
GPUクラスタを構築する(基礎インフラ自動構築編)
本チュートリアルは、8枚の NVIDIA A100 GPUと16ポートの100 Gbps RDMA対応ネットワークインタフェースを搭載するベアメタルシェイプ BM.GPU4.8/BM.GPU.A100-v2.8 を クラスタ・ネットワーク でノード間接続する、HPC/機械学習ワークロードを実行するためのGPUクラスタを構築する際のベースとなるインフラストラクチャを、予め用意された Terraform スクリプトを活用して自動構築し、 containerd と NVIDIA Container Toolkit を使用するコンテナ実行環境で起動するコンテナ上で NCCL(NVIDIA Collective Communication Library) のGPU間通信性能を NCCL Tests で検証します。
この自動構築は、 Terraform スクリプトを リソース・マネージャ に読み込ませて作成する スタック を使用する方法と、 Terraform 実行環境を用意して Terraform CLIを使用する方法から選択することが出来ます。
このチュートリアルで作成する環境は、ユーザ管理、ホスト名管理、共有ファイルシステム、プログラム開発環境等、必要なソフトウェア環境をこの上に整備し、ご自身の要件に沿ったGPUクラスタを構築する際の基礎インフラストラクチャとして利用することが可能です。
なお、これらのクラスタ管理に必要なソフトウェアの導入までを自動化する HPCクラスタスタック も利用可能で、詳細は OCI HPCチュートリアル集 の GPUクラスタを構築する(スタティッククラスタ自動構築編) を参照してください。
本チュートリアルで作成するGPUクラスタ構築用の Terraform スクリプトは、そのひな型が GitHub のパブリックレポジトリから公開されており、適用すると以下の処理を行います。
- VCN と関連するネットワークリソース作成
- Bastionノード作成
- GPUノード用 インスタンス構成 作成
- クラスタ・ネットワーク とGPUノード作成
- GPUクラスタ内のノード間SSHアクセスに使用するSSH鍵ペア作成・配布
- GPUノードの全ホスト名を記載したホストリストファイル( /home/opc/hostlist.txt )作成
- 作成したBastionノード・GPUノードのホスト名・IPアドレス出力
Bastionノードは、接続するサブネットをパブリックとプライベートから選択することが可能(※1)で、以下のBastionノードへのログイン方法に合わせて選択します。
- インターネット経由ログイン -> パブリックサブネット接続
- 拠点間接続経由ログイン > プライベートサブネット接続
※1)構築方法に Terraform CLIを採用する場合は、パブリックサブネット接続のみ選択可能です。
また VCN と関連するネットワークリソースは、既存のものを使用することも可能で、この場合はこれらが以下の条件を満たしているている必要があります。
- プライベートサブネットが存在する
- パブリックサブネットが存在する(Bastionノードパブリック接続の場合)
- パブリックサブネット・プライベートサブネット間で セキュリティ・リスト によりアクセスが制限されていない(Bastionノードパブリック接続の場合)
- プライベートサブネットが Oracle Cloud Agent HPCプラグインの動作条件を満たしている(※2)
※2)この詳細は、 OCI HPCテクニカルTips集 の クラスタネットワーキングイメージを使ったクラスタ・ネットワーク接続方法 の 1-2. 接続サブネットのOCA HPCプラグイン動作条件充足確認 を参照してください。
本チュートリアルで構築するコンテナランタイムは、ブリッジネットワークモードで起動するコンテナに於いて、 10.0.2.2 を特別なIPアドレスとして内部的に使用するため、コンテナからこのIPアドレスを含む 10.0.2.0/24 等のCIDRレンジを持つサブネットへの通信が出来ない点に留意します。
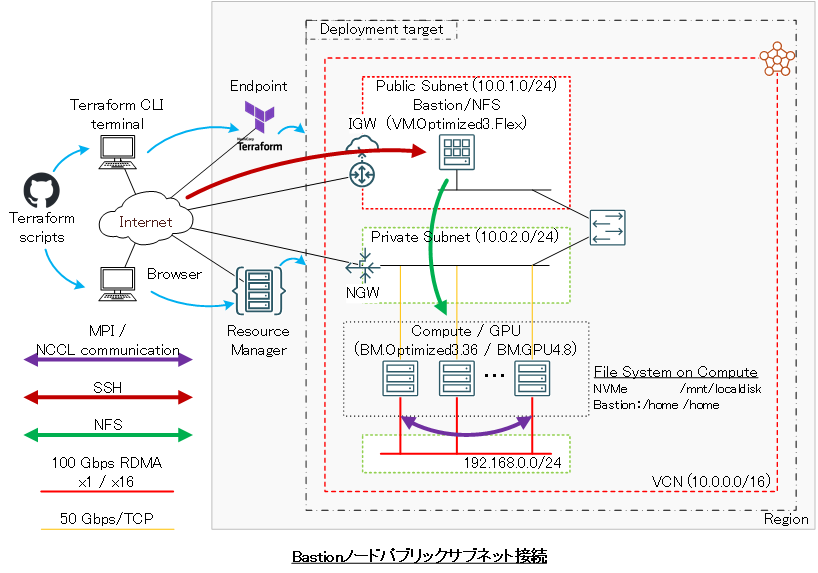
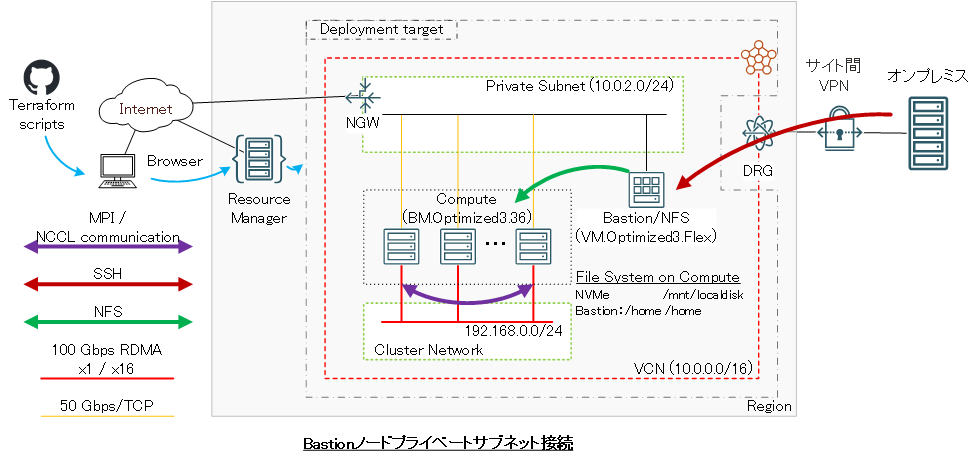
Bastionノード作成は、 cloud-init 設定ファイル(以降 cloud-config と呼称します。)を含み、 cloud-init がBastionノード作成時に以下の処理を行います。
