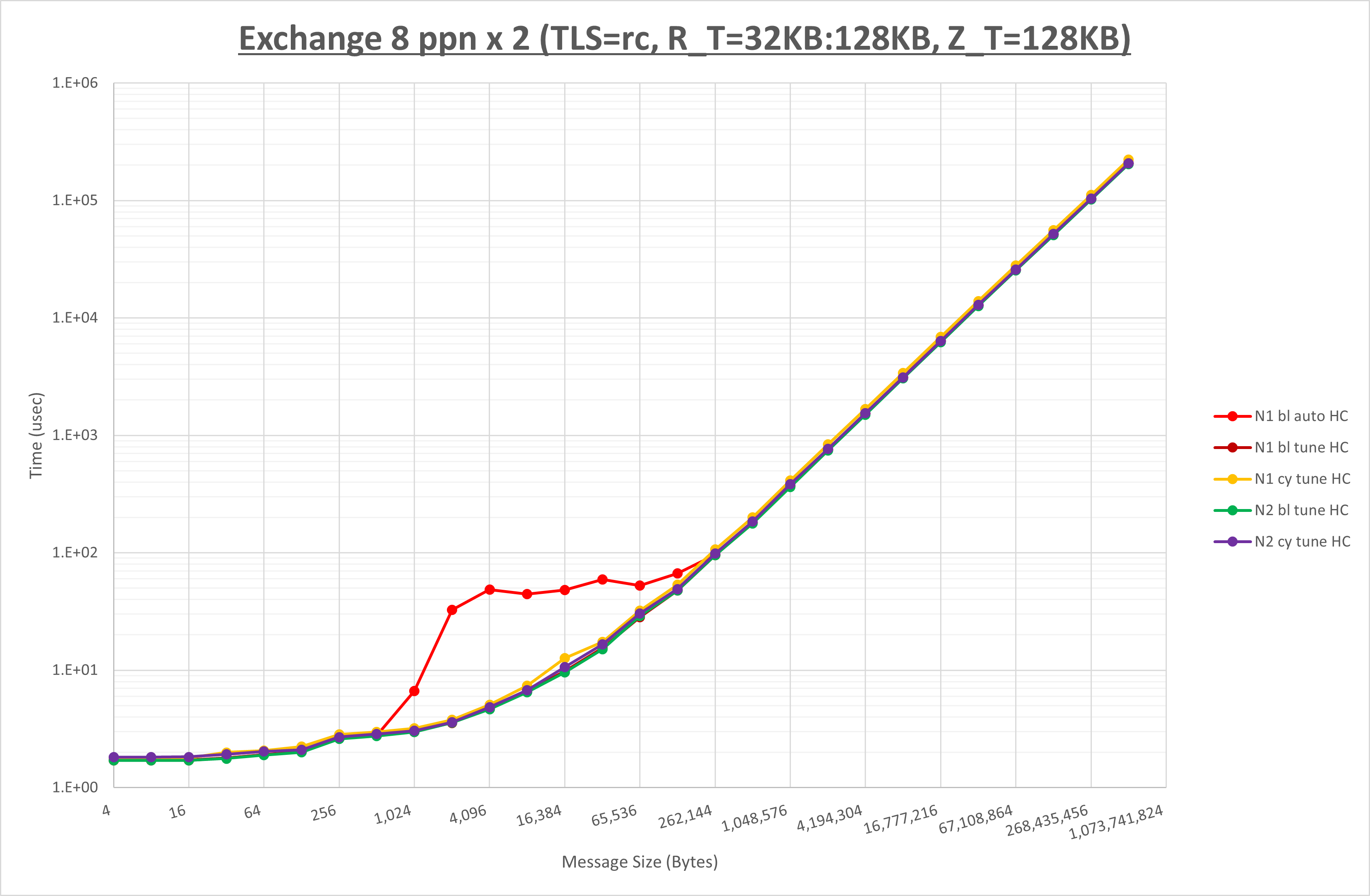
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で1KBから128KBの間で性能が向上
本章は、2ノードにノード当たり16、トータル32のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,rc | intra:32kb,inter:128kb | 128kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,ud | intra:128kb,inter:128kb | 64kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-1 Alltoall の HCOLL の結果から32KBとしています。
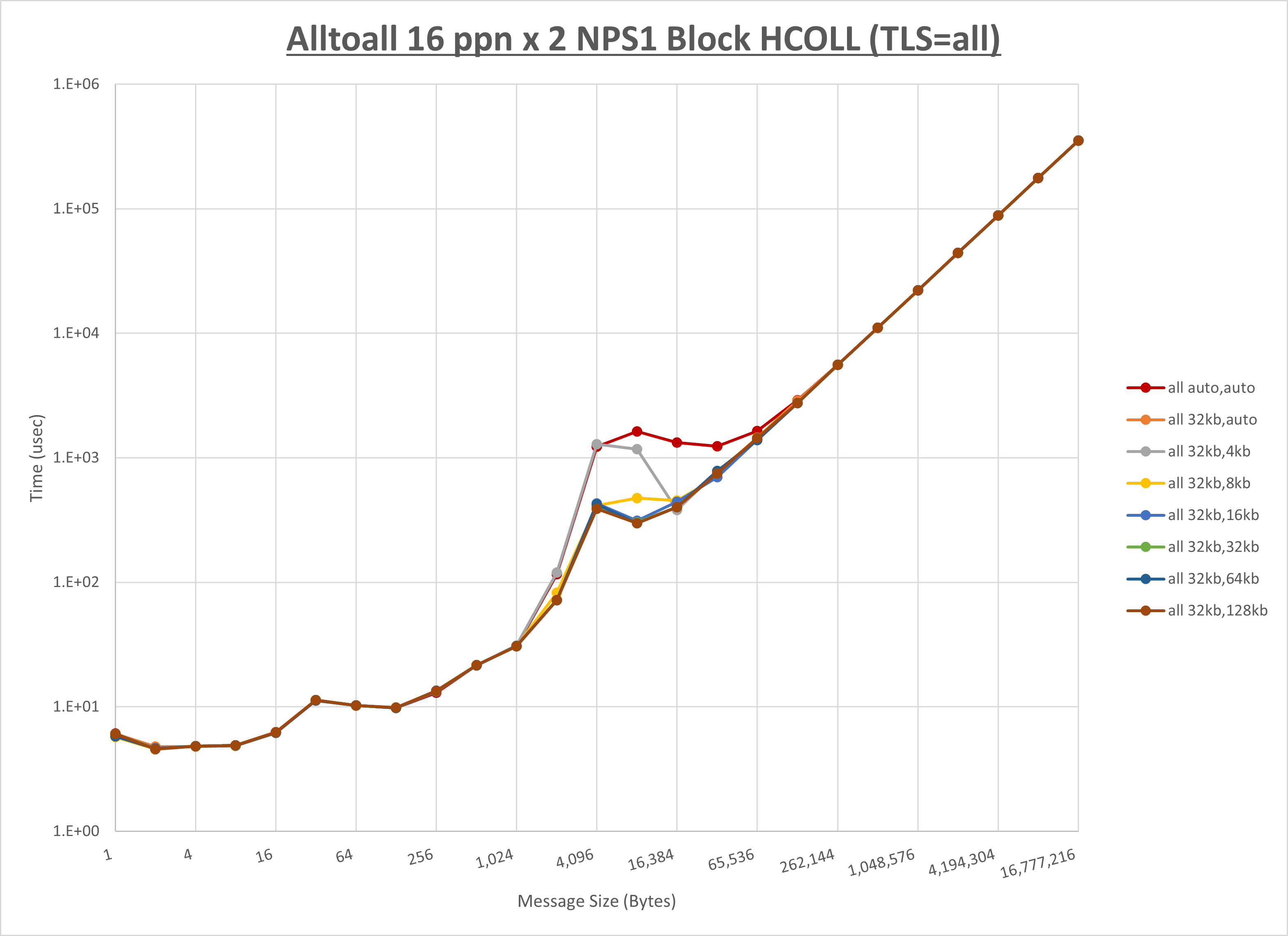
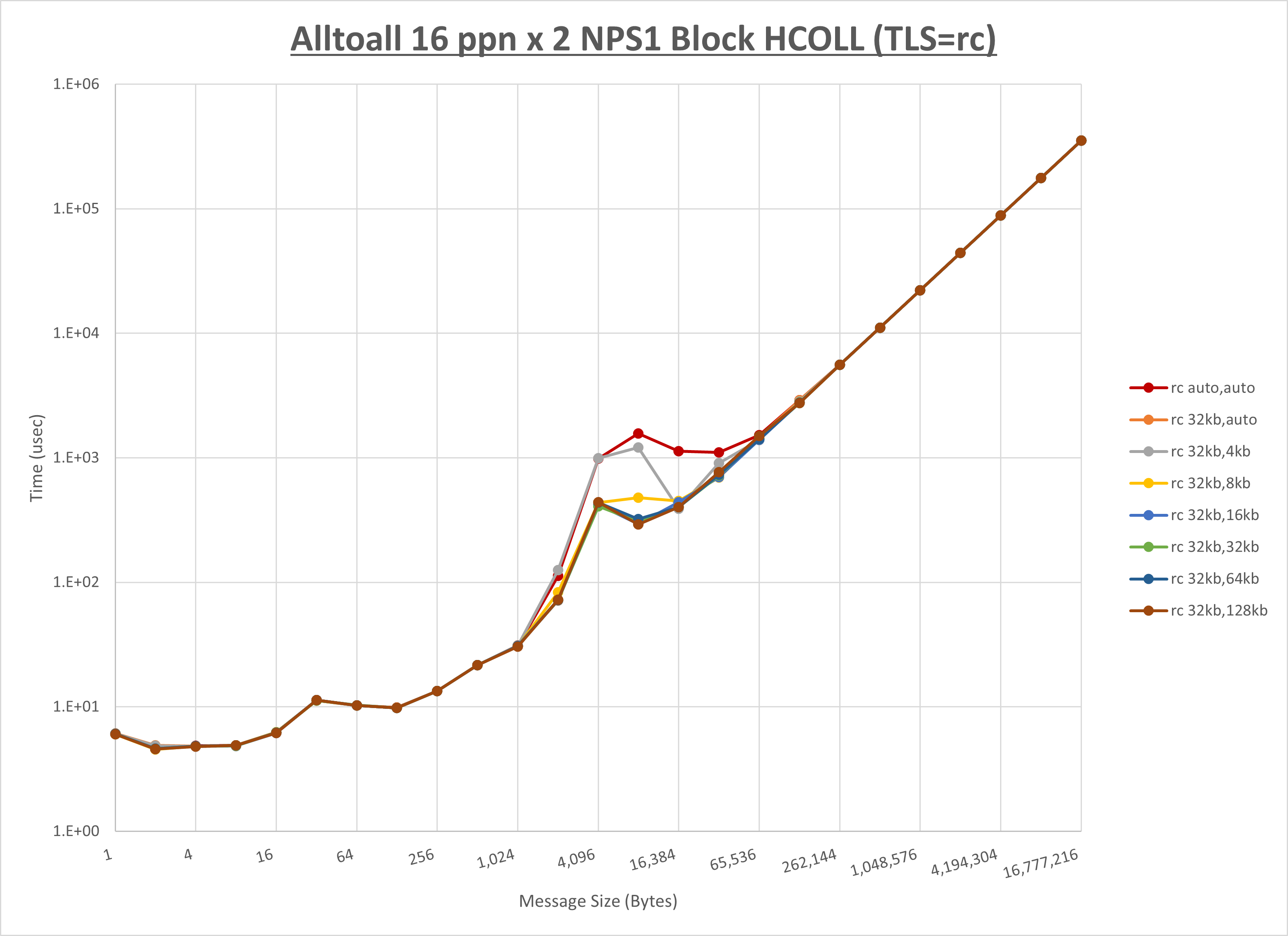
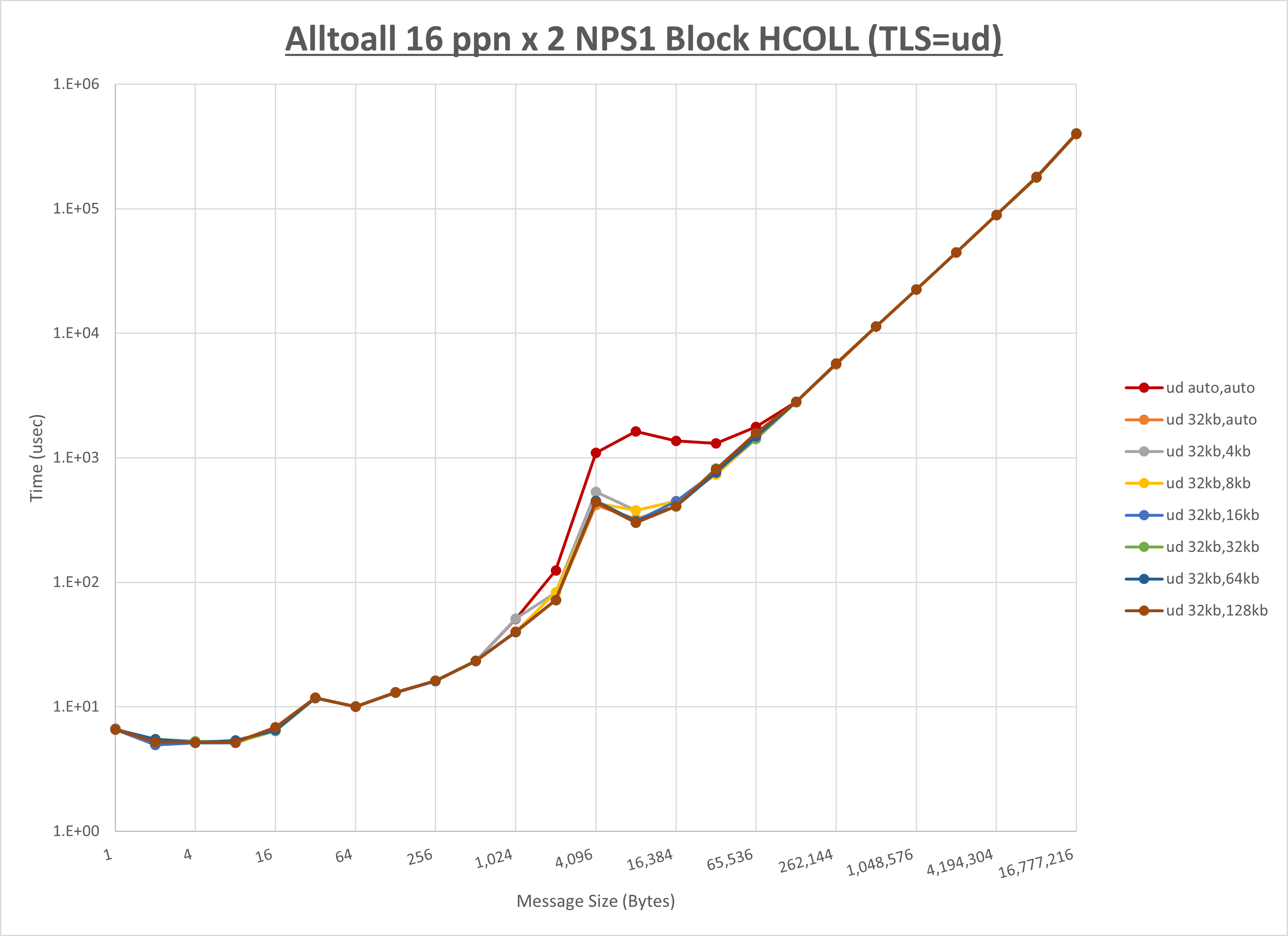
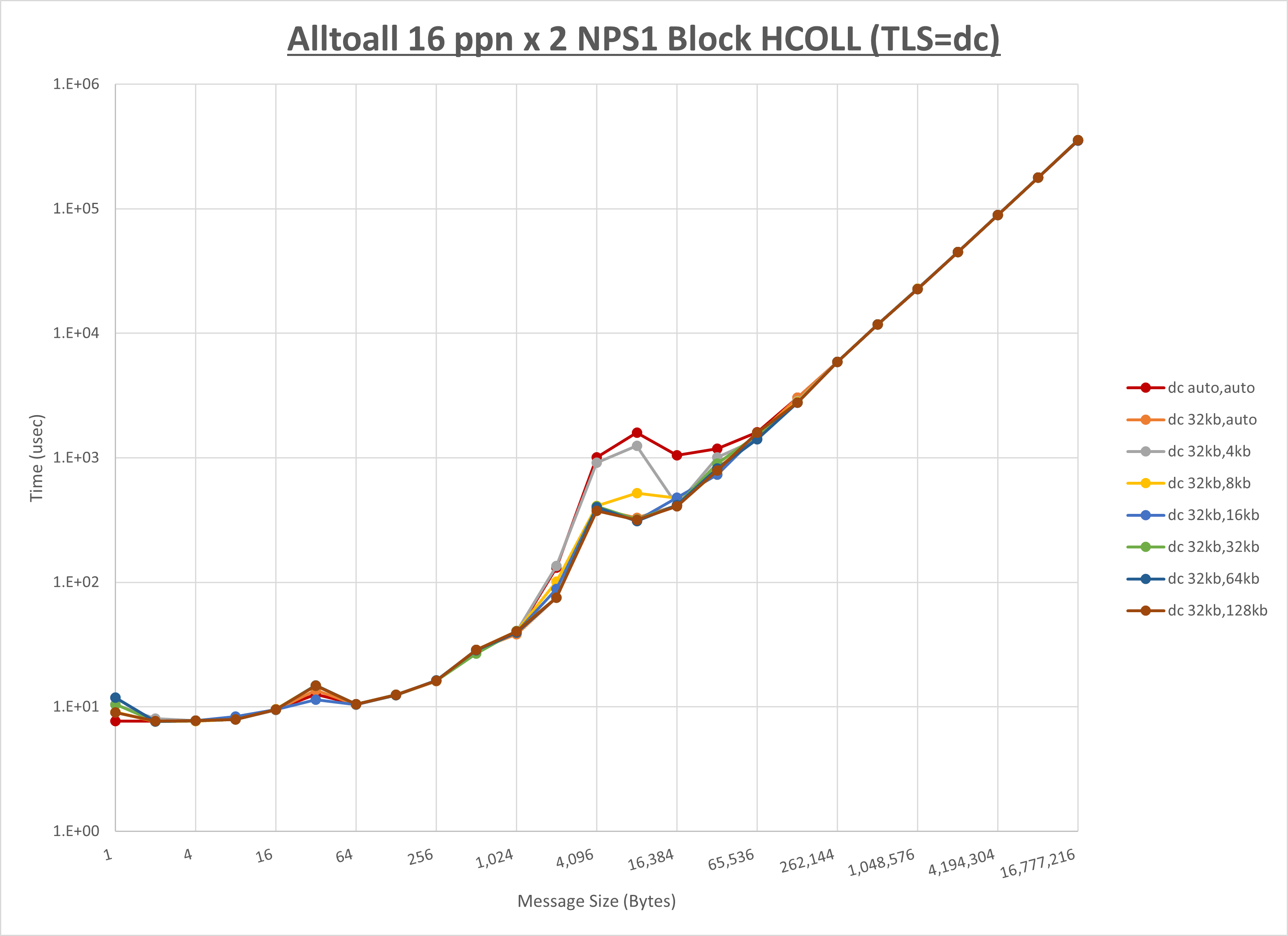
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
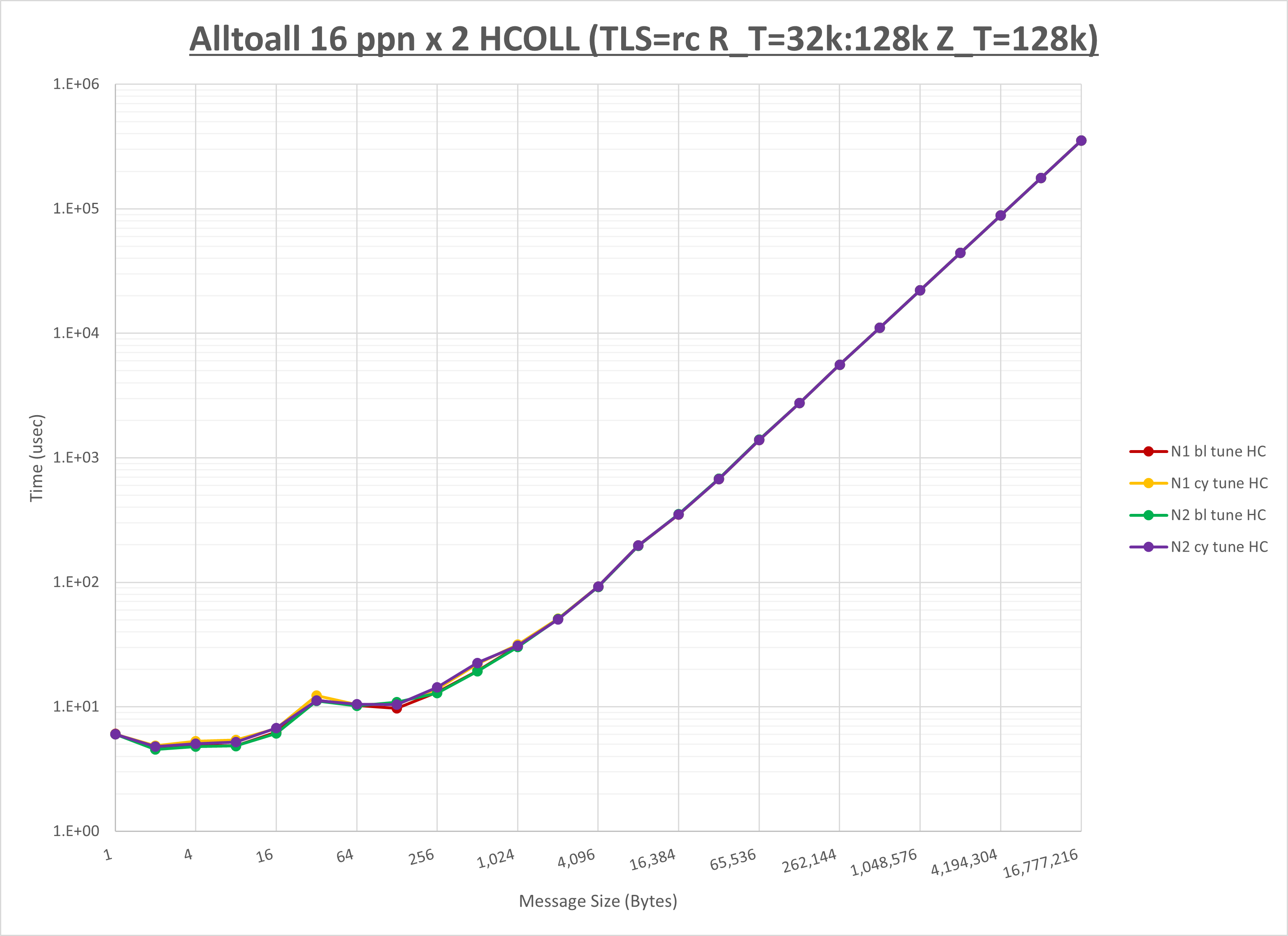
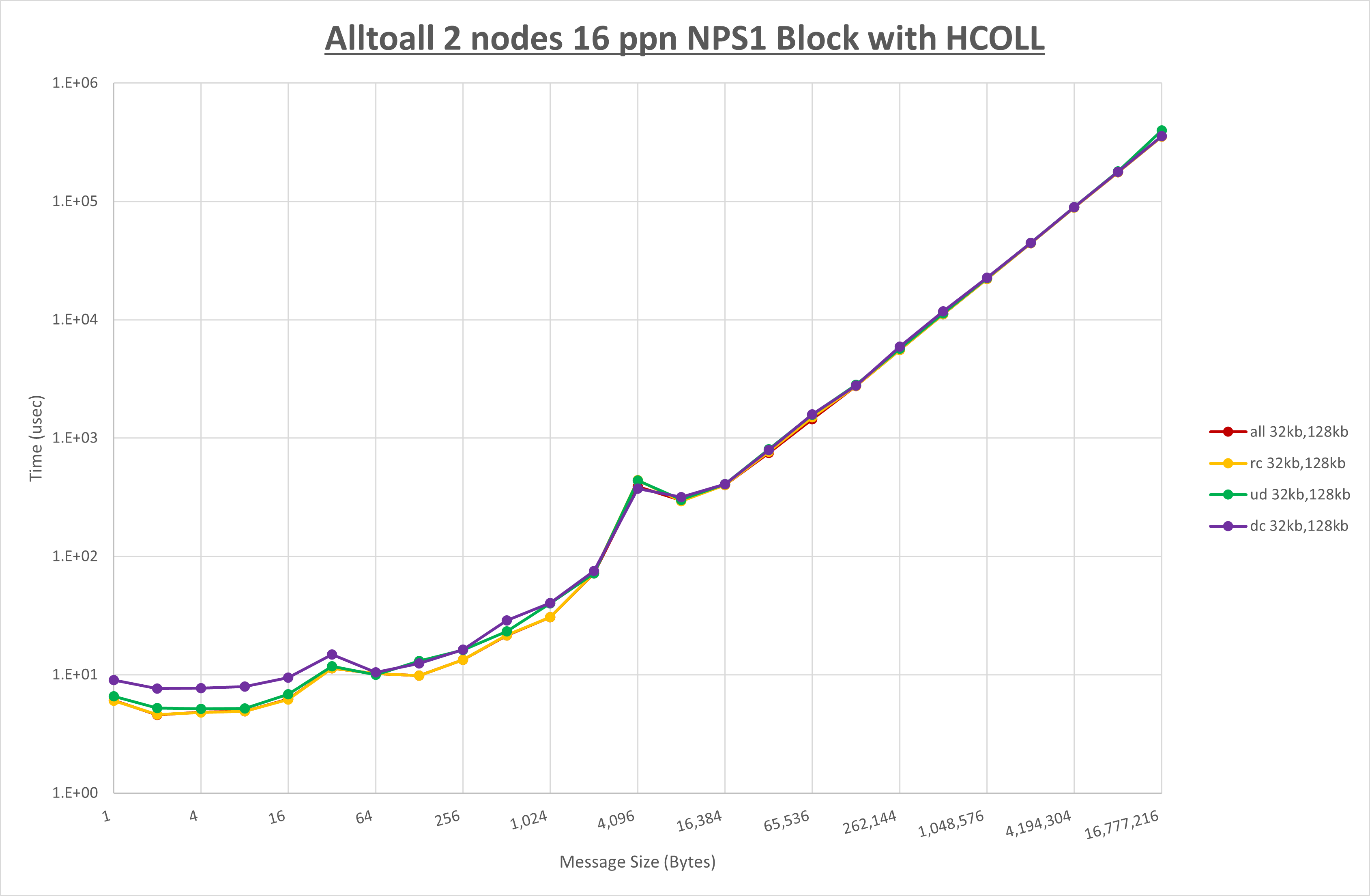
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し16B以下で性能が向上し512Bから64KBで性能が低下
- UCC は no-COLL と比較し4B以下と256KBから2MBで性能が向上し256Bから64KBで性能が低下
- チューニング適用で8KBから16KBの間で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-2 Allgather の HCOLL の結果から64KBとしています。
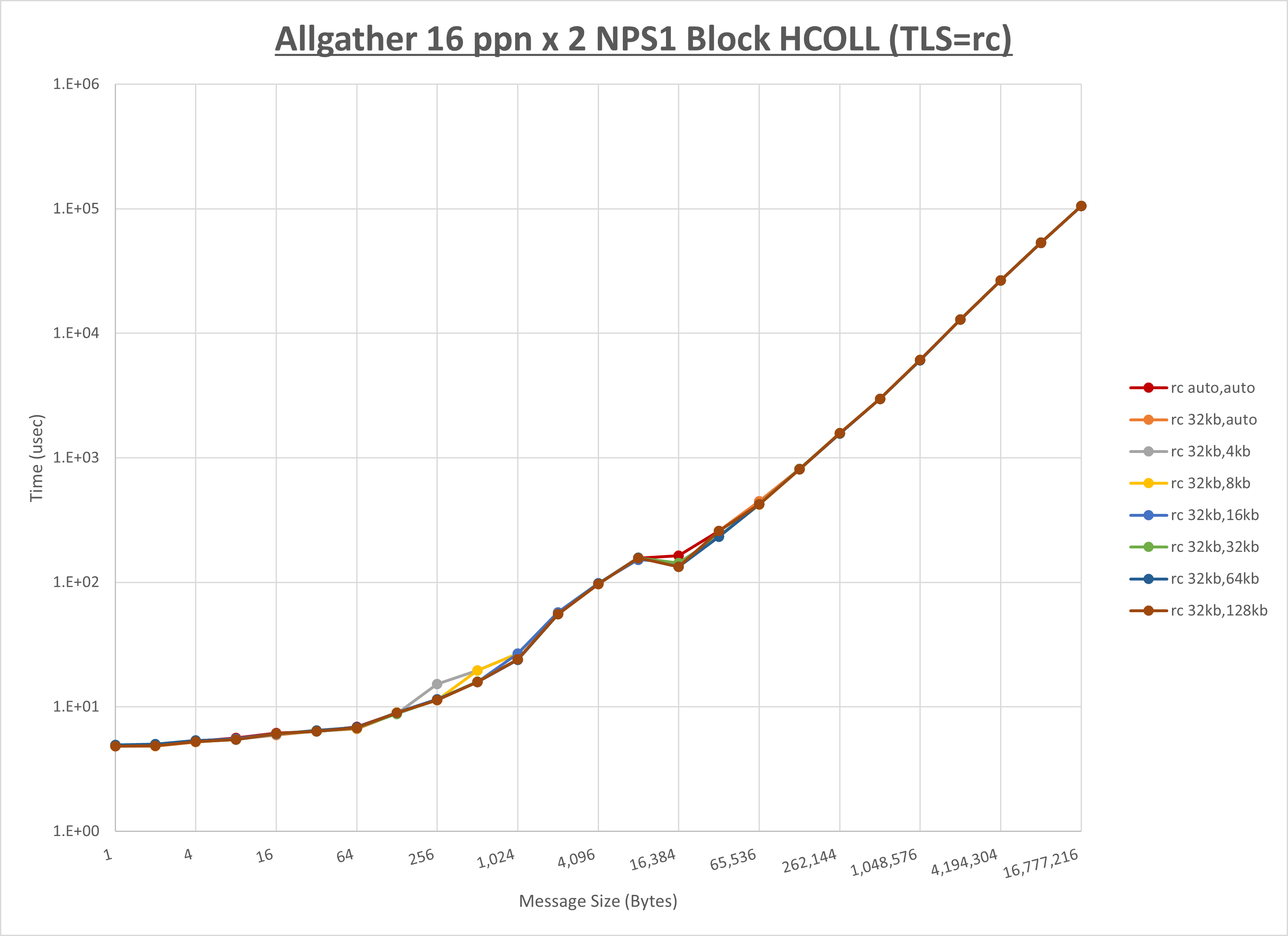
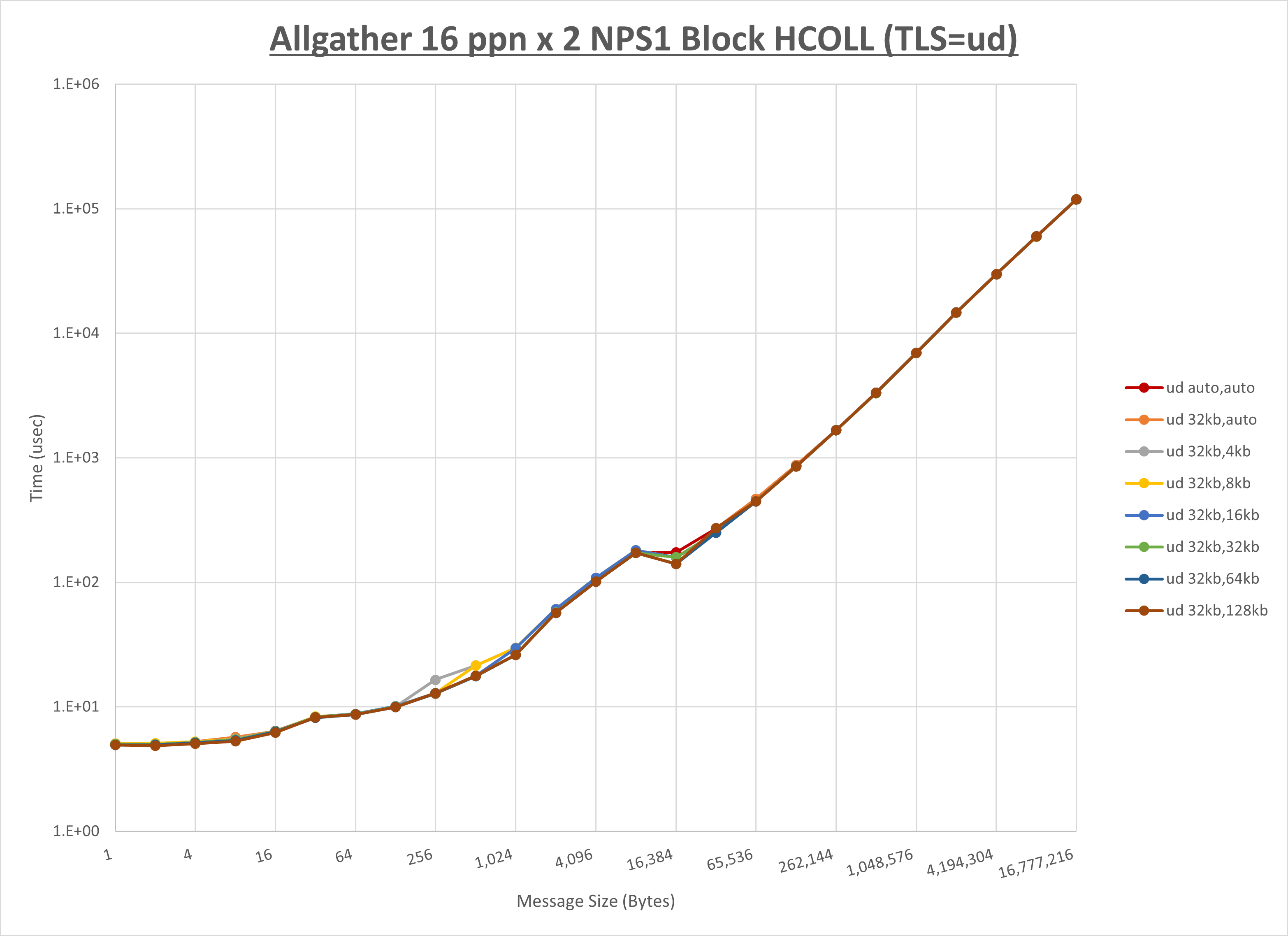
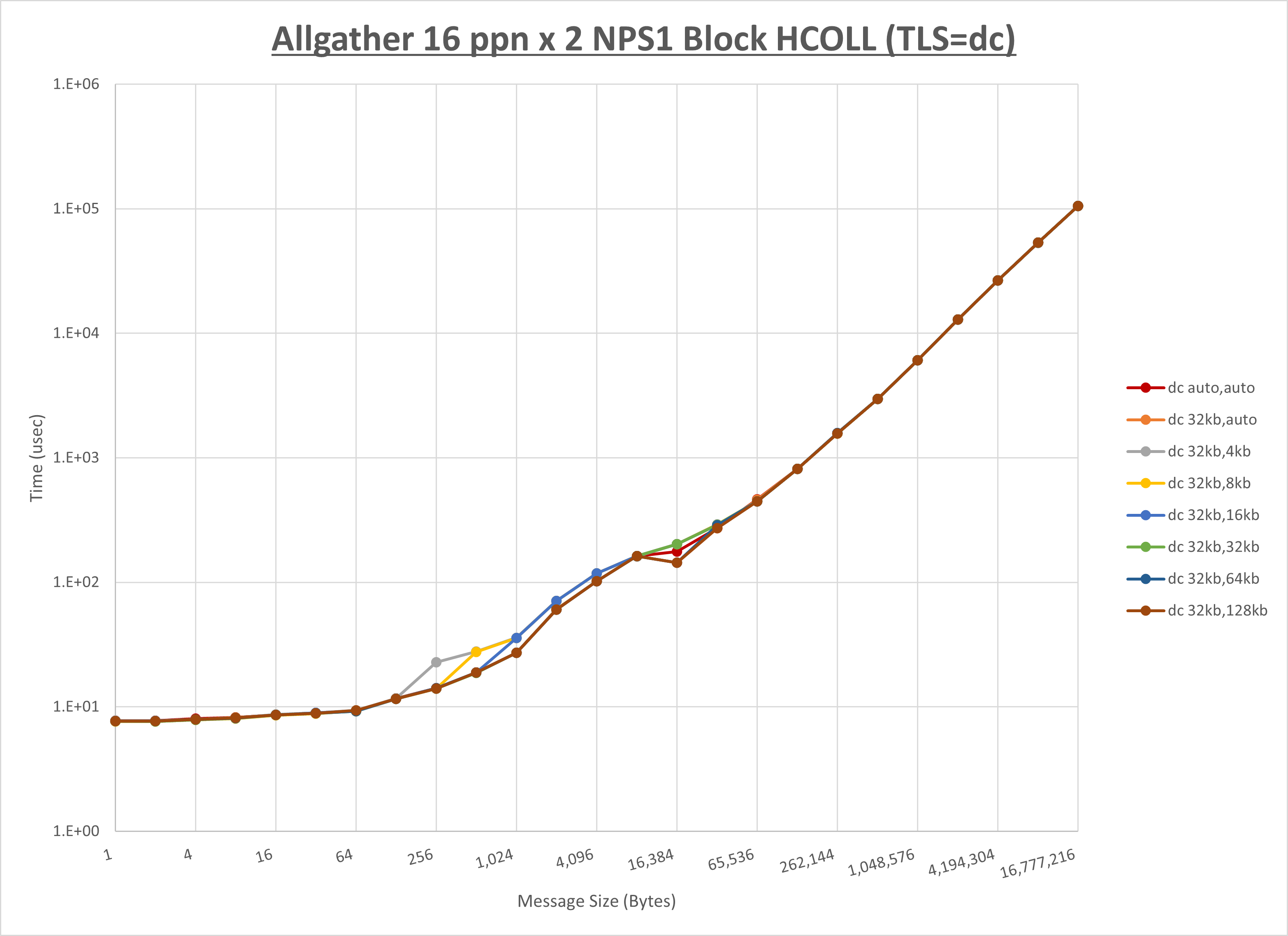
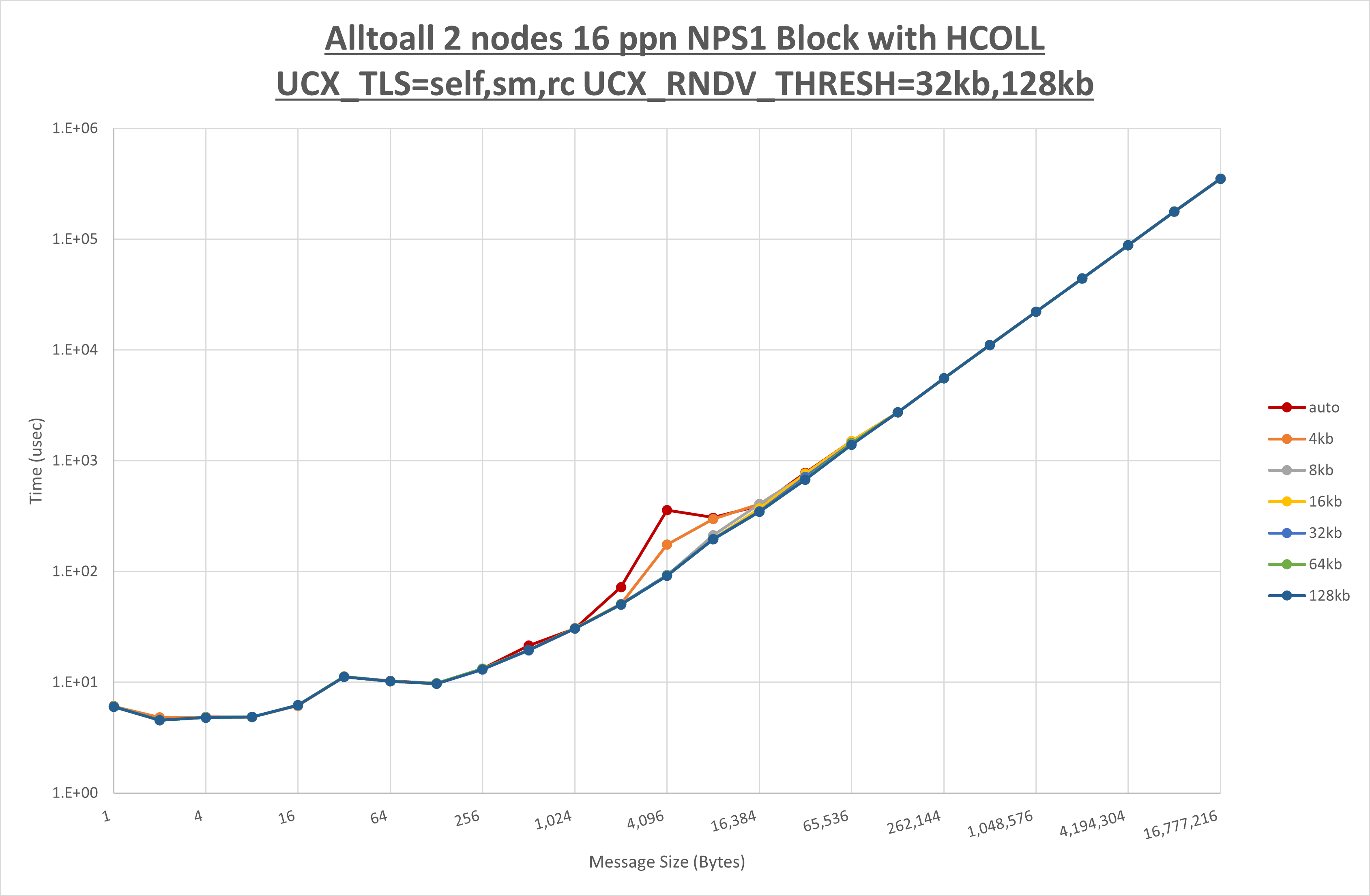
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
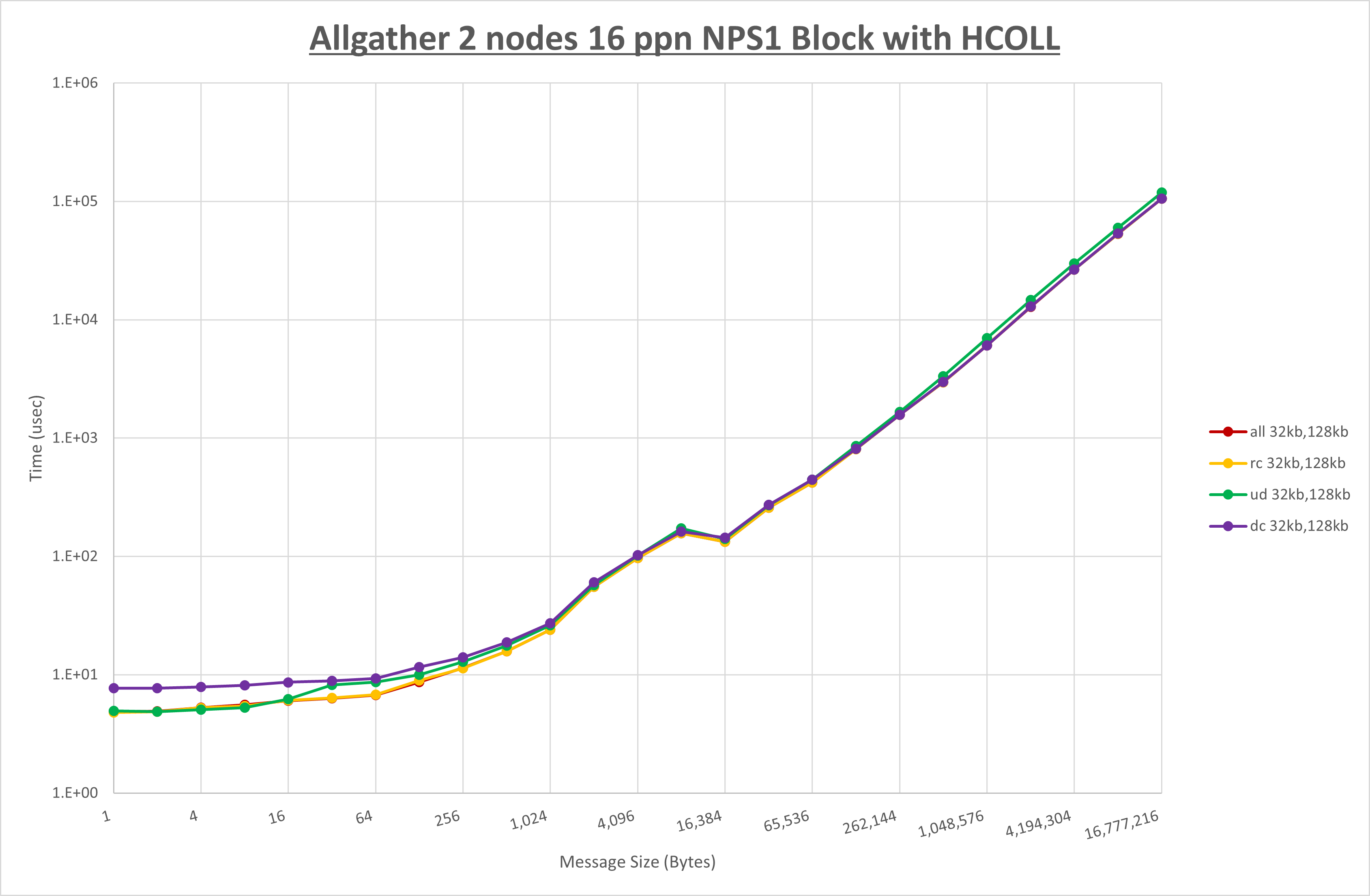
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
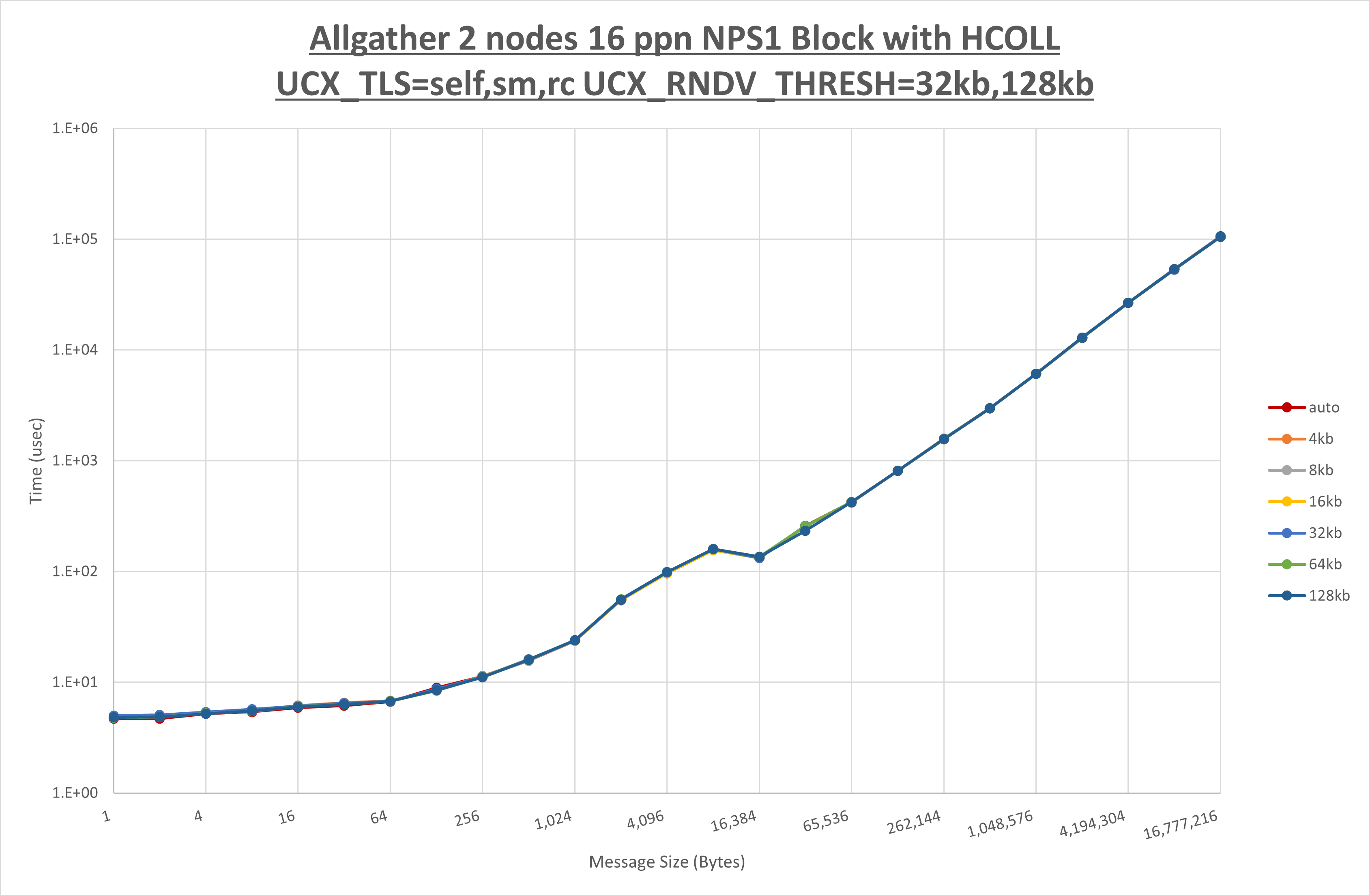
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
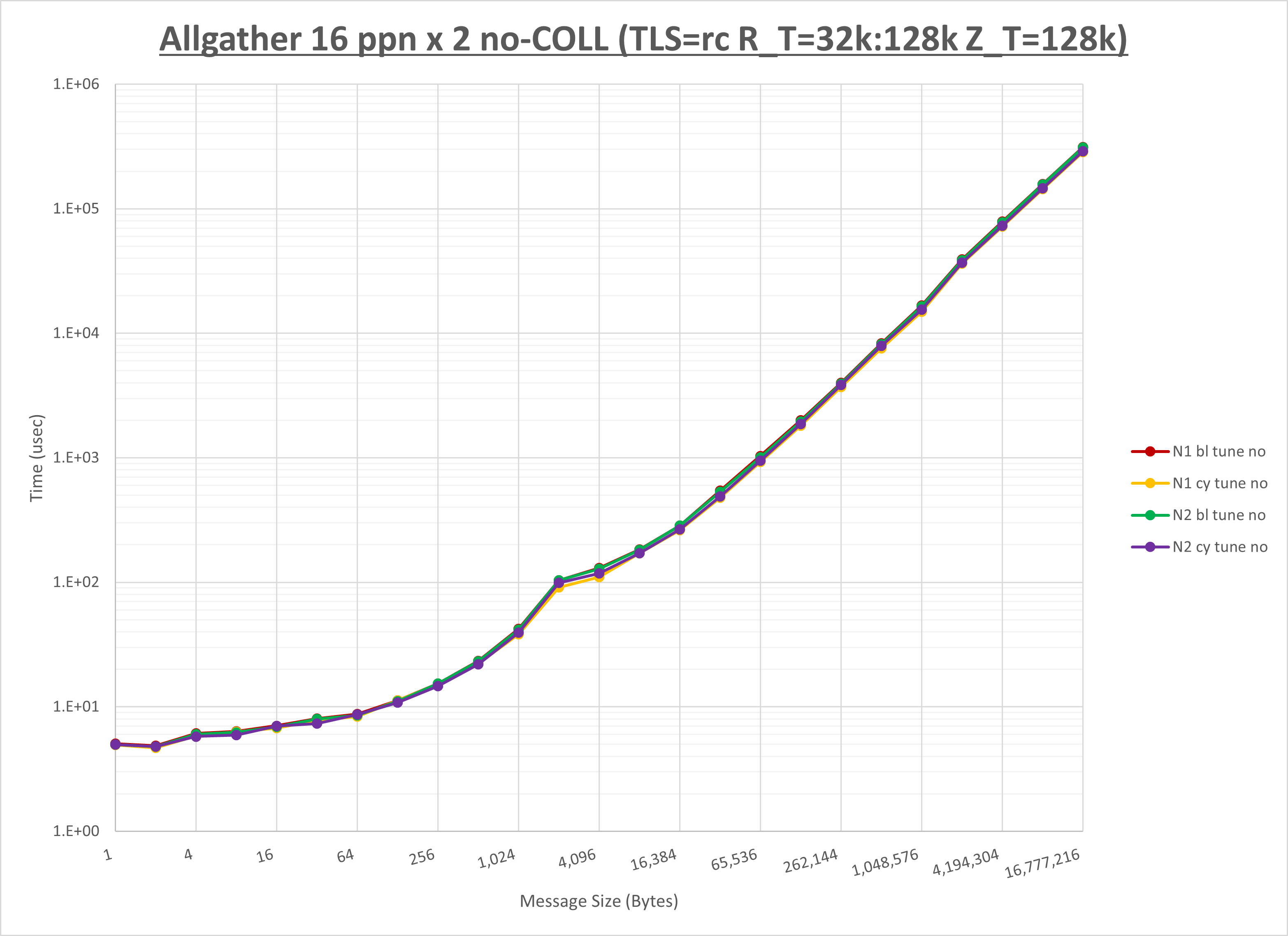
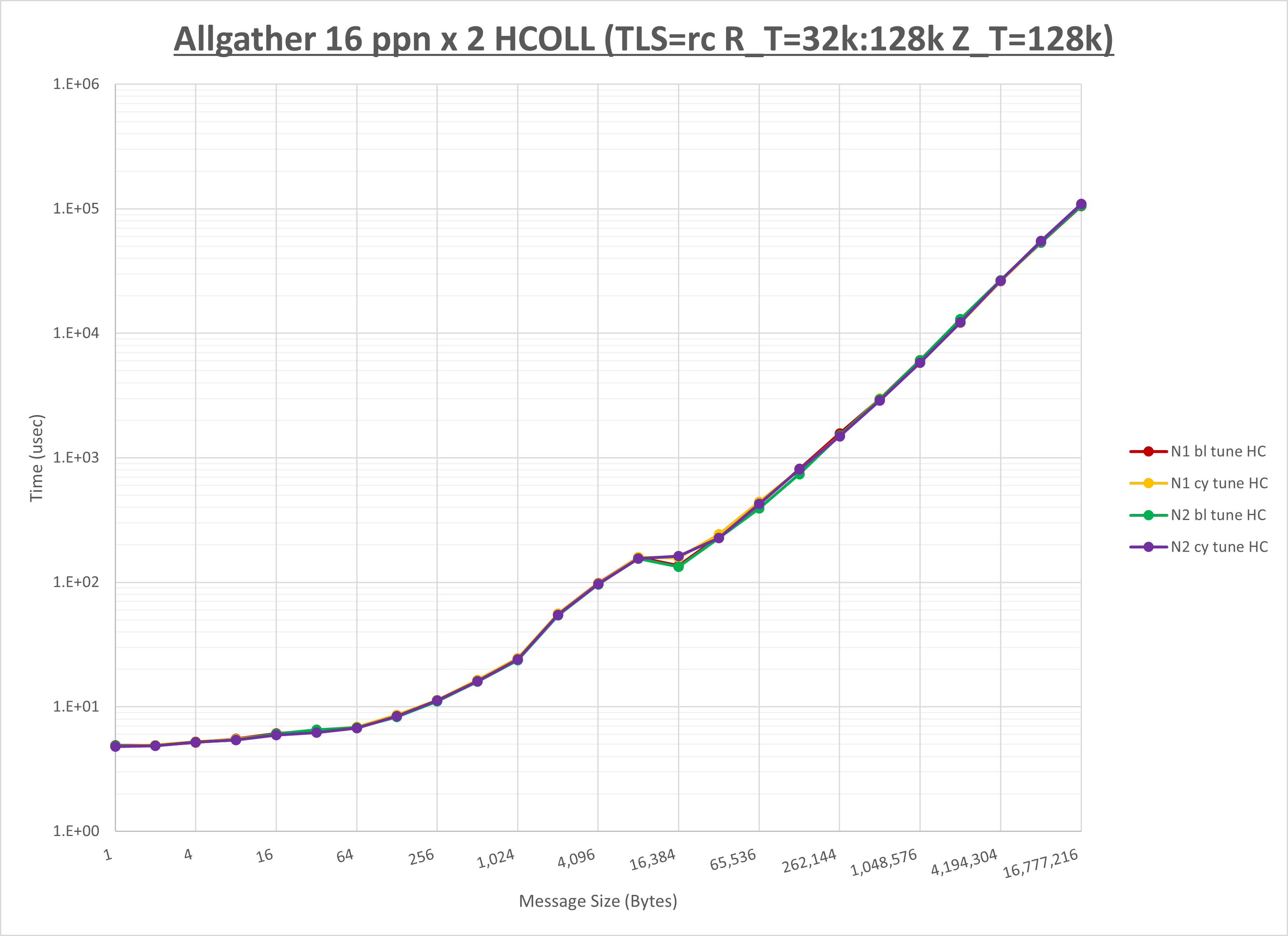
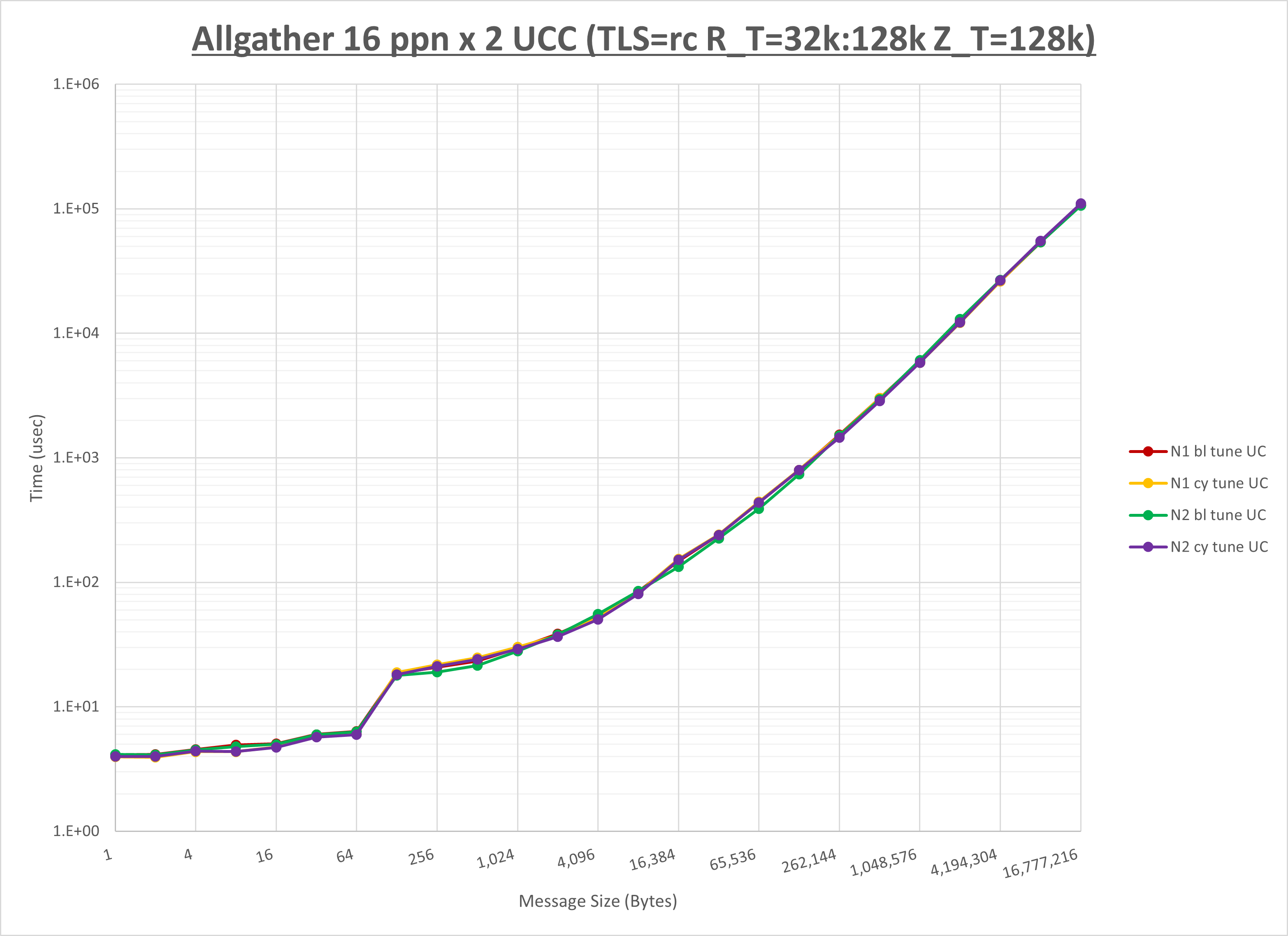
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
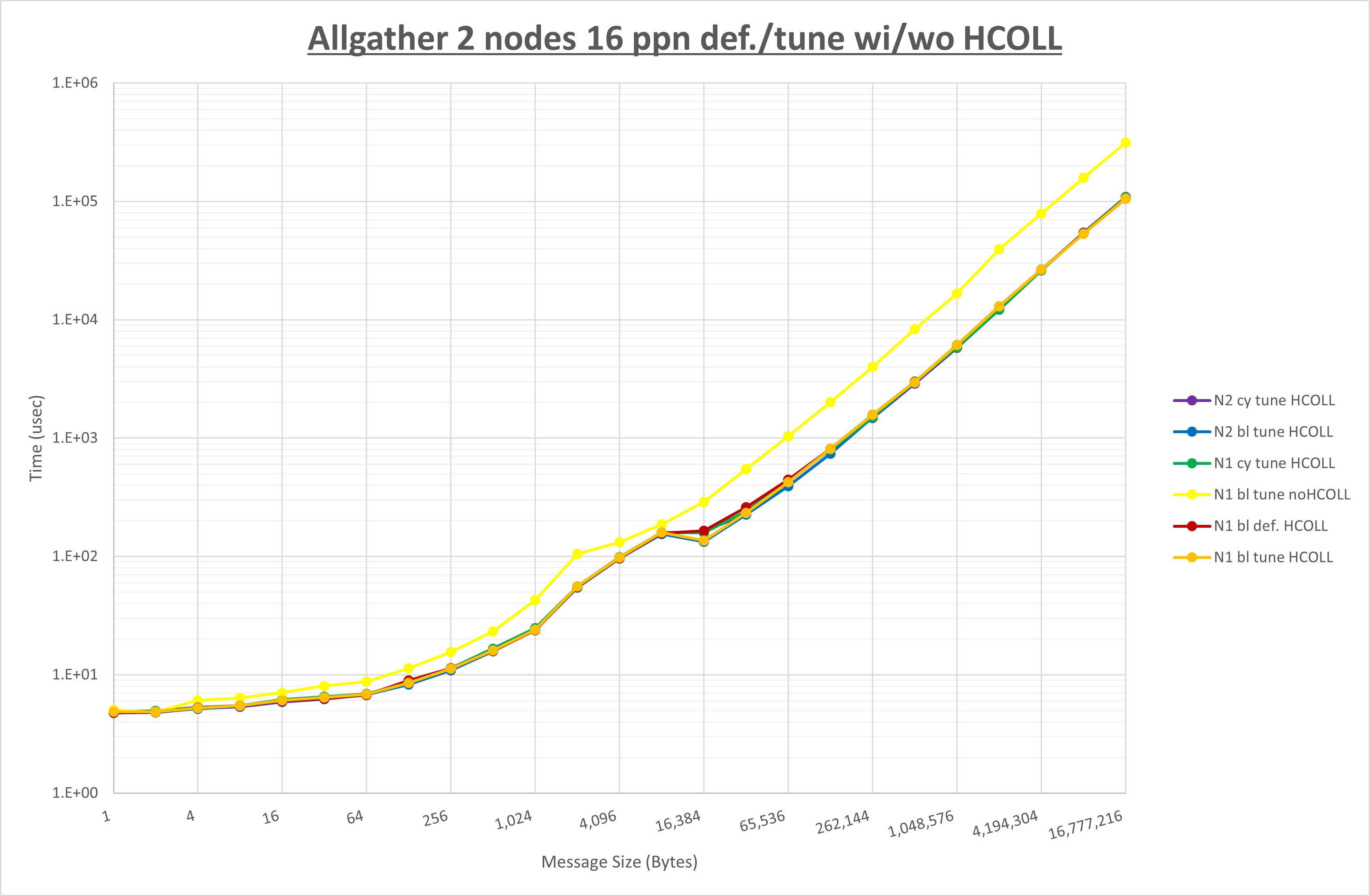
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で有意な性能の変化無し
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-3 Allreduce の HCOLL の結果から128KBとしています。

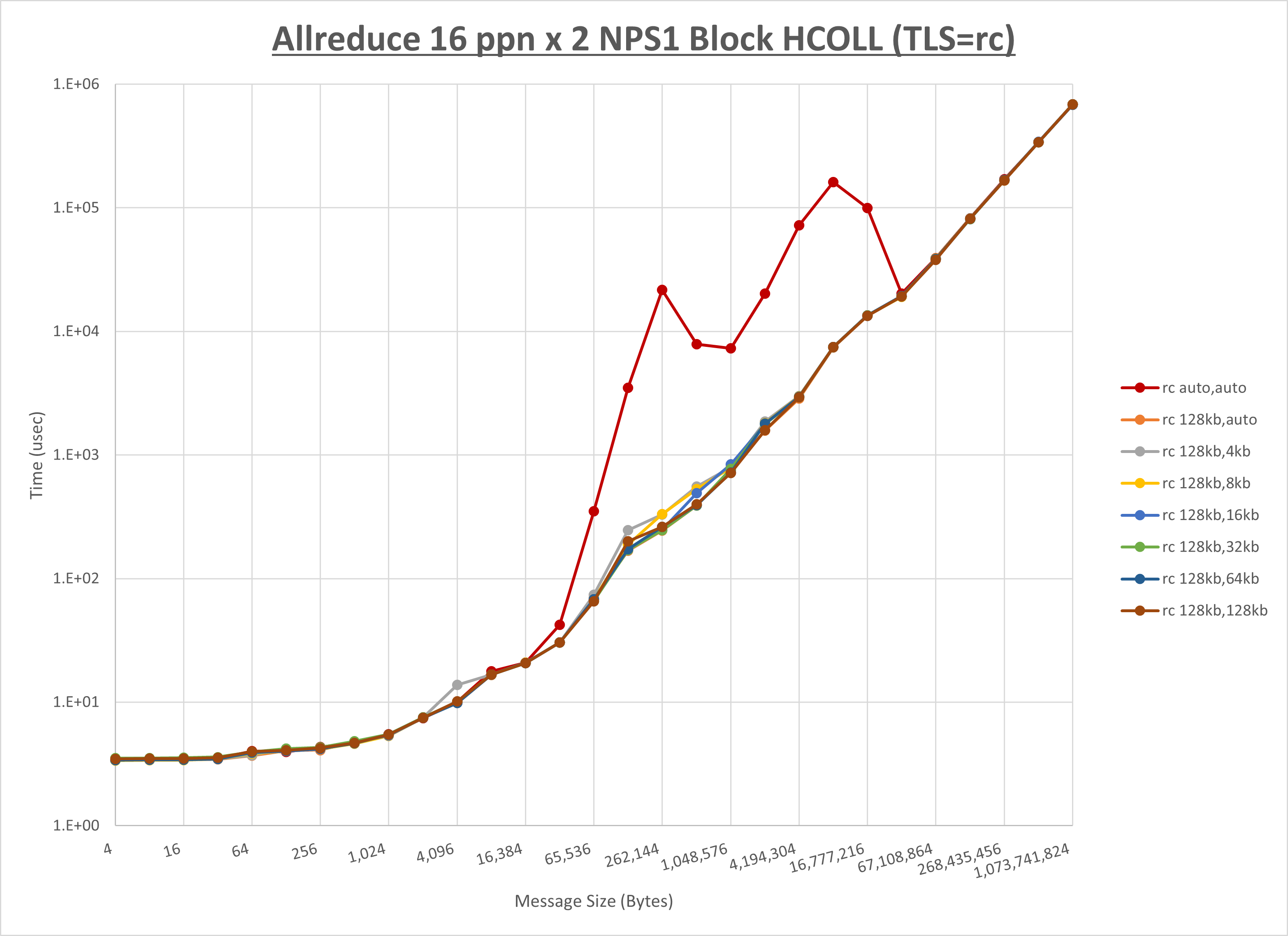
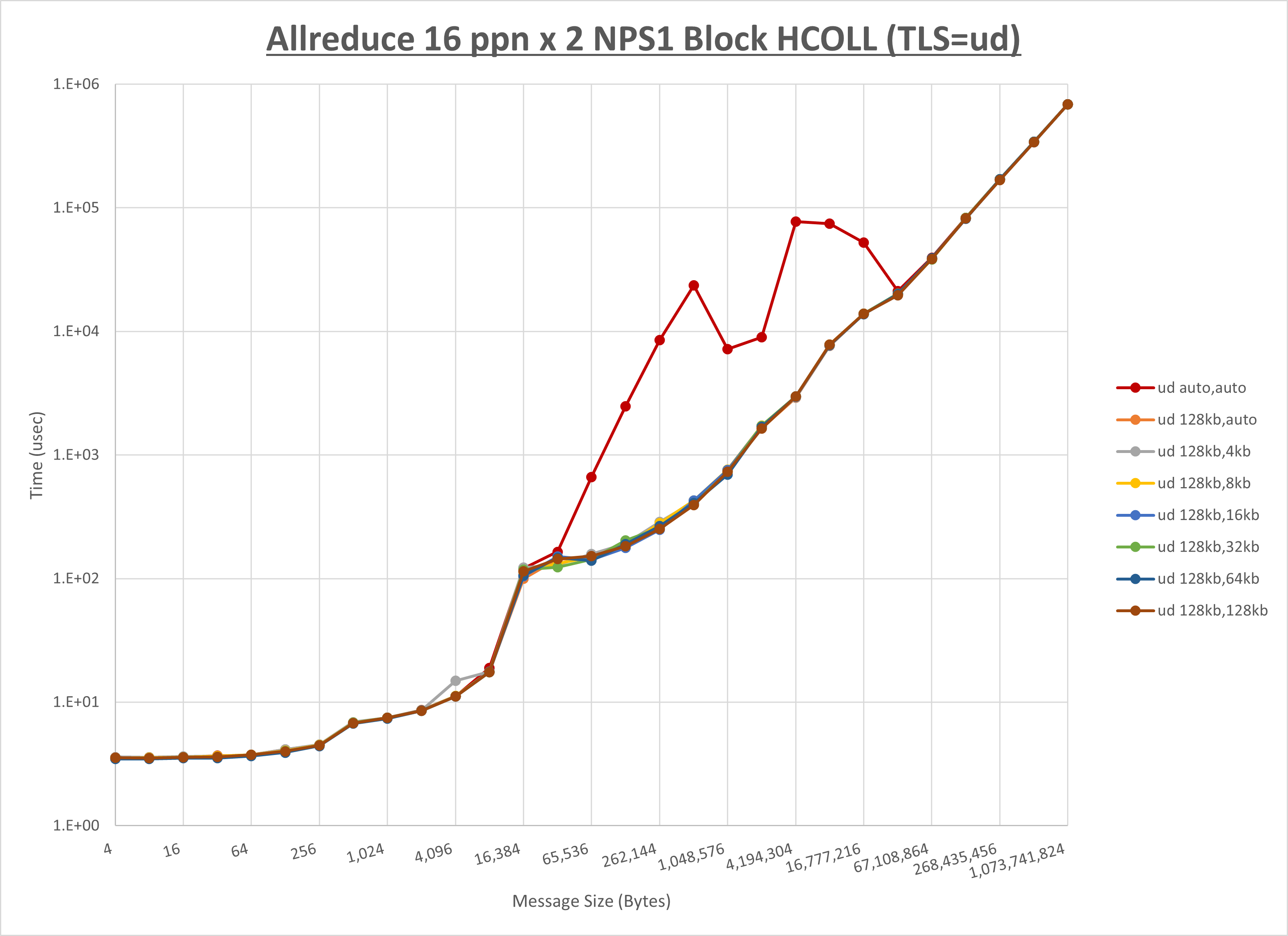
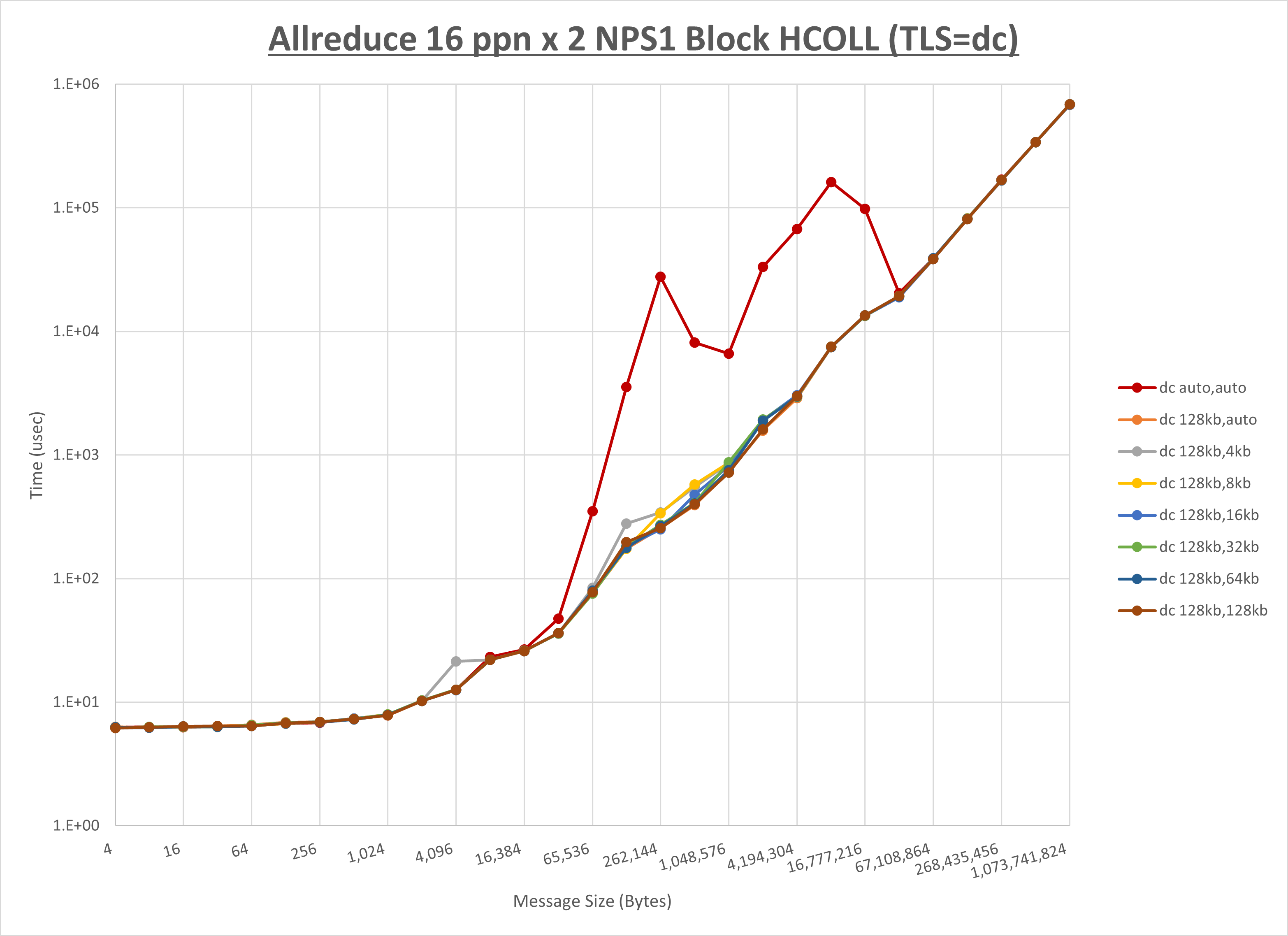
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
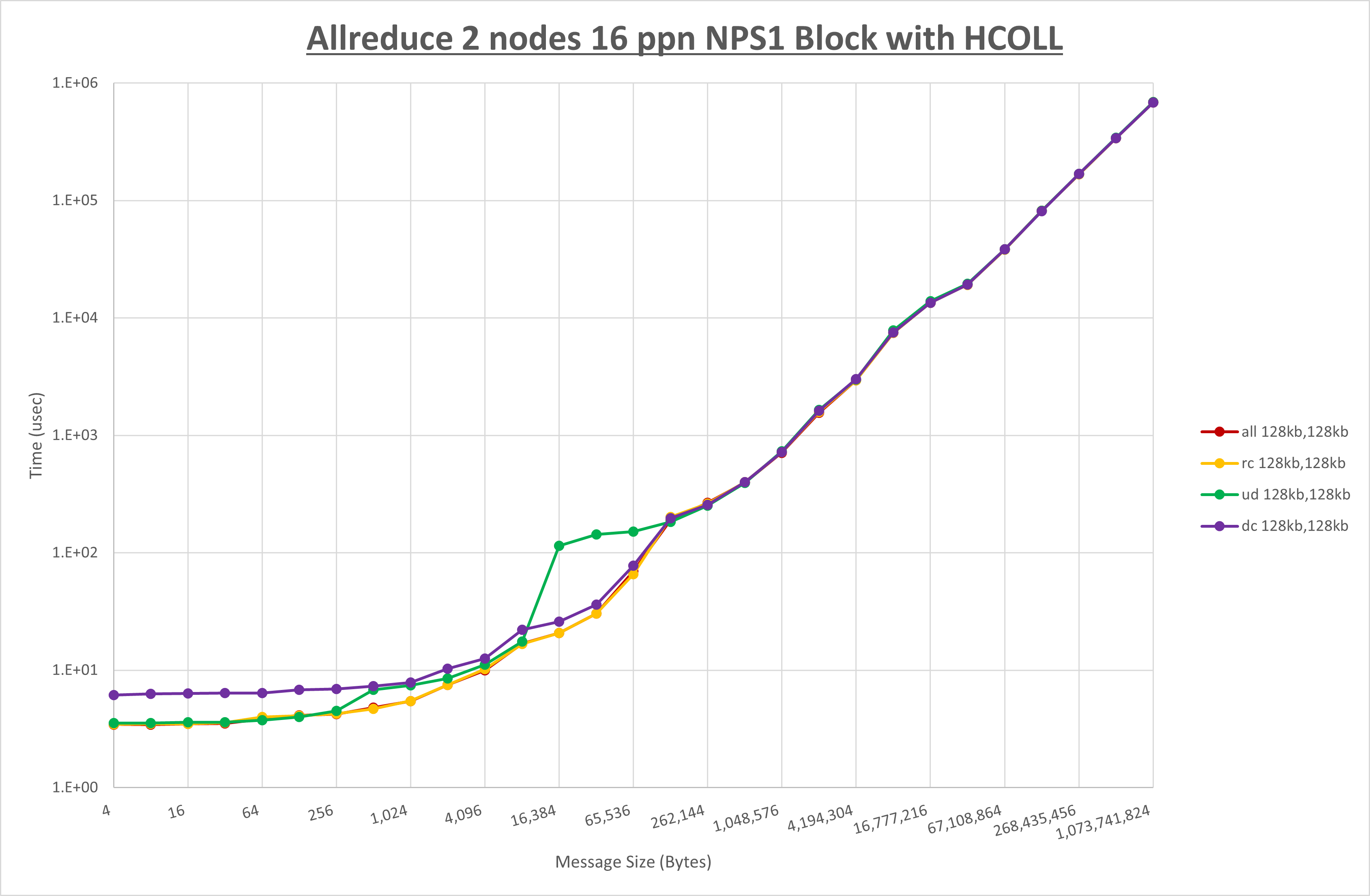
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
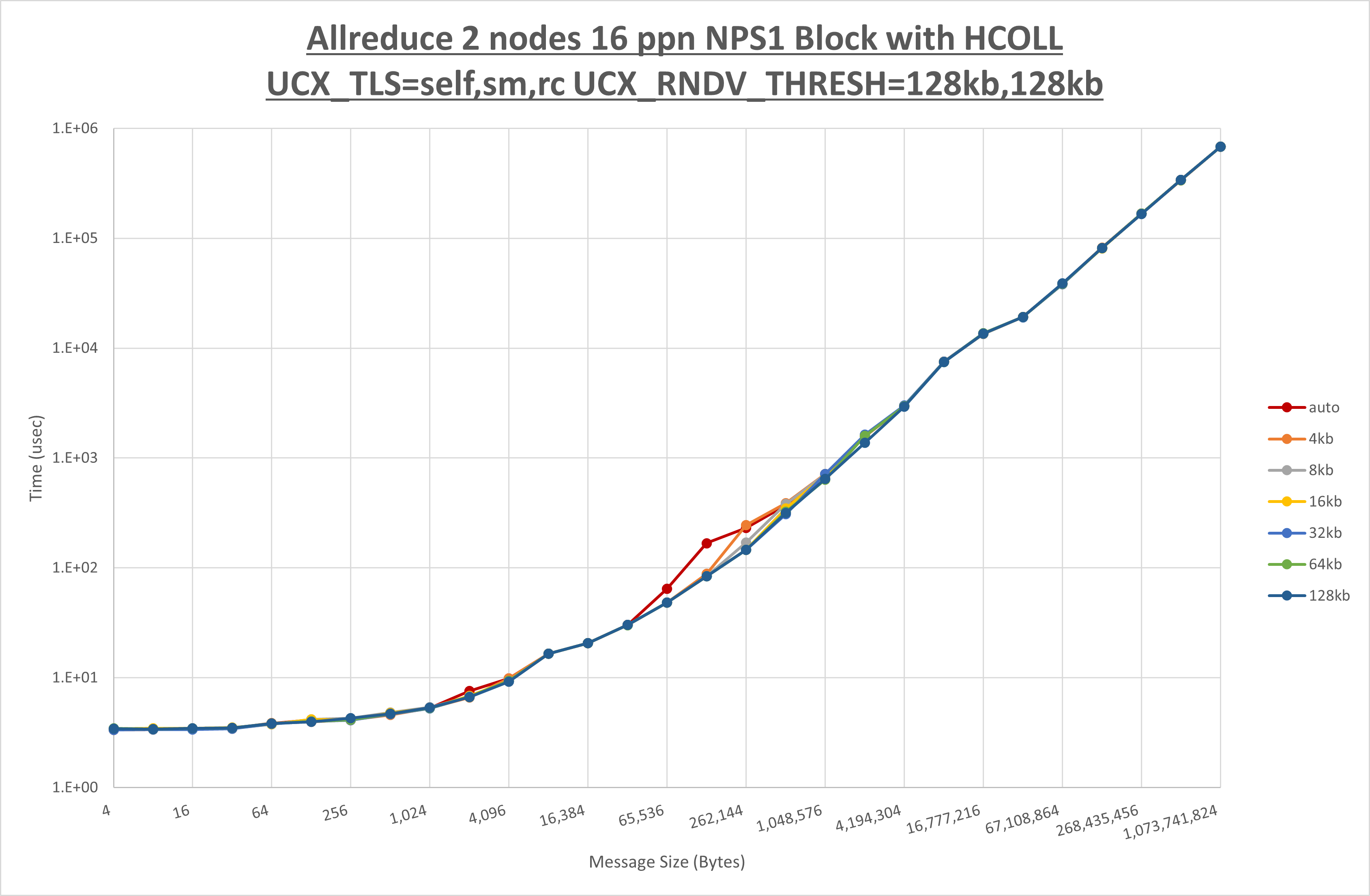
以上より、 UCX_ZCOPY_THRESH を 64kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
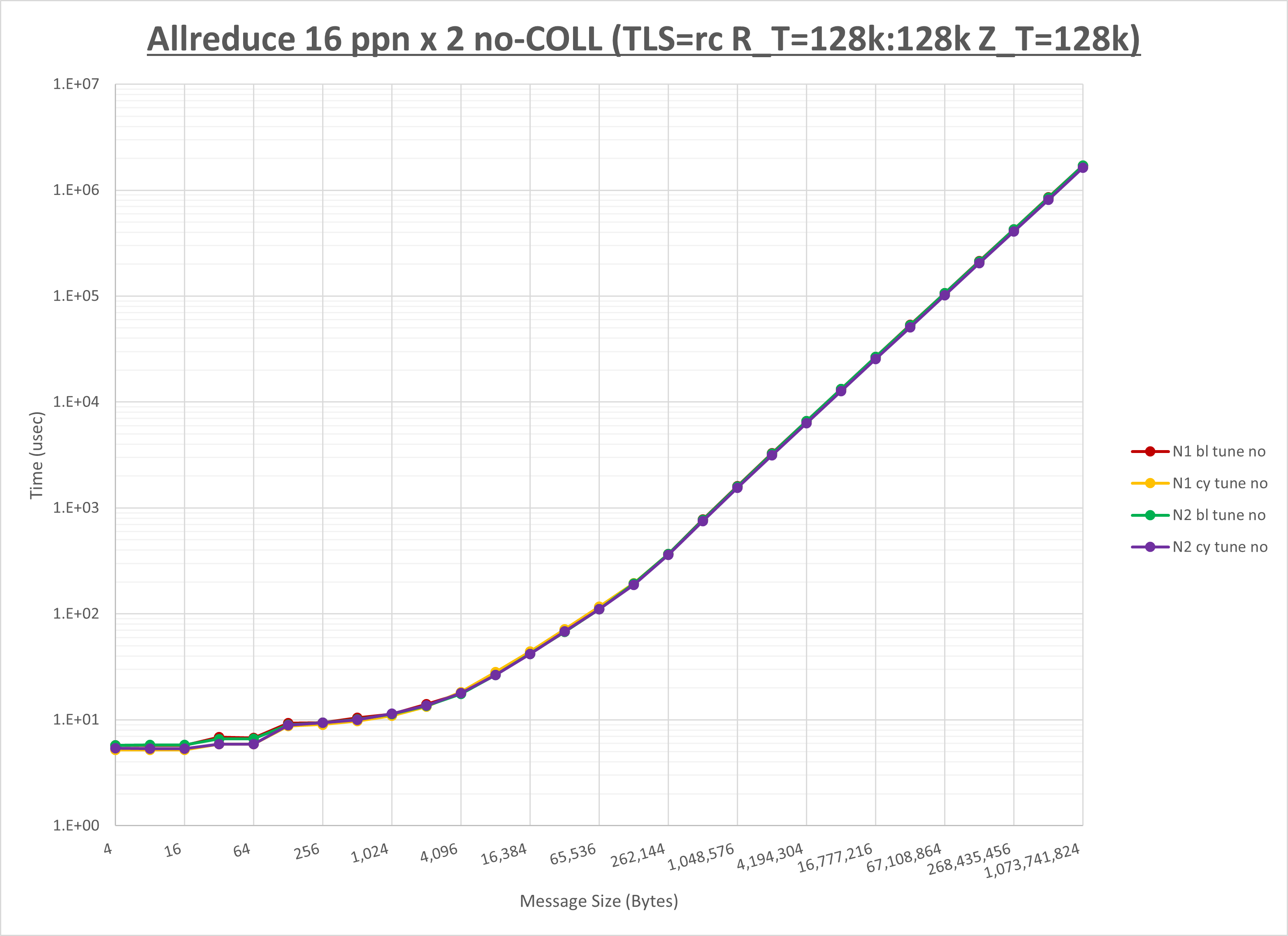
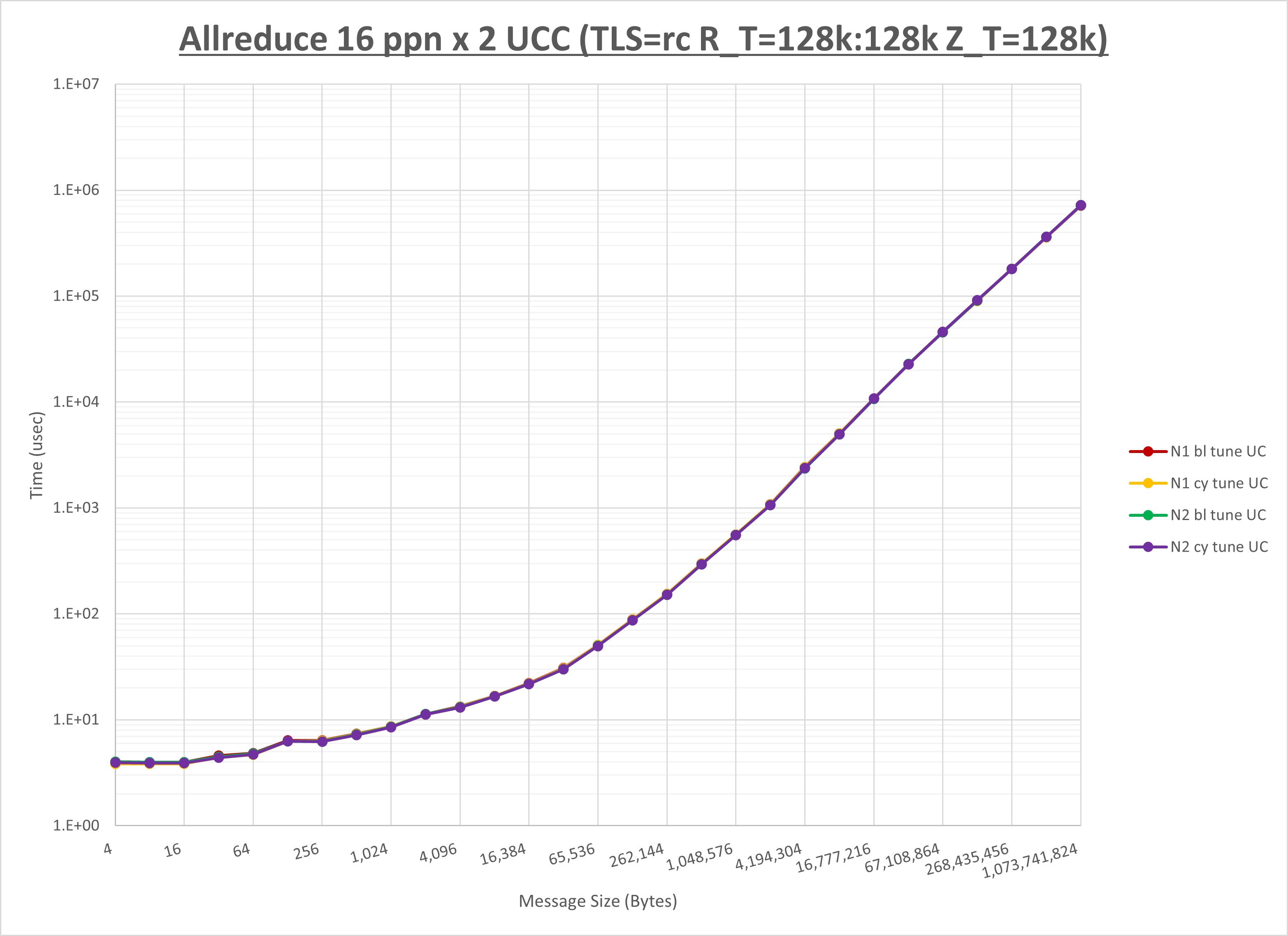
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | ブロック分割 |
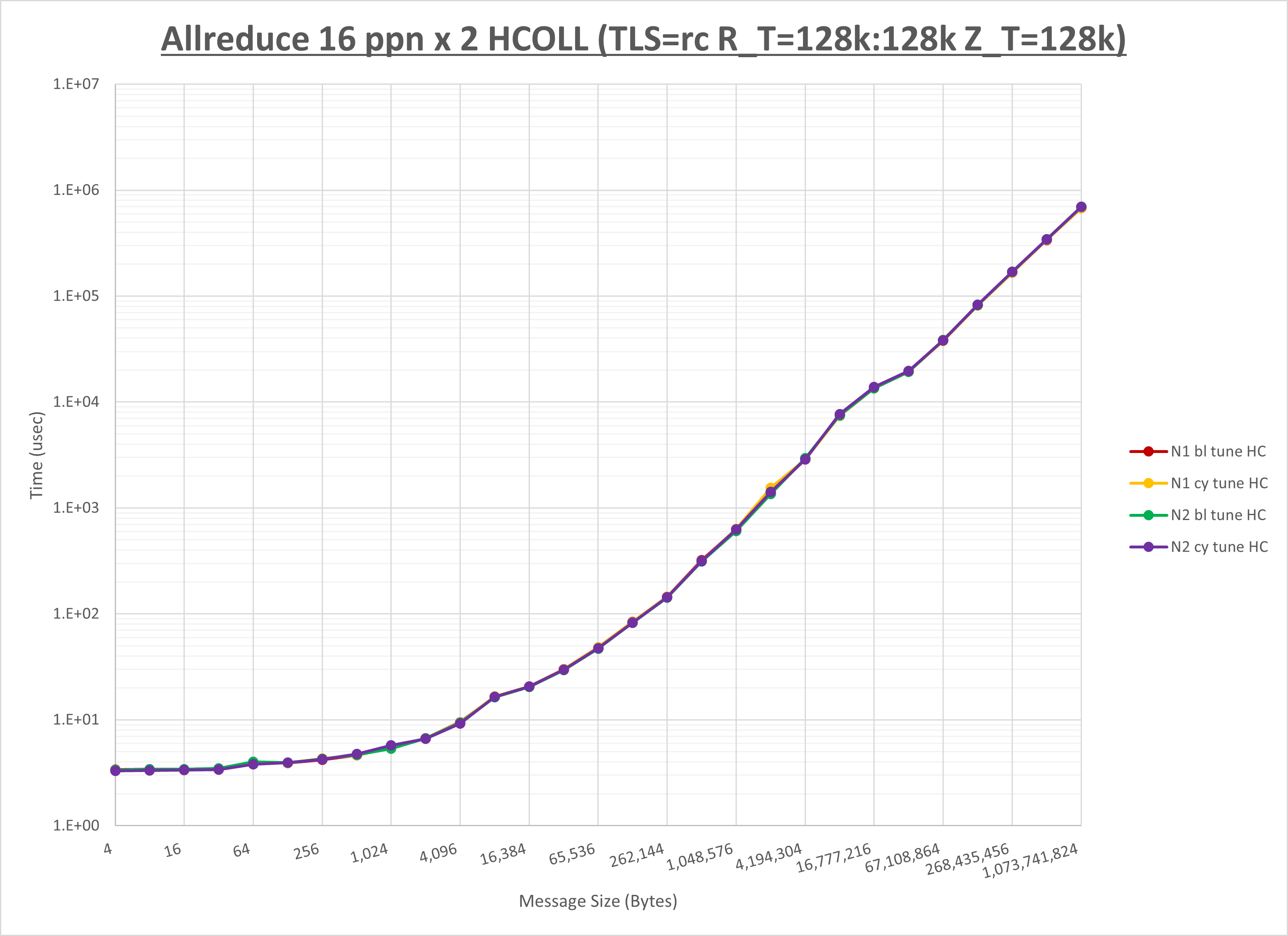
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
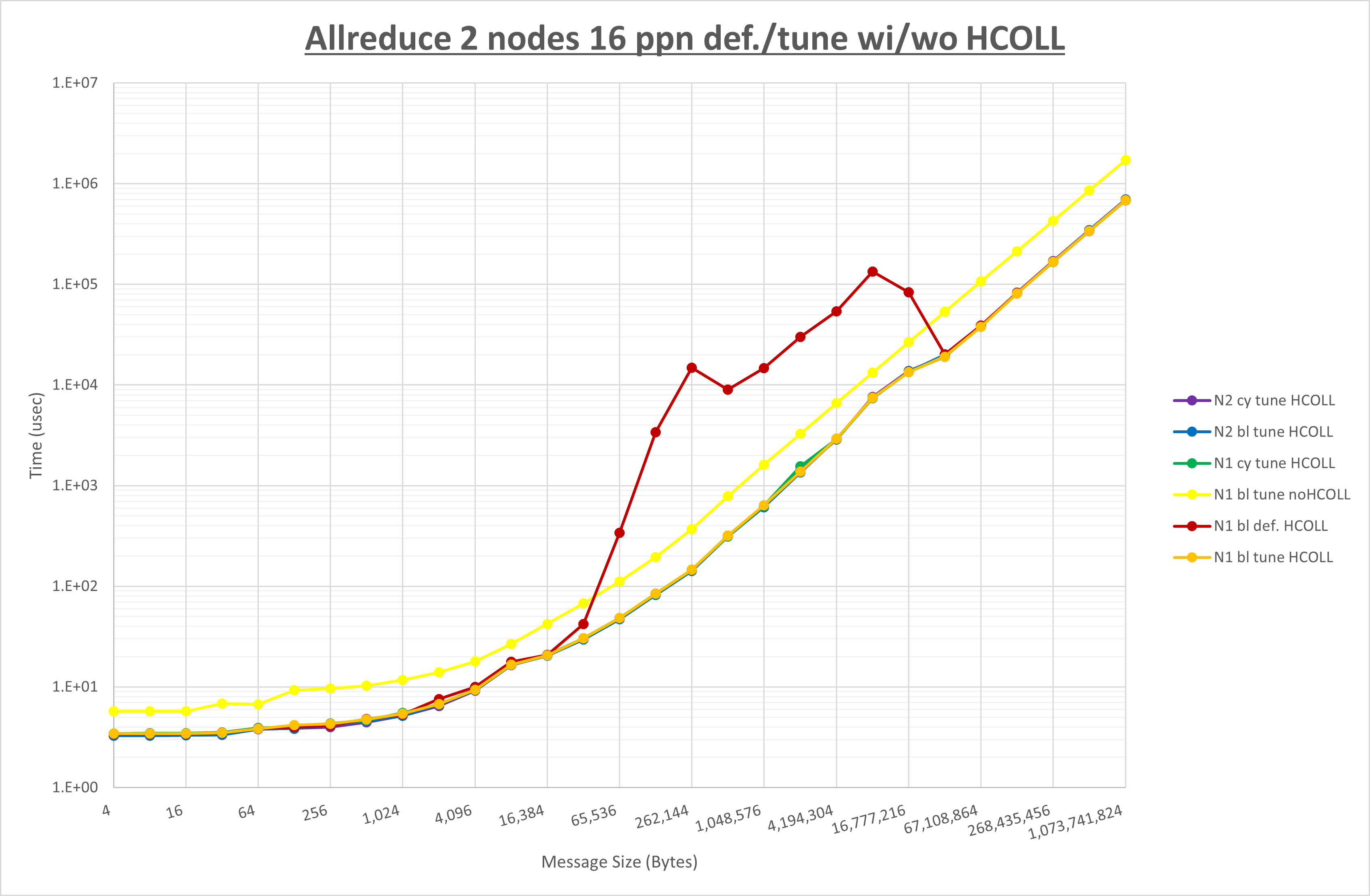
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で64KBから4MBの間で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-4 Exchange の結果から16KBとしています。
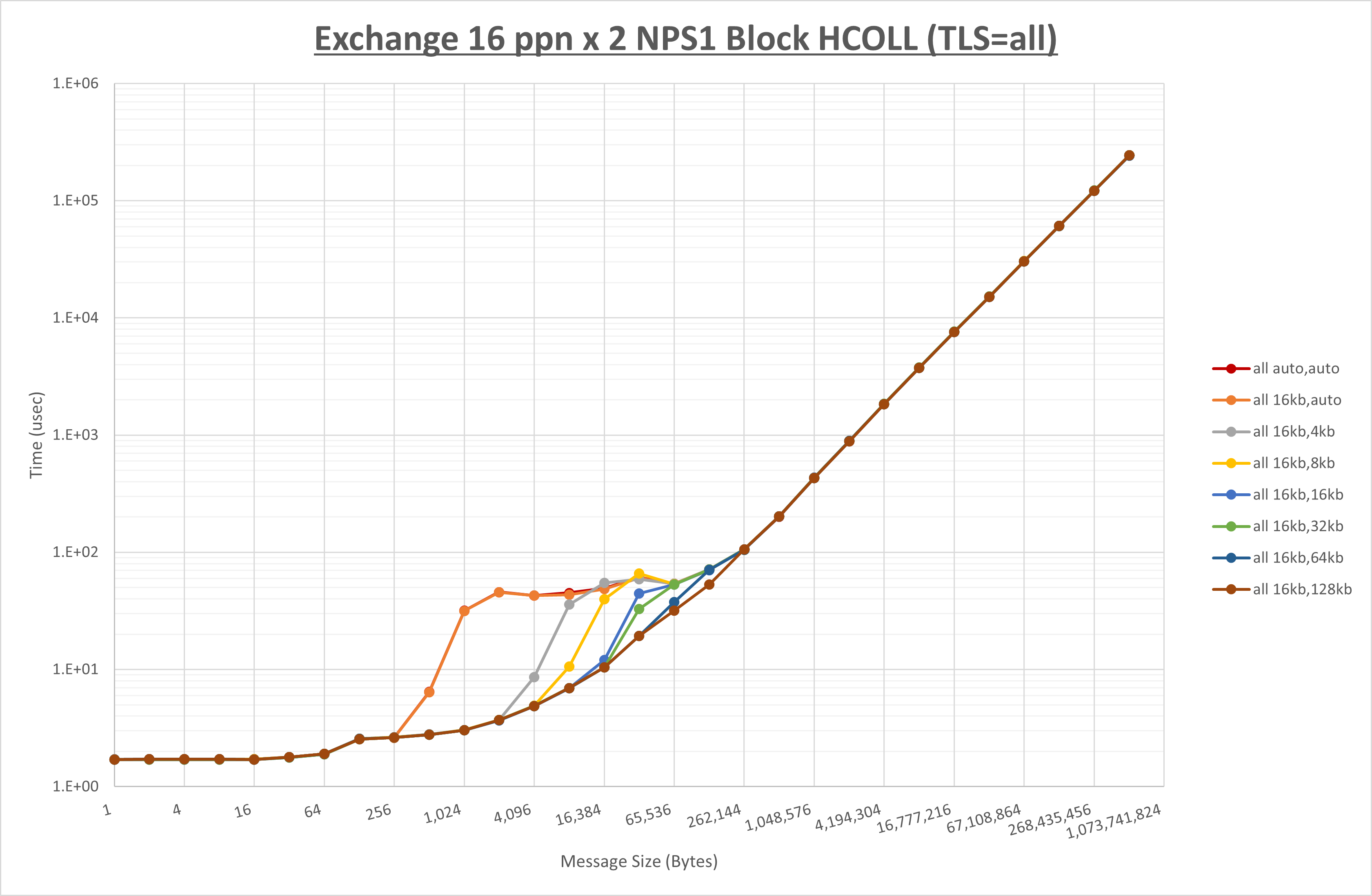
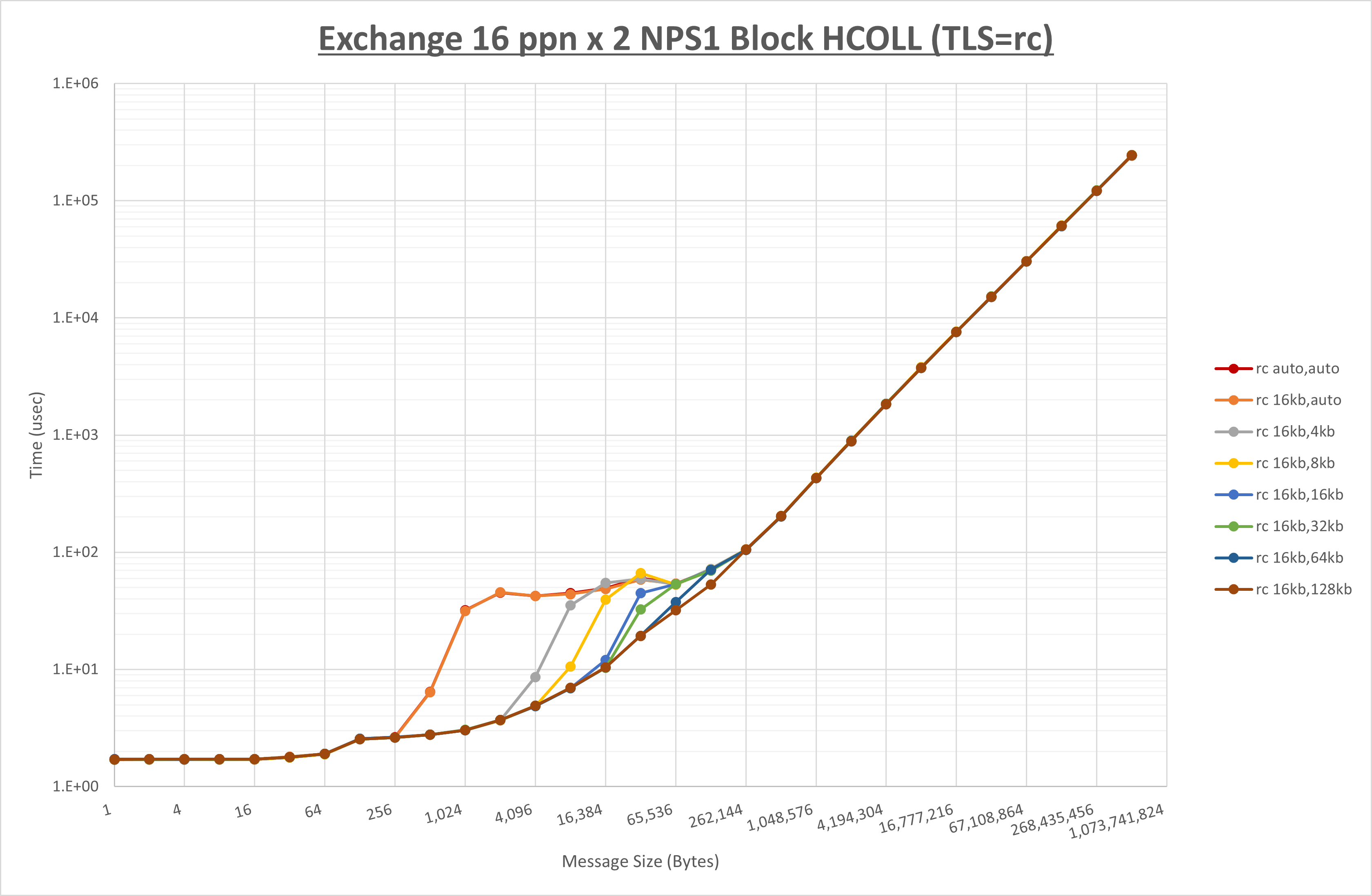
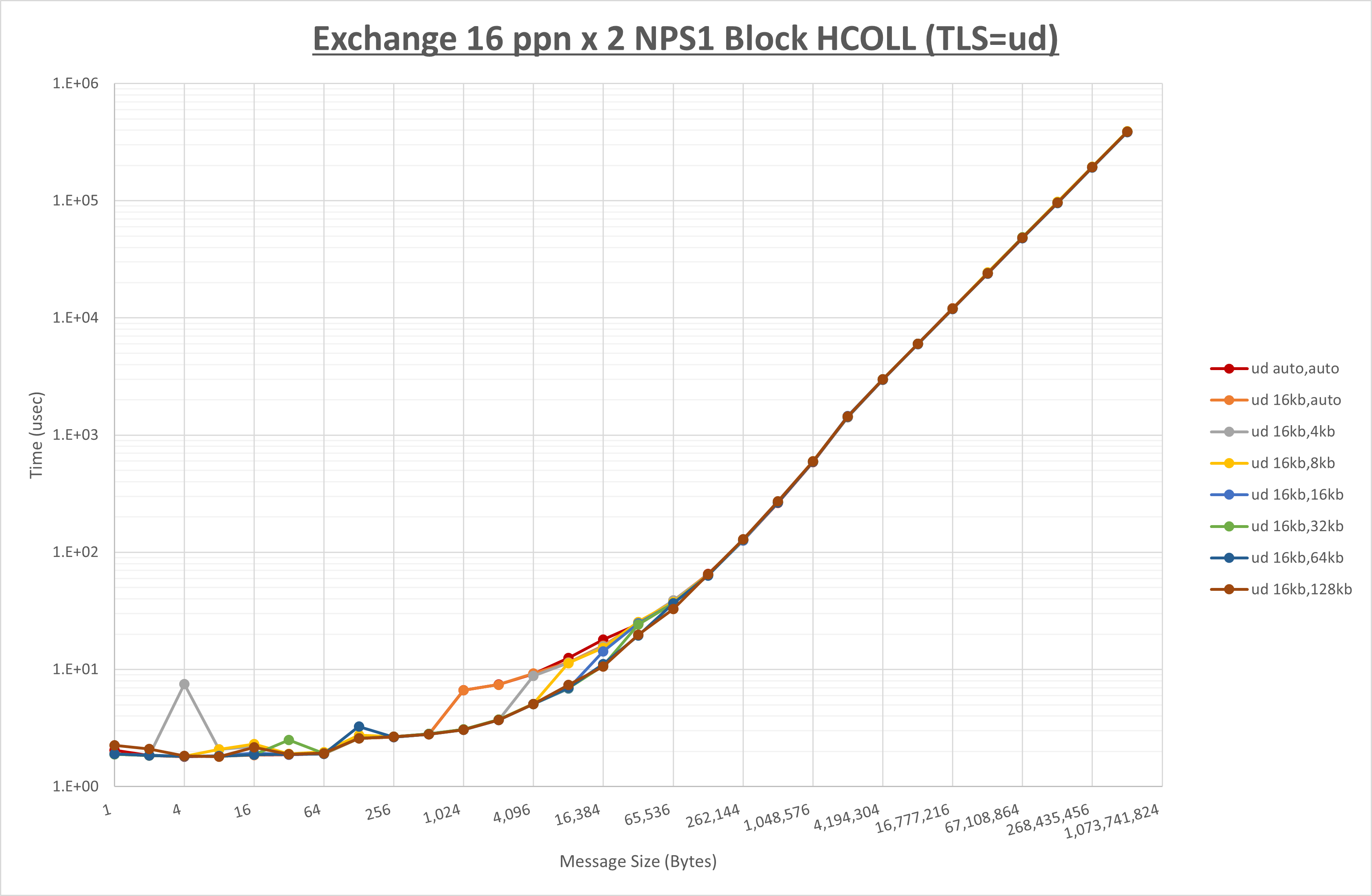
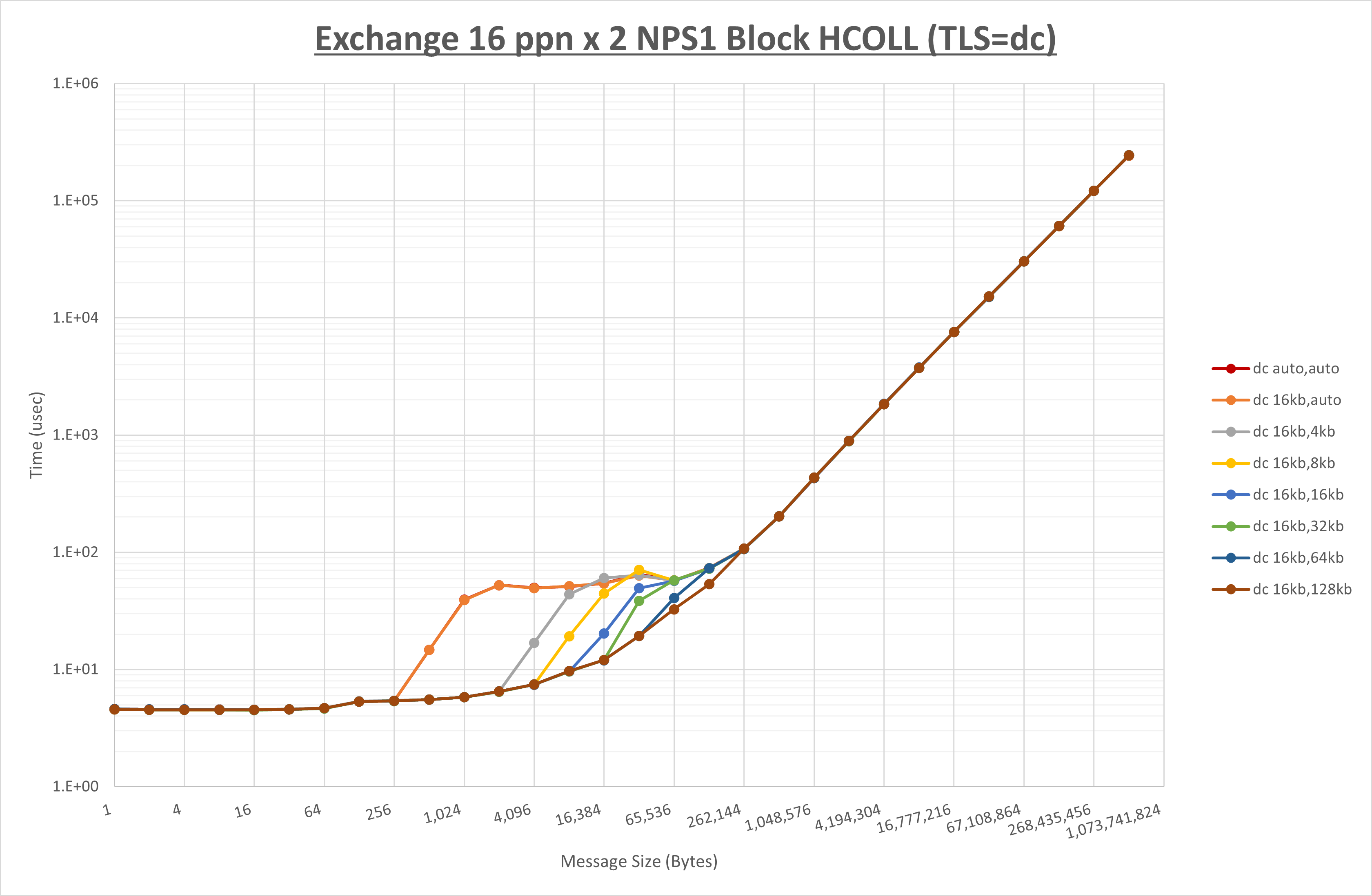
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
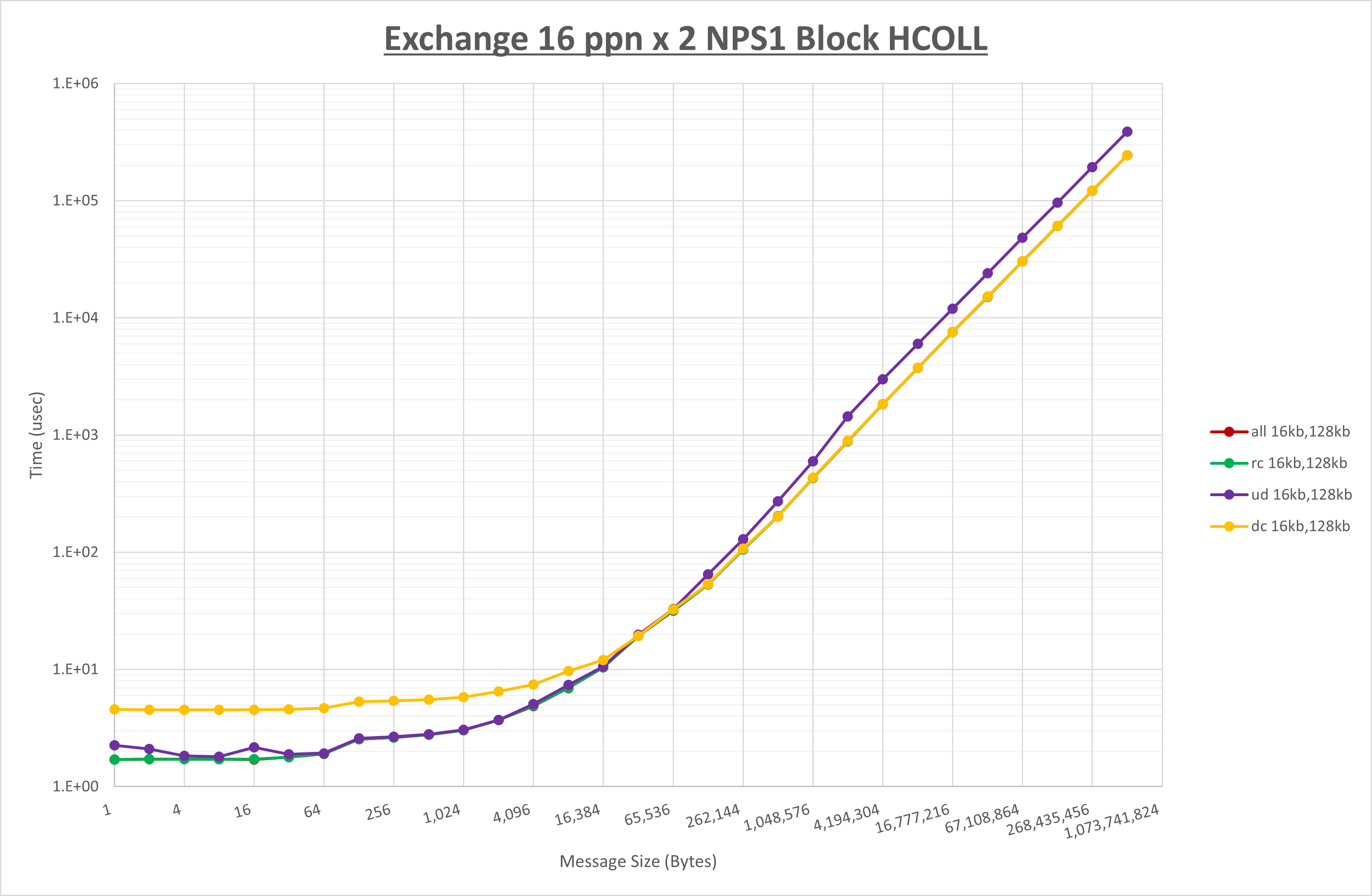
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
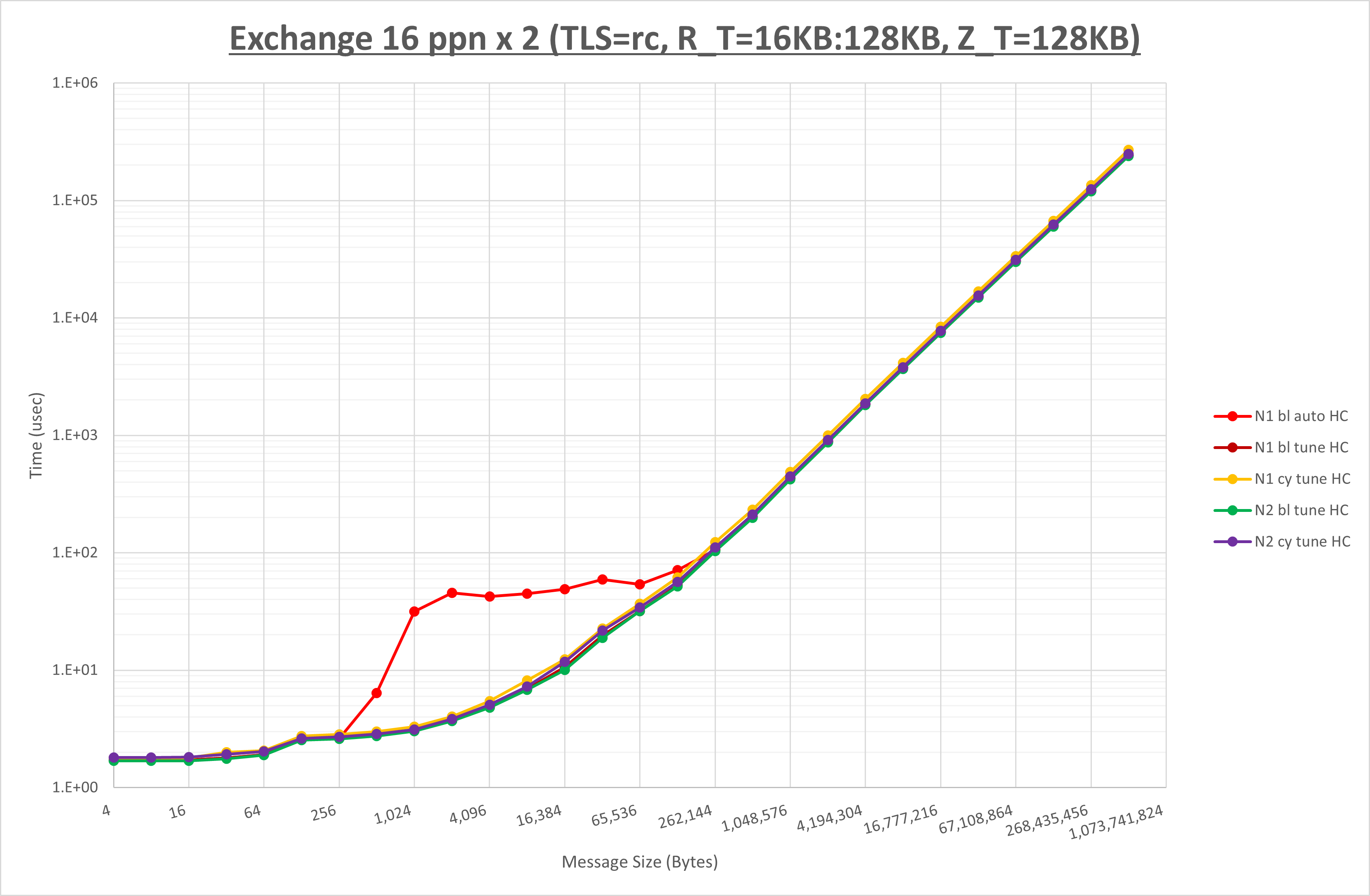
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で512Bから128KBの間で性能が向上
本章は、2ノードにノード当たり32、トータル64のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,rc | intra:16kb,inter:128kb | 128kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,ud | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-1 Alltoall の HCOLL の結果から16KBとしています。
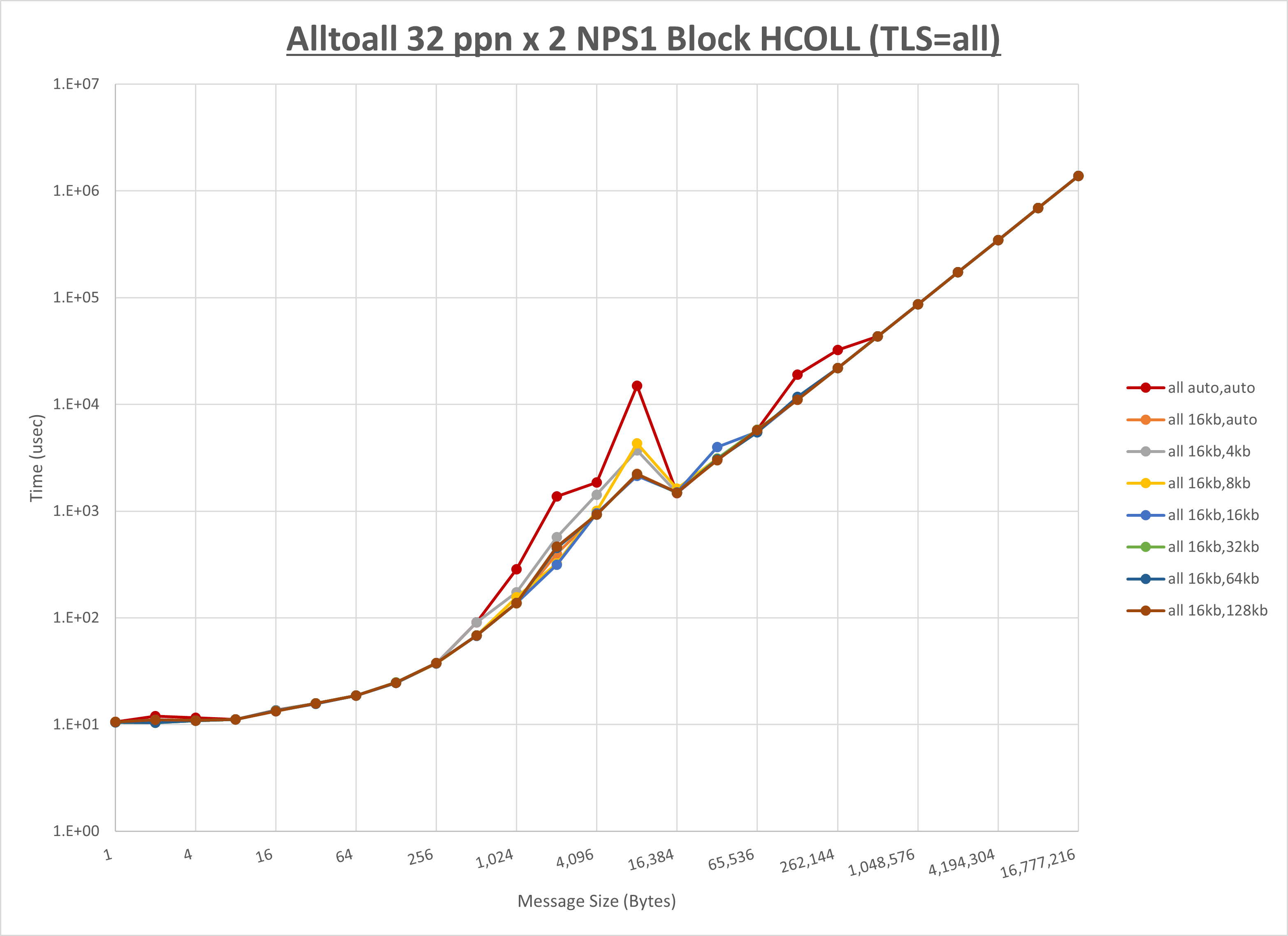
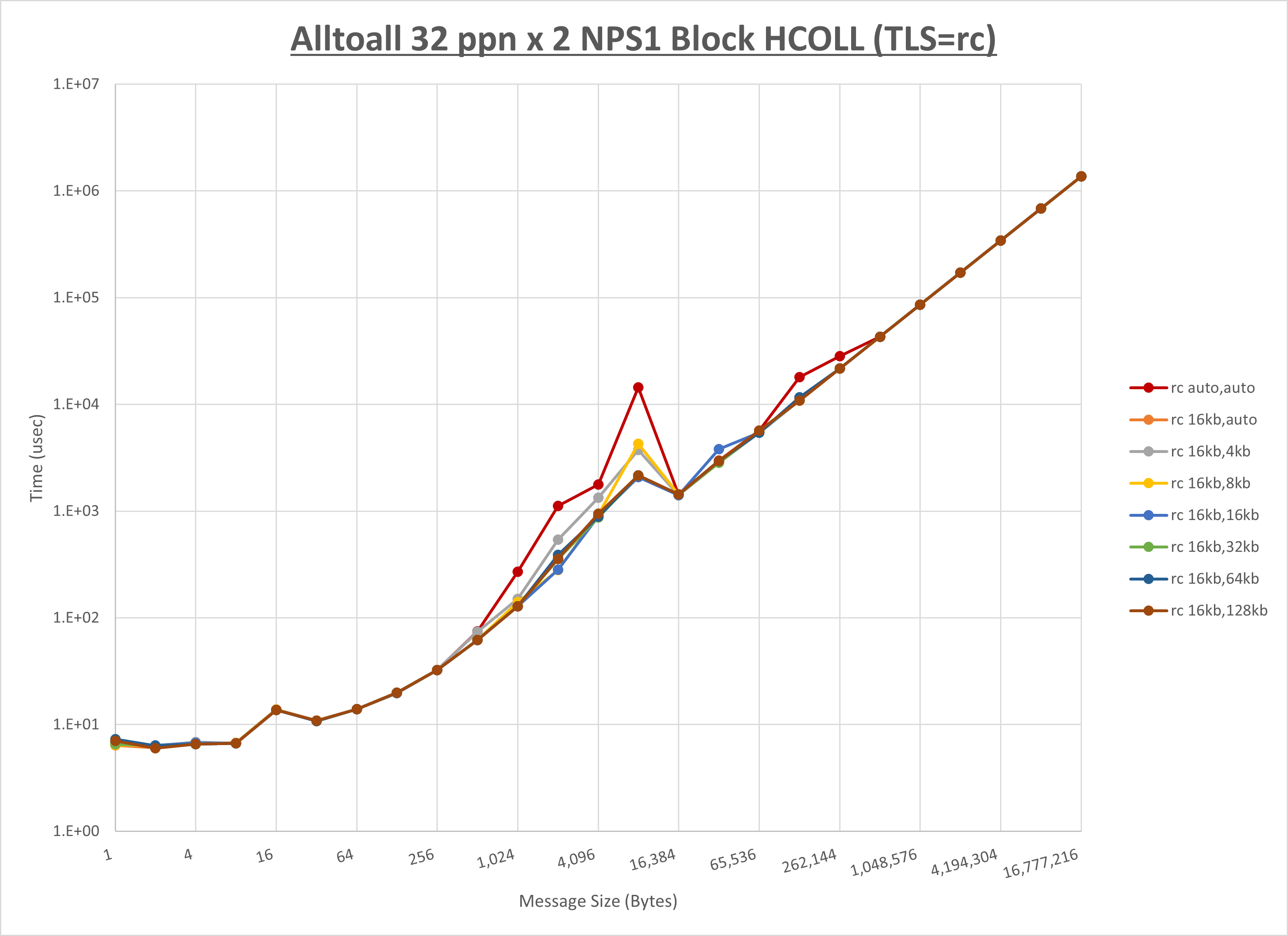
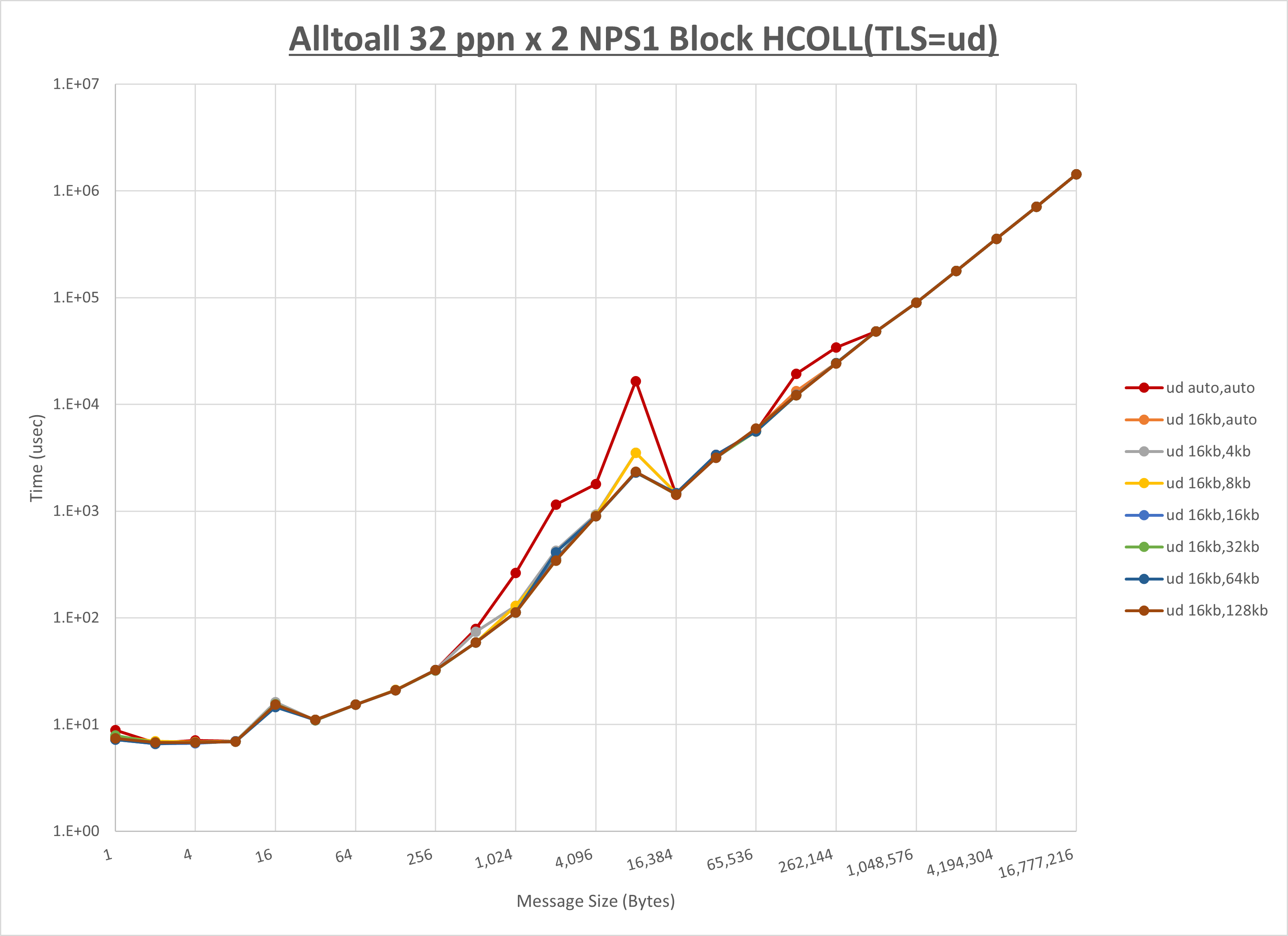
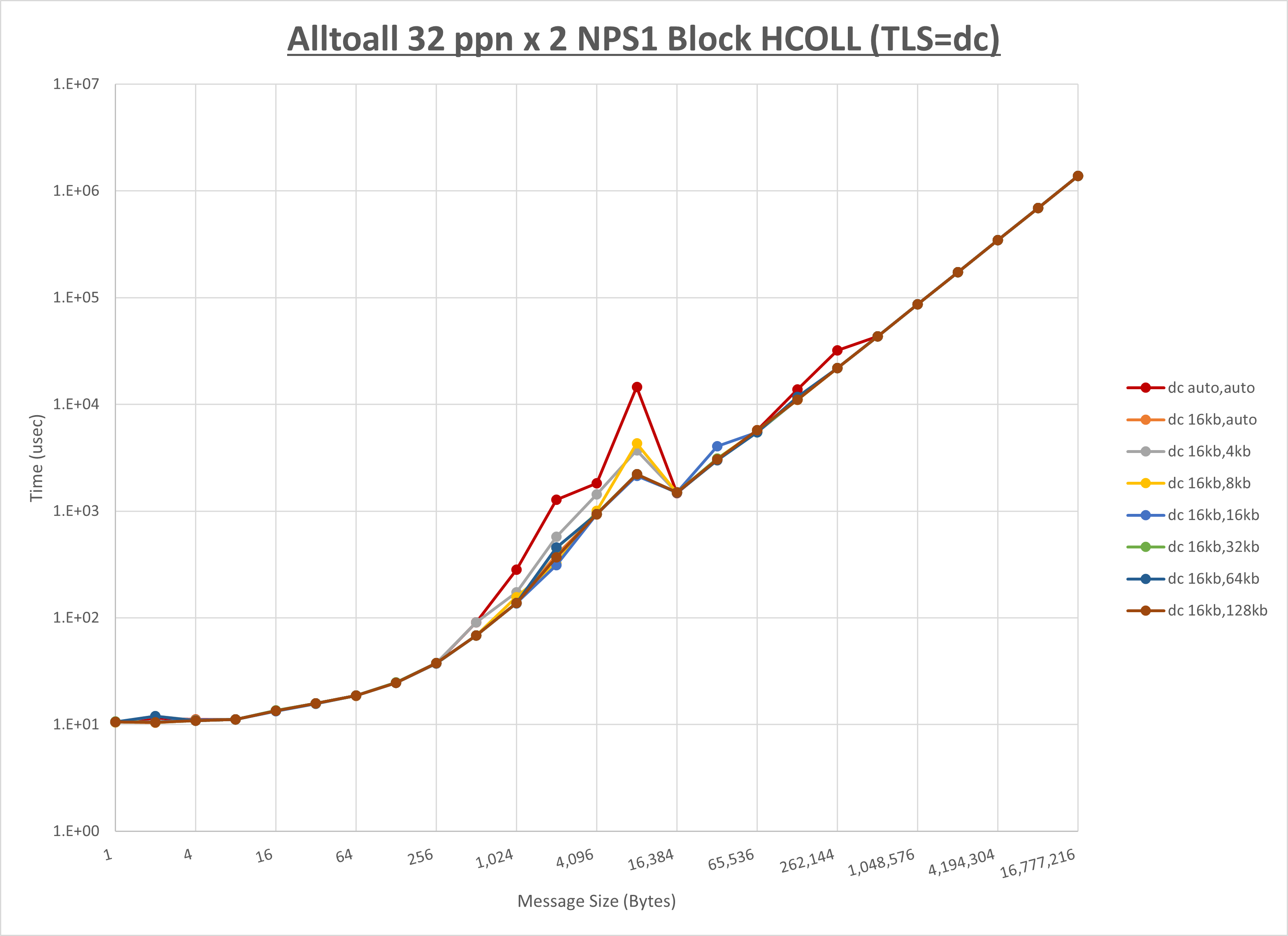
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
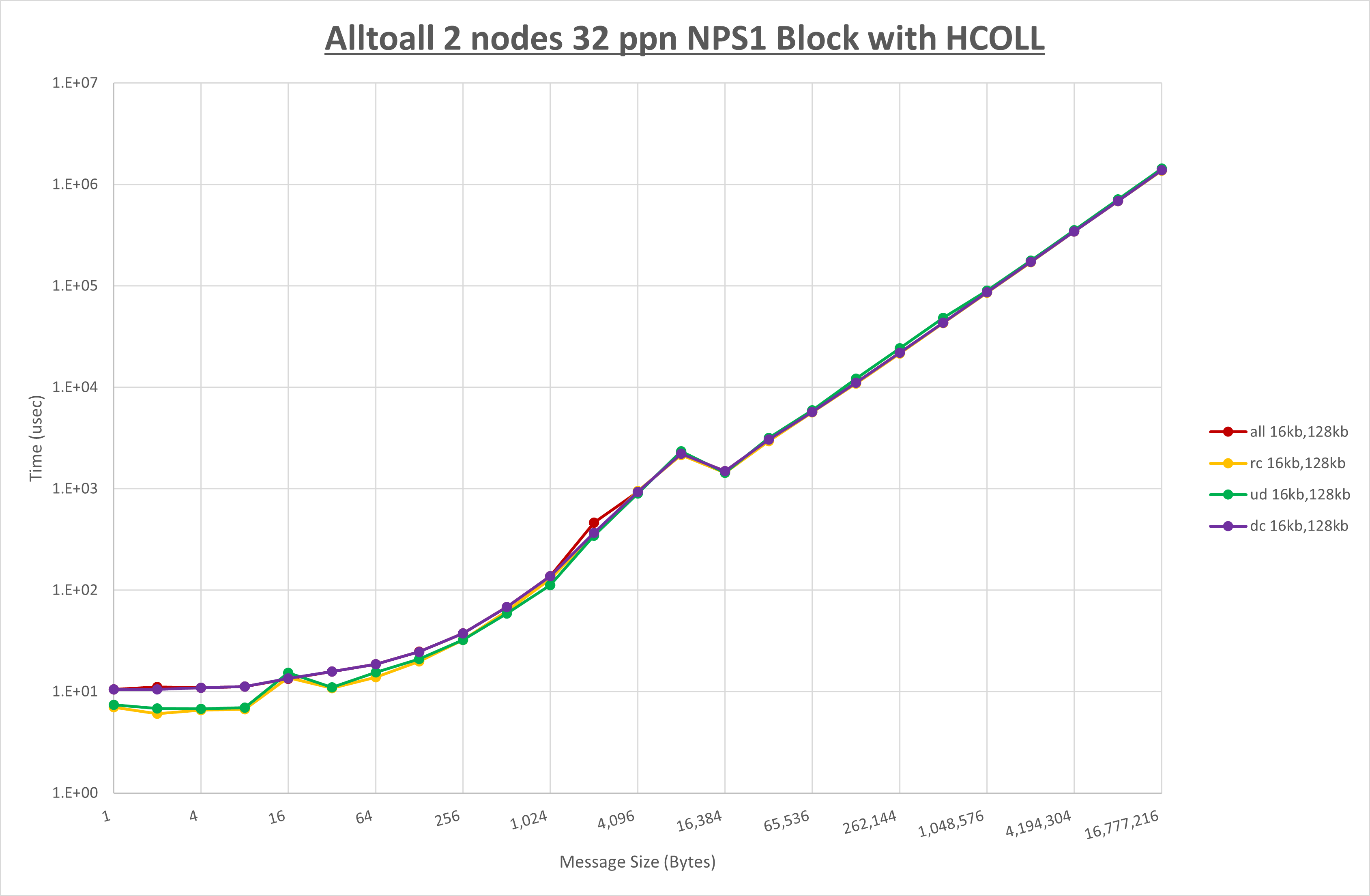
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
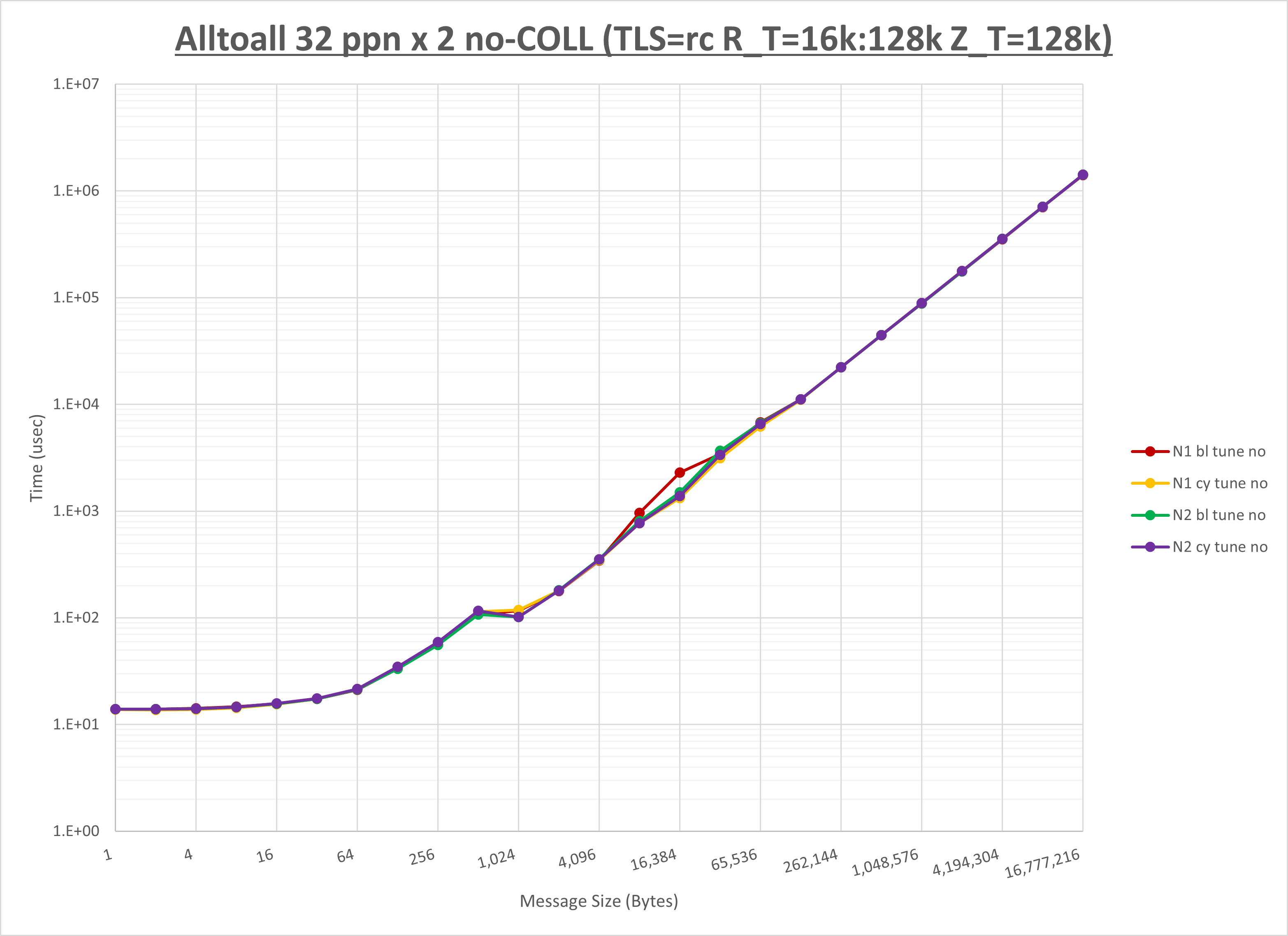
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し512B以下で性能が向上
- UCC は no-COLL と比較し512以下で性能が向上し16KBで性能が低下
- チューニング適用で8KB以下で性能が向上
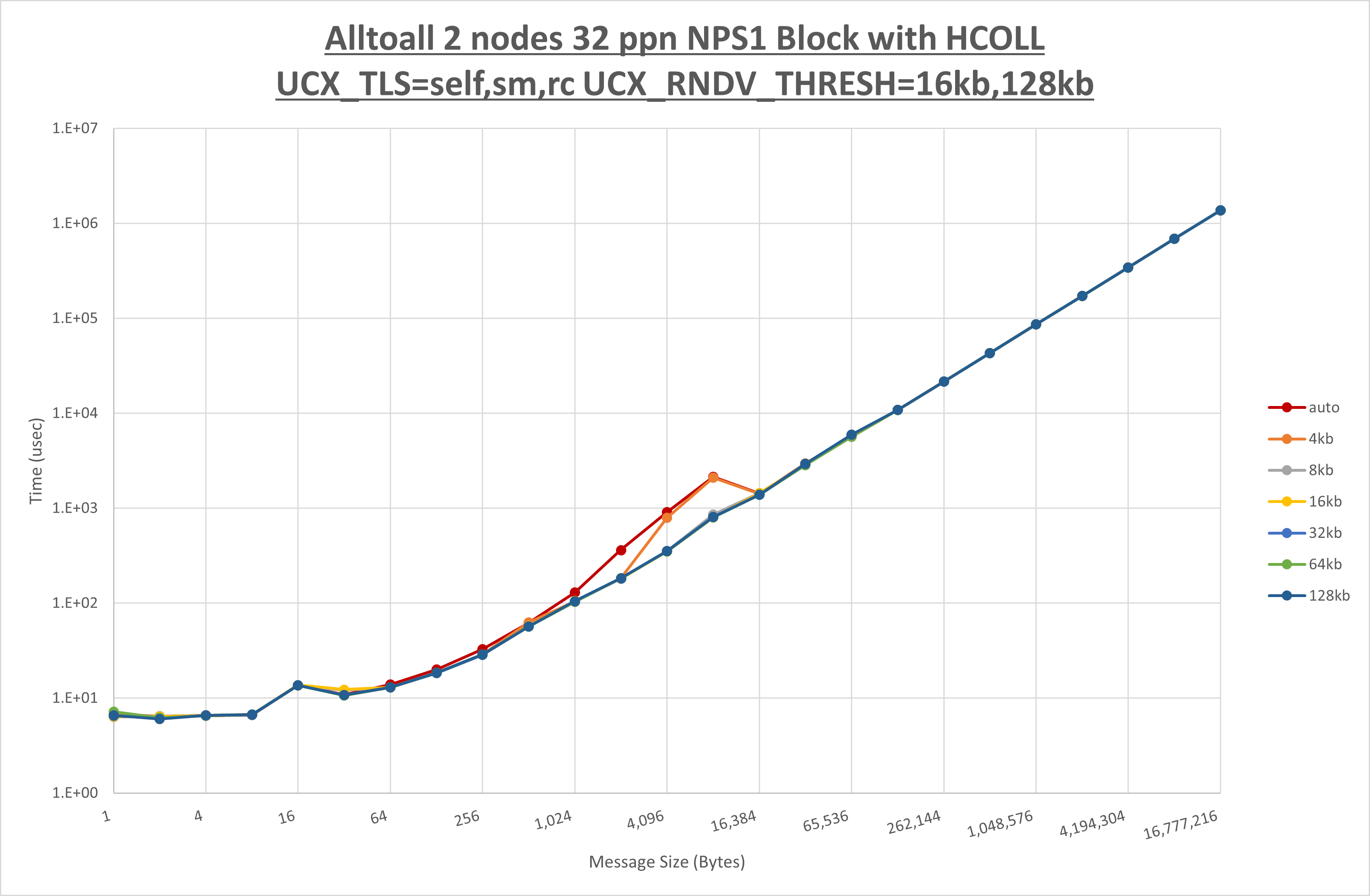
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-2 Allgather の HCOLL の結果から16KBとしています。
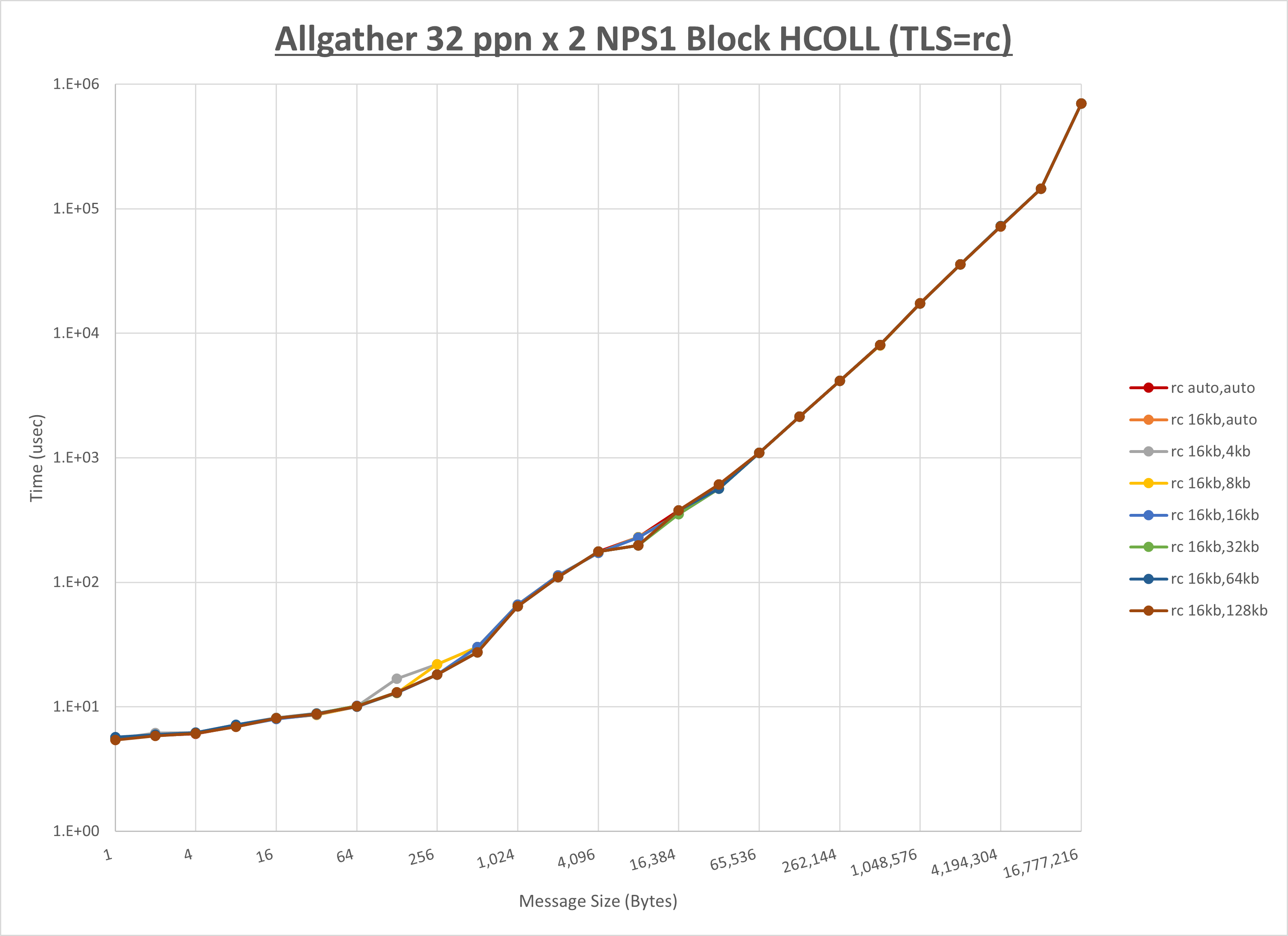
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
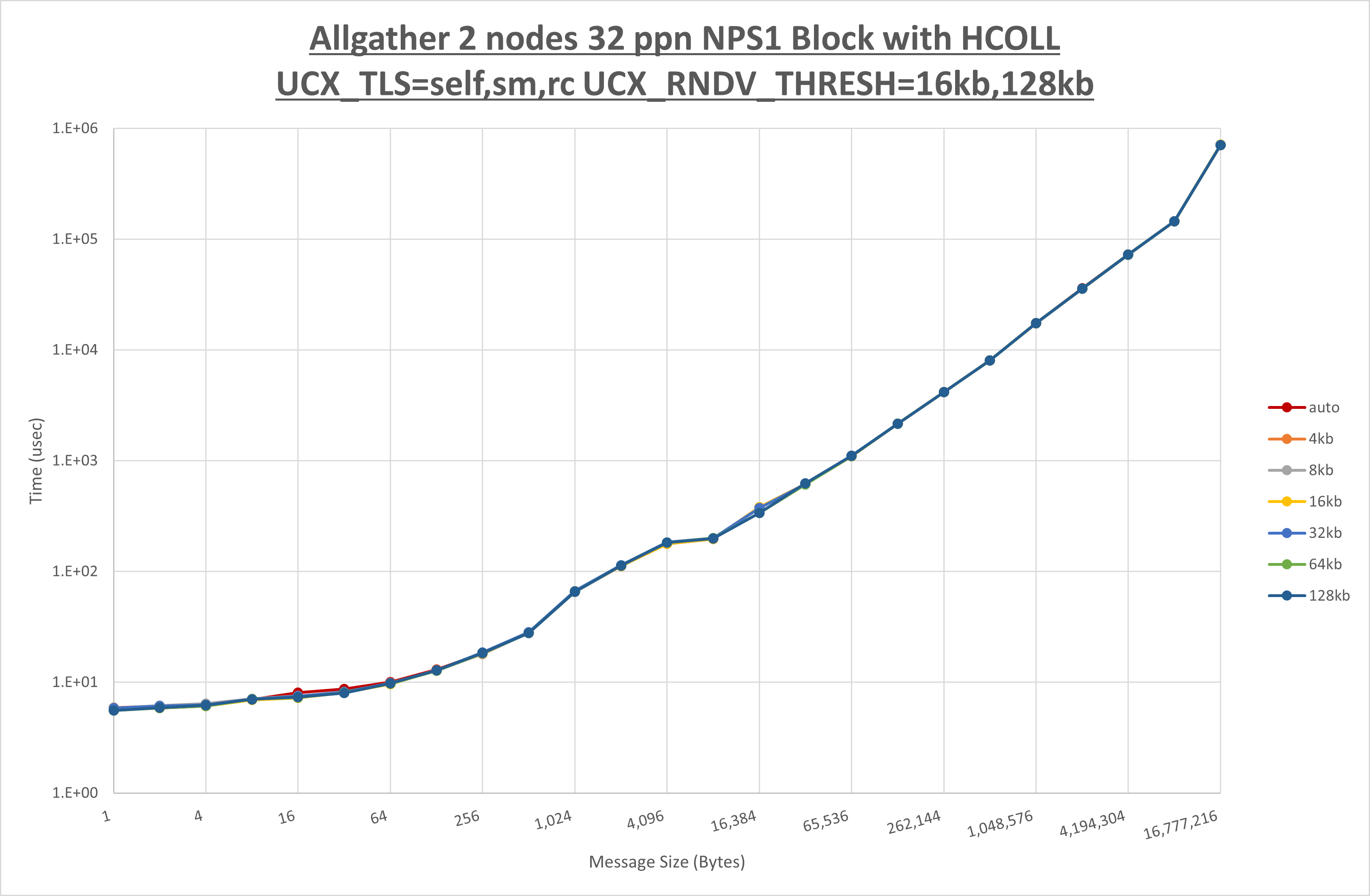
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
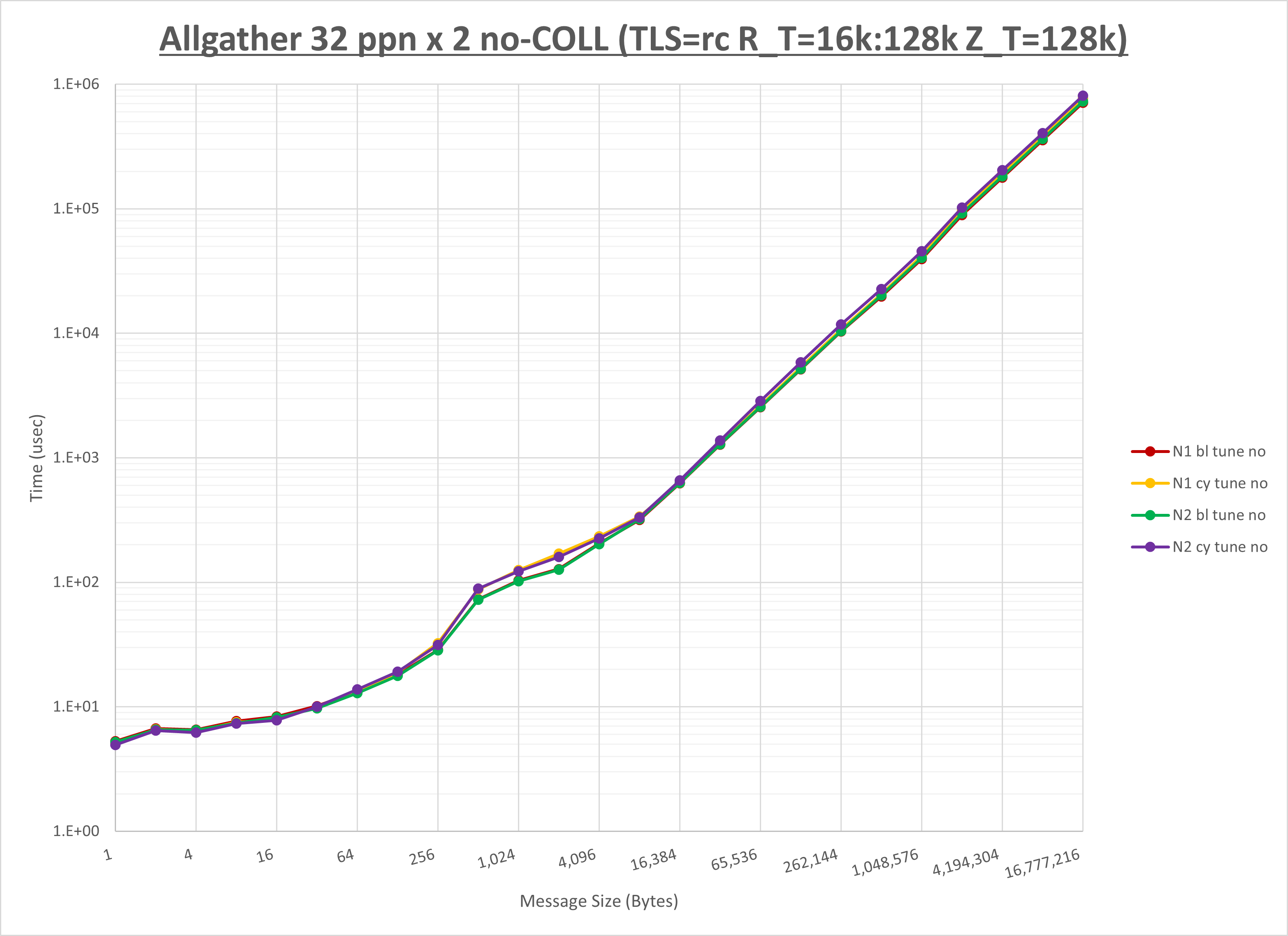
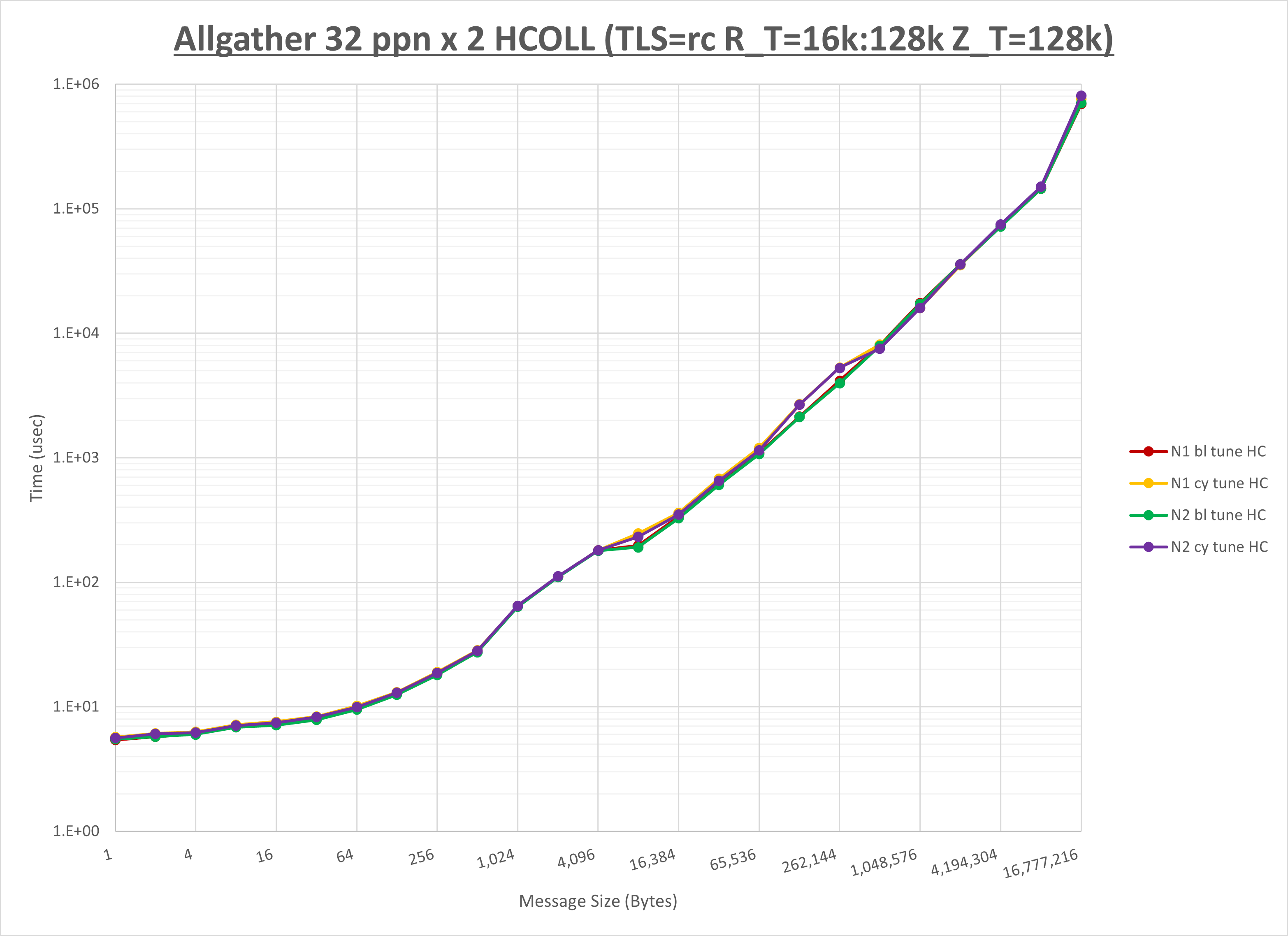
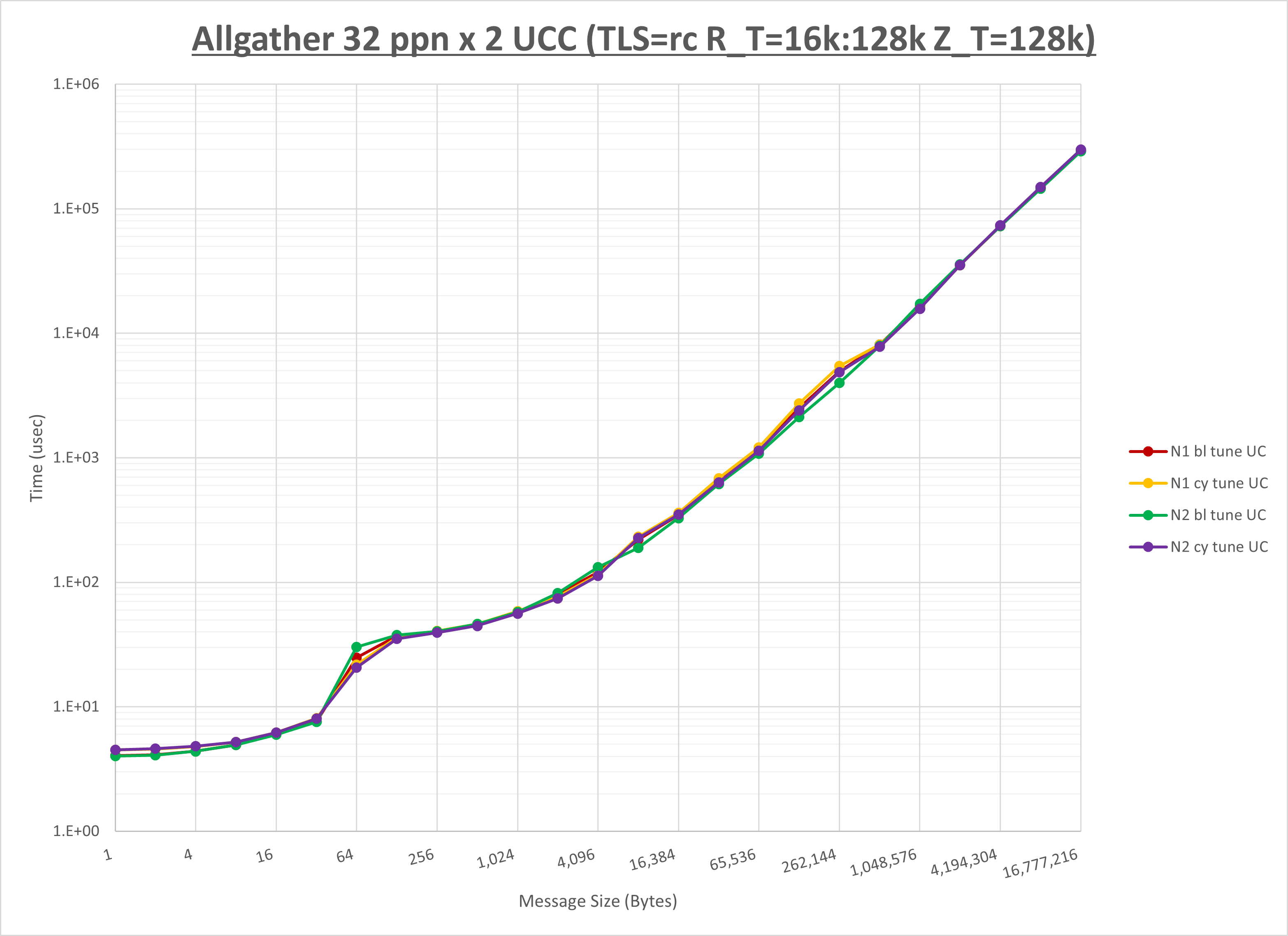
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
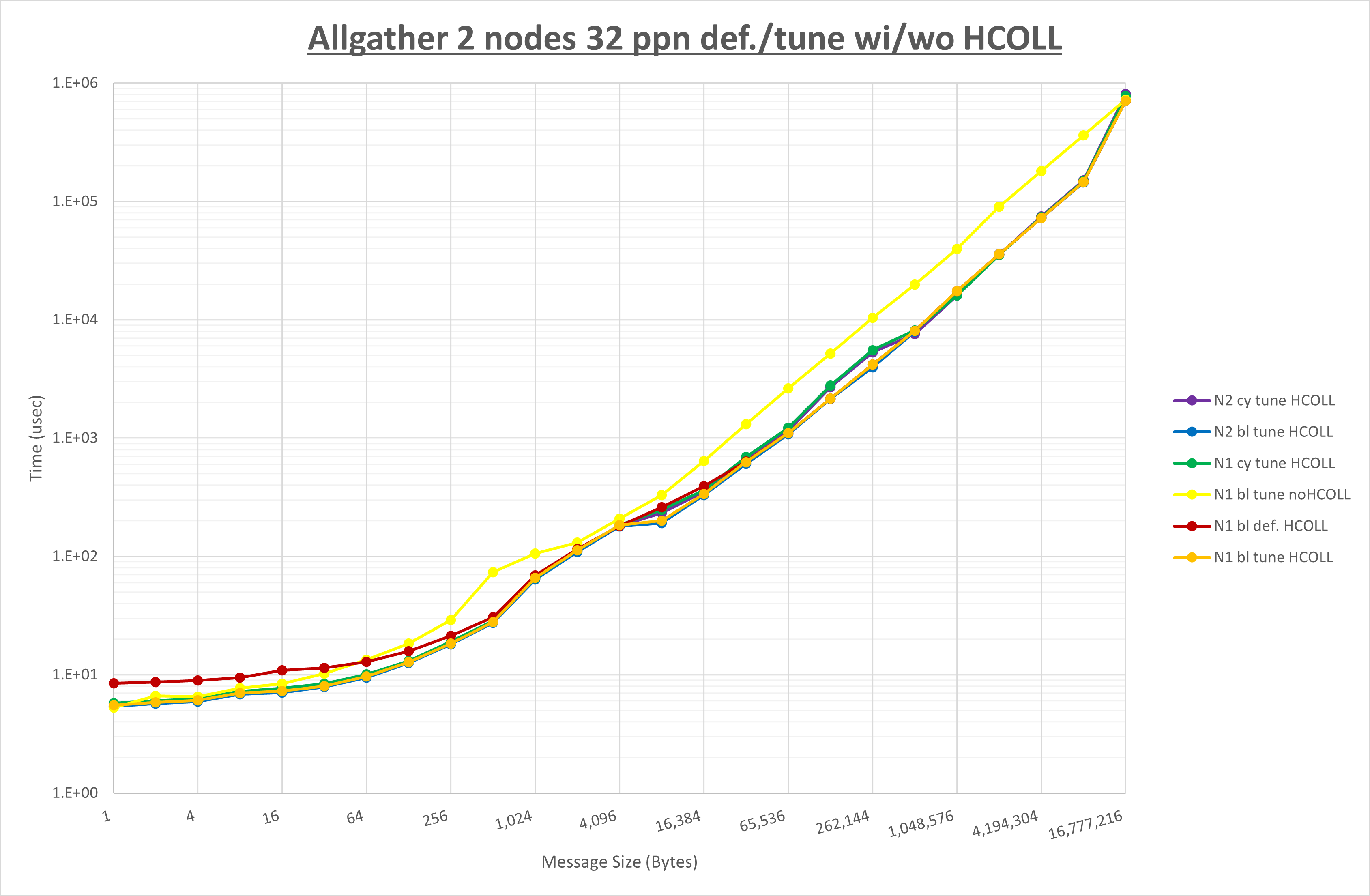
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で256B以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-3 Allreduce の HCOLL の結果から128KBとしています。
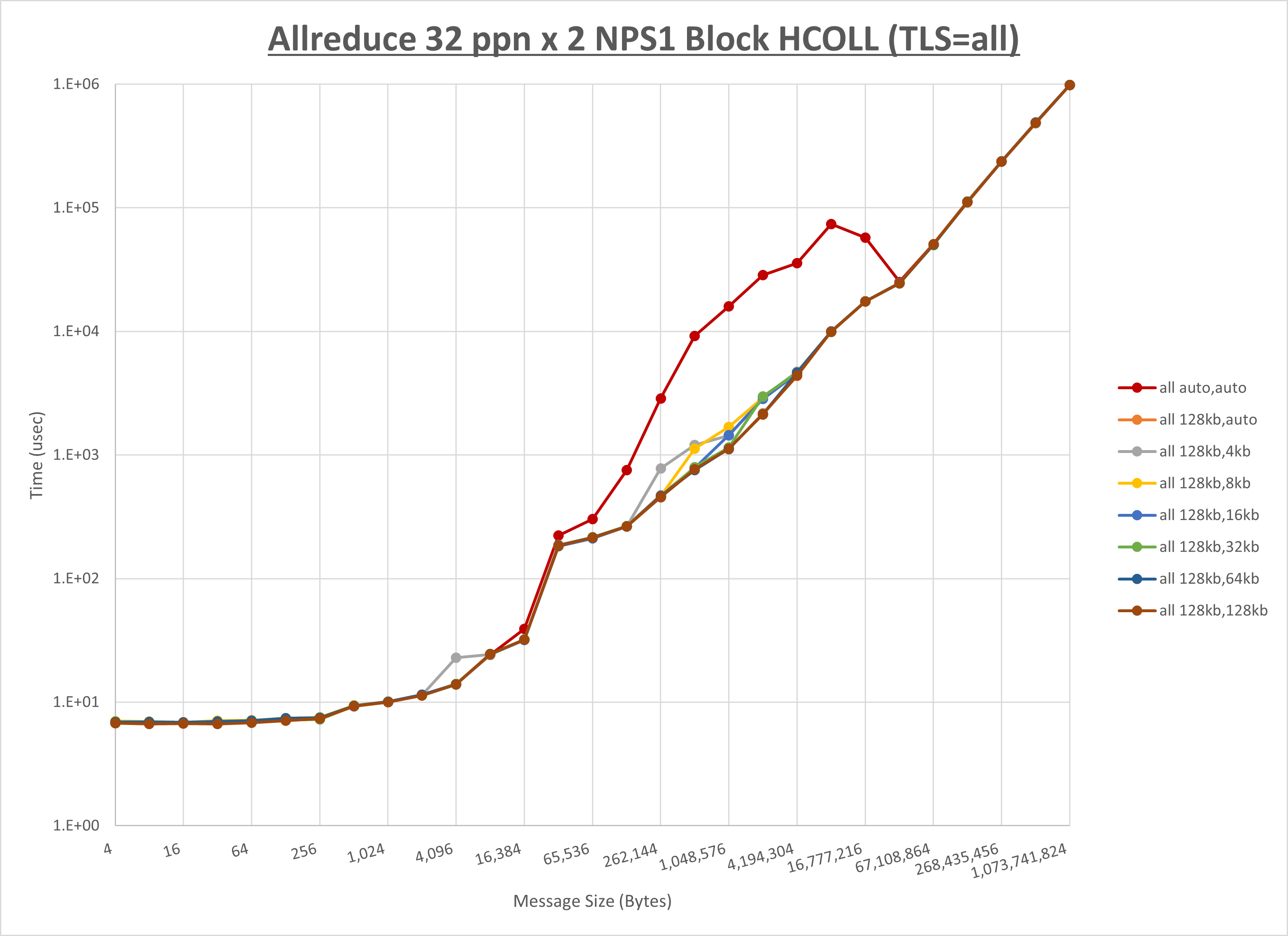
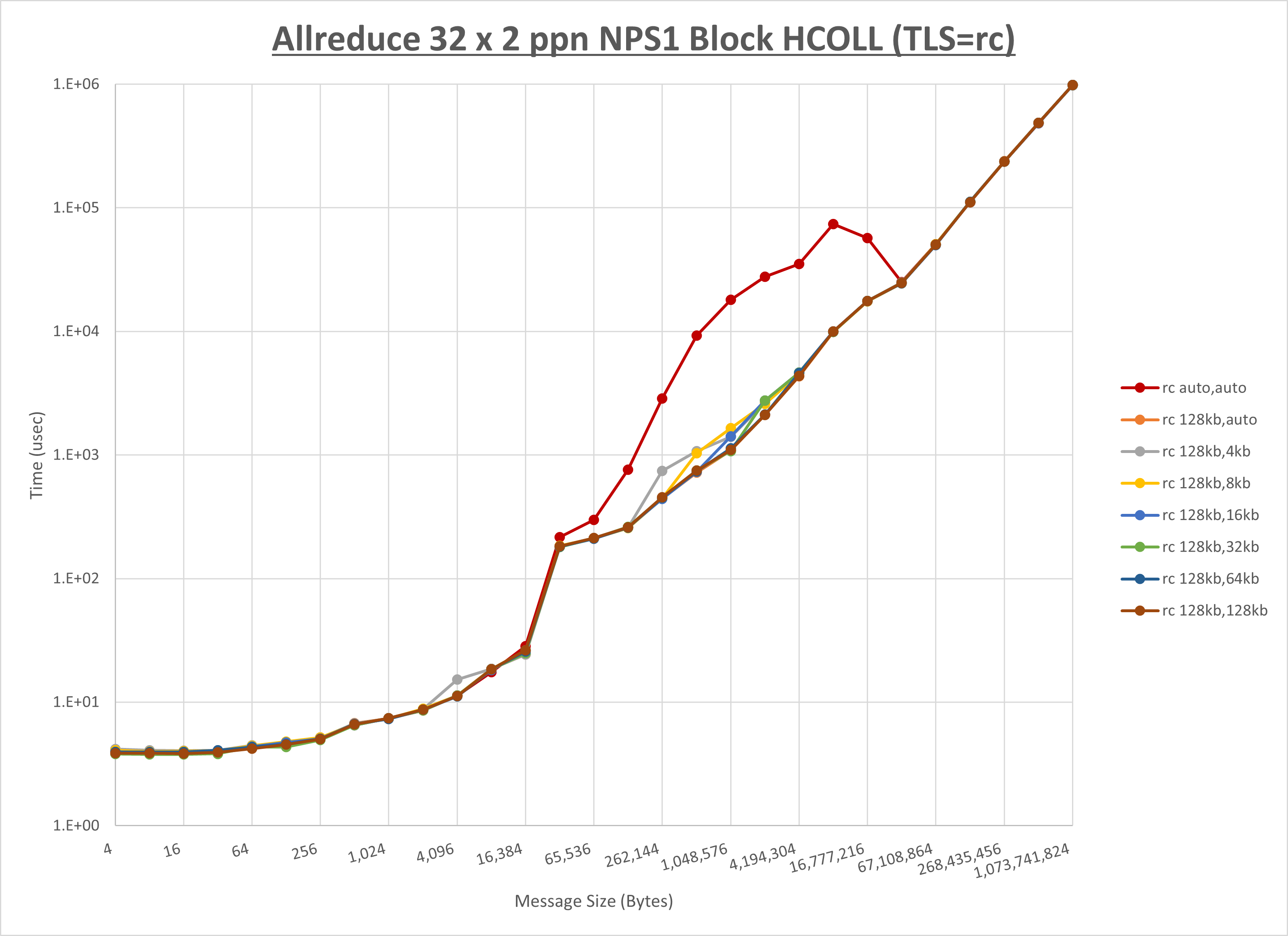
