
202: コマンドラインから大量データをロードしてみよう(DBMS_CLOUD)
大量データをAutonomous Databaseにロードするために、DBMS_CLOUDパッケージを活用したデータのロード方法を確認していきましょう。 下記のサンプルデータ(customers.csv)をローカルデバイスに事前にダウンロードして下さい。
前提条件
- ADBインスタンスが構成済みであること
※ADBインタンスを作成方法については、101:ADBインスタンスを作成してみよう を参照ください。
目次
**所要時間 :** 約10分
-
ADBインスタンスを作成しようで学習したDatabase Actionsを利用したインスタンスへの接続 を参照し、Database Actionsを起動し、Adminユーザーで接続してください。ツールタブから、データベース・アクションを開くをクリックしてください。
-
DBMS_CLOUDパッケージを使ったデータロードをワークシートで実行していきます。SQLをクリックしてください。
以下の1~5までの例を参考にコマンドを作成し、ワークシートに貼り付けスクリプトの実行をクリックし、データをロードします(集合ハンズオンセミナーでは講師の指示に従ってください)
-
クレデンシャル情報の登録
クレデンシャル情報の登録に必要な認証情報を手に入れる手順は、ADBにデータをロードしてみよう(Database Actions)の記事内のクラウド・ストレージからデータをロードしてみようを参照ください。
credential_name: DBに保存した認証情報を識別するための名前、任意
username: 上記で取得したOracle Object Storageにアクセスするための ユーザ名
password: 取得したAuth Token
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( CREDENTIAL_NAME => 'USER_CRED', USERNAME => 'myUsername', PASSWORD => 'LPB>Ktk(1M1SD+a]+r' ); END;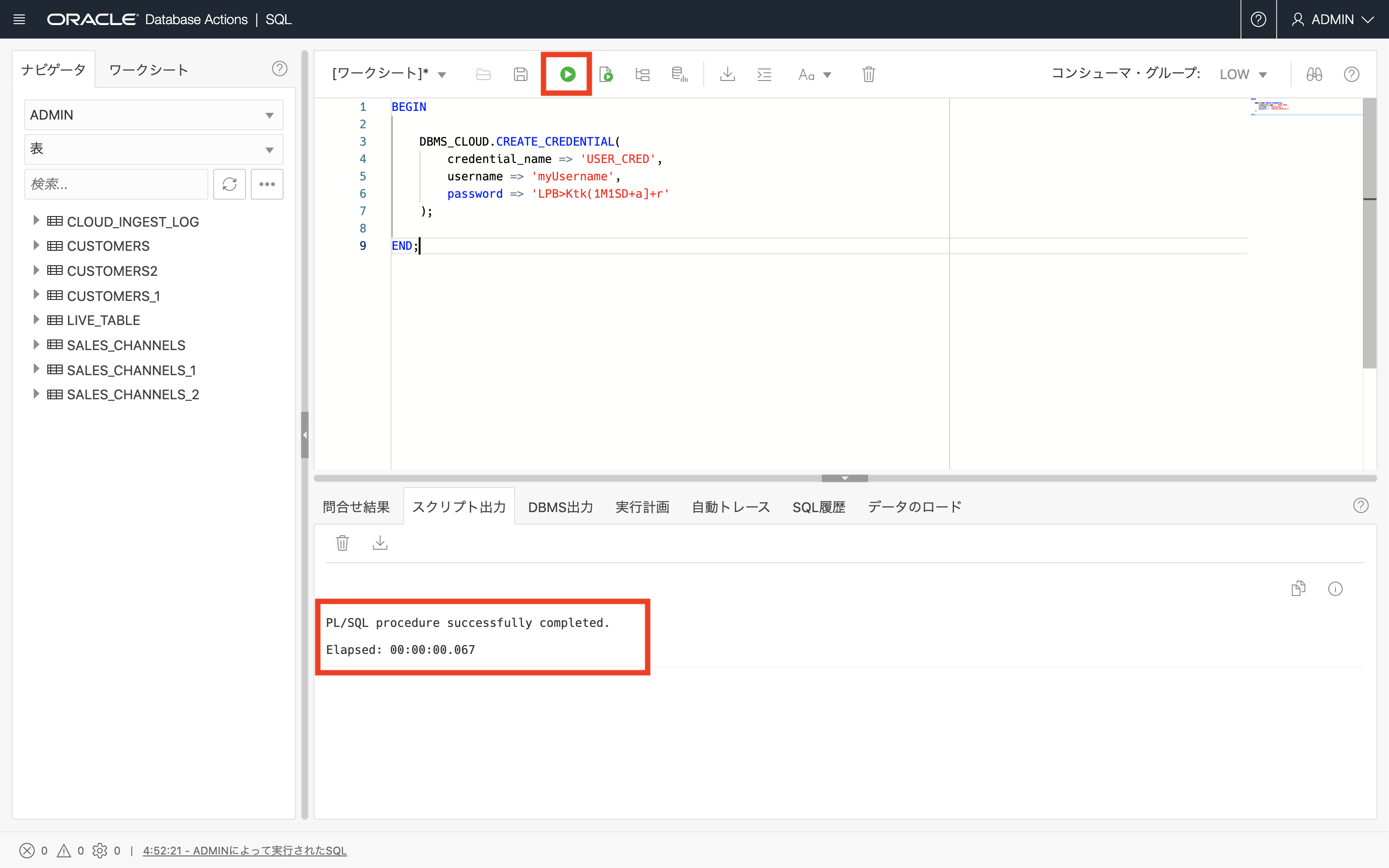