- タイムゾーンをJSTに変更
- ホームディレクトリ領域のNFSエクスポート
- GPUノードのDNS名前解決をショートホスト名で行うための resolv.conf 修正
またGPUノード用 インスタンス構成 は、 cloud-config を含み、 cloud-init がGPUノード作成時に以下の処理を行います。
- タイムゾーンをJSTに変更
- NVMe SSDローカルディスク領域ファイルシステム作成
- firewalld 停止
- ルートファイルシステム拡張
- BastionノードのDNS名前解決をショートホスト名で行うための resolv.conf 修正
- Bastionノードホームディレクトリ領域のNFSマウント
所要時間 : 約2時間
前提条件 : GPUクラスタを収容するコンパートメント(ルート・コンパートメントでもOKです)の作成と、このコンパートメントに対する必要なリソース管理権限がユーザーに付与されていること。
注意 : 本コンテンツ内の画面ショットは、現在のOCIコンソール画面と異なっている場合があります。
本章は、GPUクラスタを構築する際事前に用意しておく必要のあるリソースを作成します。
この手順は、構築手法に リソース・マネージャ を使用するか Terraform CLIを使用するかで異なります。
- リソース・マネージャを使用する場合
- 構成ソース・プロバイダ 作成
- スタック 作成
- Terraform CLIを使用する場合
- Terraform 実行環境構築
- Terraform スクリプト作成
以降では、2つの異なる構築手法毎にその手順を解説します。
構成ソース・プロバイダ の作成は、 ここ を参照してください。
OCIコンソールにログインし、GPUクラスタを構築するリージョンを選択後、 開発者サービス → リソース・マネージャ → スタック とメニューを辿ります。
表示される以下画面で、スタックの作成 ボタンをクリックします。
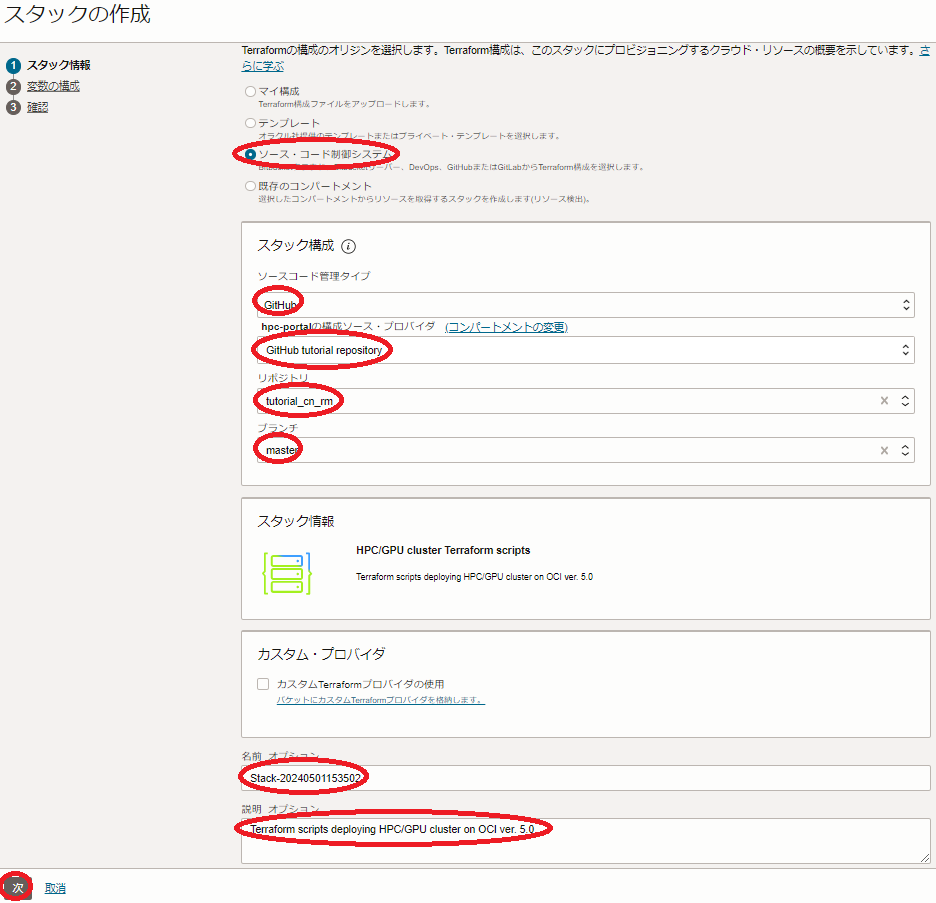
次に、表示される以下 スタック情報 画面で、以下の情報を入力し、下部の Next ボタンをクリックします。
- Terraformの構成のオリジン : ソース・コード制御システム
- ソースコード管理タイプ : GitHub
- 構成ソース・プロバイダ : 先に作成した 構成ソース・プロバイダ
- リポジトリ : tutorial_cn_rm
- ブランチ : master
- 名前 : スタックに付与する名前(任意)
- 説明 : スタックに付与する説明(任意)
次に、表示される以下 変数の構成 画面で、各画面フィールドに以下の情報を入力し、下部の Next ボタンをクリックします。
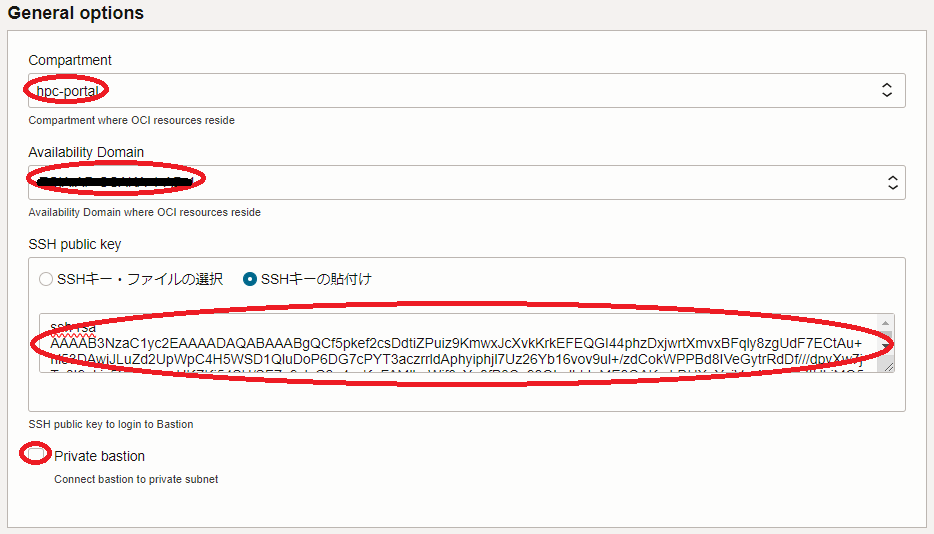
- General options フィールド
- Compartment : GPUクラスタを構築する コンパートメント
- Availability Domain : GPUクラスタを構築する 可用性ドメイン
- SSH public key : Bastionノードにログインする際使用するSSH秘密鍵に対応する公開鍵
(公開鍵ファイルのアップロード( SSHキー・ファイルの選択 )と公開鍵のフィールドへの貼り付け( SSHキーの貼付け )が選択可能) - Private bastion : Bastionノードをプライベートサブネットに接続するかどうかを指定(デフォルト:パブリックサブネット接続)
(パブリックサブネットに接続する場合はチェックオフ/プライベートサブネットに接続する場合はチェック) - Use existing VCN : 既存の VCN を使用するかどうかを指定(デフォルト: VCN を新規作成)
(既存の VCN を使用する場合は、チェックすると表示される VCN ・パブリックサブネット・プライベートサブネットの各フィールドにOCIDを指定します。)
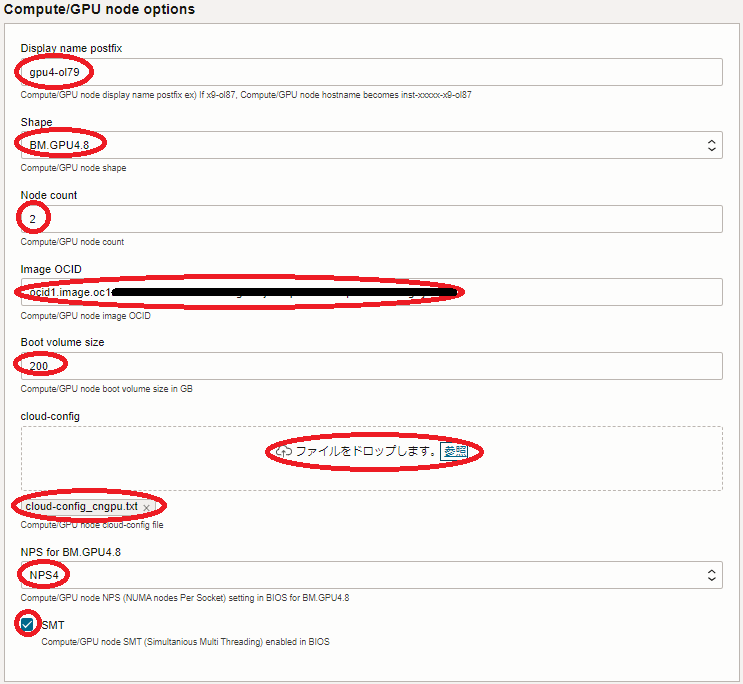
- Compute/GPU node options フィールド
- Display name postfix : GPUノードホスト名の接尾辞(※3)
- Shape : BM.GPU4.8 / BM.GPU.A100-v2.8