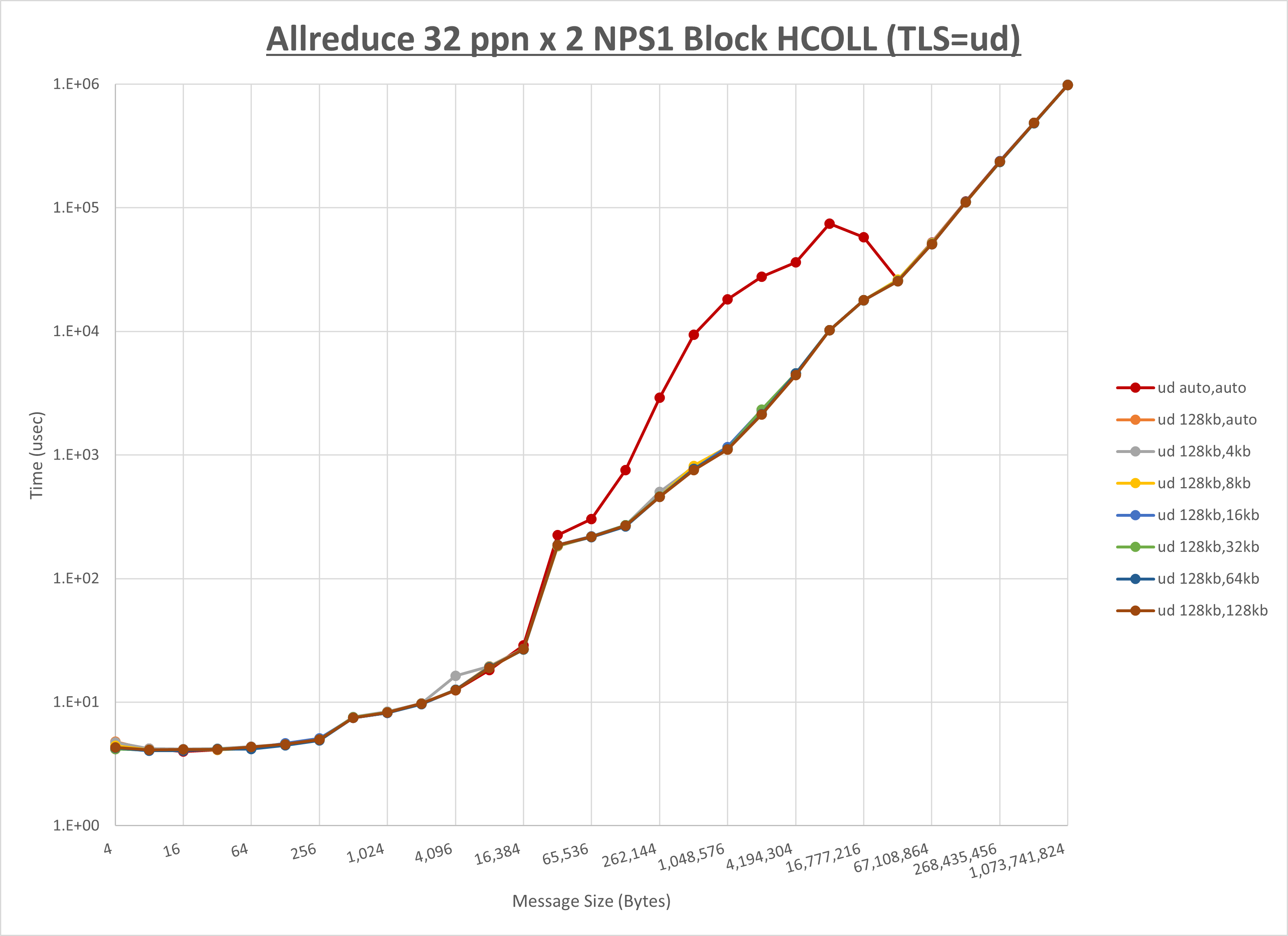
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で4MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-4 Exchange の結果から16KBとしています。
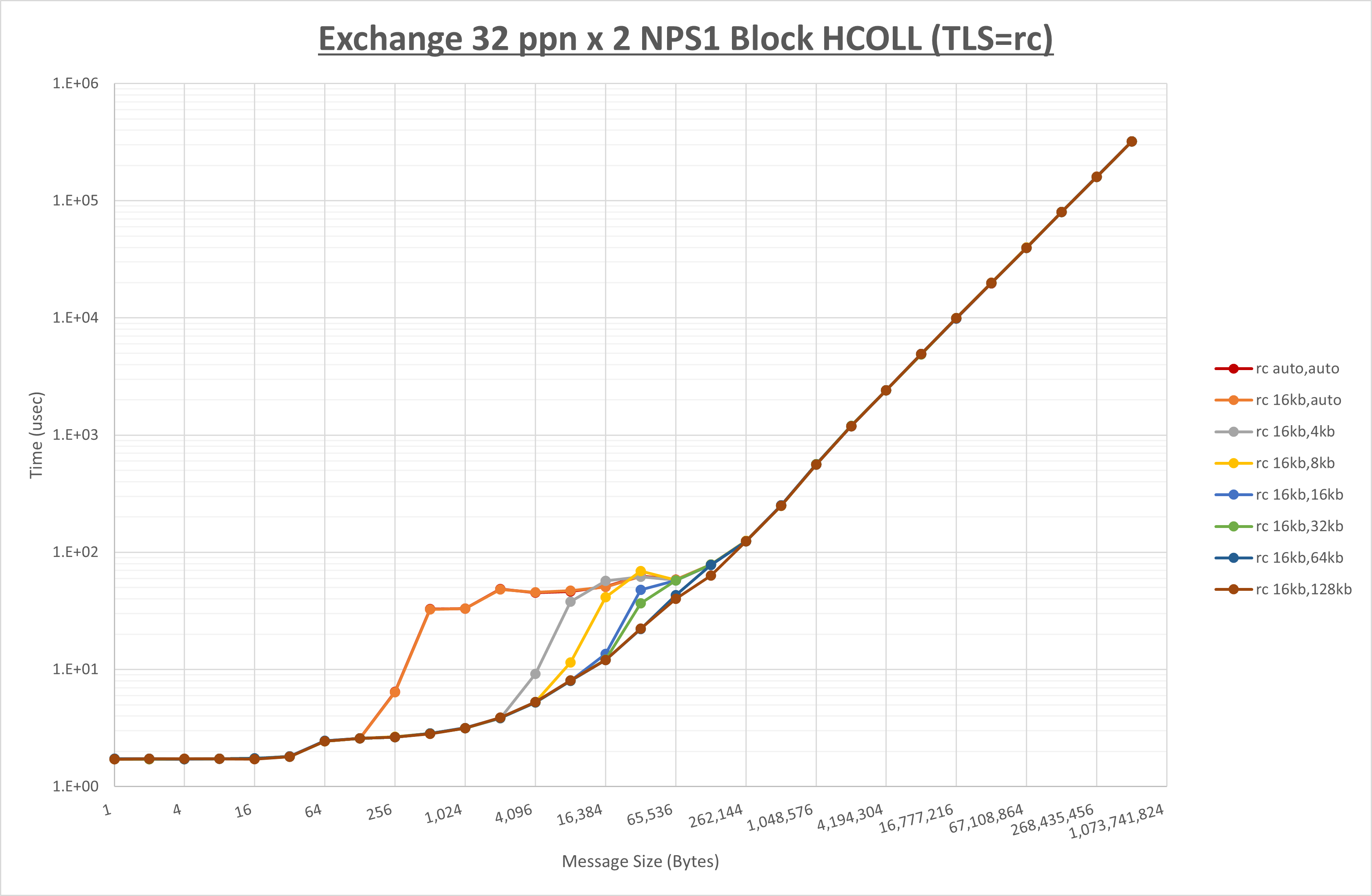
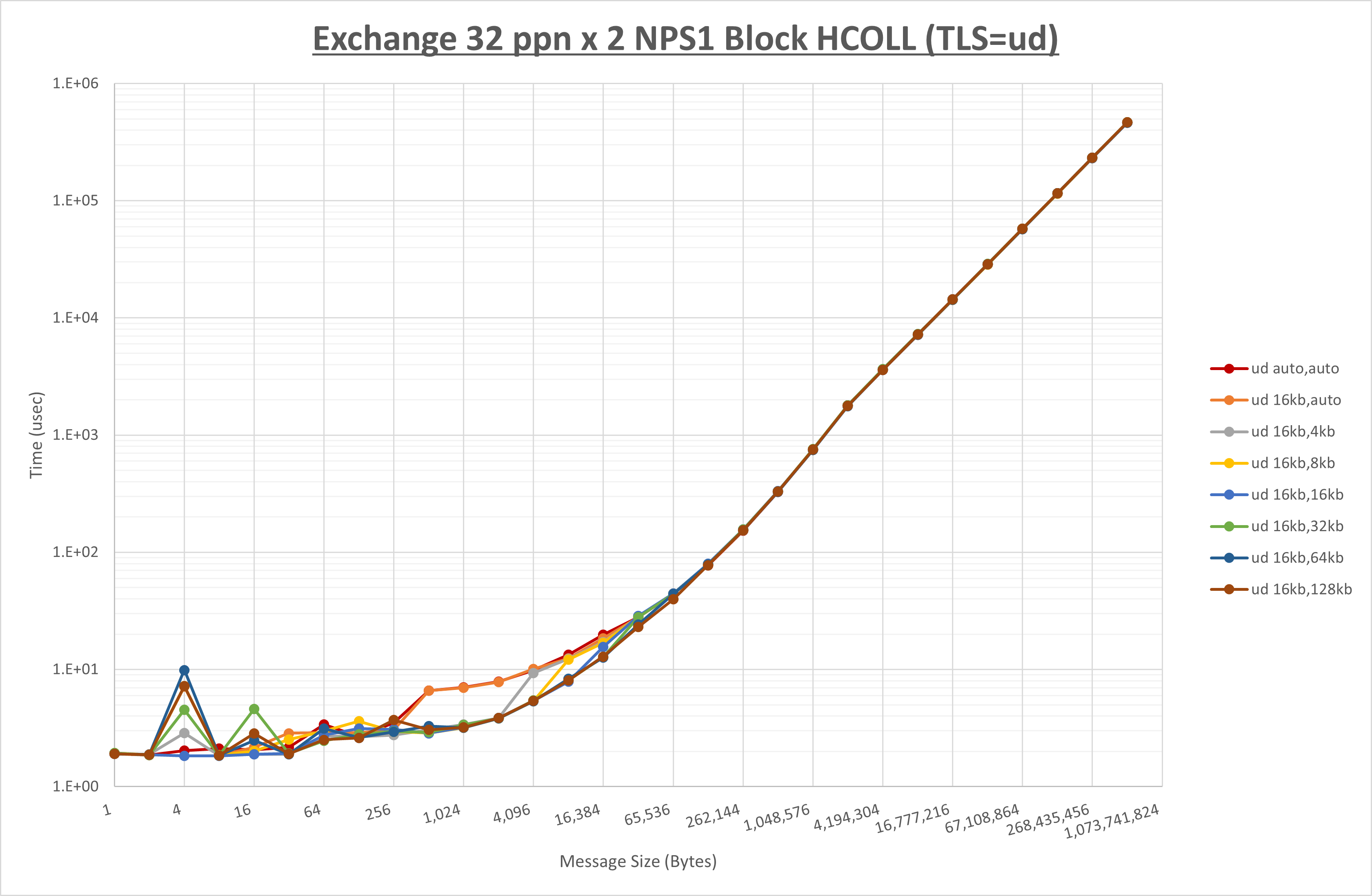
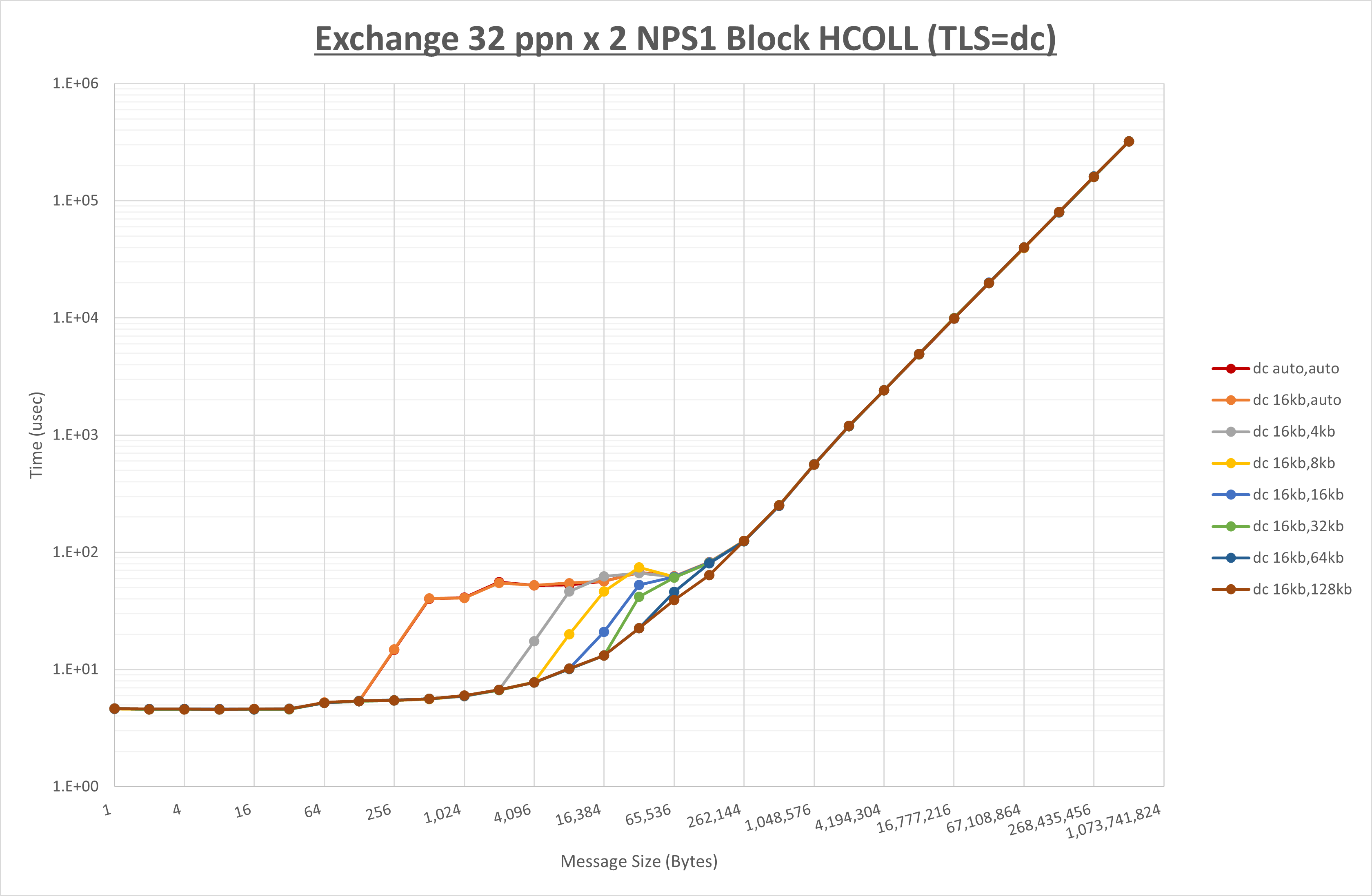
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
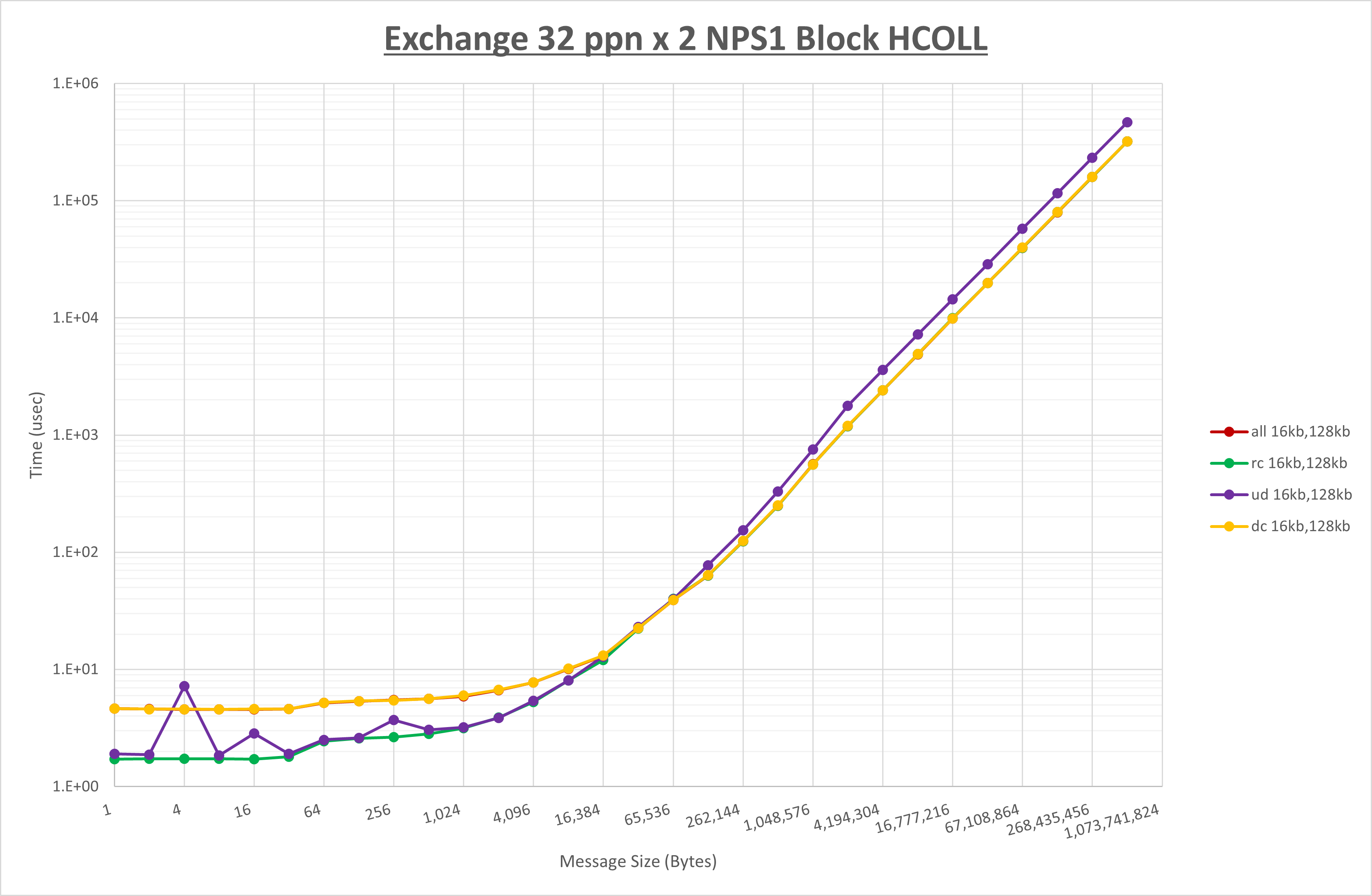
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、2ノードにノード当たり36、トータル72のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,rc | intra:16kb,inter:128kb | 128kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,ud | intra:64kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-1 Alltoall の HCOLL の結果から16KBとしています。
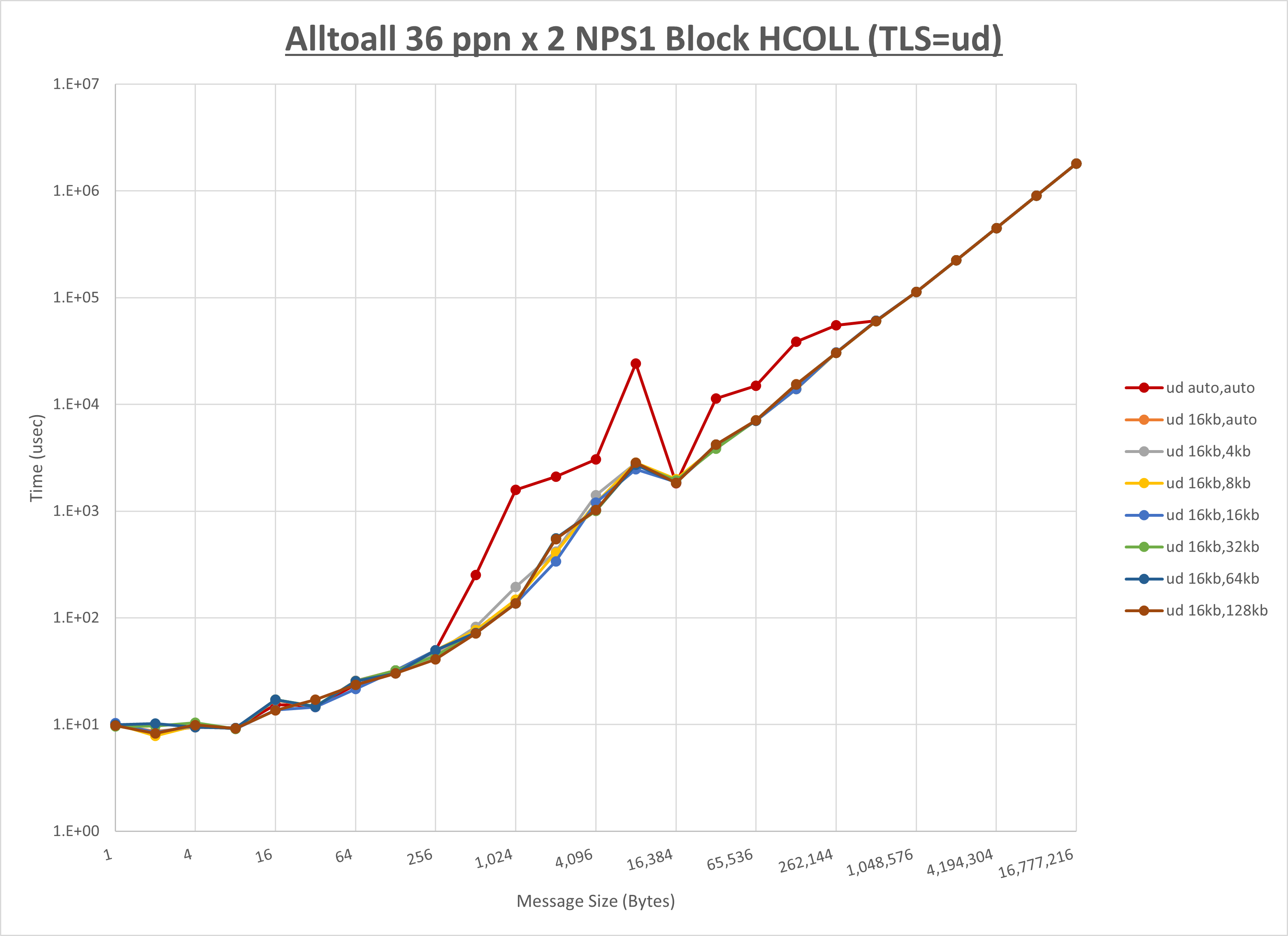
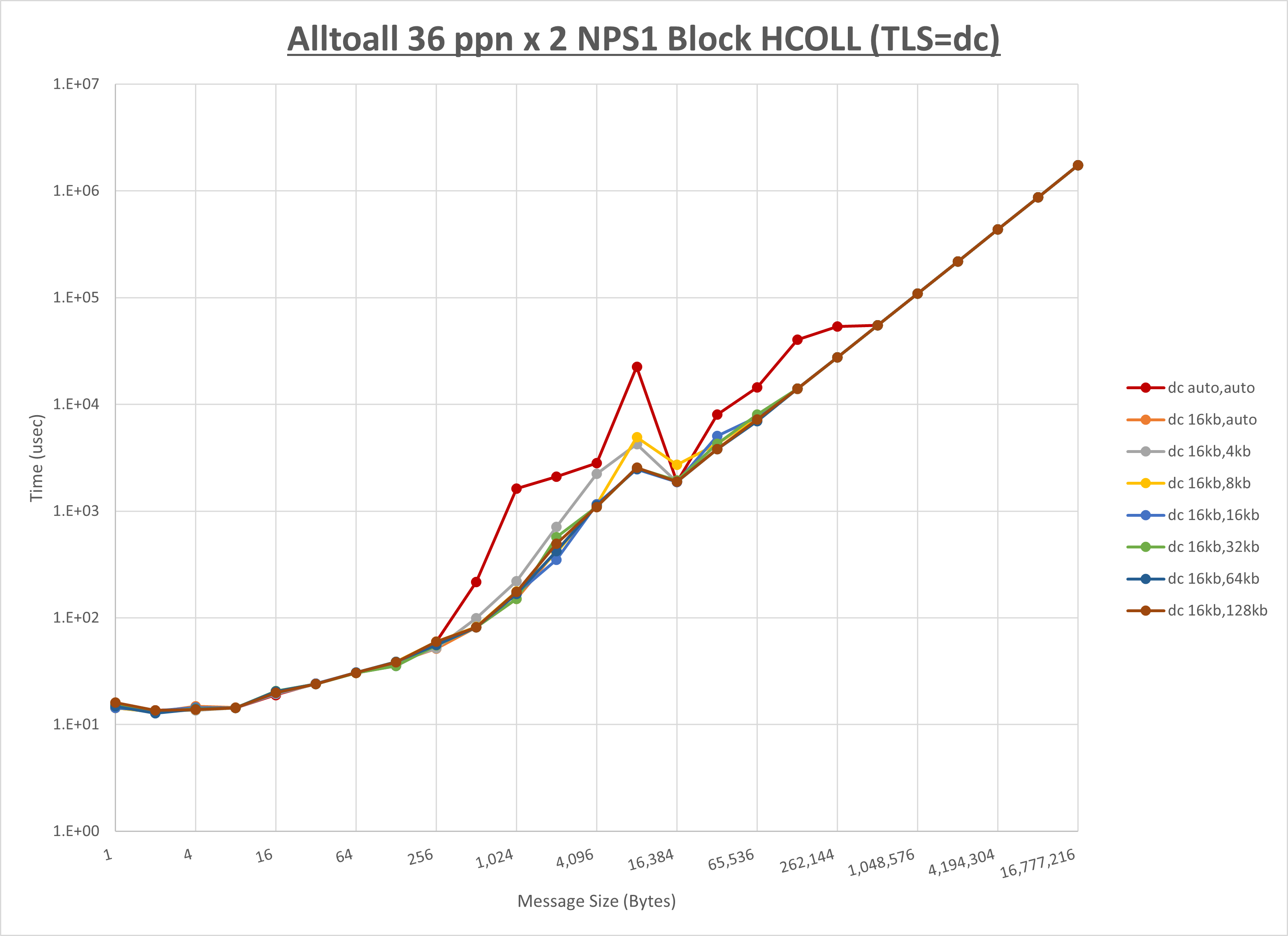
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
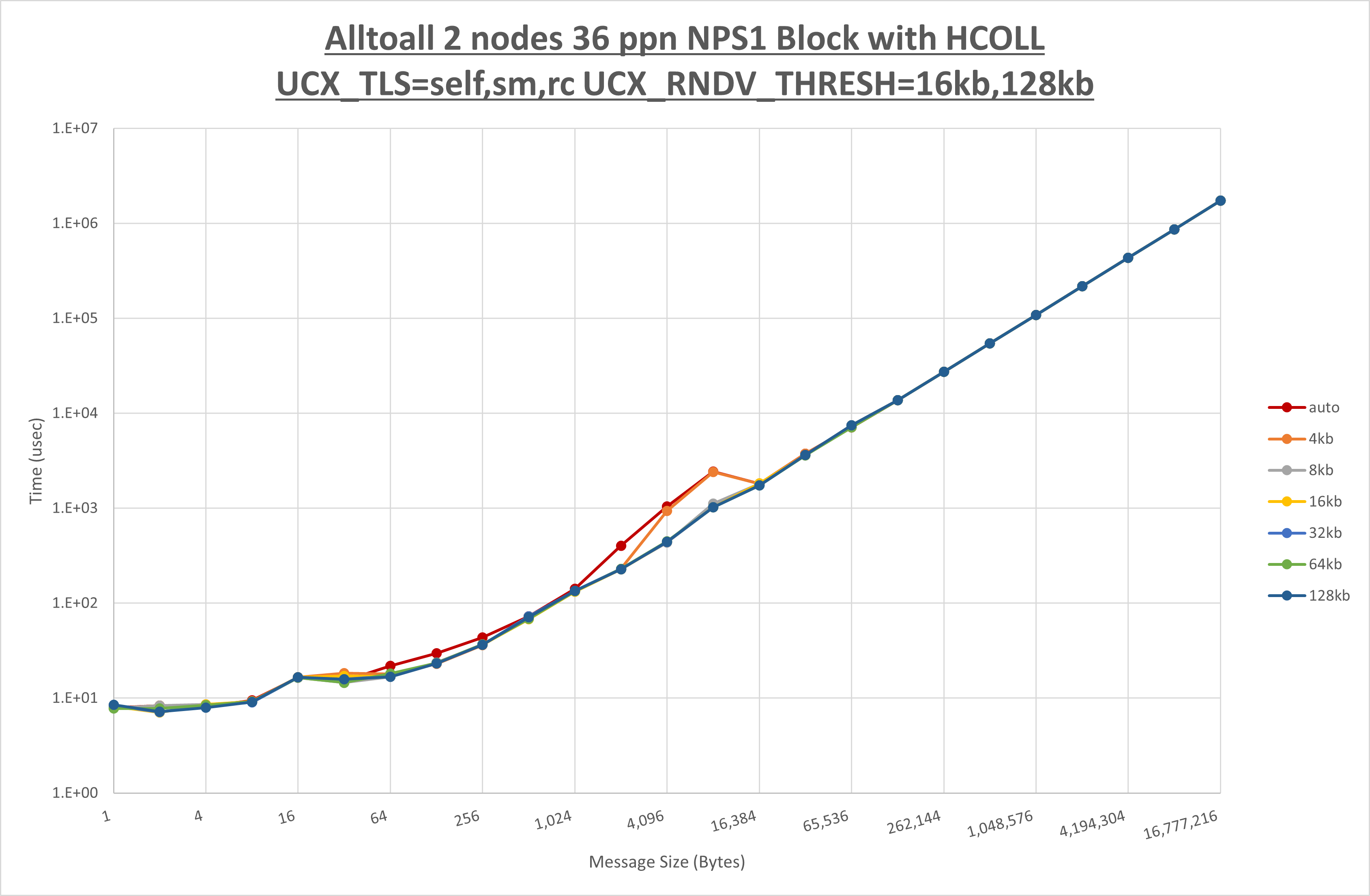
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
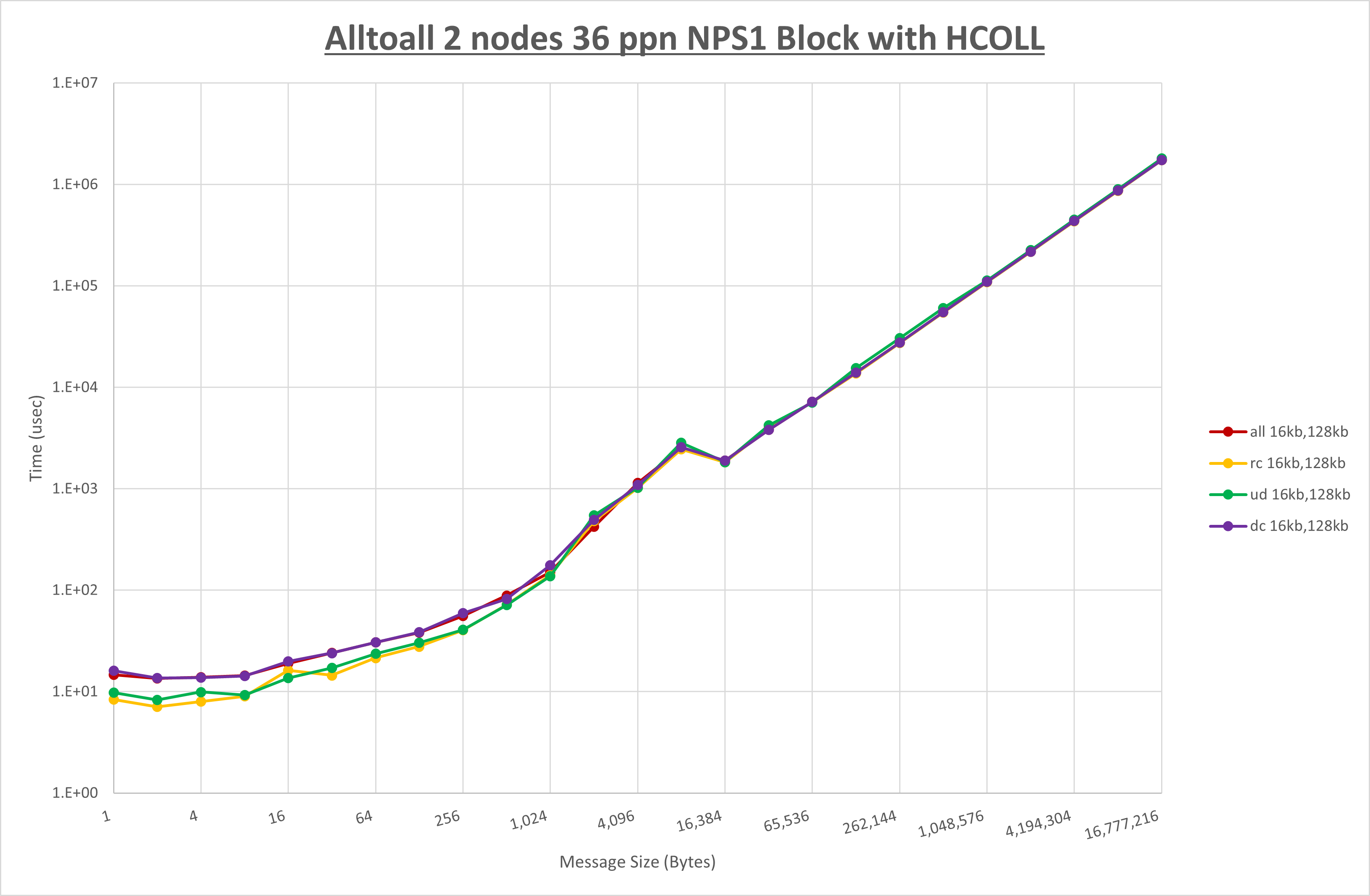
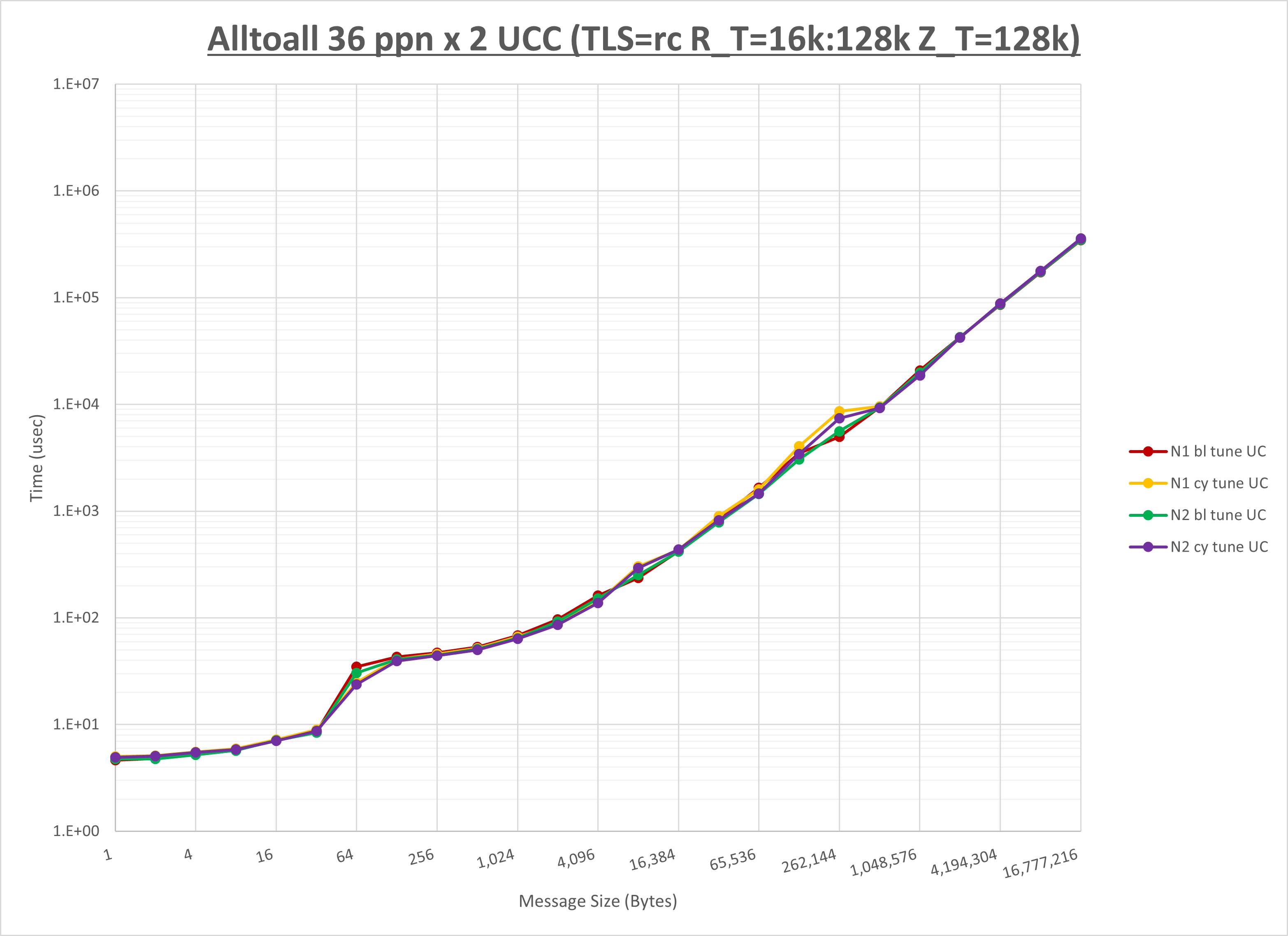
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
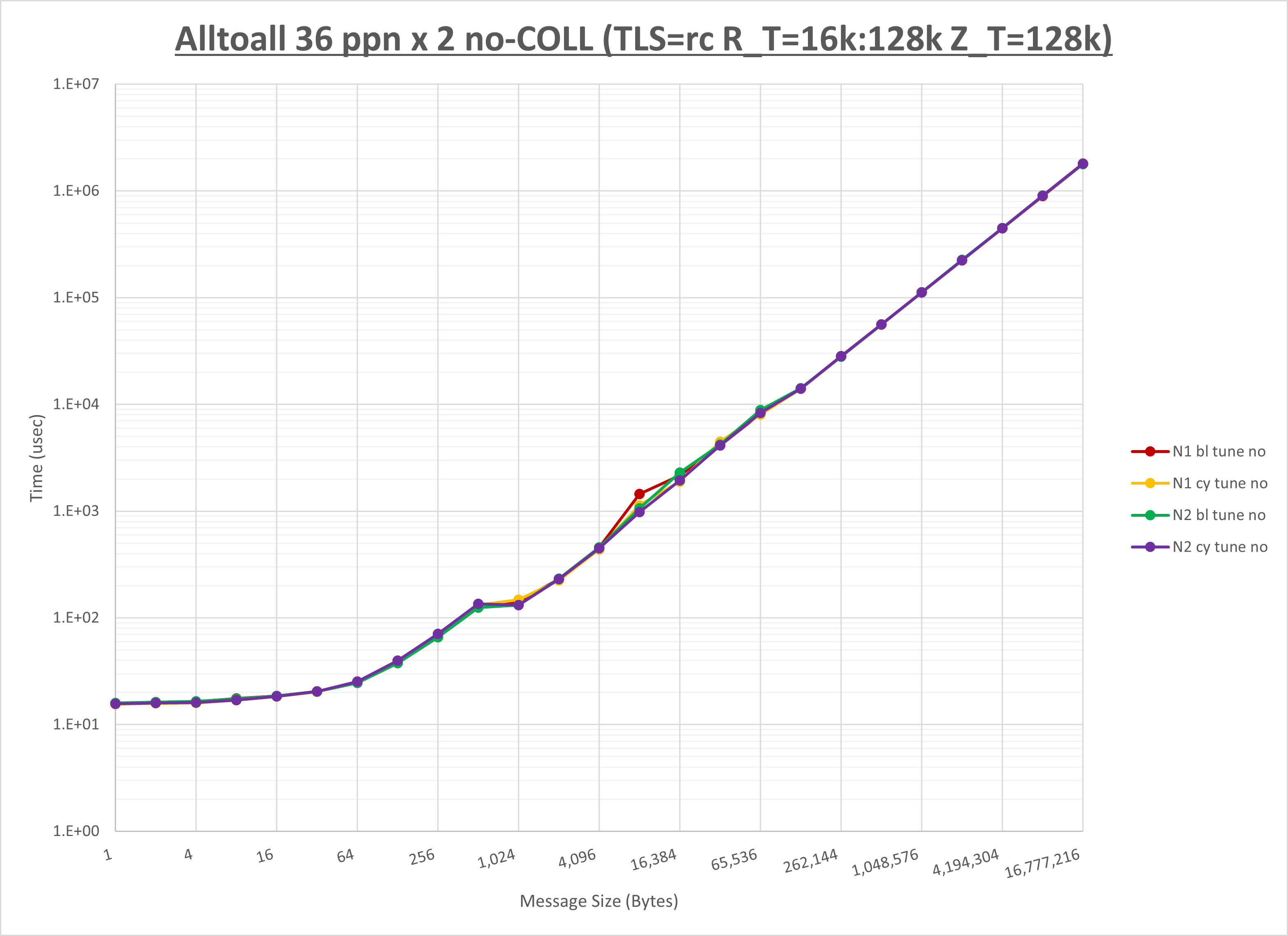
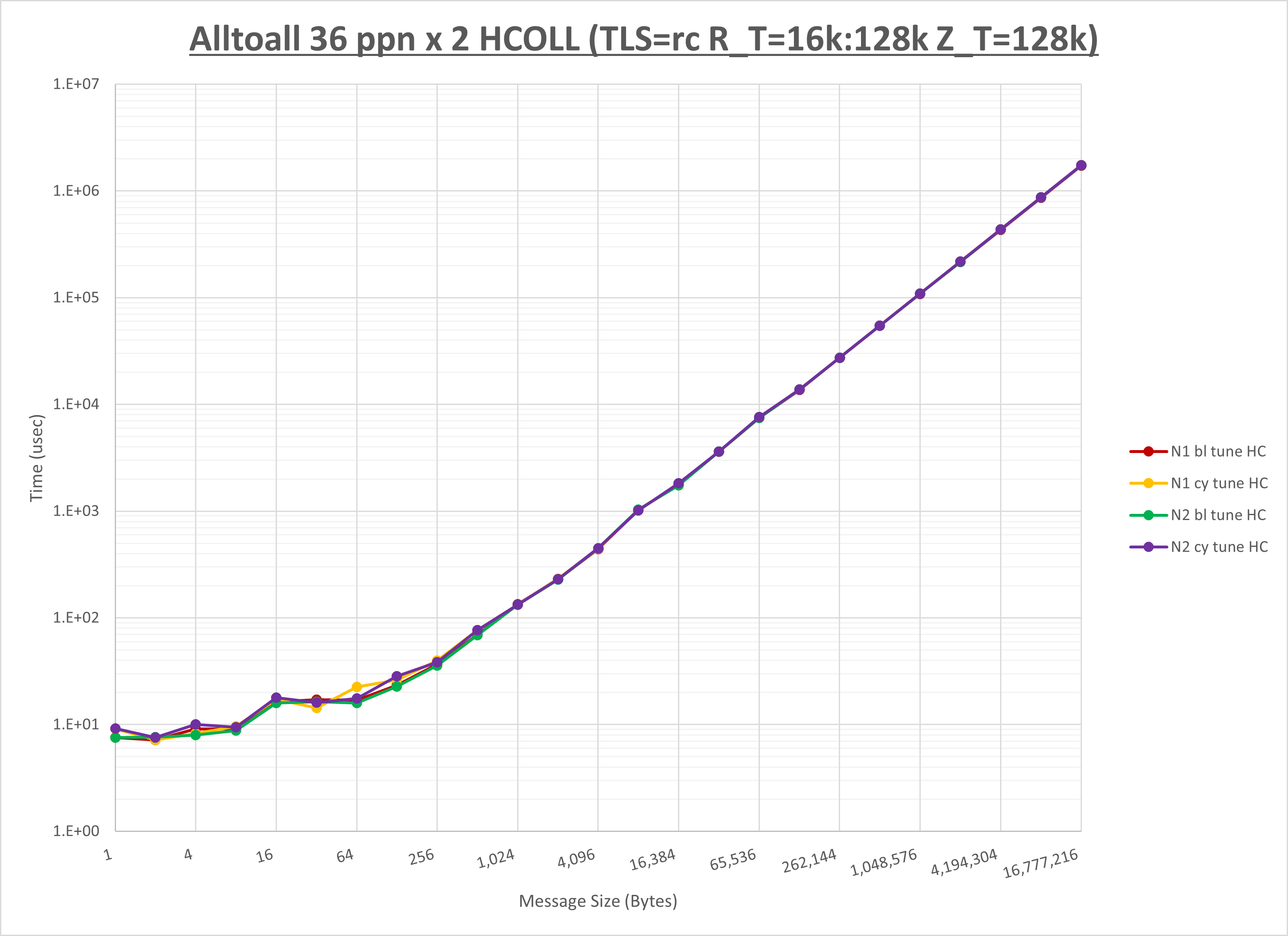
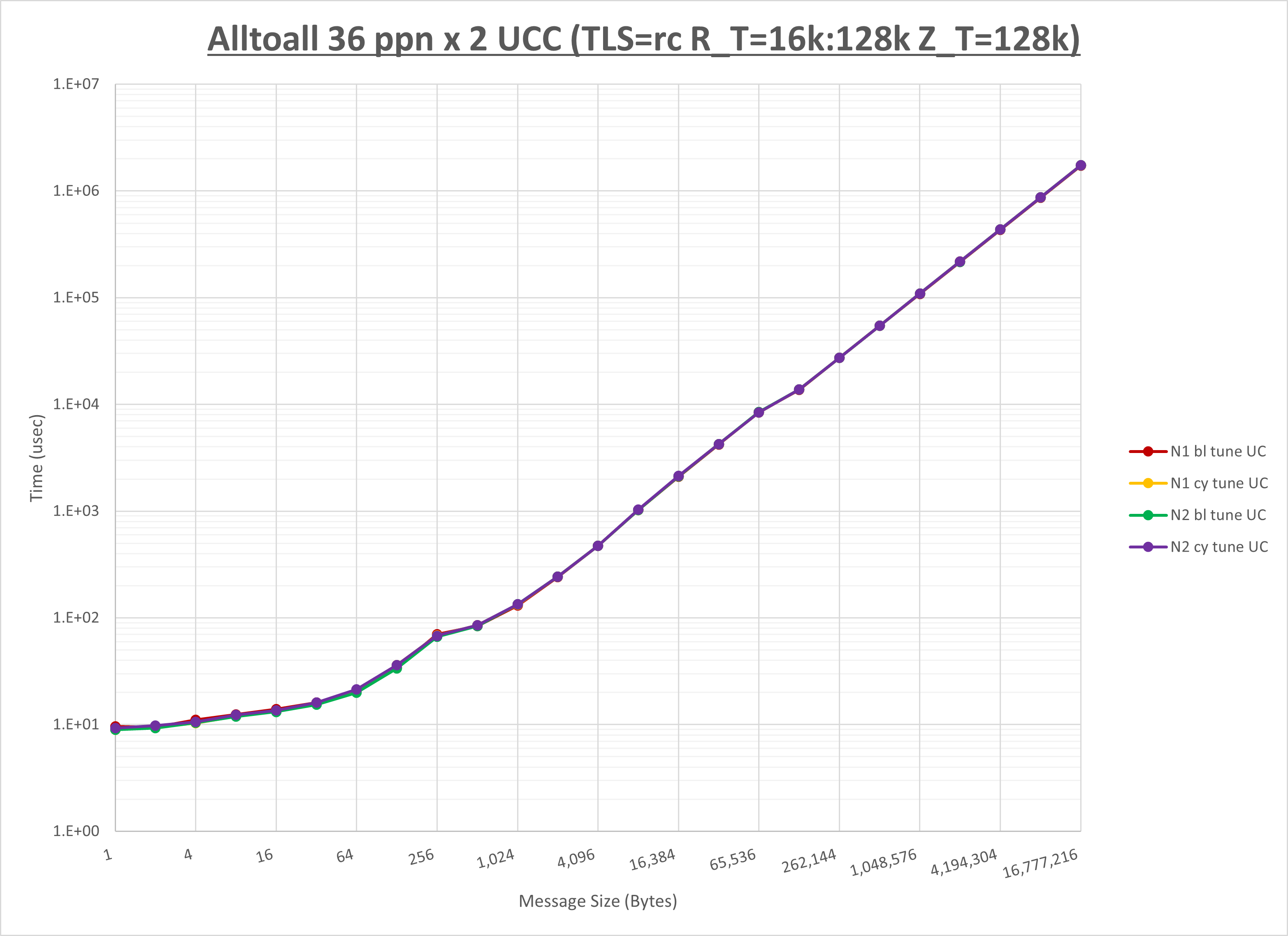
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
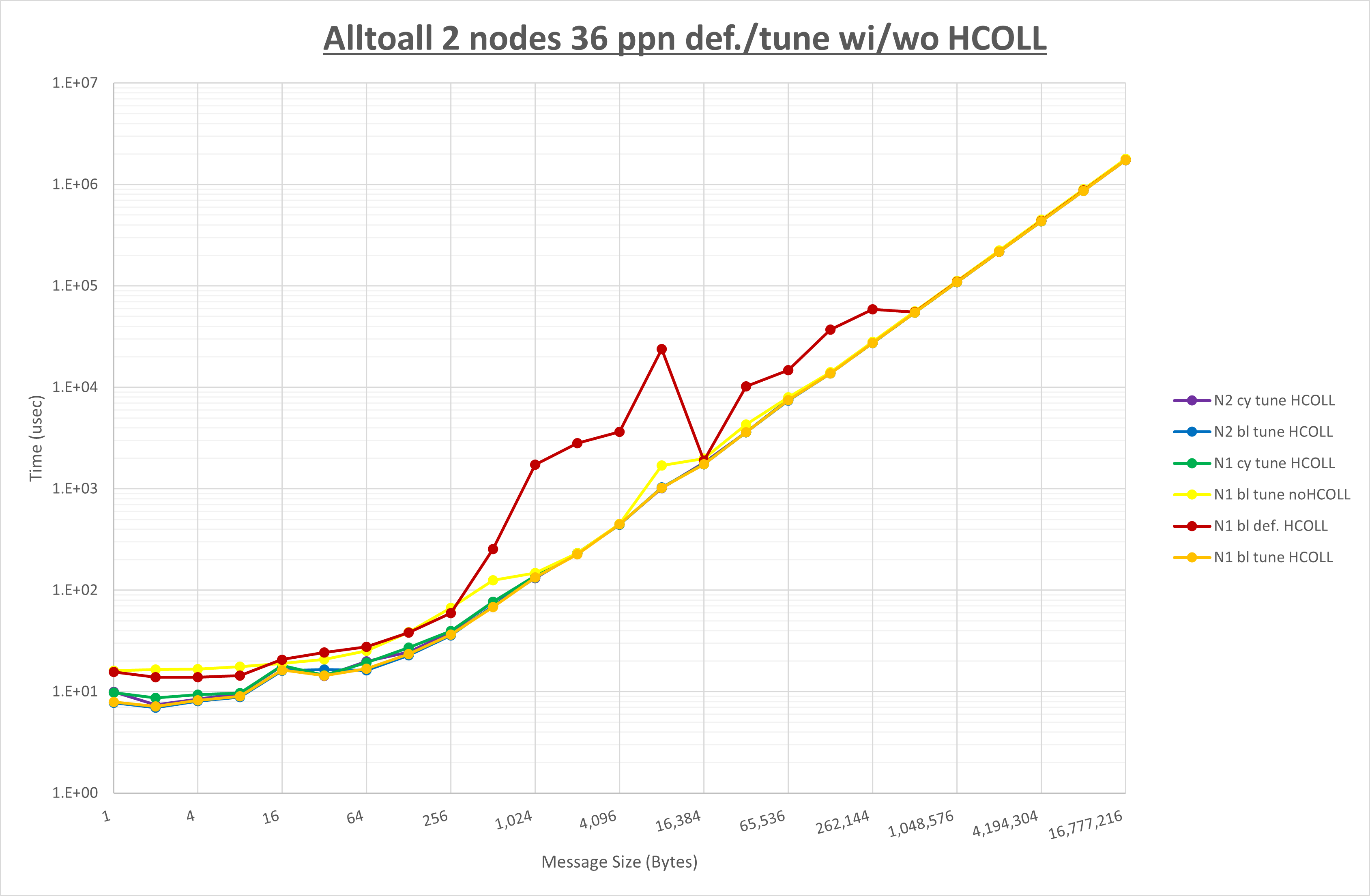
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し512B以下と8KBから64KBで性能が向上
- UCC は no-COLL と比較し64B以下で性能が向上
- チューニング適用で8KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-2 Allgather の HCOLL の結果から16KBとしています。
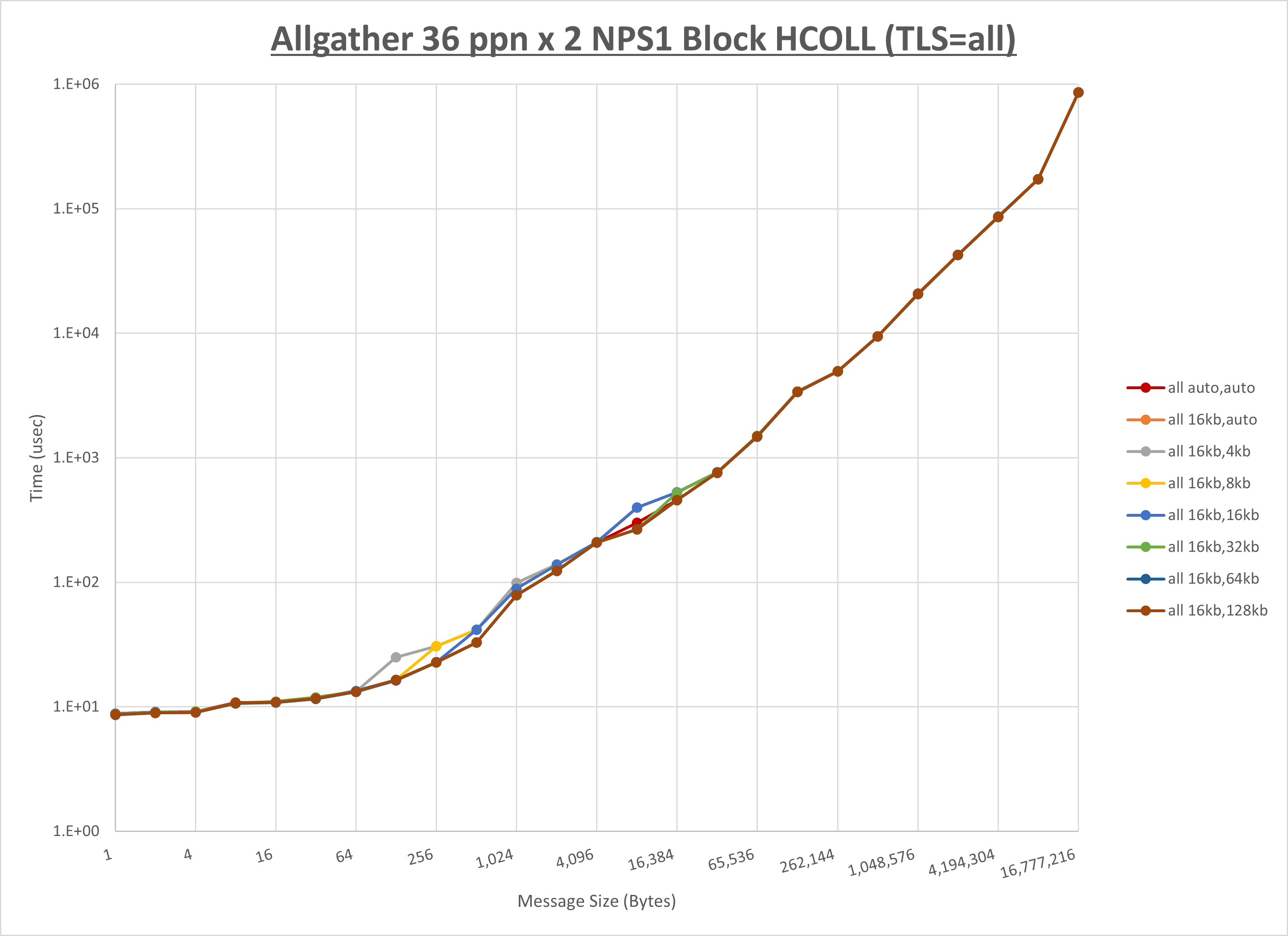
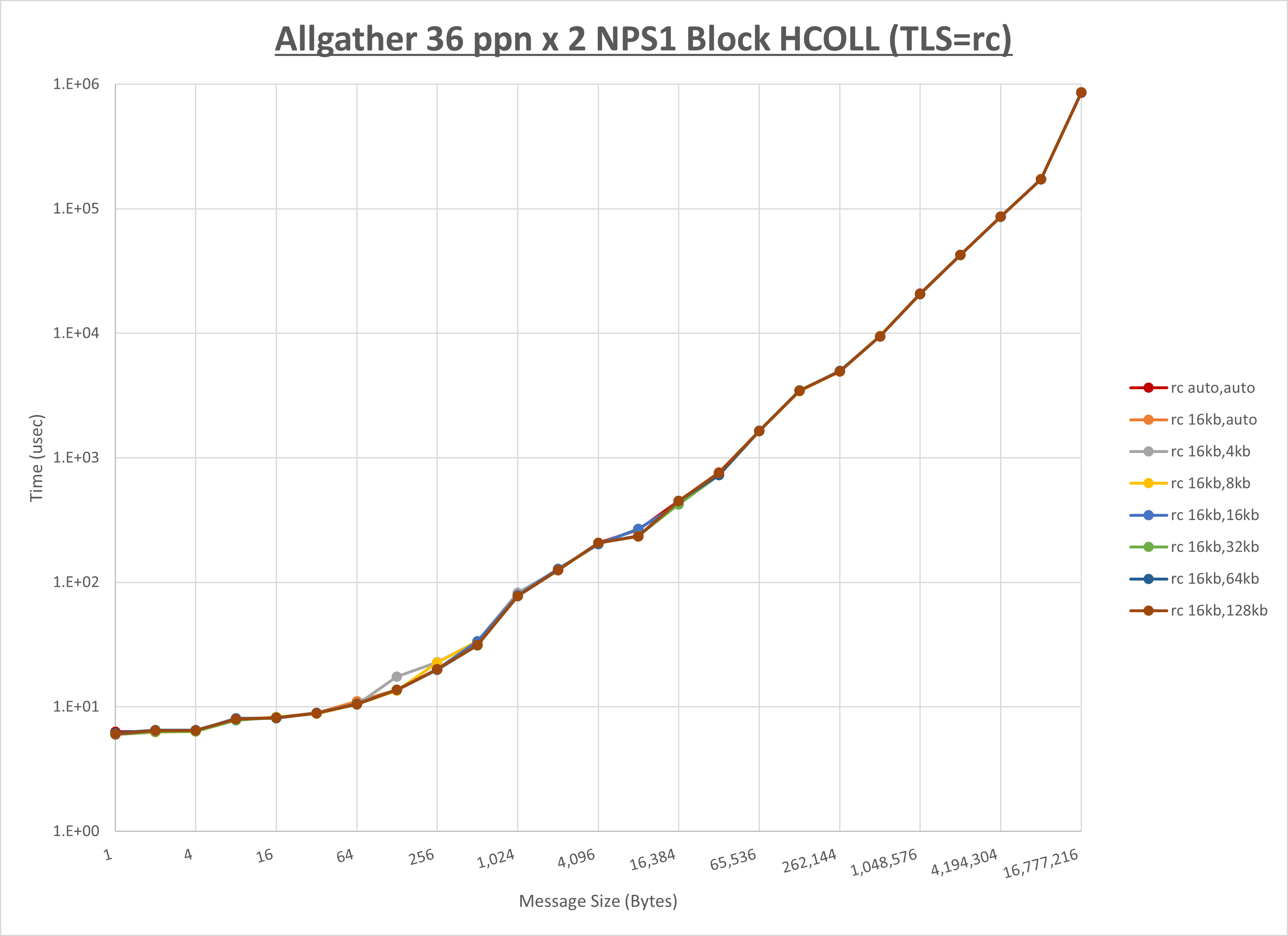
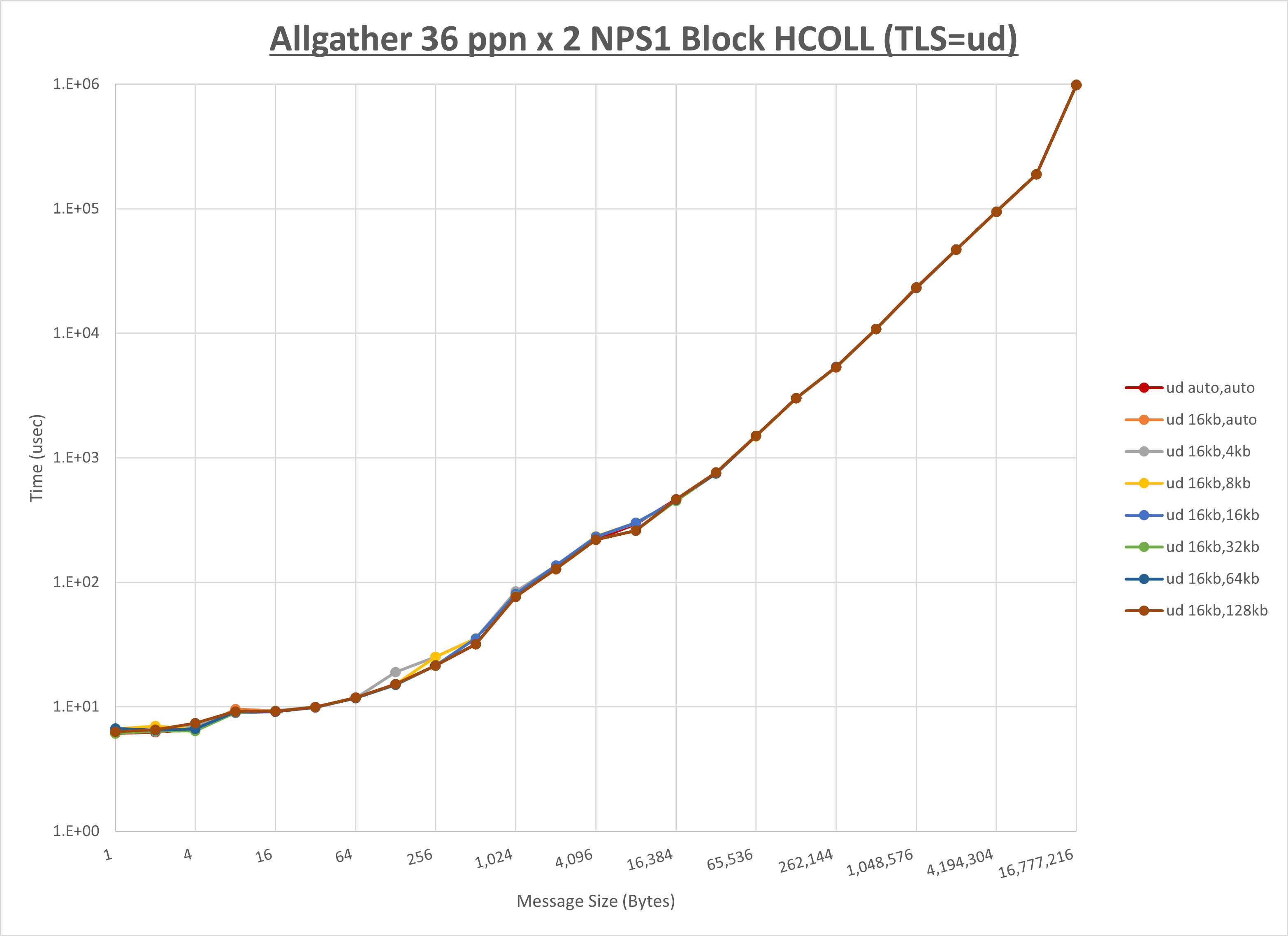
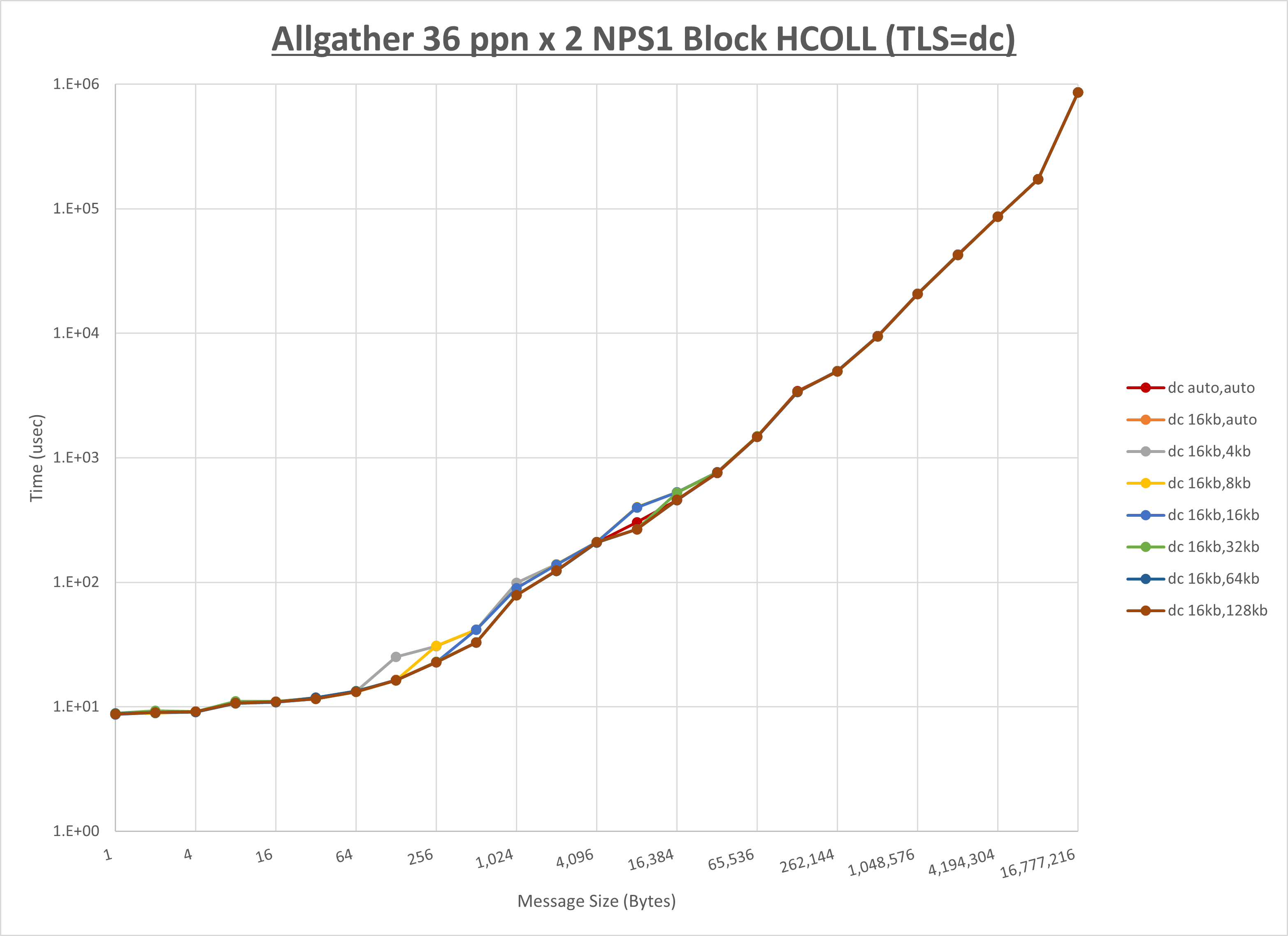
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
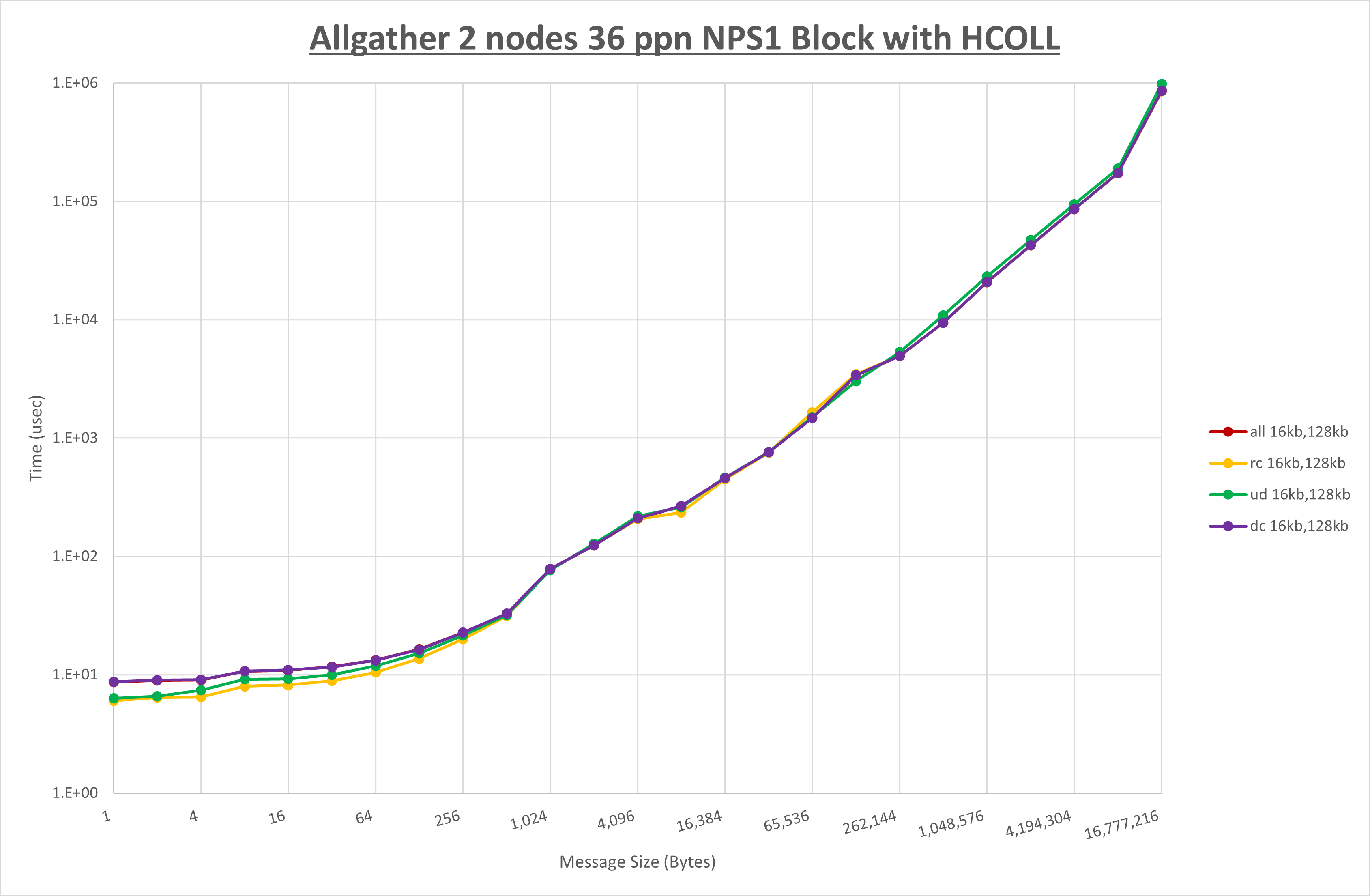
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
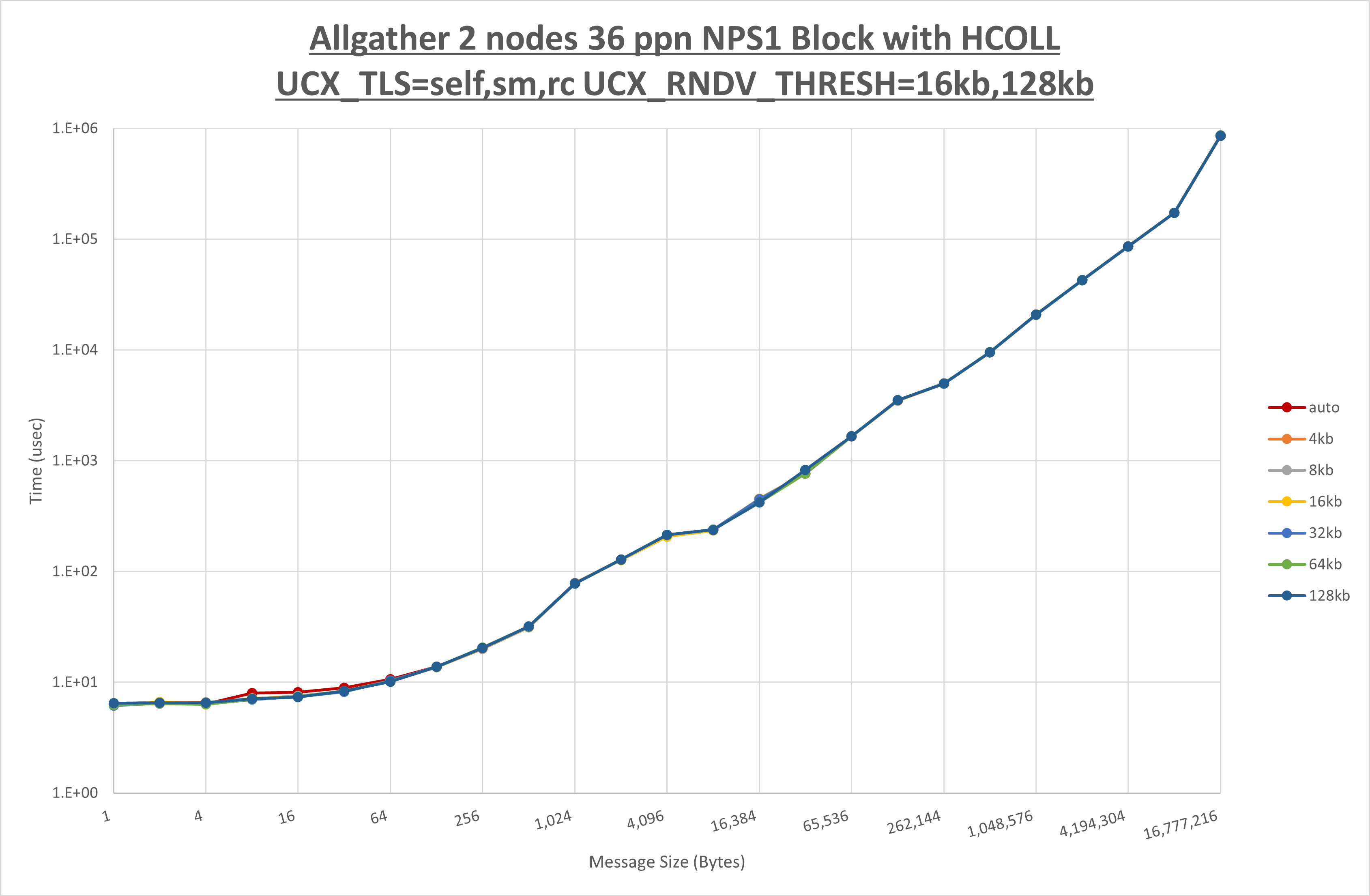
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
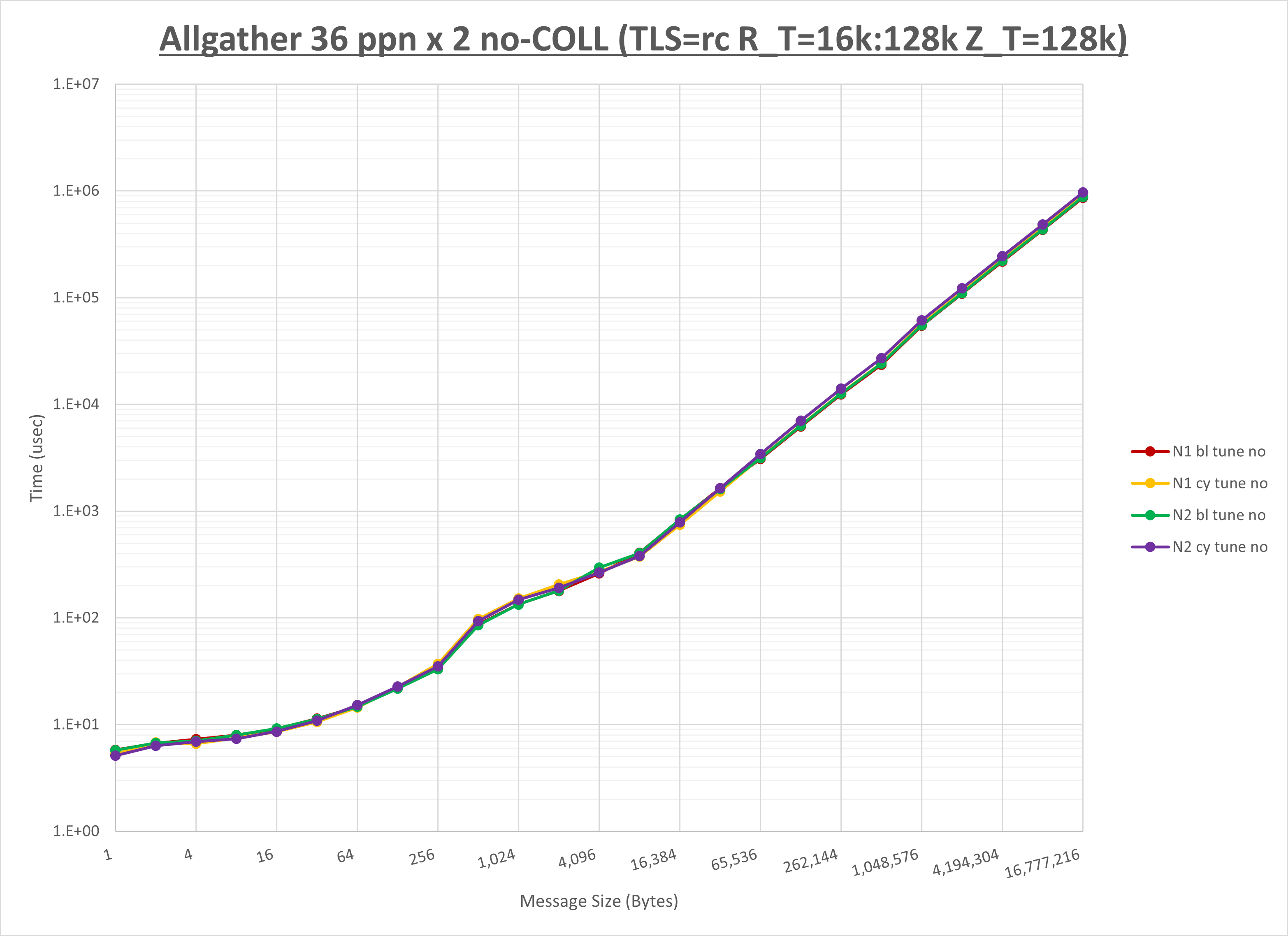
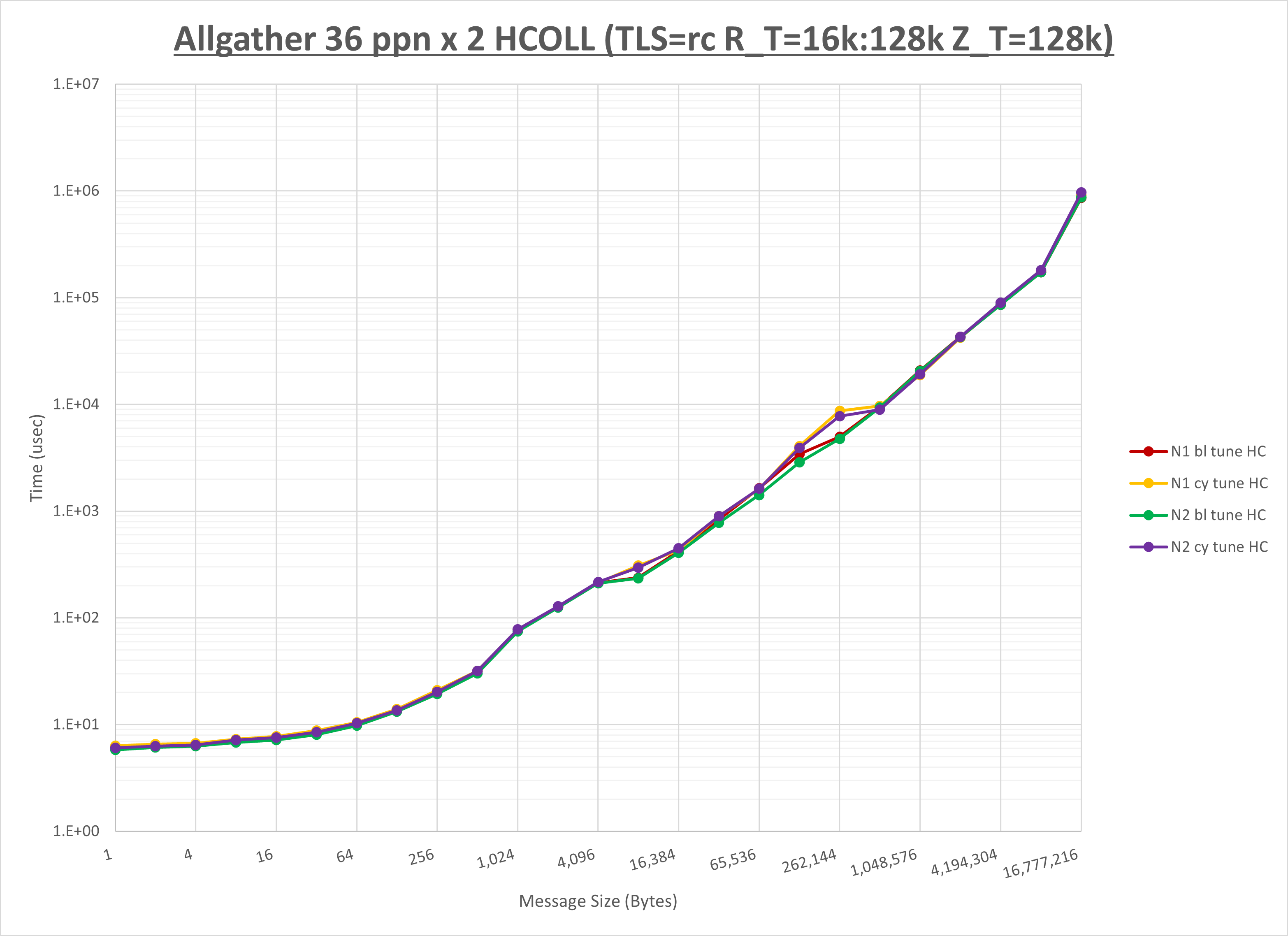
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS1 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
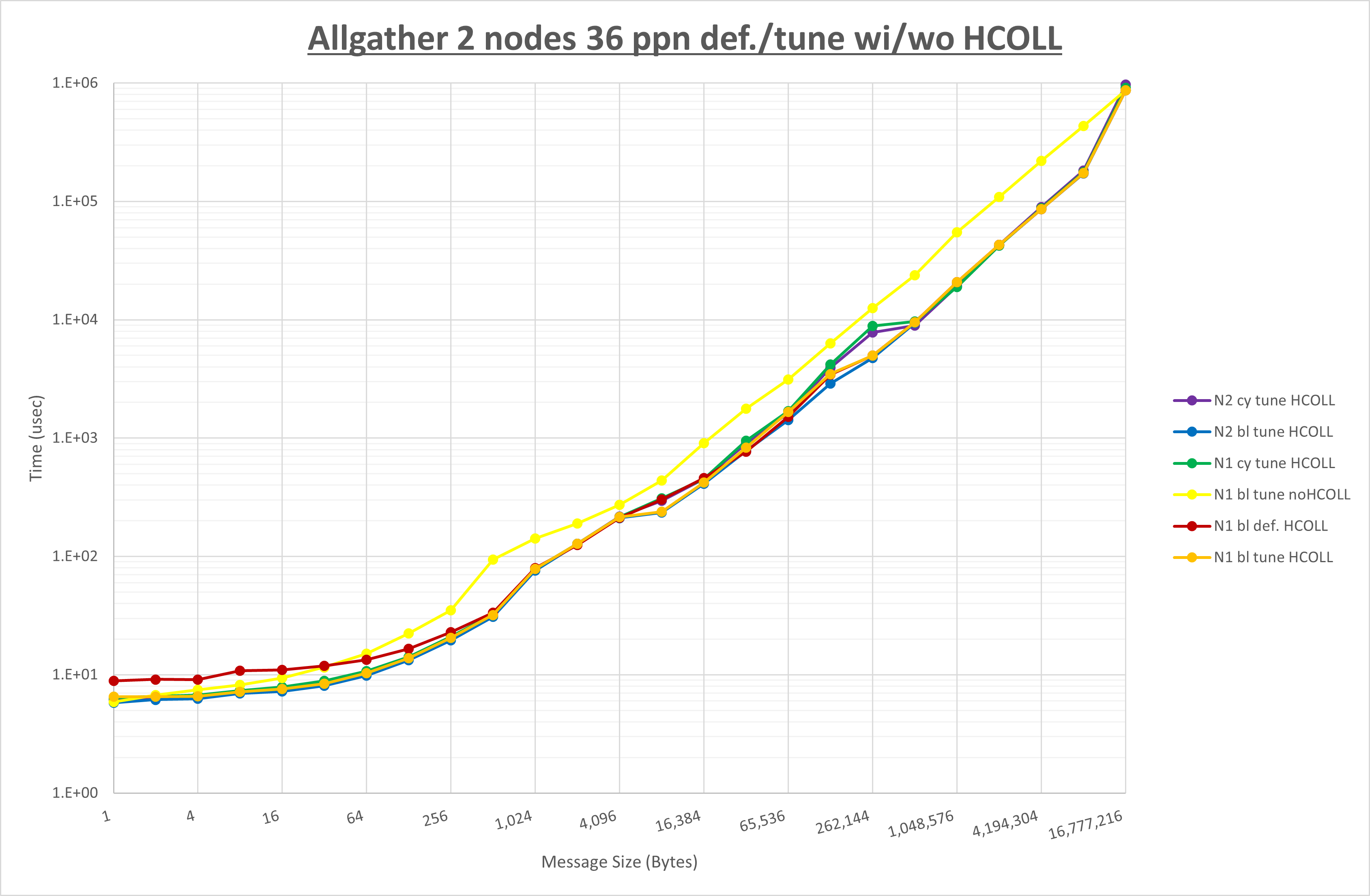
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較しほぼ全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で256B以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-3 Allreduce の HCOLL の結果から64KBとしています。
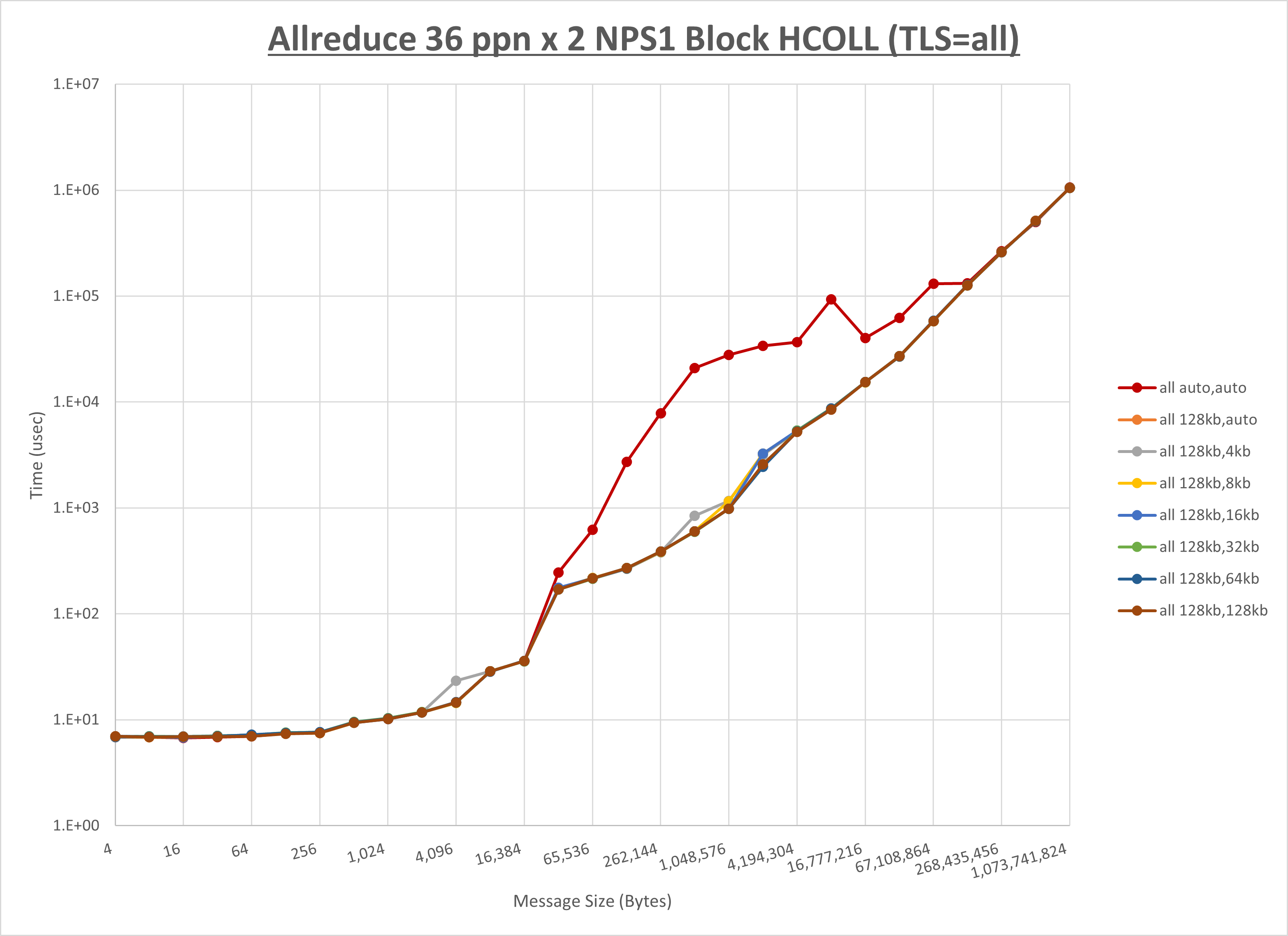
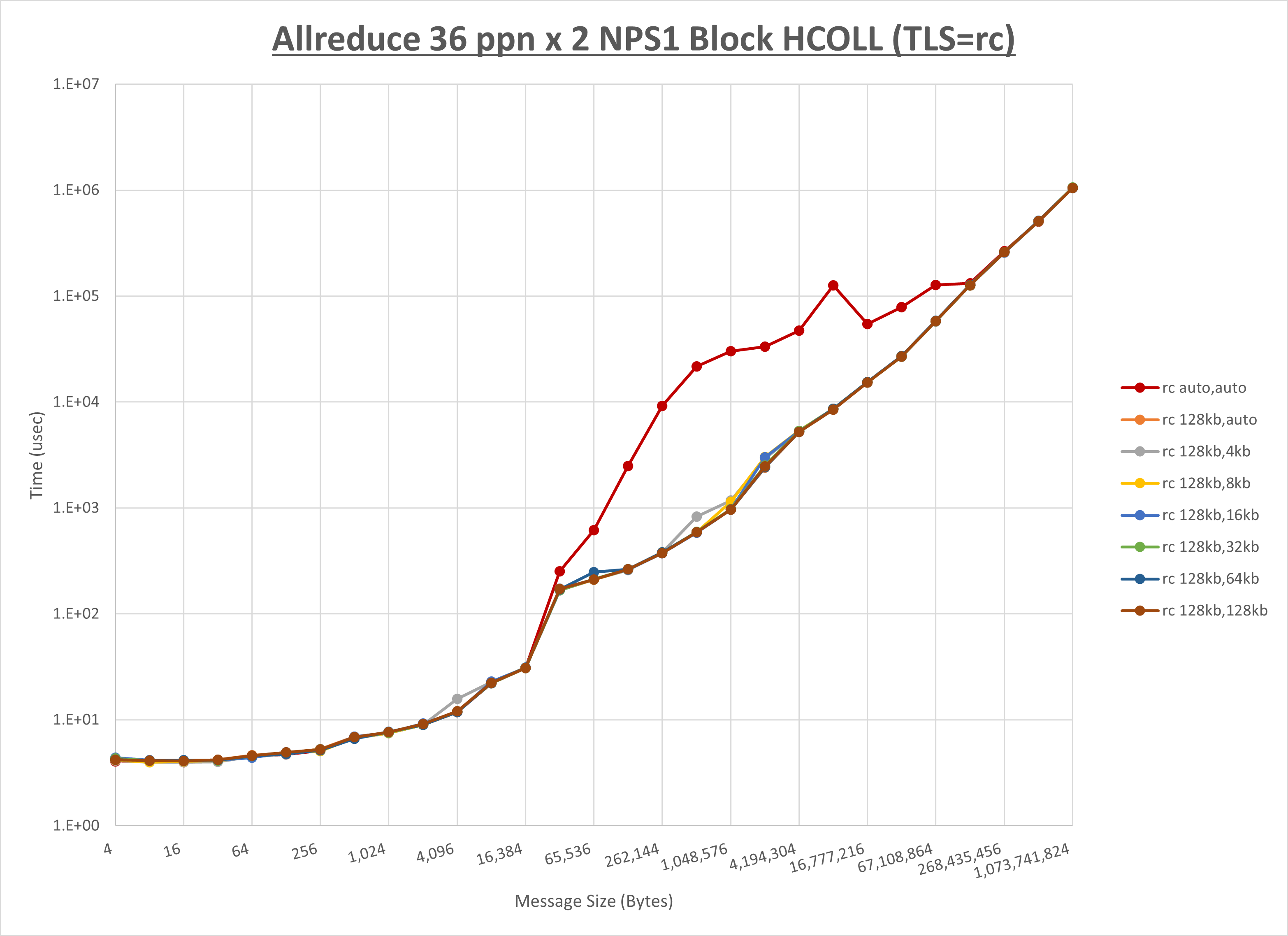
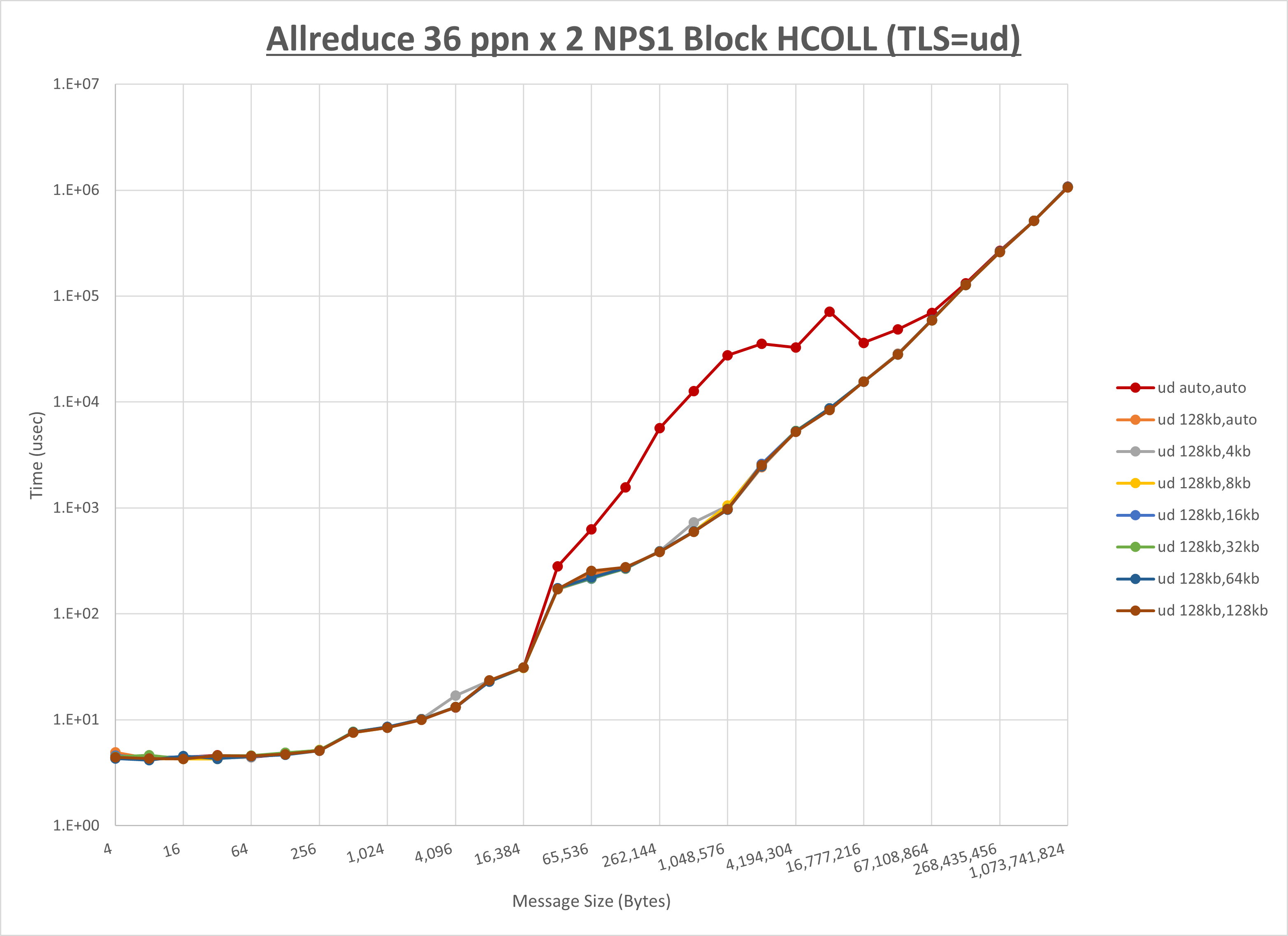
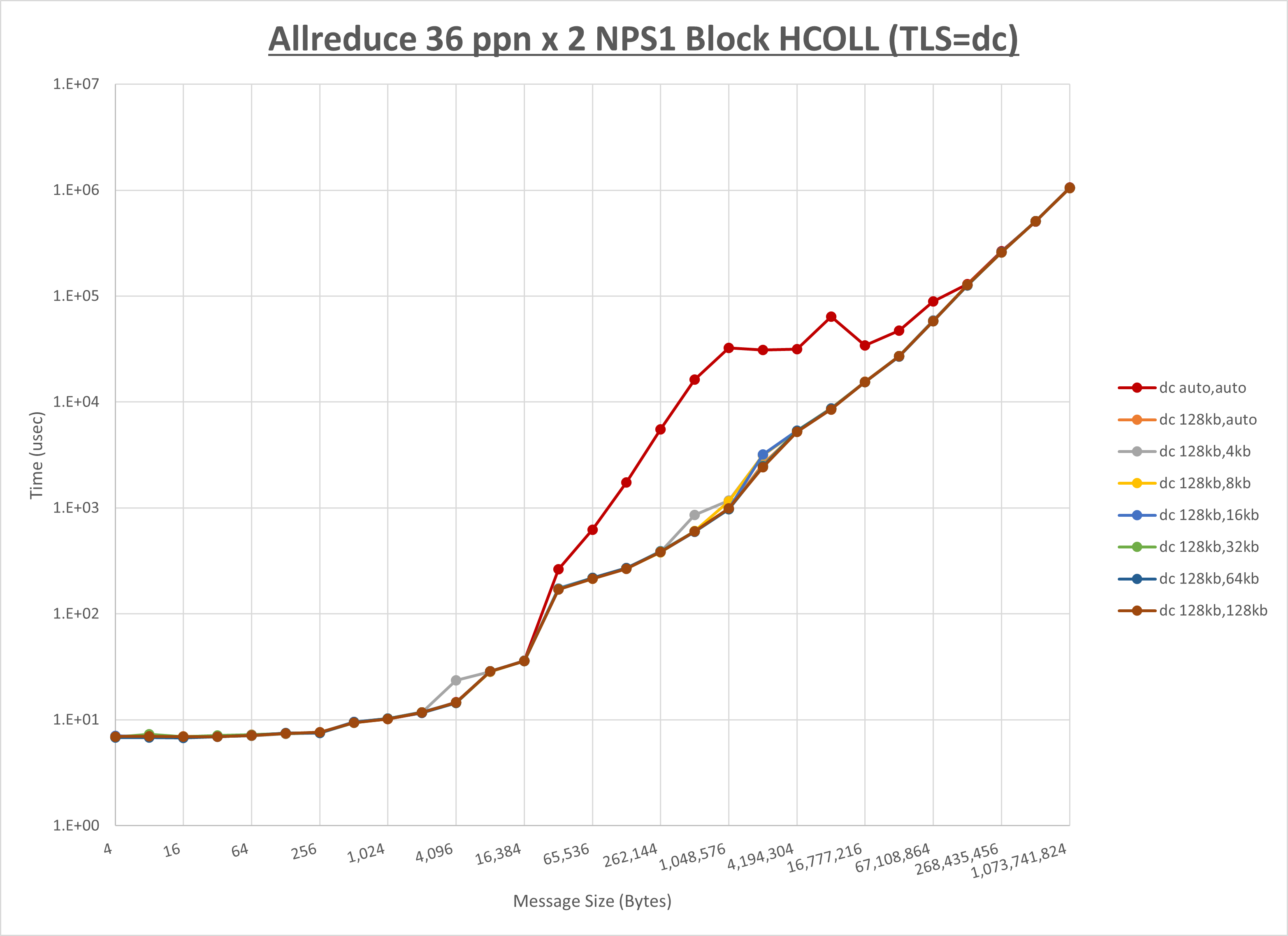
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
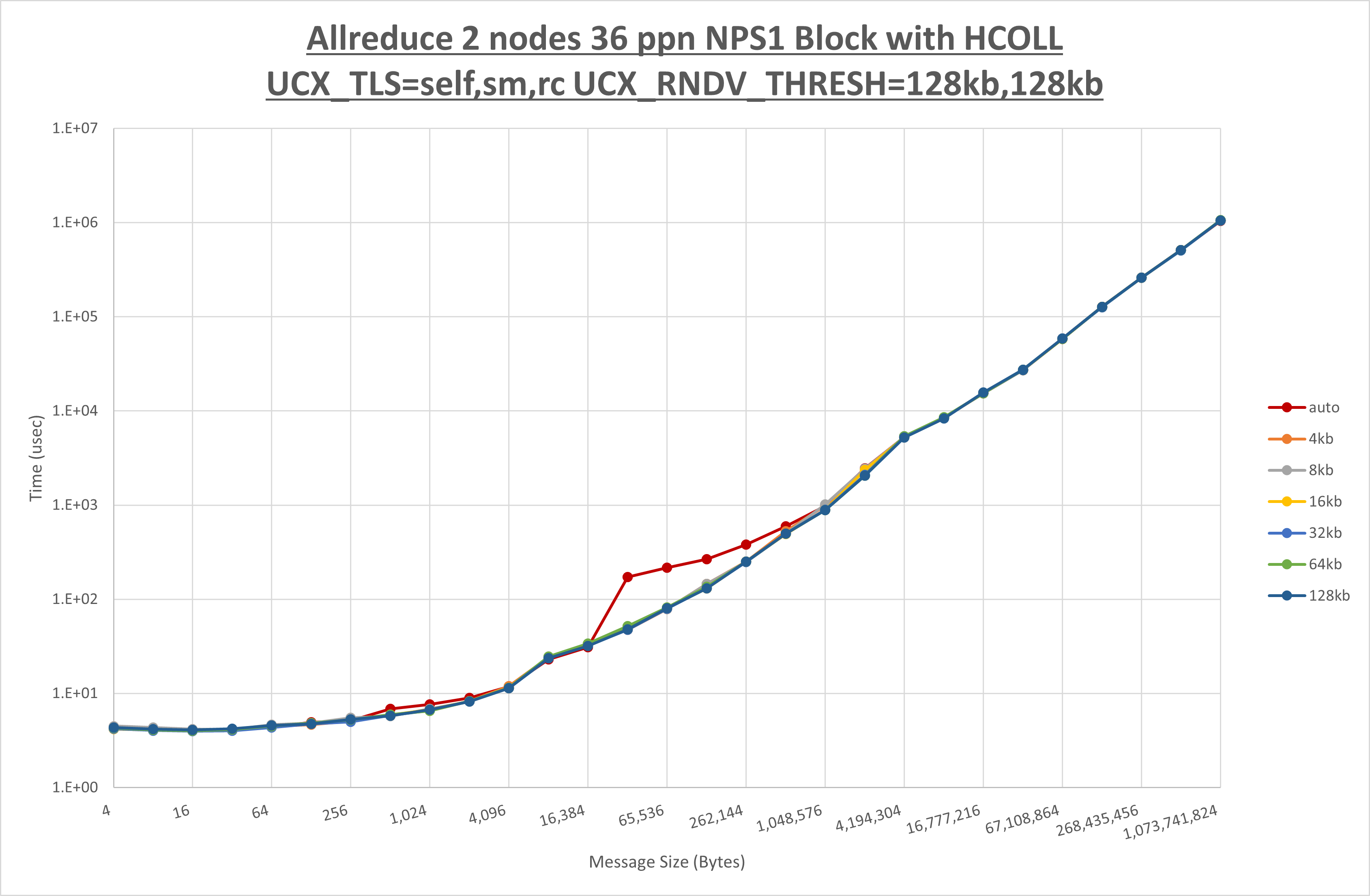
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
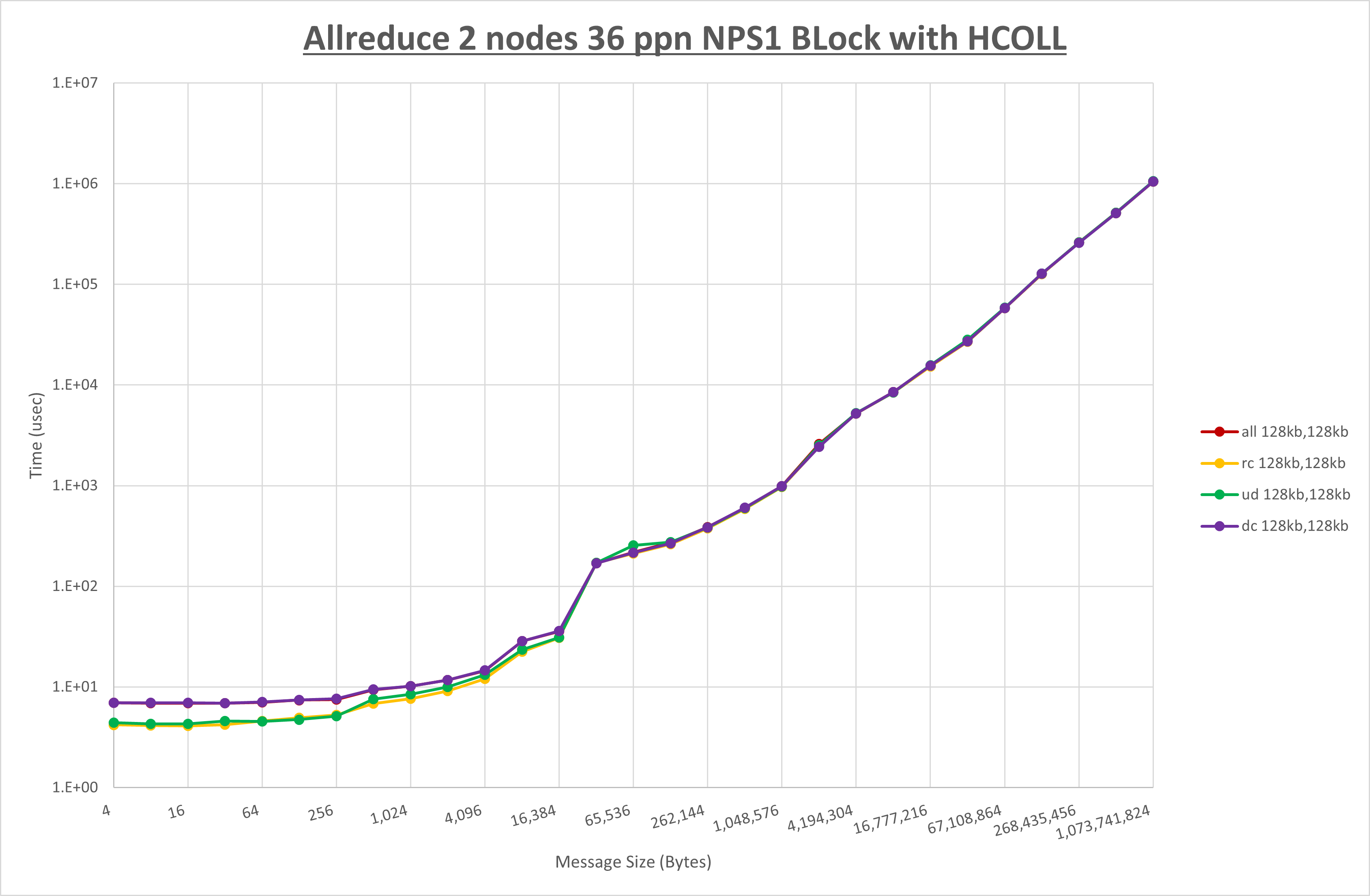
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
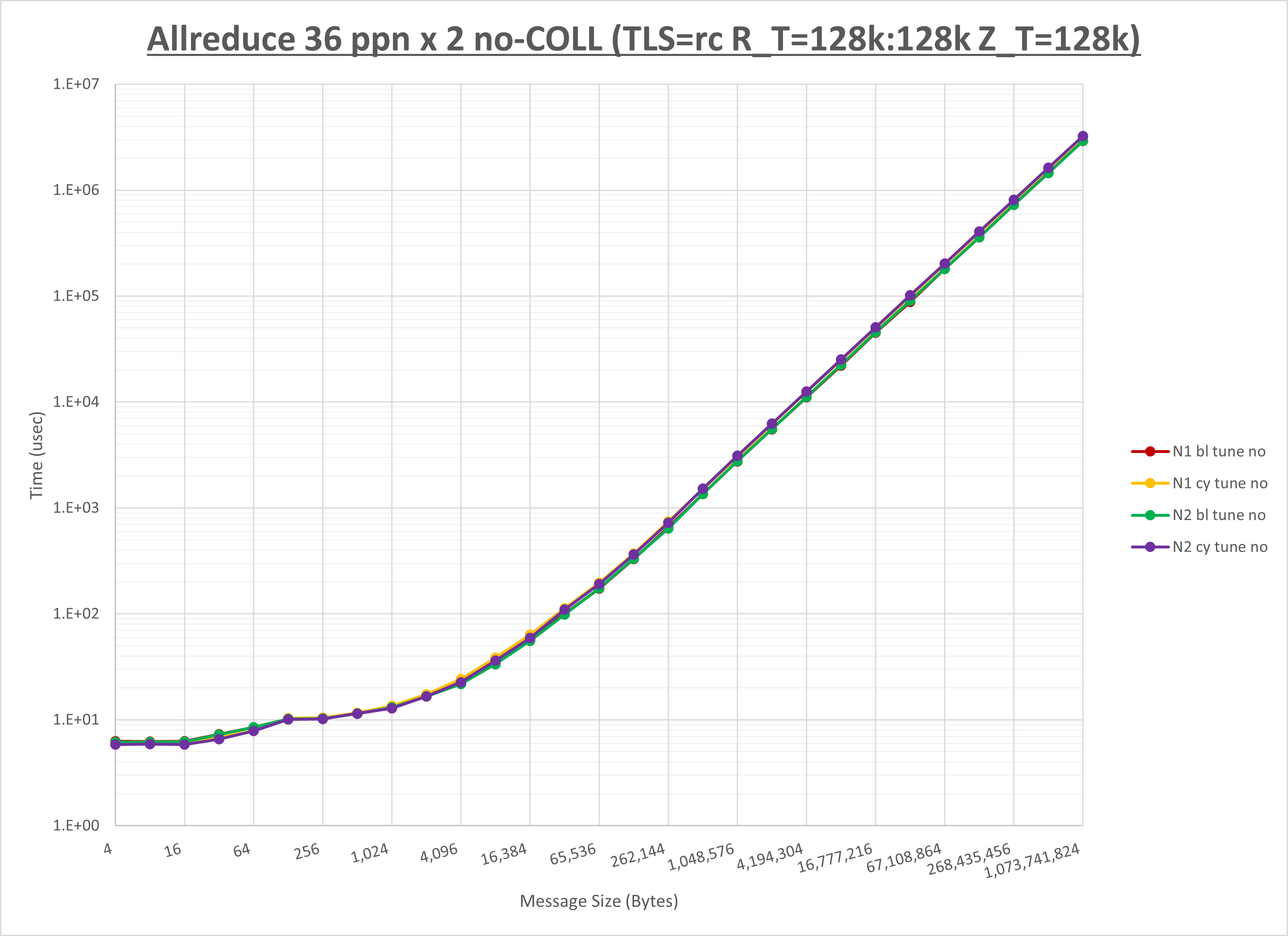
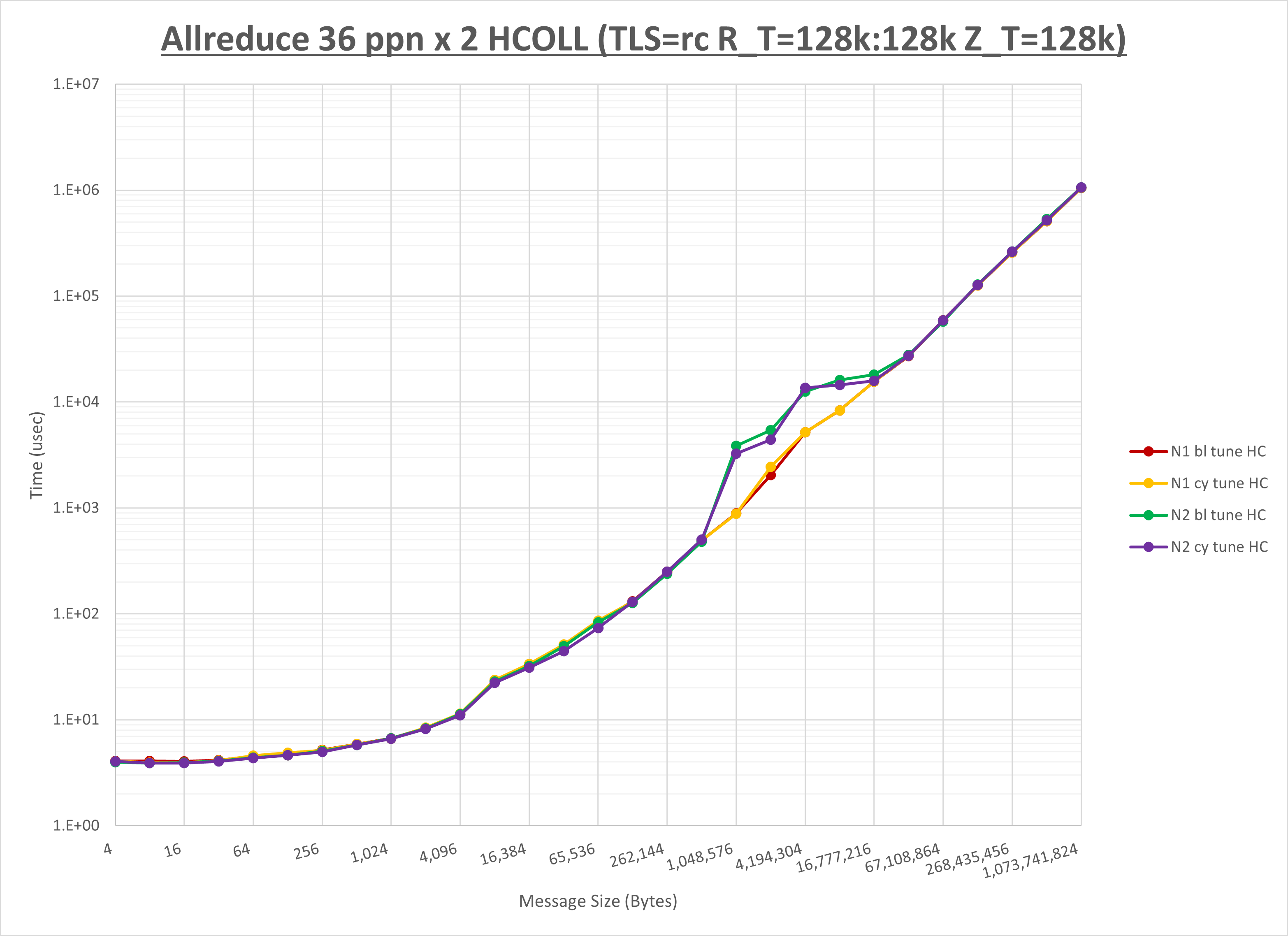
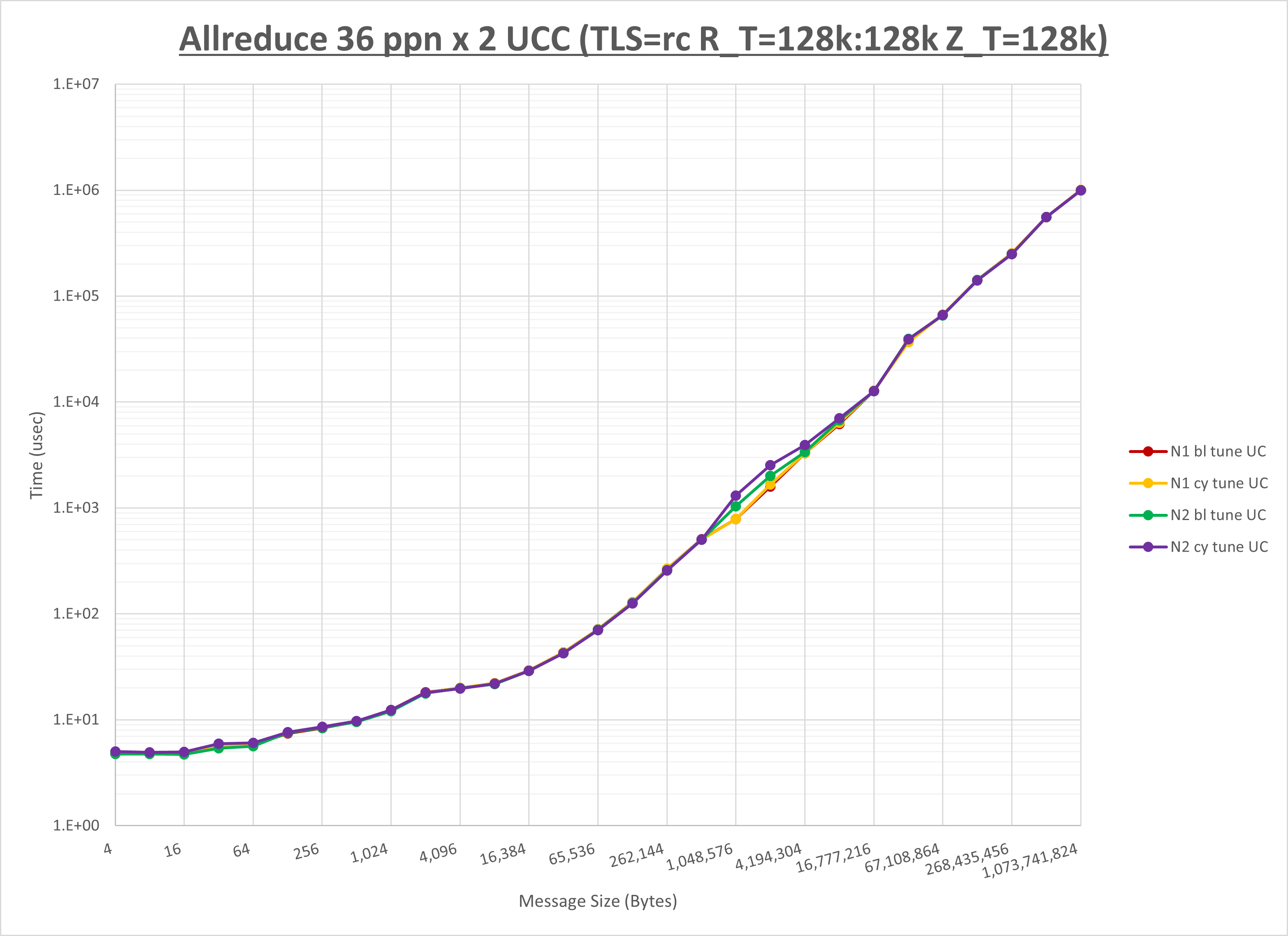
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
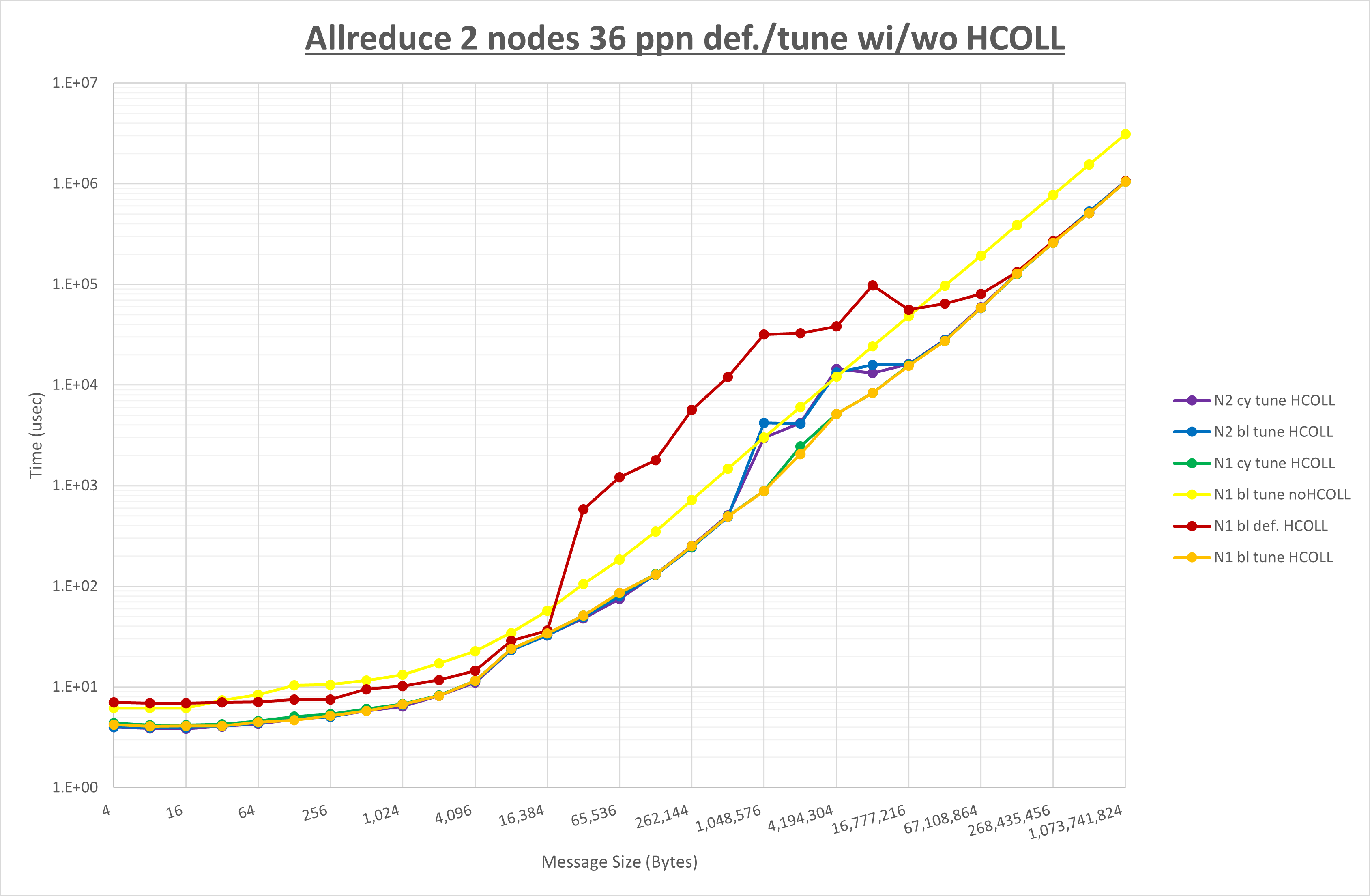
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が低下
- チューニング適用で8MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-4 Exchange の結果から16KBとしています。
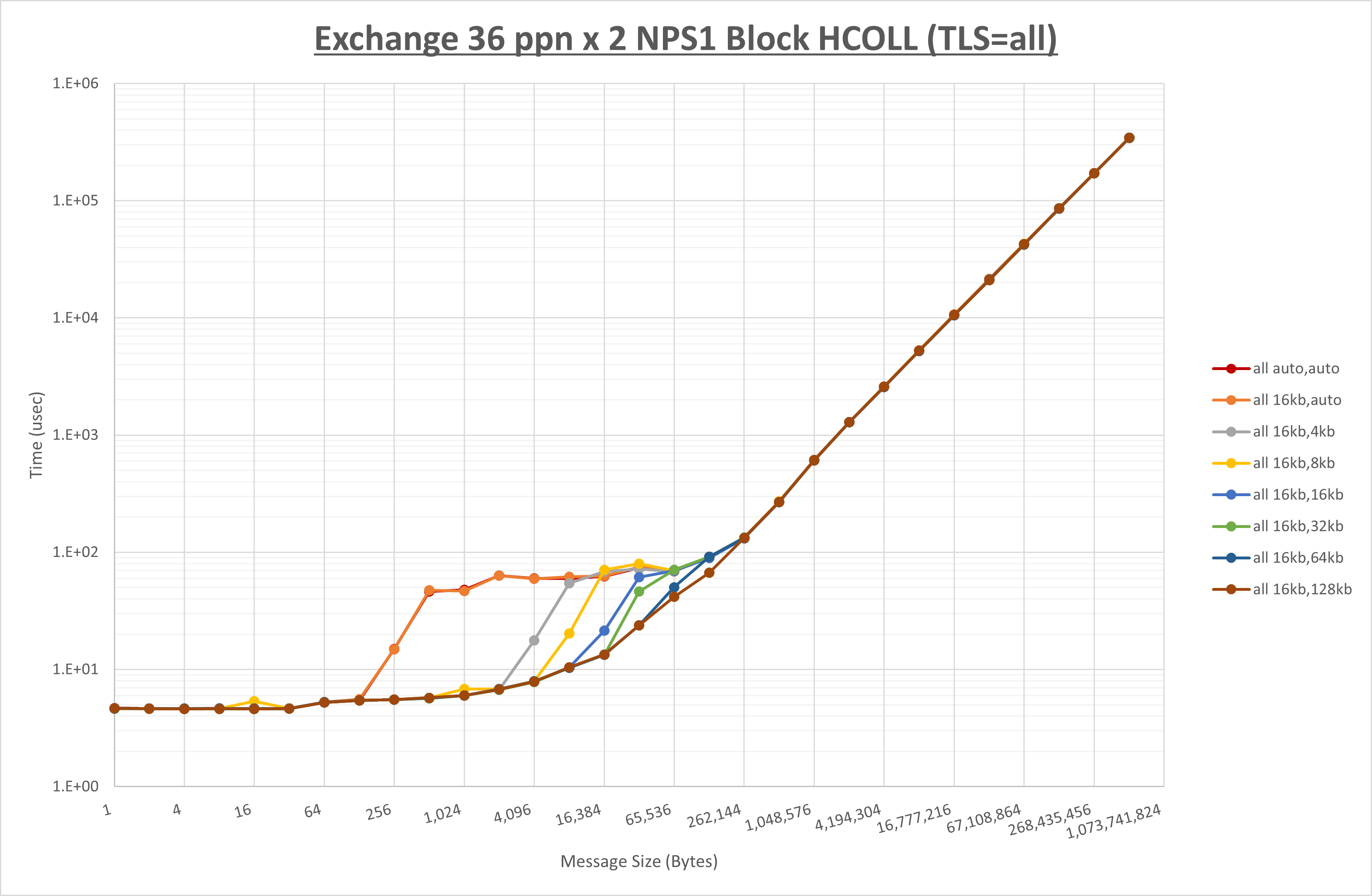
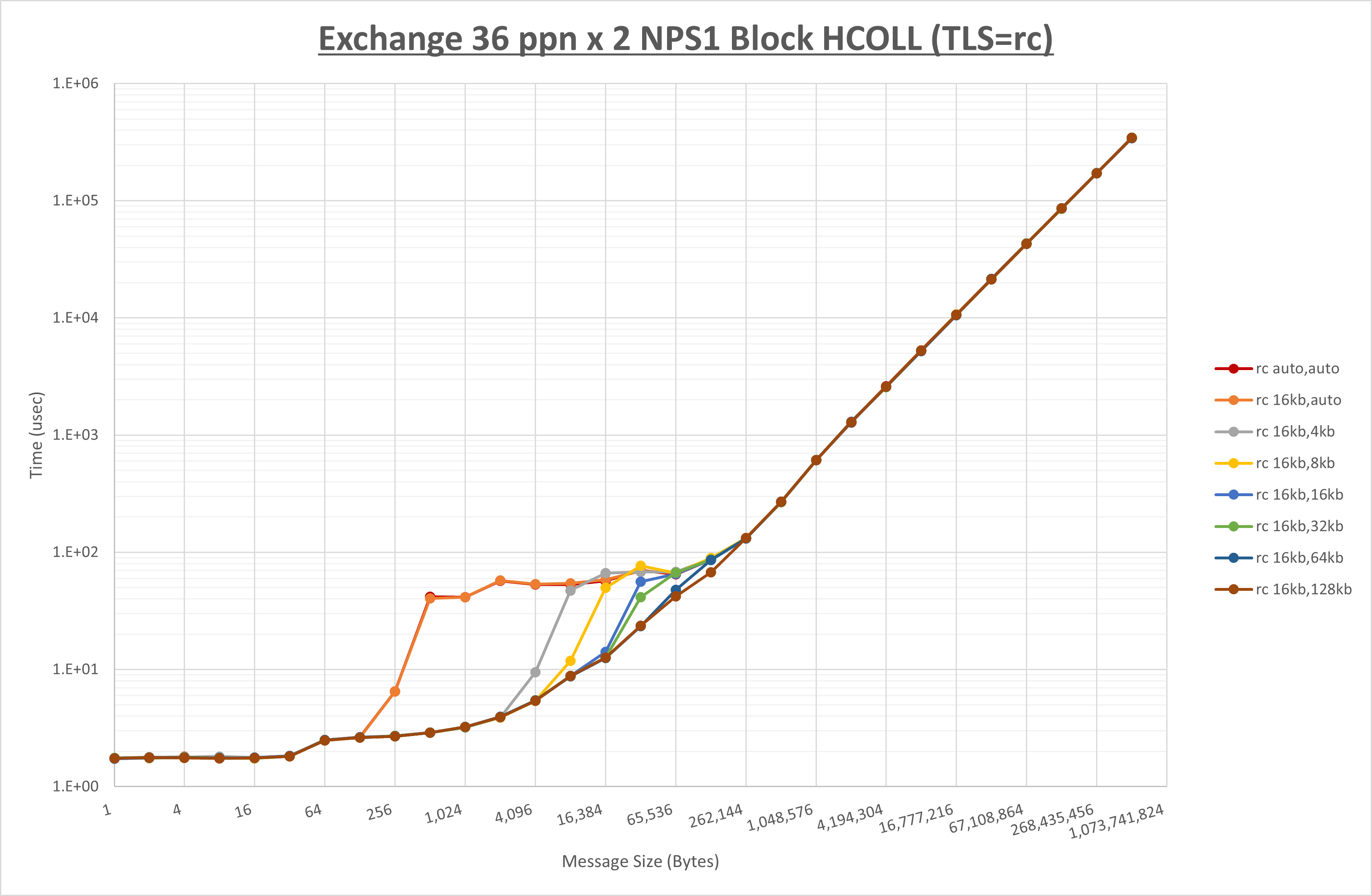
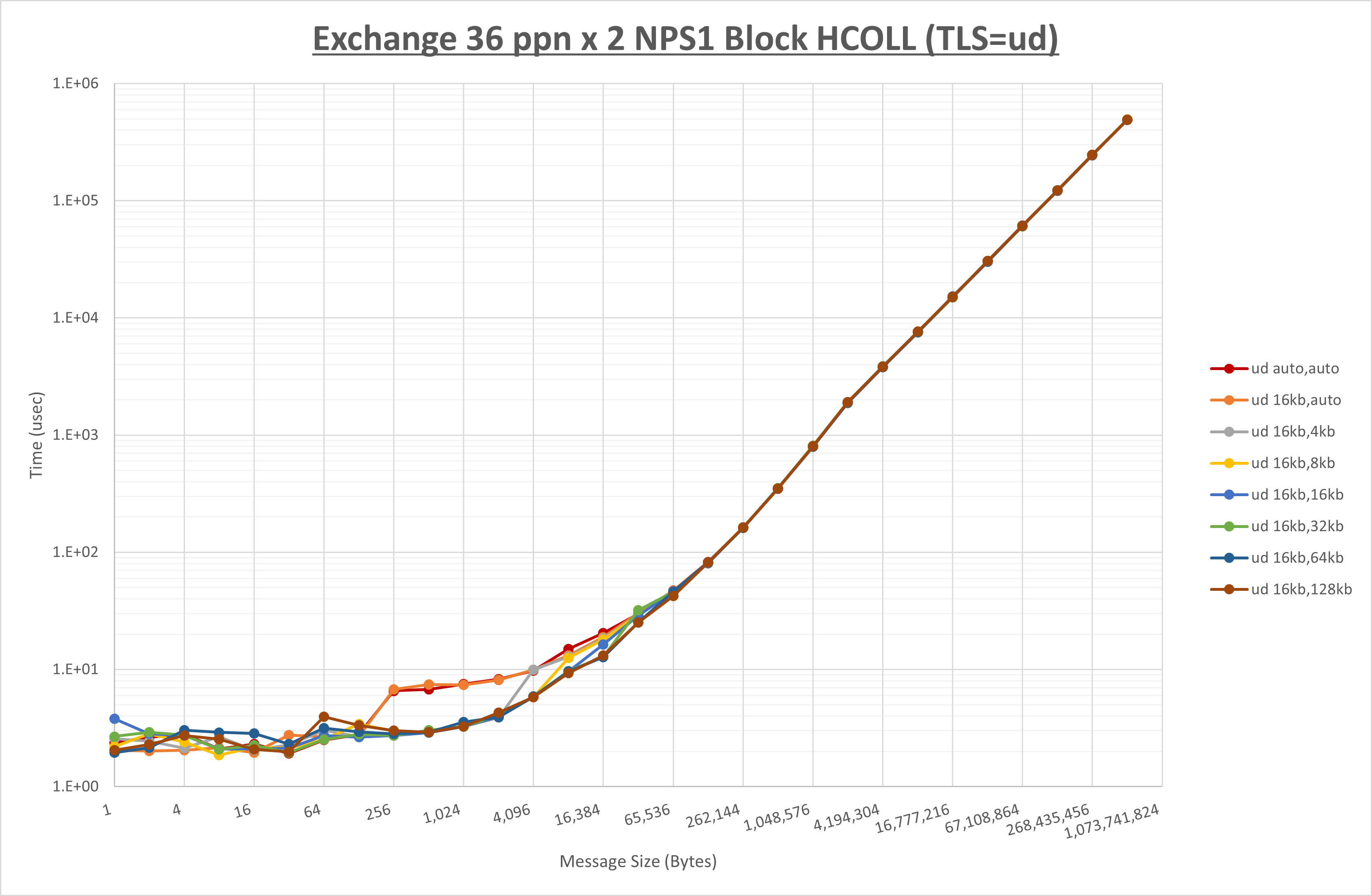
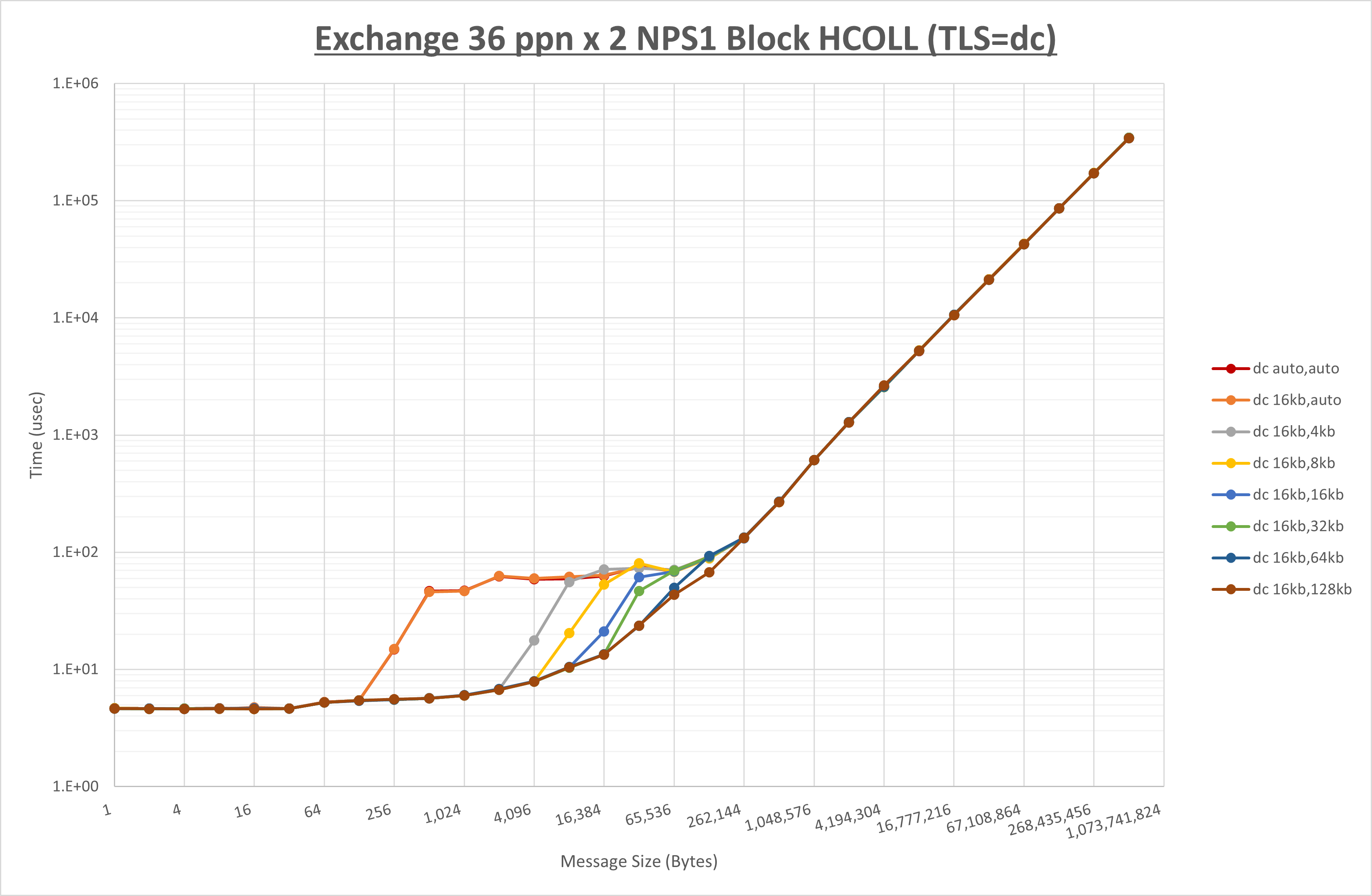
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
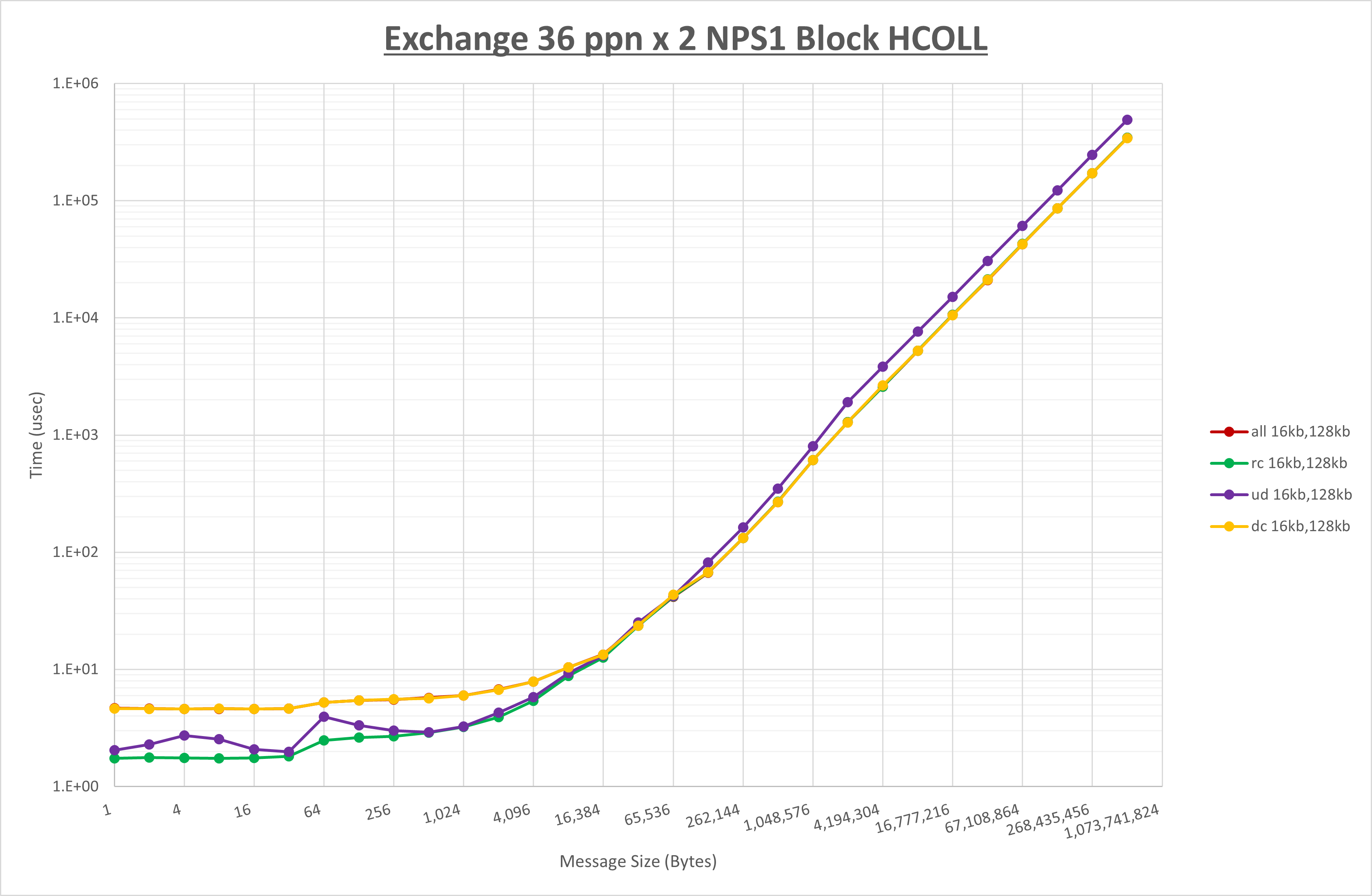
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
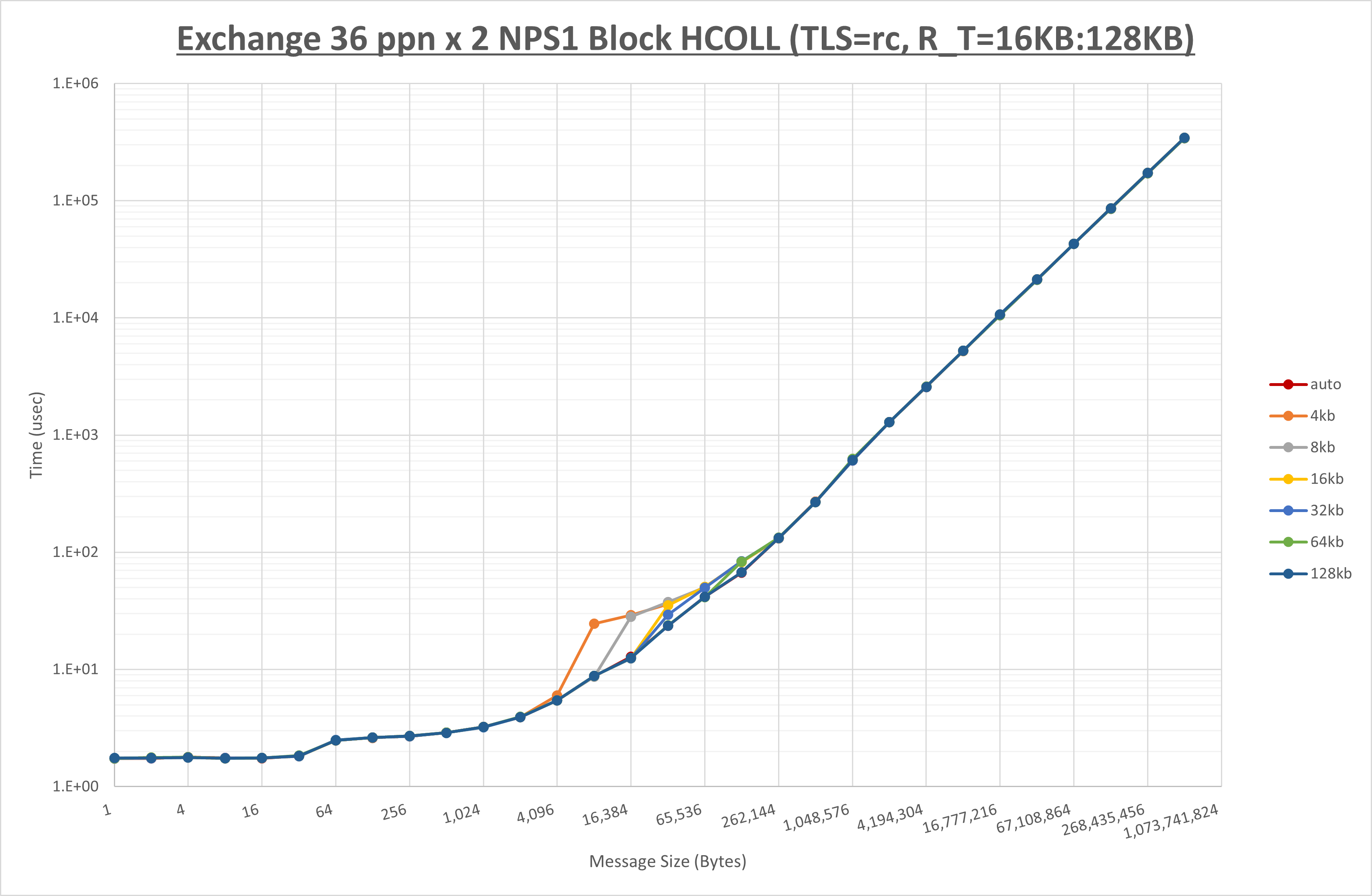
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
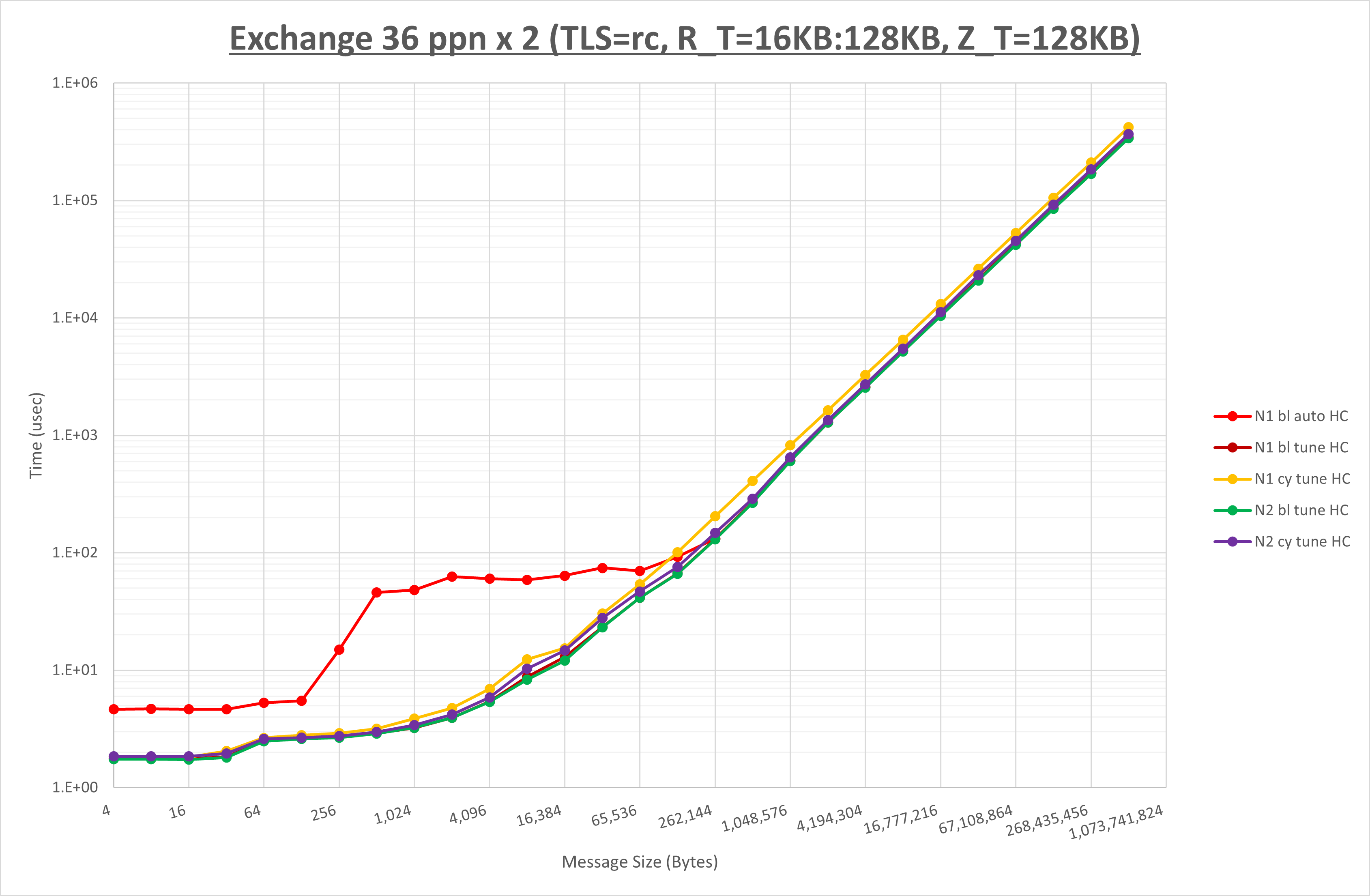
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、4ノードにノード当たり8・16・32・36、トータル32・64・128・144のMPIプロセスを割当てる場合の Alltoall ・ Allgather ・ Allreduce ・ Exchange の通信性能について、以下の 実行時パラメータ の最適な組み合わせを検証します。
- UCX_TLS : all ・ self,sm,rc ・ self,sm,ud ・ self,sm,dc
- UCX_RNDV_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb (※14)
- UCX_ZCOPY_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb
- coll_hcoll_enable : 0 ・ 1 ( Exchange を除きます。)
- coll_ucc_enable : 0 ・ 1 ( Exchange を除きます。)
- MPIプロセス分割方法 : ブロック分割・サイクリック分割
- NPS : NPS1 ・ NPS2
※14) UCX_RNDV_THRESH は、ノード内は auto と 1. 1ノード で判明した最適値、ノード間はここに記載の7種類を使用し、以下8個の組合せを検証します。
- intra:auto,inter:auto
- intra:optimal_value,inter:auto
- intra:optimal_value,inter:4kb
- intra:optimal_value,inter:8kb
- intra:optimal_value,inter:16kb
- intra:optimal_value,inter:32kb
- intra:optimal_value,inter:64kb
- intra:optimal_value,inter:128kb
ここで、全ての 実行時パラメータ の組み合わせを検証することは非現実的なため、組み合わせを減らす目的で以下3ステップに分けて検証を行います。