※ 作成済みのCredentialを削除する場合は以下を実行ください
BEGIN DBMS_CLOUD.DROP_CREDENTIAL(credential_name => 'USER_CRED'); END;
-
ADB上にロード先の表作成
DROP TABLE customers; CREATE TABLE CUSTOMERS ( CUST_ID NUMBER NOT NULL, CUST_FIRST_NAME VARCHAR2(20) NOT NULL, CUST_LAST_NAME VARCHAR2(40) NOT NULL, CUST_GENDER CHAR(1) NOT NULL, CUST_YEAR_OF_BIRTH NUMBER(4) NOT NULL, CUST_MARITAL_STATUS VARCHAR2(20), CUST_STREET_ADDRESS VARCHAR2(40) NOT NULL, CUST_POSTAL_CODE VARCHAR2(10) NOT NULL, CUST_CITY VARCHAR2(30) NOT NULL, CUST_CITY_ID NUMBER NOT NULL, CUST_STATE_PROVINCE VARCHAR2(40) NOT NULL, CUST_STATE_PROVINCE_ID NUMBER NOT NULL, COUNTRY_ID NUMBER NOT NULL, CUST_MAIN_PHONE_NUMBER VARCHAR2(25) NOT NULL, CUST_INCOME_LEVEL VARCHAR2(30), CUST_CREDIT_LIMIT NUMBER, CUST_EMAIL VARCHAR2(50), CUST_TOTAL VARCHAR2(14) NOT