- Node count : GPUノードのノード数(デフォルト:2)
- Image OCID : GPUノードのイメージOCID(※4)
- Boot volume size : GPUノードのブートボリュームサイズ(200GB以上)
- cloud-config : GPUノードの cloud-config (※5)
- NPS for BM.xxxx.xx : GPUノードの NPS 設定値 (デフォルト:NPS4) (※6)
- SMT : GPUノードの SMT 設定値 (デフォルト:有効) (※6)
※3) 例えば gpu4-ol905 と指定した場合、GPUノードのホスト名は inst-xxxxx-gpu4-ol905 となります。( xxxxx はランダムな文字列)
※4)以下のOCIDを指定します。なおこのイメージは、Bastionノードにも使用されます。
| No. (※7) |
Oracle Linux バージョン |
OCID |
|---|---|---|
| 15 | 9.5 | ocid1.image.oc1..aaaaaaaaevo5a2g6zd524mlu5aopkzxem6farzeilzqwcaax6nnpaflr2ipq |
※5)以下をテキストファイルとして保存し、ブラウザから読み込みます。
なお既存の VCN を使用する場合は、以下の cloud-config 中のDNSサーチパスにパブリックサブネット名(public.vcn.oraclevcn.com)を追加している箇所を、既存のパブリックサブネット名に変更します。
#cloud-config
timezone: Asia/Tokyo
runcmd:
#
# Mount NVMe local storage
- vgcreate nvme /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1
- lvcreate -l 100%FREE nvme
- mkfs.xfs -L localscratch /dev/nvme/lvol0
- mkdir -p /mnt/localdisk
- echo "LABEL=localscratch /mnt/localdisk/ xfs defaults,noatime 0 0" >> /etc/fstab
- systemctl daemon-reload
- mount /mnt/localdisk
#
# Stop firewalld
- systemctl disable --now firewalld
#
# Expand root file system to those set by instance configuration
- /usr/libexec/oci-growfs -y
#
# Add public subnet to DNS search
- sed -i '/^search/s/$/ public.vcn.oraclevcn.com/g' /etc/resolv.conf
- chattr -R +i /etc/resolv.conf
#
# NFS mount setting
- echo "bastion:/home /home nfs defaults,vers=3 0 0" >> /etc/fstab
- systemctl daemon-reload
- mount /home
※6)詳細は、 パフォーマンス関連Tips集 の パフォーマンスに関連するベア・メタル・インスタンスのBIOS設定方法 を参照してください。
※7)OCI HPCテクニカルTips集 の クラスタネットワーキングイメージの選び方 の 1. クラスタネットワーキングイメージ一覧 のイメージNo.です。
次に、表示される 確認 画面で、これまでの設定項目が意図したものになっているかを確認し、以下 作成されたスタックで適用を実行しますか。 フィールドの 適用の実行 をチェックオフし、下部の 作成 ボタンをクリックします。

ここで 適用の実行 をチェックした場合、 作成 ボタンのクリックと同時に スタック の適用が開始され、GPUクラスタの構築が始まりますが、このチュートリアルでは後の章で改めて スタック の適用を行います。
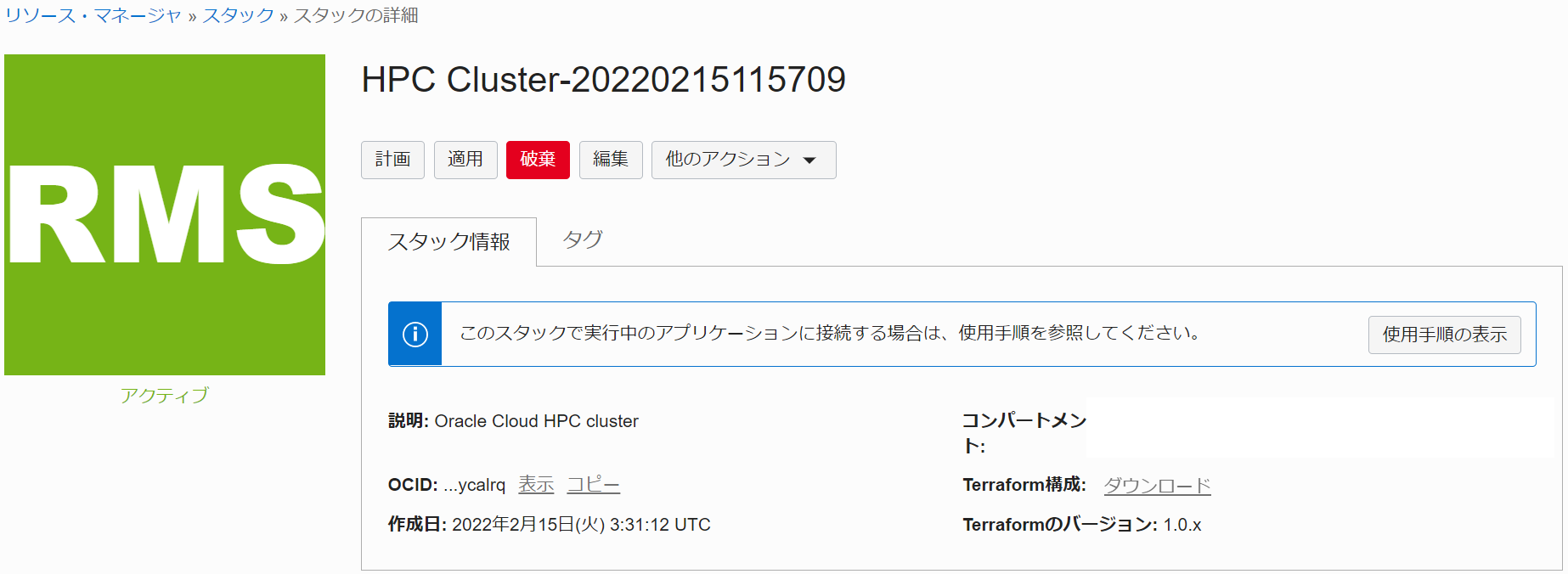
これで、以下画面のとおりGPUクラスタ構築用 スタック が作成されました。