- ステップ1
- UCX_TLS と UCX_RNDV_THRESH を組合せた32個のパターンを検証してこれらの最適値を決定
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ2
- UCX_ZCOPY_THRESH の7パターンを検証してこの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ3
- coll_hcoll_enable / coll_ucc_enable / MPIプロセス分割方法 / NPS を組合せた12パターンを検証してこれらの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- UCX_ZCOPY_THRESH はステップ2で決定した最適値を使用
本章は、4ノードにノード当たり8、トータル32のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,rc | intra:32kb,inter:32kb | 16kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:32kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-1 Alltoall の HCOLL の結果から32KBとしています。
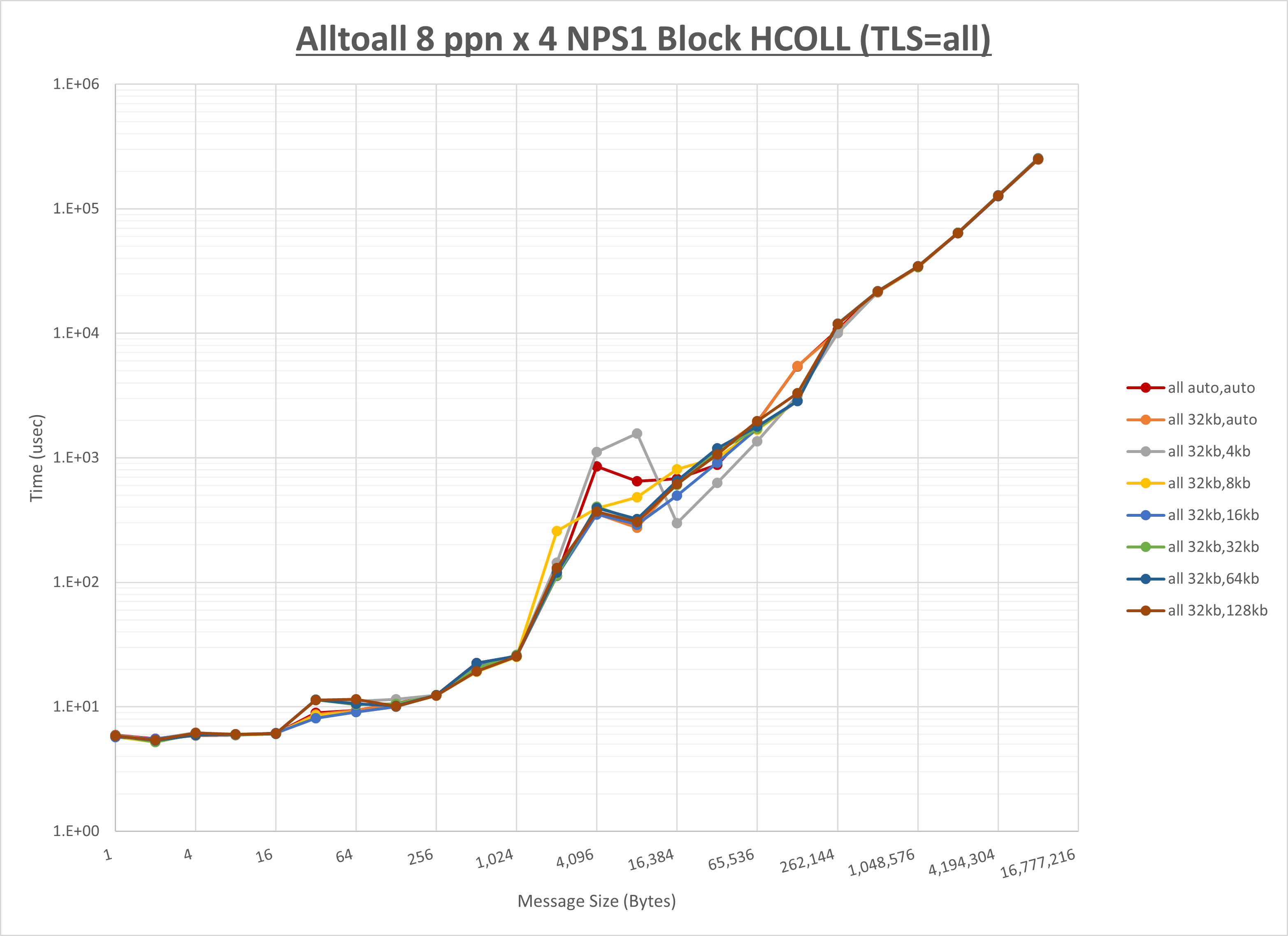
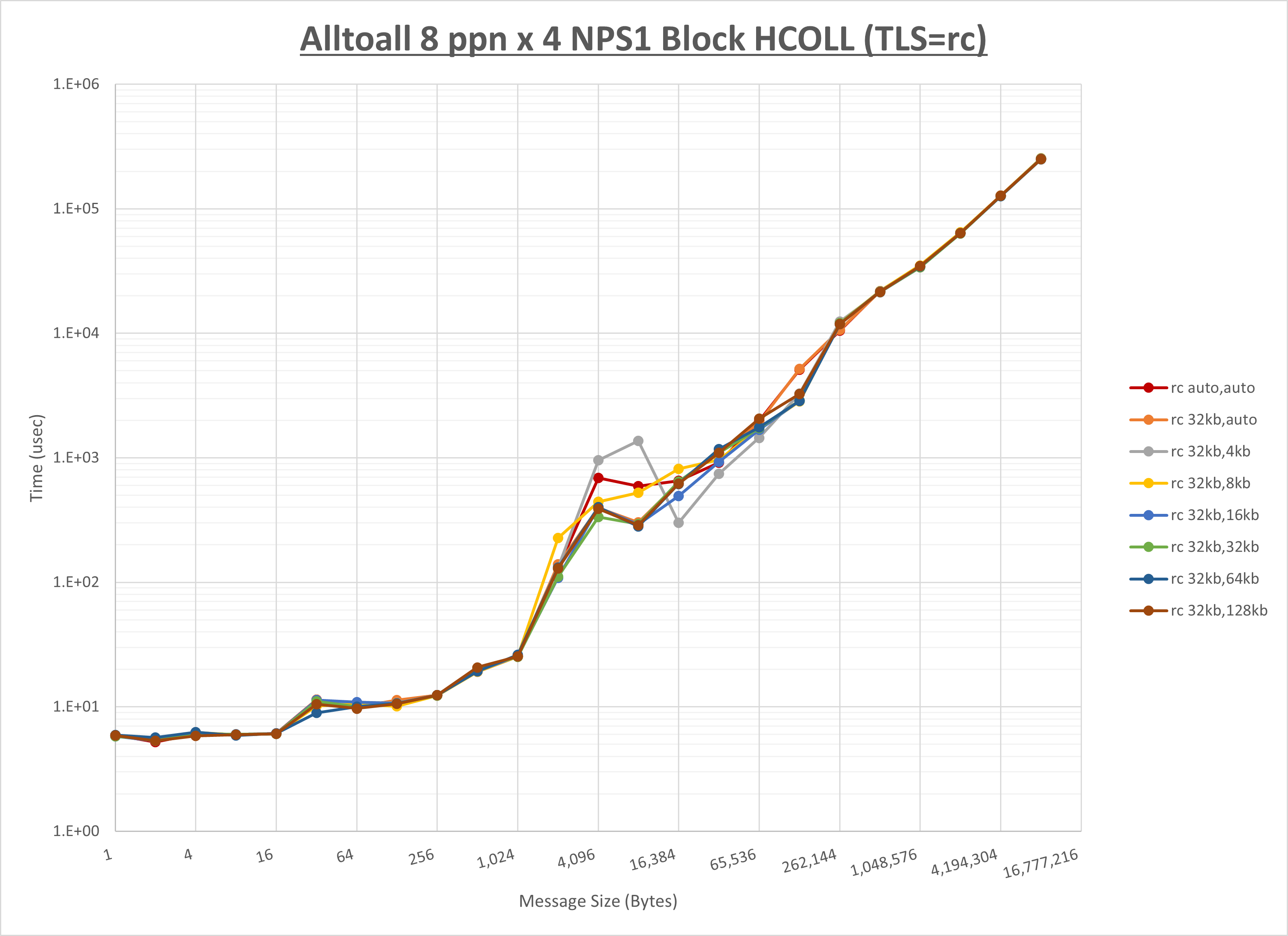
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
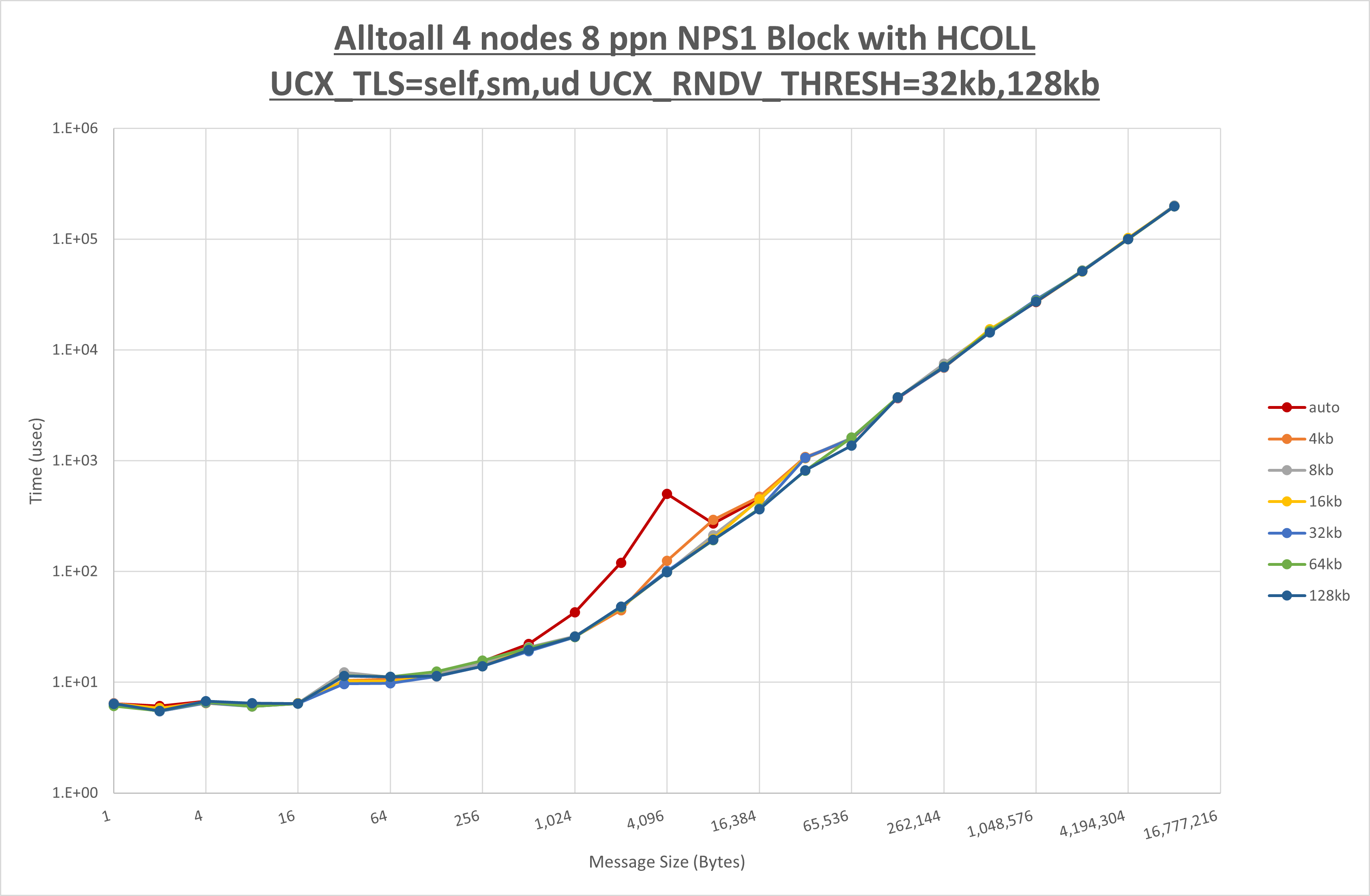
以上より、 UCX_ZCOPY_THRESH を 16kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
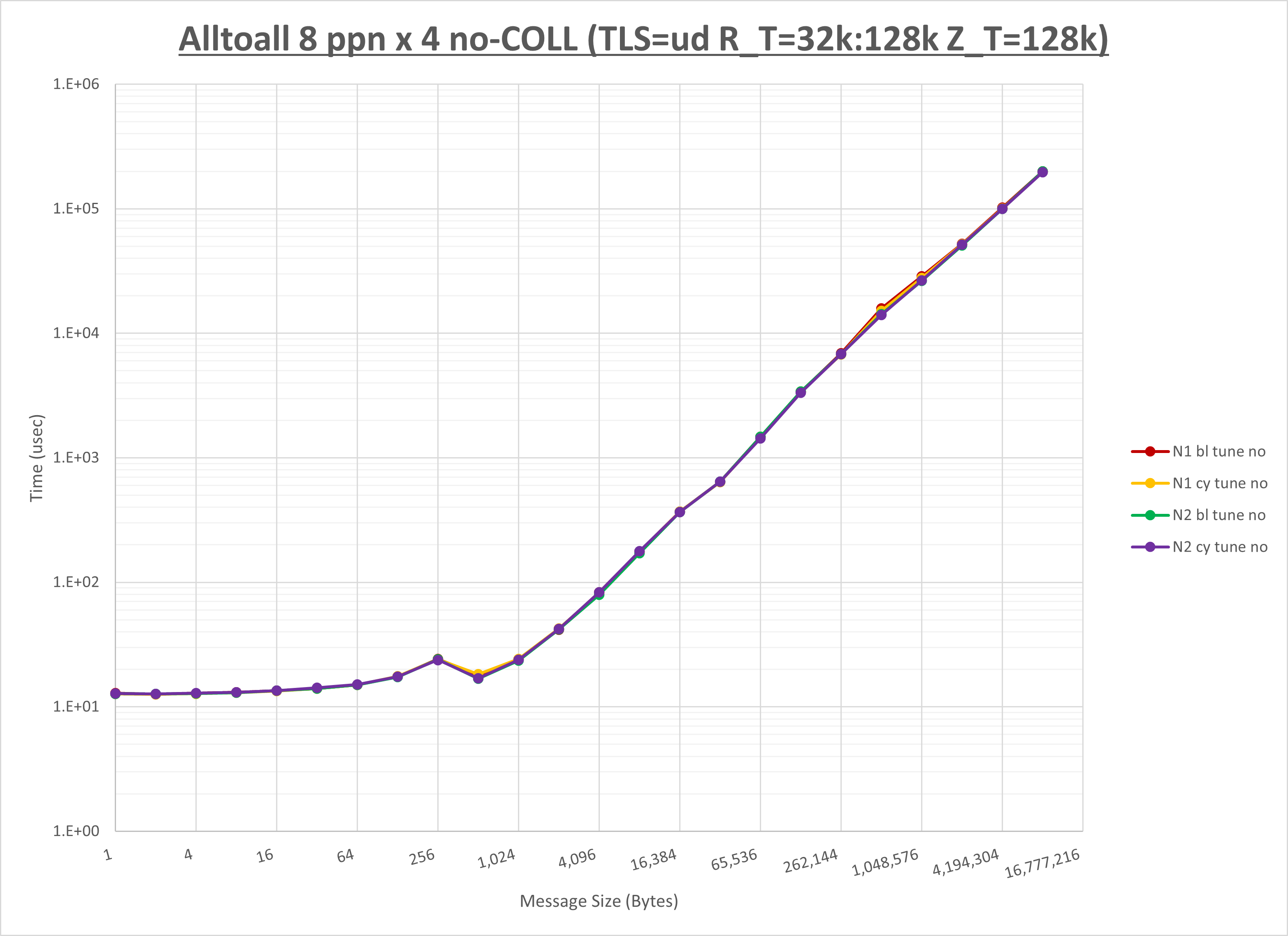
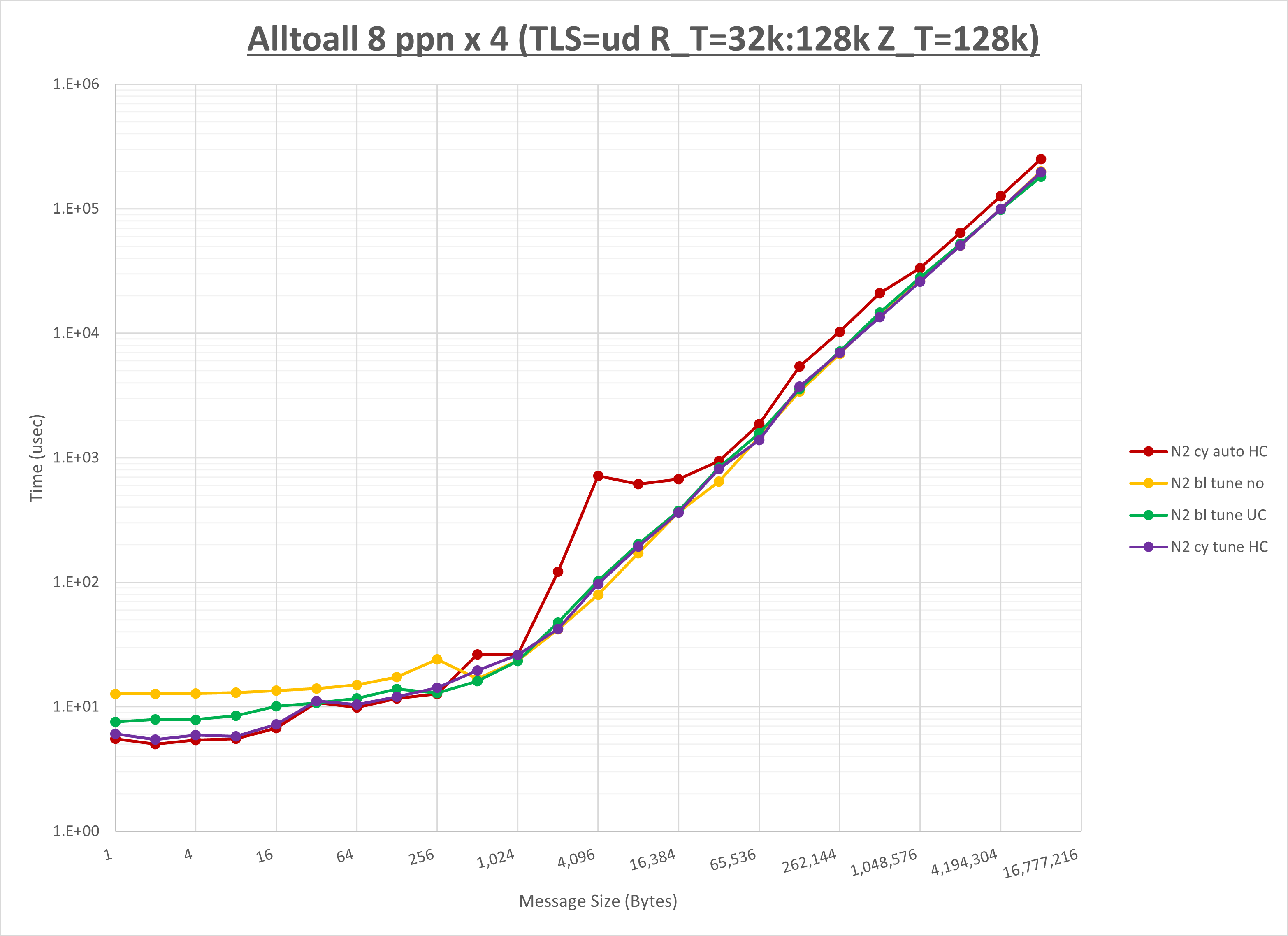
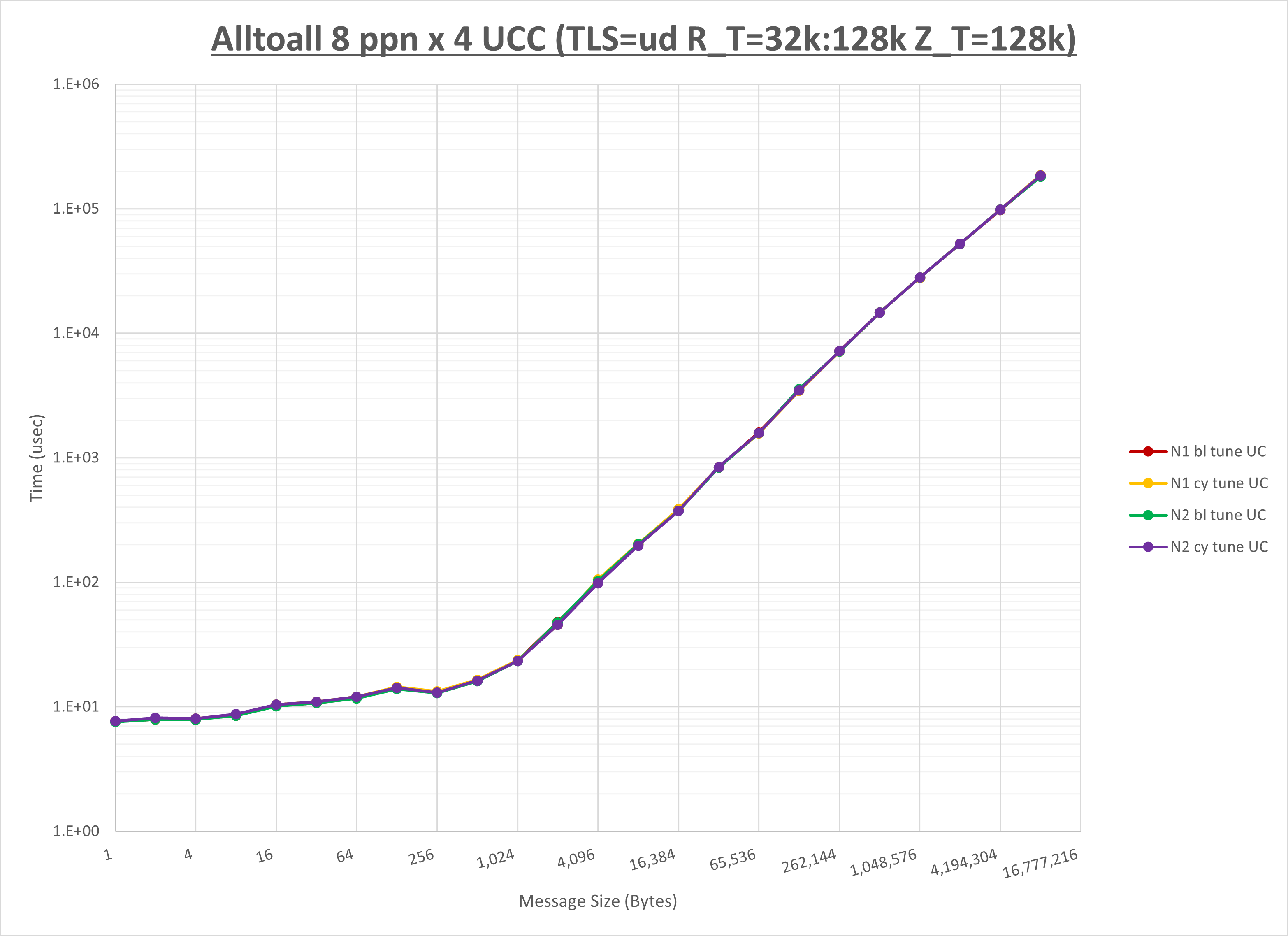
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
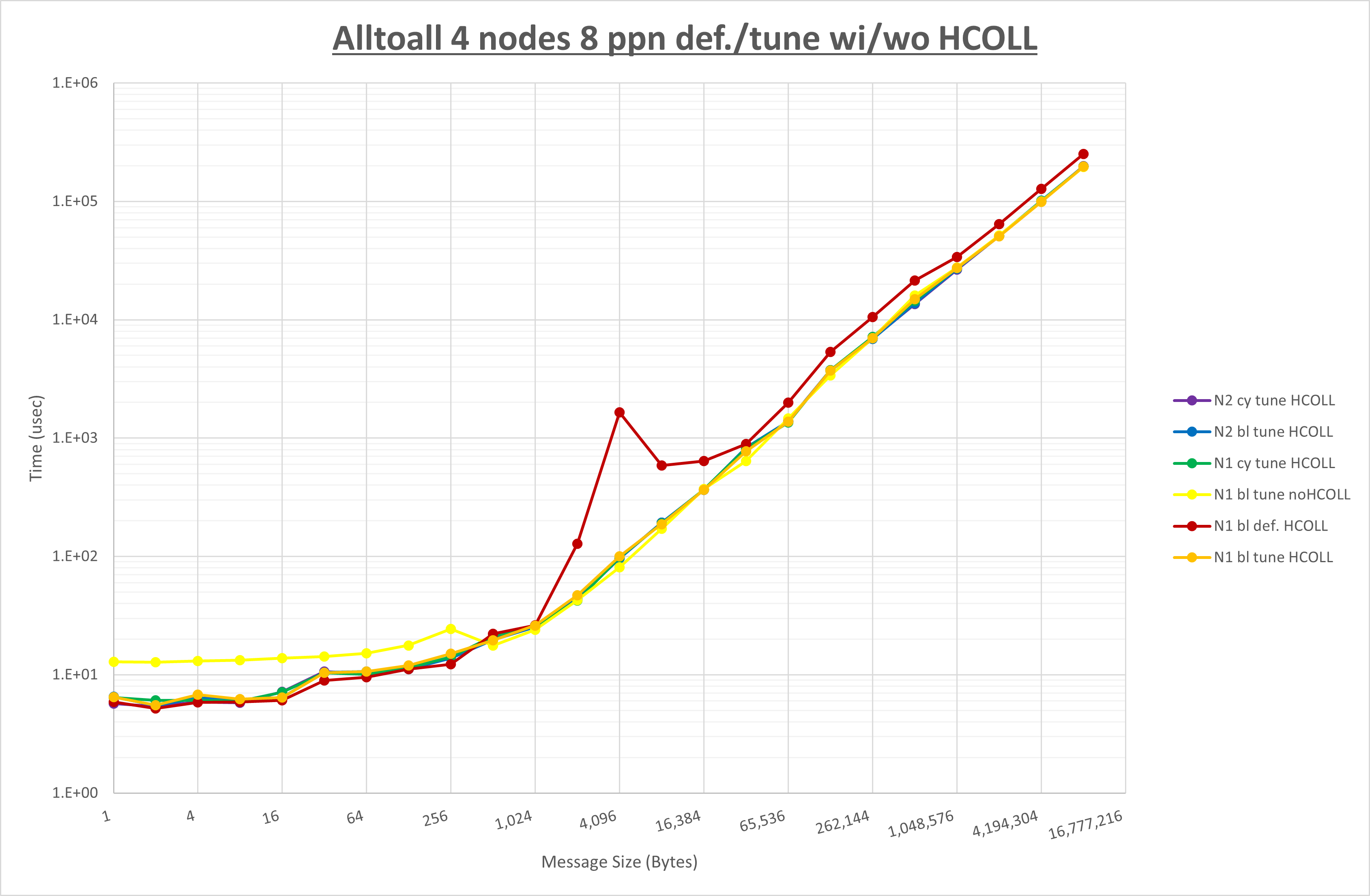
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し256B以下と32KBから128KBで性能が向上
- UCC は no-COLL と比較し2KB以下で性能が向上し128KBから256KBで性能が低下
- チューニング適用で32KBから128KBで性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-2 Allgather の HCOLL の結果から64KBとしています。
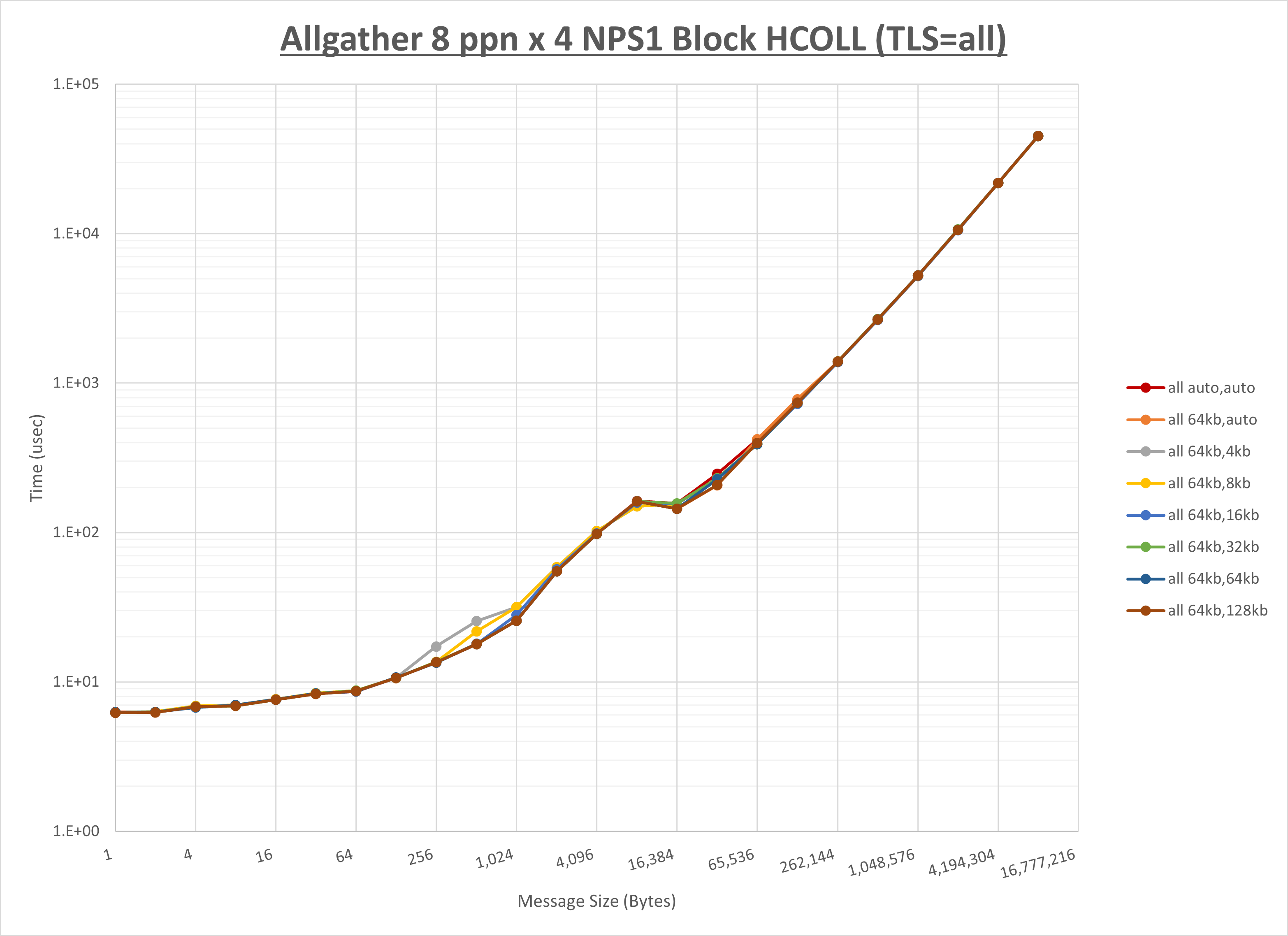
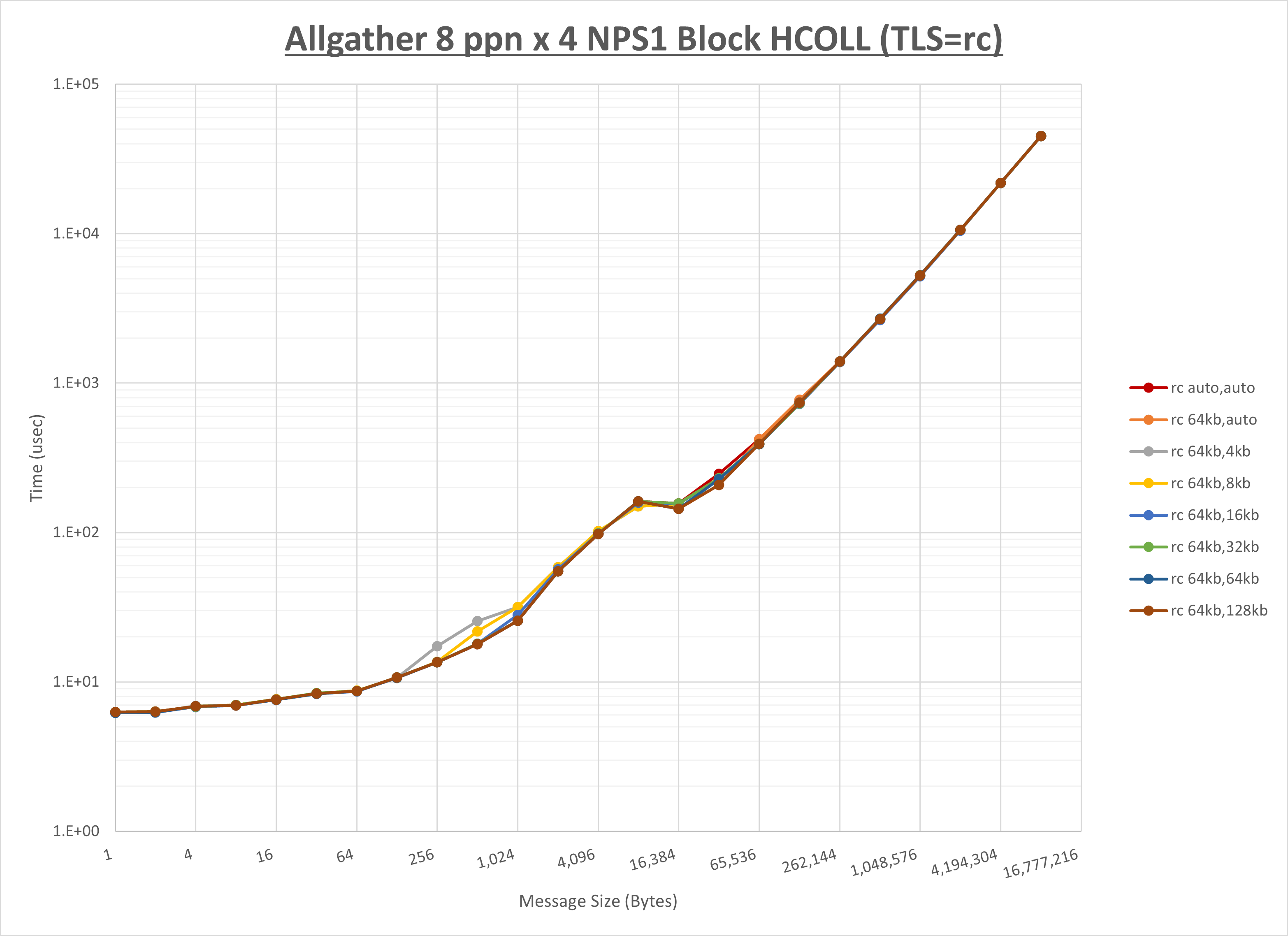
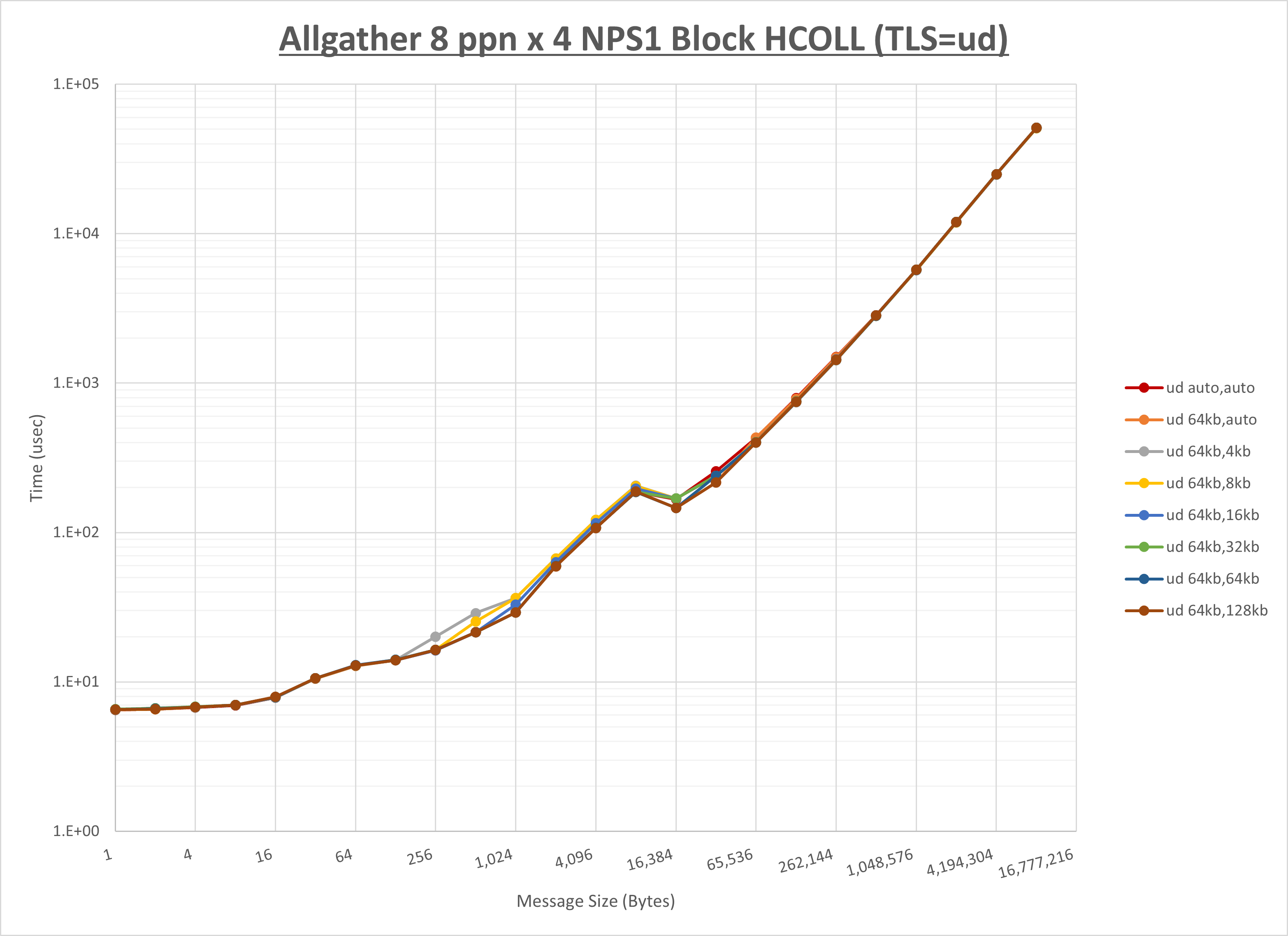
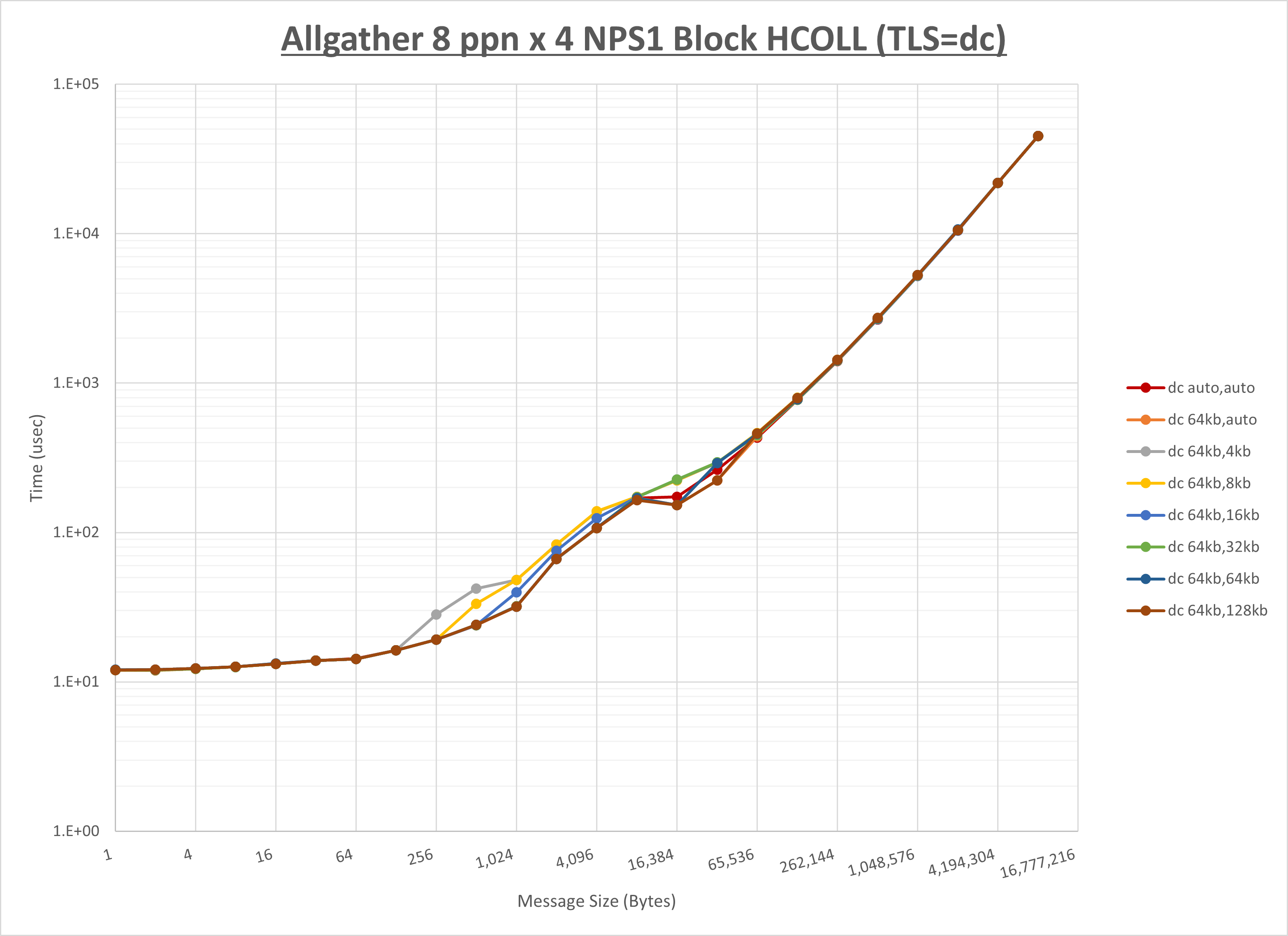
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
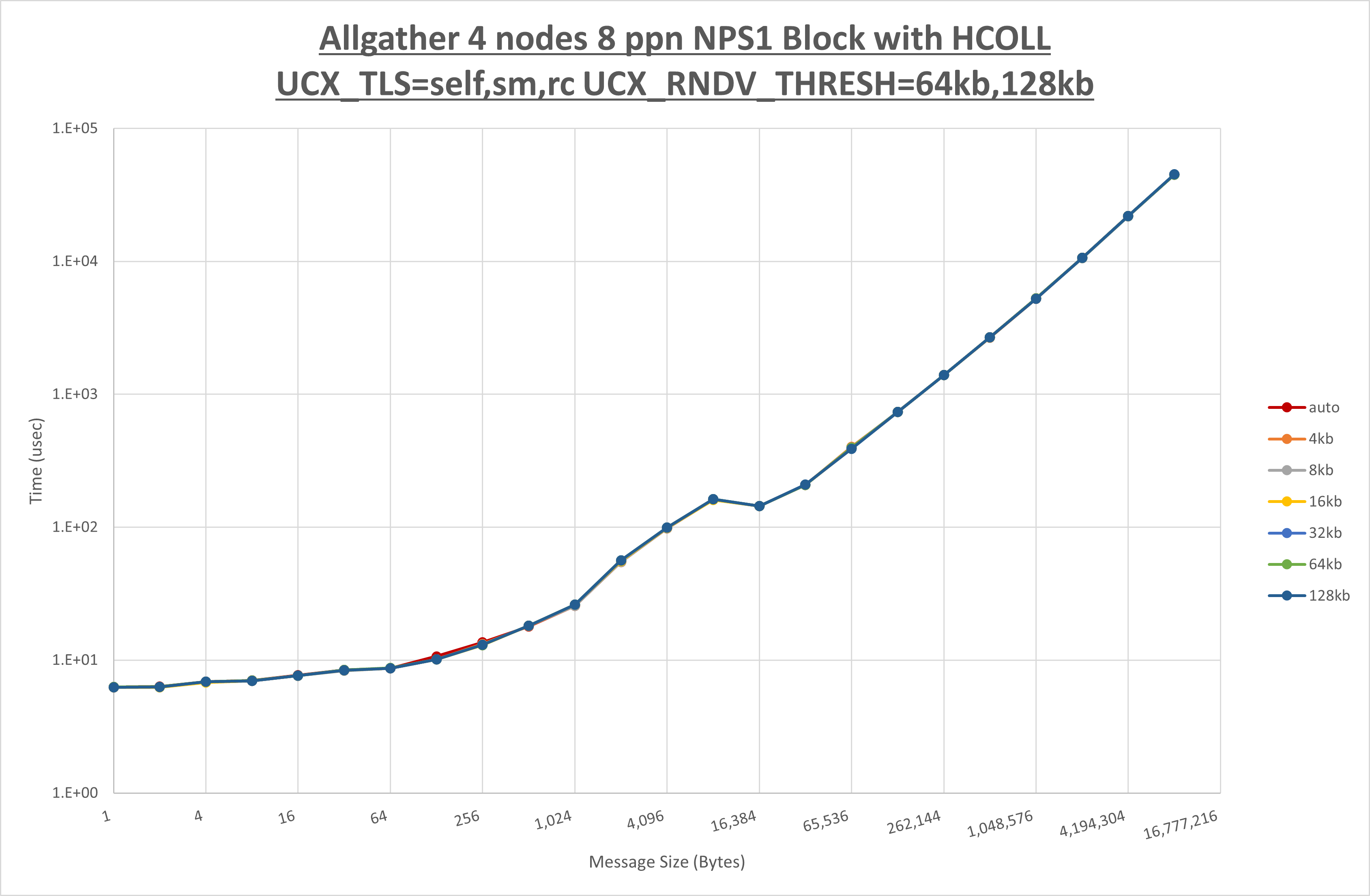
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
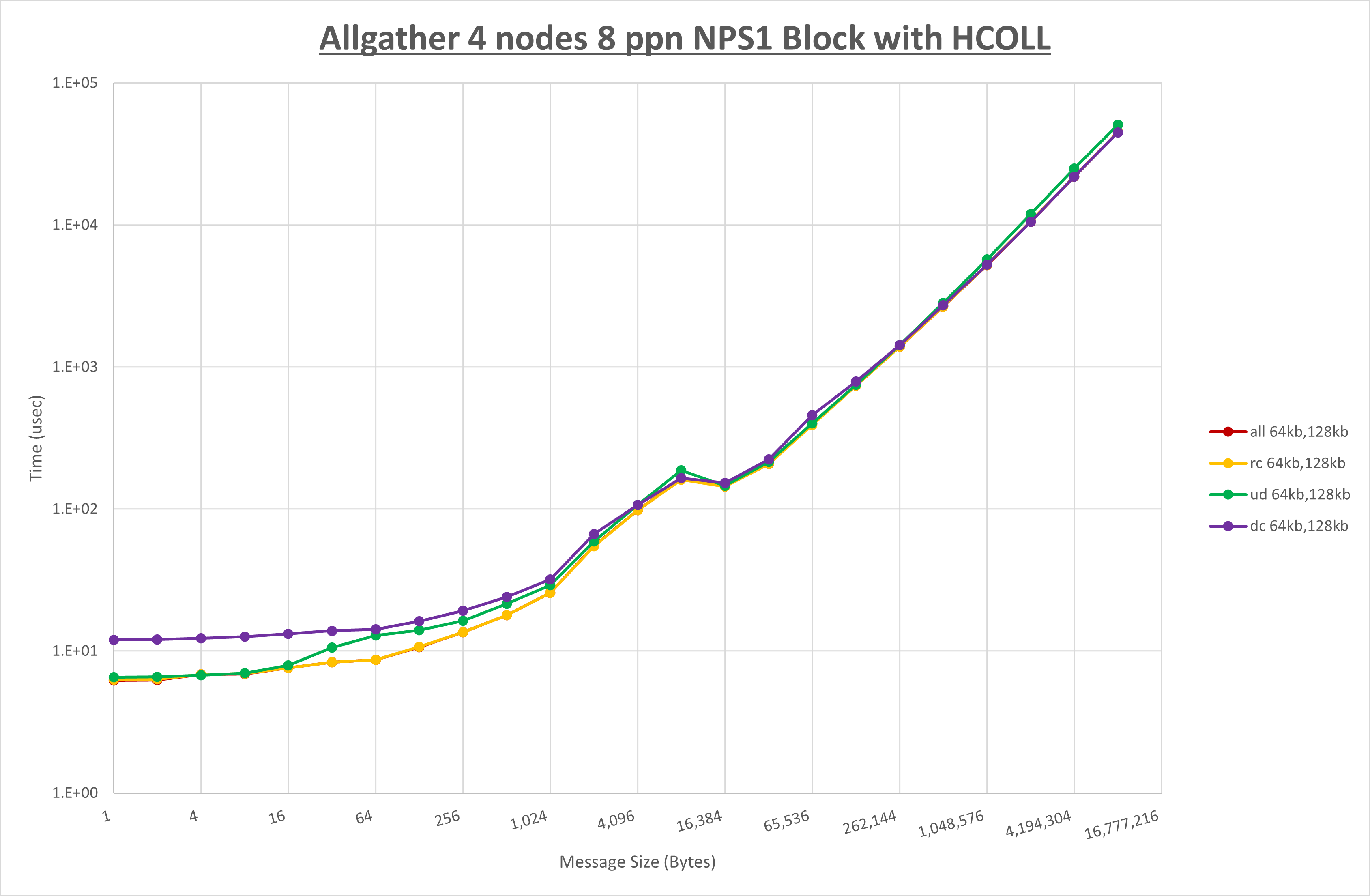
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
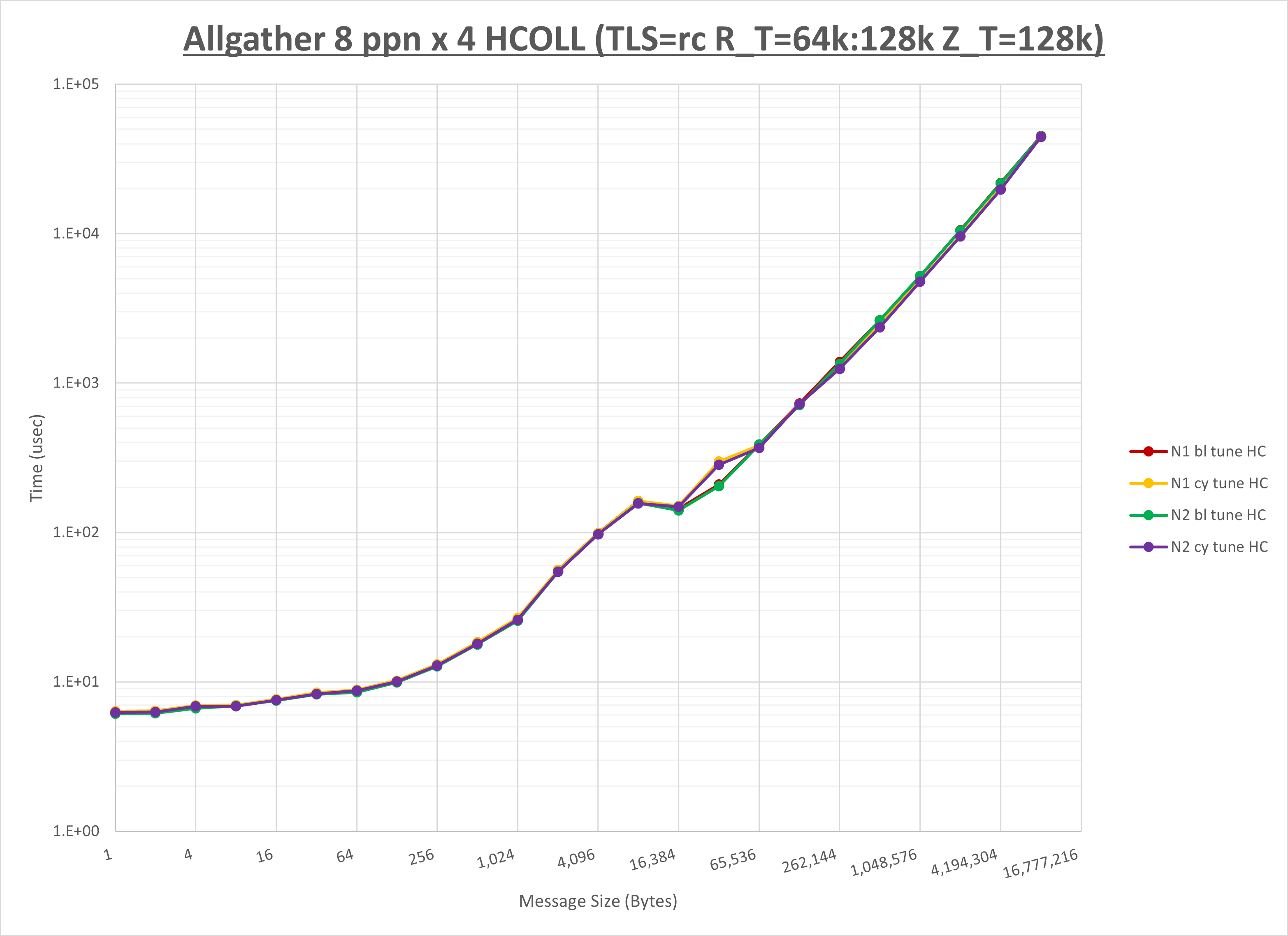
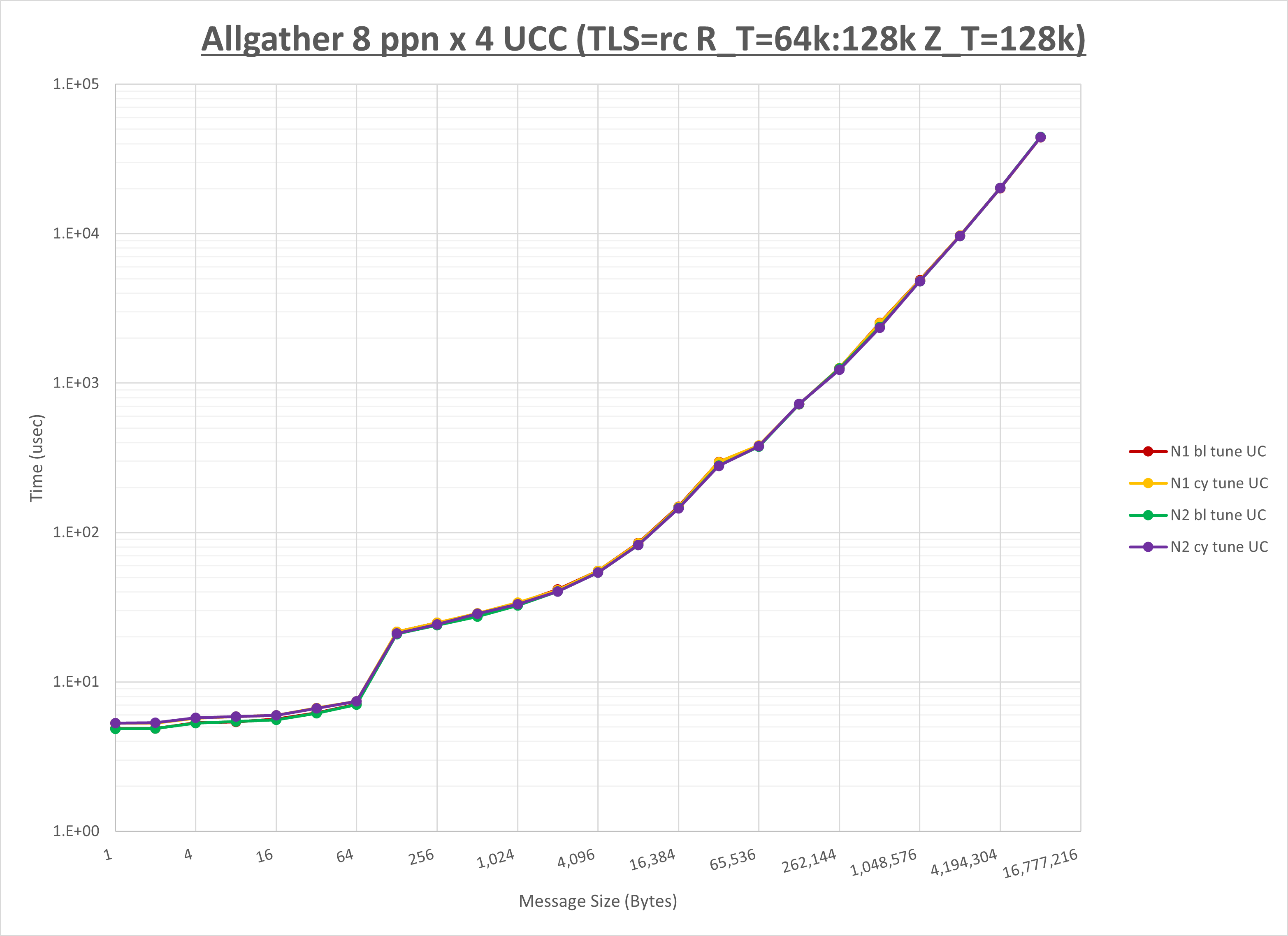
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で有意な性能の変化無し
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-3 Allreduce の HCOLL の結果から128KBとしています。
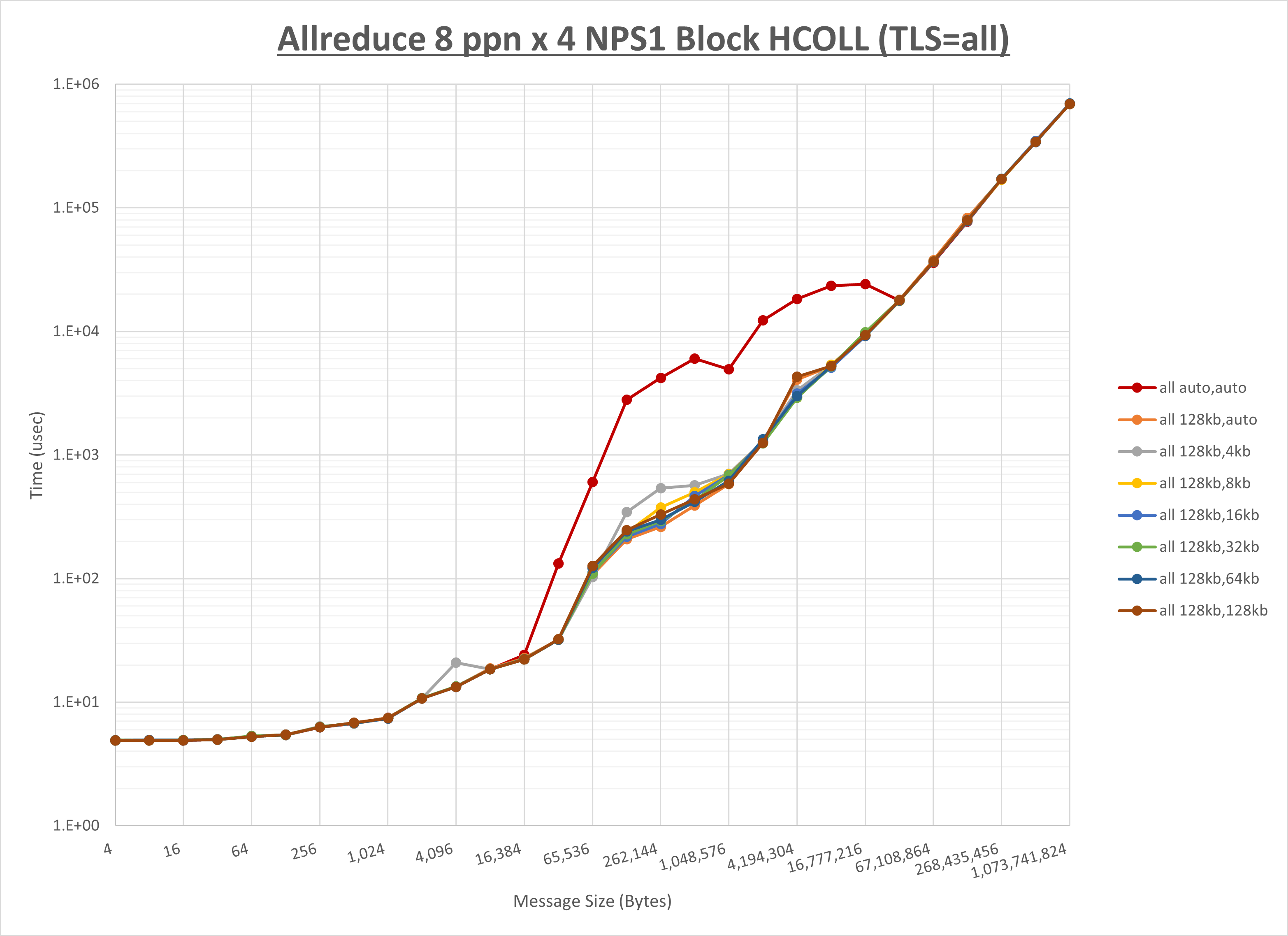
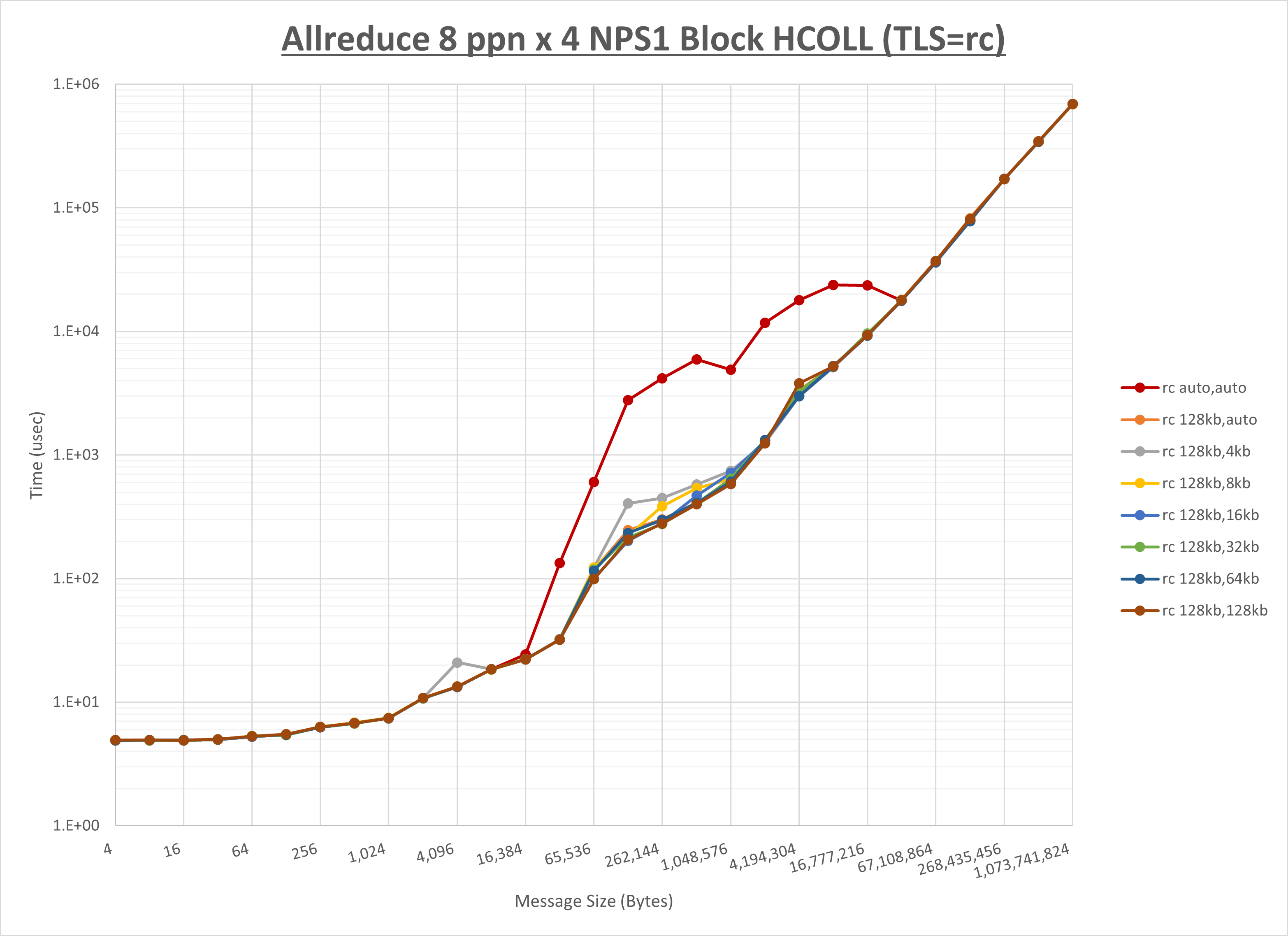
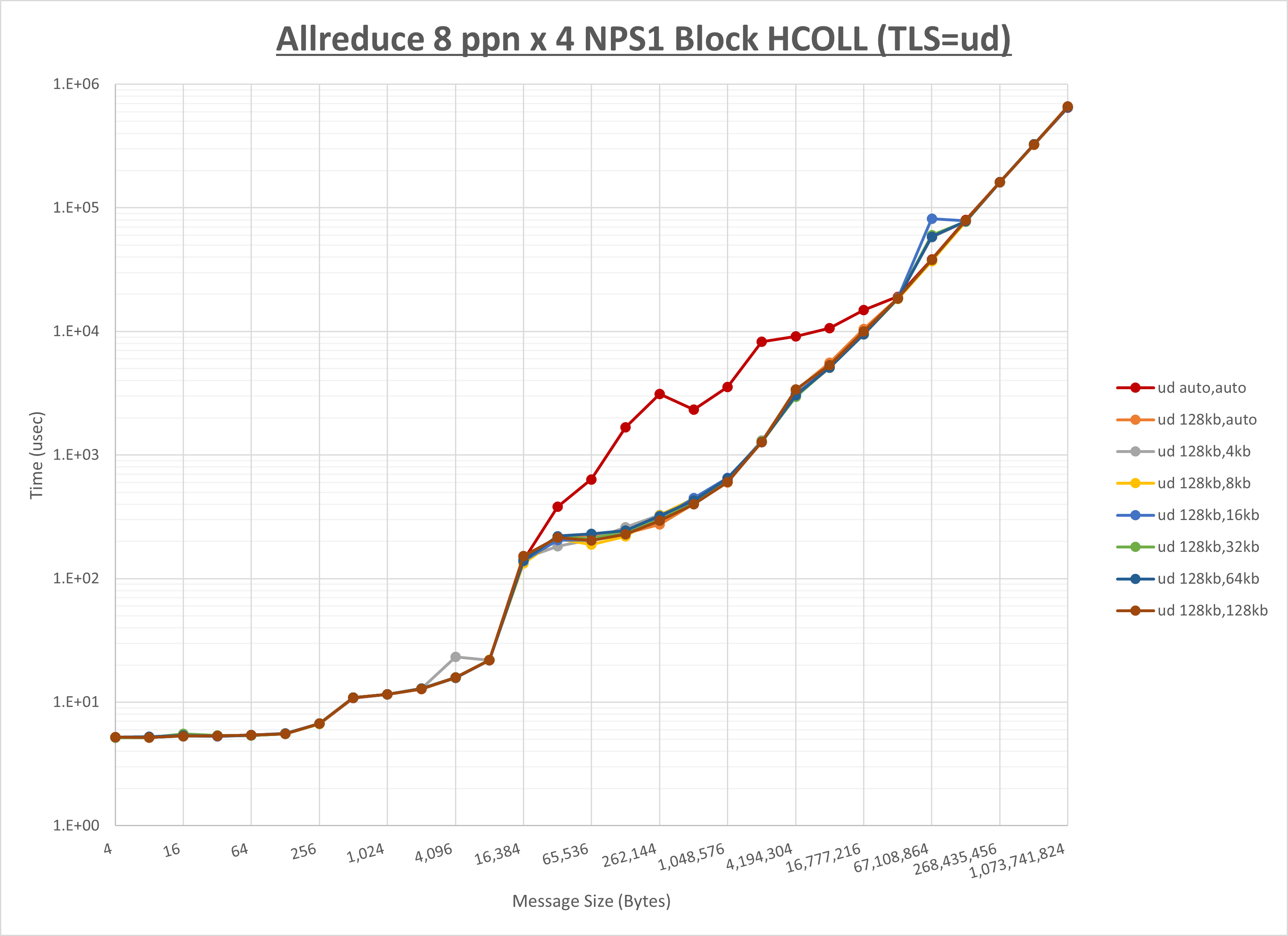
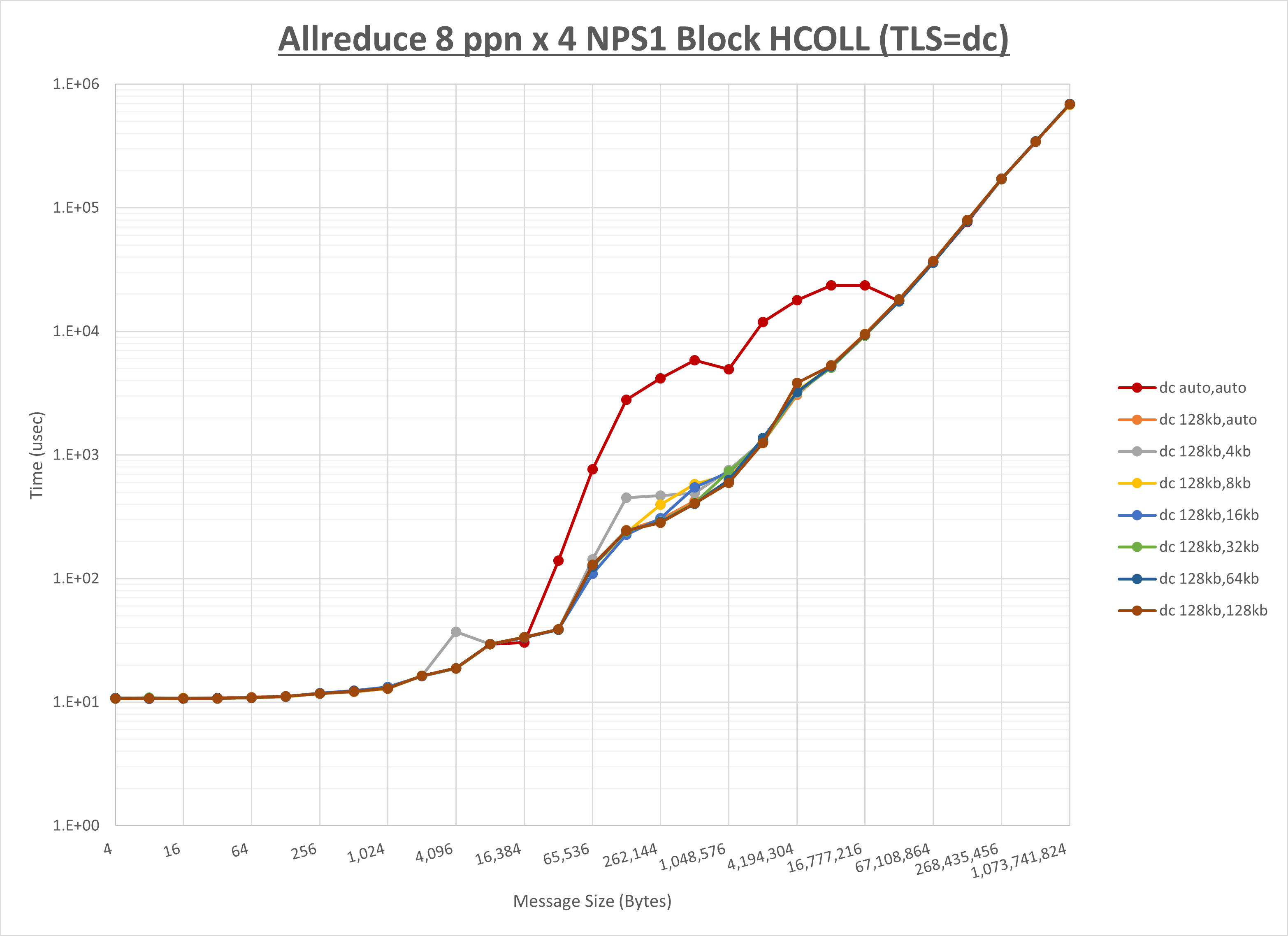
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
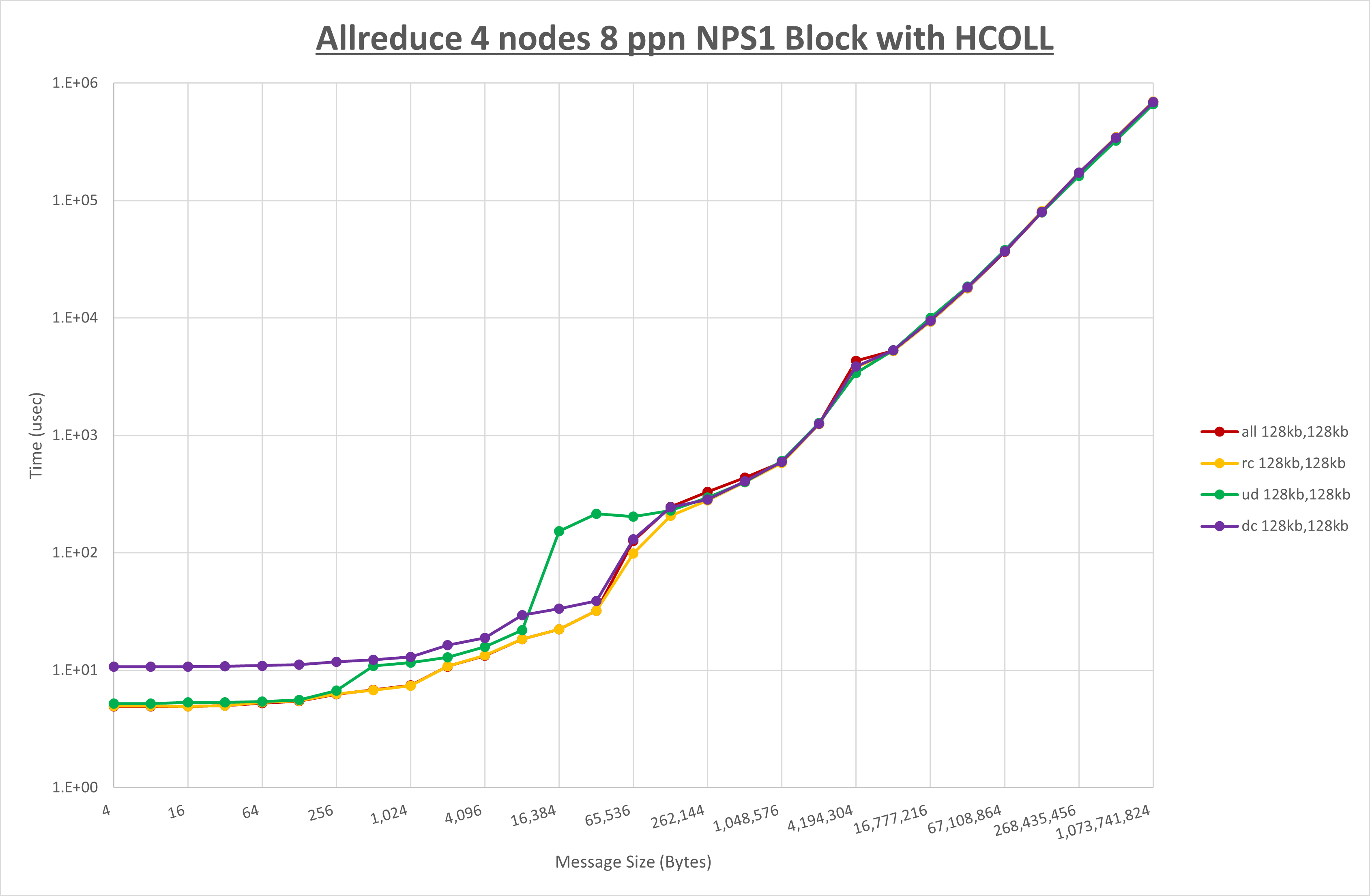
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
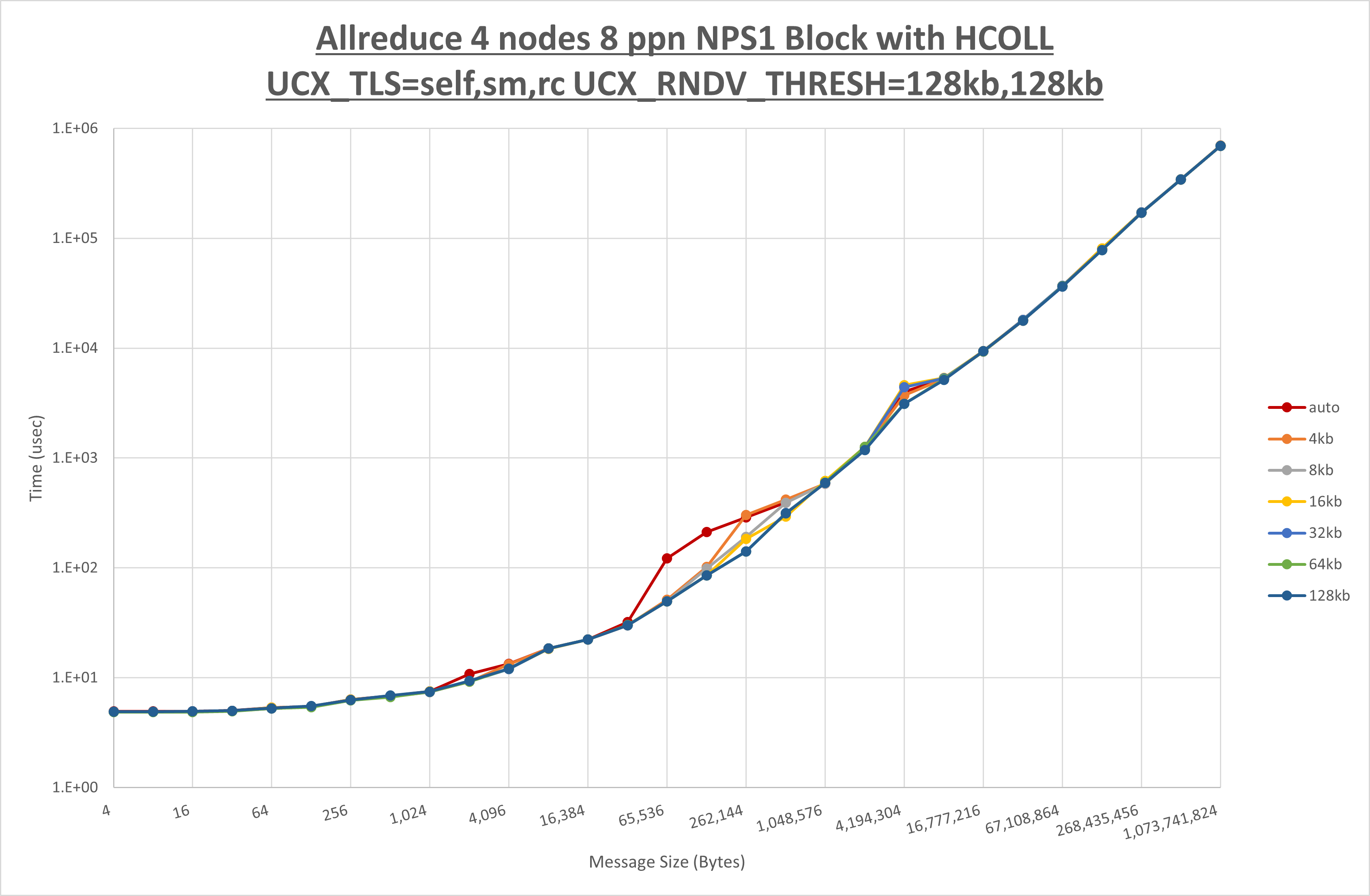
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
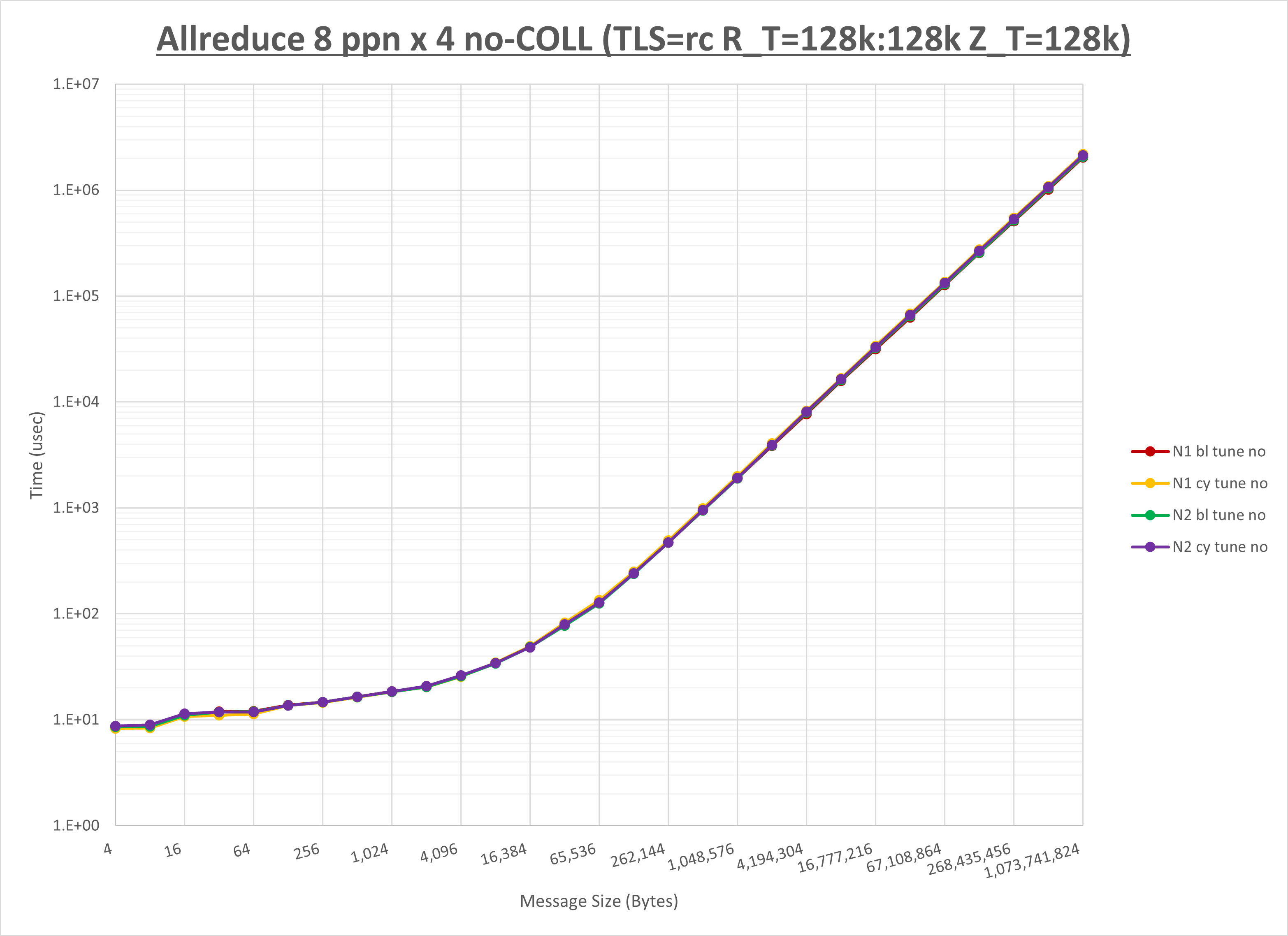
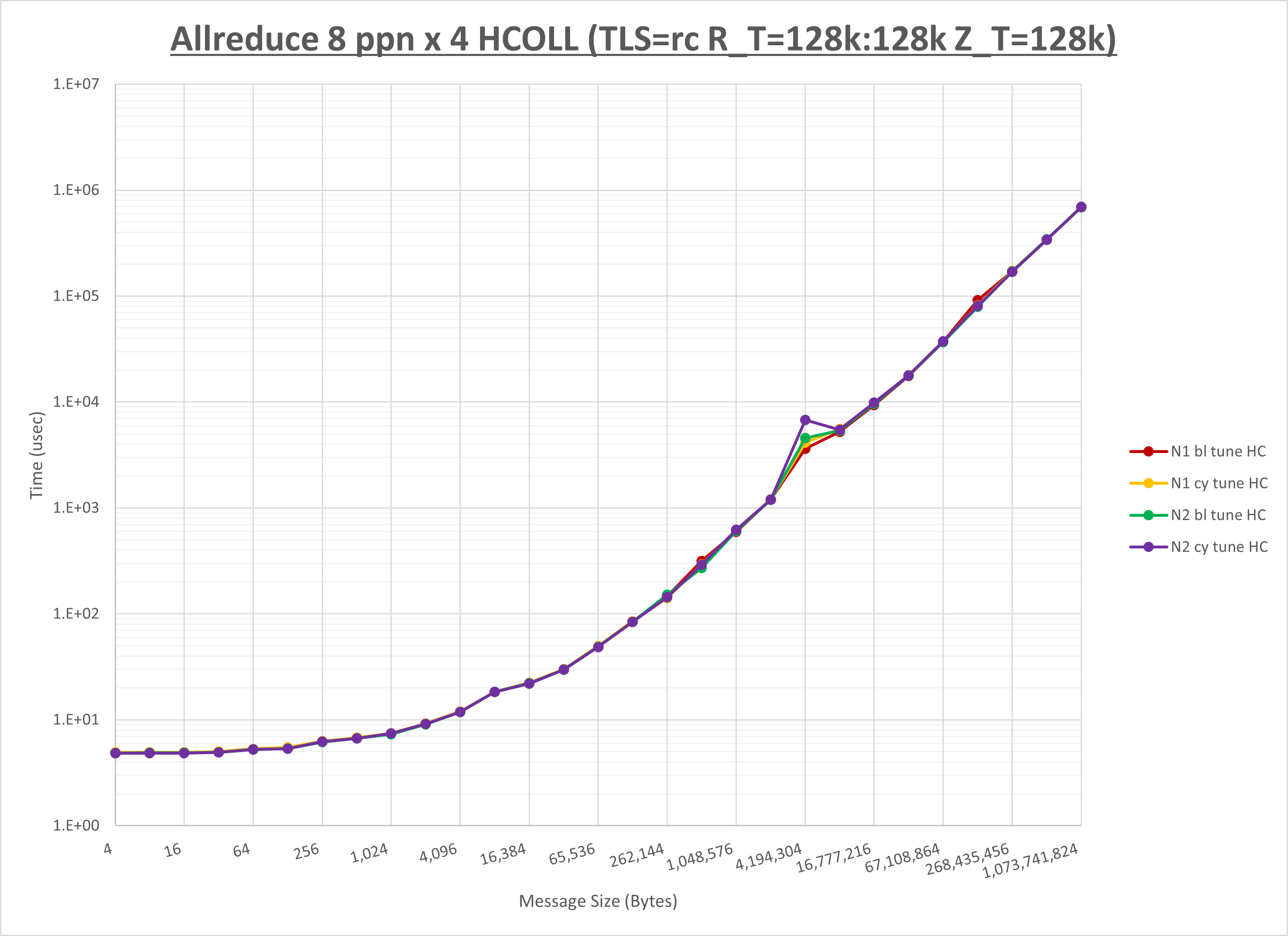
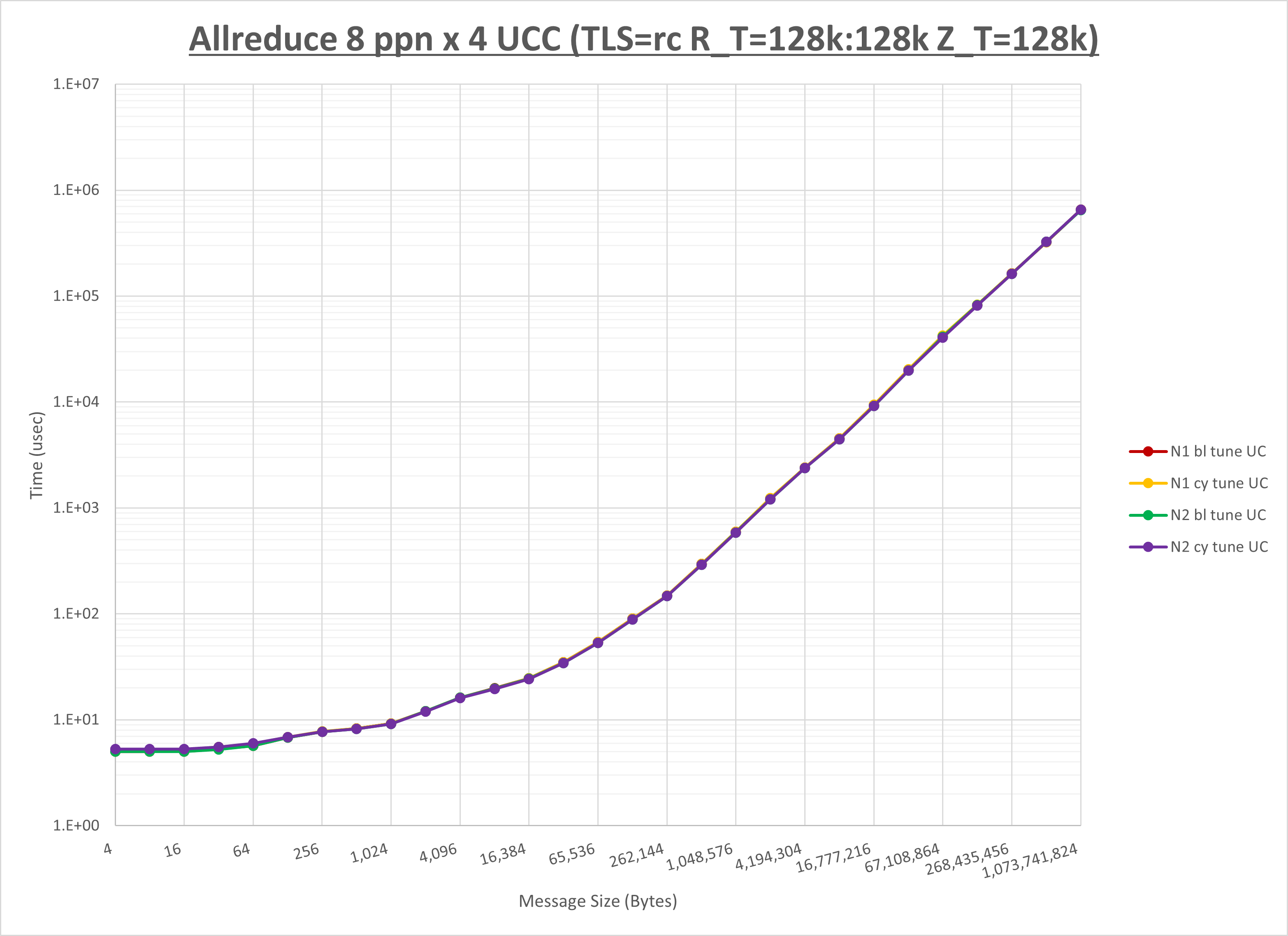
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
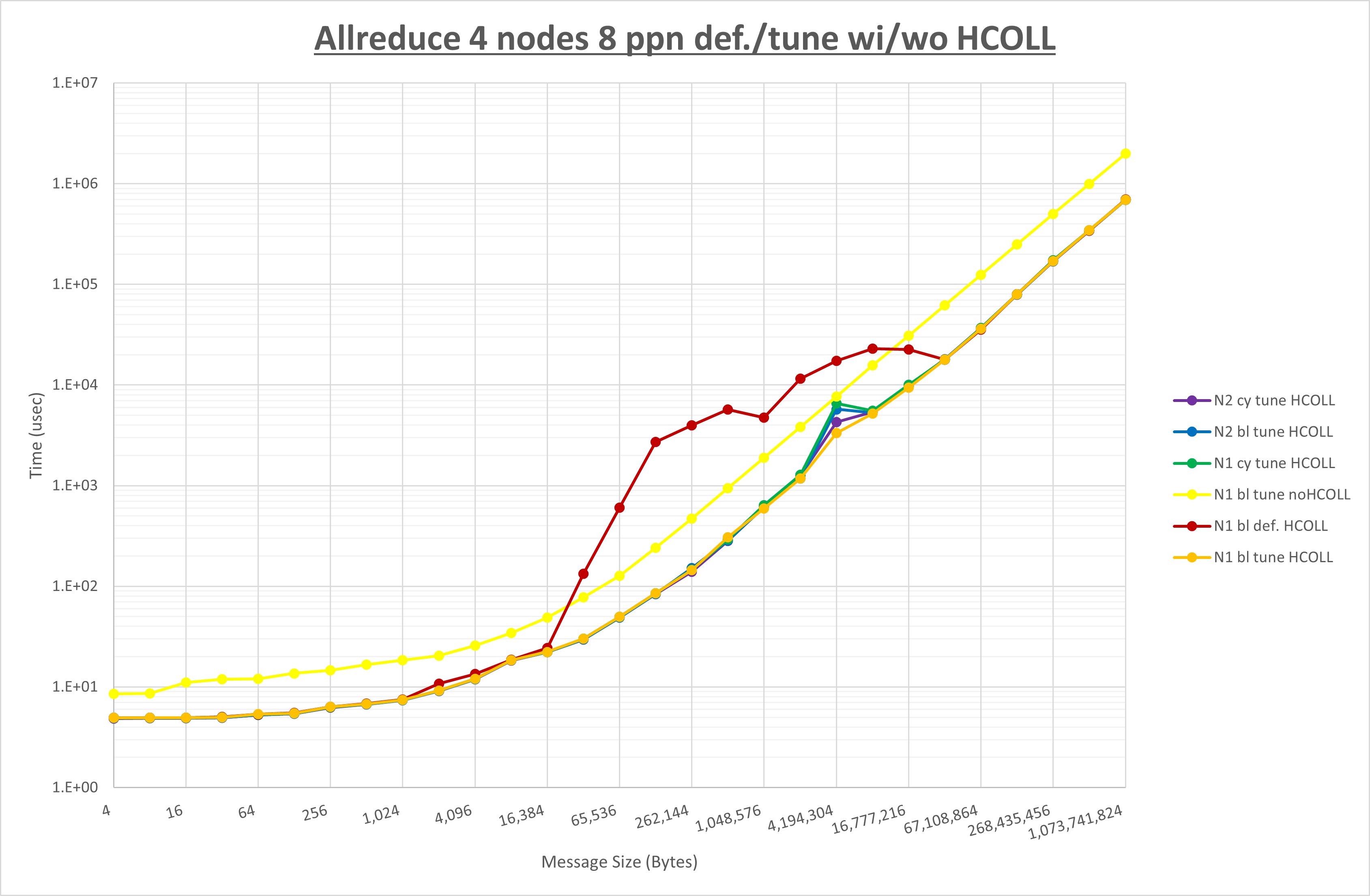
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で64KBから2MBの間で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-4 Exchange の結果から32KBとしています。
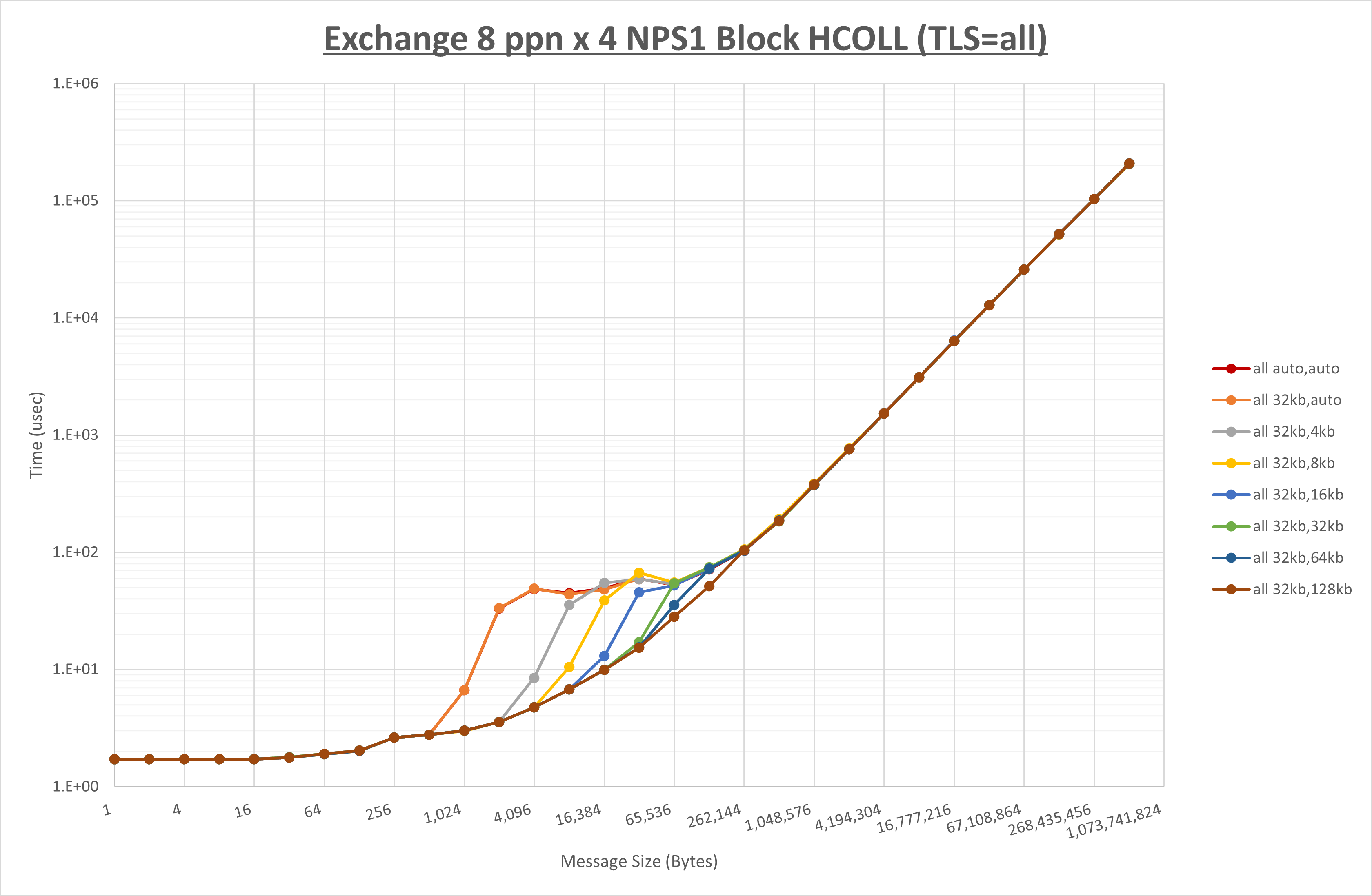
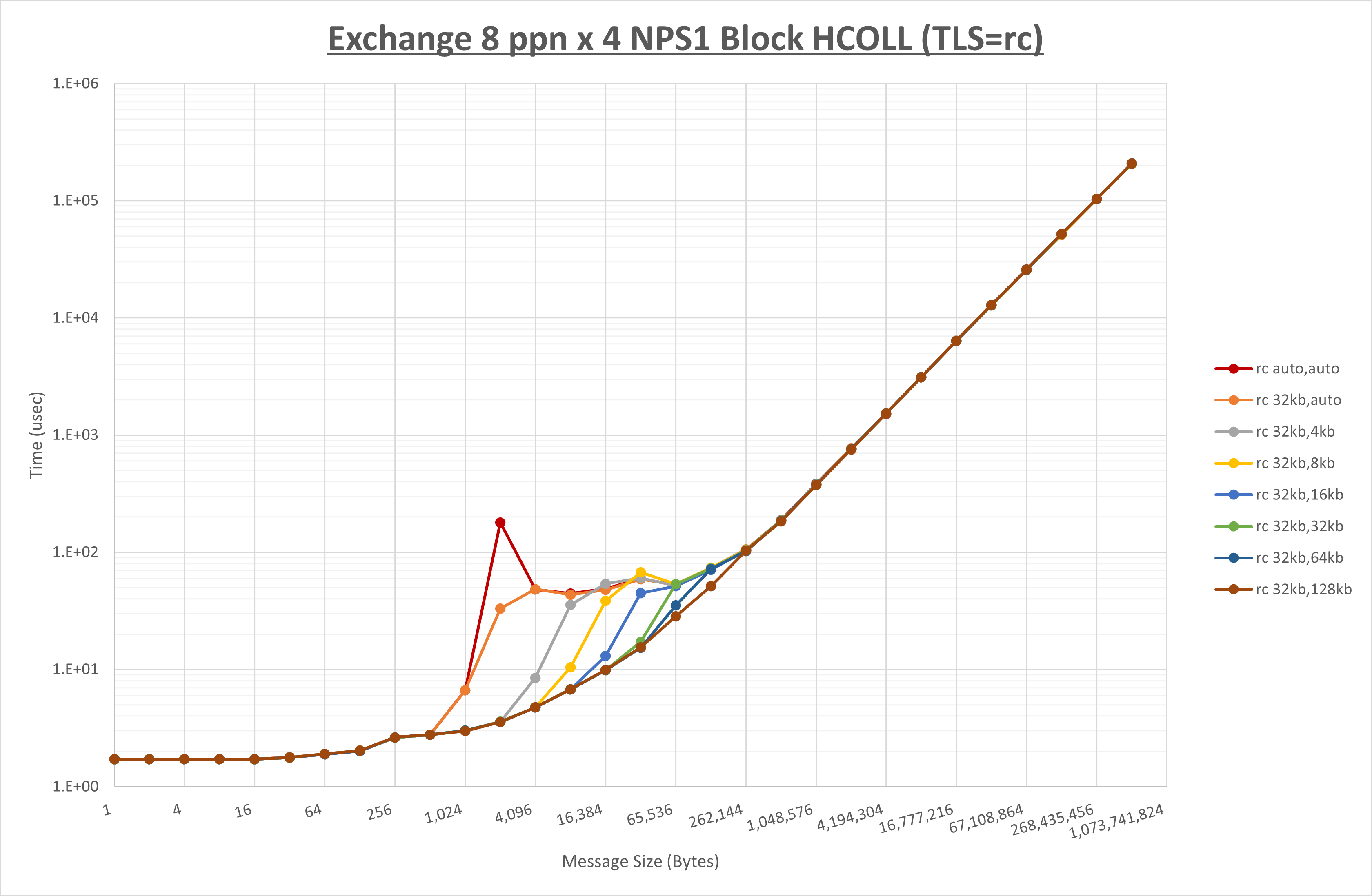
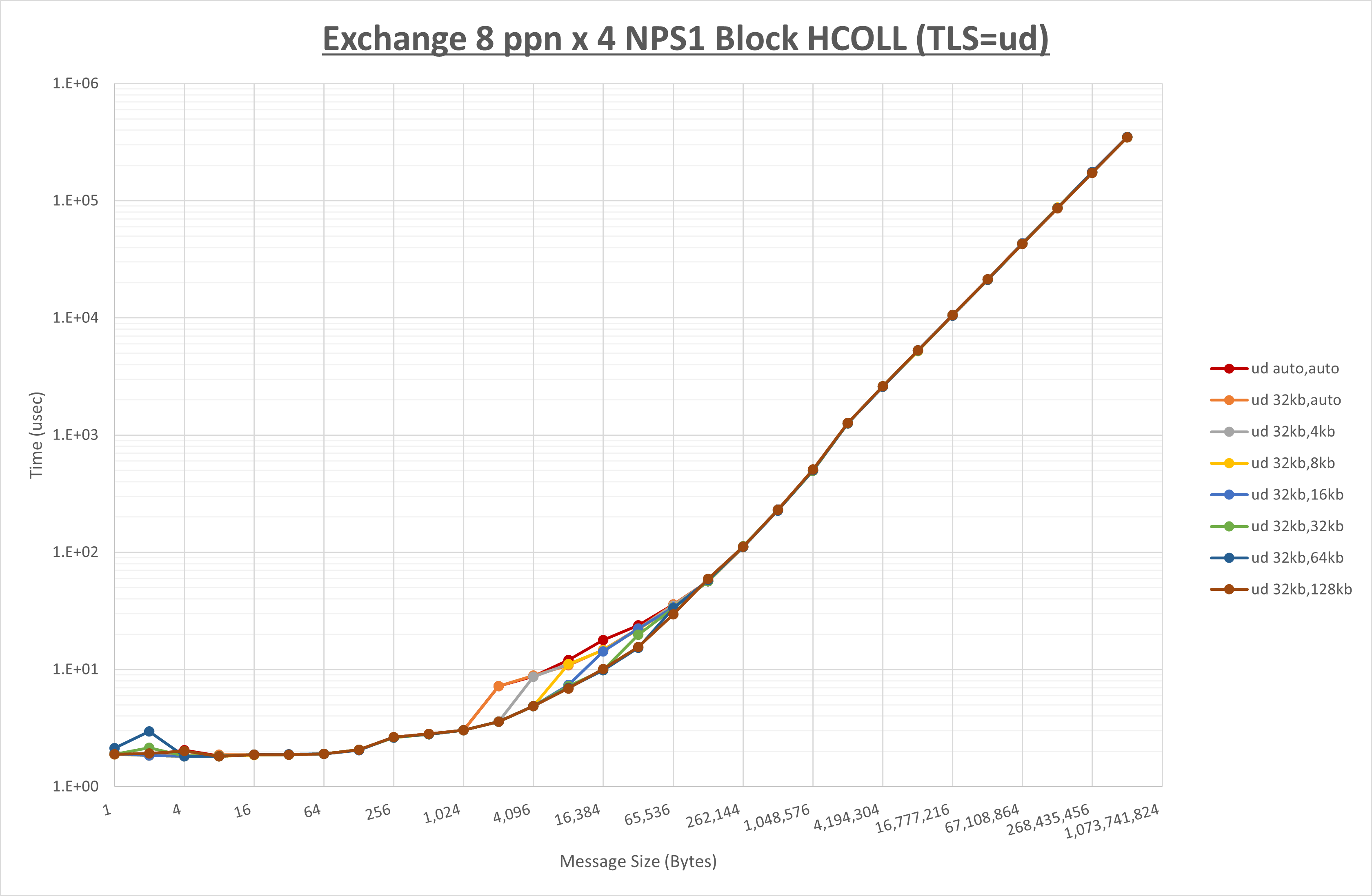
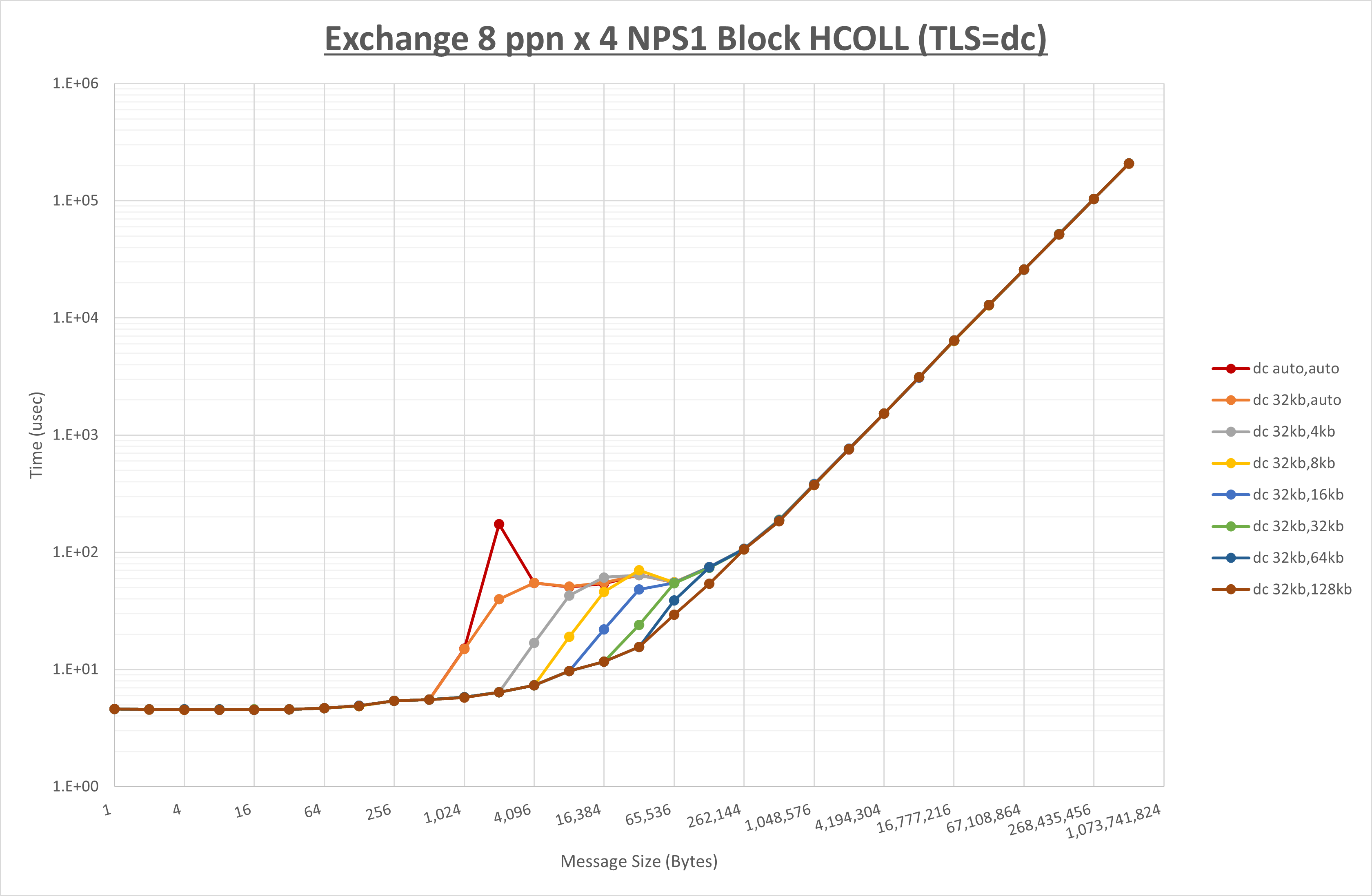
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
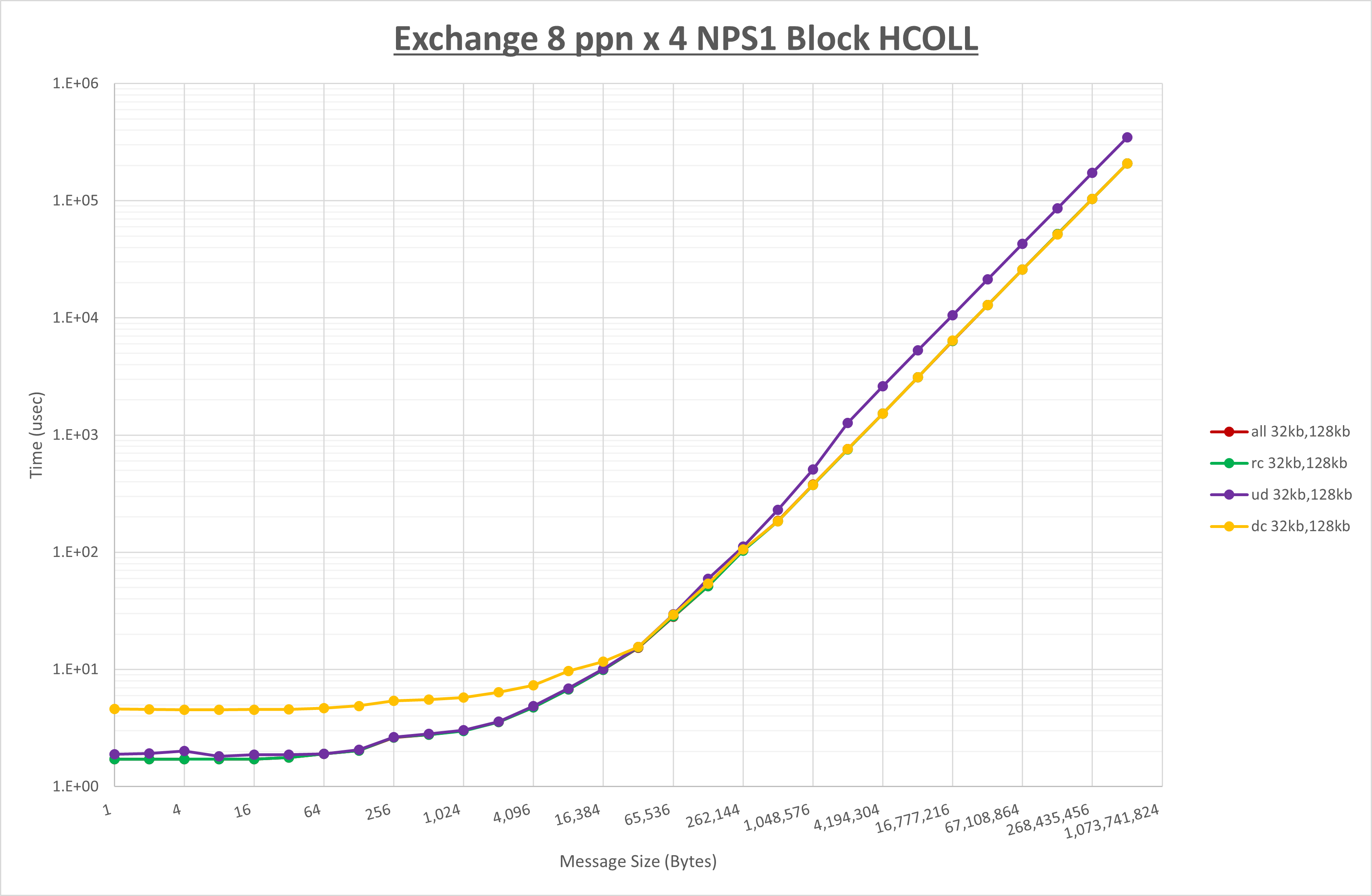
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
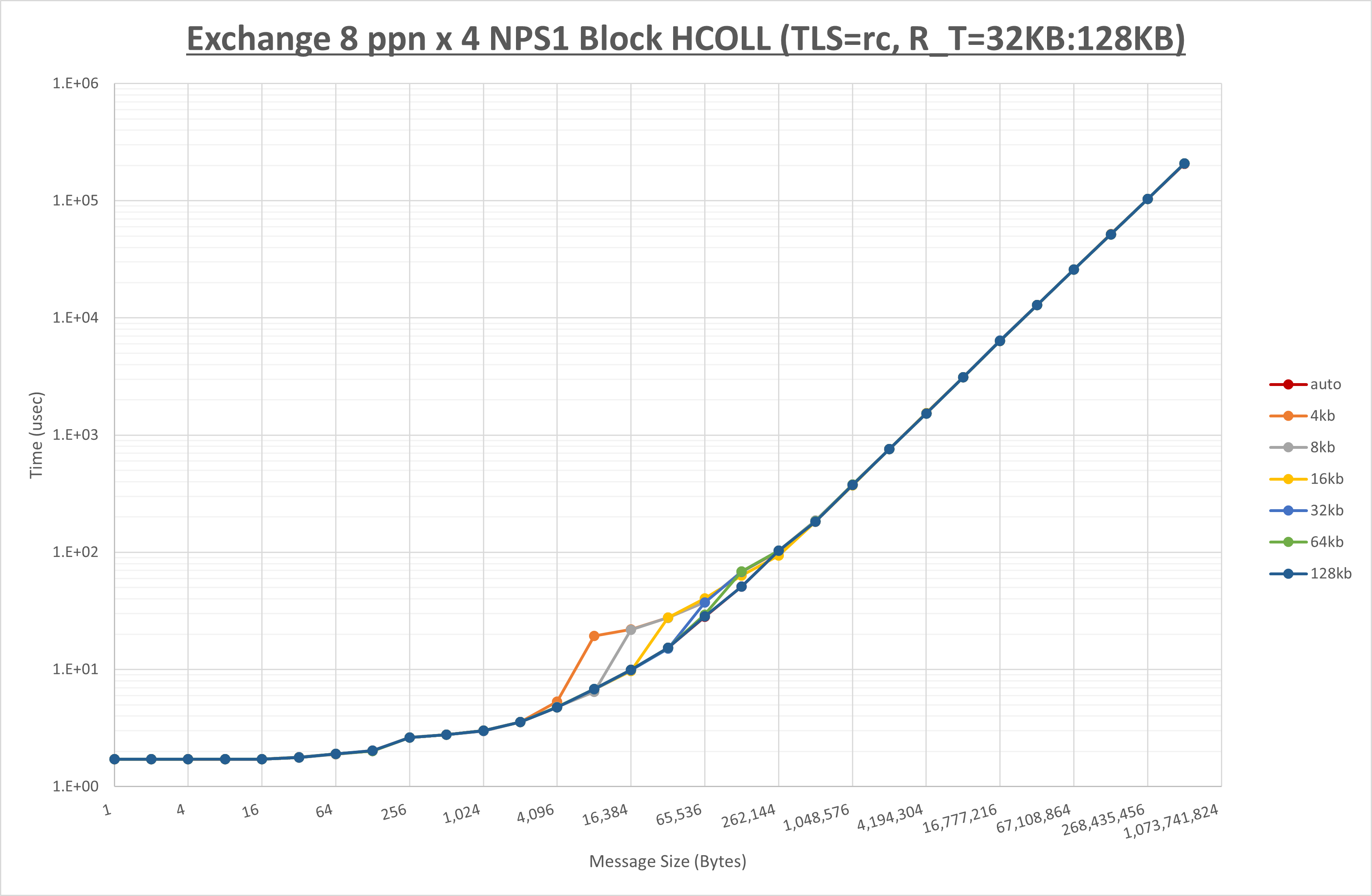
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
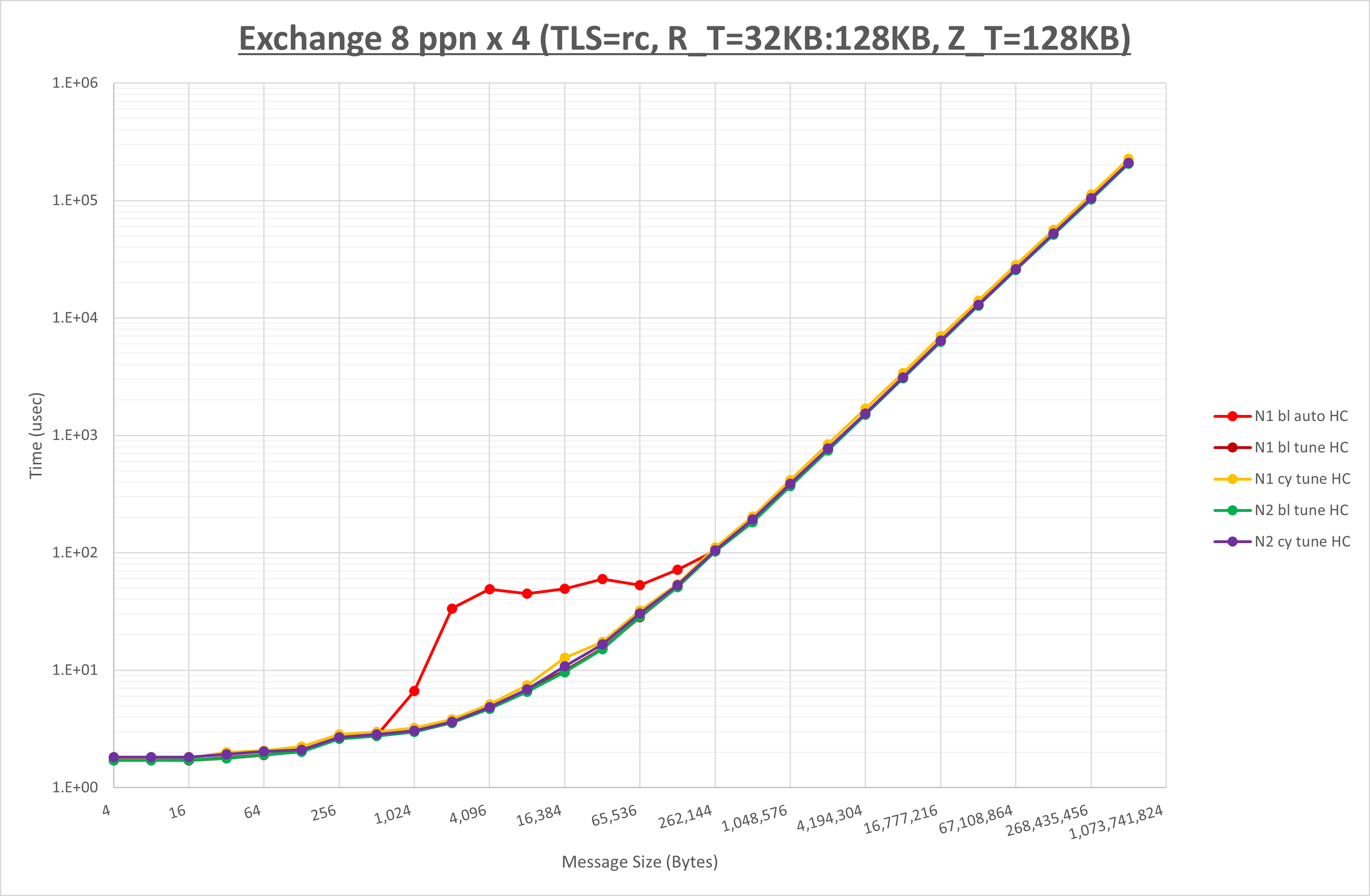
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で1KBから128KBの間で性能が向上
本章は、4ノードにノード当たり16、トータル64のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:32kb,inter:32kb | 128kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-1 Alltoall の HCOLL の結果から32KBとしています。
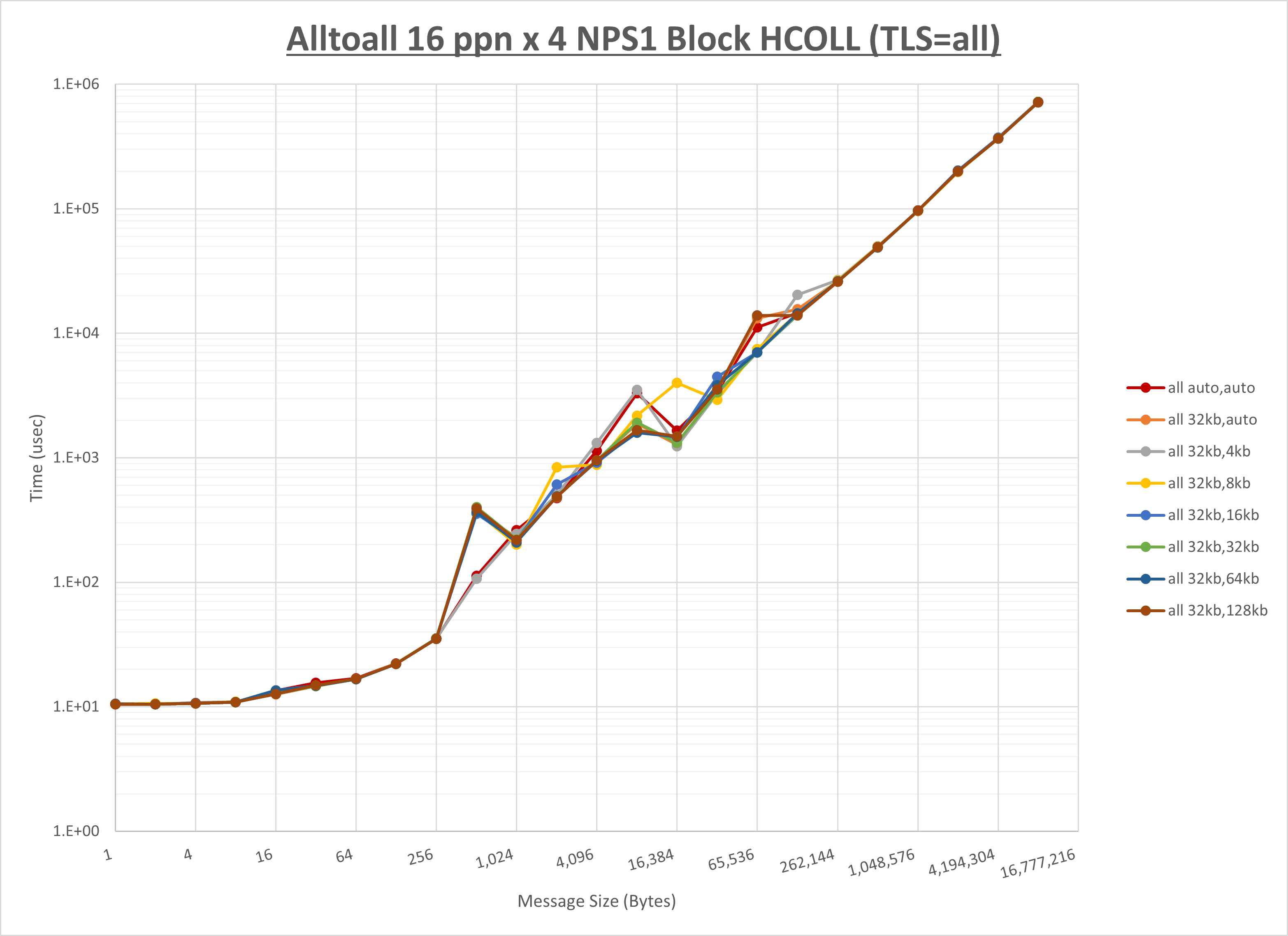
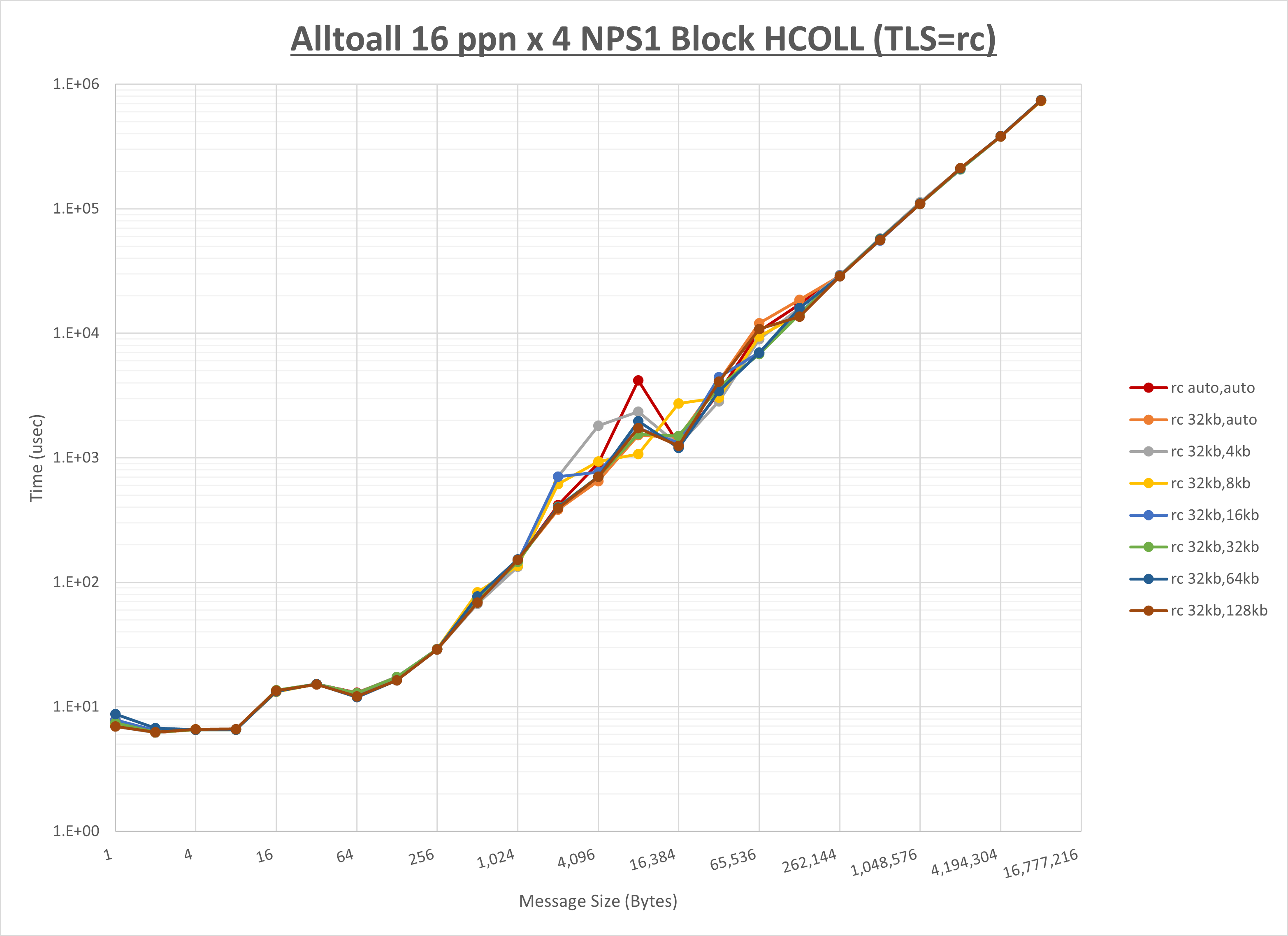
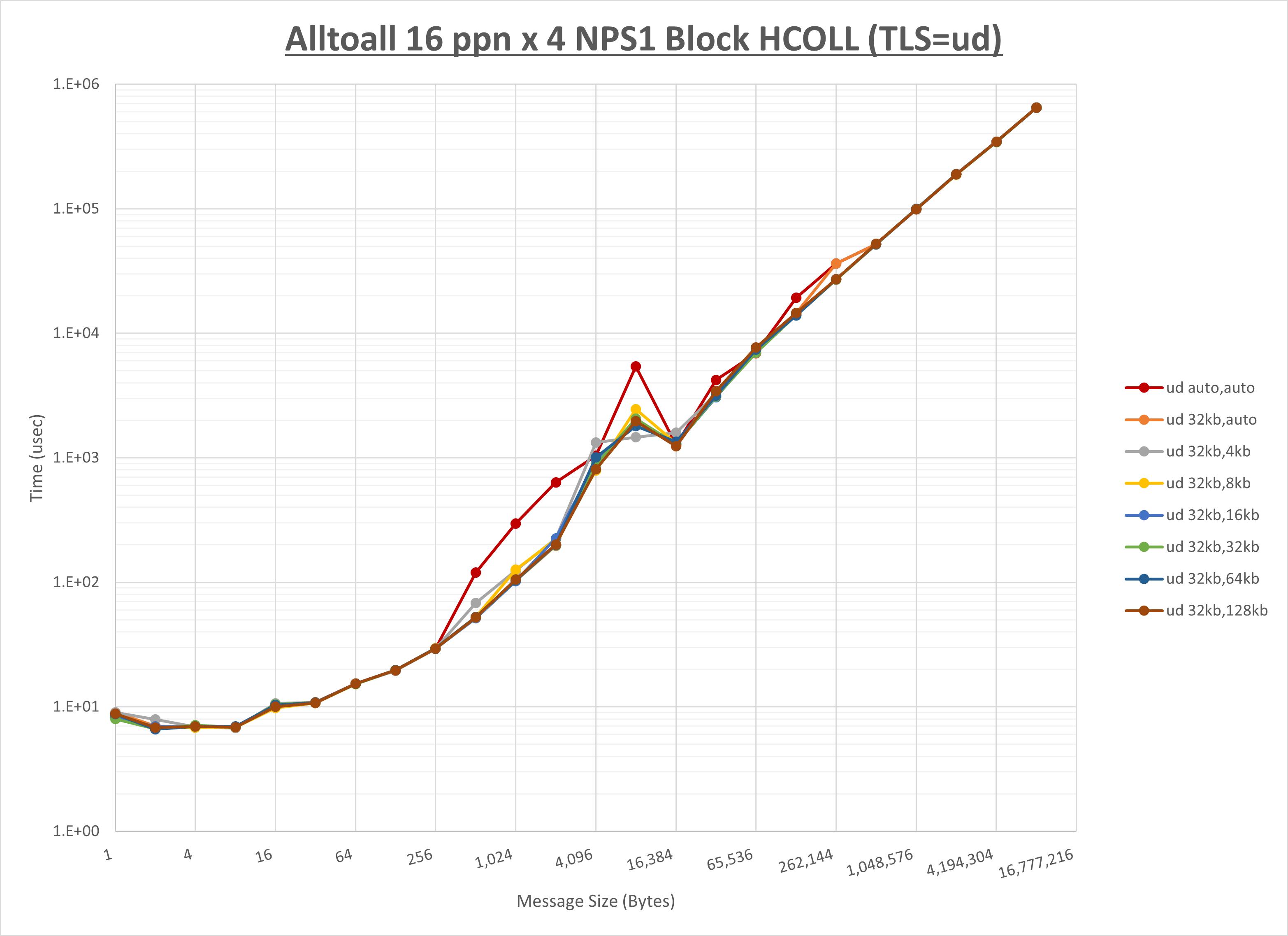
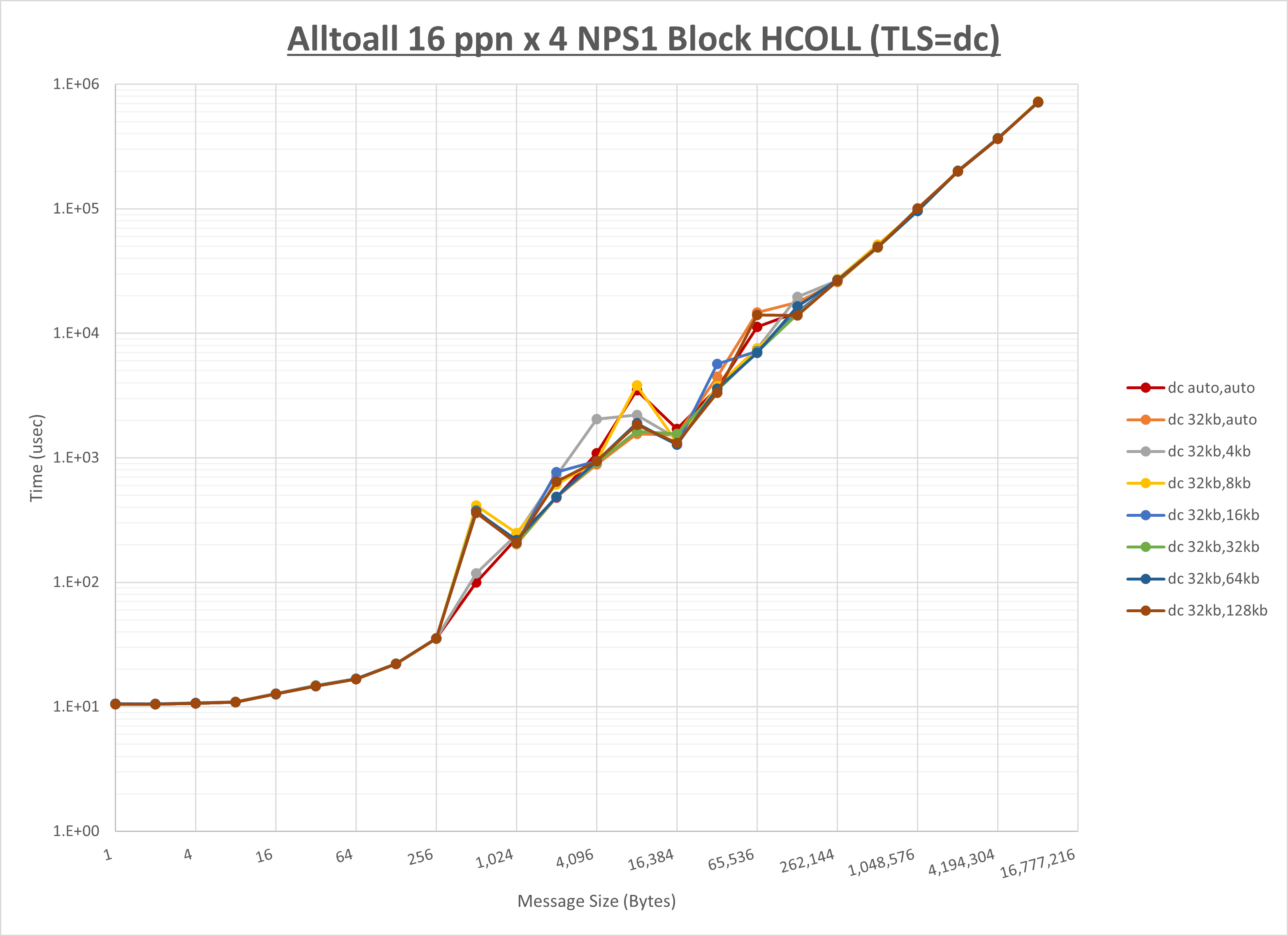
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
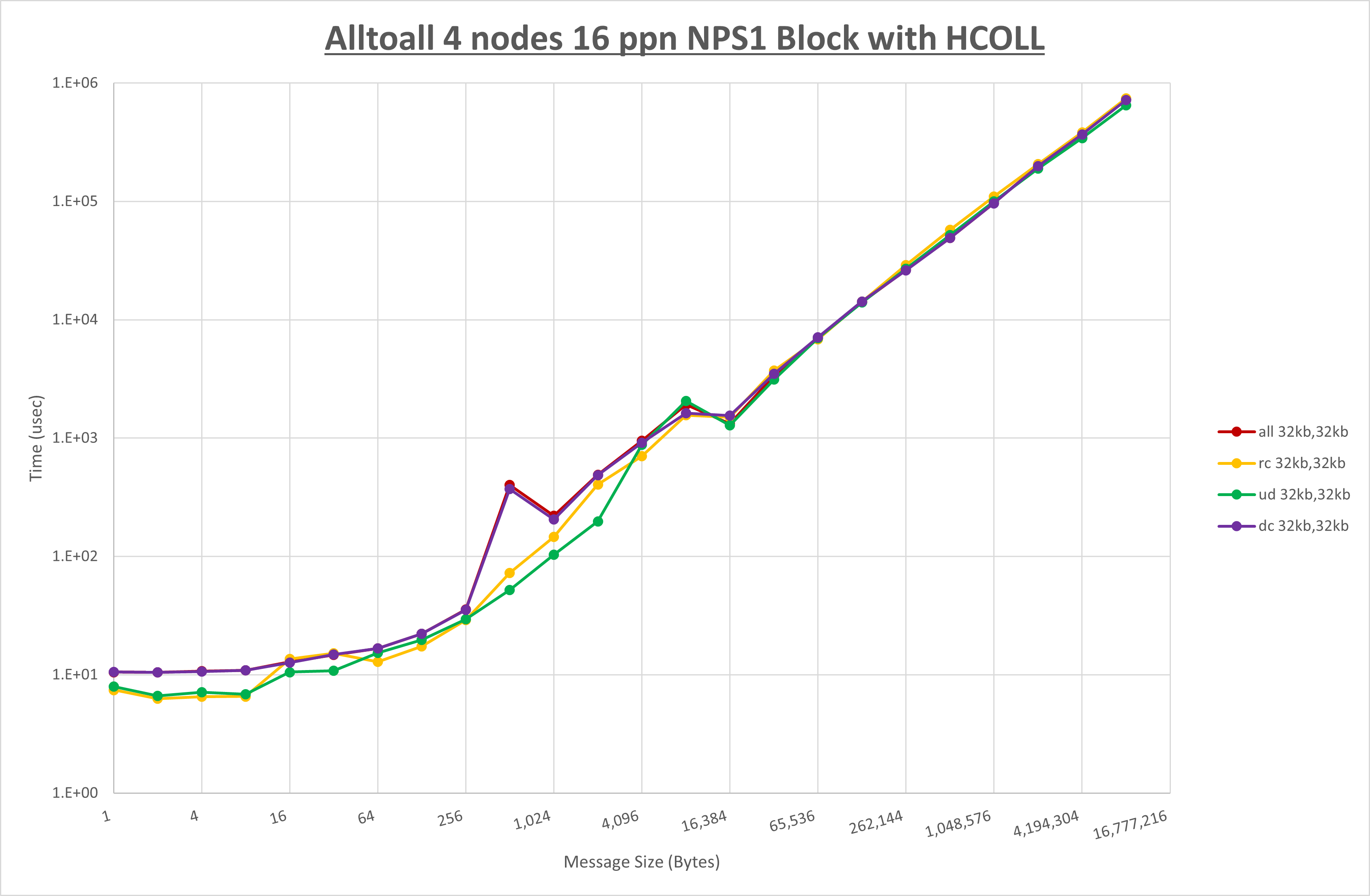
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
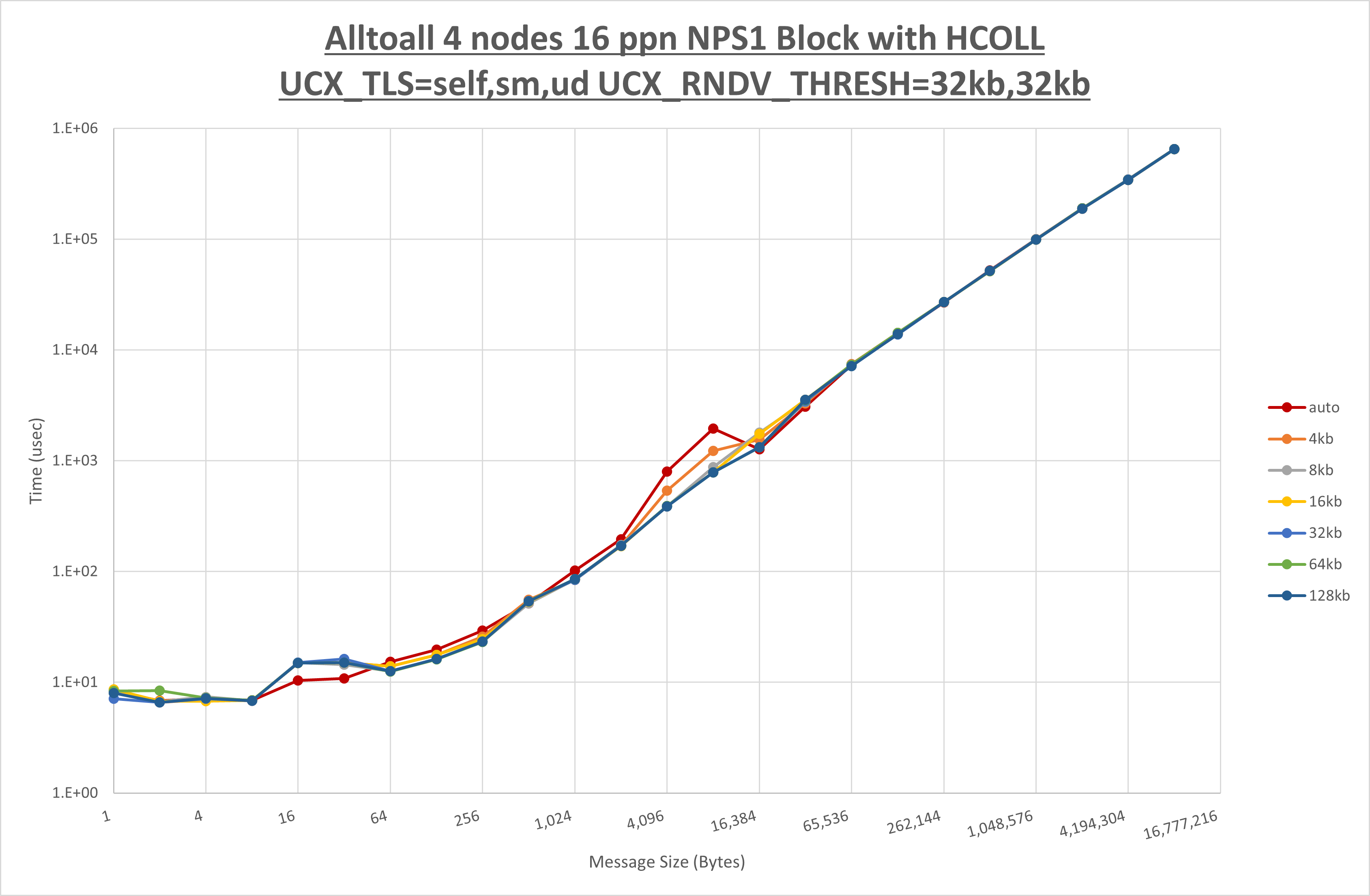
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
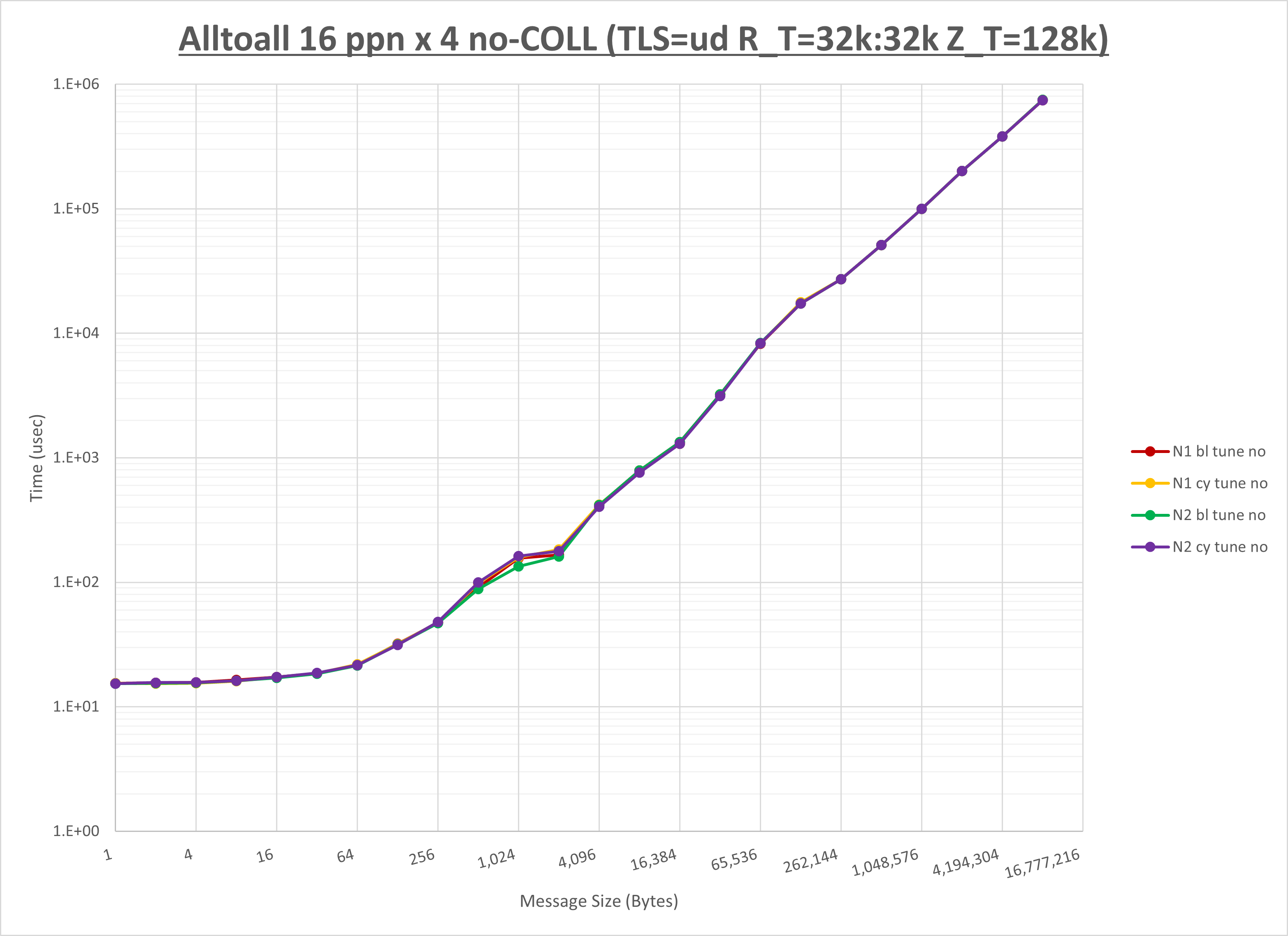
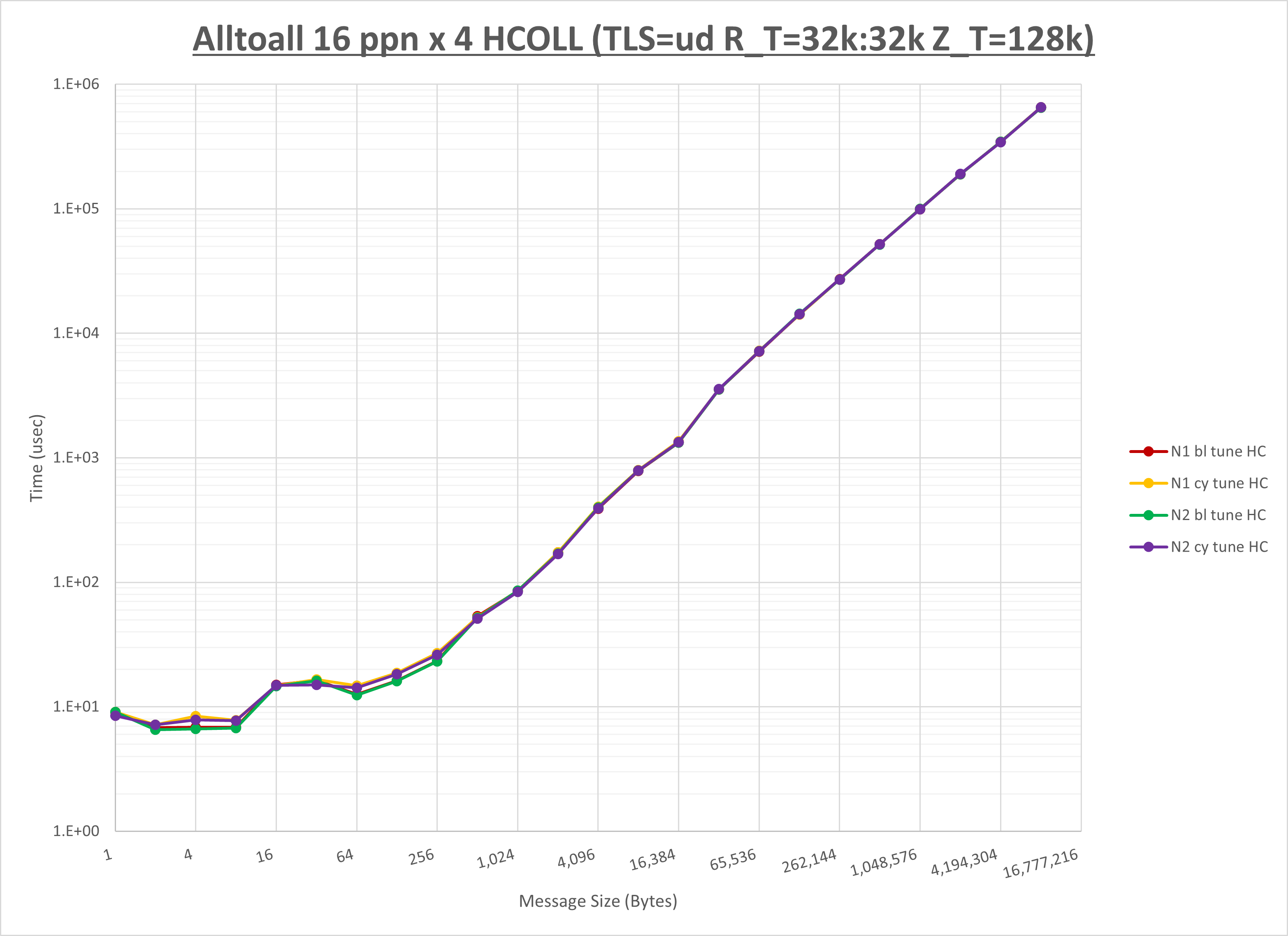
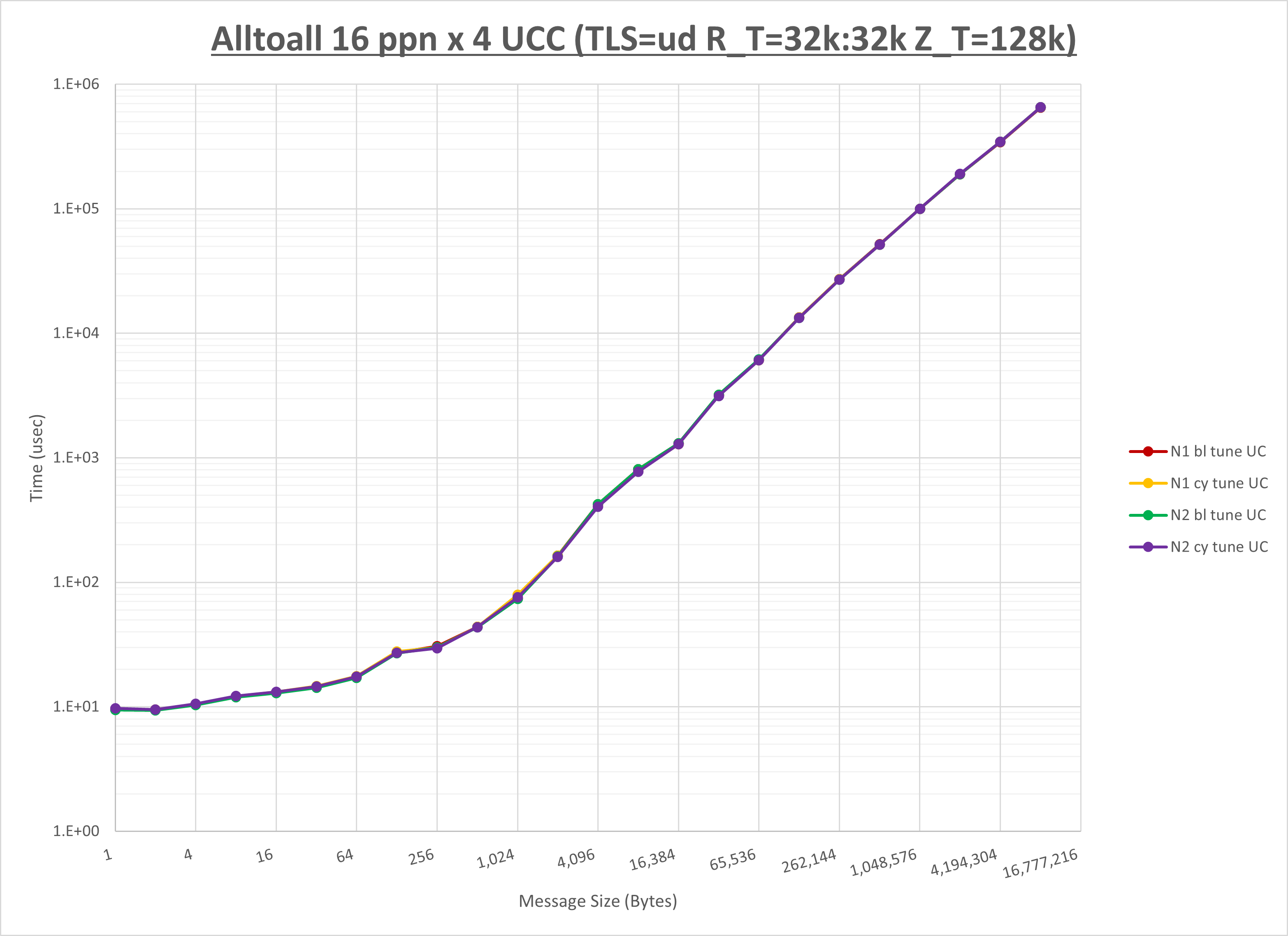
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
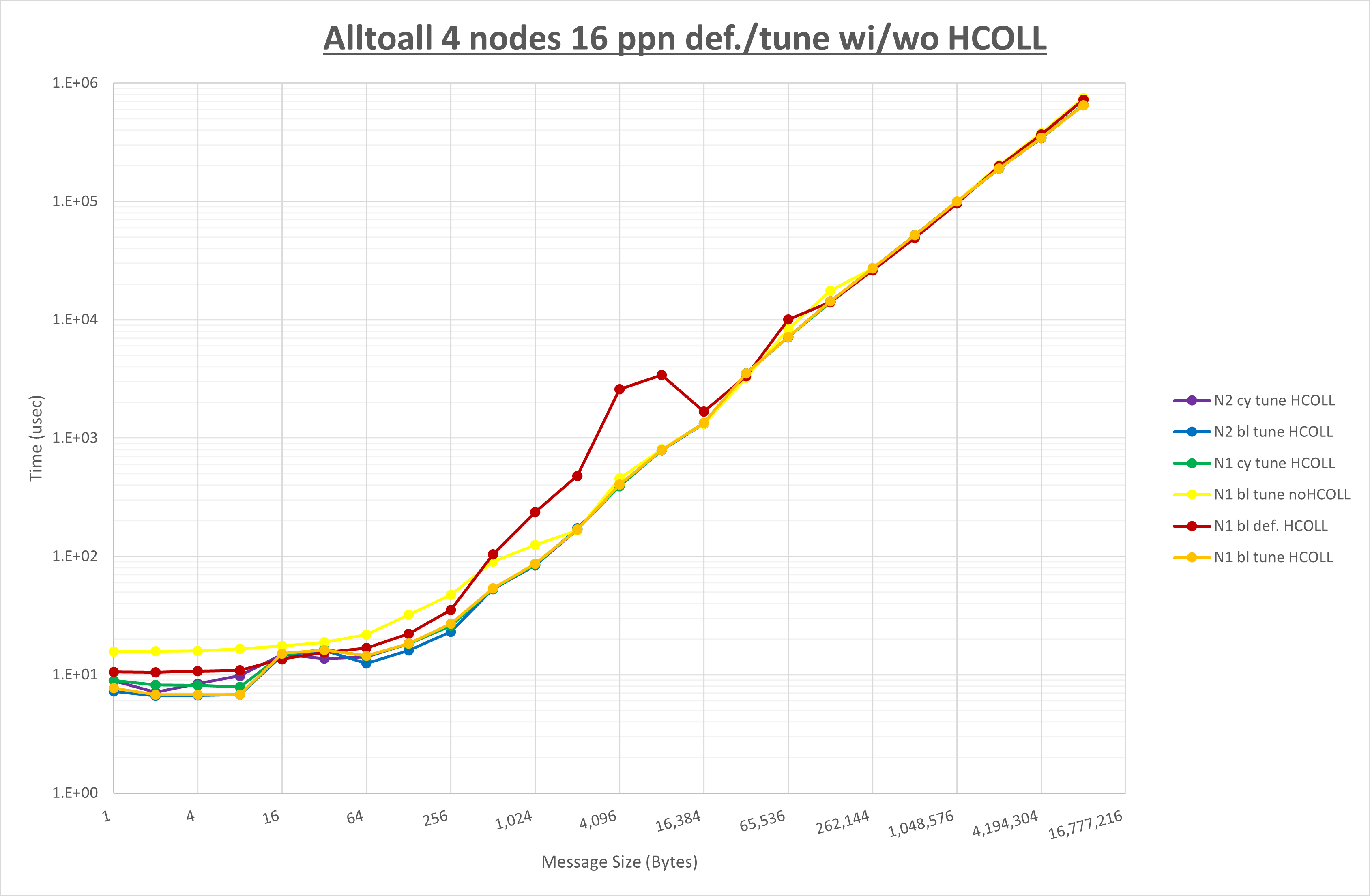
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し1KB以下と4MB以上で性能が向上
- UCC は no-COLL と比較し1KB以下と4MB以上と64KBから128KBで性能が向上し
- チューニング適用で全域にわたって性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-2 Allgather の HCOLL の結果から64KBとしています。
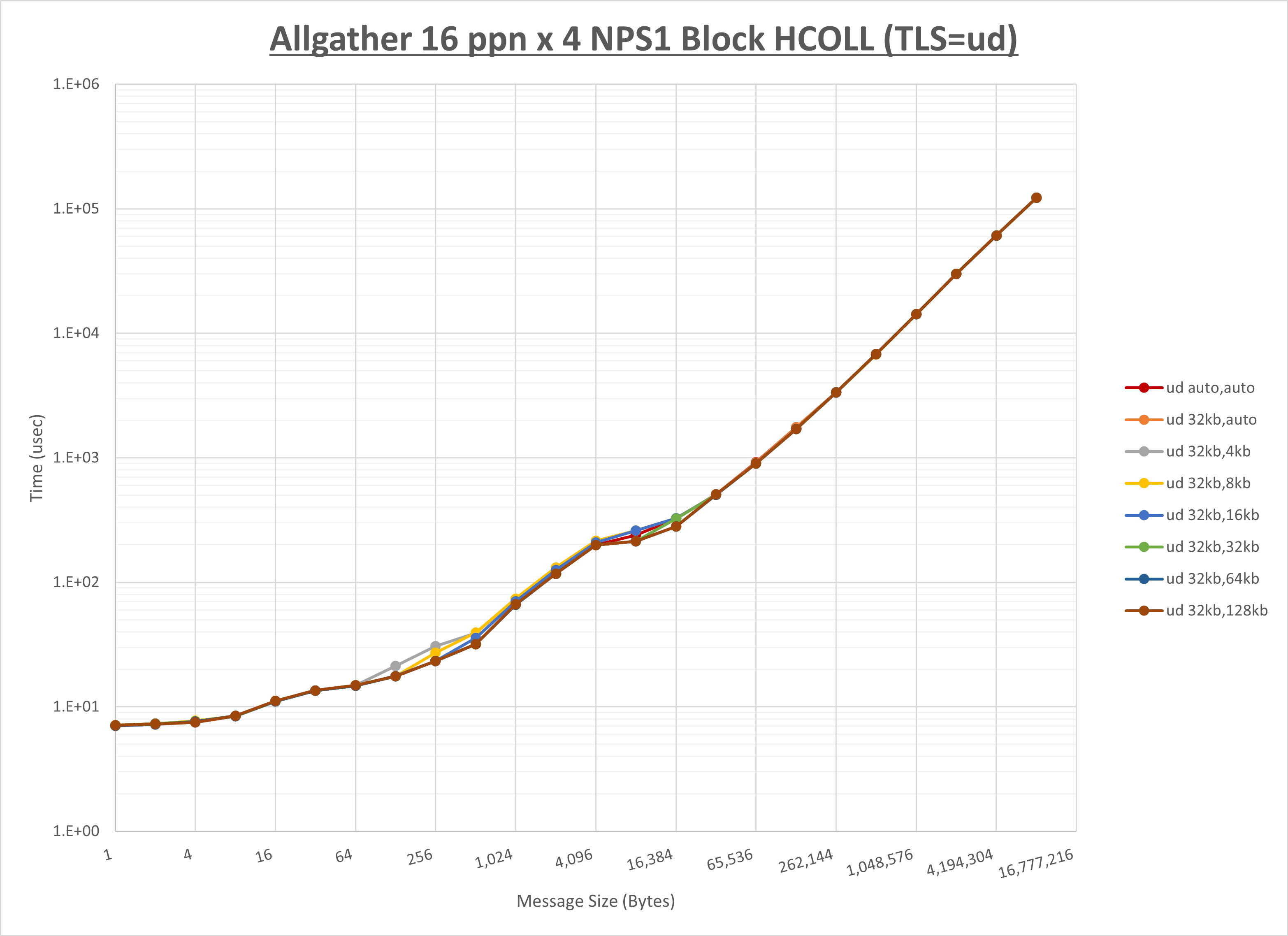
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
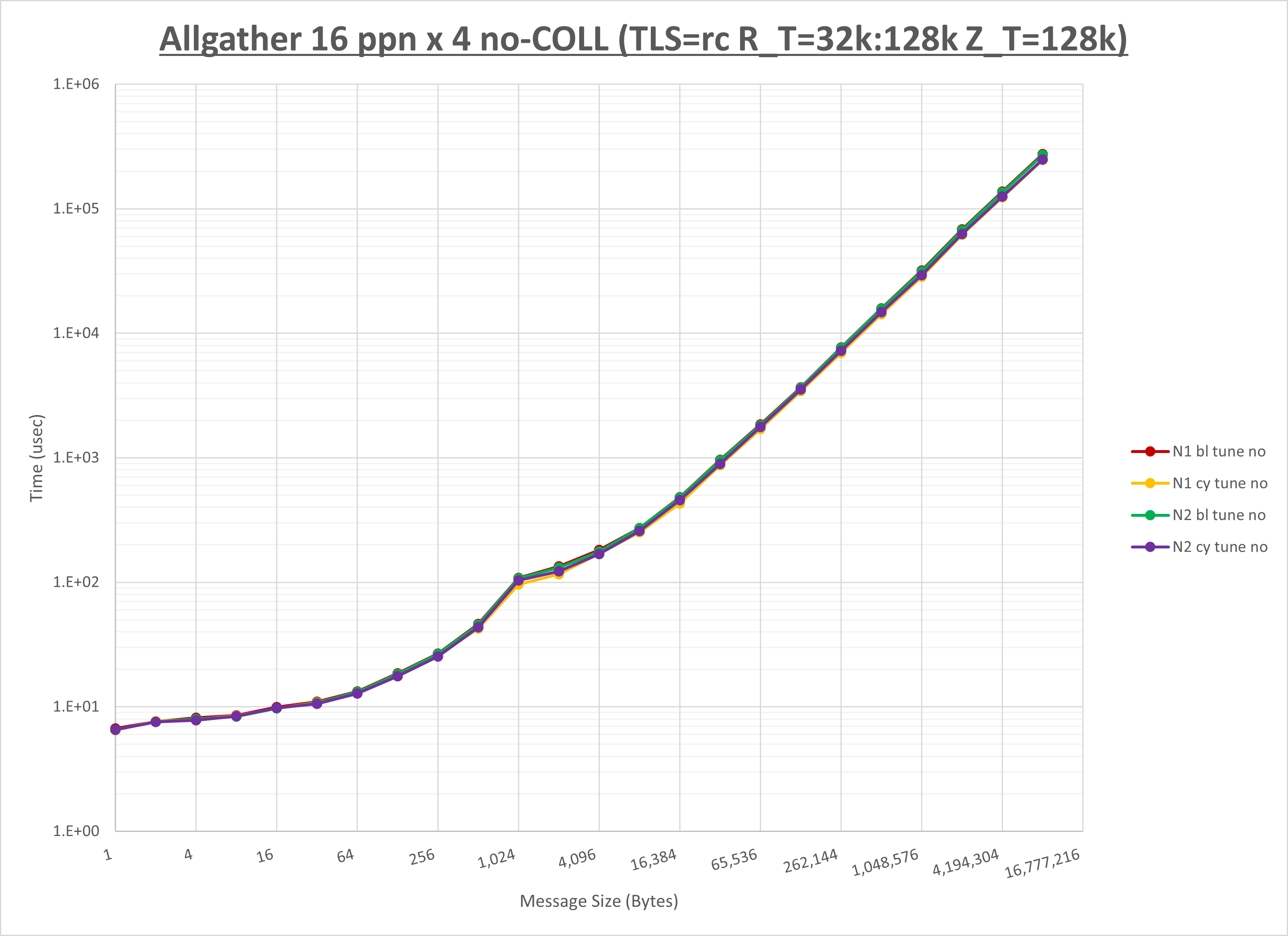
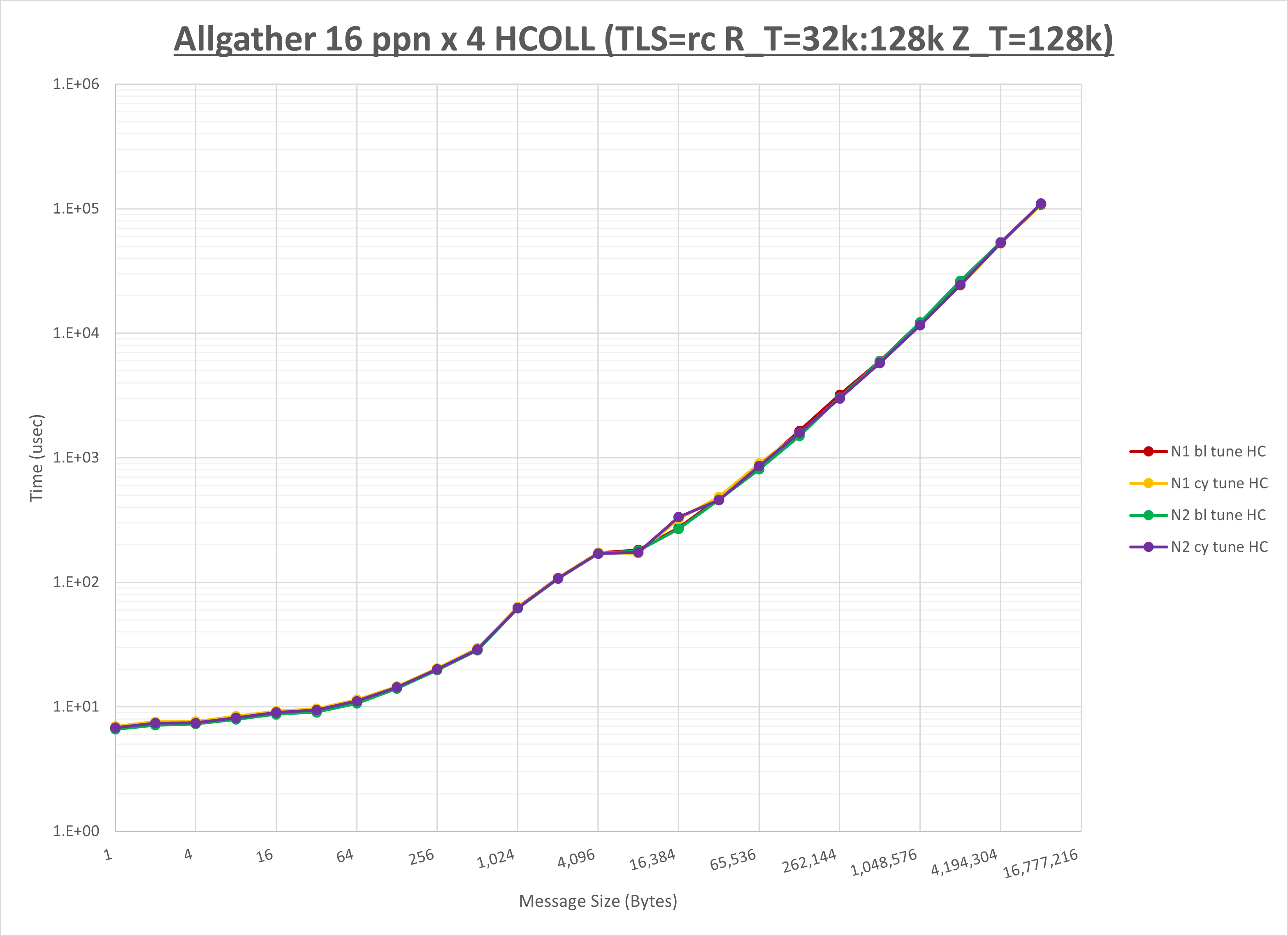