NULL, CUST_TOTAL_ID NUMBER NOT NULL, CUST_SRC_ID NUMBER, CUST_EFF_FROM DATE, CUST_EFF_TO DATE, CUST_VALID VARCHAR2(1) );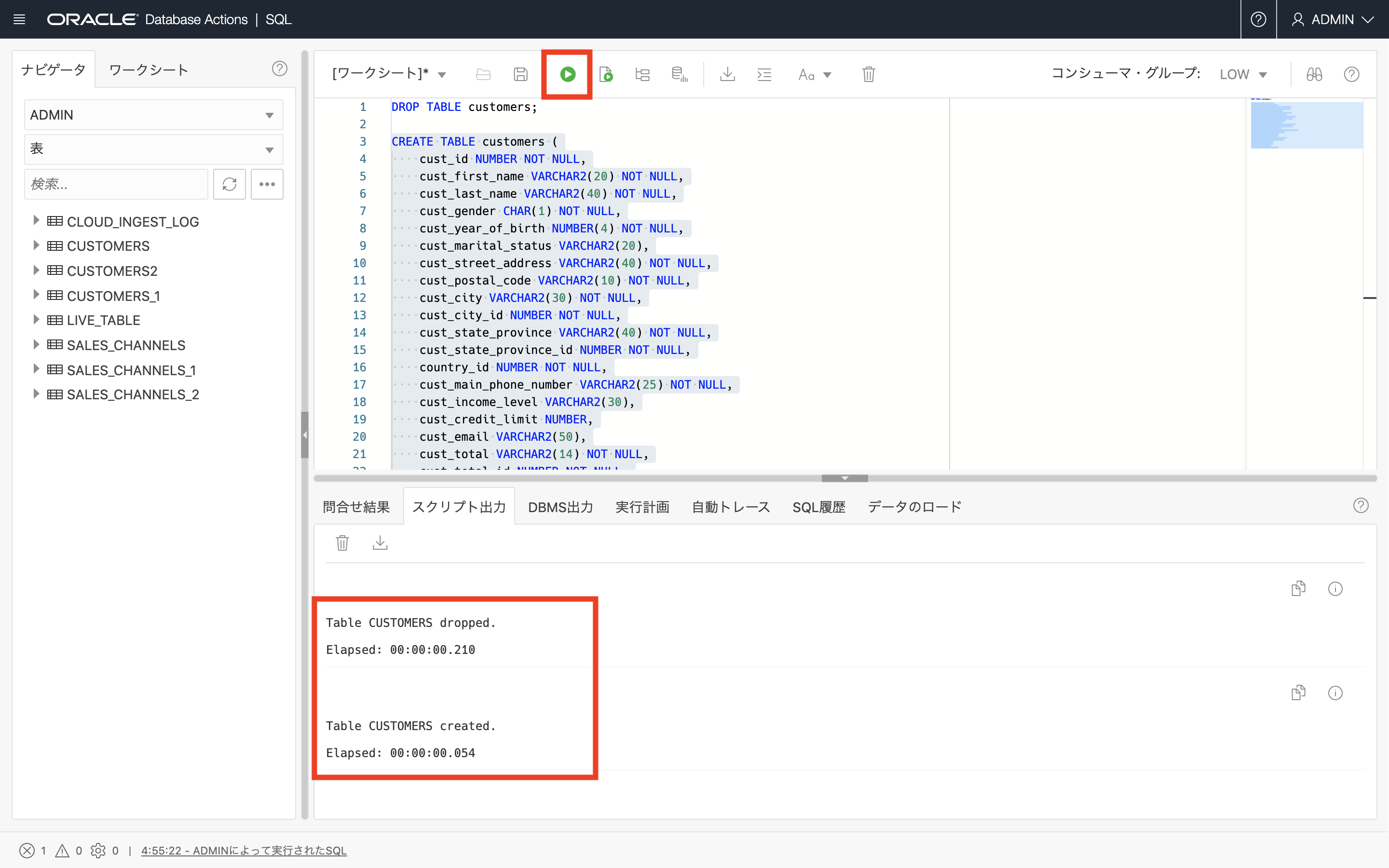
-
ADB上へのデータロード
file_uri_list: Object StorageにアップロードしたファイルのURL(< region >、< namespace >、< bucket >は実際の値に置き換えて下さい)
BEGIN DBMS_CLOUD.COPY_DATA( TABLE_NAME => 'CUSTOMERS', CREDENTIAL_NAME => 'USER_CRED', FILE_URI_LIST => 'https://objectstorage.<region>.oraclecloud.com/n/<namespace>/b/<bucket>/o/customers.csv', FORMAT => JSON_OBJECT( 'ignoremissingcolumns' VALUE 'true', 'removequotes' VALUE 'true', 'dateformat' VALUE 'YYYY-MM-DD HH24:MI:SS', 'blankasnull' VALUE 'true' ) ); END;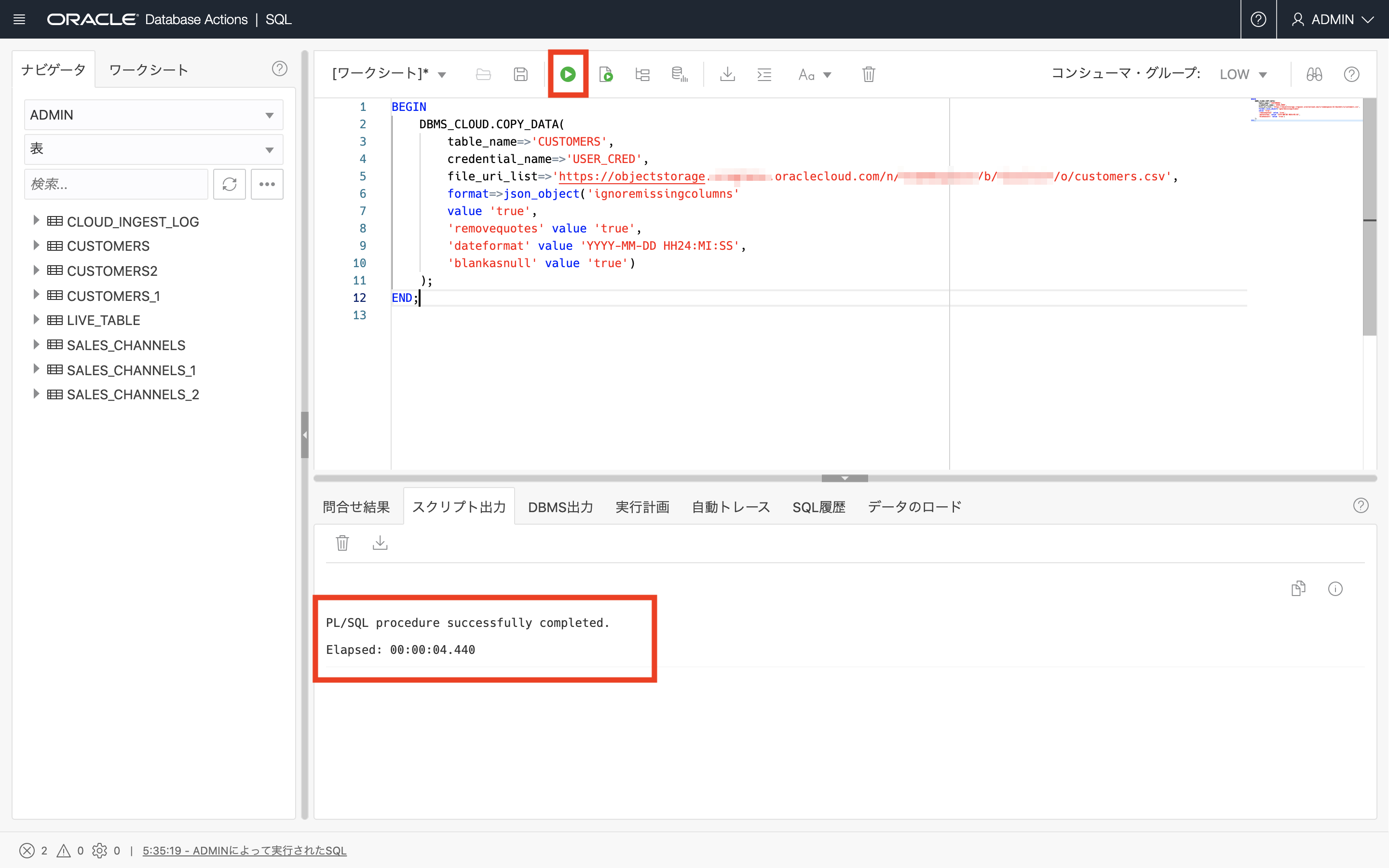
-
ロード結果の確認
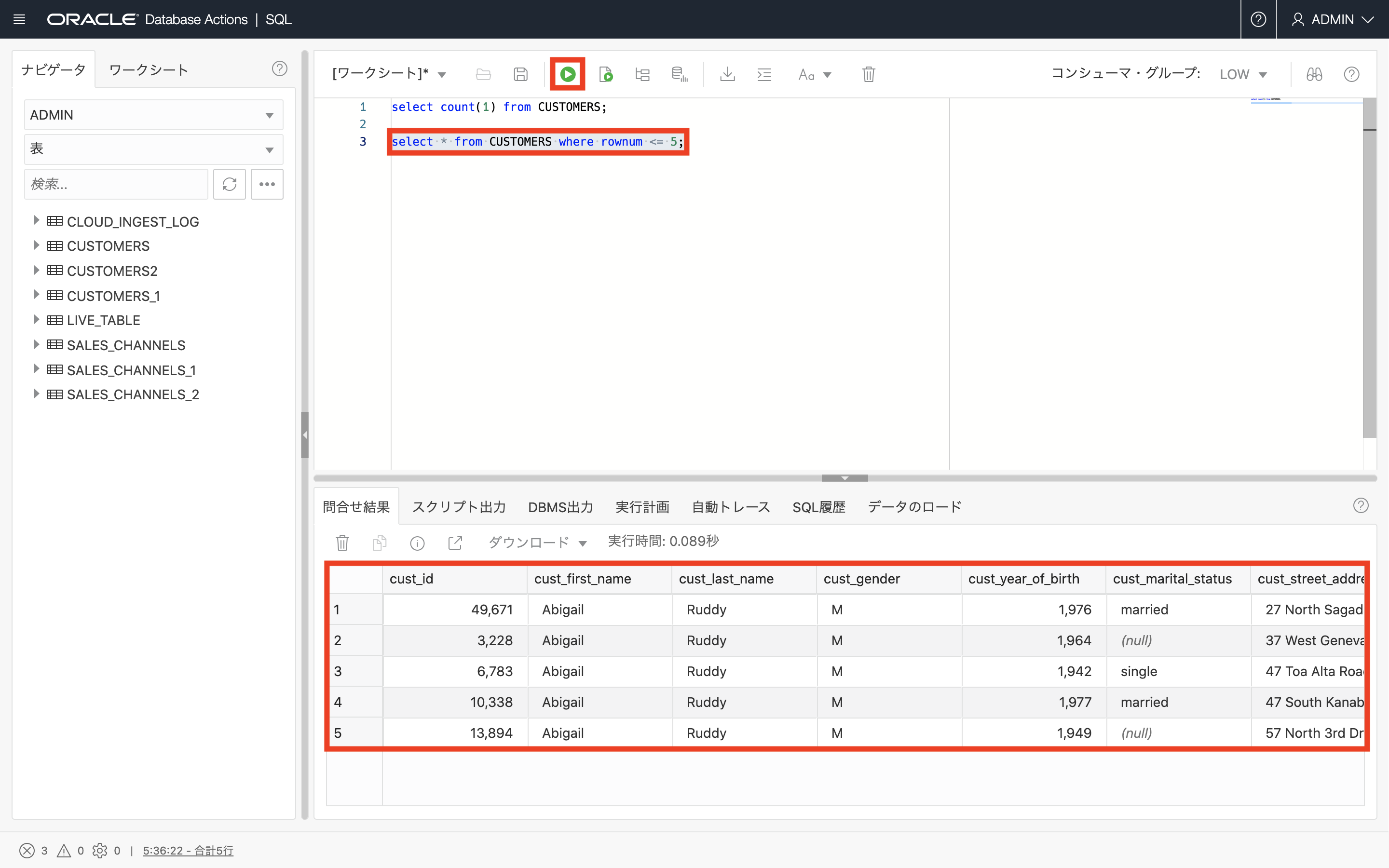
SELECT COUNT(1) FROM CUSTOMERS; SELECT * FROM CUSTOMERS WHERE ROWNUM <= 5;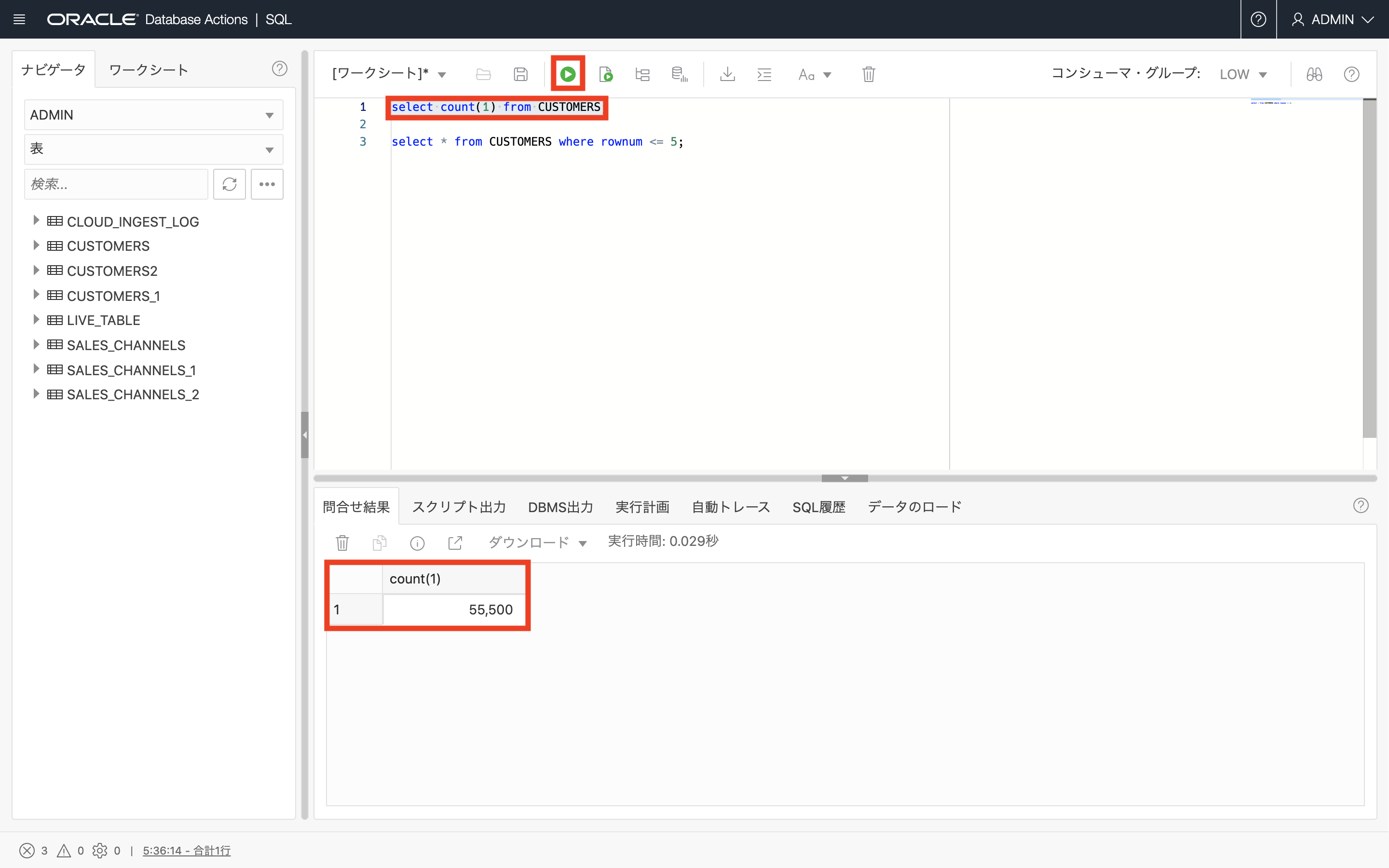
-
主キー(PK)など各種制約の作成(必要に応じて)