本章は、 Terraform CLIを使用してGPUクラスタのライフサイクル管理を実行する Terraform 実行環境を構築します。
この実行環境は、インターネットに接続された Linux ・ Windows ・ Mac の何れかのOSが稼働している端末であればよく、以下のような選択肢が考えられます。
- OCI上の Linux が稼働するVMインスタンス
- ご自身が使用する Windows / Mac パソコン
- ご自身が使用する Windows / Mac パソコンで動作する Linux ゲストOS
本チュートリアルは、この Terraform 実行環境のOSに Oracle Linux 8.9を使用します。
Terraform 実行環境は、以下のステップを経て構築します。
- Terraform インストール
- Terraform 実行環境とOCI間の認証関係締結(APIキー登録)
具体的な Terraform 実行環境構築手順は、チュートリアル TerraformでOCIの構築を自動化する の 2. Terraform環境の構築 を参照してください。
また、関連するOCI公式ドキュメントは、 ここ を参照してください。
本チュートリアルで使用するGPUクラスタ構築用の Terraform スクリプトは、そのひな型を GitHub のパブリックレポジトリで公開しており、以下のファイル群で構成されています。
| ファイル名 | 用途 |
|---|---|
| cn.tf | インスタンス構成 と クラスタ・ネットワーク の定義 |
| outputs.tf | 作成したリソース情報の出力 |
| terraform.tfvars | Terraform スクリプト内で使用する変数値の定義 |
| variables.tf | Terraform スクリプト内で使用する変数の型の定義 |
| instance.tf | Bastionノードの定義 |
| provider.tf | テナンシ ・ユーザ・ リージョン の定義 |
| vcn.tf | 仮想クラウド・ネットワーク と関連するネットワークリソースの定義 |
これらのうち自身の環境に合わせて修正する箇所は、基本的に terraform.tfvars と provider.tf に集約しています。
また、これらのファイルと同じディレクトリに user_data ディレクトリが存在し、 cloud-init 設定ファイル( cloud-config )を格納しています。
この cloud-config を修正することで、構築するGPUクラスタのOSレベルのカスタマイズをご自身の環境に合わせて追加・変更することも可能でます。
Terraform スクリプトの作成は、まず以下の GitHub レポジトリからひな型となる Terraform スクリプトを Terraform 実行環境にダウンロードしますが、
https://github.com/fwiw6430/tutorial_cn
これには、以下コマンドを Terraform 実行環境のopcユーザで実行するか、
$ sudo dnf install -y git
$ git clone https://github.com/fwiw6430/tutorial_cn
GitHub の Terraform スクリプトレポジトリのページからzipファイルを Terraform 実行環境にダウンロード・展開することで行います。
次に、ダウンロードした Terraform スクリプトのうち、 terraform.tfvars と provider.tf 内の以下 Terraform 変数を自身の環境に合わせて修正します。
この際、これらファイル内の Terraform 変数は、予めコメント( # で始まる行)として埋め込まれていたり、キーワード xxxx で仮の値が入力されているため、コメント行を有効化して自身の値に置き換える等の修正を行います。
[ provider.tf ]
| 変数名 | 設定値 | 確認方法 |
|---|---|---|
| tenancy_ocid | 使用するテナントのOCID | ここ を参照 |
| user_ocid | 使用するユーザのOCID | ここ を参照 |
| private_key_path | OCIに登録したAPIキーの秘密キーのパス | - |
| fingerprint | OCIに登録したAPIキーのフィンガープリント | ここ を参照 |