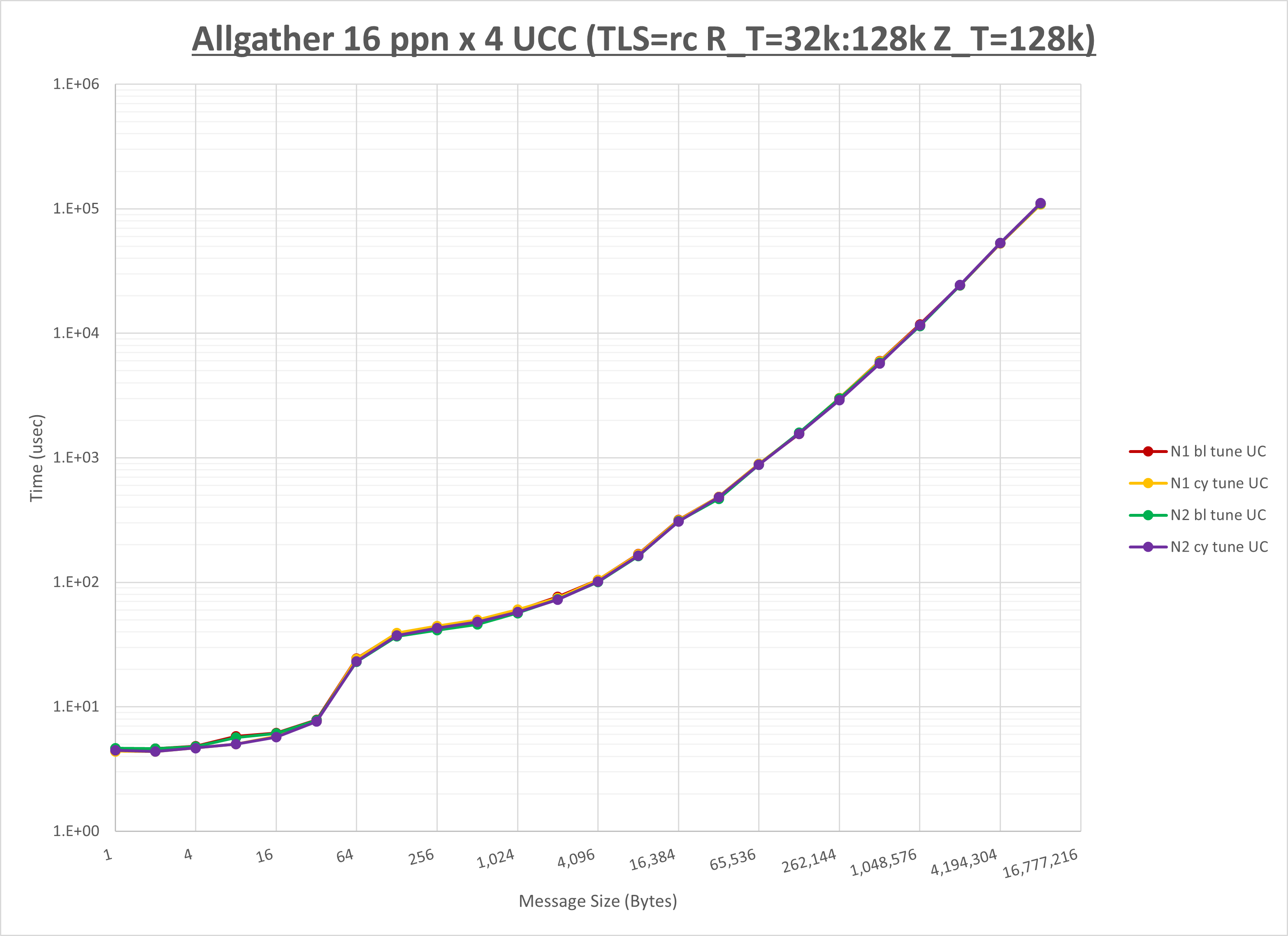
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較しほぼ全域で性能が向上
- チューニング適用で8KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-3 Allreduce の HCOLL の結果から128KBとしています。
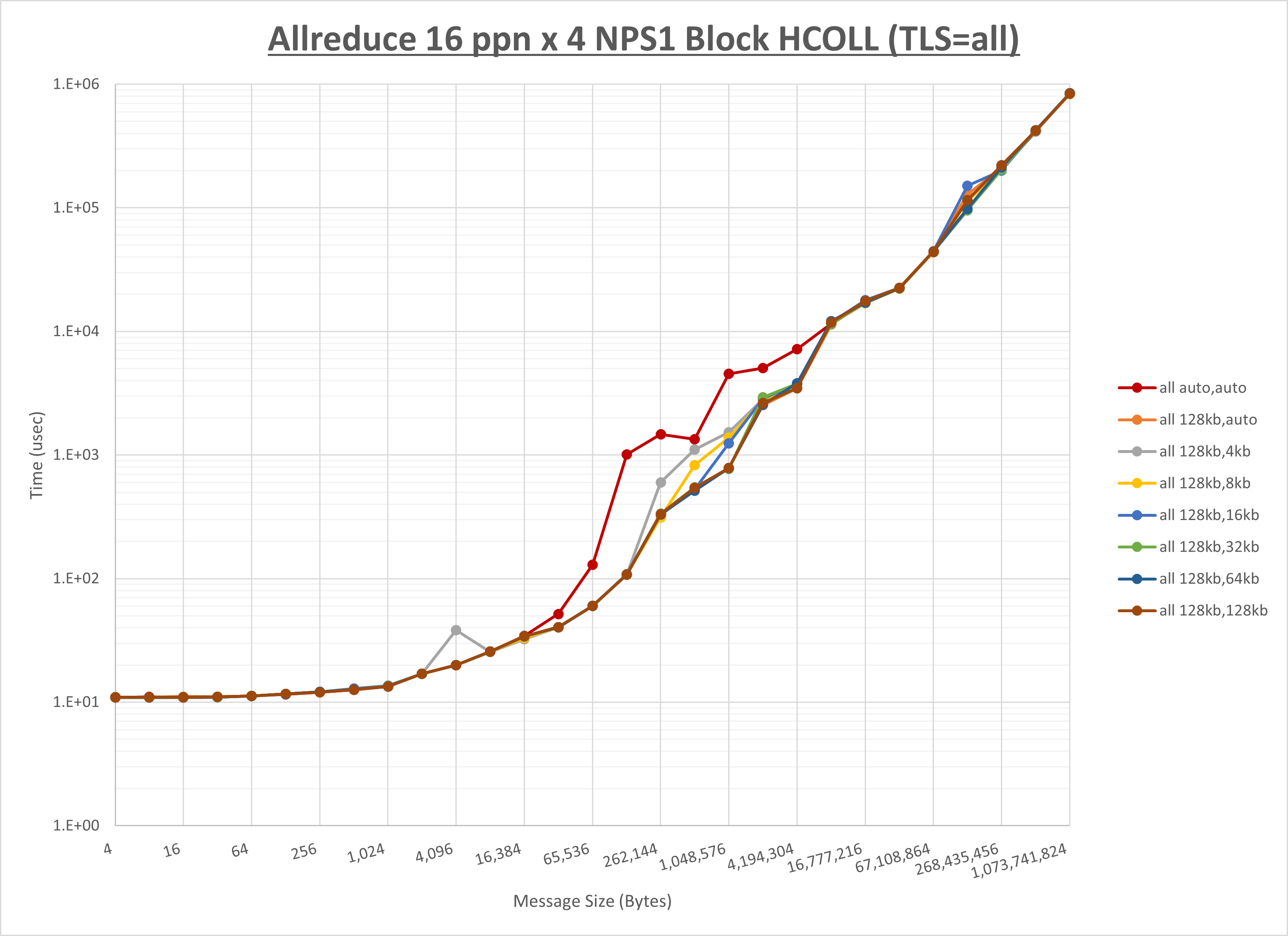
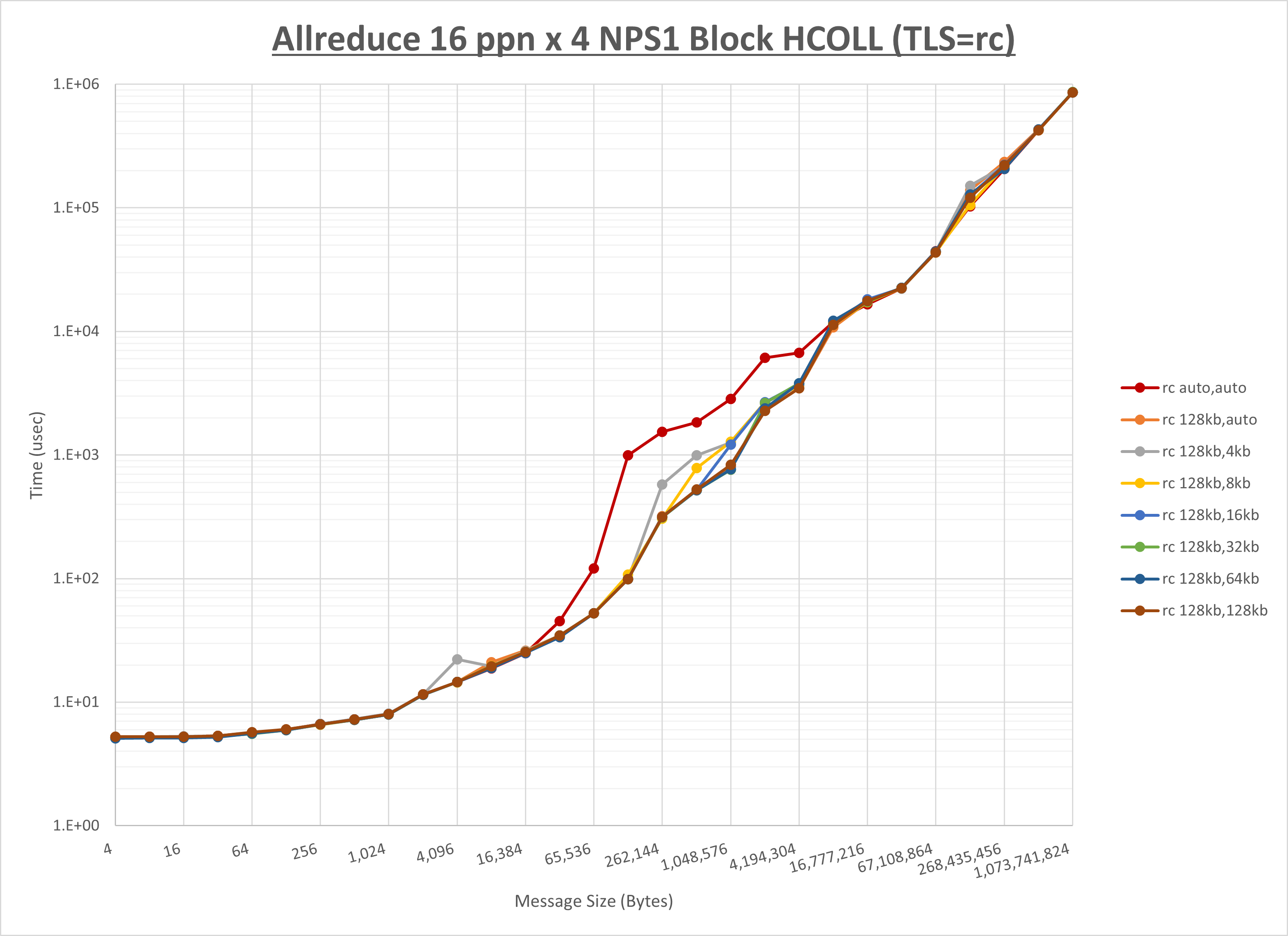
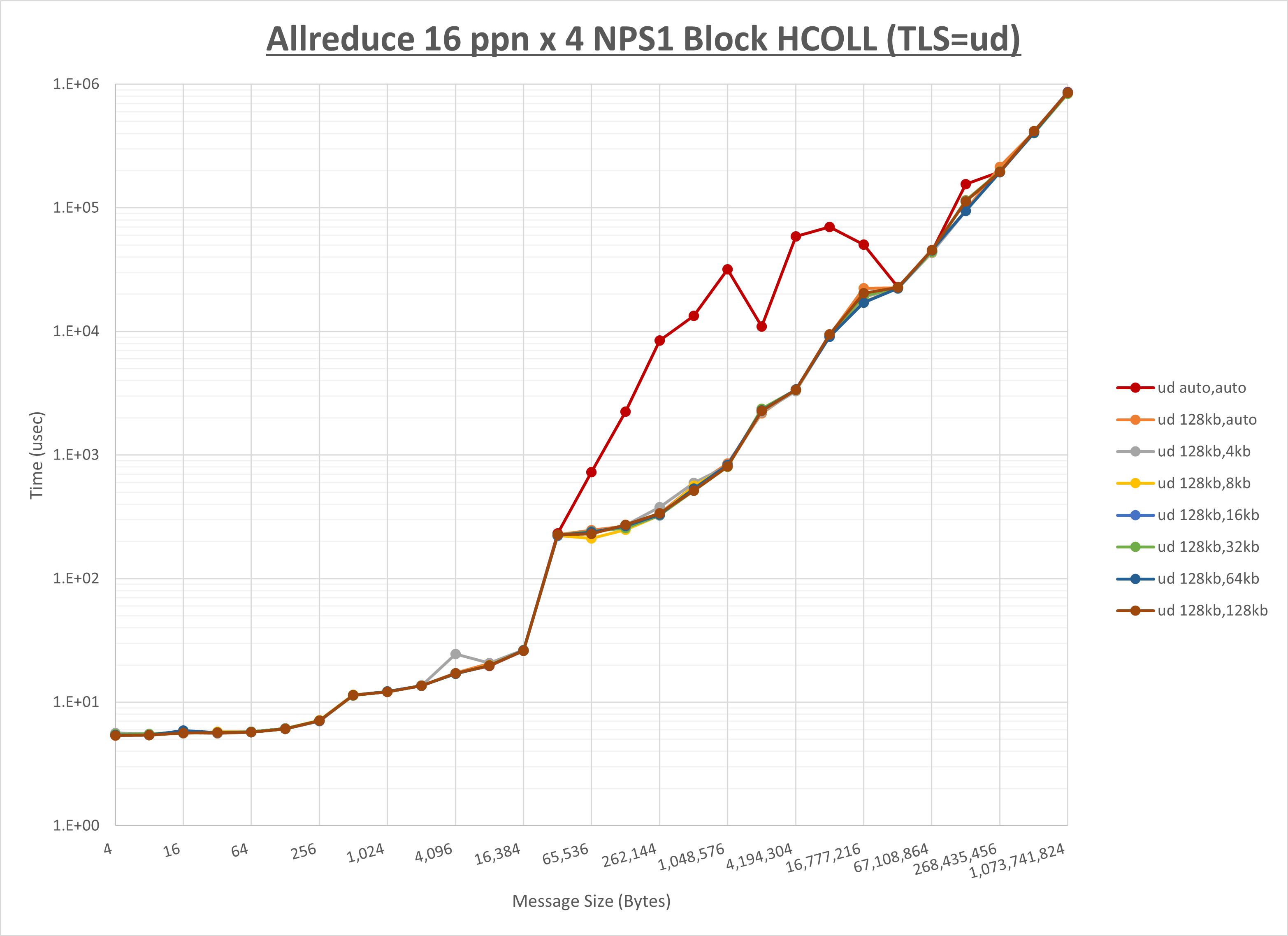
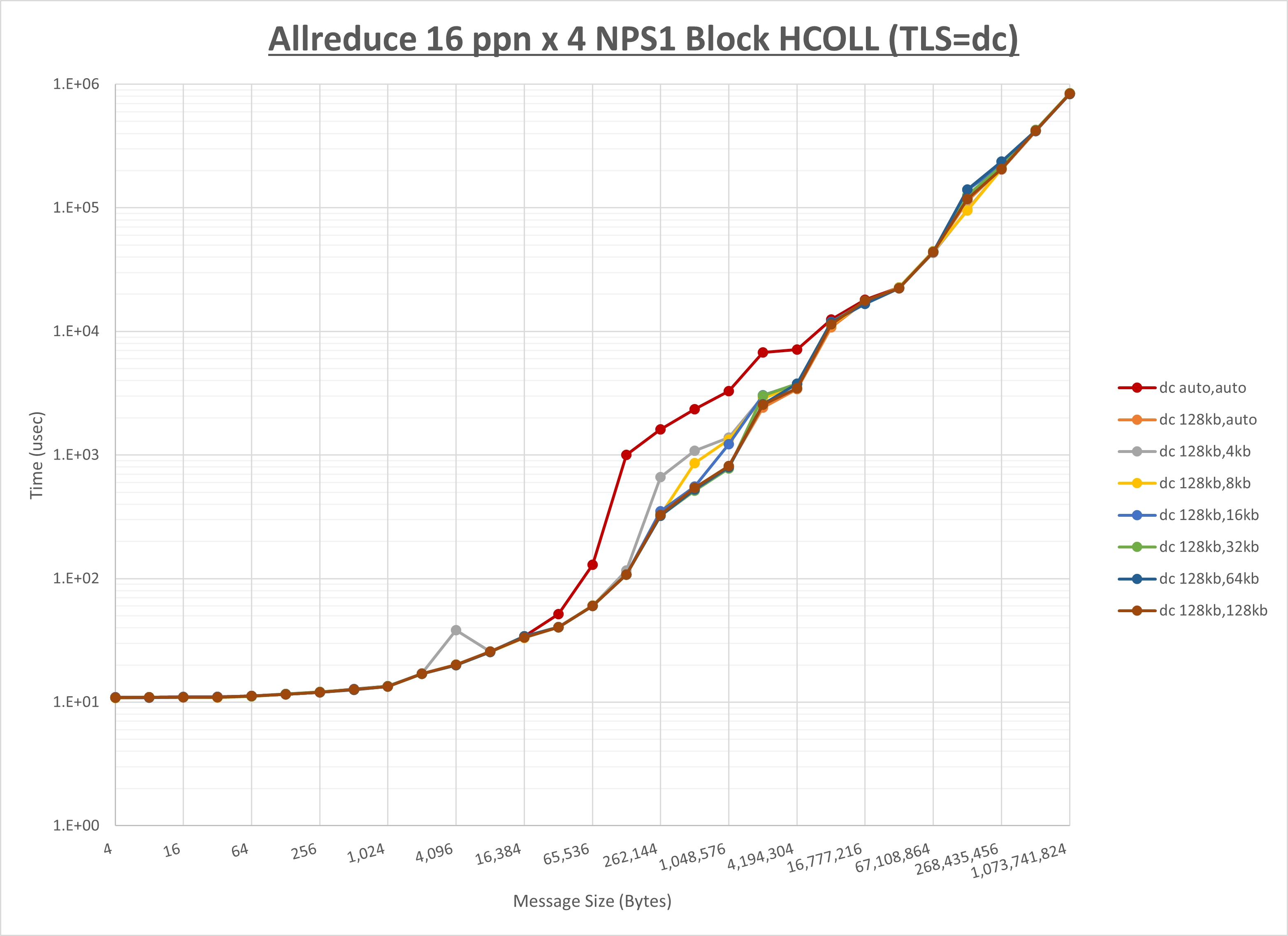
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
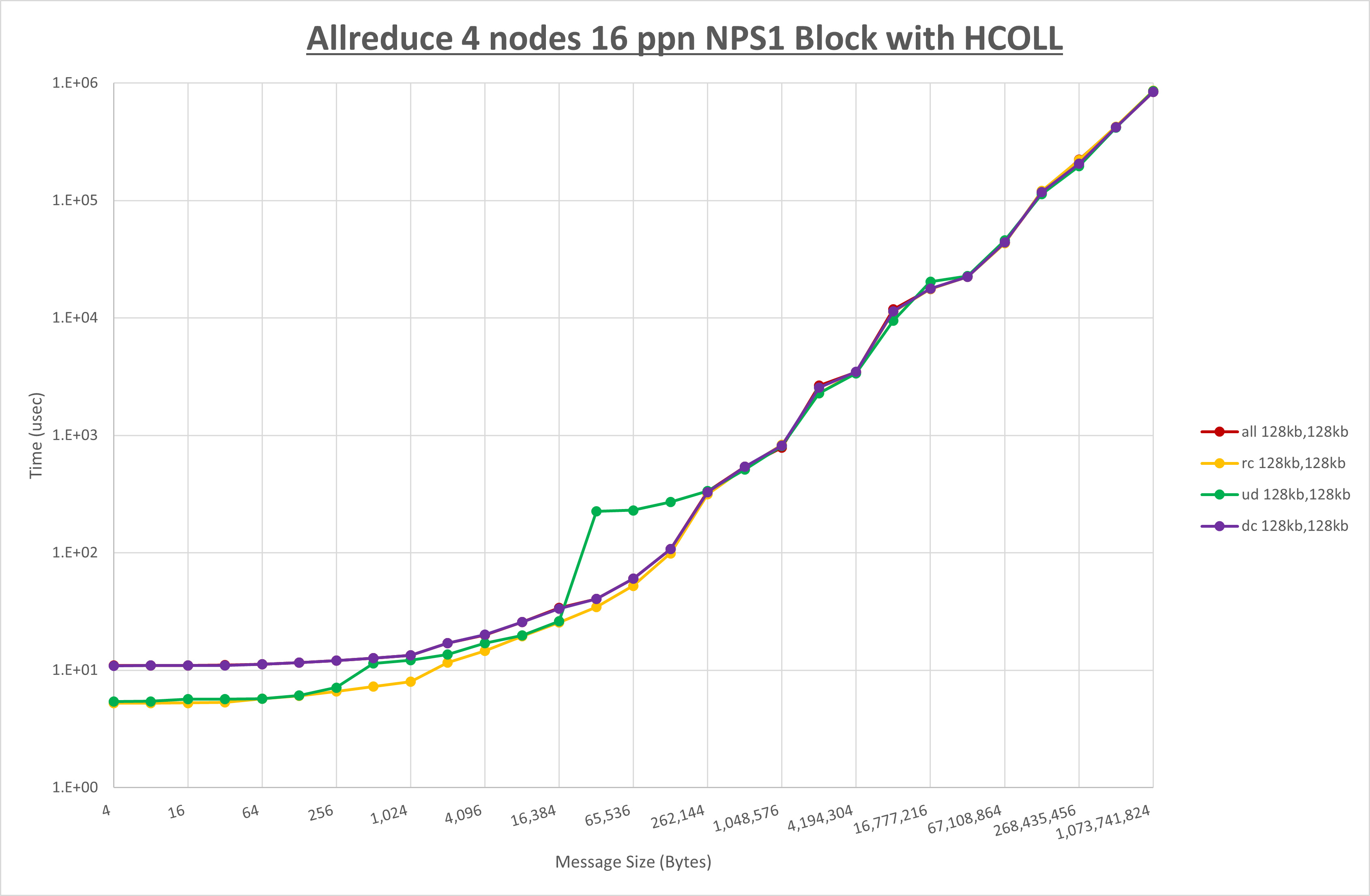
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
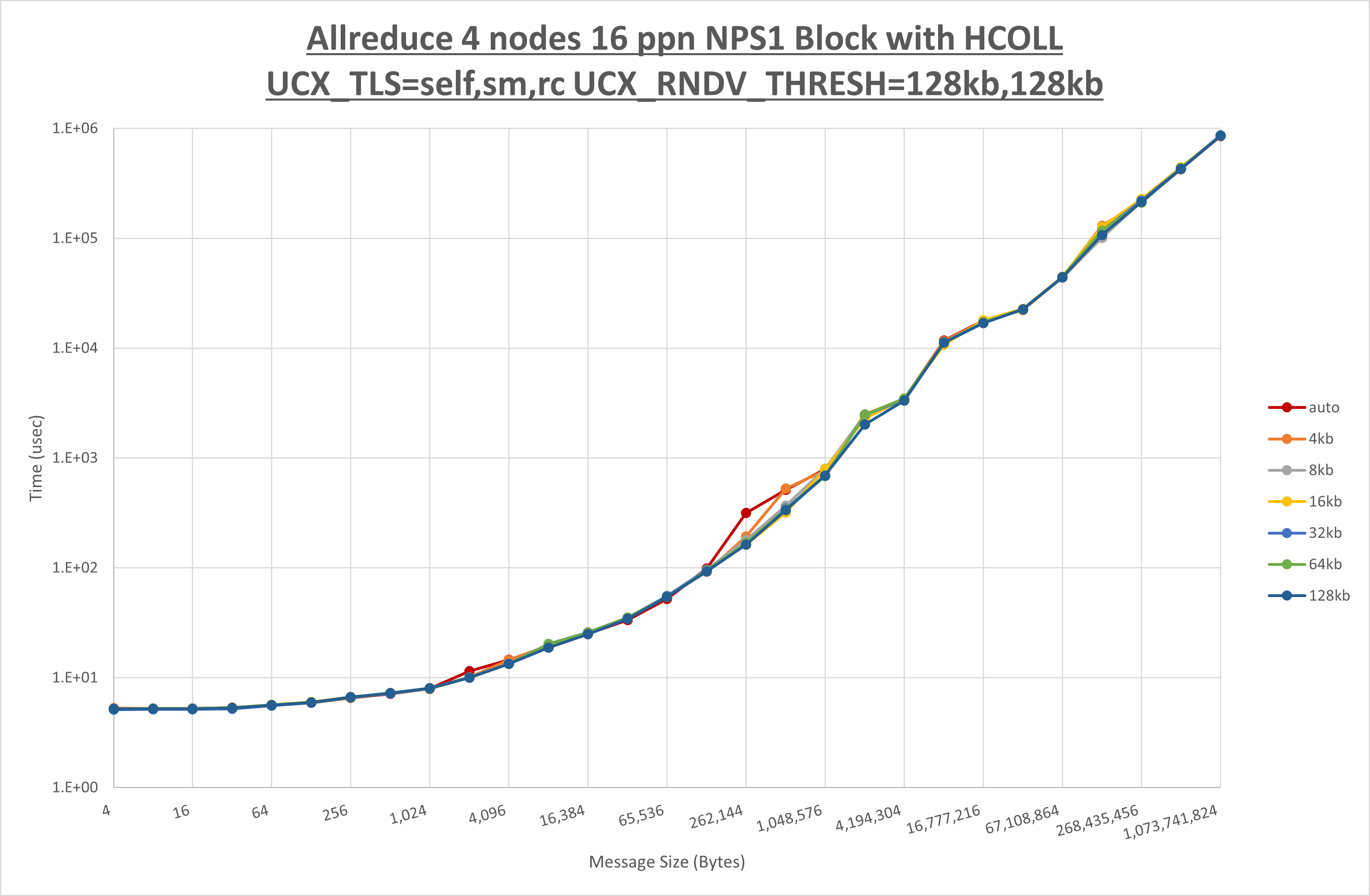
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
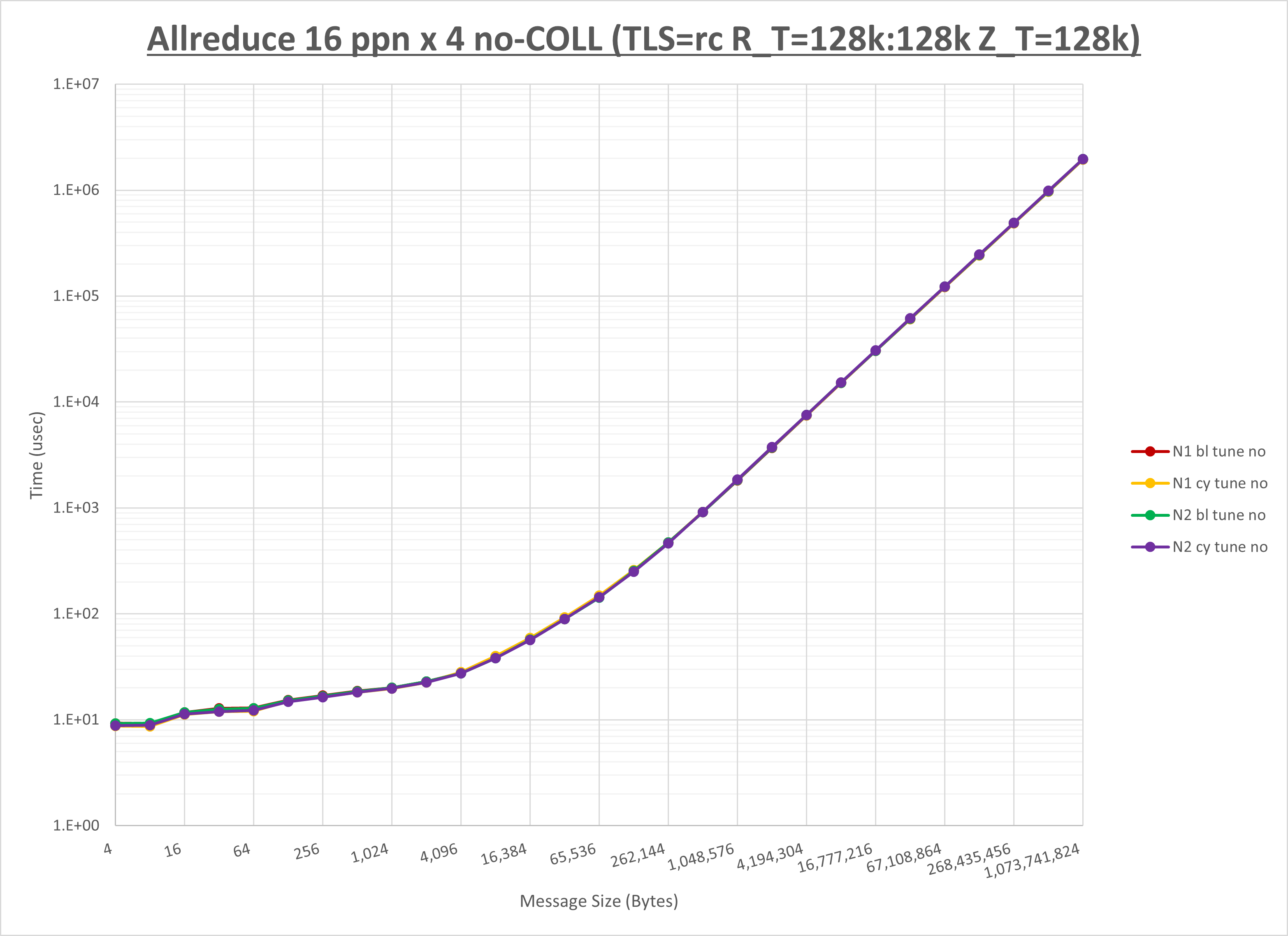
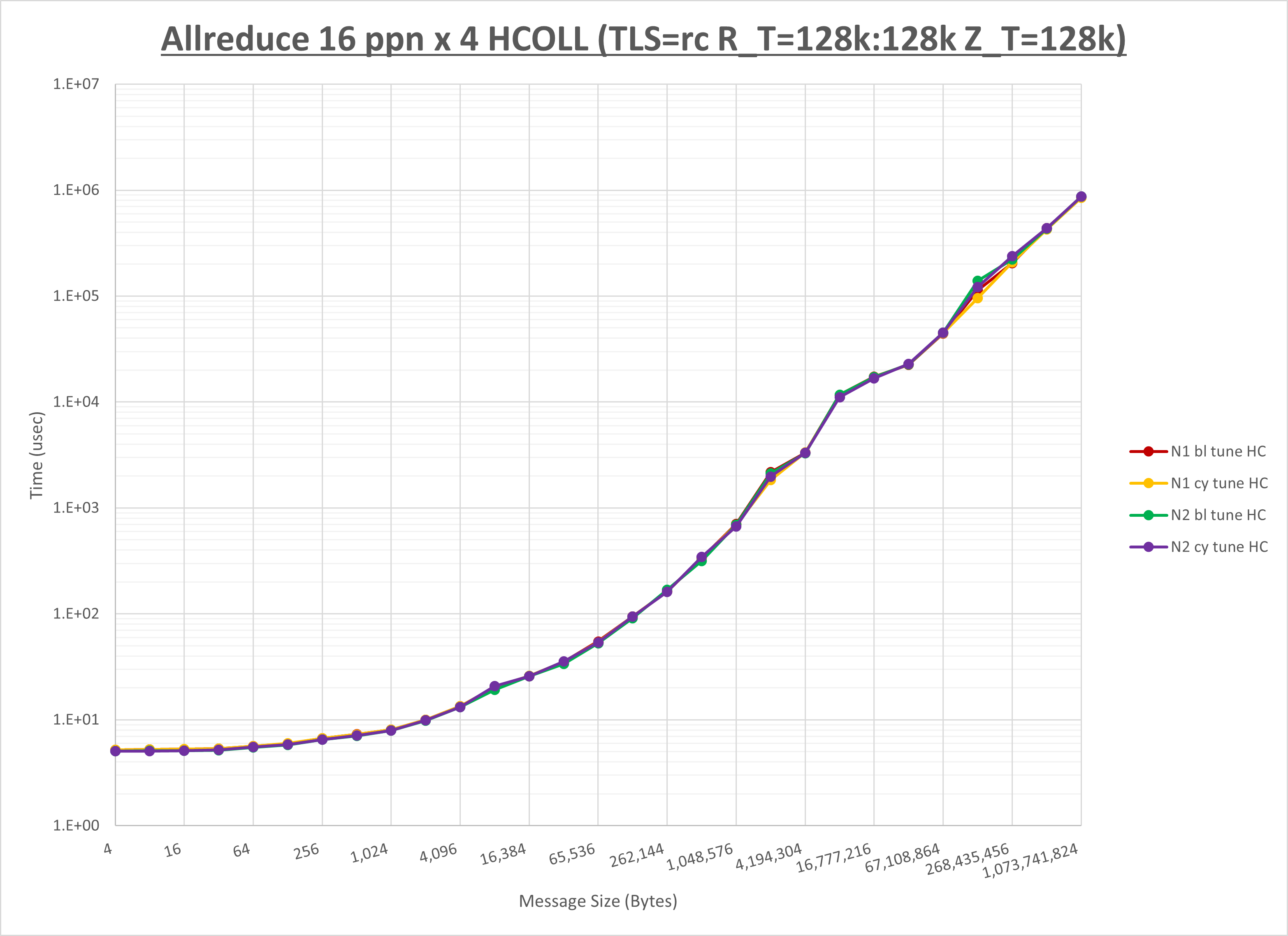
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS1 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で2MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-4 Exchange の結果から16KBとしています。
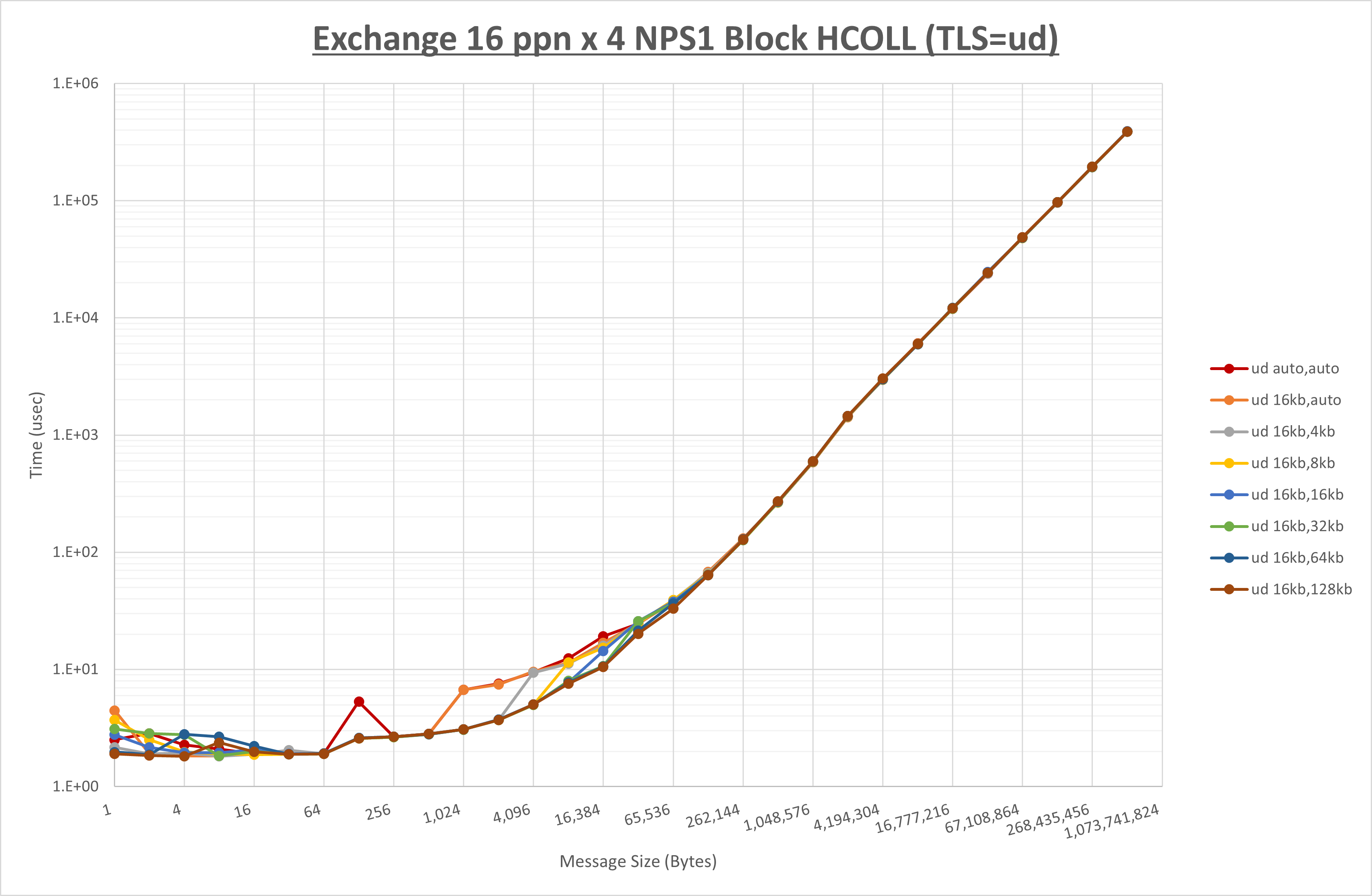
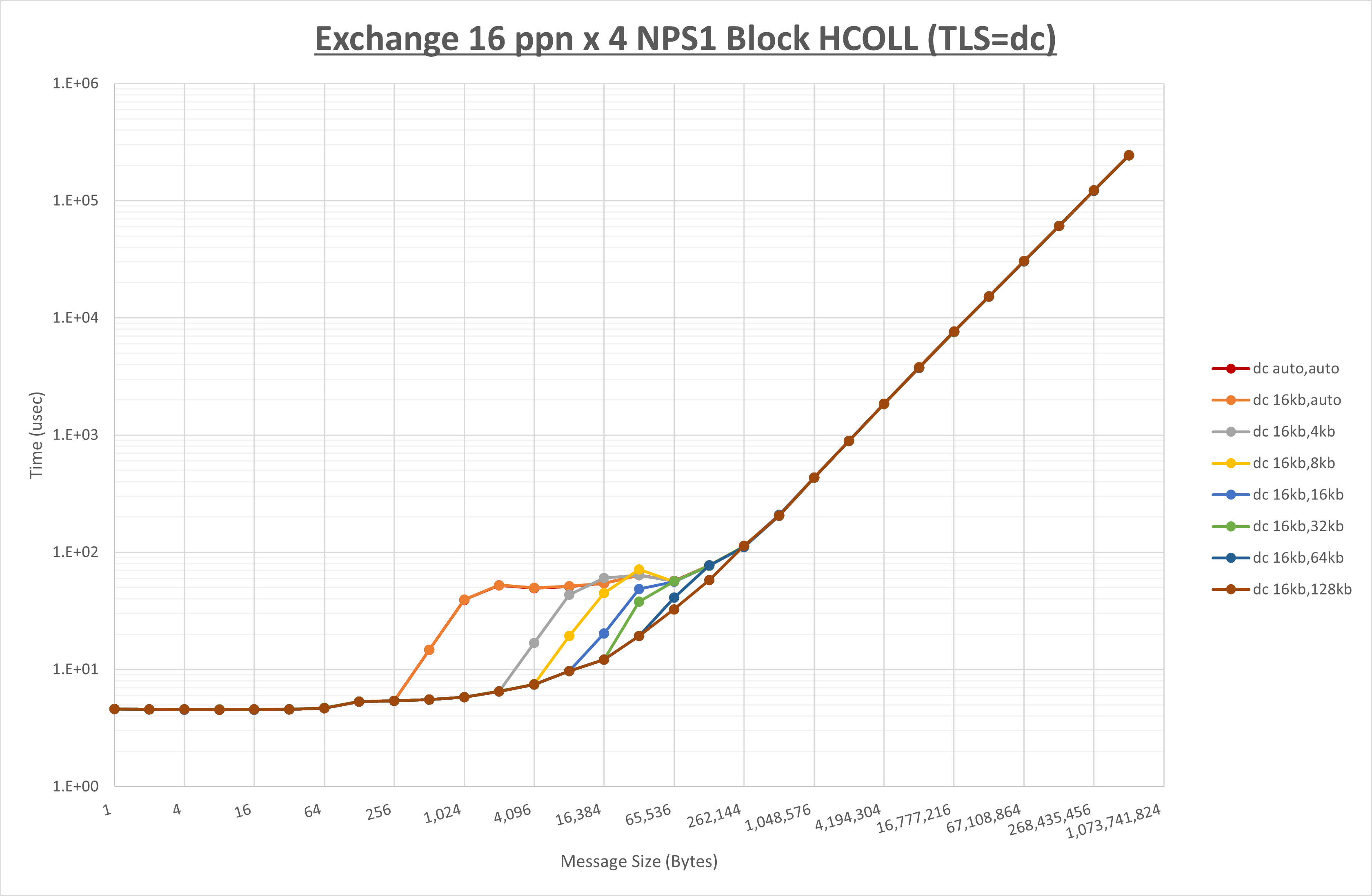
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
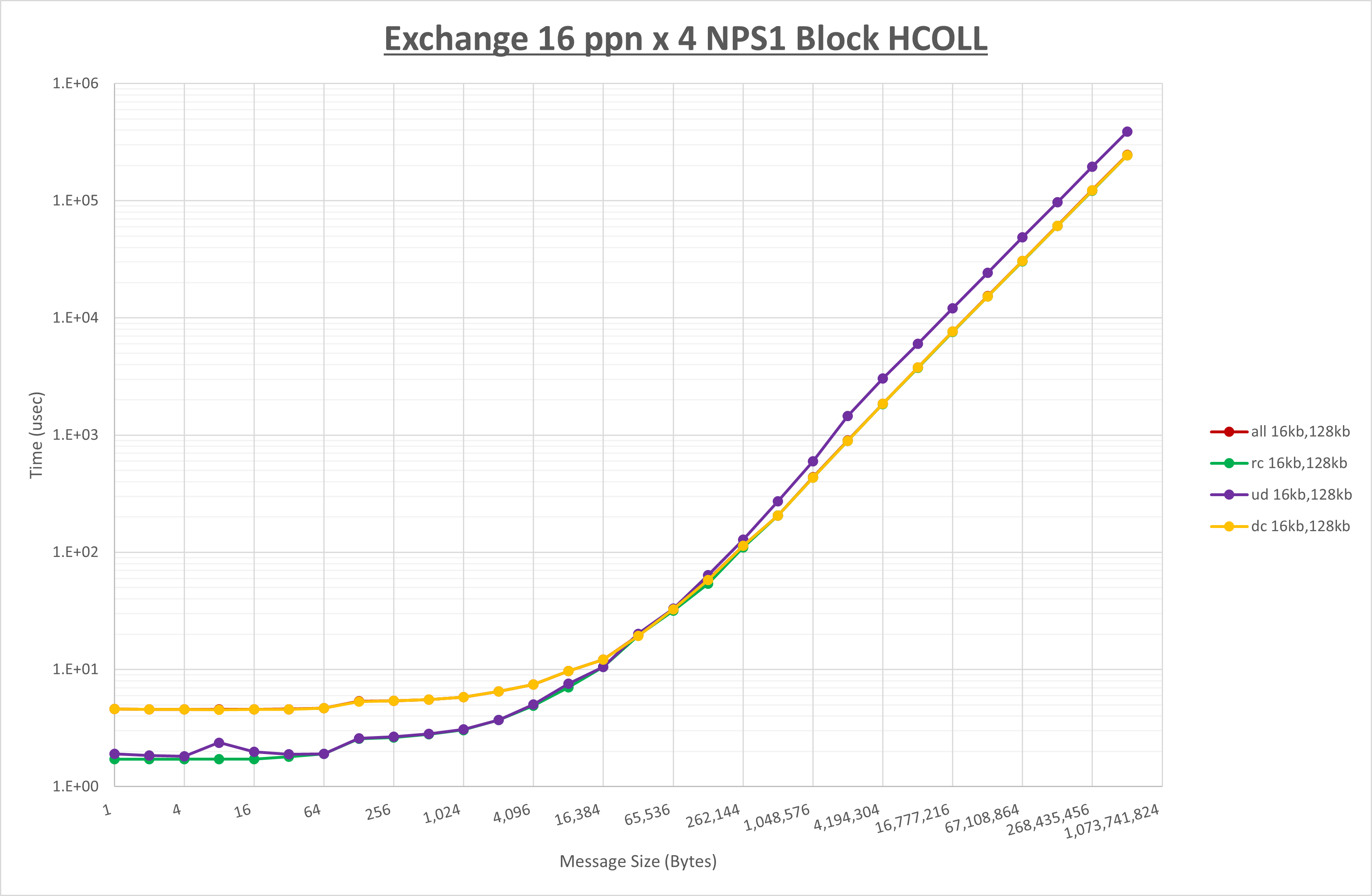
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
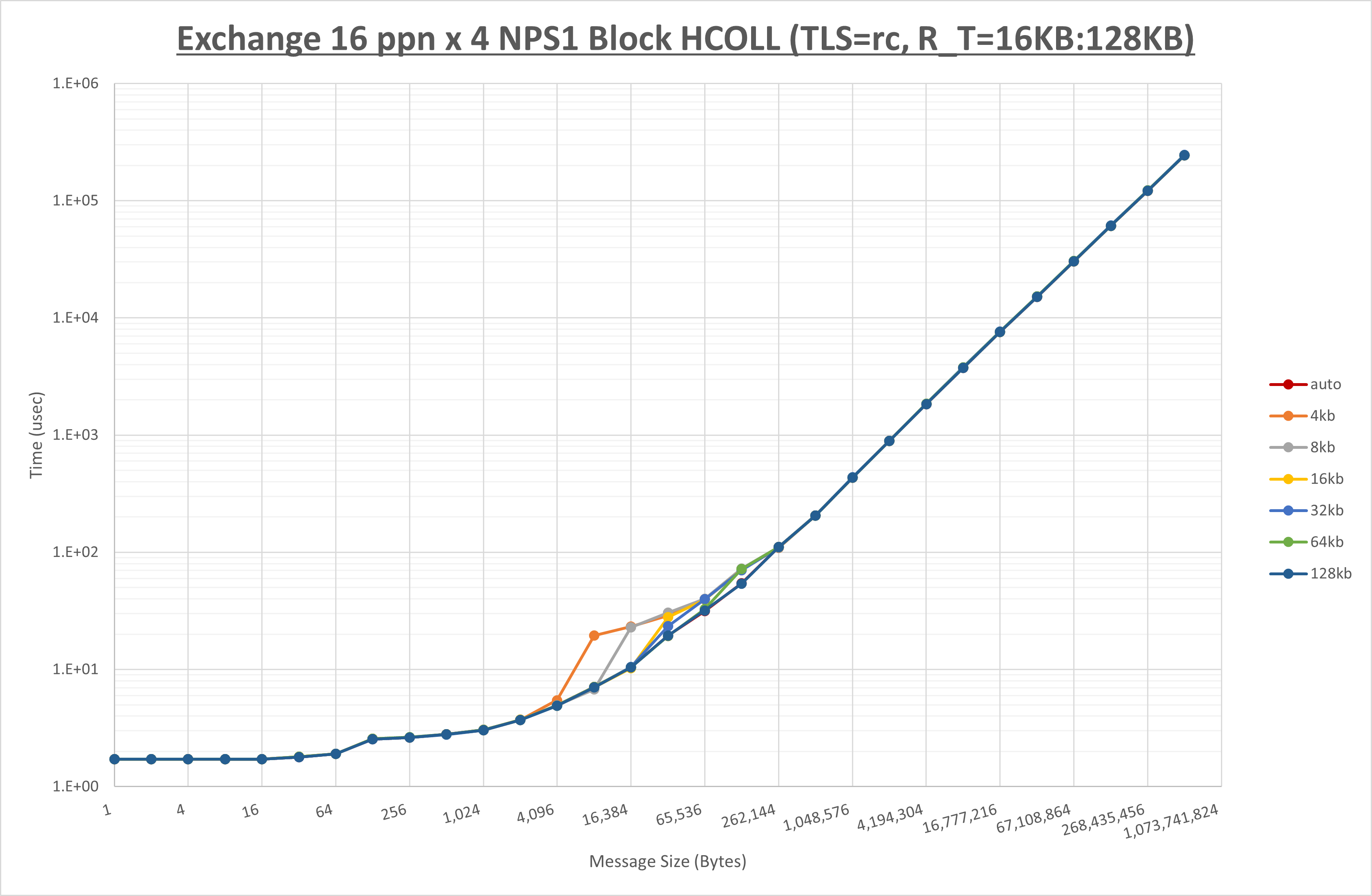
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
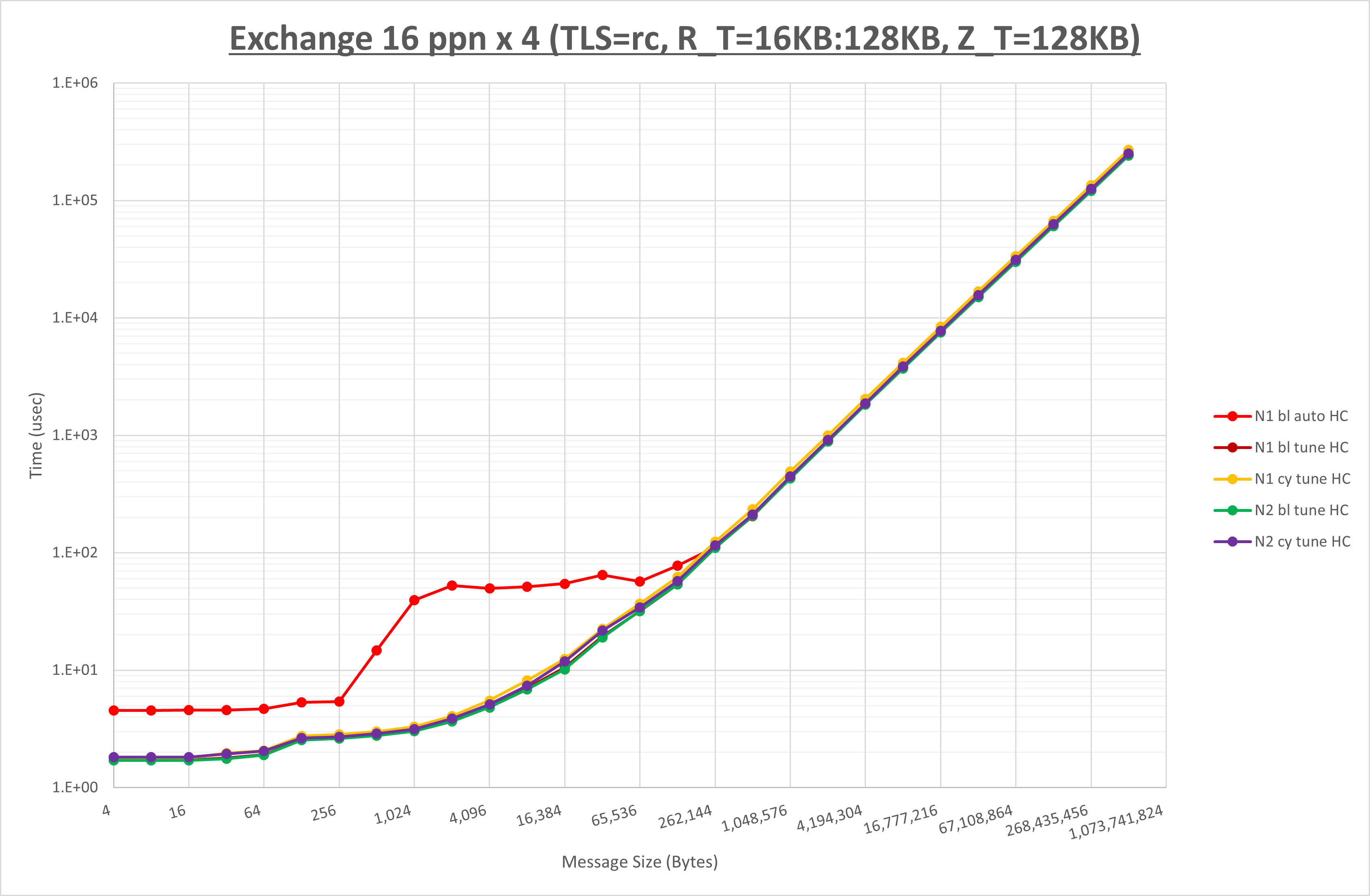
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、4ノードにノード当たり32、トータル128のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:16kb,inter:32kb | 128kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,ud | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-1 Alltoall の HCOLL の結果から16KBとしています。
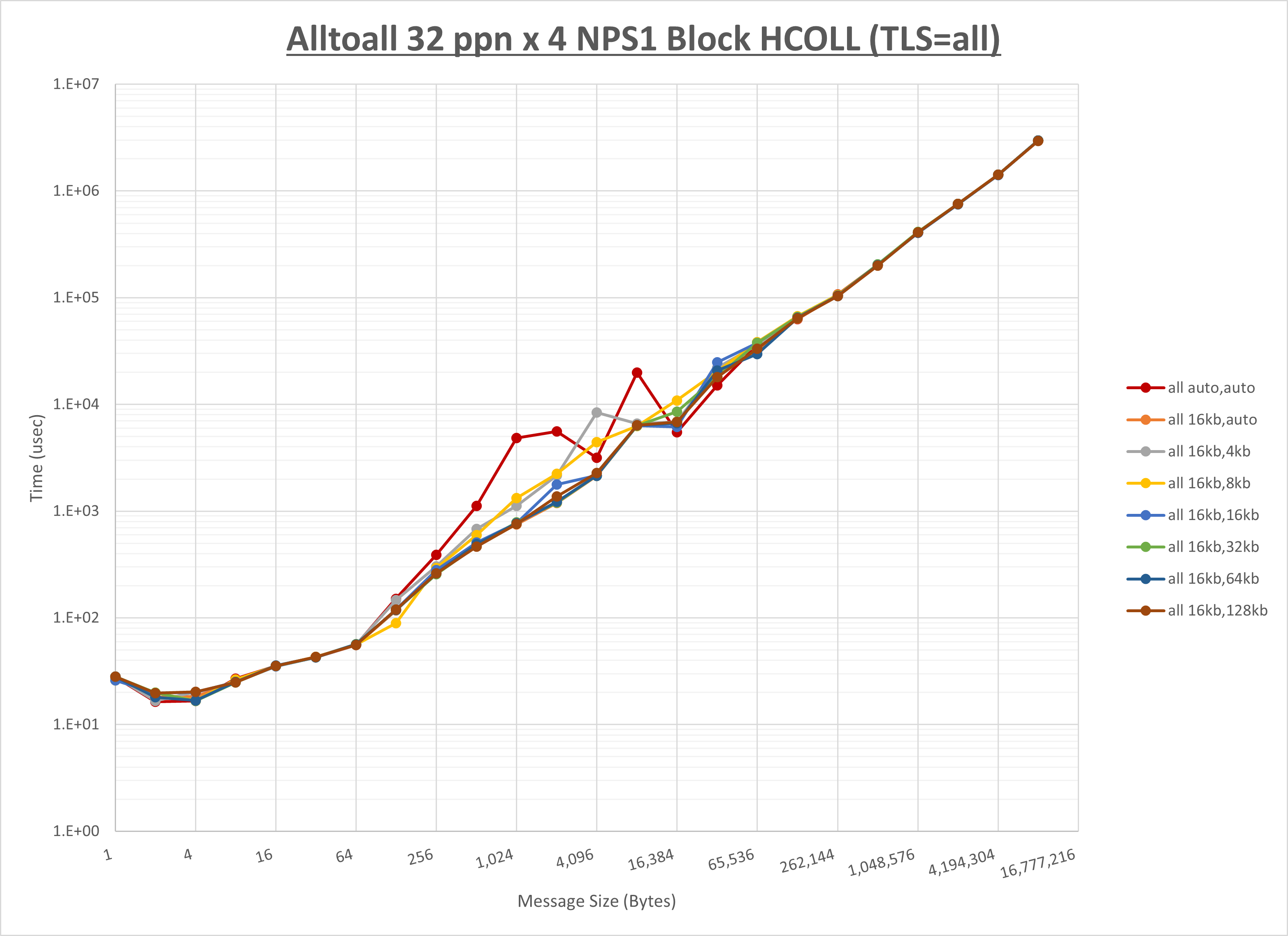
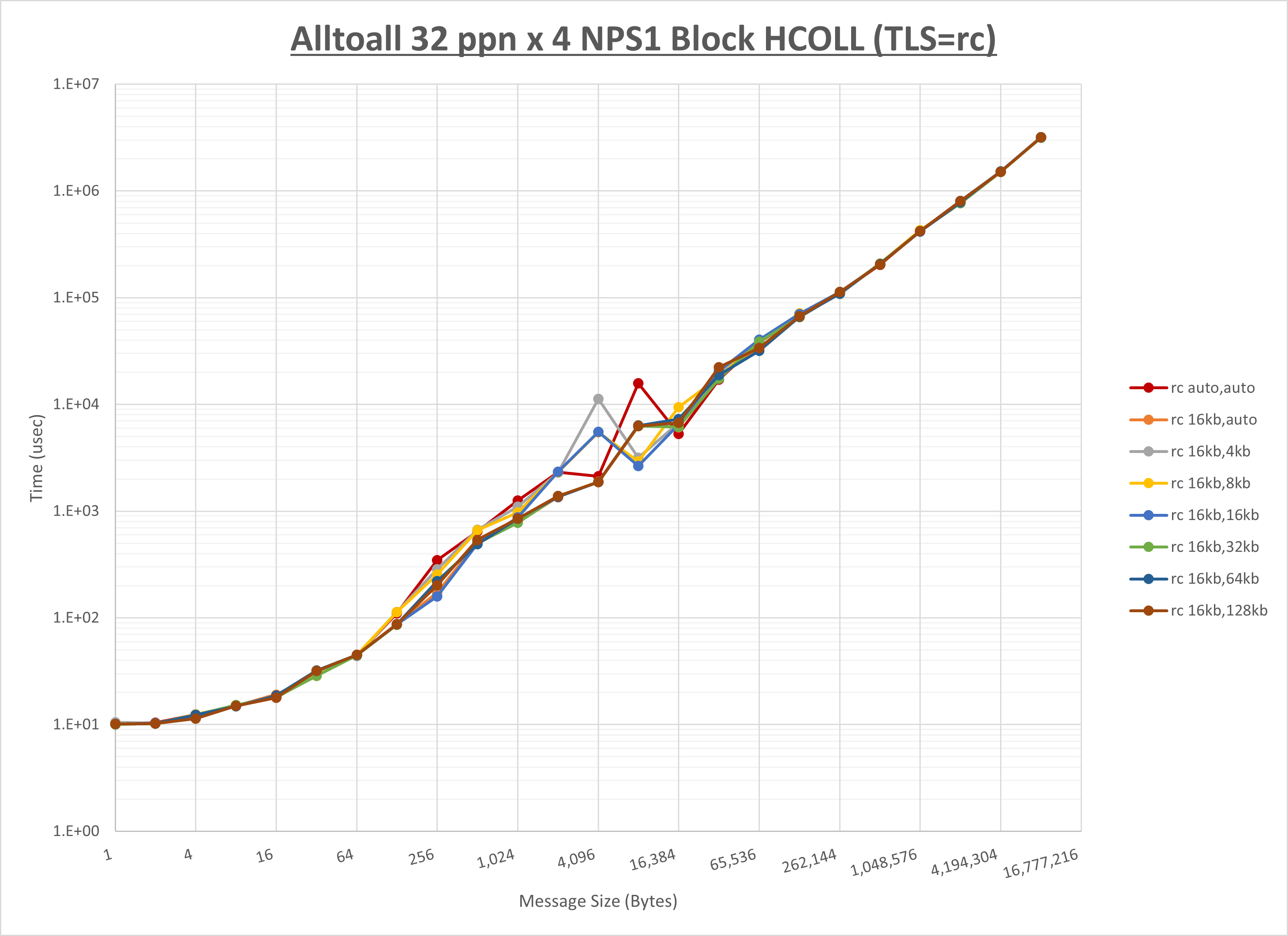
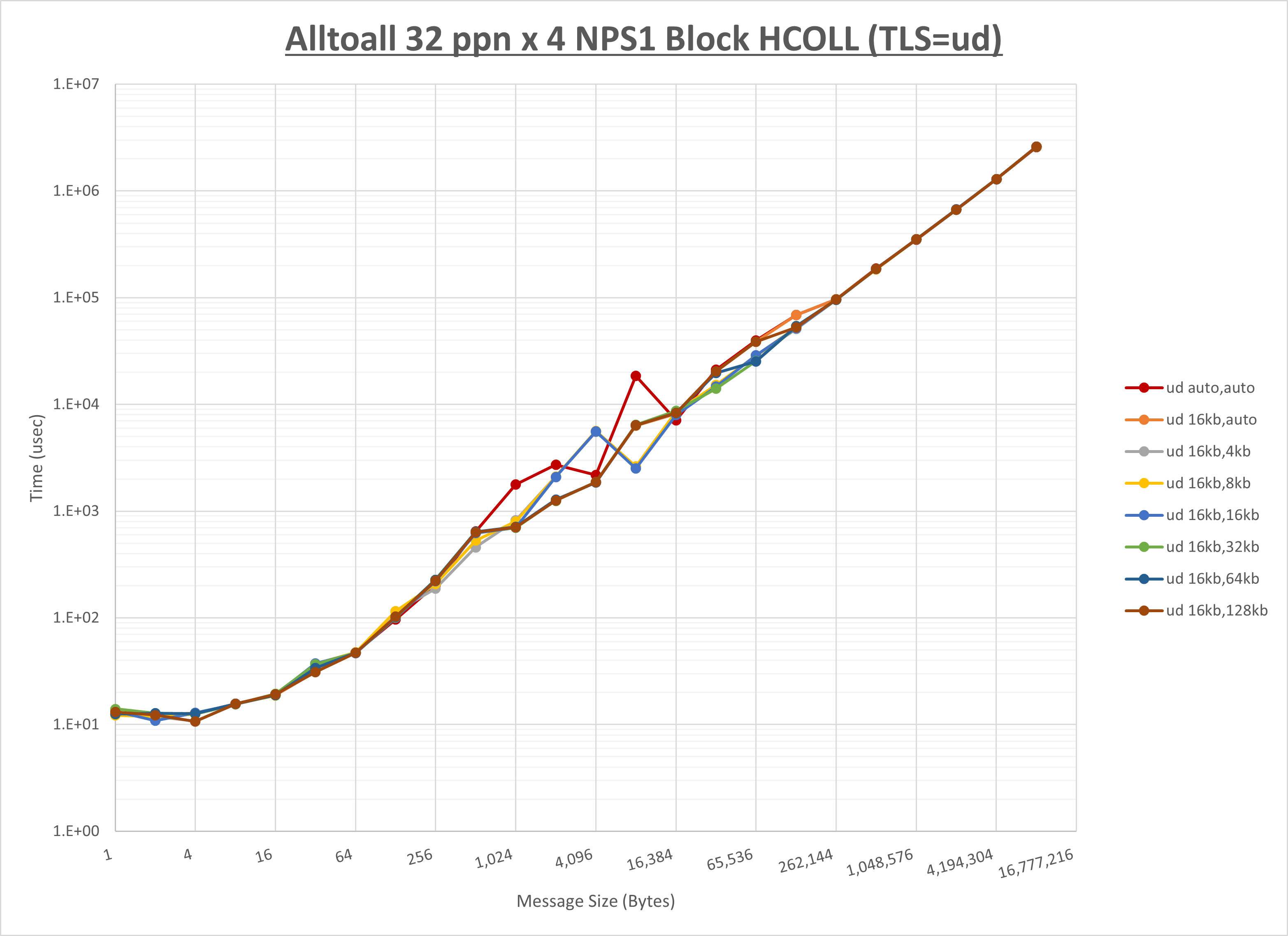
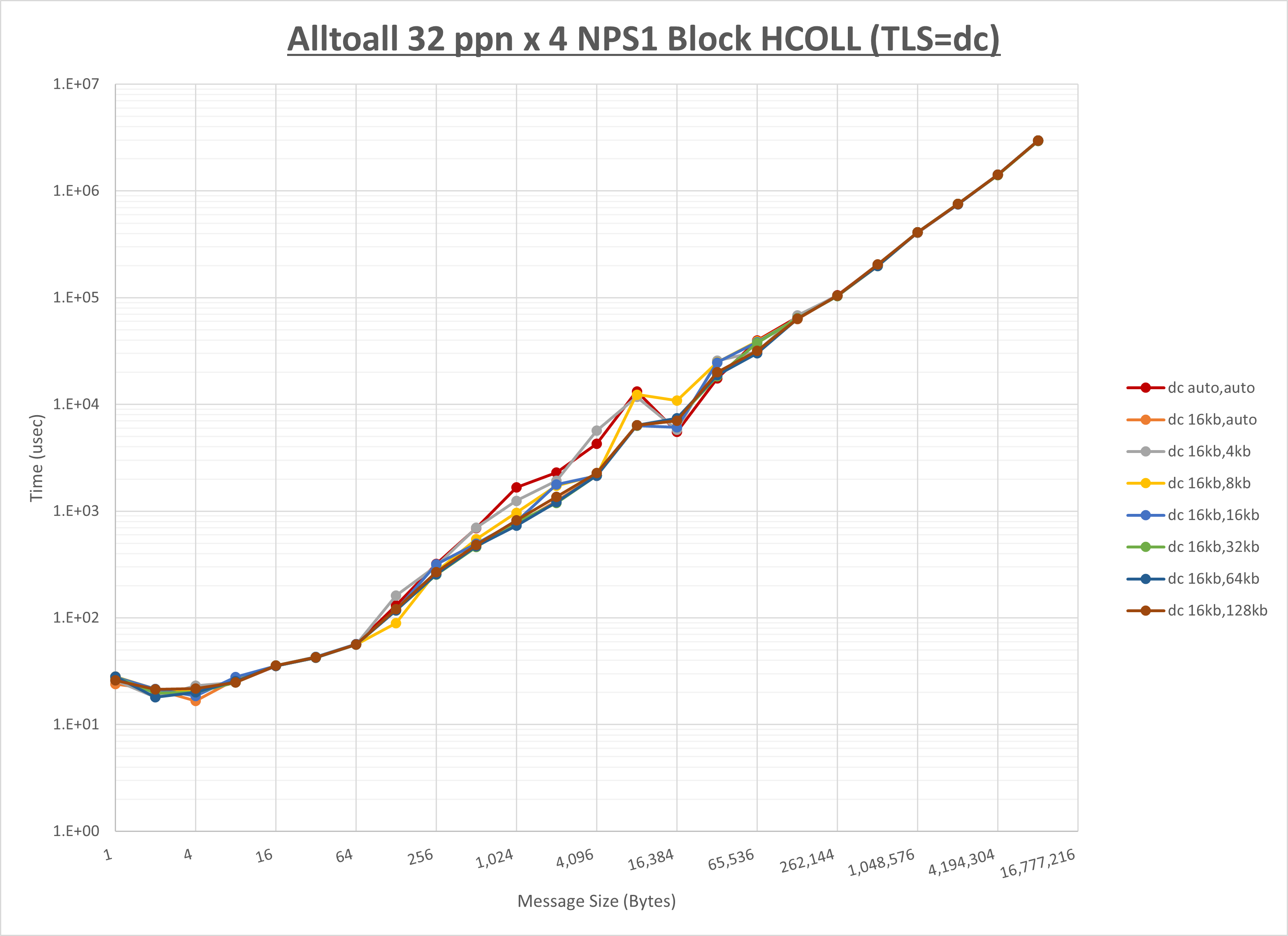
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
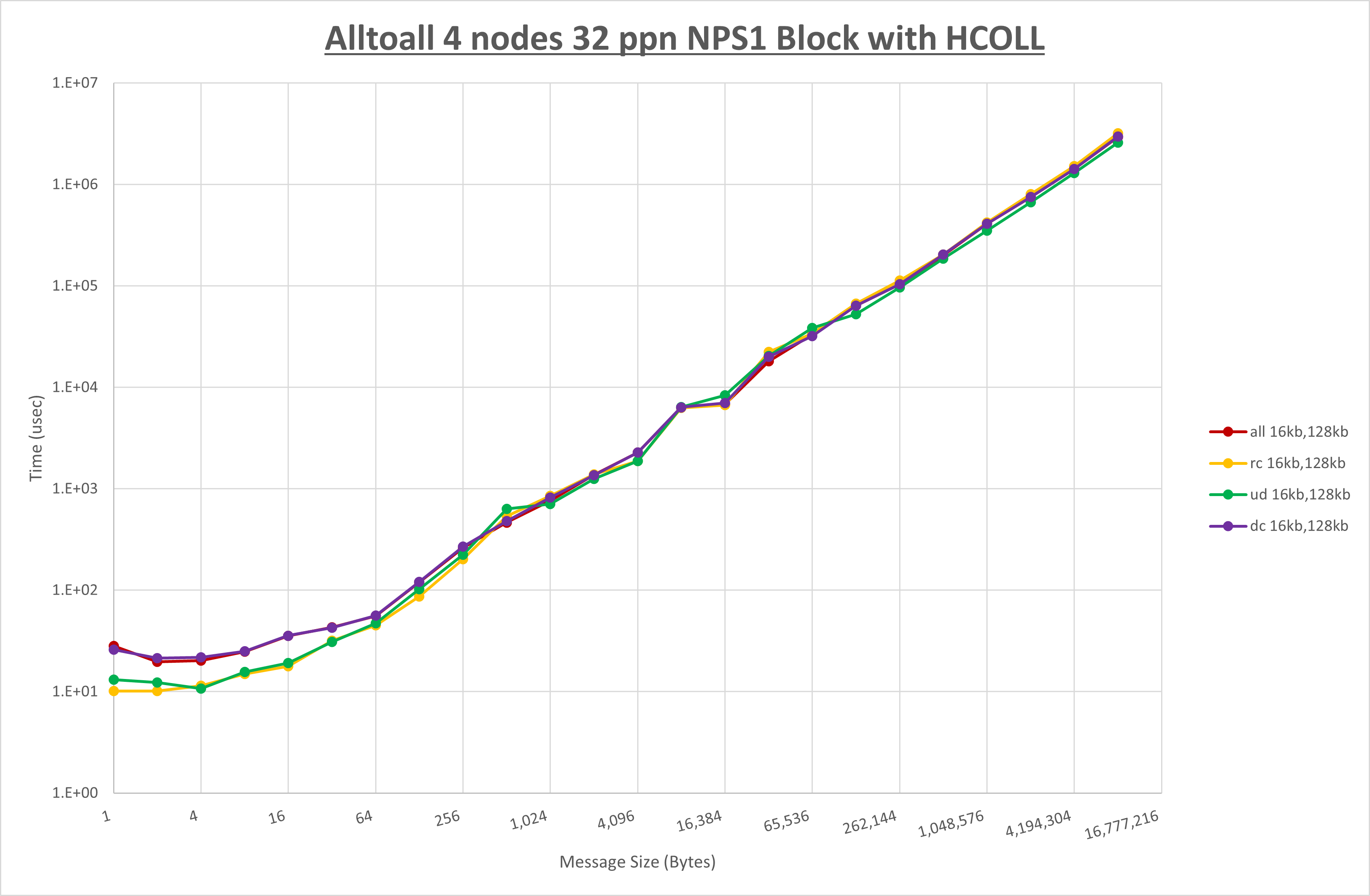
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
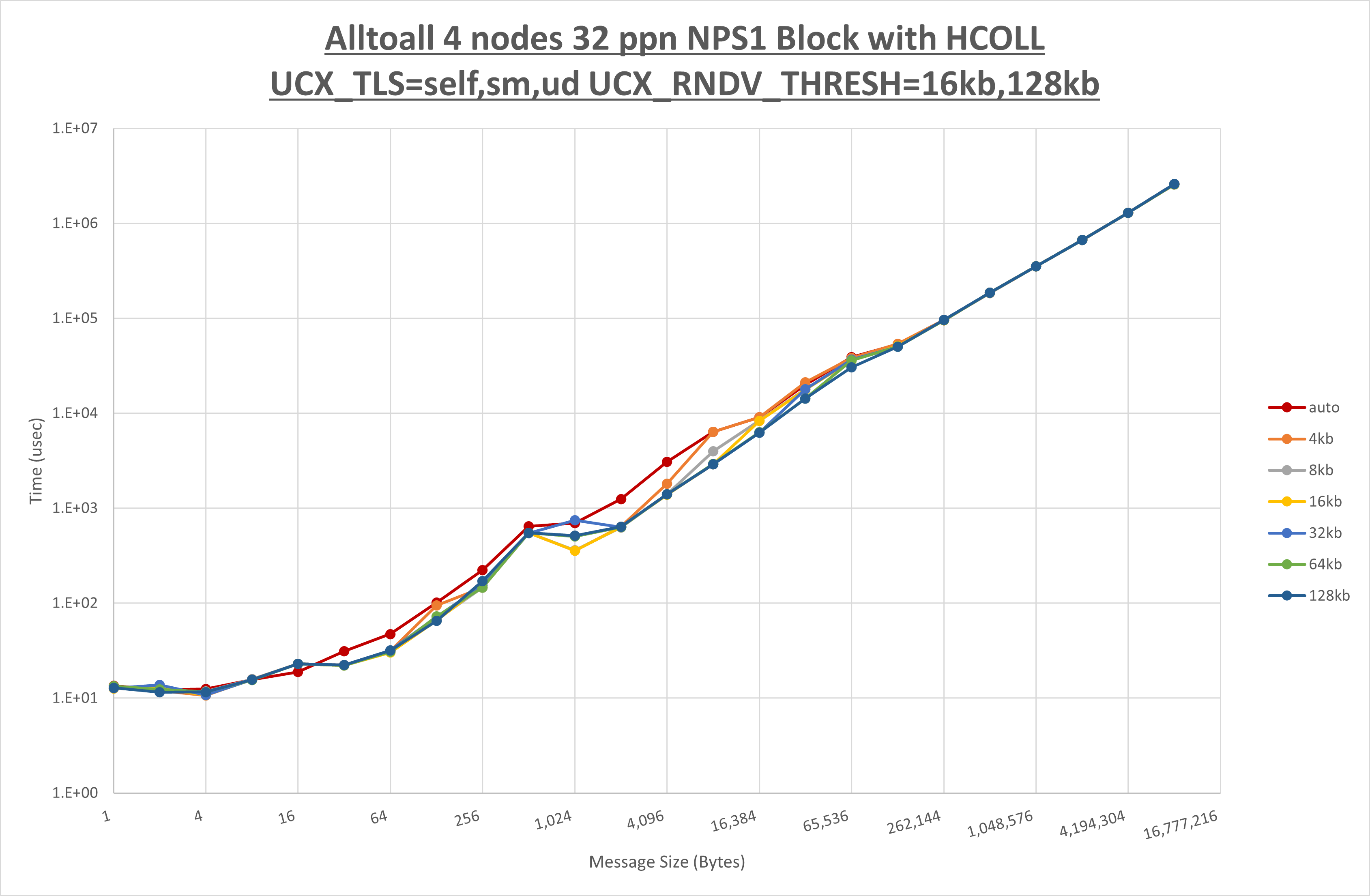
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
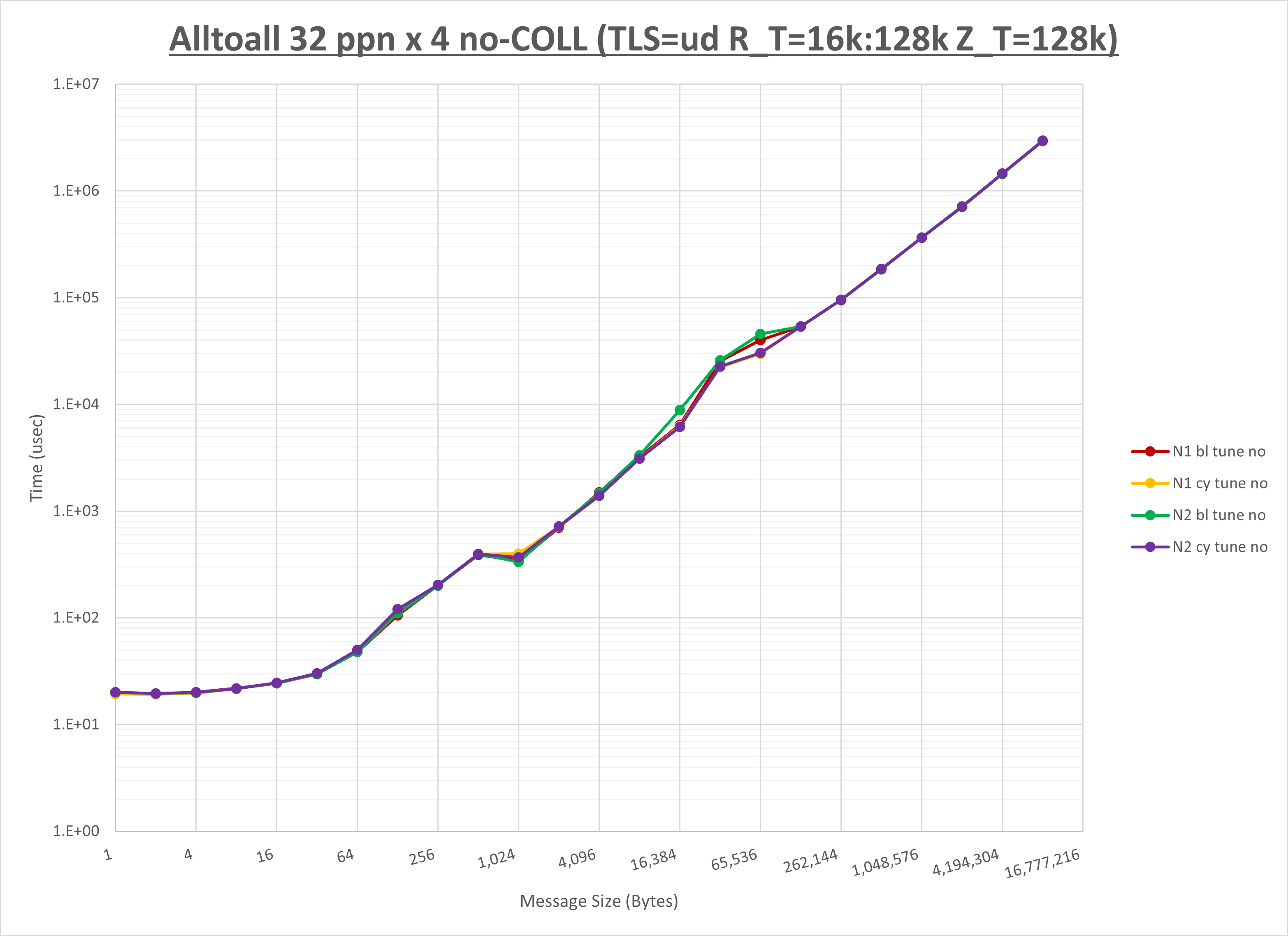
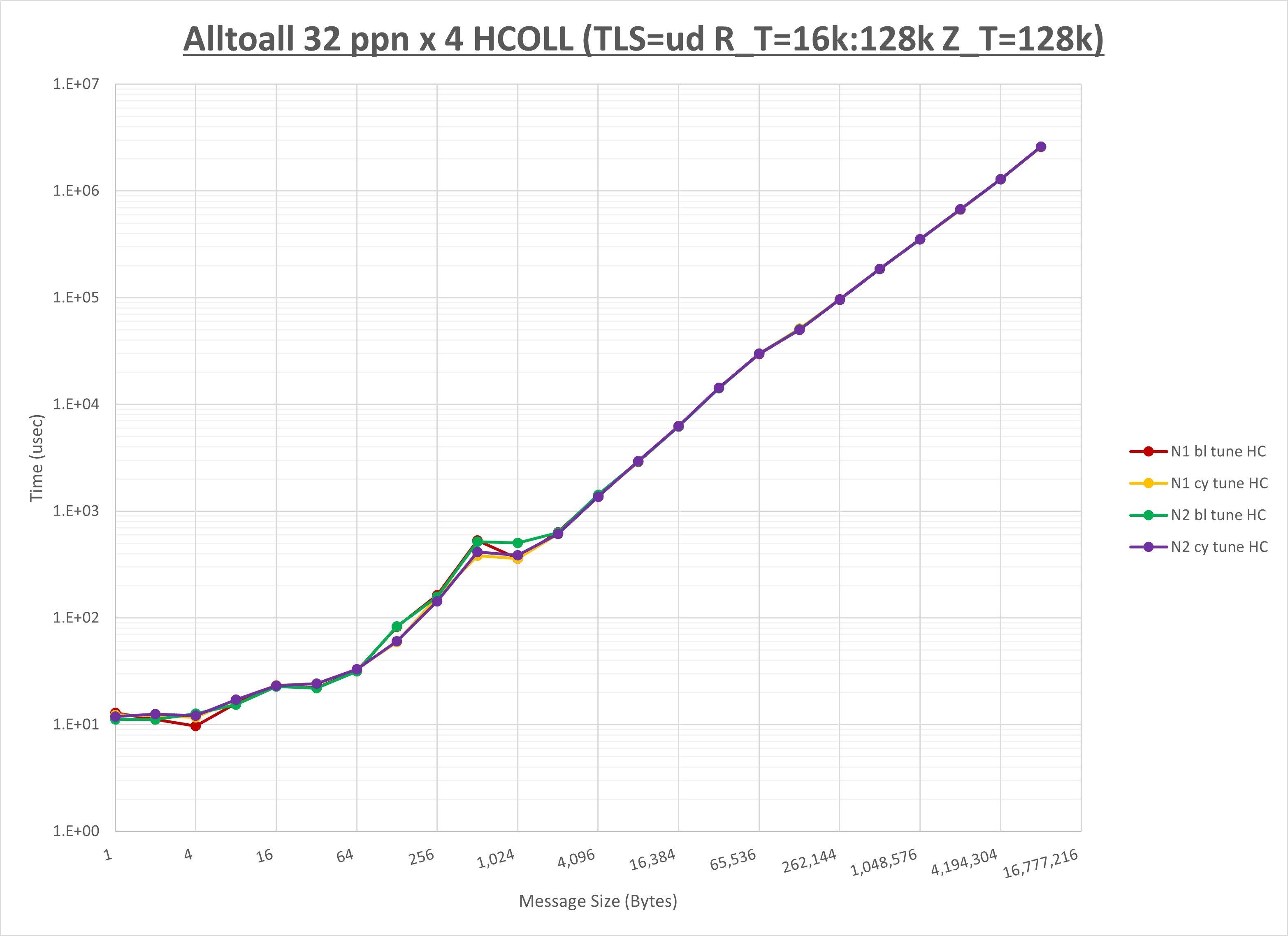
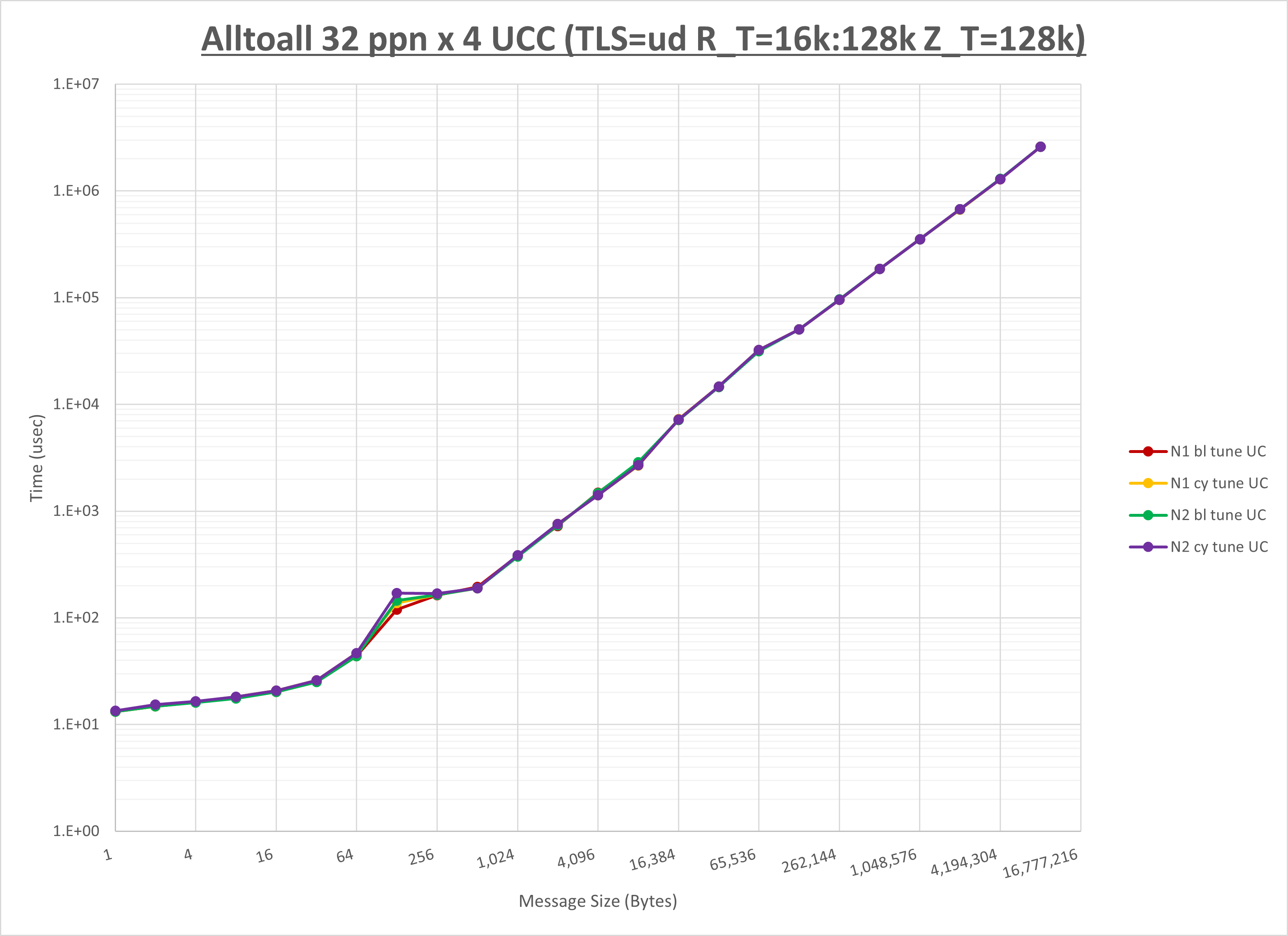
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し128B以下と32KBから64KBで性能が向上
- UCC は no-COLL と比較し4Bから64Bで性能が向上
- チューニング適用で全域にわたって性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-2 Allgather の HCOLL の結果から16KBとしています。
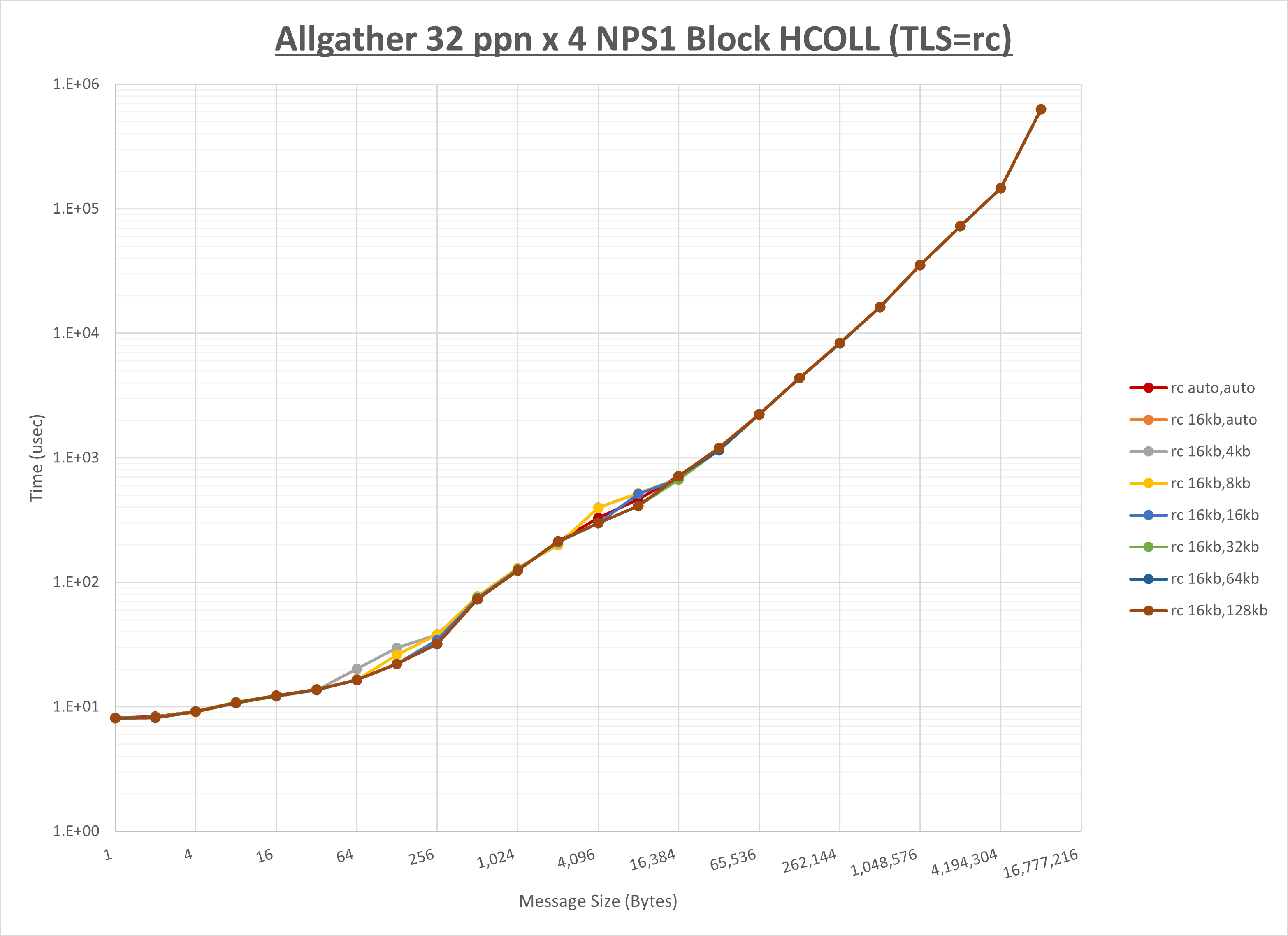
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
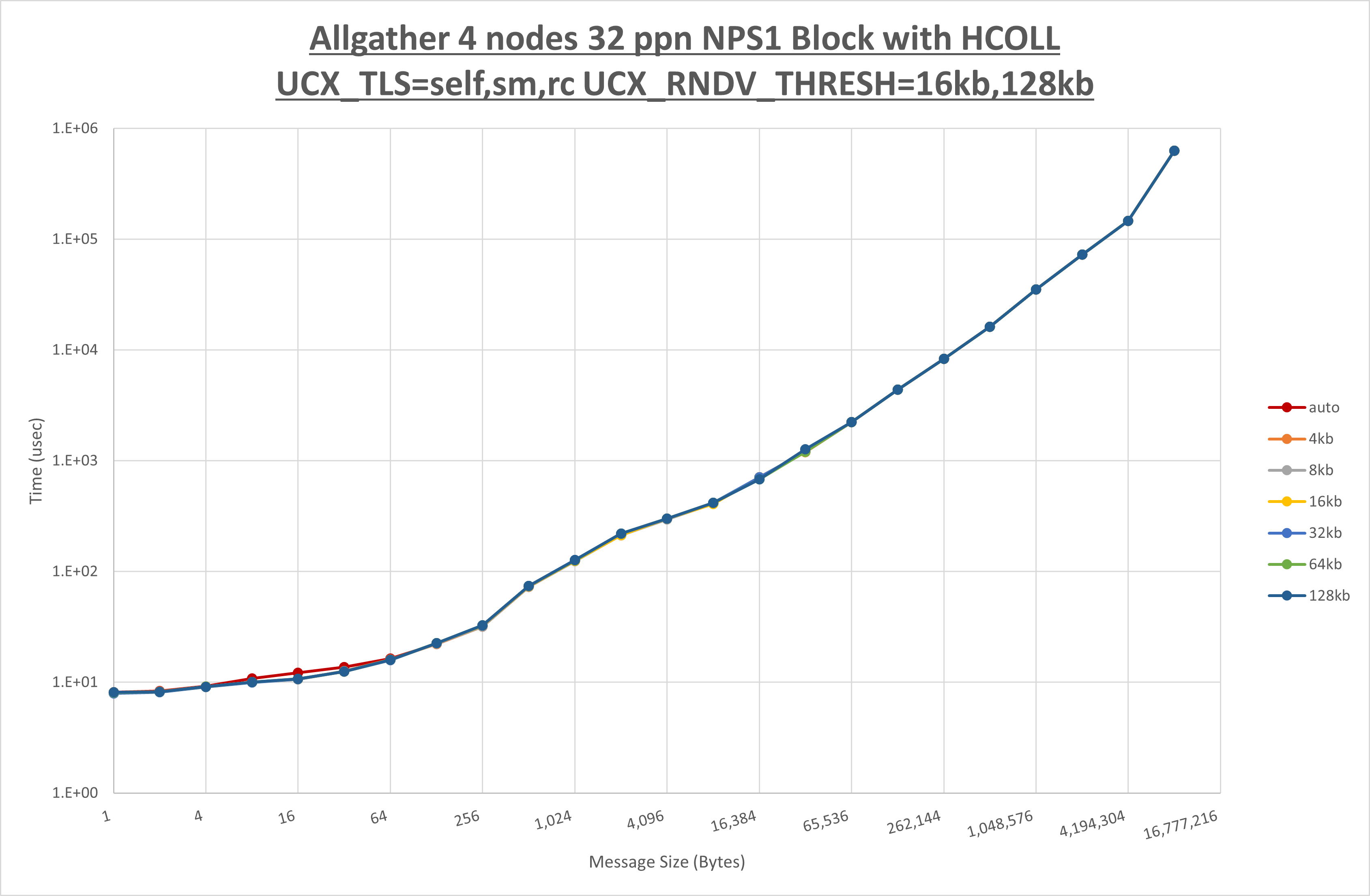
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
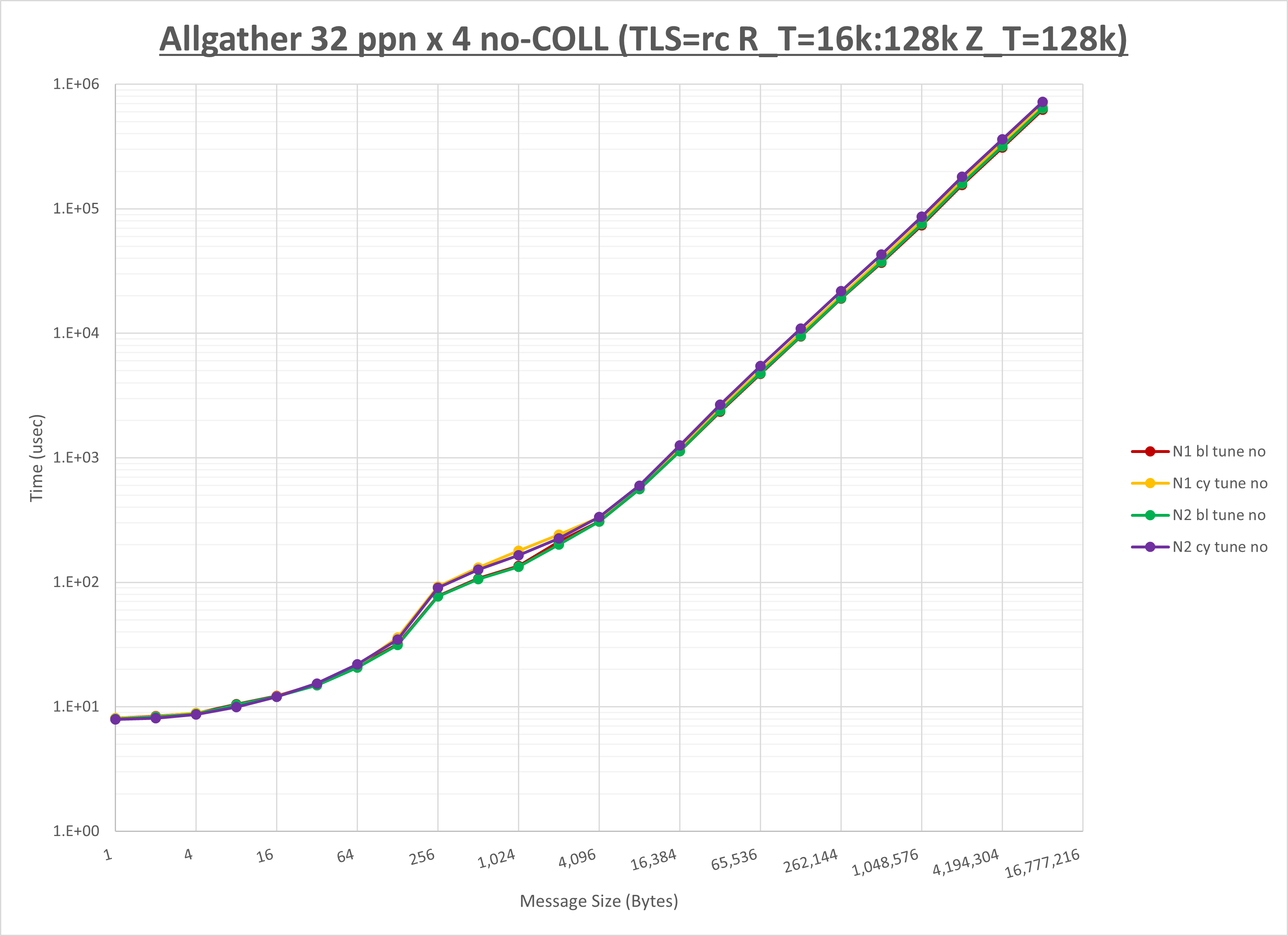
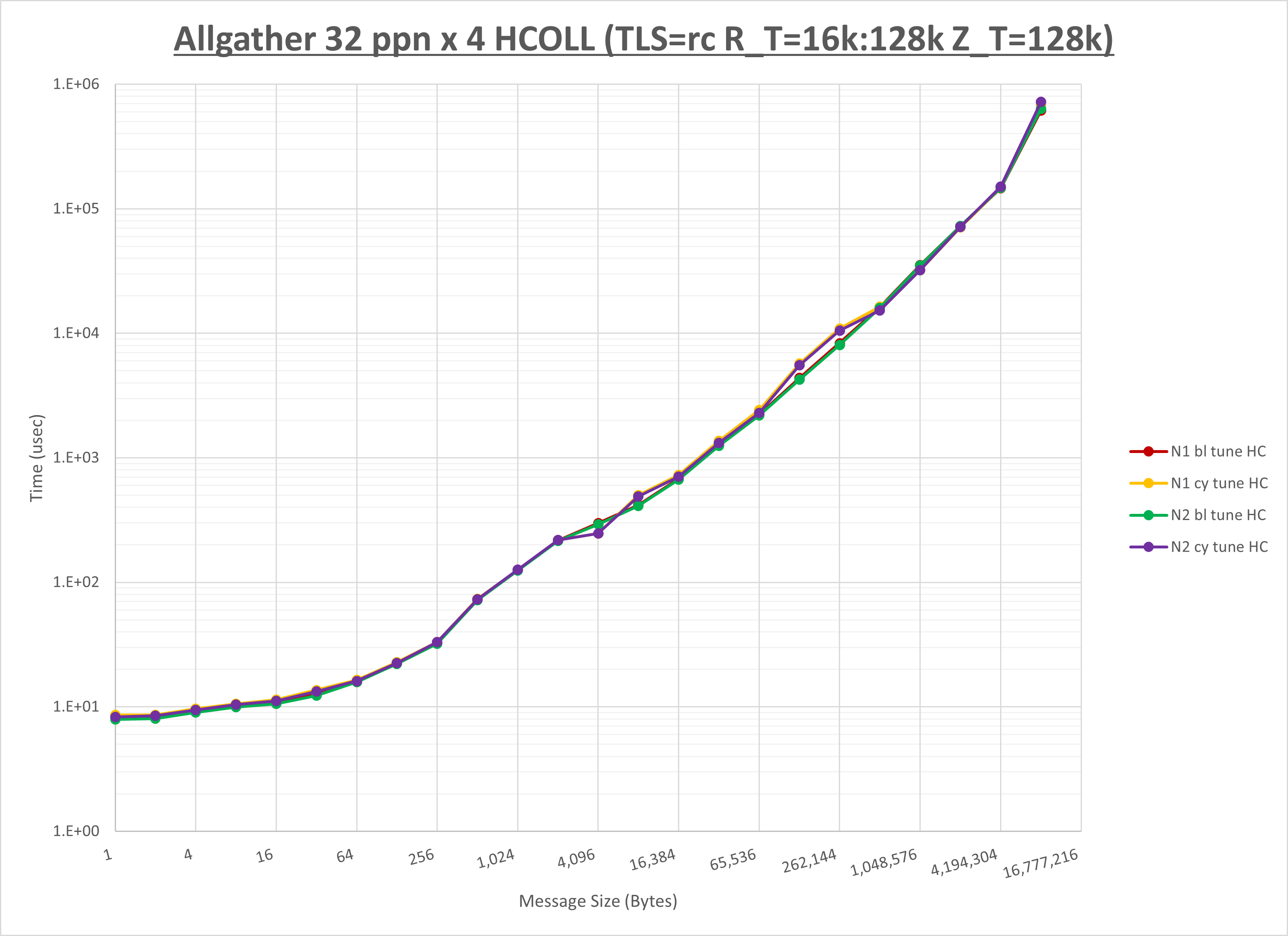
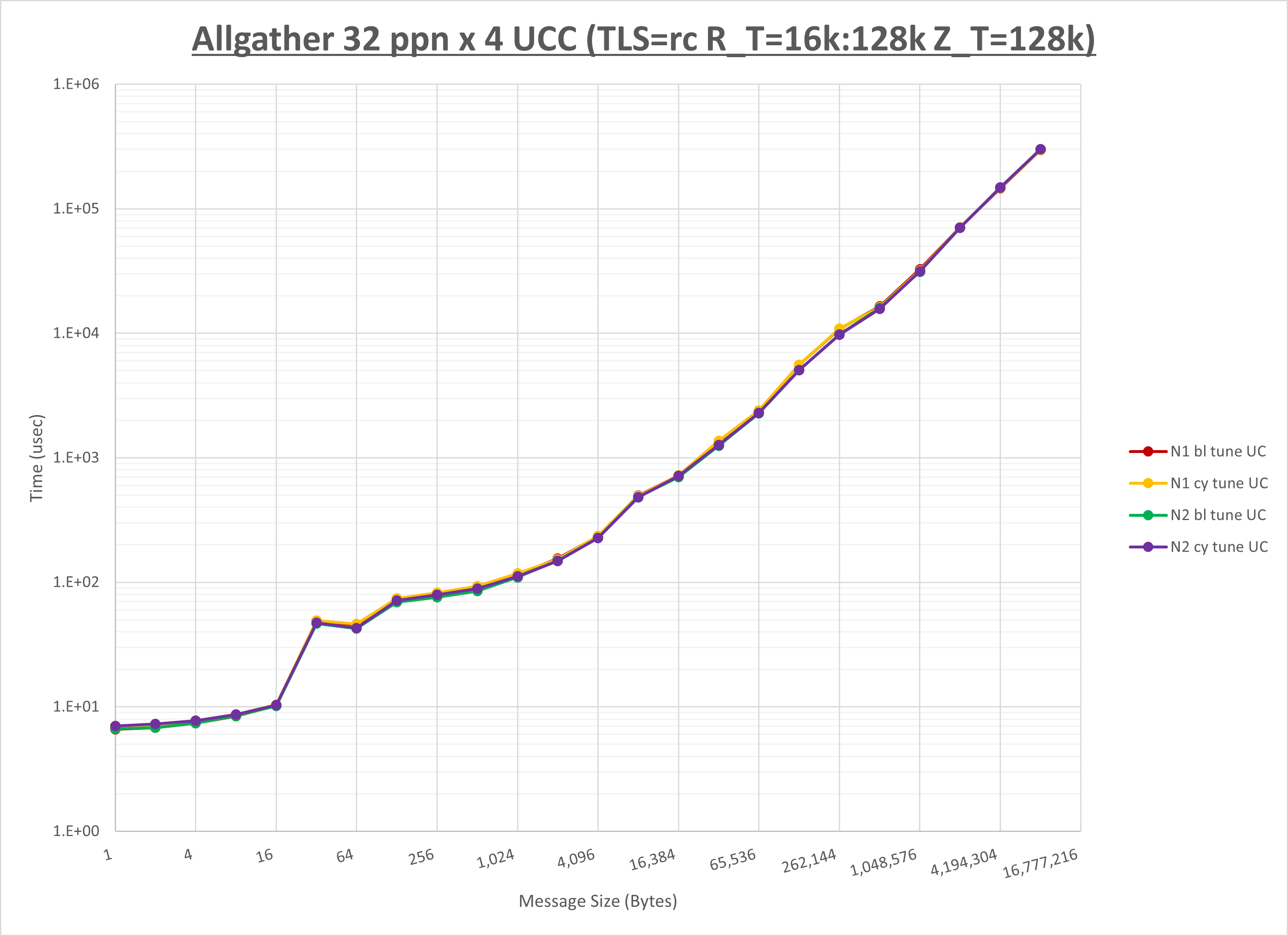
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し16B以下と512B以上で性能が向上し32Bから512Bで性能が低下
- チューニング適用で32KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-3 Allreduce の HCOLL の結果から128KBとしています。
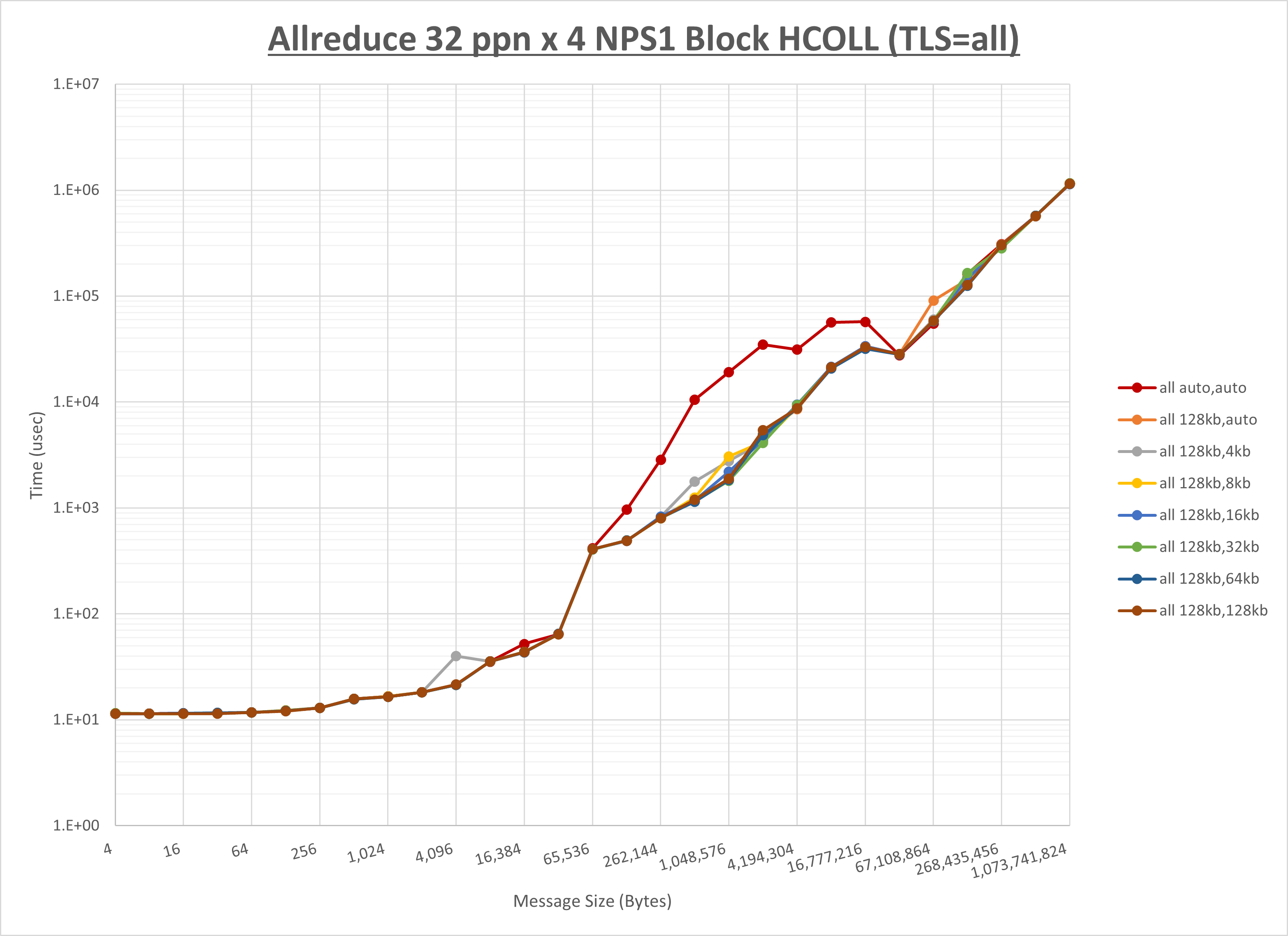
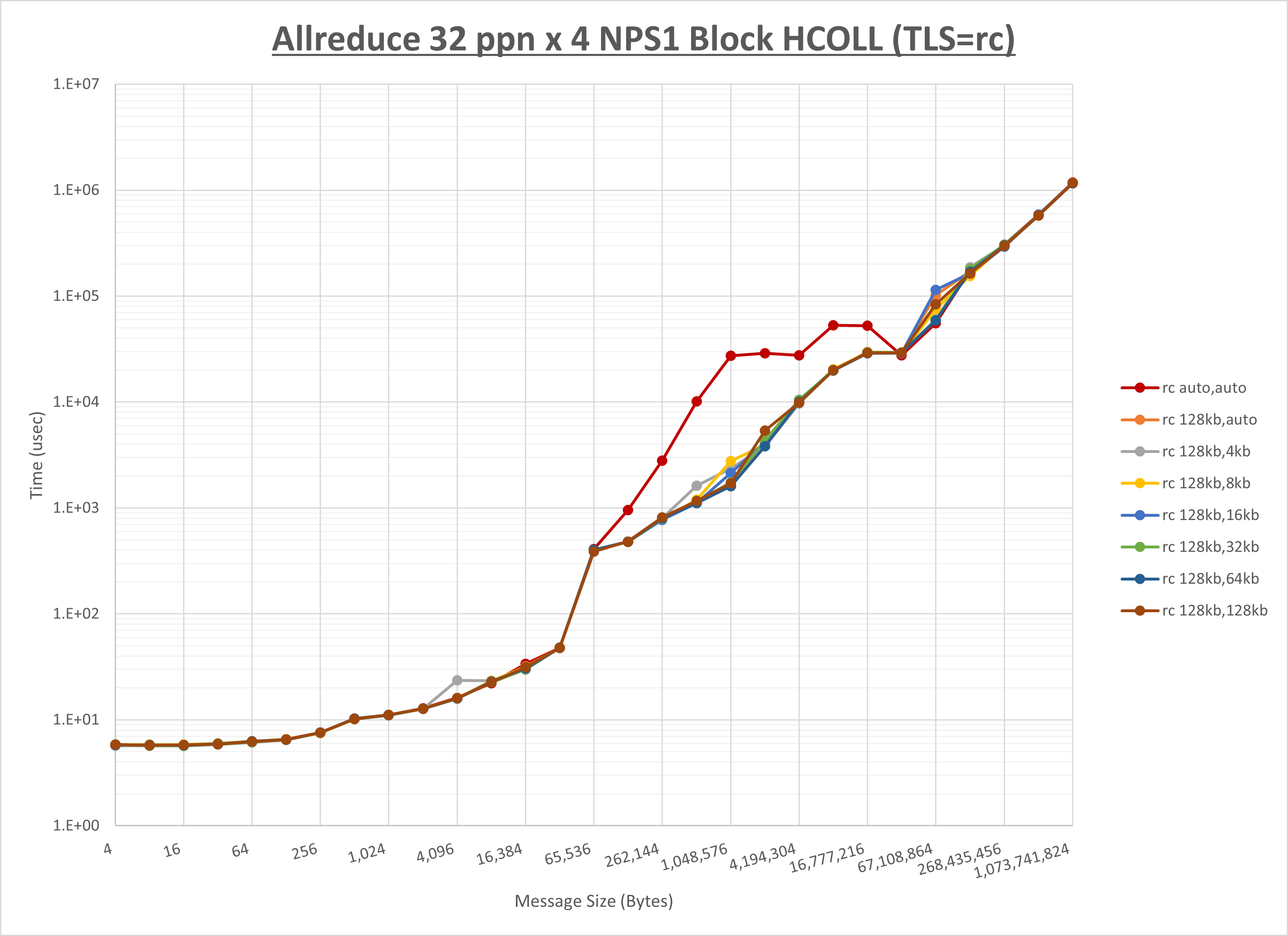
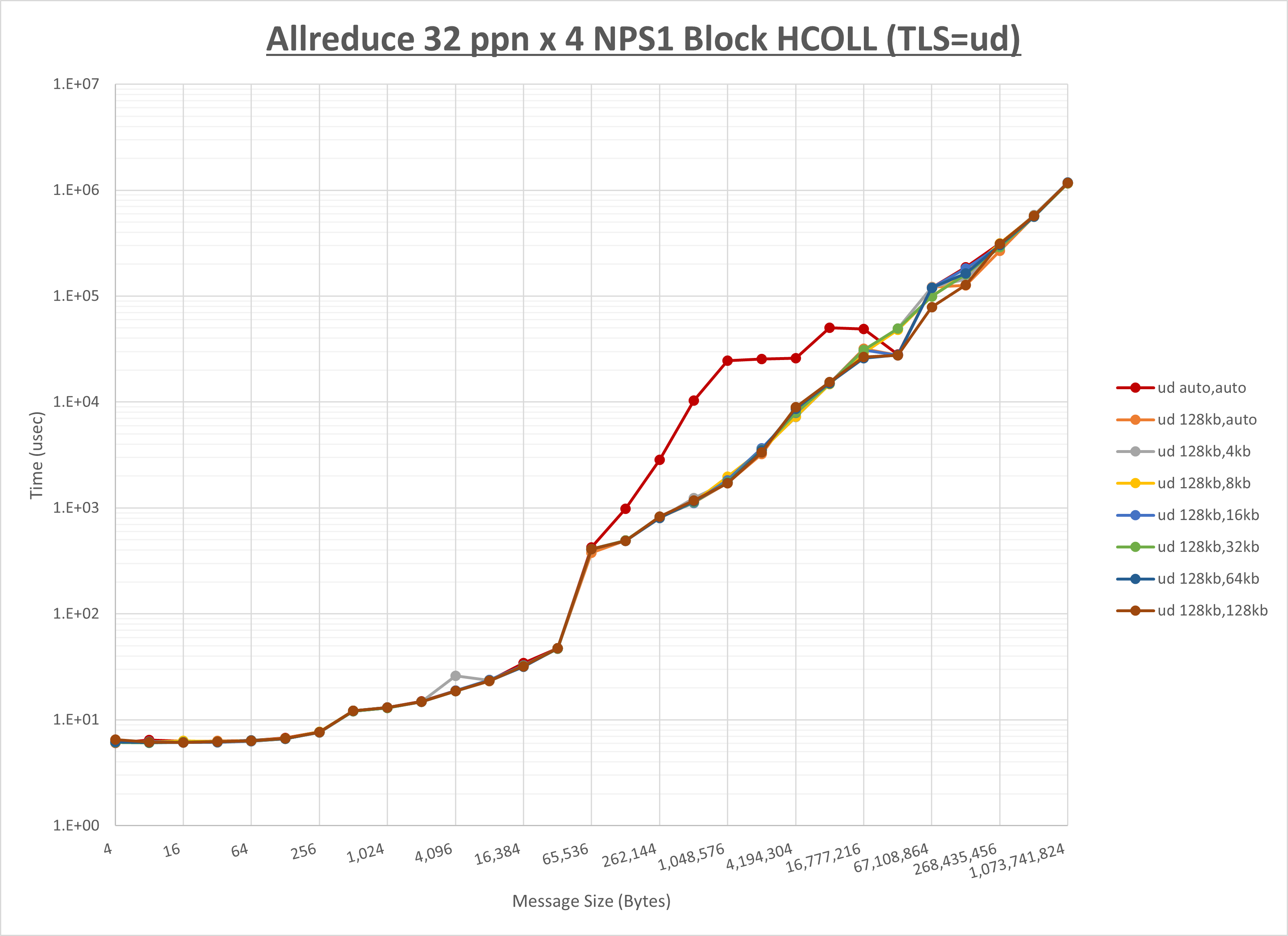
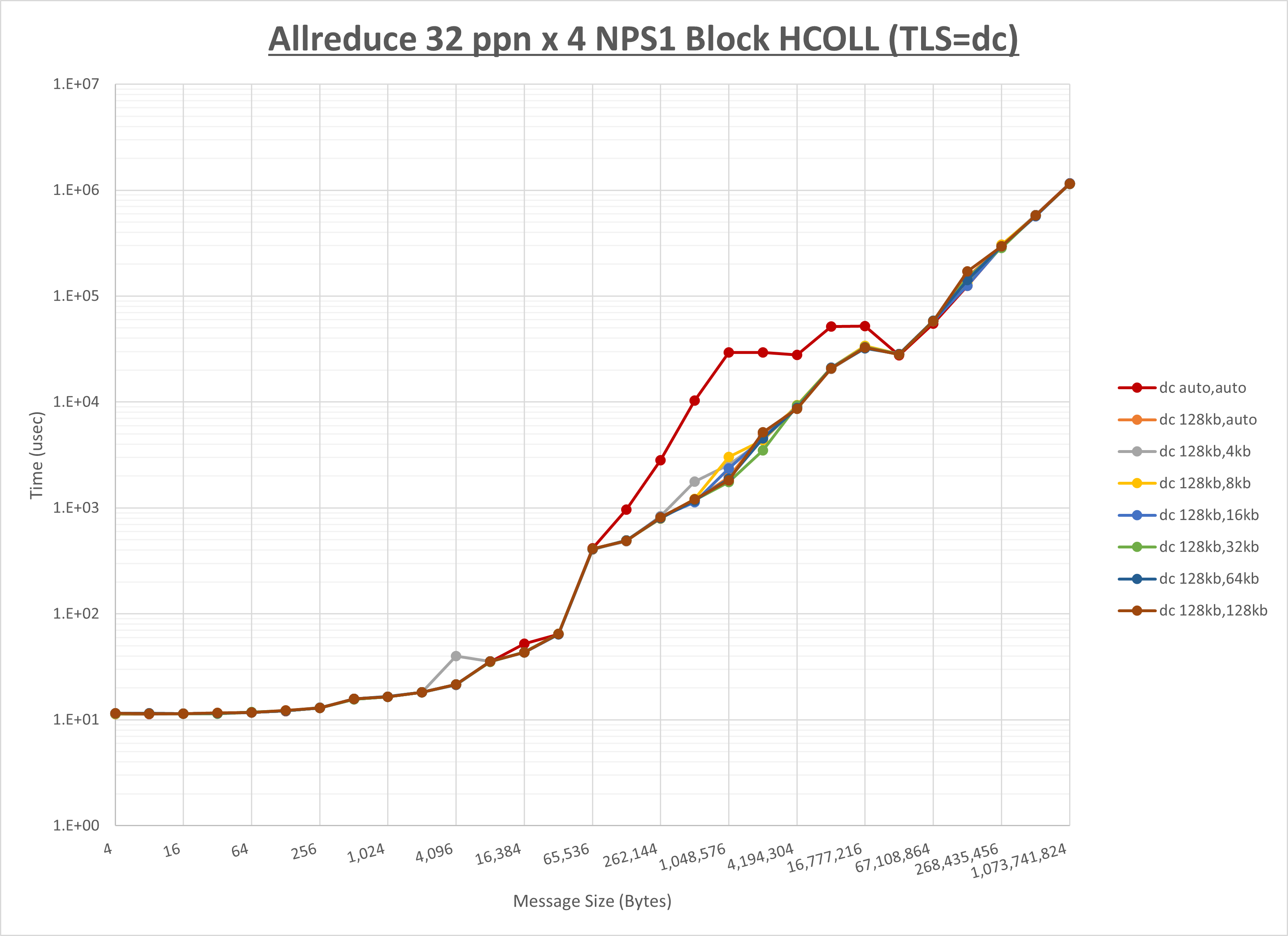
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
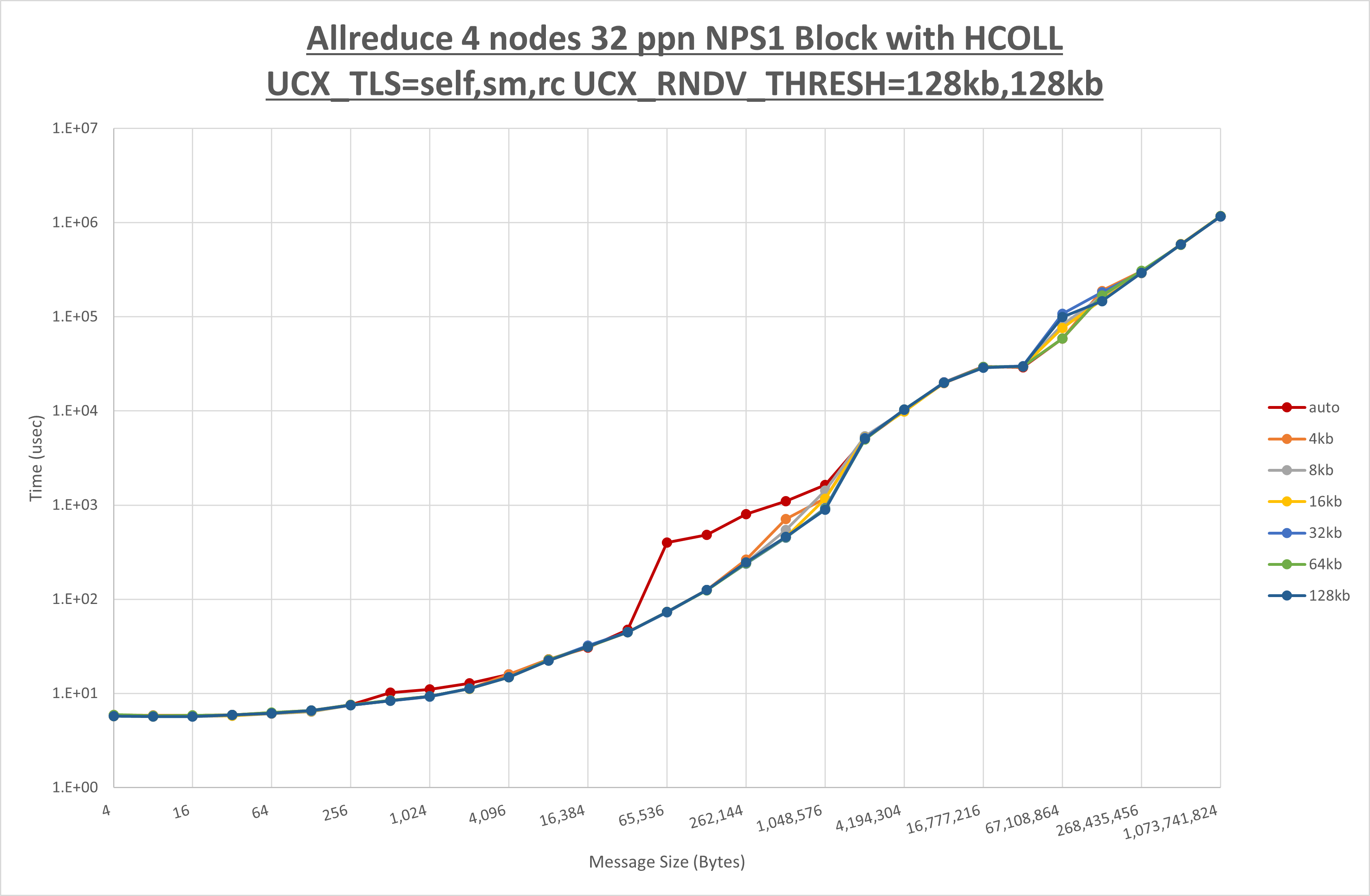
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
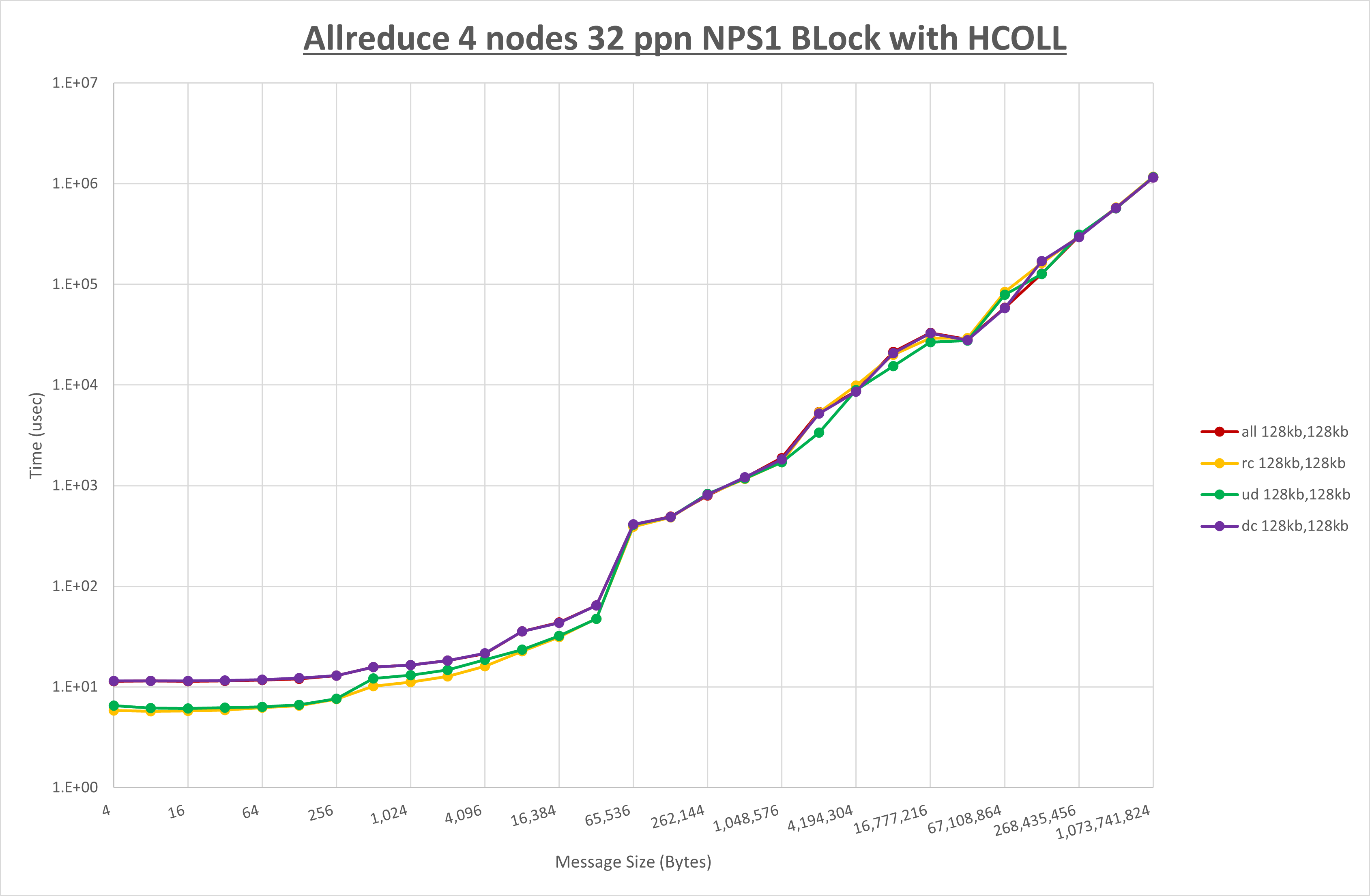
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
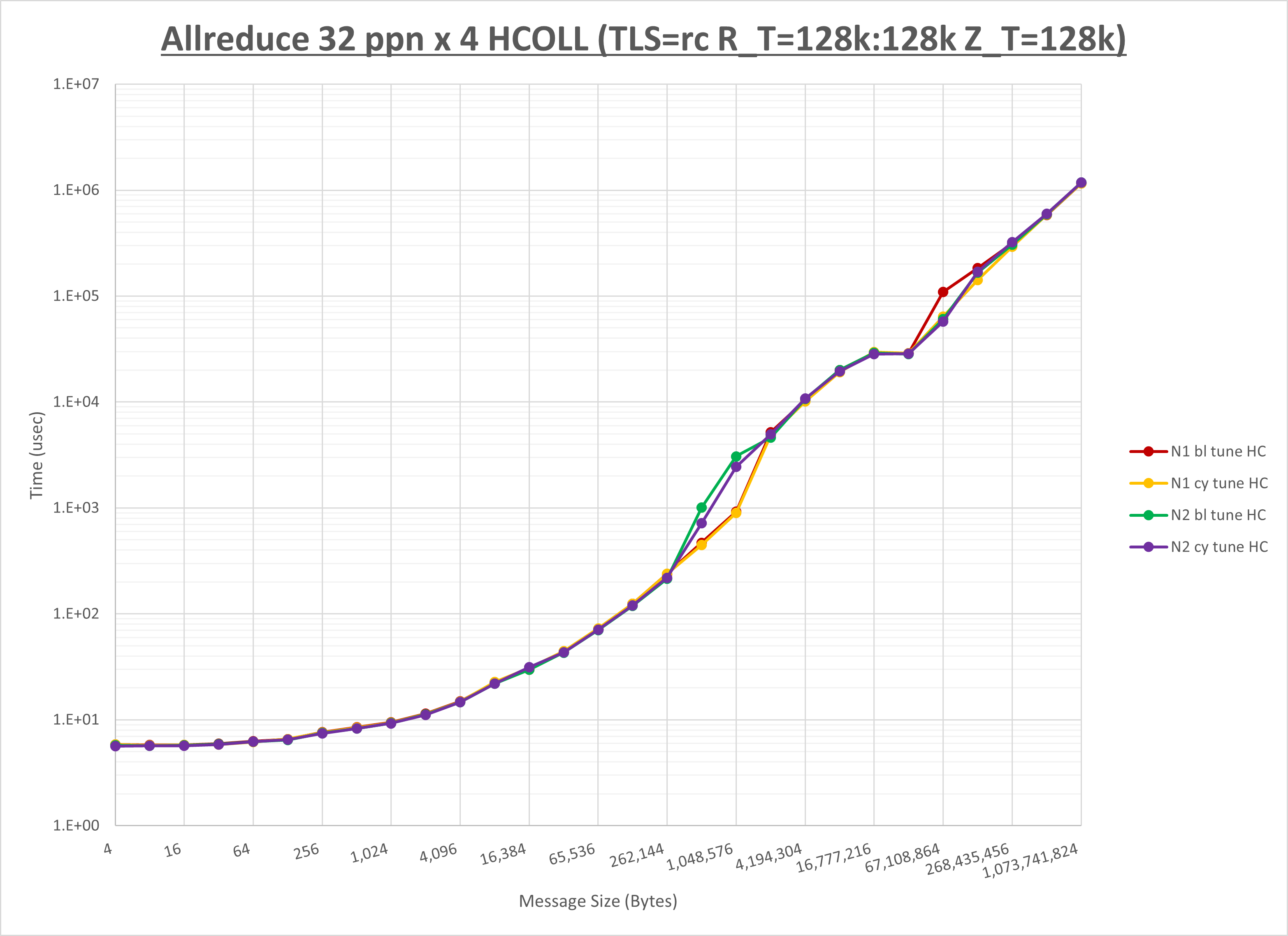
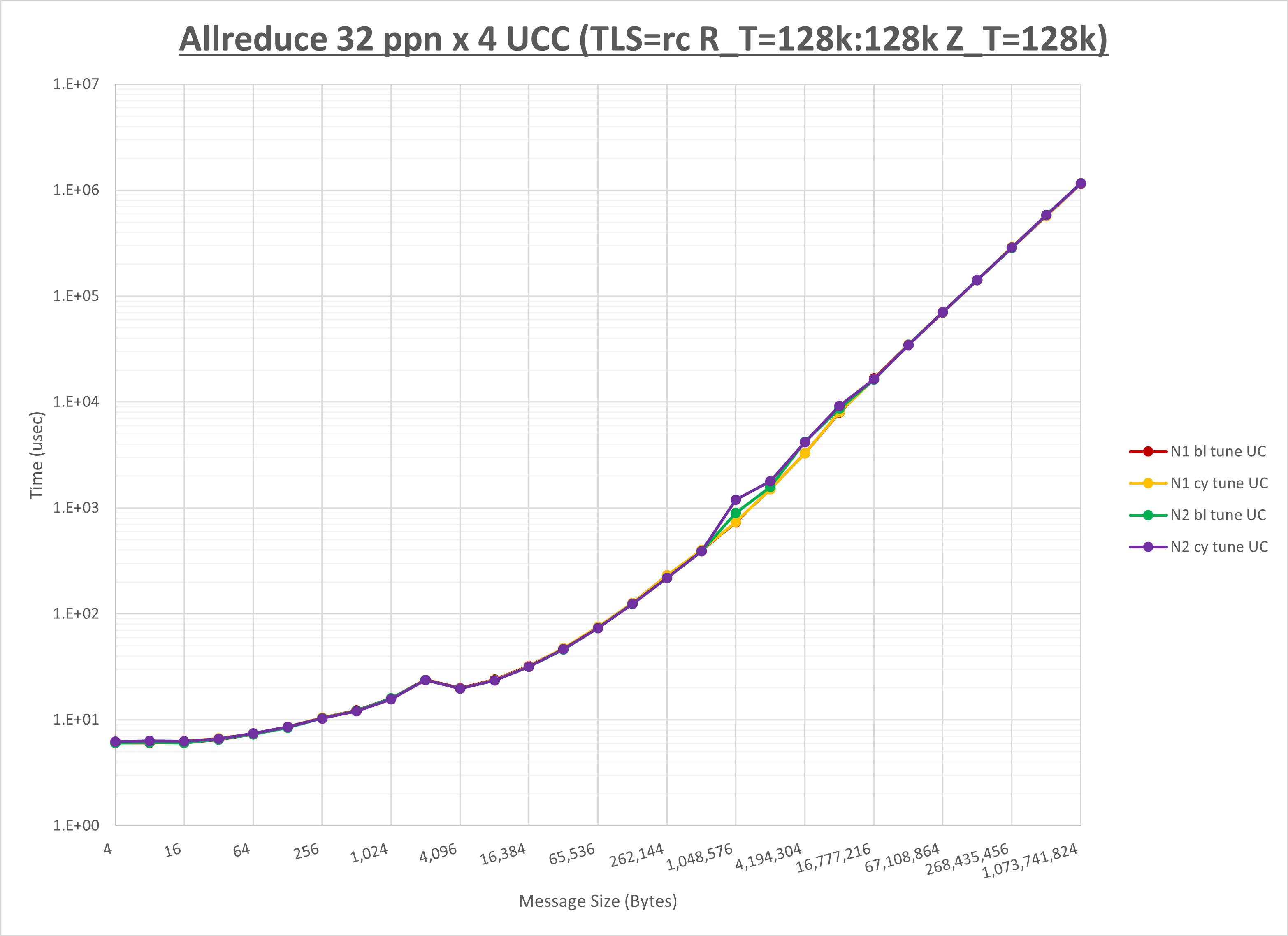
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
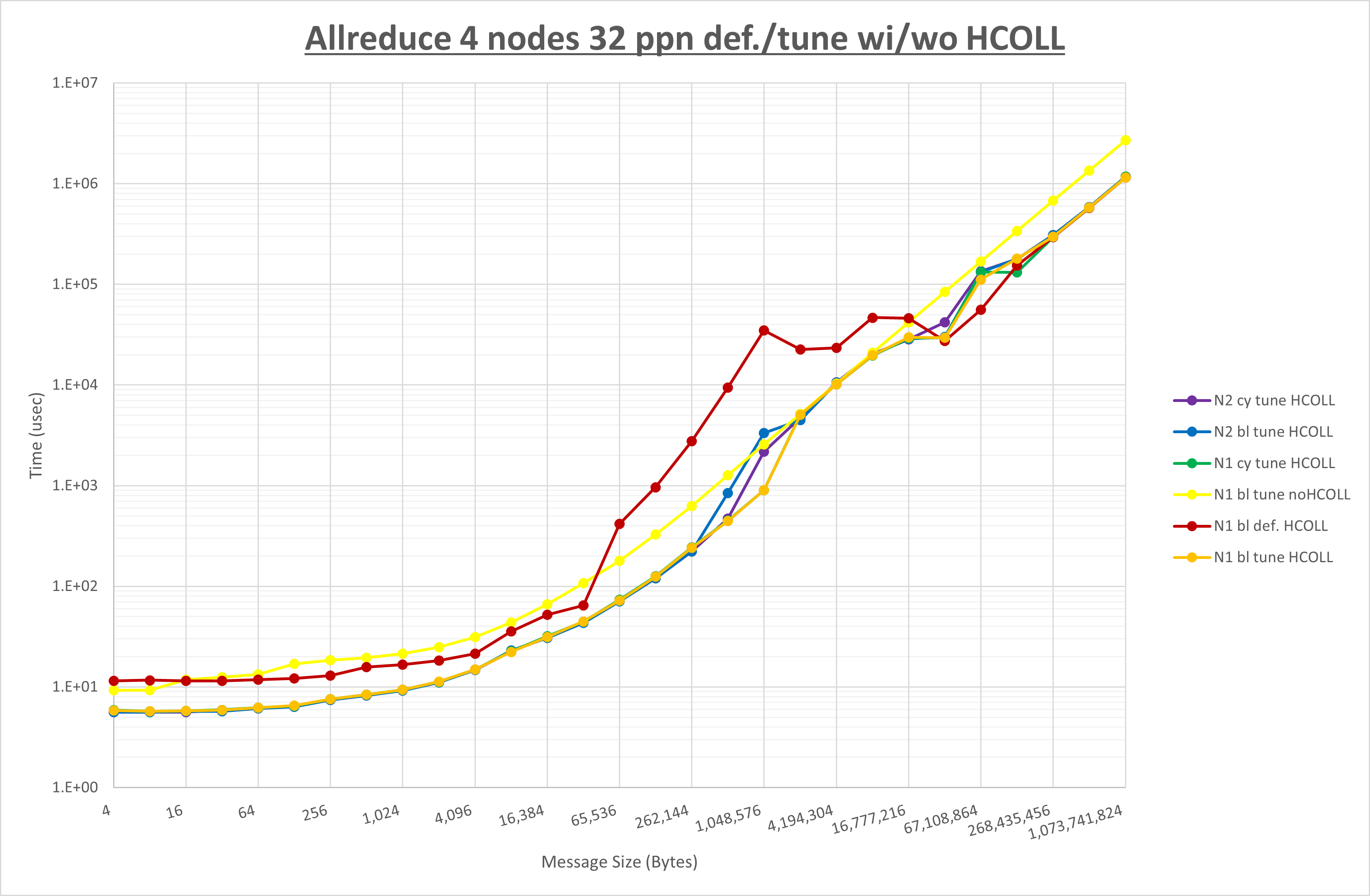
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し256B以上で性能が向上し128B以下で性能が低下
- チューニング適用で8MB以下で性能が向上し256MB以上で性能が低下
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-4 Exchange の結果から16KBとしています。
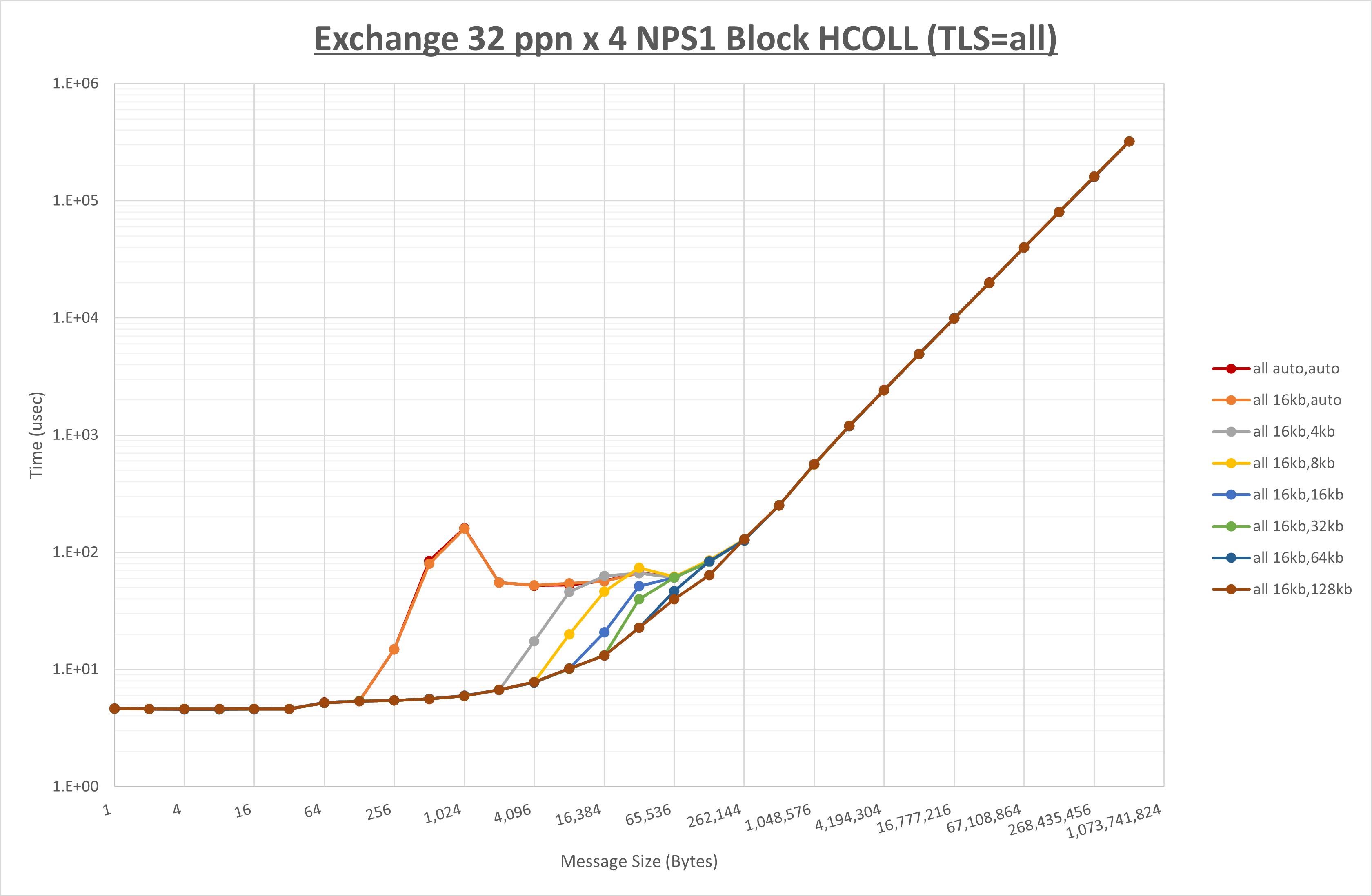
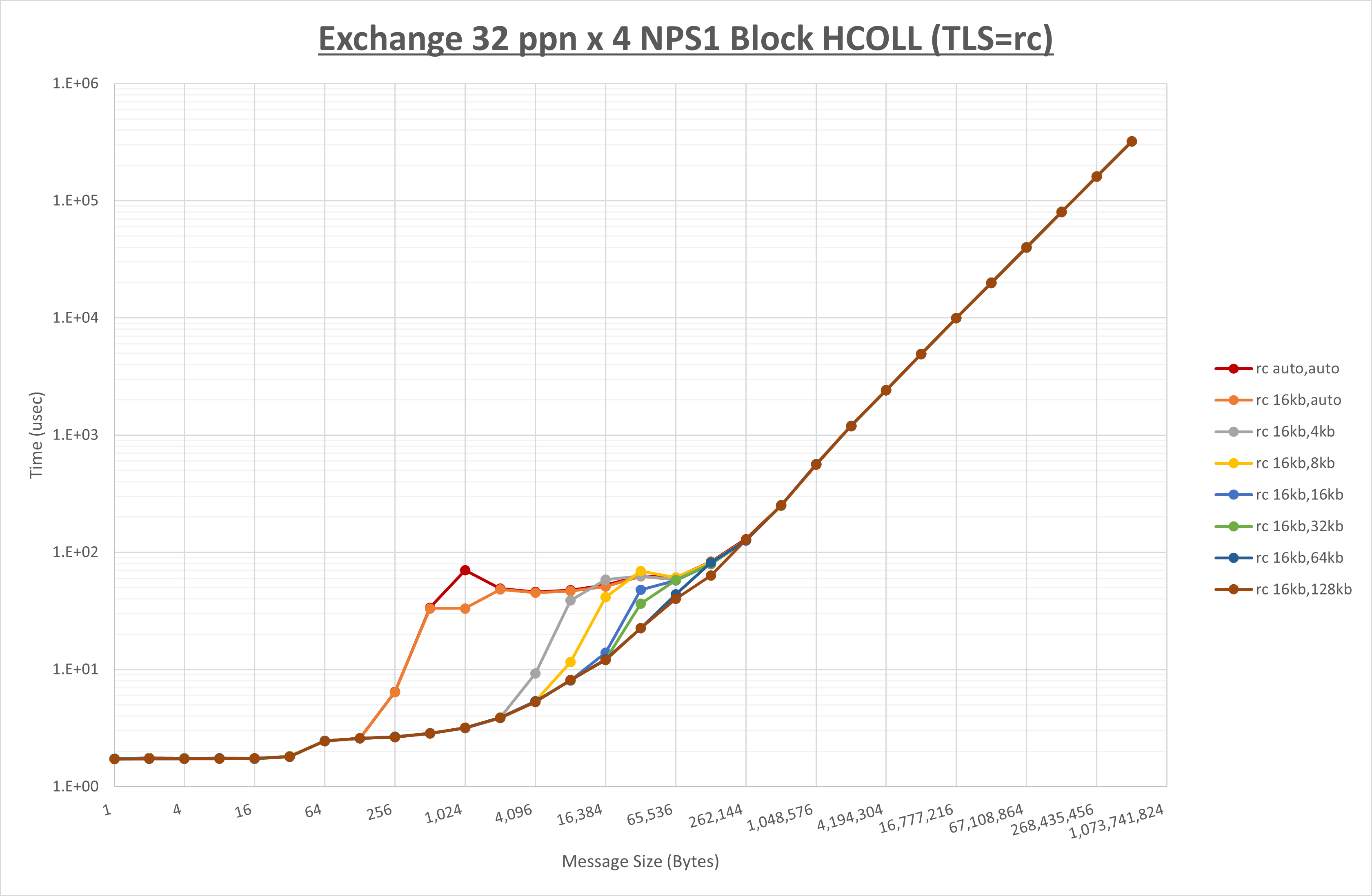
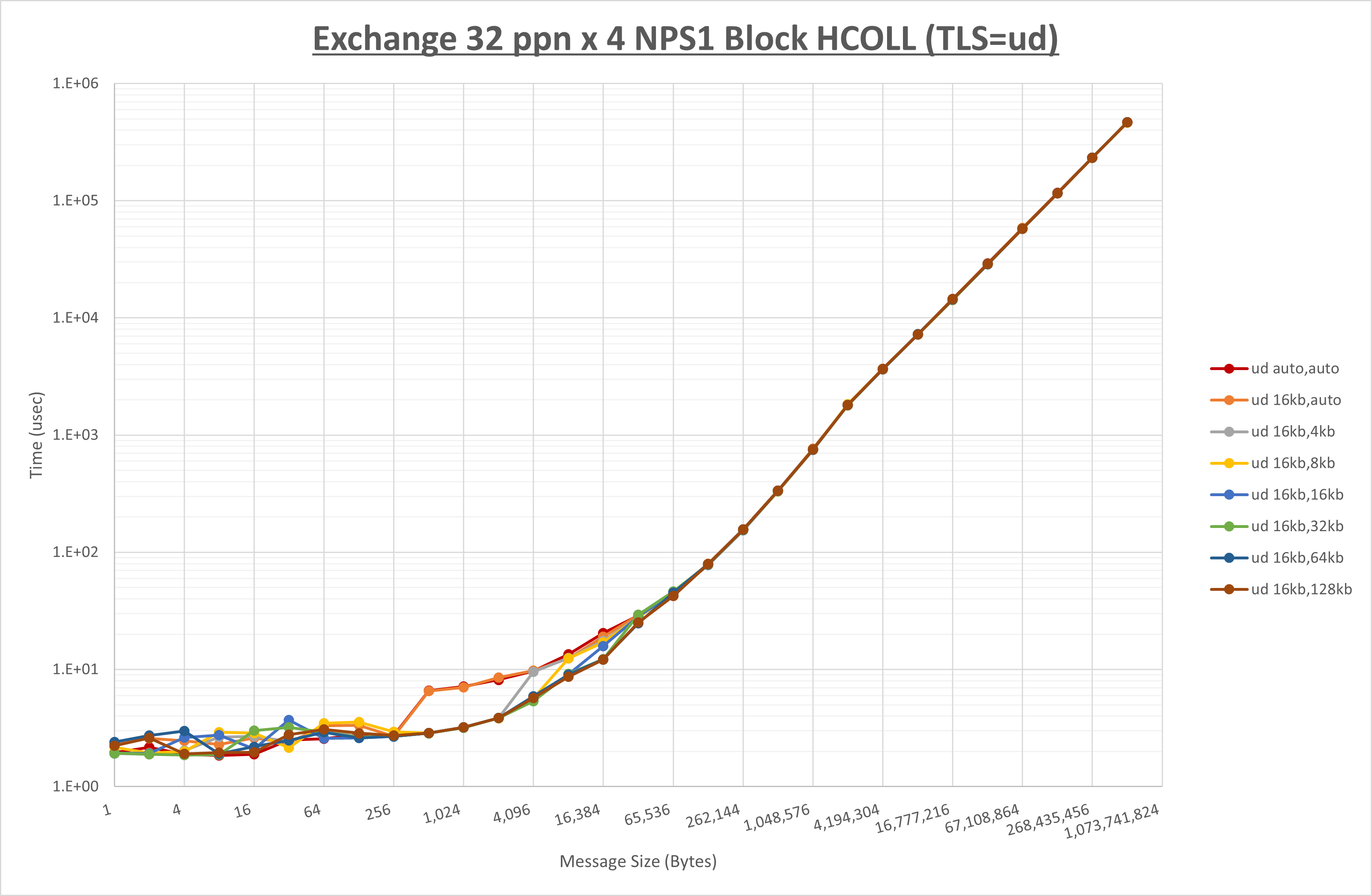
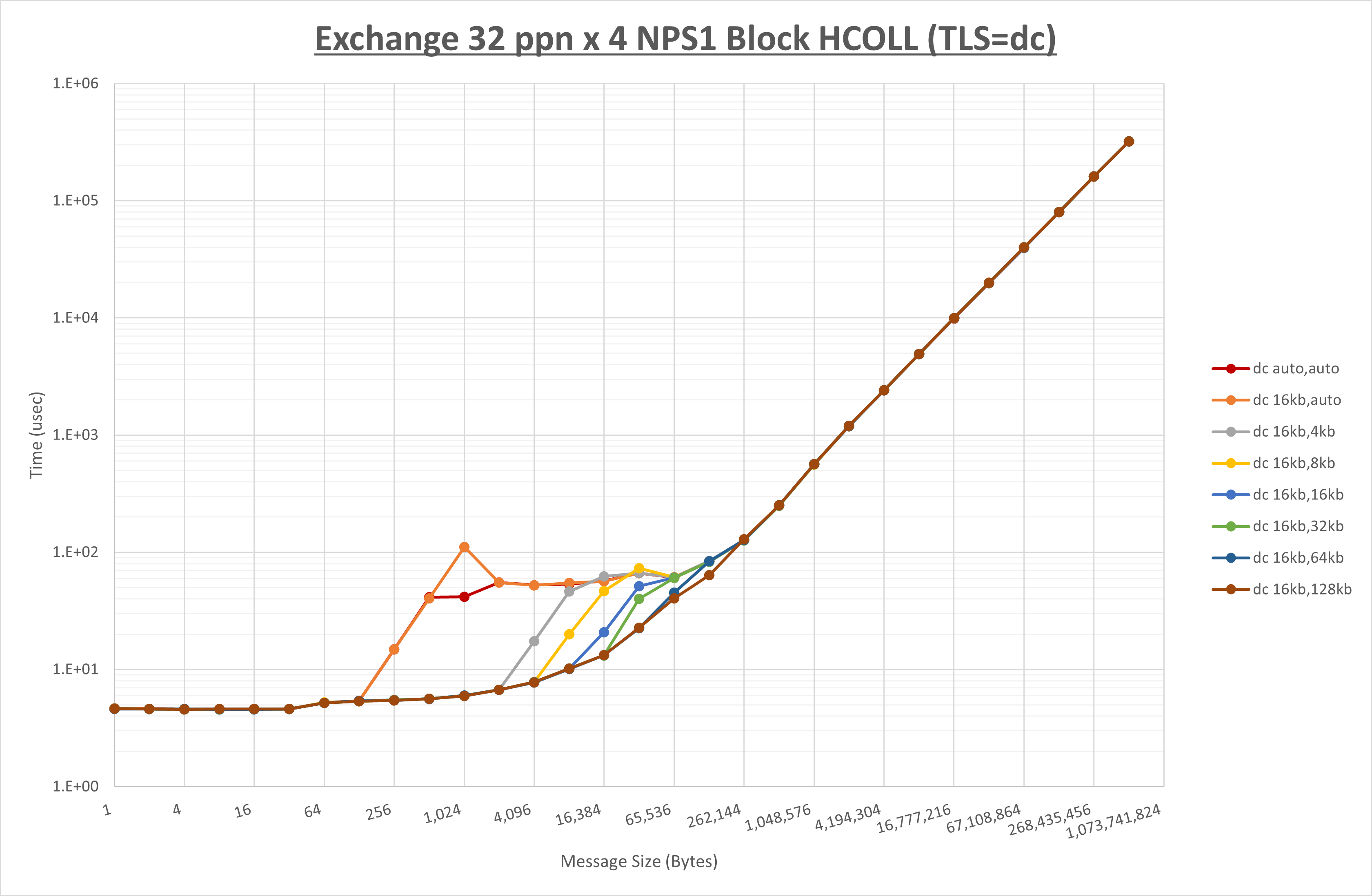
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
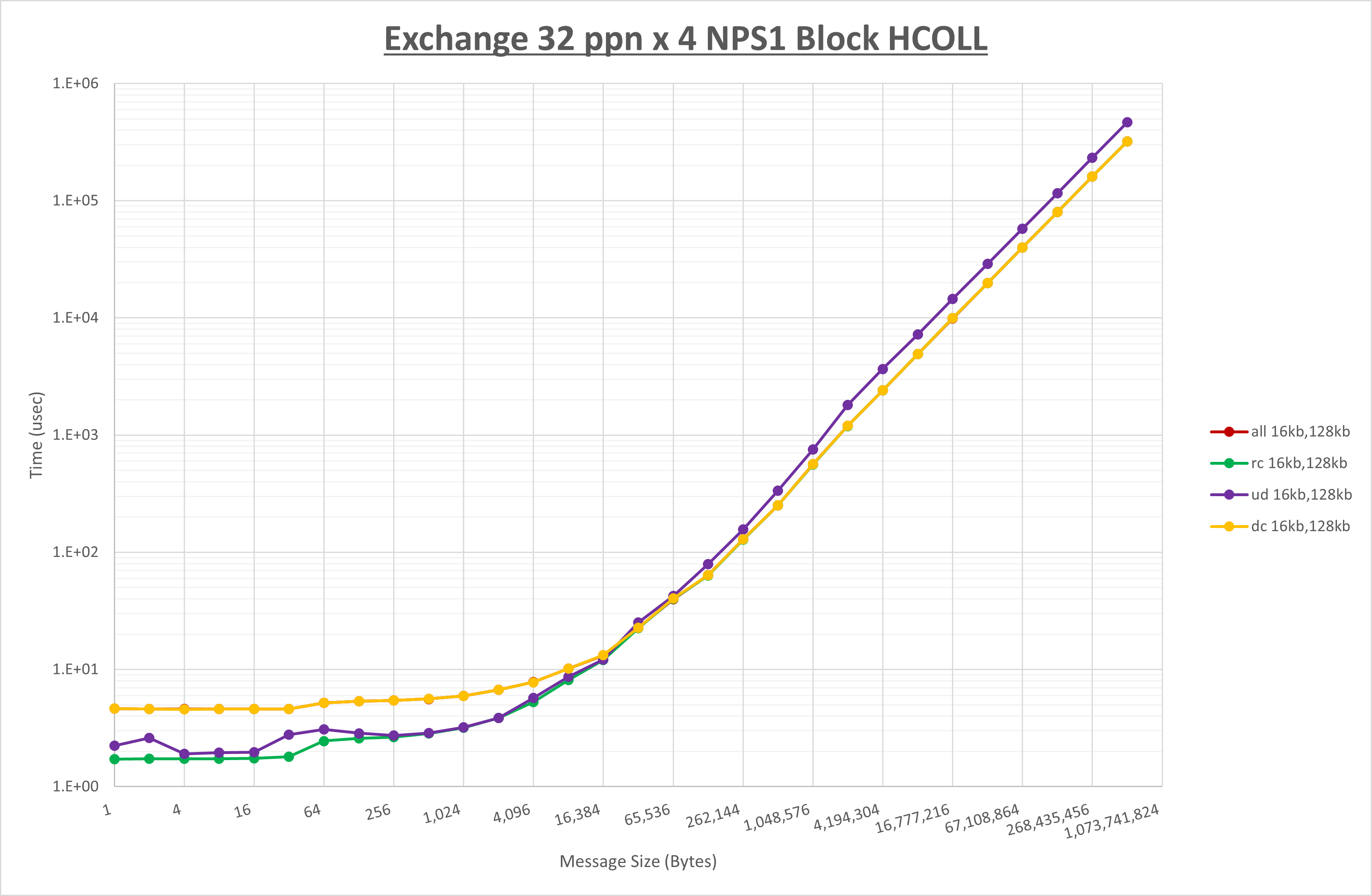
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、4ノードにノード当たり36、トータル144のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:16kb,inter:32kb | 128kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:64kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-1 Alltoall の HCOLL の結果から16KBとしています。
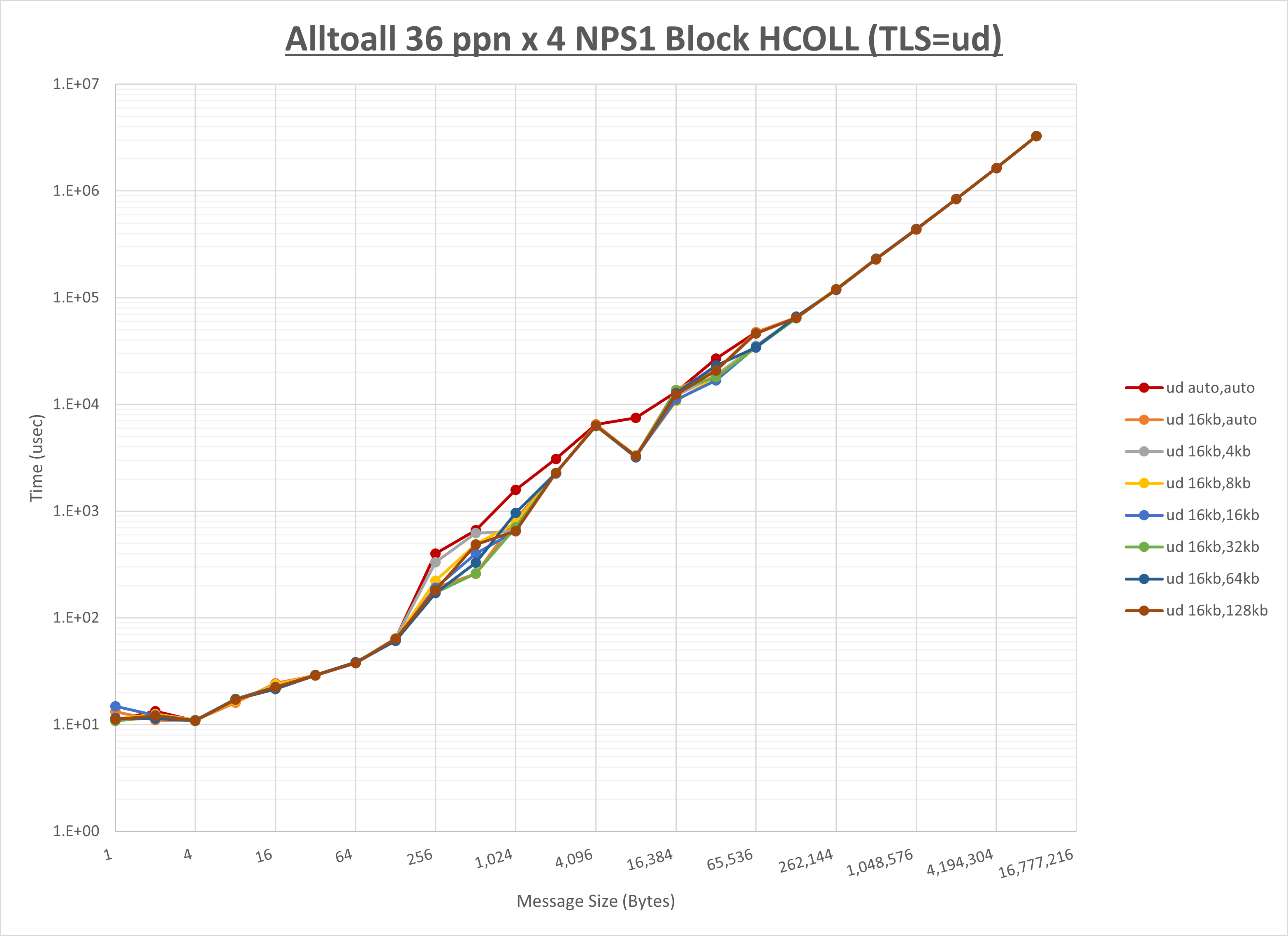
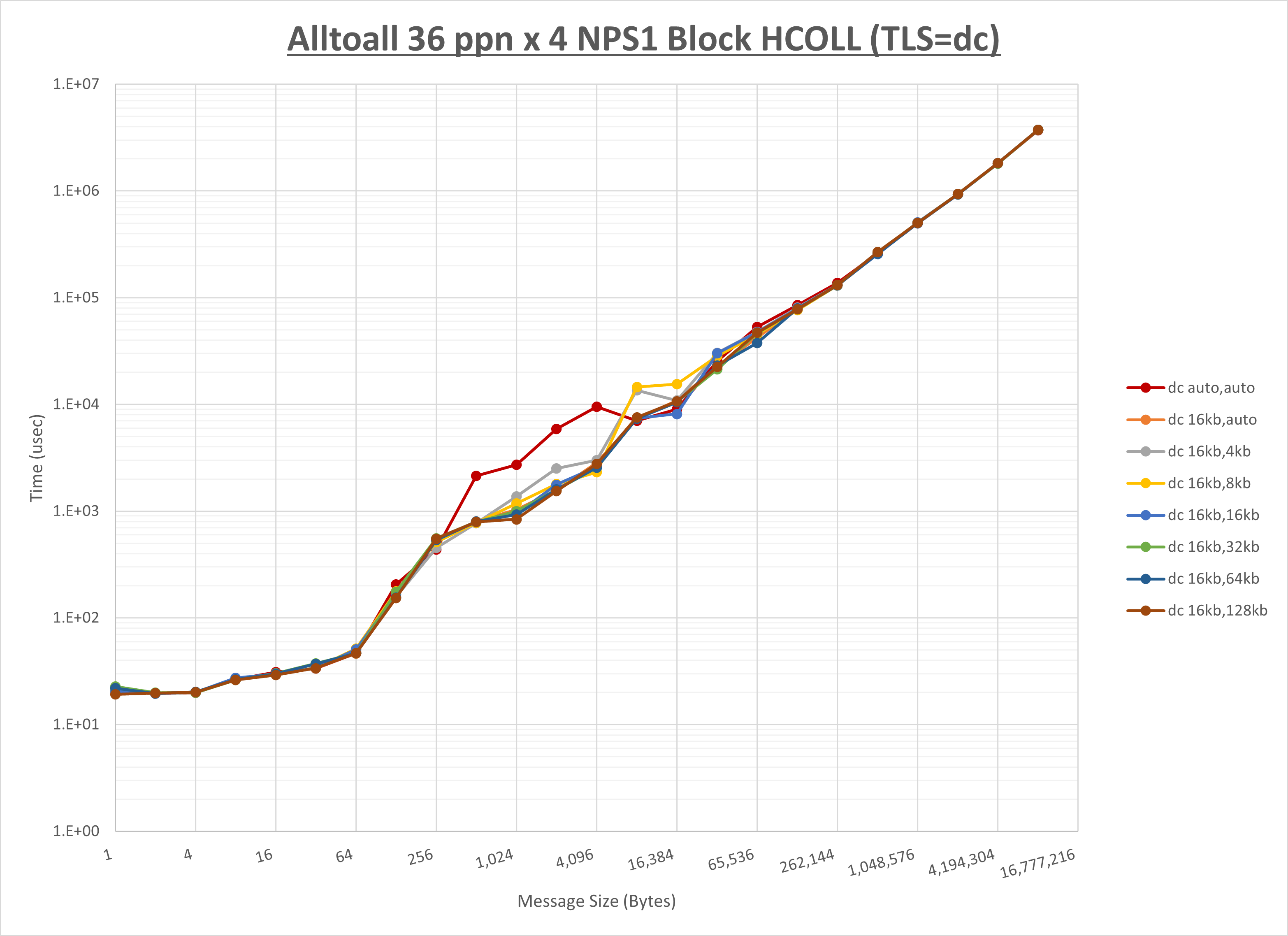
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
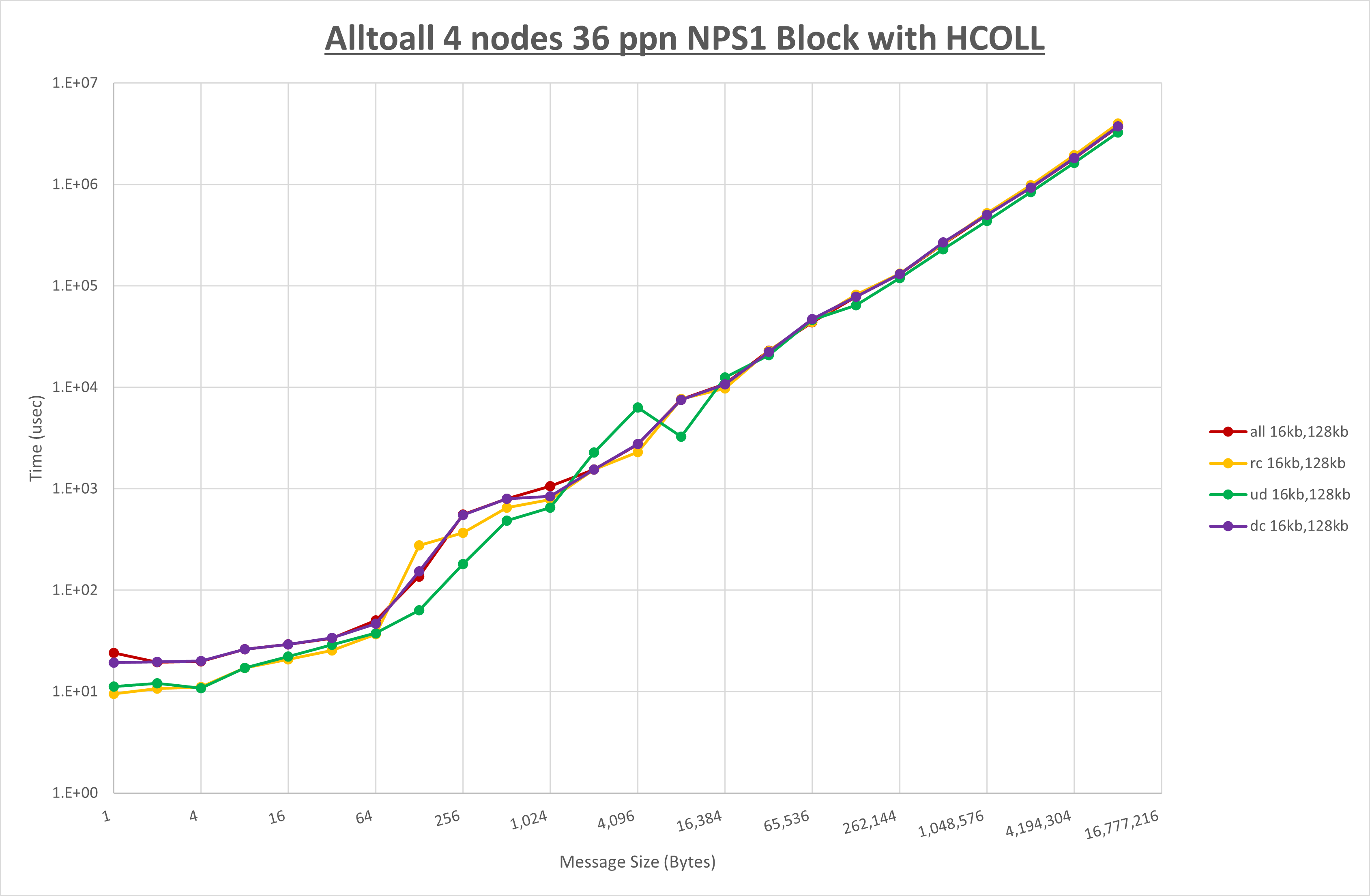
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
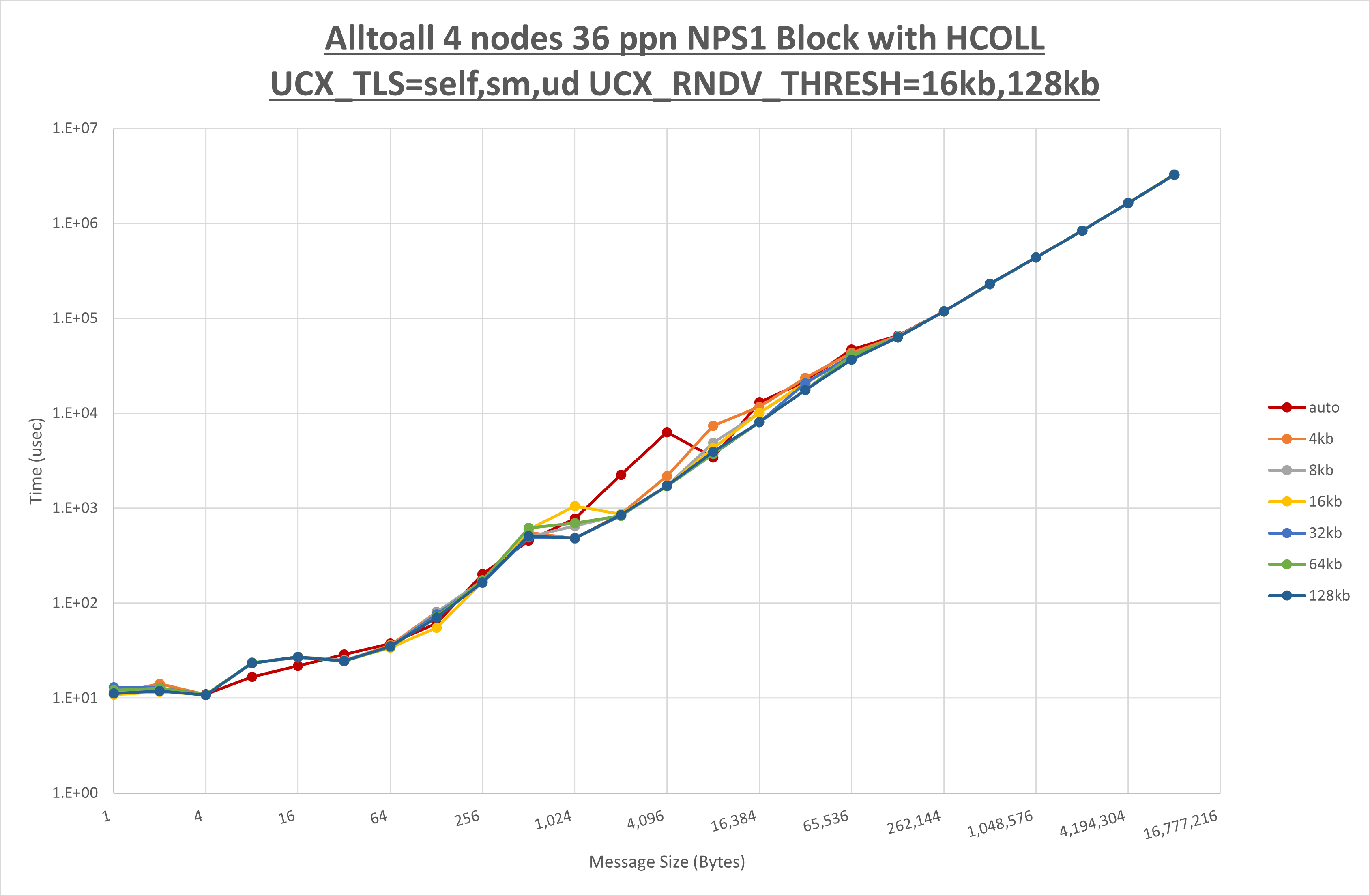
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
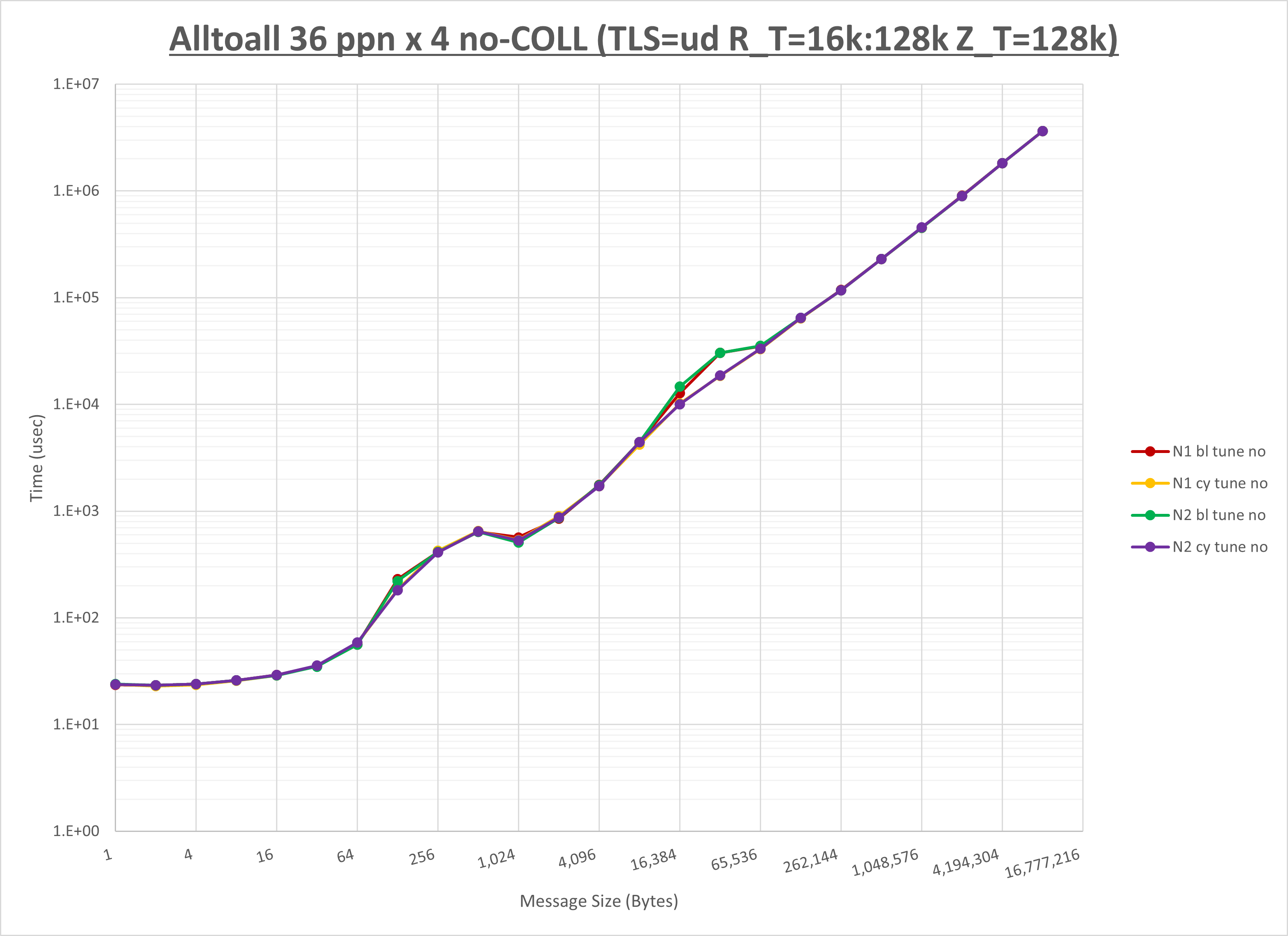