ロード完了後に実行した方が、より高速にロードすることが可能なのでおススメです
ALTER TABLE CUSTOMERS ADD CONSTRAINT CUSTOMERS_PK PRIMARY KEY ( CUST_ID );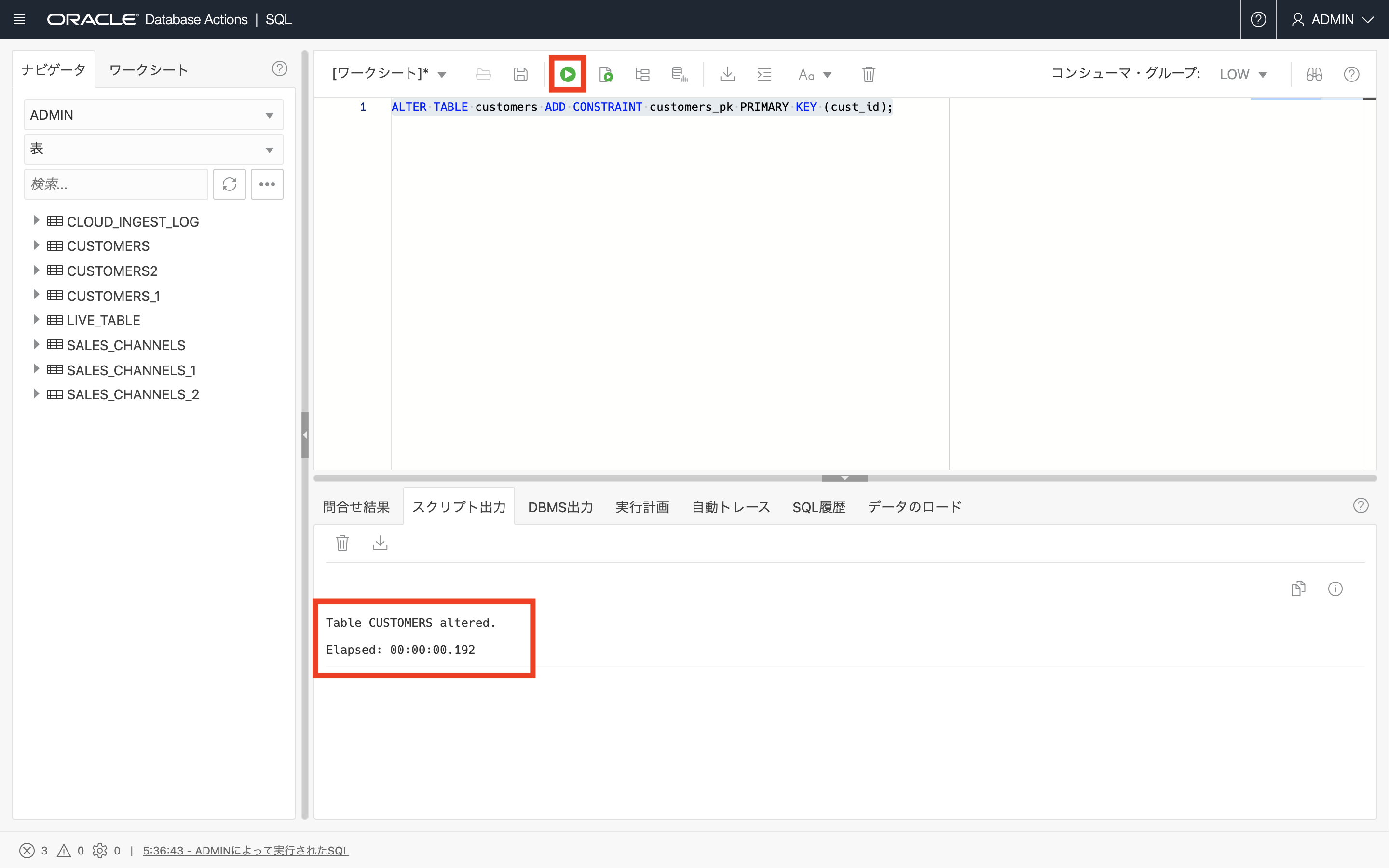
以上で、この章の作業は終了です
-
大量データのロード処理を高速化するには?
・ソースファイルを圧縮
→ DBMS_CLOUDパッケージはgzip圧縮済みのファイルを展開せずにそのままロードできます。
・ソースファイルを分割
→ ソースファイルがSJIS等の場合はロード前にファイルを分割しロードすることを推奨します。複数のCPUコアが並列に処理し高速にロードできます。ソースファイルが UTF8の場合はDBMS_CLOUD内で自動的にファイルを分割するので不要ですが、もしgzipで圧縮する場合は、事前にファイルを分割した上で圧縮してください。ロードしたいソー ファイルが固定長フォーマットの場合もUTF8の場合と同様です。ファイル分割は不要ですが、もし圧縮する場合は事前にファイルを分割した上で圧縮してください。
→ 尚、分割したCSVファイルの各ファイルの一行目に列名などのヘッダ情報がある場合はエラーとなるため、事前に削除しておくと良いです。
・具体的な実行例
DBMS_CLOUDパッケージで、compressionオプションを付与しつつ、gzip圧縮済みのファイルをロードする例を確認していきましょう。本章で使用したcustomer.csvフイルを下記のコマンドでgzip圧縮します。
圧縮後のファイル名は、customer.csv.gzとなるはずです。
gzip customers.csvcustomer.csv.gzをObject Storageにアップロード後、ADBのDatabase ActionsのSQLをクリックし、ワークシートを開いてください。
本章のチュートリアルを進めて頂いた方は、CUSTOMERS表にデータが入っている状態だと思います。