| region | GPUクラスタを構築するリージョン識別子 | ここ を参照 |
[ terraform.tfvars ]
| 変数名 | 設定値 | 確認方法 |
|---|---|---|
| compartment_ocid | GPUクラスタを構築する コンパートメント のOCID | ここ を参照 |
| ad | GPUクラスタを構築する 可用性ドメイン 識別子 | (※8) |
| ssh_key | Bastionノードログインに使用するSSH秘密鍵に対する公開鍵 | - |
| exist_vcn | 既存の VCN を使用するかどうかの指定(true/false) | - |
| vcn_ocid | 既存の VCN を使用する場合の VCN のOCID(※12) | (※13) |
| public_ocid | 既存の VCN を使用する場合のパブリックサブネットのOCID(※12) | (※13) |
| private_ocid | 既存の VCN を使用する場合のプライベートサブネットのOCID(※12) | (※13) |
| comp_shape | GPUノードに使用するシェイプ ・ BM.GPU4.8 |
- |
| comp_image | GPUノードに使用するOSイメージのOCID | (※9) |
| comp_boot_vol_size | GPUノードの ブートボリューム のサイズ(GB)(最低200GB) | - |
| comp_cloud_config | user_data ディレクトリに格納するGPUノード用 cloud-config ファイル名 ・ cloud-init_cngpu.cfg |
- |
| comp_nps_gpu40 | GPUノードの NPS BIOS設定値 | (※10) |
| comp_smt | GPUノードの SMT BIOS設定値 | (※10) |
| cn_display_name | GPUノードホスト名の接尾辞 | (※11) |
| cn_node_count | GPUノードのノード数 | - |
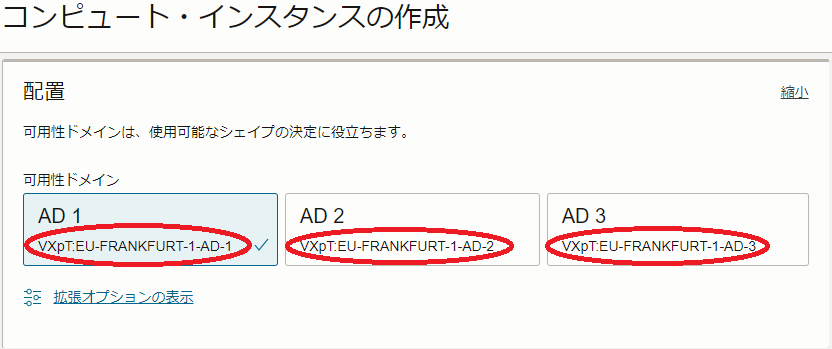
※8)OCIコンソールメニューから コンピュート → インスタンス を選択し インスタンスの作成 ボタンをクリックし、表示される以下 配置 フィールドで確認出来ます。
※9)コメントとして埋め込まれているOSイメージOCIDから、コメント文の記載を参考に適切なOSイメージOCIDのコメントを外して使用します。詳細は、 OCI HPCテクニカルTips集 の クラスタネットワーキングイメージの選び方 の 1. クラスタネットワーキングイメージ一覧 を参照してください。
※10)詳細は、 OCI HPCパフォーマンス関連情報 の パフォーマンスに関連するベア・メタル・インスタンスのBIOS設定方法 を参照してください。
※11)例えば ao-ol905 と指定した場合、GPUノードのホスト名は inst-xxxxx-ao-ol905 となります。( xxxxx はランダムな文字列)
※12)既存の VCN を使用する場合のみコメントを外して指定します。
※13)OCIコンソール上で当該 VCN ・サブネットの詳細画面を表示して確認します。
本章は、先に作成した スタック / Terraform スクリプトを使用し、GPUクラスタを構築します。
この手順は、構築手法に リソース・マネージャ を使用するか Terraform CLIを使用するかで異なり、以降では2つの異なる構築手法毎にその手順を解説します。
以下 スタックの詳細 画面で、 アクション ブルダウンメニュー → 適用 メニューをクリックします。
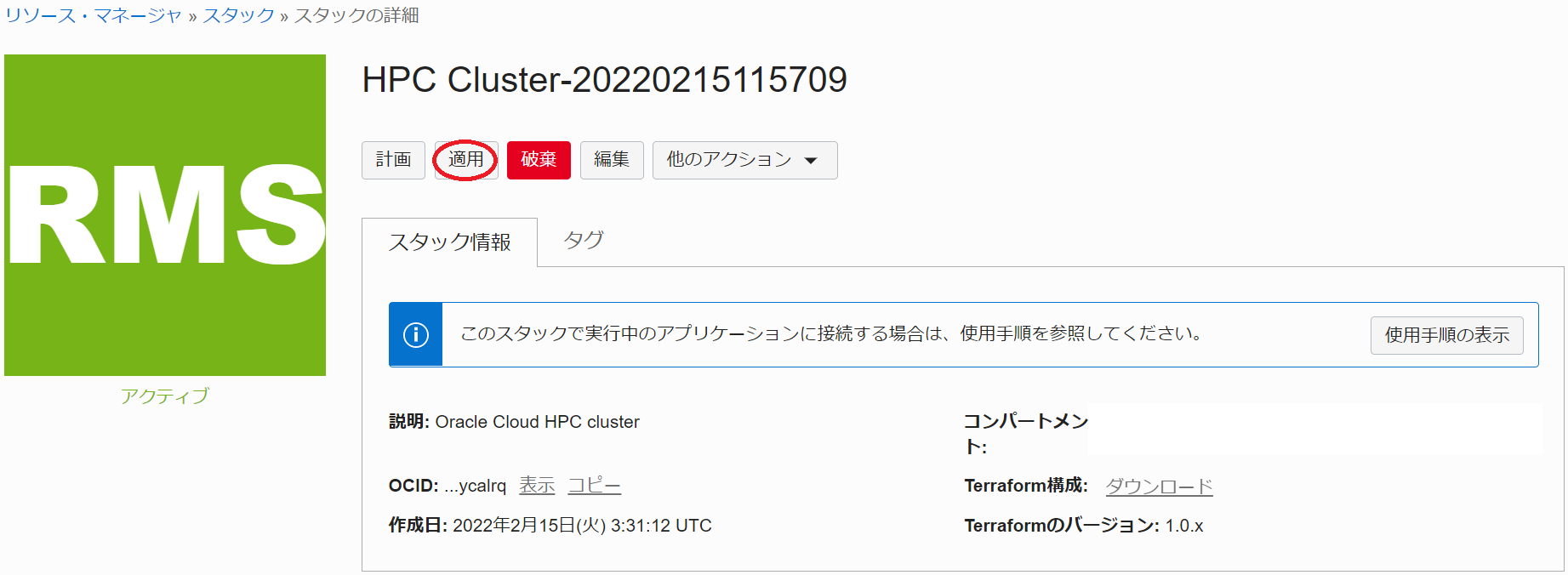
次に、表示される以下画面で、 適用 ボタンをクリックします。
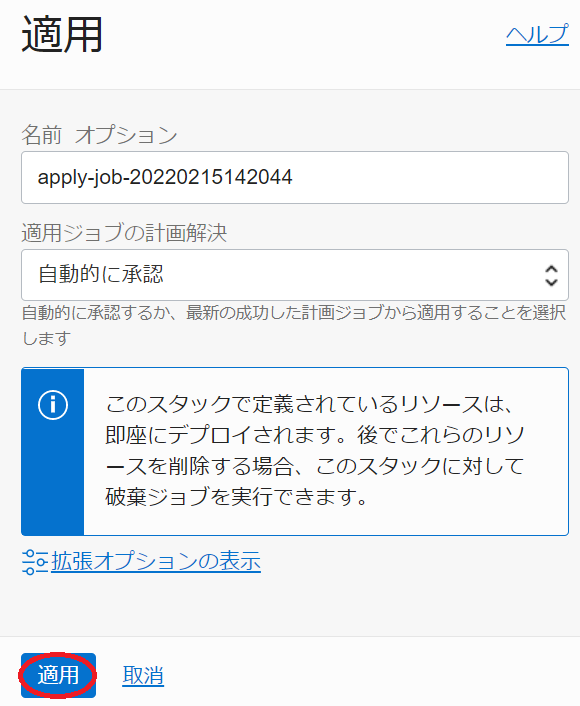
次に、表示される以下ウィンドウでステータスが 受入れ済 → 進行中 と遷移すれば、 スタック の適用が実施されており、 ログ フィールドでリソースの作成状況を確認します。
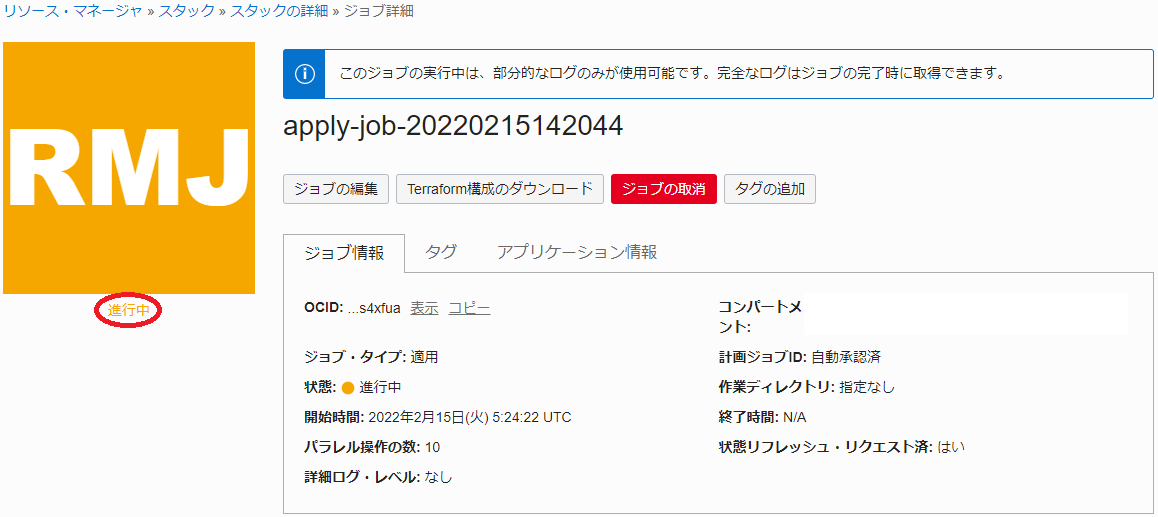
この適用が完了するまでの所要時間は、GPUノードのノード数が2ノードの場合で15分程度です。