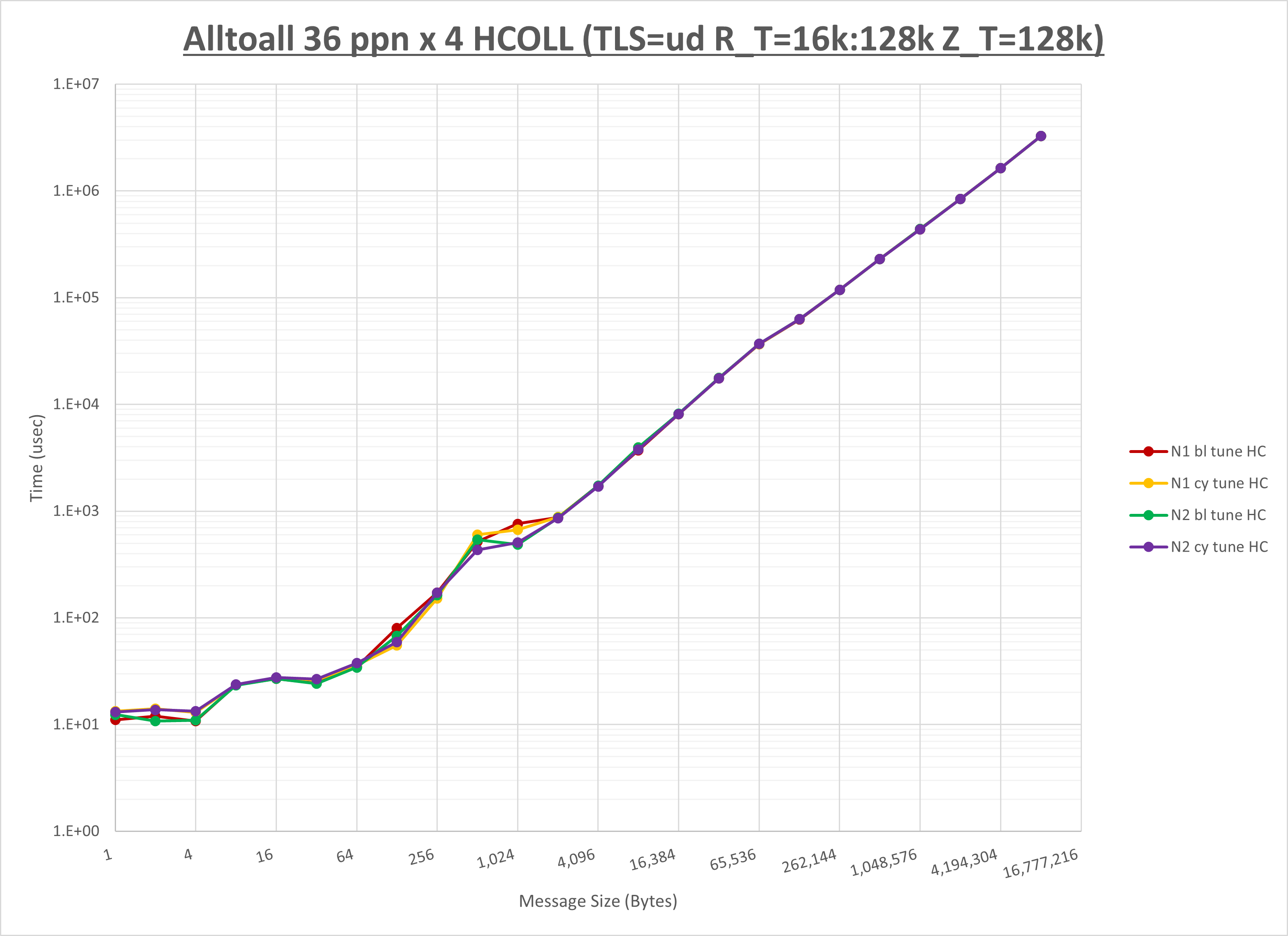
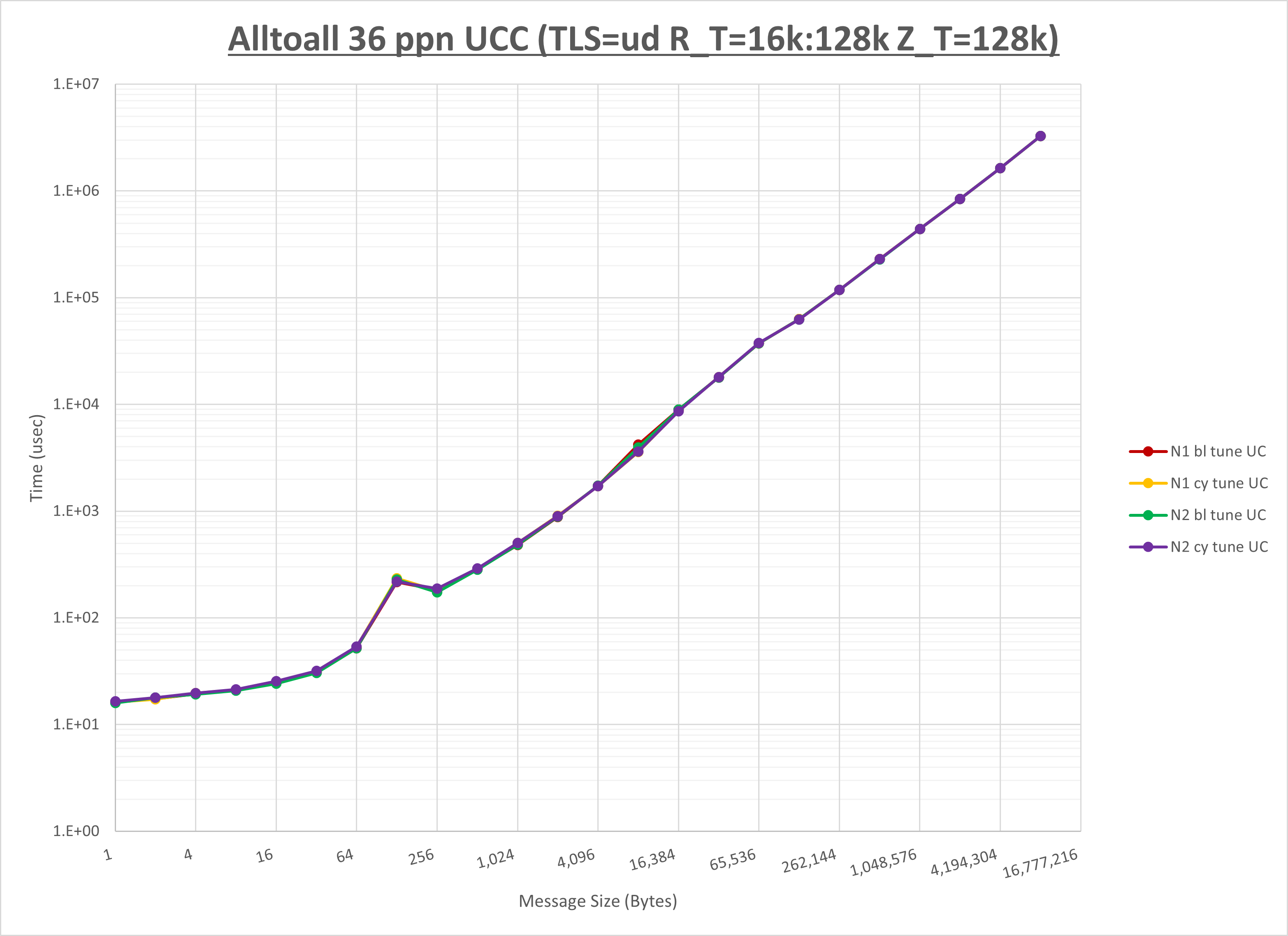
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS1 | NPS1 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
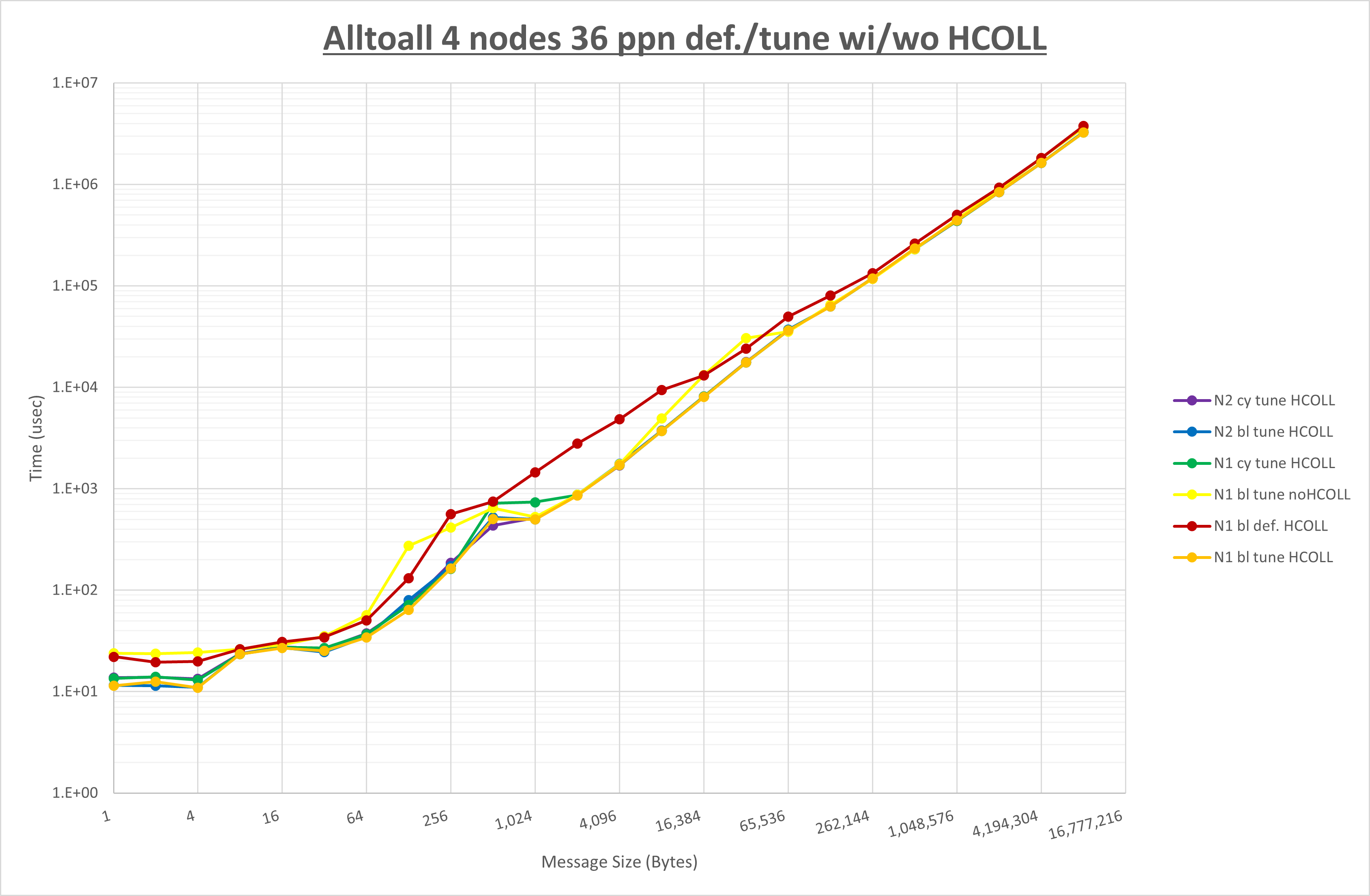
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し512B以下で性能が向上
- UCC は no-COLL と比較し1KB以下で性能が向上
- チューニング適用で全域にわたって性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-2 Allgather の HCOLL の結果から16KBとしています。
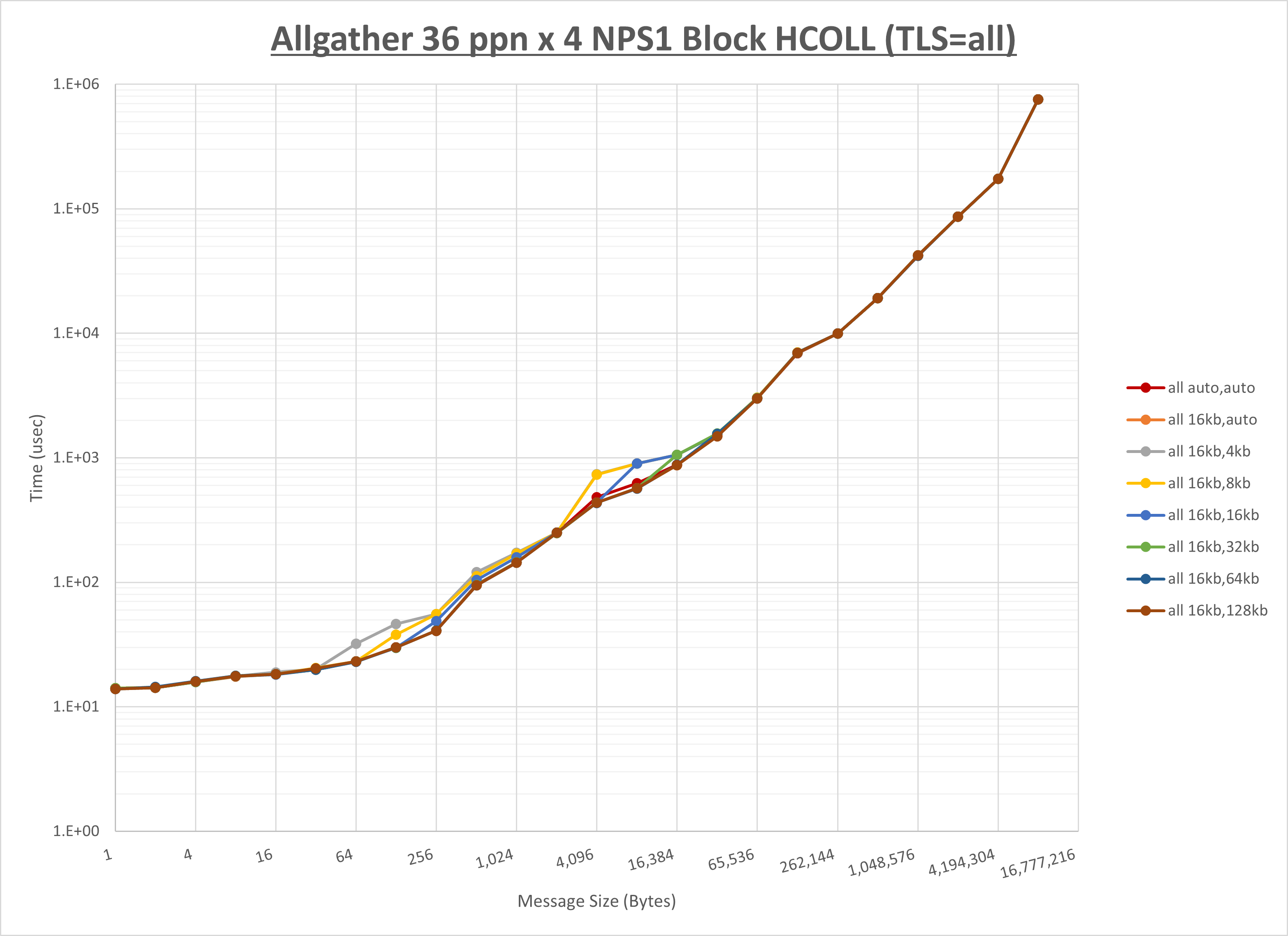
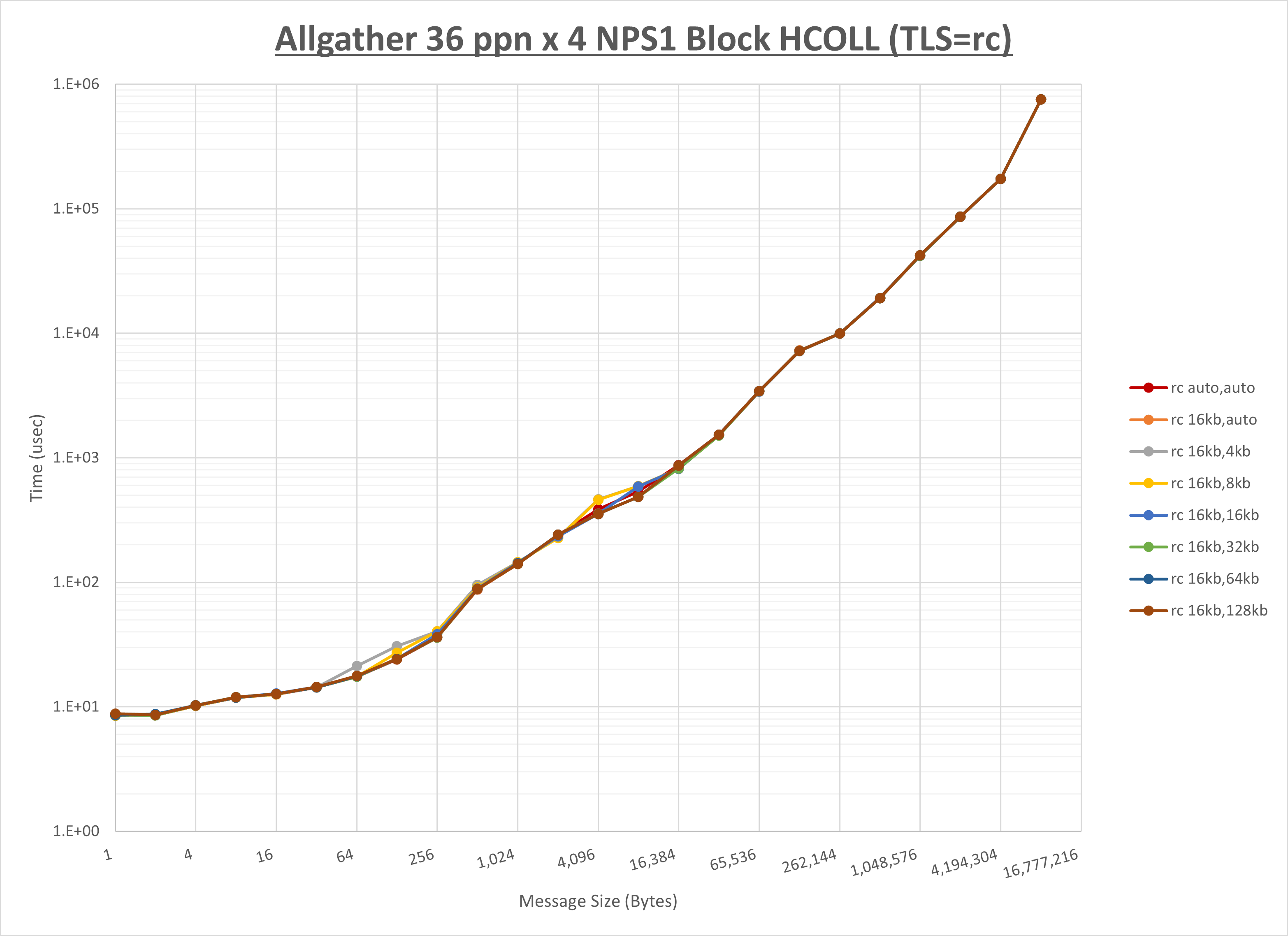
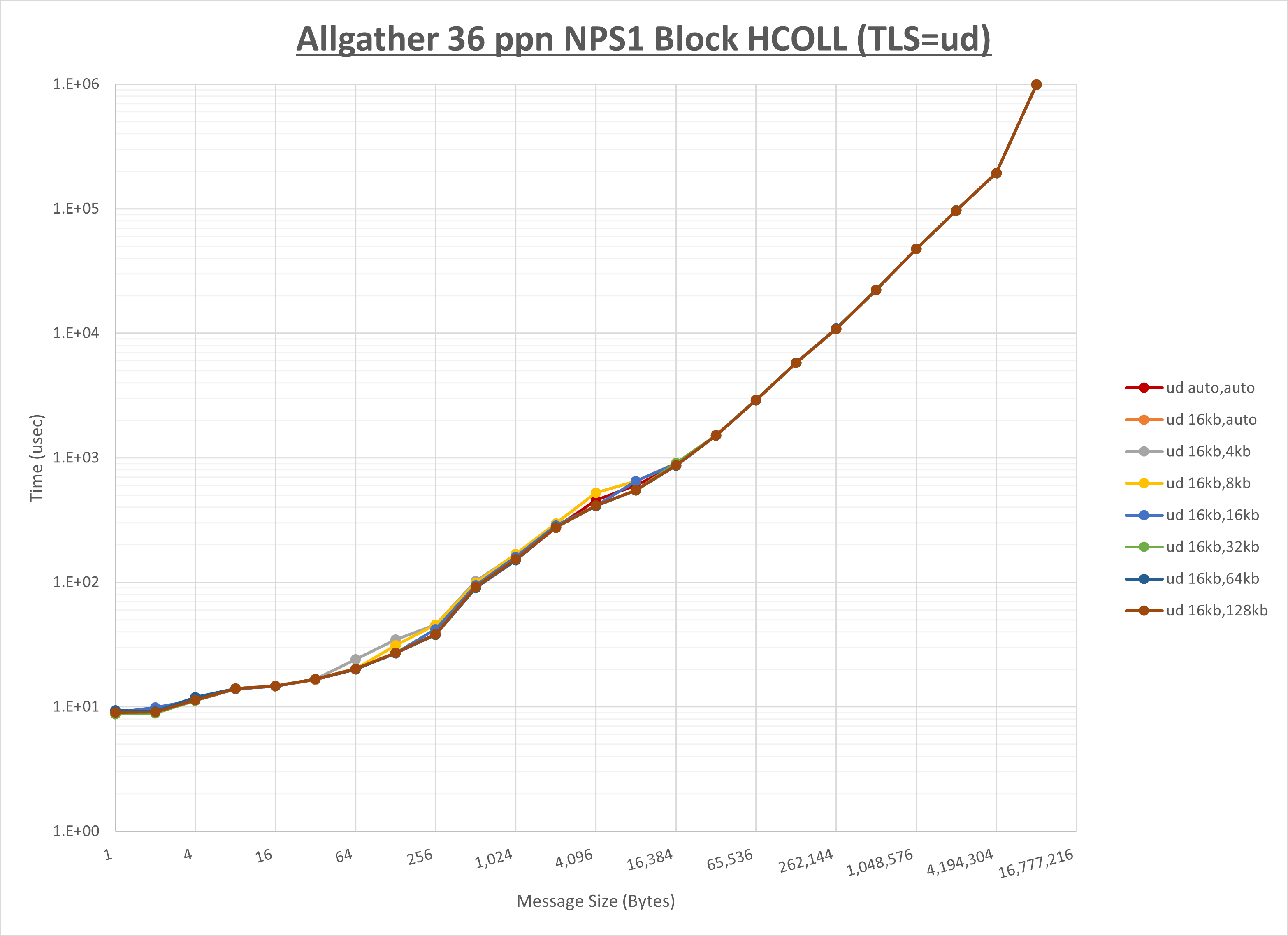
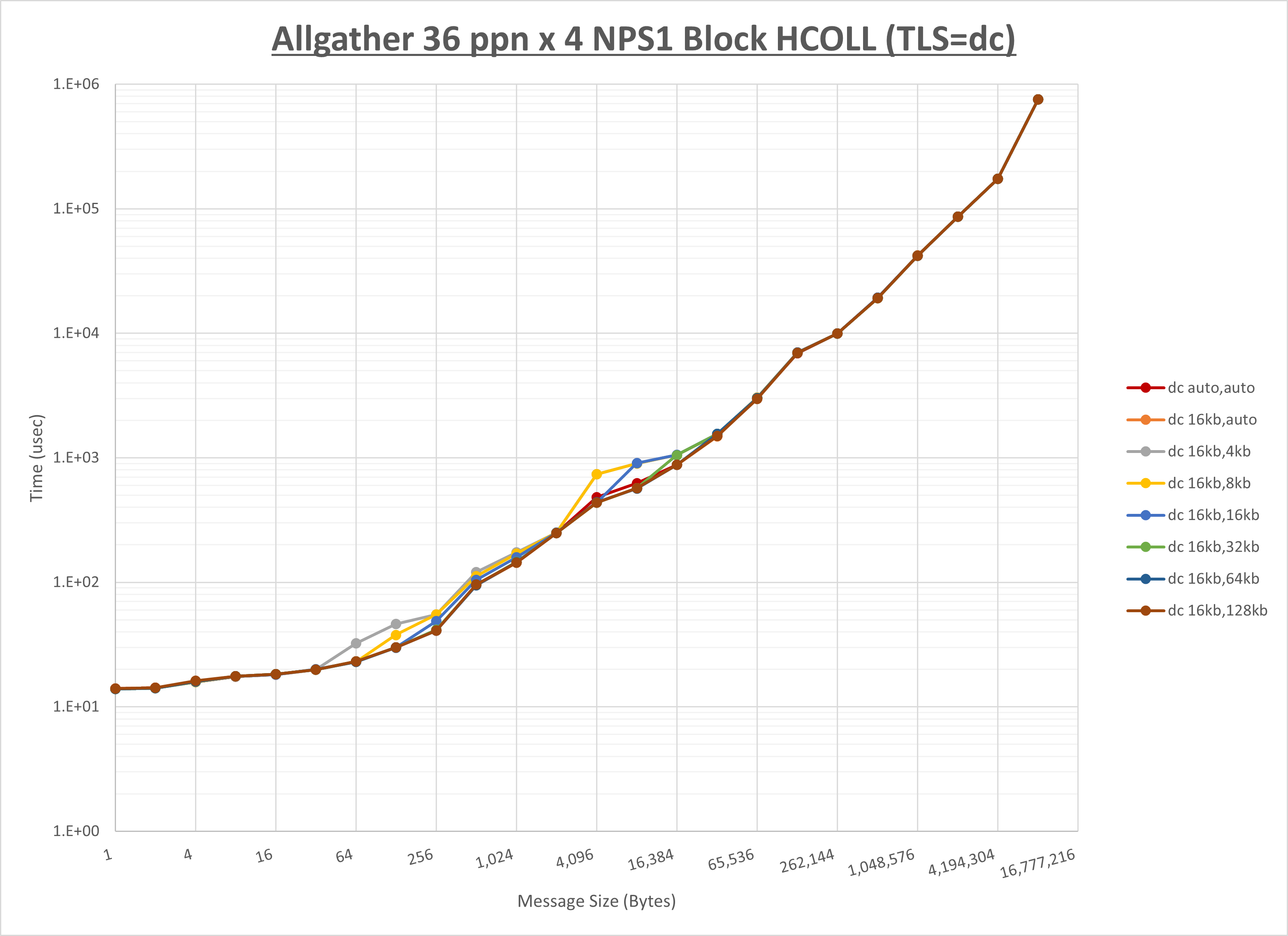
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
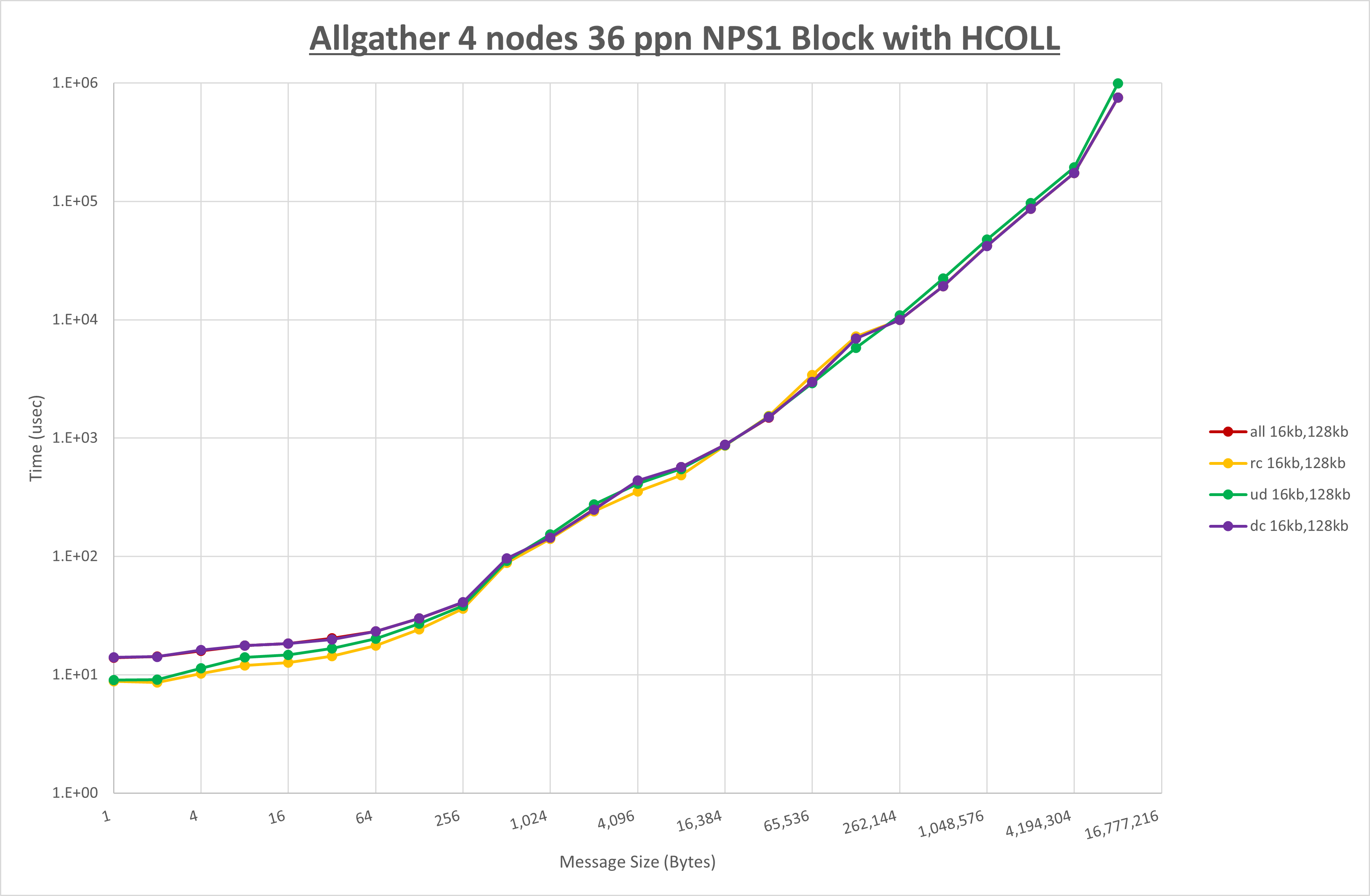
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
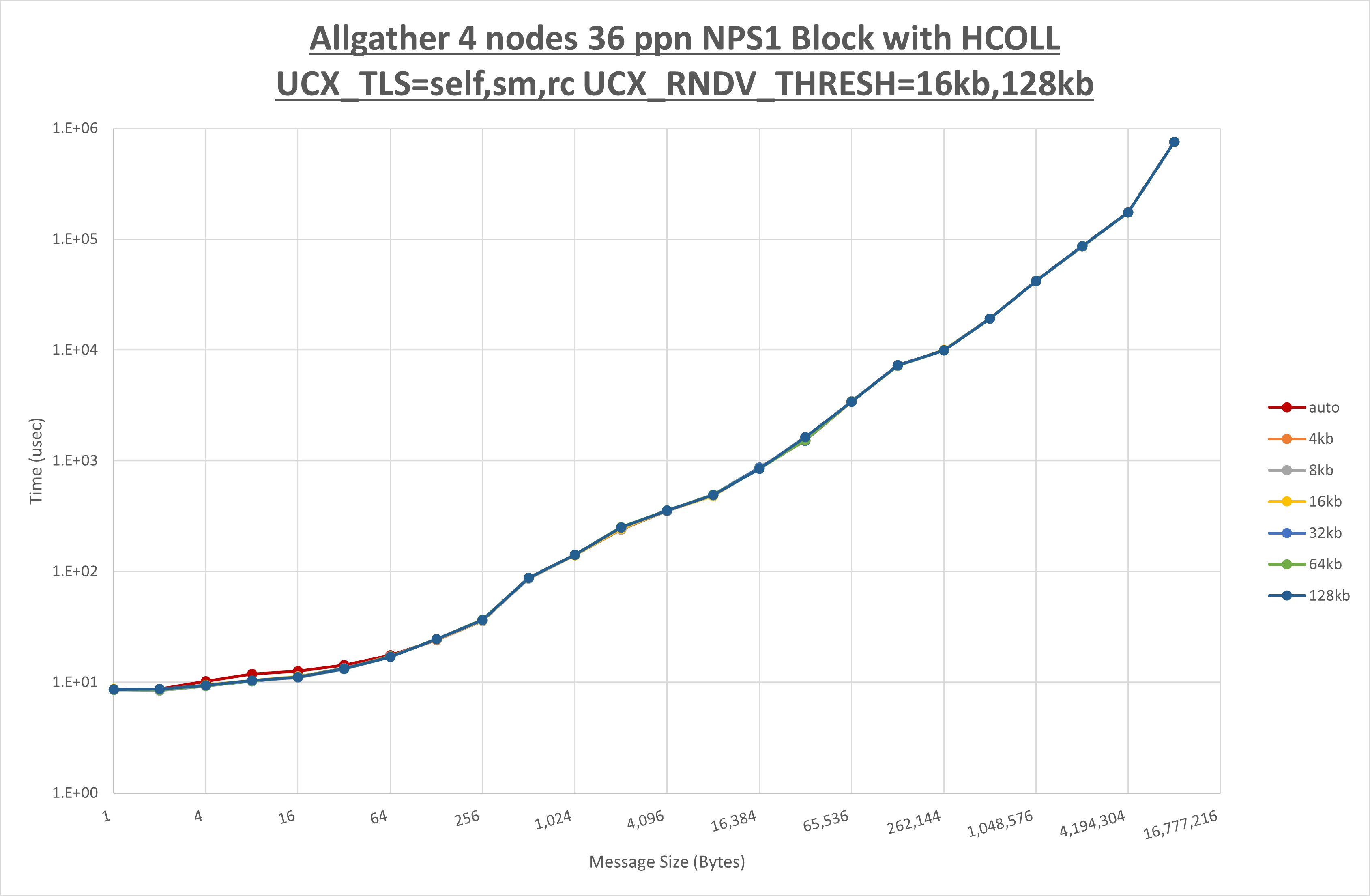
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
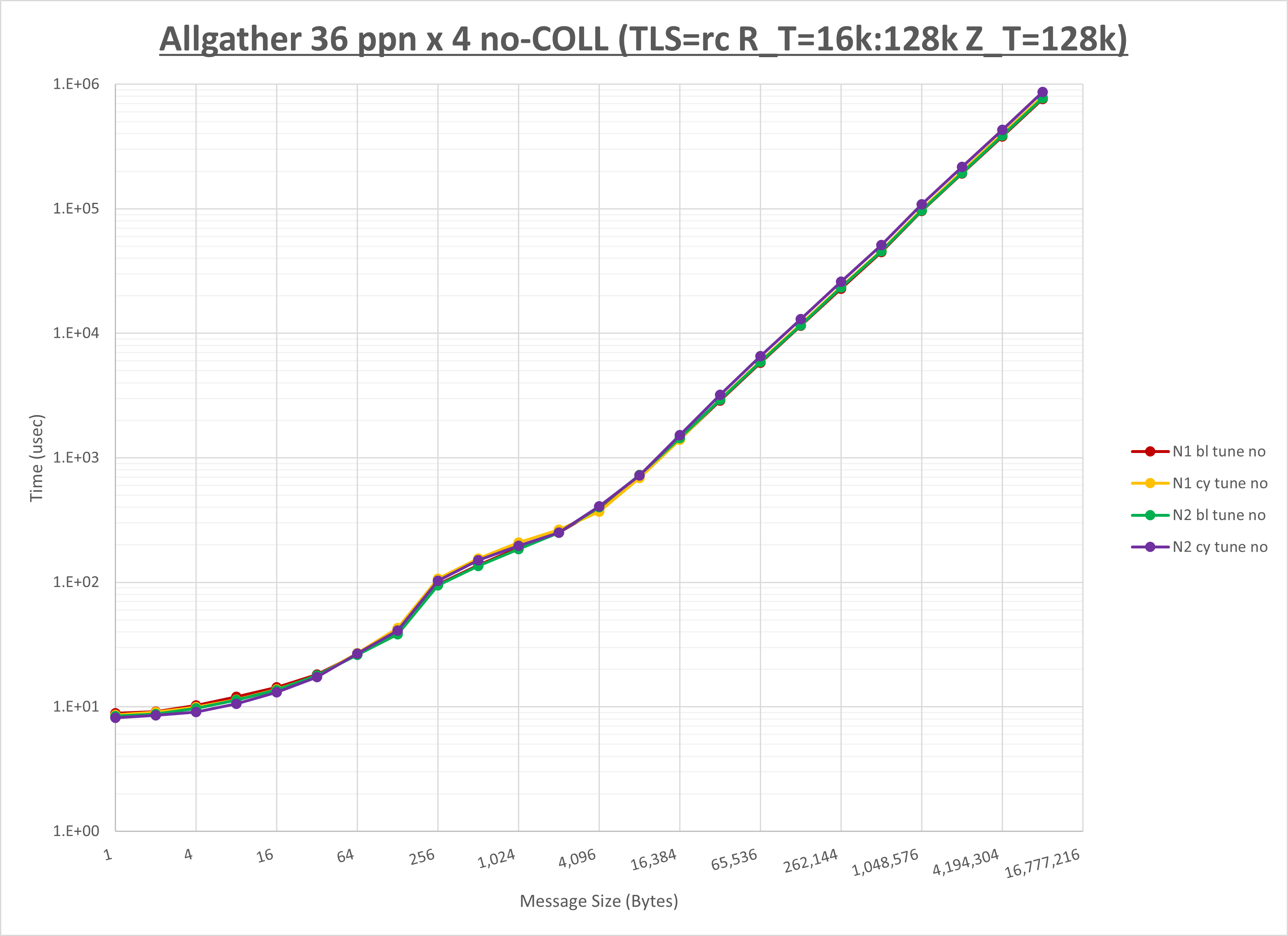
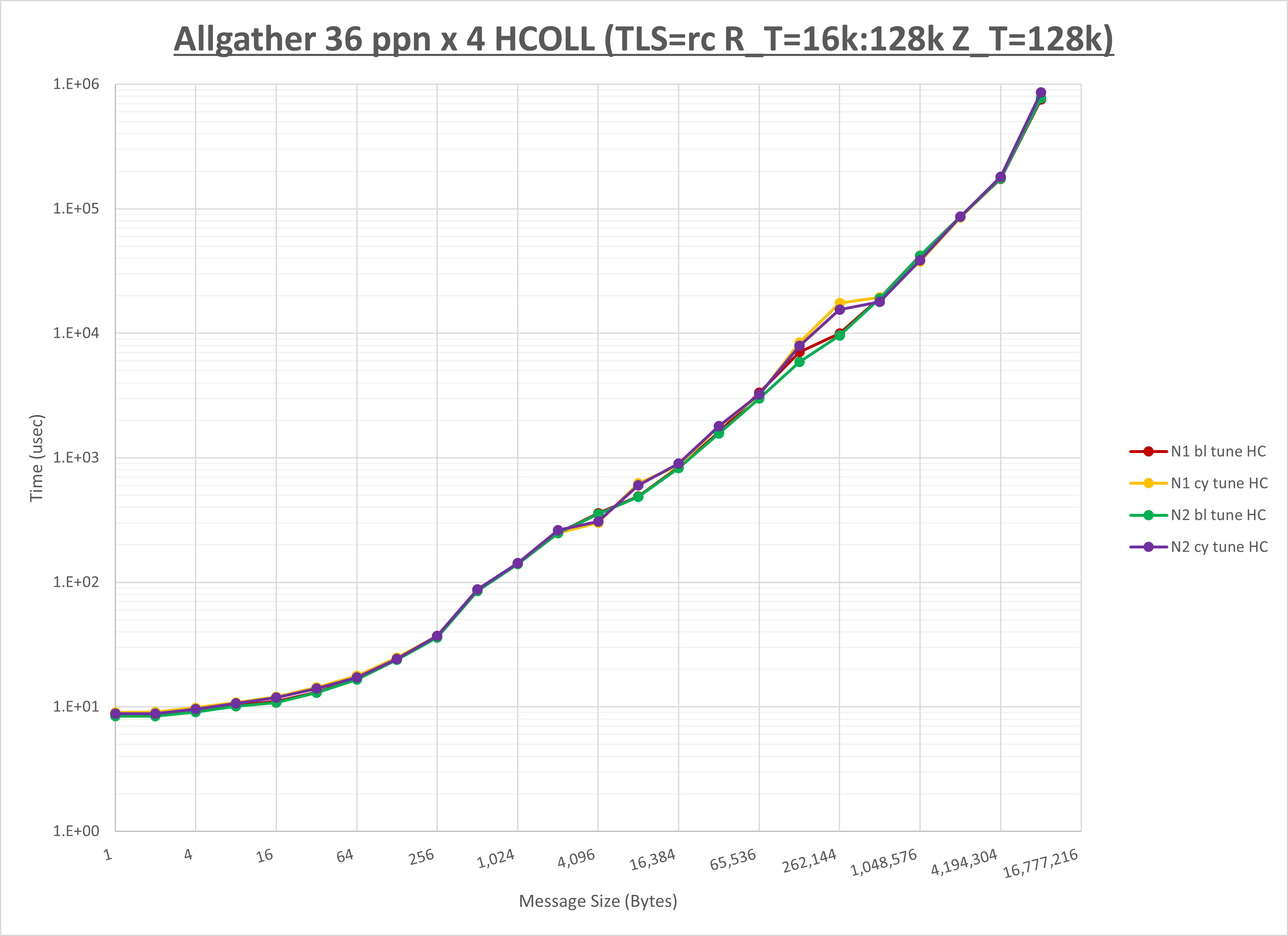
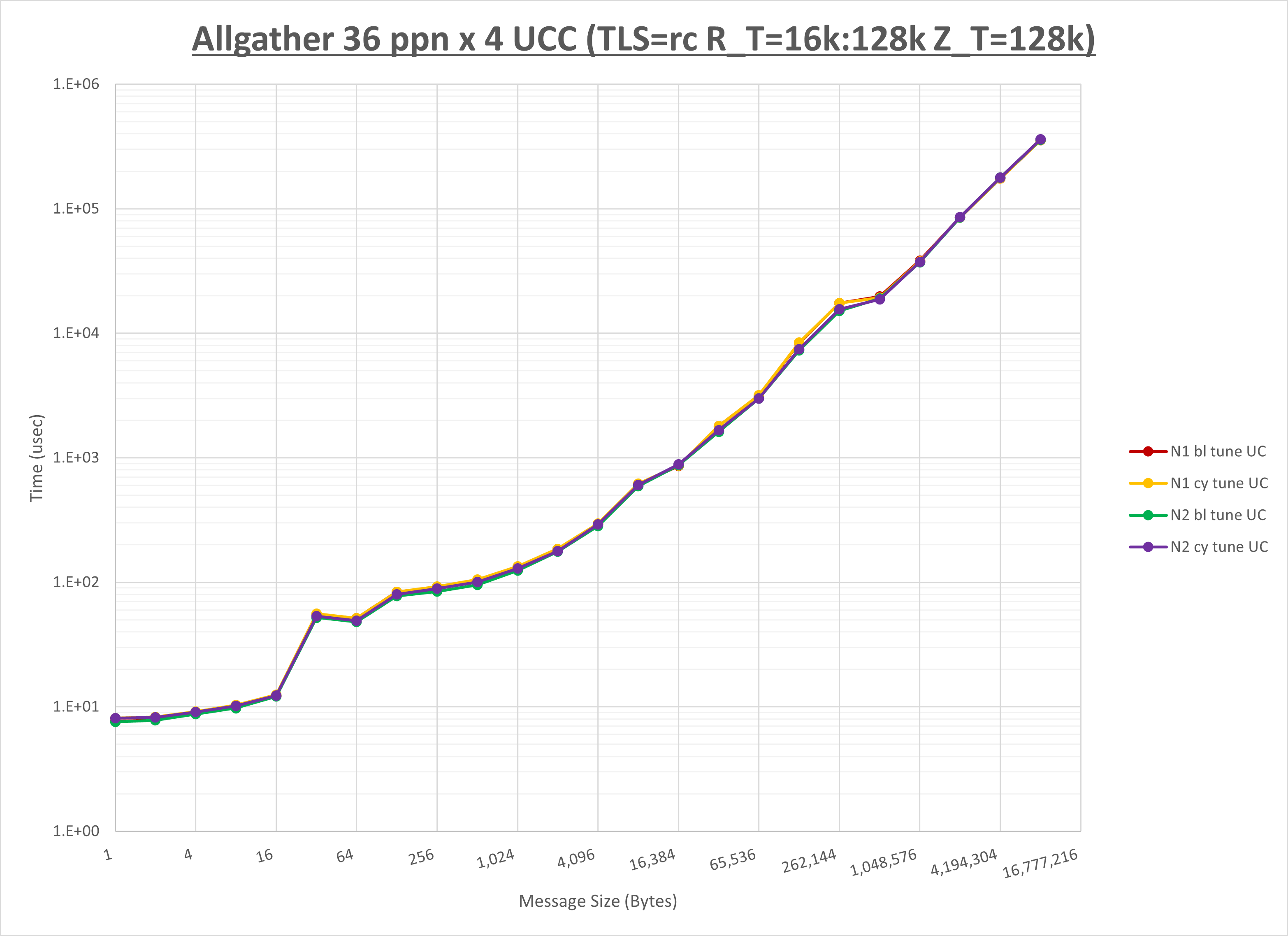
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
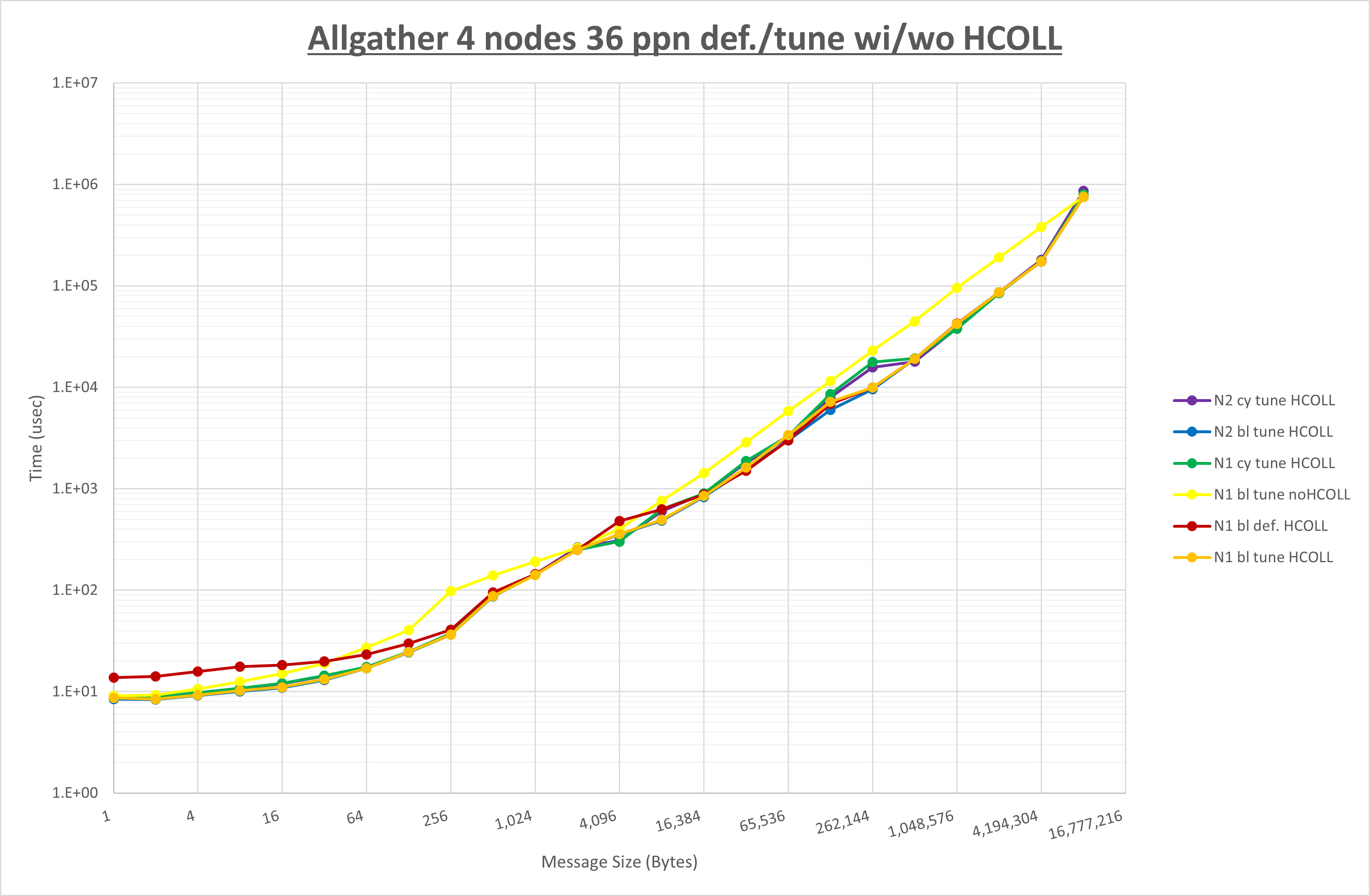
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し16B以下と512B以上性能が向上し32Bから256Bで性能が低下
- チューニング適用で512B以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-3 Allreduce の HCOLL の結果から64KBとしています。
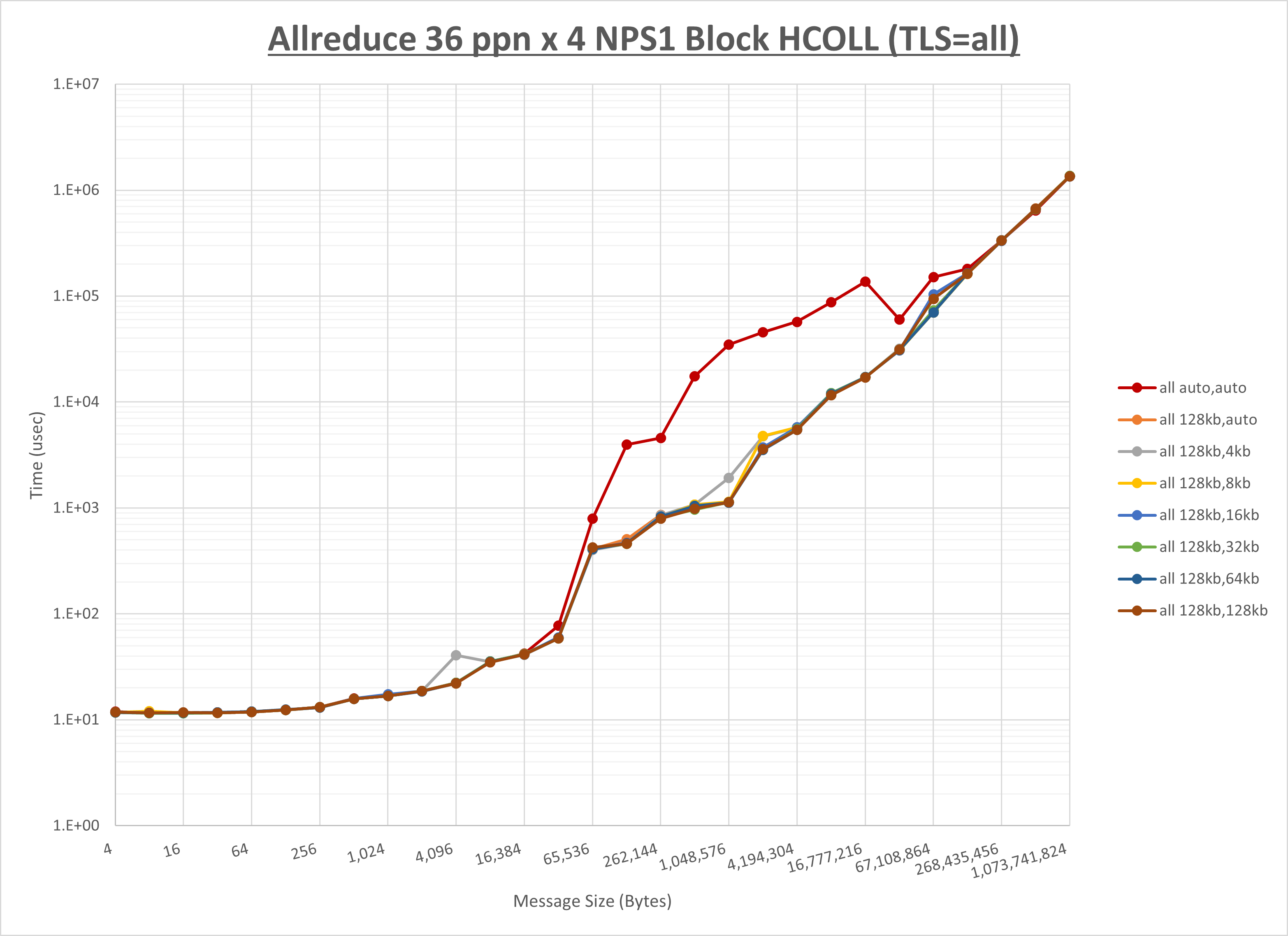
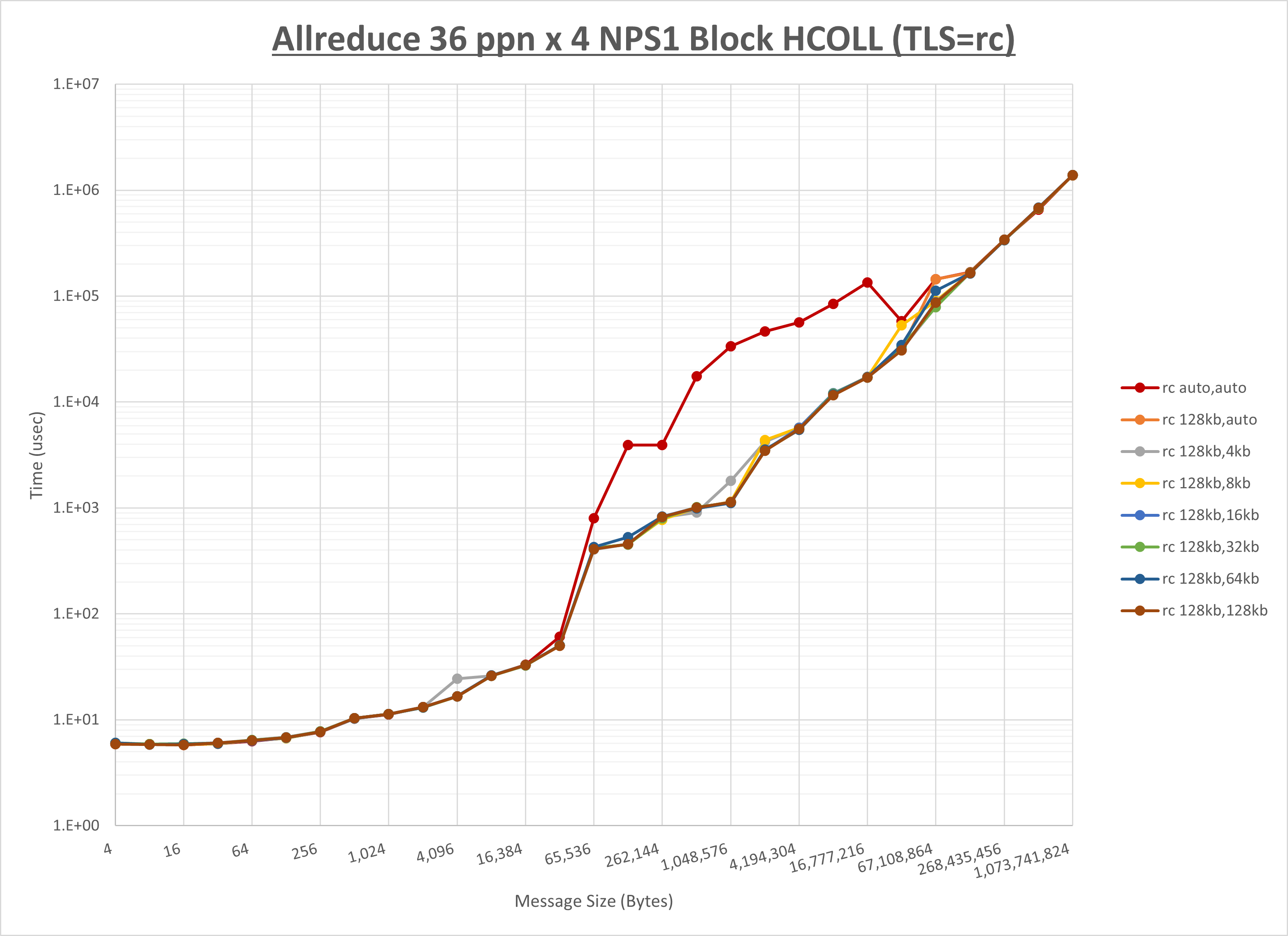
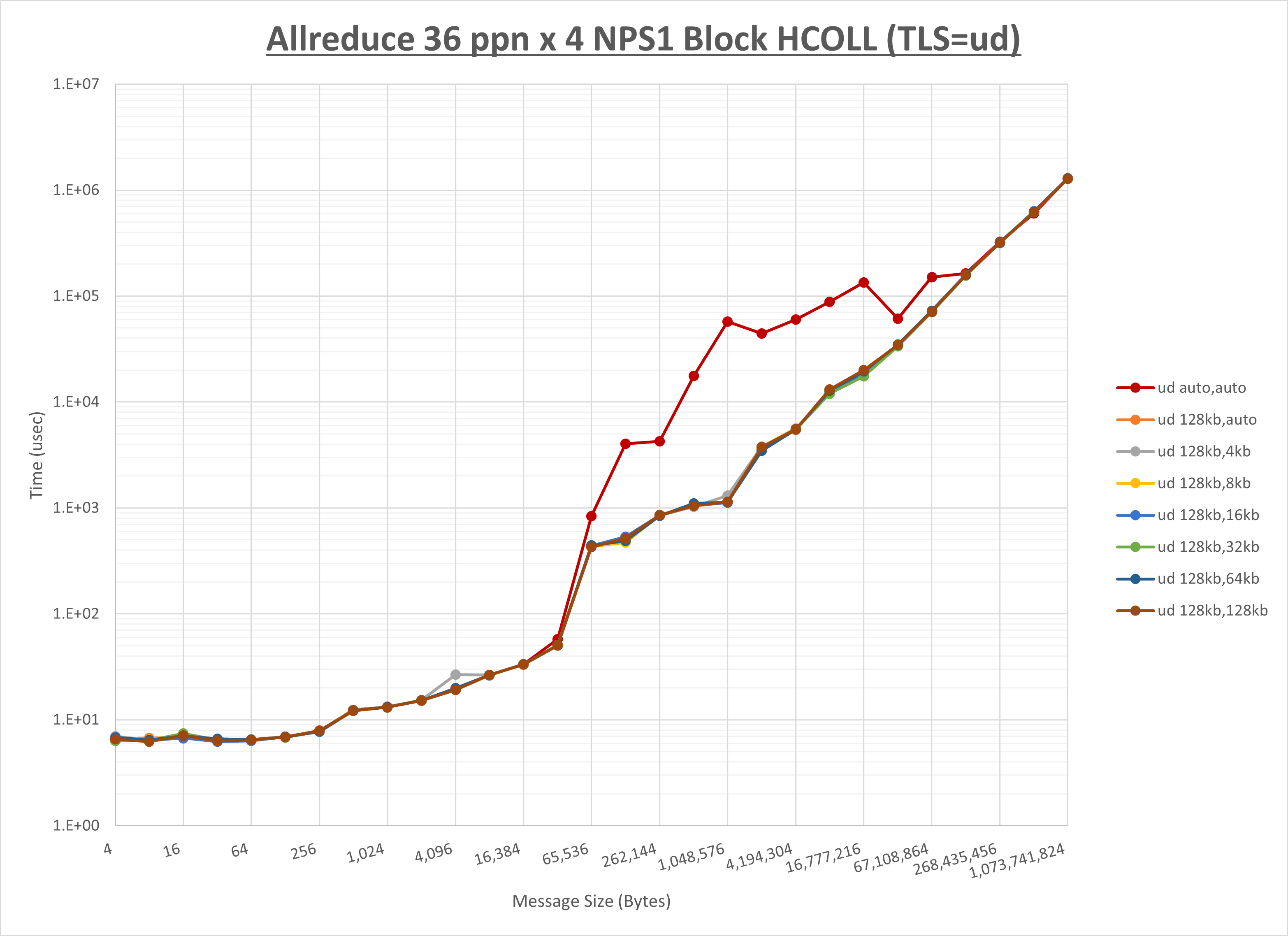
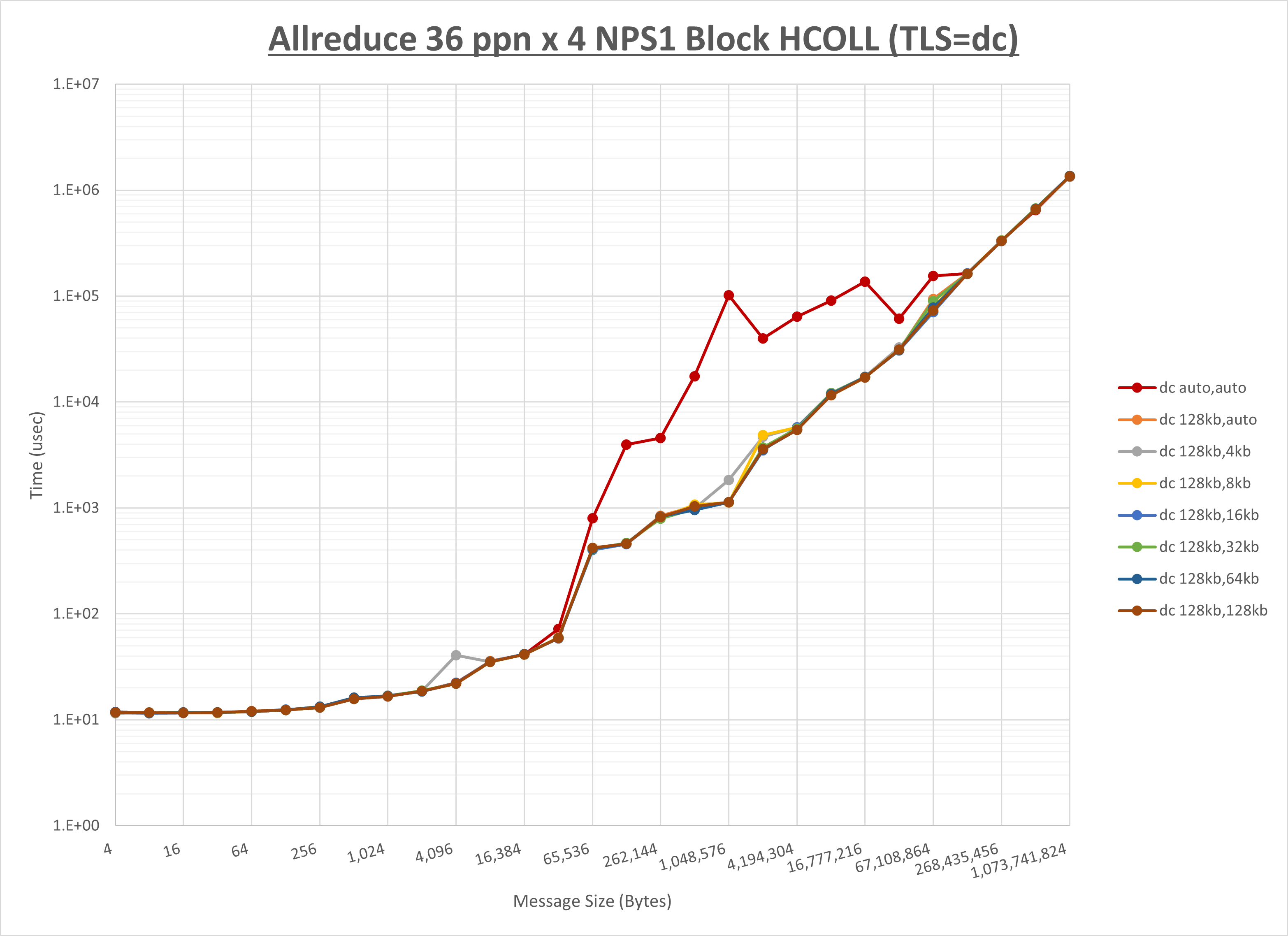
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
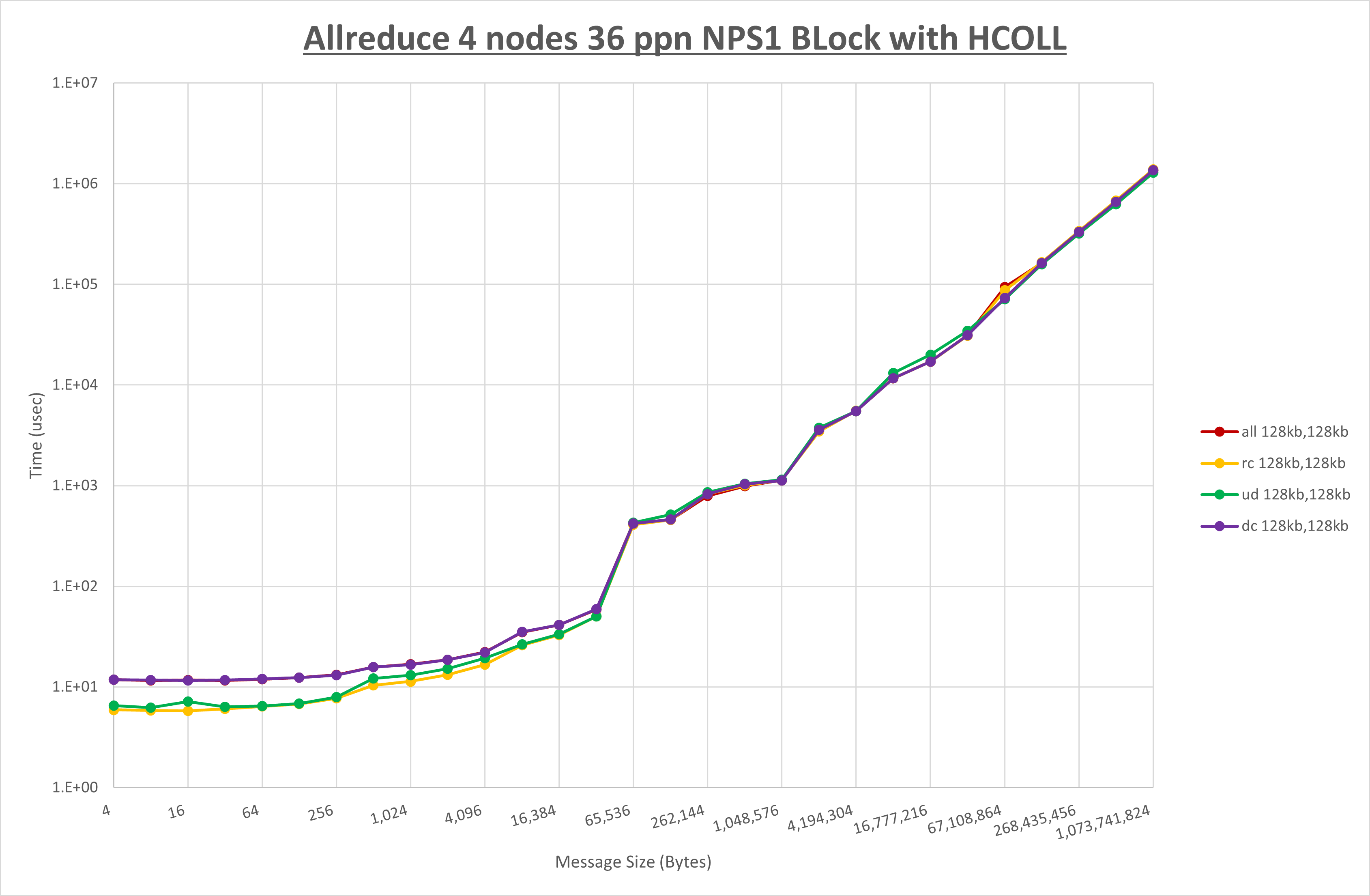
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
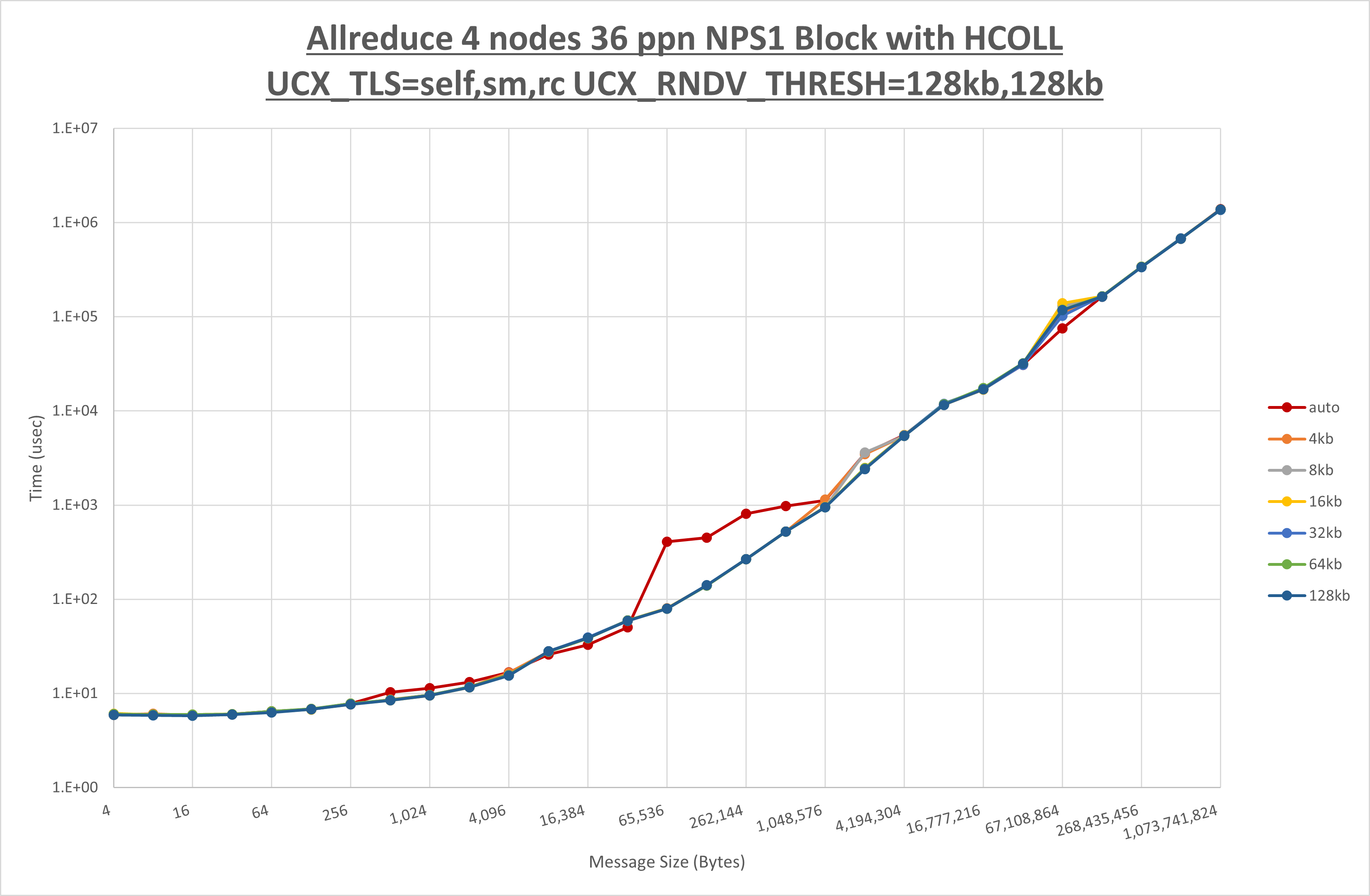
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
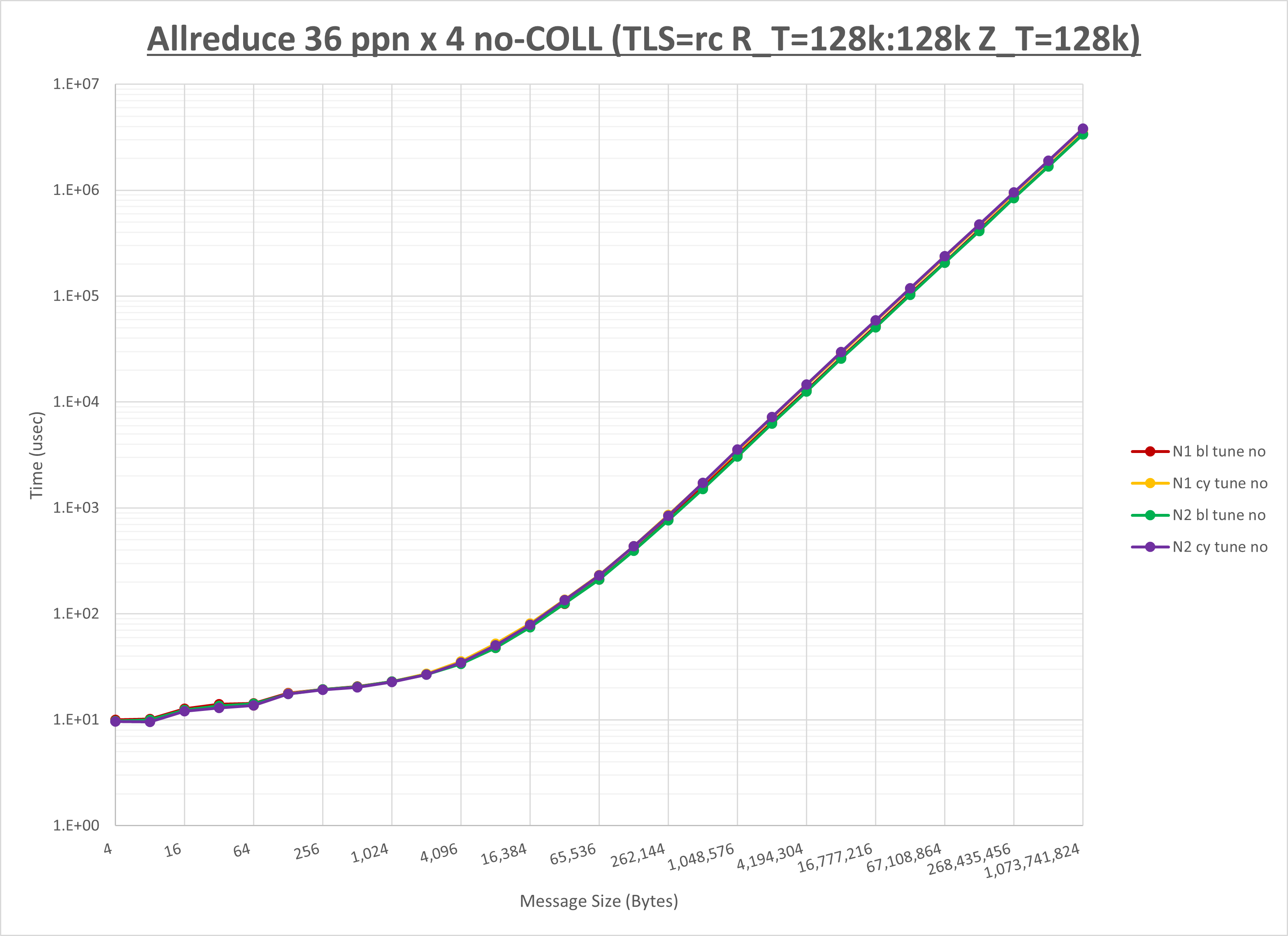
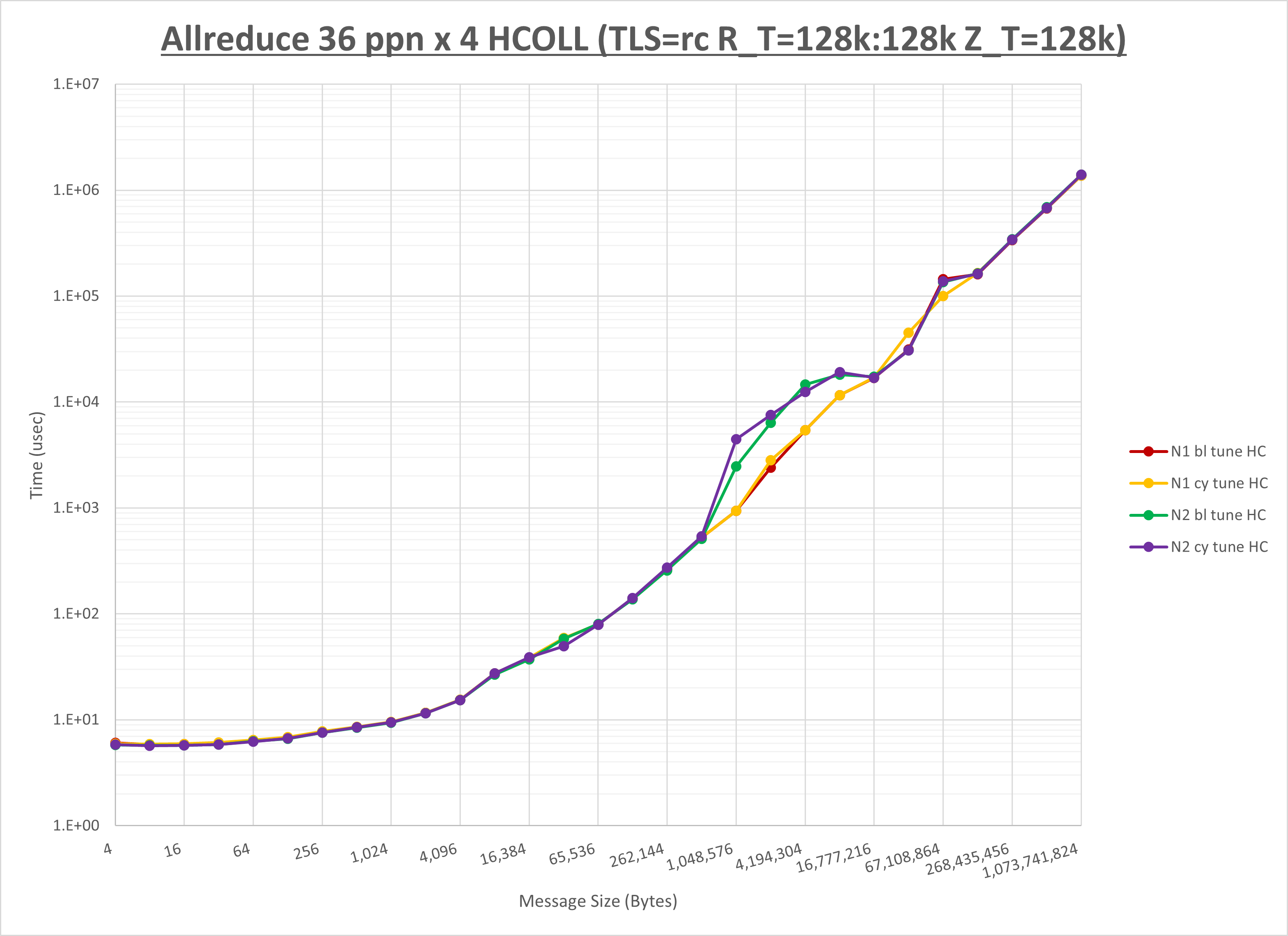
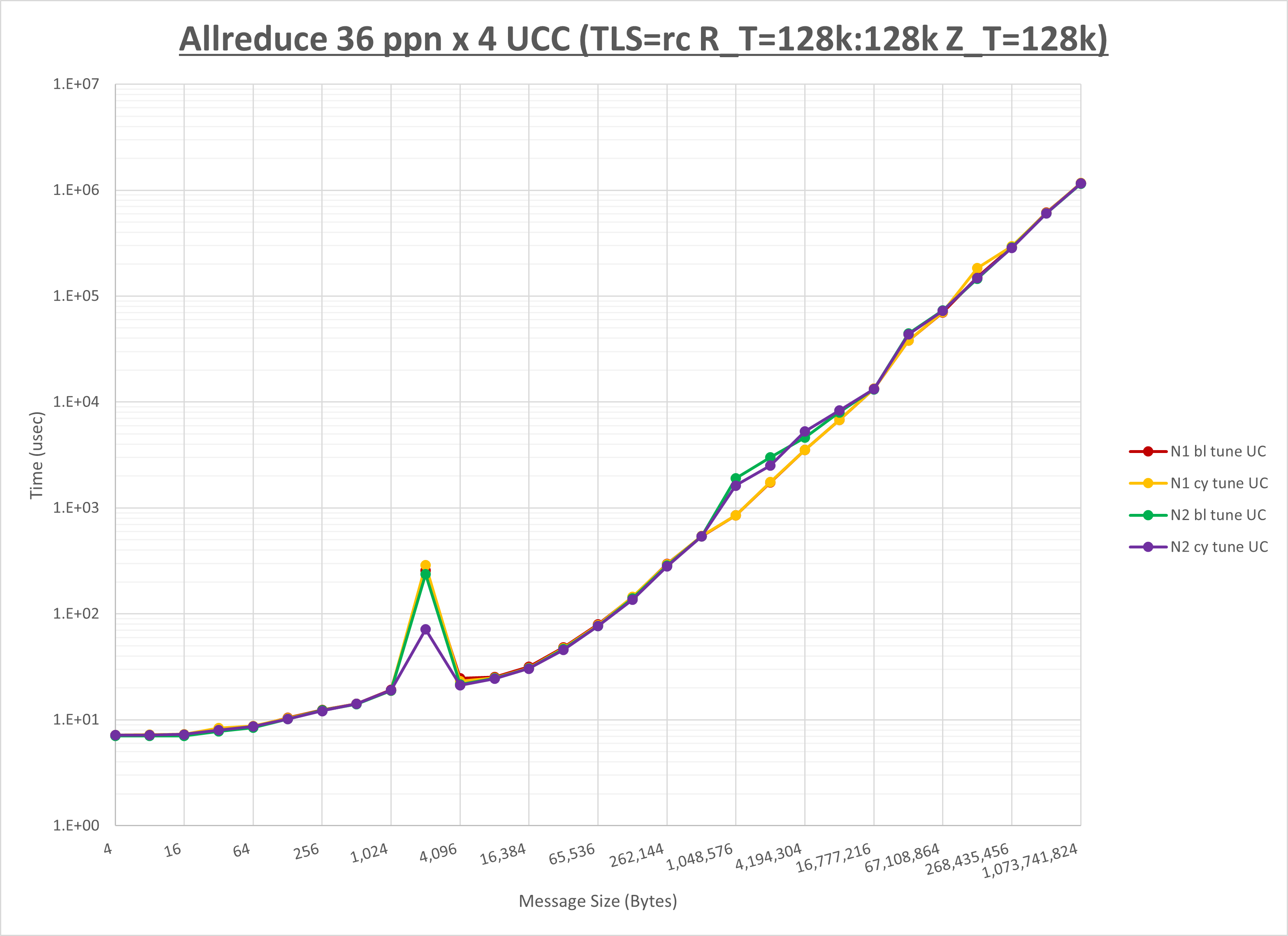
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
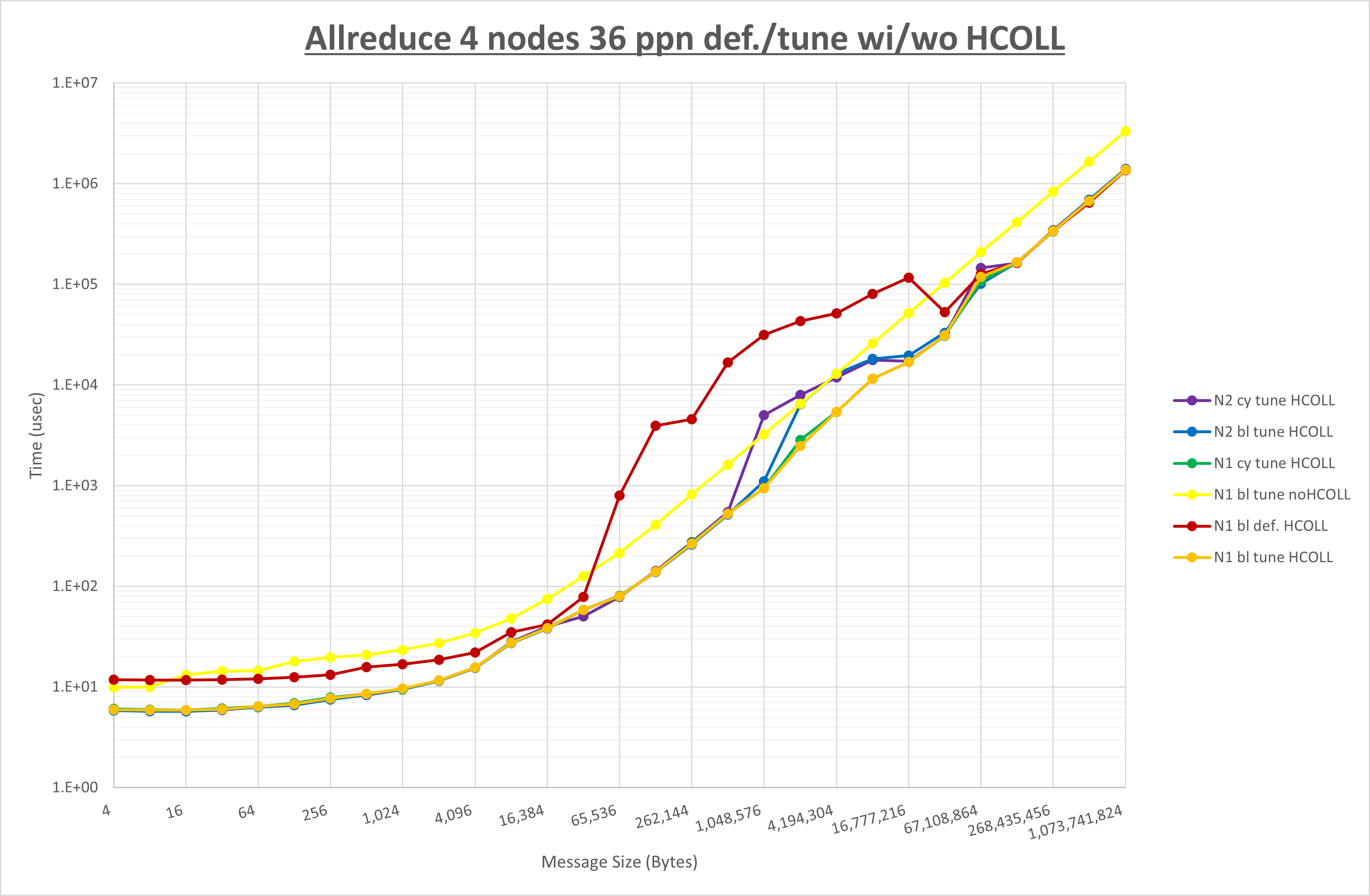
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し概ね全域で性能が向上
- チューニング適用で64MB以下で概ね性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-4 Exchange の結果から16KBとしています。
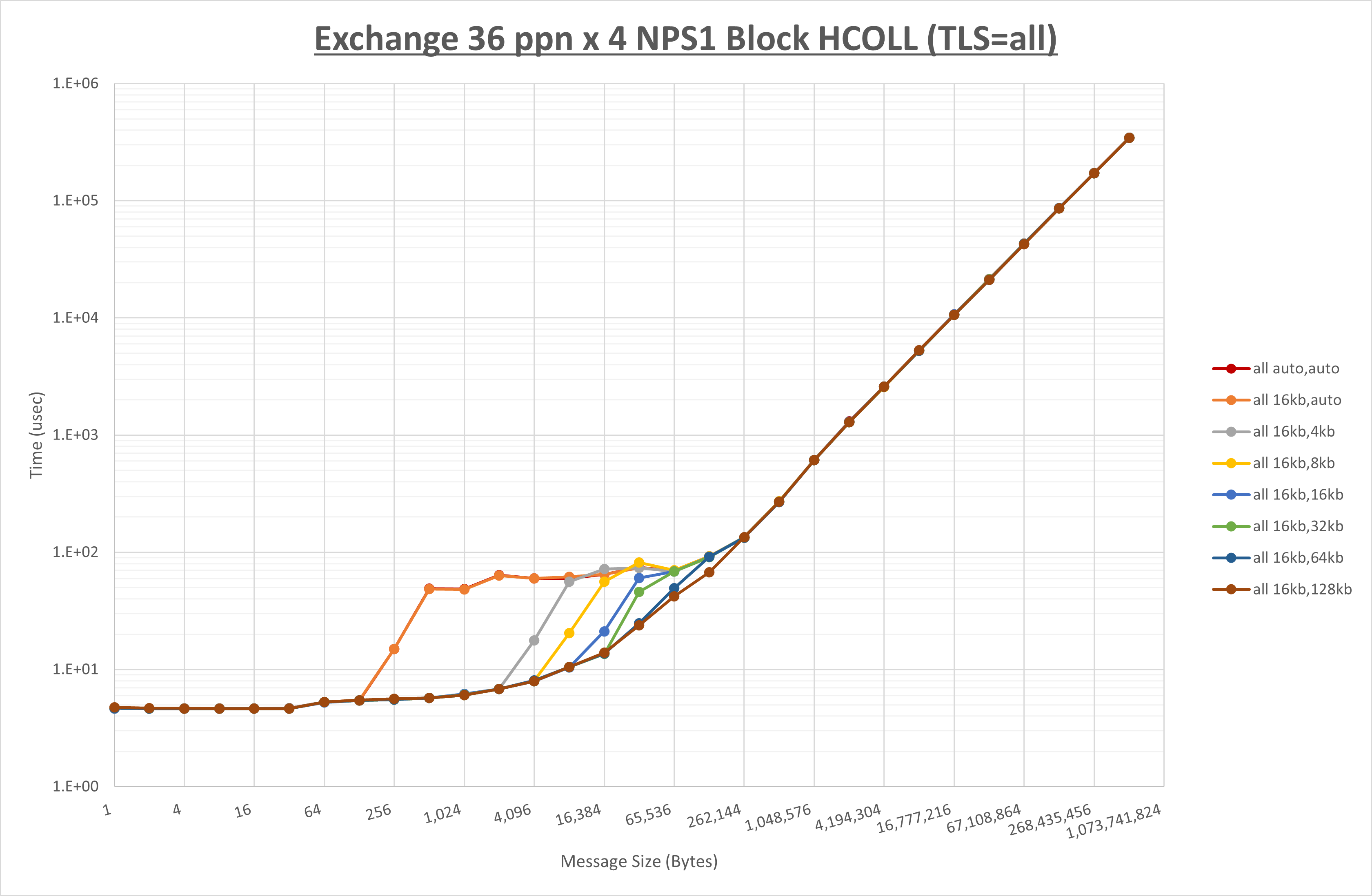
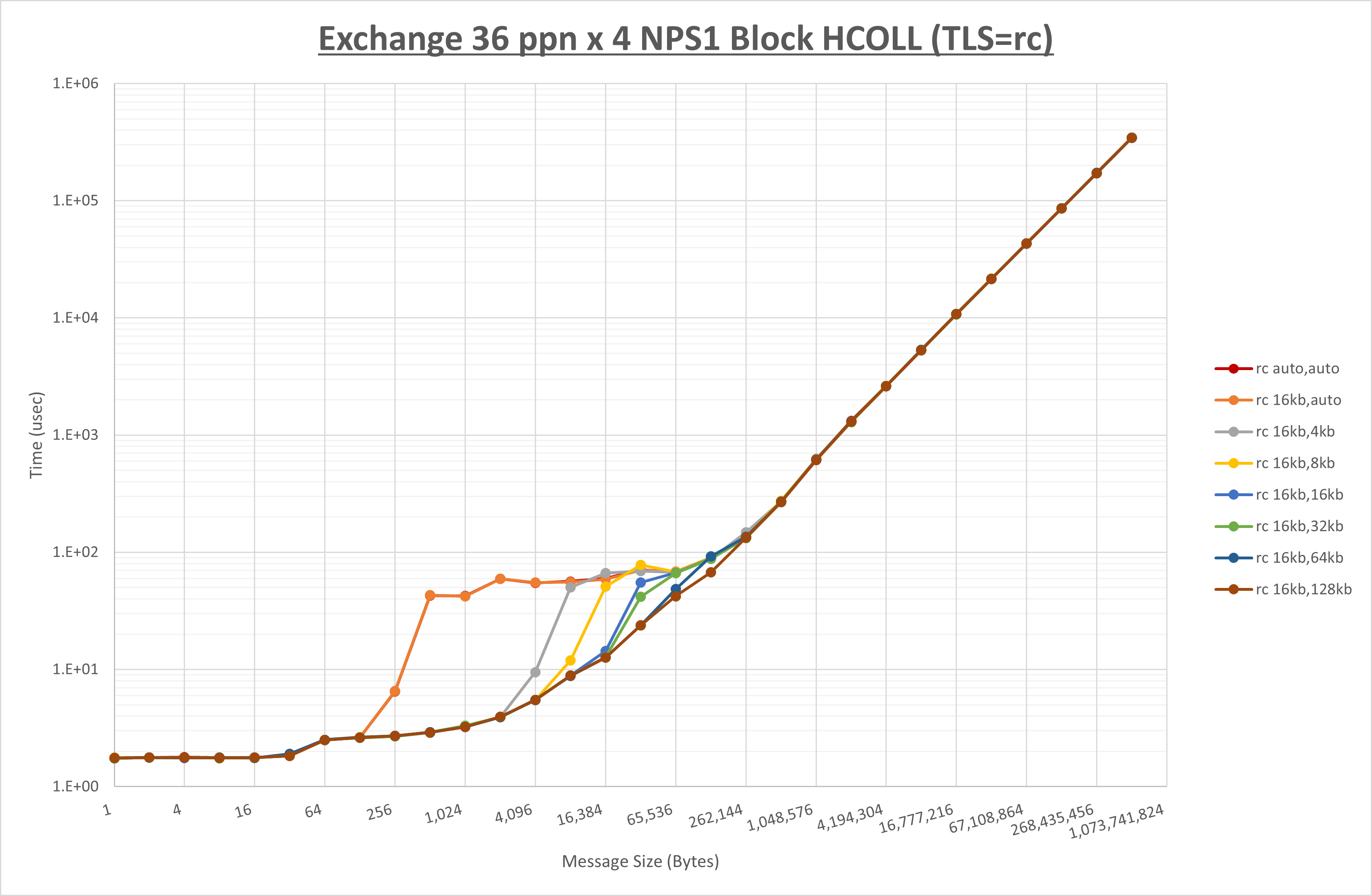
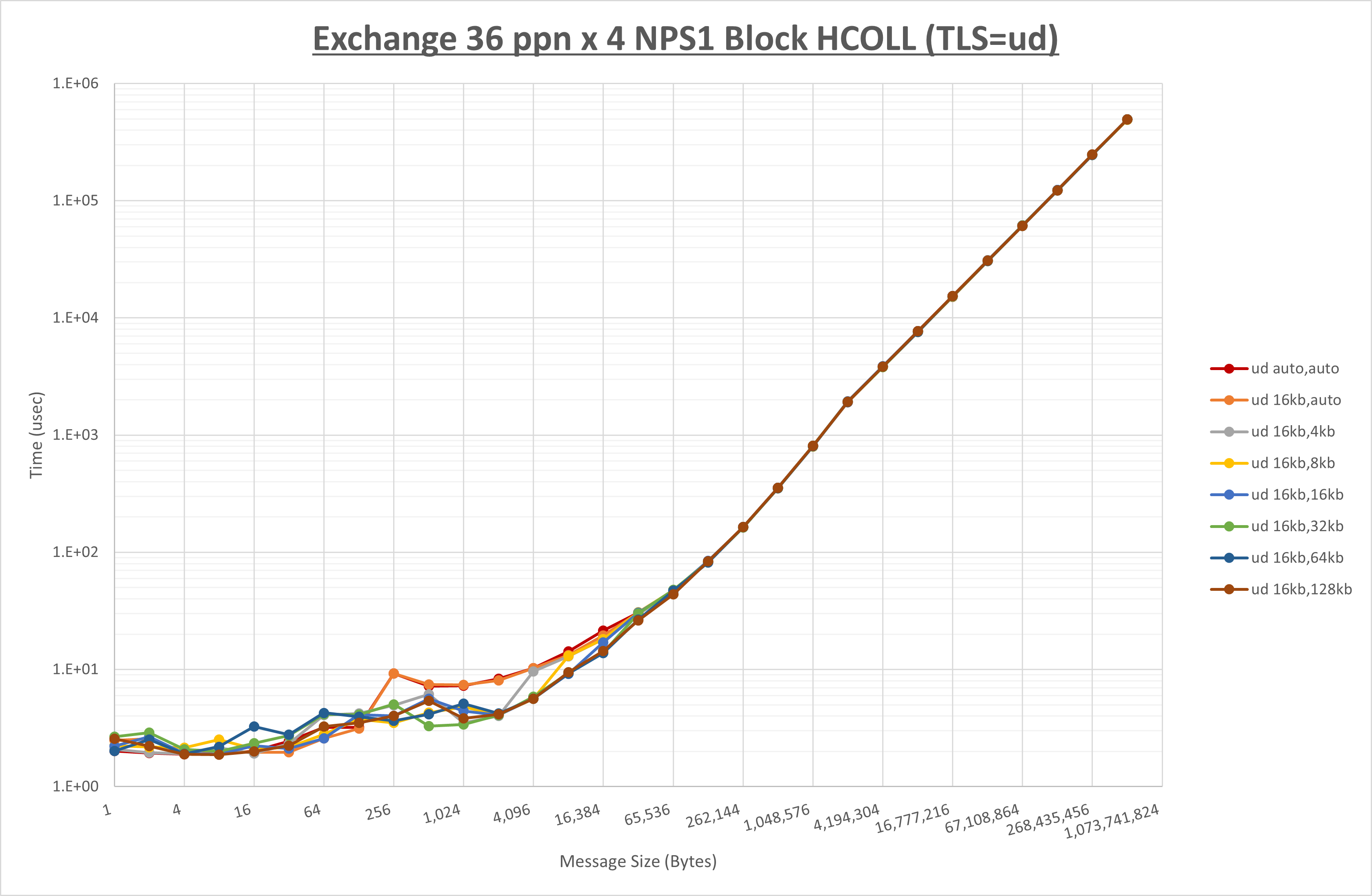
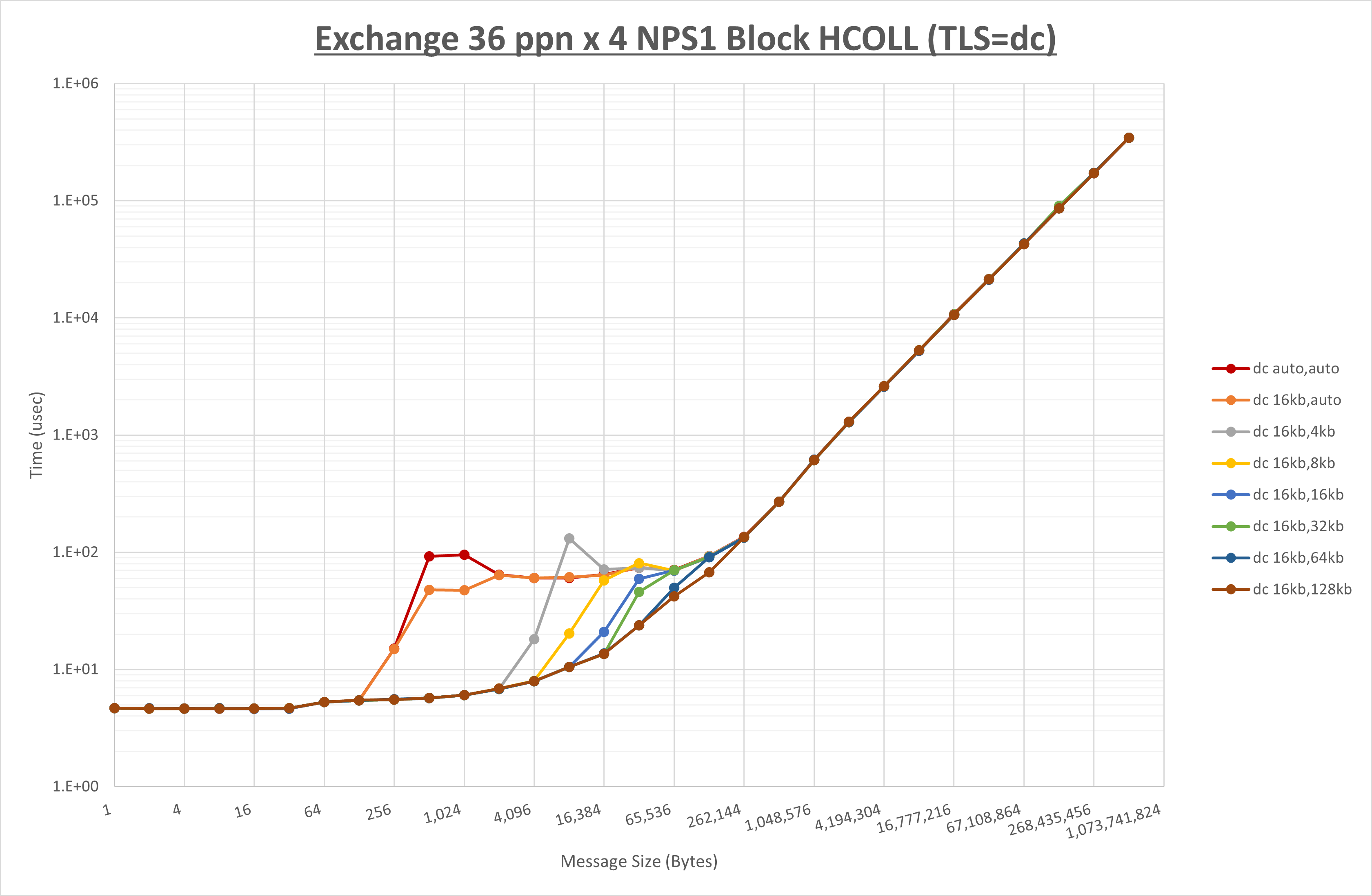
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
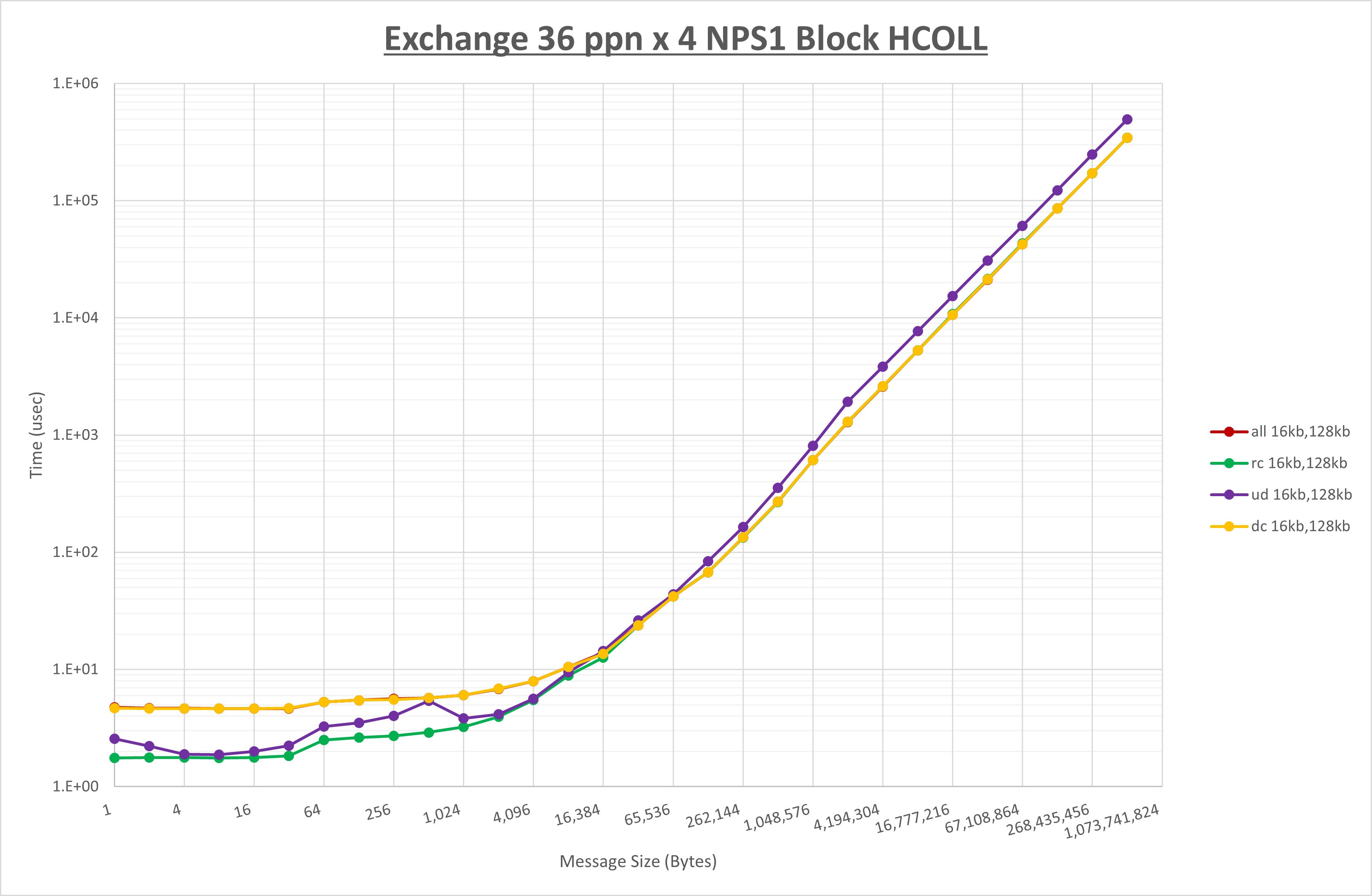
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
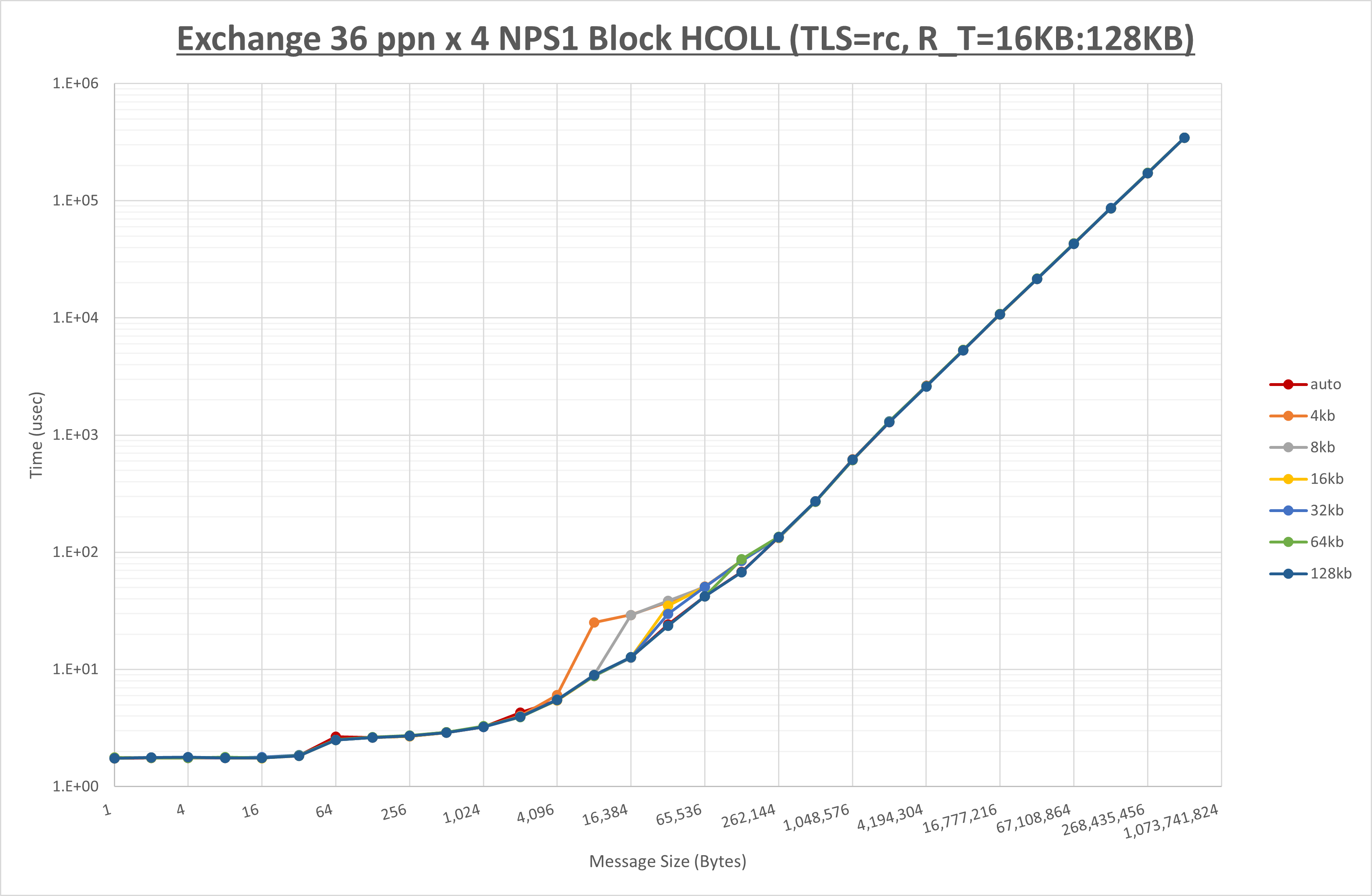
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
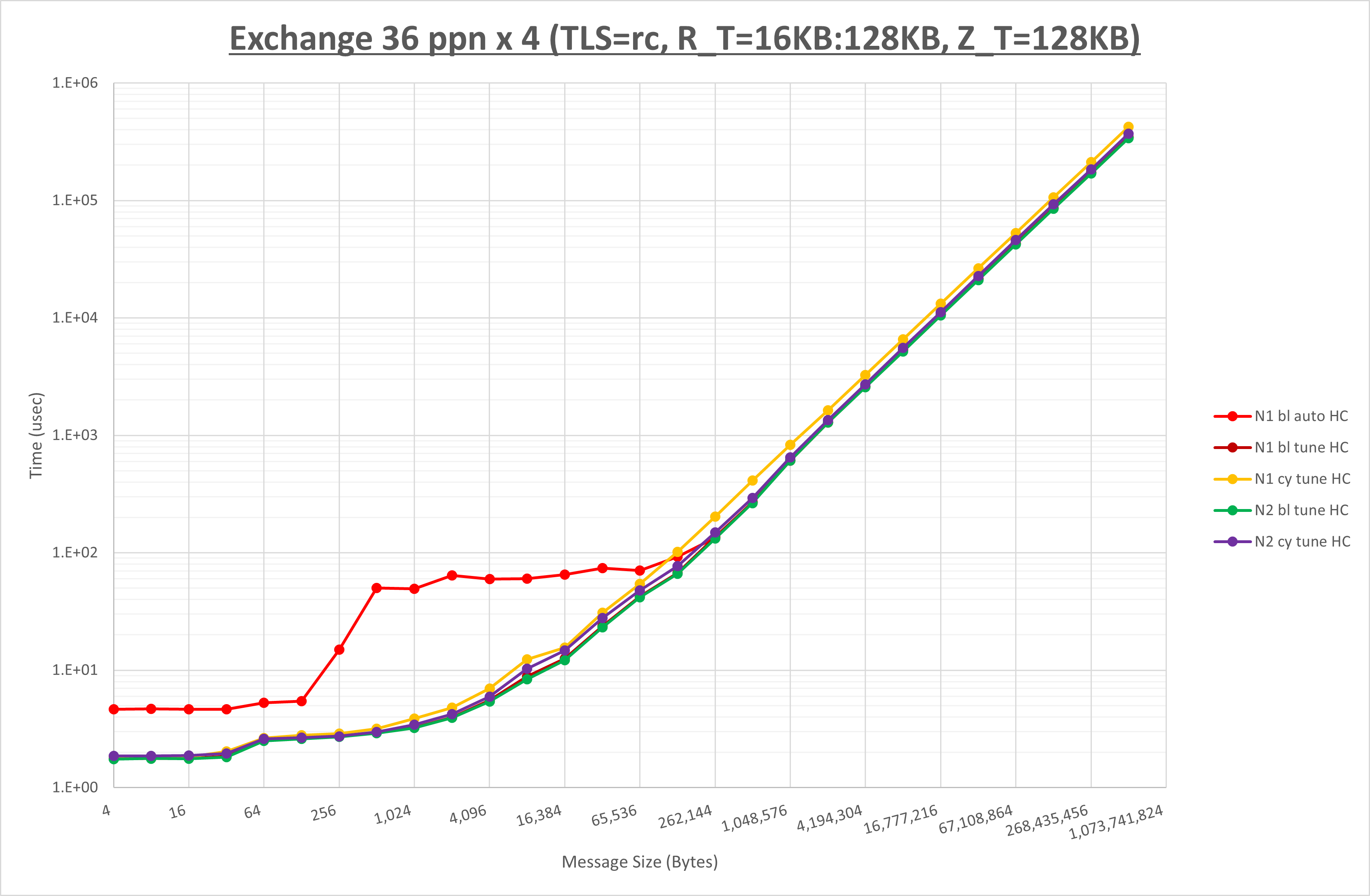
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、8ノードにノード当たり8・16・32・36、トータル64・128・256・288のMPIプロセスを割当てる場合の Alltoall ・ Allgather ・ Allreduce ・ Exchange の通信性能について、以下の 実行時パラメータ の最適な組み合わせを検証します。
- UCX_TLS : all ・ self,sm,rc ・ self,sm,ud ・ self,sm,dc
- UCX_RNDV_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb (※15)
- UCX_ZCOPY_THRESH : auto ・ 4kb ・ 8kb ・ 16kb ・ 32kb ・ 64kb ・ 128kb
- coll_hcoll_enable : 0 ・ 1 ( Exchange を除きます。)
- coll_ucc_enable : 0 ・ 1 ( Exchange を除きます。)
- MPIプロセス分割方法 : ブロック分割・サイクリック分割
- NPS : NPS1 ・ NPS2
※15) UCX_RNDV_THRESH は、ノード内は auto と 1. 1ノード で判明した最適値、ノード間はここに記載の7種類を使用し、以下8個の組合せを検証します。
- intra:auto,inter:auto
- intra:optimal_value,inter:auto
- intra:optimal_value,inter:4kb
- intra:optimal_value,inter:8kb
- intra:optimal_value,inter:16kb
- intra:optimal_value,inter:32kb
- intra:optimal_value,inter:64kb
- intra:optimal_value,inter:128kb
ここで、全ての 実行時パラメータ の組み合わせを検証することは非現実的なため、組み合わせを減らす目的で以下3ステップに分けて検証を行います。
- ステップ1
- UCX_TLS と UCX_RNDV_THRESH を組合せた32個のパターンを検証してこれらの最適値を決定
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ2
- UCX_ZCOPY_THRESH の7パターンを検証してこの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- coll_hcoll_enable は 1 に固定(デフォルト)
- coll_ucc_enable は 0 に固定(デフォルト)
- MPIプロセス分割方法はブロック分割に固定
- NPS は NPS1 に固定
- ステップ3
- coll_hcoll_enable / coll_ucc_enable / MPIプロセス分割方法 / NPS を組合せた12パターンを検証してこれらの最適値を決定
- UCX_TLS と UCX_RNDV_THRESH はステップ1で決定した最適値を使用
- UCX_ZCOPY_THRESH はステップ2で決定した最適値を使用
本章は、8ノードにノード当たり8、トータル64のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:32kb,inter:32kb | 16kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:32kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-1 Alltoall の HCOLL の結果から32KBとしています。
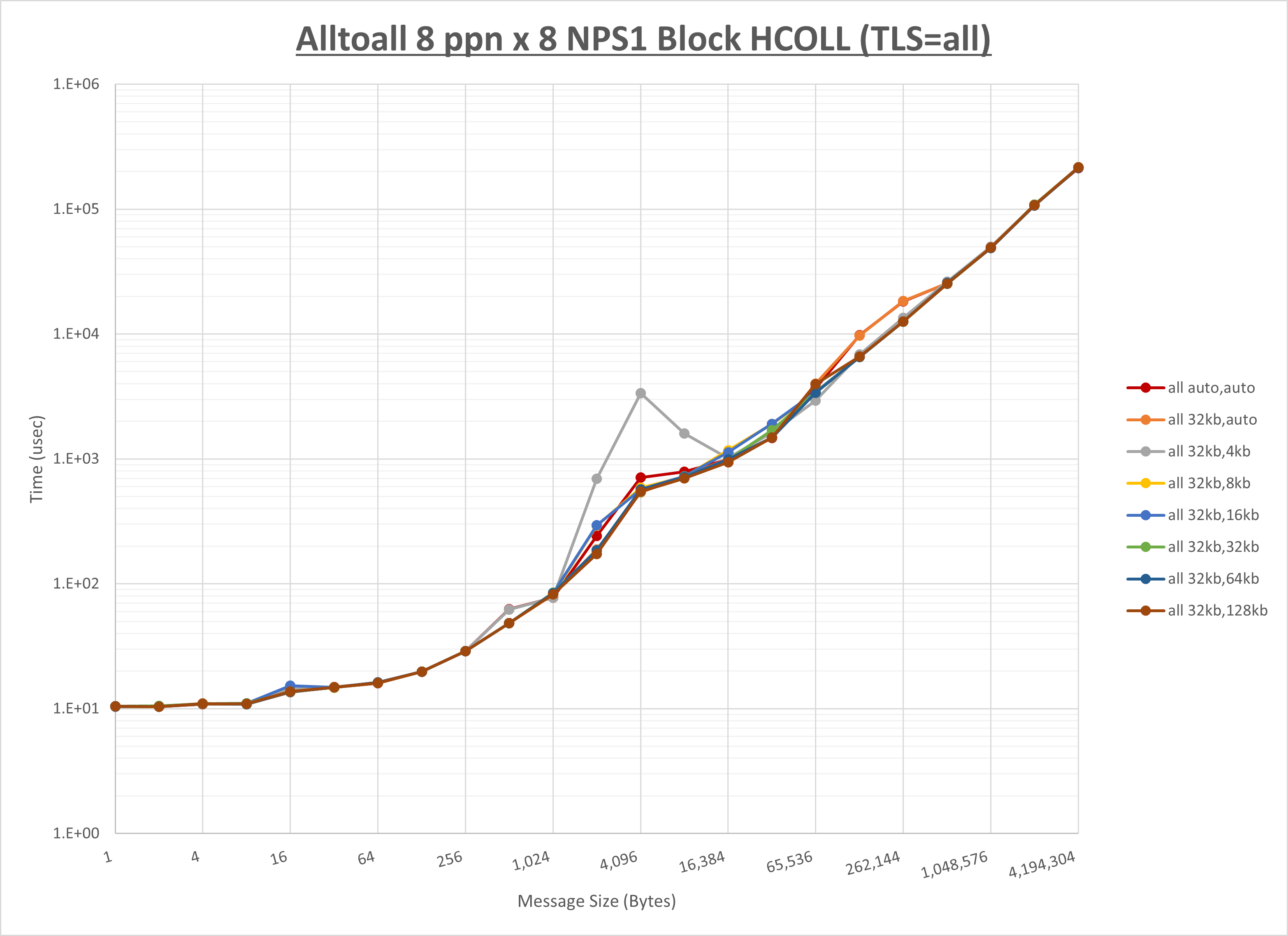
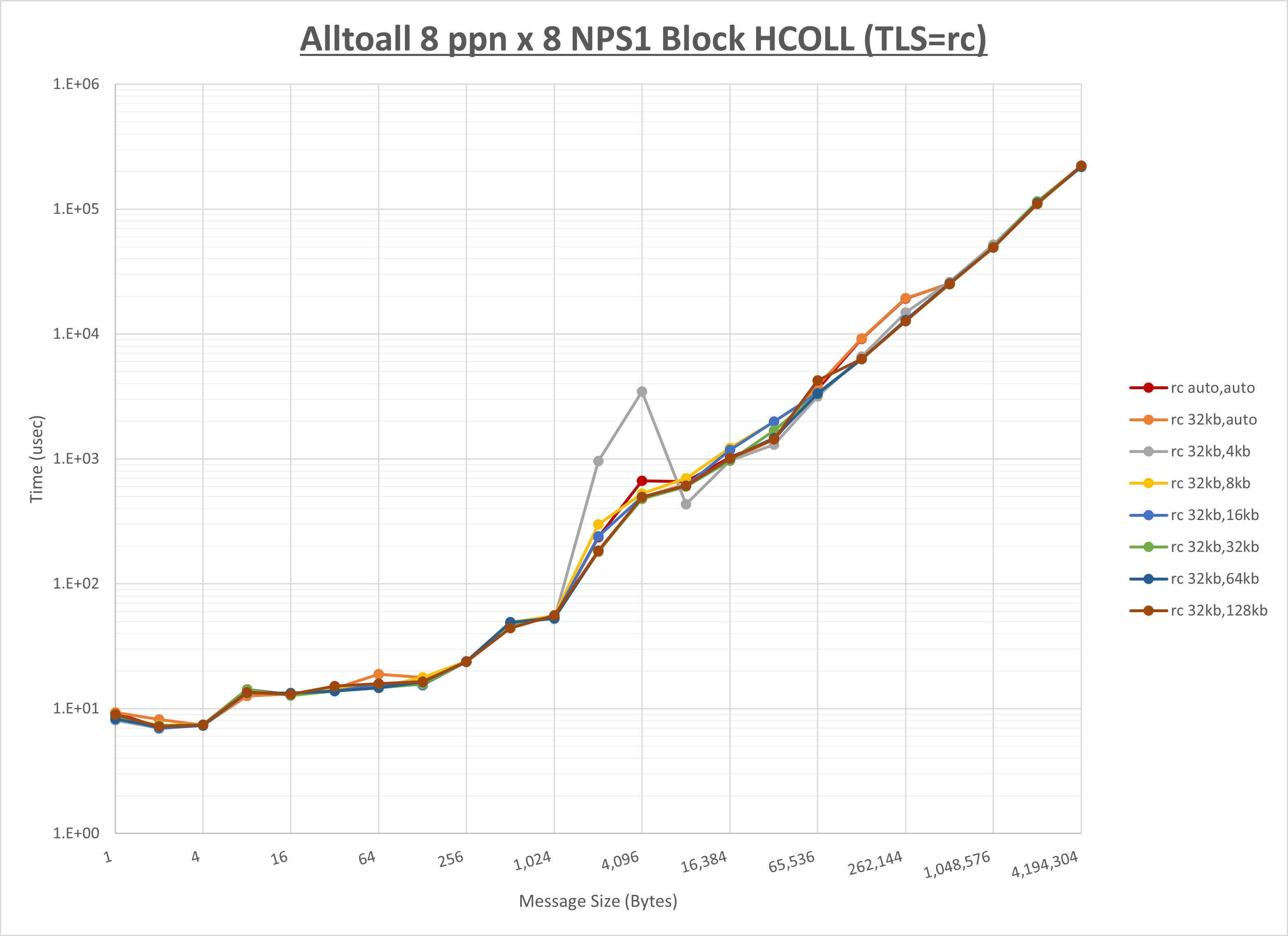
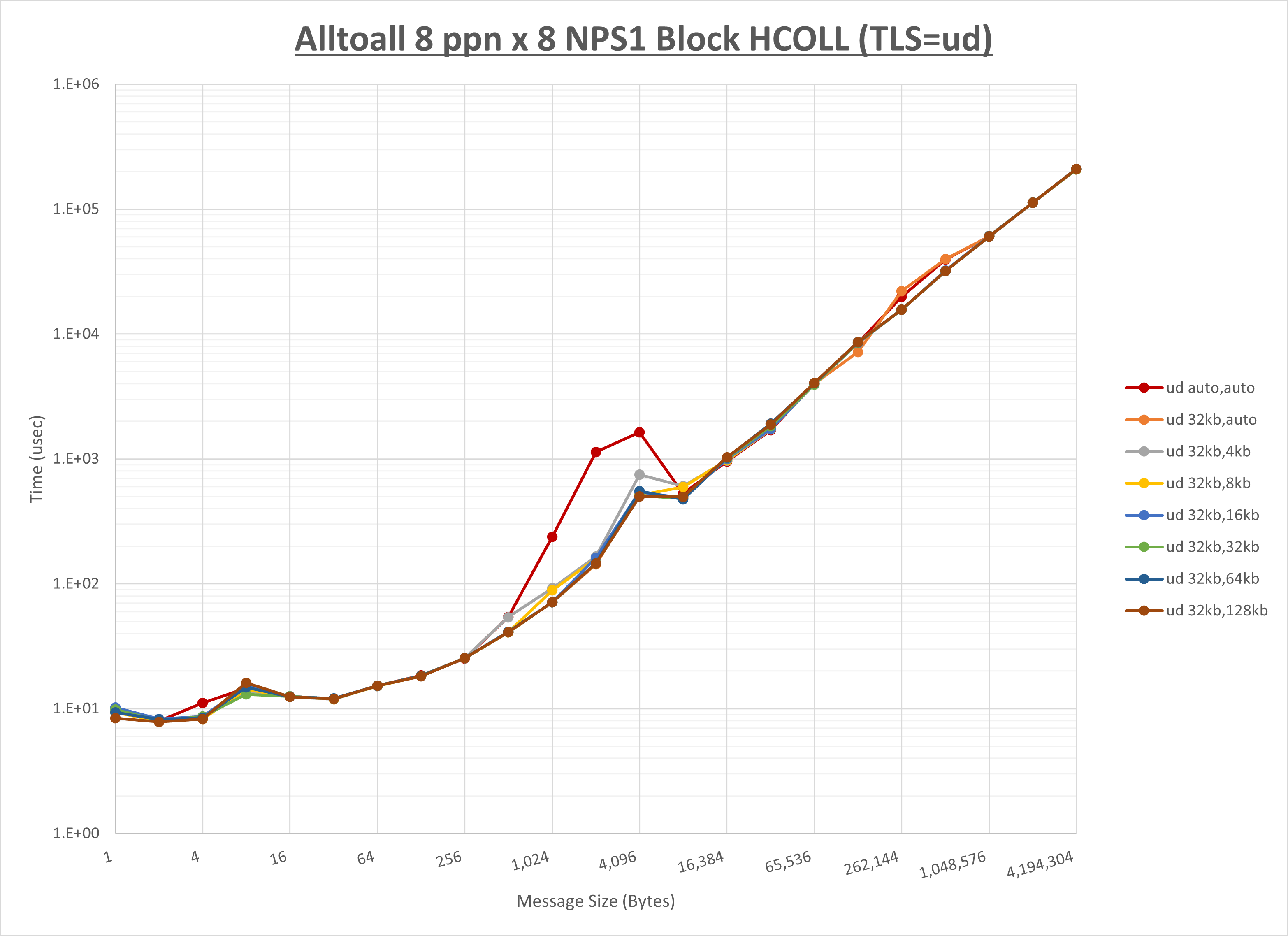
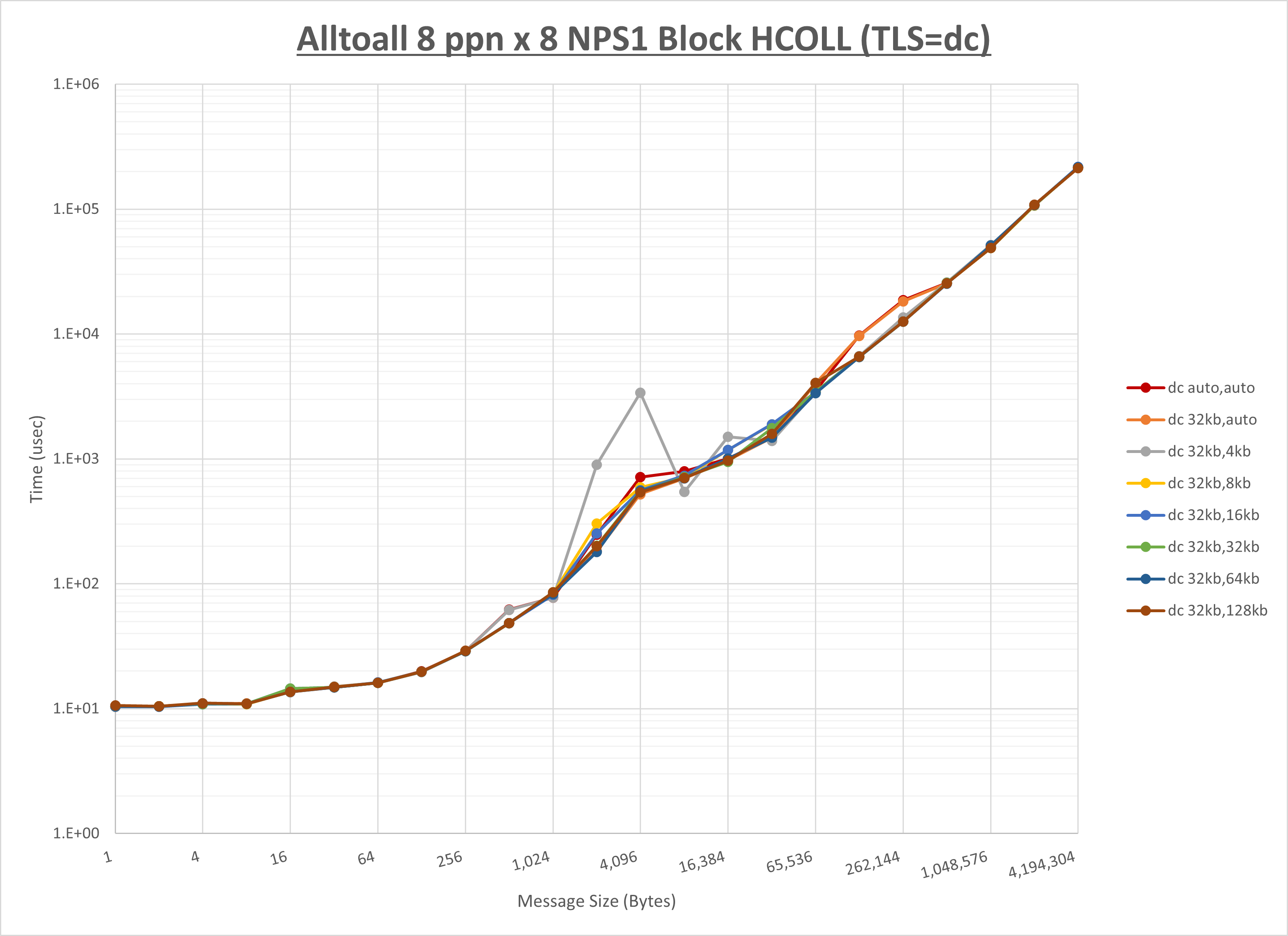
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
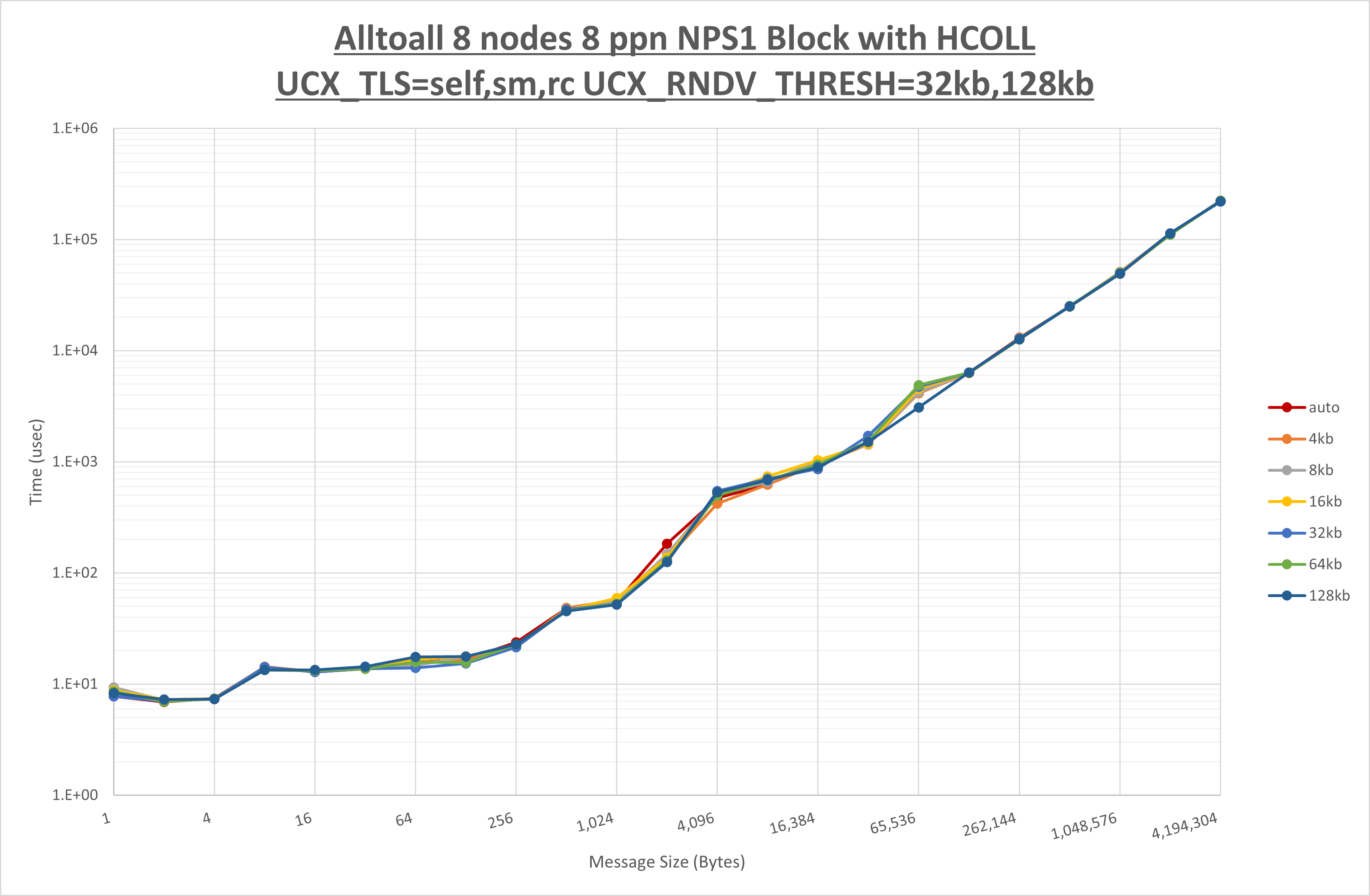
以上より、 UCX_ZCOPY_THRESH を 16kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