下記のコマンドでCUSTOMERS表をリセットしましょう。
DROP TABLE customers; CREATE TABLE CUSTOMERS ( CUST_ID NUMBER NOT NULL, CUST_FIRST_NAME VARCHAR2(20) NOT NULL, CUST_LAST_NAME VARCHAR2(40) NOT NULL, CUST_GENDER CHAR(1) NOT NULL, CUST_YEAR_OF_BIRTH NUMBER(4) NOT NULL, CUST_MARITAL_STATUS VARCHAR2(20), CUST_STREET_ADDRESS VARCHAR2(40) NOT NULL, CUST_POSTAL_CODE VARCHAR2(10) NOT NULL, CUST_CITY VARCHAR2(30) NOT NULL, CUST_CITY_ID NUMBER NOT NULL, CUST_STATE_PROVINCE VARCHAR2(40) NOT NULL, CUST_STATE_PROVINCE_ID NUMBER NOT NULL, COUNTRY_ID NUMBER NOT NULL, CUST_MAIN_PHONE_NUMBER VARCHAR2(25) NOT NULL, CUST_INCOME_LEVEL VARCHAR2(30), CUST_CREDIT_LIMIT NUMBER, CUST_EMAIL VARCHAR2(50), CUST_TOTAL VARCHAR2(14) NOT NULL, CUST_TOTAL_ID NUMBER NOT NULL, CUST_SRC_ID NUMBER, CUST_EFF_FROM DATE, CUST_EFF_TO DATE, CUST_VALID VARCHAR2(1) );それでは、CUSTOMERS表にgzip圧縮済のファイルをロードするために、DBMS_CLOUD.COPY_DATAを実行していきます。