ステータスが 成功 となれば、GPUクラスタの構築が完了しており、以下のように ログ フィールドの最後にBastionノードとGPUノードのホスト名とIPアドレスが出力されます。
:
:
:
Outputs:
Bastion_instances_created = {
"display_name" = "bastion"
"private_ip" = "10.0.1.186"
"public_ip" = "123.456.789.123"
}
Compute_in_cn_created_e5 = {}
Compute_in_cn_created_none5 = {
"inst-2tdfx-ao-ol810" = {
"display_name" = "inst-2tdfx-ao-ol810"
"private_ip" = "10.0.2.129"
}
"inst-t157c-ao-ol810" = {
"display_name" = "inst-t157c-ao-ol810"
"private_ip" = "10.0.2.247"
}
}
Terraform 実行環境で、以下コマンドを実行します。
$ cd tutorial_cn
$ terraform init
$ terraform apply --auto-approve
最後のコマンドによる Terraform スクリプトの適用完了までの所要時間は、GPUノードのノード数が2ノードの場合で15分程度です。
Terraform スクリプトの適用が正常に完了すると、以下のようにコマンド出力の最後にBastionノードとGPUノードのホスト名とIPアドレスが出力されます。
:
:
:
Outputs:
Bastion_instances_created = {
"display_name" = "bastion"
"private_ip" = "10.0.1.186"
"public_ip" = "123.456.789.123"
}
Compute_in_cn_created_e5 = {}
Compute_in_cn_created_none5 = {
"inst-2tdfx-ao-ol810" = {
"display_name" = "inst-2tdfx-ao-ol810"
"private_ip" = "10.0.2.129"
}
"inst-t157c-ao-ol810" = {
"display_name" = "inst-t157c-ao-ol810"
"private_ip" = "10.0.2.247"
}
}
本章は、構築されたGPUクラスタ環境を確認します。
この際、作成されたGPUノードの全ホスト名を記載したホストリストファイルを使用し、BastionノードからGPUクラスタ内の全GPUノードにSSHでコマンドを発行、その環境を確認します。
なおこのホストリストファイルは、Bastionノードと全GPUノードに /home/opc/hostlist.txt として存在します。
Bastionノードは、パブリックサブネット接続の場合はGPUクラスタ構築完了時に表示されるパブリックIPアドレスに対してインターネット経由SSHログインし、プライベートサブネット接続の場合はGPUクラスタ構築完了時に表示されるプライベートIPアドレスに対して拠点間接続経由SSHログインしますが、これには構築時に指定したSSH公開鍵に対応する秘密鍵を使用して以下コマンドで行います。
$ ssh -i path_to_ssh_secret_key opc@123.456.789.123
cloud-init は、GPUノードが起動してSSHログインできる状態であっても、その処理が継続している可能性があるため、以下コマンドをBastionノードのopcユーザで実行し、そのステータスが done となっていることで cloud-init の処理完了を確認します。
$ for hname in `cat /home/opc/hostlist.txt`; do echo $hname; ssh -oStrictHostKeyChecking=accept-new $hname "sudo cloud-init status"; done
inst-aizyo-ao-ol905
Warning: Permanently added 'inst-aizyo-ao-ol905' (ED25519) to the list of known hosts.