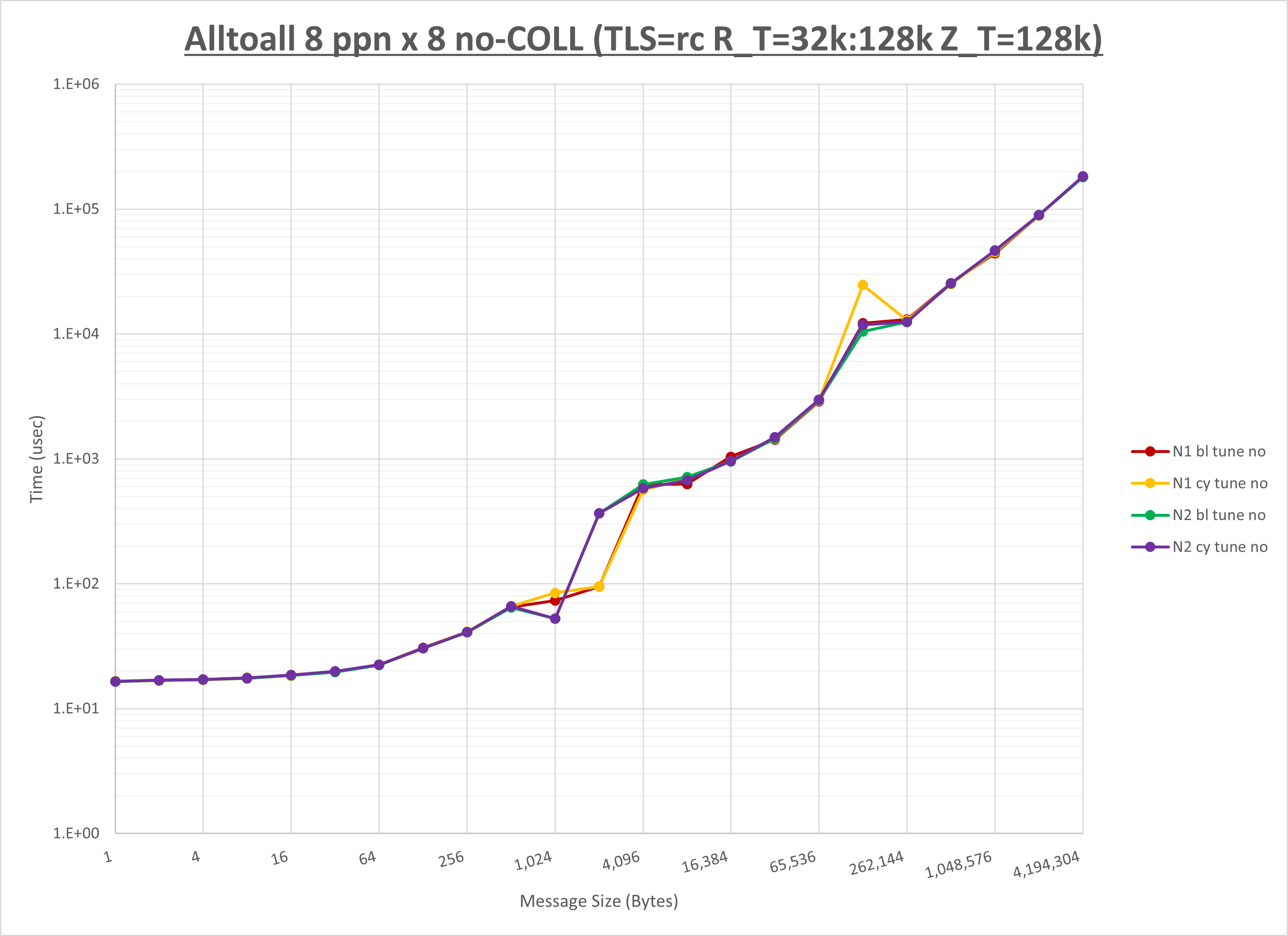
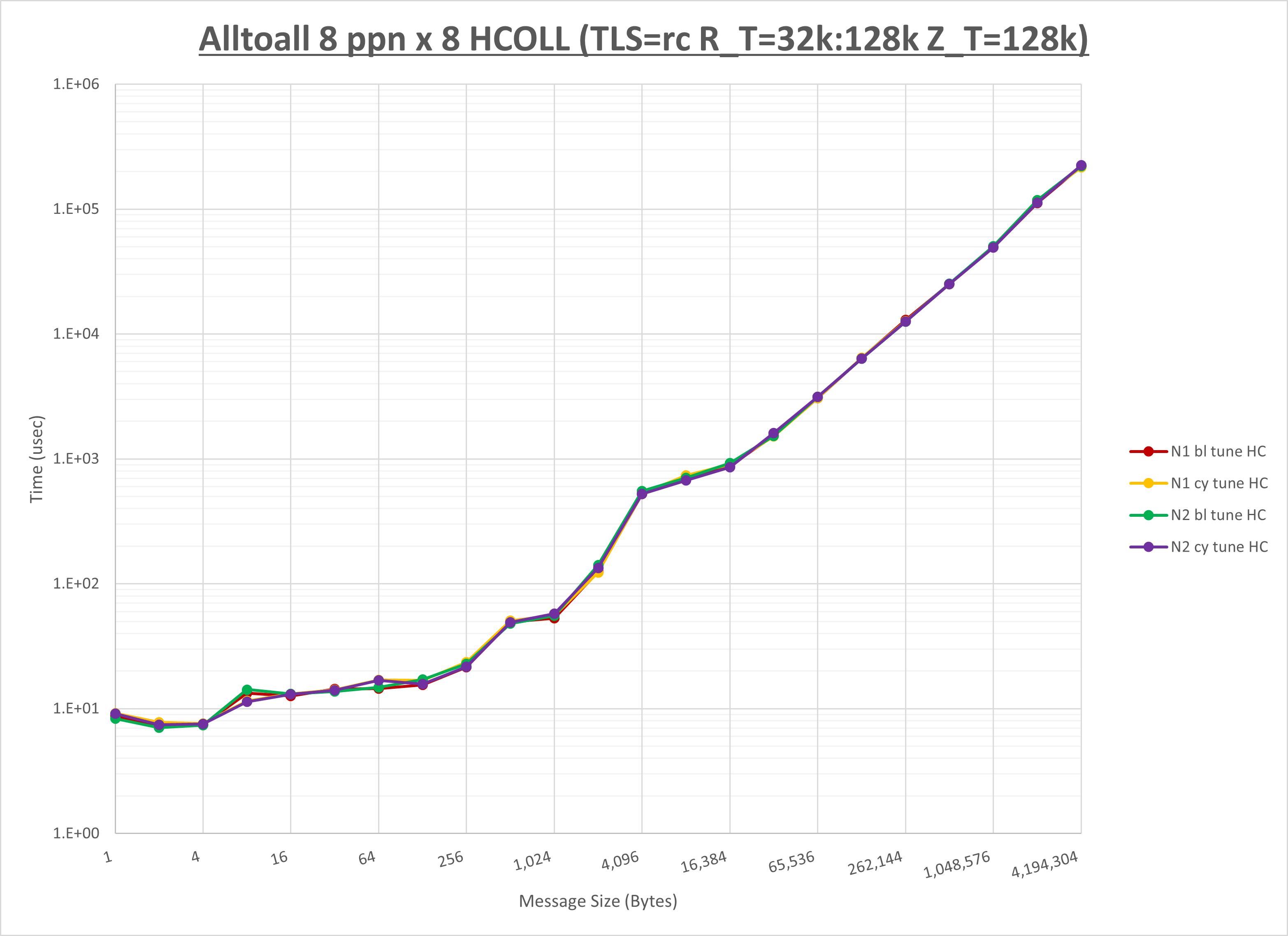
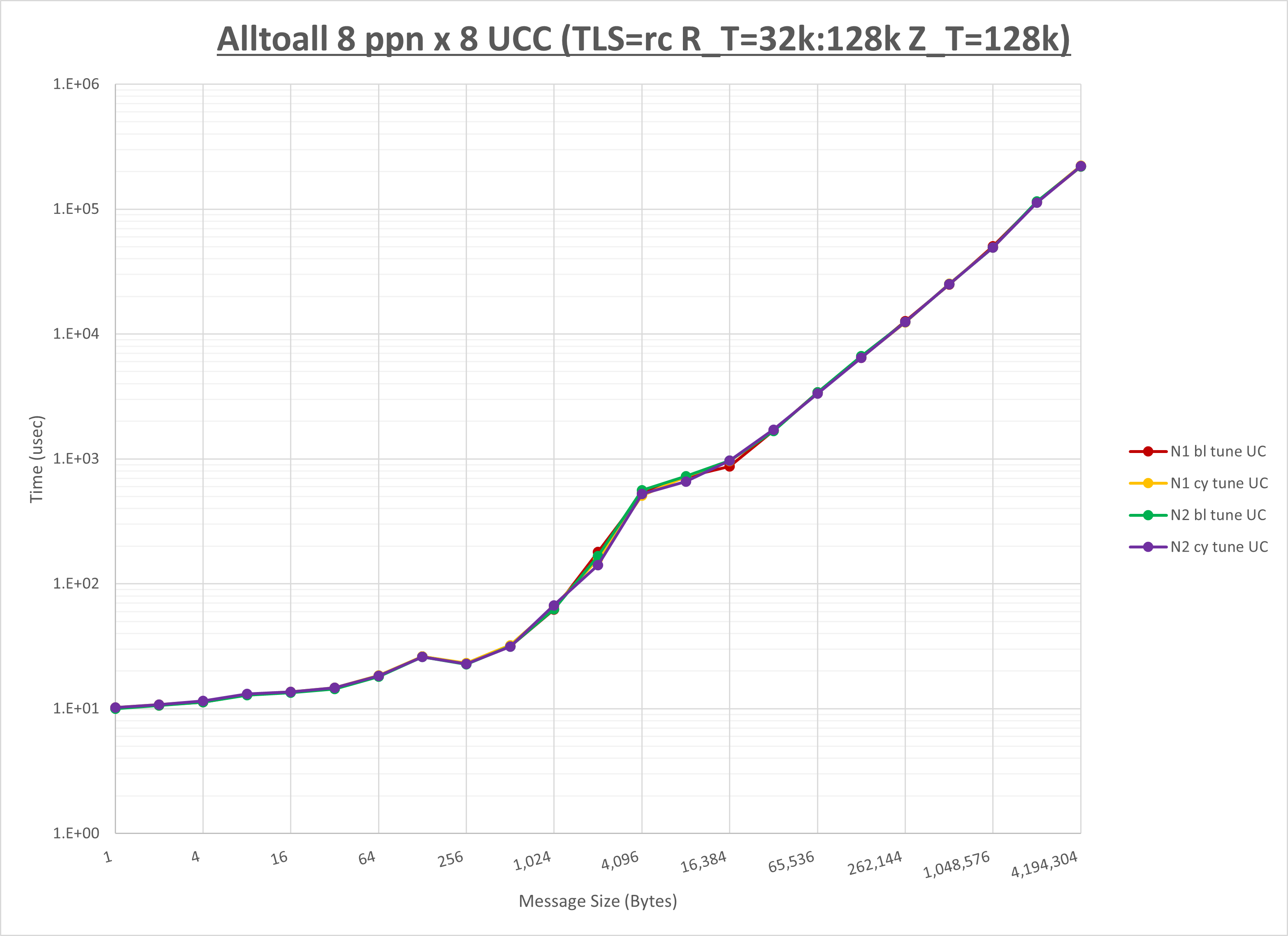
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
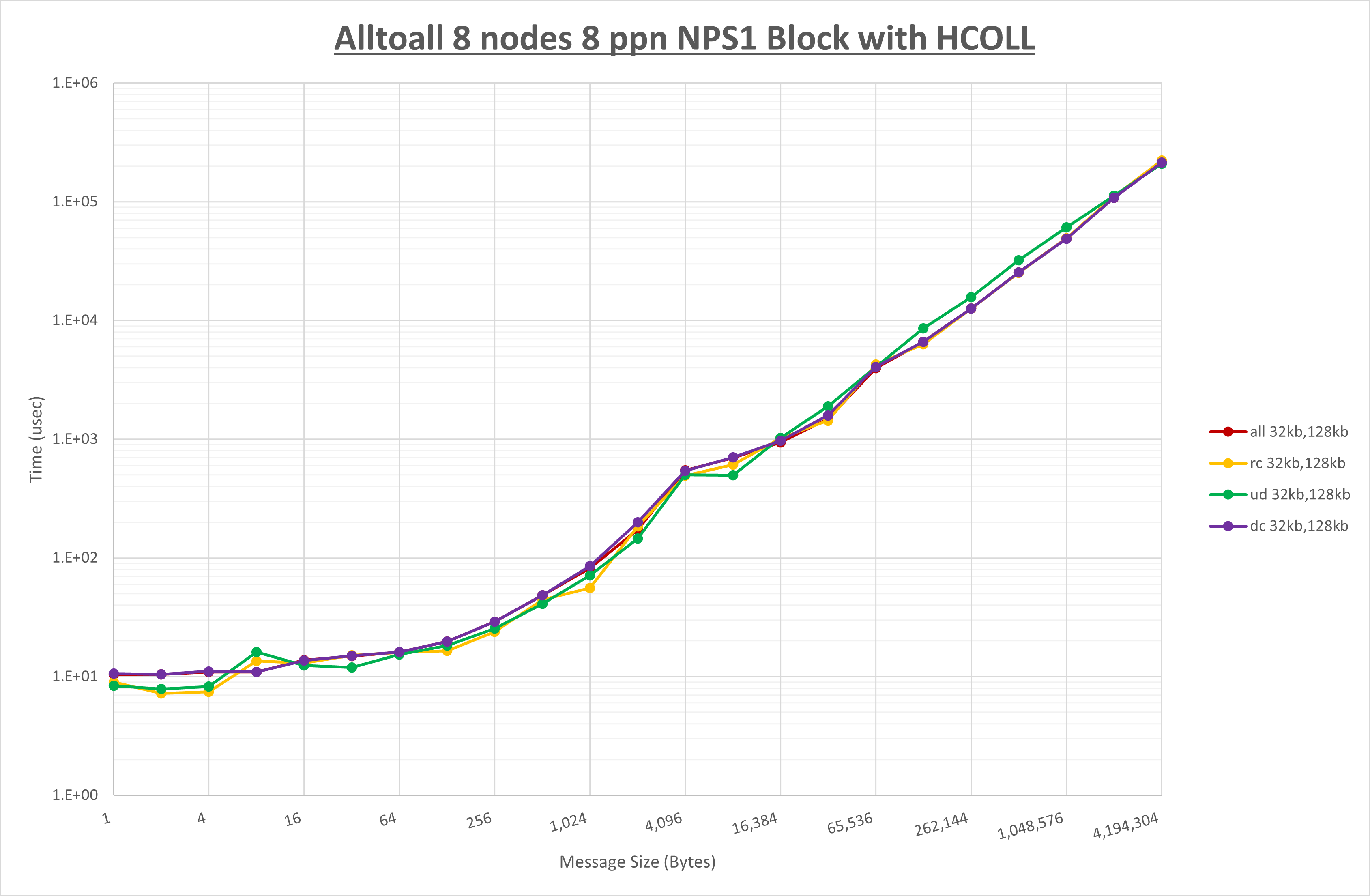
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
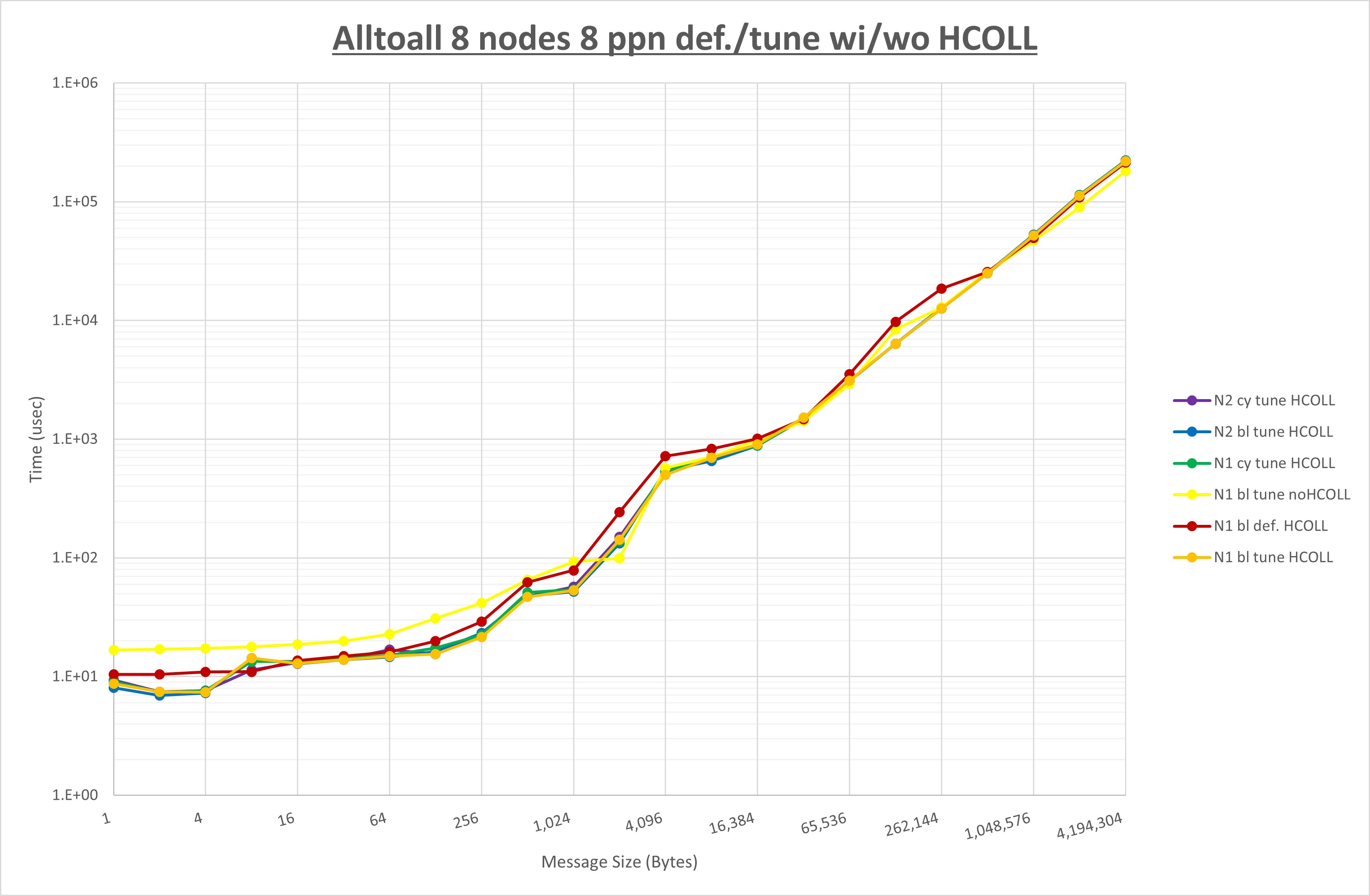
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し512B以下で性能が向上
- UCC は no-COLL と比較し4KB以下と32KBから128KBで性能が向上
- チューニング適用で256KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-2 Allgather の HCOLL の結果から64KBとしています。
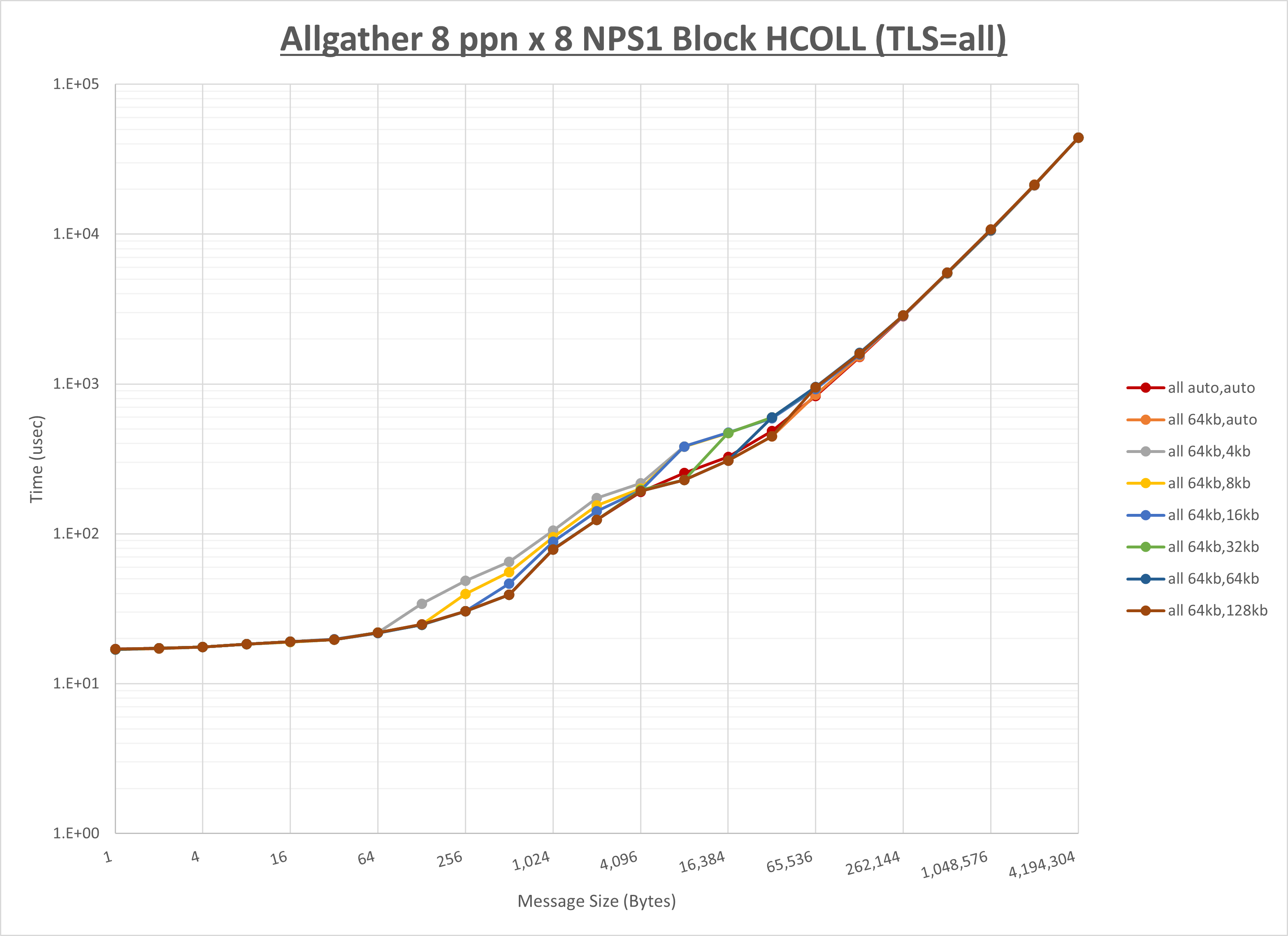
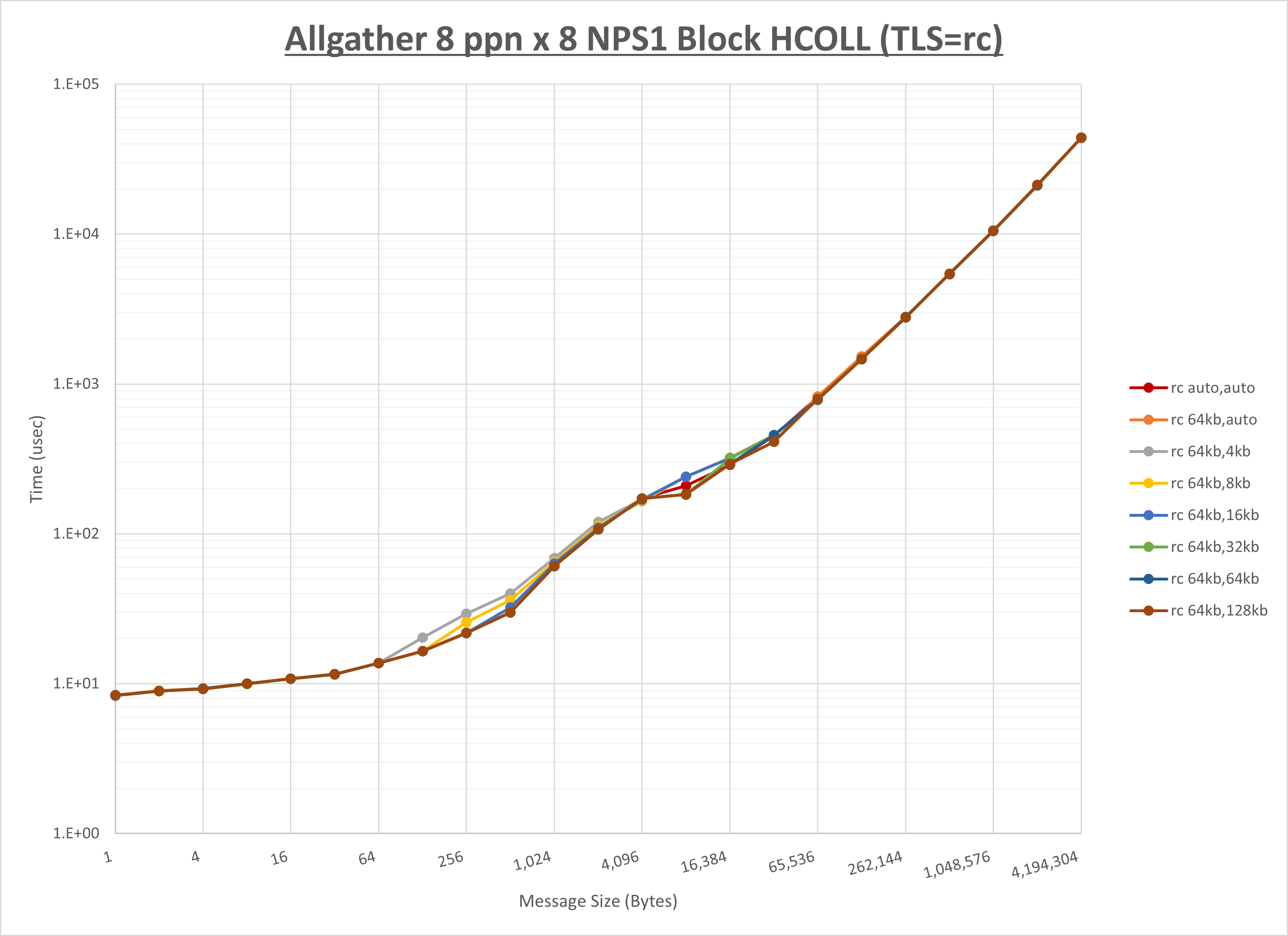
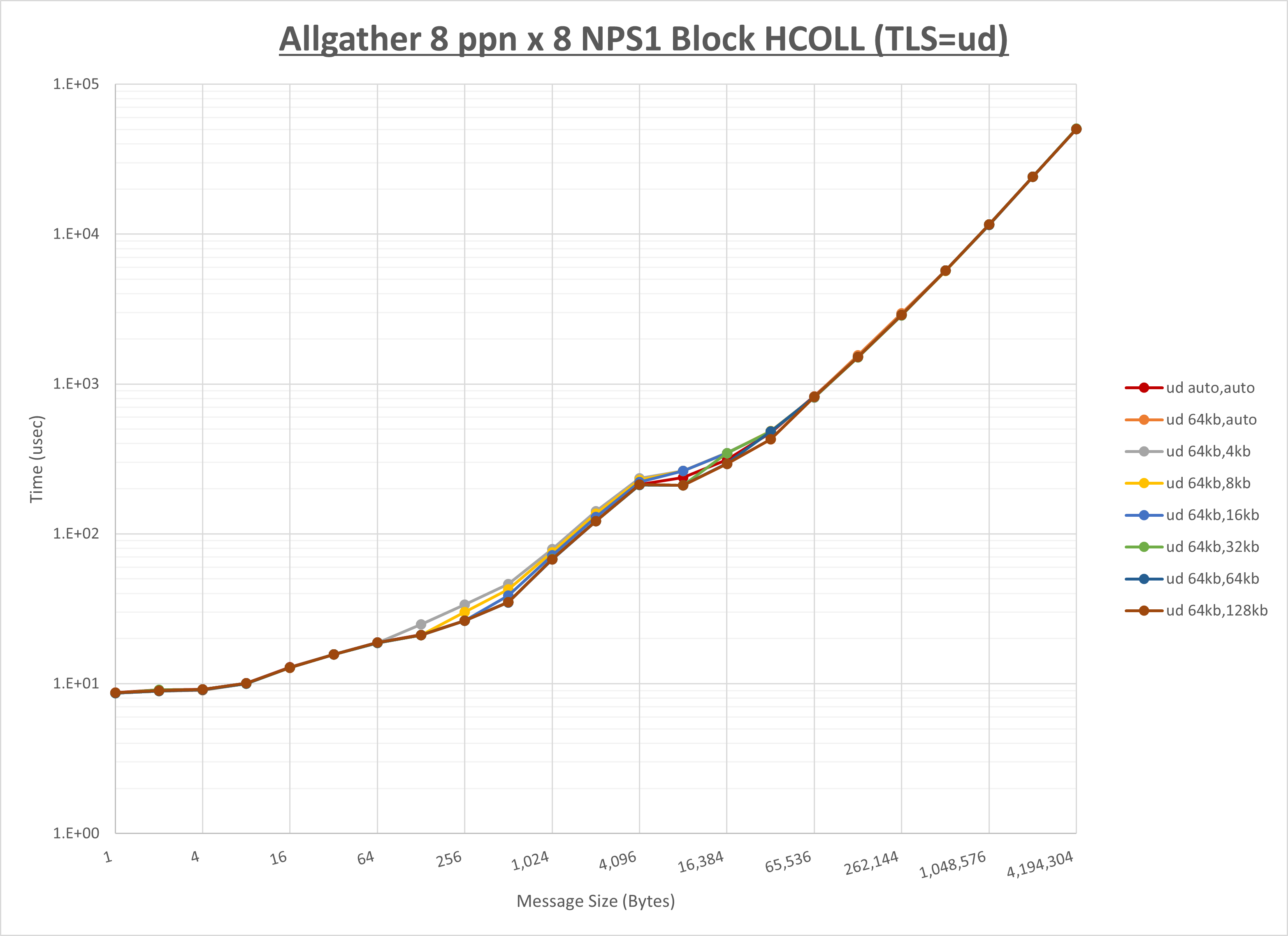
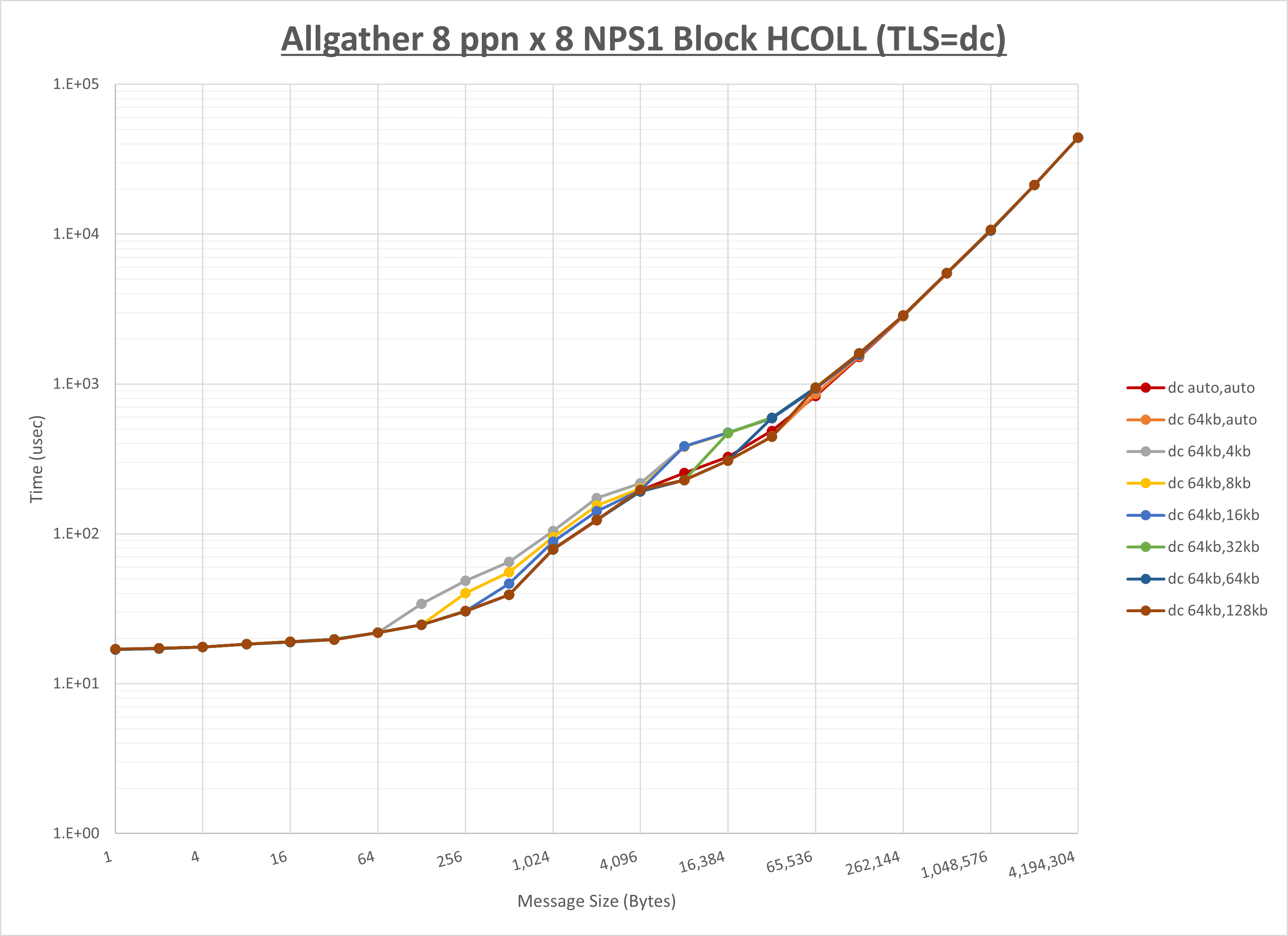
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
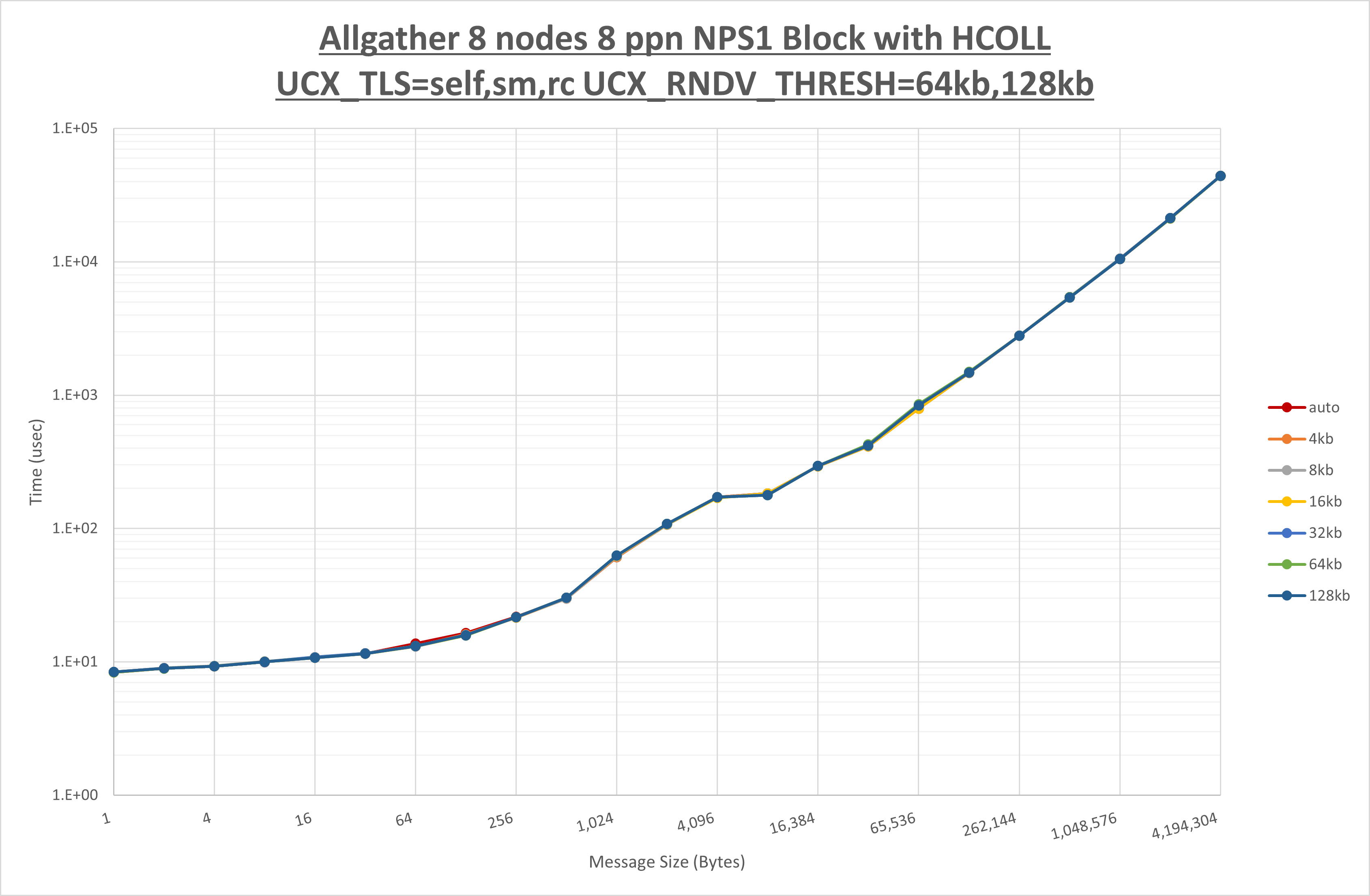
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
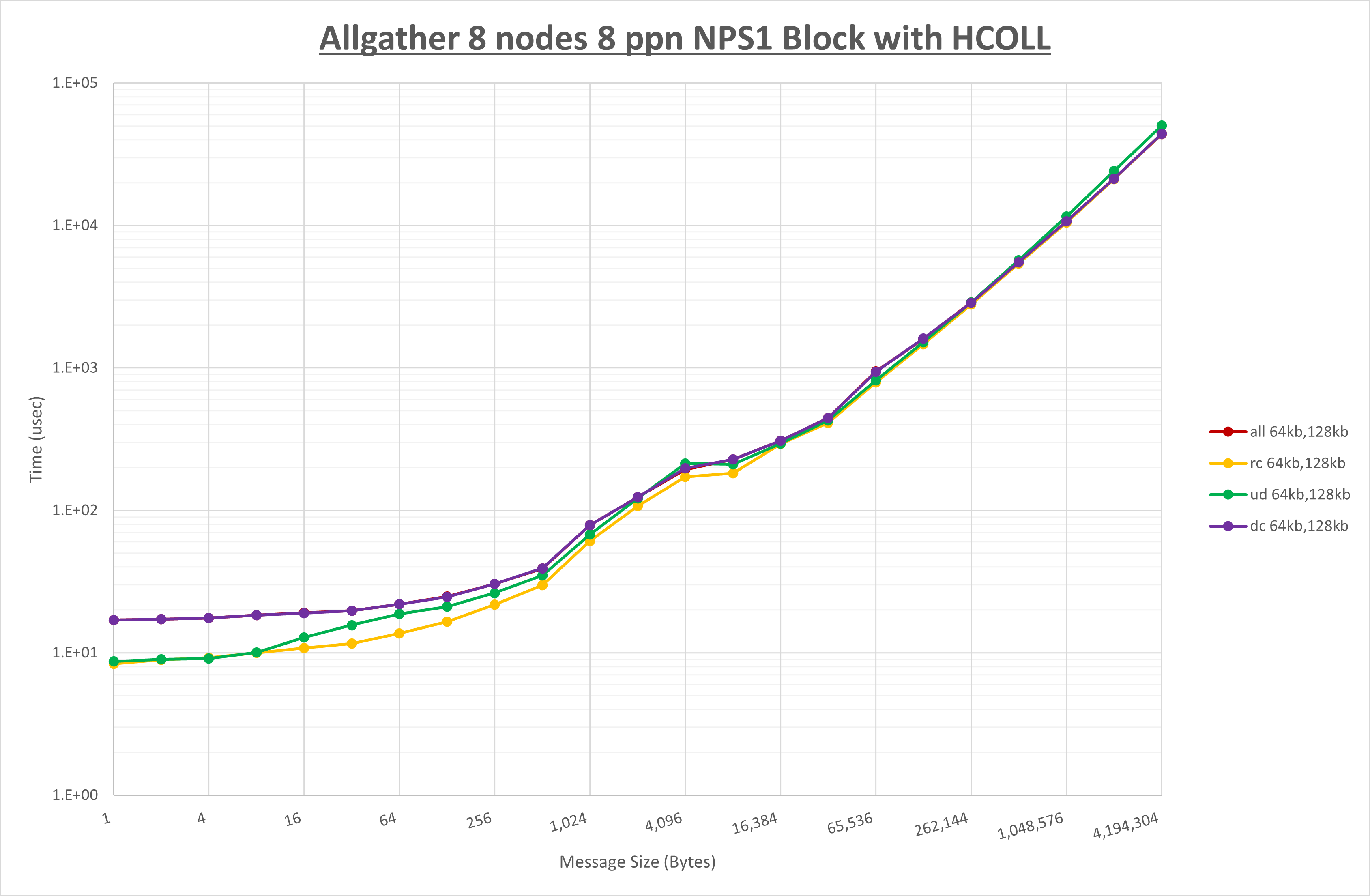
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
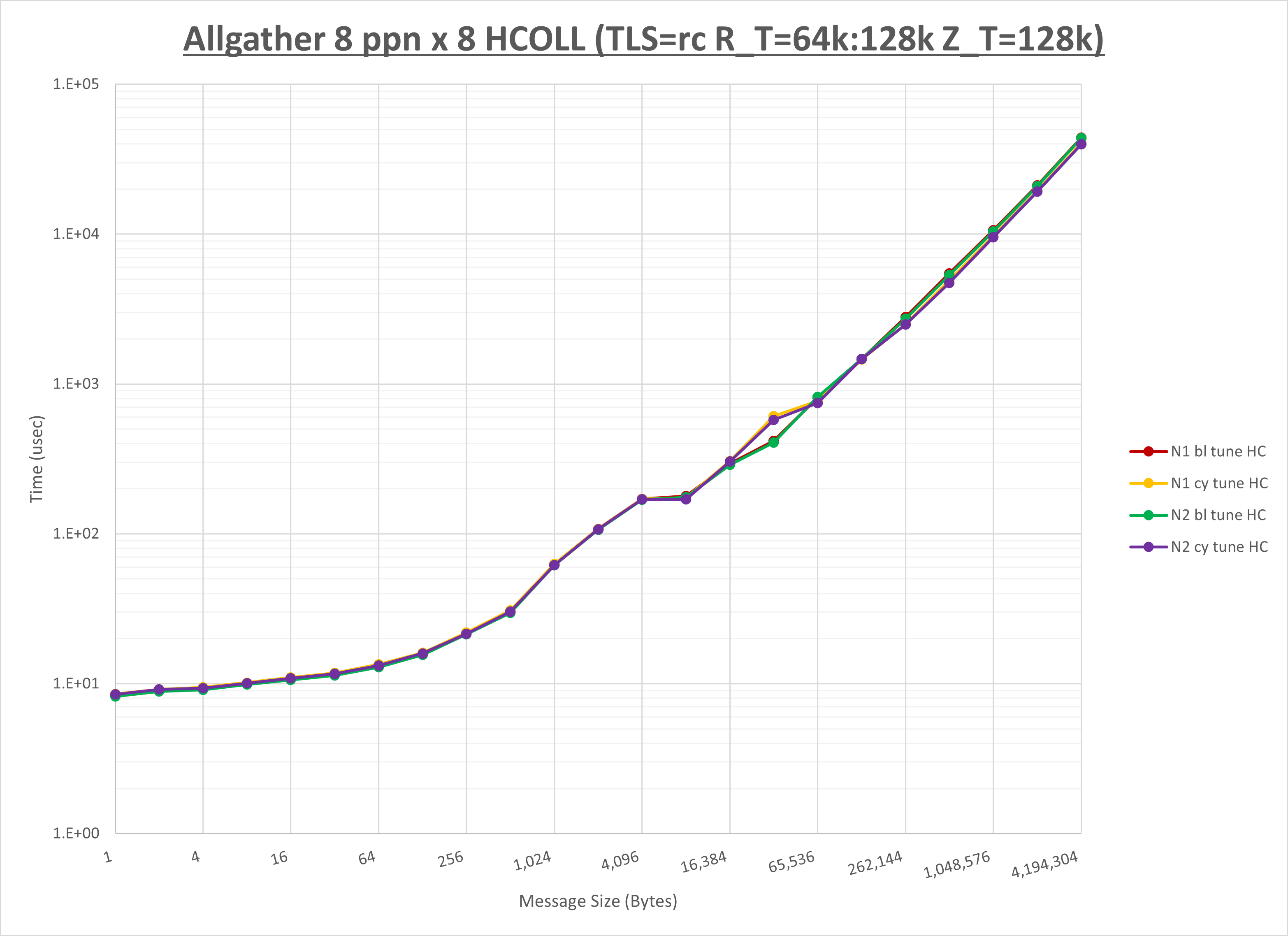
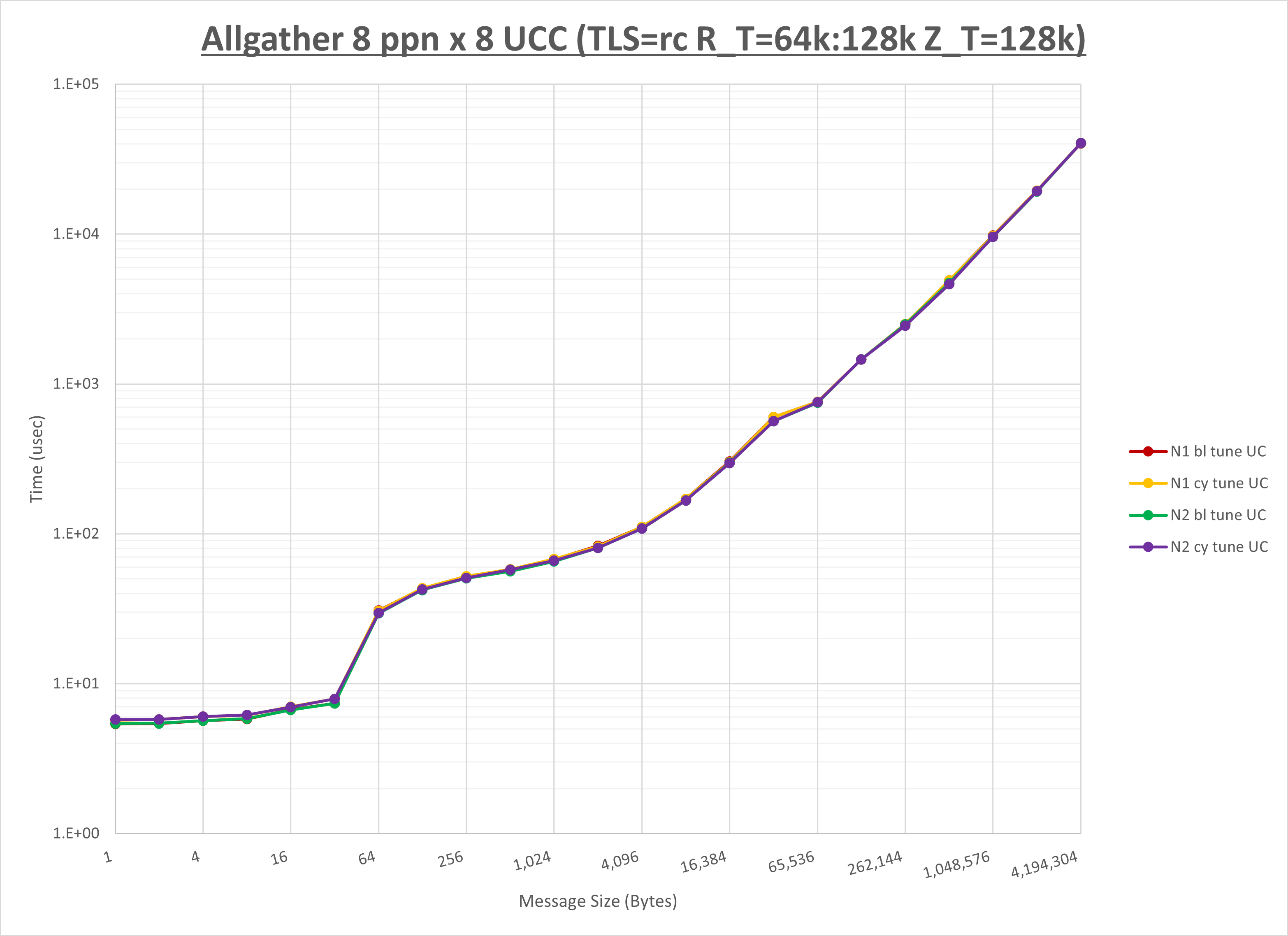
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較しほぼ全域で性能が向上
- UCC は no-COLL と比較し32B以下と1KB以上で性能が向上し64Bから512Bで性能が低下
- チューニング適用で16KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-3 Allreduce の HCOLL の結果から128KBとしています。
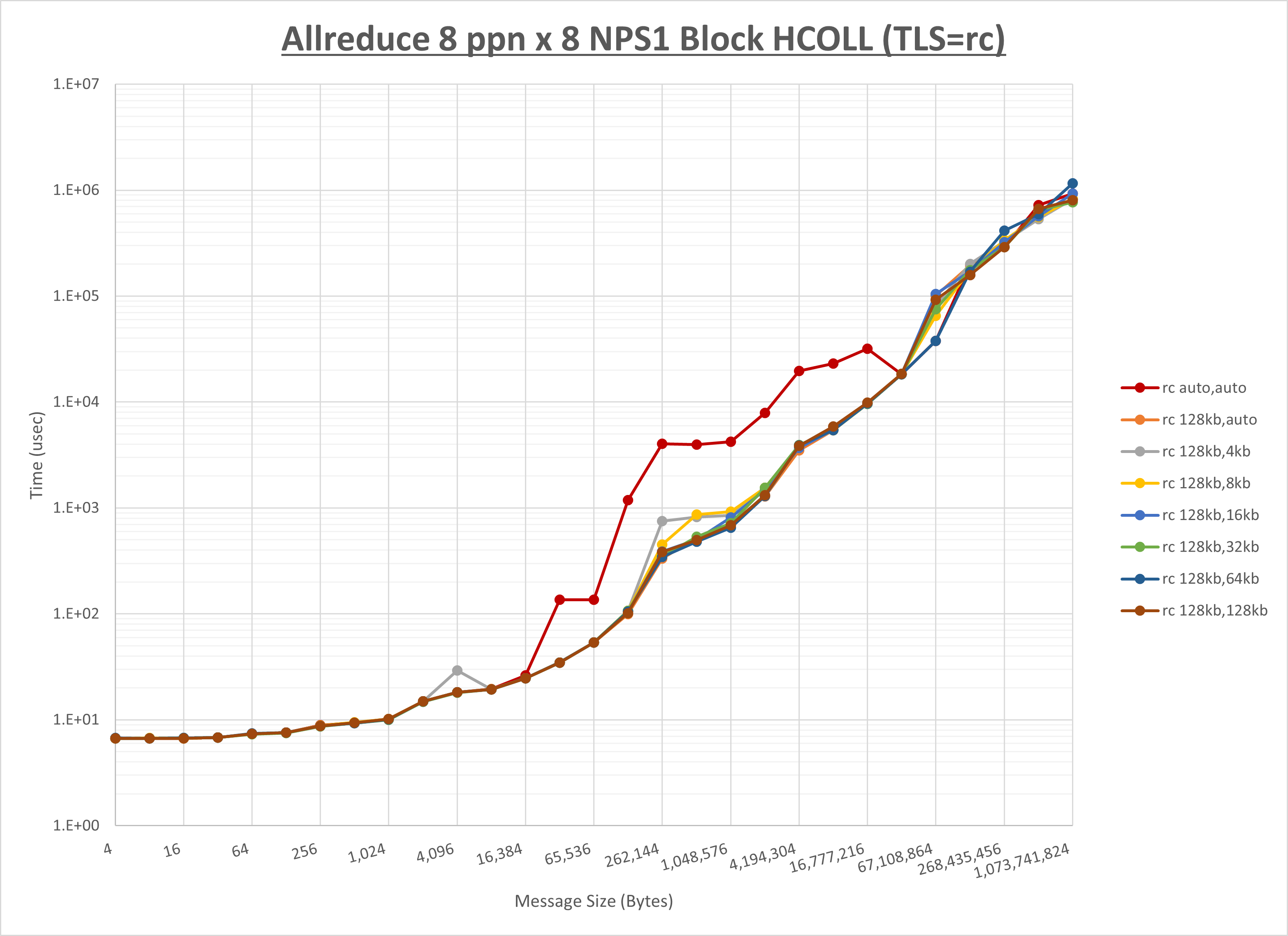
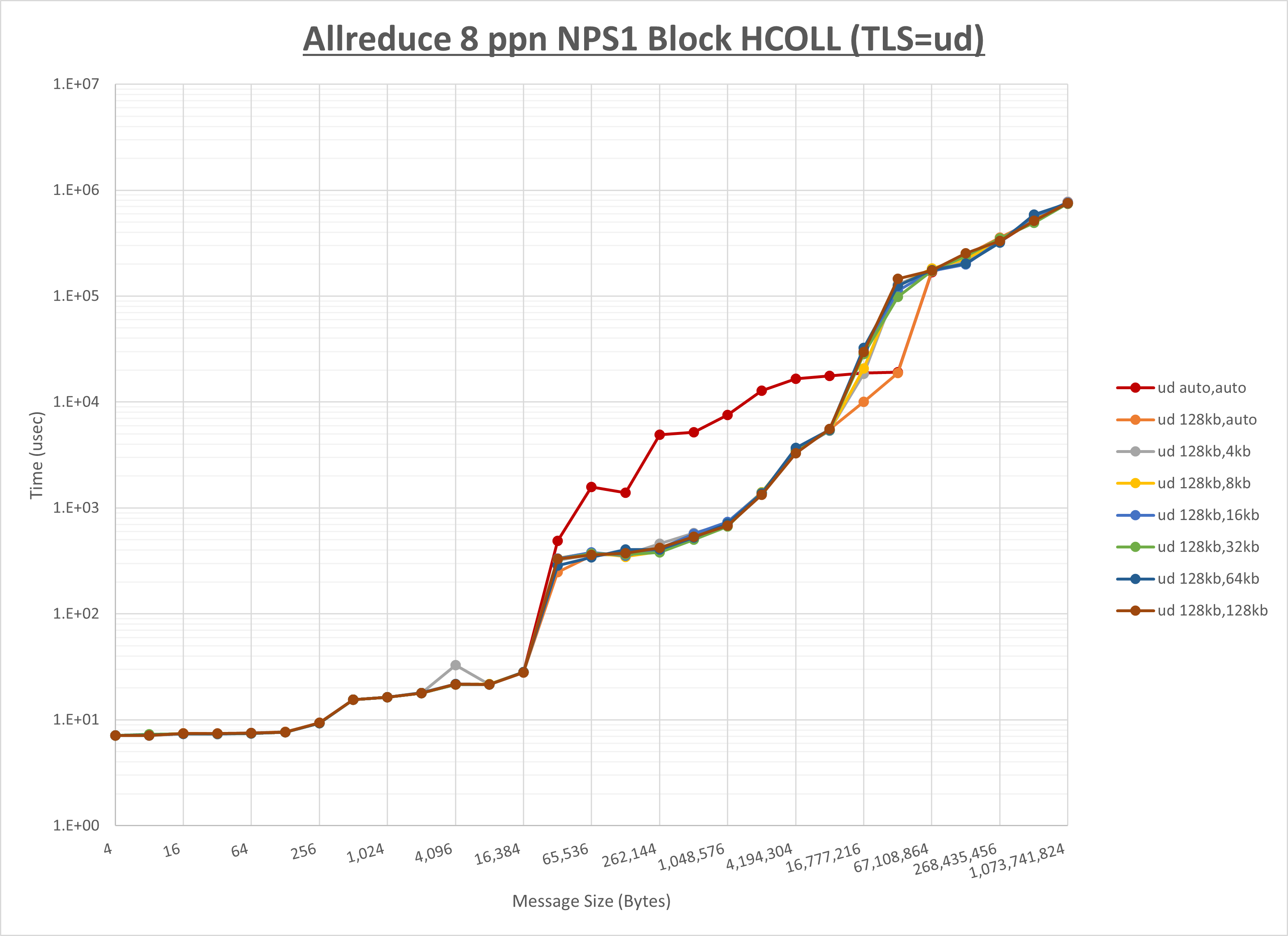
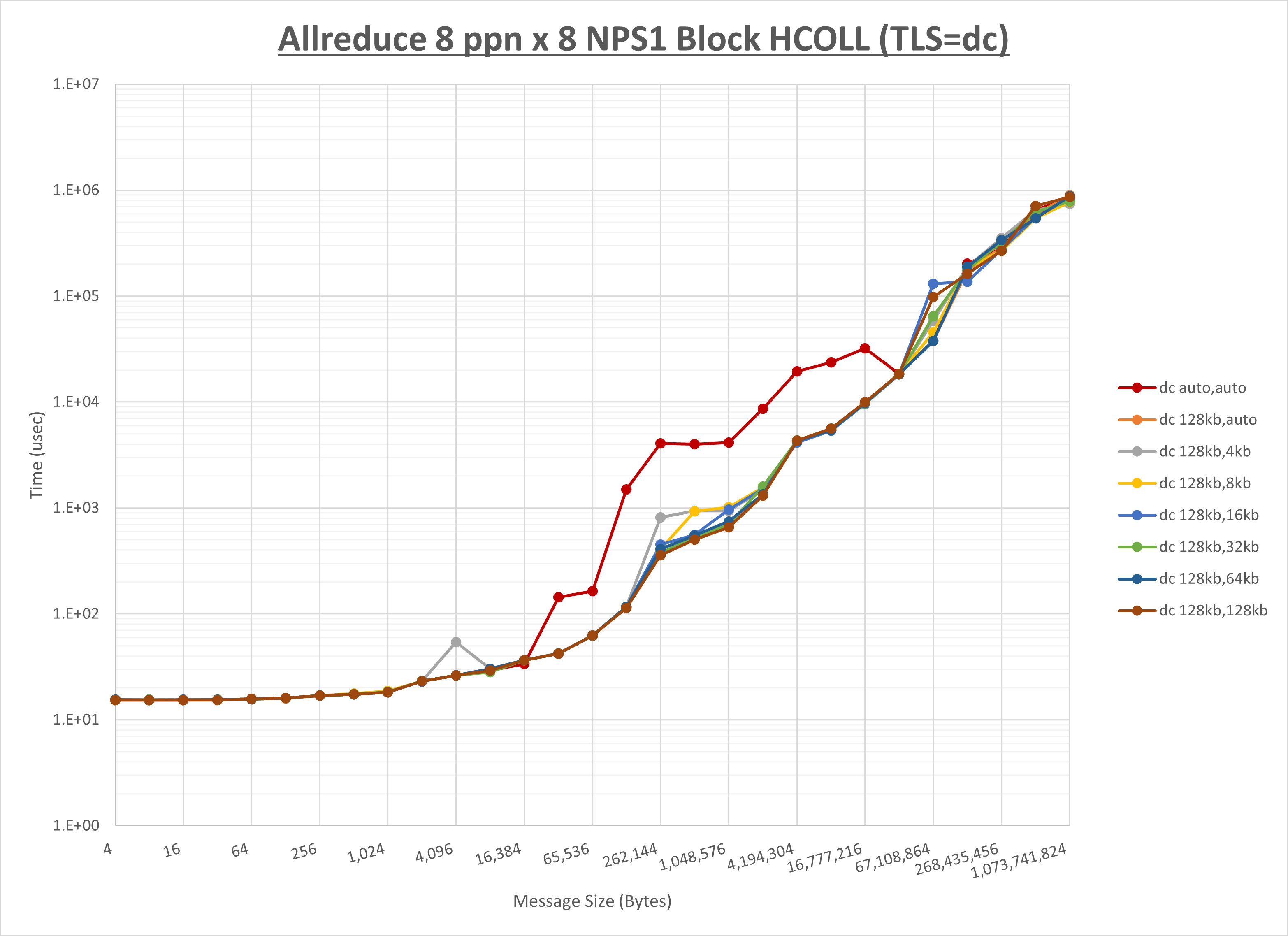
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
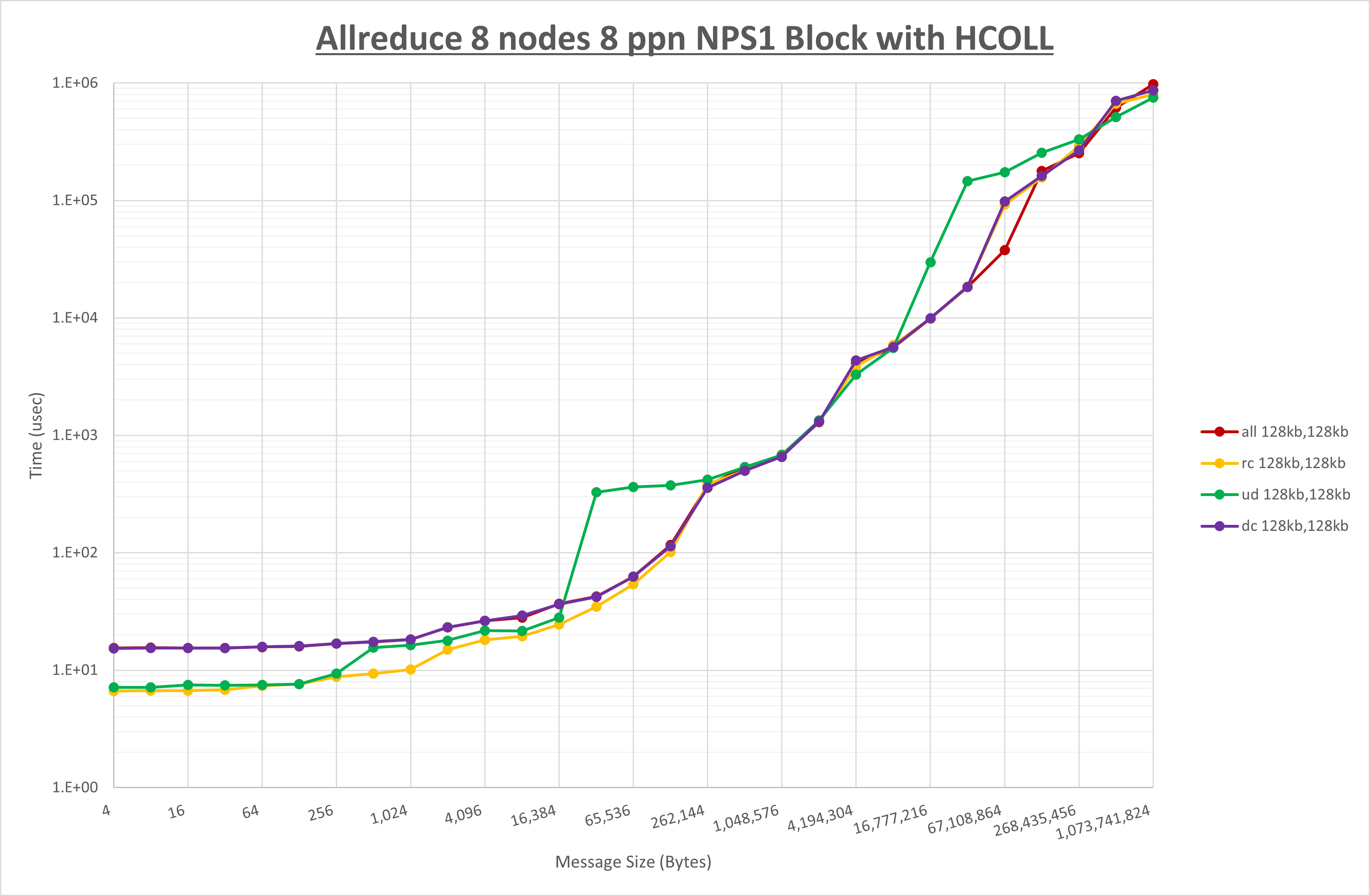
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
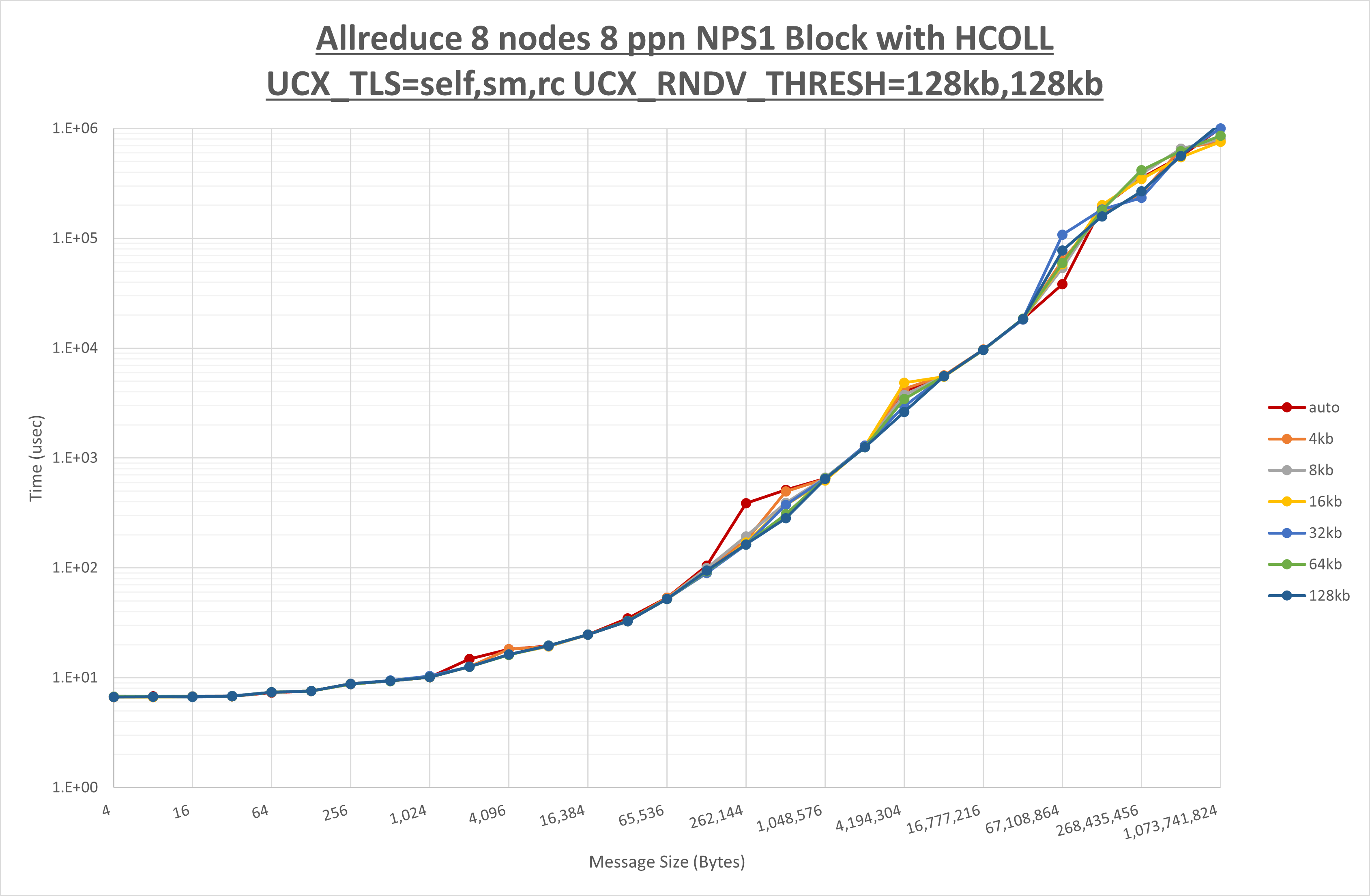
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
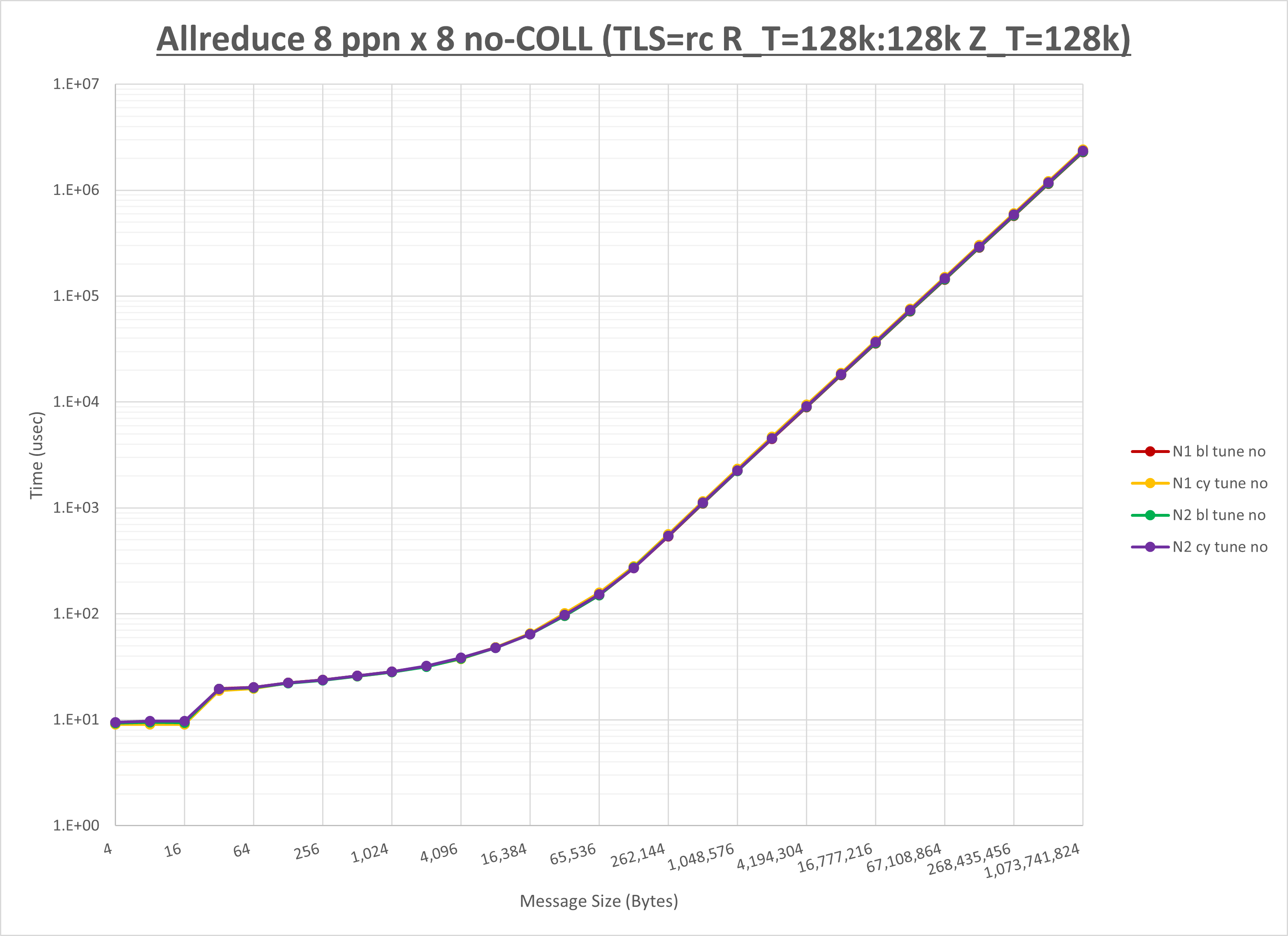
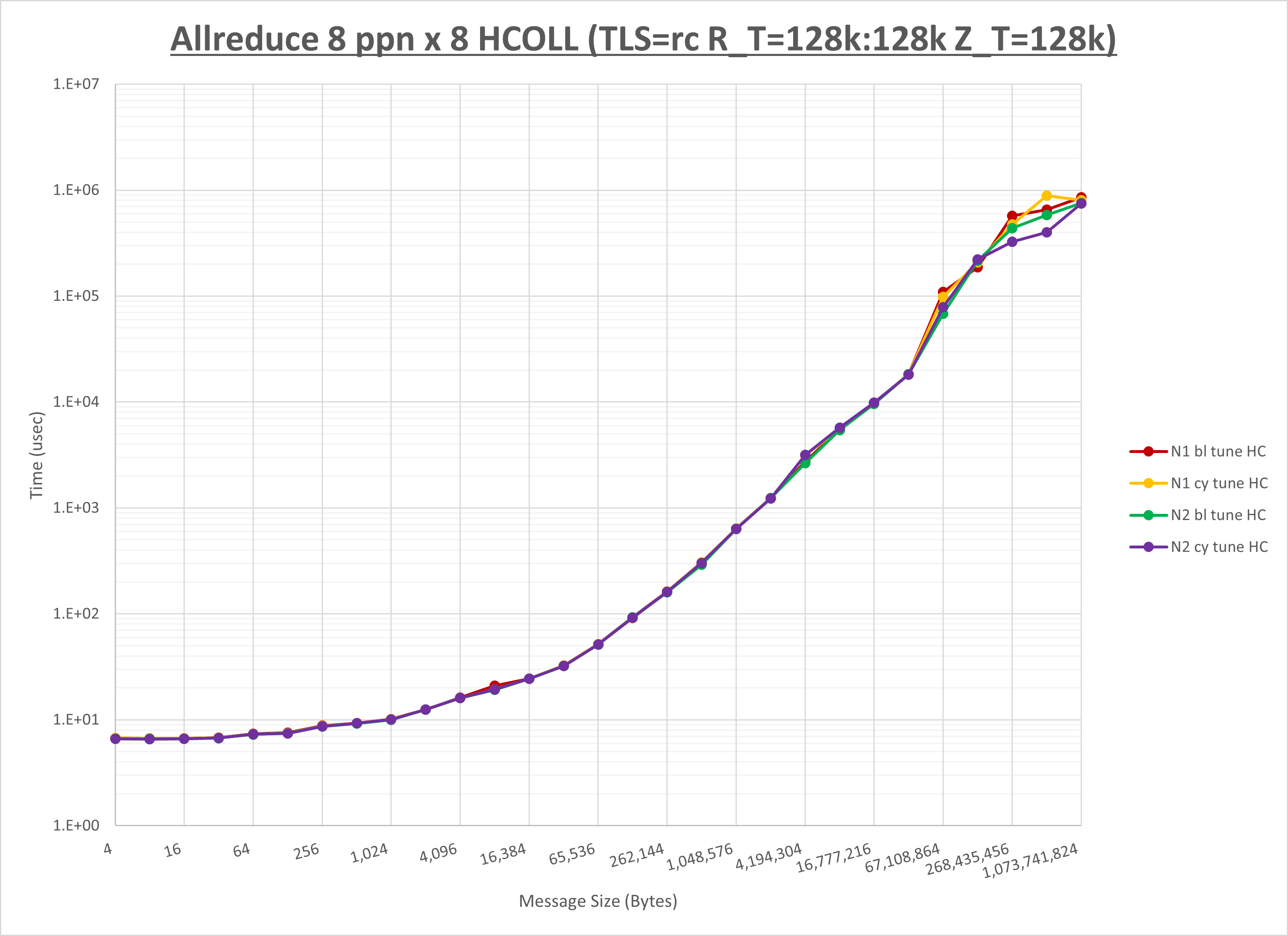
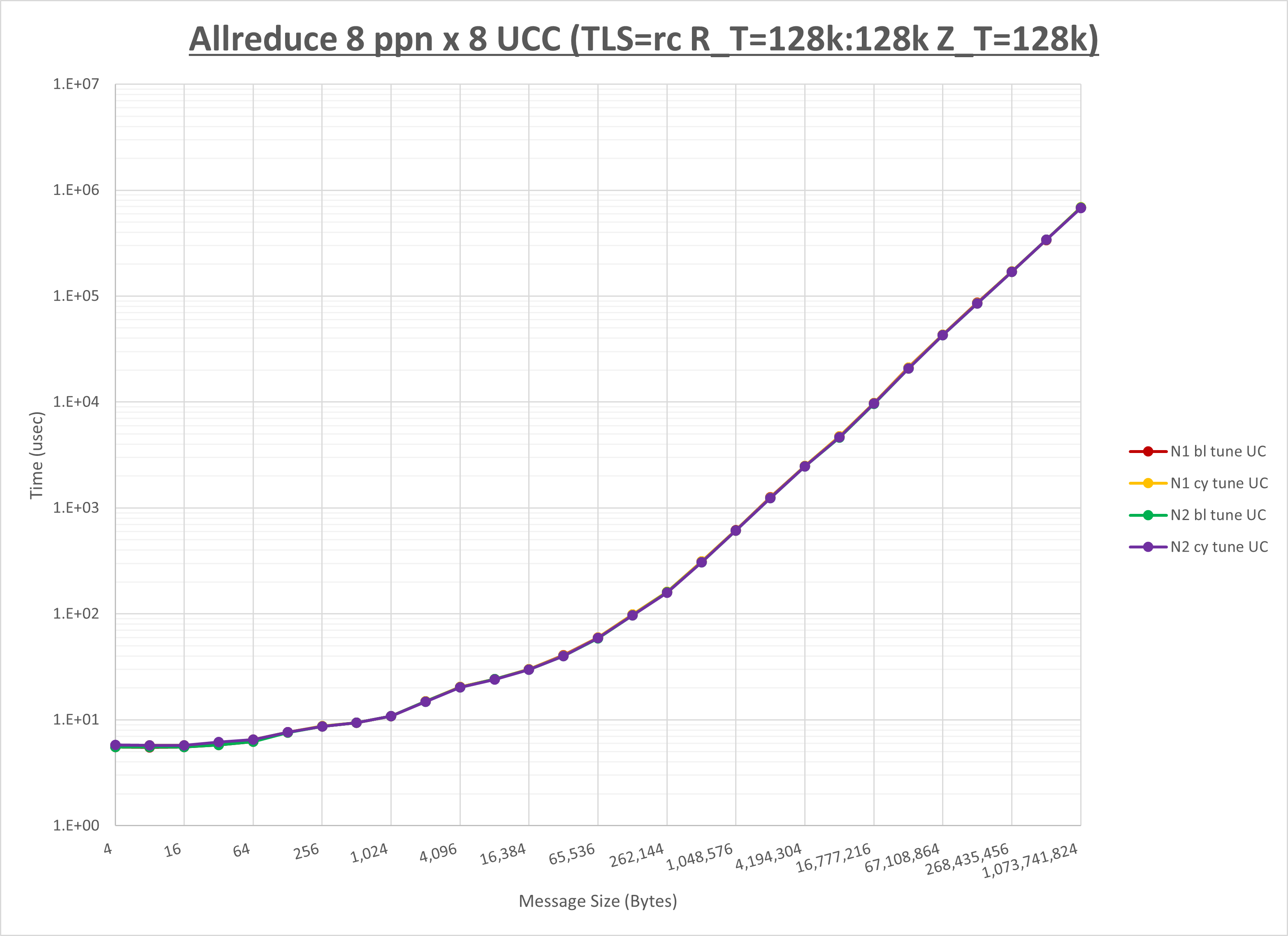
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
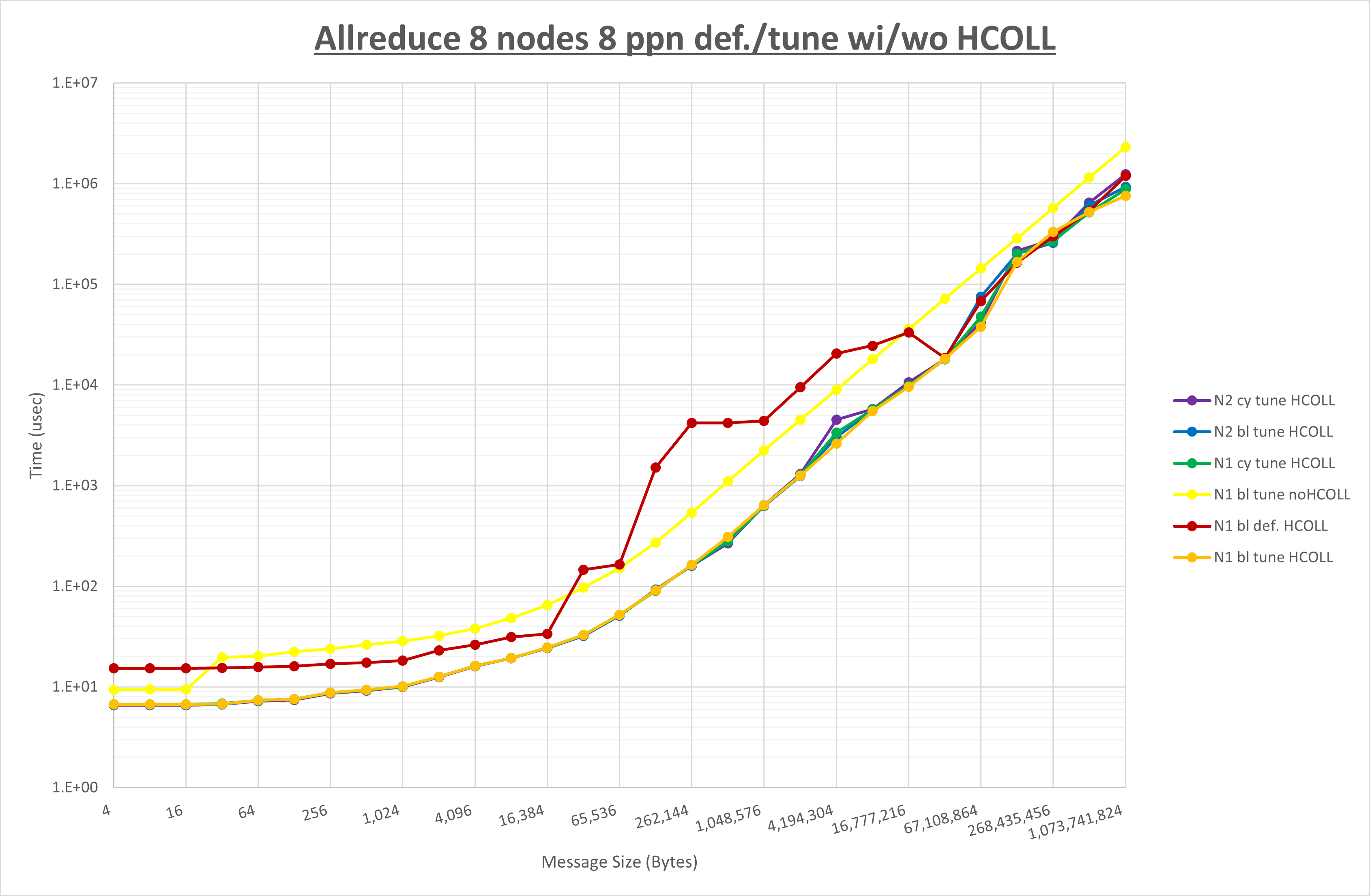
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で4MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-1-4 Exchange の結果から32KBとしています。
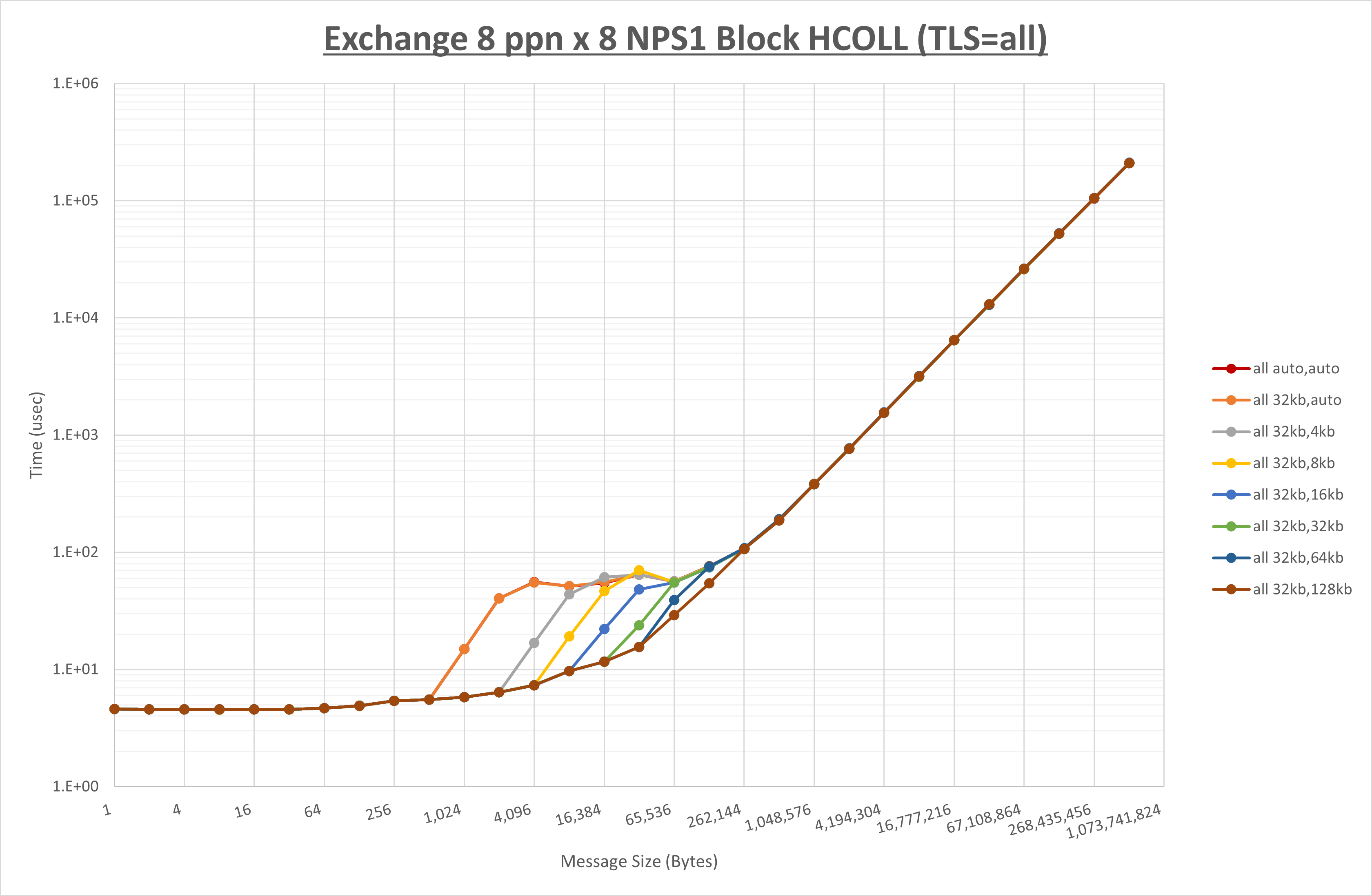
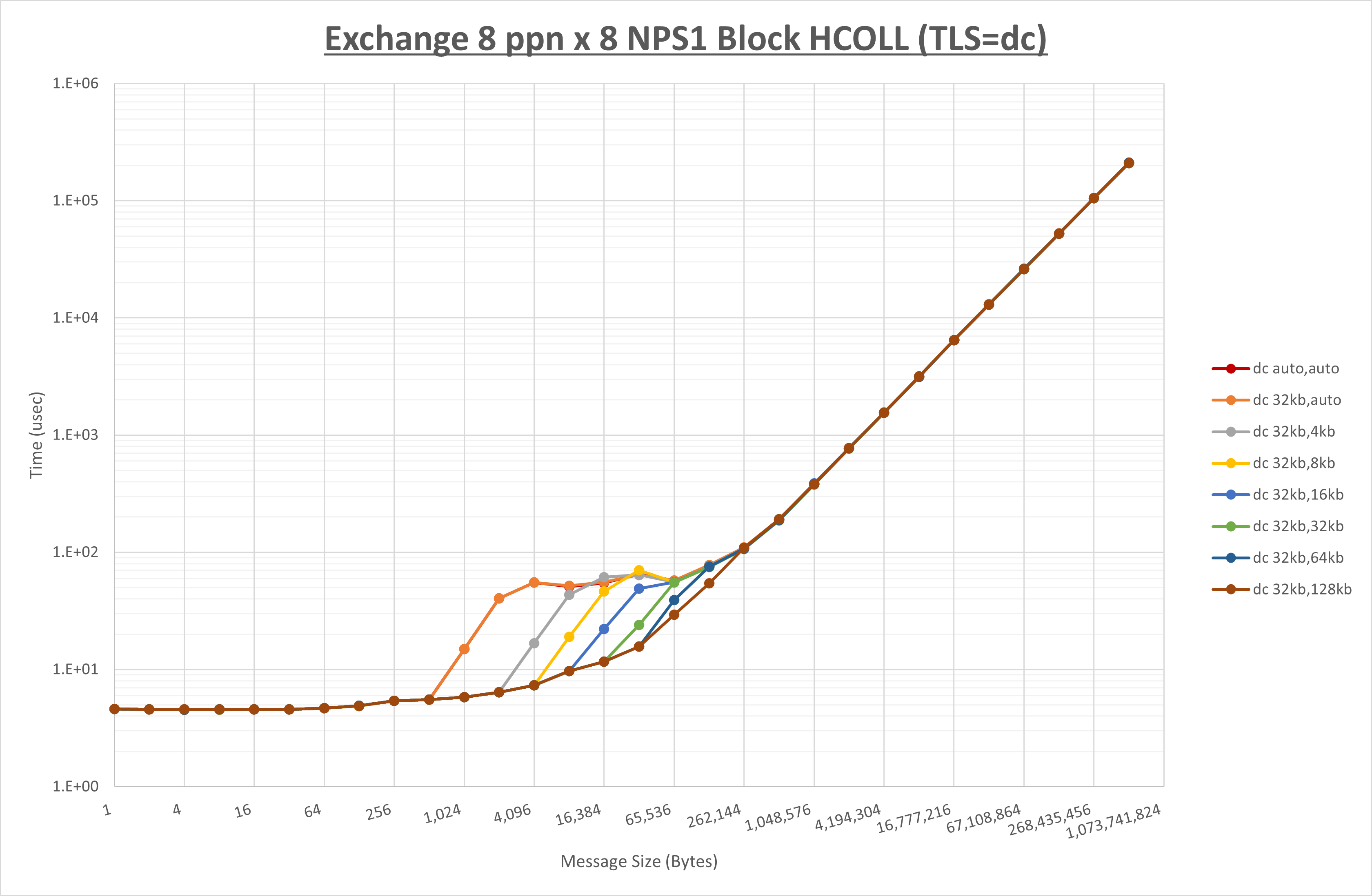
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
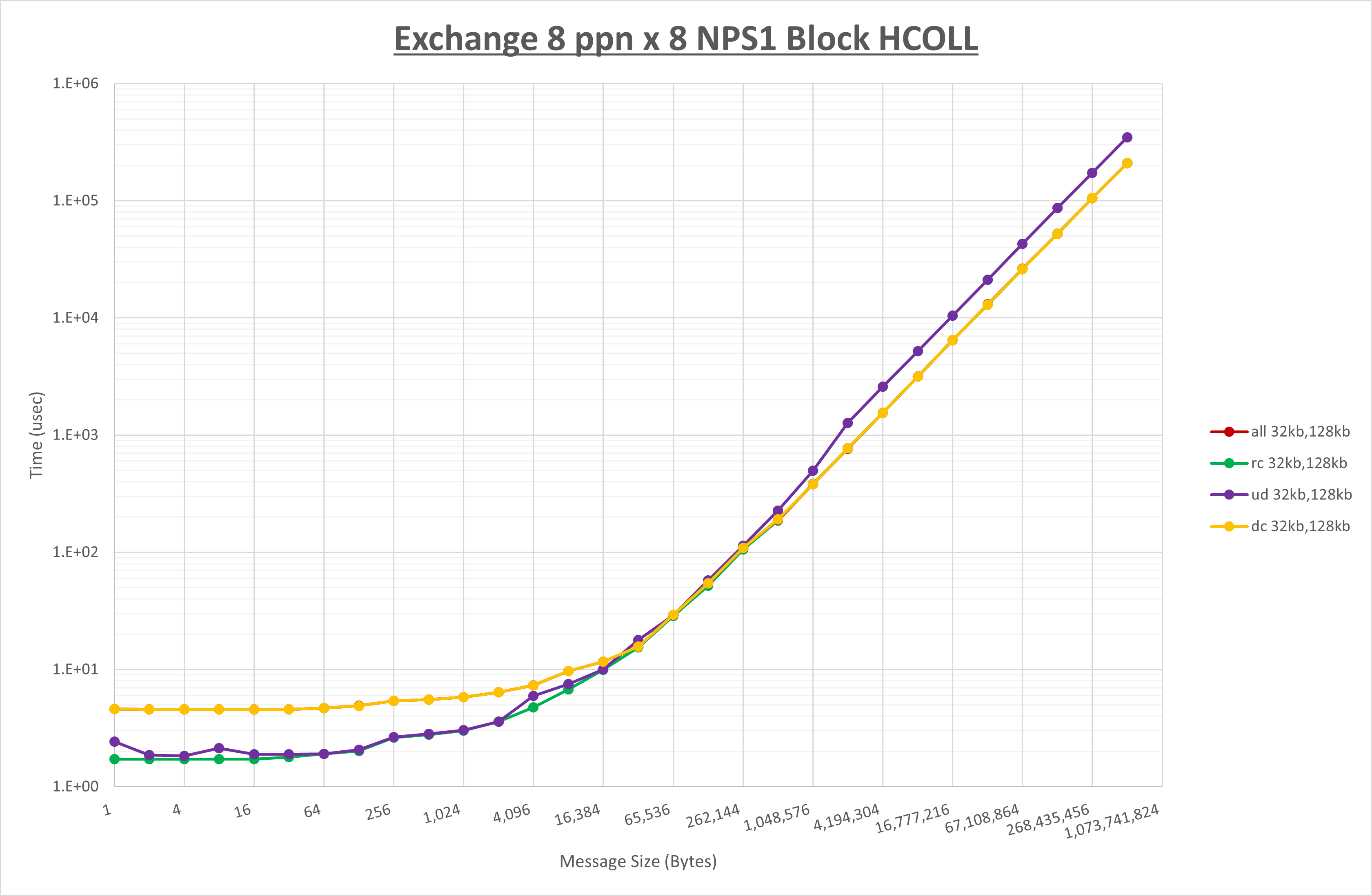
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
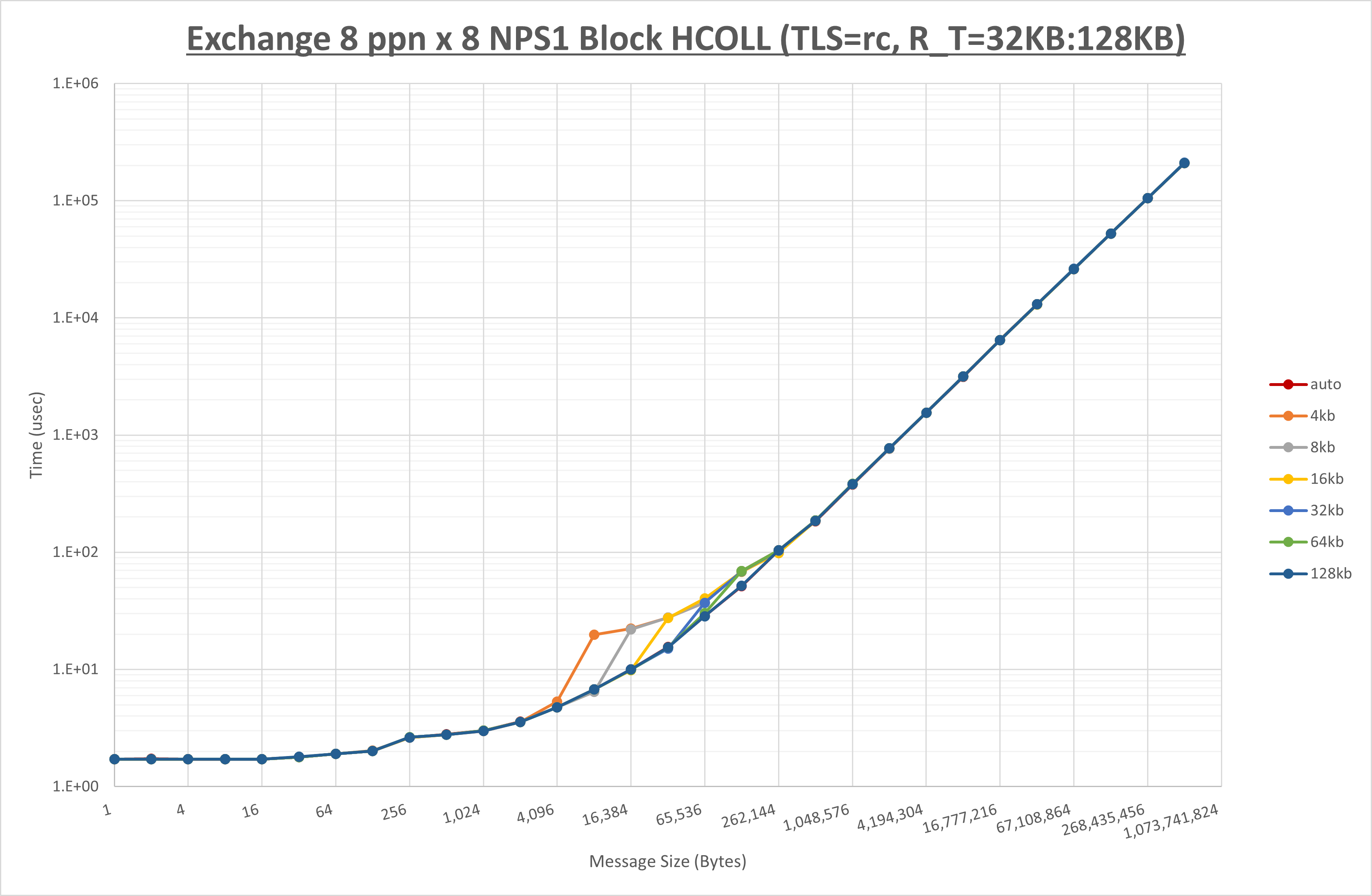
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
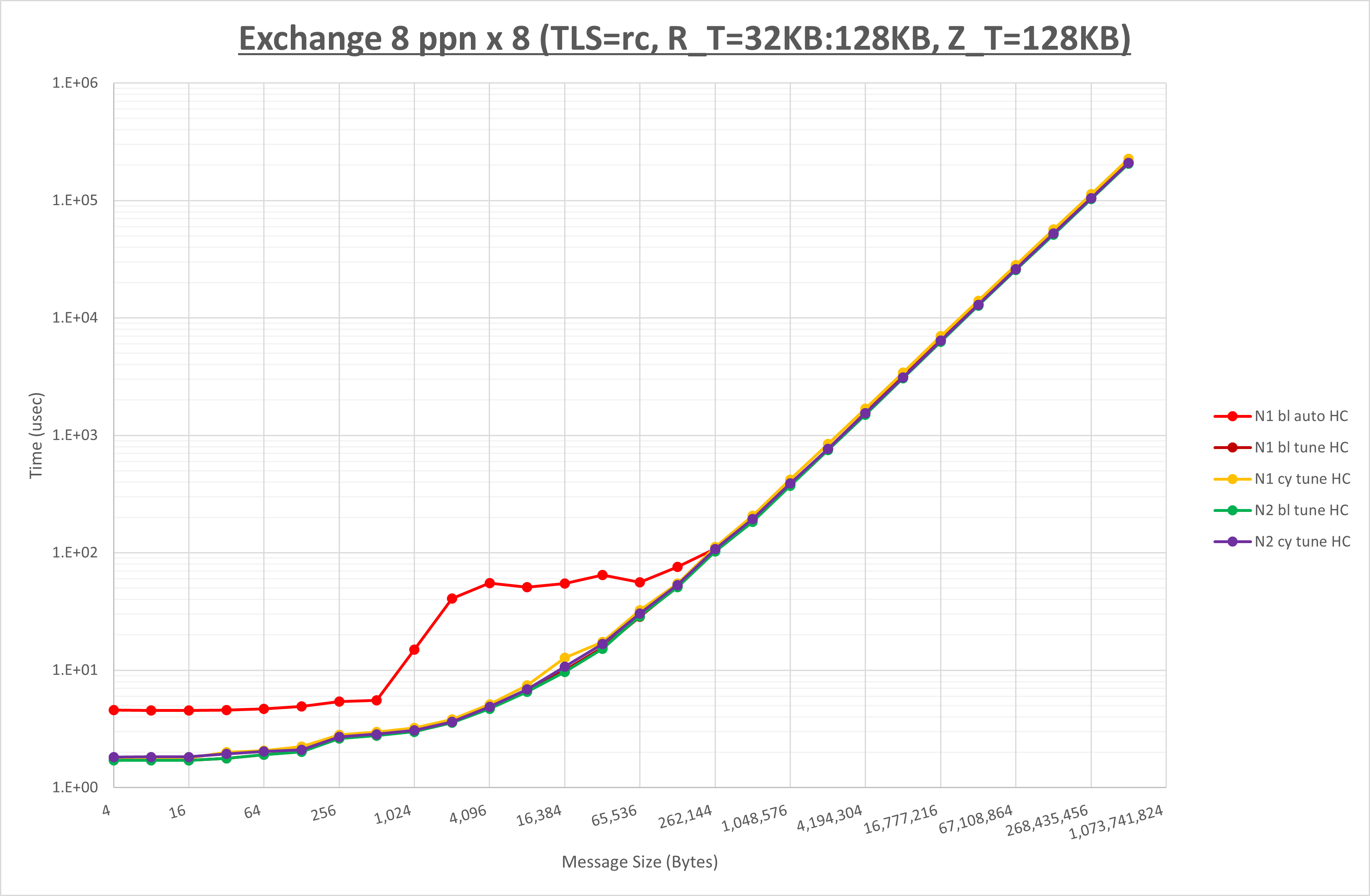
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、8ノードにノード当たり16、トータル128のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:32kb,inter:32kb | 128kb |
| Allgather | self,sm,rc | intra:64kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-1 Alltoall の HCOLL の結果から32KBとしています。
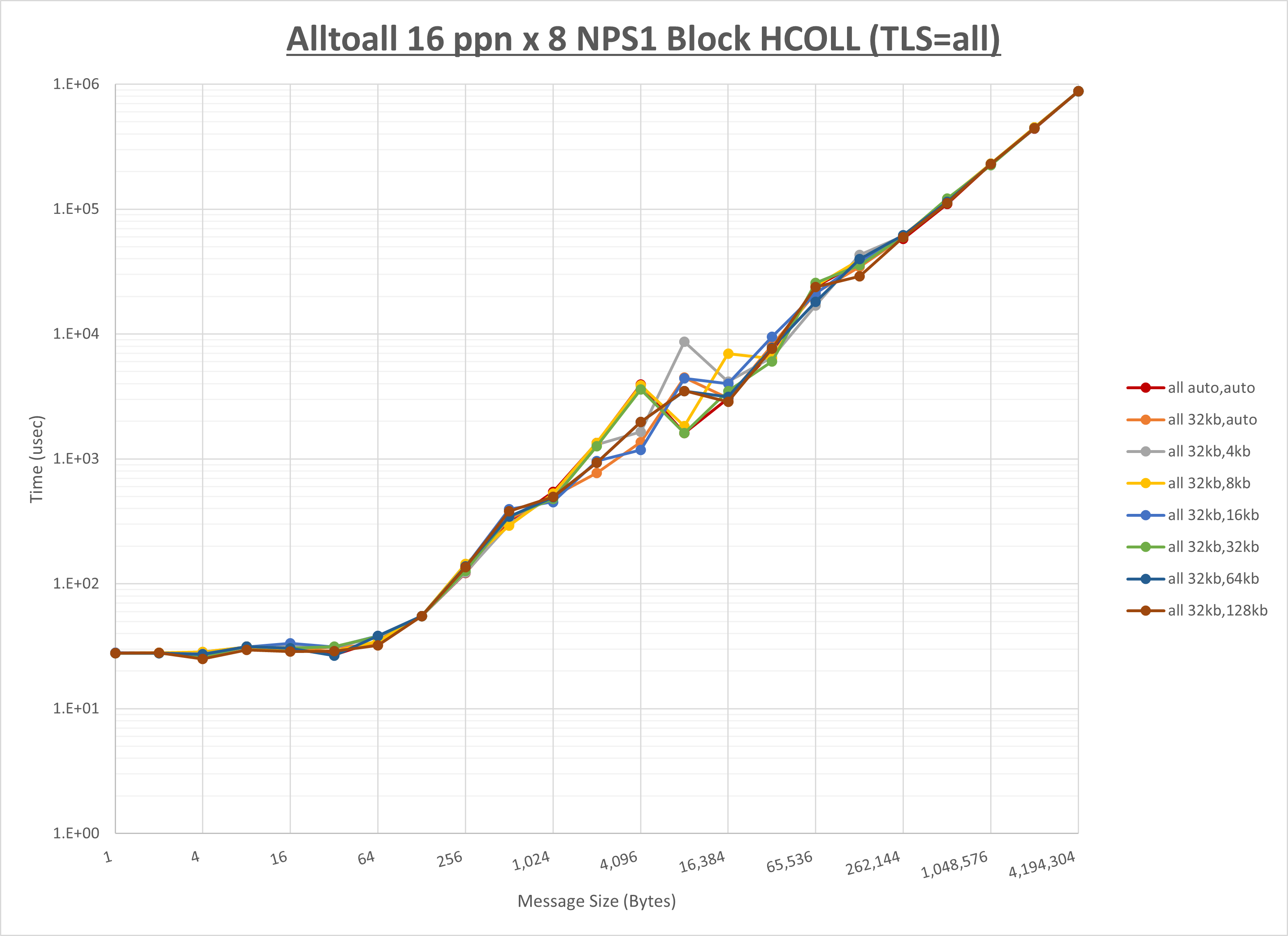
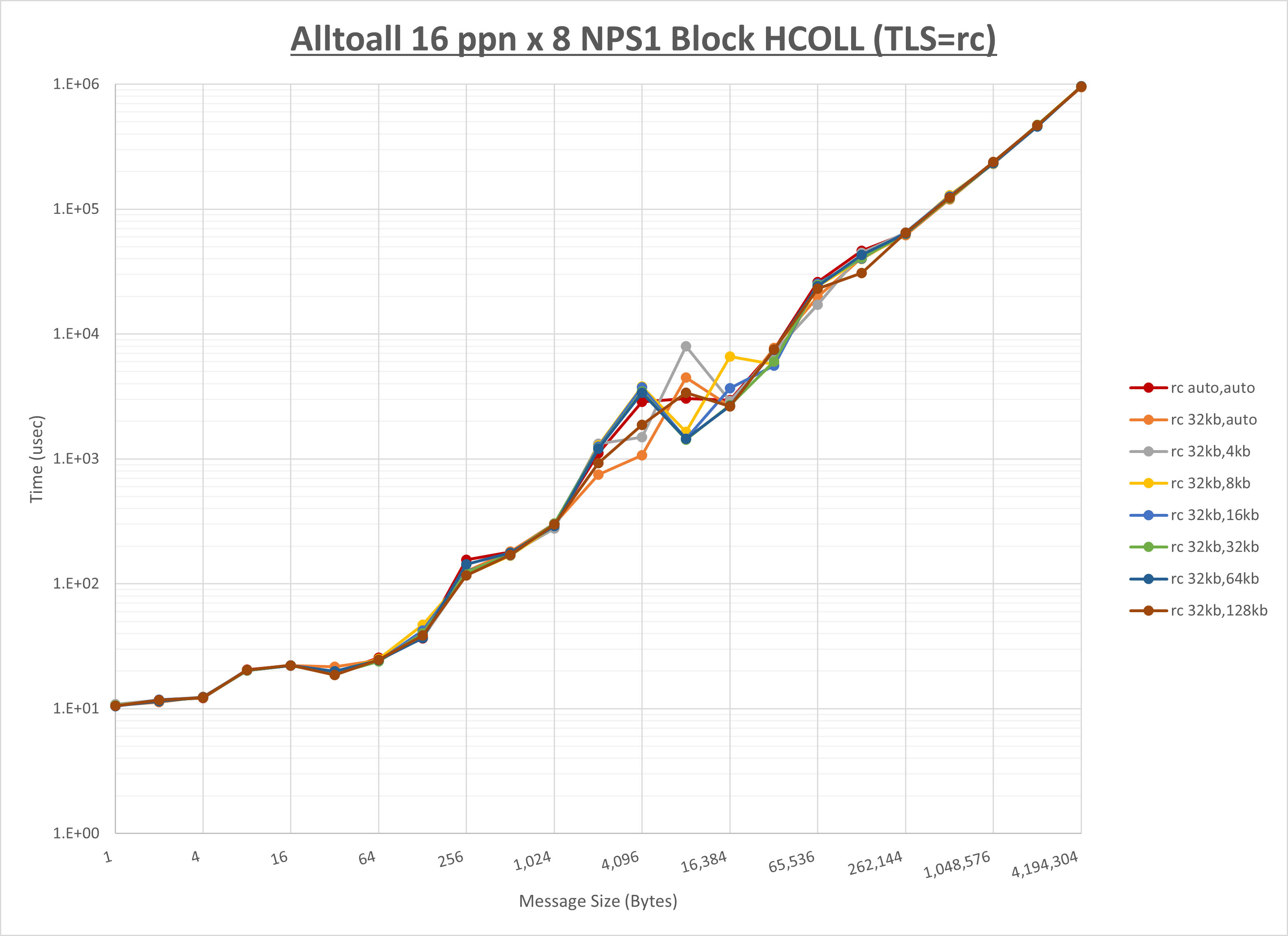
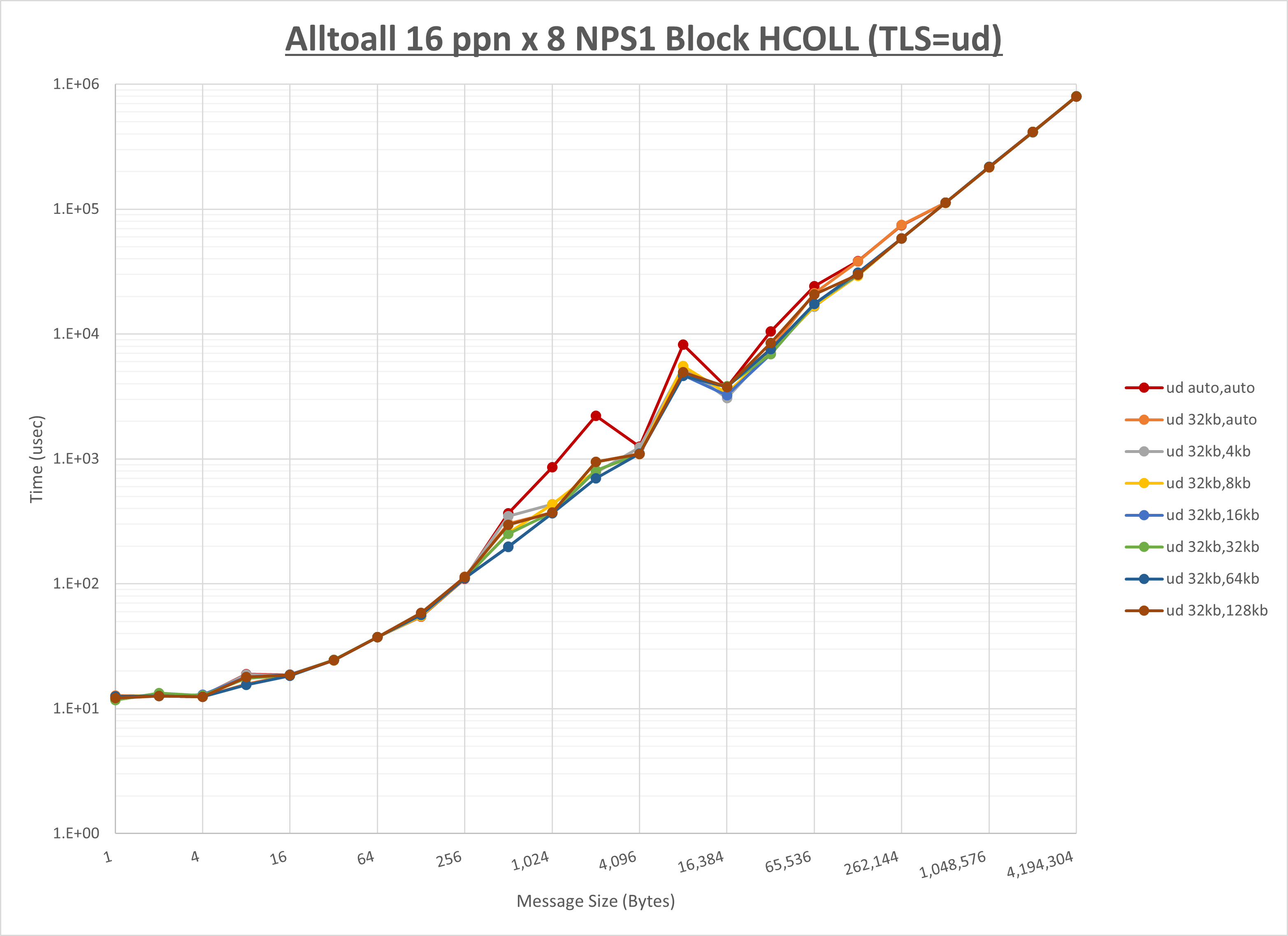
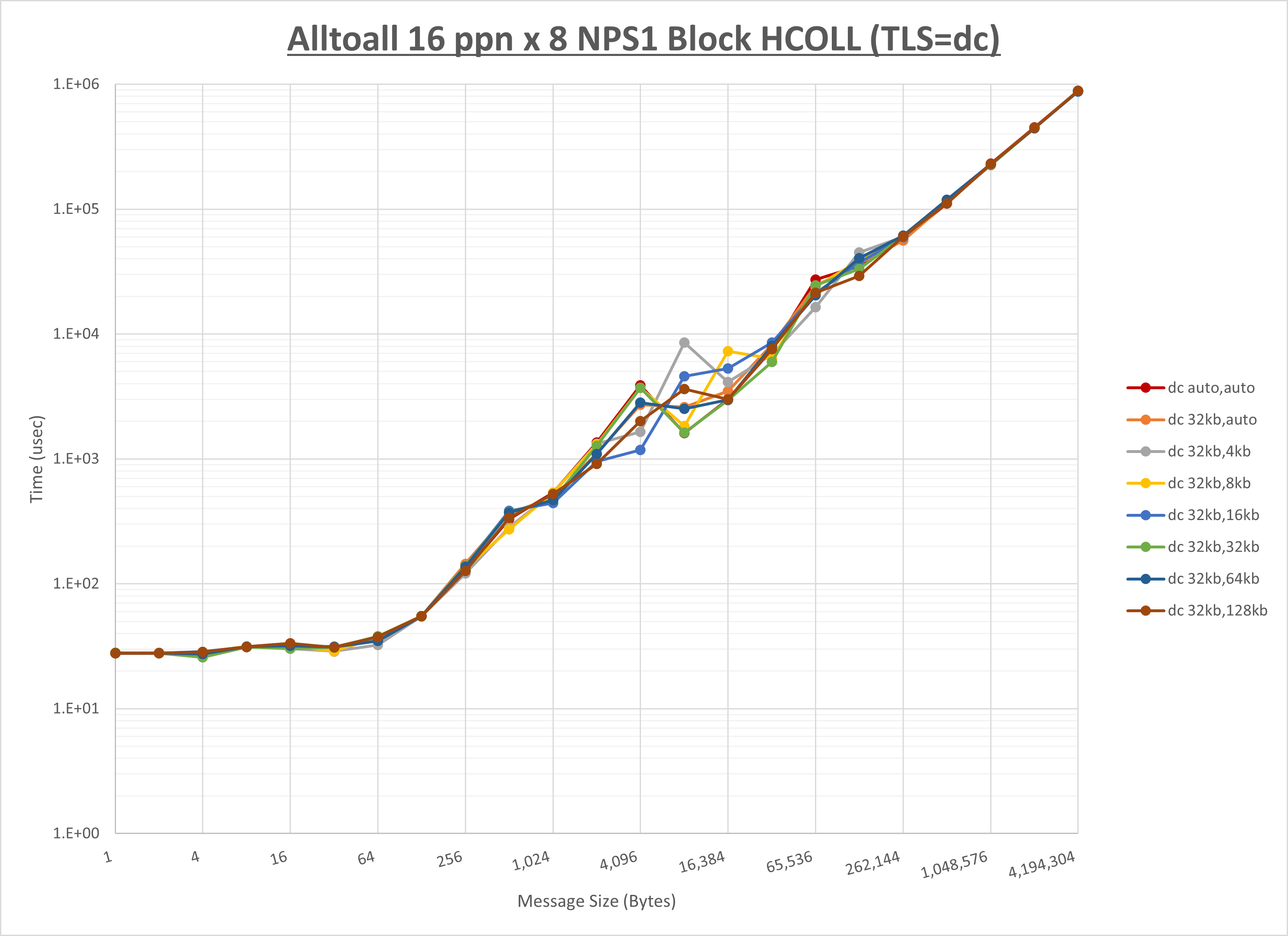
以上より、 UCX_RNDV_THRESH を intra:32kb,inter:32kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
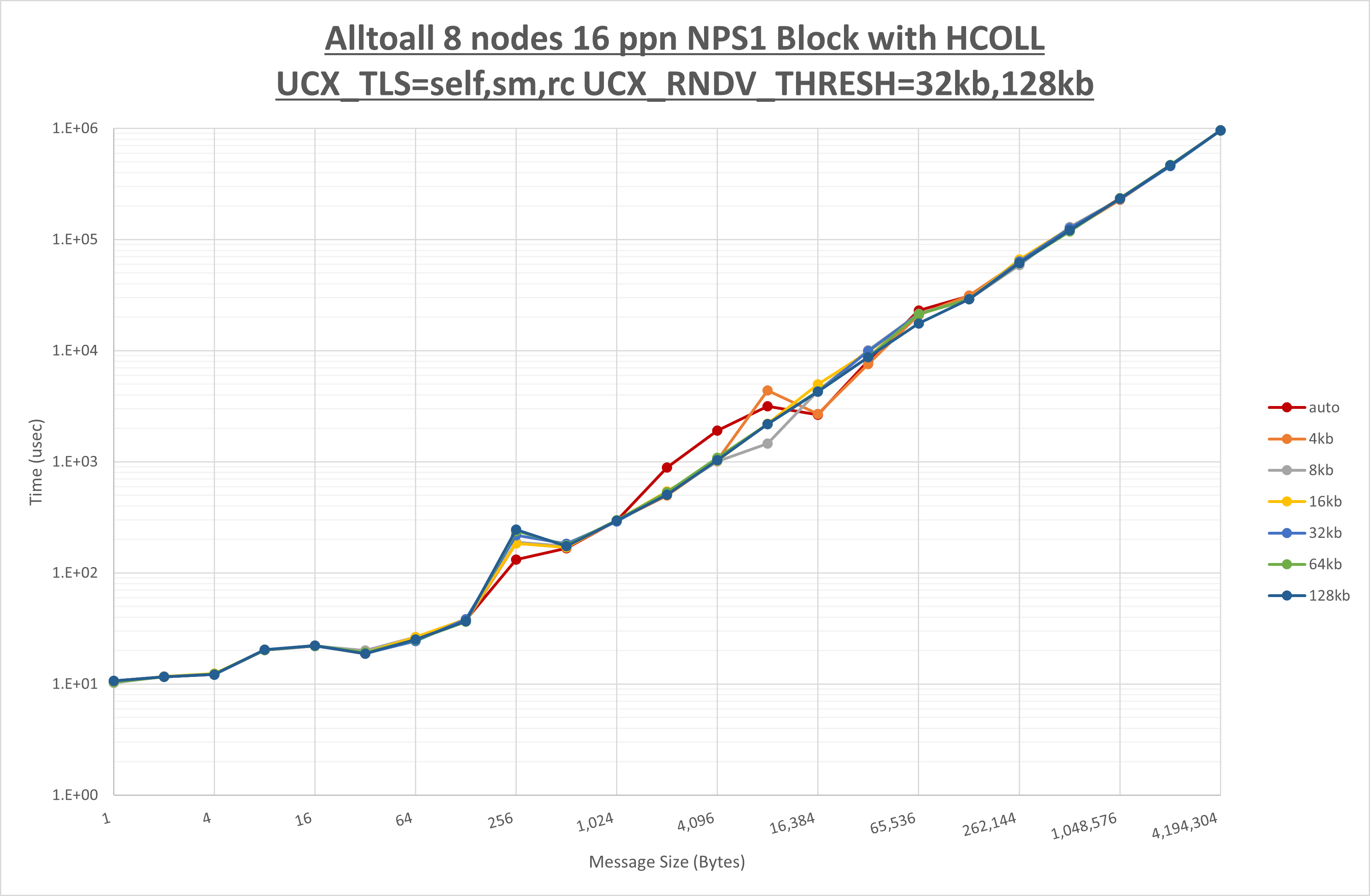
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
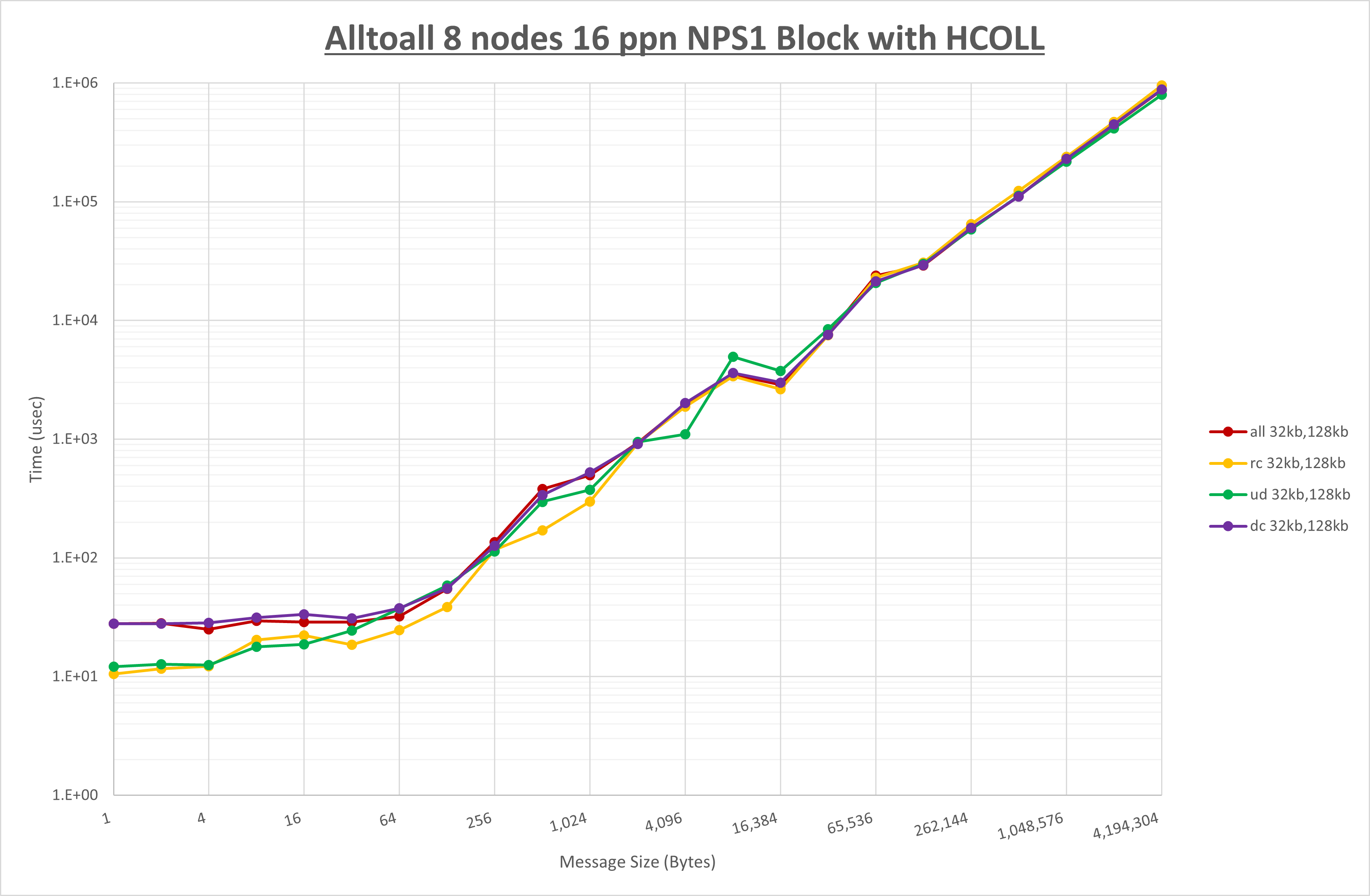
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
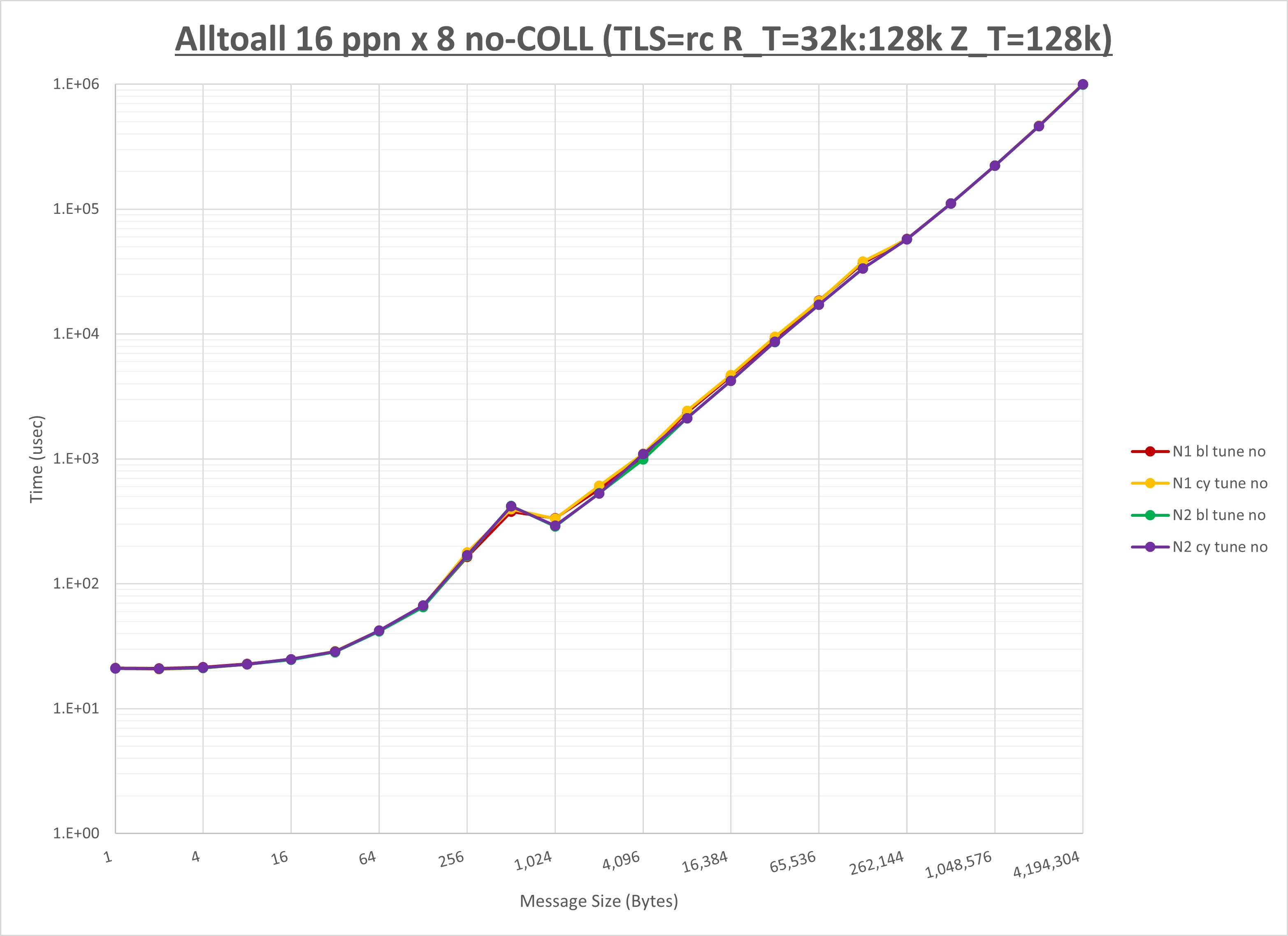
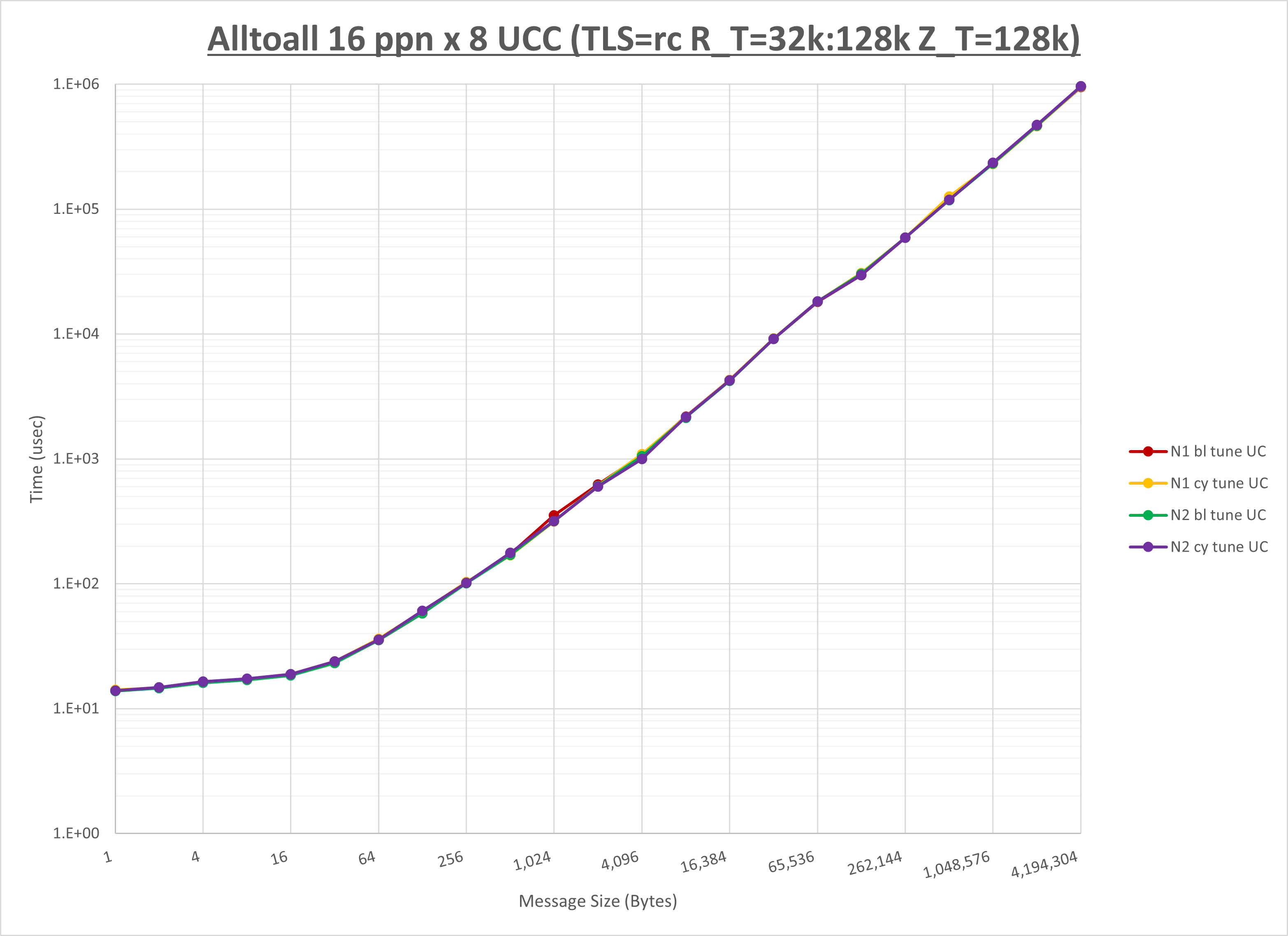
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
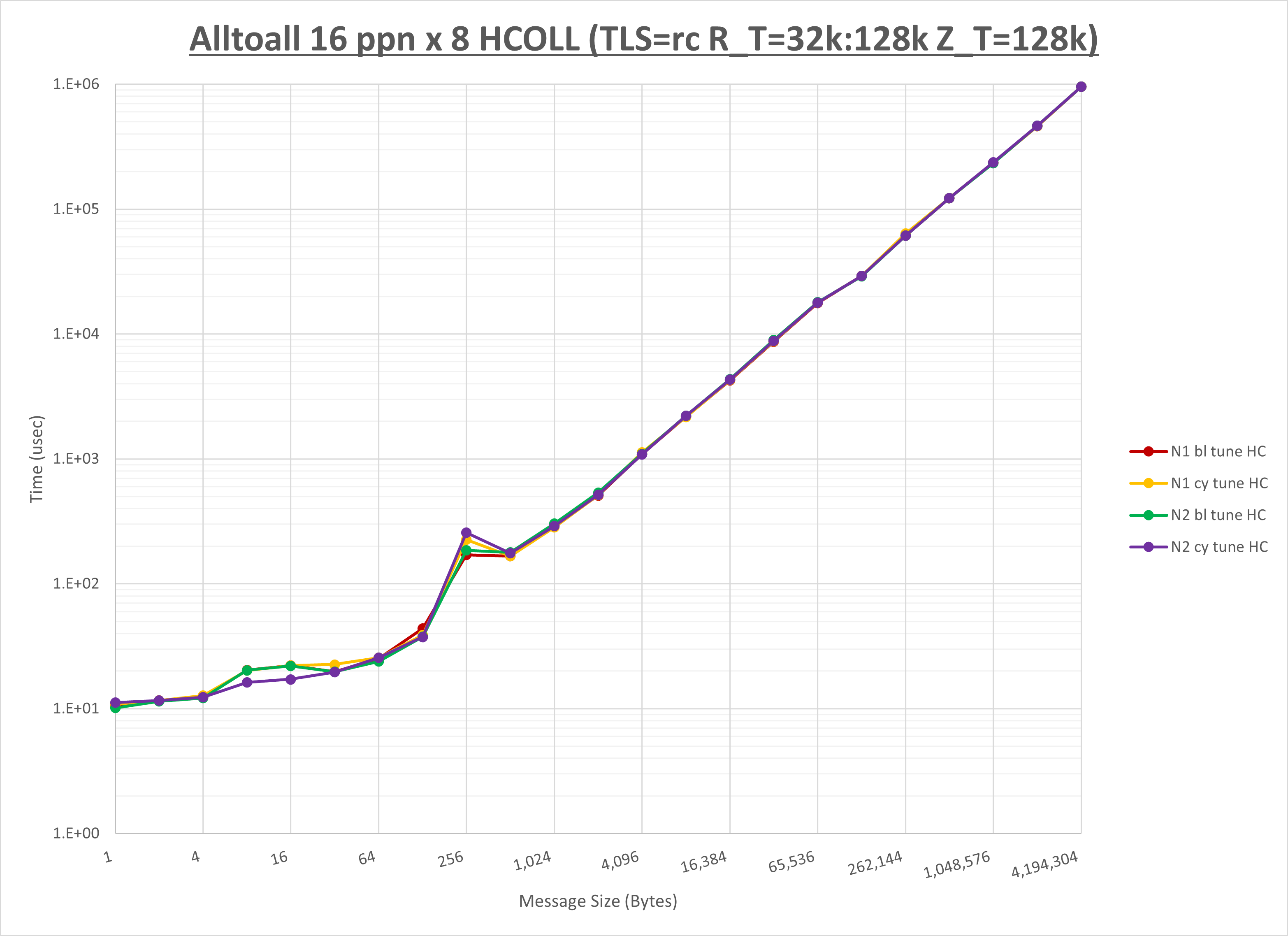
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
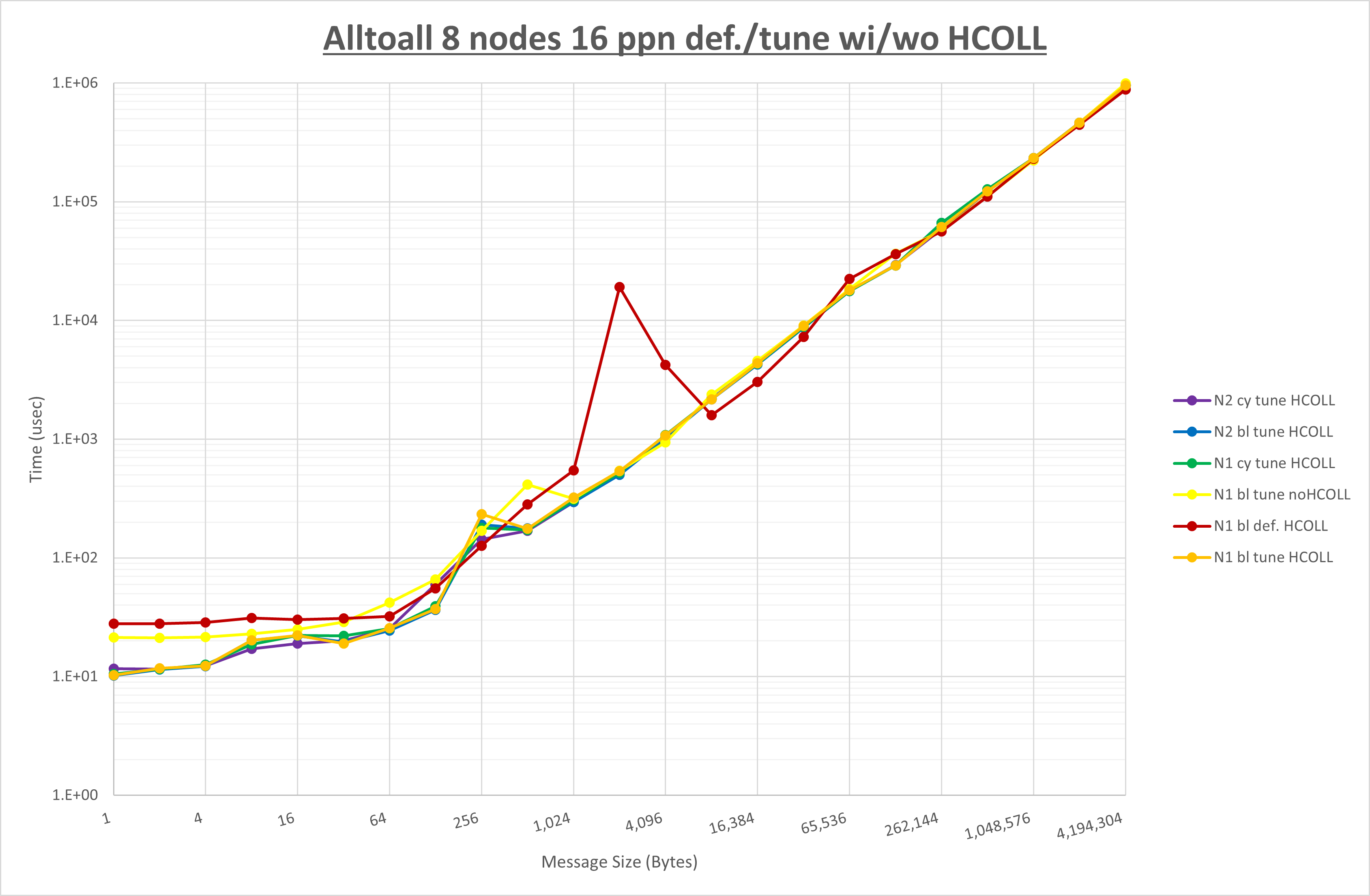
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し128KB以下のほぼ全域で性能が向上
- UCC は no-COLL と比較し128KB以下のほぼ全域で性能が向上
- チューニング適用で全域で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-2 Allgather の HCOLL の結果から64KBとしています。
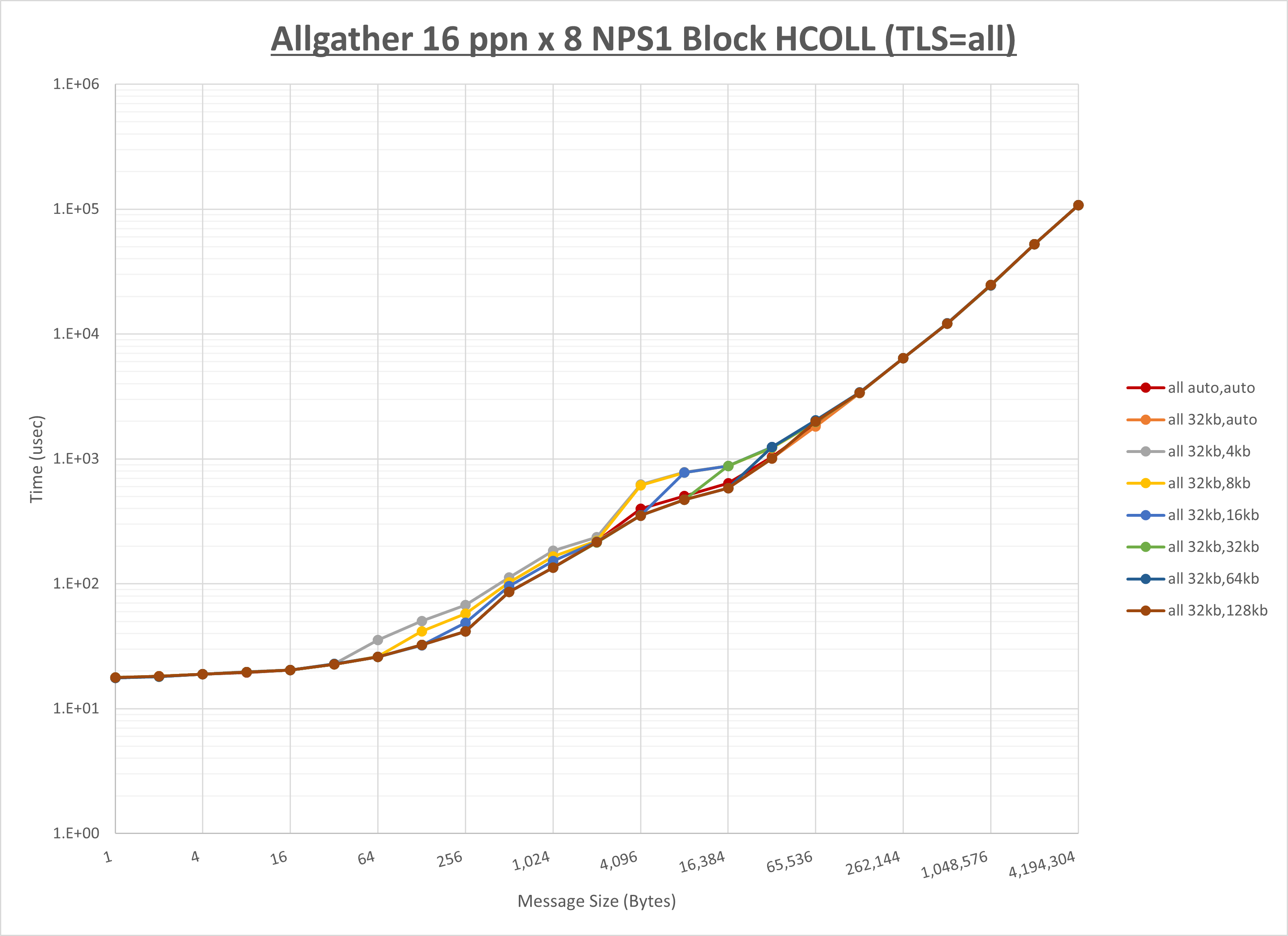
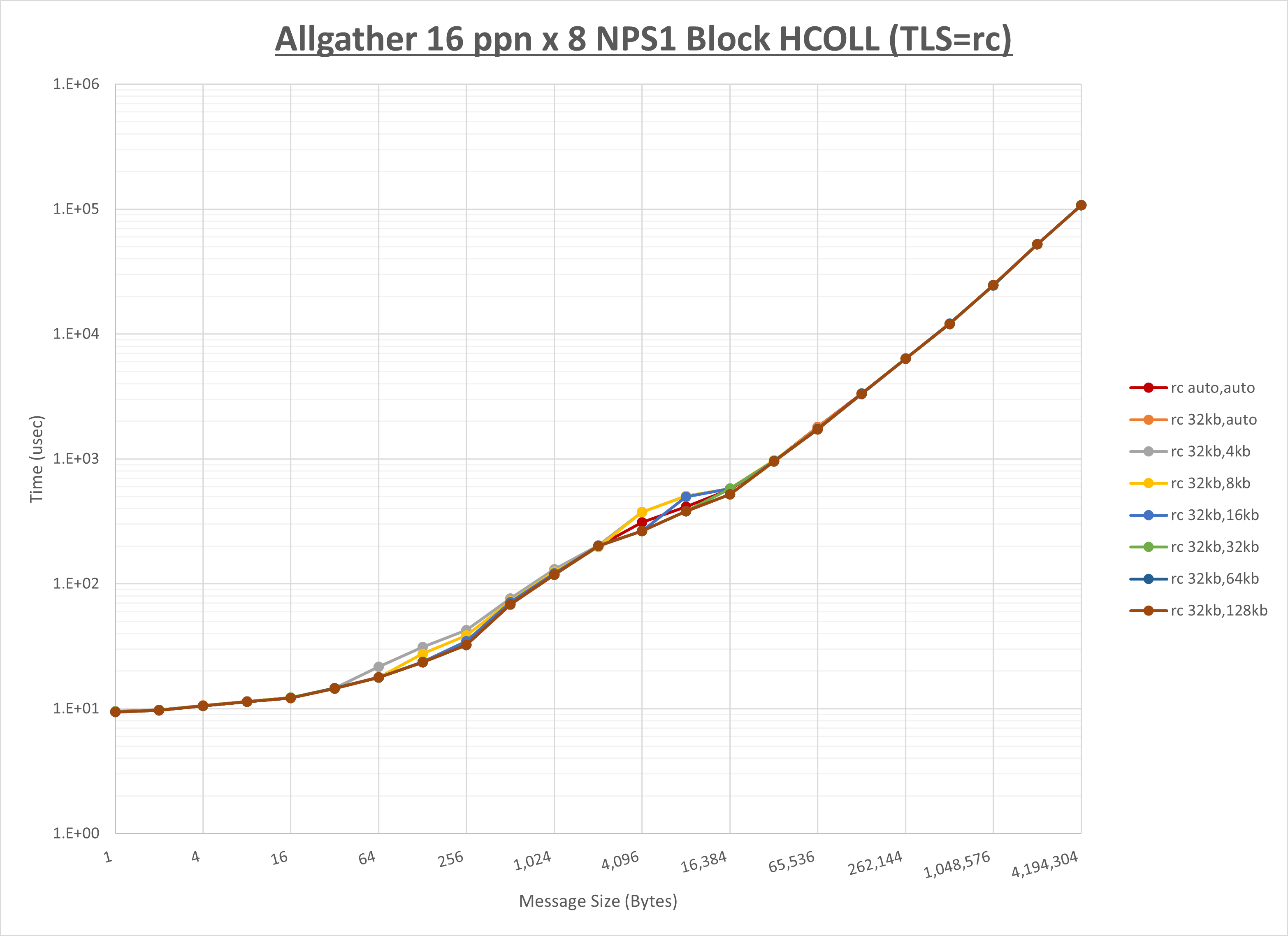
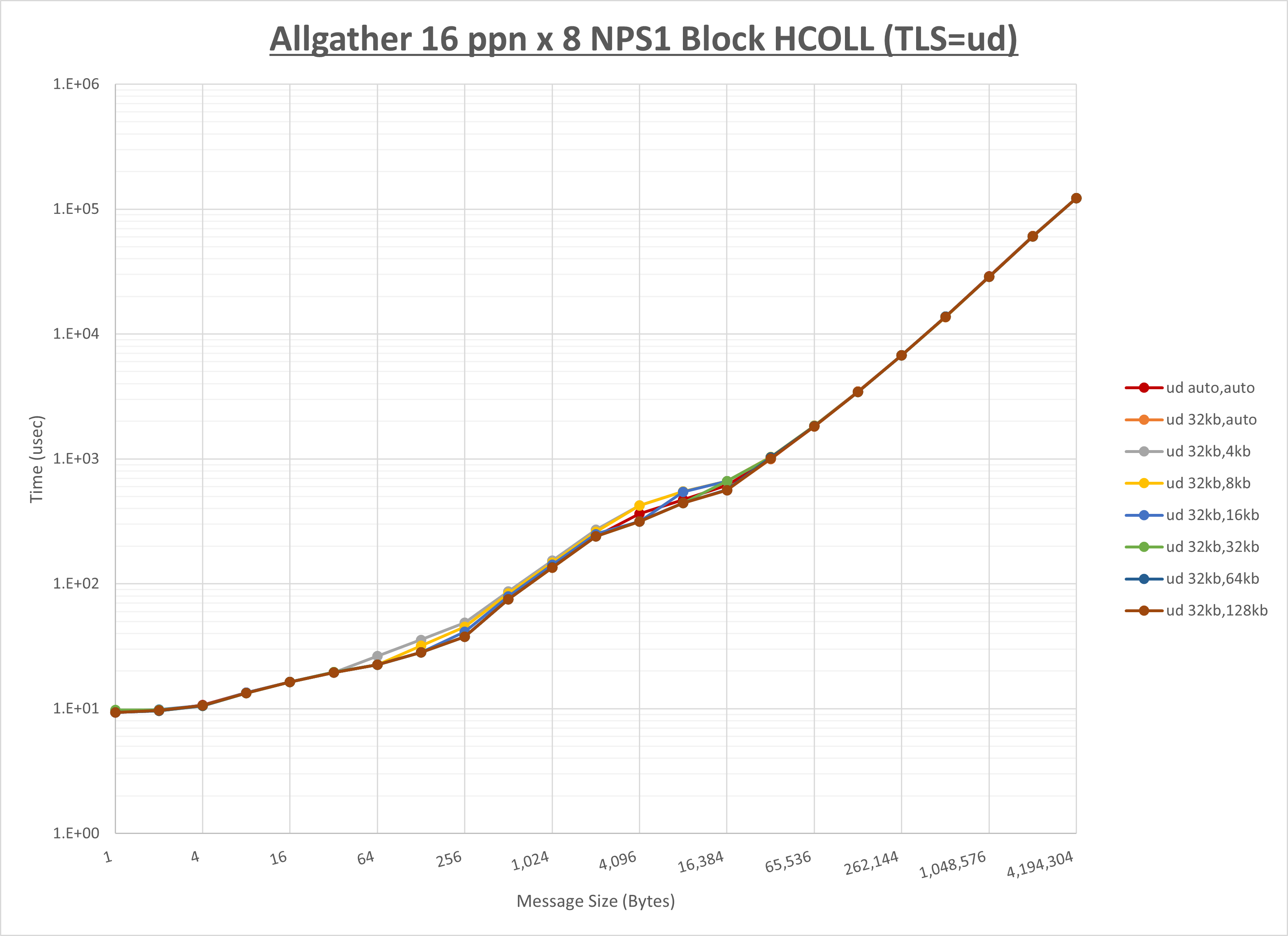
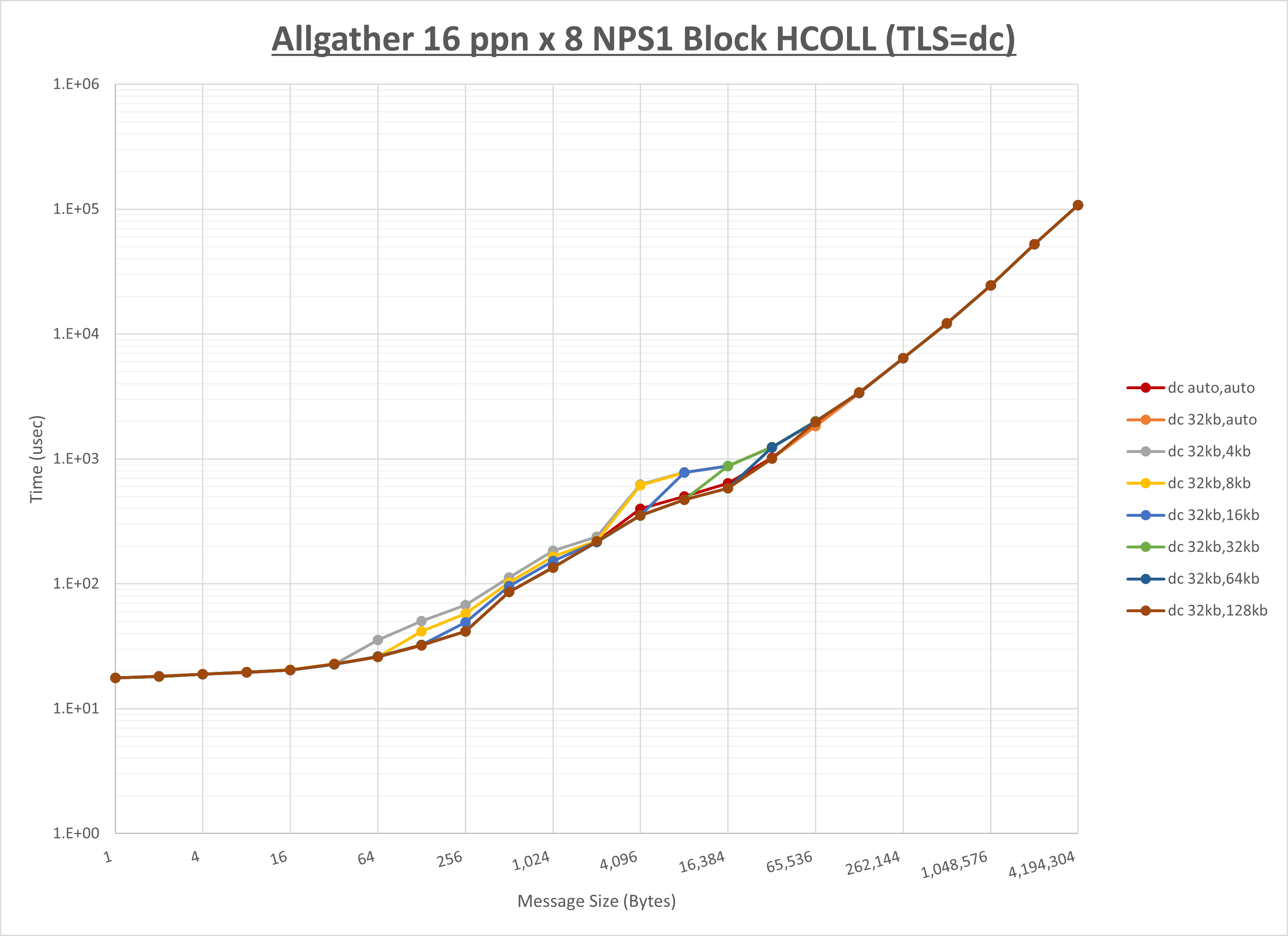
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
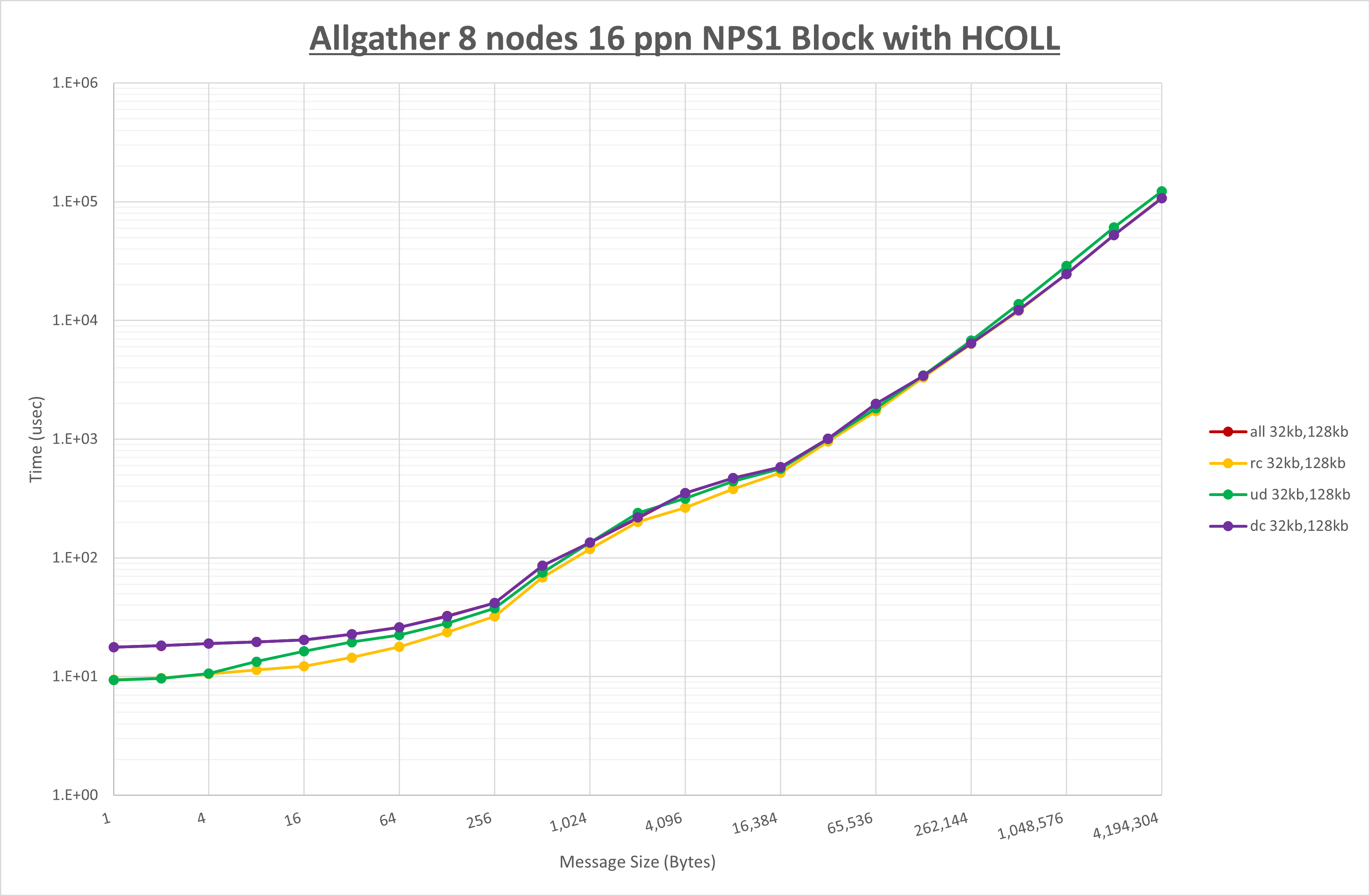
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
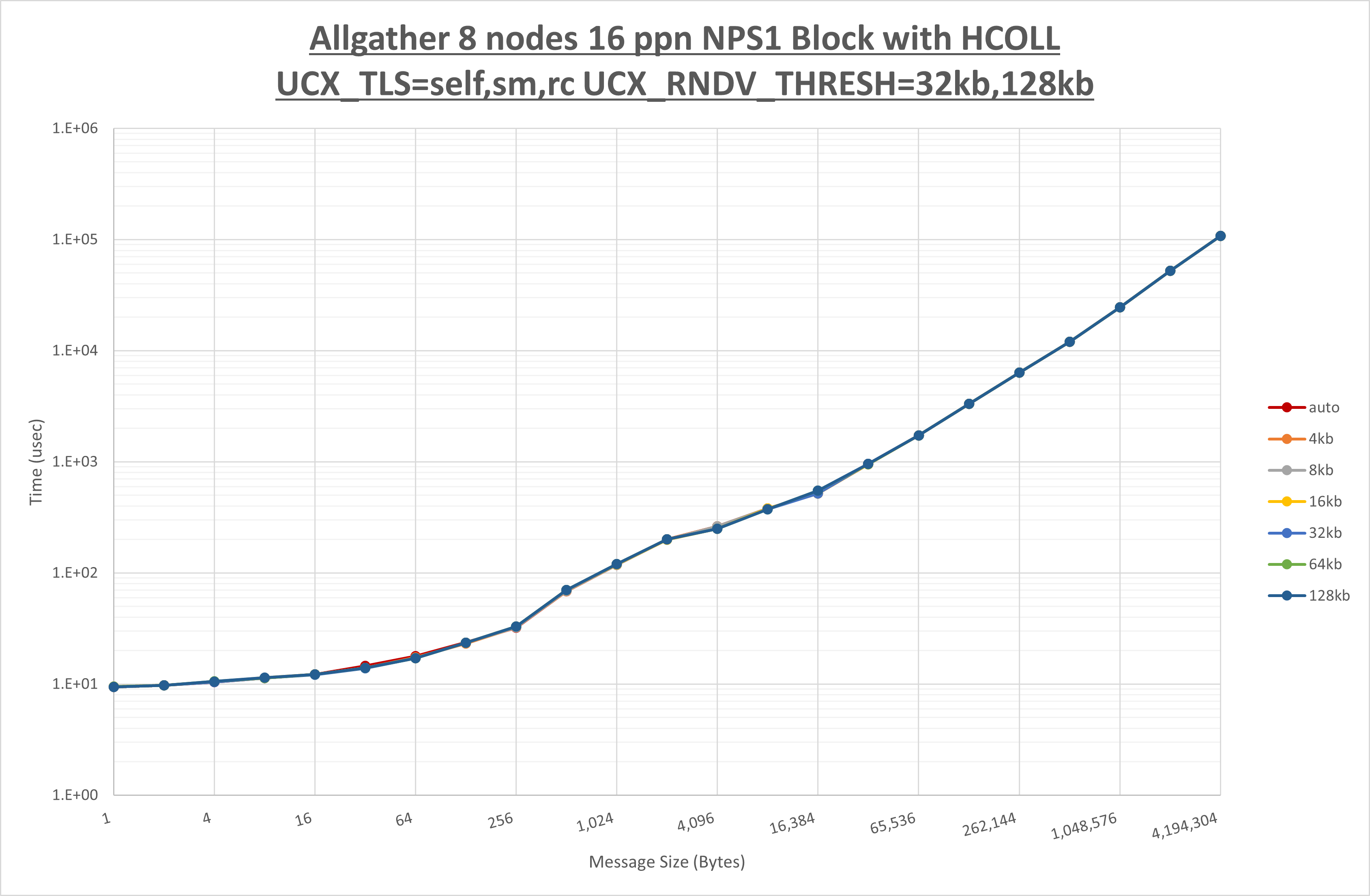
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
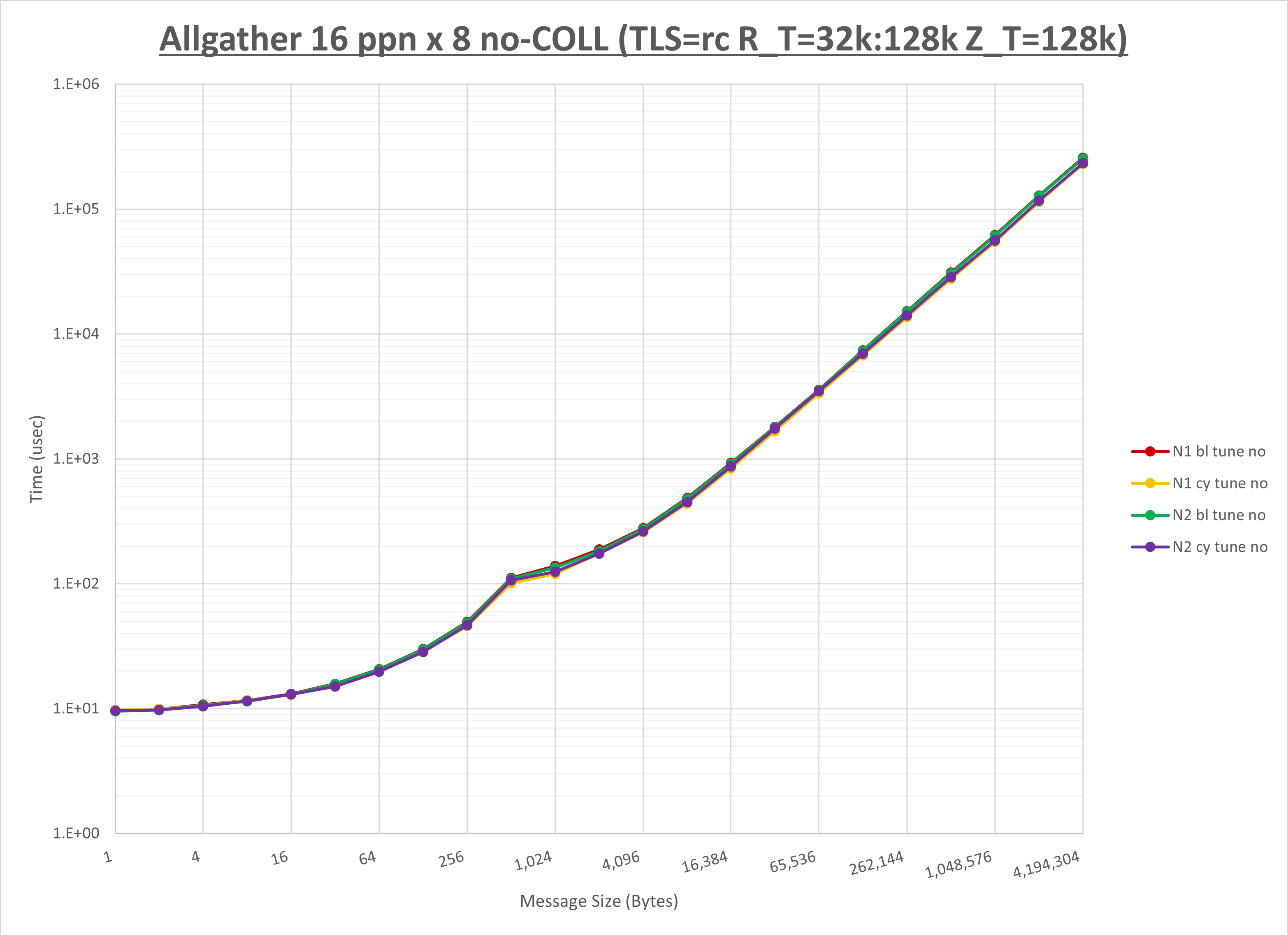
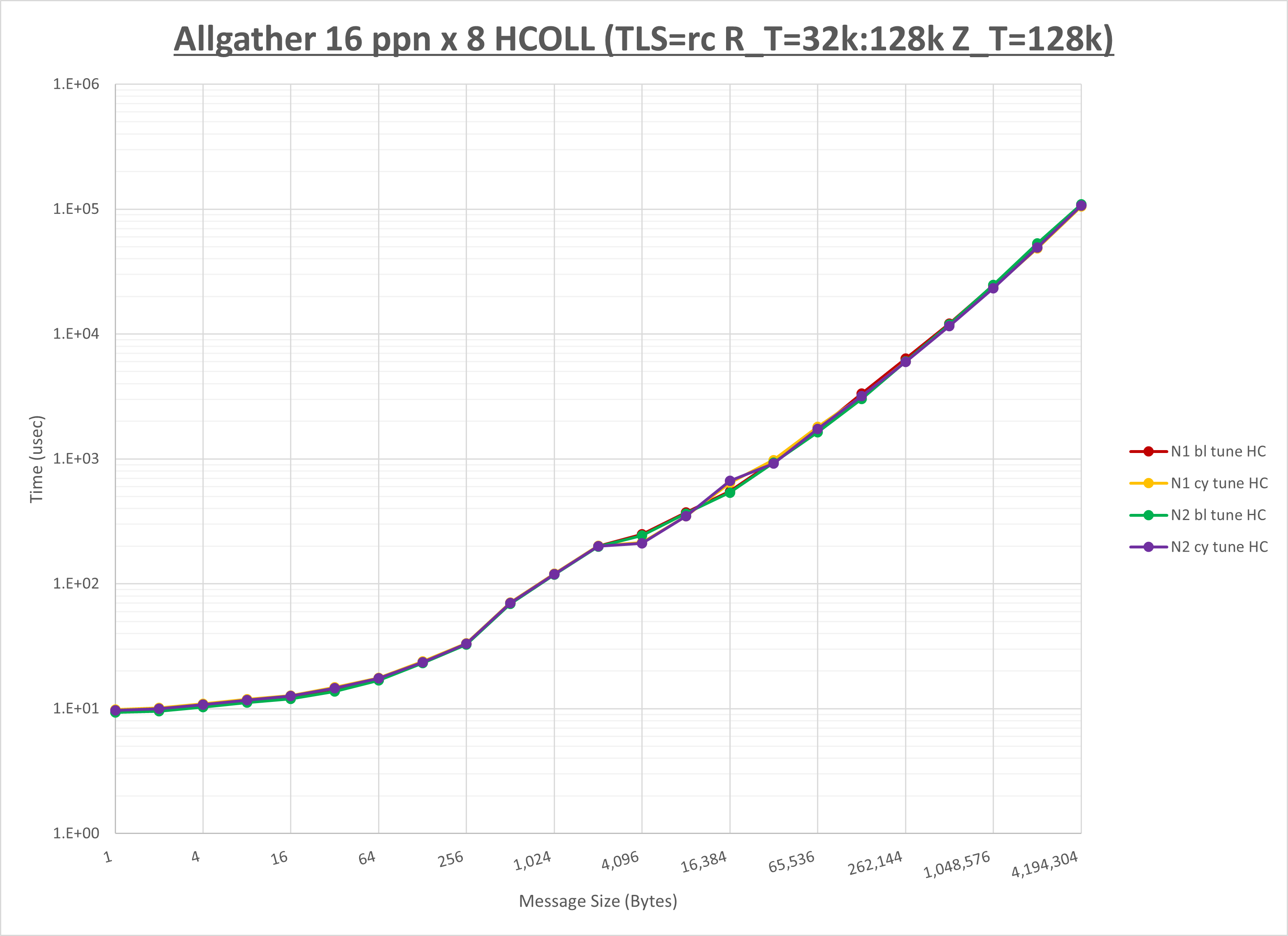
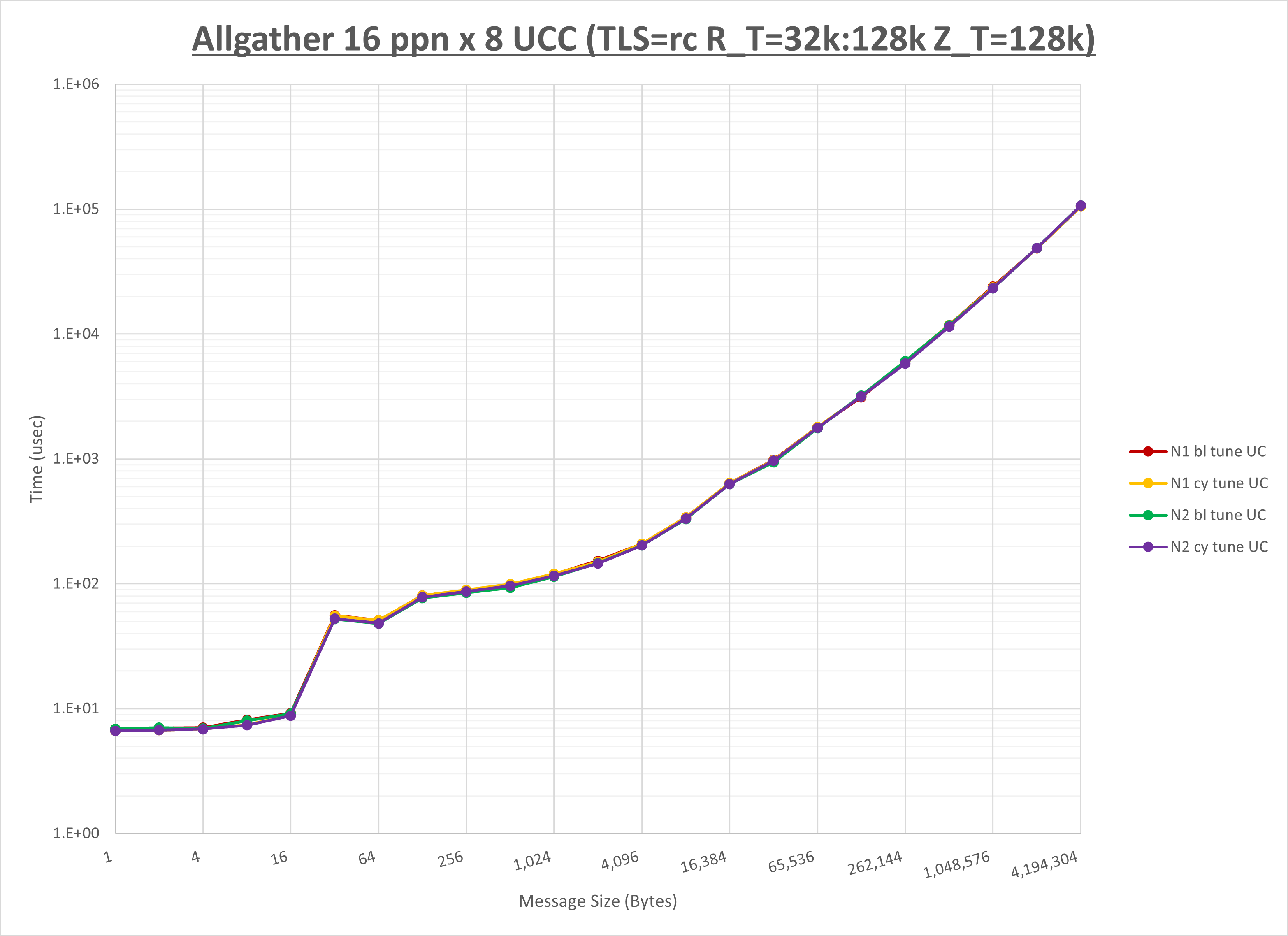
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
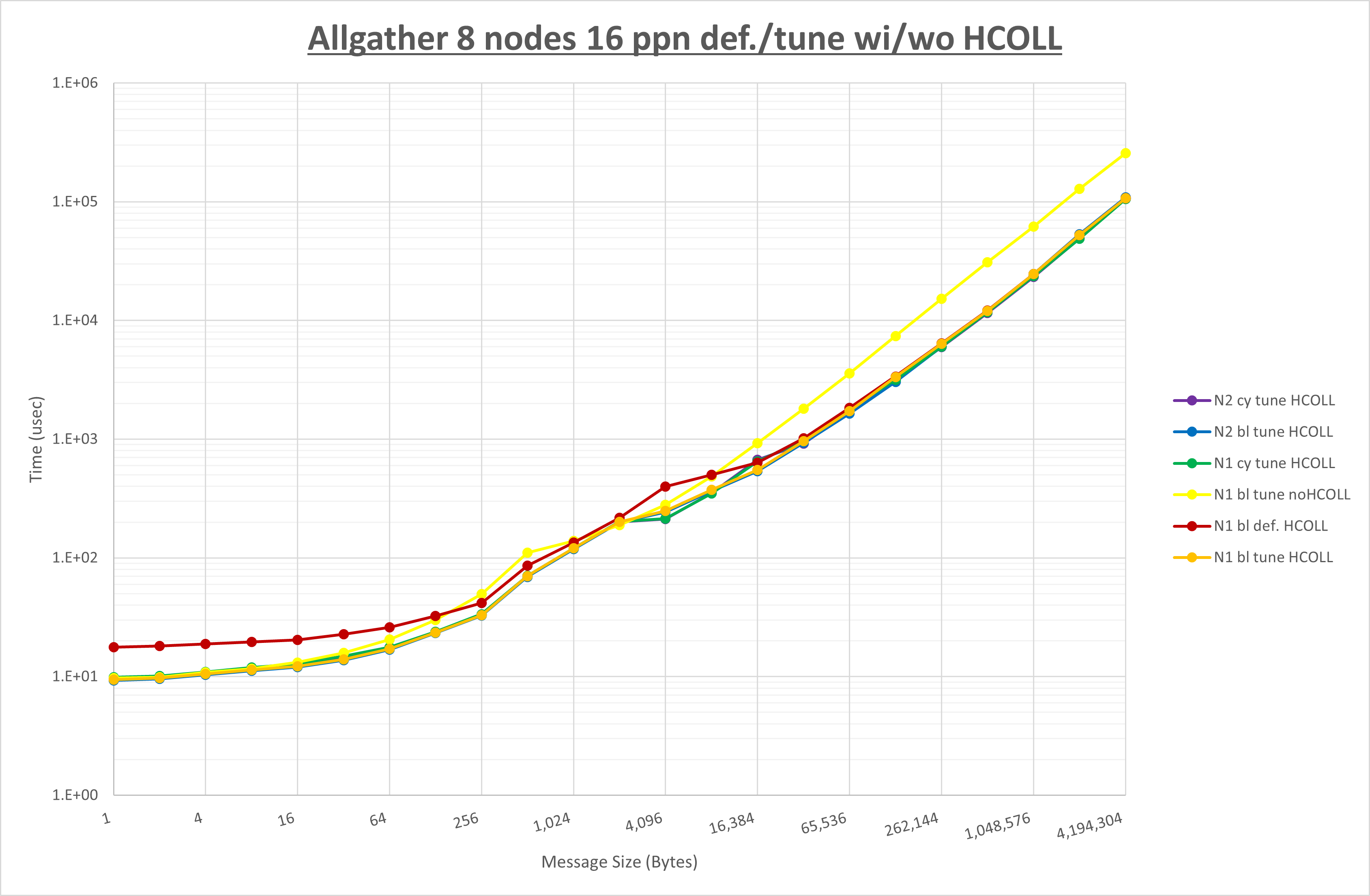
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し16B以下と1KB以上で性能が向上し32Bから256Bで性能が低下
- チューニング適用で16KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-3 Allreduce の HCOLL の結果から128KBとしています。
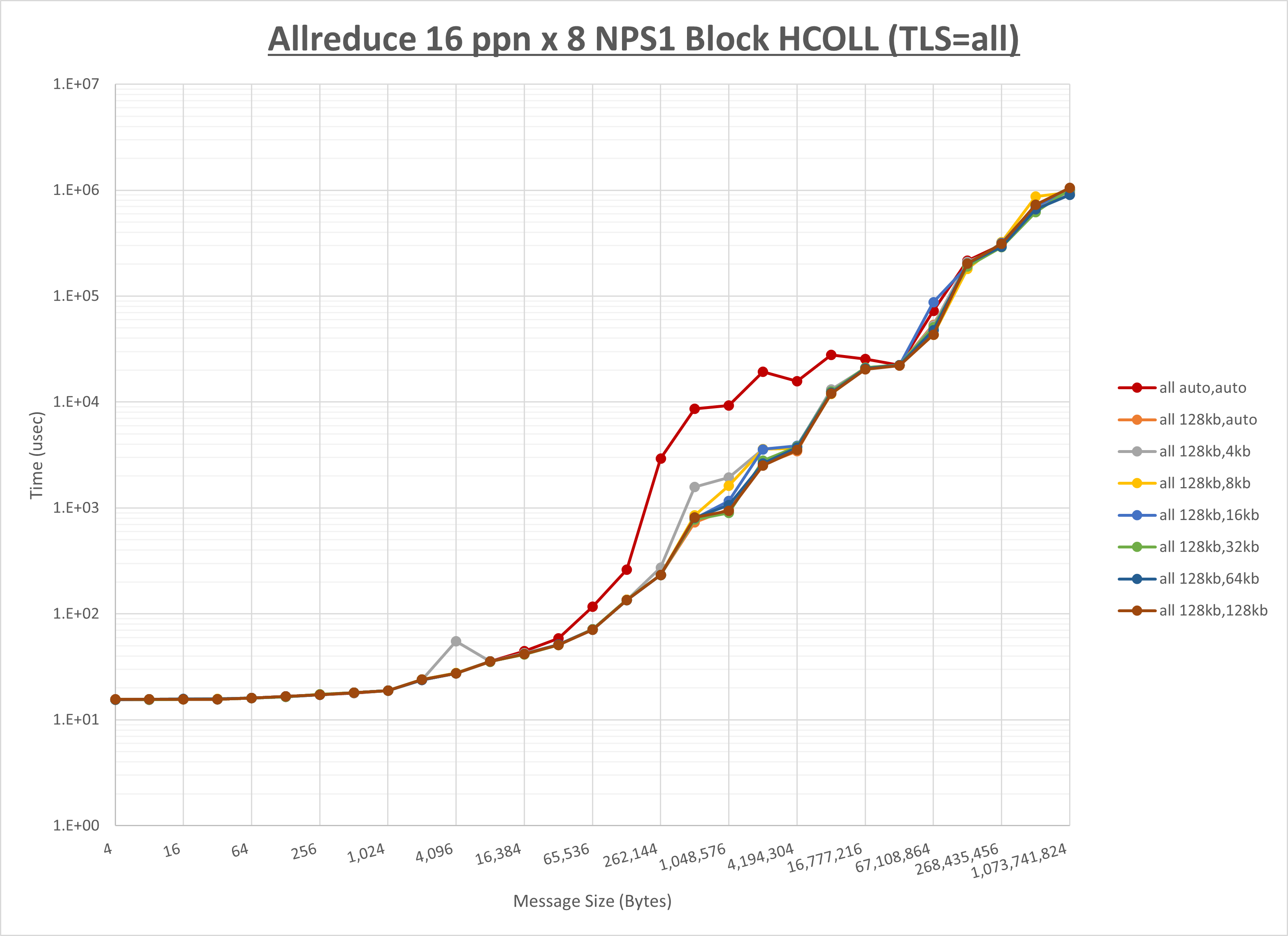
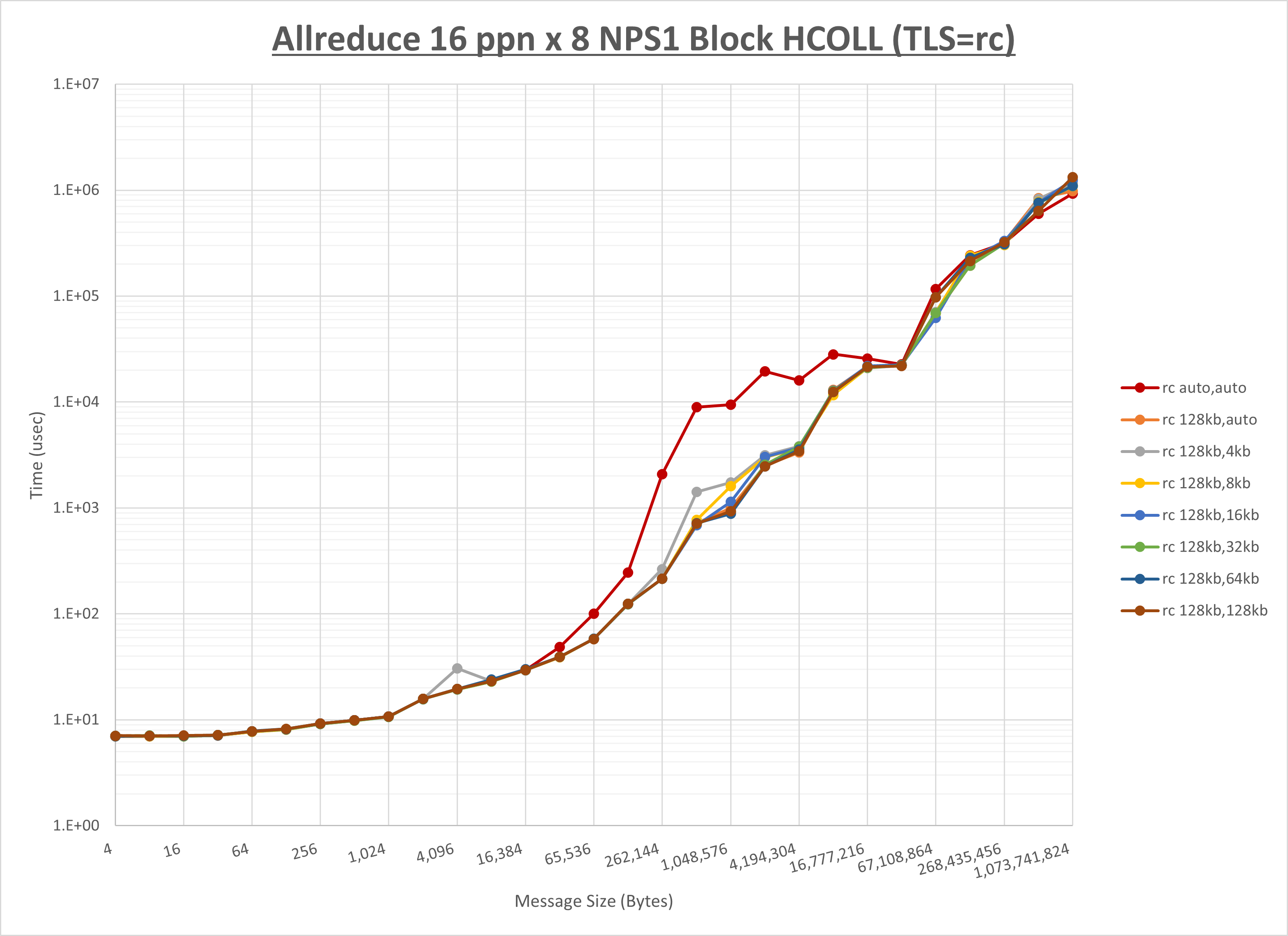
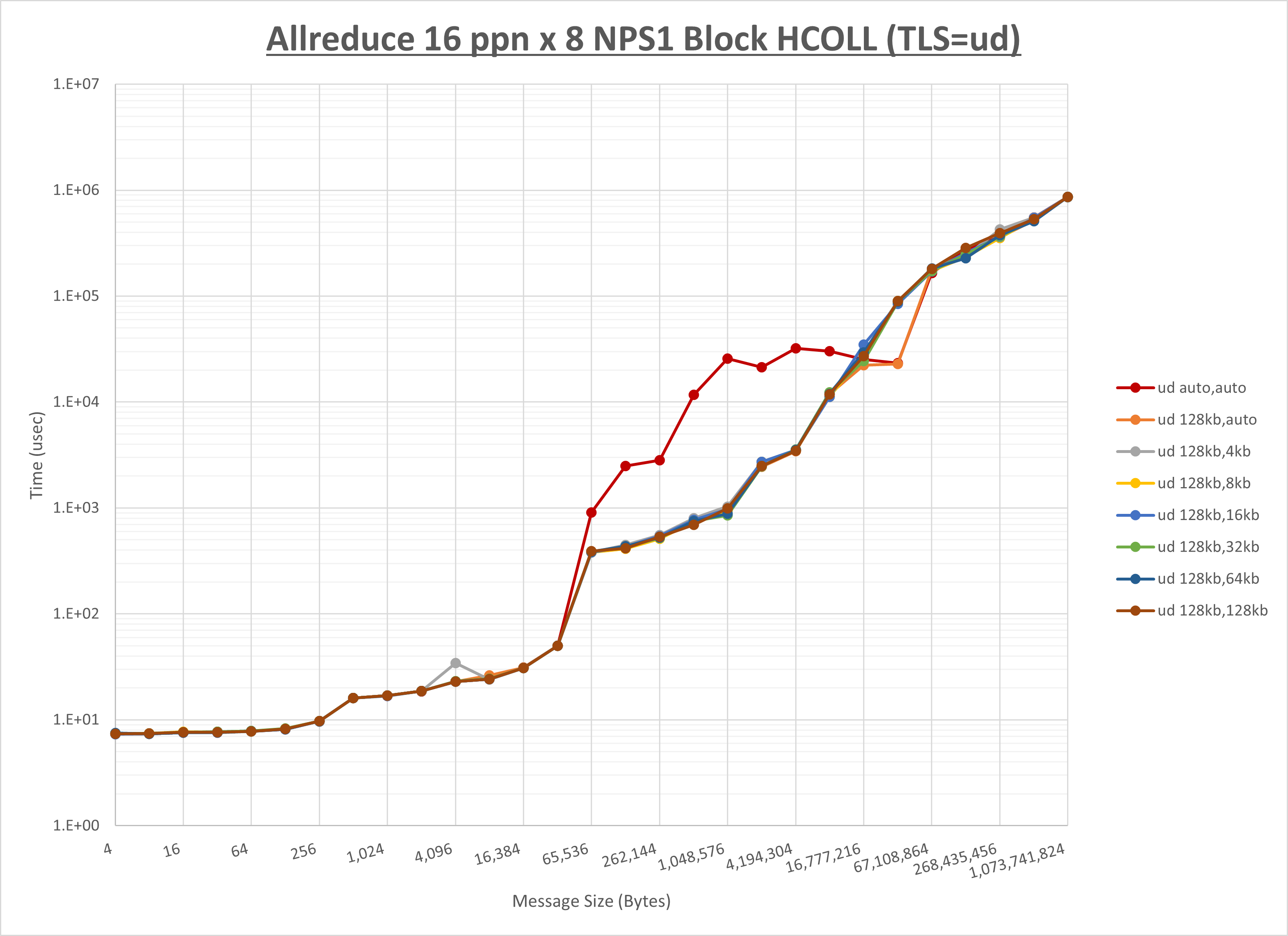