その際に下記の2通りの書き方がありますので、お好み方法で実行してください。(customer.csvは、"|“で区切られているため、delimiterには、"|“を設定します。)
BEGIN DBMS_CLOUD.COPY_DATA( TABLE_NAME =>'CUSTOMERS', CREDENTIAL_NAME =>'USER_CRED', FILE_URI_LIST =>'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<tenancy>/b/first_bucket/o/customers.csv.gz', format => '{ "delimiter" : "|", "compression" : "gzip", "ignoremissingcolumns" : "true", "removequotes" : "true", "dateformat" : "YYYY-MM-DD HH24:MI:SS", "blankasnull" : "true" }' ); END;または、
BEGIN DBMS_CLOUD.COPY_DATA( TABLE_NAME =>'CUSTOMERS', CREDENTIAL_NAME =>'USER_CRED', FILE_URI_LIST =>'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/<tenancy>/b/first_bucket/o/customers.csv.gz', format => json_object( 'delimiter' value '|', 'compression' value 'gzip', 'ignoremissingcolumns' value 'true', 'removequotes' value 'true', 'dateformat' value 'YYYY-MM-DD HH24:MI:SS', 'blankasnull' value 'true' ) ); END;上記2通りの方法で、gzip圧縮ファイルを展開せずにそのままロードすることができます。