status: done
inst-apcve-ao-ol905
Warning: Permanently added 'inst-apcve-ao-ol905' (ED25519) to the list of known hosts.
status: done
$
ステータスが running の場合は、 cloud-init の処理が継続中のため、処理が完了するまで待ちます。
GPUノードは、以下のようにルートファイルシステムがデフォルトの50 GBから指定したサイズに拡張され、NVMe SSDローカルディスクが /mnt/localdisk にマウントされ、Bastionノードの /home が /home としてマウントされています。
$ for hname in `cat /home/opc/hostlist.txt`; do echo $hname; ssh $hname "df -h / /mnt/localdisk /home"; done
inst-aizyo-ao-ol905
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ocivolume-root 183G 31G 153G 17% /
/dev/mapper/nvme-lvol0 25T 177G 25T 1% /mnt/localdisk
bastion:/home 83G 31G 53G 37% /home
inst-apcve-ao-ol905
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ocivolume-root 183G 31G 153G 17% /
/dev/mapper/nvme-lvol0 25T 177G 25T 1% /mnt/localdisk
bastion:/home 83G 31G 53G 37% /home
$
以下コマンドをBastionノードのopcユーザで実行し、GPUノードのBIOSで指定した NPS と SMT 設定が指定したとおりになっていることを確認します。
$ for hname in `cat /home/opc/hostlist.txt`; do echo $hname; ssh $hname "lscpu | grep -i -e numa -e thread"; done
inst-aizyo-ao-ol905
Thread(s) per core: 2
NUMA node(s): 8
NUMA node0 CPU(s): 0-7,64-71
NUMA node1 CPU(s): 8-15,72-79
NUMA node2 CPU(s): 16-23,80-87
NUMA node3 CPU(s): 24-31,88-95
NUMA node4 CPU(s): 32-39,96-103
NUMA node5 CPU(s): 40-47,104-111
NUMA node6 CPU(s): 48-55,112-119
NUMA node7 CPU(s): 56-63,120-127
inst-apcve-ao-ol905
Thread(s) per core: 2
NUMA node(s): 8
NUMA node0 CPU(s): 0-7,64-71
NUMA node1 CPU(s): 8-15,72-79
NUMA node2 CPU(s): 16-23,80-87
NUMA node3 CPU(s): 24-31,88-95
NUMA node4 CPU(s): 32-39,96-103
NUMA node5 CPU(s): 40-47,104-111
NUMA node6 CPU(s): 48-55,112-119
NUMA node7 CPU(s): 56-63,120-127
$
以下コマンドをBastionノードのopcユーザで実行し、GPUノードの クラスタ・ネットワーク 接続に使用する16個のネットワークインターフェースに正しくIPアドレスが設定されていることを確認します。
$ for hname in `cat /home/opc/hostlist.txt`; do echo $hname; ssh $hname "ip a | grep -e ens300f0np0 -e ens800f0np0 -e eth0 -e rdma | grep inet"; done
inst-aizyo-ao-ol905
inet 10.0.2.135/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
inet 10.224.0.135/12 scope global rdma0
inet 10.224.1.135/12 scope global rdma1
inet 10.224.2.135/12 scope global rdma2
inet 10.224.3.135/12 scope global rdma3
inet 10.224.4.135/12 scope global rdma4
inet 10.224.5.135/12 scope global rdma5
inet 10.224.6.135/12 scope global rdma6
inet 10.224.7.135/12 scope global rdma7
inet 10.224.8.135/12 scope global rdma8
inet 10.224.9.135/12 scope global rdma9
inet 10.224.10.135/12 scope global rdma10
inet 10.224.11.135/12 scope global rdma11
inet 10.224.12.135/12 scope global rdma12
inet 10.224.13.135/12 scope global rdma13
inet 10.224.14.135/12 scope global rdma14
inet 10.224.15.135/12 scope global rdma15
inst-apcve-ao-ol905
inet 10.0.2.83/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
inet 10.224.0.83/12 scope global rdma0
inet 10.224.1.83/12 scope global rdma1
inet 10.224.2.83/12 scope global rdma2
inet 10.224.3.83/12 scope global rdma3
inet 10.224.4.83/12 scope global rdma4
inet 10.224.5.83/12 scope global rdma5
inet 10.224.6.83/12 scope global rdma6
inet 10.224.7.83/12 scope global rdma7
inet 10.224.8.83/12 scope global rdma8
inet 10.224.9.83/12 scope global rdma9
inet 10.224.10.83/12 scope global rdma10
inet 10.224.11.83/12 scope global rdma11
inet 10.224.12.83/12 scope global rdma12
inet 10.224.13.83/12 scope global rdma13
inet 10.224.14.83/12 scope global rdma14
inet 10.224.15.83/12 scope global rdma15
$