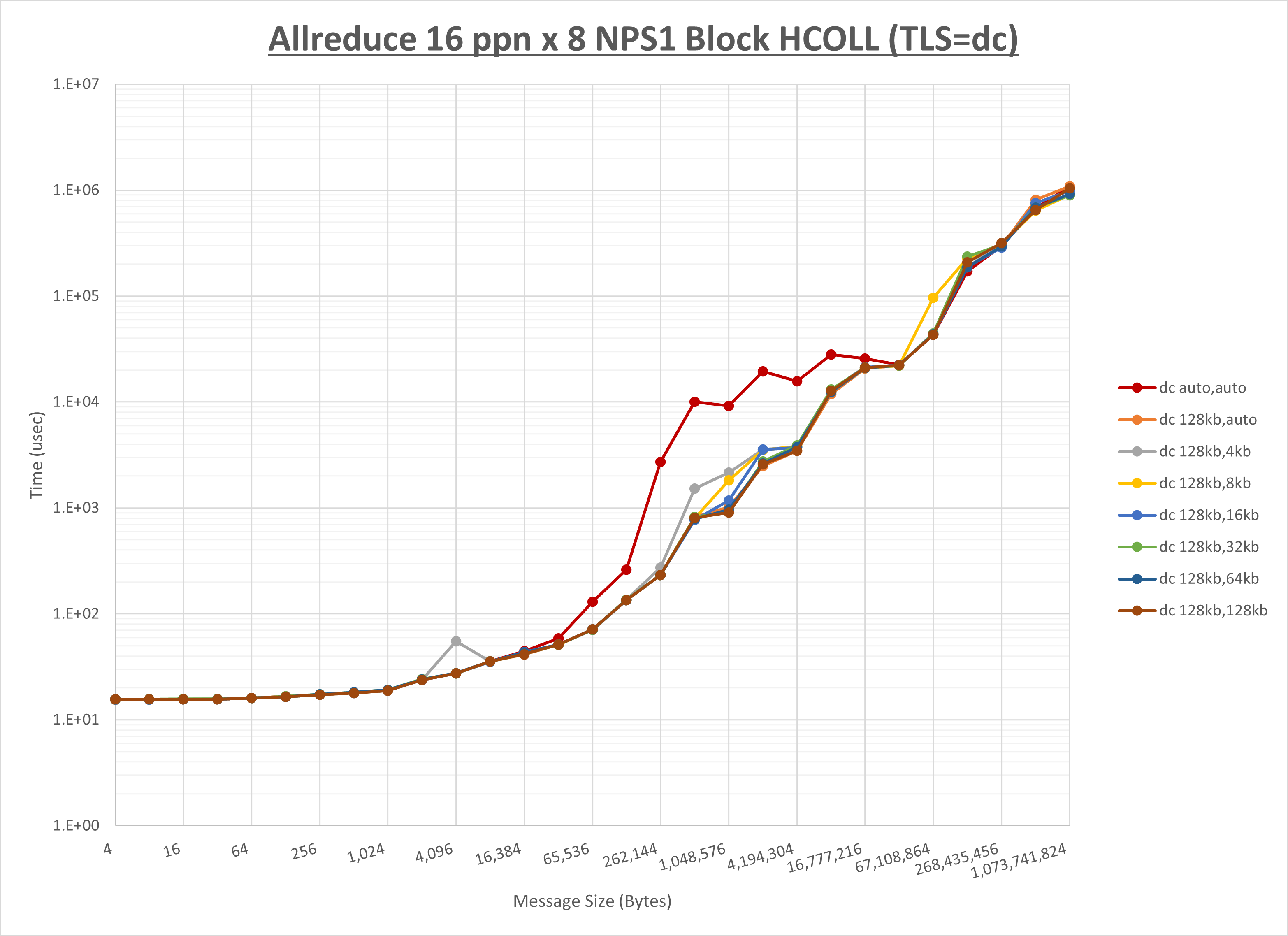
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
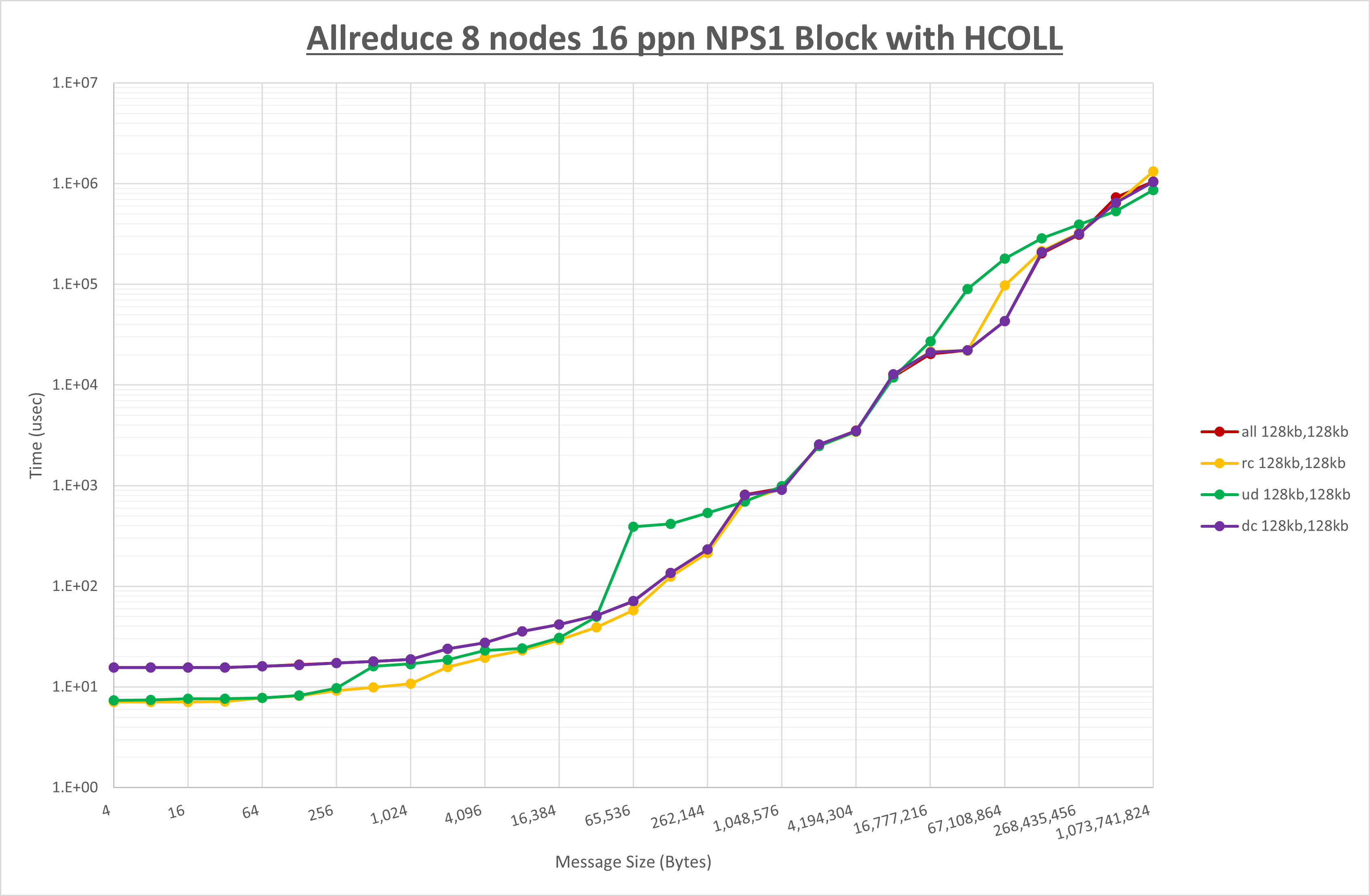
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
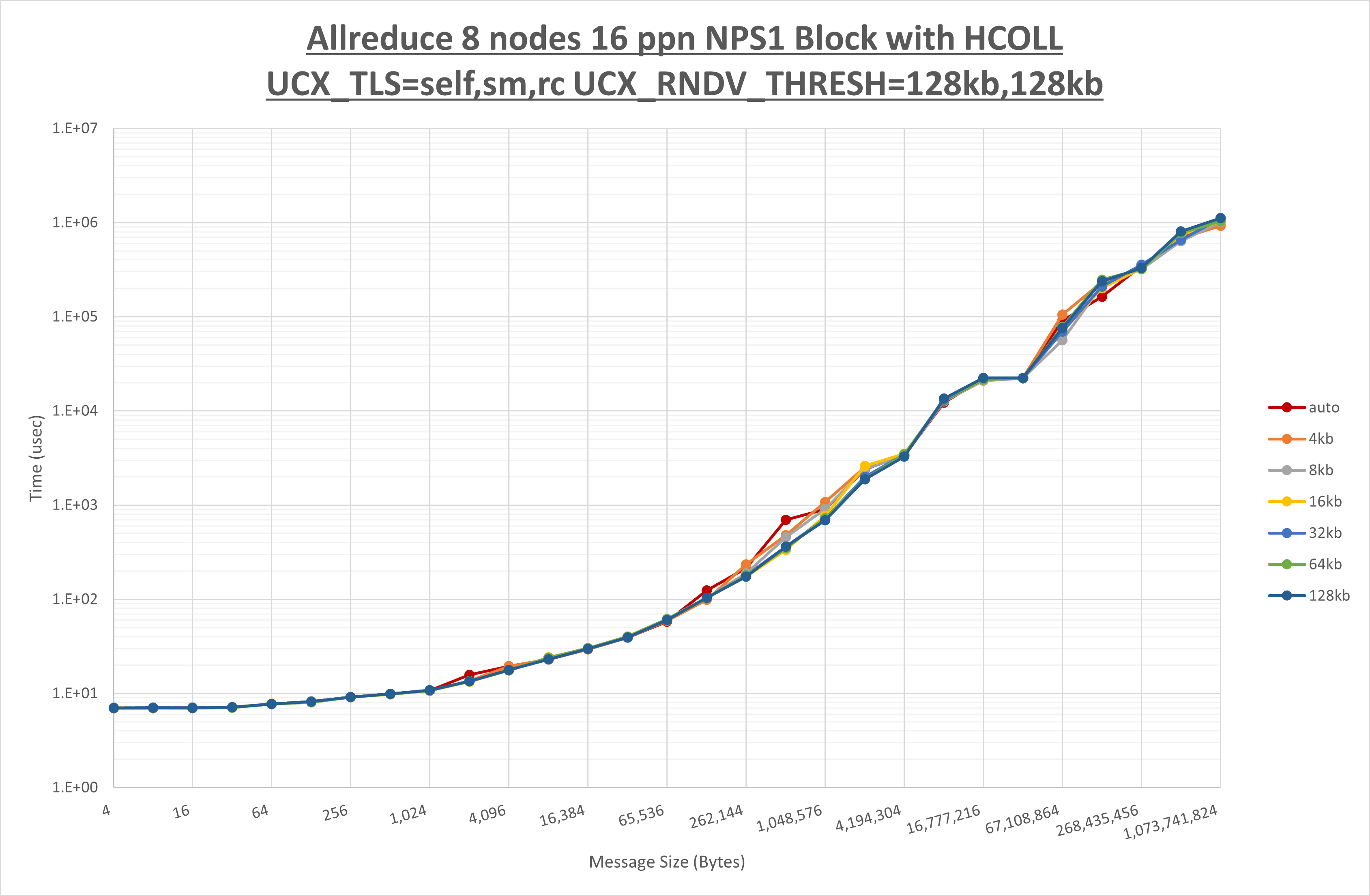
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
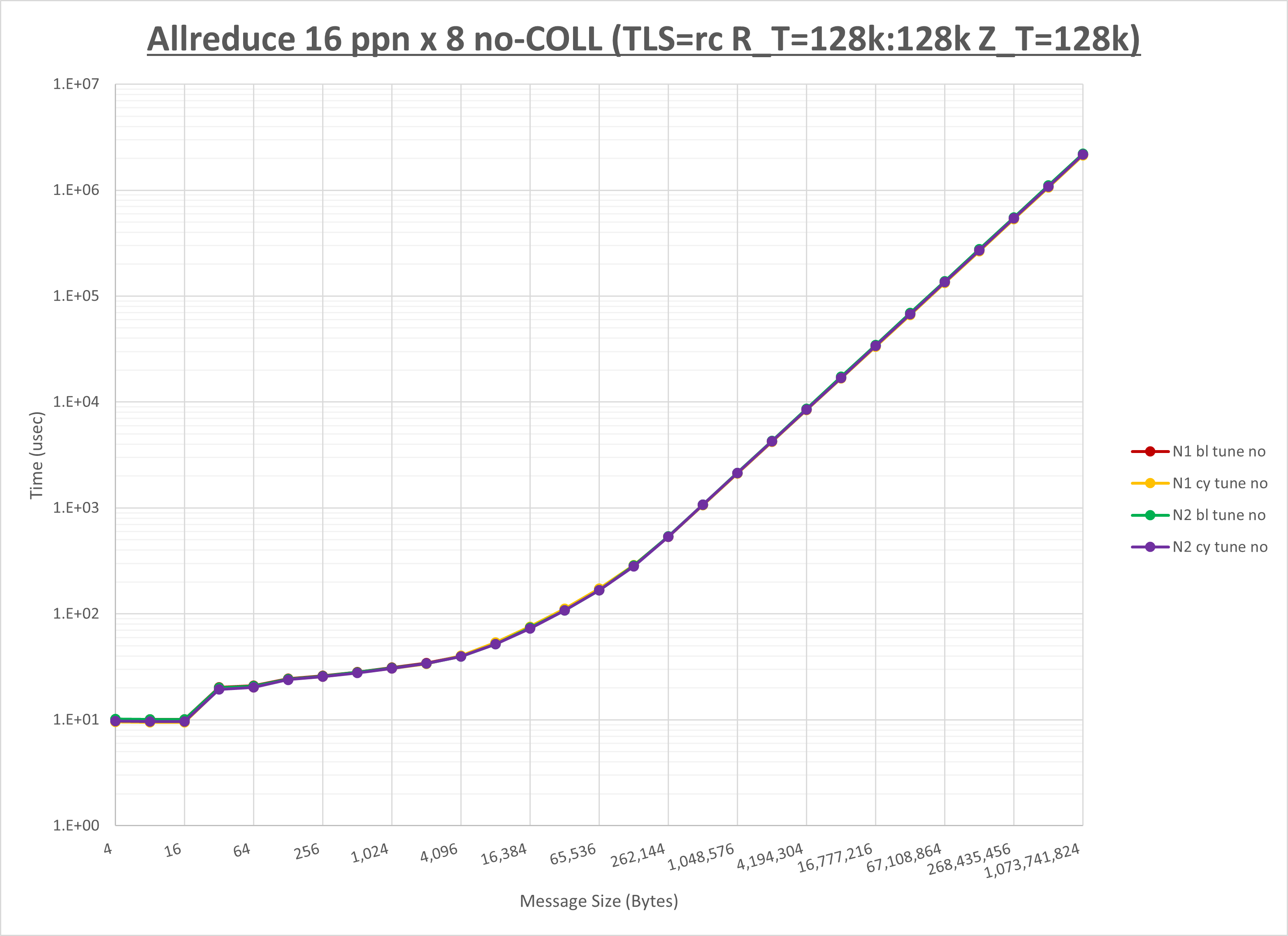
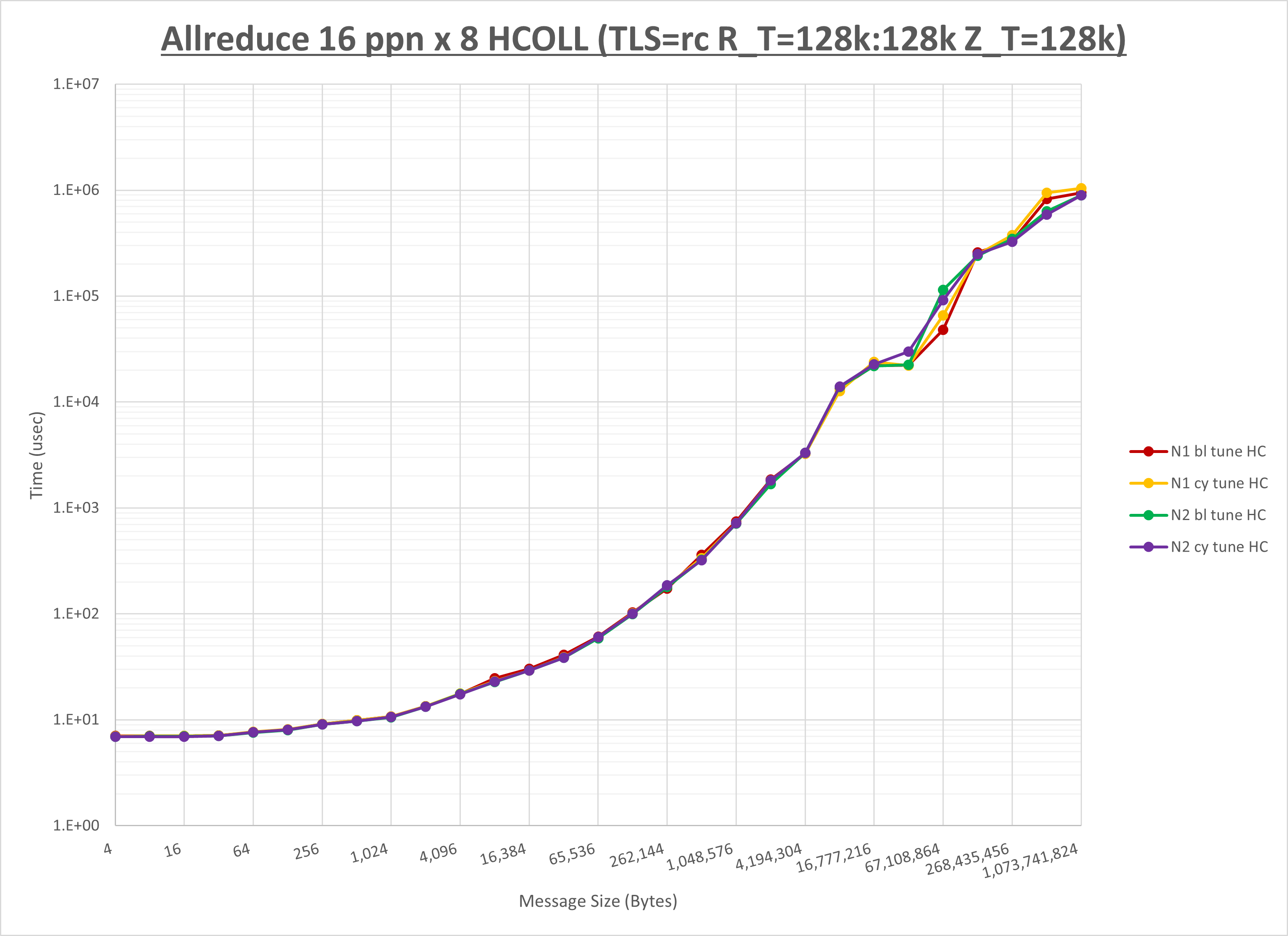
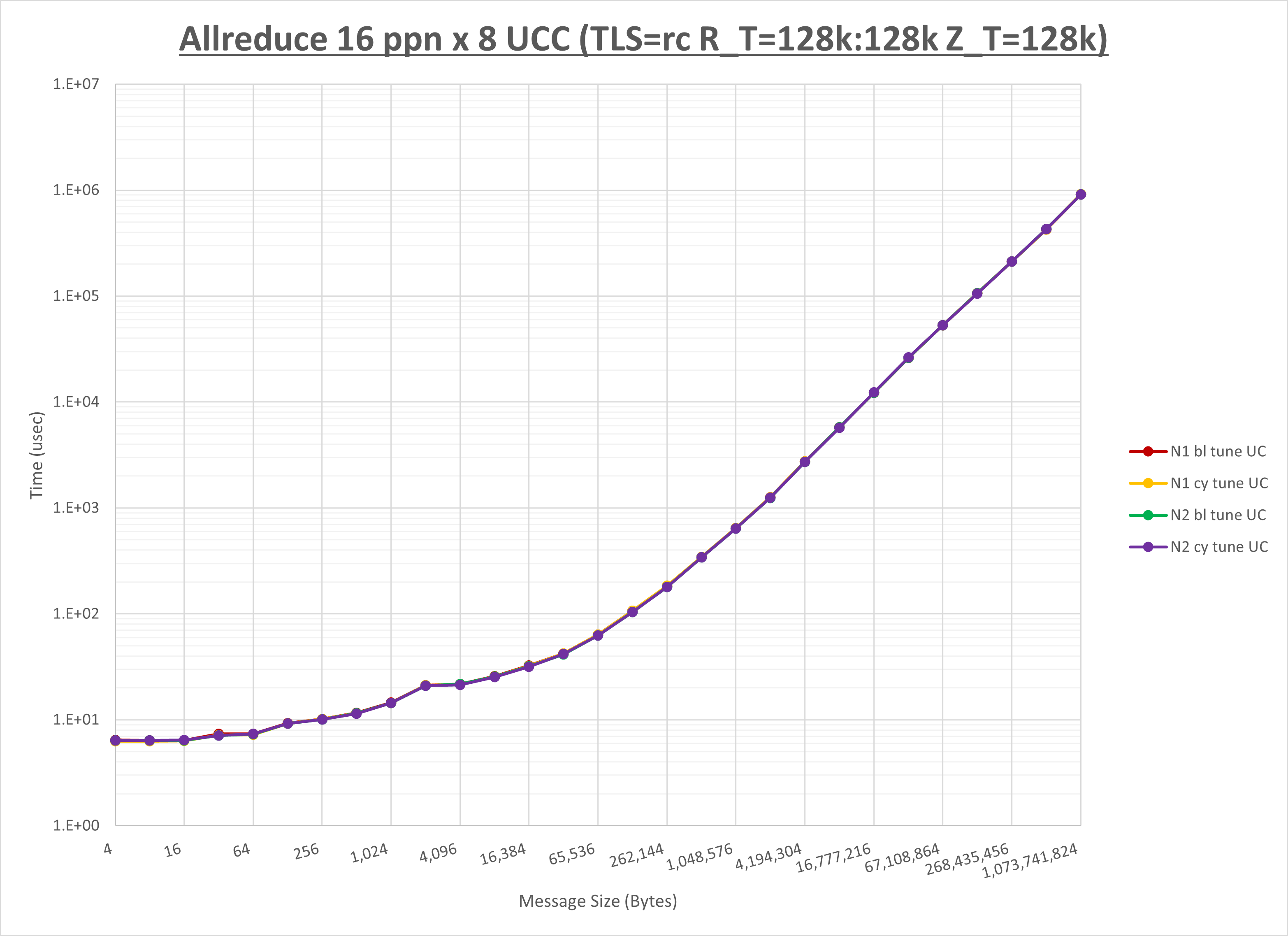
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | サイクリック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
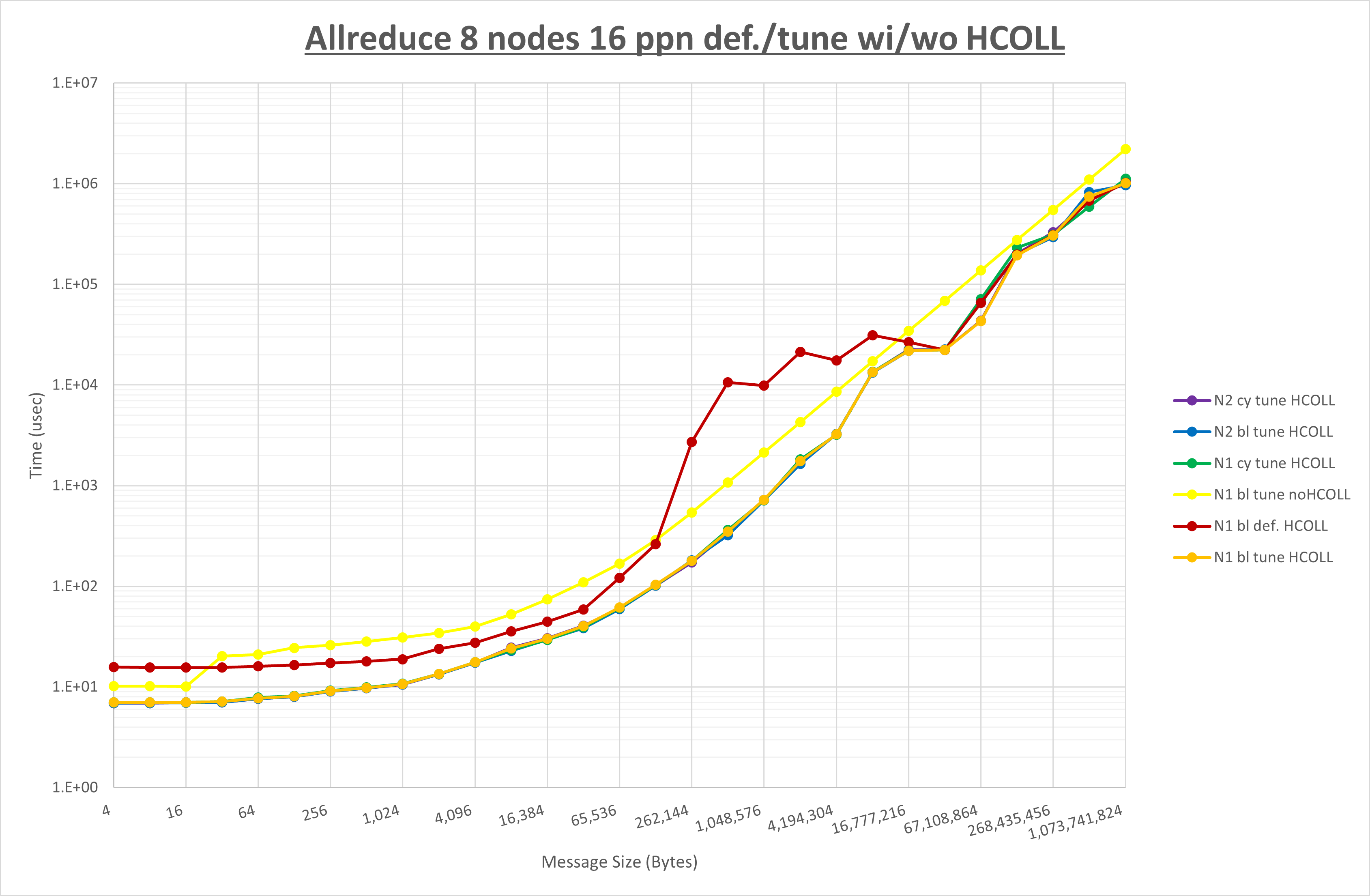
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で2MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-2-4 Exchange の結果から16KBとしています。
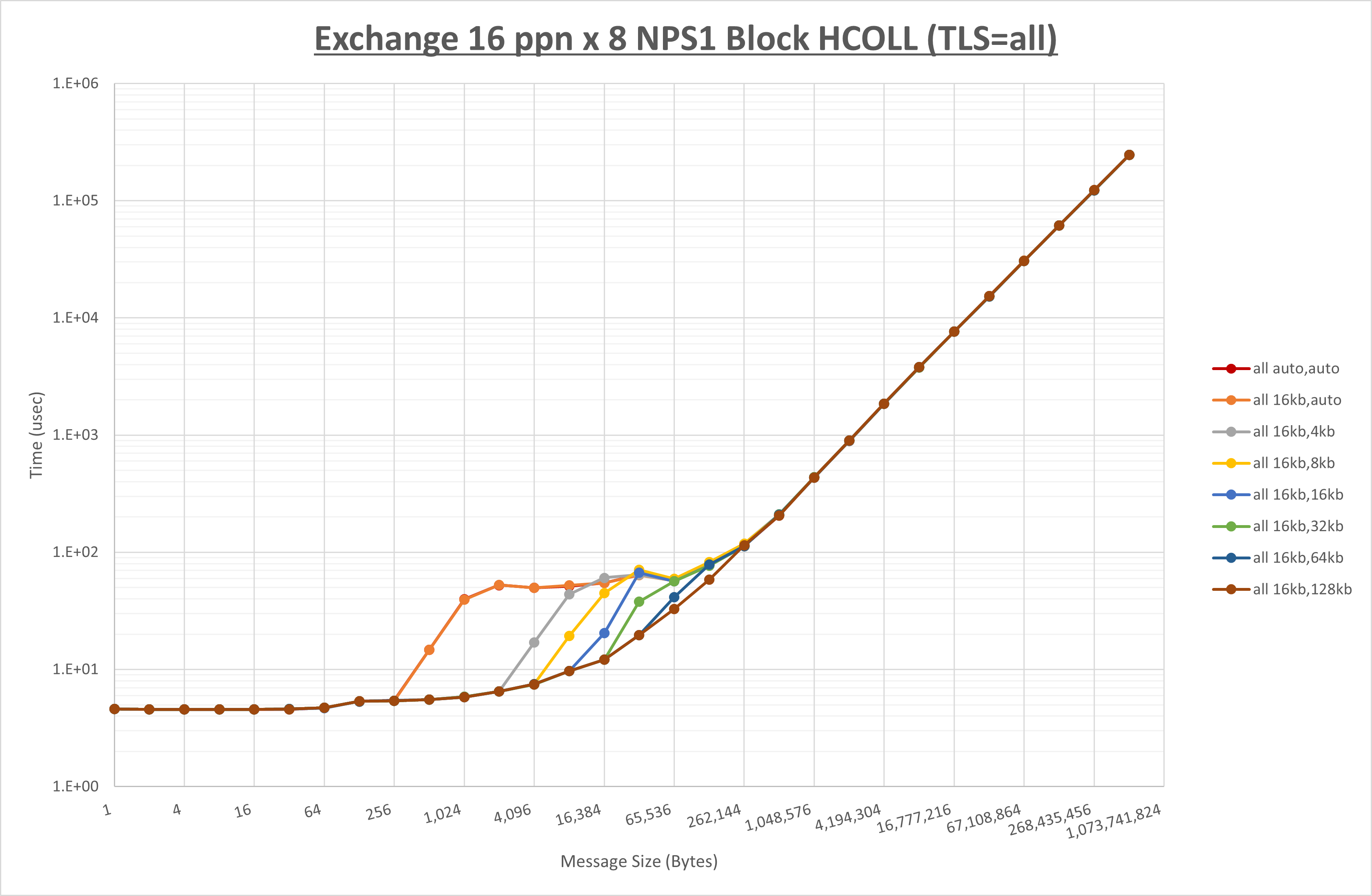
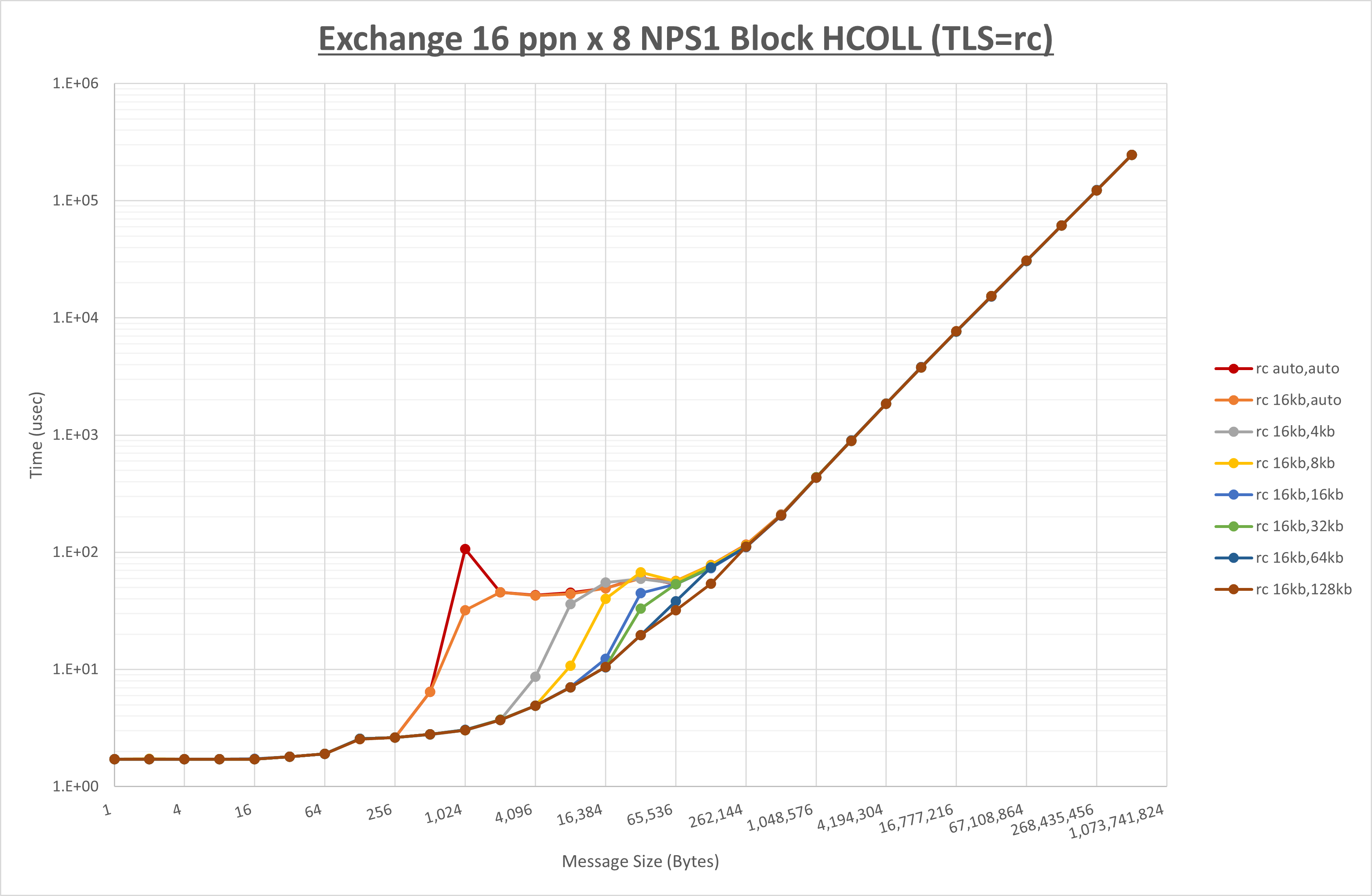
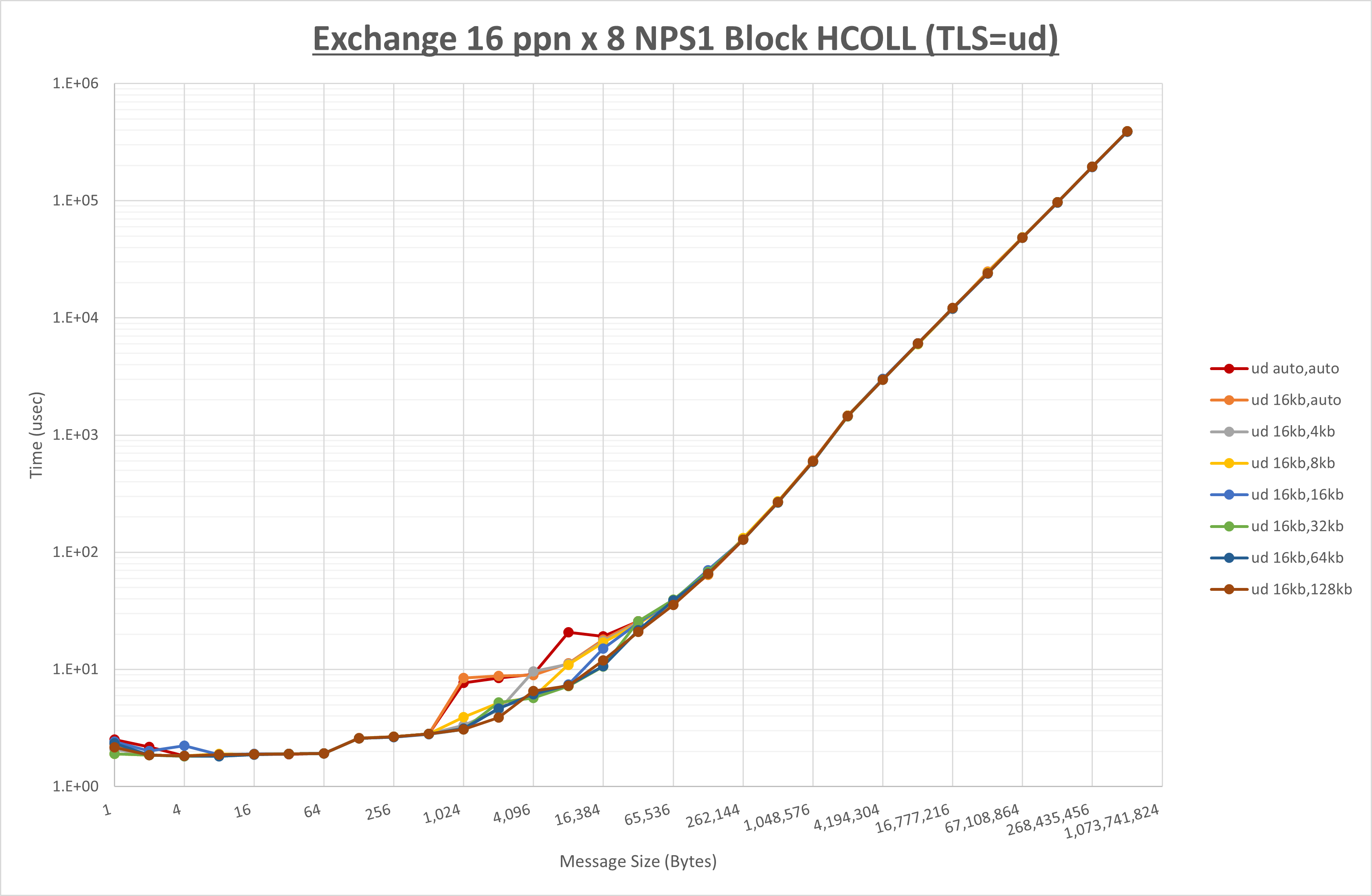
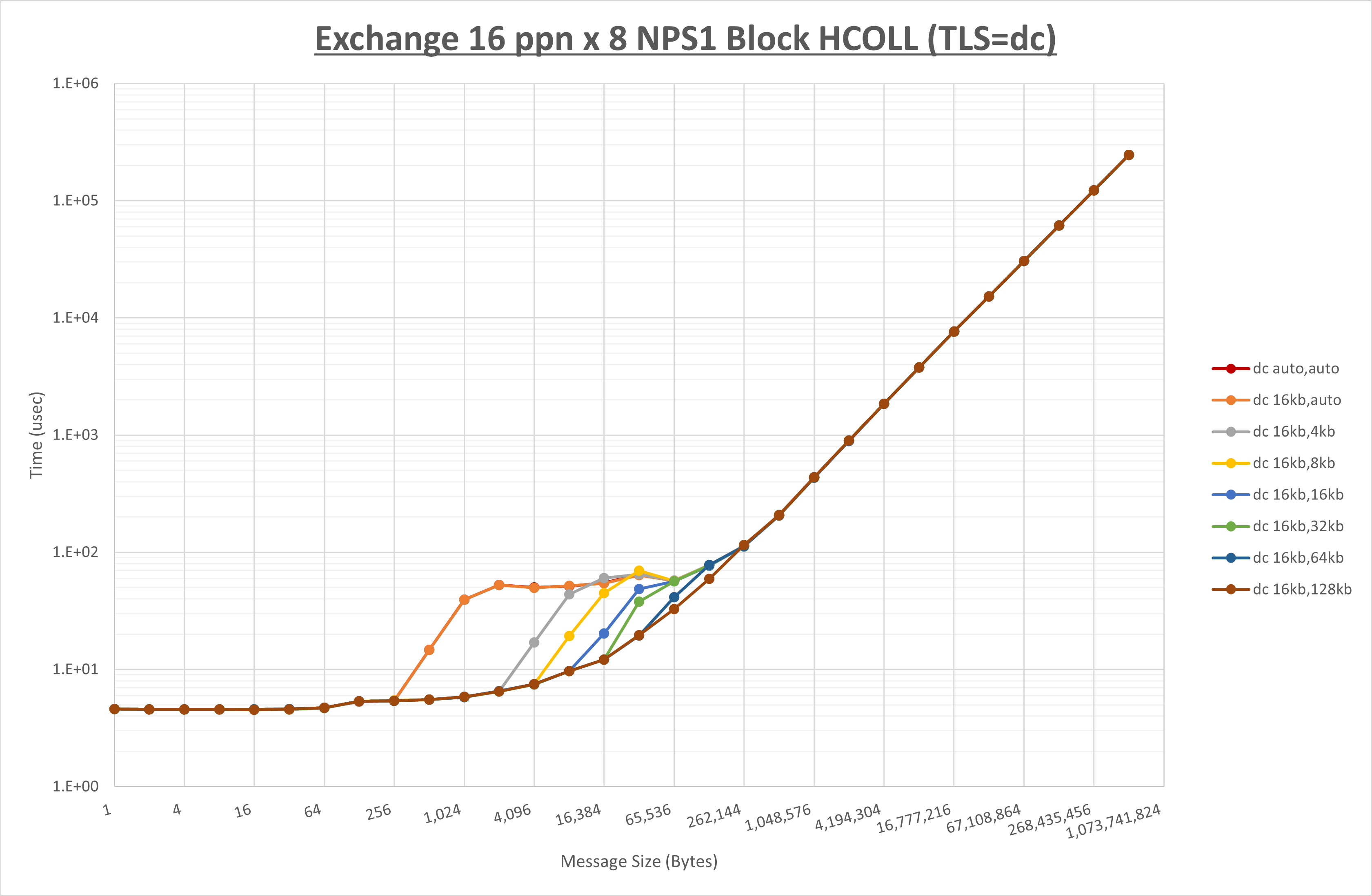
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
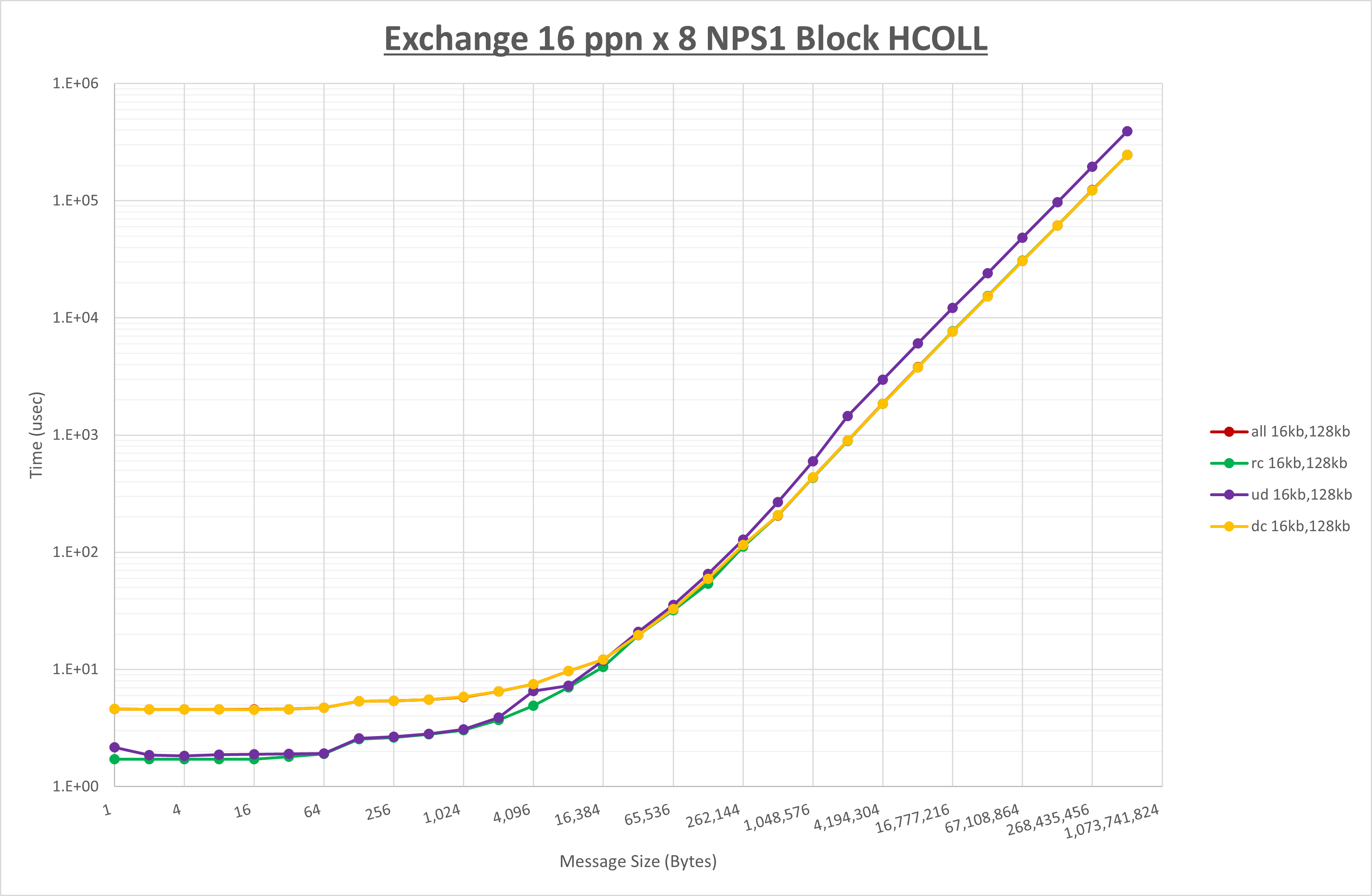
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
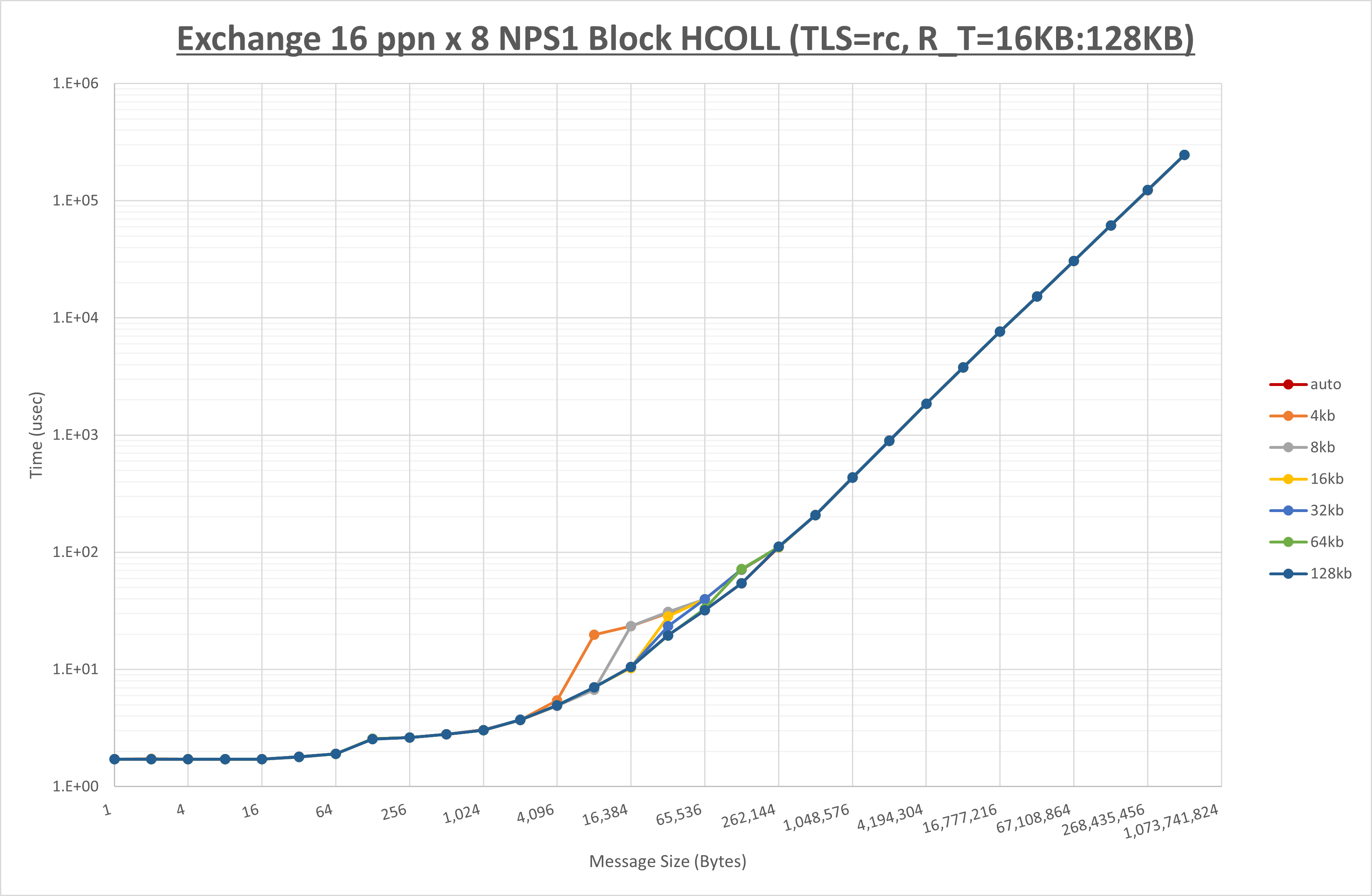
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
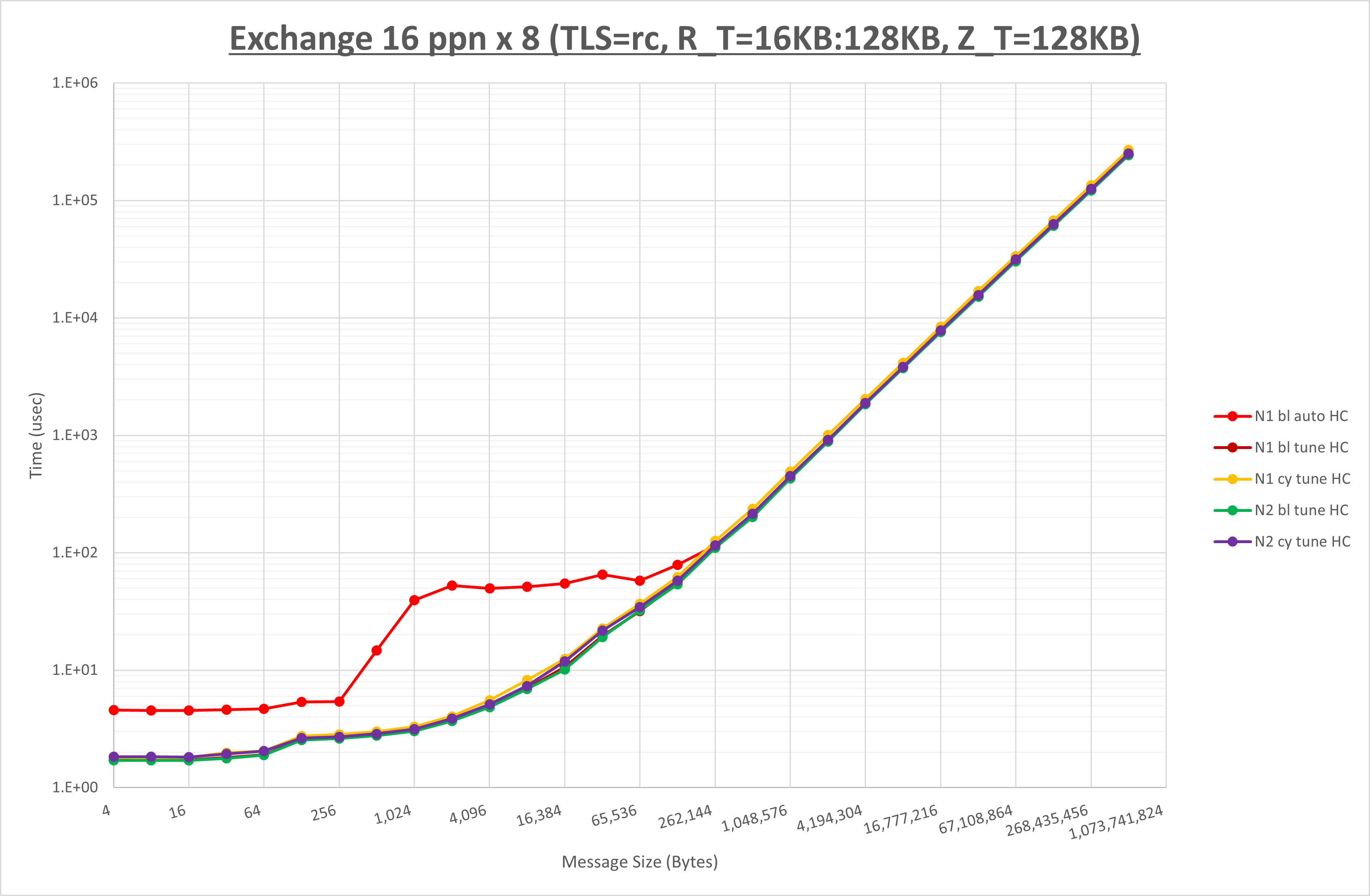
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、8ノードにノード当たり32、トータル256のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:16kb,inter:16kb | 16kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:128kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-1 Alltoall の HCOLL の結果から16KBとしています。
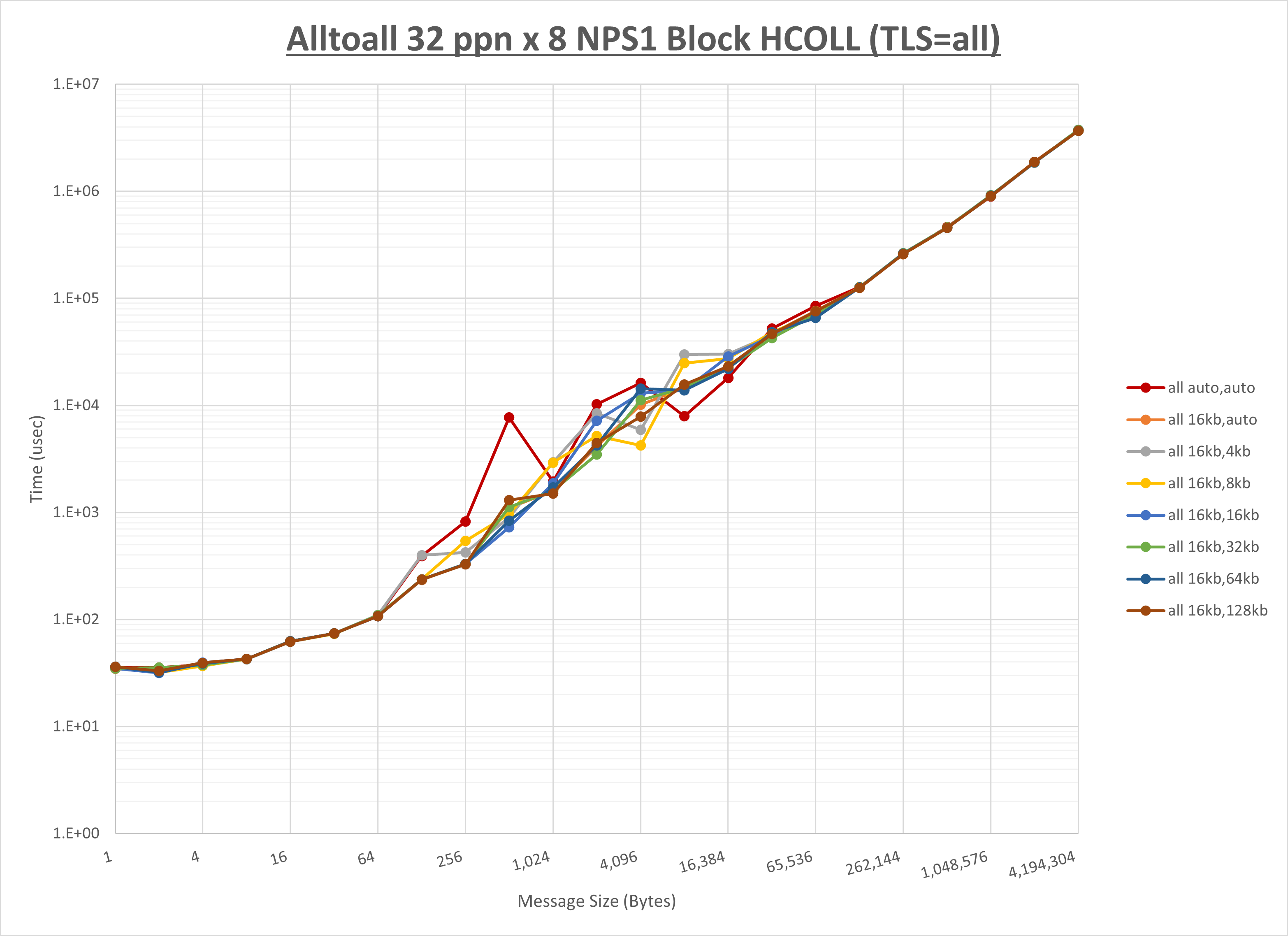
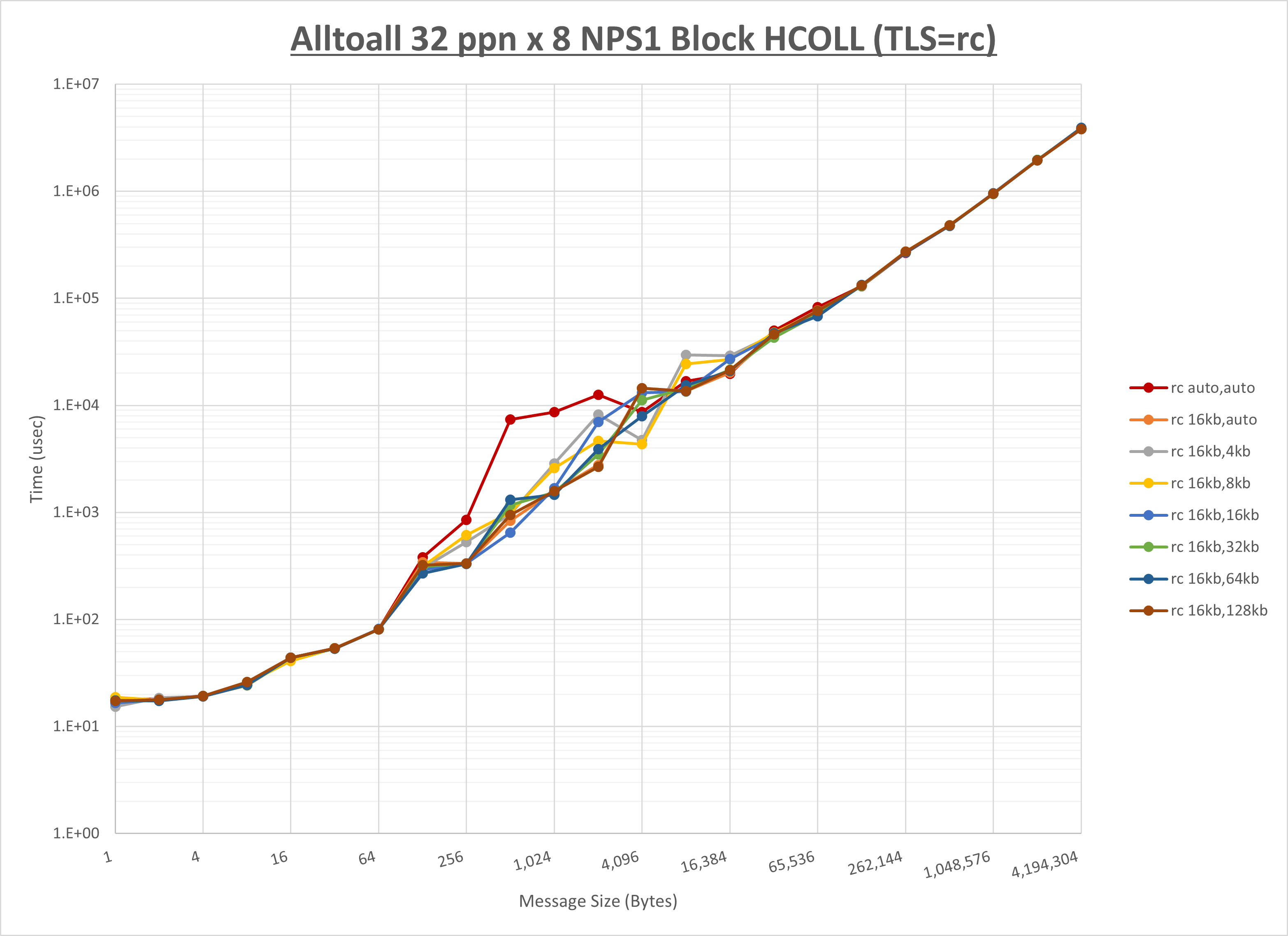
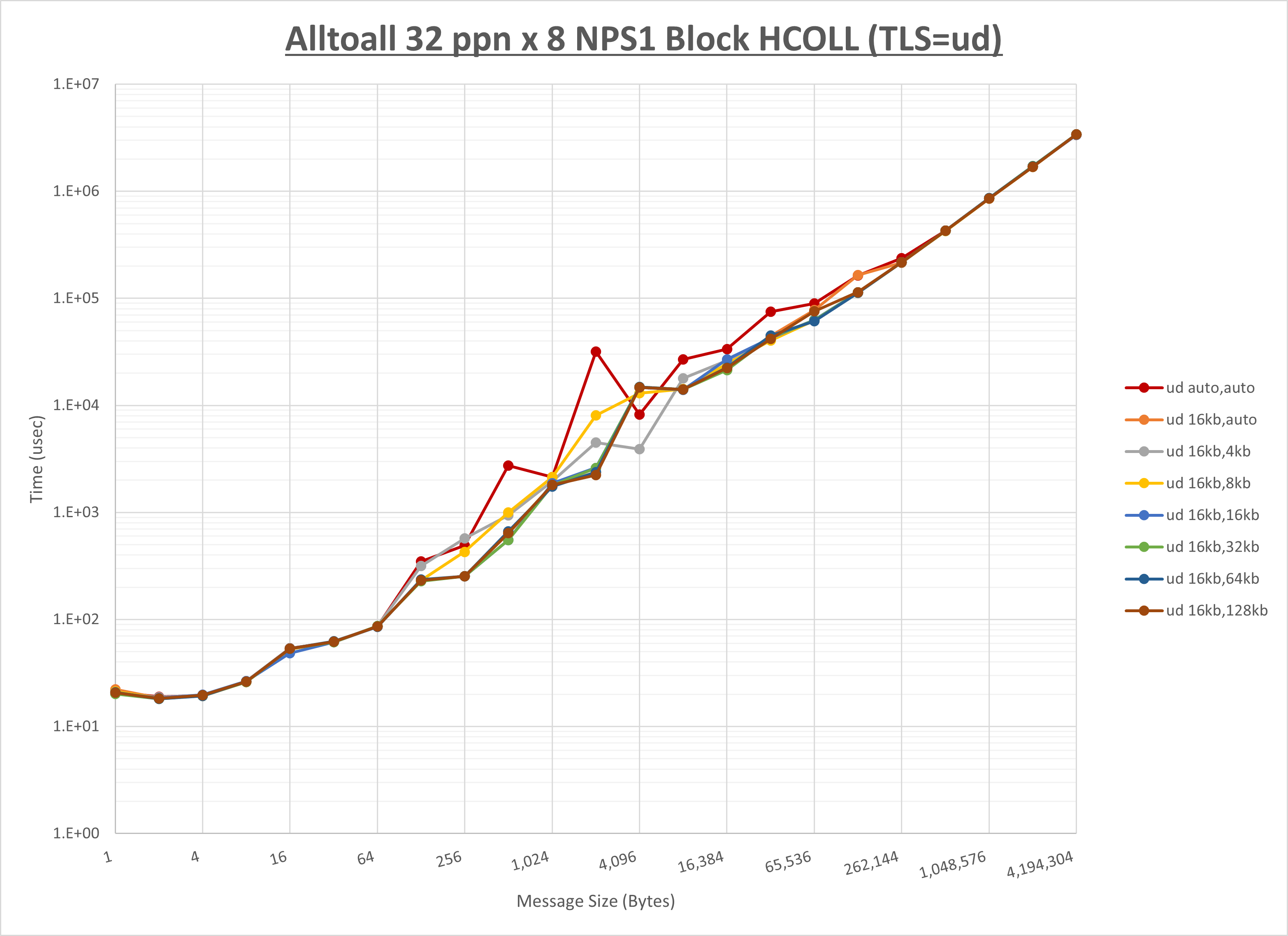
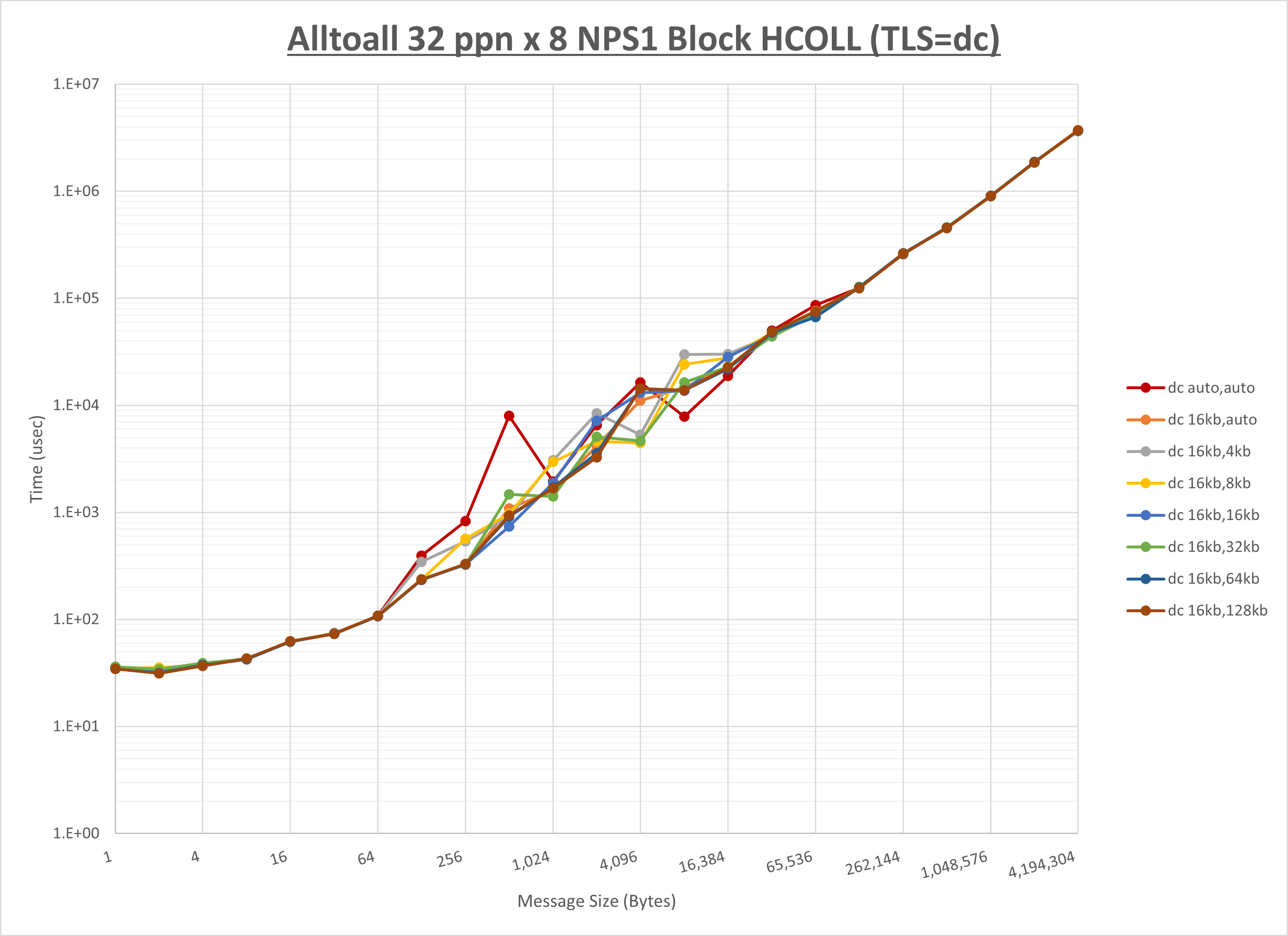
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:16kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
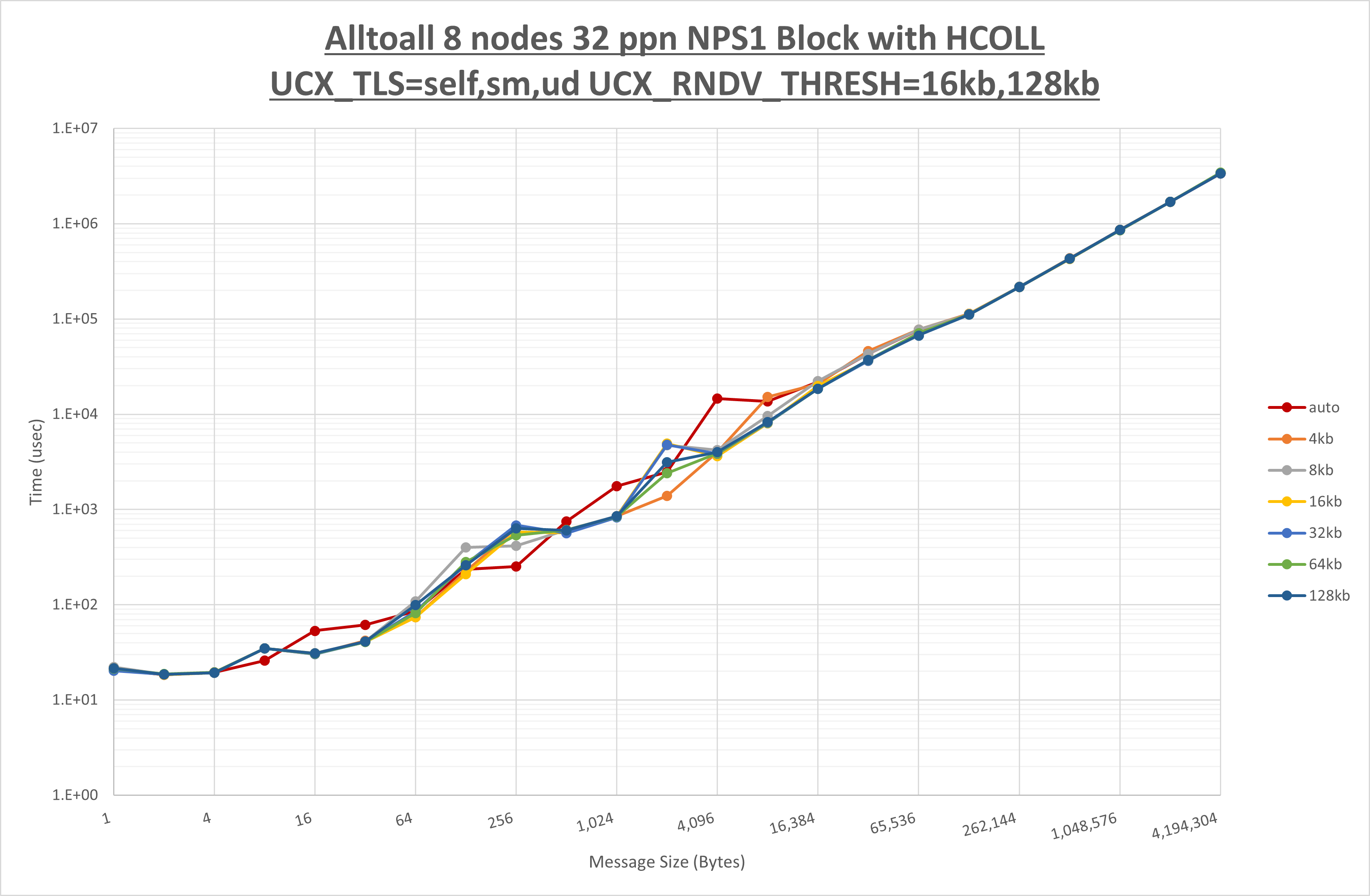
以上より、 UCX_ZCOPY_THRESH を 16kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
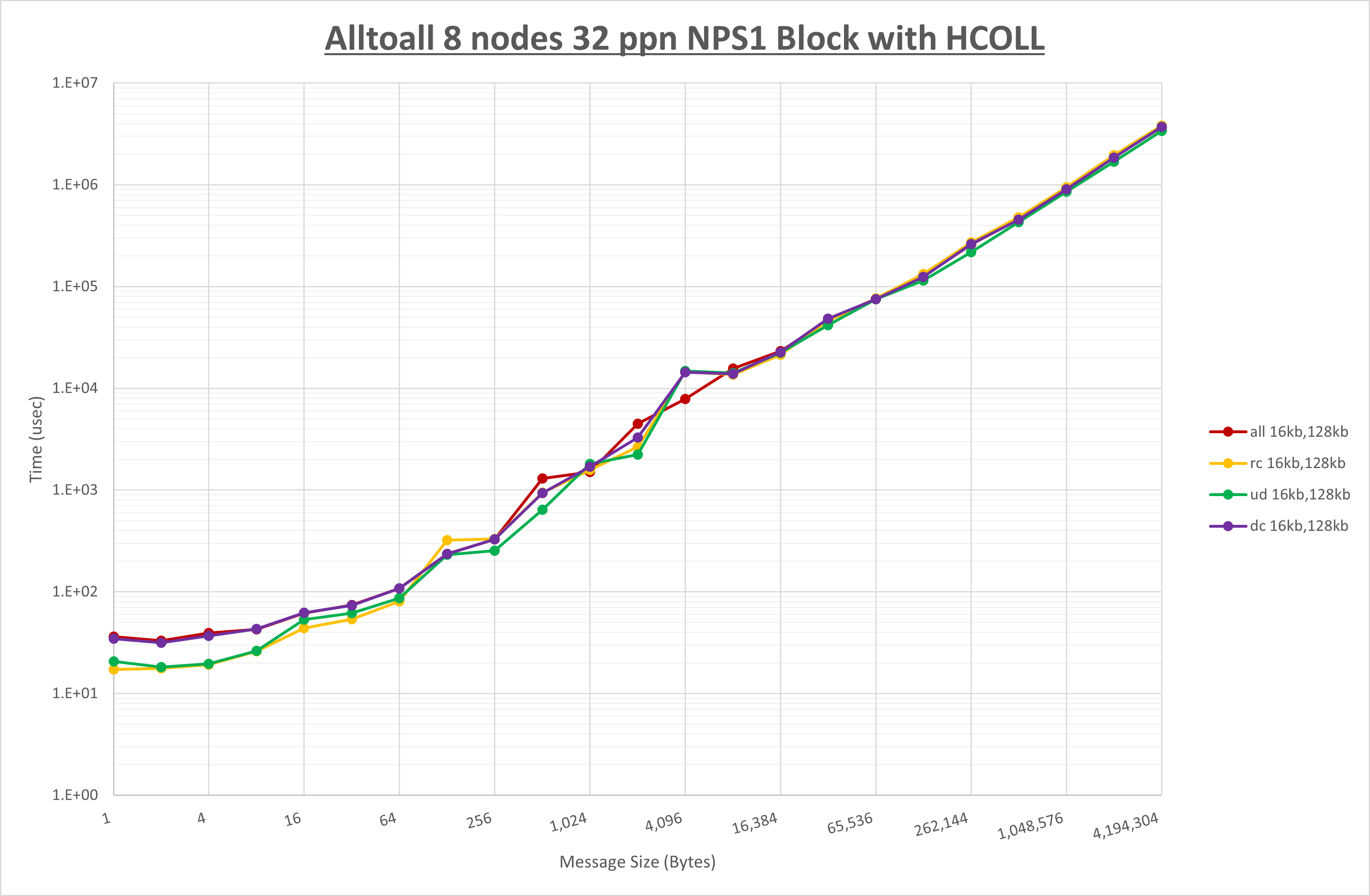
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
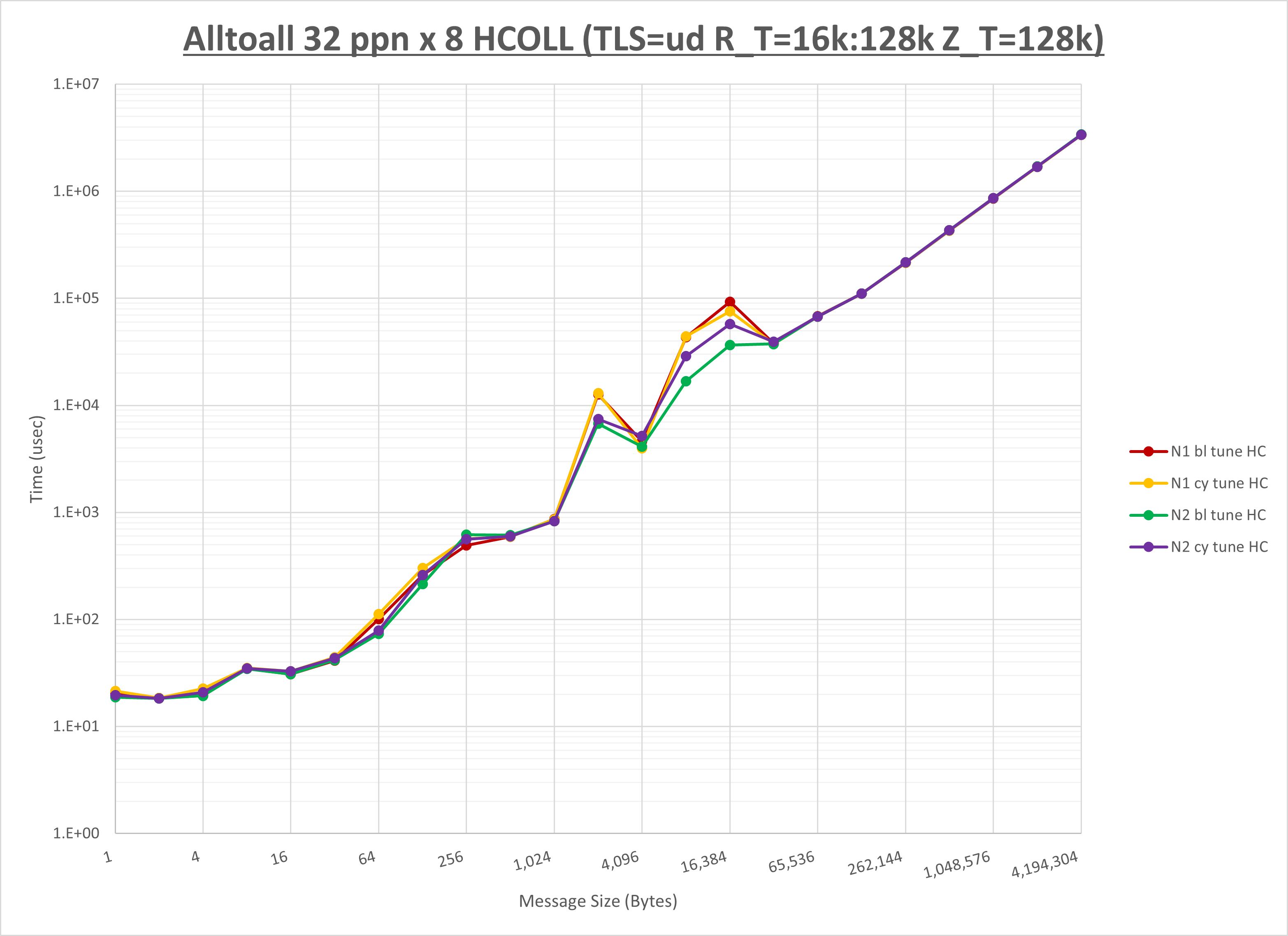
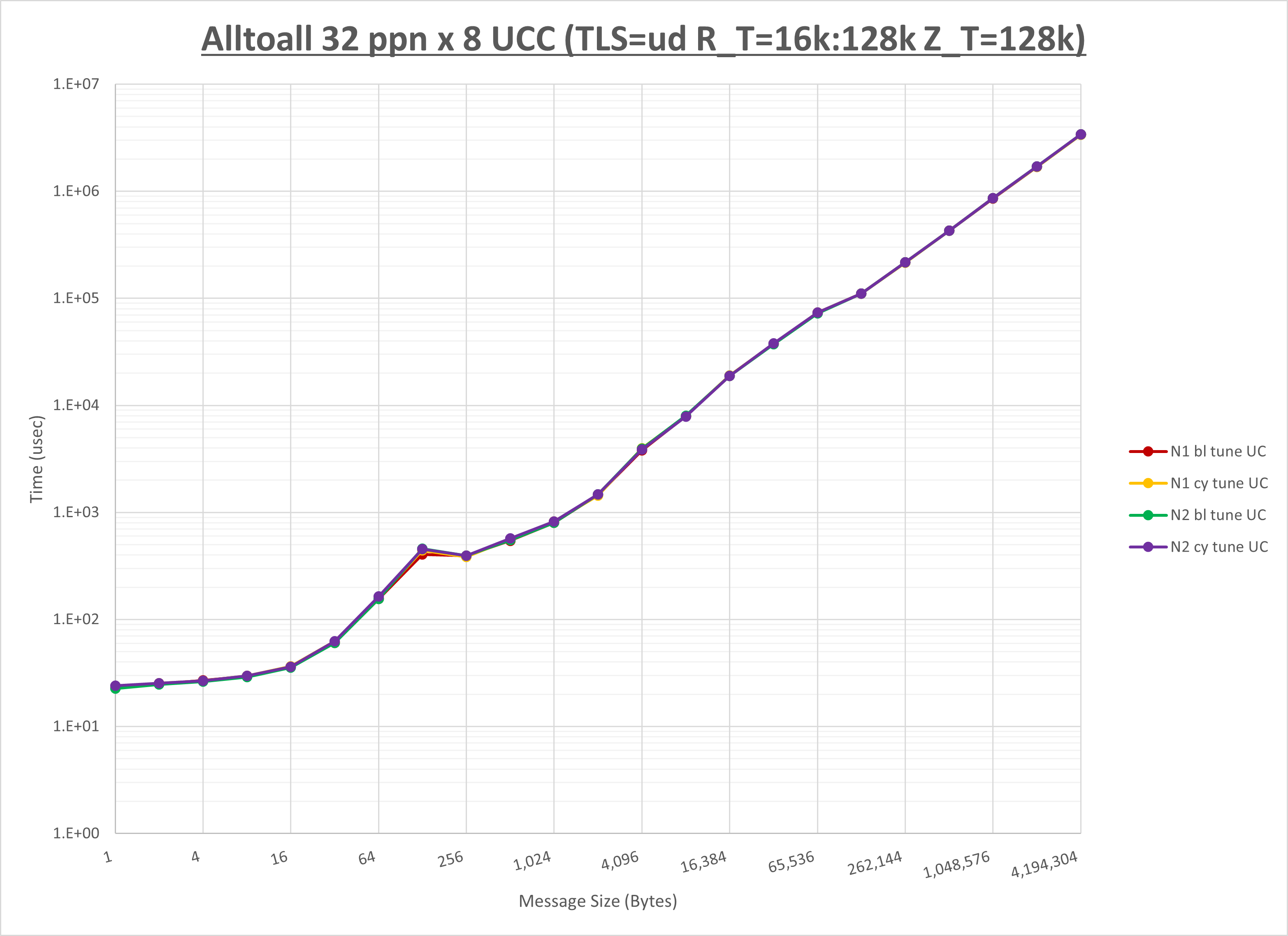
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
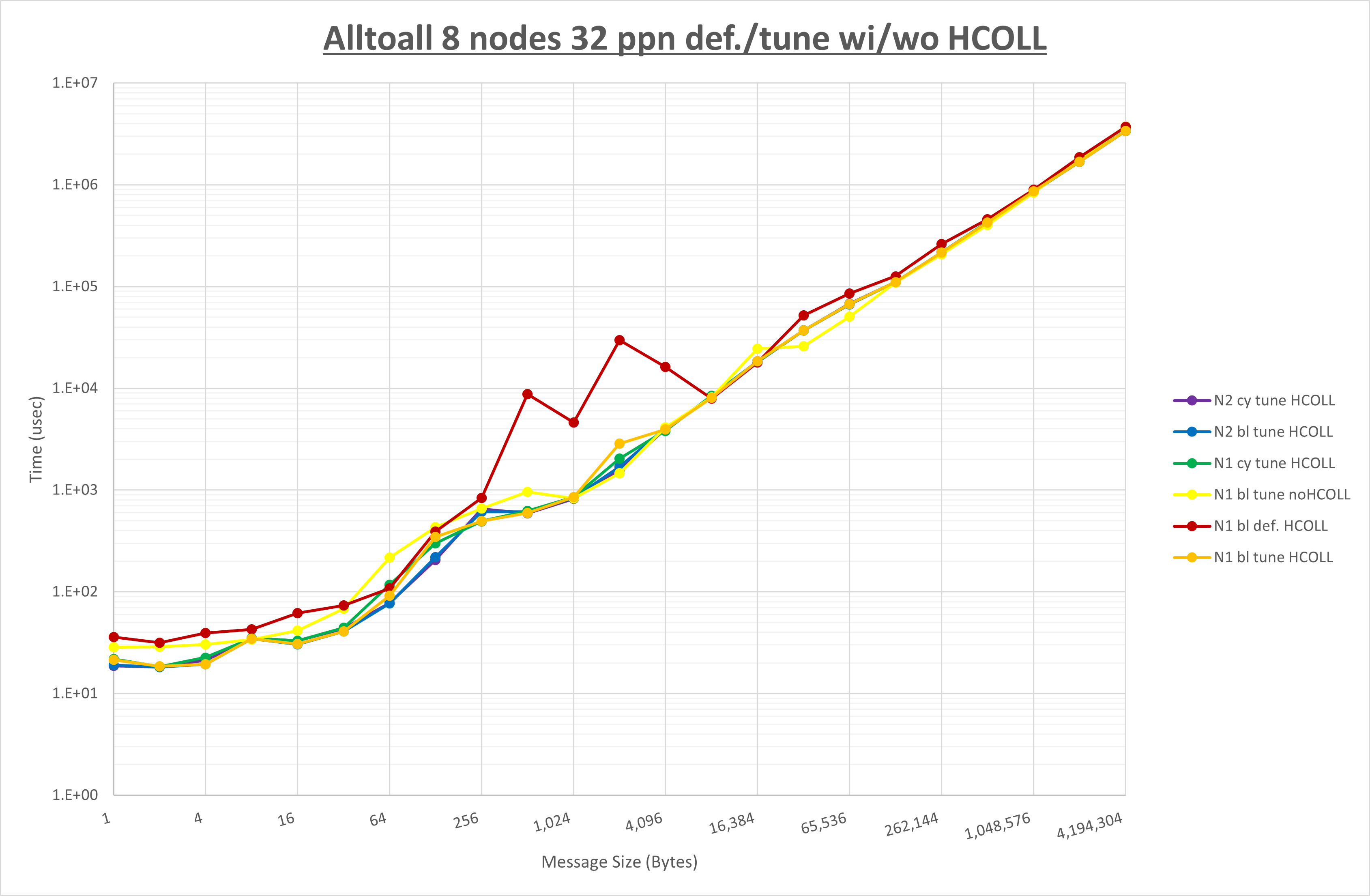
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し8KB以下のほぼ全域で性能が向上
- UCC は no-COLL と比較し64B以下で性能が向上
- チューニング適用で全域で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-2 Allgather の HCOLL の結果から16KBとしています。
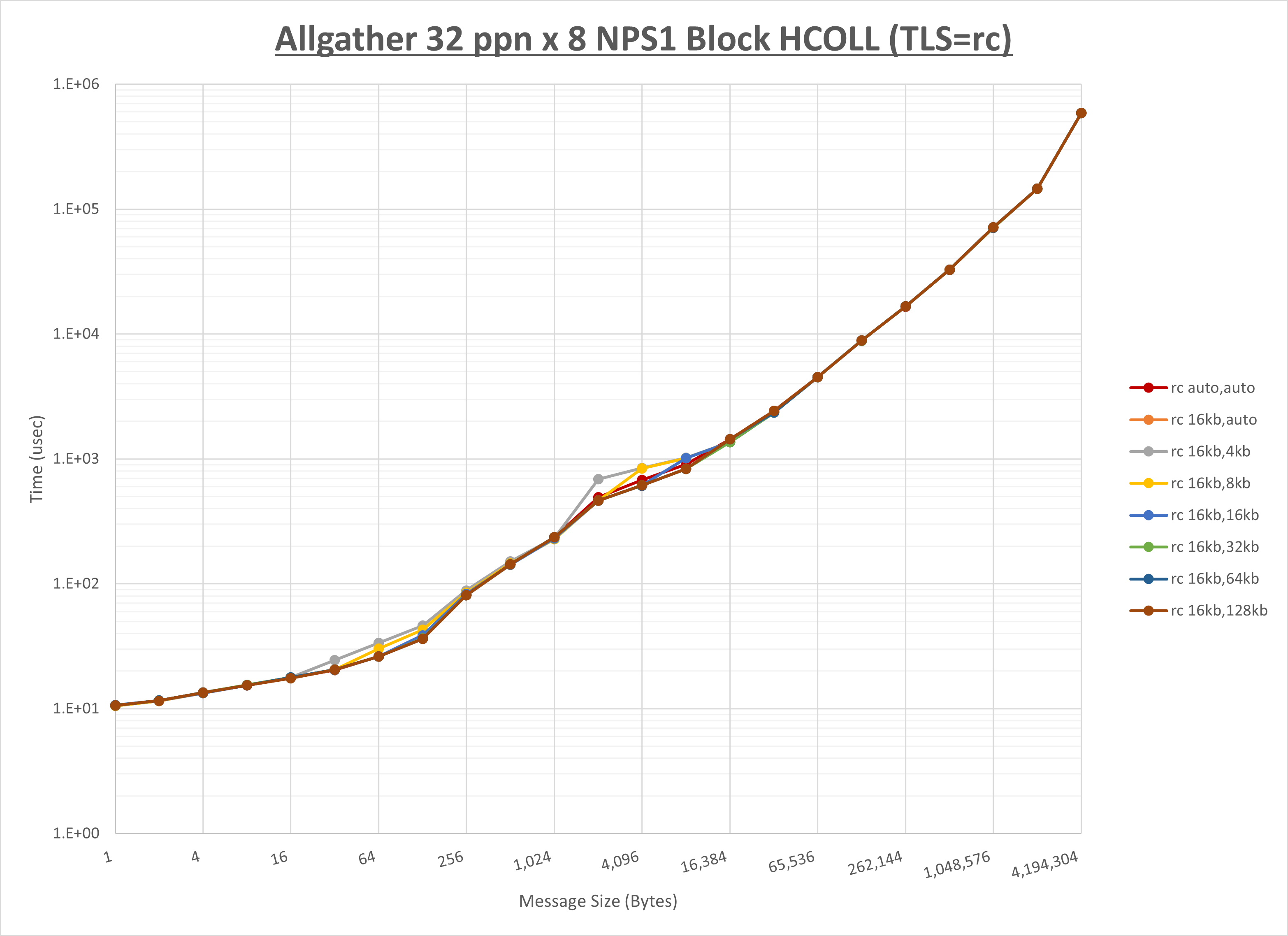
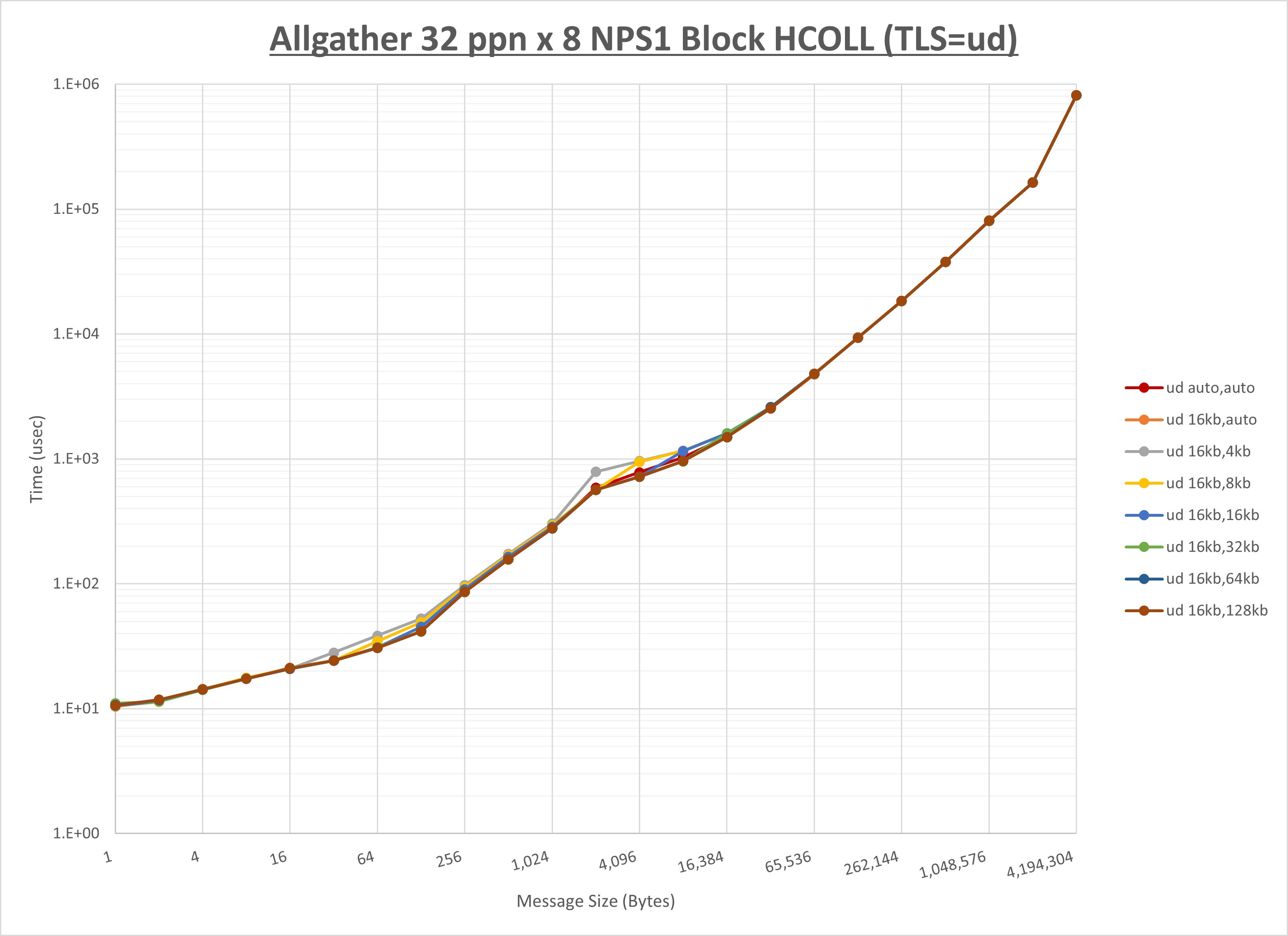
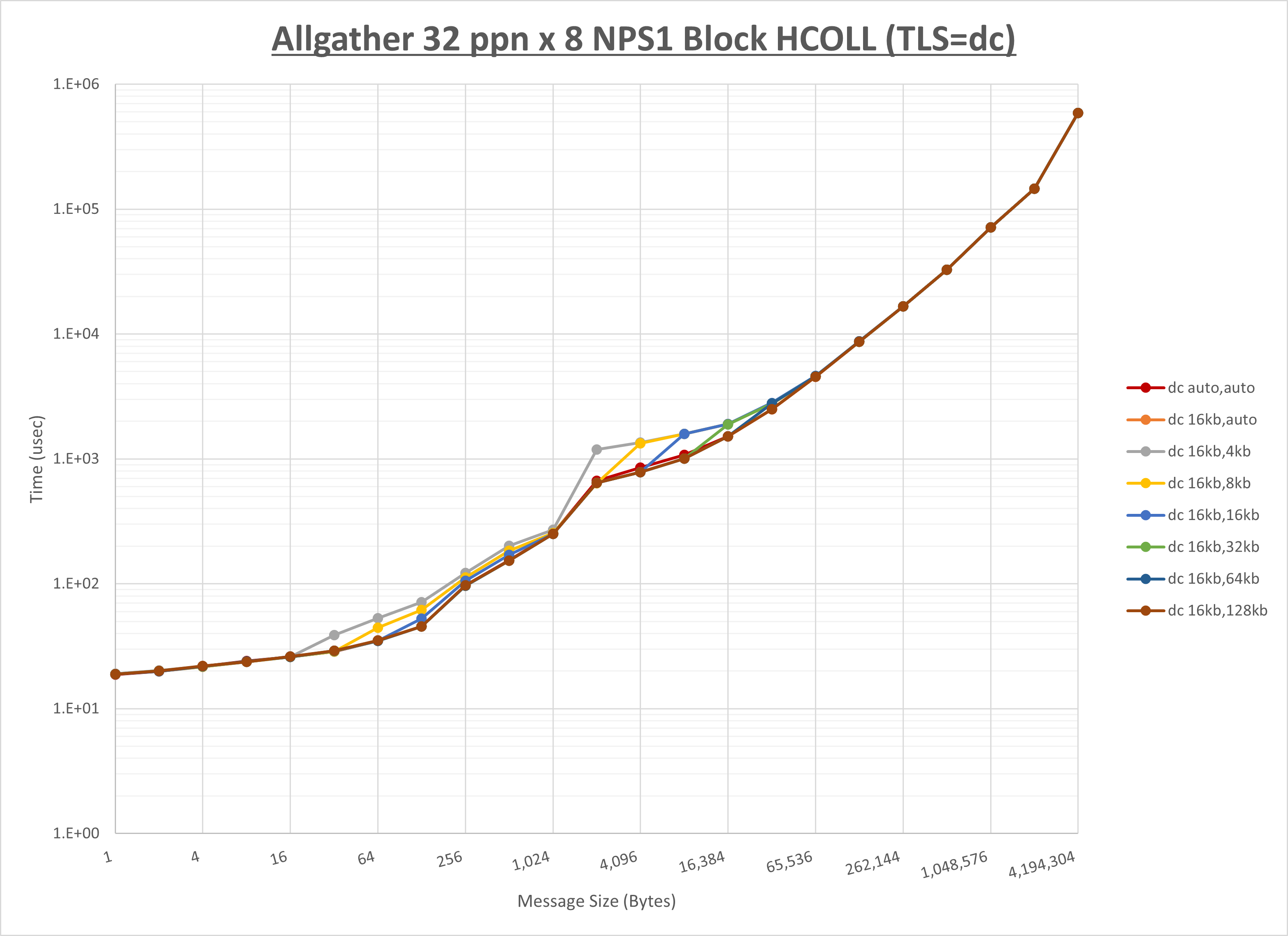
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
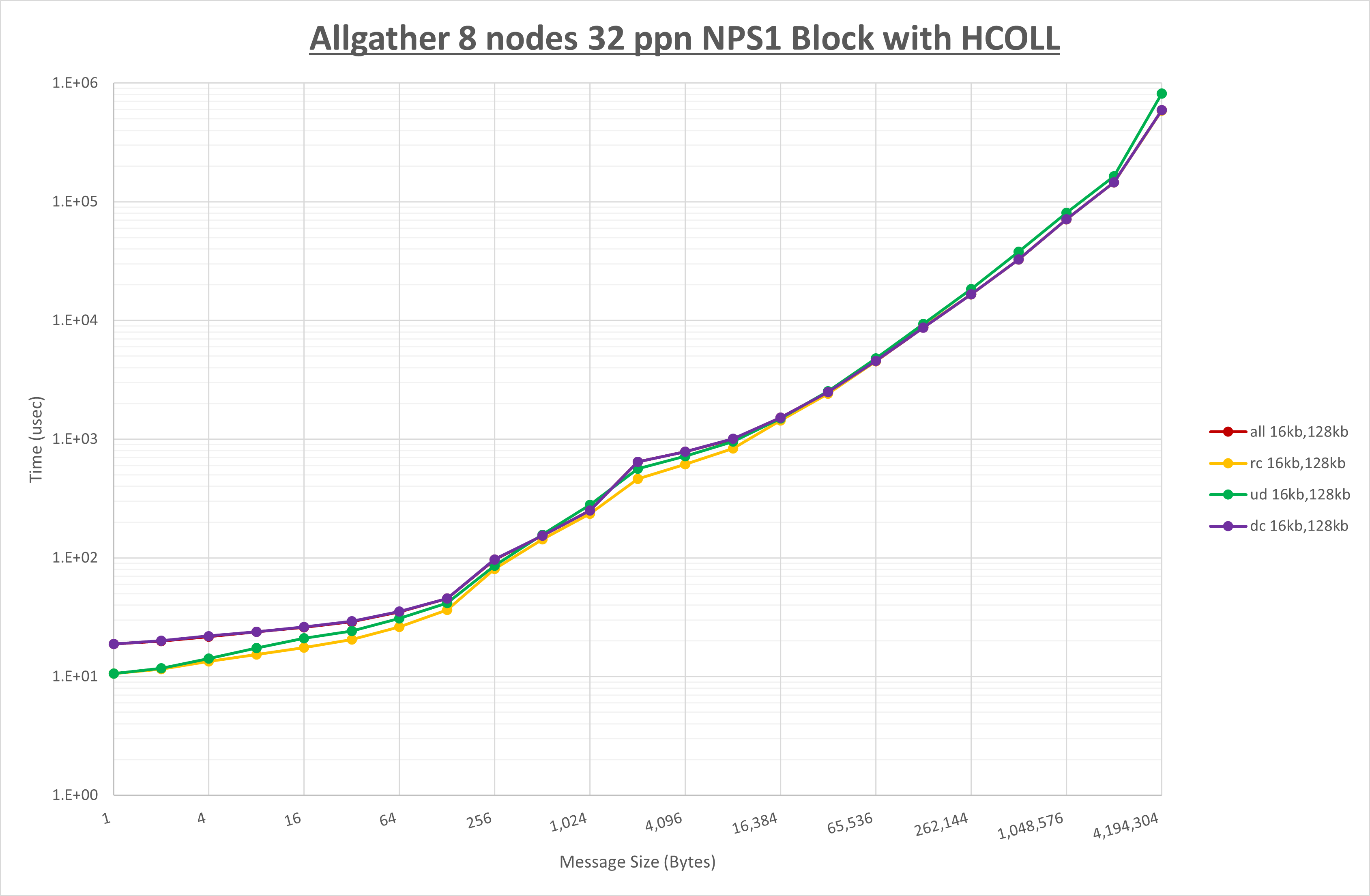
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
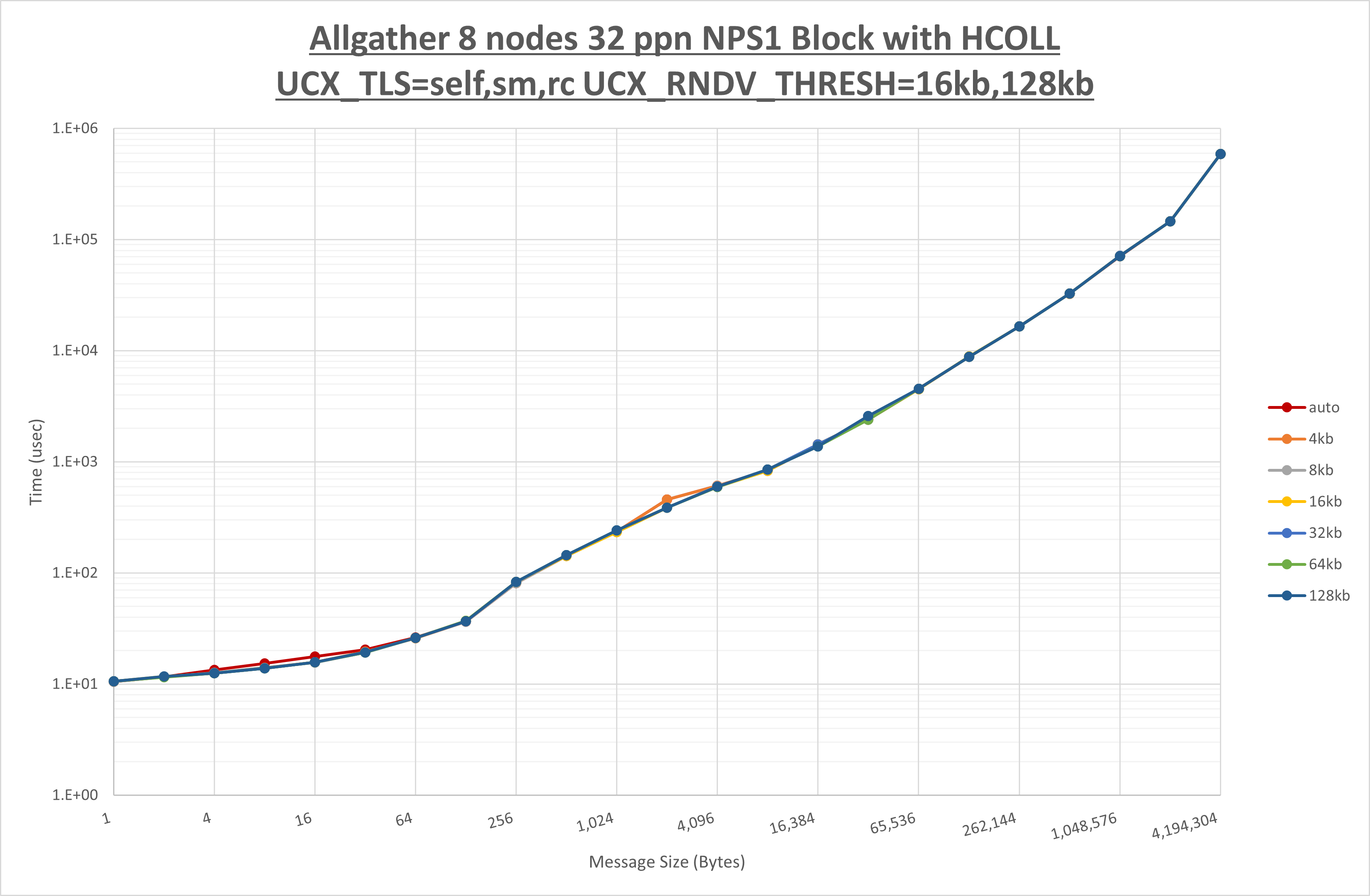
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
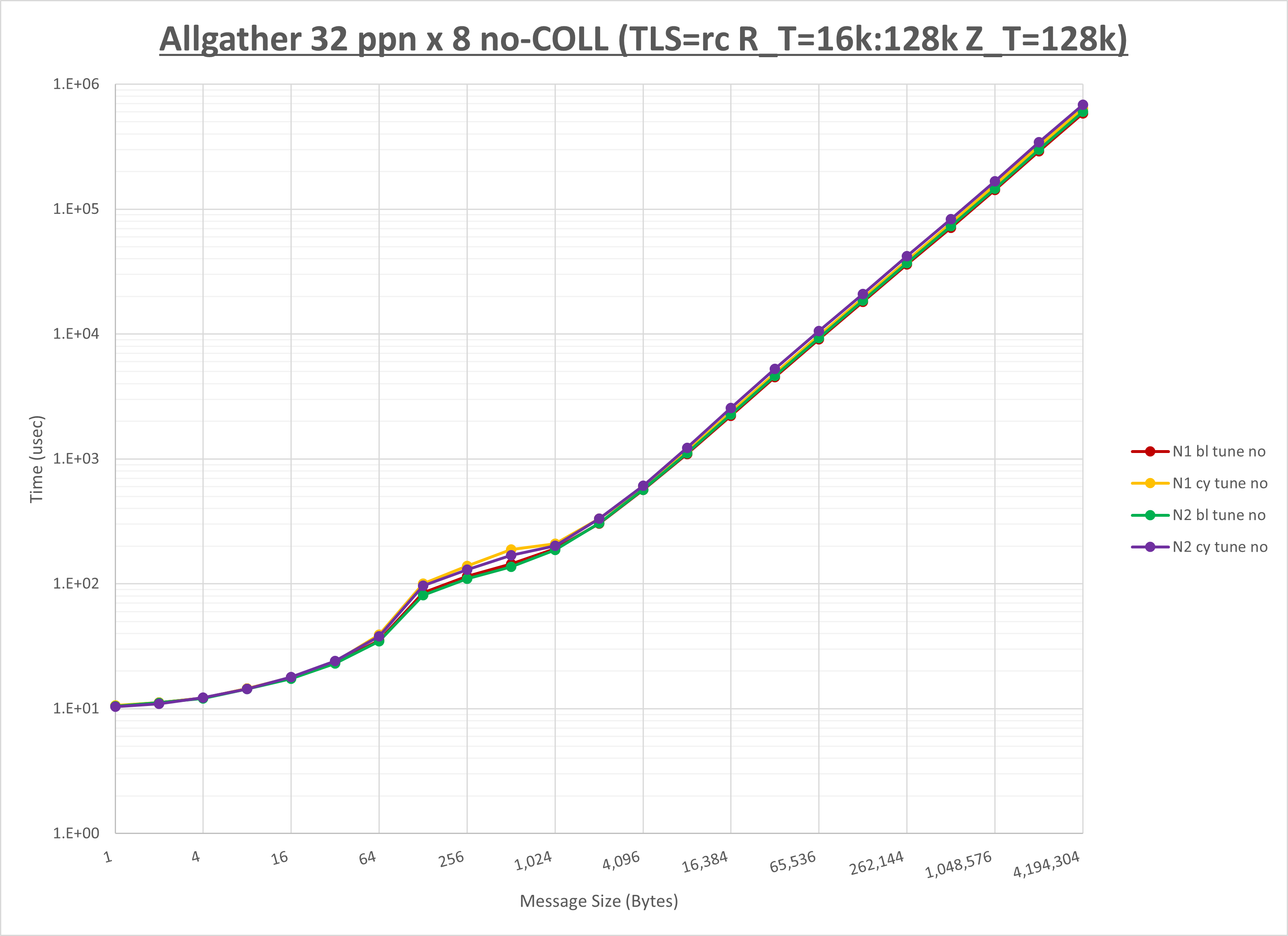
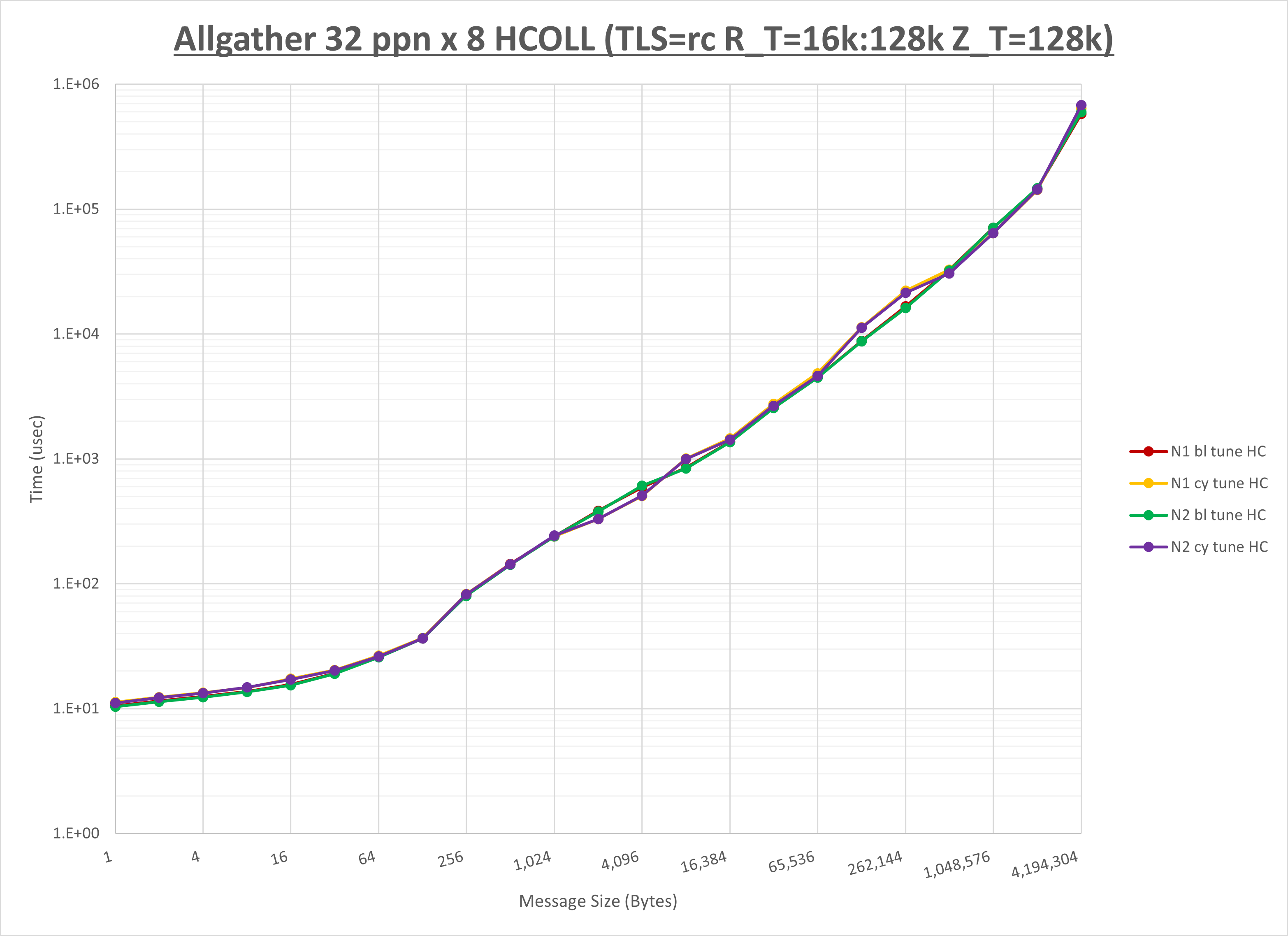
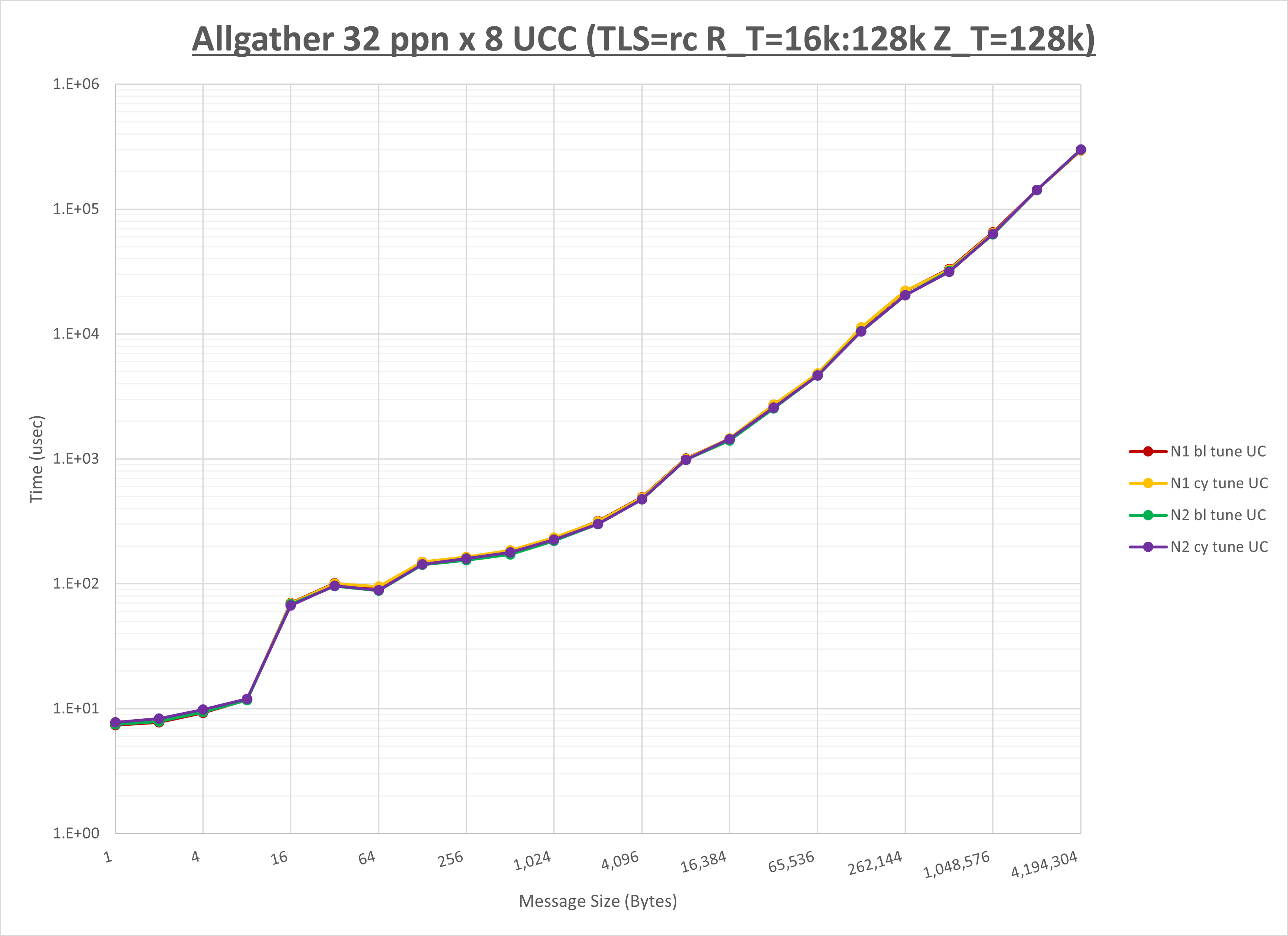
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
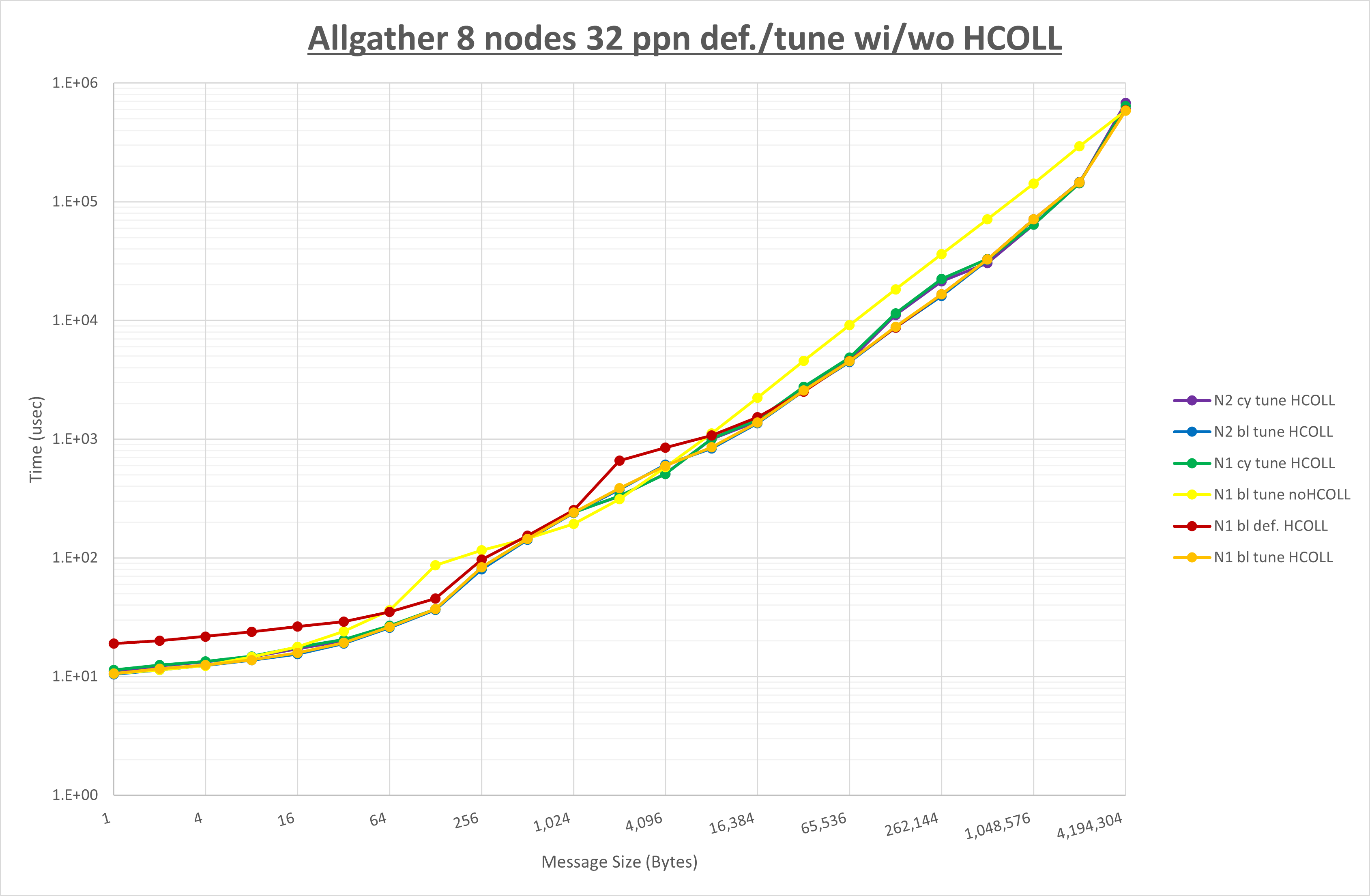
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し1KB以上で性能が向上し16Bから256Bで性能が低下
- チューニング適用で16KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-3 Allreduce の HCOLL の結果から128KBとしています。
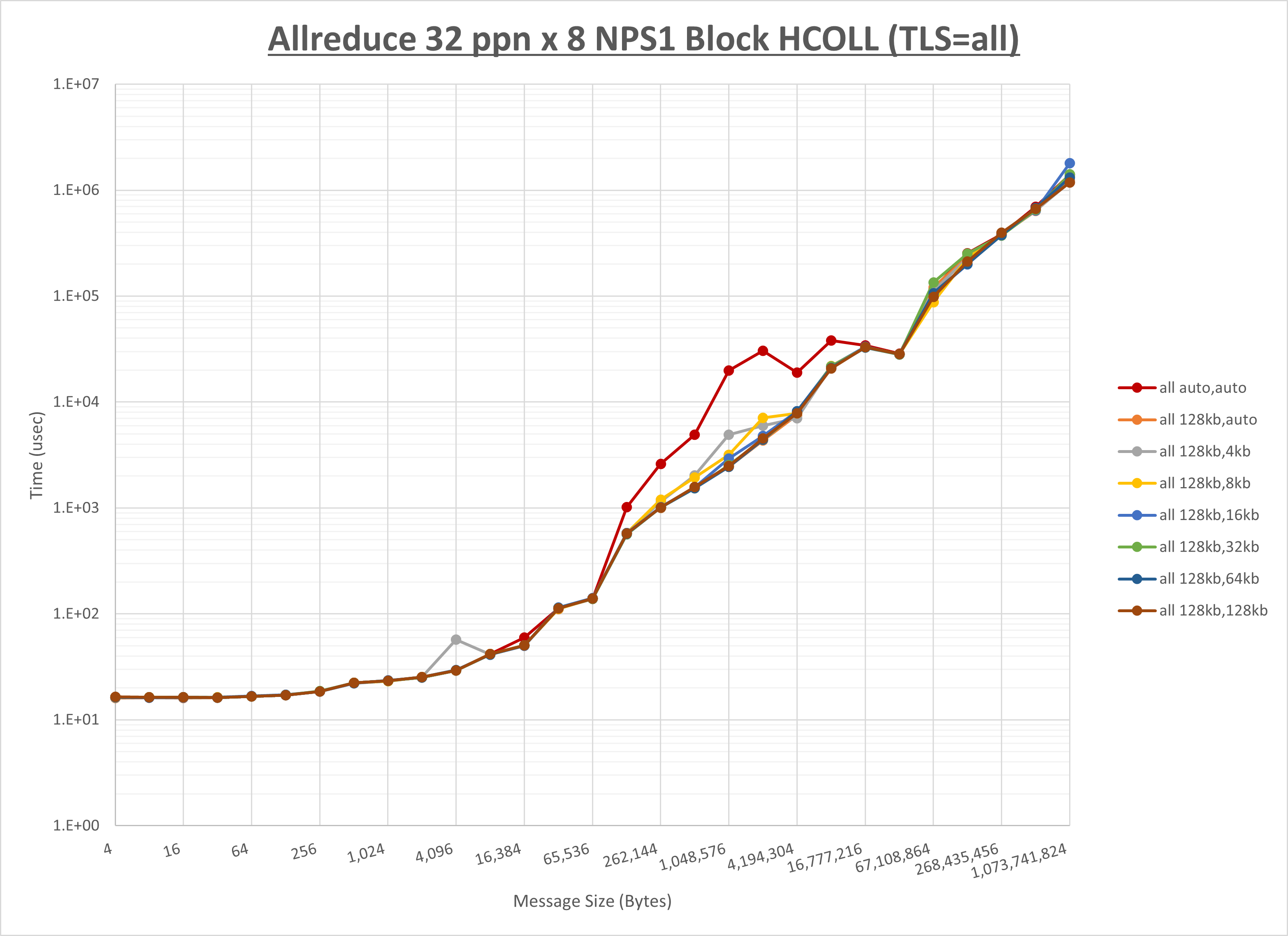
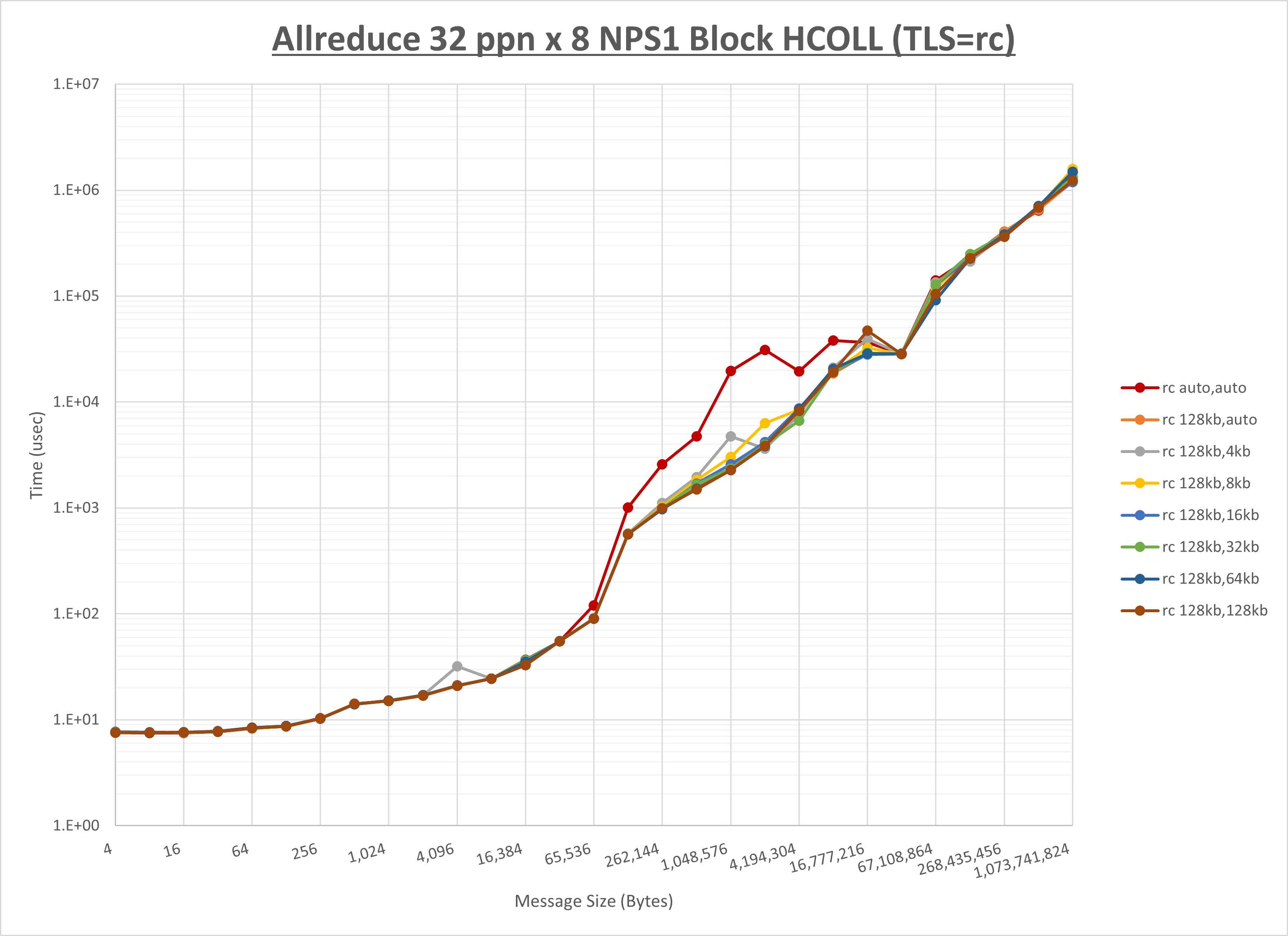
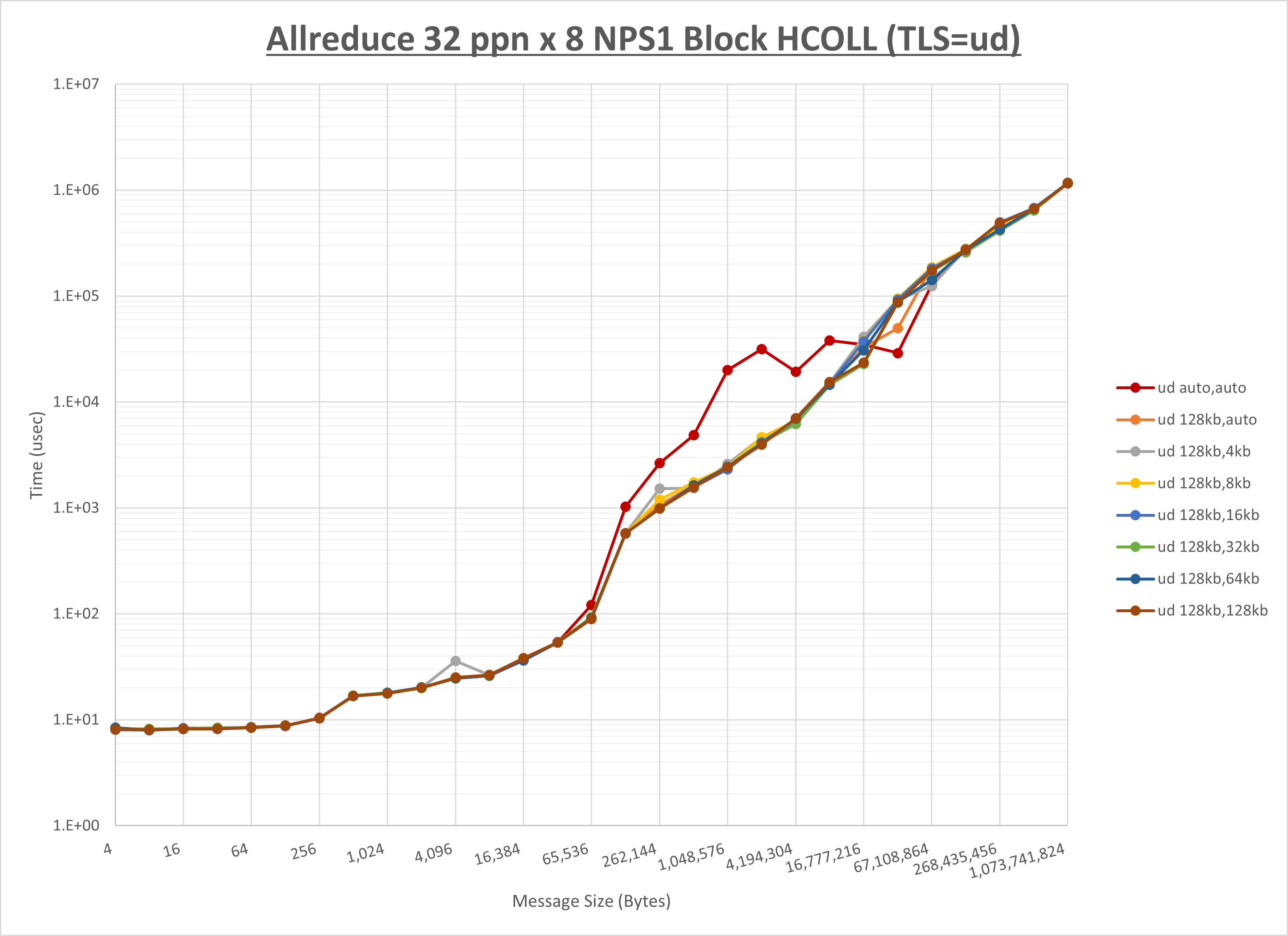
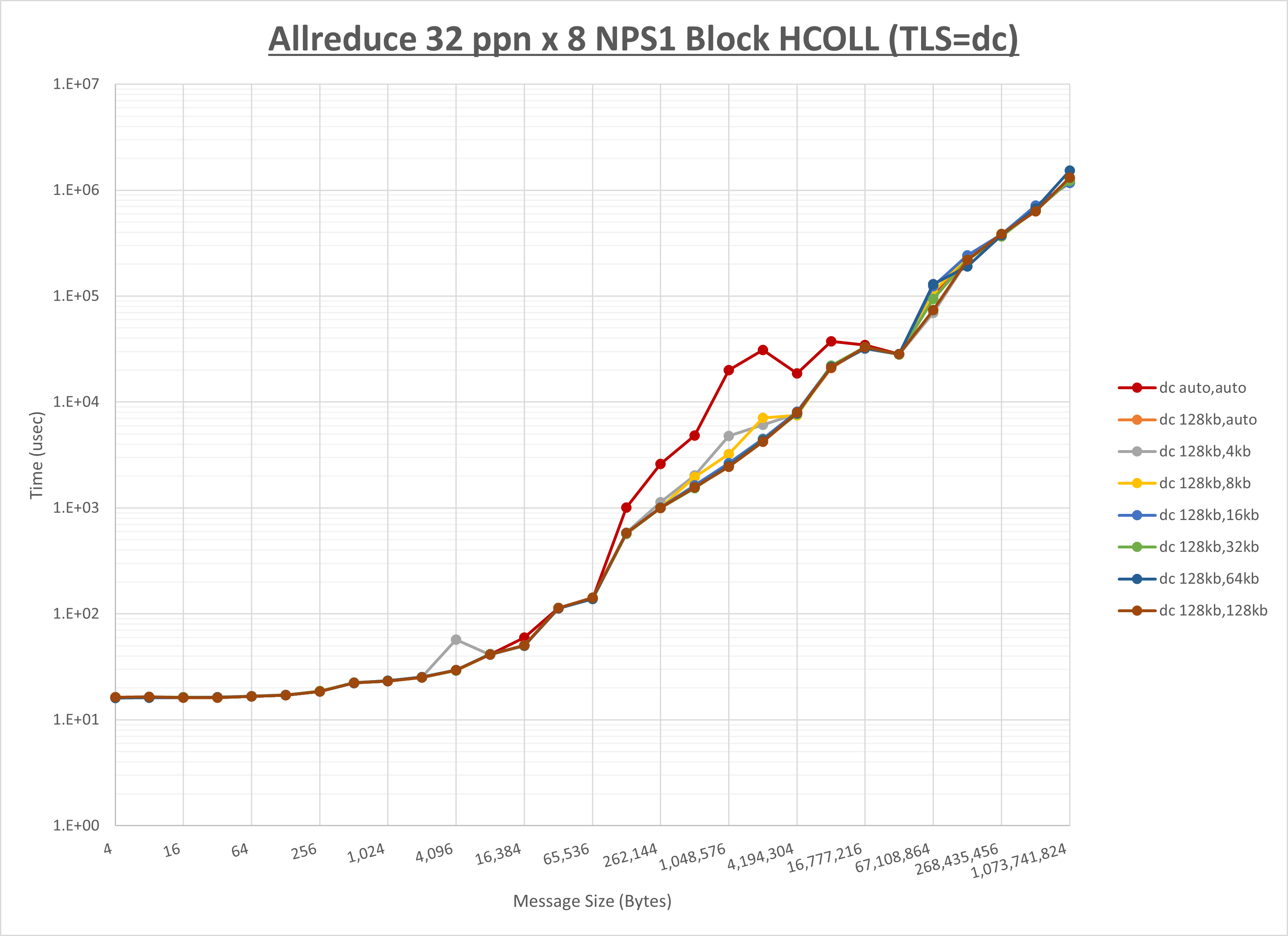
以上より、 UCX_RNDV_THRESH を intra:128kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
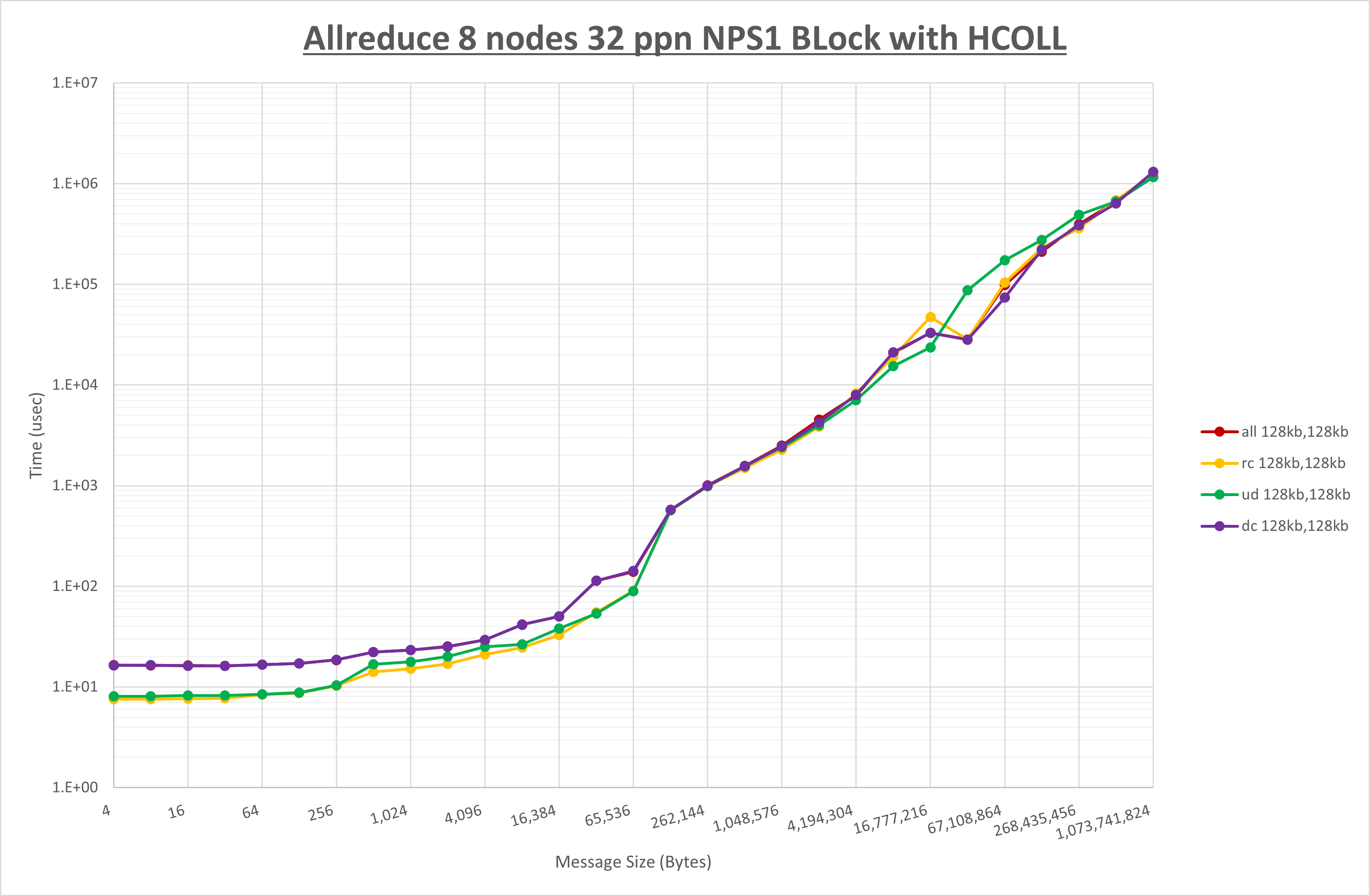
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
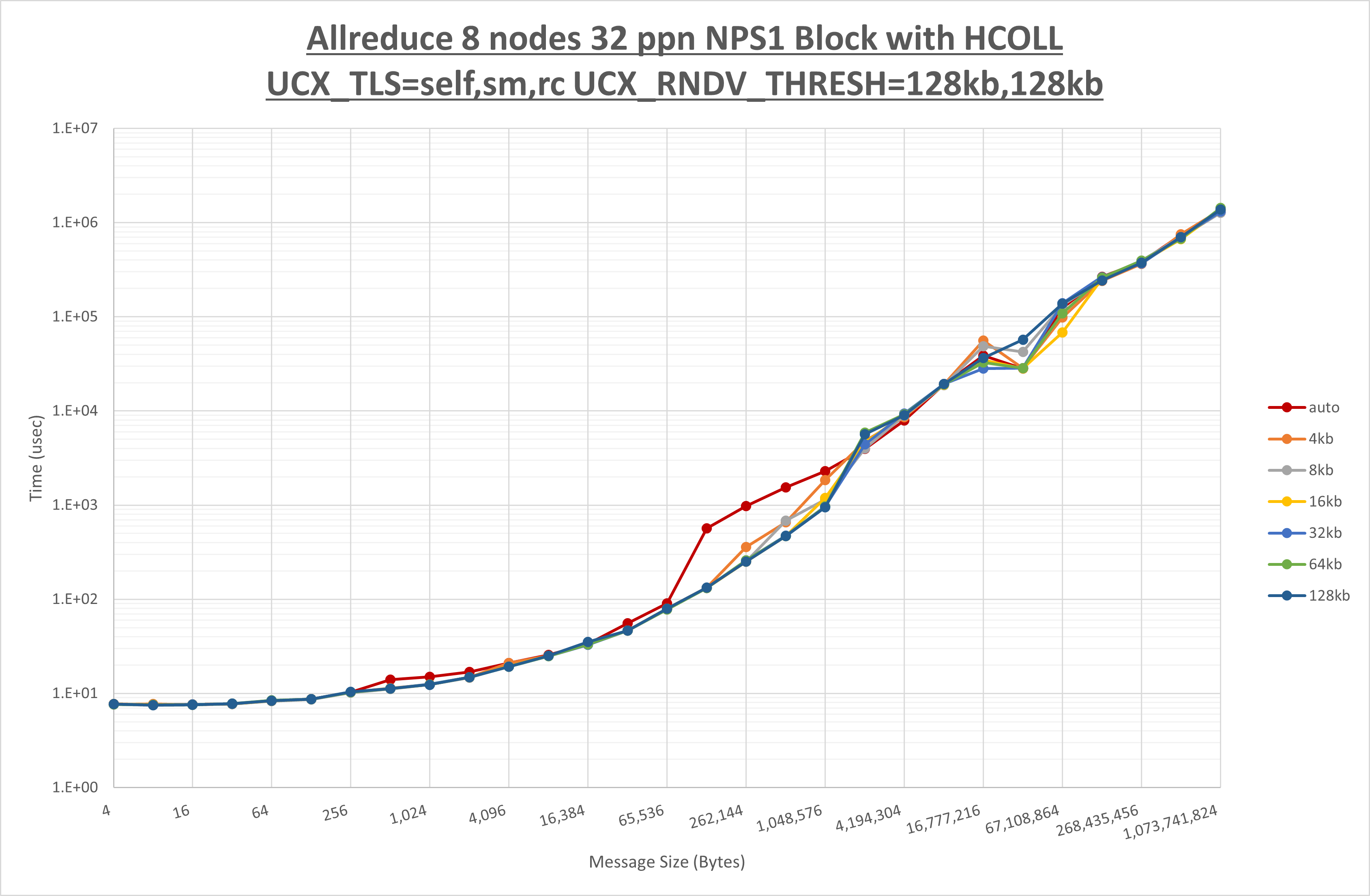
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
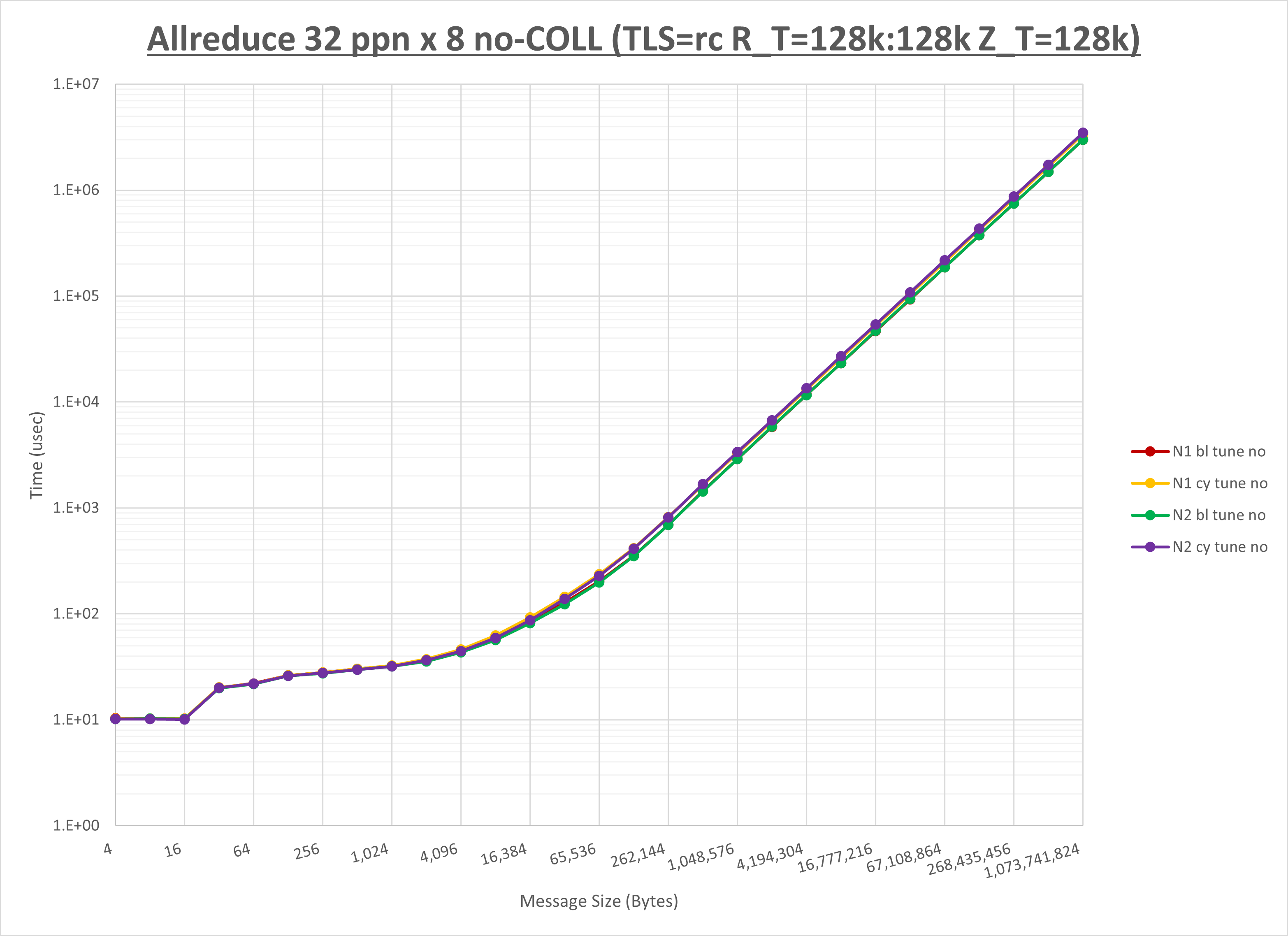
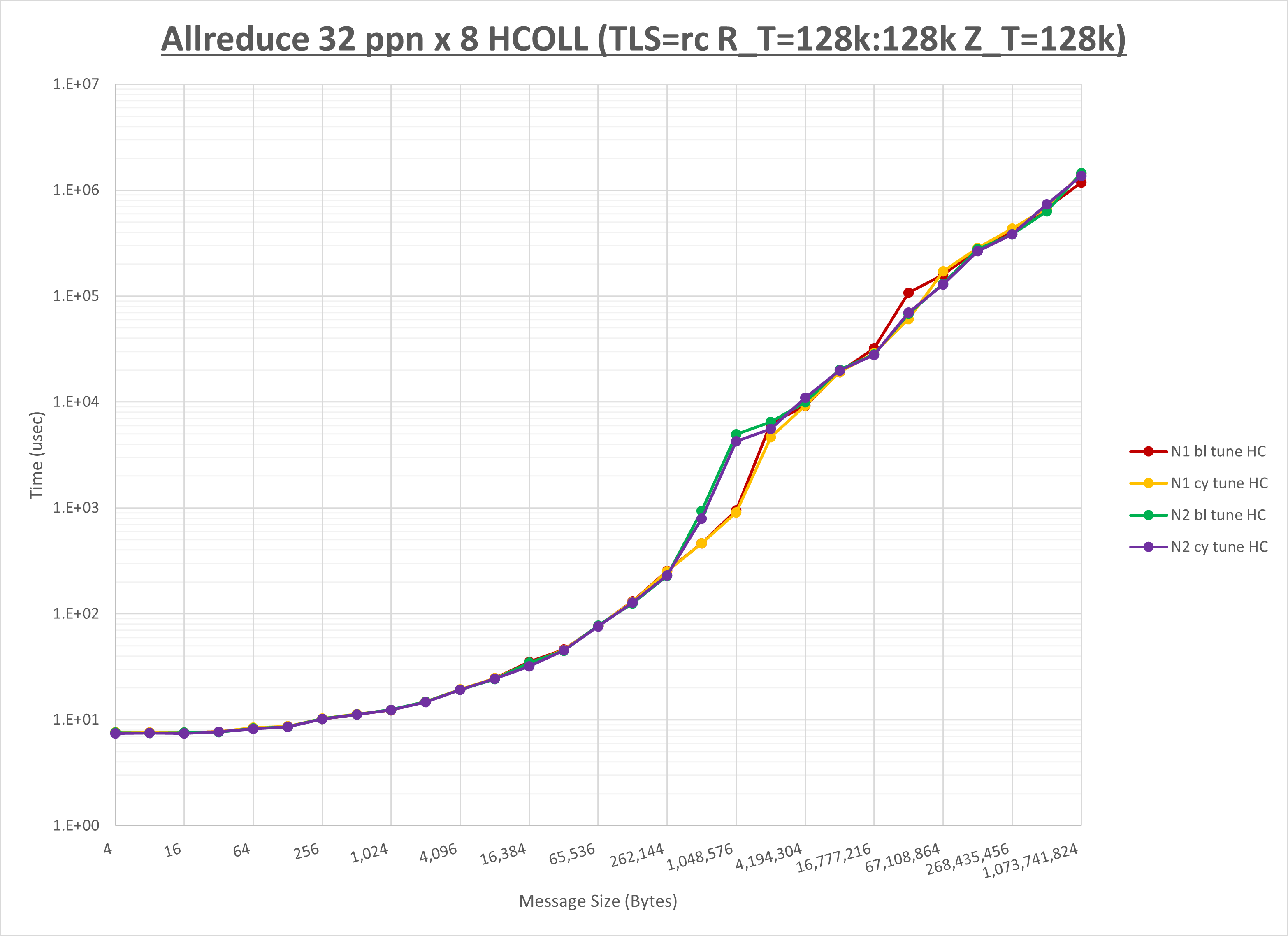
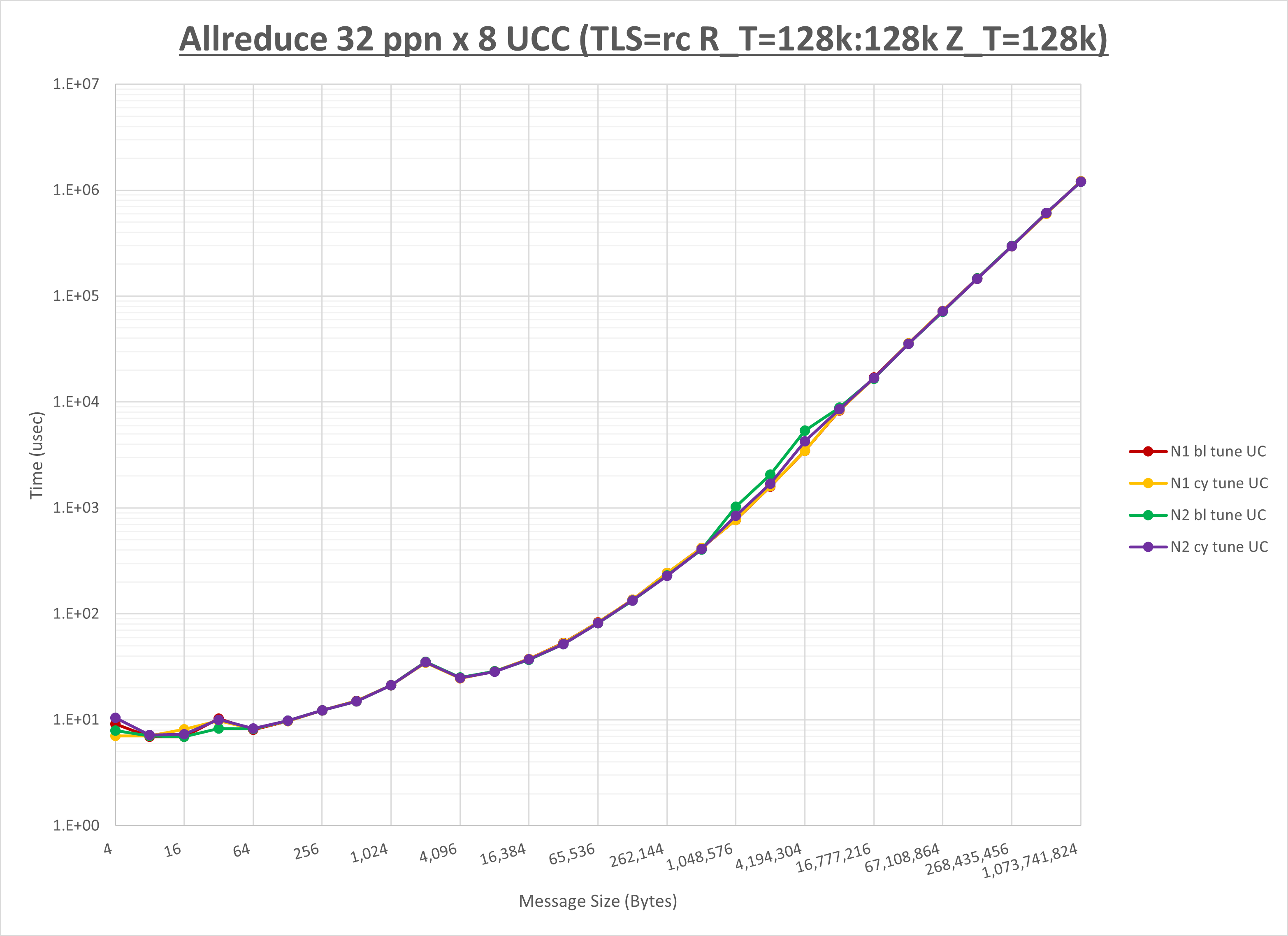
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
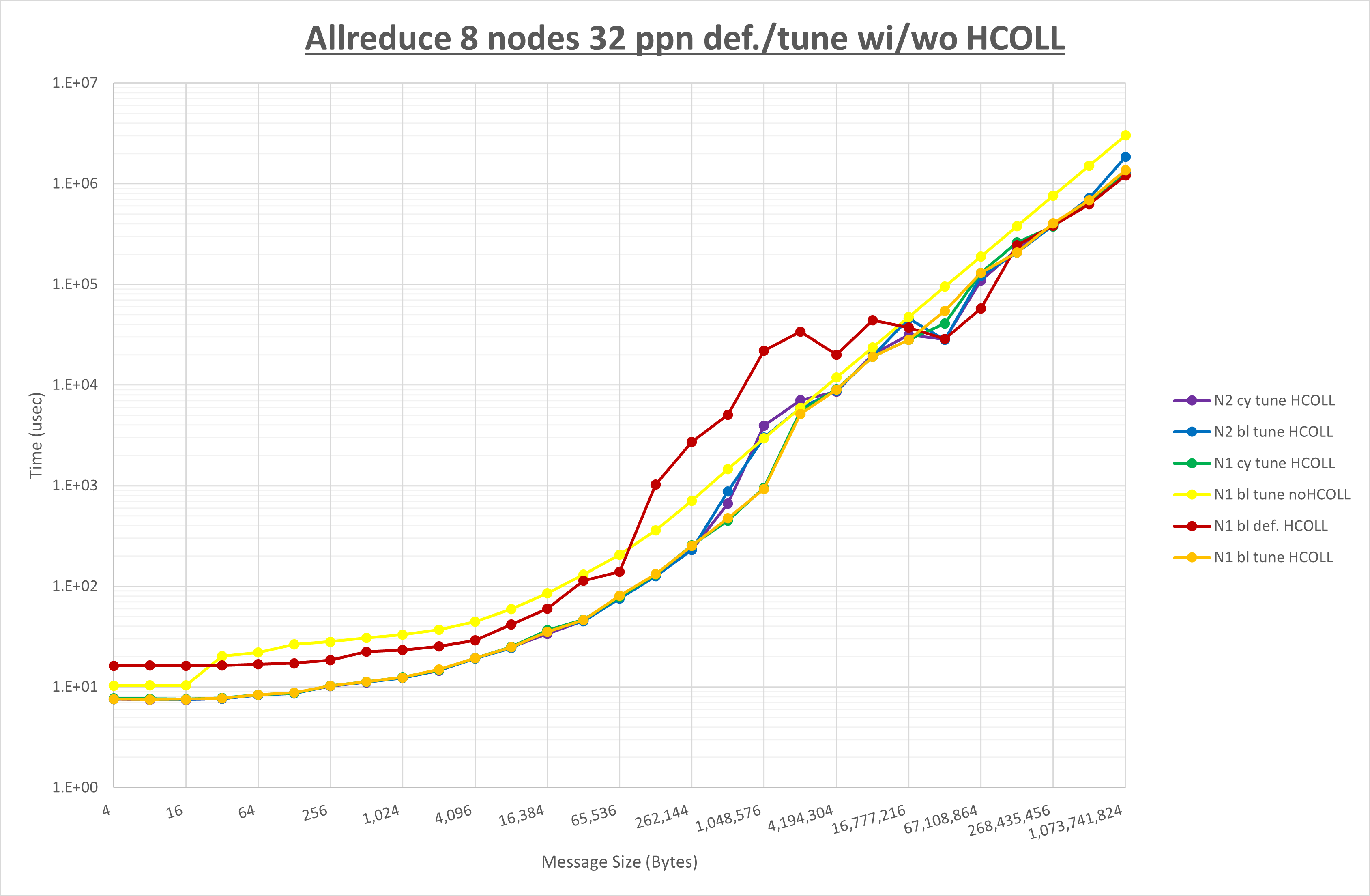
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し概ね全域で性能が向上
- UCC は no-COLL と比較し全域で性能が向上
- チューニング適用で256KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-3-4 Exchange の結果から16KBとしています。
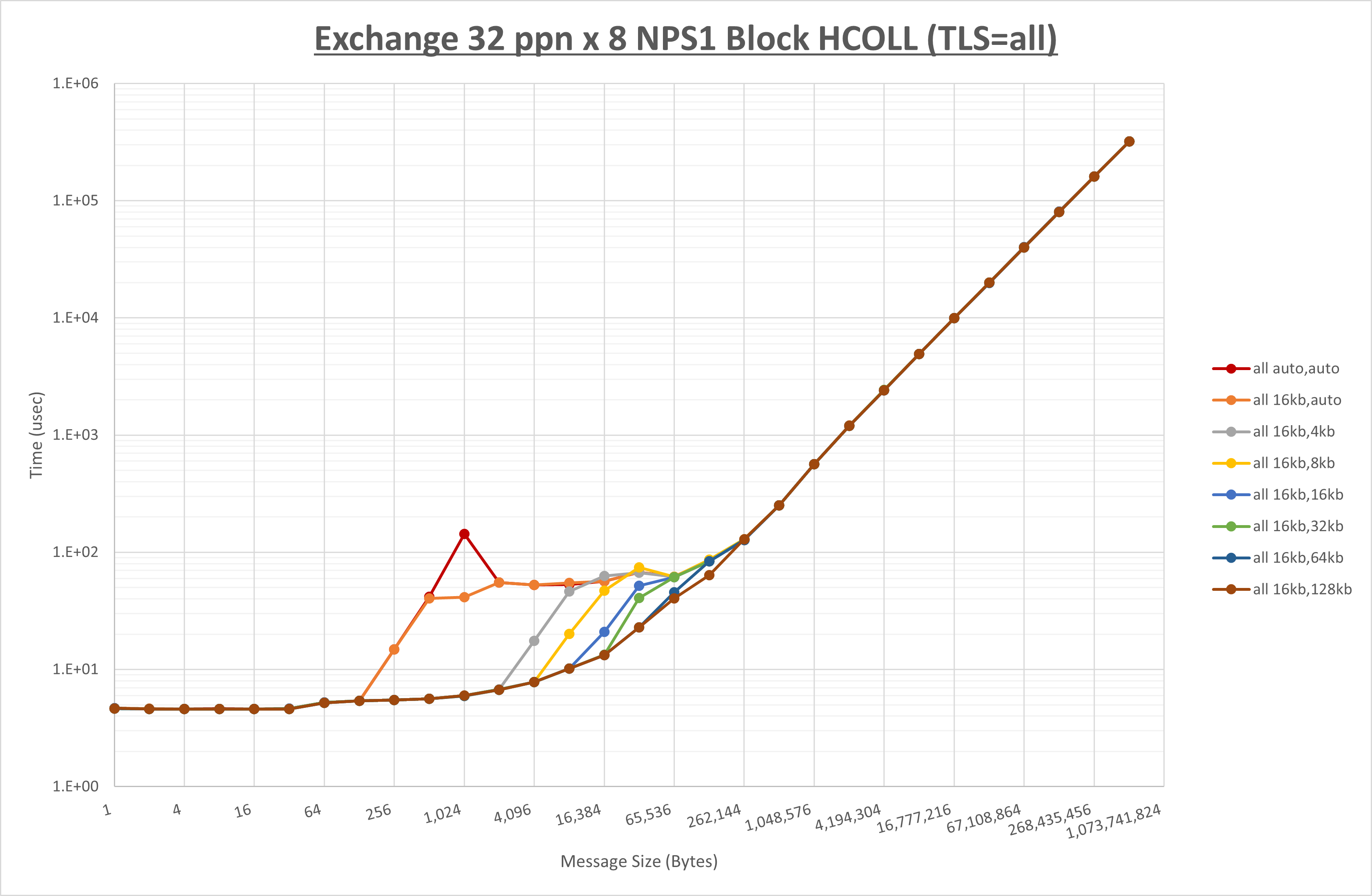
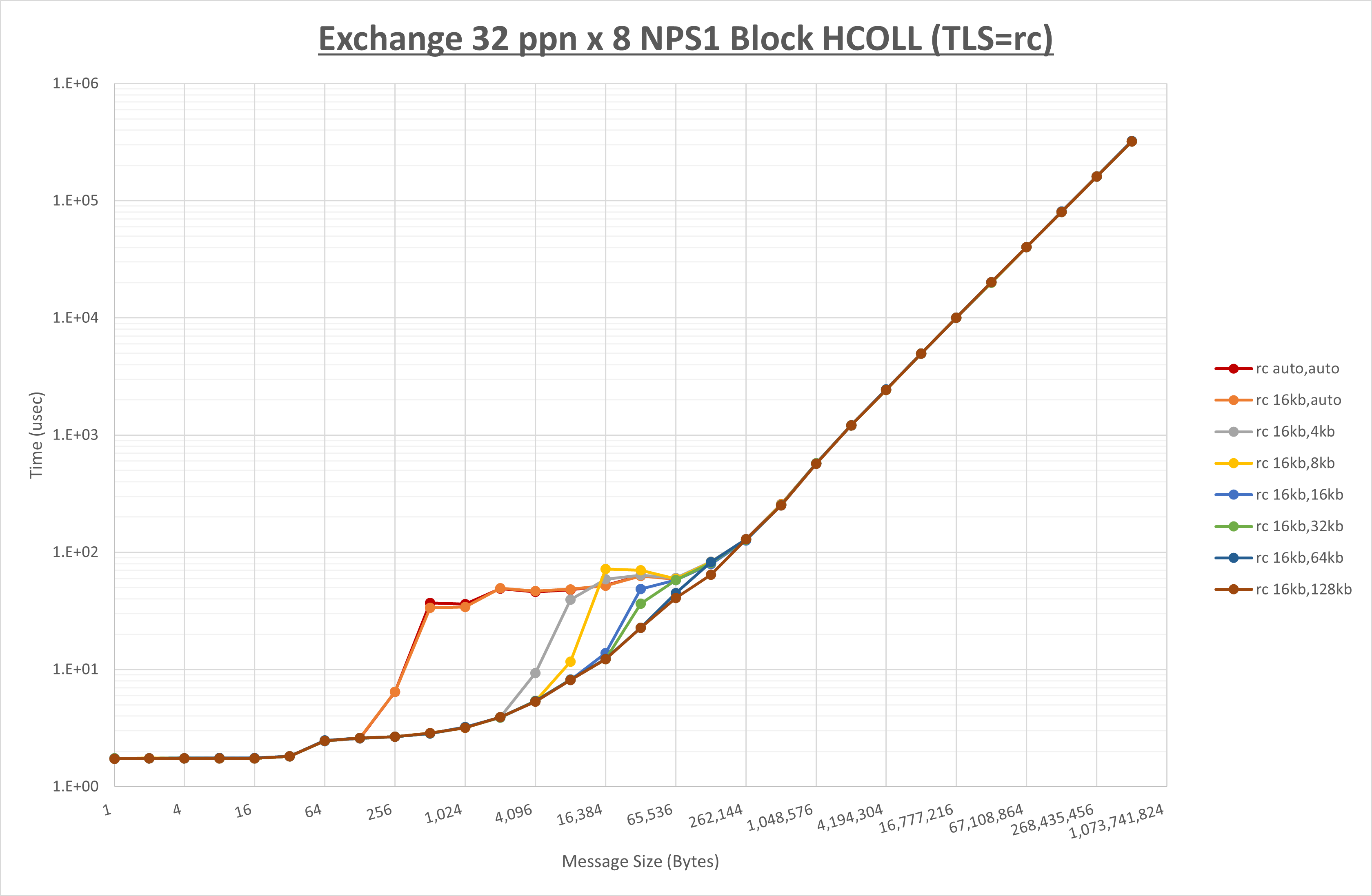
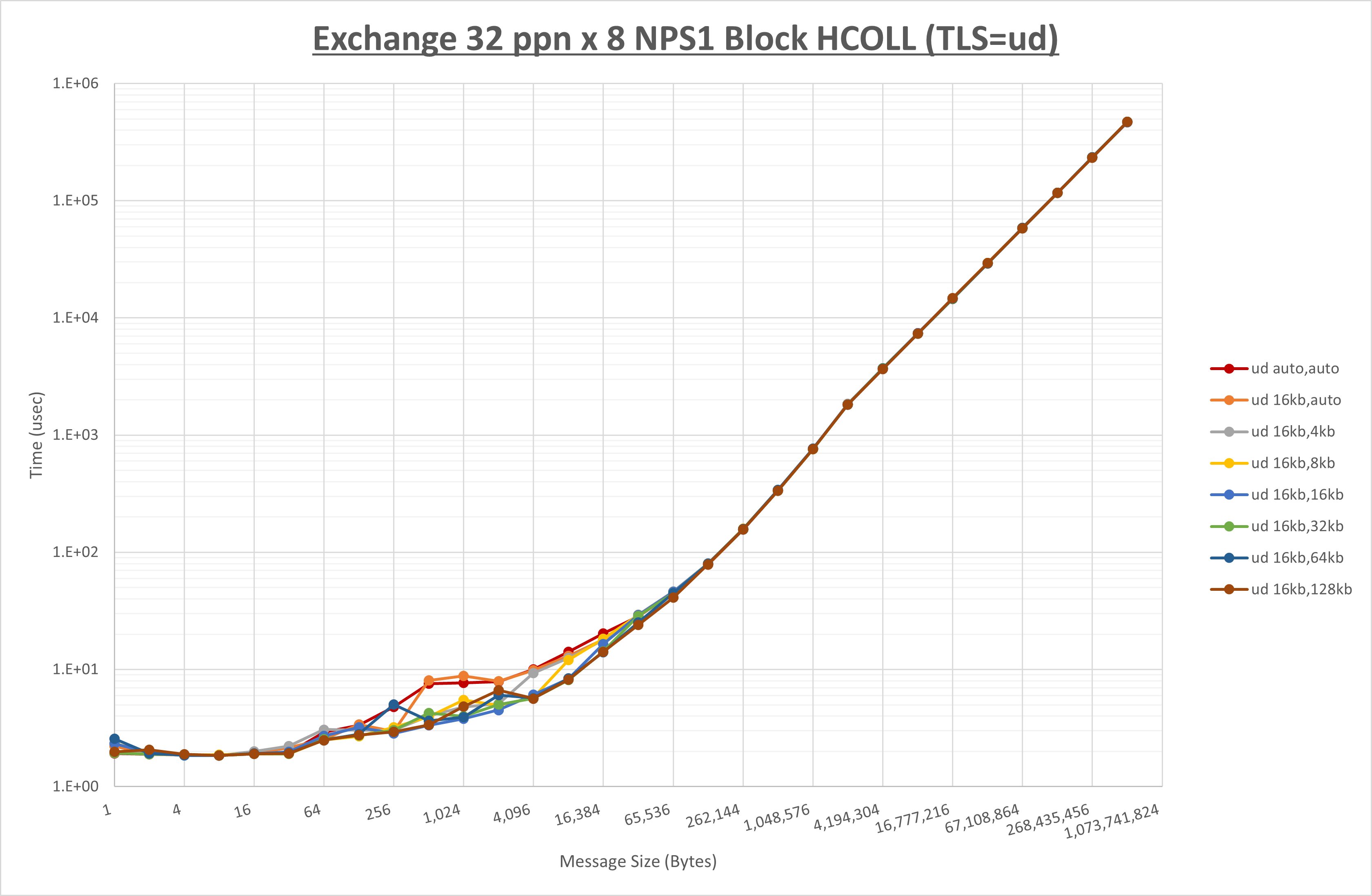
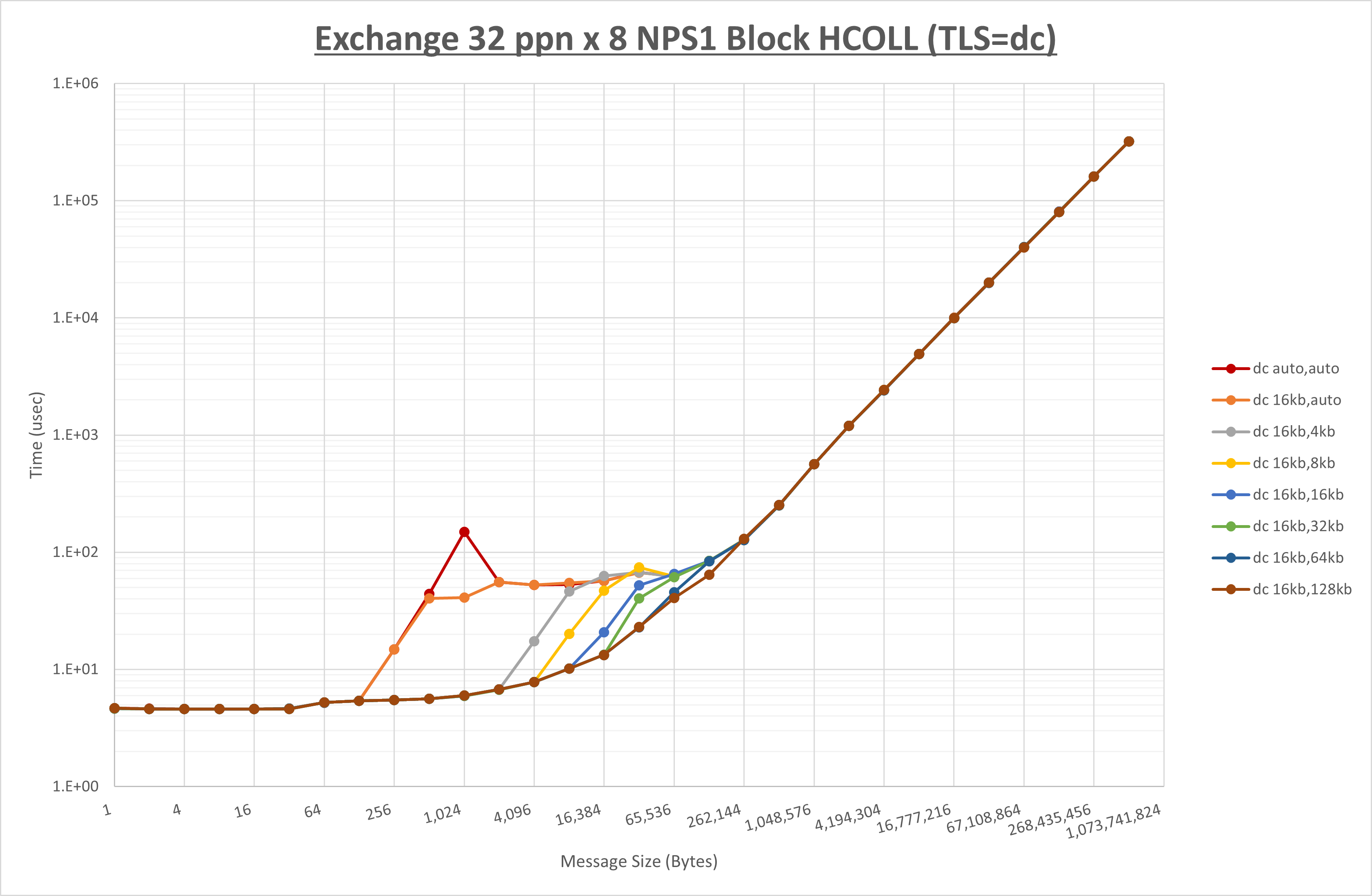
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
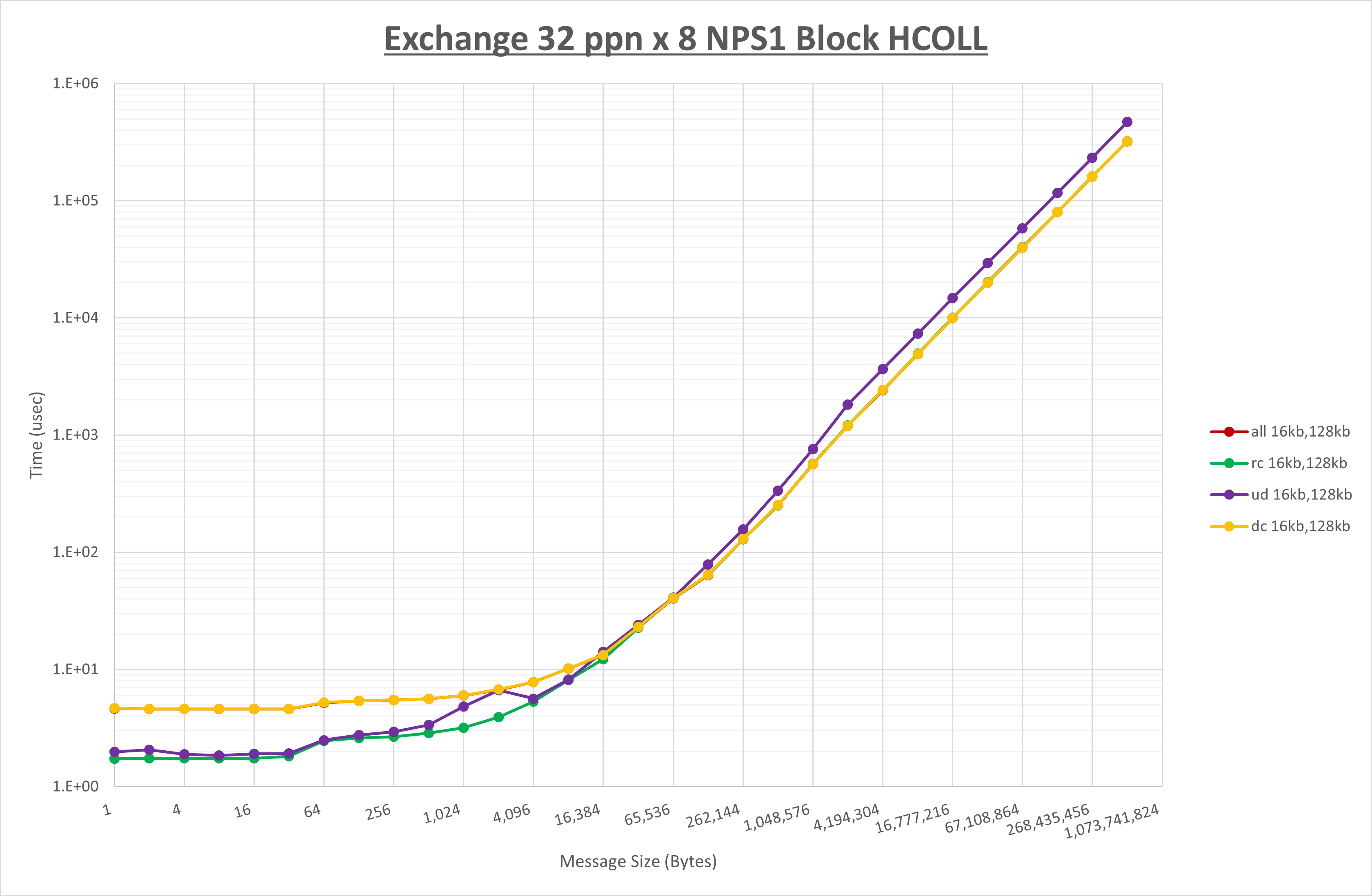
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上
本章は、8ノードにノード当たり36、トータル288のMPIプロセスを割当てる場合の 実行時パラメータ の最適な組み合わせを検証します。
下表は、各MPI集合通信関数の最適な UCX_TLS 、 UCX_RNDV_THRESH 、及び UCX_ZCOPY_THRESH を示しており、この設定値を使用することでデフォルト値に対して性能が向上します。
| MPI集合通信関数 | UCX_TLS | UCX_RNDV_THRESH | UCX_ZCOPY_THRESH |
|---|---|---|---|