※ ファイルの分割や圧縮の処理時間や、ネットワーク転送速度などとの兼ね合いから、そのままロードした方が高速なケースもあります。
-
DBMS_CLOUD.COPY_DATAによるロードが失敗する場合の確認ポイント
-
ソースファイルにアクセスできているか
-
認証系のエラー(ORA-20401: Authorization failed for URI)が出る場合
ユーザ名、Auth Tokenに誤りがないか再度確認してください。
特にIDCSと連携している場合、ユーザ名にはoracleidentitycloudservice/ の接頭辞が必要です。
下記のコマンドで、クレデンシャルが正しく登録されているか確認してください。
select * from user_credentials; -
オブジェクトが見つからないエラー(ORA-20404: Object not found)が出る場合
オブジェクトストレージへのURLが正しいか、アップロード済みのファイル名が正しいか、再度確認してください。
事前認証済みリクエストを作成し、アクセスできるか試してください。
オブジェクトストレージ上のバケットをPublic にして試してください。
ソースファイルへのアクセスに問題が無さそうな場合は、ADBインスタンスに生成されたログファイルとバッドファイルを確認していきましょう。
-
-
ADBインスタンス内のログを確認
ログファイル、バッドファイルからエラー内容を確認します(ログは 2日で自動的に削除されます)
・ログの確認
下記の例では、COPY$13_LOGというログファイルができているので、クエリして下さいと表示が出ています。同時にCOPY$13_BADというバッドファイルを生成されています。
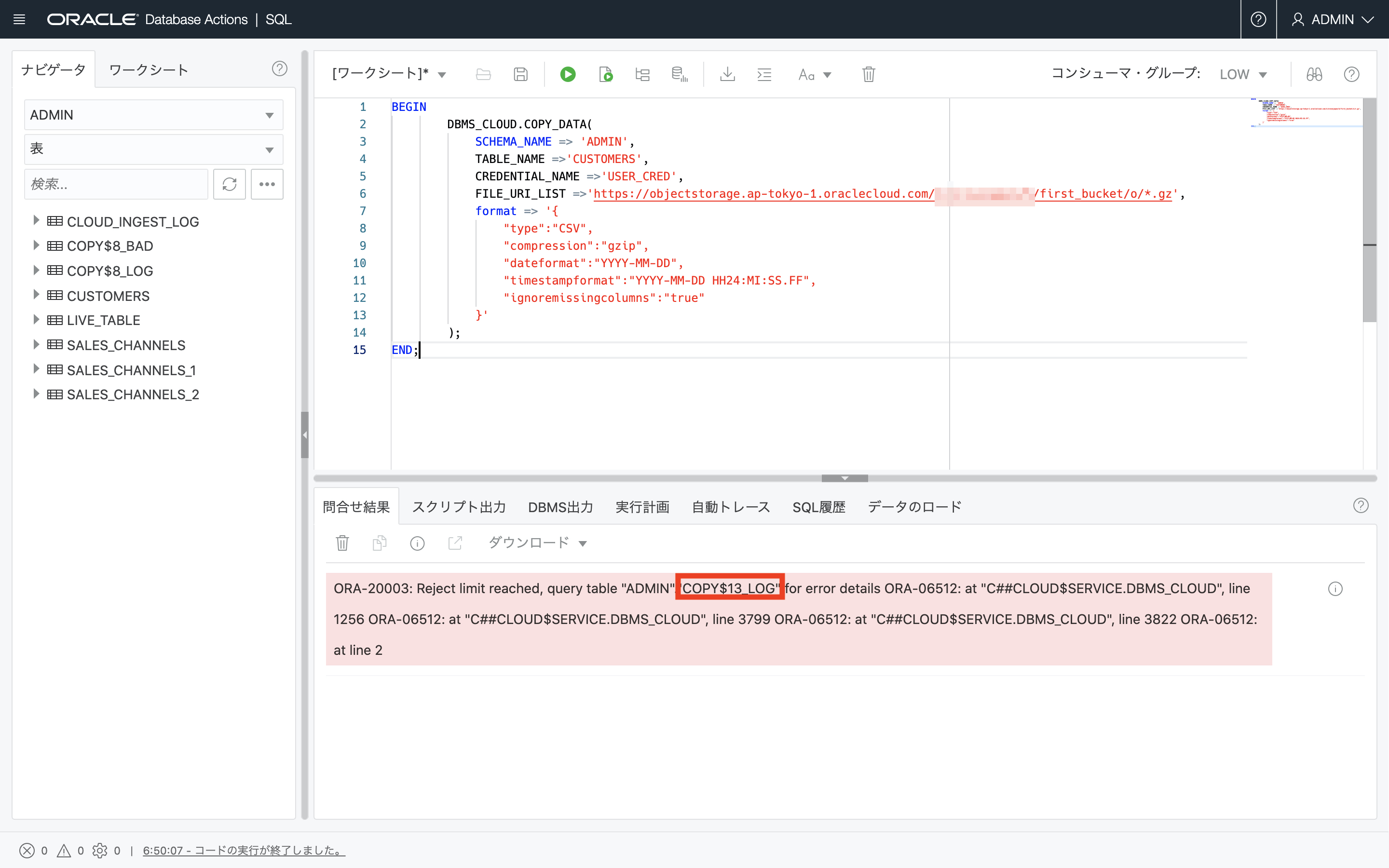
このケースでは、下記のコマンドで、ログファイルとバッドファイルを確認していきます。