なお、後に実行する NCCL Tests の起動コマンドで設定している NCCL_IB_HCA 環境変数に指定のRDMAリンク名( mlx5_xx )は、以下のように先の クラスタ・ネットワーク 接続用のネットワークインターフェースに対応しています。
$ for hname in `cat /home/opc/hostlist.txt`; do echo $hname; ssh $hname "rdma link show | grep rdma"; done
inst-aizyo-ao-ol905
link mlx5_6/1 state ACTIVE physical_state LINK_UP netdev rdma0
link mlx5_7/1 state ACTIVE physical_state LINK_UP netdev rdma1
link mlx5_8/1 state ACTIVE physical_state LINK_UP netdev rdma2
link mlx5_9/1 state ACTIVE physical_state LINK_UP netdev rdma3
link mlx5_0/1 state ACTIVE physical_state LINK_UP netdev rdma4
link mlx5_1/1 state ACTIVE physical_state LINK_UP netdev rdma5
link mlx5_2/1 state ACTIVE physical_state LINK_UP netdev rdma6
link mlx5_3/1 state ACTIVE physical_state LINK_UP netdev rdma7
link mlx5_14/1 state ACTIVE physical_state LINK_UP netdev rdma8
link mlx5_15/1 state ACTIVE physical_state LINK_UP netdev rdma9
link mlx5_16/1 state ACTIVE physical_state LINK_UP netdev rdma10
link mlx5_17/1 state ACTIVE physical_state LINK_UP netdev rdma11
link mlx5_10/1 state ACTIVE physical_state LINK_UP netdev rdma12
link mlx5_11/1 state ACTIVE physical_state LINK_UP netdev rdma13
link mlx5_12/1 state ACTIVE physical_state LINK_UP netdev rdma14
link mlx5_13/1 state ACTIVE physical_state LINK_UP netdev rdma15
inst-apcve-ao-ol905
link mlx5_6/1 state ACTIVE physical_state LINK_UP netdev rdma0
link mlx5_7/1 state ACTIVE physical_state LINK_UP netdev rdma1
link mlx5_8/1 state ACTIVE physical_state LINK_UP netdev rdma2
link mlx5_9/1 state ACTIVE physical_state LINK_UP netdev rdma3
link mlx5_0/1 state ACTIVE physical_state LINK_UP netdev rdma4
link mlx5_1/1 state ACTIVE physical_state LINK_UP netdev rdma5
link mlx5_2/1 state ACTIVE physical_state LINK_UP netdev rdma6
link mlx5_3/1 state ACTIVE physical_state LINK_UP netdev rdma7
link mlx5_14/1 state ACTIVE physical_state LINK_UP netdev rdma8
link mlx5_15/1 state ACTIVE physical_state LINK_UP netdev rdma9
link mlx5_16/1 state ACTIVE physical_state LINK_UP netdev rdma10
link mlx5_17/1 state ACTIVE physical_state LINK_UP netdev rdma11
link mlx5_10/1 state ACTIVE physical_state LINK_UP netdev rdma12
link mlx5_11/1 state ACTIVE physical_state LINK_UP netdev rdma13
link mlx5_12/1 state ACTIVE physical_state LINK_UP netdev rdma14
link mlx5_13/1 state ACTIVE physical_state LINK_UP netdev rdma15
$
本章は、 containerd と NVIDIA Container Toolkit を使用し、GPU利用可能なコンテナ環境を構築します。
このコンテナ環境構築は、 OCI HPCテクニカルTips集 の containerdによるコンテナ実行環境構築方法 の手順を全てのGPUノードに適用することで実施します。
本章は、 NGC Catalog から提供される TensorFlow NGC Container を起動し、このコンテナに含まれる NCCL とコンテナ上でビルドする NCCL Tests を使用し、コンテナ上で NCCL のGPU間通信性能を検証します。
この NCCL Tests 実行方法は、 OCI HPCパフォーマンス関連情報 の NCCL Tests実行方法(BM.GPU4.8/BM.GPU.A100-v2.8 Oracle Linux編) に従い実施します。
本章は、先に作成した スタック / Terraform スクリプトを使用し、GPUクラスタを削除します。
この手順は、構築手法に リソース・マネージャ を使用する方法を採用するか、 Terraform CLIを使用する方法を採用するかで異なり、以降では2つの異なる構築手法毎にその手順を解説します。
以下 スタックの詳細 画面で、 アクション ブルダウンメニュー → 破棄 メニューをクリックします。
次に、表示される以下画面で、 破棄 ボタンをクリックします。
次に、表示される以下ウィンドウでステータスが 受入れ済 → 進行中 と遷移すれば、 スタック の破棄が実施されており、 ログ フィールドでリソースの削除状況を確認します。
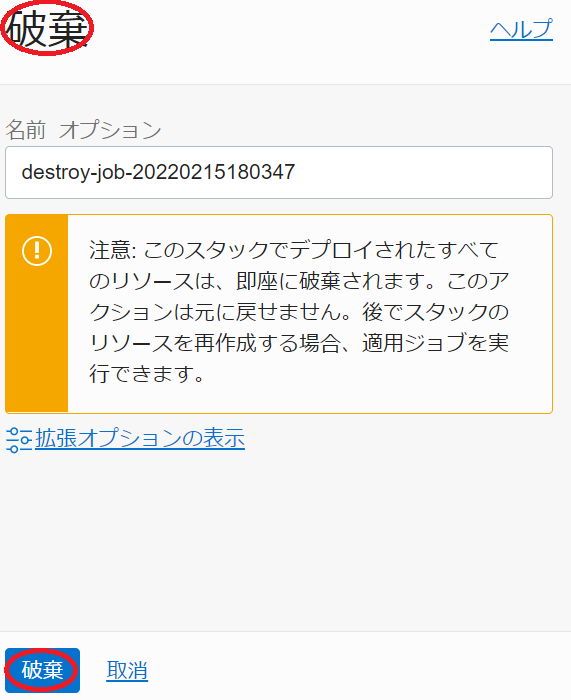
この破棄が完了するまでの所要時間は、GPUノードのノード数が2ノードの場合で5分程度です。
ステータスが 成功 となれば、GPUクラスタの削除が完了しています。
本章は、 Terraform スクリプトを Terraform CLIで破棄し、GPUクラスタを削除します。
Terraform 実行環境の tutorial_cn ディレクトリで以下コマンドを実行し、削除が正常に完了したことをメッセージから確認します。
$ terraform destroy --auto-approve
:
Destroy complete! Resources: 18 destroyed.
$
この破棄が完了するまでの所要時間は、GPUノードのノード数が2ノードの場合で5分程度です。
これで、このチュートリアルは終了です。