| Alltoall | self,sm,ud | intra:16kb,inter:16kb | 128kb |
| Allgather | self,sm,rc | intra:16kb,inter:128kb | auto |
| Allreduce | self,sm,rc | intra:64kb,inter:128kb | 128kb |
| Exchange | self,sm,rc | intra:16kb,inter:128kb | 128kb |
HCOLL / UCC / MPIプロセス分割方法 / NPS に関する傾向は、各MPI集合関数のセクションを参照して下さい。
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Alltoall の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-1 Alltoall の HCOLL の結果から16KBとしています。
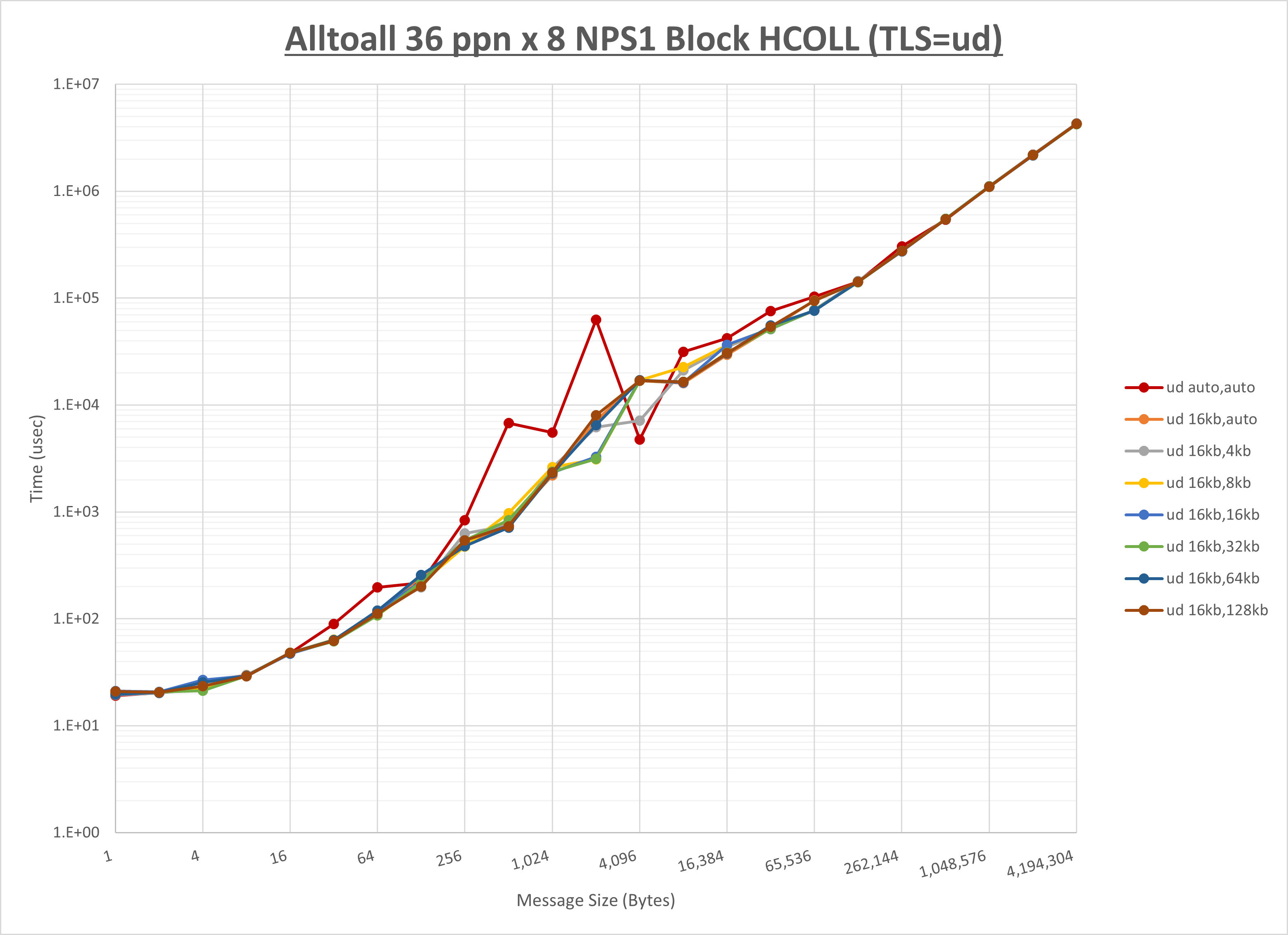
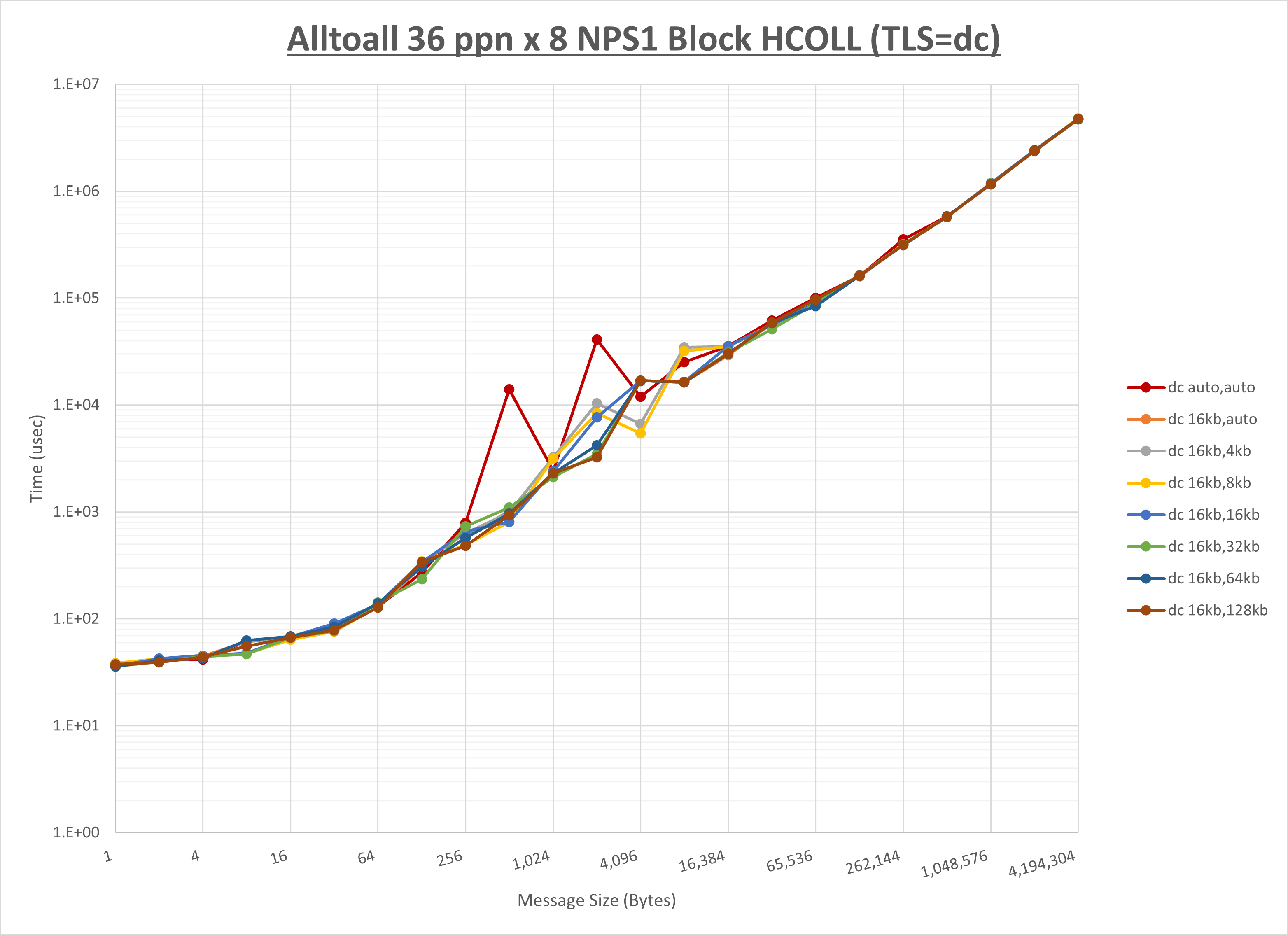
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:16kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
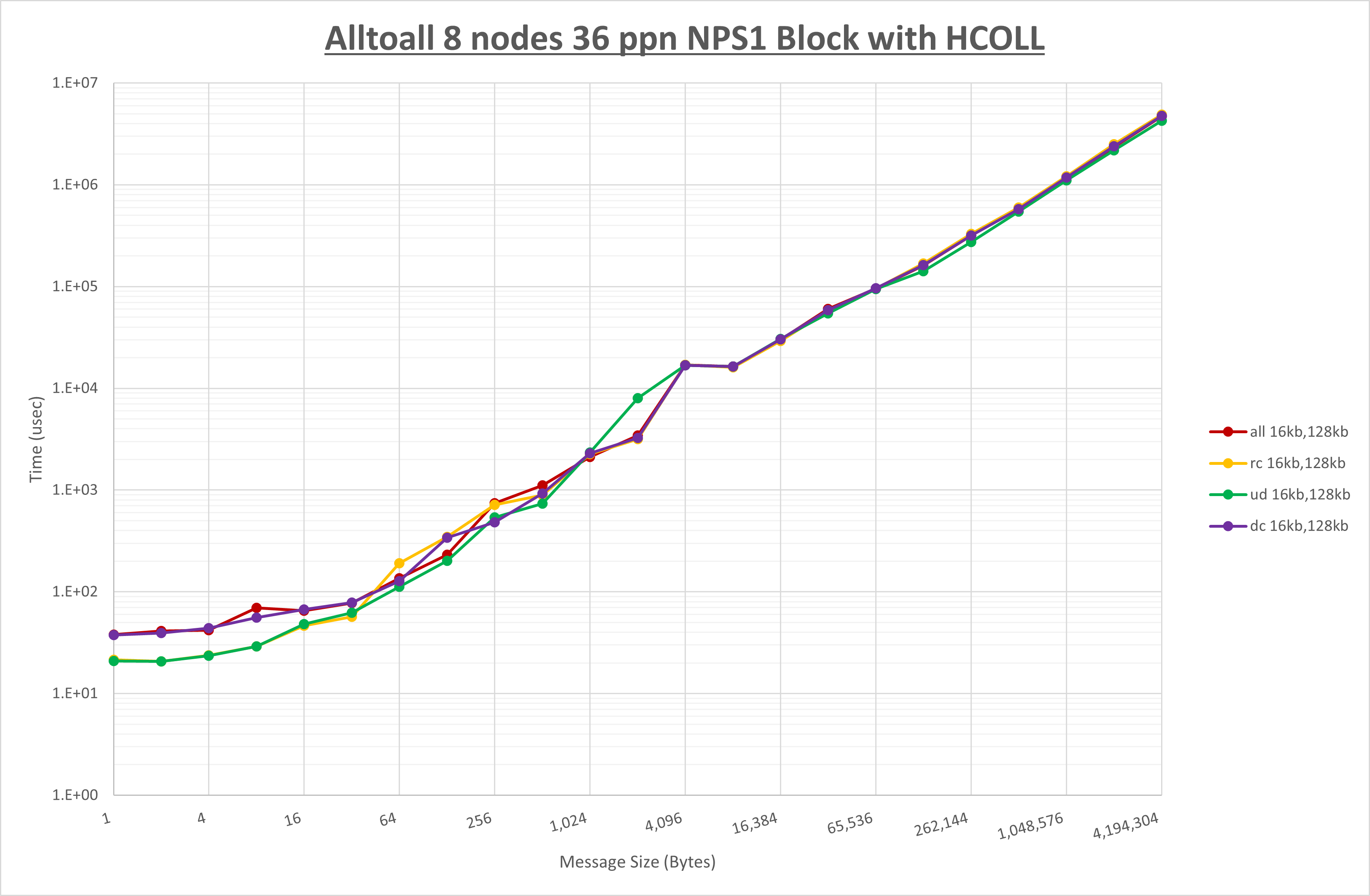
以上より、 UCX_TLS を self,sm,ud とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Alltoall の結果です。
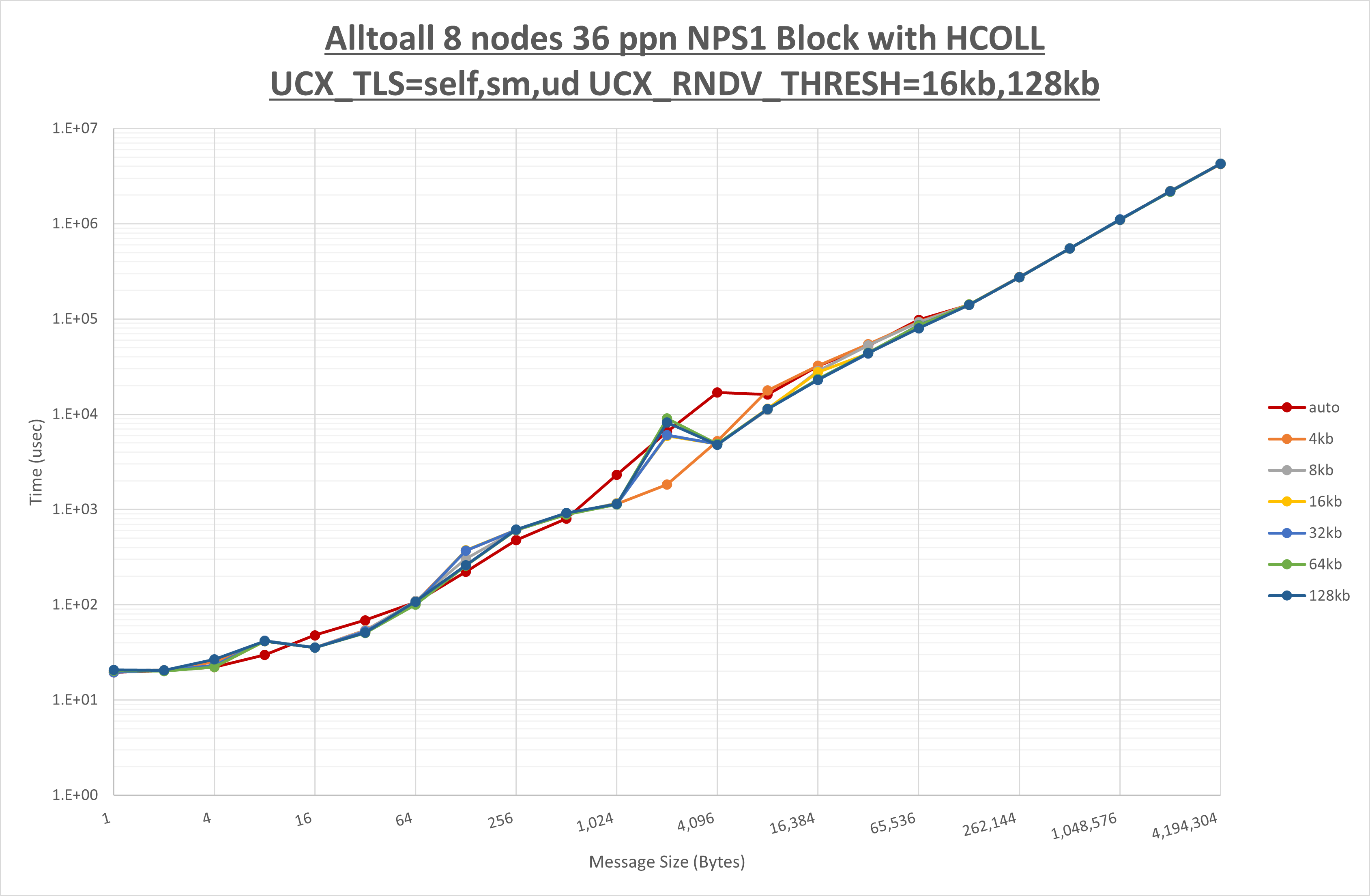
以上より、 UCX_ZCOPY_THRESH を 16kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
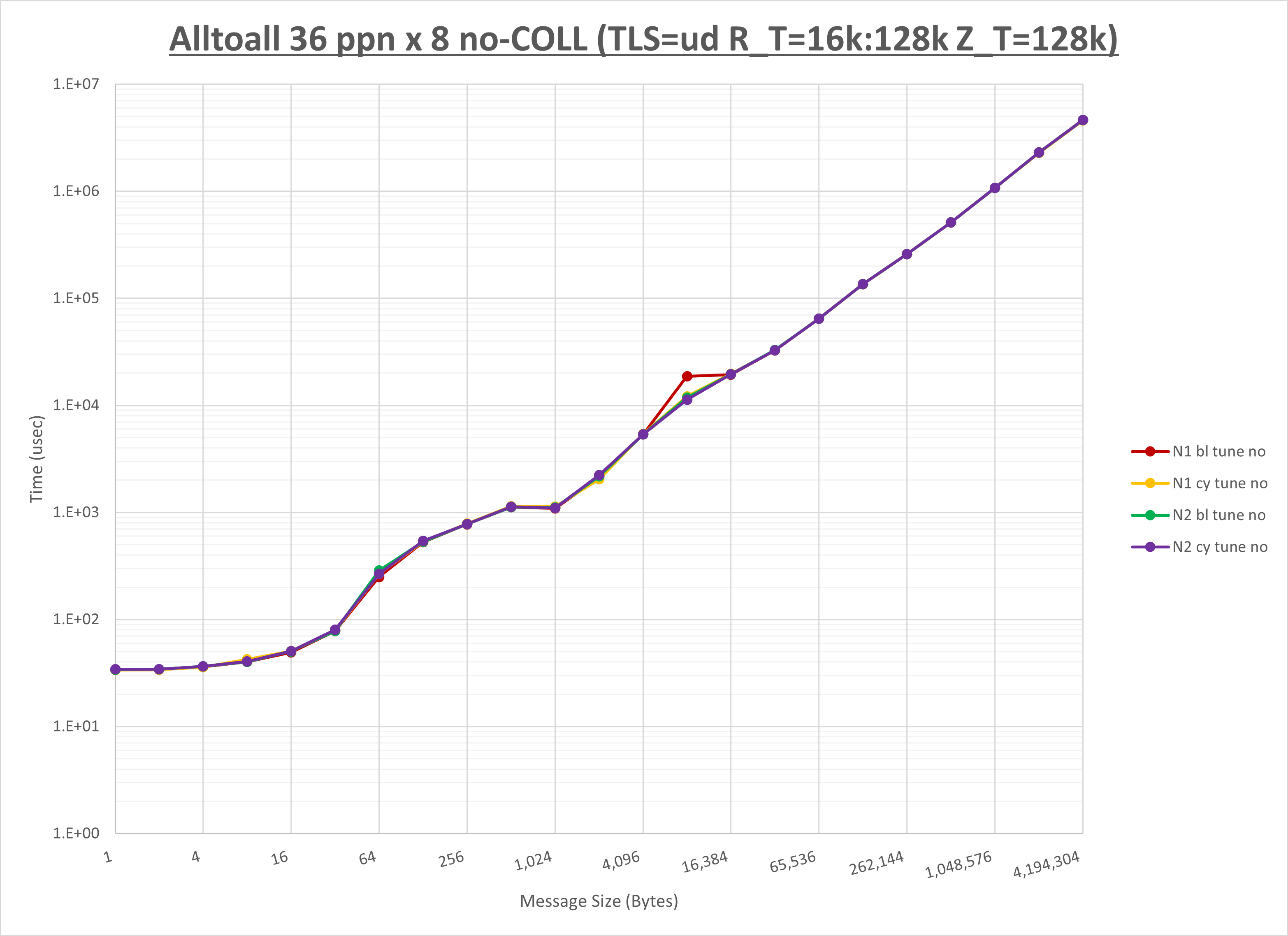
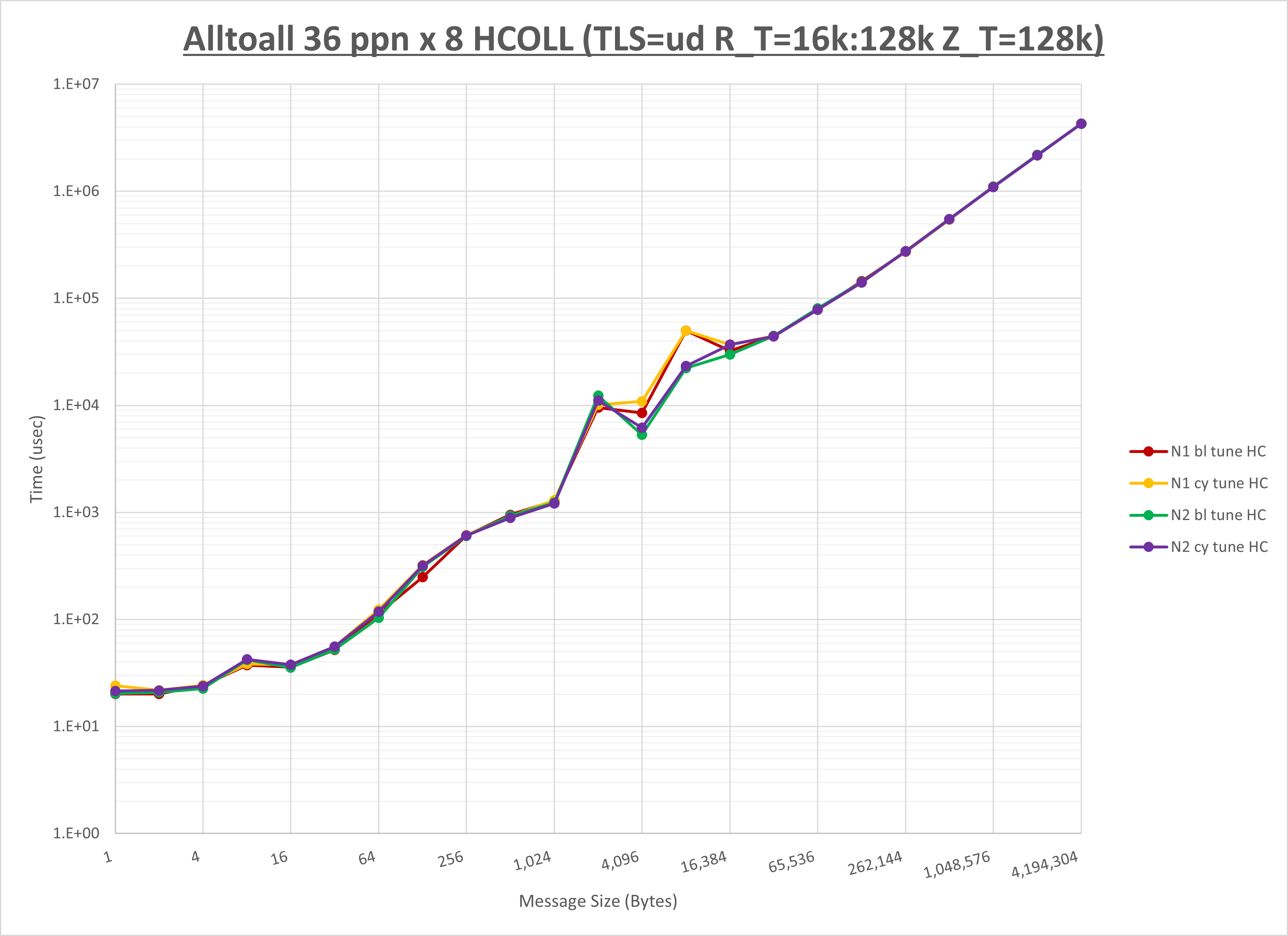
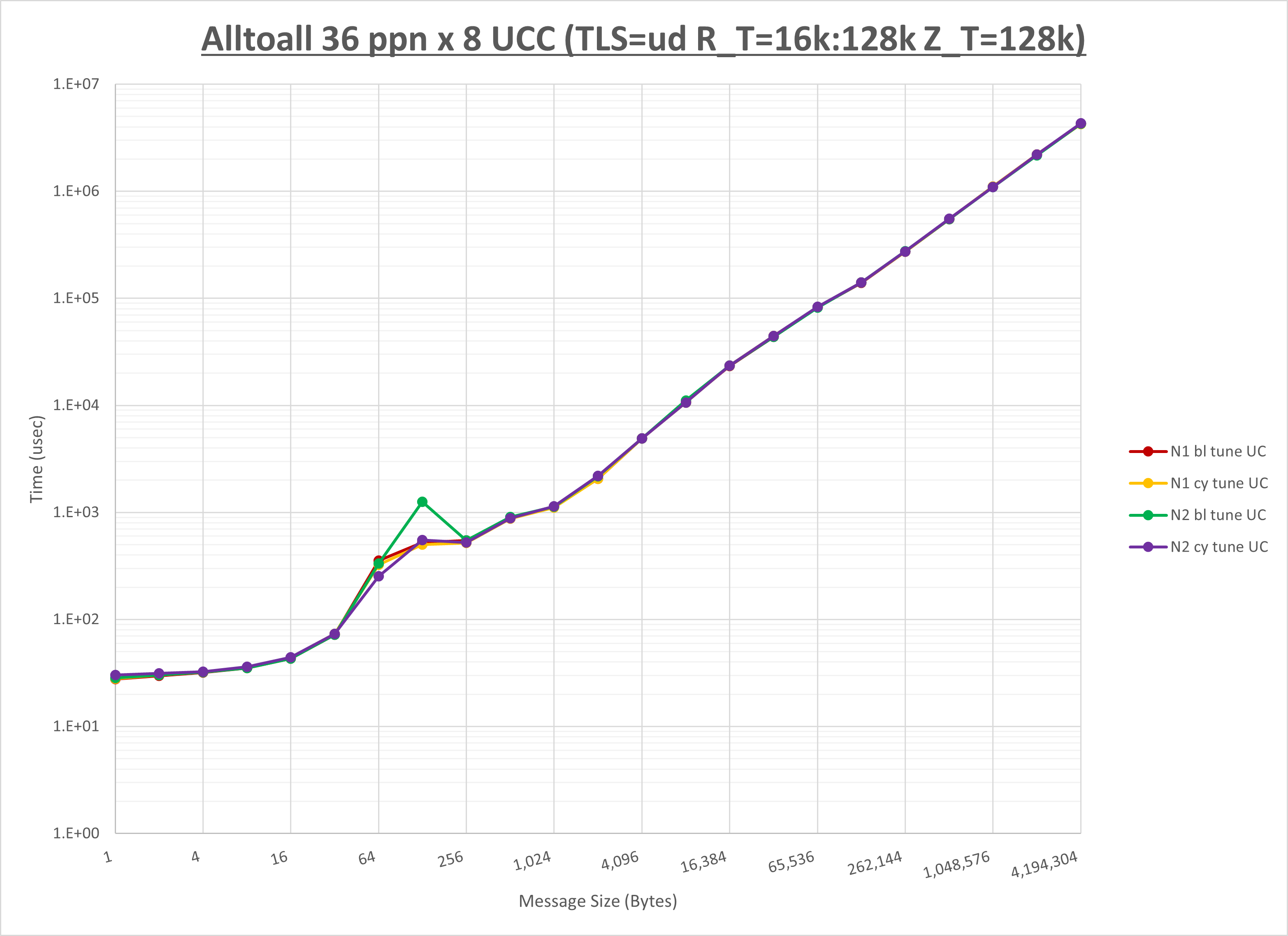
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | ブロック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
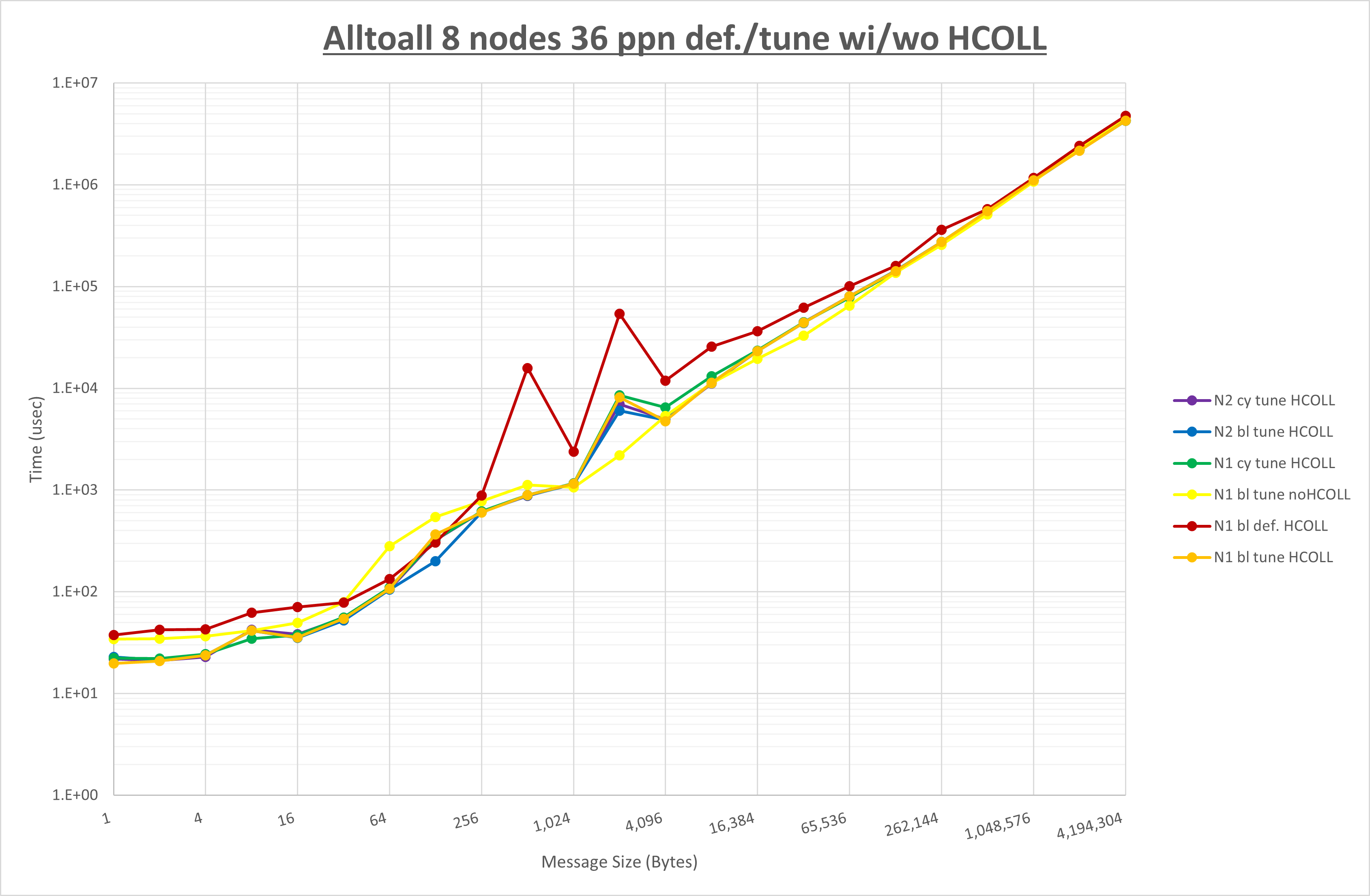
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し16KB以下で性能差が交錯
- UCC は no-COLL と比較し16KB以下で概ね性能
- チューニング適用で概ね全域で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allgather の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-2 Allgather の HCOLL の結果から16KBとしています。
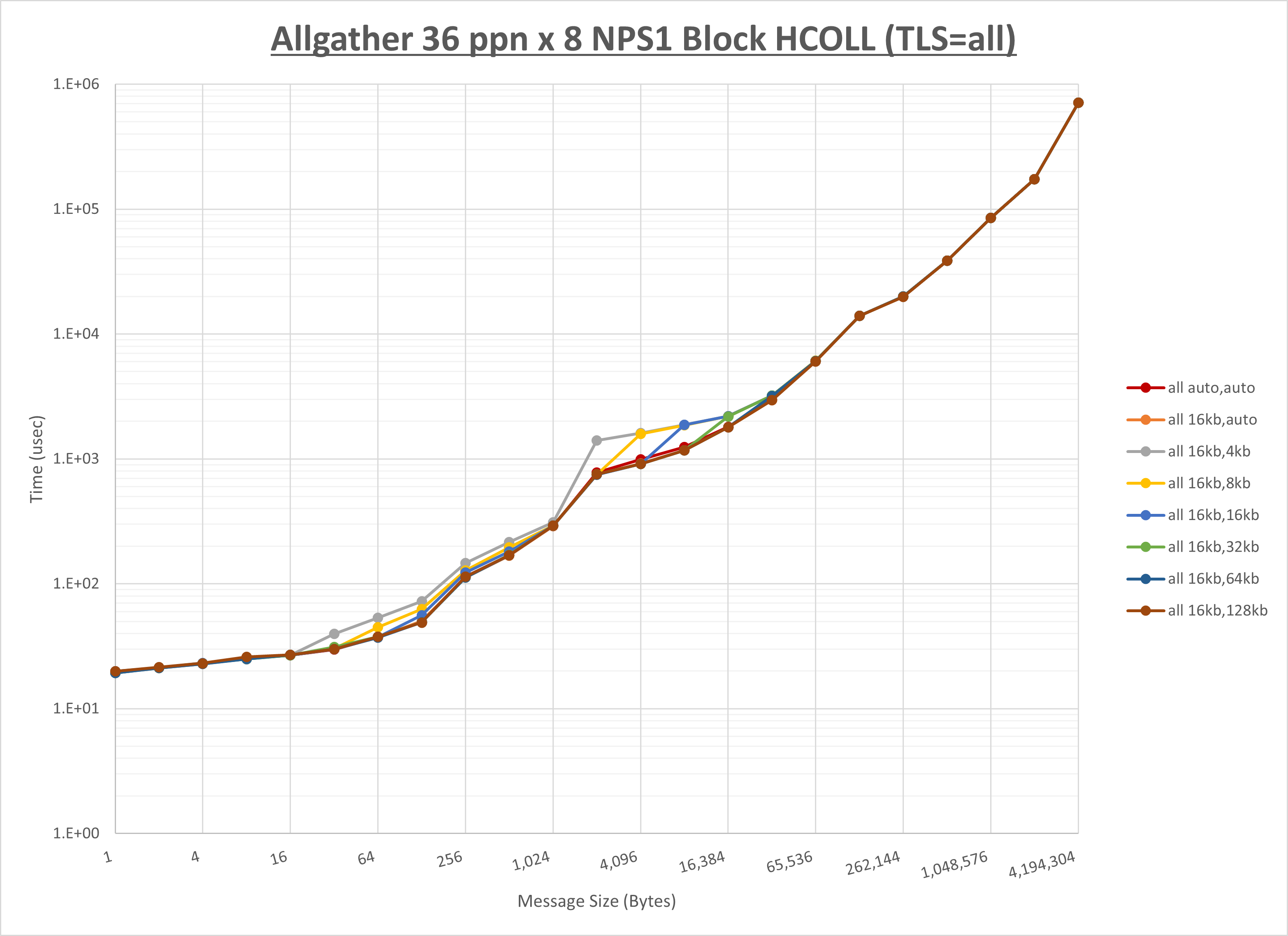
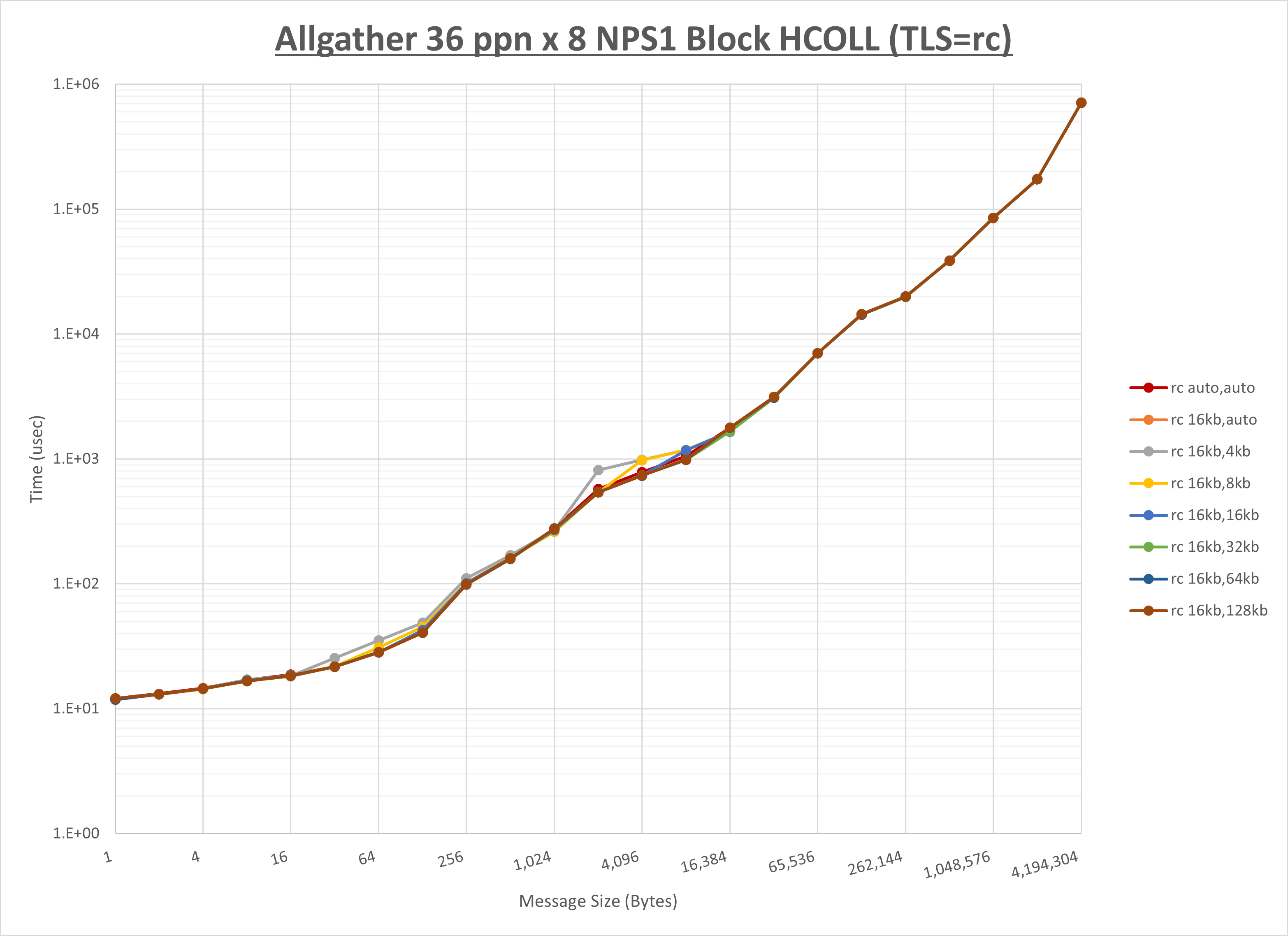
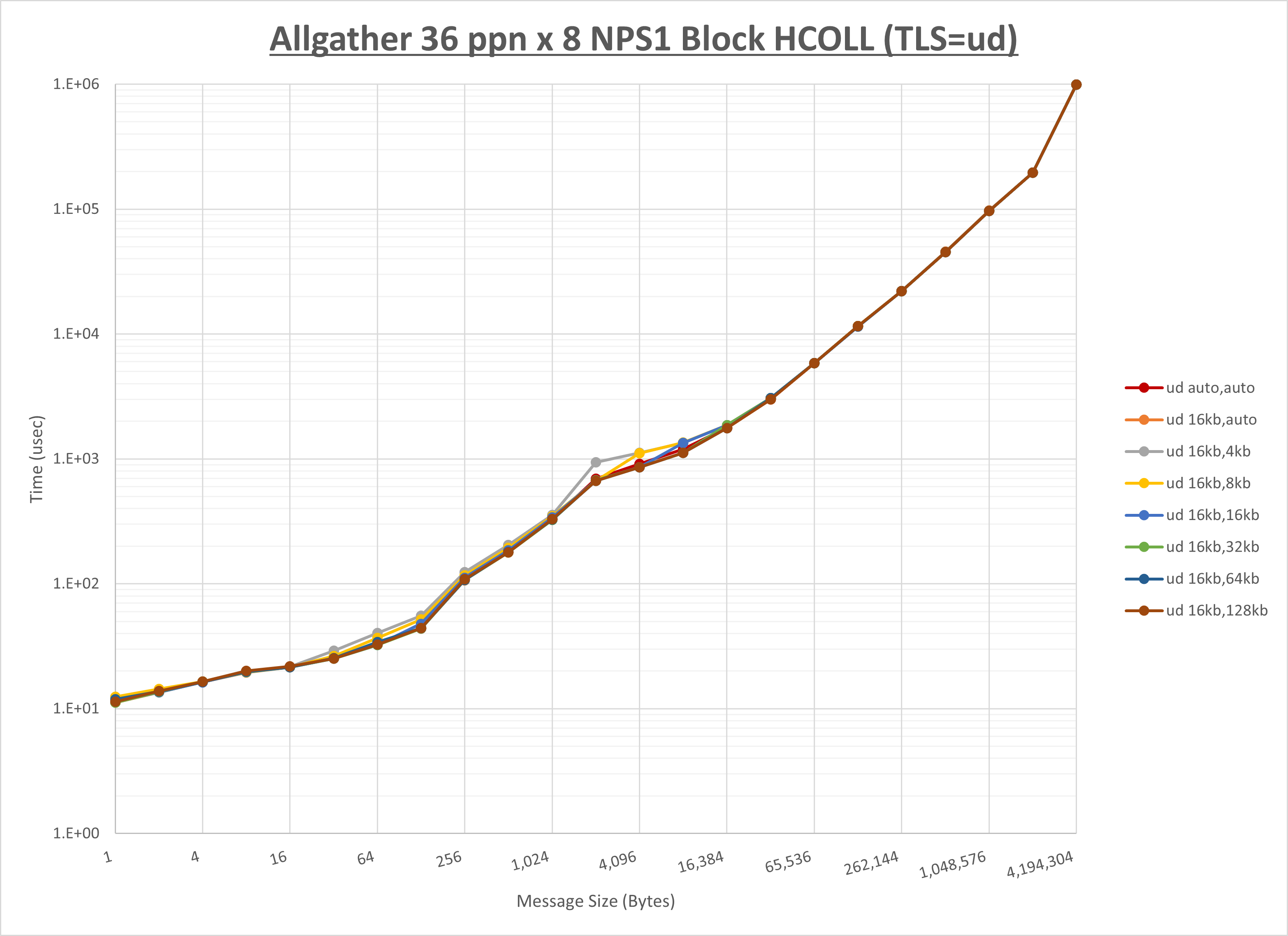
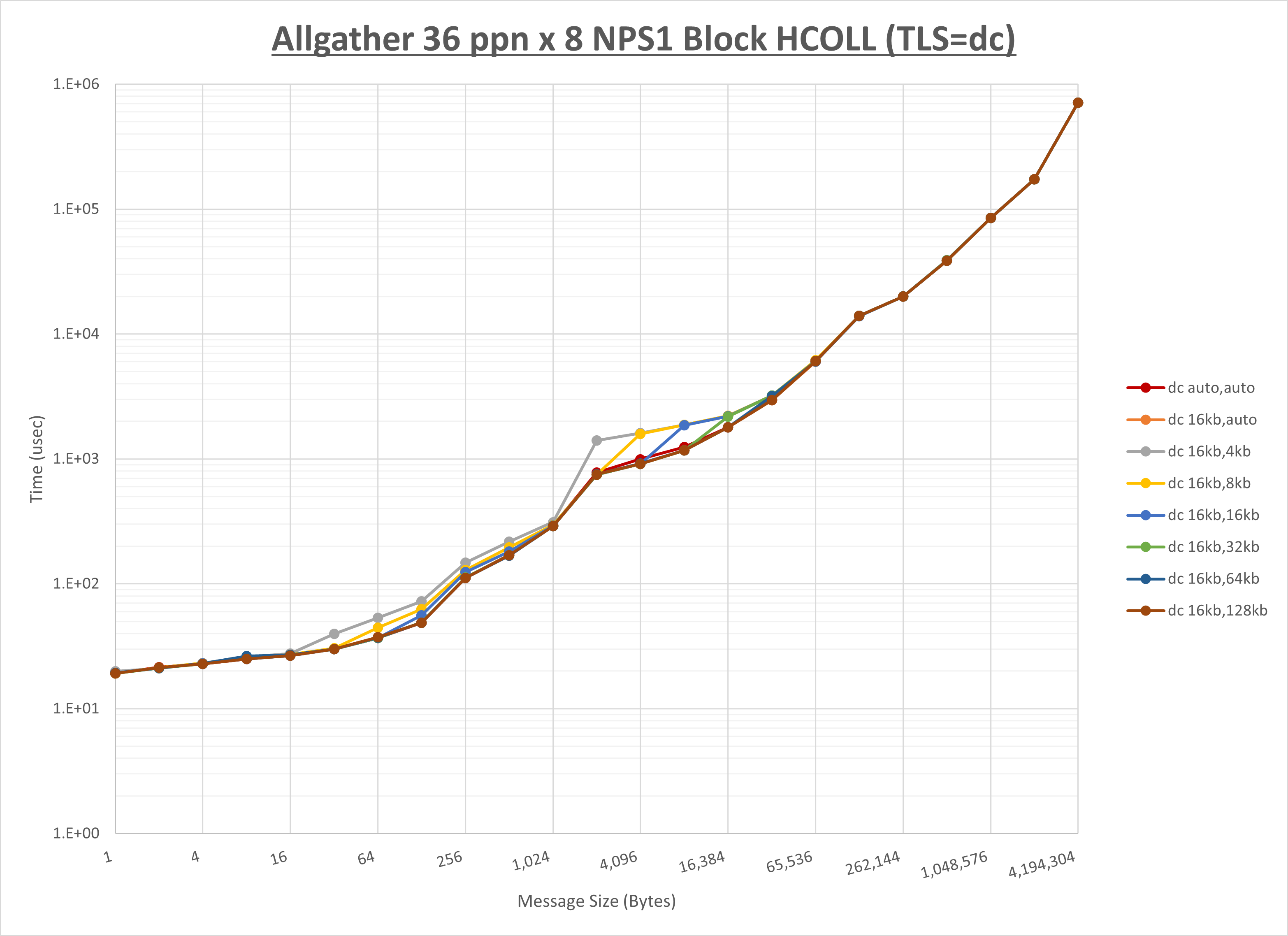
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
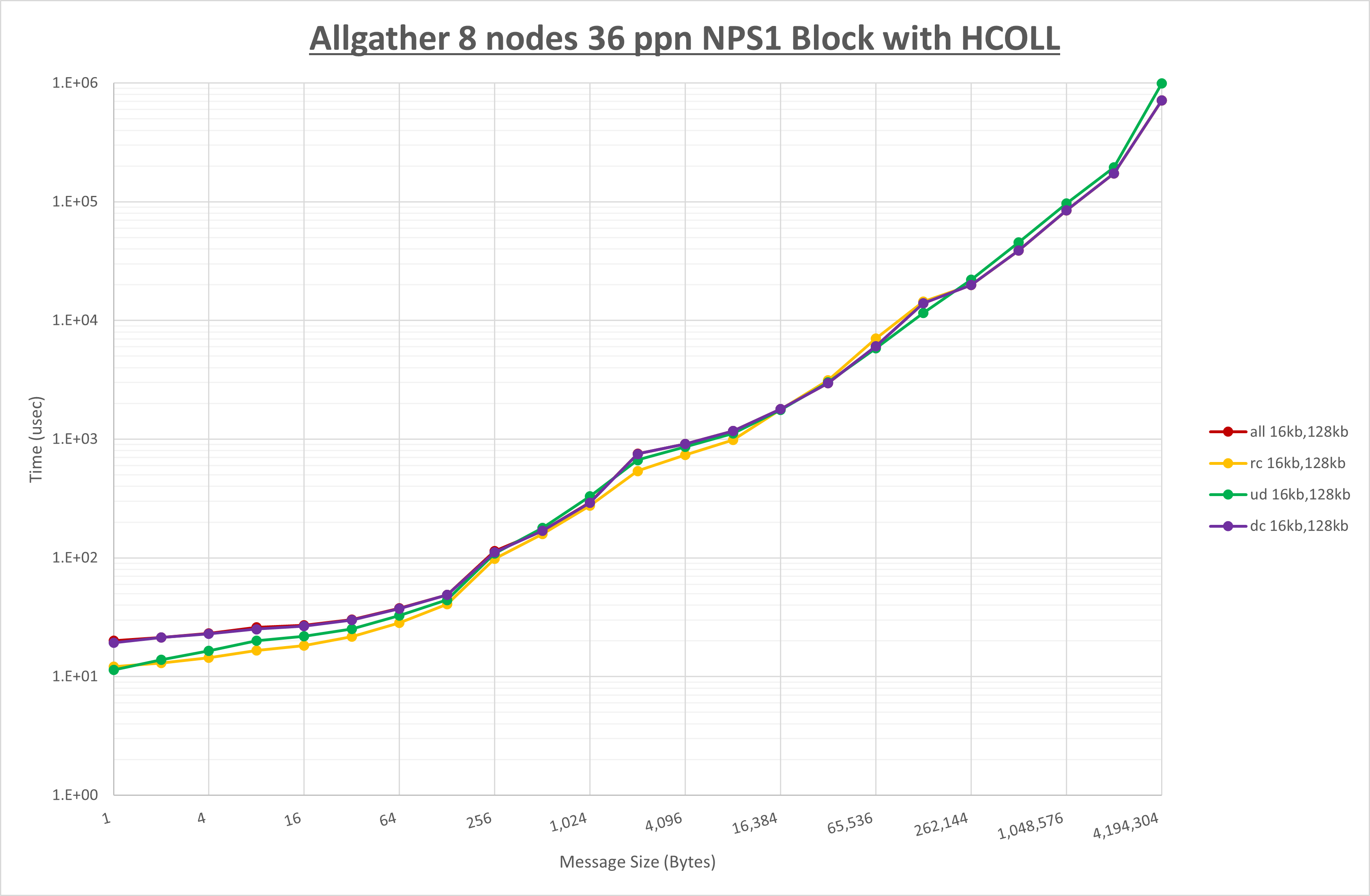
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allgather の結果です。
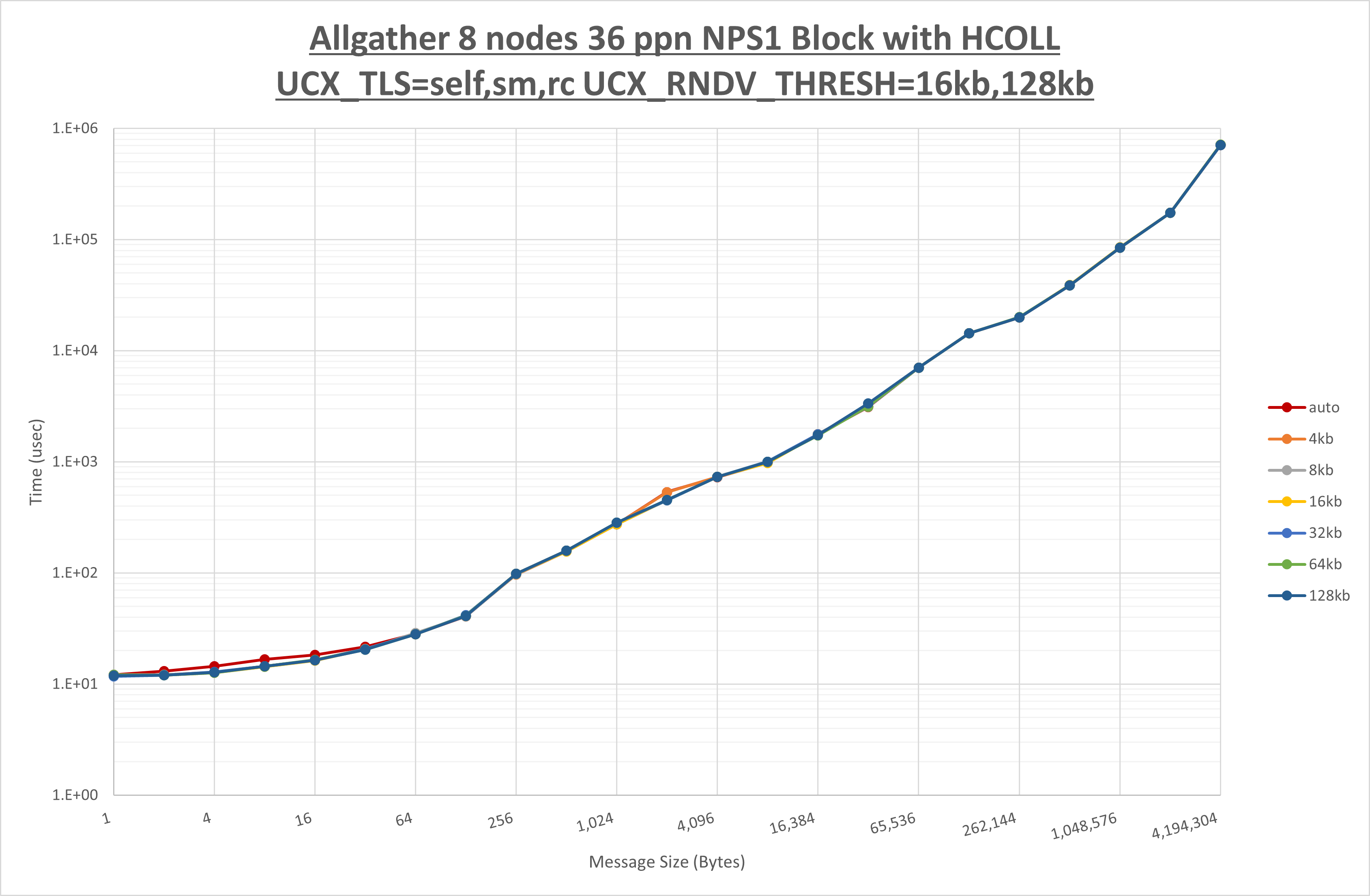
以上より、 UCX_ZCOPY_THRESH による有意な差が無いため、デフォルトの auto を採用します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
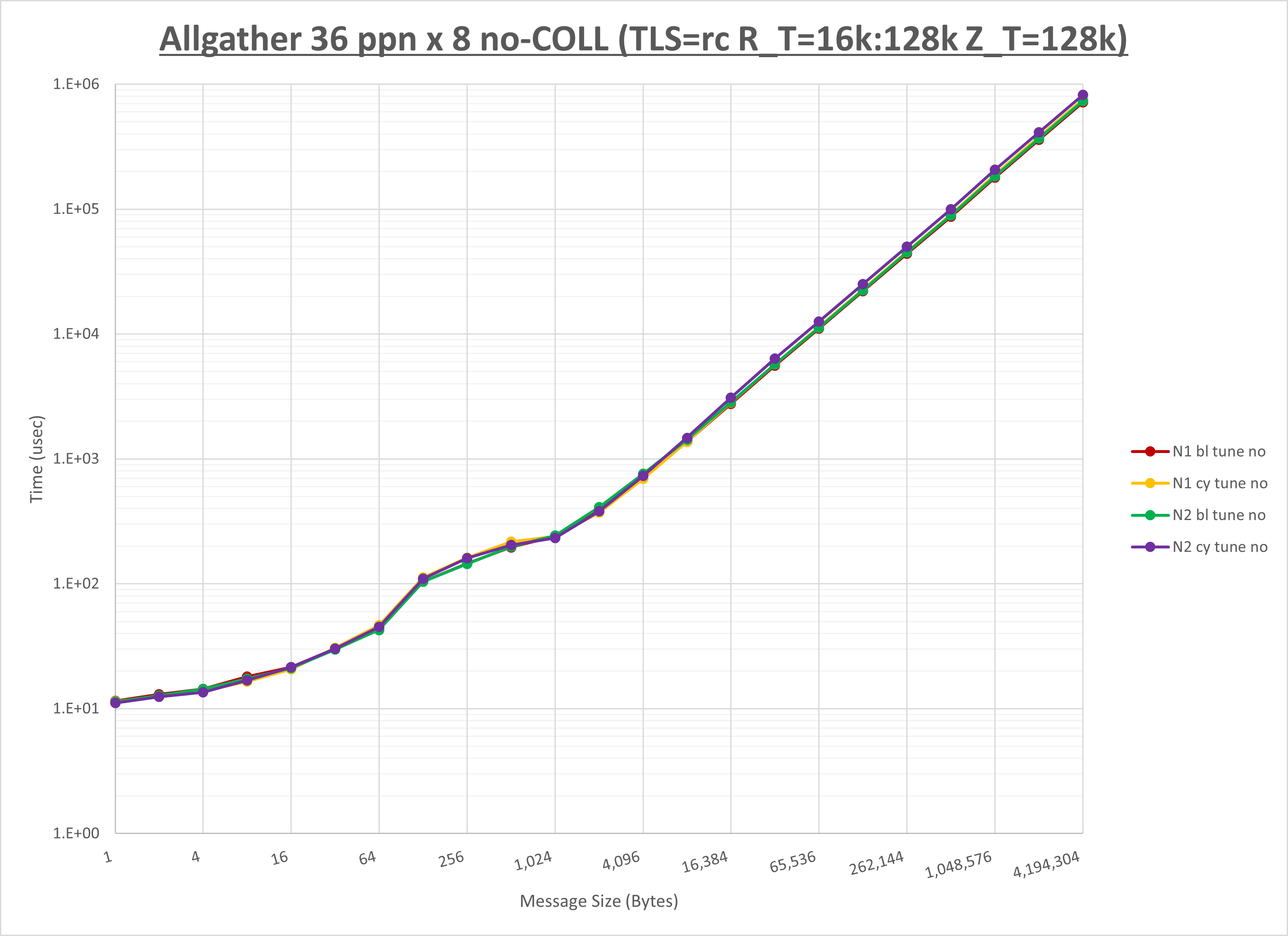
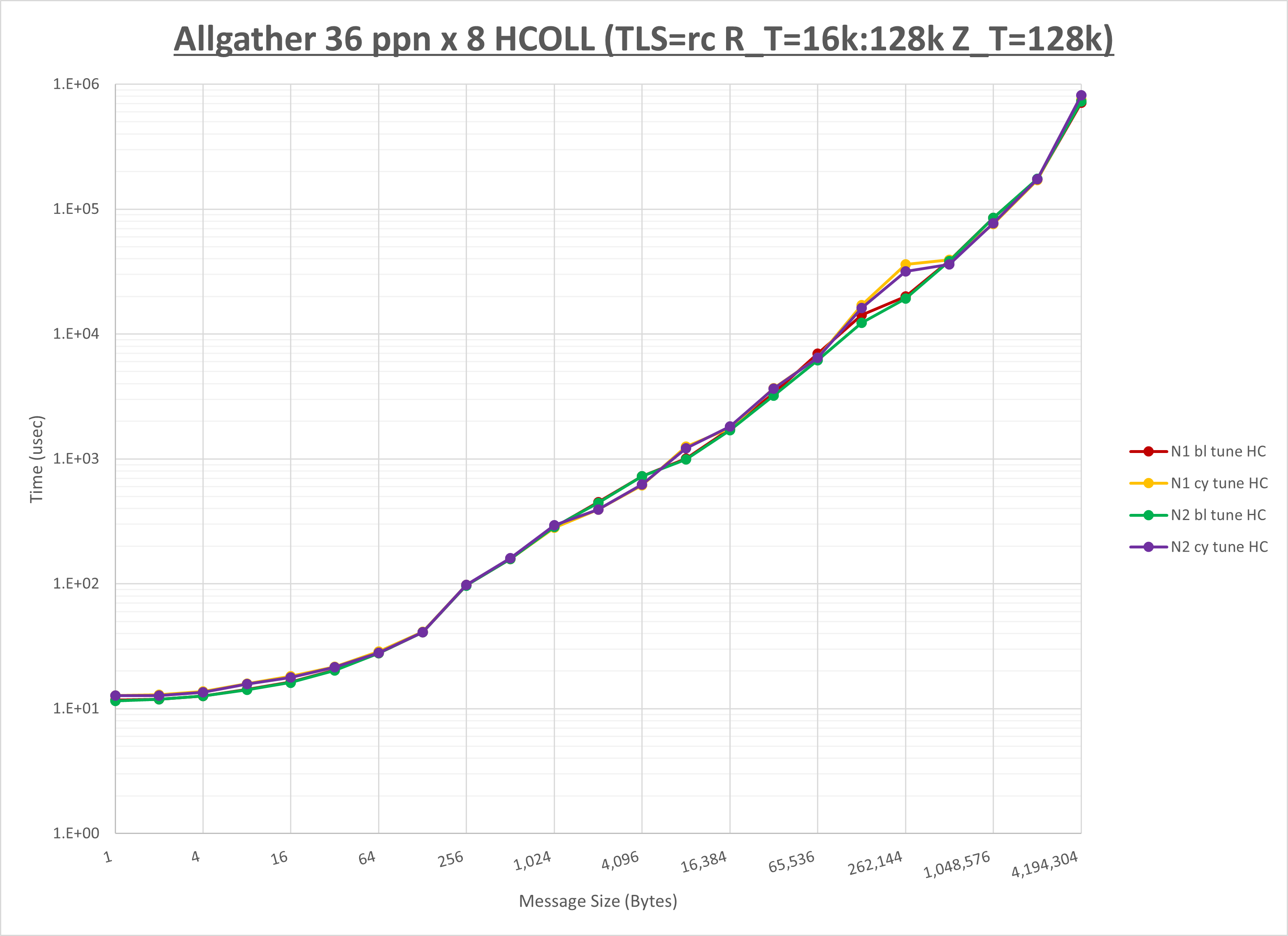
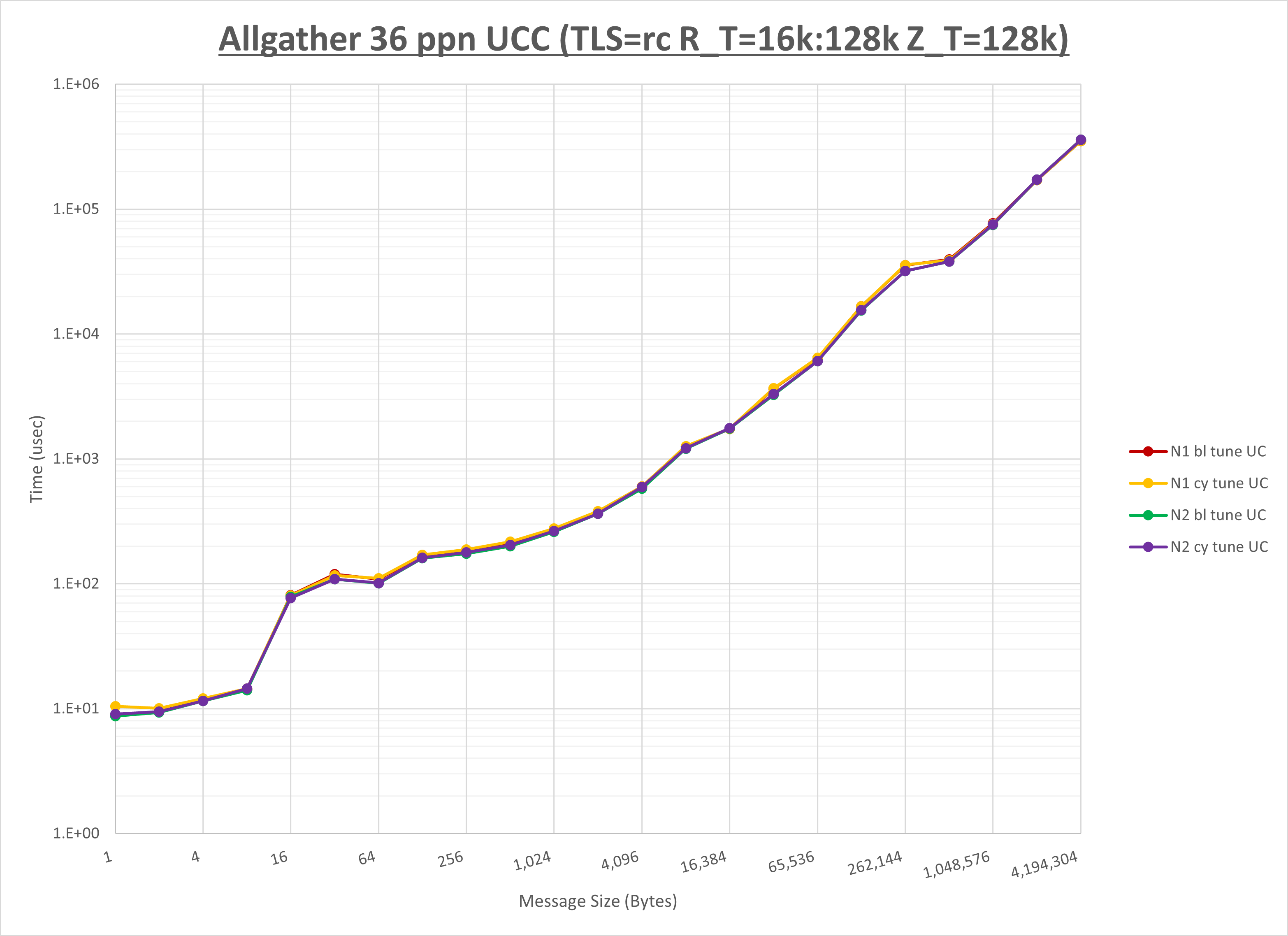
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS2 | NPS2 | NPS2 |
| MPIプロセス分割方法 | ブロック分割 | ブロック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
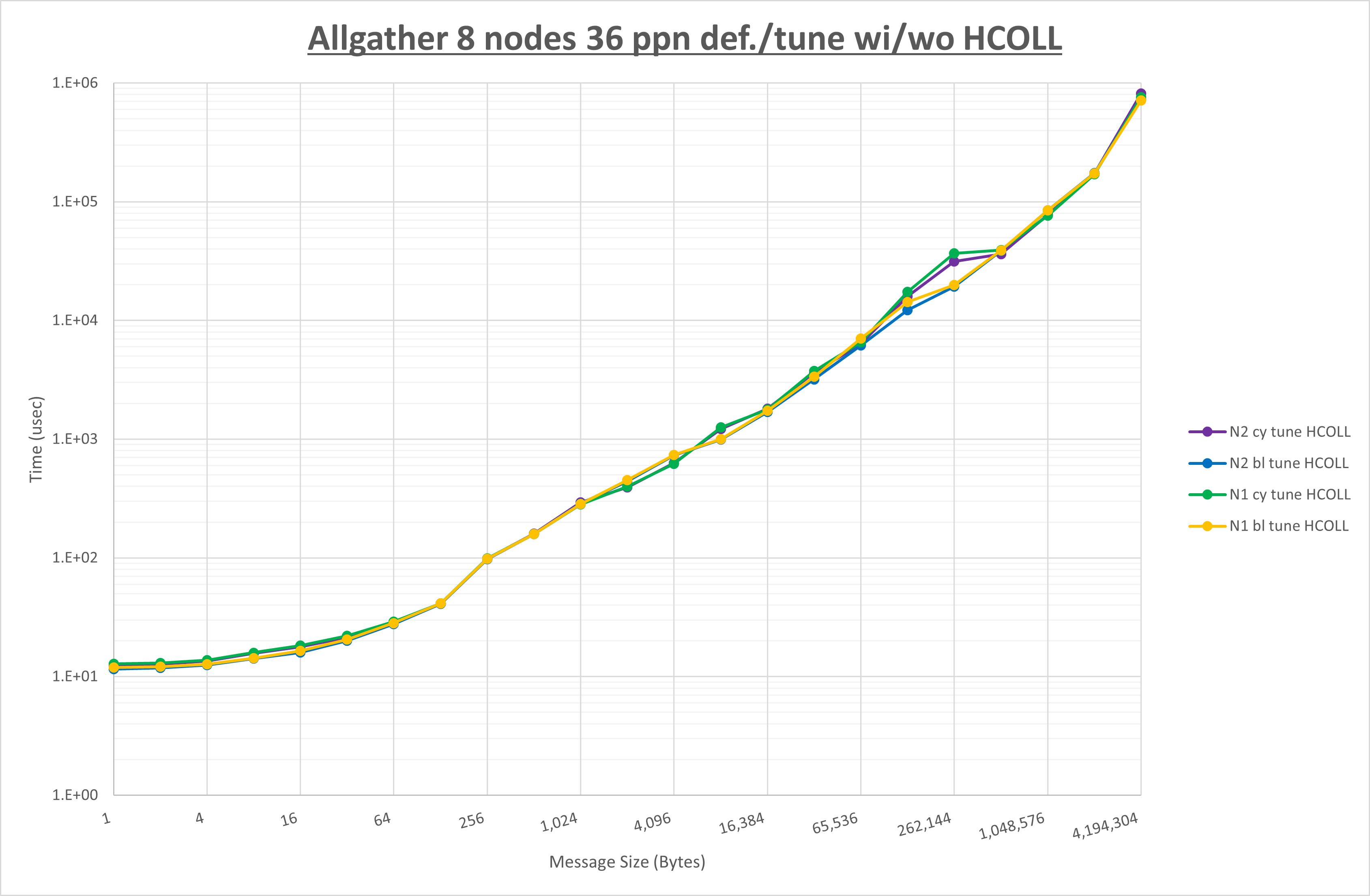
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し全域で性能が向上
- UCC は no-COLL と比較し512B以上で性能が向上し16Bから256Bで性能が低下
- チューニング適用で8KB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Allreduce の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-3 Allreduce の HCOLL の結果から64KBとしています。
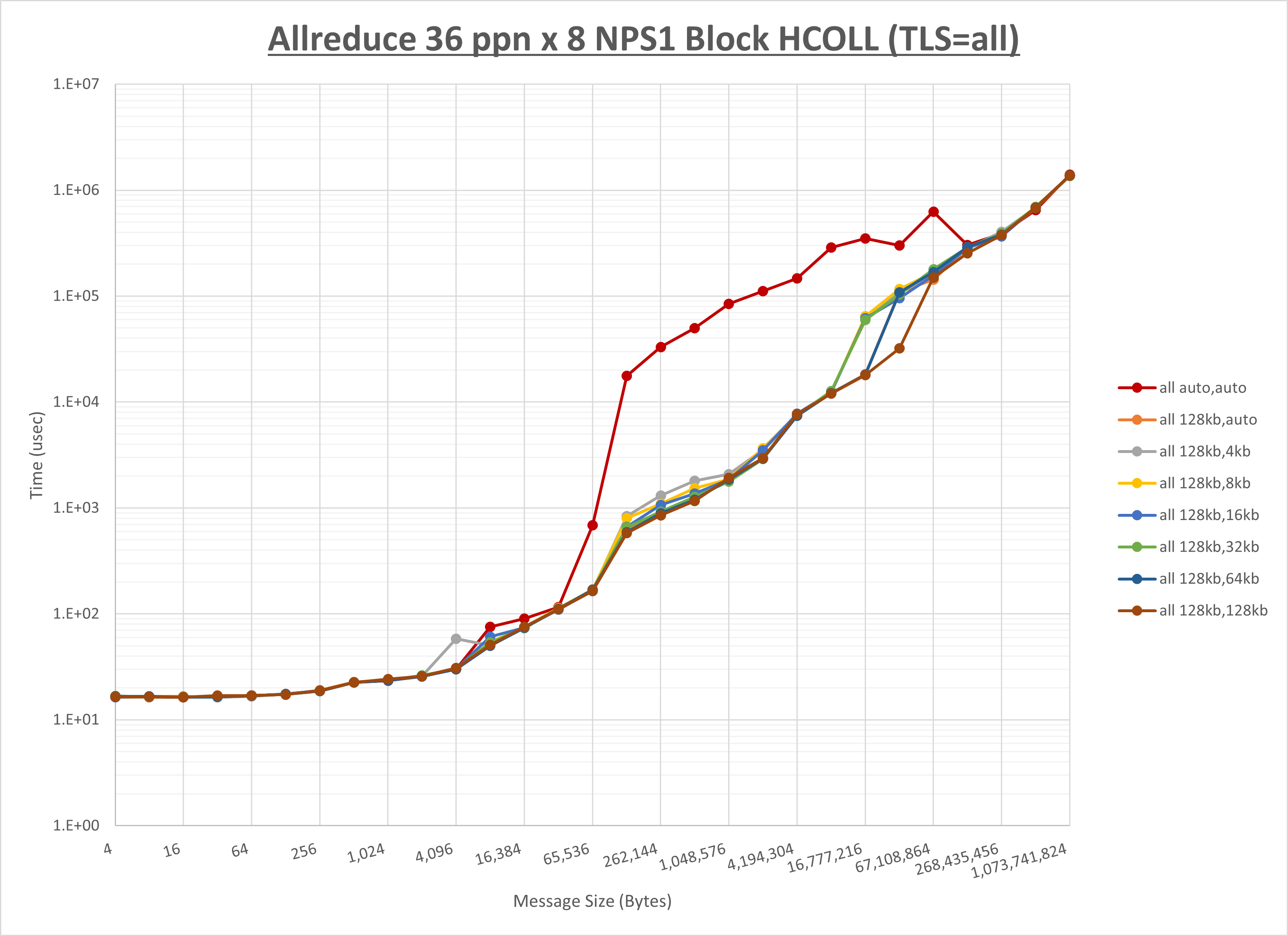
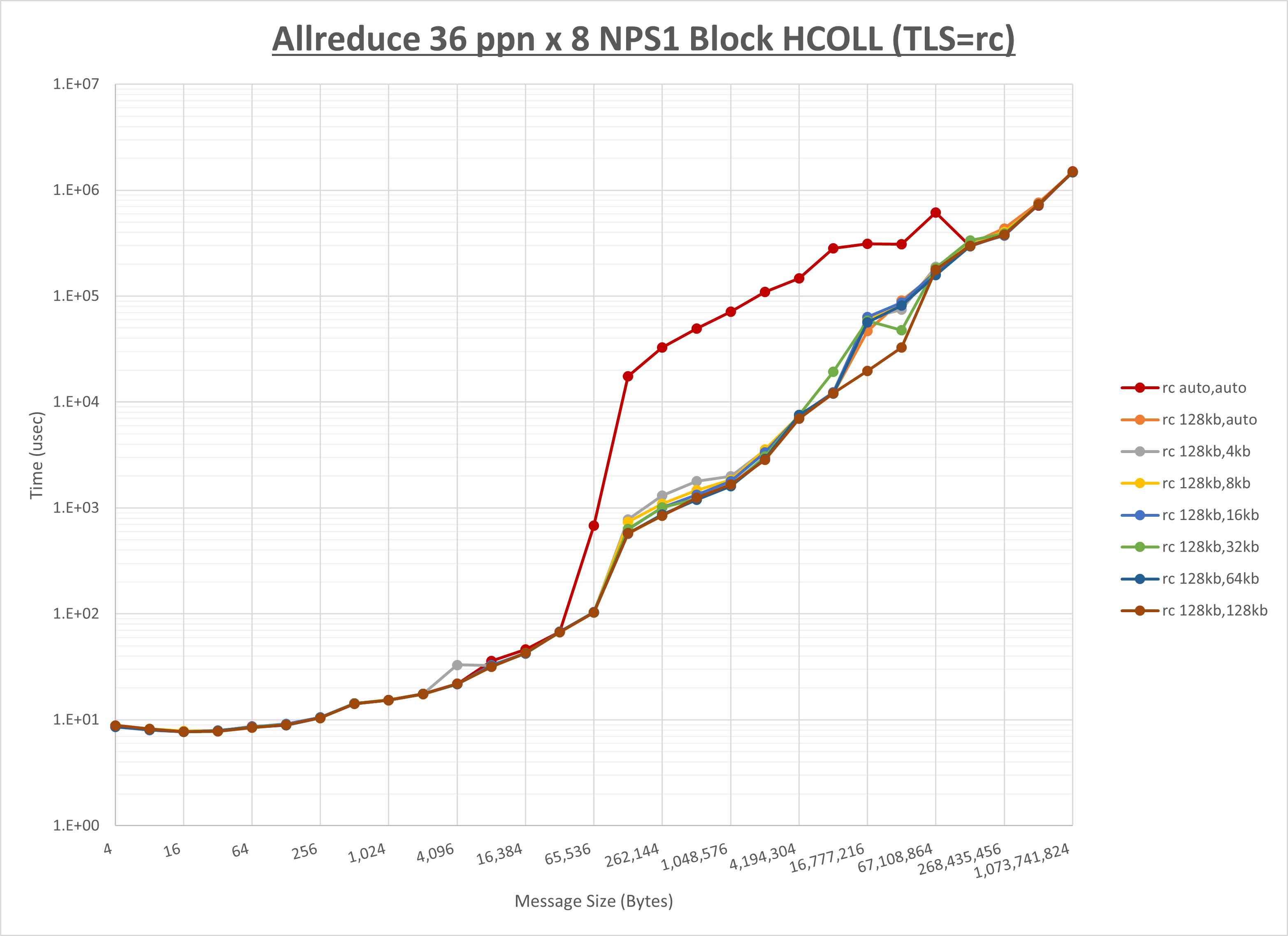
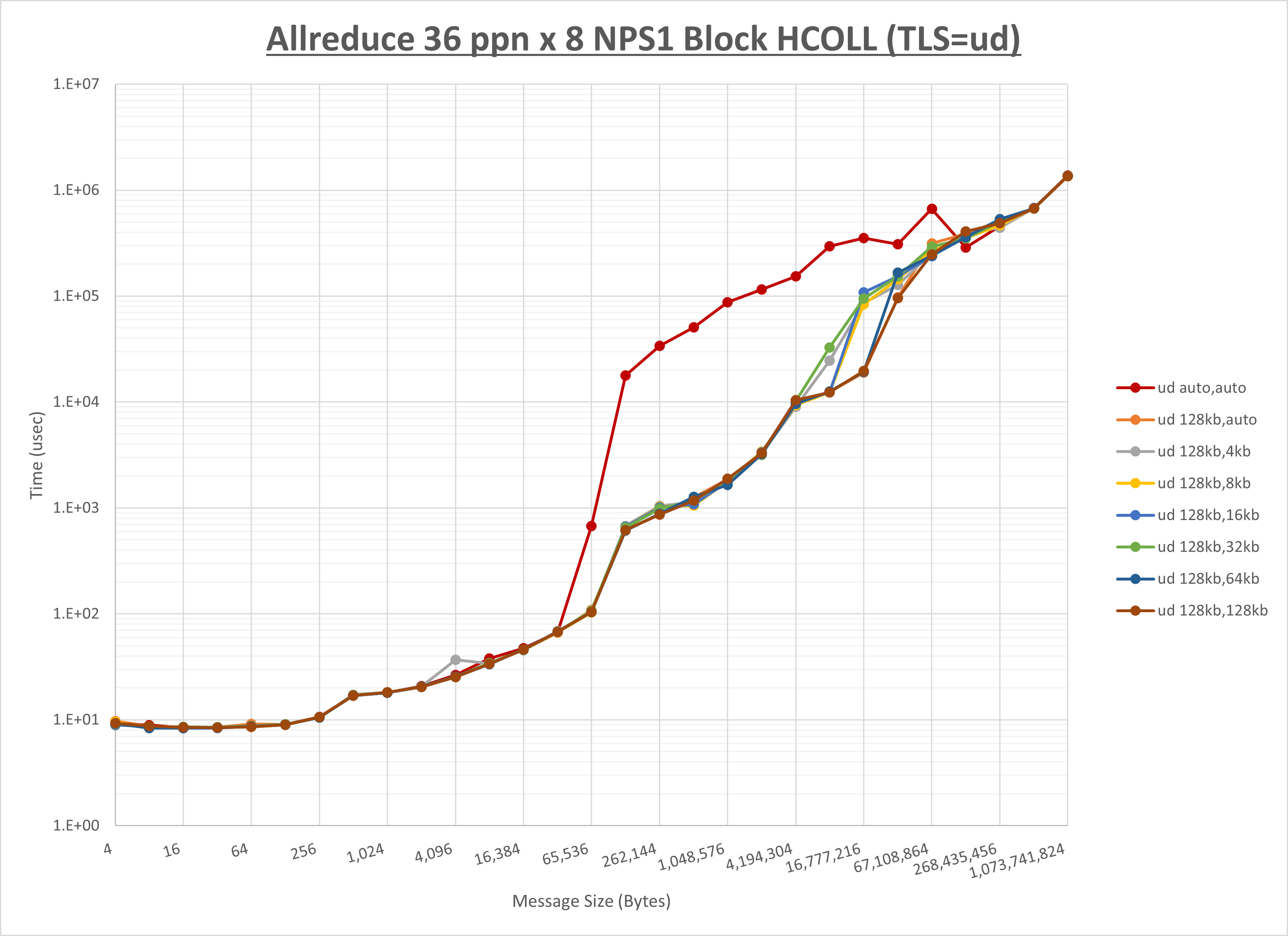
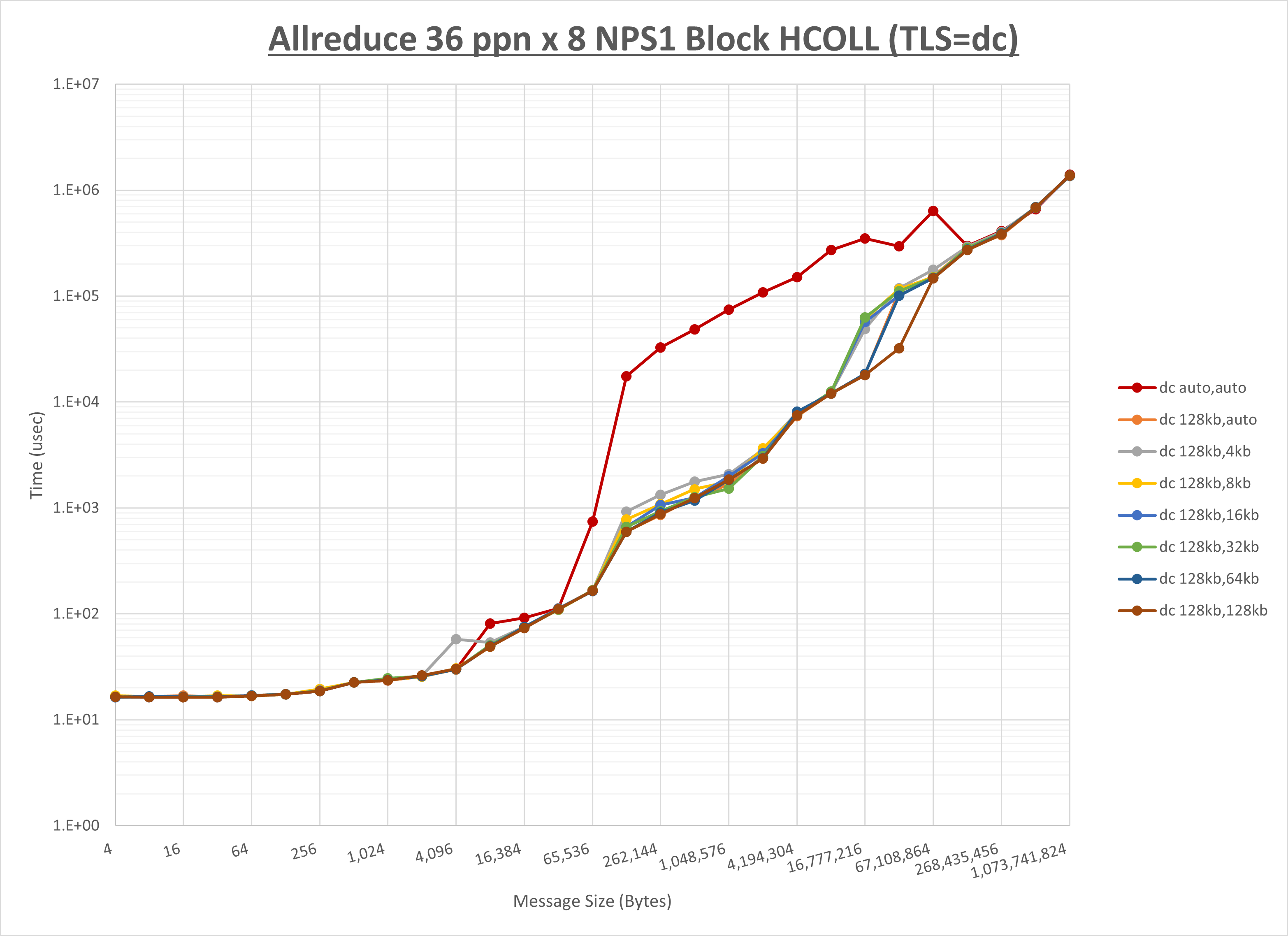
以上より、 UCX_RNDV_THRESH を intra:64kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
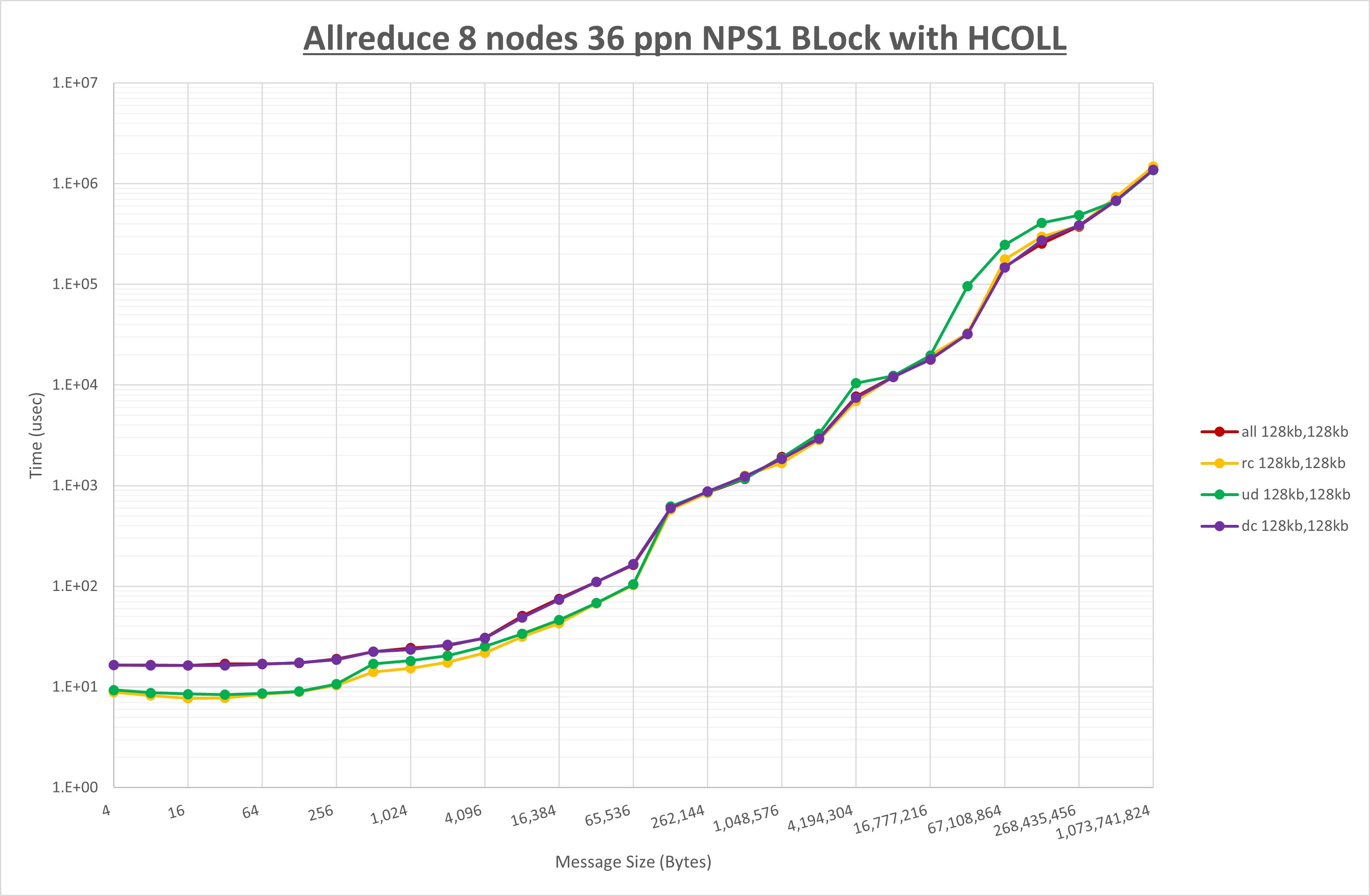
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Allreduce の結果です。
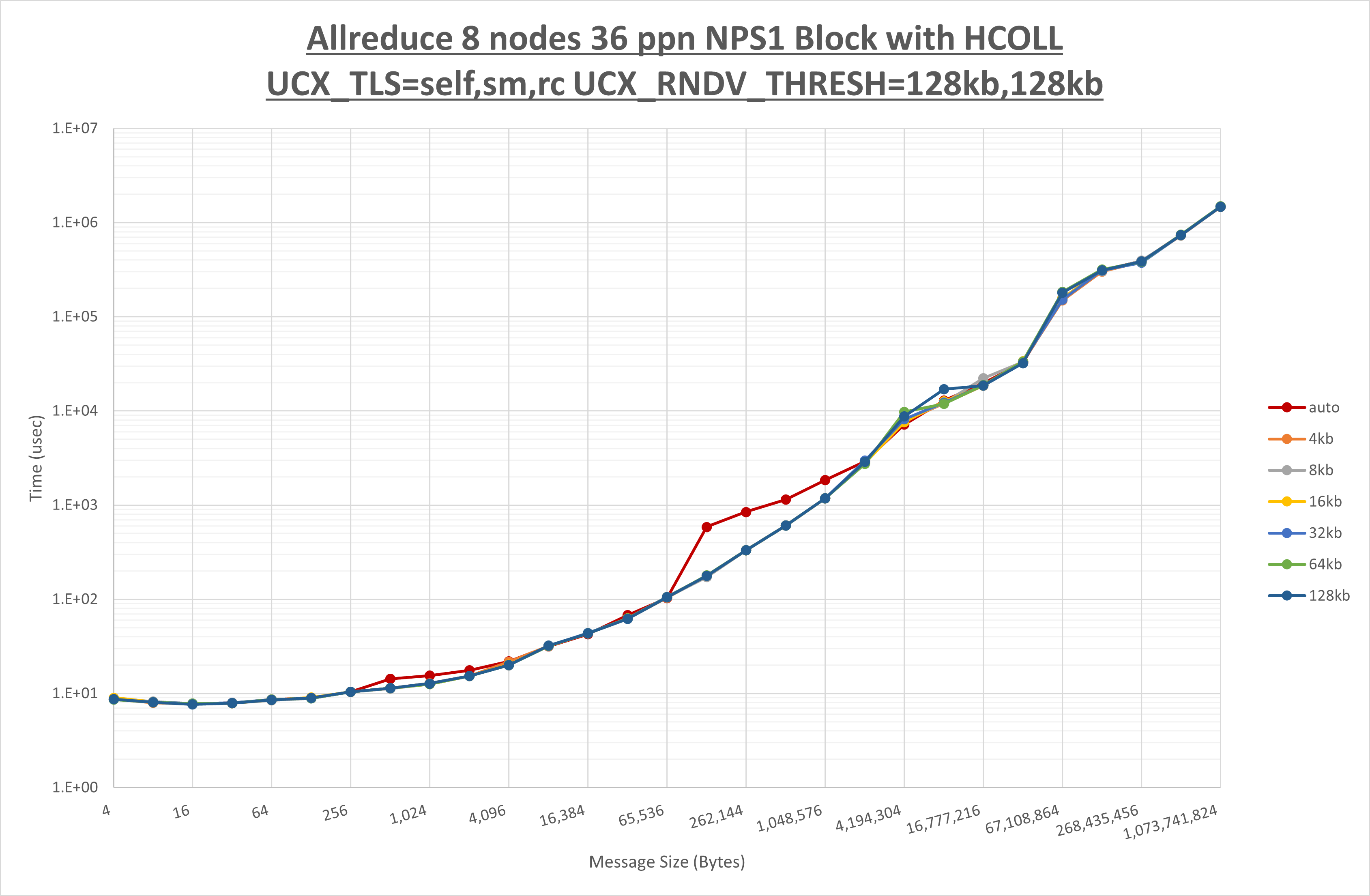
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、NPS とMPIプロセス分割方法の各組合せを集合通信コンポーネント毎に比較したものです。
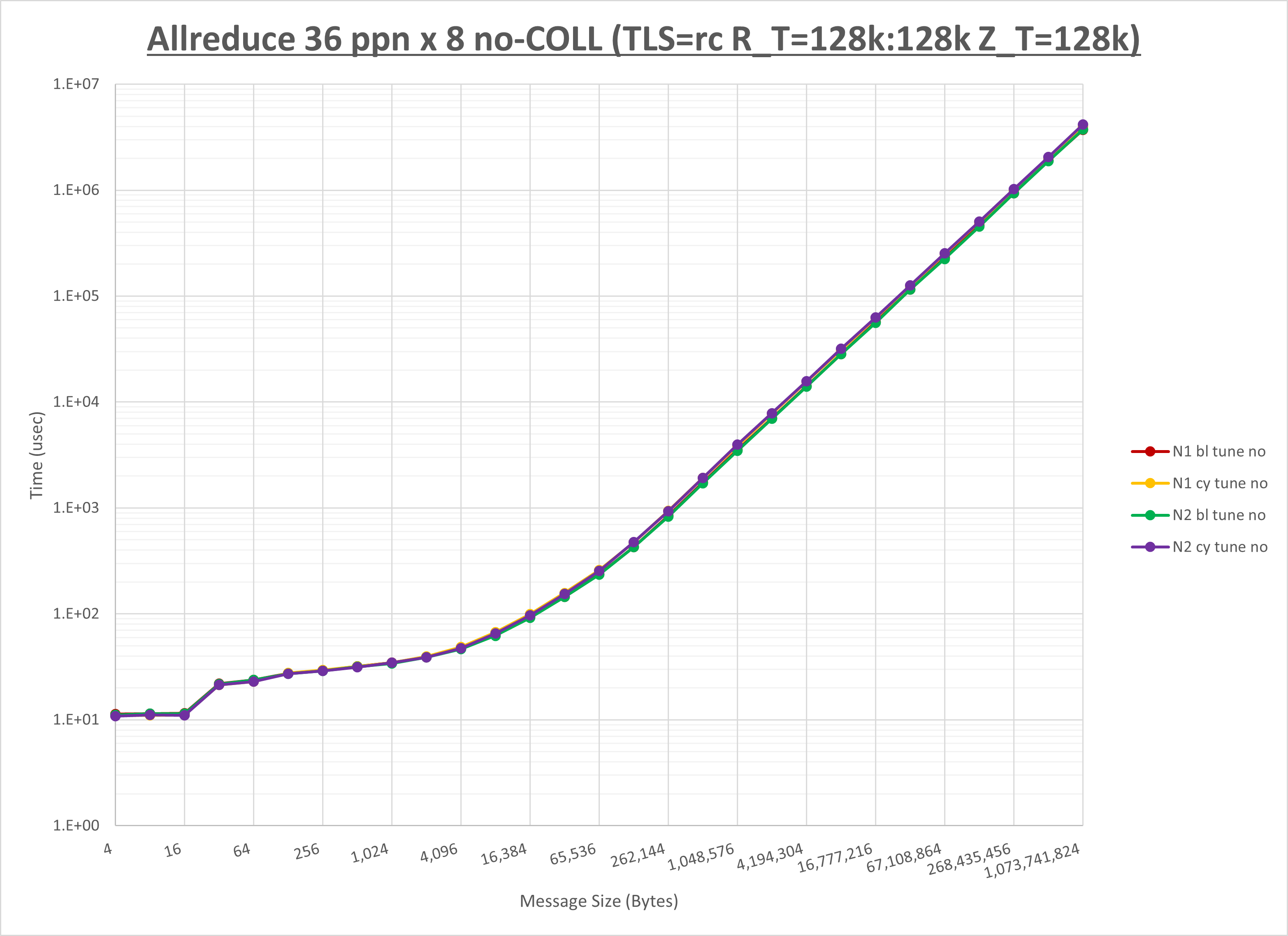
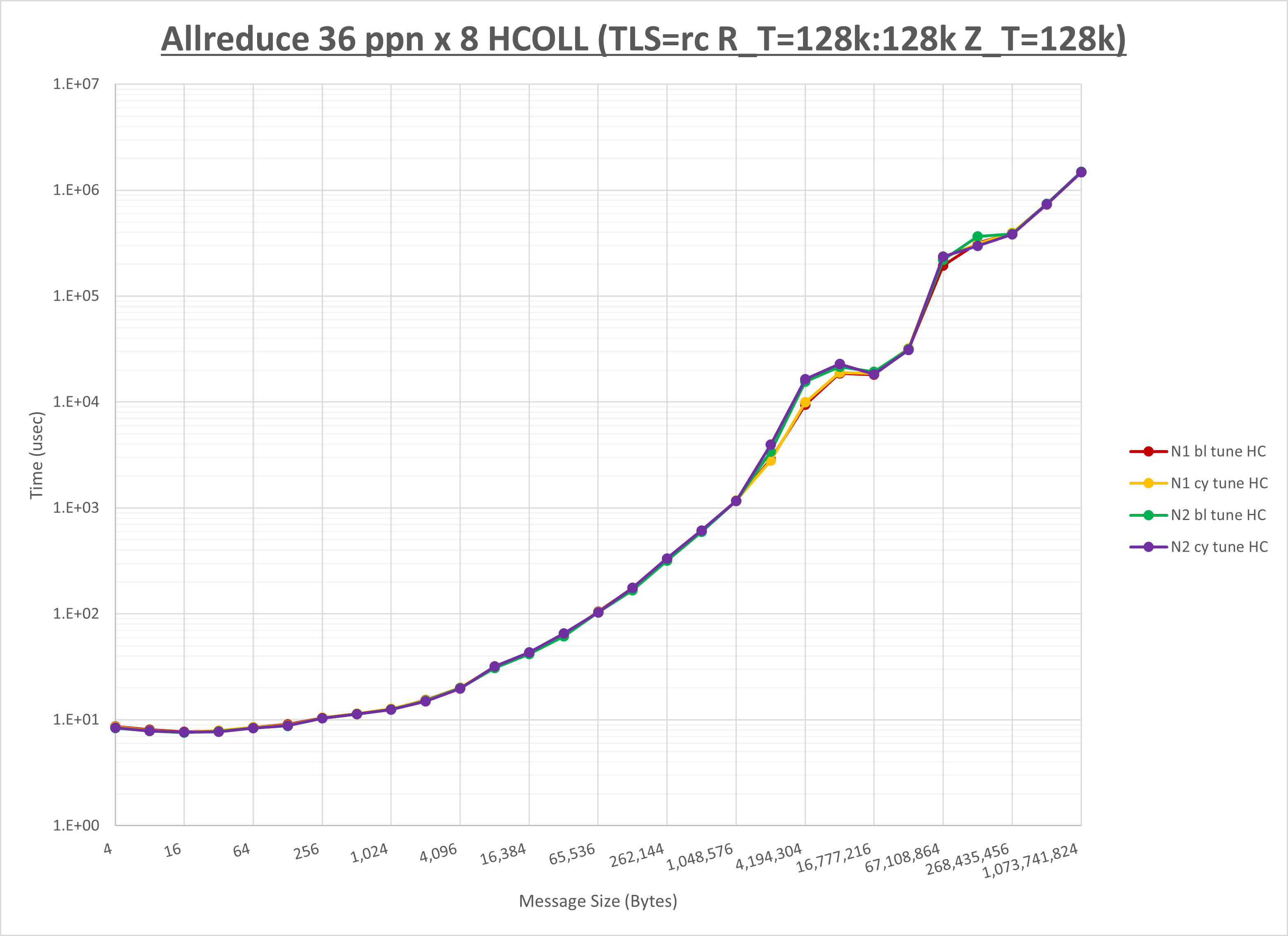
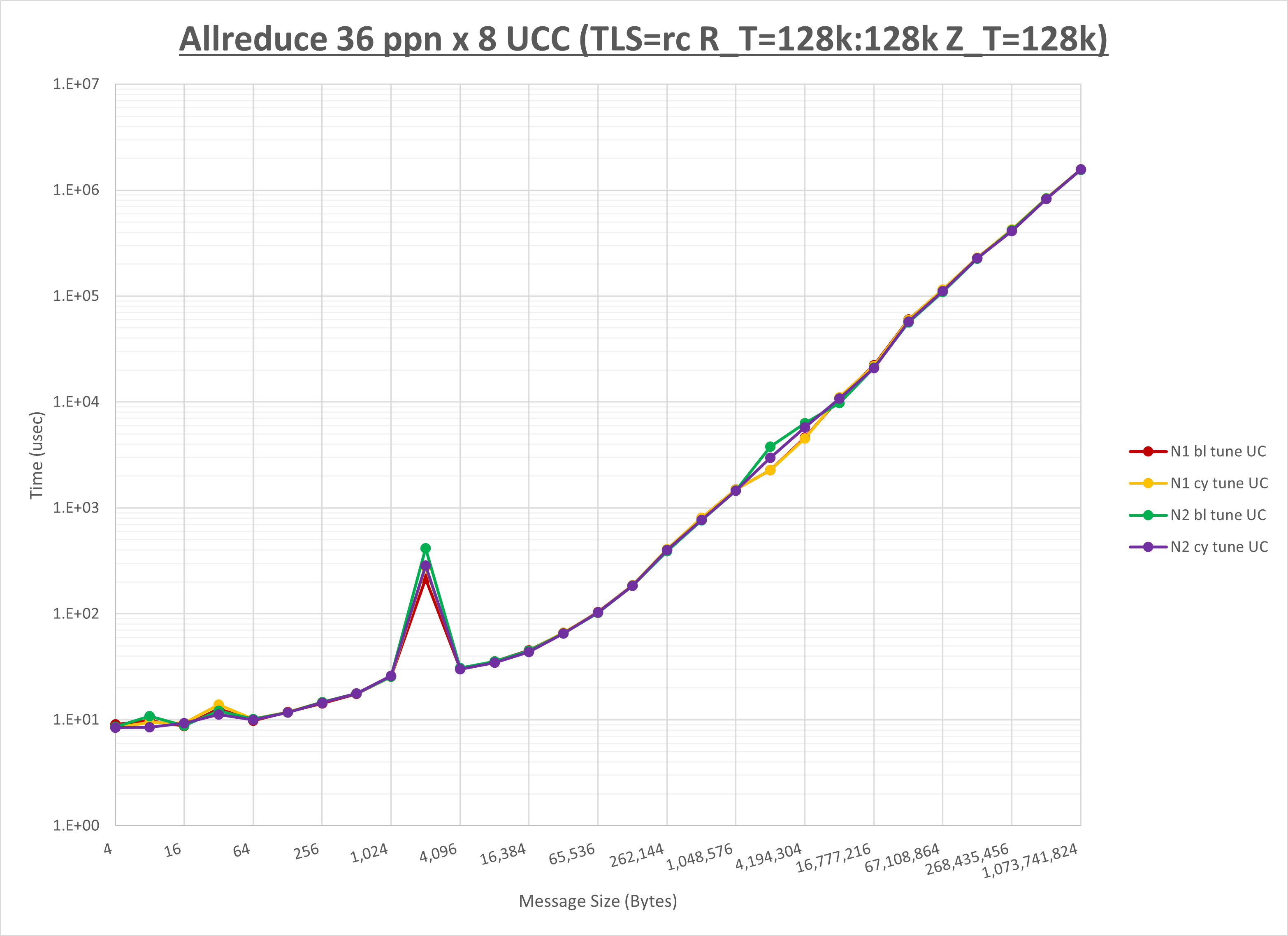
以上より、 NPS とMPIプロセス分割方法を下表の設定とした場合が最も性能が良いと判断してこれを固定、
| No COLL | HCOLL | UCC | |
|---|---|---|---|
| NPS | NPS1 | NPS2 | NPS1 |
| MPIプロセス分割方法 | ブロック分割 | サイクリック分割 | サイクリック分割 |
集合通信コンポーネントを比較したものが以下のグラフです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto ・ coll_hcoll_enable=1 ・ coll_ucc_enable=0 )を含めています。
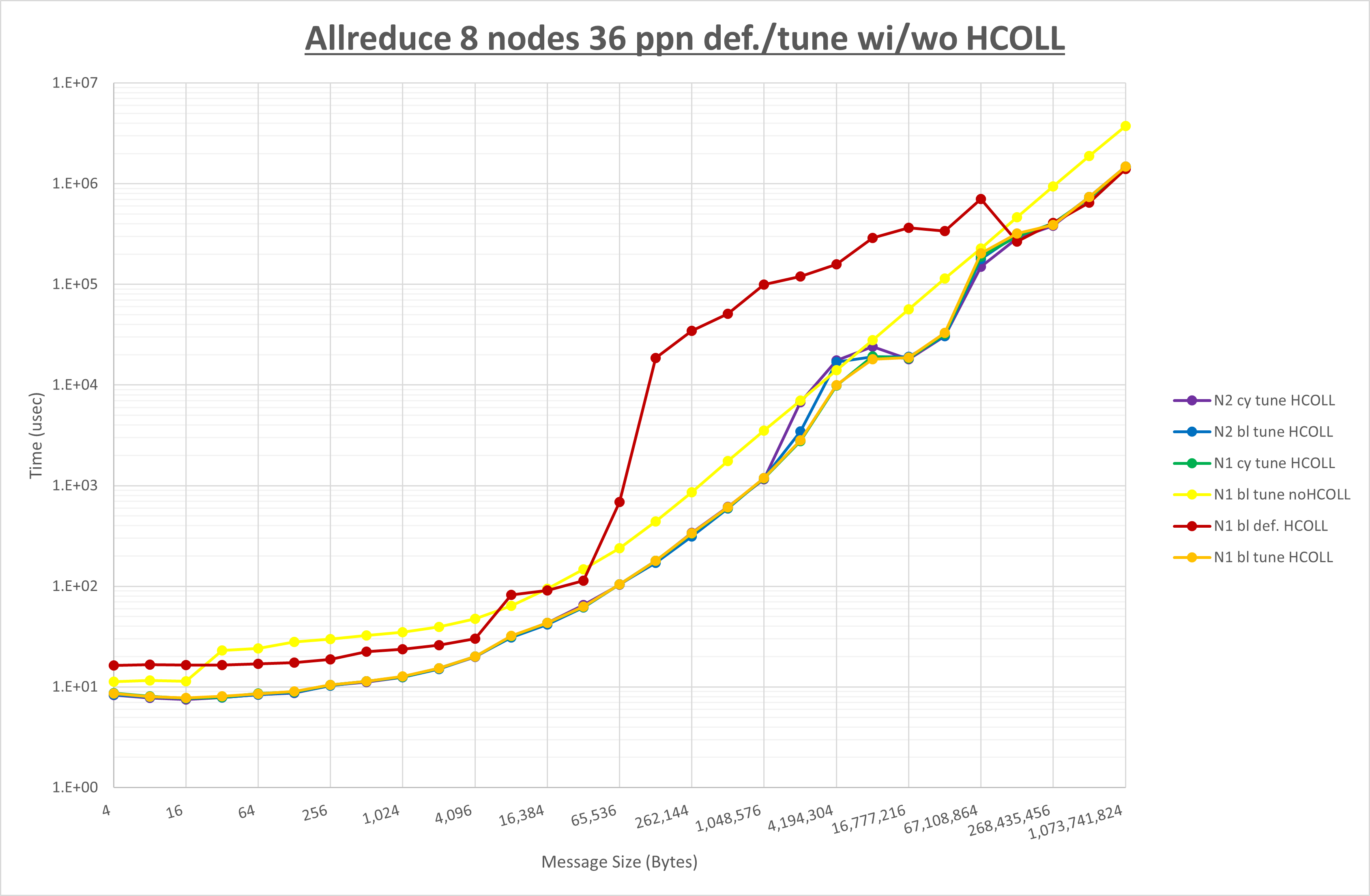
以上の結果は、以下のように考察することが出来ます。
- HCOLL は no-COLL と比較し概ね全域で性能が向上
- UCC は no-COLL と比較し概ね全域で性能が向上
- チューニング適用で2MB以下で性能が向上
[ステップ1]
以下のグラフは、 UCX_RNDV_THRESH を変化させたときの Exchange の結果を、 UCX_TLS の設定値毎に示しています。
ノード内の UCX_RNDV_THRESH の最適値は、 1-4-4 Exchange の結果から16KBとしています。
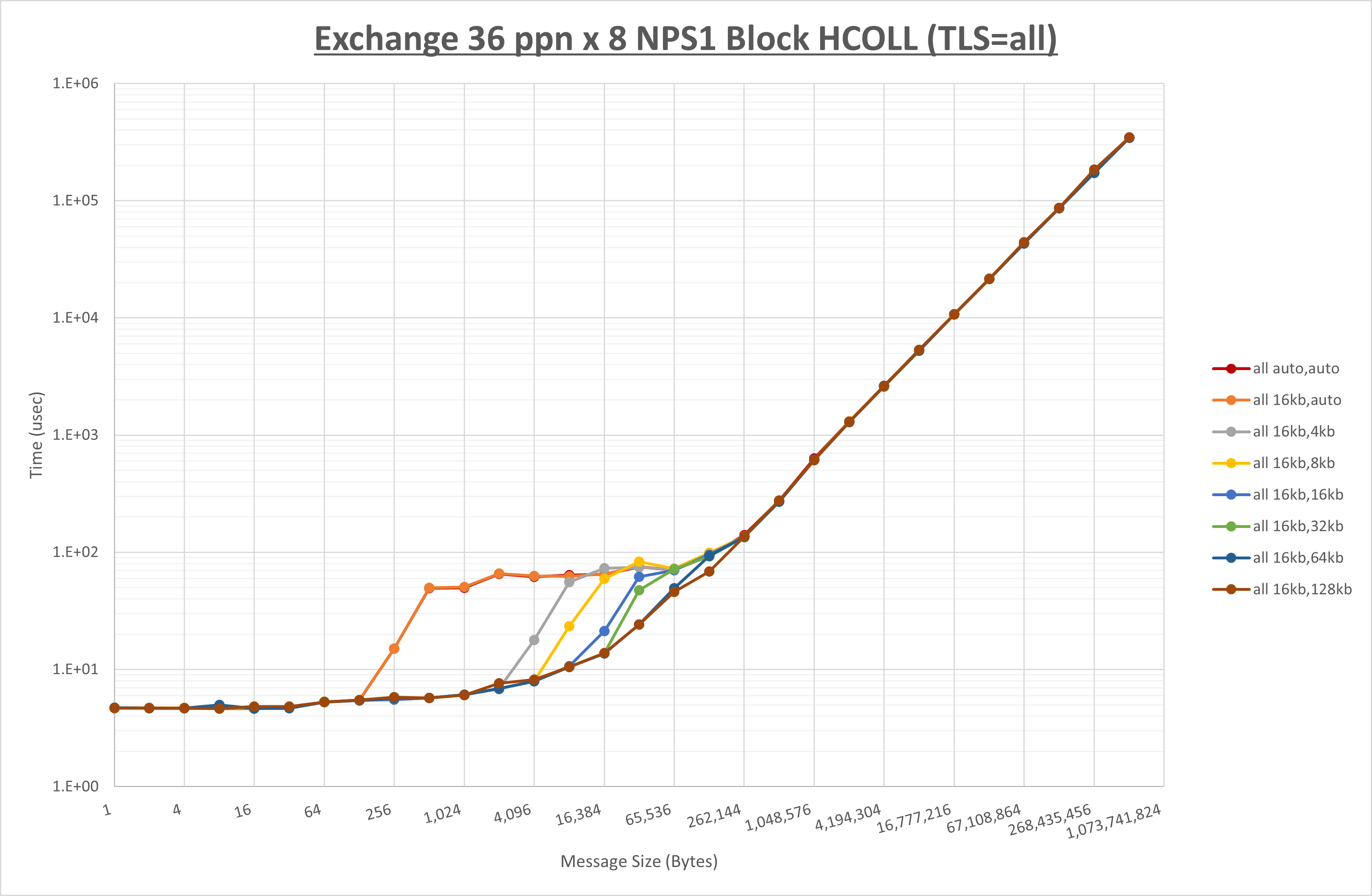
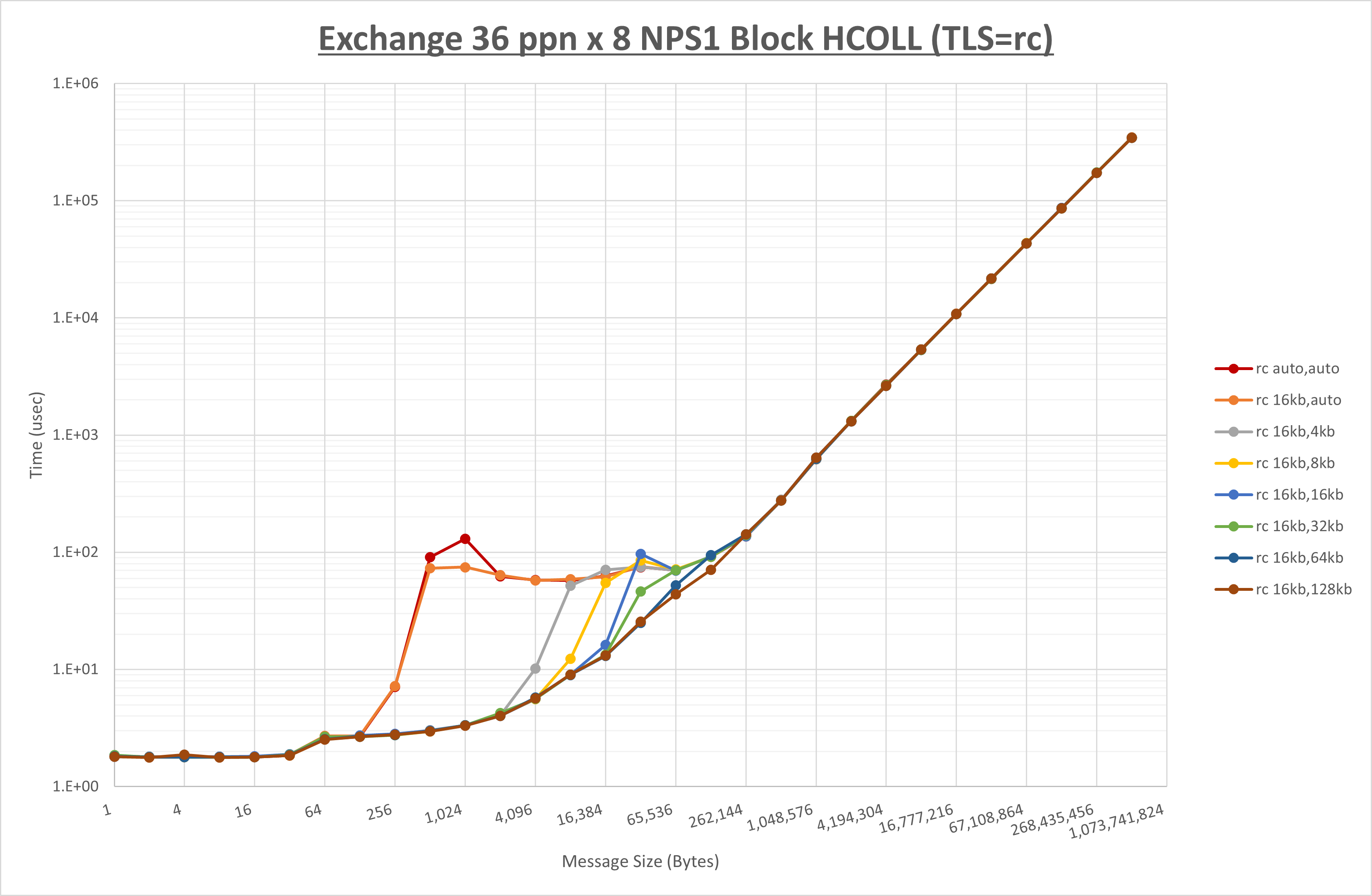
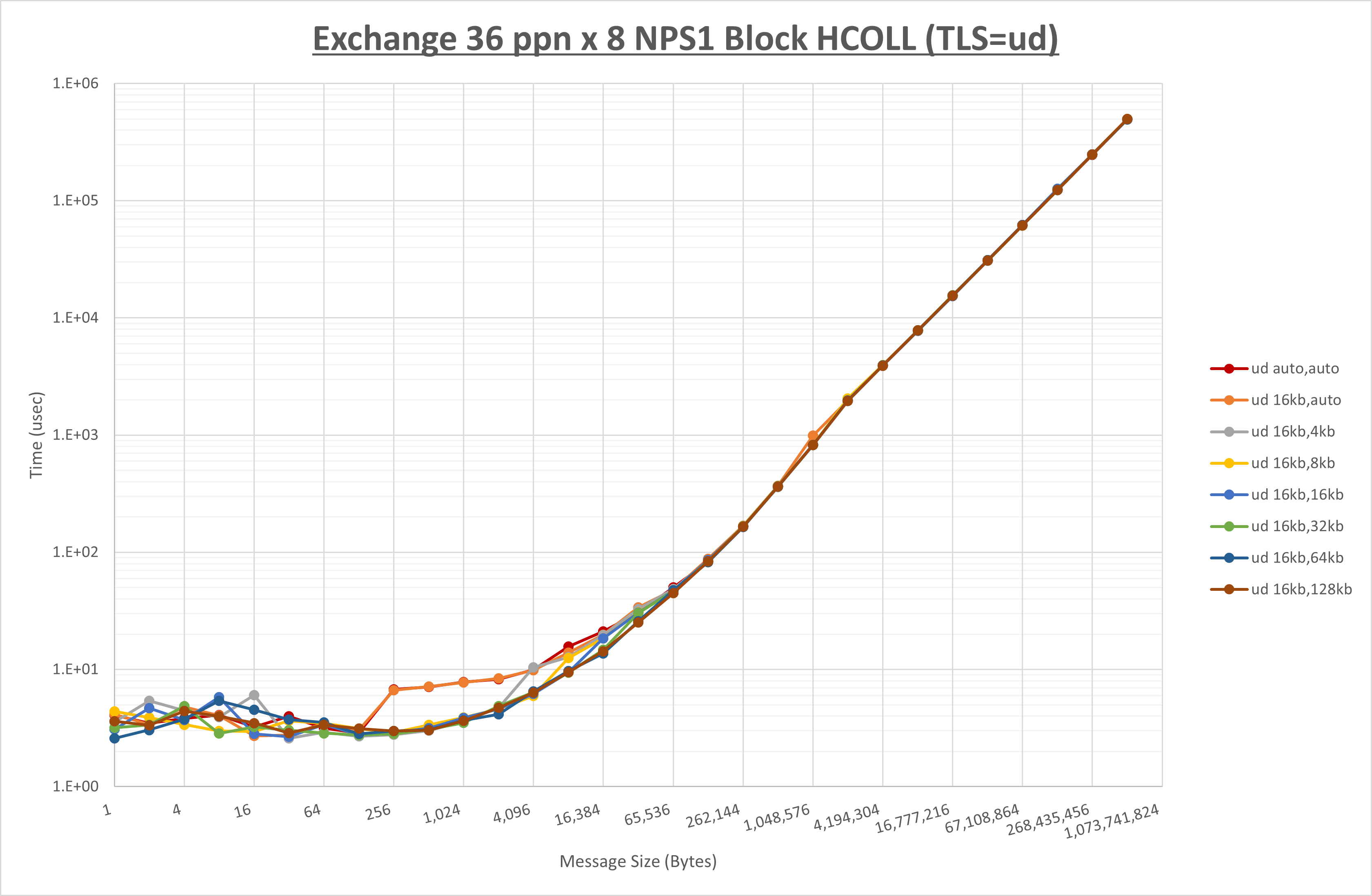
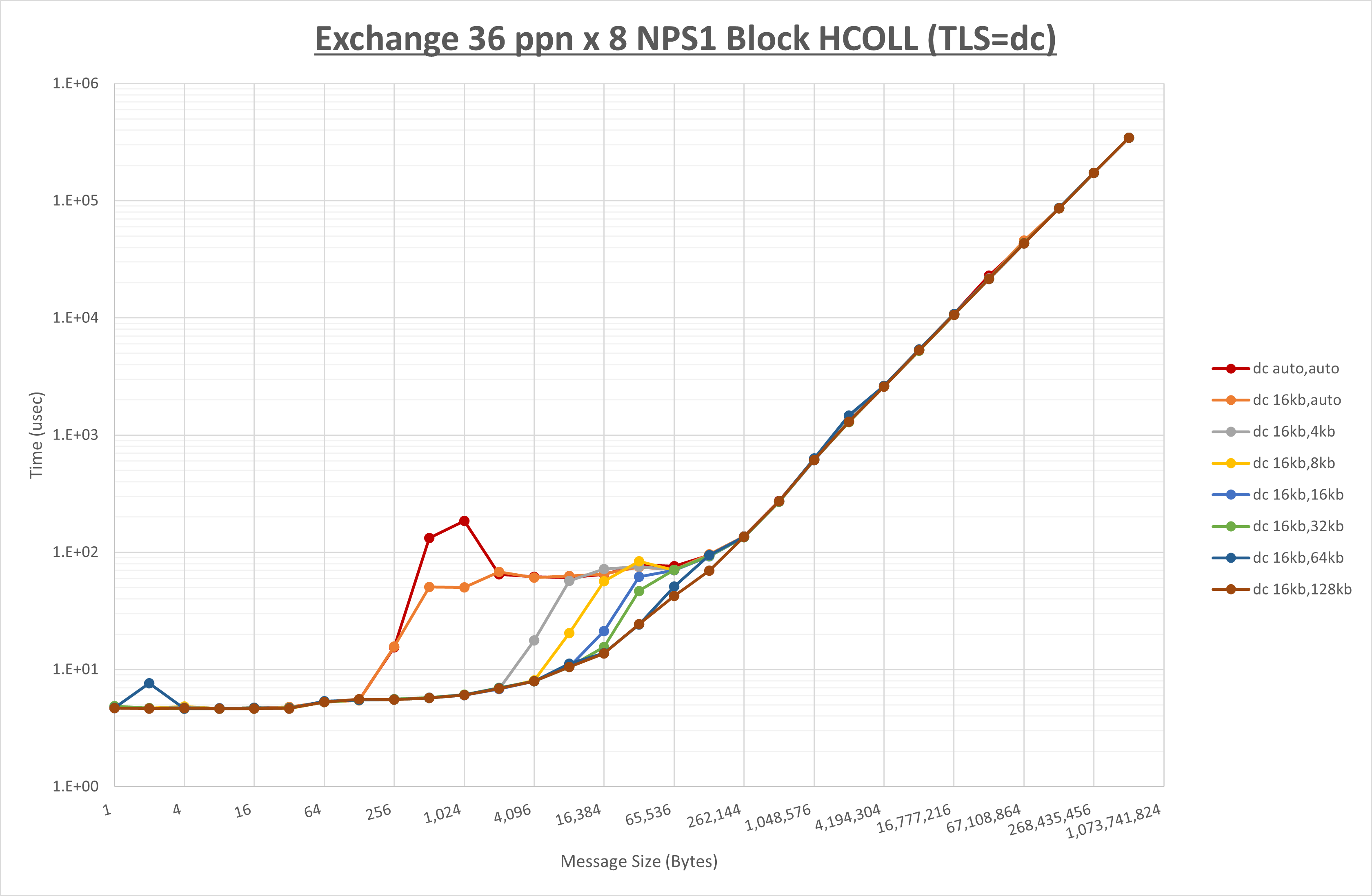
以上より、 UCX_RNDV_THRESH を intra:16kb,inter:128kb とした場合が最も性能が良いと判断してこれを固定、 UCX_TLS の各設定値を比較したものが以下のグラフです。
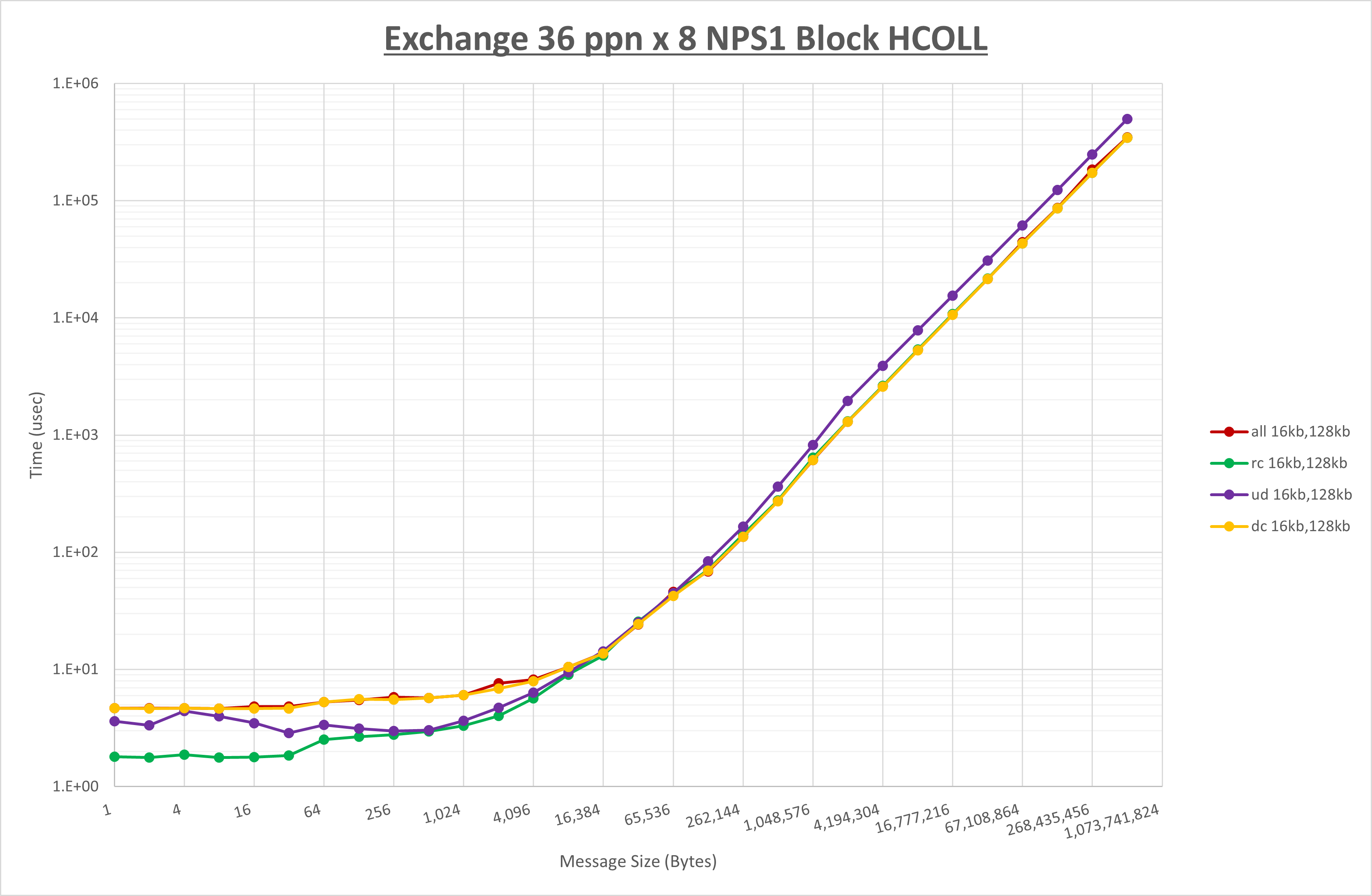
以上より、 UCX_TLS を self,sm,rc とした場合が最も性能が良いと判断してこれを固定します。
[ステップ2]
以下のグラフは、 UCX_ZCOPY_THRESH を変化させたときの Exchange の結果です。
以上より、 UCX_ZCOPY_THRESH を 128kb とした場合が最も性能が良いと判断してこれを固定します。
[ステップ3]
以下のグラフは、 NPS とMPIプロセス分割方法をの各組合せを比較したものです。
ここでは、チューニングを全く適用しなかった場合と比較するため、全パラメータがデフォルトの組合せ( UCX_TLS=all ・ UCX_RNDV_THRESH=auto ・ UCX_ZCOPY_THRESH=auto )を含めています。
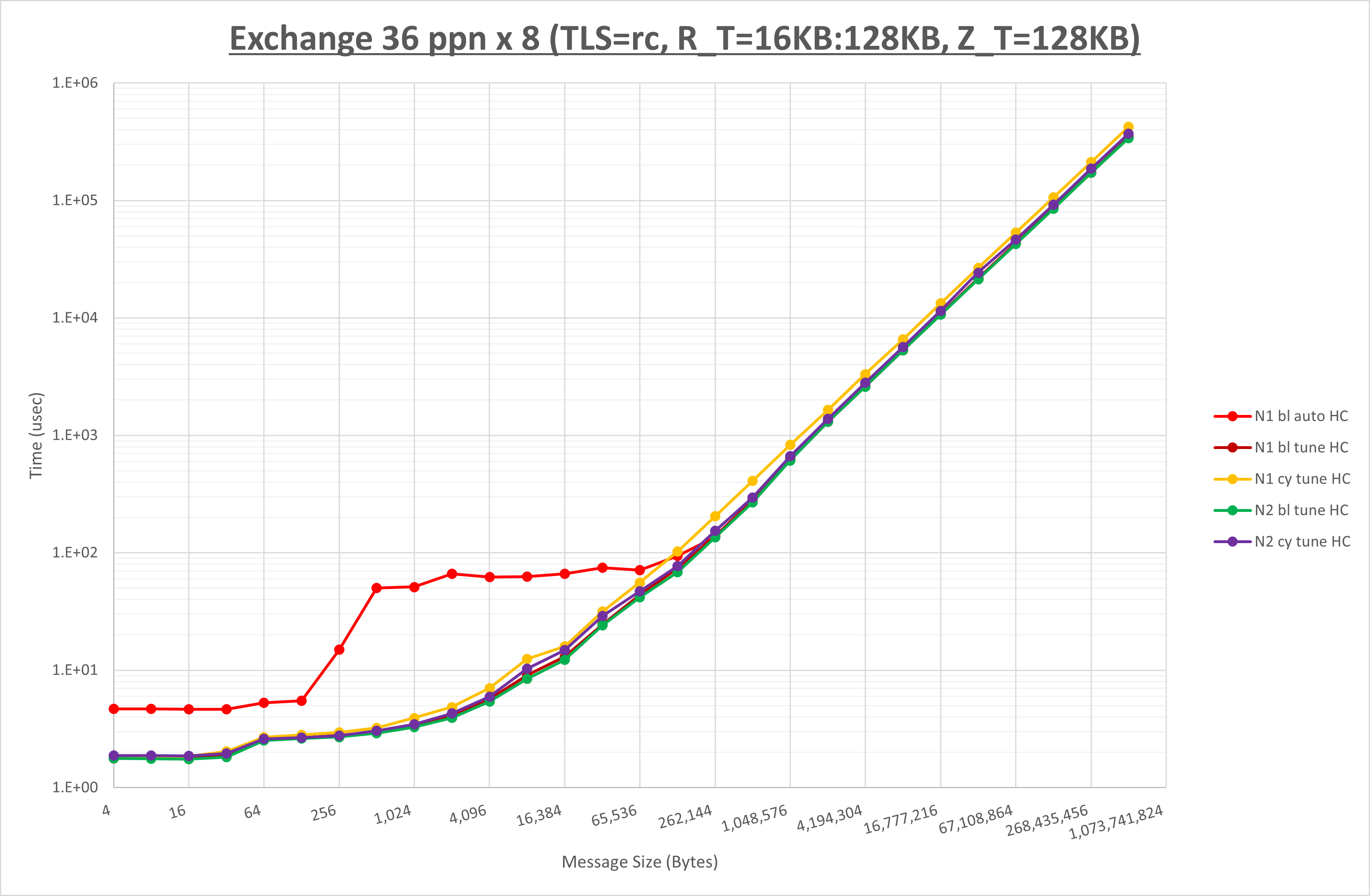
以上の結果は、以下のように考察することが出来ます。
- MPIプロセス分割方法はブロック分割が有利
- ブロック分割に於ける NPS の性能差なし
- チューニング適用で128KB以下で性能が向上