select * from COPY$13_LOG; select * from COPY$13_BAD; -
お問い合わせのあった例・確認ポイント
-
列定義の文字数に注意
文字コード(CHARACTERSET パラメータ)は変更不可(AL32UTF8がデフォルト、2019/11現在)
既存DBがSJIS等の場合、オブジェクト名、および列定義のバイト数について、定義を一律2倍にするといった変更が必要な場合があります。
-
ソースファイルについて
ヘッダ情報(通常1行目)に注意
ソースファイルを圧縮する場合、もしくはワイルドカード指定で複数のファイルを一括ロードする場合は、ソースファイルからヘッダを削除してください
*** 文字コードに注意、改行コードに注意***
文字コードがUTF-8の場合は指定は不要。その他SJIS等の場合は、format句のcharactersetを指定してください。
改行コードがCR+LFの場合、recorddelimiterを指定してください。UNIX系で利用される 改行コード = LF の場合は recorddelimiter の指定は不要
記載例
「format => json_object(‘type’ value ’CSV’ , ‘characterset’ value ’JA16SJIS’, 'recorddelimiter' value '''''') 」 タイムスタンプのフォーマットが24時間表記の場合format句のTimestampformatオプションにYYY-MM-DD HH24:MI:SS.FFを指定してください。 (YYYY-MM-DD HH:MI:SS.FFと記載するとエラーになる )
-
最後の列に空白がある場合
Ignoremissingcolumnsを指定してください。
-
列のNULLを許可する(ファイルの一部列データがNULL)の場合
‘blankasnull’ VALUE ’true’ を設定する
-
-
以上で、この章は終了です。 次の章にお進みください。